目录
3.构建向量数据库操作对象,把文档切割、向量化并存储到向量数据库中
一.前景回顾
我们通过之前的文章:
讲了RAG知识库的原理,并且可以将一些未公开的文档,分割、向量化后,存入RAG知识库,从而让大模型有回答未公开的内部知识问题的能力。(比如回答公司内部系统的使用方法等问题)。
本篇文章的目的是,如何具体实现这个操作?见下文的【二】、【三】
二.存储(构建向量数据库操作对象)
1.引入依赖
XML
<!--rag-easy依赖-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.0.1-beta6</version>
</dependency>2.加载知识数据文档
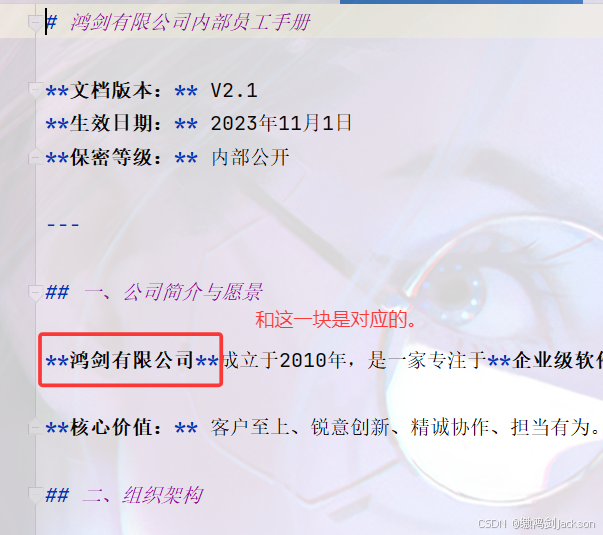
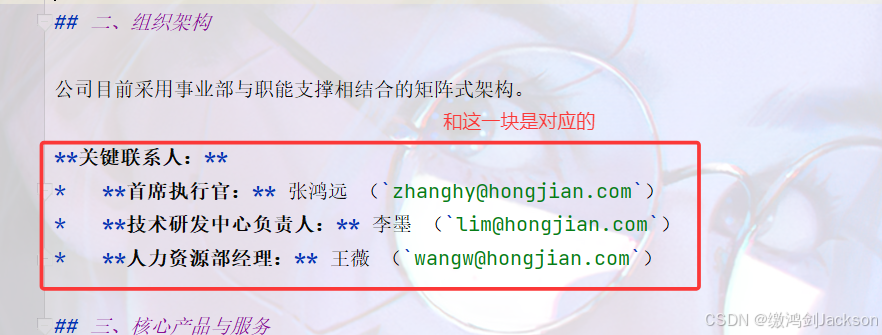
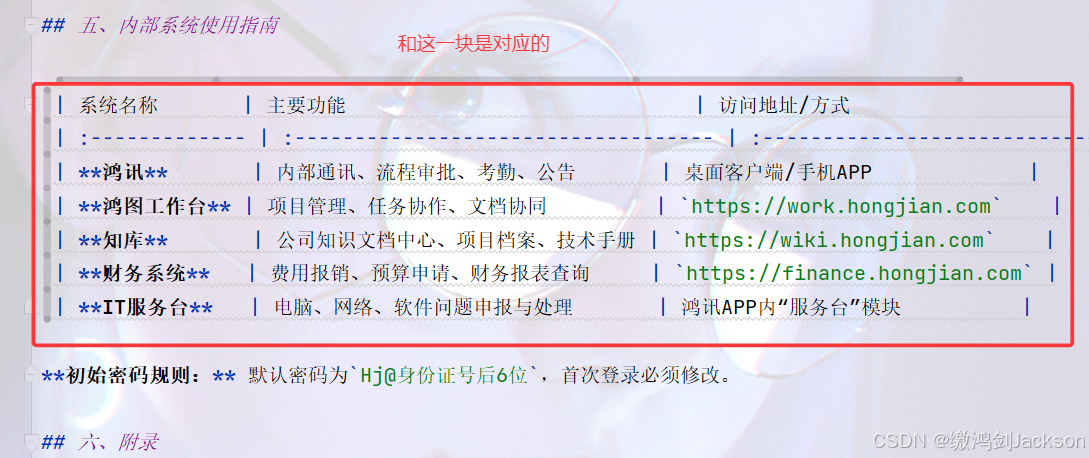
先准备一个文档(我们让AI生成了一个"鸿剑有限公司内部文档.md",是一个markdown类型的文件),如下图:
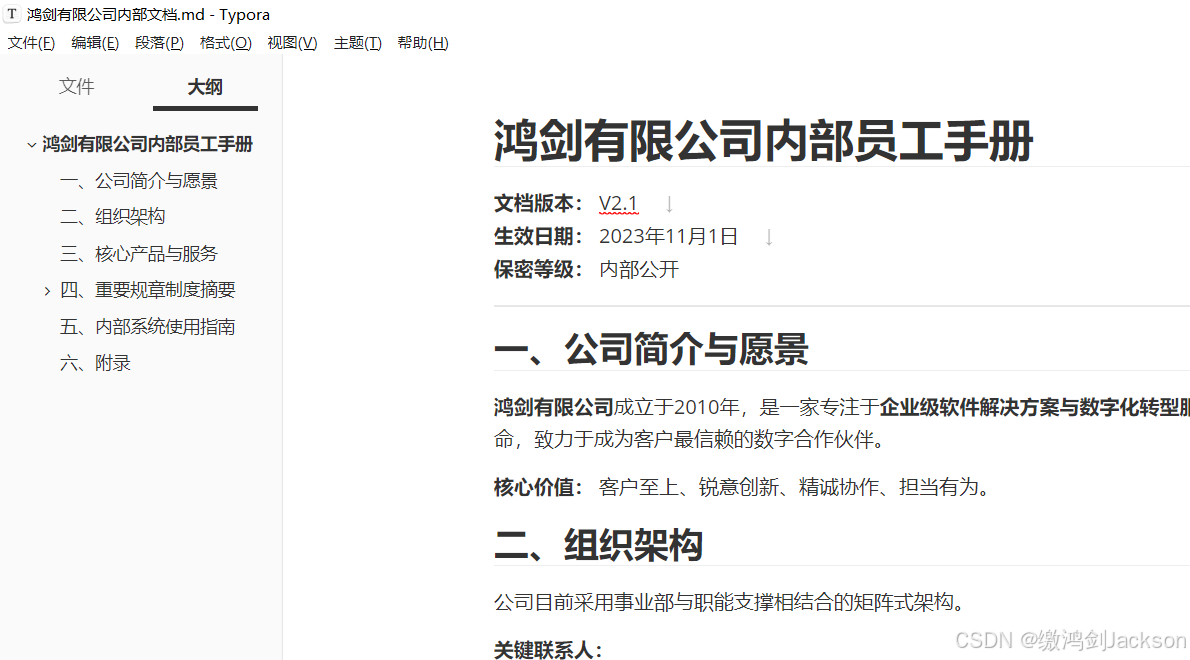
将该文档,上传到java项目中:
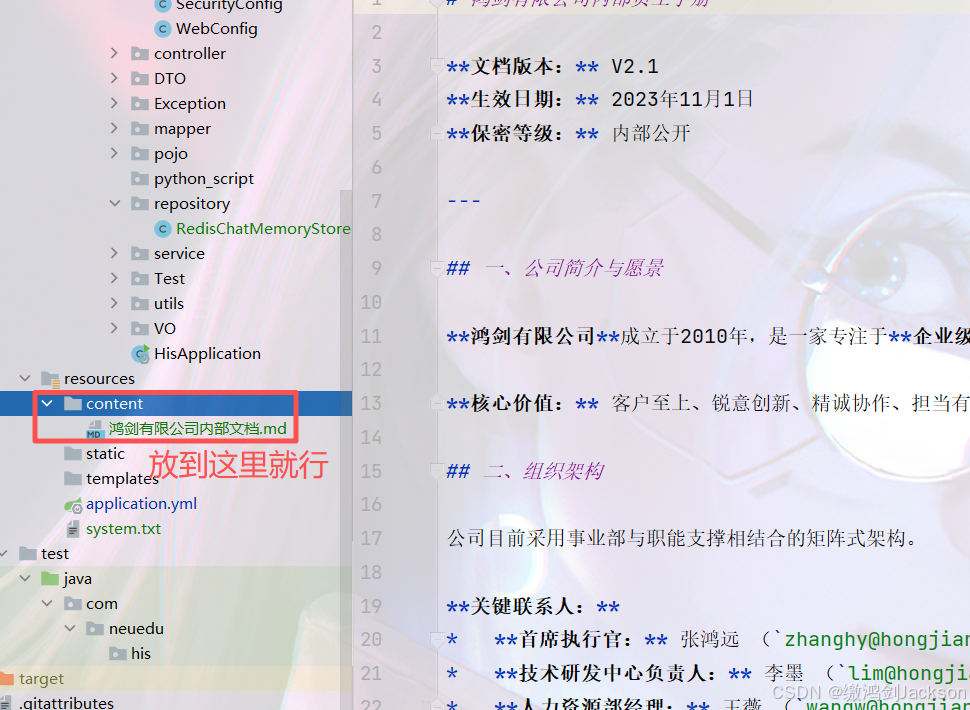
3.构建向量数据库操作对象,把文档切割、向量化并存储到向量数据库中
在下面的配置类中,添加如下代码:
java
//构建向量数据库操作对象(存储)
@Bean//将返回值放入IOC容器,供后续使用
public EmbeddingStore myEmbeddingStore(){//这个方法名不能叫embeddingStore,因为会和默认的重复,所以我们叫myEmbeddingStore
//1.加载resources/content/目录下的所有文档到内存中
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");
//2.构建向量数据库操作对象
InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();
//3.构建一个EmbeddingStoreIngestor对象,完成文本数据切割、向量化、存储
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(store)//向量化后的数据,指定存储到store中
.build();
ingestor.ingest(documents);//指定要存的内容,就是resources/content/目录下的所有文档
//4.返回store
return store;
}三.检索(构建向量数据库检索对象)
1.构建向量数据库检索对象
在下面的配置类中,添加如下代码:
java
//构建向量数据库检索对象(检索)
@Bean
public ContentRetriever contentRetriever(EmbeddingStore store){
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(store) //要从store中,检索知识片段
.minScore(0.5)//只要余弦相似度大于0.5,我们就要
.maxResults(3)//最多检索出三个知识片段
.build();
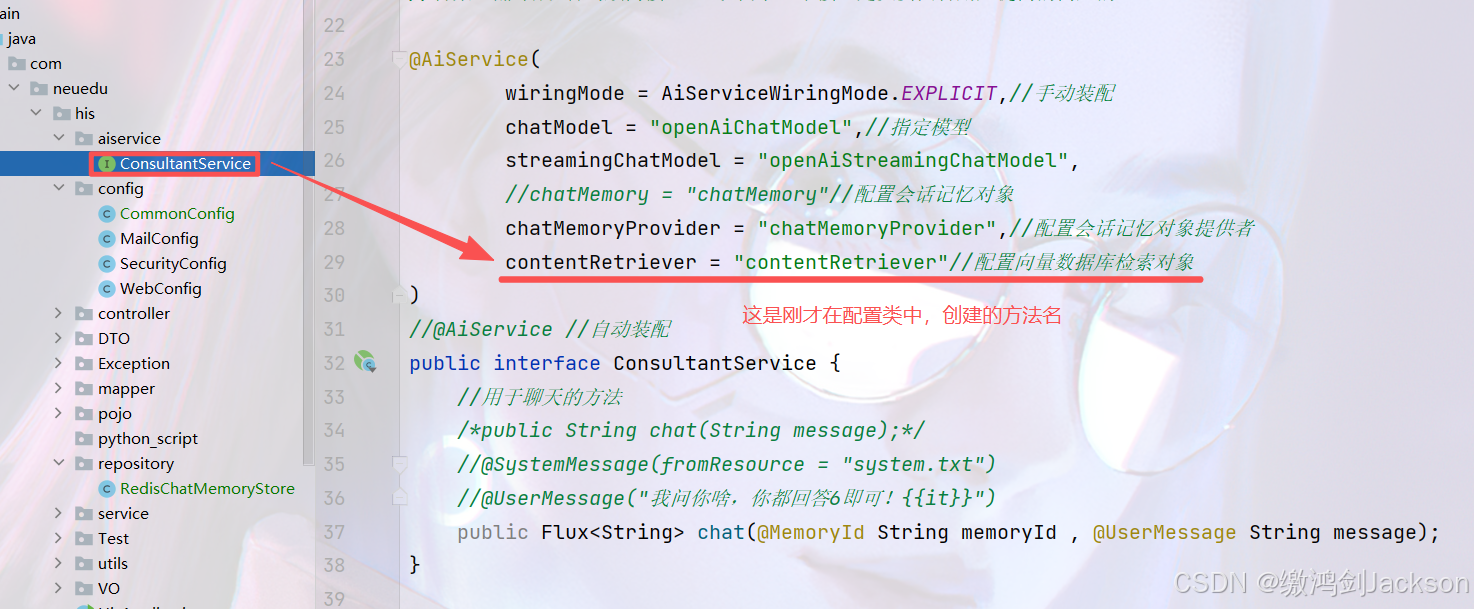
}2.配置向量数据库检索对象
四.重启项目,查看效果
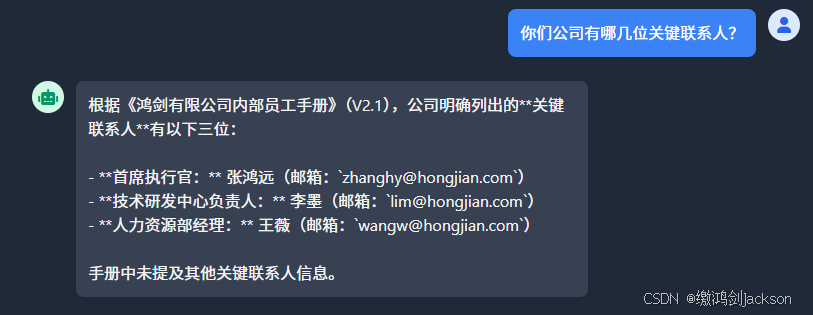
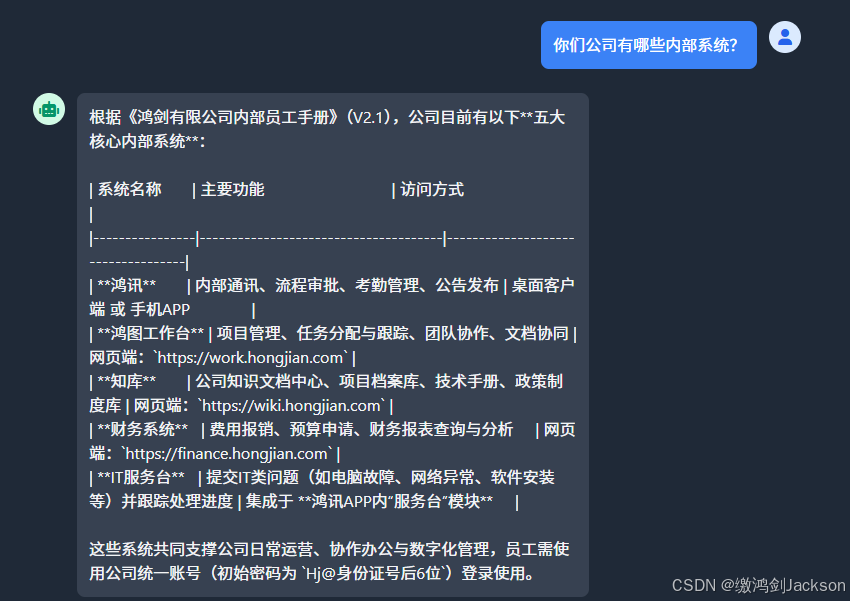
问几个问题,看看是否和我们提供的内部文档一致?

1.测试效果
此时大模型,可以完美地根据我们提供的手册,进行回答问题。
此时我们只在resources/content/目录下,传了一个文档,那么只要我们传入足够多的文档,那么RAG知识库就会有更多的知识,从而让大模型借鉴,来回答我们的各种问题。
2.原理
查看后端控制台,可见,java后端会将用户的问题,和从RAG数据库检索出的相关知识片段,一起发送给大模型,从而让大模型有专业知识的回答能力。

五.缺点与解决方案
1.缺点
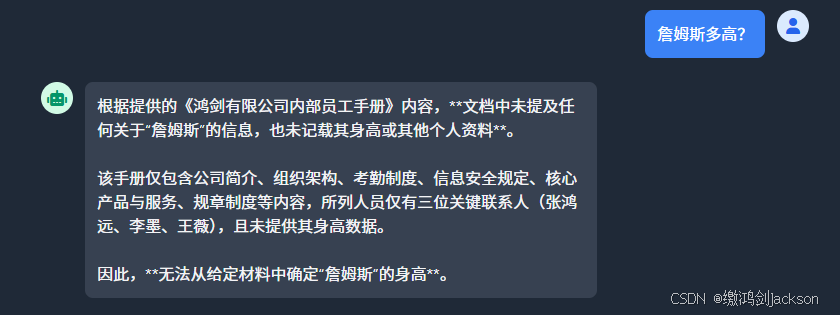
目前我们引入了RAG知识库以后,无论用户问什么问题,后端都会去RAG知识库搜索相关的知识片段,搜不到就无法回答。
2.原因
理想状态下,如果从RAG知识库中,搜不到与用户问题相关的知识片段,那就应该直接调用大模型了,不应该被知识有限的RAG知识库拖累。
说白了,就是没有意图识别的功能。
我猜测,应该是langchain4j实现这一块的功能时,如果从RAG知识库找不到用户问题相关的知识片段,调用大模型时就会给提示词"只根据知识库的结果回答"。所以我们应该去掉这个
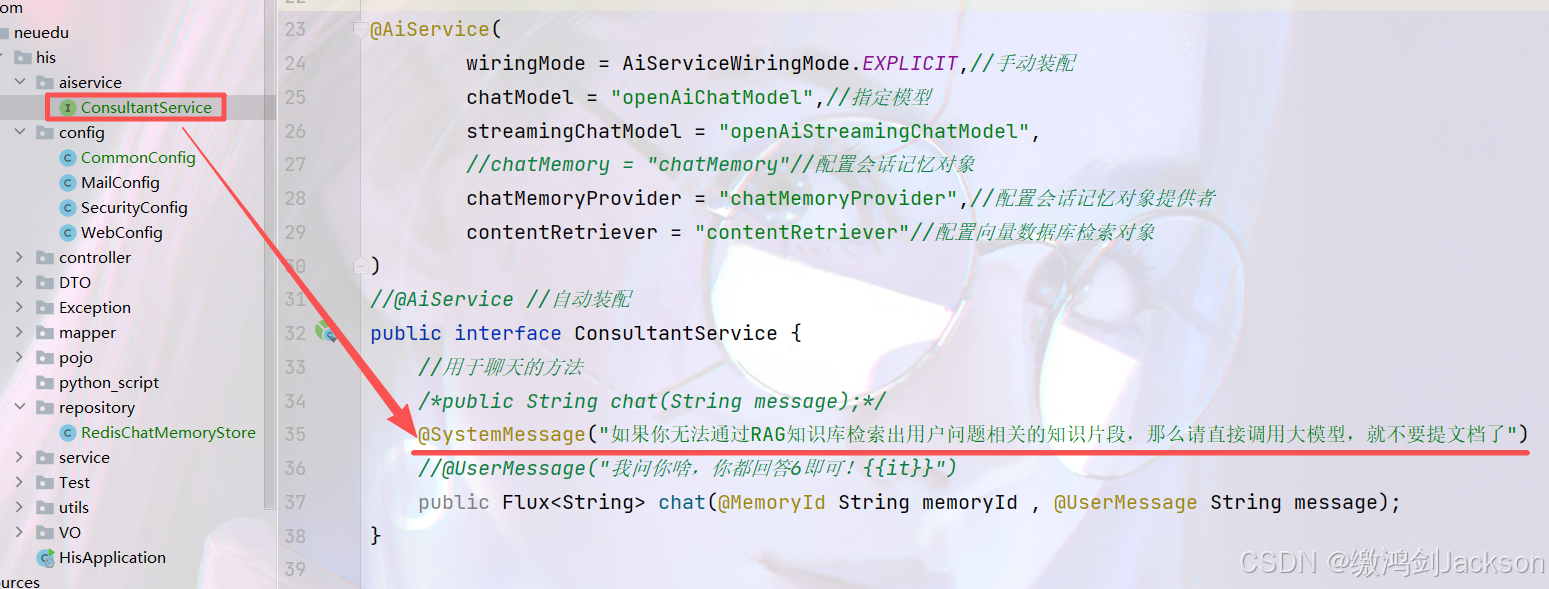
3.解决方案
添加系统提示词"如果你无法通过RAG知识库检索出用户问题相关的知识片段,那么请直接调用大模型,就不要提文档了"
4.解决效果
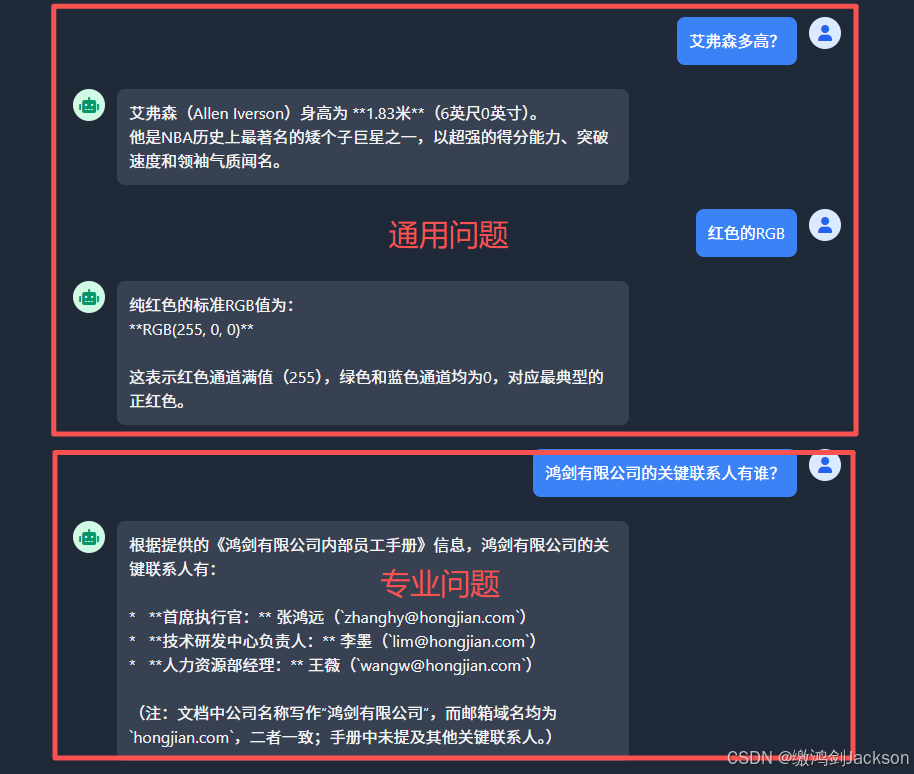
可见此时,RAG知识库就完全是锦上添花了,而不会影响大模型本身的通用问题回答能力。
到此,目的达到了!
以上就是本篇文章的全部内容,喜欢的话可以留个免费的关注呦~~~