在AI技术高速迭代的今天,多模态数据(文本、图像、音频、视频)爆发式增长,如何高效存储、检索这些非结构化数据,成为解锁AI应用落地的关键。向量数据库作为非结构化数据检索的核心载体,其中Milvus凭借生产级的稳定性、高扩展性,成为大规模向量检索场景的首选工具。
本文将从Milvus基础介绍入手,一步步带你完成单机版部署、核心组件拆解,最终通过一个完整的图文多模态检索实战案例,实现从理论到落地的闭环,适合AI、大数据开发者快速上手Milvus。
一、Milvus简介:生产级向量数据库的核心定位
Milvus 是一款开源的、专为大规模向量相似性搜索和分析设计的向量数据库,诞生于Zilliz公司,目前已成为LF AI & Data基金会的顶级项目,在全球AI领域拥有广泛的应用生态。
与FAISS、ChromaDB等轻量级本地向量存储方案相比,Milvus从设计之初就瞄准了生产环境,其核心优势体现在三点:
- 云原生架构:支持分布式部署,具备高可用、高容错能力,可根据数据规模水平扩展;
- 海量数据处理:轻松应对十亿、百亿级向量数据,兼顾检索性能与召回率;
- 多场景适配:原生支持多模态检索、标量过滤、混合检索等复杂场景,无缝对接AI模型。
官方资源:
- 官网地址: https://milvus.io/
- GitHub: https://github.com/milvus-io/milvus
二、Milvus单机版部署安装
Milvus提供单机版、集群版、云服务等多种部署方式,对于新手而言,单机版(Milvus Standalone)部署简单、资源要求低,适合本地开发与测试。本文将以单机版为例,详细讲解部署步骤。
2.1 环境准备
Milvus单机版依赖Docker与Docker Compose,需提前安装并启动:
- Docker版本要求:20.10.0+
- Docker Compose版本要求:2.0.0+
若不熟悉Docker安装,可参考教程:Docker 万字教程:从入门到掌握
提示:Codespace、云服务器(如阿里云ECS)等环境通常自带Docker Compose,无需额外安装,直接跳过安装步骤即可。
2.2 下载并启动Milvus
打开终端(Windows用PowerShell),按照以下步骤操作,全程无需复杂配置,一键启动。
第一步:下载配置文件
Milvus单机版的运行依赖etcd(元数据存储)、MinIO(对象存储)两个核心组件 ,官方已将所有配置整合到docker-compose.yml文件中,直接下载即可:
macOS / Linux(使用wget):
bash
# 下载配置文件并命名为docker-compose.yml
wget https://github.com/milvus-io/milvus/releases/download/v2.5.14/milvus-standalone-docker-compose.yml -O docker-compose.ymlWindows(使用PowerShell):
powershell
# 下载配置文件并保存到当前目录
Invoke-WebRequest -Uri "https://github.com/milvus-io/milvus/releases/download/v2.5.14/milvus-standalone-docker-compose.yml" -OutFile "docker-compose.yml"第二步:启动Milvus服务
切换到docker-compose.yml文件所在目录,执行以下命令,以后台模式启动Milvus及依赖组件:
bash
sudo docker compose up -d启动过程中,Docker会自动拉取Milvus、etcd、MinIO的镜像,耗时取决于网络速度(通常1-5分钟)。启动成功后,会创建3个容器:
milvus-standalone:Milvus核心服务milvus-minio:存储向量数据及原始文件milvus-etcd:存储Milvus的元数据(如Collection、索引信息)
2.3 验证安装
启动后,需确认Milvus服务正常运行,避免后续连接失败:
- 查看容器状态:执行
sudo docker ps命令,若3个Milvus相关容器的STATUS均为"Up"(或"running"),说明启动成功。 - 检查服务端口:Milvus单机版默认使用19530端口提供服务,后续代码连接时需用到该端口,无需额外配置。
注意:若容器启动失败,可执行docker logs milvus-standalone查看日志,排查问题(常见原因:端口占用、网络超时)。
2.4 常用管理命令
日常开发中,常用的Milvus服务管理命令如下,建议收藏:
- 停止服务(保留数据):
bash
sudo docker compose down该命令会停止并移除容器,但会保留数据卷(向量、元数据不会丢失),下次启动可恢复数据。
- 彻底清理(删除所有数据):
bash
sudo docker compose down -v适合测试环境,删除容器的同时删除数据卷,下次启动会重新创建空的Milvus服务。
- 查看服务日志:
bash
sudo docker logs milvus-standalone -f实时查看Milvus运行日志,方便排查检索、插入等操作的异常。
三、Milvus核心组件解析
要熟练使用Milvus,需先掌握其核心组件的概念与作用。Milvus的核心设计围绕"数据存储-索引加速-检索查询 "展开,关键组件包括Collection、Index、检索引擎,下面用通俗的比喻+实战细节,帮你快速理解。
3.1 Collection(集合):数据的容器
Collection是Milvus中最顶层的数据组织单位,类似于关系型数据库中的表(Table),所有数据操作(插入、删除、查询)都围绕Collection展开。用图书馆的比喻理解更直观:
- Collection(集合) :相当于整个图书馆,是所有数据的总容器;
- Partition(分区) :相当于图书馆的不同区域(如小说区、科技区),用于隔离数据;
- Schema(模式) :相当于图书馆的图书登记规则,定义数据的结构;
- Entity(实体) :相当于一本具体的书,是单条数据(含向量+元数据);
- Alias(别名) :相当于图书馆的推荐书单,可动态指向Collection,实现无缝切换。
3.1.1 Schema:数据的结构定义
创建Collection前,必须先定义Schema,规定数据的字段类型与属性,一个设计良好的Schema能提升检索性能和数据一致性。Schema通常包含3类字段:
- 主键字段(Primary Key Field):唯一标识每条数据(Entity),必填,且值唯一,常用INT64、VARCHAR类型(如文章ID、图片ID);
- 向量字段(Vector Field):存储核心的向量数据,必填,一个Collection可有多个向量字段(适配多模态场景,如文本向量+图像向量),需指定向量维度(如768维、1024维);
- 标量字段(Scalar Field):存储非向量的元数据(如文本描述、日期、类别),可选,用于过滤检索(如"只查2023年后的文档"),支持VARCHAR、INT64、FLOAT、JSON等类型。
下图展示了一个多模态场景的Schema设计(以新闻文章为例):
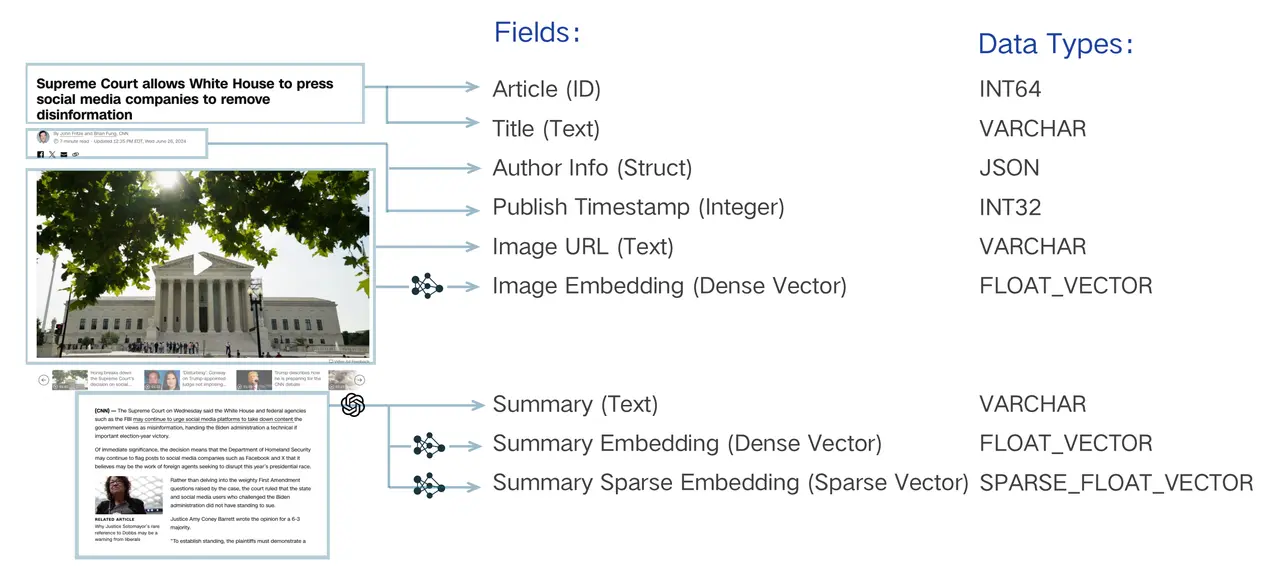
该Schema包含了文章ID(主键)、文本元数据(标题、作者)、图像URL(标量),以及图像向量、文本密集向量、文本稀疏向量(3个向量字段),完美适配图文多模态检索场景。
3.1.2 Partition(分区):提升性能的小技巧
Partition是Collection的逻辑划分,创建Collection时会自动生成一个默认分区(_default),可根据业务需求创建更多分区,将数据按规则(如类别、日期)拆分存储。
使用分区的核心优势:
- 提升检索速度:查询时可指定分区,减少扫描的数据量(如只查"2024年1月"分区的数据);
- 方便数据管理:批量删除、加载/卸载部分数据(如删除"2023年以前"的分区)。
注意:一个Collection最多支持1024个分区,分区名称需唯一,建议根据数据量合理划分(如千万级数据可按日期分区,百万级数据无需分区)。
3.1.3 Alias(别名):数据更新的无缝切换器
Alias是Collection的昵称,应用程序可通过Alias操作Collection,无需直接使用Collection名称,核心作用是实现数据的无缝更新,避免服务中断。
实战场景示例(在线服务数据更新):
- 现有在线服务使用Collection:collection_v1,别名设为my_app_collection;
- 需要更新数据时,创建新Collection:collection_v2,导入新数据并构建索引;
- 将别名my_app_collection原子性切换到collection_v2;
- 切换完成后,应用程序无需修改任何代码,直接通过别名访问新数据,旧数据可后续删除。
3.2 Index(索引):检索加速的神经系统
如果说Collection是Milvus的骨架,那么Index就是其加速检索的核心。Index是一种优化的数据结构,用于快速定位相似向量,避免暴力搜索(遍历所有数据),大幅提升检索速度(从秒级提升到毫秒级)。
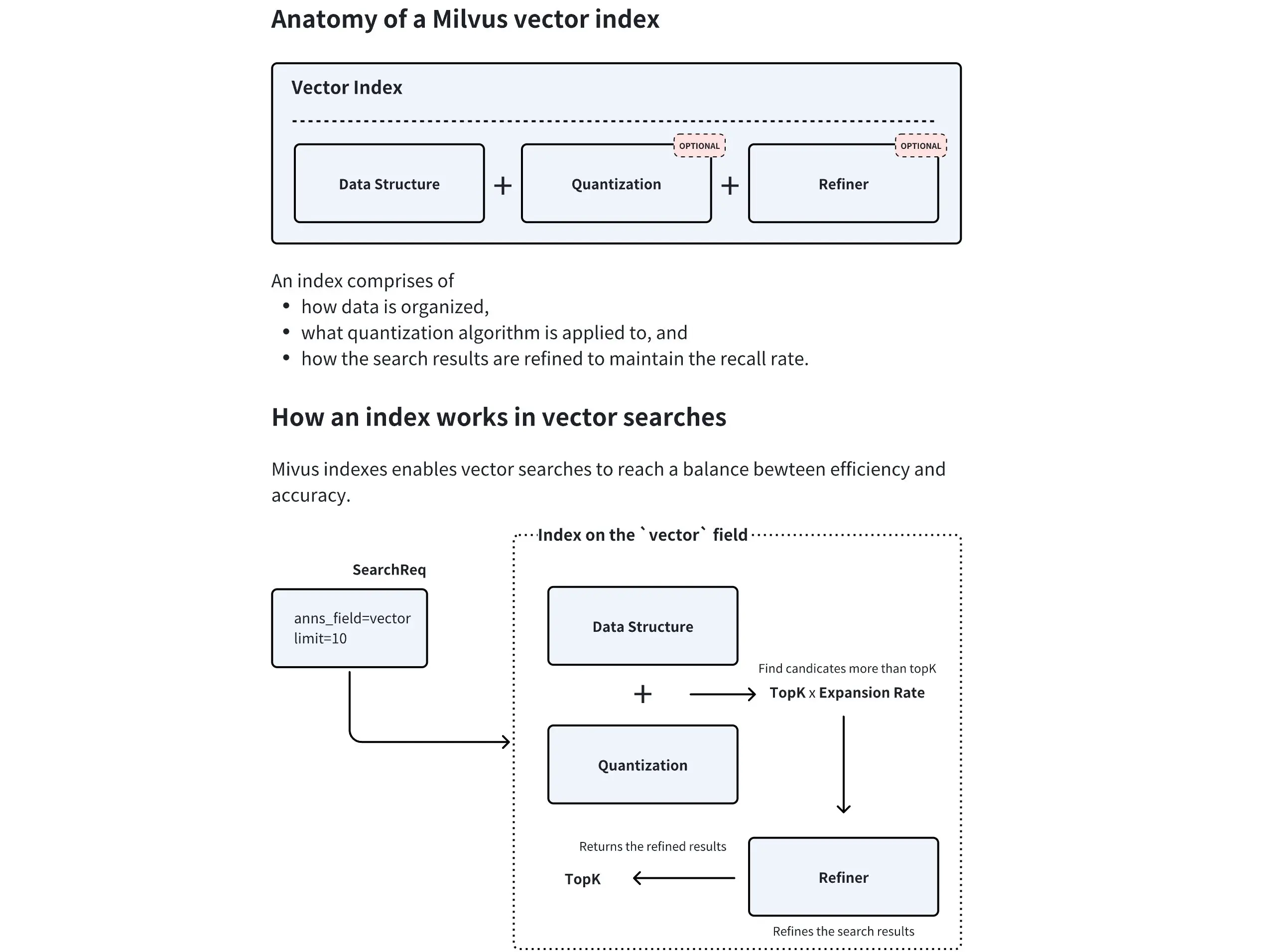
Milvus索引的核心流程:
- 数据结构:索引的核心(如HNSW的图结构、IVF的倒排结构);
- 量化(可选):压缩向量数据,减少内存占用(如IVF_SQ8将向量量化为8位整数);
- 结果精炼(可选):对初步检索结果进行精确计算,提升召回率。
Milvus支持对标量字段和向量字段分别创建索引,其中向量字段索引是核心,需重点掌握。
3.2.1 核心向量索引类型
Milvus提供多种向量索引算法,不同索引适配不同场景,需根据数据规模、内存限制、检索需求选择,以下是4种最常用的索引类型:
| 索引类型 | 核心原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| FLAT(精确查找) | 暴力搜索,计算查询向量与所有向量的距离 | 100%召回率,结果最准确 | 速度慢,内存占用大 | 数据量小(百万级以内)、对精度要求极高 |
| IVF系列(IVF_FLAT/SQ8/PQ) | 聚类分桶,查询时只搜索相似的几个桶 | 速度快,性能与精度平衡 | 召回率略低于FLAT | 通用场景,大规模数据(千万-亿级)、高吞吐量 |
| HNSW(基于图) | 构建多层邻近图,快速定位目标区域 | 检索速度极快,召回率高,适配高维数据 | 内存占用大,索引构建时间长 | 实时检索场景(如推荐、在线搜索)、低延迟需求 |
| DiskANN(基于磁盘) | 优化磁盘存储,适配SSD | 支持十亿级以上海量数据,不占内存 | 延迟略高于内存索引 | 数据量极大(十亿级+)、无法全部载入内存 |
3.2.2 索引选择技巧
选择索引的核心是权衡------在数据规模、内存、检索速度、召回率之间找到平衡点,以下是实战中的快速选择指南:
- 数据量≤100万,追求100%精度 → 选FLAT;
- 数据量100万-1亿,追求高吞吐、一般延迟 → 选IVF_FLAT/SQ8;
- 数据量100万-1亿,追求低延迟(毫秒级) → 选HNSW;
- 数据量≥10亿,内存不足 → 选DiskANN。
实战中建议先测试IVF_FLAT和HNSW两种索引,HNSW的M(节点连接数)建议设为16-32,efConstruction(索引构建精度)设为256-512,可兼顾性能与内存。
3.3 检索:Milvus的核心能力
有了Collection(数据容器)和Index(加速引擎),就可以进行检索操作了。Milvus支持基础向量检索和多种增强检索,适配不同业务场景,核心是"快速找到相似数据"。
3.3.1 基础向量检索(ANN Search)
近似最近邻(ANN)检索是Milvus的核心功能,无需遍历所有数据,利用索引快速找到与查询向量最相似的Top-K个结果,是速度与精度的平衡。
核心参数(实战必记):
anns_field:指定检索的向量字段(如"image_vector","text_vector");data:查询向量(单个或多个,与向量字段维度一致);limit/top_k:返回的最相似结果数量(如top_k=5,返回前5个最相似结果);search_params:检索参数,如距离度量方式(COSINE、L2)、索引相关参数(如HNSW的ef)。
3.3.2 增强检索
基础检索仅适用于简单场景,实际业务中更常用增强检索,结合标量过滤、多向量混合等功能,提升检索精度。
1. 过滤检索(Filtered Search)
将向量相似检索与标量字段过滤结合,实现精准检索,比如"找与这件红色连衣裙相似的商品,且价格<500元、有库存"。
工作原理:先通过标量过滤筛选出符合条件的实体,再在子集内执行ANN检索,大幅提升精度。
2. 范围检索(Range Search)
不追求Top-K结果,而是返回与查询向量相似度在指定范围内的所有数据,比如人脸识别中,相似度>0.9的所有人脸。
3. 多向量混合检索(Hybrid Search)
Milvus的核心亮点的之一,支持同时检索多个向量字段(如文本向量+图像向量),再通过重排策略(RRFRanker、WeightedRanker)融合结果,适配多模态场景。
实战示例:用户输入安静舒适的白色耳机,系统同时检索商品的文本描述向量和图片内容向量,返回最匹配的结果。
4. 分组检索(Grouping Search)
解决检索结果多样性不足的问题,比如检索机器学习,确保结果来自不同书籍。通过指定分组字段(如document_id),每个组仅返回1个最相似结果。
四、Milvus多模态检索实战
理论掌握后,通过一个完整实战案例,手把手教你用Milvus+Visualized-BGE模型,构建端到端的图文多模态检索引擎。案例核心:导入图片数据,实现图片+文本联合查询,返回最相似的图片。
4.1 实战环境准备
提前安装所需依赖库(建议使用Python 3.8+):
bash
# 安装Milvus Python客户端
pip install pymilvus==2.4.4
# 安装可视化、模型相关库
pip install torch pillow opencv-python numpy tqdm visual-bge其他准备:
- 模型:Visualized-BGE(BAAI推出的多模态嵌入模型,支持图文联合编码,本文使用base版本);
- 数据:龙的图片数据集(存放在dragon目录下,格式为png,可自行替换为其他图片);
- Milvus服务:已启动。
4.2 代码实现
代码分为8个步骤,从工具定义、Collection创建,到数据插入、索引构建、检索可视化,全程注释详细,可直接复制运行,关键步骤附带解析。
4.2.1 初始化与工具定义
导入依赖库,定义编码器(图文向量编码)和可视化函数(检索结果展示),封装逻辑,提升代码复用性。
python
import os
from tqdm import tqdm
from glob import glob
import torch
from visual_bge.visual_bge.modeling import Visualized_BGE
from pymilvus import MilvusClient, FieldSchema, CollectionSchema, DataType
import numpy as np
import cv2
from PIL import Image
# 1. 初始化设置(根据自身环境修改路径)
MODEL_NAME = "BAAI/bge-base-en-v1.5" # BGE基础模型
MODEL_PATH = "./models/bge/Visualized_base_en_v1.5.pth" # 模型权重路径
DATA_DIR = "./data/" # 数据根目录
COLLECTION_NAME = "multimodal_demo" # Milvus集合名称
MILVUS_URI = "http://localhost:19530" # Milvus连接地址(单机版默认)
# 2. 定义工具类:编码器(图文转向量)和可视化函数
class Encoder:
"""编码器类,用于将图像和文本编码为统一维度的向量"""
def __init__(self, model_name: str, model_path: str):
# 加载Visualized-BGE模型,设置为评估模式
self.model = Visualized_BGE(model_name_bge=model_name, model_weight=model_path)
self.model.eval()
def encode_query(self, image_path: str, text: str) -> list[float]:
"""图文联合编码(查询时使用,结合图片和文本意图)"""
with torch.no_grad(): # 禁用梯度计算,节省内存
query_emb = self.model.encode(image=image_path, text=text)
return query_emb.tolist()[0] # 转为列表,适配Milvus输入
def encode_image(self, image_path: str) -> list[float]:
"""单图像编码(插入数据时使用,将图片转为向量)"""
with torch.no_grad():
query_emb = self.model.encode(image=image_path)
return query_emb.tolist()[0]
def visualize_results(query_image_path: str, retrieved_images: list, img_height: int = 300, img_width: int = 300, row_count: int = 3) -> np.ndarray:
"""可视化检索结果:左侧显示查询图片,右侧显示检索到的图片"""
panoramic_width = img_width * row_count
panoramic_height = img_height * row_count
# 创建全景图画布(白色背景)
panoramic_image = np.full((panoramic_height, panoramic_width, 3), 255, dtype=np.uint8)
# 创建查询图片显示区域
query_display_area = np.full((panoramic_height, img_width, 3), 255, dtype=np.uint8)
# 处理查询图片(添加蓝色边框,标注"Query")
query_pil = Image.open(query_image_path).convert("RGB")
query_cv = np.array(query_pil)[:, :, ::-1] # PIL转OpenCV格式(RGB→BGR)
resized_query = cv2.resize(query_cv, (img_width, img_height))
bordered_query = cv2.copyMakeBorder(resized_query, 10, 10, 10, 10, cv2.BORDER_CONSTANT, value=(255, 0, 0))
query_display_area[img_height * (row_count - 1):, :] = cv2.resize(bordered_query, (img_width, img_height))
cv2.putText(query_display_area, "Query", (10, panoramic_height - 20), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
# 处理检索到的图片(添加黑色边框,标注序号)
for i, img_path in enumerate(retrieved_images):
row, col = i // row_count, i % row_count
start_row, start_col = row * img_height, col * img_width
retrieved_pil = Image.open(img_path).convert("RGB")
retrieved_cv = np.array(retrieved_pil)[:, :, ::-1]
resized_retrieved = cv2.resize(retrieved_cv, (img_width - 4, img_height - 4))
bordered_retrieved = cv2.copyMakeBorder(resized_retrieved, 2, 2, 2, 2, cv2.BORDER_CONSTANT, value=(0, 0, 0))
panoramic_image[start_row:start_row + img_height, start_col:start_col + img_width] = bordered_retrieved
cv2.putText(panoramic_image, str(i), (start_col + 10, start_row + 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
# 拼接查询区域和检索结果区域,返回全景图
return np.hstack([query_display_area, panoramic_image])4.2.2 创建Collection(集合)
初始化Milvus客户端,定义Schema,创建Collection,为后续数据插入做准备。
python
# 3. 初始化编码器和Milvus客户端
print("--> 正在初始化编码器和Milvus客户端...")
encoder = Encoder(MODEL_NAME, MODEL_PATH)
milvus_client = MilvusClient(uri=MILVUS_URI) # 连接本地Milvus服务
# 4. 创建Milvus Collection(若已存在则删除,避免冲突)
print(f"\n--> 正在创建 Collection '{COLLECTION_NAME}'")
if milvus_client.has_collection(COLLECTION_NAME):
milvus_client.drop_collection(COLLECTION_NAME)
print(f"已删除已存在的 Collection: '{COLLECTION_NAME}'")
# 获取图片列表,判断数据目录是否有图片
image_list = glob(os.path.join(DATA_DIR, "dragon", "*.png"))
if not image_list:
raise FileNotFoundError(f"在 {DATA_DIR}/dragon/ 中未找到任何 .png 图像,请检查数据路径!")
# 计算向量维度(通过编码一张图片获取,Visualized-BGE默认输出高维向量)
dim = len(encoder.encode_image(image_list[0]))
# 定义Collection的Schema(字段结构)
fields = [
# 主键字段:自增ID,唯一标识每条数据
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
# 向量字段:存储图片向量,维度为dim
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=dim),
# 标量字段:存储图片路径,用于后续可视化
FieldSchema(name="image_path", dtype=DataType.VARCHAR, max_length=512),
]
# 创建Schema对象,添加描述
schema = CollectionSchema(fields, description="多模态图文检索演示集合")
print("Schema 结构:")
print(schema)
# 创建Collection
milvus_client.create_collection(collection_name=COLLECTION_NAME, schema=schema)
print(f"成功创建 Collection: '{COLLECTION_NAME}'")
print("Collection 结构详情:")
print(milvus_client.describe_collection(collection_name=COLLECTION_NAME))代码解析:
auto_id=True:主键ID自动生成,无需手动指定,避免重复;FLOAT_VECTOR:向量字段类型,dim=768(Visualized-BGE模型的输出维度);image_path(VARCHAR):存储图片的绝对/相对路径,后续检索后可通过路径加载图片进行可视化。
运行后输出示例(关键信息):
bash
Schema 结构:
{
'auto_id': True,
'description': '多模态图文检索演示集合(龙图片)',
'fields': [
{'name': 'id', 'type': INT64, 'is_primary': True, 'auto_id': True},
{'name': 'vector', 'type': FLOAT_VECTOR, 'params': {'dim': 768}},
{'name': 'image_path', 'type': VARCHAR, 'params': {'max_length': 512}}
]
}
成功创建 Collection: 'multimodal_demo'4.2.3 准备并插入数据
遍历图片目录,将每张图片编码为向量,与图片路径一起插入到Collection中。
python
# 5. 准备数据并批量插入Milvus
print(f"\n--> 正在向 '{COLLECTION_NAME}' 插入数据(共{len(image_list)}张图片)")
data_to_insert = []
# 遍历图片,生成向量和路径的组合数据(tqdm显示进度条)
for image_path in tqdm(image_list, desc="生成图像嵌入并准备数据"):
vector = encoder.encode_image(image_path) # 图片转向量
data_to_insert.append({"vector": vector, "image_path": image_path}) # 组装数据
# 批量插入数据(Milvus支持批量插入,提升效率)
if data_to_insert:
result = milvus_client.insert(collection_name=COLLECTION_NAME, data=data_to_insert)
print(f"成功插入 {result['insert_count']} 条数据(图片向量)。")代码解析:
tqdm:显示数据插入进度条,方便查看处理进度;- 批量插入:避免单条插入效率过低,Milvus单次批量插入建议不超过10万条;
- 插入结果:
result['insert_count']表示成功插入的数据量,需与图片总数一致。
4.2.4 创建索引
为向量字段创建索引,这里选择HNSW索引(适配实时检索,平衡速度与召回率),创建完成后加载Collection到内存。
python
# 6. 为向量字段创建索引(核心:提升检索速度)
print(f"\n--> 正在为 '{COLLECTION_NAME}' 的vector字段创建索引")
# 准备索引参数(HNSW索引,余弦相似度度量)
index_params = milvus_client.prepare_index_params()
index_params.add_index(
field_name="vector", # 为vector字段创建索引
index_type="HNSW", # 索引类型:HNSW
metric_type="COSINE", # 距离度量方式:余弦相似度(适合向量检索)
params={"M": 16, "efConstruction": 256}
)
# 创建索引
milvus_client.create_index(collection_name=COLLECTION_NAME, index_params=index_params)
print("成功为向量字段创建 HNSW 索引。")
print("索引详情:")
print(milvus_client.describe_index(collection_name=COLLECTION_NAME, index_name="vector"))
# 加载Collection到内存(Milvus检索时需将Collection加载到内存,提升速度)
milvus_client.load_collection(collection_name=COLLECTION_NAME)
print("已加载 Collection 到内存中,可开始检索。")关键参数解析(HNSW):
M:图中每个节点的最大连接数,默认16,越大检索精度越高,但内存占用越大;efConstruction:索引构建时的搜索范围,默认256,越大索引构建越慢,但召回率越高;COSINE:余弦相似度(两个向量角度为0°),值越接近1,向量越相似。
4.2.5 执行多模态检索(图文联合查询)
定义查询条件(一张龙的图片+文本"一条龙"),将图文联合编码为查询向量,执行检索,返回最相似的5张图片。
python
# 7. 执行多模态检索(图文联合查询)
print(f"\n--> 正在 '{COLLECTION_NAME}' 中执行多模态检索")
# 定义查询条件:查询图片路径 + 文本描述
query_image_path = os.path.join(DATA_DIR, "dragon", "dragon01.png") # 查询图片
query_text = "一条龙" # 查询文本(描述图片内容)
# 图文联合编码,生成查询向量(结合图片和文本的意图,提升检索精度)
query_vector = encoder.encode_query(image_path=query_image_path, text=query_text)
# 执行检索(搜索最相似的5张图片)
search_results = milvus_client.search(
collection_name=COLLECTION_NAME,
data=[query_vector], # 查询向量(单个向量,可传入多个)
output_fields=["image_path"], # 检索结果返回图片路径(用于可视化)
limit=5, # 返回前5个最相似结果
search_params={"metric_type": "COSINE", "params": {"ef": 128}} # 检索参数(ef:检索时的搜索范围)
)[0] # 取第一个查询向量的结果(仅传入1个,所以取索引0)
# 提取检索结果中的图片路径,用于后续可视化
retrieved_images = []
print("检索结果(按相似度从高到低排序):")
for i, hit in enumerate(search_results):
# hit['distance']:余弦相似度,越接近1越相似;hit['entity']['image_path']:图片路径
print(f" Top {i+1}: ID={hit['id']}, 相似度={hit['distance']:.4f}, 图片路径='{hit['entity']['image_path']}'")
retrieved_images.append(hit['entity']['image_path'])检索结果示例:
bash
检索结果(按相似度从高到低排序):
Top 1: ID=459243798403756667, 相似度=0.9411, 图片路径='./data/dragon/dragon01.png'
Top 2: ID=459243798403756668, 相似度=0.5818, 图片路径='./data/dragon/dragon02.png'
Top 3: ID=459243798403756671, 相似度=0.5731, 图片路径='./data/dragon/dragon05.png'
Top 4: ID=459243798403756670, 相似度=0.4894, 图片路径='./data/dragon/dragon04.png'
Top 5: ID=459243798403756669, 相似度=0.4100, 图片路径='./data/dragon/dragon03.png'结果解析:Top1是查询图片本身,相似度最高(0.9411),说明检索有效;其余结果均为龙的图片,按相似度从高到低排序,符合预期。
4.2.6 检索结果可视化与资源清理
将查询图片和检索到的图片拼接成全景图,保存并显示,最后释放Milvus资源(避免内存占用)。
python
# 8. 检索结果可视化与资源清理
print(f"\n--> 正在可视化检索结果并清理资源")
if not retrieved_images:
print("没有检索到任何图像,请检查数据或检索参数!")
else:
# 生成可视化全景图
panoramic_image = visualize_results(query_image_path, retrieved_images)
# 保存可视化结果到数据目录
combined_image_path = os.path.join(DATA_DIR, "search_result.png")
cv2.imwrite(combined_image_path, panoramic_image)
print(f"检索结果可视化图片已保存到: {combined_image_path}")
# 打开可视化图片(Windows/Linux/macOS均支持)
Image.open(combined_image_path).show()
# 释放资源:从内存中卸载Collection
milvus_client.release_collection(collection_name=COLLECTION_NAME)
print(f"已从内存中释放 Collection: '{COLLECTION_NAME}'")
# 删除Collection(测试场景,实际生产环境可保留)
milvus_client.drop_collection(COLLECTION_NAME)
print(f"已删除 Collection: '{COLLECTION_NAME}'")可视化结果示例:

左侧为查询图片(蓝色边框,标注"Query"),右侧为检索到的5张图片(黑色边框,标注序号),序号越小相似度越高,直观清晰。
4.3 实战避坑指南
运行代码时,容易遇到以下问题,提前规避:
- 问题1:Milvus连接失败 → 检查Milvus服务是否启动(docker ps查看容器状态),MILVUS_URI是否正确(单机版默认http://localhost:19530);
- 问题2:未找到图片 → 检查DATA_DIR路径是否正确,确保dragon目录下有png图片;
- 问题3:向量维度不匹配 → 确保查询向量与Collection的向量字段维度一致(Visualized-BGE默认768维);
- 问题4:检索结果为空 → 检查数据是否插入成功,索引是否创建完成,检索参数(ef)是否合理;
- 问题5:可视化失败 → 检查cv2、PIL库是否安装成功,图片路径是否有中文(建议使用英文路径)。
五、总结
本文从Milvus基础介绍、单机版部署,到核心组件解析、图文多模态检索实战,完整覆盖了Milvus的入门到上手全流程,重点掌握:
- Milvus的定位:生产级向量数据库,适配海量多模态数据检索;
- 核心组件:Collection(数据容器)、Index(加速引擎)、检索引擎(基础+增强检索);
- 实战能力:能独立部署Milvus、创建Collection、插入数据、构建索引,实现多模态检索。
后续学习方向(进阶):
- Milvus集群部署:应对海量数据(亿级+),实现高可用、水平扩展;
- 索引调优:针对不同数据场景,优化索引参数(如HNSW的M、ef),平衡速度与召回率;
- 复杂多模态场景:结合音频、视频向量,实现跨模态检索(如"文本搜视频");
- Milvus与RAG结合:将Milvus作为向量存储,构建增强型检索问答系统。