循环神经网络(Recurrent Neural Networks, RNN) 是一种常用的神经网络结构,它源自于1982年由Saratha Sathasivam提出的霍普菲尔德网络。1986年,Elman等人正式提出了用于处理序列数据的循环神经网络。如同卷积神经网络是专门用于处理二维数据信息(如图像)的神经网络,循环神经网络是专用于处理序列信息的神经网络。它是根据"人的认知是基于过往的经验和记忆"这一观点提出的。 与DNN,CNN不同的是:它不仅考虑前一时刻的输入,而且赋予了网络对前面的内容的一种"记忆"功能。对于序列数据问题,通常使用的方法是循环神经网络。
一、文本数据预处理
文本序列数据
与时间序列数据不同,文本序列数据是一类有序的文本数据,每个数据项都是一个字符串,并且这些字符串是有序的。文本序列数据常常被用来表示自然语言文本,例如句子或者段落。例如,一段英文文本可以表示为一个文本序列数据,其中每个数据项都是一个单词。
文本序列数据常常被用来做自然语言处理任务,例如文本分类、机器翻译、文本生成等。在这些任务中,常常需要使用深度学习模型来处理文本序列数据,并使用文本序列数据来训练这些模型。
文本预处理
文本预处理是指在进行自然语言处理任务之前对文本进行的一系列处理步骤。目的是使文本变得更适合进行自然语言处理任务,并且可以提高处理效率。
文本预处理的步骤通常包括:
-
去除文本中的噪声,例如标点符号、HTML标签、空格等,或者停用词。停用词是指在文本中出现频率较高,但没有实际意义的词,例如"的","了"等。
-
将字符串拆分为词元(如单词和字符)。
-
建立词表,将拆分的词元映射到数字索引。
-
将文本转换为数字索引序列,方便模型操作。
-
编码文本,例如使用one-hot编码将单词转换成数字向量。
进行文本预处理的目的是使文本更适合进行自然语言处理任务,一方面可以把文本数据转化成计算机能理解的数字和向量,另一方面,可以减少噪声,提高模型的训练效率、提升模型的泛化能力等。
数据读取
python
with open('data/book.txt', 'r') as f:
lines = f.readlines()
print(len(lines))
print(lines[:10])去除文本噪声
去除文本噪声是指在处理文本数据时,删除文本中不相关或者无用的信息。去除文本噪声的目的是使得文本中有意义的信息更加突出,从而提高文本分析和处理的效率。
前面讲到的去停用词在传统的自然语言处理任务中非常常见,因为一些词语在文本中出现频率过高或者并不具有实际意义,所以被认为是无用信息的词,所以需要提前去掉。停用词包括英文中的介词、代词、连词等,中文中的助词、量词、叹词等。
在深度学习中,是否需要去除停用词,取决于具体的应用场景和需求。
在一些情况下,去除停用词可能会有帮助。例如,当文本数据中停用词的出现频率很高,且并没有太多意义时,去除停用词可以减少计算量,并使得文本中有意义的信息更加突出。
但是,在另一些情况下,去除停用词可能会带来负面影响。例如,在文本分类任务中,停用词可能包含与文本类别相关的信息,如"不"在负面评价中的出现。如果去除了停用词,可能会影响模型的准确性。
词元化
虽然我们去除了一些噪声,计算机依然没有办法把这些文字直接接收作为模型的输入。这时就需要进行一个名为Tokenizations的操作。
关于术语Tokenizations的翻译,其实并不是很一致。有的叫做分词,有的叫做令牌化,还有的叫做标识化。感觉翻译的都不太到位,这里倾向于叫它词元化。
词元化的目标是把输入的文本流,切分成一个个子串,每个子串相对有完整的语义,便于学习embedding表达和后续模型的使用。其中对于英文的切分比较简单,基于空格和一些符号就可以了。中文的词元化一般有三种方法,将文本切分为字或词或词缀。
python
tokens = [list(line) for line in lines ]
for i in range(5):
print(tokens[i])词表
词表是指在自然语言处理(NLP)中,将文本数据中出现的所有词汇组成的列表。词表可以帮助我们了解文本数据中词汇的分布情况,并为后续的文本处理建立基础。
词嵌入
除了这种这种词元索引,深度学习的输入有一种更好的形式------词嵌入 。词嵌入(word embedding)是指将单词 映射成一个实数向量的过程。通常来说,词嵌入会把每个单词映射成一个低维度的实数向量,这个向量可以用来表示单词的语义。
词嵌入的好处在于它能够把单词转换成数值,这样我们就可以使用数值计算来处理单词之间的关系。例如,我们可以使用词嵌入计算两个单词之间的相似度,也可以使用词嵌入计算单词之间的距离。这些计算可以帮助我们解决自然语言处理中的许多问题。
通常来说,词嵌入是使用神经网络学习得到的。可以训练一个神经网络来预测一个单词的上下文,然后使用这个神经网络的隐藏层来表示单词的语义。这里来讲一种最基础的词嵌入方法------独热编码。
独热编码
独热编码是一种常用的特征工程方法,它可以帮助我们把离散特征转换成数值从而输入模型。举个简单的例子,对于这么一句话"猫吃鱼",我们可以用三个简单的向量来表示句子中的每个词。
在独热编码中,每个离散特征都会被映射成一个二进制向量。在猫吃鱼这个例子中,第i个二进制位为1,表示该词是词表的第i个词。猫是第一个词,我们可以用1, 0, 0来表示它,吃是第二个词,就可以用0, 1, 0来表示,同理可以用0, 0, 1来表示第三个词鱼。
比如我们要创建一个索引为1的独热向量就可以用下面的代码实现。
python
import torch
from torch.nn import functional as F
F.one_hot(torch.tensor([0]), len(vocab))tensor([[1, 0, 0, ..., 0, 0, 0]])二、语言模型
简单地说,语言模型就是用来计算一个句子的概率的模型,也就是判断一句话是否是人话的概率。
给定一个词汇集合V,对于一个由V中的词构成的序列S=x1,...,xt,xi∈V,统计语言模型赋予这个序列一个概率p(S),来衡量S符合自然语言的语法和语义规则的置信度,这个p(S)就是语言模型,也叫统计语言模型(Statistical Language Model)。
这里p(S)可以用下面这个公式表示:
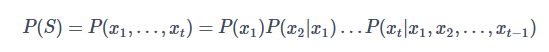
从公式里我们看出来,随着句子长度的增加,条件概率P(x1)P(x2|x1)...P(xt|x1,x2,...,xt−1)的计算会越来越困难。同时,如果语料库不够大,或者词串比较长的话,大部分的词的组合将不会出现,最终会导致数据异常稀疏。
马尔可夫假设和N元语言模型
为了解决计算困难的问题,马尔可夫假设登场了。马尔可夫假设是语言模型中一个重要的概念。它指的是一个单词出现的概率只与前面几个单词有关,与前面的所有单词无关。
例如,有这么一个句子,如果我们已经知道了前几个字 "我家猫吃",此时根据马尔可夫假设,我们可以认为下一个字 "鱼" 出现的概率只与前两个字 "猫吃" 有关,而与句子中其他单词无关。
如果假设一个词的出现与它周围的词是独立的,这样的模型就被称为一元语言模型(unigram),用公式表示如下:
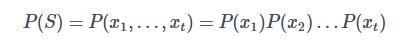
如果我们假设一个词的出现只依赖于它前一个词,而与更前面的词无关,我们就得到了二元语言模型(bigram),公式表示如下:
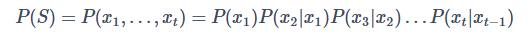
同理,三元语言模型的公式就呼之欲出了:
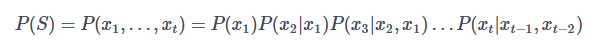
由此我们可以得到N元语言模型的一般表达式:
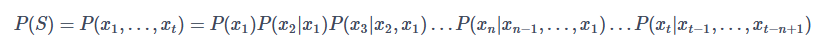
一般来说,N元模型(ngram)就是假设当前词的出现概率只与它前面的N-1个词有关。而这些概率参数都是可以通过大规模语料库来计算的。比如最简单的一元模型,我们假设语料库的总词数为T,则有:
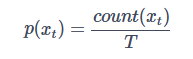
同理,如果是三元模型,则有:
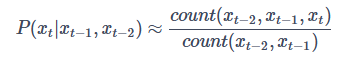
由此可以得到N元模型中,我们可以基于n-gram出现的频率来计算概率:
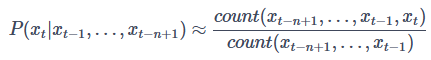
马尔可夫假设是语言模型中常用的一个假设,可以帮助我们简化计算,使得我们能够用更简单的方法来计算一句话中下一个单词的概率。
但是,马尔可夫假设并不能完全准确地描述自然语言,因为在自然语言中,一个单词出现的概率往往还与句子的整体结构有关。因此,在实际应用中,我们常常需要对马尔可夫假设进行修正,以更准确地描述自然语言。
语言模型平滑法
当语料率不够大的时候,如果直接使用训练语料库中出现过的单词来计算概率,就会有一个问题:如果训练语料库中没有出现过的单词出现在句子中,就无法计算它的概率。这个问题在自然语言处理领域常被称为OOV问题,也就是out of vocabulary。
为了解决这个问题,可以使用平滑技术来平滑语言模型的概率分布。平滑技术可以通过在计算概率时给所有单词加上一个小的概率来解决这个问题。这样,即使训练语料库中没有出现过的单词出现在句子中,也可以计算它的概率。
常用的平滑方法有很多,例如拉普拉斯平滑、平均概率平滑和Good-Turing平滑等。这些平滑方法都可以帮助我们在计算概率时避免因训练语料库中没有出现过的单词而产生的问题。
拉普拉斯平滑
拉普拉斯平滑是一种常用的平滑方法,它可以用来平滑语言模型的概率分布。
在计算一个单词的概率时,拉普拉斯平滑会将所有单词的计数加上一个常数 k,然后将所有单词的计数都除以总单词数加上单词表大小乘 k 的和。这样,即使训练语料库中没有出现过的单词出现在句子中,我们也可以计算它的概率。它的公式如下:
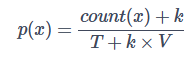
其中,P(x) 是单词 x 的概率,count(x) 是单词 x 在训练语料库中出现的次数,T 是训练语料库中单词的总数,k 是一个平滑参数,V 是单词表的大小。单词 w 的概率等于它在训练语料库中出现的次数加上 k,除以总单词数加上单词表大小乘 k 的和。这样,即使训练语料库中没有出现过的单词出现在句子中,我们也可以计算它的概率。
语言模型的评价
当构造好了一个语言模型后,如何知道模型好还是不好呢?
一种比较常用的方法是计算模型的困惑度(Preplexity),它的基本思想也很简单,就是给测试集赋予较高概率值的语言模型是更高的语言模型。
ngram语言模型的困惑度计算公式如下:
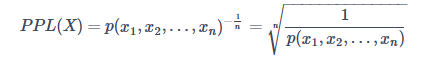
相当于测试集概率的倒数再用单词数做归一化。因为单词序列的条件概率越高,困惑度越低。测试集上困惑度越低,说明模型效果越好。不过,困惑度指标一般只能作为评价模型效果的一个参考。
三、循环神经网络
语言模型除了可以计算一个句子出现的概率,也可以用来预测给定文本情况下,下一个词到底是什么。此时可以就用N元语言模型的公式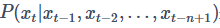 来进行计算了。
来进行计算了。
此时,如果我们把 的序列信息用一个隐变量h来存储,那么公式
的序列信息用一个隐变量h来存储,那么公式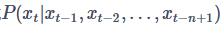 就可以近似等于
就可以近似等于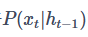 了。那么这个ht−1要如何计算呢?
了。那么这个ht−1要如何计算呢?
我们可以基于t-1时刻的输入x和它上一个时间步,t-2时刻的的隐状态ht−2来计算ht−1的值。此时可以得到隐状态计算公式:
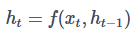
这里面直接用了等于号,是因为理论上讲,隐变量ht是可以存储到t时间步为止观测到的全部数据的。循环神经网络能够处理序列数据的秘密就在于此,它是一种具有隐状态的神经网络。
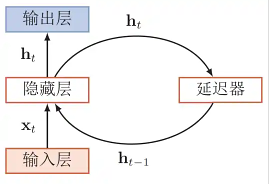
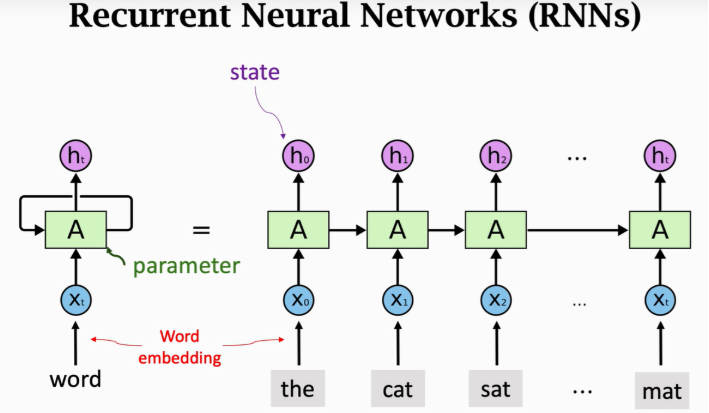
网络结构
RNN模型就是假定不同的层,也就是不同的时间步,共享同一个隐藏层权重矩阵W。 这样既可以让隐藏层包含过去的全部信息,也能够减少模型参数的数量。
在多层感知机中,隐藏层的数学表示为:
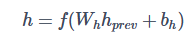
其中,h 是隐藏层的输出,hprev 是上一层(通常是输入层)的输出,Wh 是隐藏层的权值矩阵,bh 是隐藏层的偏置向量,f(⋅) 是激活函数。
那么对于循环神经网络的隐藏层输出,则有如下的数学表示:
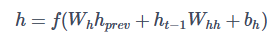
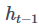 是前一个时间步的隐藏变量,
是前一个时间步的隐藏变量, 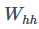 是我们引入的一个新的权重参数。多出来的这一项
是我们引入的一个新的权重参数。多出来的这一项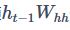 体现了在当前时间步中使用前一个时间步的隐藏变量。当然这只是循环神经网络的一种常见形式。
体现了在当前时间步中使用前一个时间步的隐藏变量。当然这只是循环神经网络的一种常见形式。
代码实现
python
import torch
from torch import nn
from torch.nn import functional as F
import string
from zhon.hanzi import punctuation
import random
# 读取文件,去除标点等无关信息
with open('data/越女剑.txt', 'r') as f:
lines = f.readlines()
exclude = set(punctuation)
tokens = [ ''.join(ch for ch in line if ch not in exclude).replace('\n','') for line in lines]
tokens = [token for line in tokens for token in line]
# 生成词表
vocab = Vocab(tokens)
corpus = [vocab[token] for line in tokens for token in line]
batch_size = 32
num_steps = 35
# 生成数据迭代器
def corpus_data_iterator(corpus, batch_size, num_steps):
offset = random.randint(0, num_steps)
num_tokens = ((len(corpus) - offset - 1) // batch_size) * batch_size
Xs = torch.tensor(corpus[offset: offset + num_tokens])
Ys = torch.tensor(corpus[offset + 1: offset + 1 + num_tokens])
Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)
num_batches = Xs.shape[1] // num_steps
for i in range(0, num_steps * num_batches, num_steps):
X = Xs[:, i: i + num_steps]
Y = Ys[:, i: i + num_steps]
yield X, Y
class DataLoader:
def __init__(self):
self.corpus = corpus
self.batch_size = batch_size
self.num_steps = num_steps
def __iter__(self):
return corpus_data_iterator(self.corpus, self.batch_size, self.num_steps)
train_iter = DataLoader()
num_hiddens = 512
rnn_layer = nn.RNN(len(vocab), num_hiddens)
state = torch.zeros((1, batch_size, num_hiddens))
state.shape
X = torch.rand(size=(num_steps, batch_size, len(vocab)))
Y, state_new = rnn_layer(X, state)
Y.shape, state_new.shape
class RNNModel(nn.Module):
"""循环神经网络模型"""
def __init__(self, rnn_layer, vocab_size, **kwargs):
super(RNNModel, self).__init__(**kwargs)
self.rnn = rnn_layer
self.vocab_size = vocab_size
self.num_hiddens = self.rnn.hidden_size
# 如果RNN是双向的(之后将介绍),num_directions应该是2,否则应该是1
if not self.rnn.bidirectional:
self.num_directions = 1
self.linear = nn.Linear(self.num_hiddens, self.vocab_size)
else:
self.num_directions = 2
self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size)
def forward(self, inputs, state):
X = F.one_hot(inputs.T.long(), self.vocab_size)
X = X.to(torch.float32)
Y, state = self.rnn(X, state)
# 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数)
# 它的输出形状是(时间步数*批量大小,词表大小)。
output = self.linear(Y.reshape((-1, Y.shape[-1])))
return output, state
def begin_state(self, batch_size=1):
if not isinstance(self.rnn, nn.LSTM):
# nn.GRU以张量作为隐状态
return torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens))
else:
# nn.LSTM以元组作为隐状态
return (torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens)),
torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens)))
net = RNNModel(rnn_layer, vocab_size=len(vocab))预测:
python
prefix = '越女'
num_preds = 10
def predict(prefix, num_preds, net, vocab):
state = net.begin_state(batch_size=1)
outputs = [vocab[prefix[0]]]
get_input = lambda: torch.tensor([outputs[-1]]).reshape(1,1)
for y in prefix[1:]: # Warm-up period
_, state = net(get_input(), state)
outputs.append(vocab[y])
for _ in range(num_preds):
y, state = net(get_input(), state)
outputs.append(int(y.argmax(dim=1).reshape(1)))
return ''.join([vocab.idx_to_token[i] for i in outputs])
print(predict(prefix, num_preds, net, vocab))由于没有进行模型训练,现在生成的内容基本上没有任何意义。
训练:
python
num_epochs, lr = 100, 1
criterion = nn.CrossEntropyLoss()
trainer = torch.optim.Adam(net.parameters(), lr)
def grad_clipping(net, theta):
"""Clip the gradient.
Defined in :numref:`sec_rnn_scratch`"""
if isinstance(net, nn.Module):
params = [p for p in net.parameters() if p.requires_grad]
else:
params = net.params
norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))
if norm > theta:
for param in params:
param.grad[:] *= theta / norm
loss_history = []
state = net.begin_state(batch_size=X.shape[0])
for epoch in range(num_epochs):
for X, Y in train_iter:
y = Y.T.reshape(-1)
y_hat, state = net(X, state)
l = criterion(y_hat, y.long()).mean()
trainer.zero_grad()
l.backward()
grad_clipping(net, 1)
trainer.step()
net.eval()
if epoch % 10 == 0:
with torch.no_grad():
total_loss = 0
t = 0
for X, y in train_iter:
y = Y.T.reshape(-1)
y_hat, state = net(X, state)
l = criterion(y_hat, y.long()).mean()
total_loss += l.sum()/l.numel()
t = t+1
avg_loss = total_loss / t
loss_history.append(avg_loss)
print(f'Epoch {epoch+1}: Validation loss = {avg_loss:.4f}')
print(predict(prefix, num_preds, net, vocab))