通过自己实现一个简单的string类,来加深对string底层原理的理解。值得注意的点基本都写在注释中。
一. string.h
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#pragma once
#include <iostream>
#include <string.h>
#include <assert.h>
namespace laosi
{
class string
{
private:
char* _str = nullptr;
size_t _size = 0; // size,capacity都不包含结尾的'\0'
size_t _capacity = 0;
public:
// 语言针对const静态的整型定制的特殊处理,新版本的标准中浮点数也支持了
// 这里不是给初始化列表用的缺省值,因为静态成员变量不走初始化列表
//static const size_t npos = -1;
static const size_t npos;
public:
// 构造
//// 无参
//string()
// :_str(new char[1]{'\0'})
// ,_size(0)
// ,_capacity(0)
//{ }
//// 带参
//string(const char* str)
// :_size(strlen(str))
//{
// _capacity = _size;
// _str = new char[_size + 1]; // 给\0留一个位置
// strcpy(_str, str);
//}
// 无参和带参的构造可以合并成带缺省的带参构造
string(const char* str = "") // 不用给"\0",语言默认自动在常量串后面加'\0'
:_size(strlen(str))
{
_capacity = _size;
_str = new char[_size + 1];
memcpy(_str, str, _size + 1);
}
// 成员函数也可以是模板,模板参数自己推导
// 迭代器区间构造
template <class InputIterator>
string(InputIterator first, InputIterator last)
{
while (first != last)
{
push_back(*first);
first++;
}
}
//// 传统写法,自己开空间、拷贝数据...
//string(const string& s)
//{
// // 拷贝构造实现深拷贝逻辑
// _str = new char[s._capacity + 1];
// memcpy(_str, s._str, s._size + 1);
// _size = s._size;
// _capacity = s._capacity;
//}
//// s1 = s2(传统写法)
//string& operator=(const string& s)
//{
// if (this != &s) // 防止自己给自己赋值,如果下面先释放空间就要出错了
// {
// char* tmp = new char[s._capacity + 1];
// memcpy(tmp, s._str, s._size + 1);
// delete[] _str;
//
// _str = tmp;
// _size = s._size;
// _capacity = s._capacity;
// }
// return *this;
//}
// 现代写法(复用的思想)
// s1(s2)
string(const string& s)
{
// 如果用这个构造,计算_size时用的是strlen遇到\0就停止了,那如果字符串中间就有\0就会出现拷贝不全的情况
// 所以实现一个迭代器的构造
// string tmp(s._str);
string tmp(s.begin(), s.end());
swap(tmp); // this也就是s1 和 tmp也就是s2交换
}
//// s1 = s2(现代写法)
//string& operator=(const string& s)
//{
// if (this != &s)
// {
// string tmp(s);
// swap(tmp);
// }
// return *this;
//}
// s1 = s2(现代写法简洁版)
string& operator=(string tmp)
{
swap(tmp);
return *this;
}
// 重载流插入流提取运算符前,方便打印
const char* c_str() const
{
return _str;
}
// 析构
~string()
{
if (_str)
{
delete[] _str;
_str = nullptr;
_size = 0;
_capacity = 0;
}
}
// 普通迭代器(指向数组的指针可以用原生指针实现)
// 其他比如链表就不可以了,通过封装实现上下层的分离,之后实现其他容器时可看到
typedef char* iterator;
iterator begin();
iterator end();
// const版本迭代器
typedef const char* const_iterator; // 修饰指针指向的内容不能修改
const_iterator begin() const;
const_iterator end() const;
size_t size() const;
size_t capacity() const;
char& operator[](size_t i);
const char& operator[](size_t i) const;
void reserve(size_t n);
void push_back(char ch);
void append(const char* str);
string& operator+=(char ch);
string& operator+=(const char* str);
string& insert(size_t pos, char ch);
string& insert(size_t pos, const char* str);
void erase(size_t pos, size_t len = npos);
size_t find(char c, size_t pos = 0) const;
size_t find(const char* str, size_t pos = 0) const;
size_t rfind(char c, size_t pos = npos) const;
//size_t rfind(const char* str, size_t pos = npos) const; // 从后往前查字符串的版本没实现出来
string substr(size_t pos = 0, size_t len = npos) const;
bool operator>(const string& s) const;
bool operator>=(const string& s) const;
bool operator<(const string& s) const;
bool operator<=(const string& s) const;
bool operator==(const string& s) const;
bool operator!=(const string& s) const;
void clear();
void swap(string& s);
};
// 重载流插入,流提取
std::ostream& operator<<(std::ostream& os, const string& s);
std::istream& operator>>(std::istream& is, string& s);
}二. string.cpp
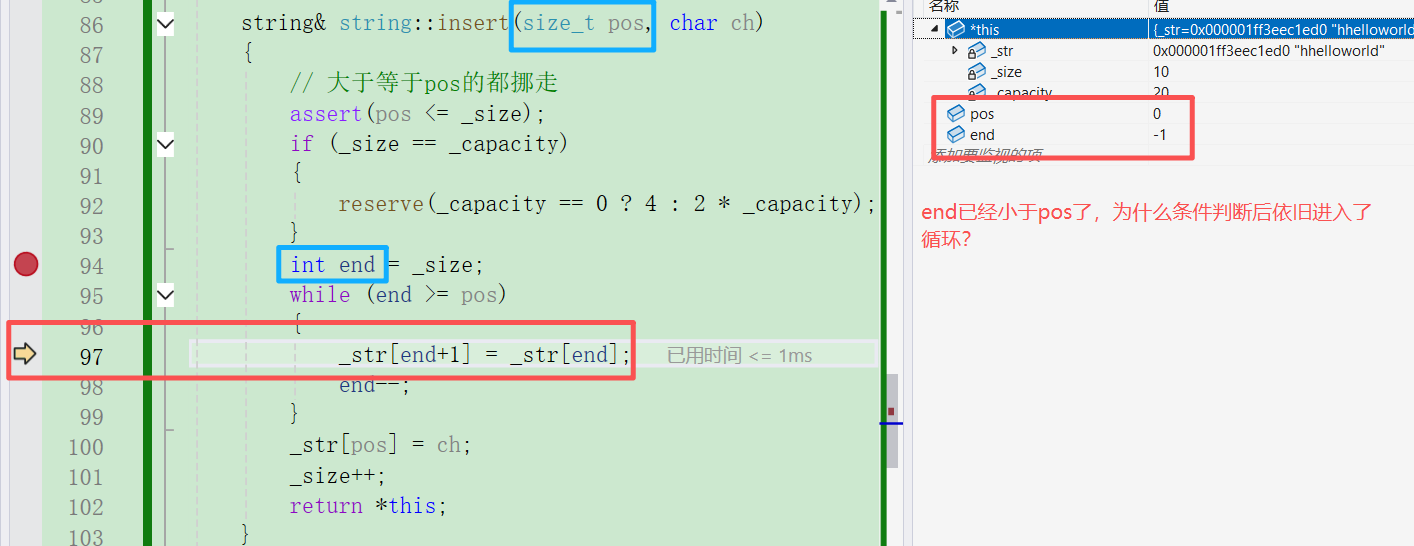
1)insert函数原本的写法是下图这样的,但是会陷入死循环,为什么呢?
-
运算符两边操作数类型不同时会发生类型提升 ,通常范围小的会向范围大的提升。int -> size_t,-1变成整型的最大值,永远大于pos。
-
解决方法
① 比较时将pos强转成int:while(end>=(int)pos
② 改成最终代码中的样子。
2)C++的算法库里有swap,string类里为什么又单独实现了一个?
因为库里的swap实现的是三次深拷贝(两操作数+临时变量),内置类型还好,对于string这种类类型深拷贝开销很大。实际只要交换一下两操作数_str的指向和_size和_capacity就好了,没必要重新开空间、拷贝数据...
3)总结来说一共有三个swap,函数库里有一个模板,string类里有一个成员函数版以及一个全局版。
C++针对string,在全局还重载了一个非成员函数的swap,函数模板和普通函数可以同时存在,会优先调用更合适的现成的函数,而不是根据类型走模板实例化。这样就保证了,调用时无论我们使用s1.swap(s2)还是swap(s1, s2);最终调到的都是效率较高的方法,而不是走函数库中模板的深拷贝。


cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include "string.h"
namespace laosi
{
// 类内定义,类外声明
const size_t string::npos = -1;
size_t string::size() const
{
return _size;
}
size_t string::capacity() const
{
return _capacity;
}
char& string::operator[](size_t i)
{
assert(i < _size);
return _str[i];
}
const char& string::operator[](size_t i) const
{
assert(i < _size);
return _str[i];
}
string::iterator string::begin()
{
return _str;
}
string::iterator string::end()
{
return _str + _size;
}
string::const_iterator string::begin() const
{
return _str;
}
string::const_iterator string::end() const
{
return _str + _size;
}
void string::reserve(size_t n)
{
if (n > _capacity)
{
char* tem = new char[n + 1];
if (_str)
{
// 用memcpy因为strcpy遇到\0就停止了,而我们的字符串内部是可能存在字符'\0'的
memcpy(tem, _str, _size + 1);
delete[] _str;
}
_str = tem;
_capacity = n;
}
}
void string::push_back(char ch)
{
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : 2 * _capacity);
}
_str[_size++] = ch;
_str[_size] = '\0';
}
void string::append(const char* str)
{
int len = _size + strlen(str);
if (len > _capacity)
{
int newlen = 2 * _capacity < len ? len : 2 * _capacity;
reserve(newlen);
}
memcpy(_str+_size, str, strlen(str) + 1);
_size = len;
}
string& string::operator+=(char ch)
{
push_back(ch);
return *this;
}
string& string::operator+=(const char* str)
{
append(str);
return *this;
}
string& string::insert(size_t pos, char ch)
{
// 大于等于pos的都挪走
assert(pos <= _size);
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : 2 * _capacity);
}
size_t end = _size + 1;
while (end > pos)
{
_str[end] = _str[end - 1];
end--;
}
_str[pos] = ch;
_size++;
return *this;
}
string& string::insert(size_t pos, const char* str)
{
assert(pos <= _size);
// 扩容
int len = strlen(str);
if (_size + len > _capacity)
{
int newlen = 2 * _capacity < _size + len ? _size + len : 2 * _capacity;
reserve(newlen);
}
// 挪动数据
size_t end = _size + len;
while (end >= pos + len)
{
_str[end] = _str[end - len];
end--;
}
// 插入字符串
for (size_t i = 0; i < len; i++)
{
_str[pos + i] = str[i];
}
_size += len;
return *this;
}
void string::erase(size_t pos, size_t len)
{
assert(pos < _size);
// 全删
if (len == npos || _size <= pos + len)
{
_str[pos] = '\0';
_size = pos;
}
else
{
// 删pos及后面的一部分,挪动覆盖
memmove(_str + pos, _str + pos + len, _size + 1 - (pos + len)); // 左闭右开,第三个参数_size如果不+1\0就没有被挪动
_size -= len;
}
}
size_t string::find(char c, size_t pos) const
{
assert(pos < _size);
for (size_t i = pos; i < _size; i++)
{
if (_str[i] == c)
return i;
}
return npos;
}
size_t string::find(const char* str, size_t pos) const
{
assert(pos < _size);
char* p = strstr(_str + pos, str); // 这里记得加pos不然每次都从头开始找
if (p == nullptr)
{
return npos;
}
else
{
return p - _str;
}
}
size_t string::rfind(char c, size_t pos) const
{
if (pos == npos) pos = _size - 1;
assert(pos < _size);
for (int i = pos; i >= 0; i--)
{
if (_str[i] == c)
return i;
}
return npos;
}
string string::substr(size_t pos, size_t len) const
{
assert(pos < _size);
if (len > _size - pos)
{
len = _size - pos;
}
string ret;
ret.reserve(len);
for (size_t i = 0; i < len; i++)
{
ret += _str[pos + i];
}
// 需要重载深拷贝的拷贝构造,否则函数返回一个浅拷贝的临时对象------和ret指向同一片空间
// ret作为局部对象出了函数就析构,把返回的对象指向的空间带走,变成野指针,测试时就会报错
return ret;
}
bool string::operator>(const string& s) const
{
size_t len1 = _size, len2 = s._size;
size_t i1 = 0, i2 = 0;
while (i1 < len1 && i2 < len2)
{
if (_str[i1] > s._str[i2]) return true;
else if (_str[i1] < s._str[i2]) return false;
else
{
i1++;
i2++;
}
}
return i1 < len1 && i2 == len2;
}
bool string::operator>=(const string& s) const
{
return *this > s || *this == s;
}
bool string::operator<(const string& s) const
{
return !(*this >= s);
}
bool string::operator<=(const string& s) const
{
return !(*this > s);
}
bool string::operator==(const string& s) const
{
size_t len1 = _size, len2 = s._size;
size_t i1 = 0, i2 = 0;
while (i1 < len1 && i2 < len2)
{
if (_str[i1] != s._str[i2]) return false;
else
{
i1++;
i2++;
}
}
return i1 == len1 && i2 == len2;
}
bool string::operator!=(const string& s) const
{
return !(*this == s);
}
void string::clear() // 只清内容,不清空间
{
_str[0] = '\0';
_size = 0;
}
std::ostream& operator<<(std::ostream& os, const string& s)
{
for (size_t i = 0; i < s.size(); i++)
{
os << s[i];
}
return os;
}
// 优化版,减少如果输入长串频繁扩容开销
std::istream& operator>>(std::istream& is, string& s)
{
s.clear();
char buff[256];
size_t i = 0;
char ch = is.get();
while (ch != ' ' && ch != '\n')
{
buff[i++] = ch;
ch = is.get();
if (i == 255)
{
buff[i] = '\0';
s += buff;
i = 0;
}
}
if (i > 0)
{
buff[i] = '\0';
s += buff;
}
return is;
}
// 简单够用版
//std::istream& operator>>(std::istream& is, string& s)
//{
// // 先将原来的字符串清空
// s.clear();
// char ch;
// //is >> ch; // 会导致下面输入陷入死循环,因为>>认为空格和换行是字符串的分隔符,不会作为一个真正的字符被读取
// // 应该使用get()函数,他不区分接收到的是什么字符,一律输入
// // get()是istream类的一个公有函数
// ch = is.get();
// while (ch != ' ' && ch != '\n')
// {
// s += ch;
// ch = is.get();
// }
// return is;
//}
// C++的算法库里有swap,string类里为什么又单独实现了一个?
// 因为库里的swap实现的是三次深拷贝(两操作数 + 临时变量),开销上内置类型还好,对于string这种自定义类型深拷贝开销很大
// 实际只要交换一下指针的指向和_size和_capacity就好了
void string::swap(string& s)
{
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
}三. test.cpp
cpp
#define _CRT_SECURE_NO_WARNINGS 1
using namespace std;
#include "string.h"
namespace laosi
{
void Test01() // 构造、析构
{
string s1; // 无参构造
cout << s1.c_str() << endl;
string s2("hello world"); // 带参构造
cout << s2.c_str() << endl;
}
void Test02() // 下标加[]访问
{
string s1("hello world");
for (size_t i = 0; i < s1.size(); i++)
cout << s1[i] << ' ';
cout << endl;
string s2("hello world");
for (size_t i = 0; i < s2.size(); i++)
{
s2[i]++;
cout << s2[i] << ' ';
}
cout << endl;
const string s3("hello world");
for (size_t i = 0; i < s3.size(); i++)
{
// s3[i]++; // const版本的operator[]返回const对象,不可修改
cout << s3[i] << ' ';
}
cout << endl;
}
void Test03() // 迭代器
{
string s1("hello world");
string::iterator it = s1.begin();
//for (size_t i = 0; i < s1.size(); i++)
while(it != s1.end())
{
(*it)++; // 修改迭代器指向的内容
cout << *it << " ";
it++; // 修改迭代器本身的指向
}
cout << endl;
// 支持迭代器就支持范围for,范围for就是替换成迭代器实现的
for (auto e : s1)
{
cout << e << " ";
}
cout << endl;
}
void Test04() // 尾插、追加
{
string s1("hello ");
s1.push_back('w');
s1.push_back('o');
s1.push_back('r');
s1.push_back('l');
s1.push_back('\0');
for (auto e : s1)
{
cout << e << " ";
}
cout << endl;
s1.append("hello laosi");
for (auto e : s1)
{
cout << e << " ";
}
cout << endl;
}
void Test05() // insert , erase
{
//string s1("helloworld");
//s1.insert(5, '#'); // hello#world
//for (auto e : s1)
// cout << e << " ";
//cout << endl;
//// 头插
//string s3("helloworld");
//s3.insert(0, '#'); // #helloworld
//for (auto e : s3)
// cout << e << " ";
//cout << endl;
//// 删完
//s1.erase(5, 30);
//for (auto e : s1)
// cout << e << " ";
//cout << endl; // hello
//s1.erase(2, -1); // npos
//for (auto e : s1)
// cout << e << " ";
//cout << endl; // he
//// 删部分
//string s2("hello laosia");
//s2.erase(6, 3);
//for (auto e : s2)
// cout << e << " ";
//cout << endl; // hello sia
string s4("hello world");
s4.insert(6, "hello");
s4.insert(0, "hello "); // hello hello helloworld
for (auto e : s4)
cout << e;
cout << endl;
}
void Test06() // find, rfind, substr,拷贝构造,赋值运算符重载=
{
// 取后缀find
string s1("Test.cpp");
size_t pos = s1.find('.');
cout << pos << endl;
string ret;
if (pos != string::npos)
ret = s1.substr(pos); // 赋值操作,需要重载赋值运算符
cout << ret.c_str() << endl;
// 只取真正的后缀.zip rfind
string s3("Tziest.tar.zip");
size_t pos3 = s3.rfind('.');
cout << pos3 << endl;
if (pos3 != string::npos)
ret = s3.substr(pos3); // 赋值操作,需要重载赋值运算符
cout << ret.c_str() << endl;
string s2 = "https://legacy.cplusplus.com/reference/string/string/find/";
size_t pos1 = s2.find(":");
if (pos1 != string::npos)
{
string sub1 = s2.substr(0, pos1); // 初始化,需要拷贝构造
cout << sub1.c_str() << endl;
}
size_t pos2 = s2.find("/", pos1 + 3);
if (pos2 != string::npos)
{
//string sub2 = s2.substr(pos1 + 3, pos2); // 注意第二个参数是子串长度,不是结束位置
string sub2 = s2.substr(pos1 + 3, pos2 - (pos1 + 3));
string sub3 = s2.substr(pos2 + 1);
cout << sub2.c_str() << endl << sub3.c_str() << endl;
}
}
void Test07() // relational operators
{
//string s1 = "hello world";
//string s2 = "hello world";
//string s3 = "hello";
//if (s1 > s2) cout << 1 << endl;
//else cout << 0 << endl;
//if (s1 >= s3) cout << 1 << endl;
//else cout << 0 << endl;
//if (s3 < s2) cout << 1 << endl;
//else cout << 0 << endl;
//if (s1 <= s2) cout << 1 << endl;
//else cout << 0 << endl;
//if (s1 == s2) cout << 1 << endl;
//else cout << 0 << endl;
//if (s1 != s3) cout << 1 << endl;
//else cout << 0 << endl;
//// 011111
string s1 = "helloworld";
string s2 = "hello";
s2 += '\0';
s2 += "world";
if (s1 != s2) cout << 1 << endl;
else cout << 0 << endl;
}
void Test08() // 重载流插入、流提取
{
string s1 = "hello world";
cout << s1 << endl;
cin >> s1;
cout << s1 << endl;
}
// 算法库做法:深拷贝
template <class T> void swap(T& a, T& b)
{
T c(a); a = b; b = c;
}
// 针对string,在全局重载了一个非成员函数的swap
void swap(string& x, string& y)
{
x.swap(y);
}
void Test09() // swap(成员函数), swap(全局函数)
{
// 实际两种最终调用的都是效率更高的成员函数版本,而不是函数库中深拷贝的版本
string s1 = "hello world";
string s2 = "hi laosi";
cout << s1 << endl;
cout << s2 << endl;
s1.swap(s2); // 成员函数
cout << s1 << endl;
cout << s2 << endl;
swap(s1, s2); // 针对string的全局swap
cout << s1 << endl;
cout << s2 << endl;
}
}
int main()
{
//laosi::Test01();
//laosi::Test02();
//laosi::Test03();
//laosi::Test04();
//laosi::Test05();
laosi::Test06();
//laosi::Test07();
//laosi::Test08();
//laosi::Test09();
return 0;
}