目录
- 一、前言
- 二、RAG架构相关概念
-
- [2.1 什么是RAG架构,解决了什么问题](#2.1 什么是RAG架构,解决了什么问题)
- [2.2 RAG应用的基本流程是怎样的](#2.2 RAG应用的基本流程是怎样的)
- [2.3 RAG架构的关键节点有哪些](#2.3 RAG架构的关键节点有哪些)
- 三、文档加载器
-
- [3.1 基本概念](#3.1 基本概念)
- [3.2 CSVLoader](#3.2 CSVLoader)
- [3.3 PDFLoader](#3.3 PDFLoader)
- [3.4 JSONLoader](#3.4 JSONLoader)
- [3.5 TextLoader](#3.5 TextLoader)
- [四、向量数据库(vector stores)](#四、向量数据库(vector stores))
-
- [4.1 InMemoryVectorStore](#4.1 InMemoryVectorStore)
- [4.2 Chroma](#4.2 Chroma)
- [4.3 Milvus](#4.3 Milvus)
- 五、rerank重排序
- [六、 一个完整的rag代码示例](#六、 一个完整的rag代码示例)
一、前言
这个系列博客主要打算汇总一下python大模型开发的所有知识体系,大模型知识点太多,包括langchain、langgraph、deepagent、RAG应用等等,时间长了脑子就乱子,这篇博客主要汇总一下基于langchain的RAG开发的相关知识点,重点在整个流程和原理,只要弄懂了原理,不一定是基于langchain,用java调用各个组件,也是可以实现rag的大部分流程
二、RAG架构相关概念
2.1 什么是RAG架构,解决了什么问题
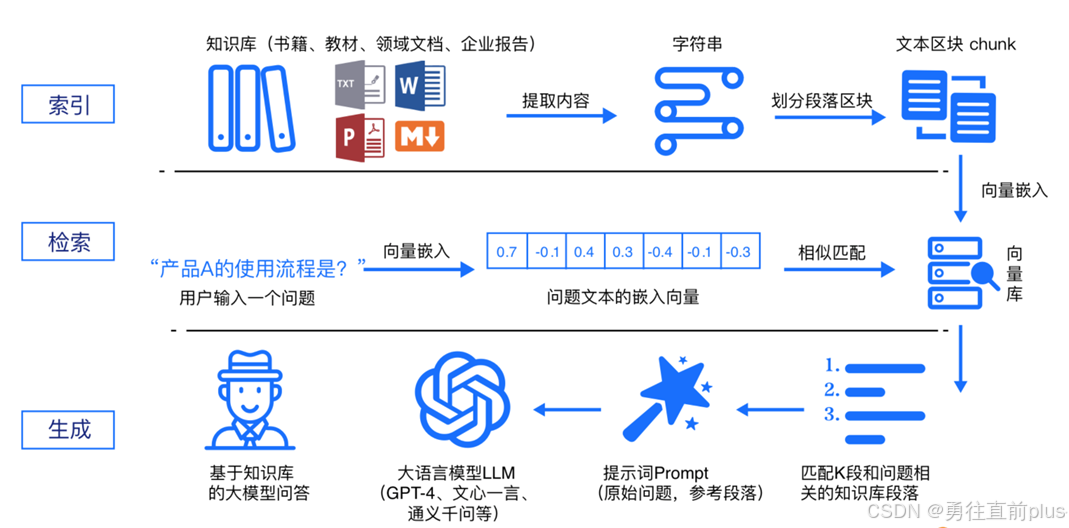
- RAG (Retrieval-Augmented Generation,检索增强生成)的核心思想是在大模型生成回答之前,先从外部知识库中"检索"出相关的实时信息,并将这些信息作为背景上下文提供给模型,然后大模型根据检索到的外部信息给出回答。
- RAG 解决了大模型应用开发的三个问题:
- 幻觉问题: 模型会一本正经地胡说八道。RAG 让模型"看书考试",有据可依。
- 知识滞后: 模型的预训练数据有截止日期,最近的信息和知识不在大模型的训练数据中,RAG 可以实时接入最新的新闻、财报或行业动态。
- 数据安全与私有化: RAG 可以在本地检索私有文档,而不泄露原始数据。
2.2 RAG应用的基本流程是怎样的
- RAG应用一般分为以下多个流程,可以参考上述的框架图
- 加载数据并切片: 将 PDF、csv等多种格式的数据读取进来,如果数据量过大可以切片,切成一个个小片段,因为模型有上下文长度限制,且小块更方便精准匹配。
- 向量化(Embedding): 利用 嵌入大模型 将文本块转化为向量。
- 存储(Store): 将向量存入专用的向量数据库。
- 检索:用户提出问题,将用户问题调用嵌入大模型生成embedding,然后向量数据库检索,检索完成之后可以再走rerank精排(这个可选,看场景),然后将检索精排后的信息,整合进提示词,调用大模型回答
2.3 RAG架构的关键节点有哪些
因此,根据上述RAG的基本流程,要构建一个高性能的 RAG 应用,需要关注以下核心节点:
-
文档清洗与切片
- 重叠度(Overlap): 切片时每一段通常会保留一部分上一段的内容,防止语义被强行切断。
- 关键点: 切片太大包含噪音多,切片太小丢失语义。
-
向量数据库(Vector DB)
它是 RAG 的"外挂大脑"。常见的向量数据库包括:
- 本地/轻量: Chroma, Faiss
- 企业级/云原生: Milvus, Pinecone, Elasticsearch
-
重排序(Rerank)
向量数据库检索可能找回 10 条相关信息,然后经过rerank精排,Reranker 模型会对这 10 条结果进行二次深度打分,确保最精准的信息排在最前面,留下与问题最相关的三条核心数据,然后只把这三条发送给大模型作为回答的依据。
-
提示词工程
告诉模型:"请参考以下资料回答问题,如果资料中没有,请回答不知道,不要瞎编。"
三、文档加载器
3.1 基本概念
-
顾名思义,文档加载器就是将外部数据(pdf,csv,html)加载到程序,然后合理地进行切片的一种组件,每种外部数据的结构、加载方式都不相同,因此这个任务还是具备一定的复杂性。
-
langchain的文档加载器都实现了BaseLoader接口,提供了一套标准接口,用于将不同来源(如 CSV、PDF 或 JSON等)的数据读取为 LangChain 的文档格式。这确保了无论数据来源如何,都能对其进行一致性处理。然后处理后的结果也都是统一的。
-
标准输出: 无论加载什么格式,返回的都是统一的 Document 对象。这个对象包含两个核心属性:
- page_content: 文本内容。
- metadata: 来源、页码等元数据,方便后续检索时回溯。
-
Class Document,是LangChain内文档的统一载体,所有文档加载器最终返回此类的实例。一个基础的Document类实例如下所示
pythonfrom langchain_core.documents import Document document = Document( page_content="Hello, world!", metadata={"source": "https://example.com"} ) -
不同的文档加载器可能定义了不同的参数,但是其都实现了统一的接口(方法)。
- load():一次性加载全部文档
- lazy_load():延迟流式传输文档,对大型数据集很有用,避免内存溢出。
3.2 CSVLoader
-
CSVLoader 的核心逻辑是将 CSV 的每一行转换为一个 Document 对象。默认情况下,它会把每一列的列名和对应的值拼接成一段文本。
pythonfrom langchain_community.document_loaders.csv_loader import CSVLoader loader = CSVLoader( file_path="salary_data.csv", csv_args={ "delimiter": ",", # 指定分隔符 "quotechar": '"', # 指定引号符 "fieldnames": ["Name", "Job", "Salary"] # 如果文件没表头,可以手动指定 } ) data = loader.load() # data是个Document类对象列表 -
默认情况下,Document 的元数据中 source 是文件路径。如果你希望在检索结果中显示该行数据的唯一标识(如 ID 或标题,或者某一个表头字段),可以使用此参数。
pythonloader = CSVLoader(file_path="products.csv", source_column="product_id") # 加载后,doc.metadata['source'] 就会变成该行对应的 product_id -
如果不希望某些列出现在 page_content(即不参与生成embedding),而是希望把它们存在 metadata 中备查,这个参数就派上用场了。
python# 假设 CSV 有 ID, Content, Date 三列 # 我们只想让模型学习 Content,而把 ID 和 Date 作为元数据 loader = CSVLoader( file_path="news.csv", metadata_columns=["ID", "Date"] )
3.3 PDFLoader
-
LangChain 提供了多种 PDF 加载方式,最主流且推荐的是 PyPDFLoader,PyPDFLoader提供两种基本模式,一种是将每一页加载成一个Document 对象,另一种是将整个PDF文档加载成一个Document 对象,一般情况下,page模式(一页一个Document)是最常用的。
pythonfrom langchain_community.document_loaders import PyPDFLoader loader = PyPDFLoader( file_path="./data/langchain.pdf", mode="page", password="password")
3.4 JSONLoader
-
LangChain 加载器中相对"复杂"的一个,因为JSON是结构化数据,不是纯文本数据,因此我们需要提取到外部JSON数据的有效信息。
-
如果直接把一整个 JSON 丢给模型,冗余的括号、键名会浪费大量的 Token。 JSONLoader 的核心优势在于它支持 JQ 语法,允许我们像手术刀一样,只提取 JSON 中真正有用的文本内容,封装为Document对象。
-
使用 JSONLoader 需要安装 jq 库(JSON 处理器) ,jq语法如下所示

-
假设有个用户的Json文件:
java[ {"name": "Alice", "bio": "AI 开发者,擅长 Python。"}, {"name": "Bob", "bio": "后端工程师,深耕 Java。"} ] -
对应的加载程序:
pythonfrom langchain_community.document_loaders import JSONLoader # .[] 表示遍历数组,.bio 表示提取 bio 字段的内容 loader = JSONLoader( file_path="users.json", jq_schema=".[].bio", text_content=False, # 抽取的数据是否是字符串,默认是true,只要抽取的数据是[xx]或者{xxx},这个设为false json_lines=False # 是否是jsonLines文件(每一行都是一个完整的json串) ) docs = loader.load() print(docs[0].page_content) # 输出: AI 开发者,擅长 Python。
3.5 TextLoader
-
除了前面三个Loader以外,还有一个基本的加载器:TextLoader,作用是读取文本文件(如.txt),将全部内容放入一个Document对象中。
pythonfrom langchain_community.document_loaders import TextLoader # 初始化加载器 loader = TextLoader("./my_data.txt", encoding='utf-8') # 执行加载 docs = loader.load() # 查看结果 print(docs[0].page_content) # 文本内容 print(docs[0].metadata) # 默认包含 {'source': './my_data.txt'} -
如果文本很大,把所有文本加载成一个Document就不太合适,可以配合使用RecursiveCharacterTextSplitter,递归字符文本分割器,主要用于按自然段落分割大文档。RecursiveCharacterTextSplitter是LangChain官方推荐的默认字符分割器,它在保持上下文完整性和控制片段大小之间实现了良好平衡
pythonfrom langchain_community.document_loaders import TextLoader from langchain_text_splitters import RecursiveCharacterTextSplitter # 1. 加载文档 loader = TextLoader("your_file.txt", encoding="utf-8") raw_documents = loader.load() # 2. 初始化切分器 text_splitter = RecursiveCharacterTextSplitter( chunk_size=500, # 每个分块的最大字符数 chunk_overlap=50, # 相邻分块之间的重叠字符数(保持上下文连贯) length_function=len, # 指定计算长度的函数 separators=["\n\n", "\n", " ", ""] # 切分的优先级顺序 ) # 3. 执行切片 documents = text_splitter.split_documents(raw_documents) print(f"切分前:1 个文档") print(f"切分后:{len(documents)} 个文档分块") -
切分结果和示例如下所示:
python# 假设txt文档如下所示: "我是人工智能。我今天很高兴能为你服务。希望我们合作愉快。" # 切分结果如下: 第 1 块: 内容:我是人工智能。我今天很高兴 (共 14 字) 解释:快满 15 个字了,在这里切断。 第 2 块: 内容:今天很高兴能为你服务。 (共 11 字) 解释:因为它要向回重叠 5 个字,所以它从第 1 块的末尾提取了"今天很高兴"这 5 个字作为开头。 第 3 块: 内容:为你服务。希望我们合作 (共 11 字) 解释:同理,从第 2 块末尾提取"为你服务。"作为开头。
四、向量数据库(vector stores)
- 基于LangChain的向量存储,存储嵌入数据,并执行相似性搜索。这里介绍三个常用的向量数据库,InMemoryVectorStore、Chroma 以及 Milvus,每个向量库有自己的适用场景,langchain都有比较好的支持。
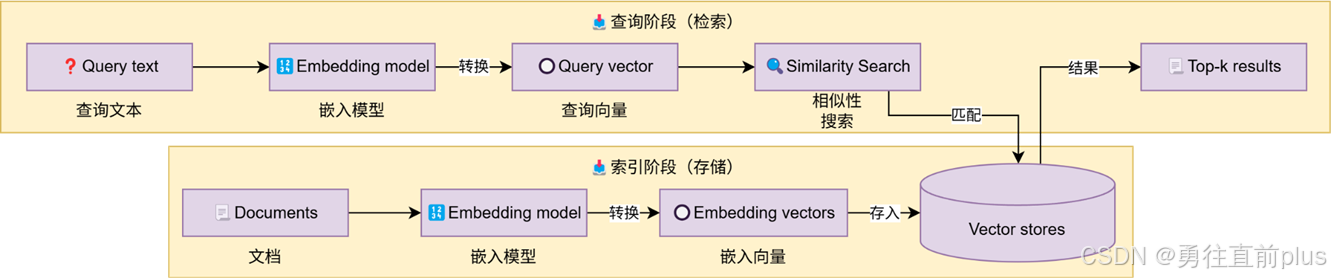
- 向量数据库属于RAG应用开发的核心环节,提前将知识库Document文档调用嵌入大模型,生成向量,然后插入向量数据库中;对于用户的问题,也生成嵌入,然后在向量库检索,将检索出来的信息,再走rerank,或者直接走大模型节点。
4.1 InMemoryVectorStore
-
这是 LangChain 核心库(langchain-core)自带的一个内存实现,主要适用于演示、单元测试或极短生命周期的场景,基于内存存储向量,重启程序数据丢失;
pythonfrom langchain_core.vectorstores import InMemoryVectorStore from langchain_community.embeddings import DashScopeEmbeddings vector_store = InMemoryVectorStore(embedding=DashScopeEmbeddings()) # 在向量库中指定嵌入大模型 vector_store.add_documents(documents=[doc1, doc2], ids=["id1", "id2"]) # 添加向量,指定id vector_store.delete(ids=["id1"])# 删除文档(通过指定的id删除) # 相似性搜索 similar_docs = vector_store.similarity_search("your query here", 4)
4.2 Chroma
-
Chroma 是目前 LLM 开发者最常用的数据库之一,使用很简单,支持持久化到本地磁盘(保存为一个 chroma.sqlite3 文件及相关文件夹),但是不支持水平扩展,只适合单机架构,适合100万数据量以下的应用场景
pythonfrom langchain_community.embeddings import DashScopeEmbeddings from langchain_chroma import Chroma # 1. 初始化向量库 vector_store = Chroma( collection_name="example_collection", embedding_function=DashScopeEmbeddings(), persist_directory="./chroma_langchain_db", ) # 2. 添加文档(带上元数据) # 注意:过滤是基于 metadata 字典里的键值对 doc1_with_meta = doc1 # 假设 doc1.metadata = {"category": "tech", "year": 2024} doc2_with_meta = doc2 # 假设 doc2.metadata = {"category": "news", "year": 2023} vector_store.add_documents(documents=[doc1_with_meta, doc2_with_meta], ids=["id1", "id2"]) # 3. 混合检索(向量相似度 + 元数据过滤) # 需求示例:搜索"AI",且只要 category 为 "tech" 的文档 similar_docs = vector_store.similarity_search( query="your query here", k=4, filter={"category": "tech"} # 这里的字典就是标量/元数据过滤条件 )
4.3 Milvus
-
Milvus 是一款为海量数据设计的分布式向量数据库。一般是我们在公司实际项目的首选,milvus有原生的java和python的SDK,当然,langchain也对milvus有很好的支持,可以直接通过langchain框架操作milvus。
特性 Chroma Milvus 定位 轻量级、开发者友好、单机 企业级、分布式、高性能 扩展性 弱(单机限制) 强(支持集群、读写分离、水平扩展) 数据规模 百万级以下 亿级、十亿级甚至更多 部署方式 Python 库直接调用 / 单容器 Docker Compose / Kubernetes 集群 高级功能 基础元数据过滤 动态 schema、多种索引类型(IVF, DiskANN)、高可用 -
milvus在企业中是一个非常常用的向量库,关于milvus的使用、部署等可以参考我的其他博客,对这个数据库我做了不少讲解。
pythonfrom langchain_milvus import Milvus from langchain_community.embeddings import DashScopeEmbeddings # 1. 初始化 Milvus 向量库 vector_store = Milvus( embedding_function=DashScopeEmbeddings(), connection_args={"uri": "http://localhost:19530"}, # 或者远程地址 collection_name="example_collection", auto_id=False # 如果你要手动指定 ids,建议关闭 auto_id ) # 2. 模拟添加文档(带元数据) # 假设 doc1.metadata = {"category": "tech", "tag": 1} # 假设 doc2.metadata = {"category": "news", "tag": 2} vector_store.add_documents(documents=[doc1, doc2], ids=["id1", "id2"]) # 3. 混合检索:向量相似度 + 元数据过滤 # Milvus 的 expr 类似于 SQL 语句的 WHERE 子句 similar_docs = vector_store.similarity_search( query="AI的发展趋势", k=4, # 标量过滤:只看分类是 tech 且 tag 大于 0 的数据 expr='category == "tech" and tag > 0' ) for doc in similar_docs: print(f"内容: {doc.page_content} | 元数据: {doc.metadata}")
五、rerank重排序
-
向量数据库的embedding检索的优势是速度极快,但存在一个缺点:比较粗糙,返回来的数据可能只是关键词长得像,实际语义并不是很匹配,此时,就需要rerank精排了。rerank大模型是直接基于文本进行深度语义比较并排序,精确计算相关得分值。rerank这一步不是必须的,可以根据实际场景选择使用。
-
langchain 对国内的rerank大模型适配的不是很好,我们可以基于模型厂商提供的原生sdk或者基于http接口进行调用。
pythonimport dashscope from http import HTTPStatus def text_rerank(): resp = dashscope.TextReRank.call( model="qwen3-rerank", query="什么是文本排序模型", documents=[ "文本排序模型广泛用于搜索引擎和推荐系统中,它们根据文本相关性对候选文本进行排序", "量子计算是计算科学的一个前沿领域", "预训练语言模型的发展给文本排序模型带来了新的进展" ], top_n=10, return_documents=True, instruct="Given a web search query, retrieve relevant passages that answer the query." ) if resp.status_code == HTTPStatus.OK: print(resp) else: print(resp) if __name__ == '__main__': text_rerank()
六、 一个完整的rag代码示例
python
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.vectorstores import Milvus
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.output_parsers import StrOutputParser
#--------------------1. 构建知识库----------------------------
# 1. 加载文档
loader = TextLoader("your_file.txt", encoding="utf-8")
raw_document = loader.load()
# 2. 初始化切分器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每个分块的最大字符数
chunk_overlap=50, # 相邻分块之间的重叠字符数(保持上下文连贯)
length_function=len, # 指定计算长度的函数
separators=["\n\n", "\n", " ", ""] # 切分的优先级顺序
)
documents = text_splitter.split_documents(raw_document)
milvus = Milvus(
embedding_function=DashScopeEmbeddings(),
connection_args={"uri": "http://localhost:19530"}, # 或者远程地址
collection_name="example_collection",
auto_id=False # 如果你要手动指定 ids,建议关闭 auto_id
)
milvus.add_documents(documents)
#--------------------2.检索知识库------------------------------
res_documents = milvus.similarity_search(
query="AI的发展趋势",
k=4,
)
#--------------------3.构建提示词模板,将检索结果 注入提示词-----------
prompt = ChatPromptTemplate.from_messages(
[
("system","以我提供的参考资料为主,简洁回答用户问题:{text}"),
("user","用户提问:{input}")
]
)
reference_text = "["
for doc in res_documents:
reference_text += doc.page_content
reference_text += "]"
#-------------------------4.构建大模型节点-------------------------
llm = ChatTongyi(
api_key="",
model = "deepseek-v3"
)
input = "回答一下你是谁"
chain = prompt | llm | StrOutputParser()
chain.invoke({"text": reference_text, "input": input})