最近刷到通义千问刚发布的旗舰推理模型 Qwen3-Max-Thinking,看完它的测试报告我直接坐不住了 ------ 这性能已经能对标 GPT-5.2、Claude Opus 4.5 这些顶流模型了?今天就带大家拆解这份测试报告,用大白话讲清楚它到底有多能打。
一、先搞懂:Qwen3-Max-Thinking 是什么?
简单来说,这是通义千问最新的「旗舰推理版」大模型,核心特点就是推理能力拉满。它通过大幅增加模型参数规模,再投入海量强化学习算力训练,在 19 项权威基准测试(相当于 AI 界的「高考卷」)中,表现已经能媲美 GPT-5.2-Thinking、Claude-Opus-4.5、Gemini 3 Pro 这些顶尖模型。
它还带了两个「黑科技」:
- 自适应工具调用:不用你手动选工具,模型会自己判断什么时候该用搜索、记忆或代码解释器。比如你问「今天北京天气」,它会自动调用搜索工具查实时数据;你写代码时,它会自动启动代码解释器帮你运行验证。
- 测试时扩展技术(TTS):这是提升推理能力的关键。它不是简单增加推理路径数量,而是通过「经验累积式多轮迭代」避免冗余推理,把有限的计算资源用在刀刃上。比如在「GPQA Diamond」(博士级科学题)测试中,开启 TTS 后得分从 87.4 直接冲到 92.8,提升非常明显。
二、表格深度分析:和顶流模型比,它到底赢在哪?
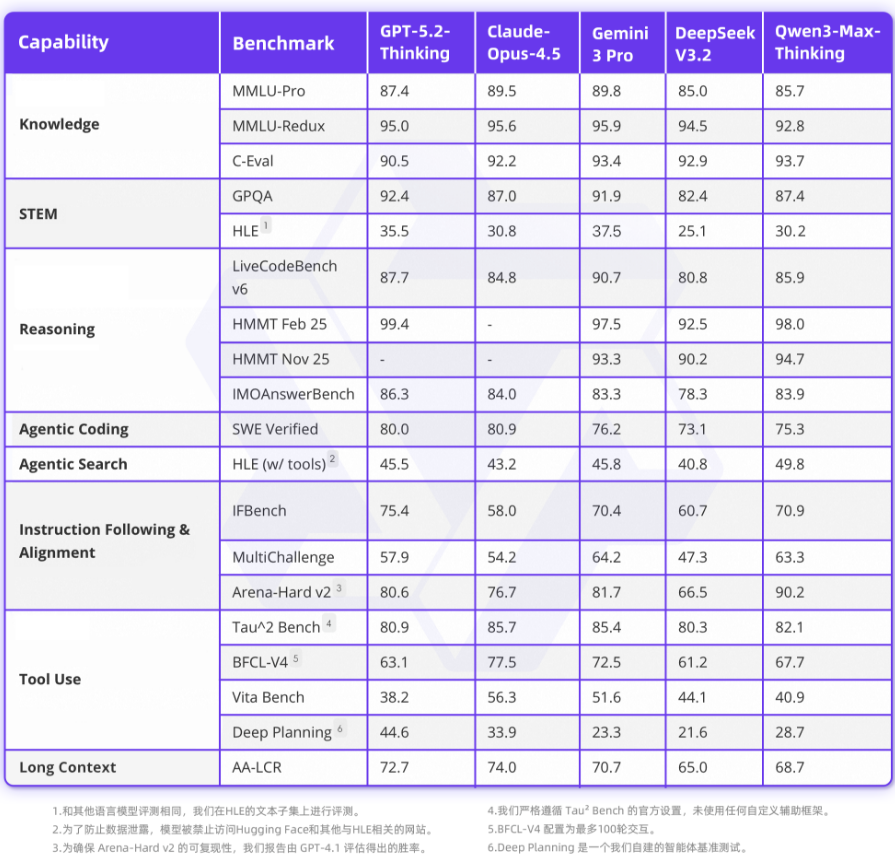
我把测试报告里的核心对比表拆成 8 个能力维度,用大白话给你讲清楚每个维度的表现:
1. 知识储备(Knowledge)
| 测试项 | Qwen3-Max-Thinking | GPT-5.2-Thinking | Claude Opus 4.5 |
|---|---|---|---|
| MMLU-Pro(综合知识) | 85.7 | 87.4 | 89.5 |
| MMLU-Redux(进阶知识) | 92.8 | 95.0 | 95.6 |
| C-Eval(中文知识) | 93.7 | 90.5 | 92.2 |
✅ 亮点 :在中文知识测试(C-Eval)中反超 GPT-5.2,得分 93.7,说明对中文场景的适配度非常高。⚠️ 不足:综合知识(MMLU-Pro)略逊于 GPT-5.2 和 Claude,但差距很小。
2. STEM 能力(科学 / 技术 / 工程 / 数学)
| 测试项 | Qwen3-Max-Thinking | GPT-5.2-Thinking | Gemini 3 Pro |
|---|---|---|---|
| GPQA(博士级科学题) | 87.4 | 92.4 | 91.9 |
| HLE(高等逻辑题) | 30.2 | 35.5 | 37.5 |
✅ 亮点 :GPQA 得分 87.4,虽然比 GPT-5.2 低,但已经超过 Claude Opus 4.5(87.0)。⚠️ 不足:HLE(高等逻辑题)得分 30.2,和 GPT-5.2 的 35.5 还有差距,这部分还有提升空间。
3. 推理能力(Reasoning)
| 测试项 | Qwen3-Max-Thinking | GPT-5.2-Thinking | DeepSeek V3.2 |
|---|---|---|---|
| LiveCodeBench v6(竞赛编程题) | 85.9 | 87.7 | 80.8 |
| HMMT Feb 25(数学竞赛题) | 98.0 | 99.4 | 92.5 |
| IMOAnswerBench(IMO 级数学题) | 83.9 | 86.3 | 78.3 |
✅ 亮点 :数学竞赛题(HMMT Feb 25)得分 98.0,几乎追平 GPT-5.2 的 99.4,表现极其亮眼;编程题(LiveCodeBench v6)得分 85.9,比 DeepSeek V3.2(80.8)高不少。⚠️ 不足:IMO 级数学题(IMOAnswerBench)略逊于 GPT-5.2,但比 DeepSeek 好很多。
4. 代理编码(Agentic Coding)
| 测试项 | Qwen3-Max-Thinking | GPT-5.2-Thinking | Claude Opus 4.5 |
|---|---|---|---|
| SWE Verified(软件工程题) | 75.3 | 80.0 | 80.9 |
✅ 亮点:得分 75.3,虽然比 GPT-5.2 和 Claude 低,但已经超过 DeepSeek V3.2(73.1),说明在复杂工程代码场景下表现不错。
5. 代理搜索(Agentic Search)
| 测试项 | Qwen3-Max-Thinking | GPT-5.2-Thinking | Gemini 3 Pro |
|---|---|---|---|
| HLE (w/tools)(带工具的逻辑题) | 49.8 | 45.5 | 45.8 |
✅ 亮点:直接反超 GPT-5.2!得分 49.8,说明它的「工具 + 推理」组合能力比 GPT-5.2 还强,适合需要实时信息或复杂搜索的场景。
6. 指令遵循与对齐(Instruction Following & Alignment)
| 测试项 | Qwen3-Max-Thinking | GPT-5.2-Thinking | Claude Opus 4.5 |
|---|---|---|---|
| IFBench(指令遵循题) | 70.9 | 75.4 | 58.0 |
| MultiChallenge(多任务对齐题) | 63.3 | 57.9 | 54.2 |
| Arena-Hard v2(硬核对齐题) | 90.2 | 80.6 | 76.7 |
✅ 亮点:这部分是「杀疯了」!Arena-Hard v2 得分 90.2,大幅反超 GPT-5.2(80.6)和 Claude(76.7);MultiChallenge 得分 63.3,也反超 GPT-5.2(57.9)。说明它对人类指令的理解和对齐能力非常强,尤其是复杂指令场景。
7. 工具使用(Tool Use)
| 测试项 | Qwen3-Max-Thinking | GPT-5.2-Thinking | Gemini 3 Pro |
|---|---|---|---|
| Tau^2 Bench(工具调用题) | 82.1 | 80.9 | 85.4 |
| BFCL-V4(复杂工具题) | 67.7 | 63.1 | 72.5 |
| Vita Bench(实时工具题) | 40.9 | 38.2 | 51.6 |
✅ 亮点 :BFCL-V4 和 Vita Bench 得分都反超 GPT-5.2,说明它在复杂工具调用和实时工具场景下表现更好。⚠️ 不足:Deep Planning(深度规划题)得分 28.7,和 GPT-5.2 的 44.6 还有差距,这部分需要优化。
8. 长上下文(Long Context)
| 测试项 | Qwen3-Max-Thinking | GPT-5.2-Thinking | Claude Opus 4.5 |
|---|---|---|---|
| AA-LCR(长上下文理解题) | 68.7 | 72.7 | 74.0 |
✅ 亮点:得分 68.7,接近 GPT-5.2 的 72.7,说明它处理长文本的能力已经很接近顶尖水平。
三、柱状图里的关键信息:TTS 技术到底有多强?
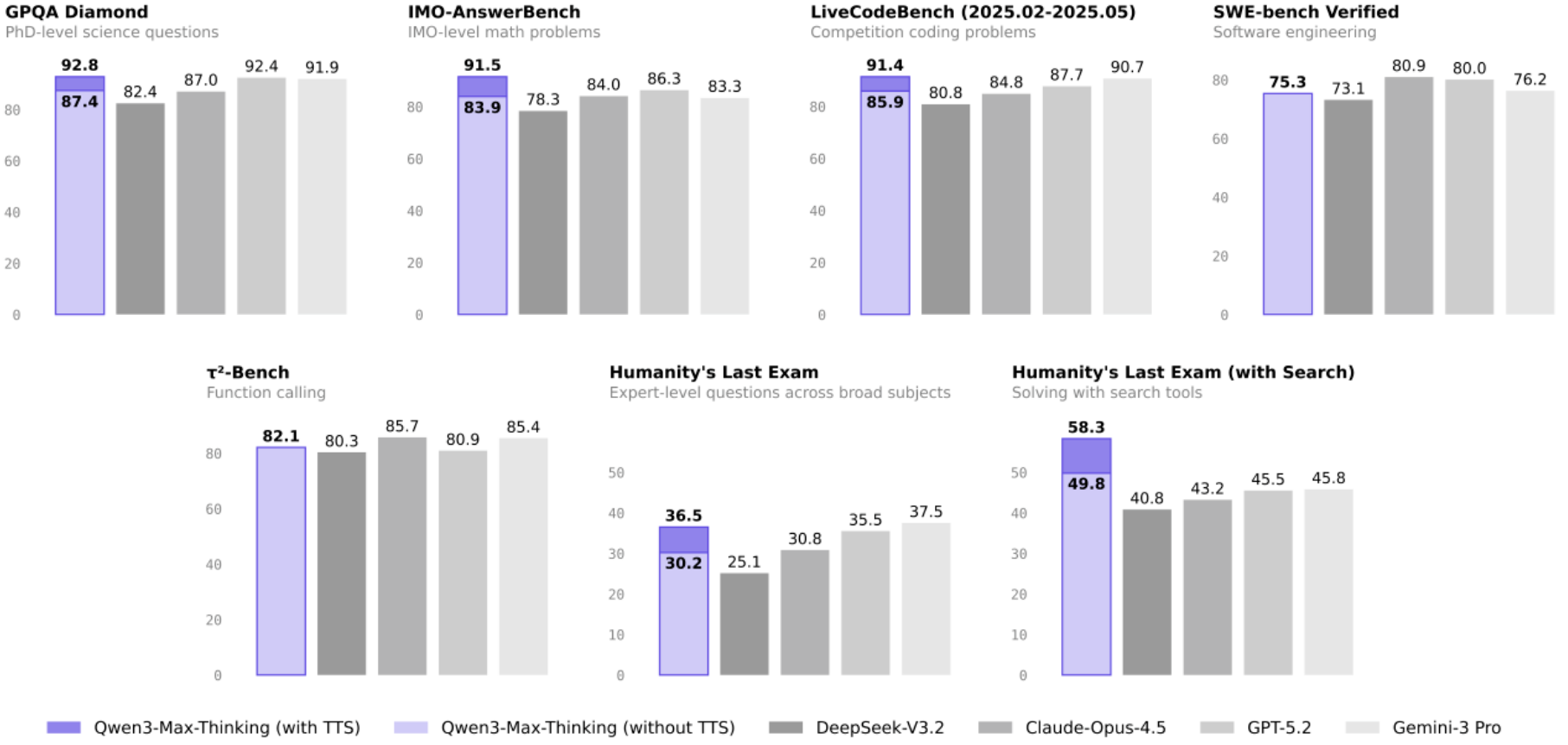
第二张图的柱状图直观展示了「测试时扩展技术(TTS)」的效果:
- GPQA Diamond:开启 TTS 后得分从 87.4→92.8,提升 5.4 分
- IMO-AnswerBench:开启 TTS 后得分从 83.9→91.5,提升 7.6 分
- LiveCodeBench:开启 TTS 后得分从 85.9→91.4,提升 5.5 分
- Humanity's Last Exam:开启 TTS 后得分从 30.2→36.5,提升 6.3 分
这说明 TTS 技术对模型的推理能力提升非常显著,尤其是在复杂问题场景下,能让模型更高效地利用计算资源,避免冗余推理。
四、怎么用?小白也能上手
Qwen3-Max-Thinking 已经上线Qwen Chat(chat.qwen.ai),你可以直接在网页上体验,也可以通过 API 调用(兼容 OpenAI API,迁移成本极低)。
Python 调用示例(兼容 OpenAI API)
python
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
# 国际用户用:https://dashscope-intl.aliyuncs.com/compatible-mode/v1
)
completion = client.chat.completions.create(
model="qwen3-max-2026-01-23",
messages=[
{"role": "user", "content": "给我介绍一下大语言模型"}
],
extra_body={"enable_thinking": True} # 开启推理增强
)
print(completion.choices[0].message)对于其他详细的接口调用过程,你可以查看我的其他文章如:通义千问 and 豆包 大模型调用代码 总结以及开源邀请_如何调用千问开源大模型的方法-CSDN博客
你也可以在阿里云百炼 (https://bailian.console.aliyun.com)上直接部署和调用,适合企业用户。
五、总结:值不值得用?
Qwen3-Max-Thinking 的表现可以用「惊喜」来形容:
- ✅ 优势:在中文知识、指令对齐、工具使用、代理搜索等维度表现媲美甚至反超 GPT-5.2;TTS 技术大幅提升推理能力;兼容 OpenAI API,迁移成本低。
- ⚠️ 不足:在高等逻辑题(HLE)、深度规划题(Deep Planning)等场景还有提升空间。
如果你需要强推理能力 (比如复杂问题解决、数学竞赛、编程开发),或者中文场景适配(比如知识问答、内容创作),Qwen3-Max-Thinking 绝对值得一试;如果你的场景需要极致的长上下文或深度规划能力,可能需要再等迭代,但目前的表现已经足够应对绝大多数业务场景。
END
如果觉得这份基础知识点总结清晰,别忘了动动小手点个赞👍,再关注一下呀~ 后续还会分享更多有关人工智能问题的干货技巧,同时一起解锁更多好用的功能,少踩坑多提效!🥰 你的支持就是我更新的最大动力,咱们下次分享再见呀~🌟