
这篇论文名为 《ConsistentID: Portrait Generation with Multimodal Fine-Grained Identity Preserving》 (ConsistentID:多模态细粒度身份保持的肖像生成),发表在人工智能顶级期刊 IEEE TPAMI (2026) 上。
该论文旨在解决扩散模型(Diffusion Models)在生成个性化肖像时,难以保持高精度身份(ID)一致性 和精细面部细节 的问题。

- 给定输入身份的若干图像,ConsistentID 仅需单张图像,即可基于文本提示生成多样化的个性化身份图像。
1. 核心挑战与初衷
现有的文生图模型(如 Stable Diffusion)虽然强大,但在"保持人脸长得像"这一点上仍存在挑战:
- 细节丢失:现有方法往往关注全局特征,忽略了细粒度的面部特征(如特定的眼角形状、鼻尖轮廓)。
- 身份不一致:局部面部区域(如眼睛、鼻子)与整张脸的特征可能在生成过程中发生冲突或融合,导致最终生成的角色"神似形不似"。
2. 主要贡献
- ConsistentID 模型 :提出了一种结合多模态(文本+图像)和 细粒度(局部特征)的身份保持方法,仅需一张参考图。
- 多模态细粒度特征提取器:利用大型多模态模型(LLaVA1.5)生成的文本描述和局部图像块,提取极其丰富的特征。
- ID 保持网络(ID-Preservation Network):通过"面部注意力定位策略",强制模型在训练时将注意力集中在特定的面部区域(眼、鼻、口、耳)。
- FGID 数据集:构建了首个具有细粒度标注的肖像数据集,包含超过 50 万张图像,提供了丰富的面部局部描述。
3. 技术架构(如何工作?)
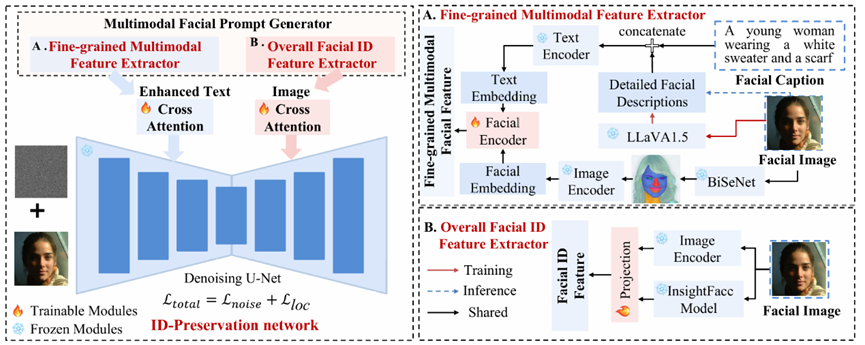
- ConsistentID 整体框架。该框架包含两个核心模块:多模态面部身份生成器和专门设计的身份保留网络。多模态面部提示生成器由两个关键组件构成:一是专注于捕捉面部细节信息的细粒度多模态特征提取器,二是致力于学习面部身份特征的面部身份特征提取器。另一方面,身份保留网络结合面部文本提示和视觉提示,通过面部注意力定位策略避免不同面部区域的身份信息混淆,该方法可确保面部区域的身份一致性得以保留。
ConsistentID 的架构由两个核心模块组成:
A. 多模态面部提示生成器(Multimodal Facial Prompt Generator)
它不只是看整张脸,而是把人脸拆解开来:
- 文本端:使用 LLaVA 自动生成对人脸局部(如"高鼻梁"、"深邃的蓝眼睛")的详细描述。
- 图像端:使用 BiSeNet 对参考图进行分割,提取眼睛、鼻子、嘴巴等局部图像块,并通过图像编码器(CLIP)转化为嵌入向量。
- 融合:将局部图像特征嵌入到对应的文本描述中(例如用""占位符替换描述词),形成一个极具表现力的多模态提示。
B. ID 保持网络(ID-Preservation Network)
- 面部注意力定位(Facial Attention Localization) :这是本文的杀手锏。在扩散模型的 U-Net 中,作者引入了一个定位损失(LlocL_{loc}Lloc)。这个损失函数强制模型在生成"眼睛"时,注意力图必须对齐真实的眼睛位置,防止身份信息在面部区域间"乱窜"。
- 全局与局部结合:同时注入全局 ID 特征(类似 IP-Adapter 的做法)和细粒度的局部特征,确保生成的肖像既有整体轮廓的相似,又有微观特征的精准。
4. FGID 数据集:强大的数据底座
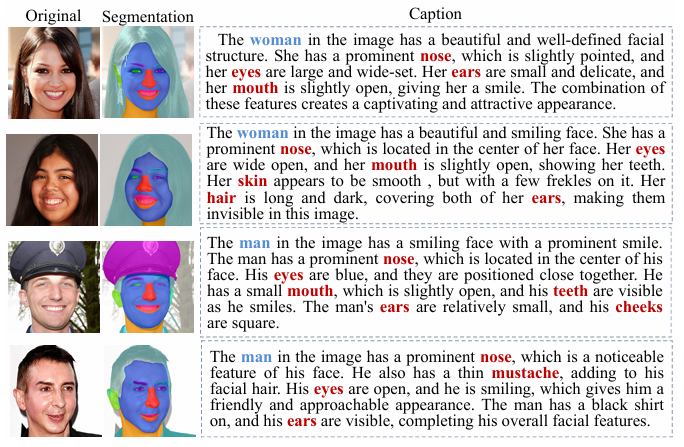
- FGID 训练数据集的可视化示例。左列展示原始图像,中列呈现以不同颜色突出显示的各类面部特征区域的可视化结果,右列提供详细说明文字(通过 LLaVA-1.5 生成;使用性能更强的 VLMs 可获得更精准的描述)。
由于现有数据集(如 FFHQ、CelebA)缺乏精细的局部特征文本描述,作者开发了 FGID (Fine-Grained ID Preservation) 数据集:
- 规模:524,258 张图像。
- 深度 :对每张图进行面部区域分割,并使用 LLaVA 生成关于性别、年龄、服饰及具体面部特征的详细文本。
5. 实验结果与性能
- 视觉质量 :相比于目前的 SOTA(尖端)模型如 FastComposer, IP-Adapter, PhotoMaker, InstantID,ConsistentID 在保持人脸细节(如眼部神态、唇形一致性)上表现更好。
- 定量指标 :
- 在 FaceSim (人脸相似度)和 FGIS(新提出的细粒度相似度指标)上均取得了领先。
- 即便引入了大量多模态信息,其推理速度依然保持在较高水平(生成一张图约 16-18 秒)。
- 灵活性 :支持各种下游任务,如给特定人物换装、改变职业、改变年龄或性别,同时保持身份不变。

- MyStyle 测试数据集上通用情境重构设置的定量比较。基准指标评估了文本一致性(CLIP-T)、粗粒度和细粒度身份信息保留能力(CLIP-I、DINO、FaceSIM、FGIS)、生成质量(FID)、推理效率(速度,单位:秒)、GPU 峰值内存(单位:兆)以及模型大小(参数数量,单位:百万)。

- 基于不同风格条件下,ConsistentID 与 IP-Adapter 及其面部版本变体的比较。

- 训练过程中注意力图面部变化的可视化实验,验证了模型对面部特征的关注度得到提升。
6. 总结与意义
ConsistentID 的成功在于"精细化"和"定位化"。
以往的方法像是让画师"看一眼,凭感觉画",而 ConsistentID 则是让画师"盯着细节画,并根据详细的说明书来画"。
亮点总结:
- 无需微调:推理时不需要像 DreamBooth 那样进行长时间的训练,属于"即插即用"的直接推理。
- 多模态融合:不仅利用图像,还利用了文本描述的语义力量。
- 开源贡献 :提供了代码和预训练权重,github 1k star,极大推动了开源社区在数字人、个性化写真领域的发展。
这篇论文代表了目前个性化肖像生成领域的前沿水平,特别是在追求"极致相似"的商业化应用(如 AI 摄影、虚拟模特)中具有极高的参考价值。
