论文信息

标题: LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders
作者: Parishad BehnamGhader,Vaibhav Adlakha,Marius Mosbach,Dzmitry Bahdanau,Nicolas Chapados,Siva Reddy
-
发布时间: 2024-04
-
会议/期刊: arXiv
论文

标题: A Text is Worth Several Tokens: Text Embedding from LLMs Secretly Aligns Well with The Key Tokens
作者: Zhijie Nie, Richong Zhang, Zhanyu Wu
-
会议/期刊: arXiv
引言:解码器式LLM的编码潜力觉醒
长久以来,因果注意力机制被视为解码器式大语言模型(decoder-only LLM)无法胜任文本编码任务的天然枷锁------每个token只能回望左侧历史,无法感知右侧上下文,似乎注定与高质量语义嵌入无缘。然而,两篇近期研究正悄然颠覆这一教条。
LLM2Vec 从架构改造切入,通过启用双向注意力、引入掩码下一词预测(MNTP)和无监督对比学习三步法,将Mistral-7B等纯生成模型转化为MTEB无监督榜单的SOTA编码器。更令人意外的是,其消融实验揭示:Mistral在切换至双向模式后表征几乎不变,暗示其预训练中可能已隐含双向理解能力。
与此同时,另一项关于语义对齐的研究从表征分析角度提供了佐证:LLM生成的文本嵌入在解码层投影后,竟能精准"指认"输入中的关键词元,甚至泛化至深层语义概念。进一步谱分析发现,这种对齐能力被原始模型中由语法噪声主导的第一主成分所掩盖;只需简单平移该分量,即可释放出模型本就具备的语义聚焦能力。
两项工作殊途同归:解码器式LLM并非天生不适合编码,而是其编码潜力长期被训练目标和表征结构所遮蔽。这一认知转变,为构建高效、通用且可解释的文本嵌入系统打开了全新路径。如下图所示,LLM嵌入与关键token的强关联性,正让黑盒向量变得可读、可控。
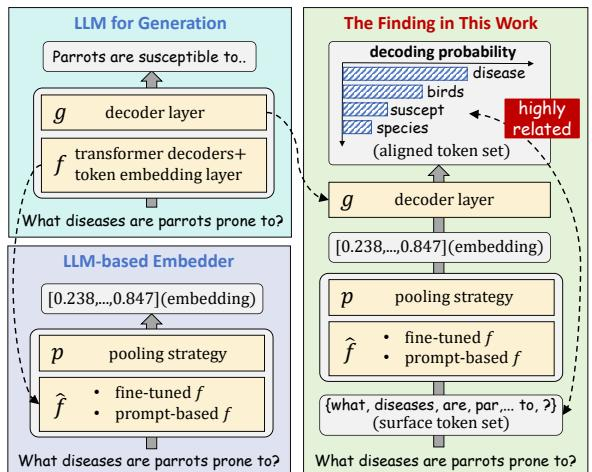
LLM2Vec架构与语义对齐发现的对比示意图:左侧为生成式LLM与编码器改造流程,右侧展示解码层嵌入与关键token的高相关性及表征对齐机制
2者异同点:架构改造与表征分析的双重视角
LLM2Vec与语义对齐研究,看似路径迥异,实则共同叩问同一个核心问题:decoder-only大语言模型(如Mistral、LLaMA)如何在无监督或弱监督场景下生成高质量文本嵌入? 它们共享相同的模型基底,却采取截然不同的策略------一个主动改造,一个被动解码。
LLM2Vec走的是"外科手术"路线。它通过三步法主动重塑模型架构 :首先启用双向注意力 打破因果掩码的桎梏;继而引入掩码下一词预测 (MNTP),让模型在保留自回归目标的同时适应双向上下文;最后施加无监督对比学习(SimCSE),锐化句子级表征的判别边界。这套组合拳直接将Mistral-7B推至MTEB无监督榜单榜首,证明了生成式LLM可被高效转化为强大编码器。
而语义对齐研究则像一位冷静的解剖学家。它不改动模型,而是深入分析现有嵌入的内在结构,发现了一个惊人事实:LLM嵌入天然与关键词高度对齐 ,只是被第一主成分中的语法噪声(如"the"、标点)所掩盖。其本质并非复杂重构,而是一次精准的去噪操作------仅需沿第一主成分方向平移原始嵌入,即可释放出模型本就具备的语义聚焦能力。
两者一动一静,一改一析,却共同揭示了LLM编码机制的深层真相:所谓"单向限制",更多是训练目标的产物,而非架构的宿命。Mistral在双向注意力下的表征稳定性,恰好为这一互补视角提供了交汇点------它的预训练或许早已埋下双向理解的种子,只待LLM2Vec这样的方法去激活,或被语义对齐研究这样的分析所识破。
迭代和演进关系:从方法创新到机理解释
2024年4月,LLM2Vec横空出世,用一套简洁的三步法------启用双向注意力、引入掩码下一词预测(MNTP)、叠加无监督对比学习(SimCSE)------将decoder-only大语言模型改造成强大的文本编码器,在MTEB上刷新无监督SOTA。这套方法高效、参数经济,却留下一个悬而未决的问题:为何如此简单的调整能释放如此巨大的编码潜力?
两个月后,语义对齐研究给出了答案。该工作通过谱分析发现,原始LLM嵌入性能受限的根源并非架构缺陷,而是第一主成分被"the"、标点等语法噪声主导。LLM2Vec的改造本质上是一次精准"去噪"------通过微调抑制该主成分中的无意义信号,从而让模型本就具备的语义聚焦能力浮出水面。更惊人的是,仅沿第一主成分方向平移原始嵌入,就能复现关键词对齐效果。
两篇工作一前一后,形成完整闭环:LLM2Vec提供方法路径,语义对齐揭示内在机理。它们共同指向一个颠覆性结论------decoder-only LLM的编码能力被严重低估,其瓶颈源于训练目标,而非架构本身。生成与编码,或许从来就不该被割裂看待。
总结:重新定义大语言模型的编码边界
两项独立研究不约而同地撕开了"解码器只能用于生成"的认知封印。LLM2Vec 提出一套简洁高效的三步法------启用双向注意力、引入掩码下一词预测(MNTP)、叠加无监督对比学习(SimCSE)------将Mistral-7B等纯生成模型转化为MTEB无监督榜单上的新SOTA,证明decoder-only架构本就蕴藏强大编码潜力。与此同时,另一项关于语义对齐的研究揭示了一个普适现象:无论采用何种嵌入方法,LLM生成的文本向量总能通过解码层精准"指认"输入中的关键词元,甚至泛化至深层语义概念。
更令人振奋的是,这种对齐并非黑箱魔法,而是源于嵌入空间中第一主成分的"去噪"效应------微调过程实质是抑制"the""and"等语法噪声,释放模型固有的语义聚焦能力。这意味着,高质量嵌入未必依赖复杂重构,而可能只需一次精准的方向校正。
未来路径已然清晰:将LLM2Vec的高效双向编码能力与语义对齐的可解释机制相结合,有望构建既高性能又透明的嵌入系统。更重要的是,Mistral在双向设置下的天然稳定性暗示,预训练策略本身可能早已悄然赋予部分LLM"类编码器"特质------这或将推动新一代兼具生成与理解能力的统一架构诞生。