文章目录
介绍一下MySQL查询语句执行过程
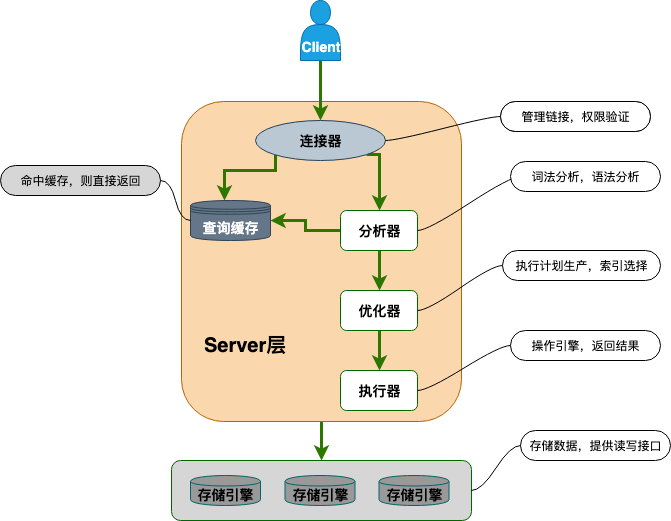
执行SQL查询语句会经过上述组件和步骤,简单说说:
- 连接器:进行身份认证和权限验证
- 查询缓存:执行查询语句的时候,会先查询缓存,如果存在缓存的话直接返回。
- 分析器:如果没有命中缓存,SQL 语句就会经过分析器,分析器说白了就是要先看你的 SQL 语句要干嘛,再检查你的 SQL 语句语法是否正确。
- 优化器:对你执行SQL语句按照一定规则去优化,保证以MySQL认为最优的方案去执行。
- 执行器:执行语句,然后从存储引擎返回数据。
简述一下MySQL的架构
逻辑架构分为三层:
- 连接层:客户端包含的服务,包括连接处理、身份验证、确保安全性。
- 核心功能层:查询解析、分析、优化以及所有的内置函数解析,所有跨存储引擎的功能都在这一层实现。 存储过程、触发器、视图等。
- 存储引擎层:负责Mysql数据的存储和提取。服务器通过存储引擎 API和存储引擎通信,屏蔽不同存储引擎差异。不同存储引擎之间不会相互通信,只会简单相应服务器的请求。
说一下你理解的数据库索引?
索引是一种用于快速查询和检索数据的数据结构,其本质可以看成是一种排序好的数据结构。索引本质是用空间换时间。可以把数据库理解为一本书:表数据相当于正文内容,索引相当于目录。没
有索引的情况下只能从头到尾扫表(全表扫描),有索引: 可以直接定位数据位置。
针对不同查询查询场景有/无索引对比
| 操作 | 没有索引 | 有索引 |
|---|---|---|
| 单条查询 | 全表扫描 | 走索引,O(log n) |
| 范围查询 | 全表扫描 | 顺序扫描 |
| 排序 | 临时排序 | 利用索引排序 |
分别说说索引的优点和缺点
优点:
- 大幅提升查询速度:通过索引,数据库可以大幅减少需要扫描的数据量,直接定位到符合条件的记录,从而显著加快数据检索速度
- 减少I/O:避免全表扫描,减少读取数据,减少磁盘I/O次数。
- 优化排序、分组操作:如果查询中的 ORDER BY 或 GROUP BY 子句涉及的列建有索引,数据库往往可以直接利用索引已经排好序的特性,避免额外的排序操作,从而提升性能。
缺点:
- 占用额外存储空间:索引本质上时数据结构,需要以本地文件/内存结构形式存储,会额外占据空间。
- 增删改时需要维护索引,索引过多会降低写性能。
说说MySQL中索引类型?
按照底层数据结构划分,索引类型可分为:
- BTREE索引:MySQL 里默认和最常用的索引类型。只有叶子节点存储 value,非叶子节点只有指针和 key。存储引擎 MyISAM 和 InnoDB 实现 BTree 索引都是使用 B+Tree。
- 哈希索引:类似键值对的形式,一次即可定位。。
- 全文索引:对文本的内容进行分词,进行搜索。目前只有
CHAR、VARCHAR、TEXT列上可以创建全文索引。一般不会使用,效率较低。 - R-TREE索引:MyISAM 存储引擎支持空间数据索引(R-Tree),可以用于地理数据存储。空间数据索引会从所有维度来索引数据,可以有效地使用任意维度来进行组合查询。
按照底层存储方式角度进行划分:
- 聚簇索引:索引结构和数据一起存放的索引,InnoDB 中的主键索引就属于聚簇索引。
- 非聚簇索引:索引结构和数据分开存放的索引,二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。
按照应用维度划分:
- 主键索引:加速查询 + 列值唯一(不可以有 NULL)+ 表中只有一个。
- 普通索引:仅加速查询。
- 唯一索引:加速查询 + 列值唯一(可以有 NULL)。
- 联合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并。
- 前置索引:对文本的前几个字符创建索引,相比普通索引建立的数据更小,因为只取前几个字符(区分度高就行)。
- 全文索引:文本的内容进行分词,进行搜索。目前只有
CHAR、VARCHAR、TEXT列上可以创建全文索引。一般不会使用,效率较低。 - 覆盖索引:属于联合索引中一种特例,一个索引包含(或者说覆盖)所有需要查询的字段的值。
如何创建合适的索引?
主要考虑点如下:
- 查询是否频率:索引的本质目的是加快查询效率,如果一个表需要进行高频查询,适合创建索引,偶尔进行查询,不一定需要创建索引。
- 考虑表数据:对于小规模数据的表,大部分情况下全表扫描比创建索引会更快。表数据大小是是否需要创建索引要考虑的一个关键因素。
- 字段本身是否创建索引:
- 选择作为索引的字段需要区分度高,(区分度 = 不重复值 / 总记录数),高区分度(用户ID、订单号等)适合创建索引,低区分度不适合创建索引。
- 字段本身需要有where、on、join等应用场景,如果根本不会使用,区分度高也是不需要创建索引的。
- 字段是否经常更新:更新会导致索引频繁维护,影响写性能。经常update的字段不一定适合创建索引。
- 考虑联合索引:如果两个/多个字段总是一起频繁进行查询,可以考虑创建联合索引,创建联合索引字段顺序可从下面角度进行考虑:
- 最左前缀原则
- 高区分度在前
- 等值条件在前,范围条件在后
- 考虑覆盖索引:索引不能包含SELECT 所有查询数据时,在InnoDB中二级索引定位到具体数据需要回表查询主键索引,获取全部数据,再返回需要的数据。如果二级索引能包含所有需要查询的数据,则不需要进行回表查询。
怎么优化查询速度
- 减少请求的数据量
- 只选择必须要列:
SELECT只选择必要的字段,尽量避免使用SELECT * - 只返回必要的行:使用LIMIT语句来限制返回的数据。
- 缓存重复查询数据:使用缓存可以避免在数据库中进行查询,特别在要查询的数据经常被重复查询时,缓存带来的查询性能提升将会是非常明显的。
- 只选择必须要列:
- 减少MySQL服务器扫描的行数
- 最有效的方式使用索引来减少扫描行数。对于不同查询场景创建合适的索引。
- 当表数据量比较大时:针对查询场景考虑对表进行分库分表,限制查询数据量。
- 避免使用大查询:一个大查询如果一次性执行的话,可能一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。可考虑再应用层代码进行大查询拆分执行。
- 避免大连接查询:将一个大连接查询分解成对每一个表进行一次单表查询,然后将结果在应用程序中进行关联。