1 背景
NIN(Network In Network)由新加坡国立大学的三位华人大佬(林敏、陈强、颜水成)于2014发表于ICLR (International Conference on Learning Representations,国际学习表征会议)。该模型对传统CNN中的全连接层部分做了突破性改进,使其输出结果能保留空间信息,这影响了后续许多模型的研究。
2 原理
具体改变其实非常简单,在之前讲解的CNN如AlexNet和VGG中都含有全连接层部分,用于把卷积部分输出的所有特征图展平成一维向量,然后再处理为若干个结果。在NIN中摈弃这种处理方法,而是把卷积部分的输出结果通过1*1卷积层处理以后,改变其输出通道数使其等于输出结果的长度,用不同的通道来代表不同维度的输出结果,最后对每个通道上的输出图像进行汇聚即可得到结果。这种方法有效避免了因为展开操作而破坏图像空间信息。
事实上NIN的提出优雅的回应了我在深度学习-卷积神经网络基础的4.2节标红部分的思考,当我们把卷积神经网络抽象成多层感知机以后,输入输出通道数其实就是输入输出的长度,所以用不同通道代表不同维度上的输出是一个很自然的想法,也就不再需要通过所谓的"展平层"来降维了。
而NIN之所以叫Network In Network,个人理解是因为其1*1卷积层实际上也是在对每个像素不同维度上的特征进行线性变换,可以看成特征图上的卷积网络中嵌入了像素级别的多层感知机,所以叫做网络中的网络。(这里理解的比较抽象,其实知道基本原理就够了)
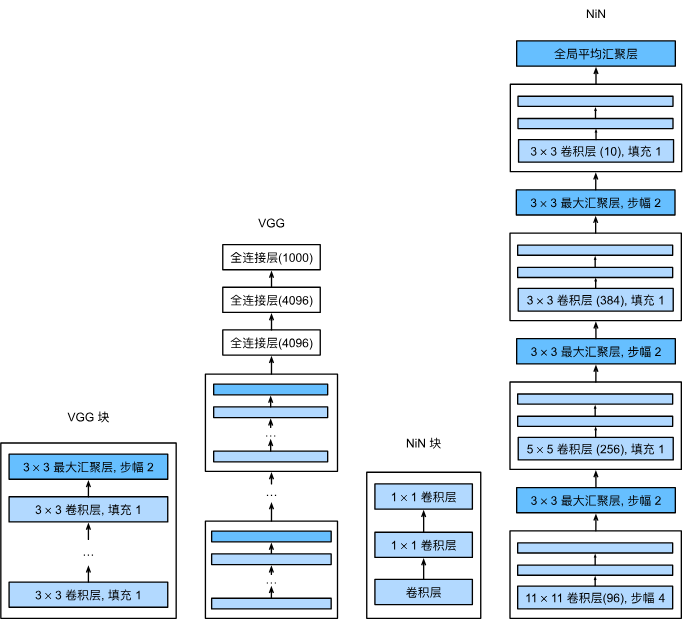
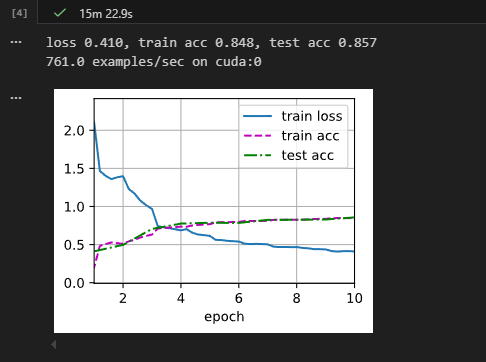
对比 VGG 和 NiN 及它们的块之间主要架构差异
上图为书中原图,展示了VGG和NIN的结构,可以看到,VGG的卷积部分为**不固定数量的3\*3卷积层+1个3\*3最大汇聚层** 的循环,这个结构称为一个VGG块;NIN则为**1个不固定大小的卷积层+2个1\*1卷积层+1个3\*3最大汇聚层** 的循环,但是最后一次的3*3最大汇聚层替换为了全局平均汇聚层,用于计算输出数值,由于最后一次没有3*3最大汇聚层,所以NIN块只封装了**1个不固定大小卷积层+2个1\*1卷积层**,所以这不代表NIN中没有汇聚处理,只是为了方便没有封装在NIN块内部。
这里提出一个设想:VGG中有一个比较好的思想,就是用若干3*3卷积层代替了1个不固定大小的卷积层,实现了更好的非线性拟合效果,这里完全可以试试利用VGG的思想把NIN中11*11的卷积层替换为5个3*3卷积层,5*5卷积层替换为2个3*3卷积层,观察能否进一步提升模型性能。
3 实现
3.1 模型定义
下面的代码定义了一个NIN块,由一个卷积层和两个1*1卷积层(带激活的逐像素全连接层)组成。
python
import torch
from torch import nn
from d2l import torch as d2l
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())下面的代码定义了NIN模型结构
python
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, strides=4, padding=0),
nn.MaxPool2d(3, stride=2),
nin_block(96, 256, kernel_size=5, strides=1, padding=2),
nn.MaxPool2d(3, stride=2),
nin_block(256, 384, kernel_size=3, strides=1, padding=1),
nn.MaxPool2d(3, stride=2),
nn.Dropout(0.5),
# 标签类别数是10
nin_block(384, 10, kernel_size=3, strides=1, padding=1),
nn.AdaptiveAvgPool2d((1, 1)),
# 将四维的输出转成二维的输出,其形状为(批量大小,10)
nn.Flatten())下面的代码用于查看模型各层输出结果的形状,与VGG块类似,一个NIN块只展示一个最终输出。
python
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)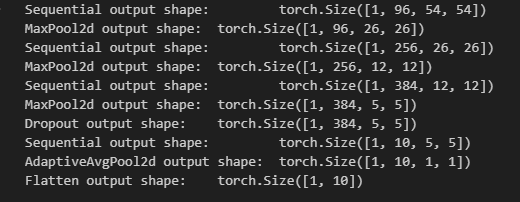
3.2 模型训练
python
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())