在 .NET 项目开发中,HTML 内容解析与数据提取是极为常见的开发需求,无论是获取富文本编辑器的内容、清洗网页片段数据,还是抽取 HTML 中的关键结构化信息,都需要可靠的组件支撑。
Free Spire.Doc for .NET 作为一款免费的 .NET 文档处理组件,提供了便捷的 HTML 解析接口,可高效完成 HTML 内容的读取与提取工作。本文将结合实际代码,详细讲解该组件在 C# 中读取 HTML 的具体实现。
文章目录
-
- 一、应用场景
- 二、开发环境准备
-
- [1. 组件安装](#1. 组件安装)
- [2. 核心命名空间引入](#2. 核心命名空间引入)
- [三、读取 HTML 内容核心功能实现](#三、读取 HTML 内容核心功能实现)
-
- [场景1:读取 HTML 字符串,提取纯净文本](#场景1:读取 HTML 字符串,提取纯净文本)
- 场景2:读取本地HTML文件,提取结构化内容
- 场景3:筛选HTML内容,提取指定段落文本
- 四、总结与实践建议
一、应用场景
借助 Free Spire.Doc for .NET,开发者可以快速实现 HTML 内容的读取操作,其核心适用场景覆盖:
- 纯文本提取:从 HTML 字符串或本地 HTML 文件中提取纯净文本,过滤所有 HTML 标签与样式代码,用于展示或存储;
- 结构化信息抽取:精准提取 HTML 中的标题、超链接、列表项等固定格式内容,无需手动解析标签;
- 批量内容清洗:对批量 HTML 片段进行内容清洗,剔除冗余数据,提取业务所需的目标内容。
注意:Free Spire.Doc 免费版本存在一定的篇幅限制,对部分复杂、高级的HTML标签解析支持有限。
二、开发环境准备
1. 组件安装
推荐通过 NuGet 包管理器安装 Free Spire.Doc for .NET,安装方式简单且便于版本管理。
- 可视化安装:在 Visual Studio 中,右键目标项目 → 选择「管理 NuGet 程序包」→ 搜索「Free Spire.Doc」→ 安装适配项目的最新版本。
- 命令行安装:在 NuGet 包管理器控制台中,执行以下安装命令:
bash
Install-Package FreeSpire.Doc2. 核心命名空间引入
在项目代码中引入以下命名空间,即可调用组件的 HTML 解析、内容提取与文件操作相关接口:
csharp
using Spire.Doc;
using Spire.Doc.Documents;
using Spire.Doc.Fields;
using System.IO;
using System.Linq;
using System.Text.RegularExpressions;三、读取 HTML 内容核心功能实现
本文将基于三种典型的业务场景,分别提供完整的代码实现与详细解析,覆盖 HTML 字符串读取、本地 HTML 文件结构化提取、指定内容筛选等常用需求。
场景1:读取 HTML 字符串,提取纯净文本
该方案适用于处理动态生成的 HTML 片段,比如前端富文本编辑器传递的内容、接口返回的 HTML 字符串。通过组件的解析能力,快速剔除标签、样式等冗余内容,获取规整的纯文本数据。
完整代码示例:
csharp
using Spire.Doc;
using System;
namespace ReadHtmlBySpireDoc
{
class ExtractTextFromHtmlString
{
static void Main(string[] args)
{
// 定义待解析的HTML字符串
string htmlContent = @"
<html>
<body>
<h2>产品功能介绍</h2>
<p>该组件支持<span style='font-size:14px;'>HTML内容解析</span>,具备以下优势:</p>
<ul>
<li>跨.NET平台兼容</li>
<li>无需依赖Office环境</li>
<li>快速提取文本内容</li>
</ul>
<p>官方地址:<a href='https://www.e-iceblue.com/'>官方网站</a></p>
</body>
</html>
";
// 初始化文档对象,作为HTML解析的载体
Document parseDoc = new Document();
Section section = parseDoc.AddSection();
Paragraph paragraph = section.AddParagraph();
try
{
// 核心方法:加载并解析HTML内容
paragraph.AppendHTML(htmlContent);
// 提取解析后的纯文本内容
string pureText = parseDoc.GetText();
// 文本清洗,去除多余空白符与换行符
pureText = Regex.Replace(pureText, @"\s+", " ").Trim();
// 输出提取结果
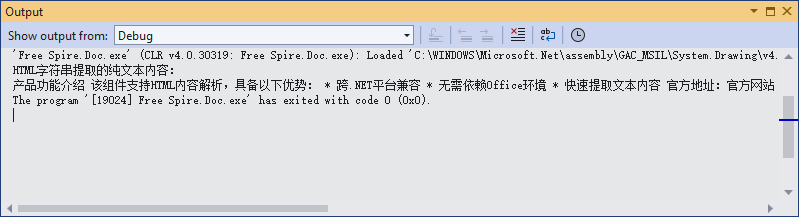
Console.WriteLine("HTML字符串提取的纯文本内容:");
Console.WriteLine(pureText);
}
catch (Exception ex)
{
Console.WriteLine($"HTML解析异常:{ex.Message}");
}
finally
{
// 释放组件资源,避免内存占用
parseDoc.Dispose();
}
}
}
}读取效果:
代码核心说明:
AppendHTML():组件提供的核心 HTML 解析方法,能够识别并加载基础 HTML 标签,将 HTML 内容转化为组件可识别的文档结构。GetText():用于提取解析后内容中的所有文本,自动过滤 HTML 标签、行内样式等非文本内容。- 正则清洗:针对解析后文本存在的多余空格、换行符,通过正则表达式完成文本格式化,提升内容可读性。
场景2:读取本地HTML文件,提取结构化内容
在处理本地存储的HTML文件时,往往需要提取标题、列表、超链接等特定类型的结构化信息,而非简单的纯文本。通过遍历组件解析后的文档对象,可实现精细化的内容提取。
完整代码示例:
csharp
using Spire.Doc;
using Spire.Doc.Documents;
using Spire.Doc.Fields;
using System;
using System.IO;
namespace ReadHtmlBySpireDoc
{
class ExtractStructFromHtmlFile
{
static void Main(string[] args)
{
// 配置本地HTML文件路径
string htmlFilePath = "溯源码.html";
// 校验文件是否存在
if (!File.Exists(htmlFilePath))
{
Console.WriteLine("目标HTML文件不存在,请检查文件路径!");
return;
}
try
{
// 加载HTML文件
Document parseDoc = new Document();
parseDoc.LoadFromFile(htmlFilePath);
// 调用方法提取不同类型的结构化内容
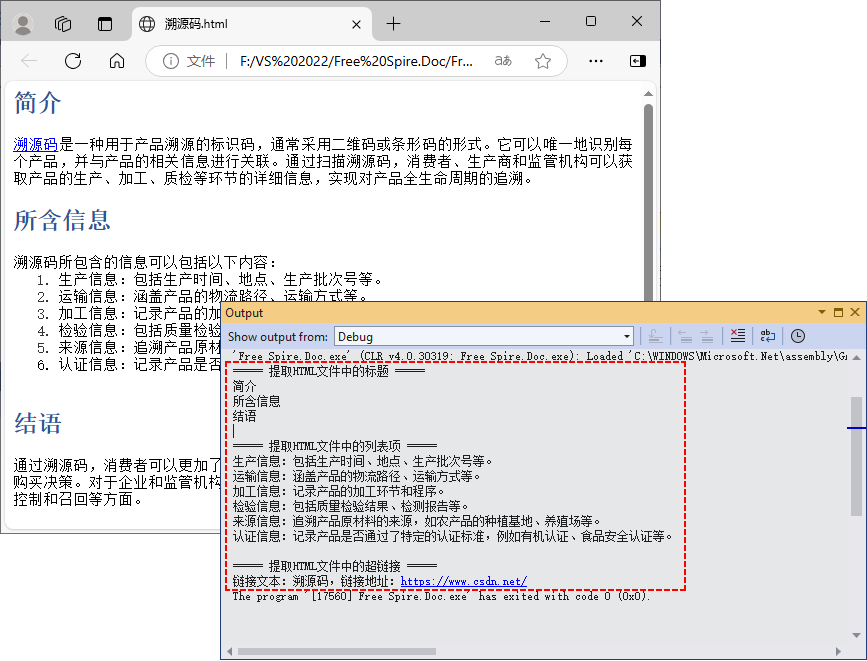
Console.WriteLine("===== 提取HTML文件中的标题 =====");
FetchAllHeadings(parseDoc);
Console.WriteLine("\n===== 提取HTML文件中的列表项 =====");
FetchAllListItems(parseDoc);
Console.WriteLine("\n===== 提取HTML文件中的超链接 =====");
FetchAllHyperlinks(parseDoc);
}
catch (Exception ex)
{
Console.WriteLine($"文件读取或解析失败:{ex.Message}");
}
}
/// <summary>
/// 提取HTML中的标题内容
/// </summary>
private static void FetchAllHeadings(Document doc)
{
foreach (Section sec in doc.Sections)
{
foreach (Paragraph para in sec.Paragraphs)
{
// 通过段落样式判断标题类型
if (para.GetStyle().Name.StartsWith("Heading"))
{
Console.WriteLine(para.Text.Trim());
}
}
}
}
/// <summary>
/// 提取HTML中的列表项
/// </summary>
private static void FetchAllListItems(Document doc)
{
foreach (Section sec in doc.Sections)
{
foreach (Paragraph para in sec.Paragraphs)
{
// 判断段落是否为列表格式
if (para.ListFormat.ListType != ListType.NoList)
{
Console.WriteLine(para.Text.Trim());
}
}
}
}
/// <summary>
/// 提取HTML中的超链接文本与跳转地址
/// </summary>
private static void FetchAllHyperlinks(Document doc)
{
foreach (Section sec in doc.Sections)
{
foreach (Paragraph para in sec.Paragraphs)
{
foreach (DocumentObject docObj in para.ChildObjects)
{
// 筛选超链接类型的文档对象
if (docObj is Field field && field.Type == FieldType.FieldHyperlink)
{
string text = field.FieldText;
string link = field.GetFieldCode();
Console.WriteLine($"链接文本:{text},链接地址:{link.Split('"')[1]}");
}
}
}
}
}
}
}读取效果:
代码核心说明:
- 标题提取 :HTML中的
h1--h6标签,解析后会被标记为 Heading 开头的段落样式,通过该特征可精准筛选所有标题。 - 列表项提取 :有序列表、无序列表的
li标签,解析后具备专属的列表格式属性,通过ListFormat.ListType可快速识别。 - 超链接提取:遍历段落的子对象,筛选出超链接域对象,进而获取链接的展示文本与目标地址。
场景3:筛选HTML内容,提取指定段落文本
在内容清洗场景中,通常只需要获取HTML中的普通段落内容,排除标题、列表等非目标信息。通过对文档对象的属性判断,可实现指定内容的精准提取。
核心代码片段:
csharp
// 加载HTML文件
Document parseDoc = new Document();
parseDoc.LoadFromFile(htmlFilePath);
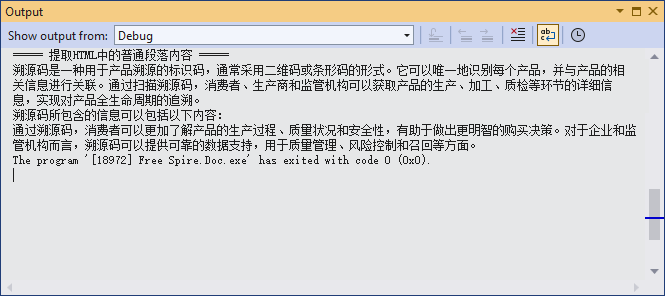
Console.WriteLine("===== 提取HTML中的普通段落内容 =====");
foreach (Section sec in parseDoc.Sections)
{
foreach (Paragraph para in sec.Paragraphs)
{
// 过滤标题、列表,仅保留普通段落
bool isNotHeading = !para.GetStyle().Name.StartsWith("Heading");
bool isNotListItem = para.ListFormat.ListType == ListType.NoList;
if (isNotHeading && isNotListItem && !string.IsNullOrWhiteSpace(para.Text))
{
Console.WriteLine(para.Text.Trim());
}
}
}
// 释放资源
parseDoc.Dispose();输出结果:
四、总结与实践建议
Free Spire.Doc for .NET为.NET 开发者提供了轻量化的 HTML 读取解决方案,无需引入额外的第三方解析库,即可完成基础的 HTML 文本提取与结构化数据获取,适合项目中已引入该组件、且仅需轻量级HTML解析的场景。
在实际项目落地时,可遵循以下实践建议:
- 针对简单HTML片段、小体积HTML文件的基础解析需求,直接使用本文提供的方案,简化项目依赖,提升开发效率。
- 针对复杂HTML结构、高性能批量解析的需求,可选用一些专业 HTML 解析库。
- 开发过程中,做好异常捕获与资源释放,同时做好文本格式化与编码校验,保障解析结果的准确性与程序的稳定性。