文章目录
- 一、性能测试监控关键指标
-
- [1.1 系统指标](#1.1 系统指标)
- [1.2 硬件服务器资源指标](#1.2 硬件服务器资源指标)
-
- [1.2.1 CPU、内存、磁盘](#1.2.1 CPU、内存、磁盘)
- [1.2.2 CPU使用率](#1.2.2 CPU使用率)
- [1.2.3 CPU占用分类](#1.2.3 CPU占用分类)
- [1.2.4 内存和虚拟内存](#1.2.4 内存和虚拟内存)
- [1.2.5 磁盘IO](#1.2.5 磁盘IO)
- [1.2.6 网络](#1.2.6 网络)
- [1.3 JAVA应用](#1.3 JAVA应用)
-
- [1.3.1 JVM-java虚拟机](#1.3.1 JVM-java虚拟机)
- [1.3.2 JAVA虚拟机内存](#1.3.2 JAVA虚拟机内存)
- [1.3.3 FULL GC机制](#1.3.3 FULL GC机制)
- [1.4 数据库监控](#1.4 数据库监控)
-
- [1.4.1 慢查询](#1.4.1 慢查询)
- [1.4.2 缓存命中率](#1.4.2 缓存命中率)
- [1.4.3 数据池连接数](#1.4.3 数据池连接数)
- [1.4.4 mysql锁](#1.4.4 mysql锁)
- [1.5 压测机资源](#1.5 压测机资源)
- 二、性能监控工具
-
- [2.1 硬件网络资源监控](#2.1 硬件网络资源监控)
-
- [2.1.1 工具](#2.1.1 工具)
- [2.1.2 Linux命令](#2.1.2 Linux命令)
-
- [2.1.2.1 top-实时查看CPU、内存](#2.1.2.1 top-实时查看CPU、内存)
- [2.1.2.2 free-查看内存](#2.1.2.2 free-查看内存)
- [2.1.2.3 vmstat-查看CPU、内存等](#2.1.2.3 vmstat-查看CPU、内存等)
- [2.1.2.4 sar-查看网络](#2.1.2.4 sar-查看网络)
- [2.1.2.5 iostat-查看磁盘IO](#2.1.2.5 iostat-查看磁盘IO)
- [2.2 应用服务器、数据库配置](#2.2 应用服务器、数据库配置)
-
- [2.2.1 应用服务器配置](#2.2.1 应用服务器配置)
- [2.2.2 数据库服务器配置](#2.2.2 数据库服务器配置)
- [2.3 数据库资源监控-慢查询](#2.3 数据库资源监控-慢查询)
-
- [2.3.1 Mysql常用监控指标](#2.3.1 Mysql常用监控指标)
- [2.3.2 设置与开启慢查询](#2.3.2 设置与开启慢查询)
- [2.3.3 准备测试数据](#2.3.3 准备测试数据)
- [2.3.4 测试-慢查询和实时日志查看](#2.3.4 测试-慢查询和实时日志查看)
- [2.4 JVM](#2.4 JVM)
-
- [2.4.1 代码常见问题](#2.4.1 代码常见问题)
- [2.4.2 内存分类](#2.4.2 内存分类)
- [2.4.3 下载并配置VisualVM](#2.4.3 下载并配置VisualVM)
- [2.4.4 JVM监控---Jvisualvm.exe](#2.4.4 JVM监控—Jvisualvm.exe)
- [2.4.5 内存溢出演示](#2.4.5 内存溢出演示)
一、性能测试监控关键指标
1、系统指标: 系统指标则与用户场景及需求直接相关
- 并发用户数: 某一物理时刻同时向系统提交请求的用户数
- 平均响应时间: 系统处理事务的响应时间的平均值。 对于系统快速响应类页面, 一般响应时间为3秒左右
- 吞吐量
2、服务器资源指标: 资源指标与硬件资源消耗直接相关
- CPU使用率: 一般可接受上限为85%
- 内存利用率: 一般可接受上限为85%
- 磁盘I/O
- 网络带宽
3、Java应用:JAVA应用程序在运行时的各项指标
- JVM监控: JVM内存、 Full GC频率
4、数据库:数据库服务器运行时需要监控的指标
- 慢查询
- 缓存命中率
- 数据池连接数
- mysql锁
5、压测机资源:数据库服务器运行时需要监控的指标
- CPU
- 内存
- 网络
- 磁盘空间
一般情况下,测试人员执行性能测试时,只需要关注1、2、5就可以,判断系统是否有性能问题而开发人员要定位性能问题时,需要再次运行,并监控所有的性能指标,来进行分析并调优。
1.1 系统指标
- 可以直接用来衡量系统处理能力的指标是(吞吐量)
- 在系统处于轻压力区(未饱和)时,并发用户数上升,平均响应时间(基本不变),系统吞吐量(上升)
- 在系统处于重压力区(基本饱和)时,并发用户数上升,平均响应时间(上升),系统吞吐量(基本不变)
- 在系统处于崩溃区(压力过载)时,并发用户数上升,平均响应时间(上升),系统吞吐量(下降)
1.2 硬件服务器资源指标
1.2.1 CPU、内存、磁盘
从处理速度来说:CPU>内存>磁盘。(CPU与内存、内存与磁盘速度差特别多)
- 快存:在CPU中起到存储作用。CPU读数据时,先从快存读,读不到再从内存读。
- 缓冲区:在内存中起到缓冲作用。内存读数据时,先从缓冲区读,读不到再从磁盘读。
- 快存和缓冲区的作用都是:读取数据时起到缓冲区的作用。
1.2.2 CPU使用率
CPU使用率的计算方法:在一段时间内,每个程序占用的CPU时间,除以总时间,得到每个程序的CPU使用率。
1.2.3 CPU占用分类
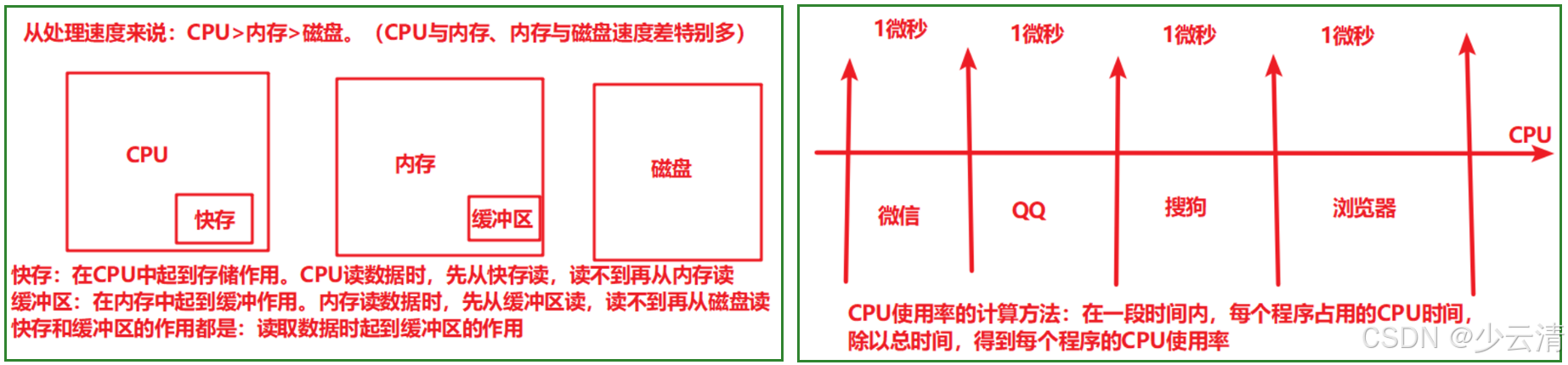
1、在电脑中的所有程序及所有操作都需要消耗CPU
- 用户使用的程序:QQ、微信、浏览器等消耗CPU,用户CPU
- 从内存中读取数据、从磁盘中读数据、磁盘管理等操作系统的工作,也需要消耗CPU,称为系统CPU
2、性能测试时统计的CPU使用率 = 用户CPU使用率+系统CPU使用率
3、因此如果性能测试时统计CPU使用率,不一定就是程序软件有问题,可能是操作系统消耗过多CPU
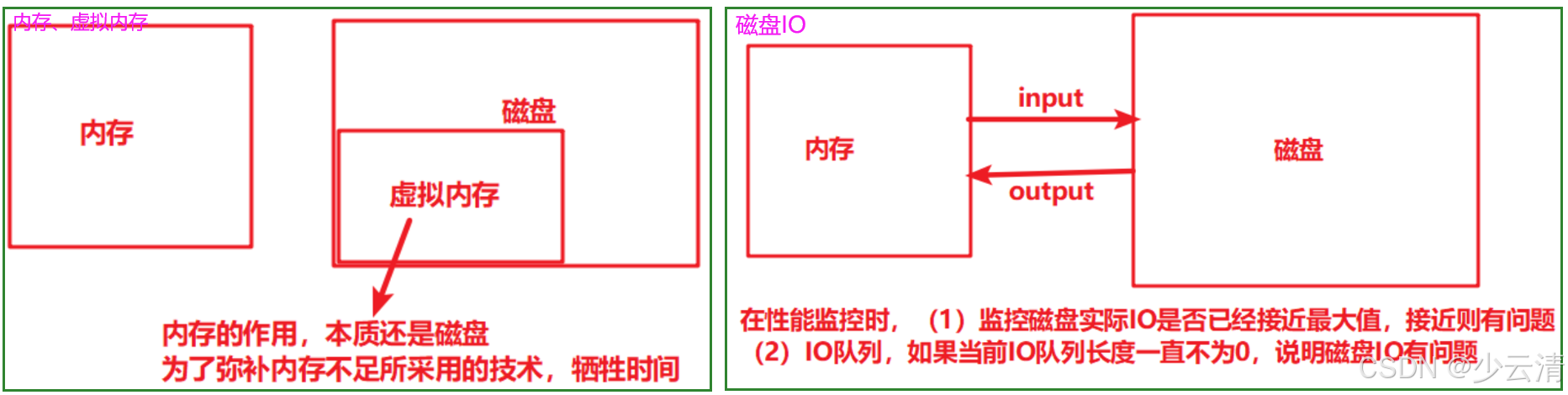
1.2.4 内存和虚拟内存
1、正常情况下,程序加载到内存中来执行。
2、当内存不够时,会加载部分立即要执行的程序到内存中,其他的程序部分放在磁盘(虚拟内存)中。
3、当立即要执行的程序执行完成后,从虚拟内存中读取其他的数据内容到实际内存中,再执行程序的处理。
4、依次循环第3步,完成程序的运行。
卡的原因的就是:每次都需要从虚拟内存(磁盘)中读取数据进行执行,磁盘的读取速度相对CPU和内存而言非常,因此感觉内存不足程序很卡。
闪退的原因就是:在第2步中,需要加载部分立即要执行的程序到内存中,如果当前的内存空间不满足最低要求(立即要执行的程序所需要的内存)时,就会出现闪退。
1.2.5 磁盘IO
- 固定硬盘lO:500M/s
- 机械硬盘IO:不超过200M/s
1.2.6 网络
- 监控实际的网络流量,与网络带宽做对比,如果实际网络流量与网络带宽接近,则说明网络存在瓶颈,需要优化。
- 百兆带宽:100Mbyte/s
- 实际技术中衡量的宽带的单位:KB/s,因此需要换算:100/8 = 12.5MKB/s
1.3 JAVA应用
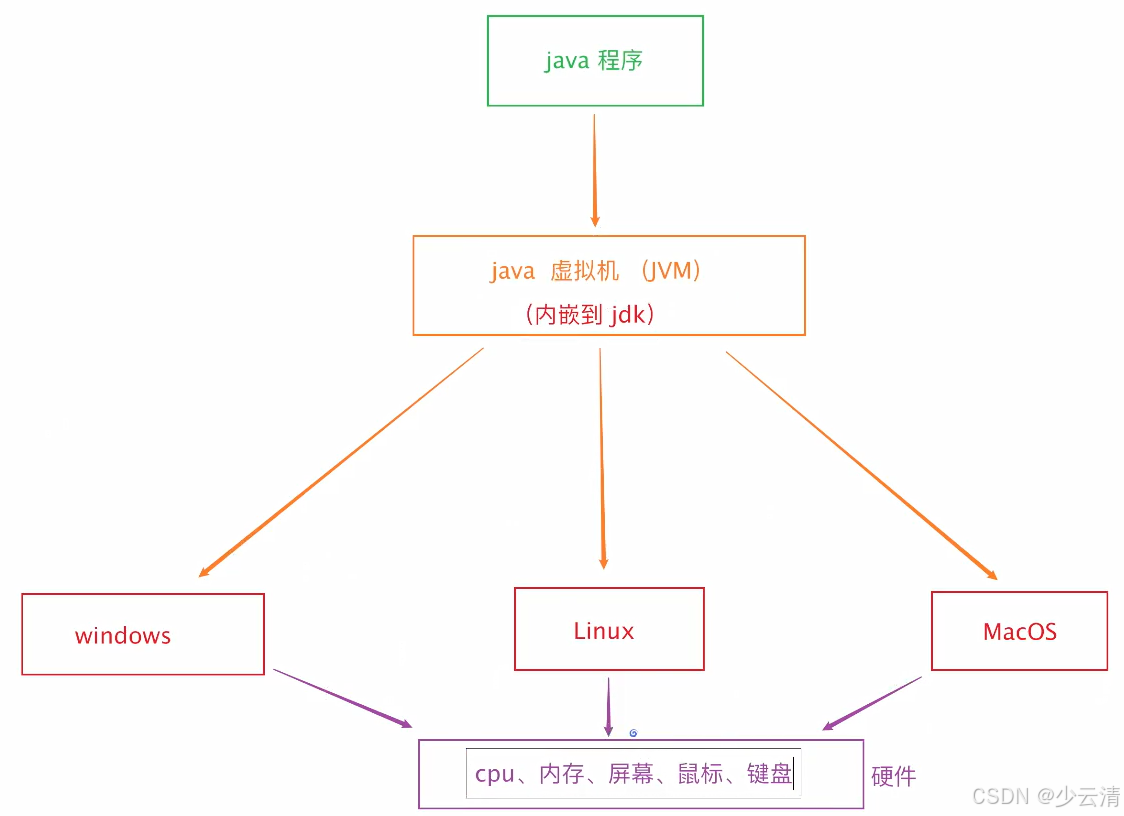
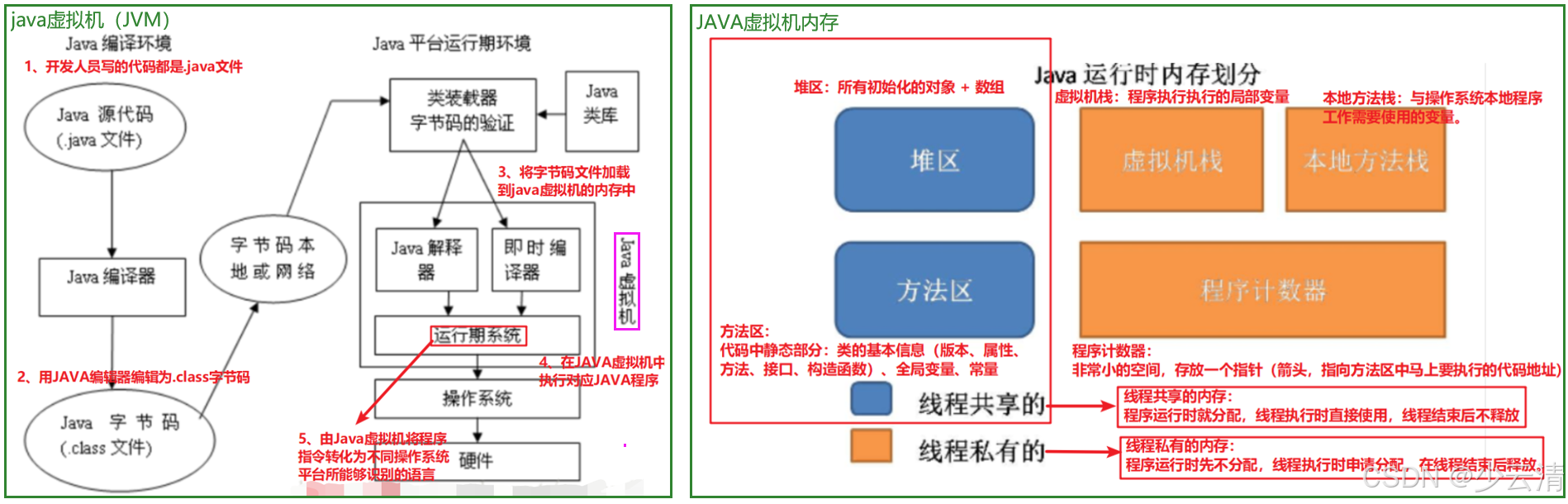
1.3.1 JVM-java虚拟机
JVM(JAVA Virtual Machine):又叫java虚拟机。 虚拟出来的空间,专门供JAVA程序运行。
1.3.2 JAVA虚拟机内存
- 堆区:需要重点关注的部分(动态变化)。
- 所有的对象在初始化会申请堆区的空间,如果申请的空间在使用结束没有及时的释放,那么这个空间就会被占用。--------- 内存泄漏
- 监控点:因此在测试时,需要关注堆区的空间是否持续上升,没有下降。
1.3.3 FULL GC机制
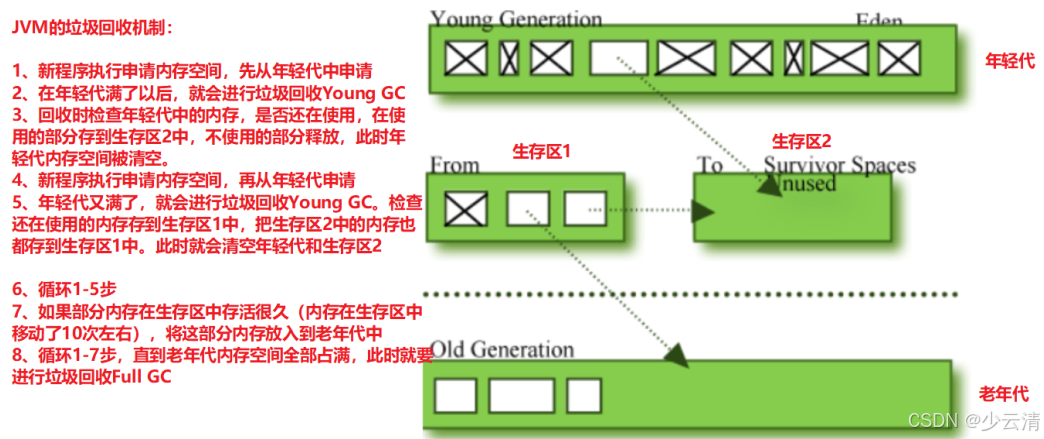
- 垃圾回收:将内存中已申请并使用完成的那部分内存空间回收,供新申请使用。
- 垃圾回收机制都是针对堆区的内存进行的。
yacas
JVM的垃圾回收机制:
1、新程序执行申请内存空间,先从年轻代中申请。
2、在年轻代满了以后,就会进行垃圾回收Young GC。
3、回收时检查年轻代中的内存,是否还在使用,在使用的部分存到生存区2中,不使用的部分释放,此时年轻代内存空间被清空。
4、新程序执行申请内存空间,再从年轻代申请。
5、年轻代又满了,就会进行垃圾回收Young GC。检查还在使用的内存存到生存区1中,把生存区2中的内存也都存到生存区1中。此时就会清空年轻代和生存区2。
6、循环1-5步
7、如果部分内存在生存区中存活很久(内存在生存区中移动了10次左右),将这部分内存放入到老年代中。
8、循环1-7步,直到老年代内存空间全部占满,此时就要进行垃圾回收Full GC。因为系统在做垃圾回收时,不能够处理任何用户业务的。如果垃圾回收过于频繁,导致系统业务处理能力下降。
监控点:
- Full GC内存比较大,垃圾回收一次时间比较长,那么这段时间内都不能处理业务,对系统影响比较大,因此我们需要关注Full GC频率。
1.4 数据库监控
1.4.1 慢查询
- 慢查询:监控系统在运行时,所执行的所有SQL语句,检查这些SQL执行时间是否慢(自己设置一个时长,执行时间超过这个时长就是慢查询)
- 通过这个方法可以把系统运行时所有执行时间比较长的SQL找出来,进行优化。
1.4.2 缓存命中率
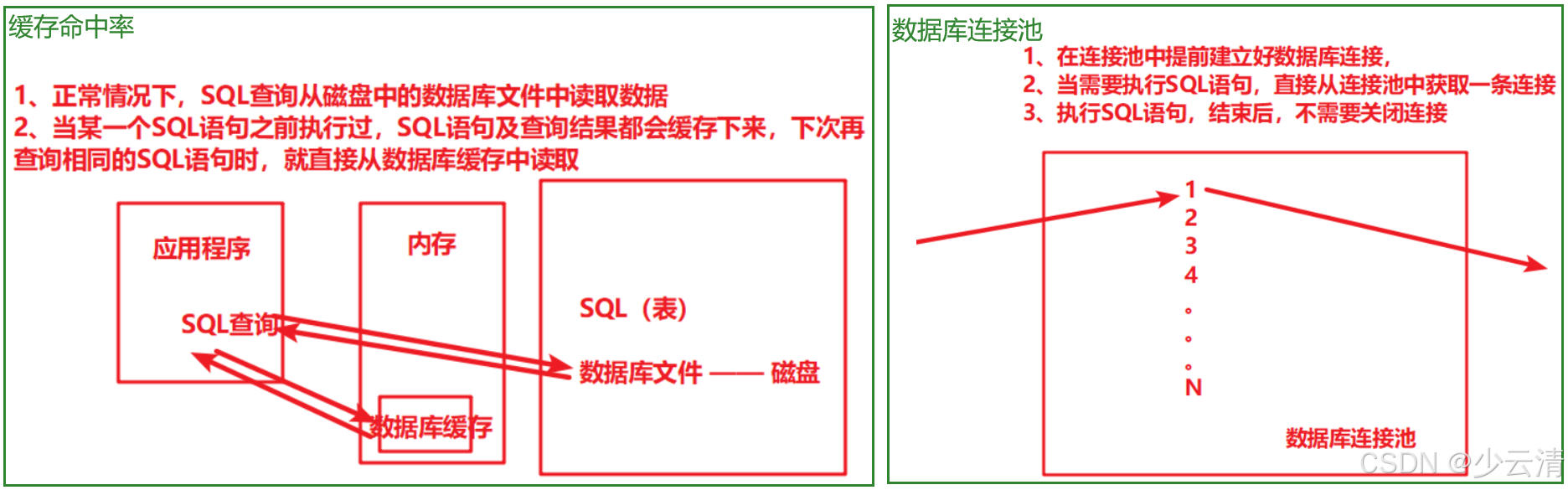
1、正常情况下,SQL查询从磁盘中的数据库文件中读取数据。
2、当某一个SQL语句之前执行过,SQL语句及查询结果都会缓存下来,下次再查询相同的SQL语句时,就直接从数据库缓存中读取。
监控点:
- 业务执行过程中SQL查询时的缓存命中率。(查询语句读取缓存的次数占总的查询次数的比例)
- 如果缓存命中率过低,需要优化对应的代码和SQL查询语句,想办法提交缓存命中率。
1.4.3 数据池连接数
监控点:
- 数据库连接池的使用率
- 如果数据库连接池被占满,此时如果有新的SQL语句要执行,只能排队等待,等待连接池中的连接被释放(之前的SQL语句执行完成)
- 如果监控发现数据库连接池的使用率过高,甚至是经常出现排队的情况,需要进行调优。
1.4.4 mysql锁
- 锁:一种保护机制,访问多人修改同一数据时,会产生不可控的后果。
AB同时修改数据L:
- A修改数据L时,会给L数据加一把锁(逻辑概念,别人不能用)
- B如果想修改数据L,系统会提示A正在修改
yacas
页面/表锁:一次只允许一个用户对这张表进行修改。适用于一些静态的页面,不经常写入的表
行锁:一次只允许一个用户对表中的一行数据进行修改,其他用户想修改表中其他行的数据是可以的。
例如:
A给B转账5W ------同时------ B给A转账500
1.A减去5W(对A的记录加行锁) 1.B减去500(对B的记录加行锁)
2.B加上5w 2.A加上500
此时就会出现死锁(死循环),两个任务都无法执行下去对比:
- 页面锁:处理效率低,但是不会出现死锁
- 行锁:处理效率高,但是可能出现死锁
监控点:
- 需要监控在性能测试过程中,是否有死锁出现,如果出现需要进行代码优化。
1.5 压测机资源
CPU:cpu使用率-不超过80%
内存:内存使用率-不超过80%。
网络:带宽
磁盘空间:
- 压测机主要是发送请求(发送请求时往外发消息,没有太多的磁盘操作,IO通常不会有问题)。
- Jmeter运行时会记录日志(注意磁盘空间不要被占满)
二、性能监控工具
要对性能测试指标进行监控, 可以使用系统自带的监控工具, 也可以使用第三方监控工具或者监控平台。
1、系统指标:
- 通过性能测试工具(如LoadRunner、 JMeter等)以图形化方式监控
2、服务器资源指标:
- 使用JMeter性能监控插件PerfMon Metrics Collector监控服务器资源。
- 使用Linux命令监控: top、 free、 vmstat、 sar、 iostat等。
- Nmon: 全面监控linux系统资源使用情况, 包括CPU、 内存、 I/O等, 可独立于应用监控。
3、Java应用:jvisualvm
4、数据库
5、压测机资源:
- Windows自带"任务管理器"
2.1 硬件网络资源监控
2.1.1 工具
结合服务器安装的ServerAgent 工具,配合JMeter性能监控插件PerfMon Metrics Collector,实现服务器硬件资源监听
2.1.2 Linux命令
2.1.2.1 top-实时查看CPU、内存
- 在Linux系统中,实时查看CPU、内存的命令(类似于Windows下的资源管理器)
- 通过q退出。(ctrl C 强制退出)
- 使用 E 修改显示的数据单位
- man top 帮助手册查看
bash
[root@localhost ~]# top
top - 04:26:17 up 12:46, 3 users, load average: 0.00, 0.01, 0.05
Tasks: 111 total, 2 running, 109 sleeping, 0 stopped, 0 zombie
%Cpu(s): 1.3 us, 2.7 sy, 0.0 ni, 96.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 995676 total, 96620 free, 643040 used, 256016 buff/cache
KiB Swap: 2097148 total, 2096884 free, 264 used. 188168 avail Mem
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1)load average: 0.08, 0.07, 0.06
1分钟,5分钟,15分钟上 CPU排队的平均时间。界面显示的时间除以CPU的数量,如果长期大于5,说明CPU硬件能力不足,超负载了。
2)0 zombie
# 表示系统的僵尸进程
# 僵尸进程:linux系统中,所有的进程都是由父进程生出来的,每个进程都有一个父进程。当一个进程执行结束,父进程有义务对子进程进行回收。如果父进程没有回收或者在父进程回收之前,它就会变成僵尸。
# 编写程序不允许当前Linux系统有僵尸出现。因为僵尸一出现,代表资源没有被回收
3)%Cpu(s): 1.3 us, 2.7 sy
# cpu占用的百分比,1.3 us 用户进程占用的百分比,2.7 sy 系统进程占用的百分比
4)KiB Mem
# Mem 内存,KiB 以KB位单位;
995676 total, 96620 free, 643040 used, 256016 buff/cache
# total内存总量,free内存剩余,used内存使用,buff/cache 缓冲区/缓存
5)KiB Swap
# Swap交换空间,KiB 以KB位单位;交换空间是拿磁盘当内存使用,Linux系统中的特有机制。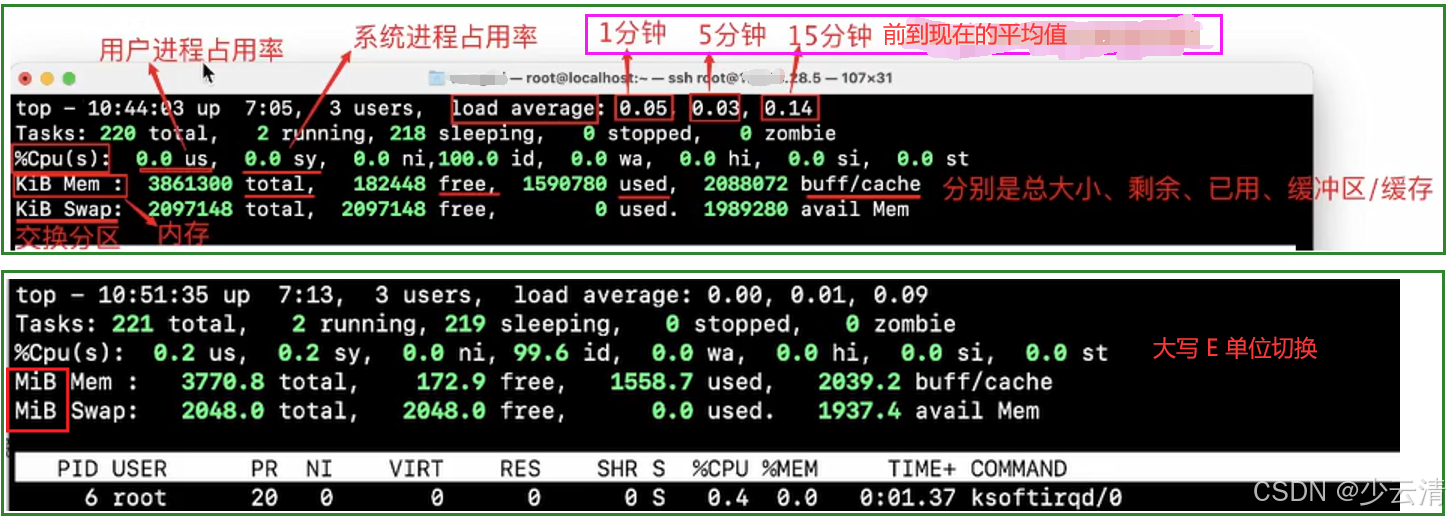
2.1.2.2 free-查看内存
作用:查看系统内存使用情况。
参数: -m 以兆 为单位显示。
- total 总的
- used 已使用
- free 空闲
- shared 共享
- buff/cache 缓冲区/缓存
- available 可使用的
- Mem 内存
- Swap 交换空间
bash
[root@localhost ~]# free
total used free shared buff/cache available
Mem: 995676 648764 66948 25676 279964 182228
Swap: 2097148 264 2096884
# 以MB为单位
[root@localhost ~]# free -m
total used free shared buff/cache available
Mem: 972 633 65 25 273 178
Swap: 2047 0 2047
# 以GB为单位
[root@localhost ~]# free -g
total used free shared buff/cache available
Mem: 0 0 0 0 0 0
Swap: 1 0 12.1.2.3 vmstat-查看CPU、内存等
- vmstat 是全面的性能分析工具,可以查看系统的进程状态、内存使用、虚拟内存使用、磁盘的IO、中断、上下文切换、CPU使用。
- vmstat 1 (每1秒检测1次,持续不停检测)
- vmstat 1 4 (1表示1秒查询一次,总共查询4次)
bash
[root@localhost ~]# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 264 75856 164 266812 0 0 5 4 57 139 1 0 99 0 0
1)procs进程
r:表示运行和等待CPU时间片的进程数,这个值如果长期大于系统CPU个数,说明CPU资源不足
b:表示等待资源的进程数。(等待资源:除CPU以外的其它资源)
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
# vmstat 1 4 1表示1秒查询一次,总共查询4次
[root@localhost ~]# vmstat 1 4
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 264 75960 164 270684 0 0 5 4 58 140 1 1 99 0 0
0 0 264 75796 164 270688 0 0 0 0 89 180 1 2 97 0 0
1 0 264 75064 164 270688 0 0 0 17 170 270 4 3 93 0 0
11 0 264 75648 164 270696 0 0 0 12 111 200 2 2 96 0 02.1.2.4 sar-查看网络
1、sar命令属于sysstat工具集的一部分,如果系统没有安装sysstat包,sar命令就无法使用。
bash
# 命令来安装sysstat包:
sudo apt-get install sysstat # Ubuntu/Debian
sudo yum install sysstat # CentOS/RHEL2、命令格式
bash
sar -n DEV 1 3
1)-n 类型
2)DEV 类型参数(可选)
3)1 时间间隔
4)5 次数
sar -h # 查看帮助- sar -n EDEV 1 2 # 统计网络设备通信失败信息
- sar -n DEV 1 2 # 网路设备的状态信息,每隔1秒监测1次,一共监测2次。
bash
[root@localhost ~]# sar -n DEV 1 2
Linux 3.10.0-1160.el7.x86_64 (localhost.localdomain) 2025年08月03日 _x86_64_ (1 CPU)
07时34分23秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
07时34分24秒 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
07时34分24秒 ens33 15.00 22.00 1.40 2.99 0.00 0.00 0.00
07时34分24秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
07时34分25秒 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
07时34分25秒 ens33 14.85 21.78 1.39 2.50 0.00 0.00 0.00
平均时间: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
平均时间: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
平均时间: ens33 14.93 21.89 1.40 2.74 0.00 0.00 0.00
# rx:表示接收
# tx:表示发送2.1.2.5 iostat-查看磁盘IO
作用:查看系统中,磁盘的读写情况
bash
[root@localhost ~]# iostat
Linux 3.10.0-1160.el7.x86_64 (localhost.localdomain) 2025年08月03日 _x86_64_ (1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.74 0.00 0.71 0.00 0.00 98.55
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 0.67 10.60 8.21 692167 536170
scd0 0.00 0.00 0.00 44 0
dm-0 0.65 10.41 8.11 679792 529598
dm-1 0.02 0.04 0.07 2568 45042.2 应用服务器、数据库配置
2.2.1 应用服务器配置
- Apache:默认最大连接数 256 。
- Nginx:默认最大连接数 受Linux系统默认打开的最大文件个数限制。(ulimit -n 查看)
bash
[root@localhost ~]# ulimit -n
1024- Tomcat:默认最大连接数 200。
------软件测试工程师,只需要定位 性能瓶颈是由应用服务器的默认最大连接数限制即可。修改工作由开发完成。
2.2.2 数据库服务器配置
- mysql:默认最大连接数 151。
bash
[root@localhost ~]# mysql -uroot -p
Enter password:
# 查看最大连接数
mysql> show variables like '%max_connections%';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 151 |
+-----------------+-------+
1 row in set (0.01 sec)
# 查看当前连接数
mysql> show status like 'max_used_connections';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| Max_used_connections | 12 |
+----------------------+-------+
1 row in set (0.01 sec)
mysql> set global max_connections=1000;--设置最大连接数为1000,可以再次查看是否设置成功------软件测试工程师,只需要定位 性能瓶颈是由数据库服务器的默认最大连接数限制即可。修改工作由数据库管理员完成。
2.3 数据库资源监控-慢查询
2.3.1 Mysql常用监控指标
由于数据库中数据量较大,并且对应的字段没有设置提高检索效率的手段,很容易导致查询速度慢,降低系统性能。
- 慢查询:指执行速度低于设置的阀值的SQL语句
- 作用:帮助定位查询速度较慢的SQL语句,方便更好的优化数据库系统的性能
2.3.2 设置与开启慢查询
1、查询Mysql慢查询开关状态 及 日志文件的位置。
sql
show variables like 'slow_query%';2、使用sql语句,开启Mysql数据库慢查询 开关(默认关闭 OFF)
sql
set global slow_query_log='ON';3、查看Mysql默认的慢查询阈值。
sql
show variables like 'long_query_time';4、修改慢查询阈值。 (默认阈值为 10s )
sql
set global long_query_time=1;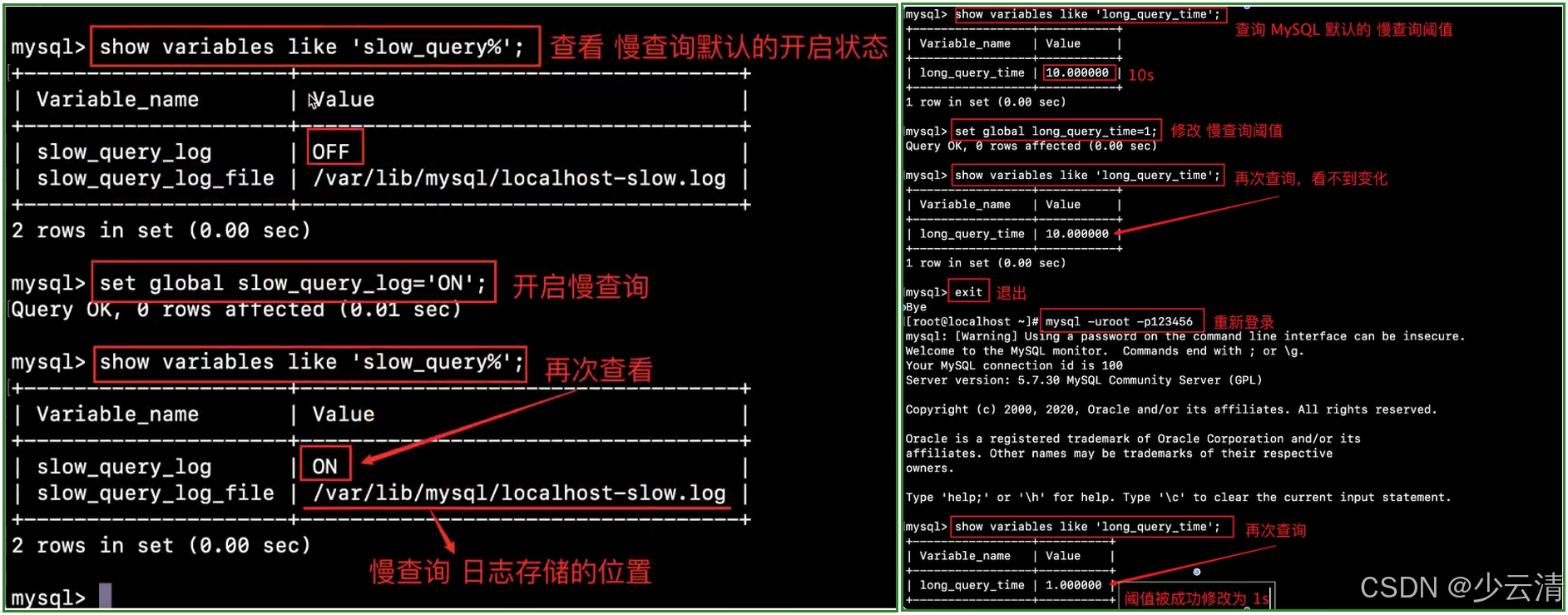
参数说明:
- slow_query_log: 慢查询日志开启状态ON:开启, OFF:关闭
- slow_query_log_file: 慢查询日志存放位置
- long_query_time: 慢查询时长设置(超过该时长才会被记录,单位:秒)
sql
# 开启慢查询日志
mysql> set global slow_query_log='ON';
# 设置慢查询日志存放位置(可选)
mysql> set global slow_query_log_file='/data/slow_query.log';
# 设置慢查询时间标准, 设置之后会在下次会话才生效
mysql> set global long_query_time=1;2.3.3 准备测试数据
使用python解释器,运行构造10万条测试数据(开发提供测试脚本或数据)
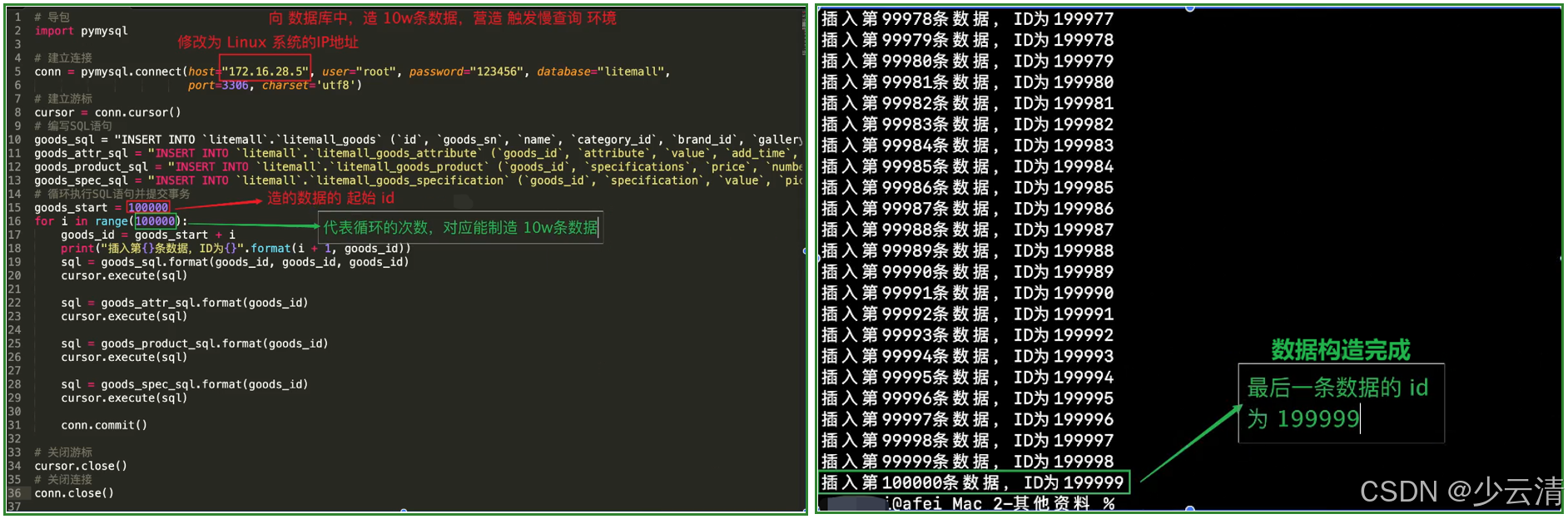
2.3.4 测试-慢查询和实时日志查看
1、为什么没有触发慢查询?
- 通过navicat软件,右键点击litemall_goods表--->选择设计表--->刚才查询的字段依赖的是id字段,id在这张表中主键。
- 主键具有唯一性,会自动添加索引,而这个索引是导致查询速度变快的原因。
sql
select count(*) from litemall_goods; -- 统计litemall_goods数据库总记录数
select * from litemall_goods limit 1; -- 查询数据库第一条数据(查看第一页数据,数据库有默认排序)
select * from litemall_goods order by id desc limit 1; -- 查询最后一条记录 (通过id,desc降序 排列)
select * from litemall_goods where name = '母亲节礼物-舒适安睡组合'; -- 触发了慢查询,用时6.637s。2、mysql数据库自带一种"缓存命中率"机制,对于相同数据的反复查询,可以借助缓存,提高查询效率。一旦缓存被清理,查询速度依然慢。
3、查询 日志文件命令:tail -f 日志文件名.log
mysql里面的时间计算是按美国时间计算,因此会出现时间不一致情况
bash
[root@localhost ~]# tail -f /var/lib/mysql/localhost-slow.log # 实时查看日志文件信息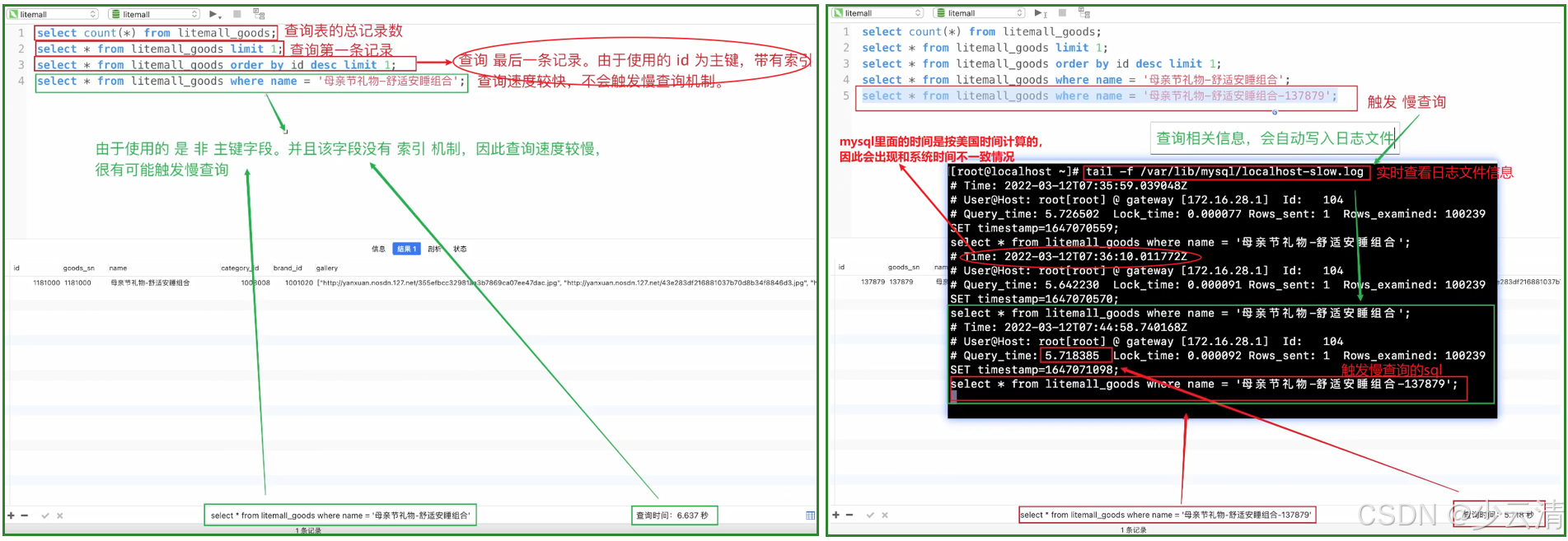
2.4 JVM
2.4.1 代码常见问题
1、内存泄漏(Memory Leak):内存不释放 (占着茅坑不拉屎)
-
程序申请的内存,使用结束后,未被释放,导致内存持续占用且无法被其他程序使用。
-
Java中对象引用未设为
null导致垃圾回收机制无法回收。
2、内存溢出(Out Of Memory):内存不够用
- 程序申请内存时,系统无法提供所需空间。
- Java堆内存或线程栈超出限制会抛出
OutOfMemoryError
yacas
两者关系:
内存泄漏是因:未释放的内存会持续占用资源,长期积累可能导致可用内存不足,最终引发内存溢出。
内存溢出是果:当系统内存不足时,程序无法继续申请新内存,导致运行异常。3、扩展:查看服务器日志文件常见 关键字
yacas
Memory Leak:内存泄漏
Out Of Memory :内存溢出
error:错误
Excepion:异常
null:空 (java空引用,C++空指针)
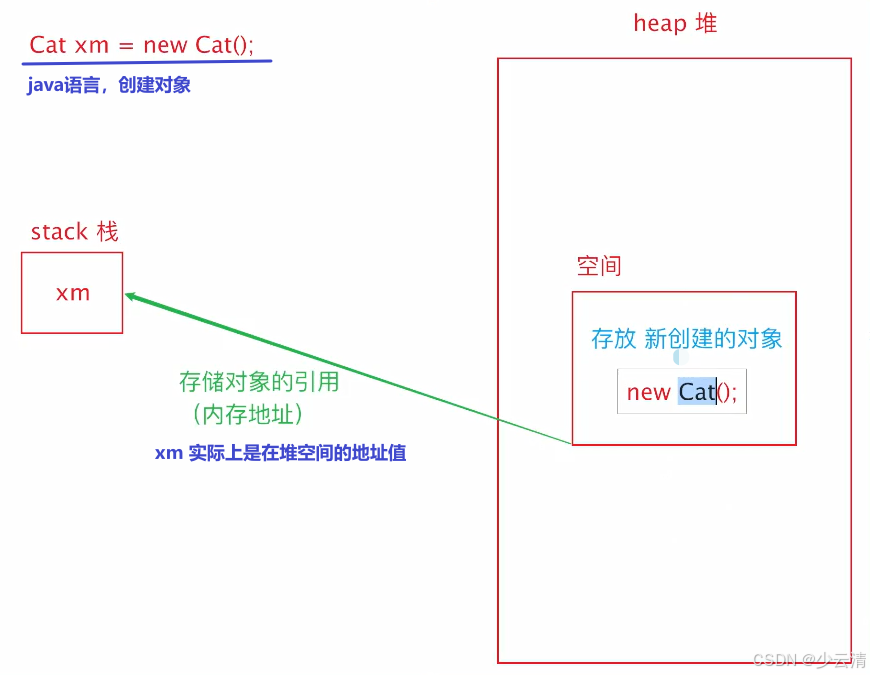
500:服务器错误2.4.2 内存分类
- stack 栈:存储新建对象的引用(内存地址)和基础数据类型
- heap 堆:存储新建对象的实际内容,是监控代码内存溢出的主要目标。
2.4.3 下载并配置VisualVM
1、下载VisualVM
- JDK 8及更高版本已不包含 VisualVM 工具,需单独下载安装。
- VisualVM下载官网: https://visualvm.github.io/
2、下载解压之后,在bin文件夹下找到 visualvm.exe 启动程序。
yacas
因为在安装java时,配置了PATH和JAVA_HOME,因此不用指定JDK也可以成功启动 (参见java安装和配置)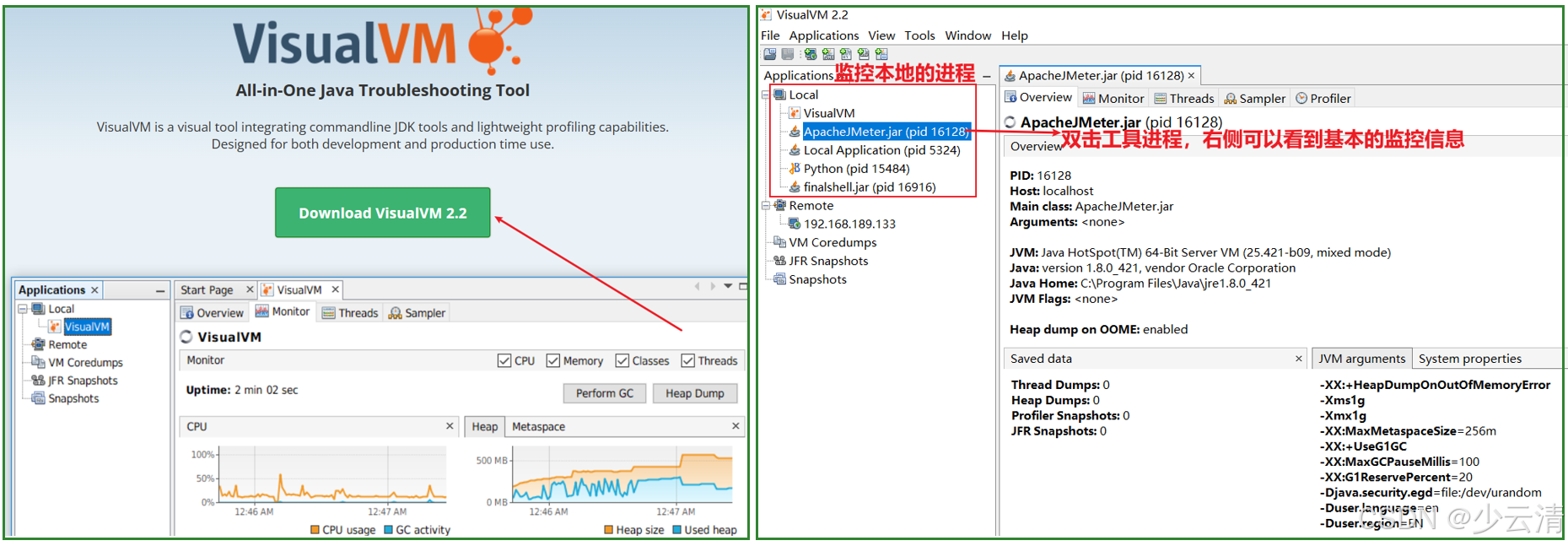
2.4.4 JVM监控---Jvisualvm.exe
yacas
Jvisualvm能监控 JVM (java虚拟机)
使用本地jvisualvm远程监控服务器1、进入项目jar包所在的目录,添加参数(来辅助Jvisualvm进行监控),重新启动litemall项目服务器。
- 保证Linux服务器和Windows系统相互之间是能ping通
- 使用 ps aux|grep litemall 查询当前 轻商城项目 的服务器 进程id
- 使用kill -9 进程id 关闭 原有的 轻商城项目 的服务器
- 使用带有参数的命令,重启litemall服务器。(注意:修改成自己linux的IP)
- 浏览器 借助http://www.litemall360.com:8082/#/user/ 测试服务器是否重启成功
shell
java -jar
-Dcom.sun.management.jmxremote
-Djava.rmi.server.hostname=172.16.28.5
-Dcom.sun.management.jmxremote.port=10086
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.authenticate=false
litemall-all-0.1.0-exec.jar
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
# 真正 运行的命令:
java -jar -Dcom.sun.management.jmxremote -Djava.rmi.server.hostname=172.16.28.5 -Dcom.sun.management.jmxremote.port=10086 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false litemall-all-0.1.0-exec.jar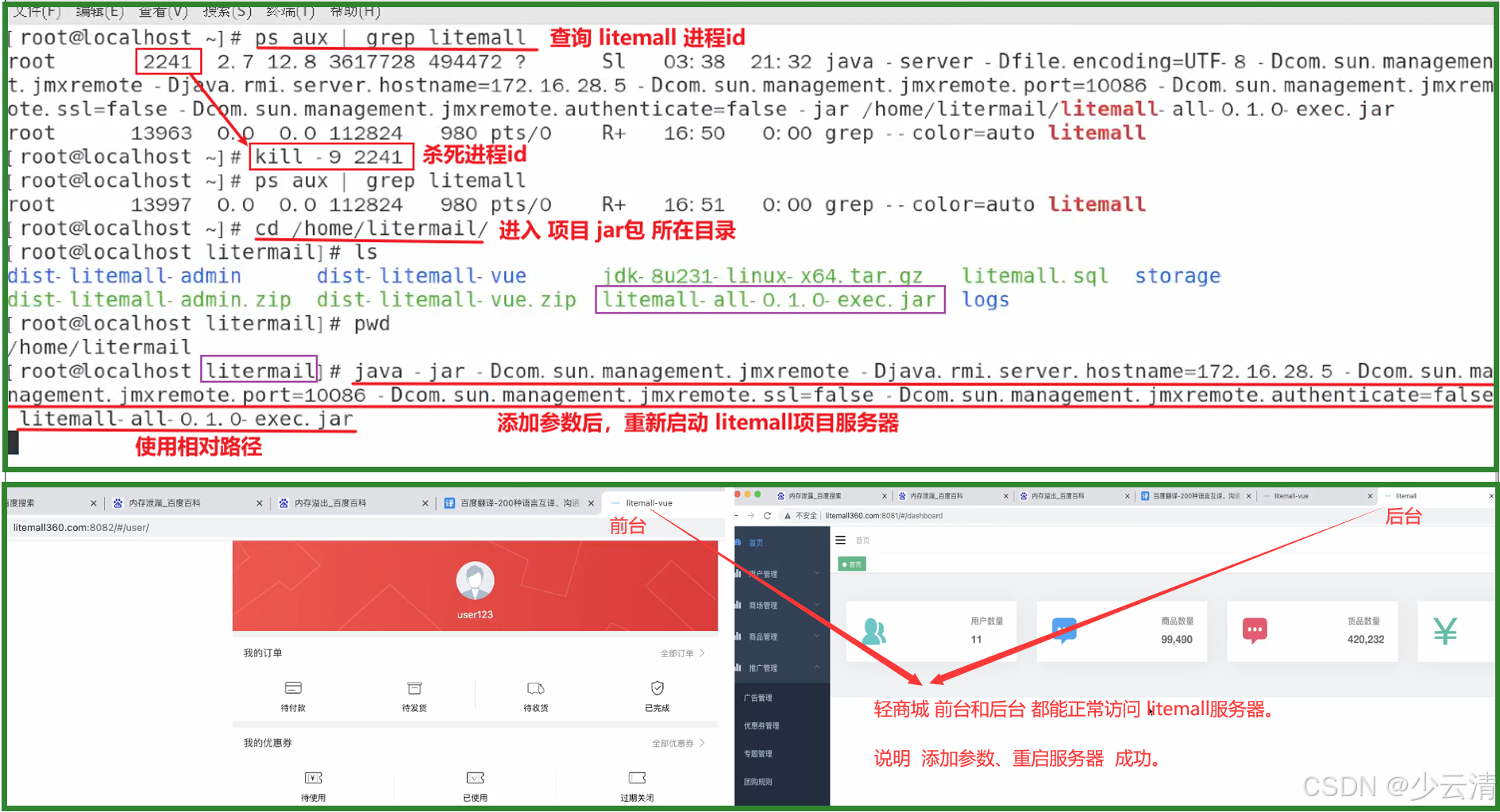
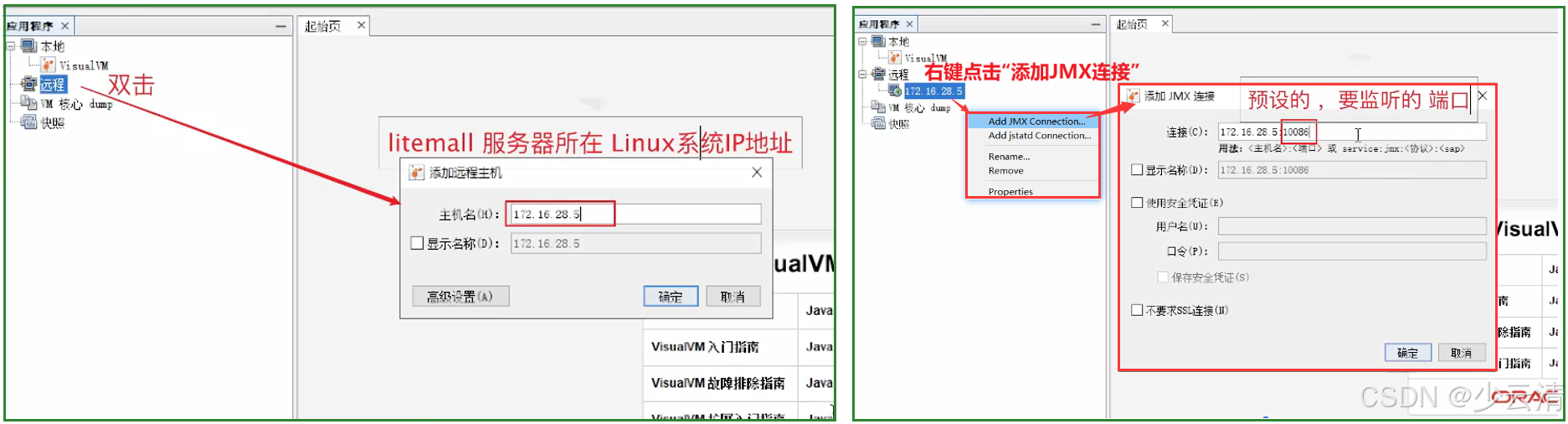
2、jdk8之前的老版本有Jvisualvm.exe,进入本地jdk安装目录bin目录, 找到jvisualvm.exe双击并启动
3、右键"远程"选择"添加远程主机", 并输入主机IP (IP地址为linux虚拟机的IP )
4、右键主机选择"添加JMX连接",右键点击"添加JMX连接",填写端口号(预设的端口号)
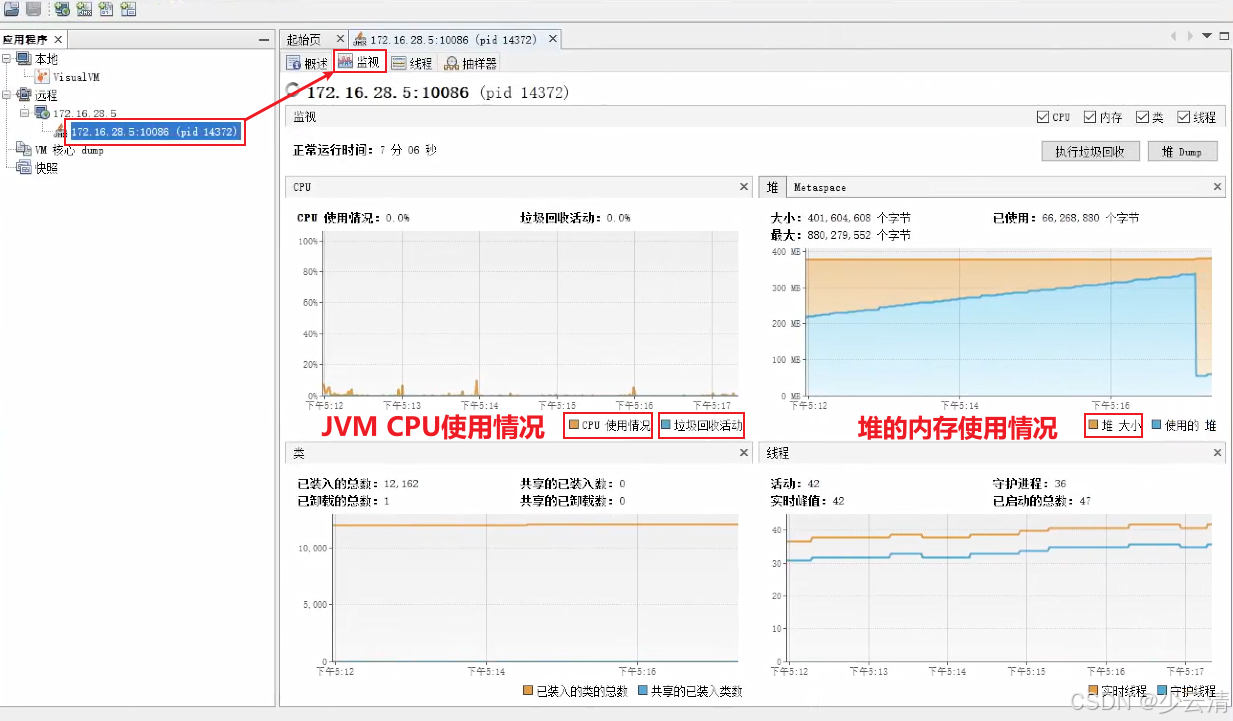
5、点击JMX连接,选择监控,看JVM对应的监控指标。(重点关注:CPU使用、堆的内存使用)
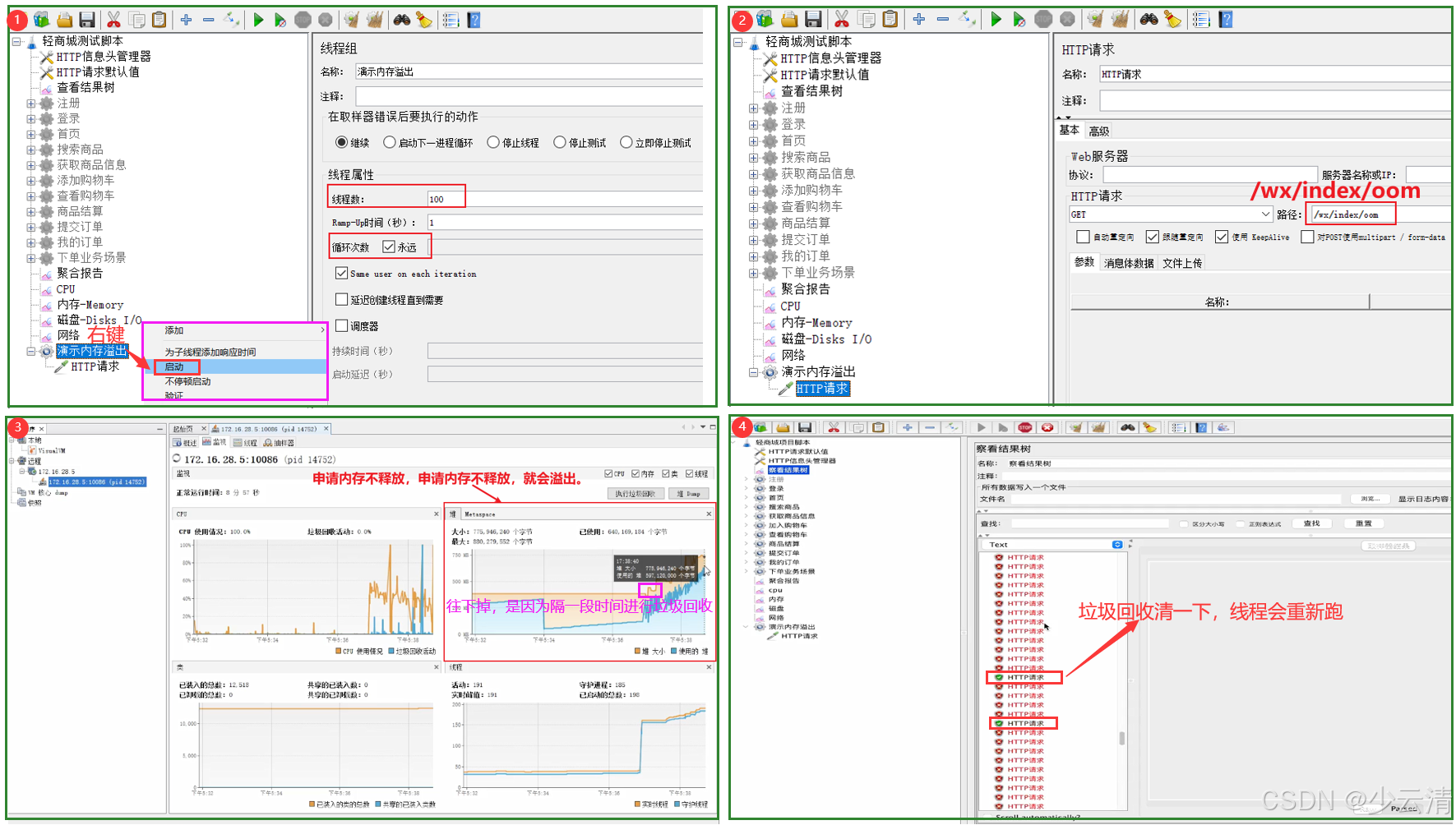
2.4.5 内存溢出演示
1、内存溢出测试路径:
yacas
/wx/index/oom
申请内存不释放,申请内存不释放,就会溢出。