作者:vivo 互联网服务器团队- Lei Zezheng
本文探讨了分布式架构下可观测体系的建设实践,提出了基于业务视角的可观测体系建设框架:明确业务核心边界、建立指标体系(业务指标+SLO指标)、构建多维度观测(业务观测、链路观测、异常观测、变更观测)和固化排障路径,以游戏中心项目为例,介绍了项目在问题发现与问题定位上的实践,有效提升了问题发现与故障处理的效率。
1分钟看图掌握核心观点👇
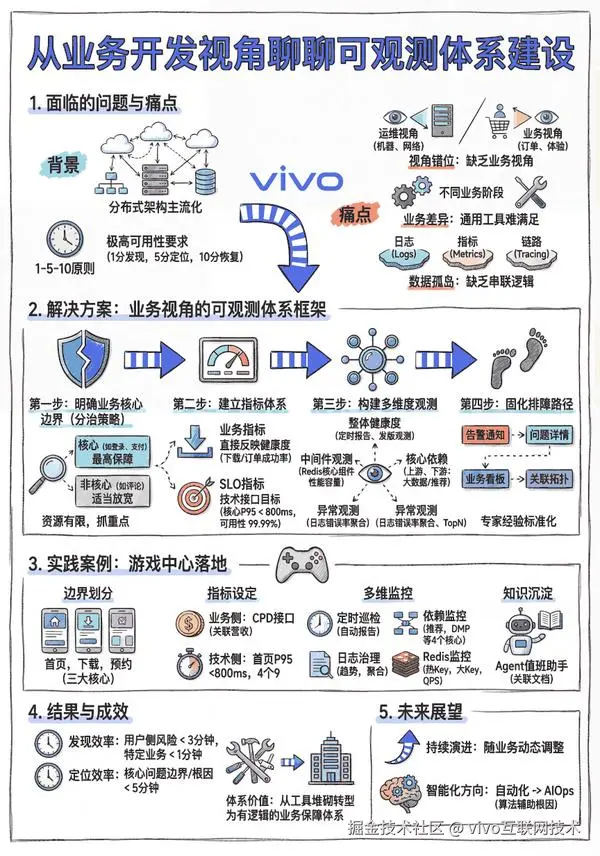
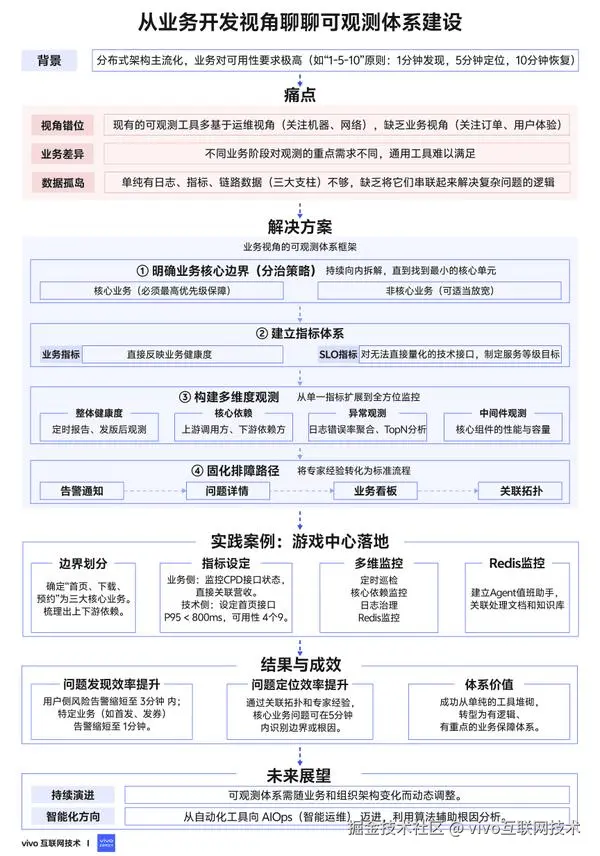
图 1 VS 图 2,您更倾向于哪张图来辅助理解全文呢?欢迎在评论区留言
一、背景介绍与痛点分析
当分布式架构渐成主流,可观测性(Observability)在行业内也越来越受到重视。可观测性是指系统可以由其外部输出,来推断其内部状态,系统的可观测性越强,我们对系统的可控制性就越强。现如今如何提升整体系统的可观测性,应用可观测工具达成业务保障可用性目标,成为了每个SRE与业务开发都必须思考的课题。但是随着业务复杂度与"1-5-10"(1分钟内发现问题,5分钟内定位问题原因,10分钟内恢复故障)可用性保障目标等的日益提升,我们也发现了可观测体系在我们业务落地上的一些问题。
- **观测视角的差异。**可观测工具建设与落地方向大多处于运维视角,而非业务视角。
- **业务的差异。**不同的业务、业务发展的不同阶段,对于观测的建设重点差异很大。
这些差异,为平台侧提供观测工具与业务开发使用工具之间带来了不少痛点。游戏中心作为toC的分发类业务的一个典型项目,可观测体系的建设过程可圈可点,现总结其中一些经验,希望对于其他业务项目有所帮助。
二、可观测体系的数据基座
对于可观测,大家或多或少都听过可观测性的"三大支柱":指标、日志和链路,2017 年Peter Bourgon 撰写的文章《Metrics, Tracing, and Logging》 系统地阐述了这三者的定义:
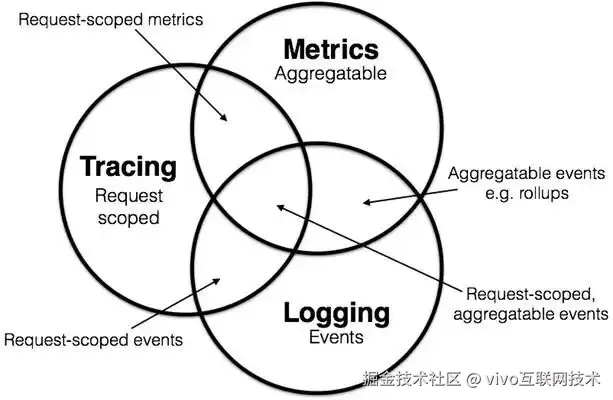
那么我们监控团队已经基本很完备的采集好了这些数据,并且呈现了诸如日志中心,应用监控,调用链指标监控等工具,是否就代表了能保证我们系统的可观测性?答案当然是否定的,有了西红柿、鸡蛋、盐,并不能代表我们就已经能吃到西红柿炒鸡蛋了,三大指标都有着自己的明显特征与使用场景:
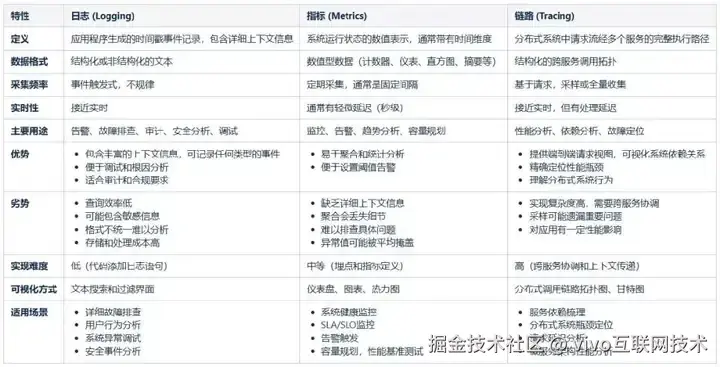
独立的使用各种指标,永远只适用于部分场景,虽不能说完全无效,但想系统化达成目标一定会比较吃力,且无条理。面对较为简单的问题,比如日志突然打印了空指针异常、数组越界的错误,我们看下日志中心就很快能定位到具体代码行上,进而分析上层参数的情况,并去迅速排除故障。但是当问题复杂度略微提升,比如:
- 我们依赖的服务耗时缓慢上升,直至导致我们服务的可用性下降;
- 服务调用者缺陷导致对我们某个服务的调用流量异常上涨,进而影响redis、mysql等基础组件,最终导致同样依赖该组件的核心服务受损。
出现这类问题时,日志中心、应用指标,超时链路都会有异常反应。除此以外,绝大多数系统问题其实都是由于变更导致或触发的,所以除了以上三个核心数据外,还需要结合一些变更系统事件来做辅助根因定位。我们无法24小时时刻关注各项指标,必须通过配置检测与告警来主动通知。
日志、指标、链路、变更事件以及告警,共同构成了我们可观测的数据基座。
三、业务视角的可观测体系建设框架
3.1 业务核心分治
对于大多数系统来说,我们建设可观测体系都是为了及时发现系统中出现的各类故障,但是作为业务开发,实践中我们会发现在这个标准下:都是故障,亦有差距。"游戏中心首页白屏"、"登录失败"、"下载失败" 这类问题出现即是致命伤,等故障爆发后再发现是不可接受的。但是对于"游戏评论刷新延迟","我的页成就刷新延迟"之类的故障,在资源有限时,可能慢一点处理也无妨。
所以基于分治的思路,首先要做的就是"明确业务核心边界"。如果拆解出的核心业务依然很复杂,那么应当持续视角向内,将业务拆解至最小的核心单元后,再分部进行观测。
3.2 指标体系的建立
对于业务系统,首要的观测指标当然是业务指标,能够直接反应业务的健康度,比如:"游戏下载成功率","游戏登录成功率","游戏订单成功率"等。不过我们很多业务场景无法直接拟定业务指标,经过实践,一定程度上可以通过SLO指标进行替代。
SLO指标是我们观测可用性的重要手段,但不是越多越好,SLO的意义在于通过告警帮助我们快速发现影响服务SLI的异常,配置过多会带来告警过多的困扰。上文已经提及到核心业务的拆分,对于微服务架构我们大部分服务是以接口调用的形式去对外提供的,那么抽离出一组或多组的核心服务接口,并对于这一批接口的SLI指标进行度量,就可以制定自己系统的SLO目标。
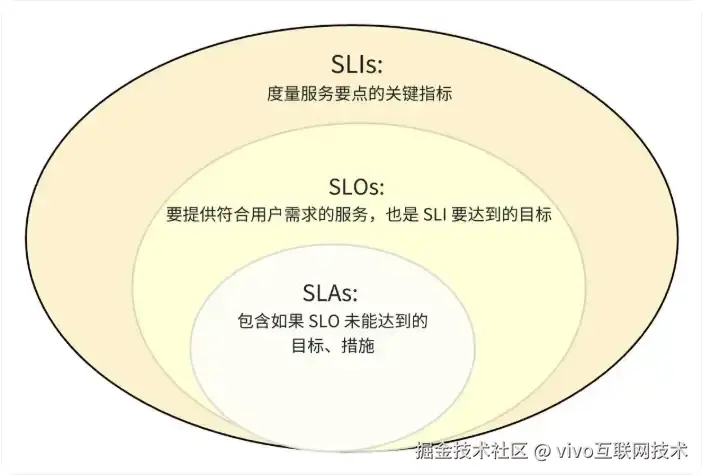
3.3 明确数据观测目的与意义
通过建立指标体系,我们就能够识别出系统中包含各式各样的指标数据,通过对数据进行分类,我们也能够进一步理解其对于系统的价值所在。
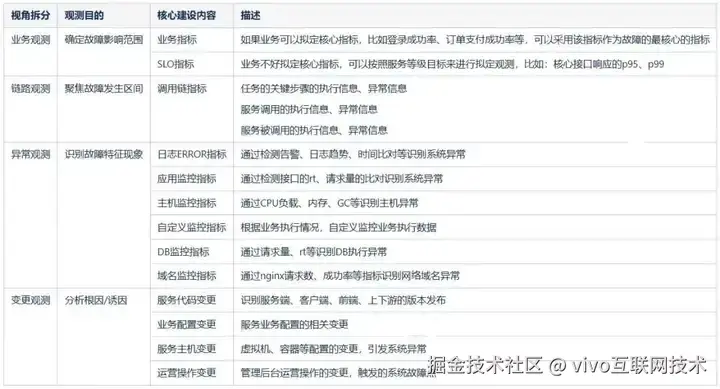
分象限观测
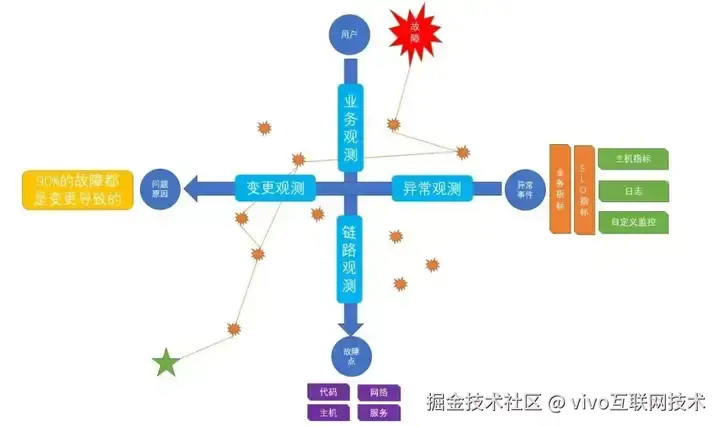
四、游戏中心可观测体系实践
4.1 明确核心边界
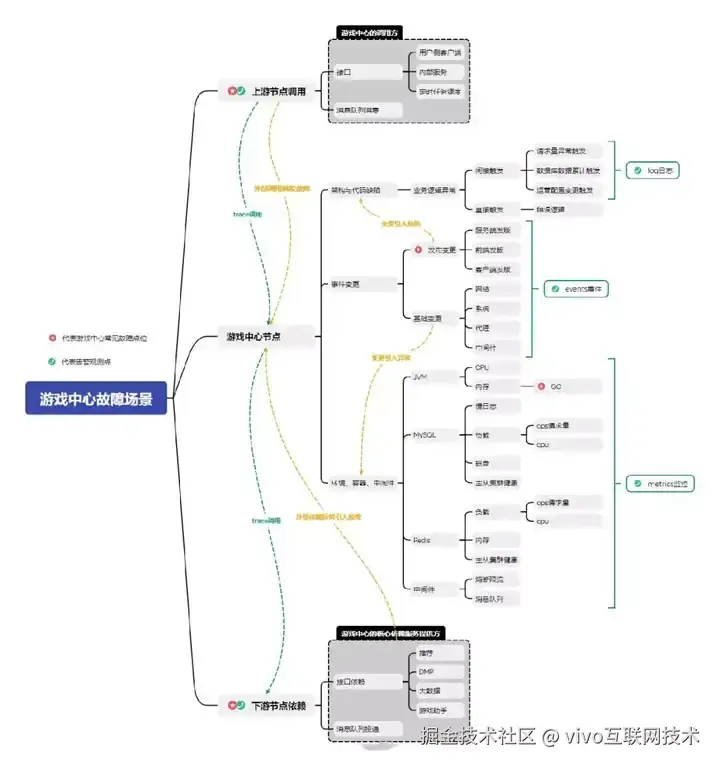
首先我们对游戏中心进行了核心业务的划分:游戏中心首页、游戏下载、游戏预约,对这三块业务进行最高优先级的保障。由于可观测体系的搭建必须依赖平台能力,相关能力最终也必须沉淀回平台,所以在边界划分上需要结合整体微服务架构设计:
公司的微服务拓扑视角
- 上游节点调用,重要调用方
- 下游节点调用,核心依赖方
游戏中心服务架构视角
- 客户端
- 网络环境
- 容器环境
- 代码
- 中间件、核心依赖组件
- 运营后台
4.2 指标体系建立
(1)业务指标的观测
对于游戏中心下载业务,下载CPD指标是很核心的业务指标,且直接与收入数据挂钩,可以通过检测cpd接口的状态来反映业务情况。

(2)SLO指标的观测
对于首页上游客户端调用,无法简单与日活、营收等数据相关联,为了达成"1-5"的目标,对于游戏中心的SLO指标的制定我们选取了核心接口的P95耗时与可用性指标,并配置相关监控。首页接口的pageData/home p95范围大概在200-300ms,根据akamai研究用户体验能明显感知到慢的程度大概是加载2秒以上,附带算上网络传输与客户端渲染时间,我们的服务目标定为P95<800ms,在可用性上全年项目SLA可用性级别为4个9,在接口服务上也保持一致。
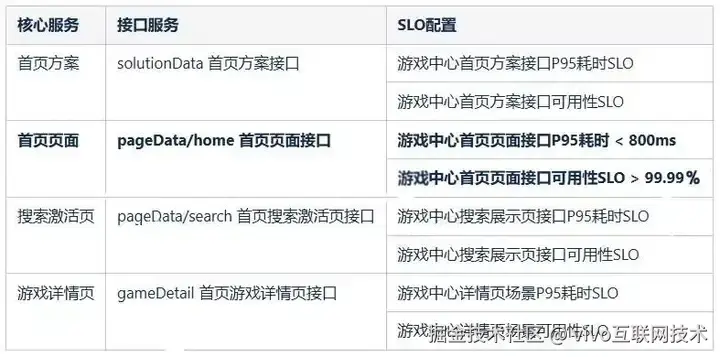
4.3 多维度的观测
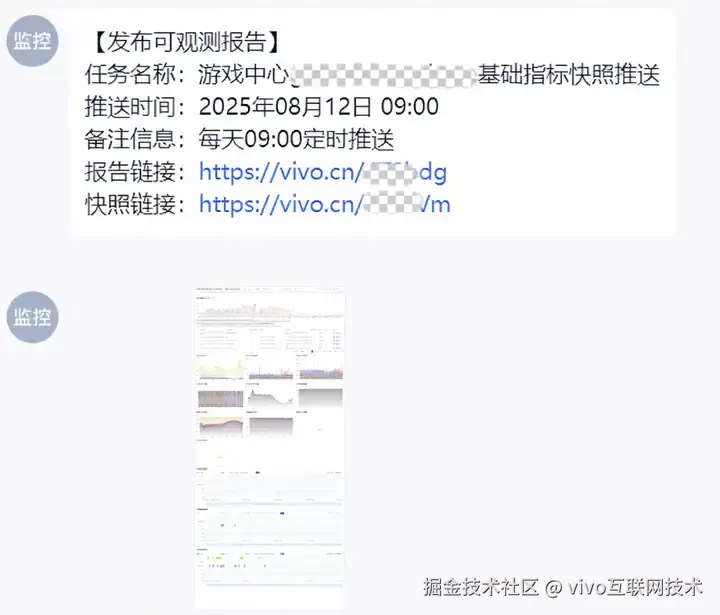
(1)整体健康度的定时观测与发版后观测
抽离核心观测数据来快速实现整体核心SLI指标的观测,是发现一些全局影响故障最直接的手段。如果一段时间所有接口的rt都缓慢上涨,那么一定代表着系统出现了影响面最大的故障。通过定时报告的配置,既防范了个人的观测习惯风险,也提升了移动端的观测能力。版本发布后的定期报告观测,也是我们当前观测版本变更后可用性的主要手段。
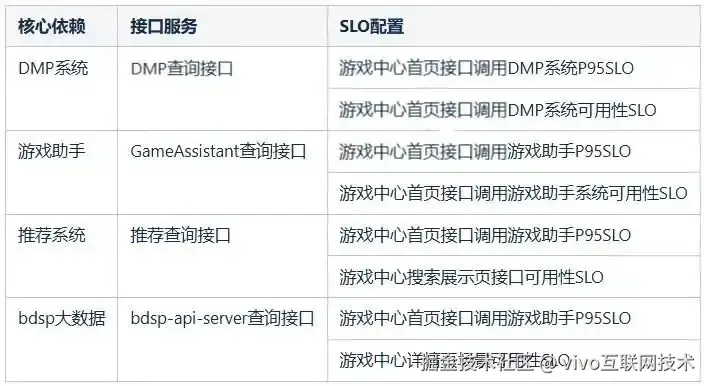
(2)服务的核心依赖观测
在游戏中心业务中,需要从推荐、dmp标签、游戏资讯、大数据四个业务方获取核心数据,那么这四个服务相关接口的SLO就需要作为核心依赖观测项。
(3)服务的日志观测
- 通过错误日志治理,降低error数量,来有效呈现异常error数据。
- 除了进行阈值数量监控外,对ERROR日志聚合1分钟级别的趋势分析,聚合topN,有效识别异常error的变化。
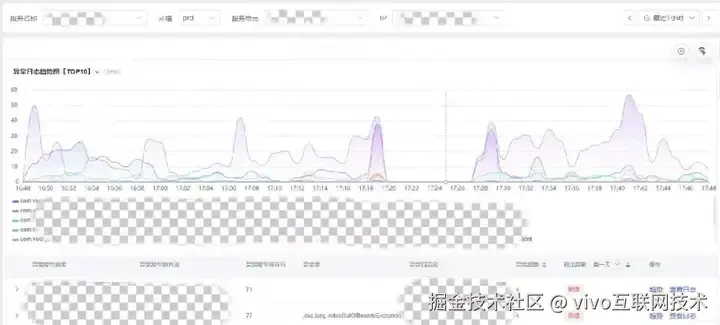
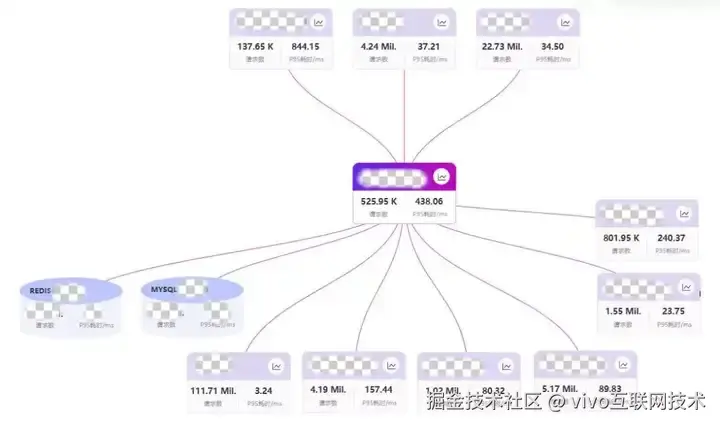
(4)中间件的观测
对于游戏中心业务,redis是最为核心的中间件,redis的稳定直接影响首页各个业务的健康度。对于redis的ops、实例cpu都进行检测,结合热key、大key分析,能够有效识别问题和风险。
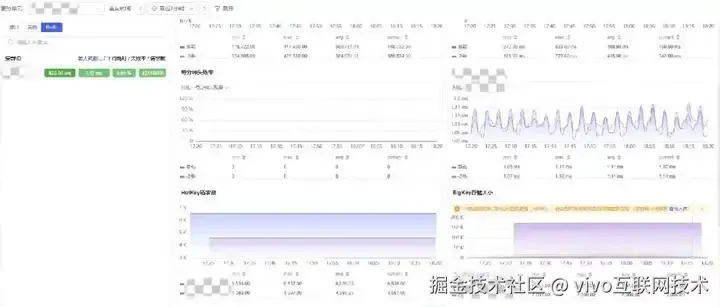
4.4 固化排障路径
通过告警入口的下钻串联,搭建了 "告警通知→问题详情→业务看板→关联拓扑" 的通用问题排障路径。
在专家经验的沉淀上,对于业务、SLO等相关告警,通过处理流程建议文档、文档知识库、日志知识库,构建agent值班助手来共享团队知识。

五、总结与展望
- 在问题发现上:对于游戏中心的三大核心业务场景明确了业务边界之后,用户侧接口访问变慢、出错的风险告警可以在3分钟内完成告警推送;通过与监控团队合作提升自定义监控数据采集,对于游戏预约首发、游戏礼券发放等业务,可以做到1分钟的问题告警推送。
- 在问题定位上:通过关联到下游依赖、服务基础指标与专家经验,游戏核心业务的组件、服务异常等问题,基本可以5分钟内做到识别风险和问题边界或原因。
可观测体系建设并非一劳永逸的事情,随着业务变化而变化,也随着团队组织架构变化而变化。对于监控平台,构建统一可观测体系的难点,一方面在于技术本身的制约,如何应对大规模数据的存储、性能挑战;另一方面则在于如何与千差万别的业务进行沟通、合作,融合业务专家经验,抽象出共性的问题。那么作为业务开发,持续提升可观测理解水平,深入挖掘沉淀业务专家经验,才能协同好平台一起做好这件事。现如今,行业AIOPS的发展日新月异,我们系统化的构建可观测体系也是融入该浪潮中,在实现的工具自动化的目标之后,我们也希望朝着智能化的建设迈出一步。