面试耻辱柱
-
-
- [一、mysql varchar 是字节还是字符?](#一、mysql varchar 是字节还是字符?)
- 二、场景(2000万数据表:id、姓名、年龄、爱好) 主键用啥类型 id 主键用啥类型 id)
- [三、bigint 8 个字节最多存多少数据,2000万够吗?](#三、bigint 8 个字节最多存多少数据,2000万够吗?)
- [四、如果2000万这个只会用到 where name = xx 或者 where age = xx ,where name =xx and age = xx,该如建立索引](#四、如果2000万这个只会用到 where name = xx 或者 where age = xx ,where name =xx and age = xx,该如建立索引)
- [四、如果2000万 name 用啥类型合适,名字包含中文名字和英文名字](#四、如果2000万 name 用啥类型合适,名字包含中文名字和英文名字)
-
一、mysql varchar 是字节还是字符?
VARCHAR 在 MySQL 中是以字符为单位计算的,而不是字节。
- 当创建 VARCHAR(10) 字段时,表示可以存储最多 10个字符
- 但实际存储占用的字节数取决于字符编码和具体存储的内容
二、场景(2000万数据表:id、姓名、年龄、爱好) 主键用啥类型 id
强烈推荐使用 BIGINT 作为主键(不是使用varchar)
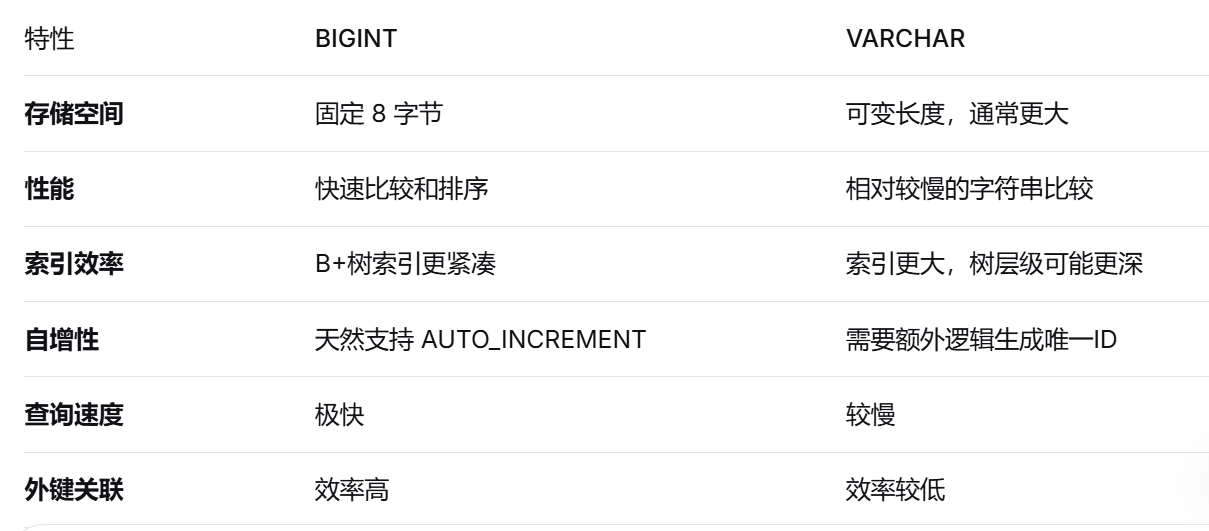
- 性能优势
bash
-- BIGINT 比较是简单的 8 字节整数比较
-- VARCHAR 比较需要逐字符比对,更耗时
SELECT * FROM users WHERE id = 12345678; -- BIGINT: 快速
SELECT * FROM users WHERE id = 'USER_12345678'; -- VARCHAR: 较慢- 存储效率
BIGINT:固定 8 字节,存储 2000万条数据 ≈ 160MB(仅ID字段
VARCHAR(20):假设平均 12 字节,2000万条 ≈ 240MB + 额外开销 - 索引性能
BIGINT 主键的 B+树索引更浅,因为每个节点能存储更多键值
VARCHAR 索引更大,可能导致更多的磁盘 I/O - 推荐的表结构
bash
CREATE TABLE users (
id BIGINT UNSIGNED AUTO_INCREMENT PRIMARY KEY, -- 推荐
name VARCHAR(50) NOT NULL,
age TINYINT UNSIGNED,
hobby VARCHAR(200),
INDEX idx_name (name),
INDEX idx_age (age)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 预计 2000万数据量:约 2-3GB(包含索引)什么情况下用 VARCHAR 作为 ID?
1.自然键:如用户名、邮箱、身份证号(已有业务含义)
2.分布式系统:需要 UUID(但可存储为 BINARY(16) 性能更好)
bash
-- 如果必须用字符串ID,考虑压缩存储
id CHAR(32) -- UUID 去除了连字符
-- 或更好的方案
id BINARY(16) -- 存储为二进制,性能好很多三、bigint 8 个字节最多存多少数据,2000万够吗?
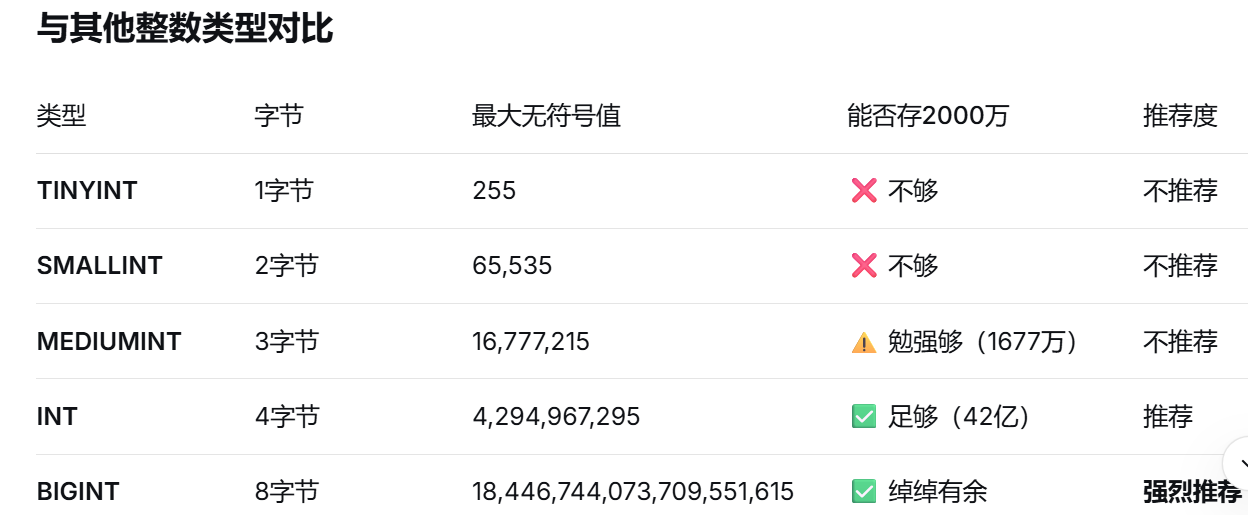
为什么2000万数据还用 BIGINT?
1.未来扩展性
bash
-- 今天:2000万用户
-- 明年:可能5000万
-- 五年后:可能2亿
-- BIGINT:完全无压力
-- INT:42亿上限,长期看可能不够2.分区和分表友好
bash
-- 使用 BIGINT 可以轻松做范围分区
PARTITION BY RANGE (id) (
PARTITION p0 VALUES LESS THAN (10000000),
PARTITION p1 VALUES LESS THAN (20000000),
PARTITION p2 VALUES LESS THAN (30000000),
-- ... 可以分很多区
)3.分布式系统兼容
- 如果未来需要分库分表,BIGINT 提供更大的 ID 空间
- Snowflake 等分布式 ID 算法生成的也是 64 位整数
实际存储示例(算出2000万的id 就是约等于160MB)
bash
-- 创建表
CREATE TABLE users (
id BIGINT UNSIGNED AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
age TINYINT UNSIGNED,
hobby VARCHAR(200)
) ENGINE=InnoDB;
-- 查看存储信息
SELECT
table_name AS '表名',
table_rows AS '行数',
data_length/1024/1024 AS '数据大小(MB)',
index_length/1024/1024 AS '索引大小(MB)'
FROM information_schema.tables
WHERE table_name = 'users';
-- 2000万数据预估:
-- ID字段占用:20,000,000 × 8字节 ≈ 160 MB
-- 整表(含索引)估计:2-4 GB4.性能考虑
bash
-- 插入性能
INSERT INTO users (name, age, hobby) VALUES ('张三', 25, '篮球');
-- BIGINT 自增:直接内存操作,极快
-- 查询性能
SELECT * FROM users WHERE id = 15372849;
-- BIGINT 比较:单次CPU指令
-- VARCHAR 比较:需要字符串解析和逐字符比较四、如果2000万这个只会用到 where name = xx 或者 where age = xx ,where name =xx and age = xx,该如建立索引
- 方案一:最推荐方案(复合索引 + 单列索引)
bash
-- 创建复合索引(最常用查询)
CREATE INDEX idx_name_age ON users(name, age);
-- 创建单列索引(用于单独按age查询)
CREATE INDEX idx_age ON users(age);为什么这样设计?
复合索引 idx_name_age(name, age) 可以覆盖
- 查询1: WHERE name = 'xx' ✅ (使用索引前缀)
- 查询3: WHERE name = 'xx' AND age = xx ✅ (完全使用索引)
- 查询2: WHERE age = xx ❌ (不能使用,因为age不是索引最左列)
单列索引 idx_age 专门用于:
- 查询2: WHERE age = xx ✅
四、如果2000万 name 用啥类型合适,名字包含中文名字和英文名字
对于包含中文和英文的名字,推荐使用 VARCHAR 配合合适的字符集和长度。
bash
name VARCHAR(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci-
字符集选择:UTF8MB4
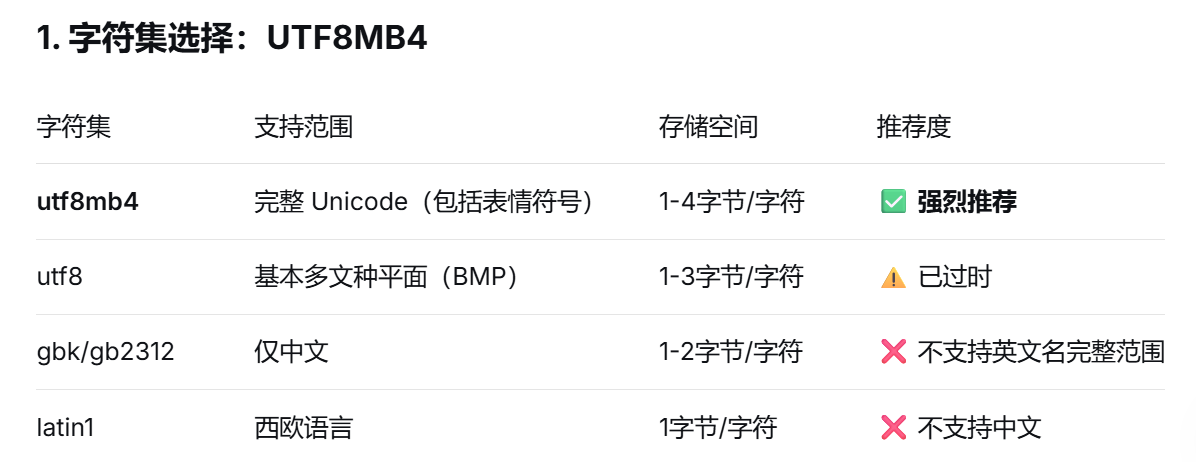
-
长度设置:VARCHAR(50)
长度分析
bash
-- 中文名:通常 2-4 个汉字
'张三' -- 2字符
'欧阳修' -- 3字符
'司马相如' -- 4字符
'慕容复' -- 3字符
-- 英文名:通常较长
'John' -- 4字符
'John Smith' -- 10字符(含空格)
'Christopher' -- 11字符
'Christopher Alexander Smith' -- 24字符
-- 特殊情况:
'Jean-Claude Van Damme' -- 21字符
'María José' -- 10字符(含重音)
'أحمد بن حنبل' -- 11字符(阿拉伯文)为什么是 VARCHAR(50):
- 足够容纳绝大多数名字:99.9%的名字在50字符内
- 考虑复姓和长英文名:Christopher Alexander Montgomery Smith ≈ 35字符
- 考虑中间名和尊称:Dr. John H. Smith Jr. ≈ 20字符
- 国际化考虑:某些语言名字较长