这篇发表在《Nature》上的论文介绍了一种名为 Emu3 的新一代多模态模型。该研究的核心贡献在于证明了:仅通过"下一标记预测"(Next-Token Prediction)这一单一目标,就能在单一模型中完美统一多模态的理解(Perception)与生成(Generation)任务。
以下是对这篇论文的详细深度解读:
1. 研究背景与核心挑战
长期以来,多模态人工智能领域处于"割裂"状态:
- 图像/视频生成:主要由扩散模型(Diffusion Models)统治(如 Stable Diffusion, Sora)。
- 多模态理解(感知) :主要由组合式框架统治(如 LLaVA),即将预训练的视觉编码器(CLIP)与大语言模型(LLM)拼接。
- 问题:这种割裂导致模型架构复杂,且难以像纯文本 LLM 那样通过简单的 Scaling Law(缩放法则)实现能力的爆发。
Emu3 的使命:验证是否可以像训练 GPT 一样,把图像、视频、文本和动作都看作"标记(Tokens)",通过预测下一个标记来完成所有任务。
2. Emu3 的核心架构:全标记化(Everything is a Token)
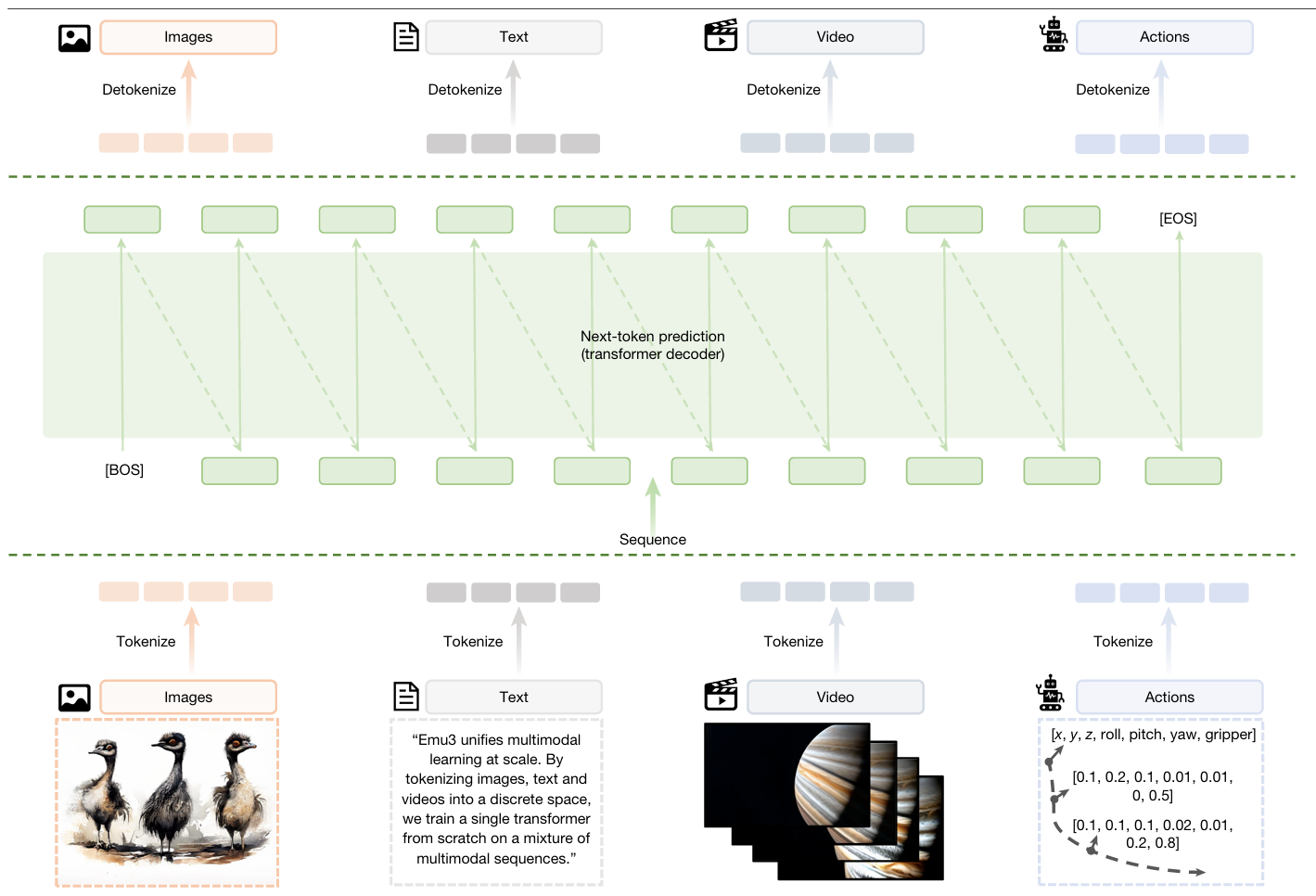
- Emu3 框架。Emu3 首先将图像、文本、视频和动作等多模态数据转换为离散token,随后通过解码器对这些token按顺序进行序列化。Emu3还通过将视觉、语言和动作视为统一的令牌序列,将该框架无缝推广至机器人操作任务,并利用 Transformer 大规模执行统一的下一个令牌预测。
Emu3 抛弃了扩散模型和 CLIP 编码器,采用了一个纯粹的 Decoder-only Transformer 架构。
- 统一的分词器(Tokenizer) :
- 图像与视频:开发了一个基于 SBER-MoVQGAN 的视觉分词器,将 512x512 的图像或视频片段压缩为 4096 个离散标记。
- 动作:在机器人任务中,使用 FAST 分词器将连续的动作信号离散化。
- 文本:沿用 Qwen 的 BPE 分词器。
- 模型规模 :论文重点介绍了一个 8.49B (约 85 亿) 参数的模型,32 层,隐藏层维度 4096。
3. 训练策略:三阶段课程学习
为了保证模型在大规模多模态数据下的训练稳定性,Emu3 采用了渐进式的训练方案:
- 预训练阶段(Pre-training) :
- Stage 1:在图像-文本对上训练,建立基础的多模态关联。
- Stage 2:引入 Dropout(0.1)防止模型崩溃,提高稳定性。
- Stage 3 :将上下文长度从 5120 扩展到 65536,并引入大量视频数据,使模型具备处理长序列视频的能力。
- 后训练阶段(Post-training) :
- 质量微调(QFT):使用高质量图像数据提升生成画质。
- 直接偏好优化(DPO):将 DPO 首次应用于自回归视觉生成,使生成的图像更符合人类审美。
- 视觉指令微调:提升模型在问答(VQA)和复杂指令下的理解力。
4. 关键科学发现
A. 多模态 Scaling Laws(缩放法则)
论文通过大量实验证明,多模态任务(文生图、图生文、文生视频)同样遵循类似纯文本模型的幂律分布。
- 发现:验证损失(Validation Loss)随模型参数和数据量的增加而稳定下降。这为未来构建百亿甚至千亿参数的统一多模态大模型提供了可预测的理论依据。
B. 下一标记预测 vs. 扩散模型
- 在图像生成上,Emu3 的 GenEval 得分超过了 SDXL,证明自回归模型生成的画质不输给扩散模型。
- 在视频生成上,Emu3 通过自回归预测未来的帧,能自然地模拟物理世界的演化,表现优于许多专门的视频扩散模型。
C. 摒弃 CLIP 的优势
传统模型依赖 CLIP 提供的"视觉先验",但 Emu3 证明了从零训练的自回归模型在视觉理解任务(如 OCR、空间推理)上能达到甚至超过 LLaVA-1.6 的水平,且没有 CLIP 带来的固有偏差。
5. 广泛的应用场景
Emu3 展示了极强的通用性:
- 文生图/文生视频:生成高保真的静态图像和动态视频。
- 视觉预测:给定视频开头,预测接下来会发生什么(模拟物理世界)。
- 交错生成:可以在一段对话中根据需求穿插生成文字和图片(类似于人类写带插图的博客)。
- 具身智能(机器人):在 CALVIN 模拟器任务中,Emu3 表现出了极强的长程操作能力,平均完成任务数(4.64)优于 RT-1 等专门模型。

- 多种多模态任务的定性可视化结果。涵盖文本到图像(T2I)生成、文本到视频(T2V)生成、未来预测、视觉 - 语言理解、交错图像 - 文本生成及具身操作任务的代表性定性结果。