【GUI-Agent】阶跃星辰 GUI-MCP 解读---(1)---论文
0x00 摘要
25年底,阶跃星辰升级发布了全新的AI Agent系列模型Step-GUI,包括云端模型Step-GUI、首个面向GUI Agent的MCP协议:GUI-MCP(Graphical User Interface - Model Context Protocol),这是首个专为图形用户界面自动化而设计的 MCP 实现,兼顾标准化与隐私保护。
- GitHub仓库 :github.com/stepfun-ai/...
- 技术论文 :github.com/stepfun-ai/...
GUI-MCP 提供一套标准化、跨平台的协议,将设备能力抽象为少量原子及组合工具。其分层双栈架构结合:"低层 MCP"提供细粒度操作(点击、滑动、文本输入等),"高层 MCP"将整个任务委派给本地部署的 GUI 专有模型(如 Step-GUI-4B)。该设计使主语言模型专注于高层规划,同时将常规 GUI 操作卸载至本地模型。尤为关键的是,GUI-MCP 支持高隐私执行模式:原始截图与敏感状态留在设备端,仅语义摘要流向外部语言模型,从而在利用云端推理能力的同时有效保护用户隐私。
因此,我们就来解读这个MCP协议,顺便看看端侧Agent的实现架构。
本文是第一篇,主要是论文解读,非MCP调用和主要组件介绍。因为是反推解读,所以可能会有各种错误,还请大家不吝指出。
0x01 GUI Agent 的核心要素
我们首先看看 GUI Agent 的一些通用信息。
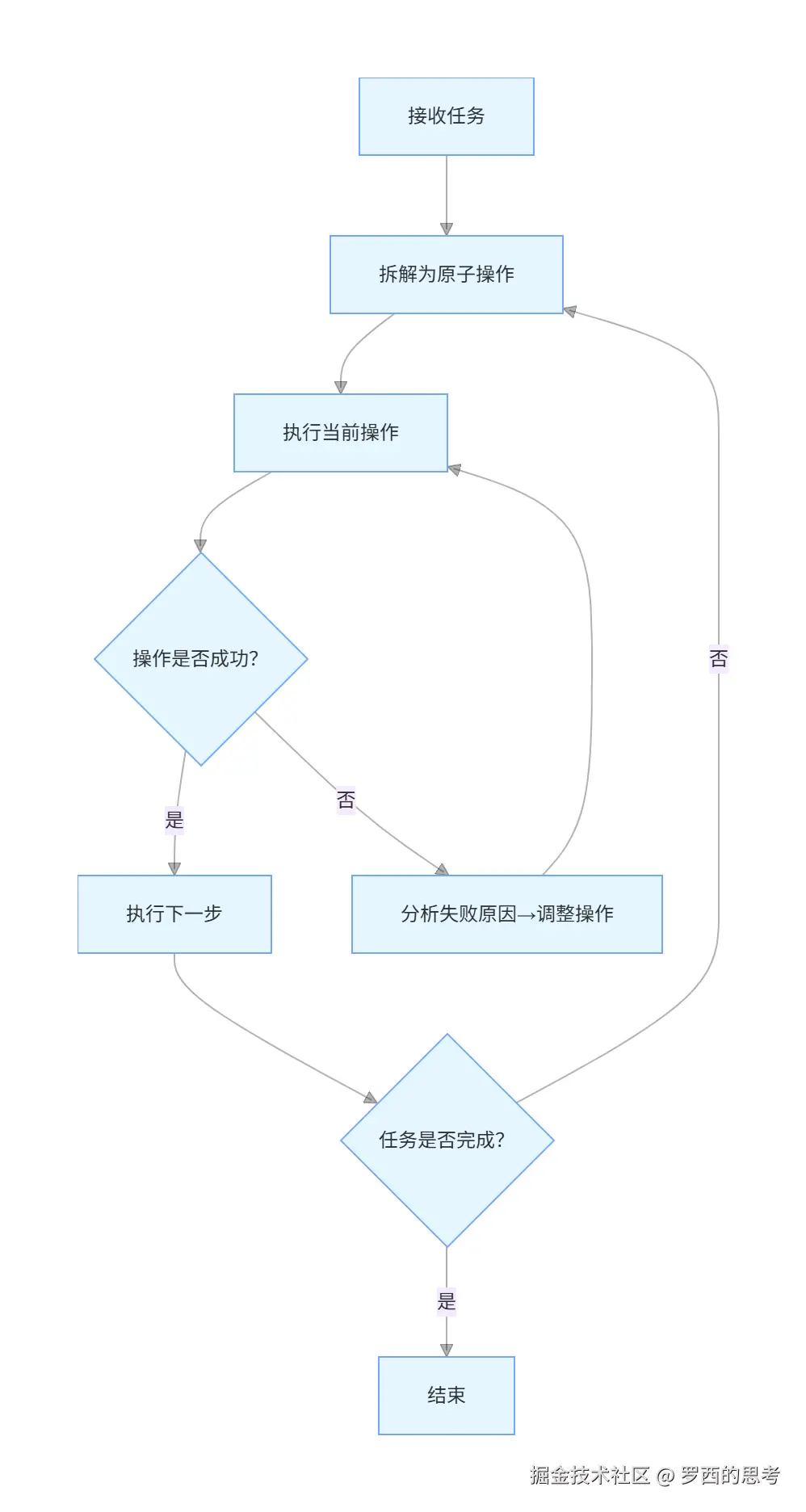
1.1 基本逻辑
GUI Agent 的基本逻辑如下:
exported_image (2)
1.2 核心要素
区别于纯文本 Agent,GUI Agent 的价值在于 "能真正操控图形界面",而非仅生成文本。GUI Agent 最核心的是 "看懂界面 + 规划步骤 + 适配变化" ,其中 "界面理解与定位" 是基础,"任务规划与纠错" 是核心,"鲁棒性" 是落地保障。具体如下:
-
像素 / 控件级的界面理解与定位能力(基础):能像人类一样 "看懂" GUI 界面的元素(按钮、输入框、菜单、弹窗),并精准定位其位置;这是 GUI Agent 区别于纯文本 Agent 的核心,也是最基础的要求 ------ 如果连 "哪个按钮是提交、输入框在哪" 都识别错,后续操作毫无意义。
-
核心要求:
- 视觉理解:通过 CV / 多模态模型来解析界面截图,区分 "可点击控件""文本区域""弹窗遮挡" 等;
- 控件定位:输出精准的坐标 / 控件标识(如安卓的 resource-id、Windows 的控件句柄),而非模糊的 "右上角按钮";
- 状态感知:识别界面 "加载中""操作成功 / 失败""需要验证" 等状态,避免无效操作。
-
-
任务驱动的操作规划与纠错能力(核心):能拆解复杂 GUI 任务为可执行的步骤(如 "登录 APP→找到设置→修改密码"),并在操作出错时自适应调整;GUI 任务往往是多步骤、有依赖的(如 "网购下单" 需:打开 APP→搜索商品→加入购物车→结算→支付),LLM 生成的单一步骤易遗漏 / 出错,需具备 "规划 - 执行 - 反馈 - 调整" 的闭环能力。
-
核心要求:
- 任务拆解:将自然语言指令(如 "帮我订明天上海到北京的高铁票")拆分为 "打开铁路 APP→点击订票→选择出发地 / 目的地→选择日期→查询→选车次→提交订单" 等原子操作;
- 实时纠错:操作失败时(如点击后界面无响应、弹窗打断),能识别错误原因并调整策略(如重试点击、先关闭弹窗);
- 上下文记忆:记住已完成的步骤(如已选好车次),避免重复操作。
-
-
跨环境 / 跨应用的鲁棒性(保障):能适配不同分辨率、系统版本、界面样式,避免因微小界面变化导致任务失败。普通自动化脚本只能适配固定界面,而 GUI Agent 需应对真实场景的界面变化 ------ 这是从 "实验室 demo" 到 "实际可用" 的核心门槛。
-
核心要求:
- 适配性:兼容不同分辨率(手机 / 平板)、系统版本(安卓 13/14)、应用版本(微信 8.0.30/8.0.40);
- 抗干扰:能处理广告弹窗、加载延迟、界面卡顿等异常情况;
- 无侵入:无需修改应用源码,通过通用方式(ADB、UI Automation、键鼠模拟)操作,符合真实用户交互逻辑。
-
1.3 关键挑战
此处我们借鉴 MAI-UI 论文来看看GUI-Agent的关键挑战。
MAI-UI是阿里通义实验室发布的一项重磅研究成果:是一个旨在 重塑人机交互方式 的"基础图形用户界面(GUI)智能体"。其实,和阶跃星辰的思路非常类似。其相关信息是:
MAI-UI的论文精准地指出了四个关键挑战:
- 缺乏自然的"人-机-人"交互 :真实场景中,用户的指令常常是模糊、不完整的。一个合格的助手必须能主动提问澄清,而不是瞎猜一通。
- 局限于"纯UI操作" :只靠点击、滑动来完成所有任务,不仅步骤冗长、容易出错,而且很多任务(如操作GitHub)在手机上几乎无法实现。
- 没有实用的"端云协同"架构 :大模型能力强但费钱、耗电、有隐私风险;小模型省资源但能力有限。目前的智能体要么全在云端,要么全在设备端,缺乏能根据任务动态调度的智能架构。
- 在动态环境中很"脆弱" :训练数据往往是静态的。但真实世界充满变数:App版本更新布局会变、突然弹出的权限对话框、网络加载慢......没有在动态环境中"摸爬滚打"过的智能体,很容易"翻车"。
0x02 阶跃星辰论文解读
本小节我们来学习下阶跃星辰的论文。
2.1 需求
尽管大语言模型进展显著,其在 GUI 自动化中的应用仍因缺乏跨平台设备控制的标准化接口而受阻。现有方案往往平台限定,且与不同语言模型及设备集成需大量工程投入。一个强大的GUI模型训练出来后,如何让各种大模型都能方便、安全地使用它来控制设备?
为弥补这一缺口,StepFun团队借鉴了"模型上下文协议(MCP)"的思想,提出了 GUI-MCP(Graphical User Interface - Model Context Protocol),这是首个专为 GUI 操作任务设计的 MCP 实现。它像一个翻译器和安全过滤器,标准化了LLM与设备间的交互。
GUI-MCP 提供标准化工具包,无缝连接多种语言模型与多设备平台(Ubuntu、macOS、Windows、Android、iOS),使语言模型能通过统一协议控制移动与桌面设备,执行 GUI 操作任务。
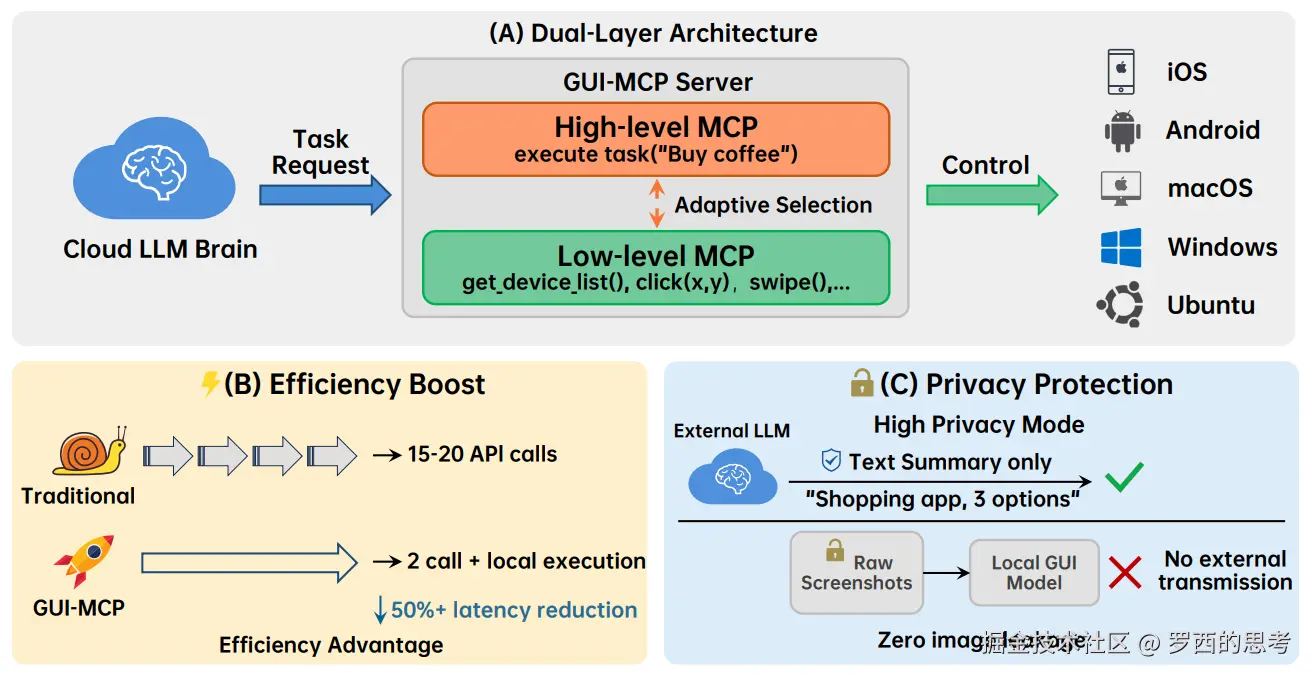
2.2 架构
GUI-MCP 采用分层设计,将功能划分为两个不同层级:低层 MCP 与高层 MCP,如下图所示。
GUI-MCP-arch
低层 MCP
低层 MCP 专注于原子级设备操作,提供细粒度控制接口。该层级公开以下类别的原语:
- 设备管理:接口 get_device_list() 获取所有已连接设备,实现多设备编排。
- 状态感知:接口 get_screenshot() 捕获当前设备屏幕状态,为决策提供视觉反馈。
- 基本操作:如下图所示的完整交互原语集合。
这些原子接口为主语言模型提供最大灵活性,使其能够根据当前状态和任务需求进行细粒度规划与控制。适合需要逐步规划的场景。

GUI-MCP-operation
高层 MCP
高层 MCP 专注于抽象任务执行,通过封装完整任务执行逻辑实现。其主要接口为:execute_task(task_description)。该接口接受自然语言任务描述,并自动完成任务。例如:
- execute_task("点击第一个元素")
- execute_task("买一杯咖啡")
- execute_task("搜索白色帆布鞋,37 码,100 元以内,并把第一个结果加入收藏")
内部集成本地部署的 GUI 专有模型(如 StepGUI-4B),该模型专门针对 GUI 操作任务进行优化,可在其能力范围内自主完成任务。主语言模型的系统提示(system prompt)明确描述 GUI 专有模型的能力边界,帮助主模型判断何时将任务委派给高层 MCP。这大幅减少了与主力大模型的交互次数,降低了延迟和成本。
2.3 优势
执行效率提升
双层次架构使主语言模型能够依据任务复杂度与当前状态,灵活选择控制策略:
低层 MCP 适用场景:
- 快速获取当前设备状态
- 需要逐步细粒度规划的任务
- 超出 GUI 专有模型能力范围的任务
- 需多轮用户交互以澄清需求的场景
高层 MCP 适用场景:
- 描述清晰且落在 GUI 专有模型能力范围内的任务
- 希望减少主语言模型推理开销与 API 调用次数
- 可一次性完成的强独立性任务
通过合理分派,主语言模型可将简单、重复的 GUI 操作卸载给本地专有模型,自身专注于高层规划与决策,从而显著提升整体执行效率。
隐私保护增强
在隐私保护日益关键的当下,许多用户对向外部云 LLM 服务商传输截图与设备信息心存顾虑。GUI-MCP 提供的高隐私模式具有以下特征:
- 数据匿名化机制:外部云 LLM 无法直接获取原始截图与详细设备信息,仅接收由本地 GUI 模型处理后的状态摘要。这些摘要仅包含完成任务所必需的关键语义信息,不含敏感视觉细节。
- 本地执行:需依赖截图分析进行规划的操作,由本地 GUI 模型完成;所有图像数据与敏感信息仅在本地设备处理,外部云 LLM 仅负责高层任务分解与决策。
- 灵活隐私级别:用户可依据自身信任偏好与任务需求,配置不同隐私保护级别。系统支持从完全开放(直接传输截图)到完全私密(仅文本摘要)的多级配置。
在此模式下,所有屏幕图像和原始设备信息都只在本地处理 。本地的GUI专家模型分析屏幕后,只向云端的主力大模型发送语义摘要(例如:"当前屏幕是微信主界面,包含'通讯录'、'发现'、'我'三个标签")。主力大模型基于摘要做出高级规划,再将具体操作指令通过MCP发回本地执行。这样,既利用了云端大模型的强大推理能力,又确保了用户的敏感视觉数据不外流。这一设计使 GUI-MCP 在充分利用强大云 LLM 推理能力的同时,有效保护用户隐私数据,实现功能与隐私的最优平衡。
通过创新的双层次架构,GUI-MCP 在效率与隐私两个维度为 LLM 驱动的 GUI 自动化提供了系统化解决方案。该协议不仅降低了将 LLM 能力扩展至 GUI 操作领域的技术门槛,也为构建既强大又兼顾隐私的 AI 助手提供了可行路径。
0x03 无MCP调用
我们先看看没有MCP时候,系统如何运行。
3.1 执行脚本
run_single_task.py 具体代码示例如下。
python
tmp_server_config = {
"log_dir": "running_log/server_log/os-copilot-local-eval-logs/traces",
"image_dir": "running_log/server_log/os-copilot-local-eval-logs/images",
"debug": False
}
local_model_config = {
"task_type": "parser_0922_summary",
"model_config": {
"model_name": "gelab-zero-4b-preview",
"model_provider": "local",
"args": {
"temperature": 0.1,
"top_p": 0.95,
"frequency_penalty": 0.0,
"max_tokens": 4096,
},
},
"max_steps": 400,
"delay_after_capture": 2,
"debug": False
}
# ===== 新增:用于记录每步耗时 =====
_step_times = []
# ===== 新增:包装 automate_step 方法 =====
def wrap_automate_step_with_timing(server_instance):
original_method = server_instance.automate_step
def timed_automate_step(payload):
step_start = time.time()
try:
result = original_method(payload)
finally:
duration = time.time() - step_start
_step_times.append(duration)
print(f"Step {len(_step_times)} took: {duration:.2f} seconds")
return result
# 替换实例方法
server_instance.automate_step = timed_automate_step
if __name__ == "__main__":
if len(sys.argv) < 2:
print("❌ 错误:未传入任务参数!")
print("📝 使用方法:")
print(f" python {sys.argv[0]} "你的任务描述"")
print(" 示例1:python script.py "去淘宝帮我买本书"")
print(" 示例2:python script.py "打开微信,给柏茗发helloworld"")
sys.exit(1)
task = ' '.join(sys.argv[1:])
# The device ID you want to use
device_id = list_devices()[0]
device_wm_size = get_device_wm_size(device_id)
device_info = {
"device_id": device_id,
"device_wm_size": device_wm_size
}
tmp_rollout_config = local_model_config
l2_server = LocalServer(tmp_server_config)
# 注入计时逻辑
wrap_automate_step_with_timing(l2_server)
# 执行任务并计总时间
total_start = time.time()
# Disable auto reply
evaluate_task_on_device(l2_server, device_info, task, tmp_rollout_config, reflush_app=True)
total_time = time.time() - total_start
# 在最后加一行总时间
print(f"总计执行时间为 {total_time} 秒")
pass3.2 流程分析
该脚本为整个系统的入口点,负责:
-
初始化阶段
- 获取用户输入的任务描述
- 初始化设备连接
- 配置服务参数,使用 LocalServer 直接创建服务器实例
-
执行循环:启动任务执行流程,即直接调用 evaluate_task_on_device 函数执行任务,形成"截图→模型→动作→执行"的闭环流水。
- 截取设备屏幕截图
- 将截图和任务信息传递给 LocalServer
- LocalServer 构造提示信息并调用 LLM
- 解析 LLM 响应为具体动作
- 执行动作并等待下一循环
-
结束条件
- 达到最大执行步数
- 任务完成或中止
- 发生错误
具体而言,用户通过 run_single_task.py 提交自然语言任务。
-
LocalServer 创建唯一会话并初始化设备屏幕。
-
evaluate_task_on_device 负责"截图→模型推理→动作执行"循环,该流程也会形成"感知-决策-执行-记录"闭环,确保移动端 GUI 自动化任务可追踪、可恢复、可审计。
-
感知:截图经 base64 编码后送入 LocalServer.automate_step,即回调 LocalServer 实现单步自动化。
-
决策:在 automate_step中,会做如下处理
- Parser 将环境、历史、任务转换为模型消息;
- ask_llm_anything 负责模型 API 调用;
- 模型返回动作经 Parser 解析后,automate_step返回。即,Parser0920Summary 完成环境→消息、模型输出→动作的转换与标准化。
-
执行 :在 evaluate_task_on_device 中,动作由 act_on_device(位于
mobile_action_helper.py)执行; -
历史动作更新后循环继续,直到任务完成标志为真。
-
-
全程由 LocalServerLogger 记录日志,支持故障追踪与回放。
3.3 数据流向
-
输入数据流
- 任务描述:用户提供的自然语言任务
- 设备信息:目标设备 ID 和屏幕尺寸
- 配置参数:任务执行参数和选项
-
处理数据流
- 屏幕截图:设备当前状态的图像数据
- 模型输入:包含任务、历史和截图的消息
- 动作输出:由 LLM 生成的设备操作指令
-
输出数据流
- 执行结果:任务执行的最终结果
- 中间日志:执行过程中的详细信息
- 截图和说明:可选的视觉反馈
3.4 逻辑层级
以上是从业务来梳理,下面是从代码层级来进行梳理。
-
业务逻辑层
- 任务执行:evaluate_task_on_device
-
模型服务层/决策层
- LocalServer:
local_server.py提供本地模型服务 - LLM 交互:
ask_llm_v2.py实现与语言模型的通信 - 解析器:
parser_0920_summary.py处理动作解析
- LocalServer:
-
设备控制层/执行层
- 设备管理:
mobile_action_helper.py提供设备操作接口 - 动作执行:
pu_frontend_executor.py执行具体动作 - ADB 接口:通过 ADB 与设备通信
- 设备管理:
3.5 evaluate_task_on_device
evaluate_task_on_device 函数 是整个系统中负责执行移动设备任务的核心函数,是高层任务指令与底层设备操作之间的桥梁,负责协调整个自动化任务的执行流程。其关键特性如下:
- 设备控制:通过 ADB 命令与 Android 设备交互
- 视觉推理:利用屏幕截图进行视觉分析和决策
- 用户交互处理:支持自动或手动处理需要用户输入的情况
- 会话跟踪:维护完整的任务执行历史
- 错误处理:检测屏幕状态,处理各种异常情况
主要功能包括:
-
任务执行控制中心
- 控制整个任务执行流程
- 管理与移动设备的交互循环
-
设备初始化
- 初始化指定的安卓设备
- 确保设备屏幕始终处于开启状态
- 根据需要重启设备环境(返回主屏幕)
-
任务执行循环
- 截取屏幕设备截图
- 将截图和任务信息发给Agent Server(即LocalServer)进行分析
- 解析server返回的操作指令
- 在设备上执行相应的操作(点击、滑动、输入等)
- 处理需要用户交互的情况(INFO操作)
-
会话管理
- 创建新的任务会话
- 跟踪任务执行状态和历史操作
-
结果返回
- 返回任务执行的日志和结果信息
具体执行流程如下:

1-3
evaluate_task_on_device 代码如下。
python
# delay after act on device
# rollout config
# device info
# def evaluate_task_on_device(agent_server, device_info, task, frontend_action_converter, ask_action_function_func, max_steps = 40, delay_after_capture = 2):
def evaluate_task_on_device(agent_server, device_info, task, rollout_config, extra_info = {}, reflush_app=True, auto_reply = False, reset_environment=True):
"""
Evaluate a task on a device using the provided frontend action converter and action function.
"""
# init device for the first time
device_id = device_info['device_id']
open_screen(device_id)
init_device(device_id)
if reset_environment:
press_home_key(device_id, print_command=True)
task, task_type = task, rollout_config['task_type']
session_id = agent_server.get_session({
"task": task,
"task_type": task_type,
"model_config": rollout_config['model_config'],
"extra_info": extra_info
})
print(f"Session ID: {session_id}")
return_log = {
"session_id": session_id,
"device_info": device_info,
"task": task,
"rollout_config": rollout_config,
"extra_info": extra_info
}
device_id, device_wm_size = device_info['device_id'], device_info['device_wm_size']
max_steps = rollout_config.get('max_steps', 40)
delay_after_capture = rollout_config.get('delay_after_capture', 2)
history_actions = []
for step_idx in range(max_steps):
if not dectect_screen_on(device_id):
print("Screen is off, turn on the screen first")
break
image_path = capture_screenshot(device_id, "tmp_screenshot", print_command=False)
image_b64_url = make_b64_url(image_path, resize_config=rollout_config['model_config'].get("resize_config", None))
smart_remove(image_path)
payload = {
"session_id": session_id,
"observation": {
"screenshot": {
"type": "image_url",
"image_url": {
"url": image_b64_url
}
},
}
}
if history_actions[-1]['action_type'] == "INFO" if len(history_actions) > 0 else False:
info_action = history_actions[-1]
if auto_reply:
print(f"AUTO REPLY INFO FROM MODEL!")
reply_info = reply_info_action(image_b64_url, task, info_action, model_provider=rollout_config['model_config']['model_provider'], model_name=rollout_config['model_config']['model_name'])
print(f"info: {reply_info}")
else:
print(f"EN: Agent asks: {history_actions[-1]['value']} Please Reply: ")
print(f"ZH: Agent 问你: {history_actions[-1]['value']} 回复一下:")
reply_info = input("Your reply:")
print(f"Replied info action: {reply_info}")
payload['observation']['query'] = reply_info
action = agent_server.automate_step(payload)['action']
#TODO: to replace with the new function
action = uiTars_to_frontend_action(action)
act_on_device(action, device_id, device_wm_size, print_command=True, reflush_app=reflush_app)
history_actions.append(action)
print(f"Step {step_idx+1}/{max_steps} done. Action: {action}")
if action['action_type'].upper() in ['COMPLETE', "ABORT"]:
stop_reason = action['action_type'].upper()
break
time.sleep(delay_after_capture)
if action['action_type'] in ['COMPLETE', "ABORT"]:
stop_reason = action['action_type']
elif step_idx == max_steps - 1:
stop_reason = "MAX_STEPS_REACHED"
else:
stop_reason = "MANUAL_STOP"
# return_log['session_id'] = session_id
return_log['stop_reason'] = stop_reason
return_log['stop_steps'] = step_idx + 1
print(f"Task {task} done in {len(history_actions)} steps. Session ID: {session_id}")
return return_log0x04 Agent在哪里?
出于好奇,我想看看项目中Agent的定义在哪里。但也许是阶跃没有开源这部分,我在代码库中没有找到传统意义上的显式 "Agent" 类或组件定义 。相反,系统通过分离的架构实现了 agent 功能,不同的组件协同工作以提供类似 agent 的行为。
4.1 隐式的 Agent 实现
Agent 功能分布在以下几个组件中:
- LocalServer:作为核心决策组件,负责与 LLM 交互
- evaluate_task_on_device 或者 gui_agent_loop:实现主要的 agent 循环,协调感知 - 行动周期
- 解析器类(如 Parser920Summary):处理环境表示和动作解析
或者说,上述组件构成了一个Agent Framework。
4.2 系统中的 Agent 特性系统
项目通过以下方式体现 agent 属性:
- 感知:通过屏幕截图捕获和环境状态管理实现
- 推理:通过 LocalServer 和解析器协调的 LLM 调用实现
- 行动:通过在移动设备上执行解析的动作实现
- 记忆:通过会话日志和交互历史维护
4.3 Agent 工作流程
Agent 行为来自于这些组件之间的交互:
css
[移动设备]
↓(截图 / 观察)
[ evaluate_task_on_device / execute_task(间接调用到 gui_agent_loop)]
↓(环境状态)
[LocalServer]
↓(格式化消息)
[LLM / 模型]
↓(动作决策)
[解析器]
↓(解析的动作)
[设备执行器]
↓(动作执行)
[移动设备]4.4 专业化的 Agent 功能
Agent 行为的不同方面由专门的函数处理:
- 任务执行:execute_task / execute_task 和 gui_agent_loop
- 信息处理:auto_reply 函数
- 图像理解:caption_current_screenshot 函数
总而言之,虽然没有单一显式的 "Agent" 类定义,但系统通过协作架构实现了 agent 行为,多个组件共同工作以提供智能 agent 特有的感知、推理和行动能力。
0xFF 参考
阿里发布MAI-UI,一个"活"在屏幕里的全能AI助手!手机真能全自动了?
本文使用 markdown.com.cn 排版