一 发布概述
2026年1月27日,DeepSeek正式开源了DeepSeek-OCR 2模型,这是对OCR(光学字符识别)领域的一次重大技术革新。该模型的核心论文为《DeepSeek-OCR 2: Visual Causal Flow》,通过首创的**"视觉因果流"(Visual Causal Flow)**技术,让AI能够像人类一样带着逻辑去"看"和理解图像。
官方资源:
-
Hugging Face模型:https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
-
论文地址: https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf
-
许可证:Apache-2.0(完全开源)
二 核心技术创新
2.1 视觉因果流(Visual Causal Flow)
这是DeepSeek-OCR 2最核心的突破,彻底改变了传统视觉模型的处理方式。
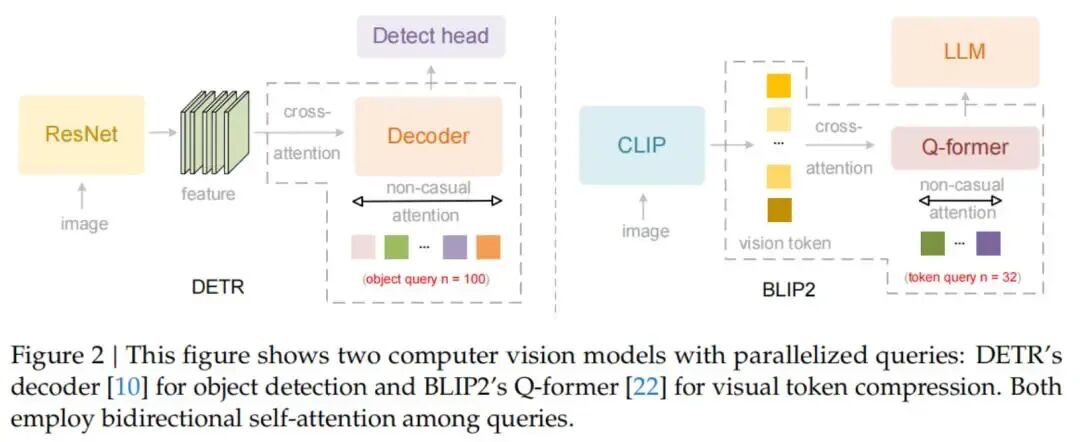 image.png
image.png
**传统OCR的局限:**传统模型(如基于CLIP的编码器)采用固定的扫描顺序------从左到右、从上到下机械式地处理图像。这种方式在处理复杂文档时常常出现问题,比如:
-
分栏文档的串读(将不同栏的内容错误连接)
-
多栏布局的阅读顺序混乱
-
公式识别困难
-
表格结构理解偏差
视觉因果流的创新: DeepSeek-OCR 2让AI能够根据已看到的内容,因果性地决定接下来要看哪里。这模拟了人类的视觉认知过程:
-
看到标题后,知道接下来应该看正文
-
看到分栏后,知道应该先读完一栏再读下一栏
-
看到公式后,知道需要用特殊的方式处理
2.2 DeepEncoder V2架构
新模型首次将LLM架构应用到视觉编码领域:
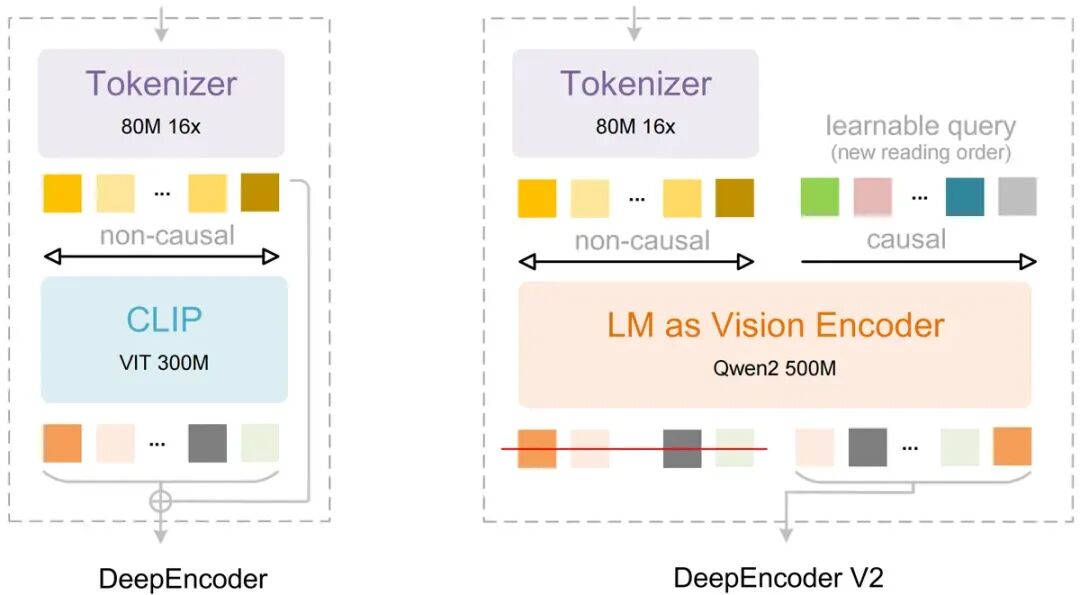 image.png
image.png
技术细节:
-
用轻量级大语言模型Qwen2-0.5B替代了传统的CLIP编码器
-
创新的因果流查询机制(Causal Flow Query)
-
双向注意力机制用于视觉token(保留CLIP的全局建模能力)
-
因果注意力机制用于因果流查询
这种架构使得模型能够:
-
动态重排图像token(基于语义而非固定位置)
-
实现两阶段级联推理
-
在保持高压缩率的同时提升准确率
这里没看错,引入了阿里的Qwen2-0.5B 小模型
技术选型,非竞争关系 DeepSeek-OCR 2是OCR/多模态模型,专注于视觉理解 Qwen2-0.5B在这里用作视觉编码器的组件,替代传统的CLIP 这是典型的技术复用------在AI领域很常见
轻量级优势 Qwen2-0.5B仅5亿参数,非常轻量 适合作为编码器嵌入到更大的架构中 不会显著增加整体模型大小
开源生态的互相支持 Qwen2系列是Apache 2.0许可,完全开源 DeepSeek也是Apache 2.0许可开源 开源社区本来就是为了互相借用和改进
2.3 动态分辨率支持
模型支持灵活的分辨率配置:
-
默认模式:(0-6)×768×768 + 1×1024×1024
-
对应的视觉token数:(0-6)×144 + 256
-
可根据实际需求调整,平衡精度与效率
三 性能提升与数据表现
根据官方发布信息,DeepSeek-OCR 2在多项指标上实现了显著提升: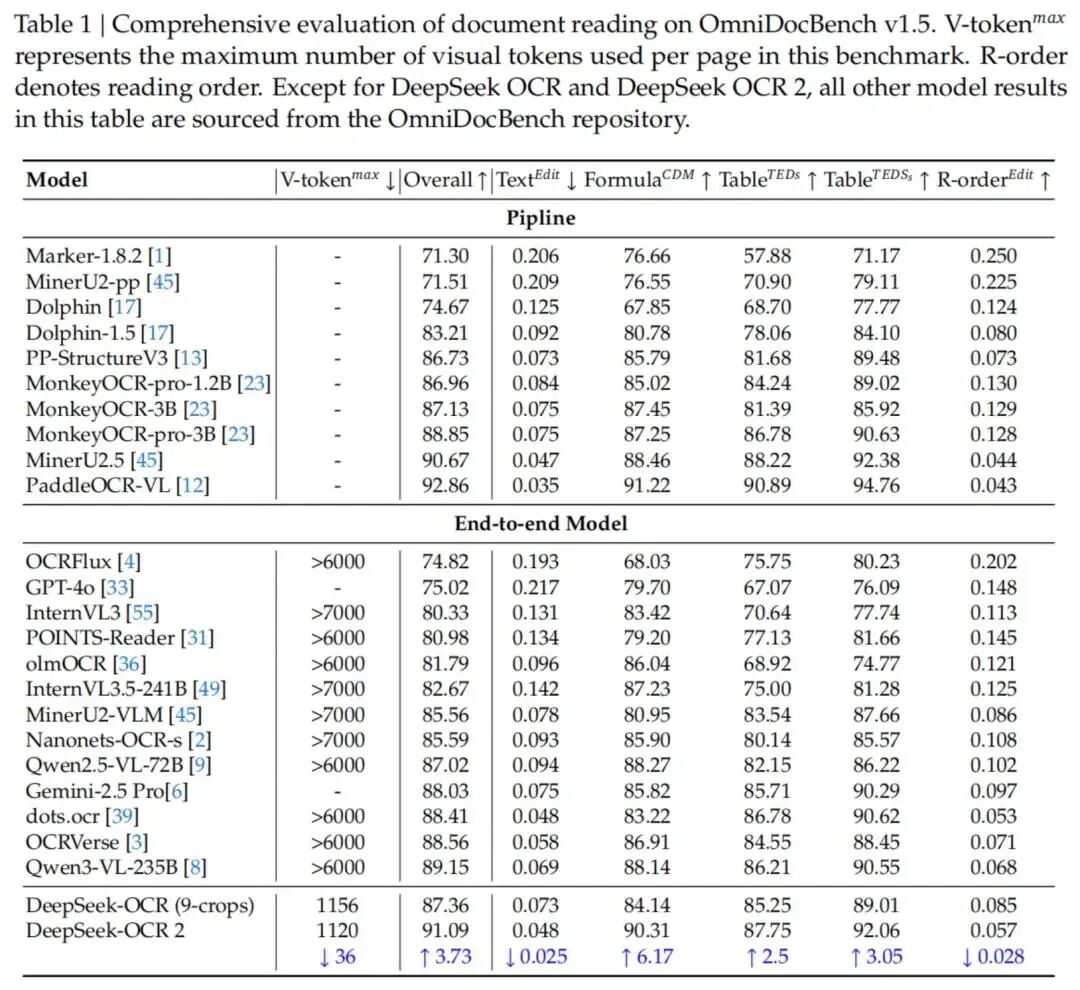
3.1 准确率提升
OmniDocBench v1.5 基准测试:
-
综合得分 :91.09%
-
相较于前代 DeepSeek-OCR 提升 3.73%
-
字符准确率:**91.1%**(相较于前代提升8.4%)
其他指标(基于实际测试):
-
阅读顺序识别:显著增强
-
长文本识别 :92.3%
-
综合内容识别 (文本、公式、表格、图像):90-99%
3.2 效率优势
根据官方发布信息:
视觉Token压缩:
-
10倍压缩:准确率可达**97%**(近乎无损)
-
20倍压缩 :准确率约60%
-
推荐使用10倍压缩比,以平衡精度与效率
-
视觉token数量:256-1,120个(主流模型通常需要6,000+个)
成本优势:
-
相比传统方案,图像文本结构化提取成本下降10倍
-
通过视觉压缩技术减少token使用量
处理速度:
-
支持PDF并发处理
-
H100 GPU :约4页/秒
-
单日处理能力:约345,000页
硬件要求:
- 仅需A100-40G显卡即可运行
3.3 基准测试表现
在OmniDocBench v1.5等权威测试中,DeepSeek-OCR 2展现了优异性能,据称超越了GOT-OCR2.0等主流模型。
四 技术架构详解
4.1 两阶段级联推理
DeepSeek-OCR 2采用级联推理方式:
-
第一阶段:使用因果流查询理解图像的整体语义结构
-
第二阶段:基于理解的结构进行精确的文本提取
这种设计让模型在处理复杂文档时能够先"理解"再"提取",而非简单的"扫描"。
4.2 关键技术组件
- 因果流查询(Causal Flow Queries)
-
可学习的查询向量
-
指导模型关注相关的图像区域
-
实现动态的视觉token重排
-
混合注意力机制
-
-
双向注意力:保留全局上下文
-
因果注意力:实现因果推理
-
-
轻量级语言模型编码器
-
-
基于Qwen2-0.5B
-
替代传统CLIP编码器
-
带来更强的语义理解能力
五 使用方式
5.1 环境要求
-
Python 3.12.9
-
CUDA 11.8
-
PyTorch 2.6.0
-
Flash Attention 2.7.3
5.2 Hugging Face Transformers推理
gofrom transformers import AutoModel, AutoTokenizer import torch import os os.environ["CUDA_VISIBLE_DEVICES"] = '0' model_name = 'deepseek-ai/DeepSeek-OCR-2' tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) model = AutoModel.from_pretrained( model_name, _attn_implementation='flash_attention_2', trust_remote_code=True, use_safetensors=True ) model = model.eval().cuda().to(torch.bfloat16) # 文档转换为Markdown prompt = "<image>\n<|grounding|>Convert the document to markdown." image_file = 'your_image.jpg' output_path = 'your/output/dir' res = model.infer( tokenizer, prompt=prompt, image_file=image_file, output_path=output_path, base_size=1024, image_size=768, crop_mode=True, save_results=True )5.3 支持的提示词模式
go# 文档处理 "<image>\n<|grounding|>Convert the document to markdown." # 通用OCR "<image>\n<|grounding|>OCR this image." # 纯文本提取(无布局) "<image>\nFree OCR." # 文档中的图表 "<image>\nParse the figure." # 图像描述 "<image>\nDescribe this image in detail."5.4 vLLM加速推理
对于需要更高吞吐量的场景,模型也支持vLLM推理框架:
-
支持流式输出
-
支持PDF并发处理
-
提供批量评估脚本(用于基准测试)
六 应用场景
DeepSeek-OCR 2特别适合以下场景:
- 复杂文档理解
-
多栏布局的学术论文
-
包含图表的技术文档
-
结构复杂的报告
-
-
高精度OCR需求
-
-
数字化文档归档
-
发票、票据信息提取
-
书籍、杂志电子化
-
-
多模态RAG系统
-
-
结合检索增强生成
-
文档问答系统
-
知识库构建
-
-
本地部署场景
-
-
模型完全开源
-
支持私有化部署
-
数据安全可控
六 安装与部署
6.1 快速开始
go# 1. 克隆仓库 git clone https://github.com/deepseek-ai/DeepSeek-OCR-2.git # 2. 创建conda环境 conda create -n deepseek-ocr2 python=3.12.9 -y conda activate deepseek-ocr2 # 3. 安装依赖 pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118 pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl pip install -r requirements.txt pip install flash-attn==2.7.3 --no-build-isolation总结
DeepSeek-OCR 2通过视觉因果流技术,让AI在视觉理解上更加接近人类的认知方式。这一突破不仅提升了OCR任务的准确率,更重要的是为多模态AI的发展开辟了新的技术路径。
核心价值:
-
✅ 更类人的视觉理解逻辑
-
✅ 更高的准确率和效率
-
✅ 完全开源,支持本地部署
-
✅ 适合复杂文档处理场景
适用人群:
-
需要处理复杂文档的开发者
-
研究多模态AI的学者
-
需要高精度OCR的企业
-
对AI视觉技术感兴趣的技术爱好者
-