一个例子
proto定义与生成
定义
在src/main/proto/目录下定义proto文件,指定入参、出参和方法:
protobuf
syntax = "proto3";
option java_multiple_files = true;
option java_package = "com.gcx.grpc";
option java_outer_classname = "MessageServiceProto";
// 定义服务
service MessageService {
// 定义一个方法:接收字符串并返回success
rpc PrintMessage (MessageRequest) returns (MessageResponse);
}
// 请求消息
message MessageRequest {
string message = 1;
}
// 响应消息
message MessageResponse {
string result = 1;
}生成
在本地安装protoc,然后在pom文件中引入grpc、protobuf、proto插件:
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.gcx</groupId>
<artifactId>main</artifactId>
<version>1.0-SNAPSHOT</version>
<name>main</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<grpc.version>1.79.0</grpc.version>
<protobuf.version>3.25.1</protobuf.version>
</properties>
<dependencies>
<!-- gRPC dependencies -->
<dependency>
<groupId>io.grpc</groupId>
<artifactId>grpc-netty-shaded</artifactId>
<version>${grpc.version}</version>
</dependency>
<dependency>
<groupId>io.grpc</groupId>
<artifactId>grpc-protobuf</artifactId>
<version>${grpc.version}</version>
</dependency>
<dependency>
<groupId>io.grpc</groupId>
<artifactId>grpc-stub</artifactId>
<version>${grpc.version}</version>
</dependency>
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java-util</artifactId>
<version>${protobuf.version}</version>
</dependency>
<!-- For Java 9+ compatibility -->
<dependency>
<groupId>org.apache.tomcat</groupId>
<artifactId>annotations-api</artifactId>
<version>6.0.53</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<extensions>
<extension>
<groupId>kr.motd.maven</groupId>
<artifactId>os-maven-plugin</artifactId>
<version>1.7.0</version>
</extension>
</extensions>
<plugins>
<plugin>
<groupId>org.xolstice.maven.plugins</groupId>
<artifactId>protobuf-maven-plugin</artifactId>
<version>0.6.1</version>
<configuration>
<!-- 1. 指定 protoc 编译器版本(与 protobuf-java 版本一致) -->
<protocArtifact>com.google.protobuf:protoc:3.25.3:exe:${os.detected.classifier}</protocArtifact>
<!-- 2. 指定 gRPC Java 插件版本(与 grpc 核心版本一致) -->
<pluginId>grpc-java</pluginId>
<pluginArtifact>io.grpc:protoc-gen-grpc-java:${grpc.version}:exe:${os.detected.classifier}</pluginArtifact>
<!-- 3. .proto 文件所在目录(必须匹配你的目录) -->
<protoSourceRoot>${project.basedir}/src/main/proto</protoSourceRoot>
<!-- 4. 生成代码的输出目录(默认 src/main/java,可省略) -->
<outputDirectory>${project.basedir}/src/main/java</outputDirectory>
<!-- 5. 不清除已有代码(避免覆盖自定义代码) -->
<clearOutputDirectory>false</clearOutputDirectory>
</configuration>
<!-- 关键:绑定插件执行到 compile 阶段 -->
<executions>
<execution>
<id>compile-protoc</id>
<goals>
<goal>compile</goal> <!-- 生成普通 Protobuf 代码 -->
</goals>
</execution>
<execution>
<id>compile-grpc-java</id>
<goals>
<goal>compile-custom</goal> <!-- 生成 gRPC 代码 -->
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>21</source>
<target>21</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
</project>如果是maven项目,在本地执行mvn clean compile之后,会自动生成proto相关的请求、响应和服务类,生成之后的文件结构如下:
plain
src/main/proto/
└── message_service.proto # Protobuf 定义文件
src/main/java/com/gcx/grpc/
├── MessageServiceGrpc.java # 核心 gRPC 服务类(最重要)
├── MessageRequest.java # 请求消息类
├── MessageResponse.java # 响应消息类
├── MessageRequestOrBuilder.java # 请求构建器接口
├── MessageResponseOrBuilder.java # 响应构建器接口
└── MessageServiceProto.java # Protobuf 元数据类MessageServiceGrpc.java
整个 gRPC 服务的核心,包含了所有与 gRPC 调用相关的方法。
服务定义和元数据方法:
java
java
// 服务名称常量
public static final String SERVICE_NAME = "MessageService";
// 获取方法描述符(核心元数据)
public static MethodDescriptor<MessageRequest, MessageResponse> getPrintMessageMethod()作用:
创建和缓存 RPC 方法的元数据描述,包括:
方法全名:MessageService/PrintMessage
请求/响应类型
方法类型(UNARY 单次调用)
序列化/反序列化器
客户端 Stub 创建方法:
java
java
// 1. 异步 Stub(推荐用于生产环境)
public static MessageServiceStub newStub(Channel channel)
// 2. 阻塞式 Stub V2(抛出 StatusException)
public static MessageServiceBlockingV2Stub newBlockingV2Stub(Channel channel)
// 3. 阻塞式 Stub(传统方式)
public static MessageServiceBlockingStub newBlockingStub(Channel channel)
// 4. Future 式 Stub(返回 ListenableFuture)
public static MessageServiceFutureStub newFutureStub(Channel channel)各 Stub 的特点:
| Stub 类型 | 调用方式 | 异常处理 | 适用场景 |
|---|---|---|---|
MessageServiceStub |
异步回调 | 通过 StreamObserver | 高并发、响应式编程 |
MessageServiceBlockingV2Stub |
同步阻塞 | 抛出 StatusException | 简单同步调用 |
MessageServiceBlockingStub |
同步阻塞 | 返回默认值 | 向后兼容 |
MessageServiceFutureStub |
Future 模式 | 返回 ListenableFuture | 需要组合多个调用 |
客户端调用方法
异步调用(MessageServiceStub)
java
public void printMessage(MessageRequest request,
StreamObserver<MessageResponse> responseObserver)调用机制:
java
ClientCalls.asyncUnaryCall(
getChannel().newCall(getPrintMessageMethod(), getCallOptions()),
request,
responseObserver
);同步调用 V2(MessageServiceBlockingV2Stub)
java
public MessageResponse printMessage(MessageRequest request) throws StatusException调用机制:
java
ClientCalls.blockingV2UnaryCall(
getChannel(),
getPrintMessageMethod(),
getCallOptions(),
request
);传统同步调用(MessageServiceBlockingStub)
java
public MessageResponse printMessage(MessageRequest request)调用机制:
java
ClientCalls.blockingUnaryCall(
getChannel(),
getPrintMessageMethod(),
getCallOptions(),
request
);Future 调用(MessageServiceFutureStub)
java
public ListenableFuture<MessageResponse> printMessage(MessageRequest request)调用机制:
java
ClientCalls.futureUnaryCall(
getChannel().newCall(getPrintMessageMethod(), getCallOptions()),
request
);服务端实现相关
java
// 服务接口定义
public interface AsyncService {
default void printMessage(MessageRequest request,
StreamObserver<MessageResponse> responseObserver)
}
// 服务基类
public static abstract class MessageServiceImplBase
implements BindableService, AsyncService服务绑定和注册
java
// 将服务实现绑定到 gRPC 服务器
public static ServerServiceDefinition bindService(AsyncService service)MessageRequest.java/MessageResponse.java
Protobuf 消息类,提供:
java
// 构建器模式创建请求
MessageRequest request = MessageRequest.newBuilder()
.setMessage("Hello World")
.build();
// 访问消息字段
String message = request.getMessage();
// 序列化/反序列化
byte[] bytes = request.toByteArray();
MessageRequest parsed = MessageRequest.parseFrom(bytes);*OrBuilder.java
提供只读访问消息数据的接口,用于:
- 避免不必要的对象创建
- 提供统一的读取接口
- 支持构建器和构建完成对象的统一访问
调用流程
客户端发起请求:
java
package com.gcx;
import com.gcx.grpc.MessageRequest;
import com.gcx.grpc.MessageResponse;
import com.gcx.grpc.MessageServiceGrpc;
import io.grpc.ManagedChannel;
import io.grpc.ManagedChannelBuilder;
public class Client {
public static void main(String[] args) {
// 1. 创建通道
ManagedChannel channel = ManagedChannelBuilder
.forAddress("localhost", 8080)
.usePlaintext()
.build();
// 2. 创建 stub
MessageServiceGrpc.MessageServiceBlockingStub stub =
MessageServiceGrpc.newBlockingStub(channel);
// 3. 构建请求
MessageRequest request = MessageRequest.newBuilder()
.setMessage("Hello gRPC")
.build();
// 4. 发起调用
MessageResponse response = stub.printMessage(request);
// 5. 处理响应
System.out.println("Response: " + response.getResult());
}
}启动服务端
java
package com.gcx;
import com.gcx.grpc.MessageRequest;
import com.gcx.grpc.MessageResponse;
import com.gcx.grpc.MessageServiceGrpc;
import io.grpc.ServerBuilder;
import io.grpc.stub.StreamObserver;
public class Server {
// 1. 实现服务
static class MessageServiceImpl extends MessageServiceGrpc.MessageServiceImplBase {
@Override
public void printMessage(MessageRequest request, StreamObserver<MessageResponse> responseObserver) {
// 处理请求
String message = request.getMessage();
System.out.println("Received: " + message);
// 构建响应
MessageResponse response = MessageResponse.newBuilder()
.setResult("success")
.build();
// 发送响应
responseObserver.onNext(response);
responseObserver.onCompleted();
}
}
public static void main(String[] args) throws Exception {
// 2. 启动服务
io.grpc.Server server = ServerBuilder
.forPort(8080)
.addService(new MessageServiceImpl())
.build()
.start();
System.out.println("Server started, listening on 8080");
Thread.sleep(1000 * 60 * 60 * 24);
}
}以上为最简单的 UNARY(单次请求-单次响应)模式,除此之外还支持:
- UNARY:单请求 → 单响应(当前使用)
- SERVER_STREAMING:单请求 → 多响应流
- CLIENT_STREAMING:多请求流 → 单响应
- BIDI_STREAMING:双向流式调用
ProtoBuf
原理
Protobuf 是先定义结构,再编译生成代码,最后基于预定义结构做二进制编码的协议,核心分三步:
步骤 1:定义数据结构(.proto 文件)
用 Protobuf 的 IDL(接口定义语言)描述数据的字段名、类型、唯一编号(字段编号是核心),比如定义一个用户信息:
protobuf
// user.proto
syntax = "proto3"; // 指定版本
package demo;
// 定义数据结构(Message)
message User {
int32 id = 1; // 字段编号1,整型
string name = 2; // 字段编号2,字符串
bool is_vip = 3; // 字段编号3,布尔型
repeated string tags = 4; // 字段编号4,字符串列表
}步骤 2:编译生成代码
通过protoc工具生成对应语言的代码(比如 Java/Python),生成的代码包含:
- 数据类(User);
- 序列化方法(toByteArray ());
- 反序列化方法(parseFrom ())。
步骤 3:二进制编码规则(核心)
Protobuf 的高性能源于极简的二进制编码,核心规则:
- 用字段编号 + 类型代替字段名(比如 "id=1" 只存编号 1,不存 "id");
- 对不同类型做压缩编码(比如整数用 Varint 编码,小整数仅占 1 字节);
- 无冗余字符(不像 JSON 的
{}/"")。
实际例子:编码后的字节对比
假设要序列化一个 User 对象:id=100,name="张三",is_vip=true,tags=["vip","new"]
Protobuf 编码后的二进制字节(十六进制):
plain
08 64 12 06 E5 BC A0 E4 B8 89 18 01 22 03 76 69 70 22 03 6E 65 77总长度:21 字节。拆解核心逻辑:
08 64:08是 "字段 1(id)+ 整型类型",64是 100 的 Varint 编码(仅 1 字节);
12 06:12是 "字段 2(name)+ 字符串类型",06是 "张三" 的字节长度(6 字节),后面 6 字节是 "张三" 的 UTF-8 编码;
无任何冗余,仅存 "编号 + 类型 + 值"。
优点:
- 速度:序列化 / 反序列化是 JSON 的 5-10 倍(二进制无需文本解析,预编译代码直接操作内存);
- 体积:21 字节 vs JSON 的 68 字节(见下文),带宽节省 60%+;
- 版本兼容:新增字段不影响老版本解析(只要字段编号不变);
- 跨语言:生成 Java/Go/Python 代码,不同语言服务可互通。不依赖Java的反射,因为
.proto定义了结构,而生成的Java类中,有硬编码的字段读写方法,无需反射。反射是 Java 中特有的非常耗时的操作,比 Protobuf 硬编码读写慢 3-5 倍;
java
// Protobuf 生成的代码(简化版)
public class User {
private int id;
private String name;
// 硬编码的序列化方法(直接读写字段,无反射)
public byte[] toByteArray() {
// 直接处理 id、name,无需反射
writeInt(1, id);
writeString(2, name);
}
// 硬编码的反序列化方法
public static User parseFrom(byte[] bytes) {
User user = new User();
// 直接读取字段值,赋值给对象,无反射
user.id = readInt(1, bytes);
user.name = readString(2, bytes);
return user;
}
}缺点:
- 可读性差:二进制字节无法直接看
- 使用成本高:需定义.proto
JSON
编码规则:
JSON 是纯文本的键值对编码,无预定义结构,核心规则:
用{}包裹对象,[]包裹数组;
键必须用双引号"",值支持字符串 / 数字 / 布尔 / 数组 / 对象;
所有内容都是可读的字符(ASCII/UTF-8),无需编译,直接解析。
编码长度:
同样的 User 对象,JSON 编码后:
json
{
"id": 100,
"name": "张三",
"is_vip": true,
"tags": ["vip", "new"]
}压缩后(去掉空格):
plain
{"id":100,"name":"张三","is_vip":true,"tags":["vip","new"]}总长度:68 字节(包含大量冗余字符:{}/""/ 逗号)。解析原理:
- 解析器逐字符遍历,先找到
"id",再解析冒号后的 100; - 解析
"name"时,需处理 UTF-8 编码的 "张三"; - 全程要处理文本转义、类型判断(比如把 "100" 转成数字),开销大。
优点:
- 零成本使用:无需定义结构、编译,所有语言原生支持;
- 可读性强:直接看文本就知道数据内容,调试 / 联调效率高;
- 灵活性高:字段可动态增减,适合快速开发;
缺点:
- 速度:解析 68 字节的 JSON,CPU 需遍历所有字符,耗时是 Protobuf 的 5 倍 +;
- 体积:68 字节 vs Protobuf 的 21 字节,带宽占用高;
- 弱类型问题:比如
"id":"100"(字符串)和"id":100(数字),解析时易出错; - 版本兼容差:后端删了
is_vip字段,前端解析时会报undefined; - 依赖反射:JSON 可以绕开反射,通过硬编码明确指定数据如何映射到对象;而 Hessian 在设计上就高度绑定Java对象,不允许绕开。
java
import com.fasterxml.jackson.core.JsonGenerator;
import com.fasterxml.jackson.core.JsonParser;
import java.io.IOException;
// 自定义User类(无get/set也能行)
class User {
public int id;
public String name;
public User(int id, String name) {
this.id = id;
this.name = name;
}
}
// 手动序列化(无反射):明确告诉JSON库"写什么键,取什么值"
public static String serializeUser(User user) throws IOException {
JsonGenerator gen = new JsonFactory().createGenerator(System.out);
gen.writeStartObject();
gen.writeNumberField("id", user.id); // 硬编码:id键对应user.id
gen.writeStringField("name", user.name); // 硬编码:name键对应user.name
gen.writeEndObject();
gen.close();
return gen.toString();
}
// 手动反序列化(无反射):明确告诉JSON库"读什么键,赋什么值"
public static User deserializeUser(String json) throws IOException {
JsonParser parser = new JsonFactory().createParser(json);
int id = 0;
String name = "";
while (parser.nextToken() != null) {
if ("id".equals(parser.getCurrentName())) {
id = parser.getIntValue(); // 硬编码:读id键,赋给id变量
}
if ("name".equals(parser.getCurrentName())) {
name = parser.getText(); // 硬编码:读name键,赋给name变量
}
}
return new User(id, name); // 手动创建对象,无反射
}Hessian
Hessian 是为 Java 设计的二进制序列化协议
编码规则:
无需预定义结构,直接序列化 Java 对象(依赖类的字段名 / 类型);
二进制编码,但规则是 "半定制"(比如用特定字节表示 Java 类型:0x42 代表 Boolean,0x53 代表 String);
核心是 "对象序列化",而非 "数据结构序列化"(绑定 Java 类)。
编码长度:
同样的 User 对象(Java 类),Hessian 编码后的二进制字节(十六进制):
plain
42 01 53 03 76 69 70 53 03 6E 65 77 49 00 00 00 64 53 06 E5 BC A0 E4 B8 89总长度:28 字节(比 JSON 小,比 Protobuf 大)。
解析:
- 解析器先识别字节对应的 Java 类型(比如
49代表 int,53代表 String); - 直接映射到 Java 类的字段(比如
id字段对应 int 类型,赋值 100),强依赖 Java 类结构,字段名变一点、加字段、类型变一点都会导致解析失败,且字符串和额外标识会占用大量字节。 - 依赖 Java 反射,无需预编译,但仅适配 Java 生态。调用
<font style="color:rgb(0, 0, 0);background-color:rgba(0, 0, 0, 0);">hessianSerializer.serialize(userObj)</font>时,Hessian 会通过反射做4个步骤:获取对象的类信息、反射获取所有字段(包括私有字段)、按 Hessian 规则编码字段信息、反射处理继承 / 复杂类型。
优点:
- Java 体系内易用:直接序列化 Java 对象,无需定义.proto,开箱即用;
- 比 JSON 高效:28 字节 vs 68 字节,速度也快(二进制无需文本解析);
缺点:
- 跨语言极差:仅 Java 友好,Go/Python 的 Hessian 库兼容差(比如解析 Java 的 List 会出错);
- 版本兼容弱:Java 类字段名改了(比如
<font style="color:rgb(0, 0, 0);background-color:rgba(0, 0, 0, 0);">is_vip</font>改<font style="color:rgb(0, 0, 0);background-color:rgba(0, 0, 0, 0);">vip</font>),老版本解析失败,系统迭代比如 User 类重构,字段名变更,所有调用方都要改。
HTTP/2
HTTP1.x的缺陷
队头阻塞
HTTP/1.x 虽然引入了 keep-alive 长连接,但一个连接只能串行请求/响应,每次请求必须等待上一次响应之后才能发起。虽然在 HTTP/1.1 中提出了管道机制(默认不开启),下一次的请求不需要等待上一个响应来之后再发送,但这要求服务端必须按照请求发送的顺序返回响应,当顺序请求多个文件时,其中一个请求因为某种原因被阻塞时,在后面排队的所有请求也一并被阻塞。
连接太多
HTTP1.x想并发只能开启多个TCP连接,但是浏览器最多开 6~8 个 TCP 连接,且每个连接都要三次握手、慢启动、维持状态,会导致网络拥塞、延迟升高。
Header重复
HTTP1.x每次请求都要发送纯文本的完整 Header,冗余极高。Cookie、User-Agent、Host 每次都重复,对于小请求而言,头可能比数据体还大。
文本传输
基于字符串的解析方式,机器解析慢、开销大,必须逐行扫描、找 \r\n、处理空格、大小写等等。
服务端被动响应
只能客户端请求之后服务器才响应,例如浏览器先下 HTML,然后解析,然后才知道要下 JS/CSS,多一轮往返,延迟升高。
核心设计
头部压缩
HTTP/2 会在客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,重复 Header 只传索引,再用Huffman编码压缩字符串,产生的效果是体积减少 80%。
多路复用
二进制帧
HTTP/2 将所有的请求和响应数据都分割成更小的、二进制的"帧"(Frame)。
- 帧 (Frame): 最小的通信单位,包含帧长度、类型、标志位和流标识符等元数据。
- 流 (Stream): 一个虚拟的双向通道,由一个或多个帧组成,代表一个完整的请求或响应。
- 消息 (Message): 对应一个完整的 HTTP 请求或响应,由属于同一个流的多个帧组成。
二进制格式更易于机器解析,更加健壮和高效,为多路复用等高级功能奠定物理基础。
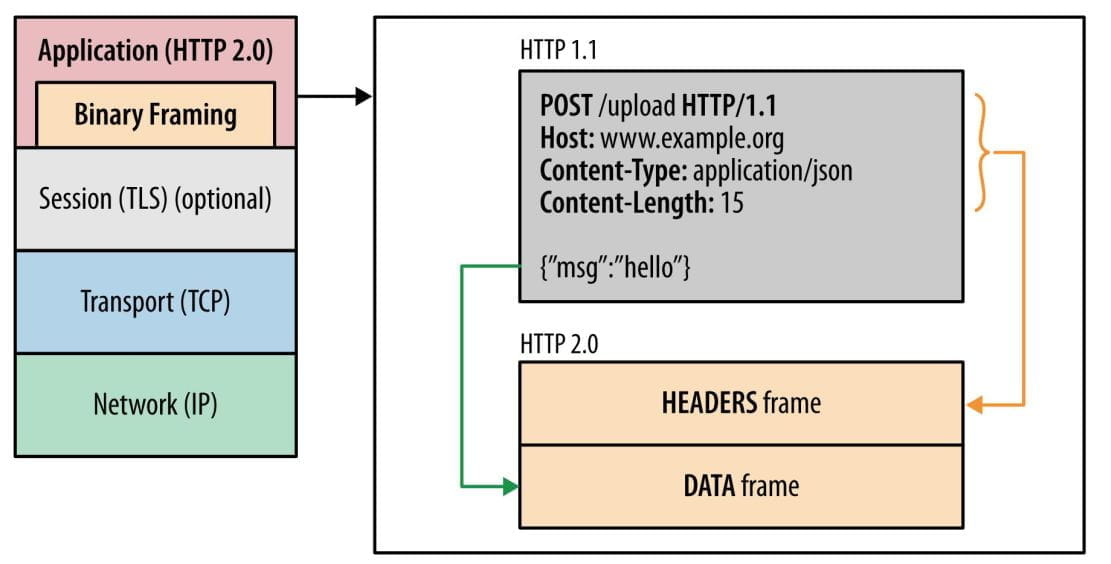
每一帧的数据结构包括:

二进制编码和解析
HTTP/1.x的文本处理
文本 → 字符编码 → 二进制
plain
客户端 服务端
│ │
│ 1. 拼接明文头部 │
│ Host: example.com\r\n │
│ │
│ 2. 按 ASCII 转二进制 │
│ 48 6F 73 74 3A 20... │
├───────────────────────────────────►│
│ │ 3. 读取二进制流
│ │
│ │ 4. 转回 ASCII 字符串
│ │ "Host: example.com\r\n"
│ │
│ │ 5. 逐行扫描 \r\n
│ │
│ │ 6. 按冒号拆分 key:value
│ │ key="Host", value="example.com"
│ │
│ │ 7. 交给应用层
│ │HTTP/2的HPACK处理
文本 → 编码 / 压缩 / 查表 → 二进制
plain
客户端 服务端
│ │
│ 1. 原始头部:Host: example.com │
│ │
│ 2. 查 HPACK 静态字典 │
│ Host → 索引 12 │
│ │
│ 3. Value 做 Huffman 编码 │
│ example.com → 一串二进制 │
│ │
│ 4. 拼成二进制帧(HEADERS 帧) │
├───────────────────────────────────►│
│ │
│ │ 5. 直接读二进制帧结构
│ │
│ │ 6. 第一段:索引 12 → 查字典 → Host
│ │
│ │ 7. 第二段:Huffman 解码 → example.com
│ │
│ │ 8. 组合成 key:value
│ │ Host: example.com
│ │
│ │ 9. 交给应用层
│ │为什么不用gzip直接压缩文本
Header 不用 gzip 而是用 HPACK,原因是 gzip 压缩率低 + 有 CRIME 安全漏洞,HPACK是静态表 + 动态表 + Huffman,更安全、压缩率更高。
Body 可以用gzip压缩。
流传输
HTTP/1.x的1个TCP连接只有1个请求 / 响应,导致队头阻塞,而HTTP/2的1个TCP连接可以复用,N个Stream并发不同请求的帧交错发送,互不阻塞。1个Stream是1个请求 / 响应,每个Stream有独立的优先级、流量控制、错误处理。
上面提到的二进制帧,每个帧都带Stream ID,客户端发起的Stream ID是奇数,服务器发起Stream ID是偶数。不同请求的帧可以乱序、交错发送,接收方根据流标识符将乱序到达的帧重新组装成完整的消息。
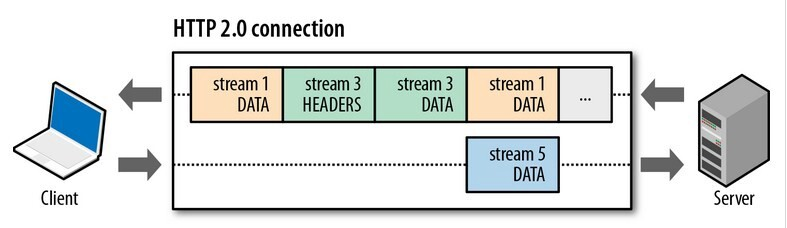
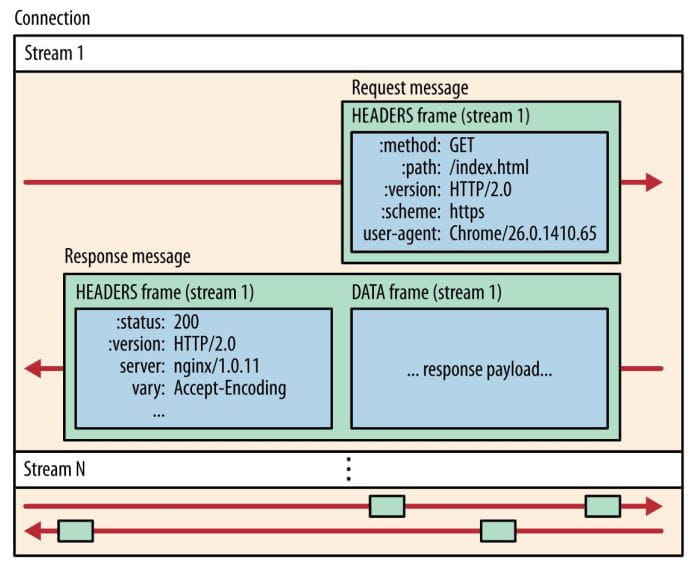
流量控制
HTTP/1的1个连接只能跑1个请求,流量控制靠TCP滑动窗口 就够了。HTTP/2 是1个TCP连接 + N个Stream(并发请求),TCP 只能控制整个连接的流速,不能控制单个请求(Stream)的流速,如果一个 Stream 疯狂发数据,会占满整个连接,把其他请求饿死。
HTTP/2在的帧流量控制支持连接级别 + Stream 级别,只控制DATA帧,Header和控制帧体积小,不受流量控制限制,保证协议能正常协商、心跳、取消。
HTTP/2用滑动窗口模型,和TCP逻辑一样,但在应用层。每个方向都有两个窗口:Connection窗口(整个连接)+Stream窗口(单个请求)。
滑动窗口规则:发送方只能在两个窗口都有剩余空间时,才能发送 DATA 帧。发送多少字节,两个窗口同时减少多少。接收方恢复窗口,发送 WINDOW_UPDATE 帧,表示可以给整个TCP连接增加窗口,也可以给某个Stream增加窗口。
举个例子:客户端向服务端发消息,建立 Stream(Stream ID=1)之后,服务端(消息接收方)维护的窗口大小为Connection 窗口65535、Stream 1 窗口65535(如果是双向发消息,则两边都分别有窗口)。由客户端发送 DATA 帧 1000 字节,当服务器收到消息后,放入缓冲区,此时Connection 窗口为65535 - 1000 = 64535、Stream 1 窗口为65535 - 1000 = 64535。服务端处理完1000字节的数据,窗口大小复原,然后发送WINDOW_UPDATE,客户端(原本是0)接收到消息后,Stream 1 +1000,Connection +1000,然后才会继续发消息。如果窗口变成0,发送方必须停止发送DATA帧,直到收到WINDOW_UPDATE。
流优先级
HTTP/2允许客户端为不同的流(资源请求)分配权重和依赖关系,告诉服务器哪些资源更重要。
客户端在请求时可以指定一个流的权重(1-256)和它所依赖的父流。服务器可以根据这些信息,优先处理和传输高优先级的资源(如关键的 CSS/JS),再处理低优先级的资源(如图片)。
服务器推送
HTTP/2允许服务器在客户端没请求前,主动推资源,不需要客户端再发起请求,可以减少请求往返,页面加载速度明显提升。
QUIC
核心原理
可靠传输
UDP是无连接、不可靠、无序、无重传、无拥塞控制的传输层协议,而 QUIC 基于 UDP 实现了可靠、加密、多路复用的传输层协议。
序列号
每一个 UDP 包都有唯一编号,全局单调递增,接收方通过序列号判断丢包、重复包、乱序包。
ACK
确认收到消息。通过 ACK 告知发送方哪些包已收到;支持区间表达,可一次性确认大量乱序包;支持显式拥塞通知。
plain
ACK 帧 {
LargestAcknowledged // 收到的最大PN
ACK Delay // 延迟时间
ACK Range Count // 连续区间数量
ACK Ranges // 收到的PN区间
}重传
触发重传的条件包括Time-out(定时器)、基于 ACK Range 的丢包推断。当更大序列号已确认,但前面 PN 区间一直未确认,立即判定丢包,不需要等待超时。
滑动窗口
发送数据时必须同时满足两个窗口限制:发送上限 = min (拥塞窗口 CWND, 流量控制窗口)
拥塞控制:防止把网络堵死,和 TCP 完全一样,慢启动、拥塞避免、基于 RTT、丢包、ACK 来调整窗口大小。拥塞窗口代表网络能承载的最大字节数。
流量控制:防止把接收方内存撑爆,和 HTTP/2 流量控制逻辑一样,但在传输层。QUIC 有两级:Connection 级流控窗口(总窗口)、Stream 级流控窗口(每个流独立窗口),接收方通过帧来动态开放窗口。
多路复用
解决TCP队头阻塞问题。
plain
QUIC Connection
├── Stream 0(加密/握手)
├── Stream 1(HTTP/3 控制流)
├── Stream 2(请求1)
├── Stream 3(请求2)
└── ...一个 Connection 包含多个独立 Stream,Stream 之间完全隔离,数据以 Frame 为单位承载,丢包只影响所属 Stream,其他 Stream 可继续发送与交付,不受阻塞。
解决队头阻塞:
TCP 是字节流有序,一个丢包,后面全部阻塞。
QUIC 是帧级乱序处理,如果一个 Stream 丢包,只阻塞该 Stream,其他 Stream 正常。
握手
HTTP/2的握手过程:
SYN:连接请求,包括客户端初始序列号。
SYN+ACK:连接请求响应,包括服务端初始序列号。
ACK:序列号交换完成,TCP连接建立完成。
ClientHello:开始加密握手,包含TLS 关键字段:Random(32 字节随机数)、Cipher Suites(加密套件)、KeyShare(ECDHE 公钥)等,并协商使用 HTTP/2。
ServerHello + Certificate + CertificateVerify + Finished:ServerHello选定加密套件、HTTP/2协议、KeyShare;服务器公钥证书;私钥证书;握手完成。
Finished:TLS 完成
QUIC的握手过程:
QUIC Initial:客户端发送给服务端,头部字段包括 QUIC 版本号、Connection ID、Packet Number(从 0 或 1 开始)等,帧里面包括 TLS 1.3 ClientHello。
QUIC Handshake:服务端返回给客户端,头部字段同样包括QUIC 版本号、Connection ID、Packet Number 等,帧里面包括 ServerHello + Certificate + CertificateVerify + Finished。
QUIC的2次通信代替TCP的6次通信:
TCP 第 3 次握手的核心目的:确认双方可达、同步序列号、防历史旧包。
QUIC的替代方案:Connection ID(防旧包)、Packet Number(自增有序,不用同步)、加密校验(验证真实客户端)。
不同客户端的CID可以相同,因为 QUIC 服务端判断 "这个包属于哪个连接",不是只看 CID,而是看一个 四元组 + CID 的组合:本地 IP、本地 Port、远端 IP、远端 Port、Connection ID。
当用户的网络环境发生变化时,比如从 WIFI 切换到 4G,基于四元组的 TCP 连接无法保持存活。而 QUIC 使用 Connection ID 标识连接,不受环境变化影响。因此,QUIC 可以实现网络变化的无缝切换,保证连接存活和数据正常收发。
相比HTTP/2的优势
1.彻底解决了 "队头阻塞"(最本质优势)
HTTP/2:虽然多路复用,但底层是 TCP→ 一个包丢包 → 整个连接所有流都卡住
QUIC:基于 UDP,流与流之间完全隔离→ 一个流丢包 → 只影响自己,不影响其他流
2. 握手延迟更低:1-RTT / 0-RTT
HTTP/2:TCP 3 次握手(1-RTT) + TLS 1.3(1-RTT)→ 共 2-RTT 才能发数据
QUIC:传输握手 + TLS 1.3 融合在一起→ 首次连接 1-RTT→ 重复连接 0-RTT(直接发数据)
3. 原生加密,更安全
HTTP/2:TCP 明文,TLS 是外挂
QUIC:从第一个包开始就强制加密
ACK、流量控制、握手信息 全部加密
防监听、防篡改、防伪造
4. 连接迁移(网络切换不断线)
HTTP/2:靠 IP+Port 四元组 标识连接→ 4G ↔ WiFi → 断开重连
QUIC:靠 Connection ID 标识连接→ IP/Port 随便变 → 连接不断、无感切换
5. 更优的可靠性与拥塞控制
QUIC ACK 支持更多乱序区间,丢包检测更快
拥塞控制在用户态,可随时升级
重传不产生歧义,效率更高
6. 更抗 DDoS、更省服务器资源
QUIC 服务端收到包先验证密码学→ 不合法包直接丢弃,不分配资源
不需要 TCP SYN 队列,天然抗 SYN Flood
gRPC与DUBBO
DUBBO指2.x版本,原理请参考博文中的DUBBO章节。
Stub与动态代理
Dubbo: 使用者在代码中注入的是一个接口,Dubbo 在运行时利用动态代理技术(如 Javassist)生成一个代理对象。当你调用方法时,代理对象拦截请求,组装参数,然后发送网络请求。
gRPC: 使用 Protobuf 生成代码。
- gRPC 不使用运行时的动态代理。它依赖于 IDL (接口定义语言)。使用者需要编写
.proto文件定义服务,然后通过编译器(protoc)静态生成 客户端代码(Stub)和服务端代码。 - 生成的
Stub类直接包含了网络传输和序列化的逻辑,是强类型约束。因为是编译期生成的代码,避免了运行时的反射开销,所以 gRPC 的调用效率很高。
序列化
Dubbo:序列化支持Hessian/JSON等多种方式,灵活性高但易出现兼容性问题。
gRPC:使用 Protobuf 序列化。
- Protobuf 是二进制序列化协议,相比 JSON/Hessian 体积小、解析快(性能是 JSON 的 3-5 倍);
- 数据结构通过
.proto定义,支持版本兼容(字段新增 / 废弃不影响老版本); - gRPC 强制绑定 Protobuf,无需开发者选择,减少序列化选型和兼容成本;
- 核心优势:跨语言(生成 Java/Go/C++ 等多语言代码)、高性能、强兼容性。
编解码
Dubbo:使用自定义 TCP 报文格式(头 + 体),自己处理编解码。
gRPC:使用 HTTP/2。
- 业务数据通过 Protobuf 编解码为二进制字节流;
- 将二进制字节流封装为 HTTP/2 的
DATA帧(或HEADERS帧),附带 gRPC 自定义元数据(如请求 ID、压缩方式); - HTTP/2 帧是标准格式,天然支持多路复用、头部压缩(HPACK 算法),比 Dubbo 自定义协议更适配现代网络。
通信协议
Dubbo:Dubbo 原生协议是自定义 TCP 协议,也支持 HTTP/1.1 等;
gRPC:使用 HTTP/2。
- 多路复用:单个 TCP 连接可同时处理多个 gRPC 请求 / 响应,避免 Dubbo 基于 HTTP/1.1 时的连接数瓶颈;
- 服务端推送:支持 Server Streaming(服务端流式响应),如实时日志推送,Dubbo 需额外扩展;
- 头部压缩:HPACK 算法压缩 HTTP 头,减少元数据传输体积;
- 双向流:支持 Client Streaming / 双向流,适合文件上传、实时交互等场景,Dubbo 需定制开发。
集群容错和负载均衡
Dubbo:支持客户端负载均衡,支持多种容错和负载均衡方法,可以自定义。
gRPC:
- 支持客户端负载均衡,核心策略:
round_robin:轮询(默认);pick_first:选第一个可用节点;weighted_round_robin:加权轮询;- 需提前获取服务端节点列表(通过服务发现组件),客户端本地计算选择节点;
- 容错机制:仅提供基础重试(如
max_retry配置)。
服务注册与发现
Dubbo:集成 Zookeeper/Nacos 等注册中心;
gRPC:
- gRPC 本身不提供注册中心,需对接 etcd、nacos、consul、k8s Service 等;
- 核心流程:服务端启动时向注册中心上报「服务名 + 地址 + 端口」,客户端从注册中心拉取节点列表,缓存到本地用于负载均衡;
- 常用方案:微服务场景结合 k8s Service(基于 DNS 解析),传统分布式对接 etcd/nacos(通过客户端 SDK 拉取节点)。
流式调用
Dubbo:只支持一元调用,客户端发 1 次请求,服务端返回 1 次响应。流式调用需要基于Netty长连接定制开发。
gRPC支持以下场景:
- 客户端流式:客户端多次发请求 → 服务端返回 1 次响应,适用文件上传、批量数据提交场景。
- 服务端流式:客户端发 1 次请求 → 服务端多次返回响应,适用实时日志、数据推送、分页查询。
- 双向流式:客户端 / 服务端都可多次收发消息,适用实时聊天、视频通话、游戏交互。
底层协议基础
gRPC 流式调用完全依赖 HTTP/2 的「流(Stream)」,每个 gRPC 流式调用对应一个独立的 HTTP/2 流(Stream ID 唯一),单个 TCP 连接可承载多个 HTTP/2 流(多路复用)。流的生命周期:创建 → 数据传输 → 关闭,支持半关闭(如客户端发完所有请求后,只关闭发送流,保留接收流等响应)。
序列化 / 传输特点
一元调用:请求 / 响应各封装为 1 个 HTTP/2 DATA 帧;
流式调用:多次发送 / 接收 DATA 帧,每个帧承载部分 Protobuf 序列化数据,最终拼接为完整消息;
gRPC 会在帧中标记「消息边界」(如 END_STREAM 标志),区分 "当前帧是消息的一部分" 还是 "消息结束"。
核心元数据
gRPC 流式调用会通过 HTTP/2 头部携带关键标识:
content-type: application/grpc(固定);
grpc-streaming: true(流式调用特有);
grpc-message-type:指定 Protobuf 消息类型;
支持自定义元数据(如 token、trace-id),可在流的生命周期内全程传递。
背压
gRPC的背压基于 HTTP/2 流量控制实现:接收方通过滑动窗口 + WINDOW_UPDATE 帧,控制发送方的发送速度。