目录
[== 和 equals() 的区别](#== 和 equals() 的区别)
[hashCode() 有什么用?](#hashCode() 有什么用?)
为什么用BigDecimal不用float/double计算出现什么问题?
[String s1 = new String("abc");创建了几个对象?](#String s1 = new String("abc");创建了几个对象?)
String和StringBuffer和StringBuilder区别
[字符串拼接用"+" 还是 StringBuilder?](#字符串拼接用“+” 还是 StringBuilder?)
== 和 equals() 的区别
== 对于基本类型和引用类型的作用效果是不同的:
对于基本数据类型来说,== 比较的是值
对于引用数据类型来说,== 比较的是对象的内存地址
equals() 方法存在两种使用情况:
类没有重写 equals() 方法:通过equals()比较该类的两个对象时,等价于通过"=="比较这两个对象,使用的默认是 Object 类equals()方法。
类重写了 equals() 方法:一般我们都重写 equals()方法来比 较两个对象中的属性是否相等;若它们的属性相等,则返回 true(即,认为这两个对象相等)。
String 中的 equals 方法是被重写过的,因为 Object 的 equals方法是比较的对象的内存地址,而 String 的 equals 方法比较的是对象的值。
hashCode () 有什么用?
hashCode() 的作用是获取哈希值。这个哈希值的作用是确定该对象在 哈希表 中的索引位置 (可以快速找到所需要的对象)
Java用hashcode()和equals()判断是否为同一个对象
如果两个对象的hashCode 值相等,那这两个对象不一定相等(哈希碰撞)。
如果两个对象的hashCode 值相等并且equals()方法也返回 true,我们才认为这两个对象相等
如果两个对象的hashCode 值不相等,我们就可以直接认为这两个对象不相等。
重写equals为什么要重写 hashcode ?
因为java判断两个对象是否是相等的, 需要先比较hashcode是否一致, 如果hashcode不一致那么就认为不相等.
如果没有重写hashcode, 那么两个相等的对象由于hashcode不相等, 就会被认为是不相等的. 但是按照重写的equals规则, 他们应该是相等的.
在集合中, 如set集合去重中就会出现, 两个相等的对象放到set中都可以存在的怪象.
为什么用BigDecimal不用float/double计算出现什么问题?
double会出现精度丢失的问题
计算机无法精确地表示小数, 所以做浮点数计算时会出现精度丢失问题.
BigDecimal底层是用字符串存储数字, 运算也是用字符串做加减乘除计算的, 所以它能做到精确计算. 所以一般牵扯到金钱等精确计算,都使用Decimal。
自动装箱与拆箱
装箱:将基本类型用它们对应的引用类型包装起来;调用了包装类的valueOf()方法
拆箱:将包装类型转换为基本数据类型;调用了 xxxValue()方法
java
// 手动装箱和拆箱
Integer i1 = Integer.valueOf(100); // 手动装箱
int n1 = i1.intValue(); // 手动拆箱
// 自动装箱和拆箱
Integer i2 = 100; // 自动装箱:编译器自动改为 Integer.valueOf(100)
int n2 = i2; // 自动拆箱:编译器自动改为 i2.intValue()深拷贝和浅拷贝区别?什么是引用拷贝
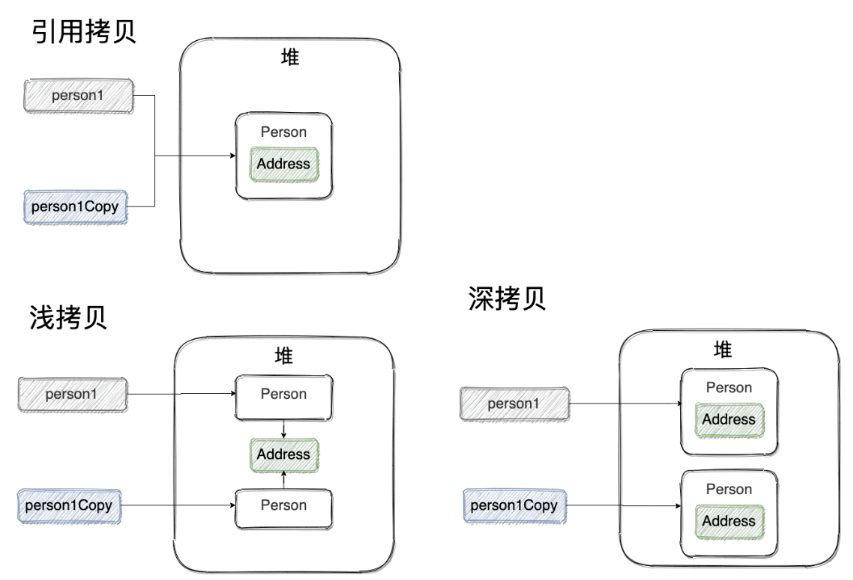
浅拷贝:浅拷贝会在堆上创建一个新的对象(区别于引用拷贝的一点),不过,如果原对象内部的属性是引用类型的话,浅拷贝会直接复制内部对象的引用地址,也就是说拷贝对象和原对象共用同一个内部对象。
深拷贝:深拷贝会完全复制整个对象,包括这个对象所包含的内部对象。
引用拷贝: 引用拷贝就是两个不同的引用指向同一个对象。
面向对象的三大特征
封装
为了提高代码的安全性,隐藏对象的内部细节,封装将对象的内部状态(字段、属性)隐藏起来,并通过定义公共的方法(接口)来操作对象
外部代码只需要知道如何使⽤这些⽅法而无需了解内部实现
继承
允许一个类(子类)继承另⼀个类(父类)的属性和⽅法的机制
子类可以重用父类的代码,并且可以通过添加新的方法或修改(重写)已有的方法来扩展或改进功能
提高了代码的可重用性和可扩展性
多态
就是多种形态,具体点就是去完成某个行为,当不同的对象去完成时会产生出不同的状态。
理解多态的三个条件
java
public class duotai {
public static class Animal {
String name;
int age;
public Animal(String name, int age){
this.name = name;
this.age = age;
}
public void eat(){
System.out.println(name + "吃饭");
}
}
public static class Cat extends Animal{
public Cat(String name, int age){
super(name, age);
}
@Override
public void eat(){
System.out.println(name+"吃鱼~~~");
}
}
public static class Dog extends Animal {
public Dog(String name, int age){
super(name, age);
}
@Override
public void eat(){
System.out.println(name+"吃骨头~~~");
}
}
public static void main(String[] args) {
// Animal animal=new Animal("花花",4);
Animal cat = new Cat("元宝",2);
Animal dog = new Dog("小七", 1);
cat.eat();
dog.eat();
// animal.eat();
}
}面向对象和面向过程的区别
面向过程: 直接将解决问题的步骤分析出来,然后用函数把步骤一步一步实现,然后再依次调用就可以了. 面向过程思想偏向于我们做一件事的流程,首先做什么,其次做什么,最后做什么。
面向对象: 将构成问题的事物,分解成若干个对象, 需要完成什么事情, 直接让某个对象来干即可,不关注是怎么完成的.
类和对象
类: 像是一个抽象的设计图/模板. 类往往保存一类事物的共性(属性), 共有行为.
对象: 是通过这个设计图/模板创造出来具体实例. 实例往往是共性个性化的表现.
String的不可变性

-
String类被final修饰,表明该类不能被继承,可防止子类添加修改方法
-
value数组被final修饰,表明value自身的值不能改变,即不能引用其他字符数组。
错误说法:因为value数组,被final修饰了,因此不可变
final修饰引用类型表明该引用变量不能引用其他对象,但是其引用对象中的内容是可以修改的。
String s1 = new String("abc"); 创建了几个对象?
这取决于字符串常量池中是否已存在'abc'这个字符串对象。
情况1 :如果常量池中没有'abc',会创建2个对象:
-
字符串'abc'对应的String对象(加载到常量池)
-
new关键字创建的String对象(在堆中)
情况2 :如果常量池中已有'abc'(比如之前代码用过),只创建1个对象:
- new关键字创建的String对象
这是因为Java在加载类时,会把字符串放入常量池。执行new String("abc")时,'abc'这个字符串会触发常量池的加载检查。"
String和StringBuffer和StringBuilder区别
String:字符串变量,private final修饰,不可变
StringBuffer:字符串变量(线程安全,可变) 没有使用 final和 private 关键字修饰
StringBuilder:字符串变量(线程不安全,可变) 没有使用final 和 private 关键字修饰
StringBuilder是StringBuffer的简易版,更快
每次对 String 类型进行改变的时候,都会生成一个新的 String对象,然后将指针指向新的 String 对象。StringBuffer 或 StringBuilder 每次都会对 StringBuffer 或 StringBuilder对象本身进行操作,而不是生成新的对象并改变对象引用。
对于三者使用的总结:
-
操作少量的数据: 适用 String
-
单线程做大量字符串拼接操作: 适用 StringBuilder
-
多线程做大量字符串拼接操作: 适用 StringBuffer
字符串拼接用"+" 还是 StringBuilder?


少量、单行拼接 :用+,因为编译器会自动优化为StringBuilder,代码更简洁。
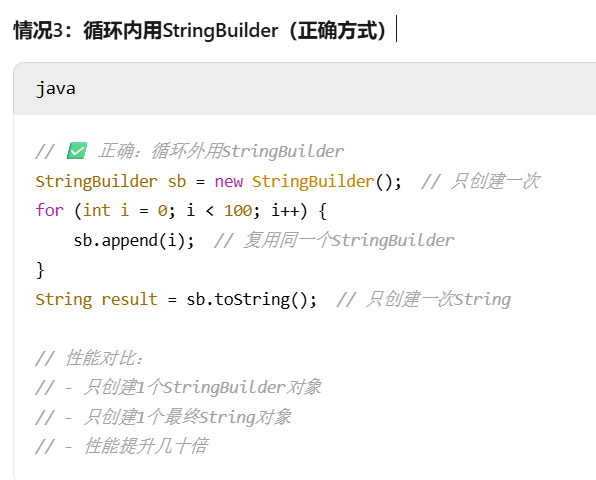
循环内或大量拼接 :必须用StringBuilder,并且要在循环外创建。
字符串常量池的作用了解吗?
字符串常量池 是 JVM 为了提升性能和减少内存消耗针对字符串 (String 类)专门开辟的一块区域,主要目的是为了避免字符串的重复创建
开发中使用的字符串很可能有大量的重复, 字符串常量池就可以将重复的字符串只保存一份, 极大地节省了内存.