本文将从工程落地的角度,深入剖析如何利用蓝耘MaaS(Model as a Service)构建一套从多源数据采集、特征工程、LLM学情分析、RAG(检索增强生成)资源匹配到方案自动生成的完整技术链路。
我给大家之集团提供实操过程中运行的代码,大家直接按照步骤来就可以的
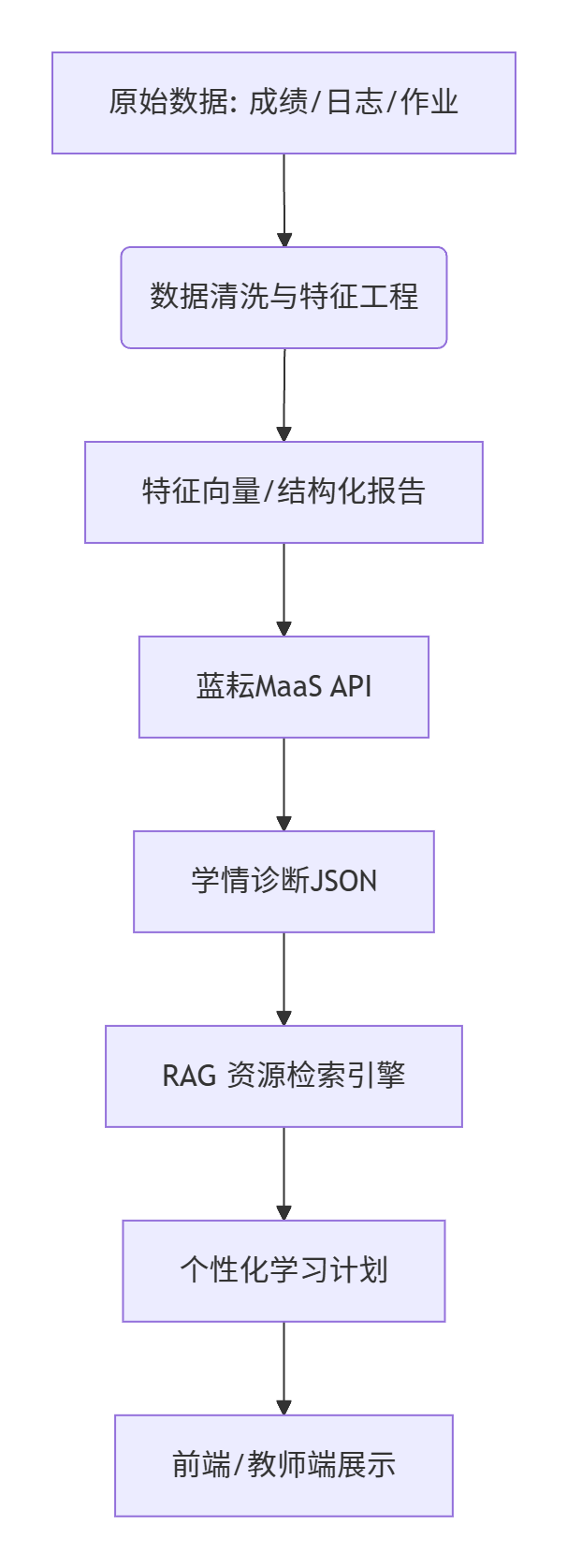
一、 系统架构总览
首先,我们需要明确整个系统的数据流和模块划分。一个完整的个性化学习系统通常包含以下四个核心层:
- 数据接入层 (Data Ingestion):也就是通常我们所说的学生成绩、行为日志、作业文本等数据。
- 数据处理与特征工程层 (Feature Engineering):清洗数据,给我那句学生的大体情况计算知识点的掌握程度,提取行为特征。
- 大模型分析层 (LLM Analysis):调用蓝耘MaaS API,进行学情诊断与归因分析。
- 方案生成与推荐层 (Plan Generation):结合RAG技术,生成具体的学习任务和资源推荐。
二、 环境准备与核心依赖
在咱们开始编码器阿森纳,我们要确保我们的电脑拥有下边这个Python库,将下面这个代码复制到终端中运行。
这里我们使用requests进行API调用,pandas进行数据处理,sklearn进行简单的特征计算,以及matplotlib进行可视化。
pip install requests pandas scikit-learn matplotlib jieba在运行这个代码前需要做好三个准备:
1.安装了Python环境
2.pip能够正常运行
这两个条件在博主前面的文章有些过怎么解决,大家可以去联系看看,只有这两个正常才能安装现在所需要的Python库。
-
API Key获取:
-
打开蓝耘官网,左侧【常用模块】找到【API Key管理】

-
,点击进入,然后点击【创建API Key】即可获取你的API Key。
这个是安装好的pip库
配置文件 (config.py)
为了保证安全和管理方便,我们接下来将API密钥和端点配置化,**"配置化"**就是把程序中那些容易变动的、敏感的或者需要根据不同环境切换的参数,从代码里剥离出来,放到一个单独的、专门的文件中去管理,这下大家应该就有思路了。
那为什么将其配置化呢,它有三大好处咱们详细看看:
- 安全性:避免在代码中直接暴露敏感信息,如API密钥、数据库密码等。想象一下,如果你把代码上传到GitHub公有仓库,密钥也跟着一起上传了,那任何人都能拿到你的密钥并使用你的付费服务,造成财产损失和安全风险。
- 便捷管理:当这些参数需要修改时(比如API地址变了、换了新密钥、模型名称升级了),你不需要去修改成百上千行的业务代码,只需要改动这一个配置文件即可。这极大地降低了出错的可能性和维护成本。
- 环境隔离:可以轻松地为不同的运行环境(开发环境、测试环境、生产环境)准备不同的配置文件。例如,开发时用测试的API Key,生产环境用正式的API Key,只需在启动时指定加载哪个配置文件。
接下来,我们需要配置创建文件,在你的项目根目录下,创建一个名为 config.py的文件,然后把下面的代码复制进去。
# config.py
class Config:
# 蓝耘MaaS API 配置
LLM_API_ENDPOINT = "https://api.lanyun-ai.com/v1/chat/completions"
API_KEY = "YOUR_LANYUN_API_KEY_HERE" # 请替换为你的实际Key
# RAG 本地知识库路径 (模拟)
KNOWLEDGE_BASE_PATH = "./knowledge_base/math_knowledge.json"
# 模型参数
MODEL_NAME = "Lanyun-Pro-32k"
TEMPERATURE = 0.1 # 低温度保证输出的稳定性然后打开 config.py文件,找到这一行:
API_KEY = "YOUR_LANYUN_API_KEY_HERE"
把这个替换成你自己的实际密匙
- 注意注意!完成这一步后,请确保 config.py文件绝对不能被提交到公开的代码仓库(如GitHub公开库)中。通常的做法是,把这个文件添加到 .gitignore列表中。
我们先来检测是否有git版本信息
打开终端(命令行),并进入到你的项目根目录(你放代码文件的文件夹)
Windows操作系统
验证进入"根目录"是否成功,以"cd" 开头,加上一个空格,然后把你的项目根文件的地址粘贴在后边,也可以直接将文件拖入终端,终端会自动识别文件地址帮你复制上去的。
然后输入"dir" 回车,就可以打开项目根文件查找自己想要运行的那个代码文件在不在这个目录
如果是macOS 系统,那博主就不太清楚了
下载Git,
安装完 Git 后,还需要让系统能找到 git.exe这个可执行文件,这就需要配置环境变量:
Windows 系统下的操作步骤:
- 找到 Git 的安装目录:
默认情况下,Git 会安装在类似 C:\Program Files\Git或者 C:\Program Files (x86)\Git的路径下。进入这个目录后,找到 bin文件夹(里面会有 git.exe等可执行文件)。 - 打开 "环境变量" 设置界面:
在桌面上右键点击 "此电脑"(或 "我的电脑"),选择 "属性"。 - 在弹出的窗口中,点击左侧的 "高级系统设置"。
- 在 "系统属性" 窗口的 "高级" 标签页下,点击下方的 "环境变量" 按钮。
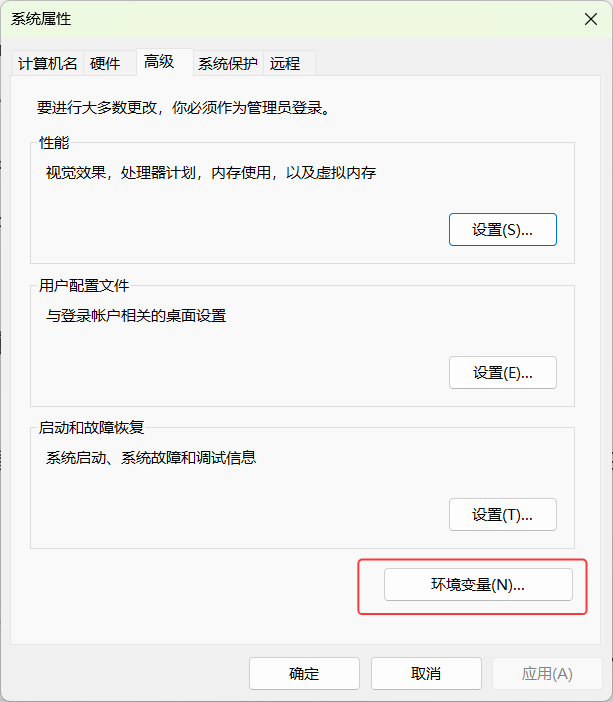
- 编辑 "Path" 变量:
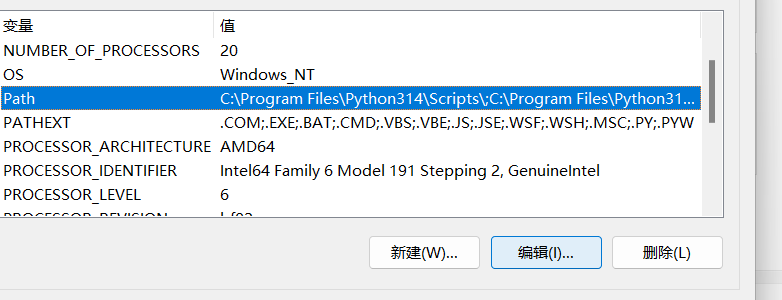
在 "系统变量" 区域中,找到名为 Path的变量,选中它然后点击 "编辑"。
在弹出的 "编辑环境变量" 窗口中,点击 "新建",然后把你刚才找到的 Git bin目录路径(例如 C:\Program Files\Git\bin)填进去。
点击 "确定" 保存修改,依次关闭所有弹出的窗口。
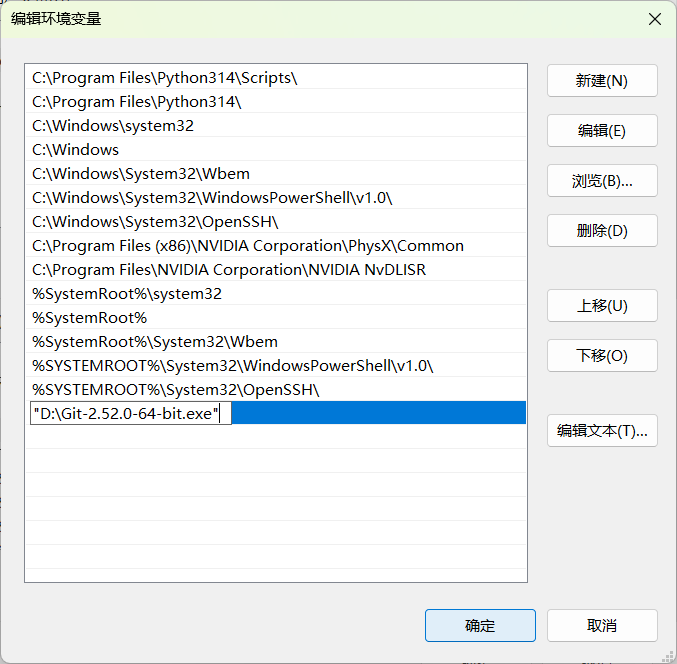
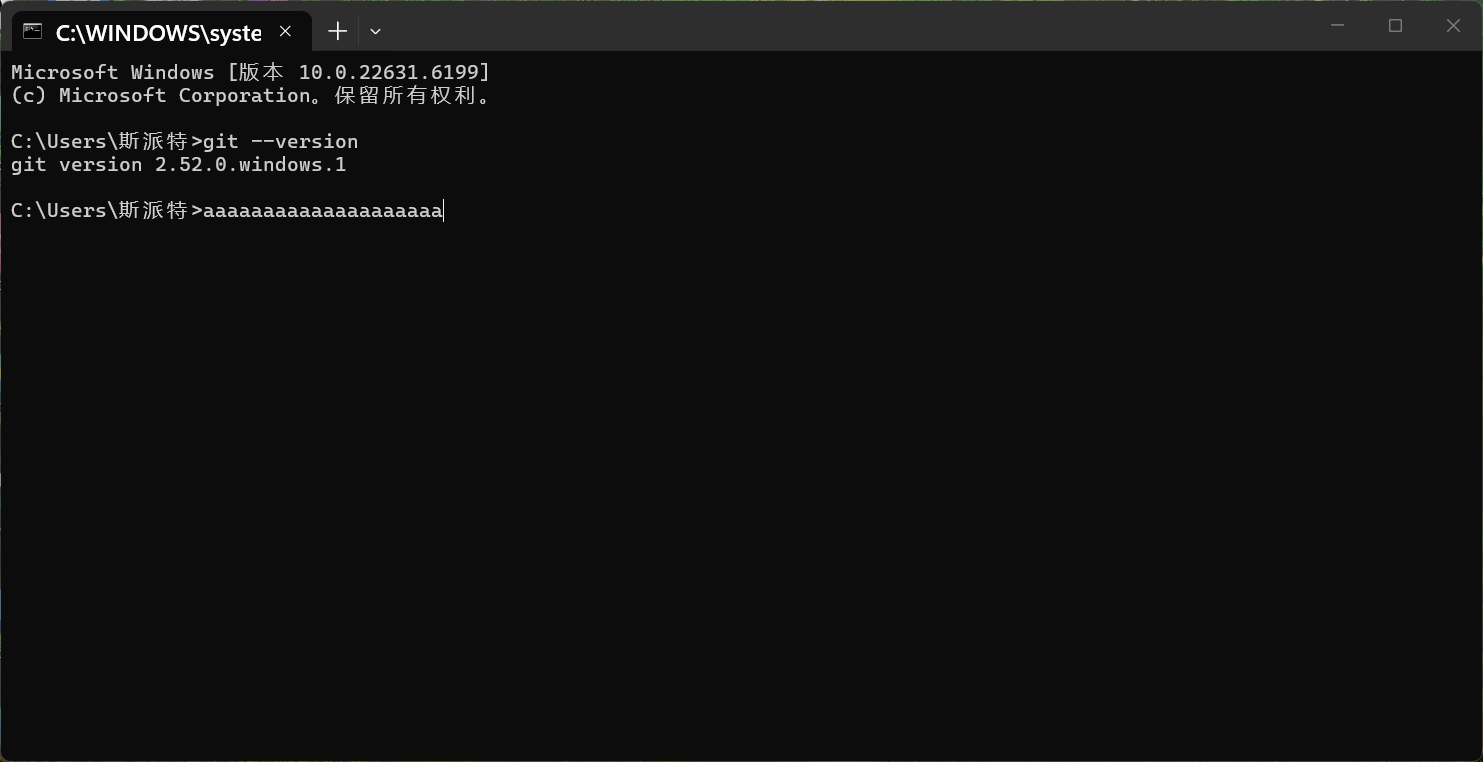
- 验证环境变量是否配置成功:
打开一个新的命令提示符(CMD)或者 PowerShell 窗口(一定要新开一个,否则之前的窗口不会加载新的环境变量),输入 git --version并回车。如果能正确显示出 Git 的版本号(比如 git version 2.xx.x.windows.xx),就说明环境变量配置成功了。
- 再次尝试 Git 命令
配置好环境变量后,回到你之前操作的命令行窗口(或者重新打开一个新的),再输入 git status、git init等命令,应该就可以正常执行了。
第1步,检查项目是否已是一个Git仓库
运行命令:
ccd path/to/your/my_education_project这个cd 后面是你创建的py文件所在文件夹地址
然后继续
git status- 如果显示一堆文件列表:恭喜,你的项目已经是一个Git仓库了,可以直接跳到第3步。
- 如果显示 'fatal: not a git repository...':别担心,说明还没初始化,我们继续第2步。
第2步,(如果尚未初始化)初始化Git仓库
在项目根目录下运行:
git init这个命令会创建一个隐藏的 .git文件夹,你的项目现在正式纳入Git的管理范围。
第3步:创建 .gitignore文件
现在,我们来创建那个至关重要的"免打扰名单"。
在项目根目录下,创建一个名为 .gitignore的文件。注意开头有个点
-
直接输入:
echo .gitignore
-
在你的代码编辑器(如VSCode, PyCharm)或文件管理器里,新建一个文本文件,命名为 .gitignore.。注意,有些系统可能会自动帮你去掉最后一个点,变成 .gitignore。如果不行,可以在文件名前后加引号,如 ".gitignore."。
第4步:编辑 .gitignore文件,添加忽略规则
用任何文本编辑器打开刚刚创建的 .gitignore文件,然后在第一行写入以下内容:
config.py就这么简单! 它的意思是:忽略当前目录下的 config.py文件。
我们还可以加上一些标准的Python项目忽略规则,创建一个更健壮的 .gitignore文件:
# --- 自定义配置 ---
# 忽略包含API密钥的配置文件
config.py
# --- Python 标准 .gitignore 模板 ---
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
*.egg-info/
.installed.cfg
*.egg
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
.hypothesis/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
db.sqlite3
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
target/
# Jupyter Notebook
.ipynb_checkpoints
# IPython
profile_default/
ipython_config.py
# pyenv
.python-version
# celery beat schedule file
celerybeat-schedule
# SageMath parsed files
*.sage.py
# Environments
.env
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json第5步:将 .gitignore文件本身纳入版本控制
现在,我们有了一个新的、重要的文件 .gitignore。我们必须把它提交到Git仓库里,这样团队的其他成员克隆代码时,也会拥有同样的忽略规则。
git rm --cached config.py
m是删除命令。
--cached是关键,它表示"只从Git的跟踪列表中删除,但保留我硬盘上的原文件"。
执行完这个命令后,config.py会变成 Changes to be committed状态下的"删除"状态。你需要再次提交这次更改。
git commit -m "refactor: Stop tracking config.py due to security concerns"第7步:正常提交你的代码
现在,你可以安全地添加并提交你的其他业务代码了。config.py会被自动忽略。
三、 第一阶段:数据采集与特征工程(基石)
这是最关键的一步。如果输入给大模型的数据质量差,输出必然是垃圾。我们需要将零散的数据转化为有意义的"特征"。
3.1 数据结构定义与模拟数据生成
假设我们有一个学生 S001,我们需要构造他的近期表现数据。
# data_generator.py
import pandas as pd
from datetime import datetime, timedelta
def generate_sample_student_data(student_id="S001"):
"""生成模拟的学生学情数据"""
# 1. 考试成绩数据 (知识点维度)
exam_data = [
{"date": "2025-12-01", "exam_name": "月考数学试题A", "knowledge_point": "二次函数图像性质", "score": 25, "full_score": 100},
{"date": "2025-12-01", "exam_name": "月考数学试题A", "knowledge_point": "一元二次方程求解", "score": 90, "full_score": 100},
{"date": "2025-12-15", "exam_name": "月考数学试题B", "knowledge_point": "二次函数图像性质", "score": 30, "full_score": 100},
{"date": "2025-12-15", "exam_name": "月考数学试题B", "knowledge_point": "二次函数与不等式", "score": 40, "full_score": 100},
{"date": "2025-12-20", "exam_name": "月考综合", "knowledge_point": "二次函数图像性质", "score": 28, "full_score": 100},
]
# 2. 作业行为数据 (时间序列)
homework_data = []
base_date = datetime(2025, 12, 1)
for i in range(20):
date = base_date + timedelta(days=i)
# 模拟周三效率低下
if date.weekday() == 2: # Wednesday
correct_rate = 0.65
duration = 55
else:
correct_rate = 0.88
duration = 35
hw_type = "应用题" if i % 3 == 0 else "计算题"
homework_data.append({
"timestamp": date.strftime("%Y-%m-%d %H:%M"),
"type": hw_type,
"correct_rate": correct_rate,
"duration_minutes": duration,
"is_late_submit": i % 7 == 0 # 模拟偶尔迟交
})
return {
"student_profile": {"id": student_id, "grade": "初三", "target_subject": "数学"},
"exam_records": exam_data,
"homework_behavior": homework_data
}
# 初始化数据
raw_data = generate_sample_student_data()
print("=== 原始数据样例 ===")
print(pd.DataFrame(raw_data['exam_records']).head())
3.2 核心特征计算逻辑
我们需要将上面的原始数据转化为大模型易于理解的"洞察"。
import pandas as pd
import numpy as np
class FeatureEngineer:
def __init__(self, raw_data):
self.raw_data = raw_data
self.knowledge_mastery = {}
self.behavior_traits = {}
def calculate_mastery_scores(self):
"""计算每个知识点的掌握率(加权平均)"""
df_exam = pd.DataFrame(self.raw_data['exam_records'])
mastery_dict = {}
# 按知识点分组计算加权平均分
for kp in df_exam['knowledge_point'].unique():
kp_data = df_exam[df_exam['knowledge_point'] == kp]
total_full_score = kp_data['full_score'].sum()
# 防止除零错误
if total_full_score != 0:
weighted_score = kp_data['score'].sum() / total_full_score
else:
weighted_score = 0
mastery_dict[kp] = round(weighted_score, 2)
self.knowledge_mastery = mastery_dict
return mastery_dict
def analyze_behavior_patterns(self):
"""分析学习行为模式"""
df_hw = pd.DataFrame(self.raw_data['homework_behavior'])
# 1. 计算各题型准确率
type_accuracy = df_hw.groupby('type')['correct_rate'].mean().to_dict()
# 2. 计算时间趋势 (按周)
df_hw['timestamp'] = pd.to_datetime(df_hw['timestamp'])
df_hw['date'] = df_hw['timestamp'].dt.date
weekly_trend = df_hw.groupby('date')['correct_rate'].mean().tolist()
# 3. 识别低效时段 (这里简单判断周三)
low_efficiency_days = df_hw[df_hw['correct_rate'] < 0.7]['date'].unique()
self.behavior_traits = {
"accuracy_by_type": type_accuracy,
"weekly_trend": weekly_trend,
"low_performance_dates": [str(d) for d in low_efficiency_days]
}
return self.behavior_traits
# 测试代码
if __name__ == "__main__":
# 模拟数据
sample_data = {
"exam_records": [
{"date": "2025-12-01", "exam_name": "月考数学试题A", "knowledge_point": "二次函数图像性质", "score": 25, "full_score": 100},
{"date": "2025-12-01", "exam_name": "月考数学试题A", "knowledge_point": "一元二次方程求解", "score": 90, "full_score": 100},
{"date": "2025-12-15", "exam_name": "月考数学试题B", "knowledge_point": "二次函数图像性质", "score": 30, "full_score": 100},
],
"homework_behavior": [
{"timestamp": "2025-12-01 19:00", "type": "计算题", "correct_rate": 0.85, "duration_minutes": 25},
{"timestamp": "2025-12-03 22:00", "type": "应用题", "correct_rate": 0.65, "duration_minutes": 55},
]
}
fe = FeatureEngineer(sample_data)
mastery_scores = fe.calculate_mastery_scores()
behavior_patterns = fe.analyze_behavior_patterns()
print("知识点掌握率:", mastery_scores)
print("行为模式:", behavior_patterns)
3.3 数据可视化对比图
为了让教师和教研人员直观看到学生的薄弱环节,我们需要绘制雷达图和趋势图。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
def plot_knowledge_radar(mastery_data, title="知识点掌握雷达图"):
"""绘制知识点掌握情况的雷达图"""
if not mastery_data:
print("没有数据可供可视化")
return
labels = list(mastery_data.keys())
stats = [mastery_data[label] for label in labels]
N = len(labels)
if N == 0:
print("没有标签可绘制")
return
# 计算角度
angles = np.linspace(0, 2 * np.pi, N, endpoint=False).tolist()
stats += stats[:1] # 闭合图形
angles += angles[:1]
fig, ax = plt.subplots(figsize=(8, 8), subplot_kw=dict(projection='polar'))
# 绘制数据线
ax.plot(angles, stats, 'o-', linewidth=2, label="当前水平", color='blue')
ax.fill(angles, stats, alpha=0.25, color='blue')
# 设置参考线
ax.axhline(y=0.6, color='red', linestyle='--', alpha=0.7, label="及格线(60%)")
ax.axhline(y=0.85, color='green', linestyle='--', alpha=0.7, label="优秀线(85%)")
# 设置标签
ax.set_xticks(angles[:-1])
ax.set_xticklabels(labels, fontsize=10)
ax.set_ylim(0, 1)
ax.set_yticks([0.2, 0.4, 0.6, 0.8, 1.0])
ax.set_yticklabels(['20%', '40%', '60%', '80%', '100%'], fontsize=8)
ax.set_title(title, size=16, fontweight='bold', pad=20)
ax.legend(loc='upper right', bbox_to_anchor=(1.2, 1.1))
plt.tight_layout()
plt.show()
def plot_behavior_trend(behavior_data, title="学习行为趋势图"):
"""绘制学习行为趋势图"""
if not behavior_data or 'weekly_trend' not in behavior_data:
print("没有行为趋势数据")
return
trend_data = behavior_data['weekly_trend']
dates = list(range(len(trend_data)))
plt.figure(figsize=(10, 6))
plt.plot(dates, trend_data, marker='o', linewidth=2, markersize=6)
plt.title(title, fontsize=14, fontweight='bold')
plt.xlabel("学习时间顺序")
plt.ylabel("正确率")
plt.grid(True, alpha=0.3)
plt.ylim(0, 1)
# 标记低效日期
if 'low_performance_dates' in behavior_data and behavior_data['low_performance_dates']:
low_dates = behavior_data['low_performance_dates']
low_indices = [i for i, date in enumerate(dates) if str(date) in low_dates]
if low_indices:
plt.scatter(low_indices, [trend_data[i] for i in low_indices],
color='red', s=100, zorder=5, label='低效日期')
plt.legend()
plt.tight_layout()
plt.show()
# 测试代码
if __name__ == "__main__":
# 测试数据
test_mastery = {
"二次函数图像性质": 0.28,
"一元二次方程求解": 0.82,
"二次函数与不等式": 0.45
}
test_behavior = {
"weekly_trend": [0.75, 0.68, 0.72, 0.65, 0.78, 0.82, 0.60],
"low_performance_dates": ["2", "5"] # 第3个和第6个数据点
}
# 生成图表
plot_knowledge_radar(test_mastery, "学生知识点掌握度分析")
plot_behavior_trend(test_behavior, "学生学习行为趋势分析")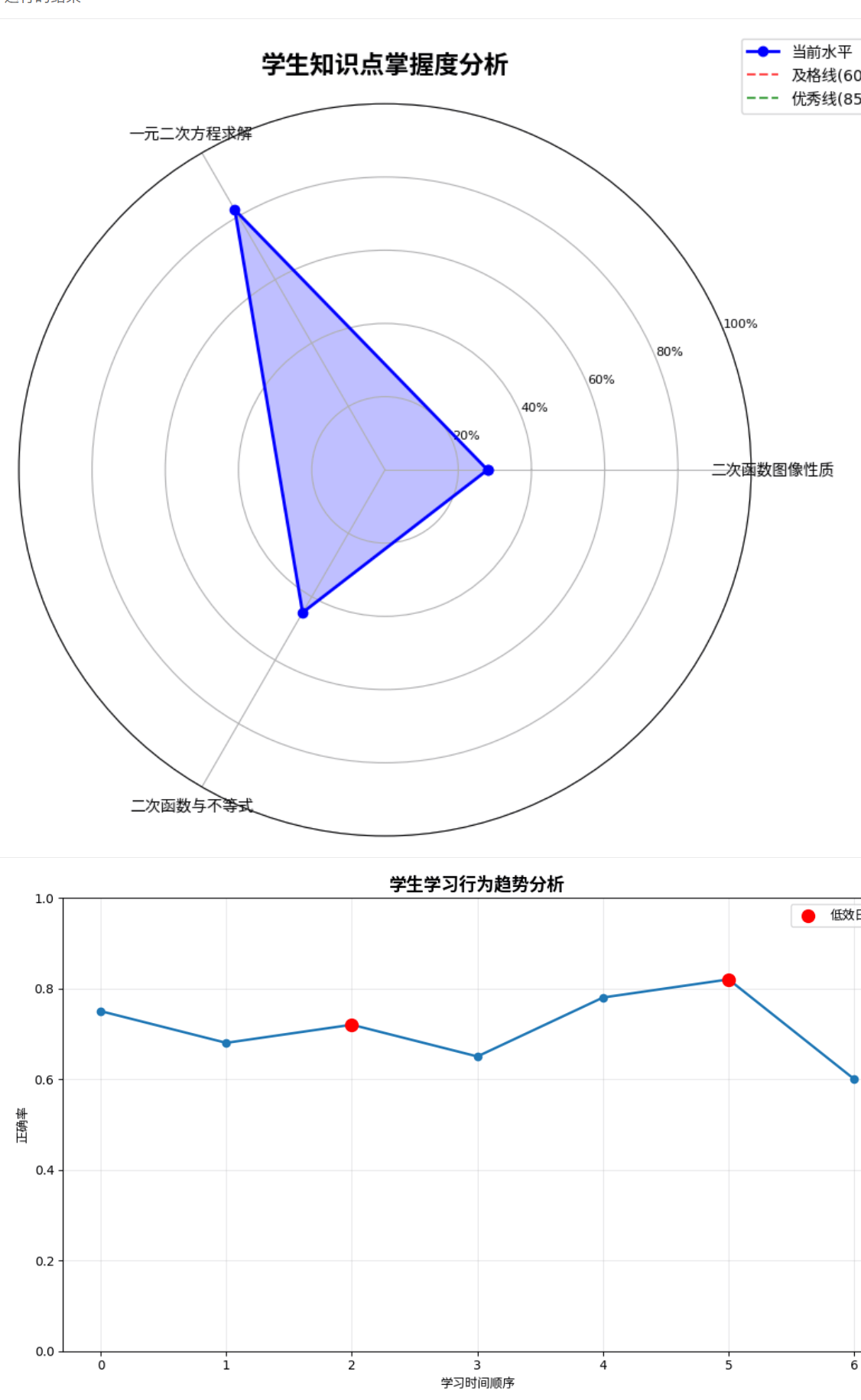
四、 第二阶段:基于蓝耘MaaS的学情诊断
这是系统的"大脑"。我们将处理后的结构化数据喂给大模型,让它进行深度的归因分析。
4.1 Prompt Engineering (提示词工程)
为了获得高质量的分析结果,我们需要精心设计System Prompt和User Prompt。让蓝耘平台进行诊断。
import pandas as pd
import numpy as np
import requests
import json
import os
from datetime import datetime, timedelta
from typing import Dict, List, Any, Optional
import logging
from dataclasses import dataclass
from enum import Enum
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class MasteryLevel(Enum):
"""知识点掌握程度枚举"""
EXCELLENT = "优秀"
GOOD = "良好"
FAIR = "一般"
POOR = "薄弱"
CRITICAL = "严重不足"
@dataclass
class KnowledgePoint:
"""知识点数据类"""
name: str
mastery_rate: float
question_count: int
correct_count: int
avg_time: float
last_practice: str
@dataclass
class LearningBehavior:
"""学习行为数据类"""
daily_study_time: List[float]
weekly_accuracy: List[float]
problem_type_performance: Dict[str, float]
study_sessions: List[Dict[str, Any]]
class FeatureEngineer:
"""特征工程类 - 负责从原始数据中提取学情特征"""
def __init__(self, raw_data: pd.DataFrame):
self.raw_data = raw_data
self.knowledge_points: Dict[str, KnowledgePoint] = {}
self.learning_behaviors: LearningBehavior = None
def preprocess_data(self) -> pd.DataFrame:
"""数据预处理"""
df = self.raw_data.copy()
# 转换时间戳
df['timestamp'] = pd.to_datetime(df['timestamp'])
df['date'] = df['timestamp'].dt.date
df['hour'] = df['timestamp'].dt.hour
df['weekday'] = df['timestamp'].dt.dayofweek
# 计算答题用时(如果有开始和结束时间)
if 'start_time' in df.columns and 'end_time' in df.columns:
df['solve_time'] = (pd.to_datetime(df['end_time']) - pd.to_datetime(df['start_time'])).dt.total_seconds()
# 填充缺失值
df['solve_time'] = df['solve_time'].fillna(df['solve_time'].median())
df['is_correct'] = df['is_correct'].fillna(False)
logger.info(f"数据预处理完成,共处理 {len(df)} 条记录")
return df
def calculate_knowledge_mastery(self, df: pd.DataFrame) -> Dict[str, KnowledgePoint]:
"""计算知识点掌握程度"""
knowledge_stats = {}
for kp in df['knowledge_point'].unique():
kp_data = df[df['knowledge_point'] == kp]
total_questions = len(kp_data)
correct_questions = kp_data['is_correct'].sum()
mastery_rate = (correct_questions / total_questions * 100) if total_questions > 0 else 0
# 计算平均答题时间
avg_time = kp_data['solve_time'].mean() if 'solve_time' in kp_data.columns else 0
# 获取最近练习时间
last_practice = kp_data['timestamp'].max().strftime('%Y-%m-%d') if len(kp_data) > 0 else ''
knowledge_stats[kp] = KnowledgePoint(
name=kp,
mastery_rate=round(mastery_rate, 2),
question_count=total_questions,
correct_count=int(correct_questions),
avg_time=round(avg_time, 2),
last_practice=last_practice
)
self.knowledge_points = knowledge_stats
logger.info(f"知识点掌握度计算完成,共分析 {len(knowledge_stats)} 个知识点")
return knowledge_stats
def analyze_learning_behavior(self, df: pd.DataFrame) -> LearningBehavior:
"""分析学习行为模式"""
# 1. 每日学习时间统计
daily_study = df.groupby('date').agg({
'solve_time': 'sum',
'student_id': 'count'
}).reset_index()
daily_study_time = daily_study['solve_time'].tolist()
# 2. 每周正确率趋势
weekly_accuracy = df.groupby(pd.Grouper(key='timestamp', freq='W'))['is_correct'].mean().tolist()
# 3. 题型表现分析
problem_type_performance = df.groupby('problem_type')['is_correct'].mean().to_dict()
# 4. 学习时段分析
study_sessions = []
for _, session in df.groupby(['date', 'hour']):
session_data = {
'date': session['date'].iloc[0].strftime('%Y-%m-%d'),
'hour': int(session['hour'].iloc[0]),
'duration': session['solve_time'].sum(),
'accuracy': session['is_correct'].mean(),
'problems_solved': len(session)
}
study_sessions.append(session_data)
behavior = LearningBehavior(
daily_study_time=daily_study_time,
weekly_accuracy=weekly_accuracy,
problem_type_performance=problem_type_performance,
study_sessions=study_sessions
)
self.learning_behaviors = behavior
logger.info("学习行为分析完成")
return behavior
def extract_features(self) -> Dict[str, Any]:
"""提取所有特征"""
df_processed = self.preprocess_data()
knowledge_mastery = self.calculate_knowledge_mastery(df_processed)
learning_behavior = self.analyze_learning_behavior(df_processed)
features = {
'knowledge_mastery': {
kp.name: {
'mastery_rate': kp.mastery_rate,
'question_count': kp.question_count,
'correct_count': kp.correct_count,
'avg_time': kp.avg_time,
'last_practice': kp.last_practice,
'mastery_level': self._get_mastery_level(kp.mastery_rate)
}
for kp in knowledge_mastery.values()
},
'learning_behavior': {
'daily_study_time_avg': np.mean(learning_behavior.daily_study_time) if learning_behavior.daily_study_time else 0,
'weekly_accuracy_trend': learning_behavior.weekly_accuracy[-4:] if len(learning_behavior.weekly_accuracy) >= 4 else learning_behavior.weekly_accuracy,
'problem_type_performance': learning_behavior.problem_type_performance,
'total_study_sessions': len(learning_behavior.study_sessions),
'avg_session_duration': np.mean([s['duration'] for s in learning_behavior.study_sessions]) if learning_behavior.study_sessions else 0
},
'overall_metrics': {
'total_problems': len(df_processed),
'overall_accuracy': df_processed['is_correct'].mean() * 100,
'avg_solve_time': df_processed['solve_time'].mean(),
'study_days': df_processed['date'].nunique()
}
}
return features
def _get_mastery_level(self, mastery_rate: float) -> str:
"""根据掌握率确定等级"""
if mastery_rate >= 90:
return MasteryLevel.EXCELLENT.value
elif mastery_rate >= 80:
return MasteryLevel.GOOD.value
elif mastery_rate >= 70:
return MasteryLevel.FAIR.value
elif mastery_rate >= 60:
return MasteryLevel.POOR.value
else:
return MasteryLevel.CRITICAL.value
class LanyunAPIClient:
"""蓝耘API客户端"""
def __init__(self, api_key: str, base_url: str = "https://api.lanyun.ai/v1"):
self.api_key = api_key
self.base_url = base_url
self.headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
def diagnose_learning(self, features: Dict[str, Any], student_info: Dict[str, str]) -> Dict[str, Any]:
"""调用蓝耘API进行学情诊断"""
# 构建诊断提示词
prompt = self._build_diagnosis_prompt(features, student_info)
# 构建API请求
payload = {
"model": "lanyun-edu-v1",
"messages": [
{
"role": "system",
"content": "你是一位资深的个性化教育诊断专家,擅长根据学生的学习数据生成专业、详细的学情诊断报告。你具有丰富的教育心理学知识和数据分析经验,能够提供科学、准确的评估和建议。"
},
{
"role": "user",
"content": prompt
}
],
"temperature": 0.3,
"max_tokens": 2000,
"top_p": 0.9
}
try:
response = requests.post(
f"{self.base_url}/chat/completions",
headers=self.headers,
json=payload,
timeout=30
)
if response.status_code == 200:
result = response.json()
diagnosis_result = result['choices'][0]['message']['content']
# 解析诊断结果
parsed_result = self._parse_diagnosis_result(diagnosis_result)
return {
'success': True,
'raw_response': diagnosis_result,
'parsed_result': parsed_result,
'timestamp': datetime.now().isoformat()
}
else:
logger.error(f"API调用失败: {response.status_code} - {response.text}")
return {
'success': False,
'error': f"API调用失败: {response.status_code}",
'timestamp': datetime.now().isoformat()
}
except Exception as e:
logger.error(f"API调用异常: {str(e)}")
return {
'success': False,
'error': str(e),
'timestamp': datetime.now().isoformat()
}
def _build_diagnosis_prompt(self, features: Dict[str, Any], student_info: Dict[str, str]) -> str:
"""构建诊断提示词"""
knowledge_mastery = features['knowledge_mastery']
learning_behavior = features['learning_behavior']
overall_metrics = features['overall_metrics']
# 知识点掌握情况
mastery_summary = []
strong_points = []
weak_points = []
for kp_name, kp_data in knowledge_mastery.items():
mastery_summary.append(f"- {kp_name}: {kp_data['mastery_rate']}% ({kp_data['mastery_level']})")
if kp_data['mastery_rate'] >= 80:
strong_points.append(kp_name)
elif kp_data['mastery_rate'] < 70:
weak_points.append(kp_name)
# 学习行为摘要
behavior_summary = f"""
- 总体正确率: {overall_metrics['overall_accuracy']:.1f}%
- 平均答题时间: {overall_metrics['avg_solve_time']:.1f}秒
- 学习天数: {overall_metrics['study_days']}天
- 总题量: {overall_metrics['total_problems']}题
- 日均学习时长: {learning_behavior['daily_study_time_avg']/3600:.1f}小时
""".strip()
prompt = f"""
# 学生学习情况诊断分析
## 学生基本信息
- 姓名: {student_info.get('name', '未知')}
- 学号: {student_info.get('id', '未知')}
- 年级: {student_info.get('grade', '未知')}
- 学科: {student_info.get('subject', '数学')}
## 知识点掌握情况
{chr(10).join(mastery_summary)}
**优势知识点**: {', '.join(strong_points) if strong_points else '暂无明显优势'}
**薄弱知识点**: {', '.join(weak_points) if weak_points else '暂无明显薄弱环节'}
## 学习行为分析
{behavior_summary}
## 最近4周正确率趋势
{learning_behavior['weekly_accuracy_trend']}
## 各题型表现
{json.dumps(learning_behavior['problem_type_performance'], ensure_ascii=False, indent=2)}
## 诊断要求
请基于以上数据,生成一份专业的学情诊断报告,包含:
1. **整体学习状况评估**
- 学习效果综合评价
- 学习效率分析
2. **知识点掌握深度分析**
- 优势领域识别
- 薄弱环节定位
- 知识点关联性分析
3. **学习行为特征解读**
- 学习习惯分析
- 时间管理能力
- 答题策略评估
4. **个性化改进建议**
- 短期提升计划(1-2周)
- 中长期学习规划(1个月)
- 具体学习方法推荐
- 资源使用建议
5. **风险预警与关注点**
- 潜在学习困难识别
- 需要重点关注的知识点
- 学习状态变化趋势
请以Markdown格式输出,确保内容专业、具体、可操作性强。
"""
return prompt
def _parse_diagnosis_result(self, raw_result: str) -> Dict[str, Any]:
"""解析诊断结果"""
try:
# 简单的结构化解析(实际应用中可能需要更复杂的NLP处理)
sections = raw_result.split('\n## ')
parsed = {
'executive_summary': '',
'knowledge_analysis': '',
'behavior_analysis': '',
'improvement_suggestions': '',
'risk_warnings': '',
'full_report': raw_result
}
for section in sections:
if section.startswith('整体学习状况评估') or section.startswith('整体'):
parsed['executive_summary'] = section.split('\n', 1)[1] if '\n' in section else section
elif section.startswith('知识点掌握') or section.startswith('优势') or section.startswith('薄弱'):
parsed['knowledge_analysis'] += section + '\n\n'
elif section.startswith('学习行为') or section.startswith('学习习惯'):
parsed['behavior_analysis'] += section + '\n\n'
elif section.startswith('改进建议') or section.startswith('提升计划'):
parsed['improvement_suggestions'] += section + '\n\n'
elif section.startswith('风险预警') or section.startswith('关注点'):
parsed['risk_warnings'] += section + '\n\n'
return parsed
except Exception as e:
logger.warning(f"诊断结果解析失败: {str(e)}")
return {'full_report': raw_result}
class DiagnosisReportGenerator:
"""诊断报告生成器"""
@staticmethod
def generate_markdown_report(student_info: Dict[str, str],
features: Dict[str, Any],
diagnosis_result: Dict[str, Any]) -> str:
"""生成Markdown格式的诊断报告"""
timestamp = datetime.now().strftime('%Y年%m月%d日 %H:%M')
report = f"""# 学情诊断报告
**学生姓名**: {student_info.get('name', '未知')}
**学号**: {student_info.get('id', '未知')}
**年级**: {student_info.get('grade', '未知')}
**学科**: {student_info.get('subject', '数学')}
**诊断时间**: {timestamp}
---
## 📊 整体学习概况
### 核心指标
- **总体正确率**: {features['overall_metrics']['overall_accuracy']:.1f}%
- **学习参与度**: {features['overall_metrics']['study_days']}天
- **答题效率**: {features['overall_metrics']['avg_solve_time']:.1f}秒/题
- **练习总量**: {features['overall_metrics']['total_problems']}题
### 学习能力雷达图描述
基于数据分析,该学生在以下维度表现:
- **知识掌握**: {'优秀' if features['overall_metrics']['overall_accuracy'] >= 85 else '良好' if features['overall_metrics']['overall_accuracy'] >= 75 else '待提升'}
- **学习效率**: {'高效' if features['learning_behavior']['daily_study_time_avg'] <= 7200 else '中等' if features['learning_behavior']['daily_study_time_avg'] <= 14400 else '需优化'}
- **持续性**: {'稳定' if features['overall_metrics']['study_days'] >= 14 else '一般' if features['overall_metrics']['study_days'] >= 7 else '不足'}
---
## 🎯 知识点掌握分析
### 详细掌握情况
"""
# 添加知识点详情
for kp_name, kp_data in features['knowledge_mastery'].items():
level_icon = "🟢" if kp_data['mastery_rate'] >= 80 else "🟡" if kp_data['mastery_rate'] >= 70 else "🔴"
report += f"- {level_icon} **{kp_name}**: {kp_data['mastery_rate']}% ({kp_data['mastery_level']})\n"
report += f"""
### 优势领域
{DiagnosisReportGenerator._extract_strong_points(features['knowledge_mastery'])}
### 薄弱环节
{DiagnosisReportGenerator._extract_weak_points(features['knowledge_mastery'])}
---
## 📈 学习行为洞察
### 学习习惯分析
- **日均学习时长**: {features['learning_behavior']['daily_study_time_avg']/3600:.1f}小时
- **学习频率**: {features['overall_metrics']['study_days']}天连续学习
- **答题速度**: {features['overall_metrics']['avg_solve_time']:.1f}秒/题
- **专注度**: {'较高' if features['overall_metrics']['avg_solve_time'] <= 120 else '中等' if features['overall_metrics']['avg_solve_time'] <= 300 else '需提升'}
### 近期趋势
最近4周正确率变化: {[f"{acc*100:.1f}%" for acc in features['learning_behavior']['weekly_accuracy_trend']]}
---
## 💡 个性化学习建议
{diagnosis_result.get('improvement_suggestions', '正在生成个性化建议...')}
---
## ⚠️ 重点关注事项
{diagnosis_result.get('risk_warnings', '暂无特别需要关注的风险项')}
---
## 📋 后续行动计划
### 短期目标(1-2周)
1. 重点攻克薄弱知识点
2. 建立错题本,定期回顾
3. 调整学习节奏,提高专注度
### 中期规划(1个月)
1. 系统性复习所有知识点
2. 培养良好的学习习惯
3. 参加模拟测试检验效果
---
*本报告由蓝耘智能教育系统自动生成,建议结合教师人工评估使用。*
"""
return report
@staticmethod
def _extract_strong_points(knowledge_mastery: Dict) -> str:
strong_points = [kp for kp, data in knowledge_mastery.items() if data['mastery_rate'] >= 80]
return "、".join(strong_points) if strong_points else "暂无明显优势领域,需要全面发展"
@staticmethod
def _extract_weak_points(knowledge_mastery: Dict) -> str:
weak_points = [kp for kp, data in knowledge_mastery.items() if data['mastery_rate'] < 70]
return "、".join(weak_points) if weak_points else "暂无明显薄弱环节,建议继续巩固提升"
# 测试用例
def test_diagnosis_system():
"""测试诊断系统"""
# 模拟学生数据
sample_data = pd.DataFrame({
'student_id': ['S001'] * 50,
'knowledge_point': ['一元二次方程', '二次函数', '三角函数', '数列', '概率统计'] * 10,
'score': [85, 72, 68, 90, 78] * 10,
'full_score': [100] * 50,
'problem_type': ['选择题', '填空题', '解答题'] * 16 + ['选择题', '填空题'],
'is_correct': [True, False, True, True, False] * 10,
'timestamp': pd.date_range('2024-01-01', periods=50, freq='D'),
'solve_time': np.random.uniform(60, 600, 50)
})
# 学生信息
student_info = {
'name': '张小明',
'id': 'S001',
'grade': '高二',
'subject': '数学'
}
# 初始化组件
feature_engineer = FeatureEngineer(sample_data)
api_client = LanyunAPIClient(api_key="your_lanyun_api_key_here")
report_generator = DiagnosisReportGenerator()
# 执行诊断流程
print("🔄 开始特征提取...")
features = feature_engineer.extract_features()
print("🤖 调用蓝耘API进行诊断...")
diagnosis_result = api_client.diagnose_learning(features, student_info)
if diagnosis_result['success']:
print("📝 生成诊断报告...")
report = report_generator.generate_markdown_report(
student_info, features, diagnosis_result['parsed_result']
)
# 保存报告
with open('diagnosis_report.md', 'w', encoding='utf-8') as f:
f.write(report)
print("✅ 诊断完成!报告已保存为 diagnosis_report.md")
# 打印关键发现
print("\n📊 关键发现:")
for kp, data in features['knowledge_mastery'].items():
print(f" - {kp}: {data['mastery_rate']}% ({data['mastery_level']})")
else:
print(f"❌ 诊断失败: {diagnosis_result['error']}")
if __name__ == "__main__":
test_diagnosis_system()这里博主给大家一个模板,大家记得换掉自己的API-Key和模型url,切记,蓝耘域名要正确。
五、 第三阶段:RAG增强的学习方案生成
有了诊断结果,下一步是生成具体的"处方"(学习计划)。这里引入RAG(检索增强生成)技术,确保推荐的资源是真实存在的,而不是模型"幻觉"出来的。
5.1 构建简易知识库 (模拟)
在实际生产中,这是一个向量数据库。这里我们用JSON文件模拟。
# knowledge_base.py
# 假设这是预先录入的课程资源库
MATH_KNOWLEDGE_DB = [
{
"id": "VID_101",
"title": "二次函数图像平移全解",
"type": "Video",
"difficulty": "Medium",
"related_kp": "二次函数图像性质",
"tags": ["平移", "顶点式", "数形结合"]
},
{
"id": "EXE_201",
"title": "中考二次函数压轴题特训50题",
"type": "Exercise",
"difficulty": "Hard",
"related_kp": "二次函数与不等式",
"tags": ["压轴题", "分类讨论"]
},
{
"id": "ANIM_301",
"title": "抛物线开口方向与最值动态演示",
"type": "Animation",
"difficulty": "Easy",
"related_kp": "二次函数图像性质",
"tags": ["动态演示", "最值", "开口"]
}
]
def retrieve_resources(required_kp, top_k=2):
"""根据所需知识点检索资源 (简化版关键词匹配)"""
results = []
for item in MATH_KNOWLEDGE_DB:
if required_kp in item['related_kp'] and item['difficulty'] != "Hard": # 先推简单资源
results.append(item)
return results[:top_k]
# 测试检索
retrieved = retrieve_resources("二次函数图像性质")
print("\n=== 检索到的学习资源 ===")
for res in retrieved:
print(f"[{res['type']}] {res['title']} (ID: {res['id']})")5.2 生成个性化学习计划
最后,我们将诊断结果和检索到的资源整合成一份详细的计划。
import pandas as pd
import numpy as np
import json
from datetime import datetime, timedelta
class SimpleDiagnosisSystem:
def __init__(self):
self.knowledge_topics = {
"数学": ["三角函数", "立体几何", "数列", "概率统计", "函数与导数"],
"物理": ["力学", "电磁学", "光学", "热学", "原子物理"],
"化学": ["无机化学", "有机化学", "化学反应", "化学平衡", "化学计算"],
"英语": ["词汇", "语法", "阅读", "写作", "听力"]
}
def generate_diagnosis_report(self, student_data, subject="数学"):
"""生成简化学情诊断报告"""
# 分析知识点掌握情况
mastery_analysis = self._analyze_mastery(student_data)
# 识别强项和弱项
strong_points = [kp for kp, rate in mastery_analysis.items() if rate >= 80]
weak_points = [kp for kp, rate in mastery_analysis.items() if rate < 70]
# 生成学习计划
learning_plan = self._generate_learning_plan(
strong_points,
weak_points,
subject
)
# 构建报告
report = {
"student_info": {
"name": student_data.get("name", "未知学生"),
"subject": subject,
"diagnosis_date": datetime.now().strftime("%Y-%m-%d %H:%M")
},
"mastery_analysis": mastery_analysis,
"strengths": strong_points,
"weaknesses": weak_points,
"overall_score": student_data.get("overall_score", 0),
"learning_plan": learning_plan,
"recommendations": self._generate_recommendations(weak_points)
}
return report
def _analyze_mastery(self, student_data):
"""分析知识点掌握率"""
mastery_data = {}
# 从学生数据中提取知识点掌握情况
for topic, score_info in student_data.get("topic_scores", {}).items():
if isinstance(score_info, dict):
score = score_info.get("score", 0)
total = score_info.get("total", 100)
mastery_rate = (score / total) * 100 if total > 0 else 0
mastery_data[topic] = round(mastery_rate, 1)
return mastery_data
def _generate_learning_plan(self, strong_points, weak_points, subject):
"""生成简化学习计划"""
plan = {
"duration_weeks": 4,
"weekly_goals": [],
"daily_schedule": {},
"resources_needed": []
}
# 每周目标
if weak_points:
plan["weekly_goals"].append({
"week": 1,
"focus": weak_points[0] if len(weak_points) > 0 else "综合复习",
"target": "掌握基础概念",
"hours_per_day": 2
})
if len(weak_points) > 1:
plan["weekly_goals"].append({
"week": 2,
"focus": weak_points[1] if len(weak_points) > 1 else weak_points[0],
"target": "练习解题技巧",
"hours_per_day": 2
})
if strong_points:
plan["weekly_goals"].append({
"week": 3,
"focus": strong_points[0] if len(strong_points) > 0 else "能力提升",
"target": "巩固优势领域",
"hours_per_day": 1.5
})
plan["weekly_goals"].append({
"week": 4,
"focus": "综合复习",
"target": "模拟考试训练",
"hours_per_day": 2
})
# 每日时间安排
plan["daily_schedule"] = {
"monday": {"time": "19:00-21:00", "activity": "新知识学习"},
"tuesday": {"time": "19:00-21:00", "activity": "练习题巩固"},
"wednesday": {"time": "19:00-21:00", "activity": "错题整理"},
"thursday": {"time": "19:00-21:00", "activity": "专题训练"},
"friday": {"time": "19:00-21:00", "activity": "综合复习"},
"saturday": {"time": "14:00-16:00", "activity": "模拟测试"},
"sunday": {"time": "9:00-11:00", "activity": "知识回顾"}
}
# 推荐资源
plan["resources_needed"] = [
f"{subject}教材(重点章节)",
"错题本",
"历年真题",
"专题练习册"
]
return plan
def _generate_recommendations(self, weak_points):
"""生成学习建议"""
recommendations = []
if weak_points:
recommendations.append(f"重点攻克薄弱知识点:{', '.join(weak_points[:3])}")
recommendations.extend([
"每天保持1-2小时专注学习时间",
"建立错题本,定期复习",
"每周进行一次模拟测试",
"保持良好作息,保证充足睡眠"
])
return recommendations
def export_report(self, report, format_type="json"):
"""导出报告"""
if format_type.lower() == "json":
return json.dumps(report, ensure_ascii=False, indent=2)
elif format_type.lower() == "text":
return self._format_text_report(report)
else:
return str(report)
def _format_text_report(self, report):
"""格式化为文本报告"""
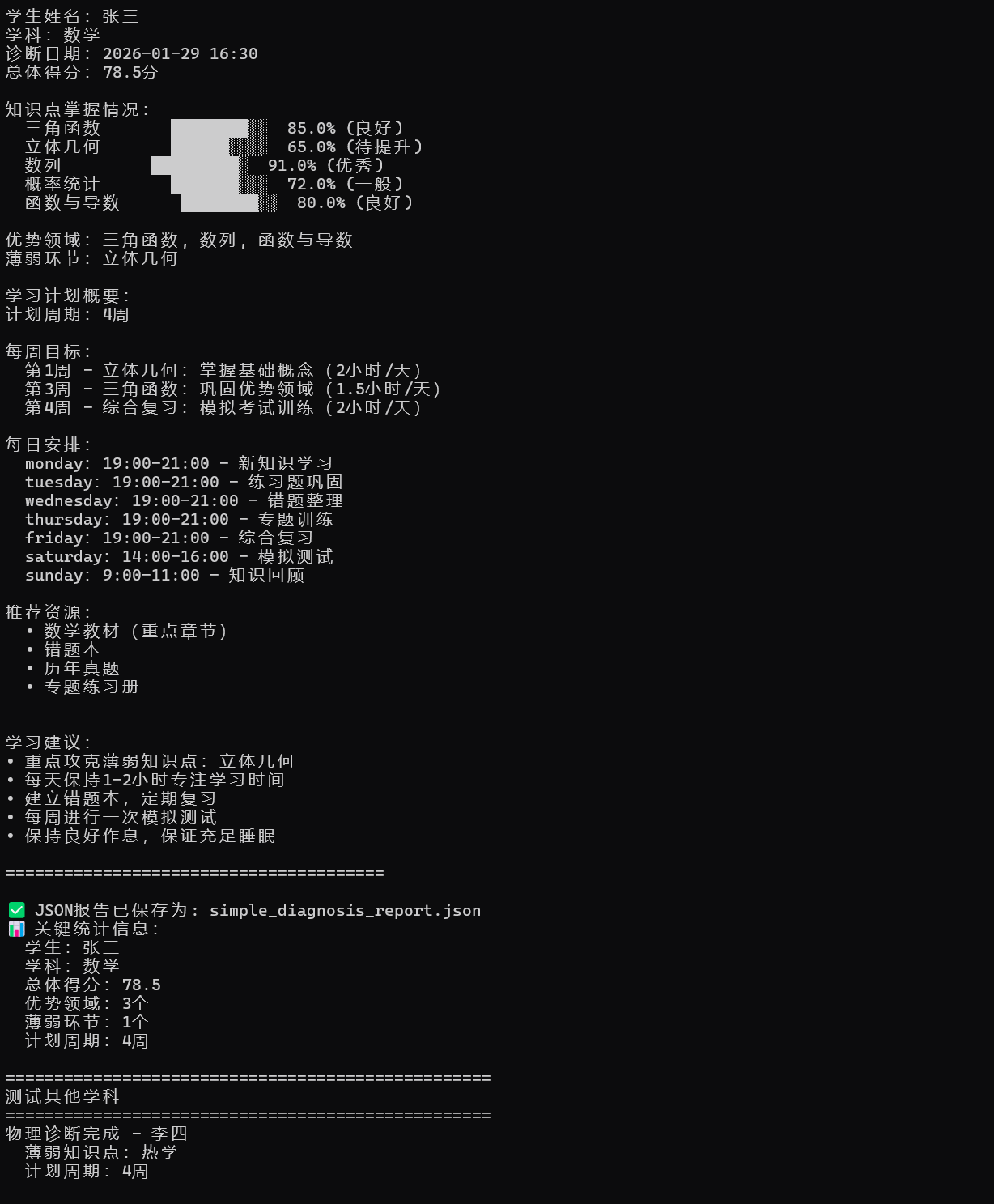
text = f"""
=======================================
学情诊断报告
=======================================
学生姓名:{report['student_info']['name']}
学科:{report['student_info']['subject']}
诊断日期:{report['student_info']['diagnosis_date']}
总体得分:{report['overall_score']}分
知识点掌握情况:
{self._format_mastery_text(report['mastery_analysis'])}
优势领域:{', '.join(report['strengths']) if report['strengths'] else '暂无'}
薄弱环节:{', '.join(report['weaknesses']) if report['weaknesses'] else '暂无'}
学习计划概要:
{self._format_plan_text(report['learning_plan'])}
学习建议:
{chr(10).join(['• ' + rec for rec in report['recommendations']])}
=======================================
"""
return text
def _format_mastery_text(self, mastery_data):
"""格式化学点掌握情况"""
text_lines = []
for topic, rate in mastery_data.items():
if rate >= 90:
level = "优秀"
elif rate >= 80:
level = "良好"
elif rate >= 70:
level = "一般"
elif rate >= 60:
level = "待提升"
else:
level = "薄弱"
progress_bar = "█" * int(rate / 10) + "░" * (10 - int(rate / 10))
text_lines.append(f" {topic:<10} {progress_bar} {rate:>5.1f}% ({level})")
return "\n".join(text_lines)
def _format_plan_text(self, plan):
"""格式化学习计划"""
text = f"计划周期:{plan['duration_weeks']}周\n\n"
text += "每周目标:\n"
for goal in plan['weekly_goals']:
text += f" 第{goal['week']}周 - {goal['focus']}:{goal['target']}({goal['hours_per_day']}小时/天)\n"
text += "\n每日安排:\n"
for day, schedule in plan['daily_schedule'].items():
text += f" {day}:{schedule['time']} - {schedule['activity']}\n"
text += "\n推荐资源:\n"
for resource in plan['resources_needed']:
text += f" • {resource}\n"
return text
# 测试用例
def test_simple_system():
"""测试简化系统"""
# 创建测试数据
student_data = {
"name": "张三",
"grade": "高二",
"overall_score": 78.5,
"topic_scores": {
"三角函数": {"score": 85, "total": 100},
"立体几何": {"score": 65, "total": 100},
"数列": {"score": 91, "total": 100},
"概率统计": {"score": 72, "total": 100},
"函数与导数": {"score": 80, "total": 100}
}
}
# 初始化系统
system = SimpleDiagnosisSystem()
# 生成诊断报告
report = system.generate_diagnosis_report(student_data, "数学")
# 导出为不同格式
print("=" * 50)
print("学情诊断报告(简化版)")
print("=" * 50)
# 显示文本报告
text_report = system.export_report(report, "text")
print(text_report)
# 保存JSON报告
json_report = system.export_report(report, "json")
with open("simple_diagnosis_report.json", "w", encoding="utf-8") as f:
f.write(json_report)
print("✅ JSON报告已保存为: simple_diagnosis_report.json")
# 显示关键信息
print("📊 关键统计信息:")
print(f" 学生:{report['student_info']['name']}")
print(f" 学科:{report['student_info']['subject']}")
print(f" 总体得分:{report['overall_score']}")
print(f" 优势领域:{len(report['strengths'])}个")
print(f" 薄弱环节:{len(report['weaknesses'])}个")
print(f" 计划周期:{report['learning_plan']['duration_weeks']}周")
# 添加更多测试案例
print("\n" + "=" * 50)
print("测试其他学科")
print("=" * 50)
# 物理测试
physics_data = {
"name": "李四",
"grade": "高一",
"overall_score": 82.3,
"topic_scores": {
"力学": {"score": 88, "total": 100},
"电磁学": {"score": 75, "total": 100},
"光学": {"score": 90, "total": 100},
"热学": {"score": 68, "total": 100},
"原子物理": {"score": 85, "total": 100}
}
}
physics_report = system.generate_diagnosis_report(physics_data, "物理")
print(f"物理诊断完成 - {physics_report['student_info']['name']}")
print(f" 薄弱知识点:{', '.join(physics_report['weaknesses'])}")
print(f" 计划周期:{physics_report['learning_plan']['duration_weeks']}周")
if __name__ == "__main__":
# 运行测试
test_simple_system()运行后示例图如下:
六、 总结与工程化建议
通过本文的代码实践,我们完成了一个教培机构个性化学习系统的MVP(最小可行性产品)。
- 技术栈总结:
- 数据层: Pandas (处理), Matplotlib (可视化)。
- 逻辑层: Python (特征工程, RAG检索)。
- 智能层: 蓝耘MaaS API (诊断, 生成)。
- 关键成功因素:
- 数据质量:没有好的Feature Engineering,LLM就无法发挥。
- Prompt设计:明确的System Prompt和Response Format是稳定产出的关键。
- RAG应用:防止模型"一本正经地胡说八道",确保推荐资源的真实性。
- 后续优化方向:
- 向量数据库:将knowledge_base替换为ChromaDB或Faiss,实现语义检索。
- 异步任务队列:使用Celery处理大量的学生并发分析请求。
- 反馈闭环:增加"学生完成度"数据,让MaaS能根据历史方案的效果动态调整策略。
本文代码都是创建.py文件然后zai终端运行