
系列文章目录
C语言常见概念
C 语言:操作符详解------驾驭比特的艺术
扫雷游戏的实现初步
数据结构---顺序表的奥秘(上)
C语言数据结构----贪吃蛇(上)---开始前的知识储备
文章目录
- 系列文章目录
- 前言
- 一.完善顺序表函数代码
-
- 1.顺序表的初始化
- 2.顺序表的销毁
- 3.检查顺序表的容量
- 4.尾插和头插
-
- [4.1 尾插](#4.1 尾插)
- [4.2 头插](#4.2 头插)
- 5.尾删和头删
-
- [5.1 尾删](#5.1 尾删)
- [5.2 头删](#5.2 头删)
- [6. 顺序表的打印](#6. 顺序表的打印)
- 二.通讯录的实现
-
- 1.顺序表与通讯录的关系
- 2.通讯录所需要的功能
- [3. 代码实现](#3. 代码实现)
-
- [3.1 通讯录的初始化和销毁](#3.1 通讯录的初始化和销毁)
- [3.2 通讯录添加数据](#3.2 通讯录添加数据)
- [3.3 通讯录查找功能](#3.3 通讯录查找功能)
-
- [3.3.1 FindByName函数实现](#3.3.1 FindByName函数实现)
- [3.4 通讯录删除数据](#3.4 通讯录删除数据)
- [3.5 展示通讯录数据](#3.5 展示通讯录数据)
- [3.6 修改通讯录的数据](#3.6 修改通讯录的数据)
- [3.7 通讯录数据存储](#3.7 通讯录数据存储)
- 4.主函数
- 总结
前言
继续上篇博客数据结构---顺序表的奥秘(上)的内容往下之前,让我们先简短复习一下顺序表的基础概念。
顺序表的核心思想
顺序表的本质 :用一段连续的内存空间 ,按照线性顺序存储数据元素。
想象一下超市的储物柜:
- 每个格子有固定编号(索引)
- 格子大小相同(相同数据类型)
- 格子一个挨着一个(连续存储)
- 按编号快速找到物品(随机访问)
"程序 = 数据结构 + 算法" ------ Niklaus Wirth
理解数据结构,就是理解如何用计算机的方式组织世界。
一.完善顺序表函数代码
1.顺序表的初始化
c
void SLInit(SL* ps)
{
ps->arr = NULL;
ps->size = 0;// 顺序表当前存储量
ps->capacity = 0;//顺序表容量
}顺序表初始化为空,后续通过需求增删查改。
2.顺序表的销毁
c
void SLDestroy(SL* ps)
{
if (ps->arr)
{
free(ps->arr);
}
ps->arr = NULL;
ps->size = 0;
ps->capacity = 0;
}首先free释放出空间,避免内存泄漏。随后再将顺序表还原成最初的样子。
3.检查顺序表的容量
c
void SLCheckCapacity(SL* ps)
{
if (ps->size == ps->capacity)
{
int newCapacity = (ps->capacity == 0 ? 4 : ps->capacity * 2);//新容量
SLDataType* tmp = (SLDataType*)realloc(ps->arr, newCapacity * sizeof(SLDataType));
if (tmp == NULL)
{
printf("realloc fail!\n");
exit(1);//退出程序
}
ps->arr = tmp;
ps->capacity = newCapacity;
}
}检查顺序表容量是否足够,如果不够对其进行扩容操作。通过三目操作符,避免了capacity容量直接乘2,而有可能capacity原本值为0,而导致0乘2依旧为0的无效操作。直接翻倍扩容是扩容的惯例,避免扩太大导致浪费,太小导致不够用。
4.尾插和头插
4.1 尾插
c
void SLPushBack(SL* ps, SLDataType x)
{
//ps->arr[ps->size] = x;
//ps->size++;
//if(ps==NULL)
//{
// return;
//}//容错处理
assert(ps);//断言 等价于上面的容错处理
SLCheckCapacity(ps);
ps->arr[ps->size++] = x;
}照常需要对ps是否为空指针进行判断,再进行判断容量是否足够进行尾插。
4.2 头插
c
void SLPushFront(SL* ps, SLDataType x)
{
assert(ps);
SLCheckCapacity(ps);
//数据搬移
int i;
for (i = ps->size; i > 0; --i)
{
ps->arr[i] = ps->arr[i - 1];
}
ps->arr[0] = x;
ps->size++;
}头插需要进行数据搬移,将整体数据向后移动一位,腾出位置来插入新数据。
5.尾删和头删
5.1 尾删
c
void SLPopBack(SL* ps)
{
assert(ps);
assert(ps->size);//保证顺序表不为空
ps->size--;
}尾删的代码,及其简洁,只用首先保证顺序表不为空,随后直接让size自减即可,无需对原本储存在最后一位的数据进行处理,原因是此时原本的数据无论是任何数字都已经失去了意义,都不存在在顺序表中,都其没有任何影响。
5.2 头删
c
//头删
void SLPopFront(SL* ps)
{
assert(ps);
assert(ps->size);//保证顺序表不为空
int i;
//数据搬移
for (i = 0; i < ps->size - 1; ++i)
{
ps->arr[i] = ps->arr[i + 1];
}
ps->size--;
}头删的代码相较于尾删的代码只是多出了将所有数据整体向后搬迁一位。
6. 顺序表的打印
c
void SLPrint(SL s)
{
int i;
for (i = 0; i < s.size; ++i)
{
printf("%d ", s.arr[i]);
}
printf("\n");
}该函数只是普通的利用for循环,将其一个一个遍历打印在屏幕上。
二.通讯录的实现
1.顺序表与通讯录的关系

c
//要用到顺序表相关的方法,对通讯录的操作实际就是对顺序表进行操作
//给顺序表改个名字,叫做通讯录
typedef struct SeqList Contact; //sl
//通讯录相关的方法
//通讯录的初始化
void ContactInit(Contact* con);
//通讯录的销毁
void ContactDesTroy(Contact* con);
//通讯录添加数据
void ContactAdd(Contact* con);
//通讯录删除数据
void ContactDel(Contact* con);
//通讯录的修改
void ContactModify(Contact* con);
//通讯录查找
void ContactFind(Contact* con);
//展示通讯录数据
void ContactShow(Contact* con);2.通讯录所需要的功能
c
#define NAME_MAX 20
#define GENDER_MAX 10
#define TEL_MAX 20
#define ADDR_MAX 100
//定义联系人数据 结构
//姓名 性别 年龄 电话 地址
typedef struct personInfo
{
char name[NAME_MAX];
char gender[GENDER_MAX];
int age;
char tel[TEL_MAX];
char addr[ADDR_MAX];
}peoInfo;作为一个正常使用的通讯录,我们需要
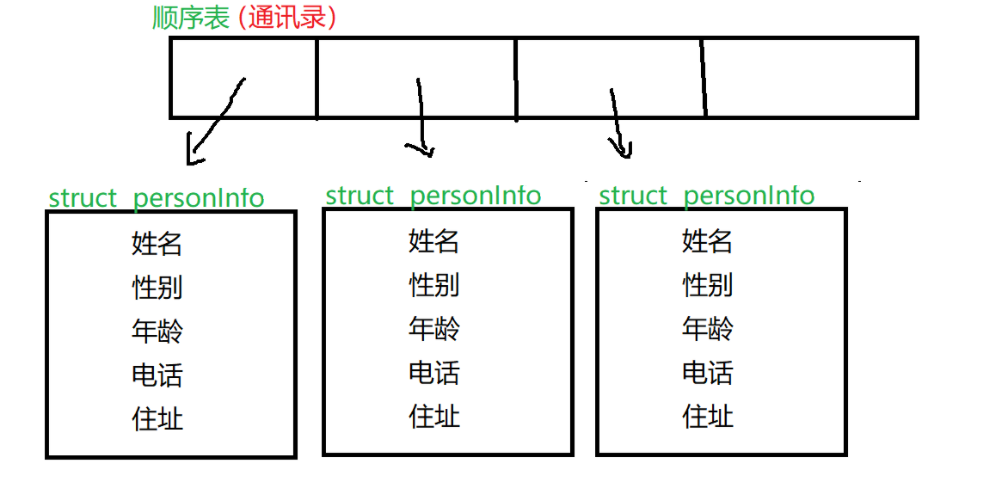
1)⾄少能够存储100个⼈的通讯信息
2)能够保存⽤⼾信息:名字、性别、年龄、电话、地址等
3)增加联系⼈信息
4)删除指定联系⼈
5)查找制定联系⼈
6)修改指定联系⼈
7)显示联系⼈信息
思考
【思考1】⽤静态顺序表和动态顺序表分别如何实现
【思考2】如何保证程序结束后,历史通讯录信息不会丢失
3. 代码实现
3.1 通讯录的初始化和销毁
c
//通讯录的初始化
void ContactInit(Contact* con)//sl
{
//实际上要进行的是顺序表的初始化
//顺序表的初始化已经实现好了
SLInit(con);
}
c
//通讯录的销毁
void ContactDesTroy(Contact* con)
{
SLDestroy(con);
}初始化和销毁都只是将顺序表的相应功能套了一层皮。
3.2 通讯录添加数据
作为通讯录,我们需要输入姓名,性别,年龄,电话以及地址等基础信息才能存入,完善通讯录。
c
//通讯录添加数据
void ContactAdd(Contact* con)
{
//获取用户输入的内容:姓名+性别+年龄+电话+地址
peoInfo info;
printf("请输入要添加的联系人姓名:\n");
scanf("%s", info.name);
printf("请输入要添加的联系人性别:\n");
scanf("%s", info.gender);
printf("请输入要添加的联系人年龄:\n");
scanf("%d", &info.age);
printf("请输入要添加的联系人电话:\n");
scanf("%s", info.tel);
printf("请输入要添加的联系人住址:\n");
scanf("%s", info.addr);
//往通讯录中添加联系人数据
SLPushBack(con, info);
}3.3 通讯录查找功能
我们实现通讯录大部分时候的目的都是为了方便查找信息,找到想找的人,并显现出其所有信息。
c
//通讯录查找
void ContactFind(Contact* con)
{
//11
char name[NAME_MAX];
printf("请输入要查找的联系人姓名\n");
scanf("%s", name);
int find = FindByName(con, name);
if (find < 0)
{
printf("要查找的联系人数据不存在!\n");
return;
}
// 姓名 性别 年龄 电话 地址
// 11 11 11 11 11
printf("%s %s %s %s %s\n", "姓名", "性别", "年龄", "电话", "地址");
printf("%3s %3s %3d %3s %3s\n", //手动调整一下格式
con->arr[find].name,
con->arr[find].gender,
con->arr[find].age,
con->arr[find].tel,
con->arr[find].addr
);
}3.3.1 FindByName函数实现
该函数将纯粹查找功能封存,遍历寻找。
c
int FindByName(Contact* con, char name[])
{
for (int i = 0; i < con->size; i++)
{
if (0 == strcmp(con->arr[i].name, name))
{
//找到了
return i;
}
}
//没有找到
return -1;
}3.4 通讯录删除数据
对通讯录进行删除工作,删去多余存储的信息,以腾出空间。
c
//通讯录删除数据
void ContactDel(Contact* con)
{
//要删除的数据必须要存在,才能执行删除操作
//查找
char name[NAME_MAX];
printf("请输入要删除的联系人姓名:\n");
scanf("%s", name);
int find = FindByName(con, name);
if (find < 0)
{
printf("要删除的联系人数据不存在!\n");
return;
}
//要删除的联系人数据存在--->知道了要删除的联系人数据对应的下标
SLErase(con, find);
printf("删除成功!\n");
}要删除的数据必须要存在,才能执行删除操作,所以先进行判断。
3.5 展示通讯录数据
c
void ContactShow(Contact* con)
{
//表头:姓名 性别 年龄 电话 地址
printf("%s %s %s %s %s\n", "姓名", "性别", "年龄", "电话", "地址");
//遍历通讯录,按照格式打印每个联系人数据
for (int i = 0; i < con->size; i++)
{
printf("%3s %3s %3d %3s %3s\n", //手动调整一下格式
con->arr[i].name,
con->arr[i].gender,
con->arr[i].age,
con->arr[i].tel,
con->arr[i].addr
);
}
}3.6 修改通讯录的数据
对通讯录成员数据进行修改,确保有效,首先判断所要修改的联系人数据是否存在,然后一项一项数据遍历修改。
c
void ContactModify(Contact* con)
{
//要修改的联系人数据存在
char name[NAME_MAX];
printf("请输入要修改的用户姓名:\n");
scanf("%s", name);
int find = FindByName(con, name);
if (find < 0)
{
printf("要修改的联系人数据不存在!\n");
return;
}
//直接修改
printf("请输入新的姓名:\n");
scanf("%s", con->arr[find].name);
printf("请输入新的性别:\n");
scanf("%s", con->arr[find].gender);
printf("请输入新的年龄:\n");
scanf("%d", &con->arr[find].age);
printf("请输入新的电话:\n");
scanf("%s", con->arr[find].tel);
printf("请输入新的住址:\n");
scanf("%s", con->arr[find].addr);
printf("修改成功!\n");
}3.7 通讯录数据存储
额外拓展功能:将通讯录数据写入文件中存储。
需要掌握有关文件操作的函数。
c
void SaveContact(contact* con) {
FILE* pf = fopen("contact.txt", "wb");
if (pf == NULL) {
perror("fopen error!\n");
return;
}
//将通讯录数据写⼊⽂件
for (int i = 0; i < con->size; i++)
{
fwrite(con->a + i, sizeof(PeoInfo), 1, pf);
}
printf("通讯录数据保存成功!\n");
}4.主函数
c
#include"SeqList.h"
#include"contact.h"
void menu() {
//通讯录初始化
contact con;
InitContact(&con);
int op = -1;
do {
printf("********************************\n");
printf("*****1、添加⽤⼾ 2、删除⽤⼾*****\n");
printf("*****3、查找⽤⼾ 4、修改⽤⼾*****\n");
printf("*****5、展⽰⽤⼾ 0、退出 *****\n");
printf("********************************\n");
printf("请选择您的操作:\n");
scanf("%d", &op);
switch (op)
{
case 1:
AddContact(&con);
break;
case 2:
DelContact(&con);
break;
case 3:
FindContact(&con);
break;
case 4:
ModifyContact(&con);
break;
case 5:
ShowContact(&con);
break;
default:
printf("输⼊有误,请重新输⼊\n");
break;
}
} while (op!=0);
//销毁通讯录
DestroyContact(&con);
}通讯录的主函数,展示页面,并通过switch语句达成让用户选择功能进行使用的目的。
总结
首先,课后可以思考一下静态顺序表实现通讯录以及一下问题:
问题与思考
- 中间/头部的插⼊删除,时间复杂度为O(N) 2. 增容需要申请新空间,拷⻉数据,释放旧空间。会有不⼩的消耗。
- 增容⼀般是呈2倍的增⻓,势必会有⼀定的空间浪费。例如当前容量为100,满了以后增容到200,我们再继续插⼊了5个数据,后⾯没有数据插⼊了,那么就浪费了95个数据空间。
思考:如何解决以上问题呢?
通讯录系统的架构设计
系统层次结构
应用层 (通讯录功能)
↓
业务层 (联系人管理)
↓
数据层 (顺序表实现)
↓
存储层 (内存/文件)- 团队协作更方便
从通讯录看顺序表的优缺点
优点
- 随机访问快 -
O(1)时间访问任意联系人 - 内存连续 - 缓存友好,访问效率高
- 实现简单 - 逻辑直观,易于理解和调试
缺点
- 插入/删除效率低 - 中间操作需要移动大量数据
- 容量固定 - 静态分配可能浪费空间或不够用
- 扩容成本高 - 需要重新分配和复制数据
思考与挑战---作者粗糙的思考
挑战1:静态顺序表实现
如果用静态数组实现通讯录:
c
#define MAX_SIZE 100
typedef struct {
peoInfo data[MAX_SIZE];
int size;
} StaticContact;优点 :实现更简单,无需动态内存管理
缺点:容量固定,无法动态调整
挑战2:解决顺序表的固有缺陷
针对文中提到的问题,可能的解决方案:
问题1:中间操作时间复杂度高
解决方案:考虑使用链表结构,插入删除操作时间复杂度为O(1)
问题2:扩容带来的性能损耗
解决方案:
- 预分配策略:根据使用模式预测容量
- 延迟释放:不立即缩小容量,减少频繁重分配
问题3:空间浪费问题
解决方案:
- 按需扩容:使用更智能的扩容因子(如1.5倍)
- 内存池:预先分配大块内存,减少碎片
挑战3:功能扩展建议
- 分组功能 - 将联系人按家庭、朋友、同事分组
- 搜索优化 - 支持模糊搜索、多条件搜索
- 导入导出 - 支持CSV、Excel格式
- 数据加密 - 保护用户隐私
- 多平台同步 - 云存储支持
学习收获总结
通过这个通讯录项目,你不仅学会了:
- 数据结构应用 - 将顺序表用于实际问题解决
- 系统设计 - 从需求分析到功能实现的全过程
- 代码组织 - 合理的文件划分和模块设计
- 问题分析 - 识别并解决实际开发中的问题
更重要的是,你培养了工程化思维------知道如何将理论知识转化为实际可用的软件。
写在最后
数据结构的学习是一个循序渐进的过程。顺序表作为入门,看似简单却包含了数据结构设计的核心思想:在时间与空间之间寻找平衡,在简单与复杂之间做出取舍。
记住,优秀的程序员不是记住所有数据结构的人,而是知道在什么时候选择什么数据结构的人。
编程的真谛:不在于写出多么复杂的代码,而在于用简单的方案解决复杂的问题。
学习之路永无止境,但每一步都算数。继续加油,各位大佬!
下一篇预告:我们将探索链表的奥秘,看看它如何解决顺序表的痛点,并探究其区别。敬请期待!