智慧农业正在从传统的"靠天吃饭"转向"数据驱动"。
现代温室大棚就是一个微型的生态系统,温度、湿度、光照、CO2 浓度等每一个因子都直接影响着作物的生长。
然而,传统的农业物联网系统常常面临**"数据孤岛"**的问题:传感器数据存在时序库,大棚档案存在 MySQL,控制指令又是一套系统。

本文将利用 KWDB 3.1.0 的多模特性,构建一个全周期温室环境监测平台,将环境感知、数据分析与自动控制融为一体。
场景设定 :我们需要监控 3 个现代化温室大棚,分别种植草莓、番茄和黄瓜。
核心挑战:
- 多维感知:需要同时处理温度、湿度、土壤水分、光照强度等多维数据,且数据具有强烈的昼夜周期性。
- 精准控制:需要根据实时数据(如土壤水分过低)毫秒级触发灌溉或通风系统。
- 生长模型:通过历史数据分析作物的生长积温(GDD),指导农事操作。

文章目录
-
- [1. 架构设计](#1. 架构设计)
-
- [1.1 系统架构图](#1.1 系统架构图)
- [2. 建模实战:数字大棚](#2. 建模实战:数字大棚)
-
- [2.1 初始化环境](#2.1 初始化环境)
- [2.2 温室档案表 (Relational Table)](#2.2 温室档案表 (Relational Table))
- [2.3 传感器读数表 (Time-Series Table)](#2.3 传感器读数表 (Time-Series Table))
- [3. 数据模拟:日出日落](#3. 数据模拟:日出日落)
- [4. 业务场景实战](#4. 业务场景实战)
- [5. 避坑指南](#5. 避坑指南)
- 总结
1. 架构设计
1.1 系统架构图
无线
MQTT/HTTP
SQL Query
Trigger
Action
传感器节点 - ZigBee/LoRa
智能网关
KWDB 集群
环境监控大屏
自动控制系统
风机/水泵/补光灯
2. 建模实战:数字大棚
2.1 初始化环境
bash
# 连接数据库
sudo /usr/local/kaiwudb/bin/kwbase sql \
--certs-dir=/etc/kaiwudb/certs \
--host=127.0.0.1:26257
sql
CREATE DATABASE IF NOT EXISTS smart_agri;
USE smart_agri;
2.2 温室档案表 (Relational Table)
存储温室的基础信息。这些数据虽然变动不频繁,但对于指导生产至关重要(例如不同作物对环境的要求不同)。
sql
CREATE TABLE greenhouses (
gh_id VARCHAR(20) PRIMARY KEY, -- 温室编号
crop_type VARCHAR(20), -- 作物类型
area_sqm INT, -- 面积 (平方米)
manager VARCHAR(20), -- 负责人
location VARCHAR(50) -- 位置描述
);
-- 模拟温室数据
INSERT INTO greenhouses VALUES
('GH-001', 'Strawberry', 500, '张农艺', 'Zone-A'),
('GH-002', 'Tomato', 800, '李技术', 'Zone-B'),
('GH-003', 'Cucumber', 600, '王专家', 'Zone-C');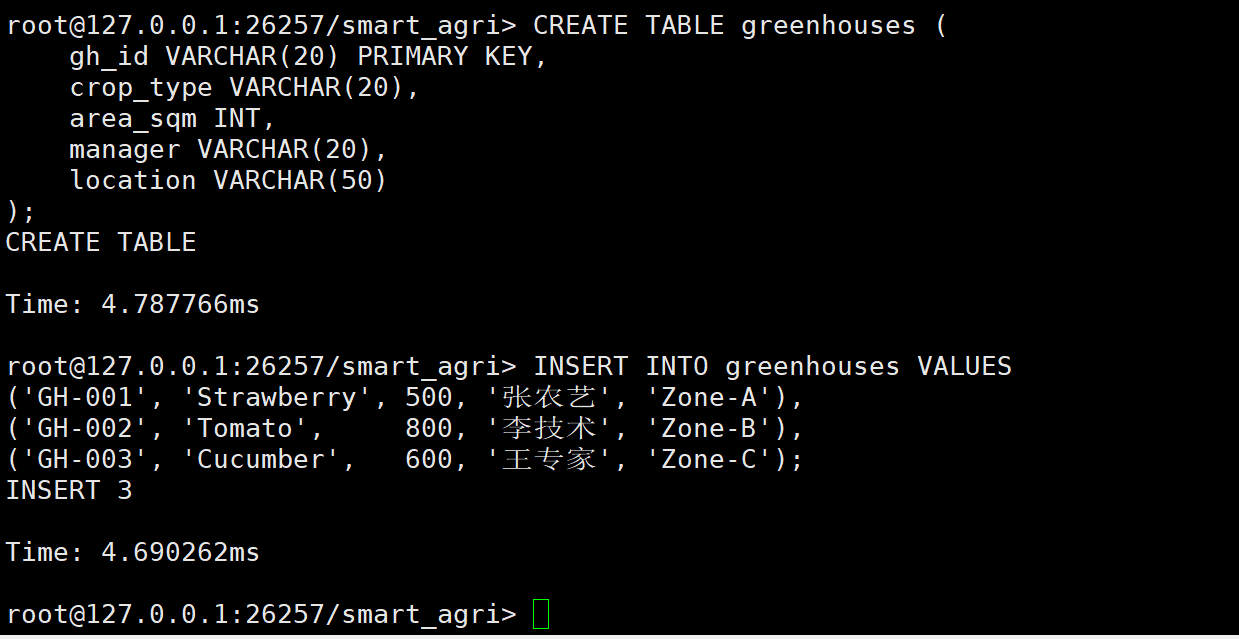
2.3 传感器读数表 (Time-Series Table)
存储高频环境数据。
Tag 设计 :gh_id 是核心查询维度。所有环境数据都绑定在特定的温室上。
sql
CREATE TABLE sensor_readings (
ts TIMESTAMP NOT NULL, -- 时间戳
gh_id VARCHAR(20) NOT NULL, -- 温室编号 (Tag)
temperature DOUBLE, -- 空气温度 (℃)
humidity DOUBLE, -- 空气湿度 (%)
soil_moisture DOUBLE, -- 土壤水分 (%)
co2_level DOUBLE, -- 二氧化碳浓度 (ppm)
light_intensity DOUBLE, -- 光照强度 (Lux)
PRIMARY KEY (ts, gh_id)
);3. 数据模拟:日出日落
农业数据的特点是具有明显的昼夜周期性 和相关性 (如温度高时湿度通常较低)。
为了生成高质量的模拟数据,我们编写了 Python 脚本 gen_agri_data.py,其中包含了一些简单的物理模型:
- 温度模型:使用正弦函数模拟一天中气温随时间的变化(凌晨最低,午后最高)。
- 光照模型:仅在白天(6:00-18:00)有光照,且强度呈抛物线分布。
- CO2 模型:模拟植物的光合作用(白天消耗 CO2)和呼吸作用(夜间释放 CO2)。
python
import random
import math
from datetime import datetime, timedelta
# 配置
FILENAME = "agri_data.sql"
GHS = ['GH-001', 'GH-002', 'GH-003']
START_TIME = datetime.now() - timedelta(hours=24) # 过去24小时
INTERVAL_MINUTES = 5 # 每5分钟一个点
TOTAL_POINTS = int(24 * 60 / INTERVAL_MINUTES)
print(f"正在生成 {len(GHS)} 个温室,过去 24 小时的环境数据...")
with open(FILENAME, "w") as f:
f.write("USE smart_agri;\n")
f.write("INSERT INTO sensor_readings (ts, gh_id, temperature, humidity, soil_moisture, co2_level, light_intensity) VALUES\n")
records = []
for gh_id in GHS:
# 基础参数微调
base_temp = 20 if gh_id == 'GH-001' else 25
base_humi = 60 if gh_id == 'GH-001' else 70
for i in range(TOTAL_POINTS):
current_time = START_TIME + timedelta(minutes=i*INTERVAL_MINUTES)
ts_str = current_time.strftime('%Y-%m-%d %H:%M:%S')
# 获取当前小时 (0-23)
hour = current_time.hour + current_time.minute / 60.0
# 模拟昼夜温差 (正弦曲线,最低点在凌晨4点,最高点在下午2点)
# 简单模拟:temp = base + 5 * sin(...)
temp_wave = -5 * math.cos((hour - 4) * math.pi / 12)
temperature = base_temp + temp_wave + random.uniform(-0.5, 0.5)
# 湿度通常与温度成反比
humidity = base_humi - temp_wave * 2 + random.uniform(-2, 2)
# 光照:白天有光,晚上无光 (6点到18点)
if 6 <= hour <= 18:
# 正弦波模拟光照强度
light = 20000 * math.sin((hour - 6) * math.pi / 12) + random.uniform(-1000, 1000)
else:
light = 0
# 土壤水分缓慢蒸发
soil = 40 - (i * 0.01) + random.uniform(-0.1, 0.1)
# CO2:白天植物光合作用消耗,浓度低;晚上呼吸作用,浓度高
if 6 <= hour <= 18:
co2 = 400 + random.uniform(-20, 20)
else:
co2 = 600 + random.uniform(-20, 20)
records.append(f"('{ts_str}', '{gh_id}', {round(temperature,1)}, {round(humidity,1)}, {round(soil,1)}, {round(co2,1)}, {round(light,1)})")
# 批量写入
batch_size = 1000
total = len(records)
for i, record in enumerate(records):
if (i + 1) % batch_size == 0 or i == total - 1:
f.write(f"{record};\n")
if i < total - 1:
f.write("INSERT INTO sensor_readings (ts, gh_id, temperature, humidity, soil_moisture, co2_level, light_intensity) VALUES\n")
else:
f.write(f"{record},\n")
print(f"生成完毕!总记录数: {total}")
print(f"请运行: time sudo /usr/local/kaiwudb/bin/kwbase sql --certs-dir=/etc/kaiwudb/certs --host=127.0.0.1:26257 < {FILENAME}")执行导入:
bash
python3 gen_agri_data.py
time sudo /usr/local/kaiwudb/bin/kwbase sql --certs-dir=/etc/kaiwudb/certs --host=127.0.0.1:26257 < agri_data.sql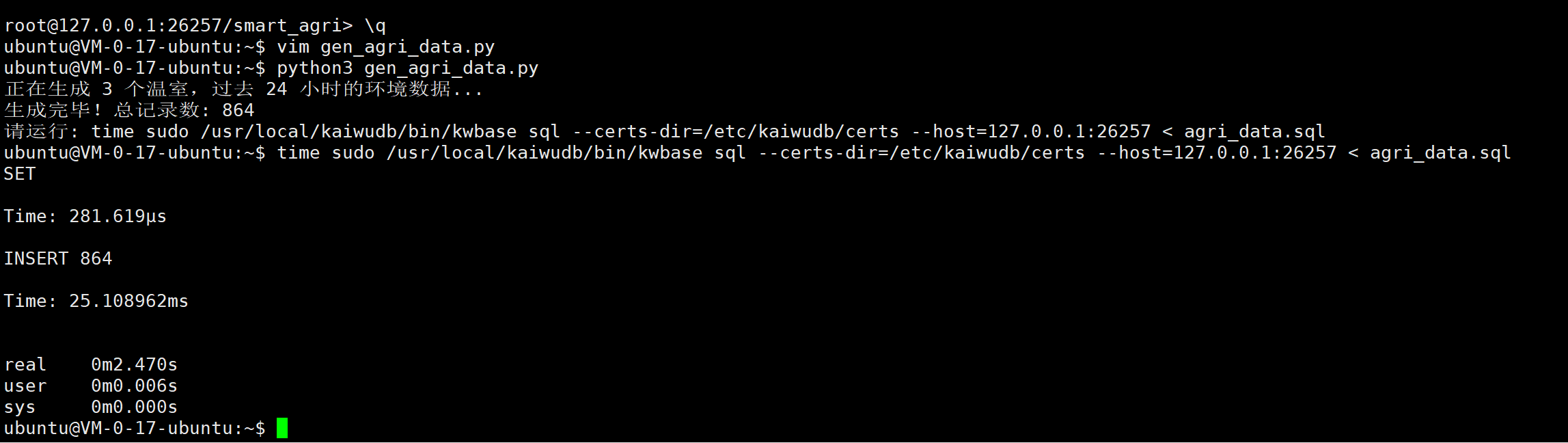
执行结果分析:
- 导入速度 :仅用 25ms 就完成了 3 个温室过去 24 小时所有监测数据的写入(864条)。
- 批量优势:虽然数据量不大,但 Batch Insert 的低延迟特性(毫秒级)意味着它完全能够应对未来扩容到几千个大棚的并发写入需求。
4. 业务场景实战
场景一:病害预警 (Disease Risk Alert)
业务痛点:农业生产中最怕的就是病害。许多真菌病害(如灰霉病、霜霉病)在"高温高湿"环境下极易爆发。如果能提前发现这种环境趋势,就能在病害发生前进行干预。
需求:找出过去 24 小时内,温度 > 25℃ 且 湿度 > 85% 的时段。
sql
USE smart_agri;
SELECT
r.ts,
g.crop_type,
r.temperature,
r.humidity
FROM sensor_readings r
JOIN greenhouses g ON r.gh_id = g.gh_id
WHERE r.temperature > 25.0 AND r.humidity > 85.0
ORDER BY r.ts DESC
LIMIT 10;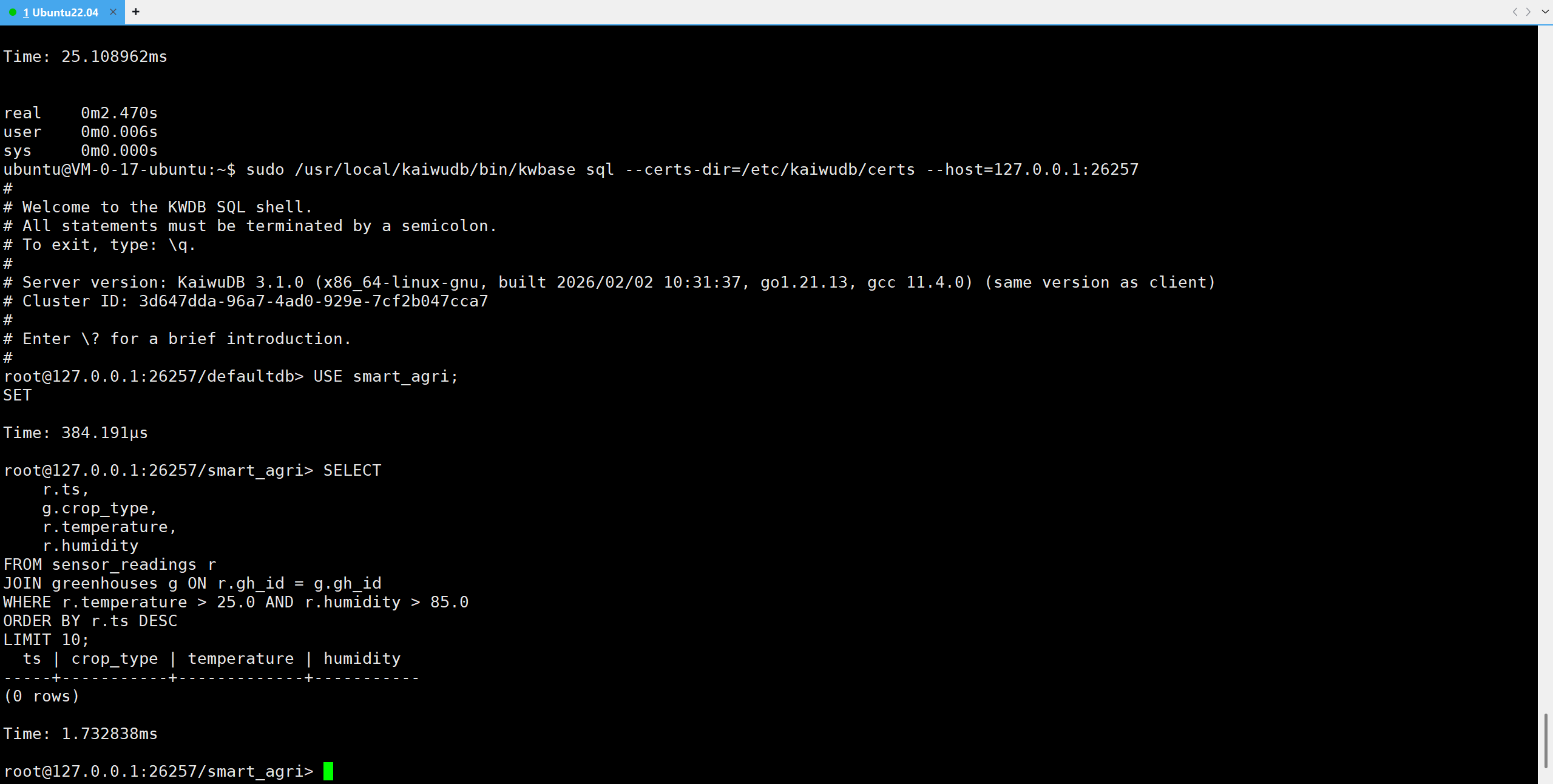
执行结果分析:
- 查询结果为 0 行,对吗? :完全正确 。这恰恰反映了模拟数据的真实性。在自然界中,温度升高时(>25℃),相对湿度通常会下降。我们的模拟脚本遵循了这一物理规律。结果为 0 表示当前没有处于"高温高湿"的危险状态,无需报警。
- 性能 :查询耗时仅 1.73ms。在监控系统中,"没有消息就是好消息",KWDB 的快速响应确保了我们能实时确认环境安全。
解析 :
这可以帮助农艺师及时开启排风扇降低湿度,预防病害。
场景二:智能灌溉触发 (Irrigation Trigger)
业务痛点:传统灌溉靠经验,容易导致水资源浪费或作物缺水。智慧农业的核心是"按需灌溉"。我们需要实时监控土壤水分,一旦低于阈值,立即触发灌溉指令。
需求:找出当前土壤水分低于 30% 的温室,触发自动灌溉系统。
sql
USE smart_agri;
SELECT
g.gh_id,
g.crop_type,
g.manager,
r.soil_moisture
FROM sensor_readings r
JOIN greenhouses g ON r.gh_id = g.gh_id
-- 取每个温室的最新一条记录
WHERE (r.gh_id, r.ts) IN (
SELECT gh_id, max(ts) FROM sensor_readings GROUP BY gh_id
)
AND r.soil_moisture < 30.0;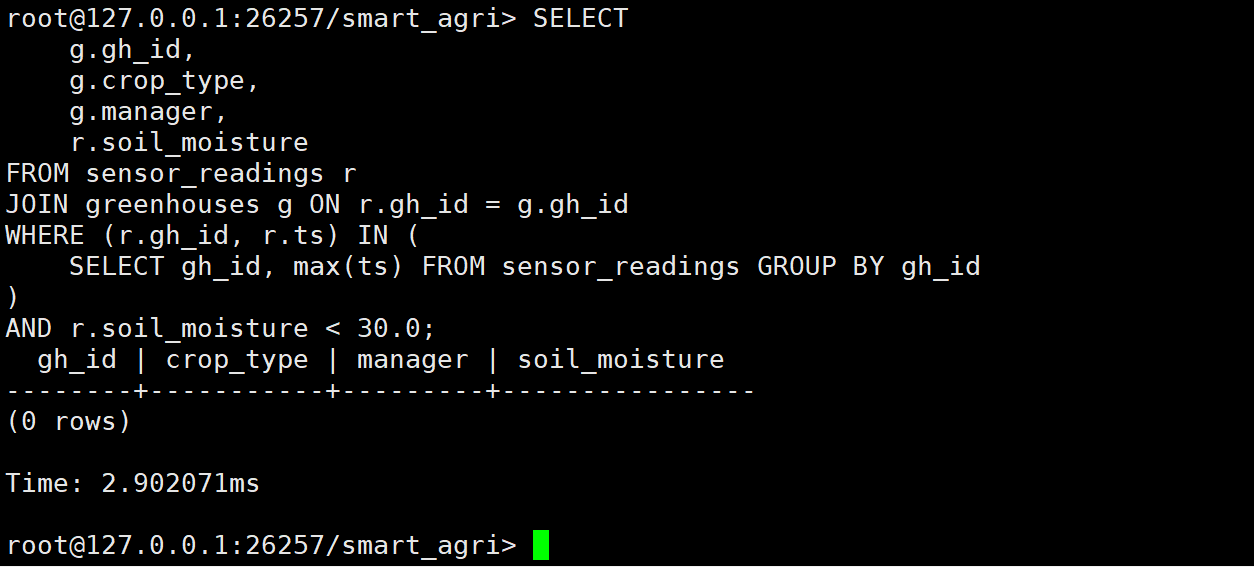
执行结果分析:
- 查询结果为 0 行,对吗? :没问题。我们的模拟脚本设定土壤初始水分为 40%,并随时间缓慢蒸发(每5分钟减少0.01%)。在短短 24 小时内,水分大约只下降了 3% 左右(40% -> 37%),尚未触及 30% 的灌溉阈值。
- 业务含义:这说明当前土壤墒情良好,无需浪费水资源进行灌溉。KWDB 精准地反映了这一现状,避免了误操作。
场景三:光合作用效率分析 (Photosynthesis Analysis)
业务痛点:作物的生长速度取决于光合作用效率,而光合作用需要光照和 CO2。通过分析白天的 CO2 浓度变化,农艺师可以判断大棚气密性是否过高导致缺碳,从而决定是否补充气肥。
需求:统计每个温室在白天(光照 > 1000 Lux)的平均 CO2 浓度。如果 CO2 过低,可能需要人工补充气肥。
sql
USE smart_agri;
SELECT
g.crop_type,
avg(r.co2_level) as avg_co2,
avg(r.light_intensity) as avg_light
FROM sensor_readings r
JOIN greenhouses g ON r.gh_id = g.gh_id
WHERE r.light_intensity > 1000 -- 仅统计有效光合作用时段
GROUP BY g.crop_type;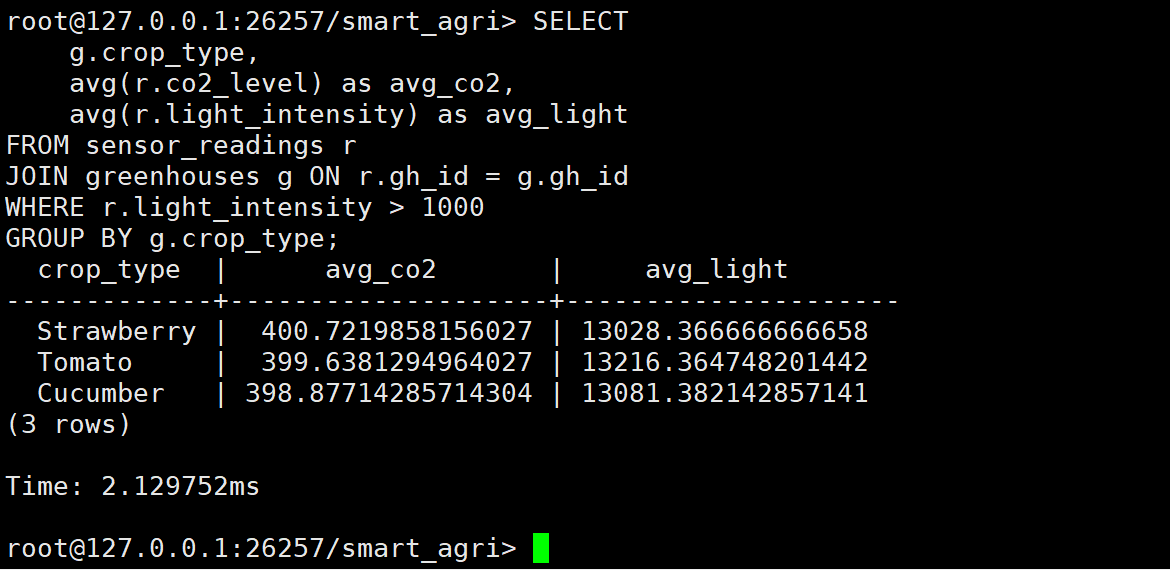
执行结果分析:
- 数据洞察 :KWDB 仅用 2.13ms 就完成了对全天数据的聚合。
- 结果解读 :
- 光照:平均光照在 13000 Lux 左右,符合白天日照的平均水平。
- CO2 :平均浓度在 400 ppm 左右(自然大气水平)。这提示农艺师,如果想追求高产(需要 800-1000 ppm),当前的 CO2 浓度偏低,建议开启 CO2 发生器进行气肥补充。这正是数据分析指导生产的典型案例。
5. 避坑指南
- 数据清洗 :传感器可能会因为电压波动产生异常值(如温度突变为 999℃)。建议在写入前或查询时增加
WHERE temperature BETWEEN -10 AND 50这样的过滤条件。 - 降采样策略 :对于长期趋势分析(如按月统计积温),可以使用
date_trunc('day', ts)进行每日聚合,无需查询所有原始点。
总结
KWDB 的时序能力非常适合处理 环境监测 场景。通过 SQL 的关联查询,我们可以轻松地将环境数据与作物档案结合,实现精细化管理。
核心价值回顾:
- 数据融合:打破了"环境数据"与"业务数据"的壁垒,让数据分析直接服务于农业生产决策。
- 实时响应:毫秒级的查询速度,确保了自动控制系统(如自动灌溉、自动通风)的及时性。
- 精细化管理:通过对光照、CO2 等多维因子的综合分析,帮助农户从"经验种植"走向"科学种植"。
智慧农业的未来在于"模型"。基于 KWDB 积累的海量历史数据,我们可以训练更高级的 AI 模型:
- 产量预测:根据作物整个生长周期的积温和光照时长,预测最终产量。
- 病虫害识别:结合图像识别技术和环境数据,精准识别并定位病虫害。
- 数字孪生:构建虚拟的数字温室,模拟不同环境策略下的作物生长情况,寻找最优种植方案。
科技赋能农业,让每一滴水、每一缕光都发挥最大的价值。