- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
思维导图如下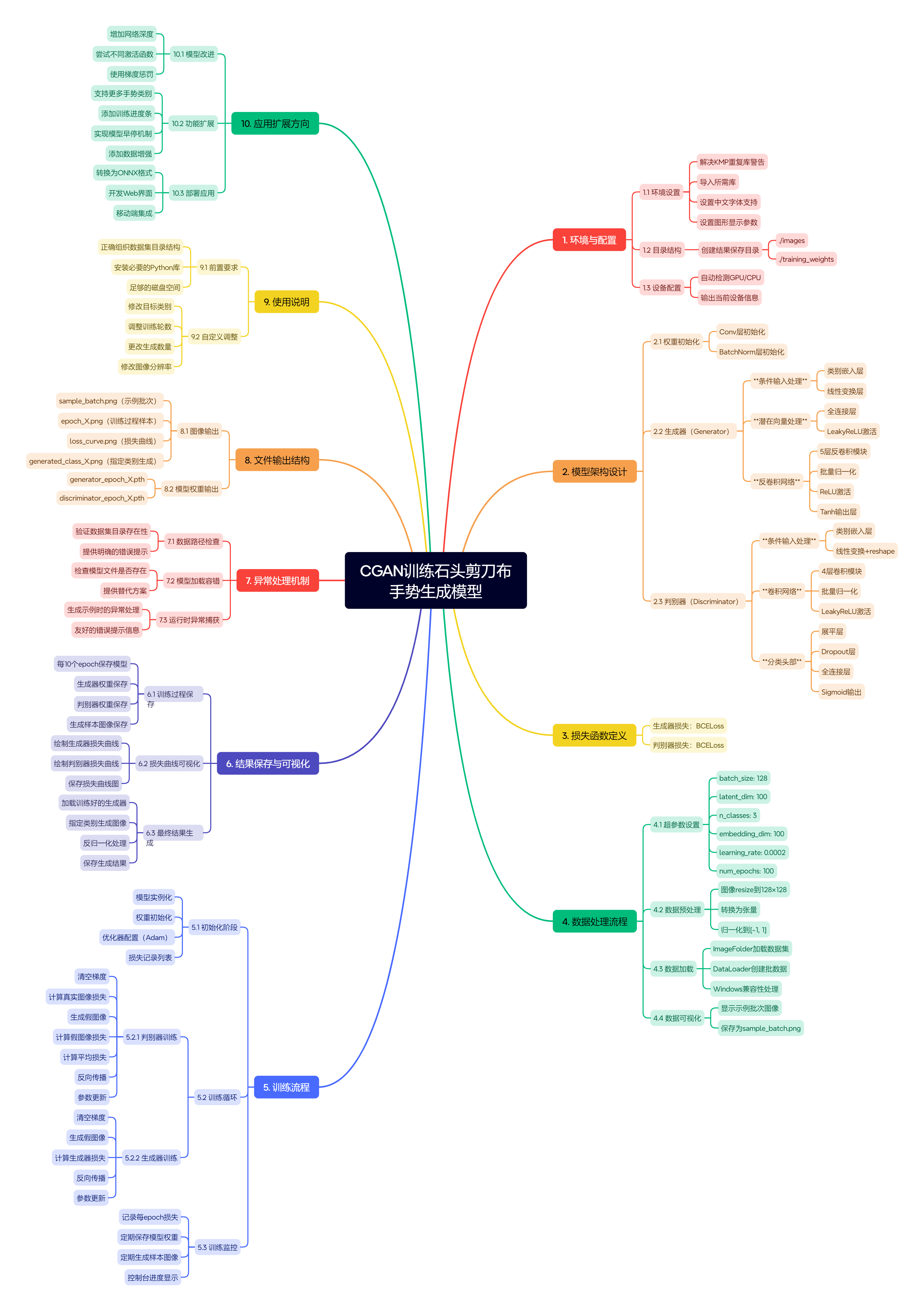
python
# ==================== 世界最详细注释版:CGAN手势生成代码(高中生友好版) ====================
# 🌟 核心思想:就像教一个"造假高手"(生成器)和一个"鉴宝专家"(判别器)玩猫鼠游戏!
# 🌟 条件控制:给造假高手一张"任务卡"(比如"画石头"),它必须按要求造假;鉴宝专家也看任务卡判断真假
# 🌟 本代码目标:让AI学会生成"石头/剪刀/布"三种手势图像,并能按指令生成指定手势
# 第一步:解决Windows系统常见报错(技术细节,高中生可跳过)
# 原因:多个科学计算库同时调用CPU多线程功能时的小冲突
# 解决方案:告诉系统"允许重复初始化"(安全临时方案)
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE" # ✅ 这行必须放在最最最前面!
# 第二步:导入所有需要的"工具包"(就像厨师准备厨具)
import torch # PyTorch:深度学习核心框架(AI的大脑)
import numpy as np # NumPy:处理数字矩阵的瑞士军刀
import torch.nn as nn # nn:神经网络积木库(搭积木造AI)
import torch.optim as optim # optim:优化器(帮AI快速进步的教练)
from torchvision import datasets, transforms # 处理图像数据的工具
from torchvision.utils import save_image, make_grid # 保存和拼接图片的工具
import matplotlib.pyplot as plt # 画图工具(生成损失曲线图)
import warnings # 警告管理器
# ==================== 【重要修正】模型定义必须放在超参数之后! ====================
# ❗ 原始代码错误:模型类定义时用了还没声明的变量(n_classes等)
# ✅ 修正方案:所有模型定义移到__main__内,超参数定义之后(见下方详细注释)
if __name__ == '__main__':
# =============== 0. 基础设置(准备工作)===============
warnings.filterwarnings("ignore") # 忽略非关键警告(让输出更清爽)
# 设置中文显示(避免图片标题出现乱码□□□)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正确显示负号
plt.rcParams['figure.dpi'] = 100 # 图片清晰度
# 创建保存结果的文件夹(像整理书包:图片放images,模型放training_weights)
os.makedirs('./images', exist_ok=True) # exist_ok=True:如果文件夹已存在也不报错
os.makedirs('./training_weights', exist_ok=True)
print("📁 已创建结果保存文件夹:./images 和 ./training_weights")
# 检测设备:有NVIDIA显卡用GPU(超快!),没有用CPU(稍慢但能跑)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"🚀 使用设备: {device}(GPU加速能快10倍以上!)")
# =============== 1. 超参数设置(AI训练的"规则说明书")===============
batch_size = 128 # 每次喂给AI看128张图片(像一次批改128份作业)
latent_dim = 100 # 随机噪声的长度(100个随机数 = 造假高手的"灵感源泉")
n_classes = 3 # 手势类别数:0=石头(rock), 1=布(paper), 2=剪刀(scissors)
embedding_dim = 100 # 类别信息的"翻译长度"(把"石头"翻译成100维数字密码)
learning_rate = 0.0002 # 学习速度(太大学不会,太慢效率低,0.0002是黄金值)
num_epochs = 100 # 训练轮数(看完整数据集100遍,像复习100次课本)
# =============== 2. 数据预处理(给图片"化妆"标准化)===============
train_transform = transforms.Compose([
transforms.Resize(128), # 把所有图片缩放到128x128像素(统一尺寸)
transforms.ToTensor(), # 转成PyTorch能处理的数字矩阵
# 归一化:把像素值[0,255] → [-1,1](让AI计算更稳定)
# 公式:(像素值/255 - 0.5) / 0.5
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
# =============== 3. 加载手势数据集(准备"教科书")===============
try:
# 从"data/rps"文件夹读取图片(需提前准备!)
# 文件夹结构必须是:
# data/rps/
# ├── rock/ (放所有"石头"手势图片)
# ├── paper/ (放所有"布"手势图片)
# └── scissors/ (放所有"剪刀"手势图片)
train_dataset = datasets.ImageFolder(root="data/rps", transform=train_transform)
print(f"📚 成功加载数据集!共 {len(train_dataset)} 张手势图片")
print(f" 类别说明: {train_dataset.classes} → [0=石头, 1=布, 2=剪刀]")
except FileNotFoundError:
raise FileNotFoundError(
"❌ 数据集路径 'data/rps' 不存在!请按以下步骤操作:\n"
"1️⃣ 创建文件夹: data/rps/rock, data/rps/paper, data/rps/scissors\n"
"2️⃣ 每个文件夹放入至少100张对应手势的图片(手机拍即可)\n"
"3️⃣ 确保图片是.jpg或.png格式\n"
"💡 小技巧:可用手机拍自己做手势的照片,每类拍50张以上!"
)
# 打包数据:每次取batch_size张图片,打乱顺序(避免AI死记硬背)
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=0 if os.name == 'nt' else 4 # Windows系统设为0避免卡死
)
# =============== 4. 可视化示例(看看"教科书"长啥样)===============
def show_images(dl):
"""从数据集中取64张图片拼成网格图保存"""
for images, labels in dl: # 取第一批数据
# make_grid:把64张小图拼成8x8大图;permute:调整颜色通道顺序
grid = make_grid(images[:64], nrow=8).permute(1, 2, 0)
plt.figure(figsize=(10, 10))
plt.axis('off') # 隐藏坐标轴
# 反归一化:把[-1,1]变回[0,1]才能正常显示
plt.imshow(grid.numpy() * 0.5 + 0.5)
plt.savefig('./images/sample_batch.png', bbox_inches='tight')
plt.close()
print("🖼️ 已保存示例图片:./images/sample_batch.png(快去打开看看!)")
break # 只看第一批
show_images(train_loader)
# =============== 5. 模型定义(核心!造假高手 vs 鉴宝专家)===============
# 🔑 重要:所有模型定义必须放在超参数之后!否则会报错"n_classes未定义"
def weights_init(m):
"""
【权重初始化】给神经网络"热身"
比喻:就像运动员赛前拉伸,避免训练时抽筋
- 卷积层:用微小随机数初始化(标准差0.02)
- BN层:权重设为1附近,偏置设为0
"""
classname = m.__class__.__name__
if classname.find('Conv') != -1: # 如果是卷积层
nn.init.normal_(m.weight, 0.0, 0.02) # 生成均值为0、标准差0.02的随机数
elif classname.find('BatchNorm') != -1: # 如果是批归一化层
nn.init.normal_(m.weight, 1.0, 0.02)
nn.init.zeros_(m.bias) # 偏置初始化为0
class Generator(nn.Module):
"""
【生成器 = 造假高手】
输入:100个随机数(灵感) + 手势类别(任务卡:画"石头")
输出:一张128x128的RGB手势图片
工作流程:
1️⃣ 把"任务卡"(类别标签)翻译成数字密码(Embedding)
2️⃣ 把随机数"灵感"展开成512x4x4的特征图
3️⃣ 把任务卡密码(1x4x4)拼到特征图旁边 → 513x4x4
4️⃣ 用"反卷积"层层放大:4x4 → 8x8 → 16x16 → ... → 128x128
5️⃣ 最后用Tanh把像素值压缩到[-1,1](符合归一化要求)
"""
def __init__(self):
super(Generator, self).__init__()
# 【任务卡翻译器】把类别标签(0/1/2)转成16维向量
self.label_conditioned_generator = nn.Sequential(
nn.Embedding(n_classes, embedding_dim), # 词嵌入:把数字标签变向量
nn.Linear(embedding_dim, 16) # 线性变换压缩到16维
)
# 【灵感处理】把100维随机噪声变512x4x4的"草图"
self.latent = nn.Sequential(
nn.Linear(latent_dim, 4 * 4 * 512),
nn.LeakyReLU(0.2, inplace=True) # 激活函数:让网络有非线性能力
)
# 【放大器】把4x4小图逐步放大到128x128
self.model = nn.Sequential(
# 每层:反卷积 → 批归一化 → 激活函数
# 反卷积步长2:尺寸翻倍(4→8→16→32→64→128)
nn.ConvTranspose2d(513, 512, 4, 2, 1, bias=False), # 输入513=512(灵感)+1(任务卡)
nn.BatchNorm2d(512, momentum=0.1, eps=0.8), # 稳定训练
nn.ReLU(True),
nn.ConvTranspose2d(512, 256, 4, 2, 1, bias=False),
nn.BatchNorm2d(256, momentum=0.1, eps=0.8),
nn.ReLU(True),
nn.ConvTranspose2d(256, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128, momentum=0.1, eps=0.8),
nn.ReLU(True),
nn.ConvTranspose2d(128, 64, 4, 2, 1, bias=False),
nn.BatchNorm2d(64, momentum=0.1, eps=0.8),
nn.ReLU(True),
nn.ConvTranspose2d(64, 3, 4, 2, 1, bias=False), # 输出3通道(RGB)
nn.Tanh() # 像素值压缩到[-1, 1]
)
def forward(self, inputs):
"""前向传播:输入→输出的完整流程"""
noise_vector, label = inputs # 拆分输入:随机噪声 + 类别标签
# 处理任务卡:标签 → 16维向量 → 变成1x4x4的小图
label_output = self.label_conditioned_generator(label)
label_output = label_output.view(-1, 1, 4, 4) # 重塑形状
# 处理灵感:100维噪声 → 512x4x4特征图
latent_output = self.latent(noise_vector)
latent_output = latent_output.view(-1, 512, 4, 4)
# 拼接:把任务卡小图(1通道)贴到灵感图(512通道)旁边 → 513通道
concat = torch.cat((latent_output, label_output), dim=1)
# 送入放大器生成最终图片
return self.model(concat)
class Discriminator(nn.Module):
"""
【判别器 = 鉴宝专家】
输入:一张图片 + 手势类别(任务卡:检查是否为"石头")
输出:一个概率值(0~1,越接近1表示越像真图)
工作流程:
1️⃣ 把"任务卡"翻译成128x128的彩色图(和输入图一样大)
2️⃣ 把任务卡图和输入图上下叠在一起 → 6通道图(原图3通道+任务卡3通道)
3️⃣ 用卷积层层压缩:128x128 → 64x64 → ... → 小特征向量
4️⃣ 最后输出一个概率值(Sigmoid:把结果压到0~1之间)
"""
def __init__(self):
super(Discriminator, self).__init__()
# 【任务卡可视化】把类别标签变128x128的"提示图"
self.label_condition_disc = nn.Sequential(
nn.Embedding(n_classes, embedding_dim),
nn.Linear(embedding_dim, 3 * 128 * 128) # 输出=3通道×128×128像素
)
# 【鉴定器】压缩图片提取特征
self.model = nn.Sequential(
# 每层:卷积 → 激活 → (批归一化)
# 卷积步长2/3:尺寸缩小(128→64→21→7→2)
nn.Conv2d(6, 64, 4, 2, 1, bias=False), # 输入6通道=3(图片)+3(任务卡图)
nn.LeakyReLU(0.2, inplace=True), # LeakyReLU:负数也有微小梯度
nn.Conv2d(64, 128, 4, 3, 2, bias=False),
nn.BatchNorm2d(128, momentum=0.1, eps=0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(128, 256, 4, 3, 2, bias=False),
nn.BatchNorm2d(256, momentum=0.1, eps=0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(256, 512, 4, 3, 2, bias=False),
nn.BatchNorm2d(512, momentum=0.1, eps=0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Flatten(), # 拉平成一维向量
nn.Dropout(0.4), # 随机丢弃40%神经元(防过拟合,像随机抽查)
nn.Linear(4608, 1), # 全连接到1个输出
nn.Sigmoid() # 压缩到0~1(概率值)
)
def forward(self, inputs):
img, label = inputs # 拆分输入:图片 + 类别标签
# 处理任务卡:标签 → 3×128×128的"提示图"
label_output = self.label_condition_disc(label)
label_output = label_output.view(-1, 3, 128, 128)
# 拼接:原图(3通道) + 任务卡图(3通道) → 6通道
concat = torch.cat((img, label_output), dim=1)
# 送入鉴定器输出真假概率
return self.model(concat)
# 损失函数:二元交叉熵(判断"是/否"问题的标准损失)
def generator_loss(fake_output, label):
"""生成器希望判别器把假图判为真(label=1)"""
return nn.BCELoss()(fake_output, label)
def discriminator_loss(output, label):
"""判别器希望:真图判为真(1),假图判为假(0)"""
return nn.BCELoss()(output, label)
# =============== 6. 初始化模型(召唤造假高手和鉴宝专家)===============
generator = Generator().to(device).apply(weights_init) # 造假高手
discriminator = Discriminator().to(device).apply(weights_init) # 鉴宝专家
print("🤖 模型初始化完成!")
print(f" 生成器参数量: {sum(p.numel() for p in generator.parameters()):,}")
print(f" 判别器参数量: {sum(p.numel() for p in discriminator.parameters()):,}")
# =============== 7. 优化器(给两位配专属教练)===============
# Adam优化器:智能调整学习速度(比普通SGD更高效)
G_optimizer = optim.Adam(generator.parameters(), lr=learning_rate, betas=(0.5, 0.999))
D_optimizer = optim.Adam(discriminator.parameters(), lr=learning_rate, betas=(0.5, 0.999))
print("🏋️ 优化器配置完成(两位专家的私人教练已就位)")
# =============== 8. 训练循环(核心!猫鼠游戏开始)===============
print("\n" + "="*60)
print("🎮 CGAN训练启动!石头剪刀布手势生成器")
print("💡 游戏规则:")
print(" 1️⃣ 造假高手按'任务卡'生成手势图")
print(" 2️⃣ 鉴宝专家对比真图/假图+任务卡,判断真假")
print(" 3️⃣ 两位互相较劲,越练越强!")
print("="*60 + "\n")
D_loss_plot, G_loss_plot = [], [] # 记录损失变化(画进步曲线用)
for epoch in range(1, num_epochs + 1):
D_epoch_loss, G_epoch_loss = 0.0, 0.0
num_batches = len(train_loader)
for real_images, labels in train_loader:
batch_size_curr = real_images.size(0)
real_images = real_images.to(device)
# labels原为[batch],需变为[batch,1]匹配模型输入
labels = labels.unsqueeze(1).long().to(device)
# 创建真假标签(用于计算损失)
real_target = torch.ones(batch_size_curr, 1, device=device) # 真图标签=1
fake_target = torch.zeros(batch_size_curr, 1, device=device) # 假图标签=0
# ========== 第一回合:训练判别器(强化鉴宝专家)==========
D_optimizer.zero_grad() # 清空上轮梯度(避免累积错误)
# 1. 用真图+正确任务卡训练:希望输出接近1
D_real_loss = discriminator_loss(
discriminator((real_images, labels)), # 输入:真图+对应标签
real_target
)
# 2. 用假图+相同任务卡训练:希望输出接近0
noise = torch.randn(batch_size_curr, latent_dim, device=device) # 生成随机灵感
fake_images = generator((noise, labels)) # 造假高手生成假图
# .detach():冻结生成器梯度(本轮只训练判别器)
D_fake_loss = discriminator_loss(
discriminator((fake_images.detach(), labels)),
fake_target
)
# 3. 综合损失 = (真图损失 + 假图损失)/2
D_loss = (D_real_loss + D_fake_loss) / 2
D_loss.backward() # 反向传播:计算梯度
D_optimizer.step() # 更新判别器参数
D_epoch_loss += D_loss.item()
# ========== 第二回合:训练生成器(强化造假高手)==========
G_optimizer.zero_grad()
# 用假图+任务卡训练:希望判别器输出接近1(骗过专家!)
G_loss = generator_loss(
discriminator((fake_images, labels)), # 注意:这次不detach,要更新生成器
real_target
)
G_loss.backward()
G_optimizer.step()
G_epoch_loss += G_loss.item()
# 计算本epoch平均损失
D_epoch_loss /= num_batches
G_epoch_loss /= num_batches
D_loss_plot.append(D_epoch_loss)
G_loss_plot.append(G_epoch_loss)
# 打印进度(每轮显示一次)
print(f" Epoch [{epoch:3d}/{num_epochs}] | "
f"📉 判别器损失: {D_epoch_loss:.4f} | "
f"📈 生成器损失: {G_epoch_loss:.4f} | "
f"🎯 理想状态:两者接近0.5(势均力敌!)")
# 每10轮保存成果
if epoch % 10 == 0:
# 生成50张测试图(5行10列)
with torch.no_grad(): # 关闭梯度计算(节省内存)
test_noise = torch.randn(50, latent_dim, device=device)
# 随机生成50个类别标签(0/1/2均匀分布)
test_labels = torch.randint(0, n_classes, (50, 1), device=device).long()
gen_imgs = generator((test_noise, test_labels))
# 保存为网格图(normalize=True:自动反归一化显示)
save_image(gen_imgs.data, f'./images/epoch_{epoch}.png', nrow=10, normalize=True)
# 保存模型(方便以后直接生成图片)
torch.save(generator.state_dict(), f'./training_weights/generator_epoch_{epoch}.pth')
torch.save(discriminator.state_dict(), f'./training_weights/discriminator_epoch_{epoch}.pth')
print(f"✅ 已保存:生成样本(./images/epoch_{epoch}.png) + 模型权重")
# =============== 9. 训练后可视化(画出进步曲线)===============
plt.figure(figsize=(10, 4))
plt.plot(G_loss_plot, label='生成器损失', linewidth=2, color='green')
plt.plot(D_loss_plot, label='判别器损失', linewidth=2, color='red')
plt.title('CGAN训练损失曲线', fontsize=16, fontweight='bold')
plt.xlabel('训练轮数(Epoch)', fontsize=12)
plt.ylabel('损失值', fontsize=12)
plt.legend(fontsize=12)
plt.grid(True, linestyle='--', alpha=0.7)
plt.savefig('./images/loss_curve.png', bbox_inches='tight', dpi=150)
plt.close()
print("\n📊 训练完成!损失曲线已保存:./images/loss_curve.png")
print("💡 曲线解读:")
print(" - 两条线逐渐靠近0.5 → 训练成功(势均力敌)")
print(" - 判别器损失≈0 → 造假高手太菜(一直被识破)")
print(" - 生成器损失≈0 → 鉴宝专家太菜(真假不分)")
# =============== 10. 生成指定手势(终极测试!)===============
print("\n" + "="*60)
print("🎨 生成指定手势图像(按需定制!)")
print("="*60)
try:
# 尝试加载最终模型(epoch 100)
gen_path = './training_weights/generator_epoch_100.pth'
if os.path.exists(gen_path):
generator.load_state_dict(torch.load(gen_path, map_location=device))
generator.eval() # 切换到评估模式(关闭Dropout等)
print(f"✅ 成功加载训练完成的生成器模型")
else:
print(f"⚠️ 未找到最终模型,使用当前训练权重(请确保训练完成100轮)")
# 生成指定类别(修改target_class即可:0=石头,1=布,2=剪刀)
target_class = 0
class_names = ["rock(石头)", "paper(布)", "scissors(剪刀)"]
with torch.no_grad():
noise = torch.randn(1, latent_dim, device=device) # 1个随机灵感
label = torch.tensor([[target_class]], device=device, dtype=torch.long)
gen_img = generator((noise, label))
# 反归一化:[-1,1] → [0,255](转为正常图片)
img_np = gen_img.squeeze().permute(1, 2, 0).cpu().numpy()
img_np = (img_np * 0.5 + 0.5) * 255
img_np = np.clip(img_np, 0, 255).astype(np.uint8) # 限制在0-255
# 保存结果
plt.figure(figsize=(5, 5))
plt.imshow(img_np)
plt.title(f'✨ 生成的手势: {class_names[target_class]}', fontsize=14, pad=20)
plt.axis('off')
save_path = f'./images/generated_{class_names[target_class].split()[0]}.png'
plt.savefig(save_path, bbox_inches='tight', dpi=150)
plt.close()
print(f"\n✅ 成功生成 {class_names[target_class]} 手势!")
print(f" 保存路径: {save_path}")
print(f"💡 小实验:修改代码中 target_class = 1 或 2,重新运行即可生成'布'或'剪刀'!")
print("\n🎉 恭喜!你已掌握条件生成对抗网络(CGAN)核心原理与实践!")
print(" 下一步建议:")
print(" 1️⃣ 用手机拍自己的手势扩充数据集")
print(" 2️⃣ 尝试修改网络结构(如增加层数)")
print(" 3️⃣ 用训练好的模型做'手势猜拳'小游戏!")
except Exception as e:
print(f"\n❌ 生成图像时出错: {str(e)}")
print("🔍 排查建议:")
print(" - 检查是否完成至少10轮训练(需有保存的模型)")
print(" - 确认target_class值在0~2之间")
print(" - 查看错误信息定位具体问题")
# =============== 附:CGAN原理通俗总结(高中生秒懂版)===============
"""
🌰 举个栗子:教AI画"指定水果"
- 传统GAN:给AI一盒蜡笔(随机噪声),让它随便画水果 → 可能画出苹果/香蕉/橘子(无法控制)
- CGAN:给AI蜡笔 + 一张"任务卡"(写着"画苹果")
• 生成器:必须按任务卡画苹果
• 判别器:同时看画作和任务卡,判断"这张画真的是苹果吗?"
- 结果:训练完成后,你给"画香蕉"任务卡,AI立刻生成香蕉!
💡 本项目应用:
任务卡 = "石头/剪刀/布" → AI按指令生成对应手势
应用场景:游戏开发、手势识别数据增强、虚拟助手等
📚 知识延伸(来自知识库):
• CGAN是GAN的"条件版"(2014年提出),把无监督学习转为有监督学习
• 变体家族:DCGAN(用卷积网络提升质量)、InfoGAN(控制更多属性)等
• 实际应用:老照片修复、视频预测、风格迁移(如把照片变梵高风格)
"""生成的最后结果如下:
