PyTorch实战(35)------使用PyTorch Profiler分析模型推理性能
0. 前言
我们已经介绍了 PyTorch 深度学习原型库 fastai 和 PyTorch Lightning,虽然这些库能极大提升开发效率,但其抽象化设计会隐藏底层实现细节。当涉及定制化研究流程时(例如需要实现原型库未内置的自定义损失函数),仍需调整底层代码。在下一节中,我们将通过剖析 PyTorch 模型推理代码,实时监控硬件资源(包括 CPU/GPU 算力及内存)的消耗情况。
1. 使用 PyTorch Profiler 分析模型推理性能
代码性能分析是指通过评估程序的时间复杂度和空间复杂度(内存占用),统计代码中各子模块或函数的执行时间和内存消耗情况。当运行 PyTorch 深度学习模型推理时,系统会通过一系列函数调用从输入 (X) 生成输出 (y)。本节将介绍如何运用 PyTorch Profiler 工具进行模型推理分析。我们将分析两个场景下的 MNIST 手写数字识别模型:
- 《PyTorch 深度学习》一节中训练的模型
- 《PyTorch 模型生产化部署》一节中部署的模型
首先在 CPU 上运行模型推理并分析各内部操作的 CPU 时间与内存消耗,随后在 GPU 上重复分析流程,最终可视化分析结果。
2. 分析模型在 CPU 上的推理性能
(1) 我们使用的已训练 MNIST 手写数字识别模型具有如下架构:
python
print(model)
(2) 同时准备用于推理的输入数据样本 (X):
python
print(sample_data.shape)
# torch.Size([500, 1, 28, 28])该输入样本本质上是包含 500 张 28x28 像素灰度图像的数据批次。接下来,我们将使用这个模型和数据样本进行推理,并使用 PyTorch Profiler 对模型推理代码进行性能分析。
(3) 首先导入 PyTorch Profiler 相关库:
python
from torch.profiler import profile, record_function, ProfilerActivityPyTorch Profiler 全局上下文管理器由 profile 实现,而 record_function 则作为有标签的上下文管理器,用于分析每个子任务的性能。ProfilerActivity 是活动类,支持 CPU 和 CUDA 两种活动组用于性能分析。
(4) 导入相关库后,使用 PyTorch Profiler 分析模型推理过程中 CPU 的使用情况:
python
with profile(activities=[ProfilerActivity.CPU], record_shapes=True) as prof:
with record_function("model_inference"):
model(sample_data)由于当前聚焦 CPU 分析,活动组仅限定为 CPU。将 record_shapes 设为 True 以保留每个分析操作涉及的张量形状信息。
(5) 最后打印模型推理分析结果:
python
print(prof.key_averages().table(sort_by="cpu_time_total"))输出结果如下所示:
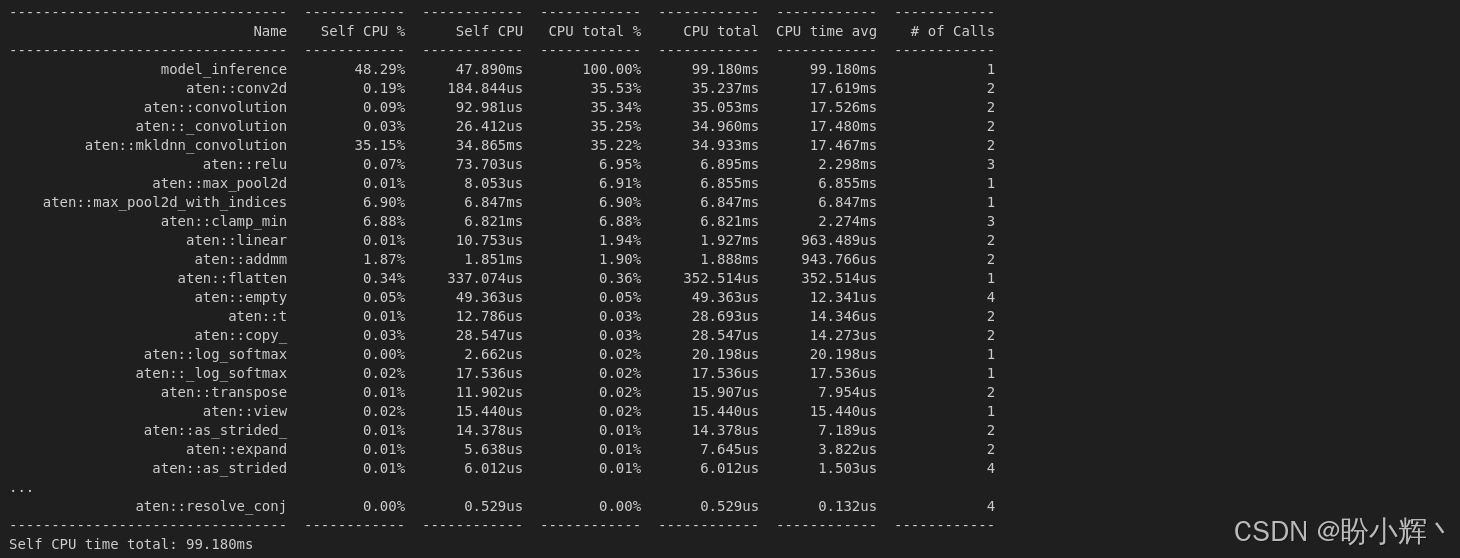
从分析结果可见,该模型推理 500 张图像总耗时为 99 毫秒。更有价值的是对运行时间的细分:按降序排列可以看出,卷积操作耗时最长达 35 毫秒,而最大池化操作耗时 7 毫秒。
我们可以看到多行显示卷积操作,这些行反映了公共 conv_2d 类所调用的内部(子级)函数。CPU total 列显示了一个函数执行的总时间,包括其底层子级调用的时间,而 Self CPU 则排除了内部调用的时间。因此,CPU total 显示的是 Self CPU 值的累计总和。同样的逻辑也适用于 CPU 使用率百分比,它包含了 CPU 时间的标准化值。
值得注意的是,由于模型包含两个卷积层,系统会进行两次调用,因此卷积操作的平均 CPU 时间为 17 毫秒。但实际上两个卷积层的耗时并不相同,接下来,我们将介绍如何获取它们的精确耗时。
(6) 相较于前一步默认的粗粒度分组(卷积、最大池化、ReLU 等),我们可以通过输入张量形状进行更精细的操作分组:
python
print(prof.key_averages(group_by_input_shape=True).table(sort_by="cpu_time_total"))输出结果如下所示:
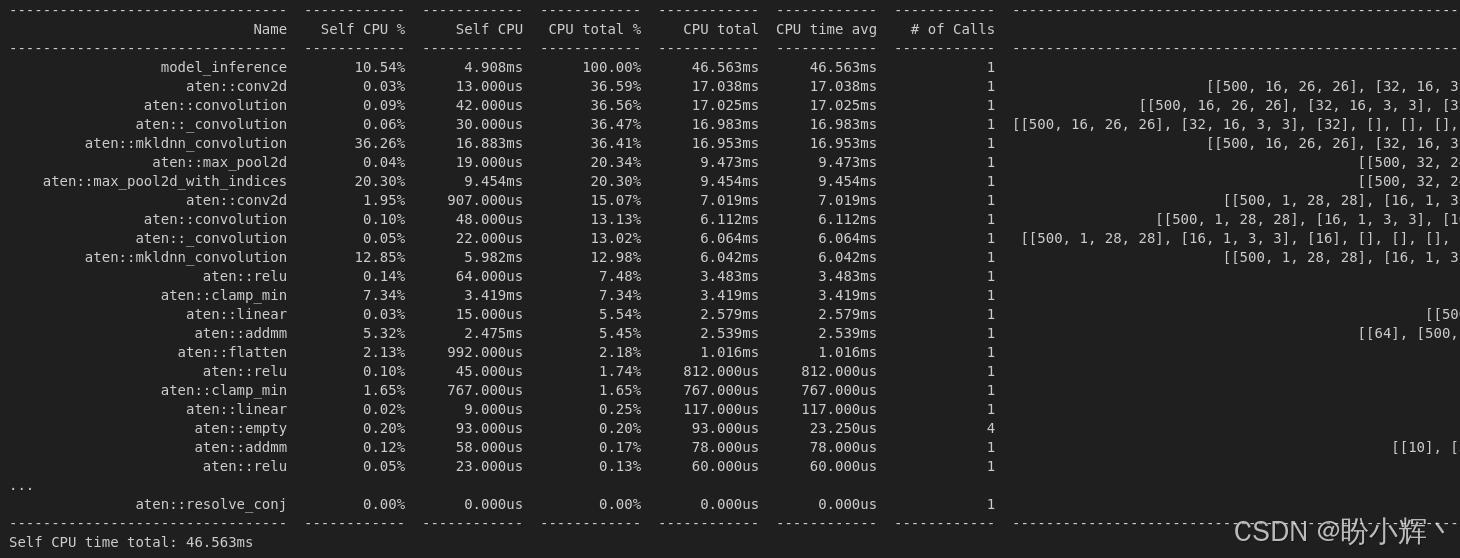
现在我们可以看到两个卷积层被单独显示:第二卷积层总共消耗 17 毫秒CPU时间,而第一卷积层仅消耗 7 毫秒。这是因为第一卷积层的输入只有 1 个特征图,而第二卷积层的输入则有 16 个特征图。
(7) 分析 CPU 时间后,我们继续分析内存消耗情况。得益于 PyTorch Profiler 提供的简洁 API,我们只需在分析语句中添加 profile_memory=True 参数即可实现内存分析:
python
with profile(activities=[ProfilerActivity.CPU],
profile_memory=True, record_shapes=True) as prof:
model(sample_data)
print(prof.key_averages().table(sort_by="cpu_memory_usage"))输出结果如下所示:
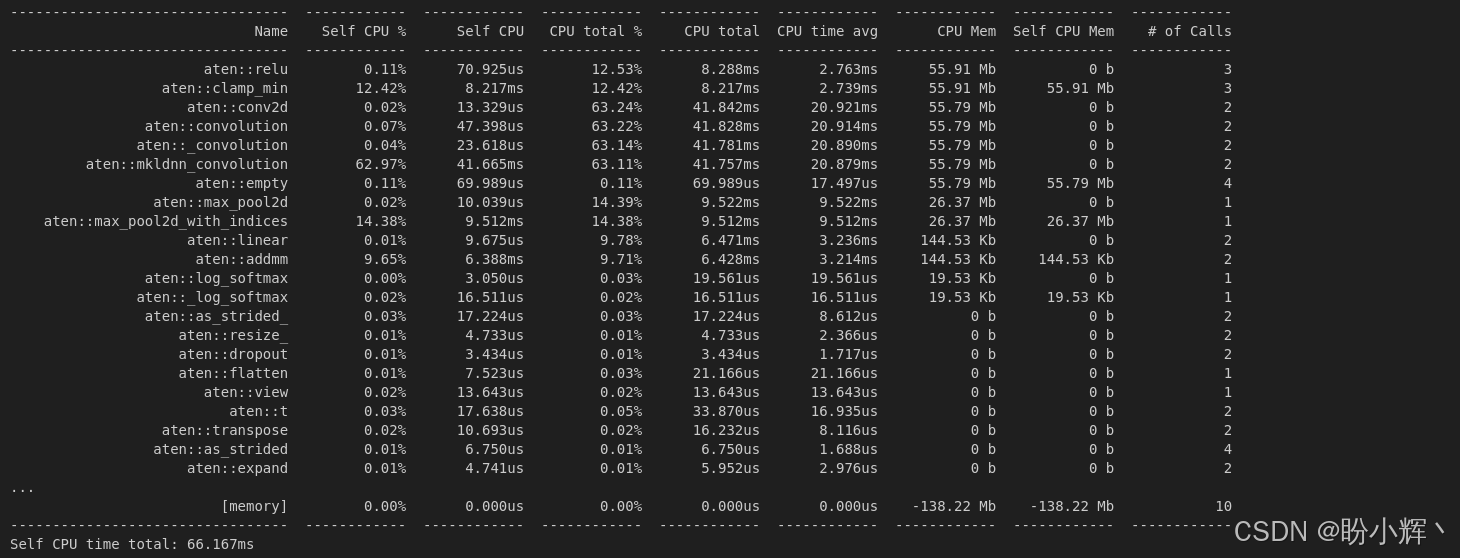
值得注意的是,ReLU 层的内存消耗最高。这是因为 ReLU 层需要为激活后的输出分配新内存。通过使用 nn.ReLU(inplace=True) 替代普通 nn.ReLU() 可以规避这个问题,这就是代码剖析的作用所在。
接下来我们将在 GPU 上运行模型推理,并通过性能分析了解 GPU 利用率情况。
3. 分析模型在 GPU 上的推理性能
(1) 要分析 GPU 上的模型推理,首先需要将模型和输入数据载入 GPU:
python
model=model.cuda()
sample_data=sample_data.cuda()(2) 接着我们只需在待分析的活动组中添加 ProfilerActivity.CUDA 即可:
python
with profile(activities=[
ProfilerActivity.CPU, ProfilerActivity.CUDA], record_shapes=True) as prof:
with record_function("model_inference"):
model(sample_data)
print(prof.key_averages().table(sort_by="cuda_time_total"))输出结果如下所示:
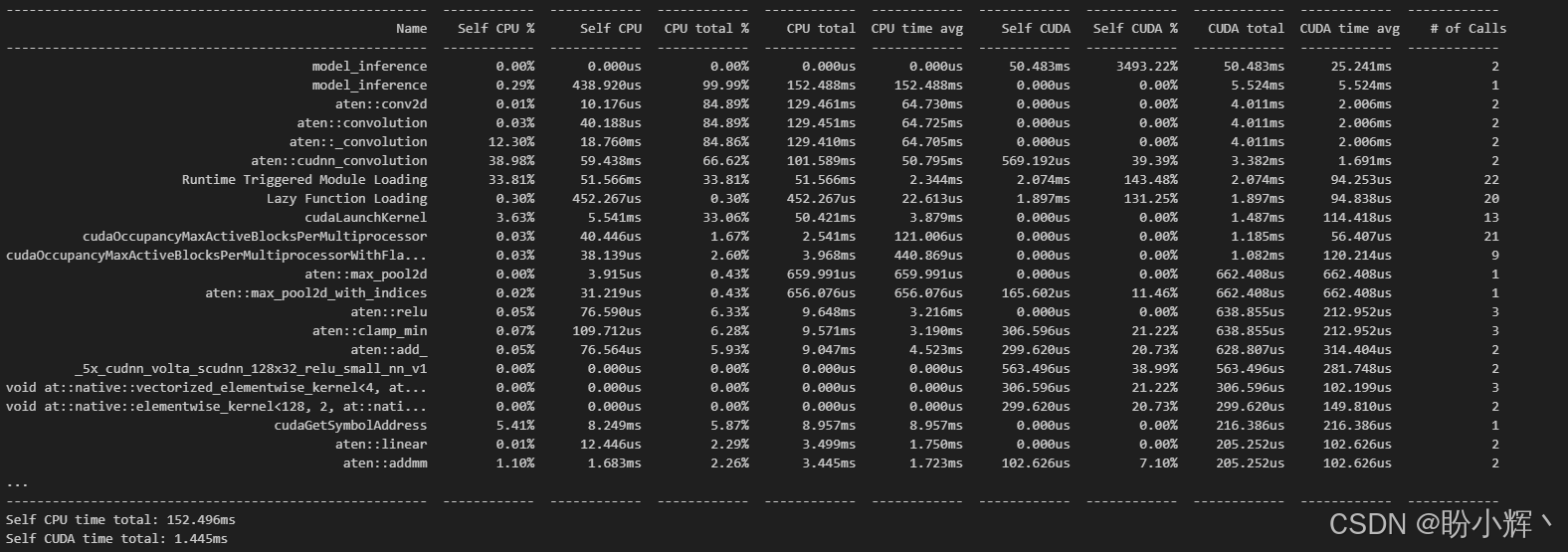
首先,我们可以明显观察到,当使用 GPU 时,推理时间大幅缩短。性能分析将 1.4 毫秒的 GPU 推理时间进行了细分:卷积操作占据了主要耗时 (40%)。值得注意的是,在 GPU 环境下,torch conv2d 操作会自动调用 cudnn 后端来执行底层优化卷积运算。而在 CPU 性能分析中,我们看到 torch 使用的是 mk1 作为底层卷积运算后端。这种性能分析能帮助我们理解不同硬件 (CPU/GPU) 对运算的底层优化细节。
接下来,我们将学习如何可视化模型推理的性能分析结果。
4. 可视化模型性能分析结果
PyTorch Profiler 允许我们将分析结果保存为 trace.json 文件,可以在 Google Chrome 中打开并以图表形式进行可视化。将模型和输入数据加载到 GPU 后,我们只需要执行以下操作:
python
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA]) as prof:
model(sample_data)
prof.export_chrome_trace("trace.json")随后在 Chrome 浏览器新建标签页访问 chrome://tracing 并打开该 JSON 文件,即可看到如下图所示的性能分析图:
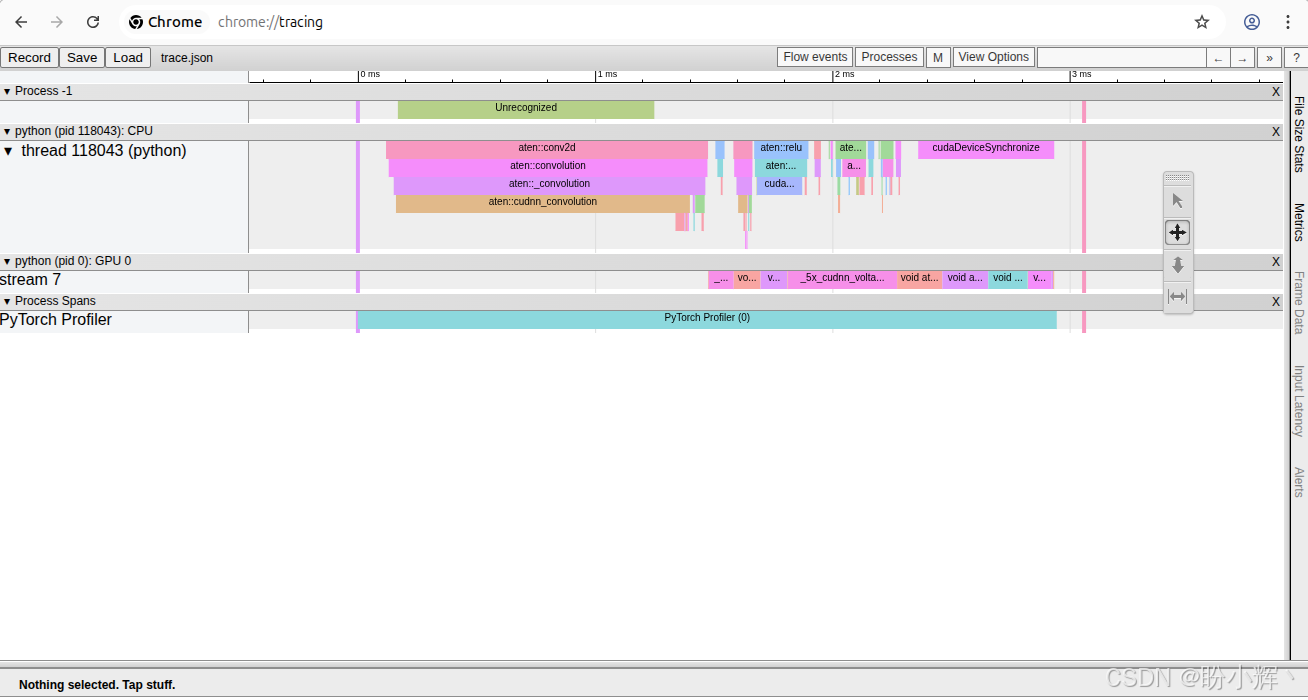
在本节中,我们介绍了如何使用 PyTorch Profiler 分析 MNIST 模型在 CPU 和 GPU 上推理性能。
小结
本节介绍了使用 PyTorch Profiler 工具分析 MNIST 手写数字识别模型在 CPU 与 GPU 上的推理性能。通过记录操作执行时间与内存消耗,可识别计算瓶颈和内存问题。通过本节学习,能够掌握在模型推理过程中进行性能分析的方法,从而能更准确地评估模型在 CPU 和 GPU 上的运行表现。
系列链接
PyTorch实战(1)------深度学习(Deep Learning)
PyTorch实战(2)------使用PyTorch构建神经网络
PyTorch实战(3)------PyTorch vs. TensorFlow详解
PyTorch实战(4)------卷积神经网络(Convolutional Neural Network,CNN)
PyTorch实战(5)------深度卷积神经网络
PyTorch实战(6)------模型微调详解
PyTorch实战(7)------循环神经网络
PyTorch实战(8)------图像描述生成
PyTorch实战(9)------从零开始实现Transformer
PyTorch实战(10)------从零开始实现GPT模型
PyTorch实战(11)------随机连接神经网络(RandWireNN)
PyTorch实战(12)------图神经网络(Graph Neural Network,GNN)
PyTorch实战(13)------图卷积网络(Graph Convolutional Network,GCN)
PyTorch实战(14)------图注意力网络(Graph Attention Network,GAT)
PyTorch实战(15)------基于Transformer的文本生成技术
PyTorch实战(16)------基于LSTM实现音乐生成
PyTorch实战(17)------神经风格迁移
PyTorch实战(18)------自编码器(Autoencoder,AE)
PyTorch实战(19)------变分自编码器(Variational Autoencoder,VAE)
PyTorch实战(20)------生成对抗网络(Generative Adversarial Network,GAN)
PyTorch实战(21)------扩散模型(Diffusion Model)
PyTorch实战(22)------MuseGAN详解与实现
PyTorch实战(23)------基于Transformer生成音乐
PyTorch实战(24)------深度强化学习
PyTorch实战(25)------使用PyTorch构建DQN模型
PyTorch实战(26)------PyTorch分布式训练
PyTorch实战(27)------自动混合精度训练
PyTorch实战(28)------PyTorch深度学习模型部署
PyTorch实战(29)------使用TorchServe部署PyTorch模型
PyTorch实战(30)------使用TorchScript和ONNX导出通用PyTorch模型
PyTorch实战(31)------在Android上部署PyTorch模型
PyTorch实战(32)------在iOS上构建PyTorch应用
PyTorch实战(33)------使用fastai进行快速原型开发
PyTorch实战(34)------基于PyTorch Lightning的跨硬件模型训练