步骤:
(1)准备数据集
(2)定义线性模型
(3)选择损失函数和优化器
(4)训练循环
(i)先进行前向传播,计算y估计和loss函数
(ii)再进行反向传播。【注意】在反向传播前记得梯度清零,否则每轮梯度会累加起来。
(iii)权重更新
python
import torch
import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
# 1. 准备数据集
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
# 2. 定义线性模型
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear = torch.nn.Linear(1, 1, bias=True)
def forward(self, x):
return self.linear(x)
model = LinearModel()
# 3. 损失函数和优化器
criterion = torch.nn.MSELoss(reduction='sum')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 记录训练过程的w、b、loss
w_list, b_list, loss_list = [], [], []
# step 4: Training Cycle 训练循环
for epoch in range(100):
y_pred = model(x_data) # y的预测值
loss = criterion(y_pred, y_data) # 损失值
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 权重更新
# 记录参数和损失
w_list.append(model.linear.weight.item())
b_list.append(model.linear.bias.item())
loss_list.append(loss.item())
# -------------------------- 精简版可视化 --------------------------
# 仅保留核心的3D损失曲面+训练轨迹
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, projection='3d')
# 生成w和b的网格(精简范围,提升效率)
w_range = np.linspace(0, 4, 50) # 减少点数,加快绘图
b_range = np.linspace(-2, 2, 50)
W, B = np.meshgrid(w_range, b_range)
# 计算网格对应的损失值(核心逻辑保留)
Loss = np.zeros_like(W)
for i in range(len(w_range)):
for j in range(len(b_range)):
y_pred_grid = W[j, i] * x_data + B[j, i]
Loss[j, i] = criterion(y_pred_grid, y_data).item()
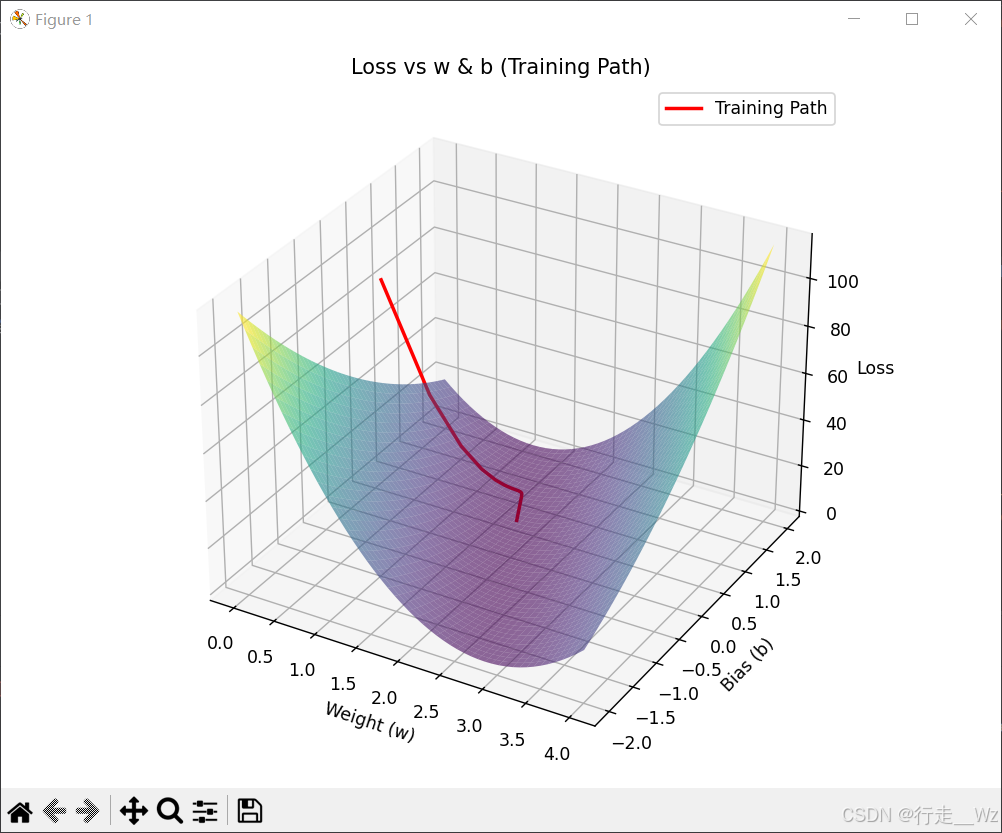
# 绘制核心内容:损失曲面 + 训练轨迹
ax.plot_surface(W, B, Loss, cmap='viridis', alpha=0.6) # 损失曲面(半透明)
ax.plot(w_list, b_list, loss_list, 'r-', linewidth=2, label='Training Path') # 训练轨迹
# 基础标注(仅保留关键标签)
ax.set_xlabel('Weight (w)')
ax.set_ylabel('Bias (b)')
ax.set_zlabel('Loss')
ax.set_title('Loss vs w & b (Training Path)')
ax.legend()
plt.tight_layout()
plt.show()
# 输出最终结果(精简版)
print(f"最终w: {w_list[-1]:.4f}, 最终b: {b_list[-1]:.4f}, 最终Loss: {loss_list[-1]:.4f}")运行结果:
作业
python
import torch
import matplotlib.pyplot as plt
# step 1: Prepare Dataset
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
# step 2: Design Model
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear = torch.nn.Linear(1, 1, bias=True)
def forward(self, x):
y_pred = self.linear(x)
return y_pred
models = {
'SGD': LinearModel(),
'Adam': LinearModel(),
'Adagrad': LinearModel(),
'Adamax': LinearModel(),
'ASGD': LinearModel(),
'RMSprop': LinearModel(),
'Rprop': LinearModel(),
}
# step 3: Donstruct Loss and Optimizer
criterion = torch.nn.MSELoss(size_average=False)
optimizer = {
'SGD': torch.optim.SGD(models['SGD'].parameters(), lr=0.01),
'Adam': torch.optim.Adam(models['Adam'].parameters(), lr=0.01),
'Adagrad': torch.optim.Adagrad(models['Adagrad'].parameters(), lr=0.01),
'Adamax': torch.optim.Adamax(models['Adamax'].parameters(), lr=0.01),
'ASGD': torch.optim.ASGD(models['ASGD'].parameters(), lr=0.01),
'RMSprop': torch.optim.RMSprop(models['RMSprop'].parameters(), lr=0.01),
'Rprop': torch.optim.Rprop(models['RMSprop'].parameters(), lr=0.01),
}
loss_values = {k: [] for k in optimizer.keys()}
# step 4: Training Cycle
for opt_name, optimizer in optimizer.items():
model = models[opt_name]
for epoch in range(100):
y_pred = model(x_data) # forward predict
loss = criterion(y_pred, y_data) # forward loss
optimizer.zero_grad() # set the grad to zero
loss.backward() # backward
optimizer.step() # update
loss_values[opt_name].append(loss.item())
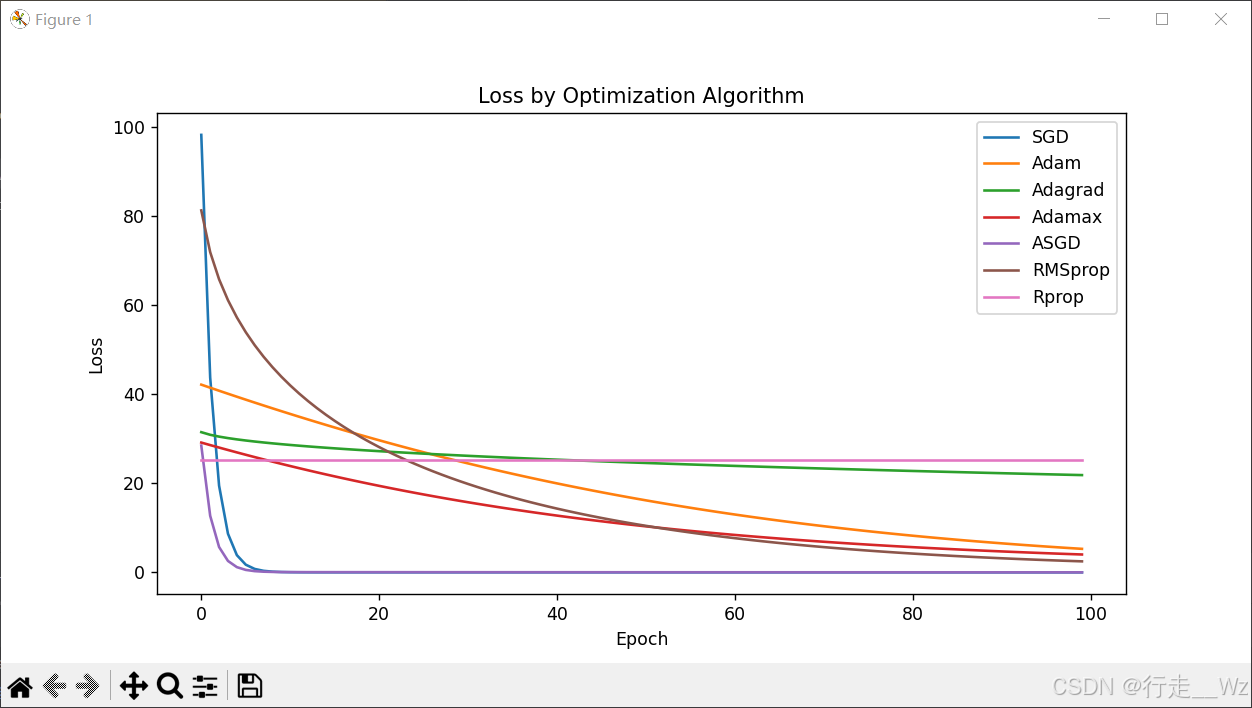
plt.figure(figsize=(10, 5))
for opt_name, losses in loss_values.items():
plt.plot(losses, label=opt_name)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.title("Loss by Optimization Algorithm")
plt.show()运行结果: