一、数据存储简介
文件存储
对于这种中小规模的爬虫而言,可以将爬虫结果汇合到一个文件进行持久化存储。
数据库存储
对于抓取的数据种类丰富、数量庞大的大规模爬虫来说,我们可以将这些爬虫结果存入数据库中,不仅方便存储,也方便进一步整理。
Python中常用的数据库系统
MySQL
一种开源的关系型数据库,使用最常用的数据库管理语言(结构化查询语言SQL)进行数据库管理。它会将数据保存到不同的表中,不仅速度快,而且灵活性高。
MongoDB
一个基于分布式文件存储的数据库,是当前NoSQL(非关系型的数据库)数据库中比较热门的一种。它面向集合存储,易存储对象类型的数据,具有高性能、易部署、易使用等特点。
二、MongoDB数据库简介
MongoDB是一款基于分布式文件存储的NoSQL数据库,具有免费、操作简单、面向文档存储等强大特点,旨在为Web应用提供可扩展的高性能数据存储解决方案。
功能 特性
Windows平台安装MongoDB数据库
(1)打开MongoDB下载网站,单击【Community Server】选项查看当前可用于下载的数据库版本。
(2)单击【DOWNLOAD (msi)】按钮,下载msi文件。当下载完成以后,双击刚刚下载的文件。
(3)单击【Next】按钮,开始安装程序,之后直接按照提示安装即可。
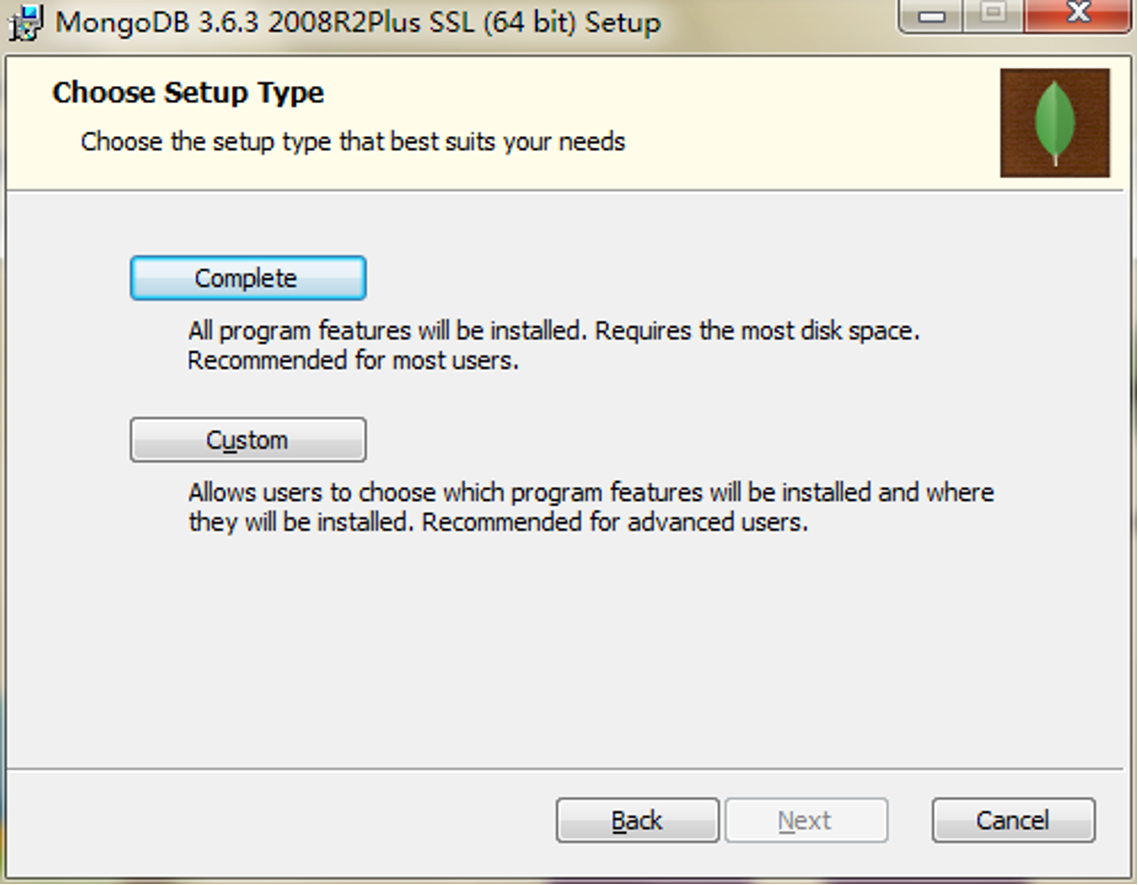
(4)取消对【Install MongoDB Compass】的勾选,即不安装MongoDB Compass。
(5)创建两个目录"C:\MongoDBData\db"和"C:\MongoDBData\log",分别作为数据和日志文件夹。
(6)打开控制台,将当前路径切换到MongoDB的安装目录下,在该路径下输入如下命令:
bash
mongod.exe --dbpath c:\MongoDBData\db(7)在实际使用中,使用Windows服务的方式打开比较方便。打开控制台,切换到MongoDB的安装目录,之后输入如下命令:
bash
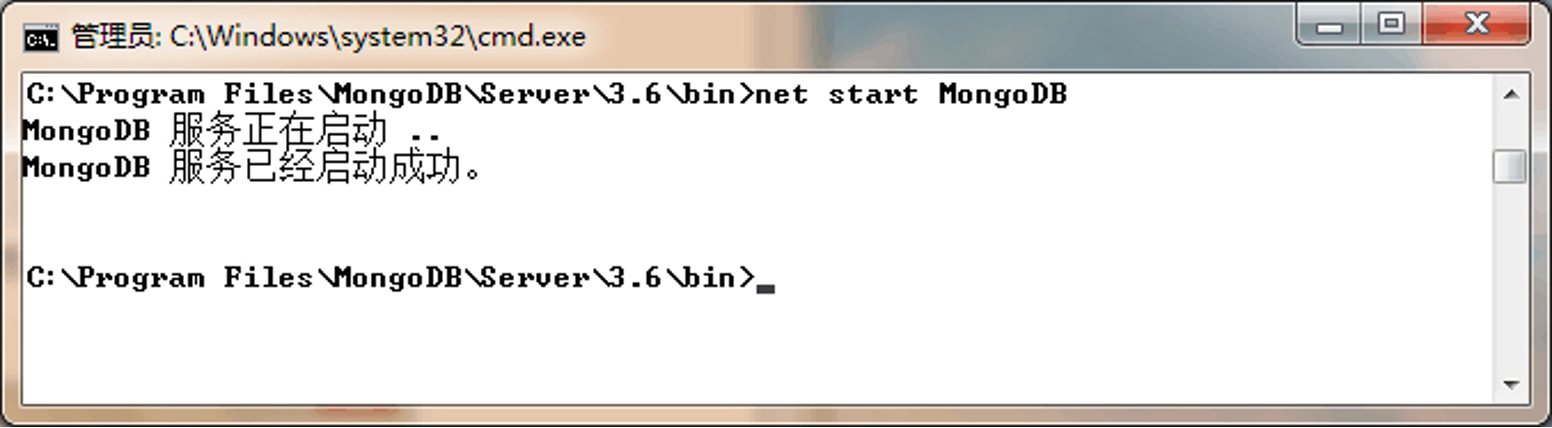
mongod.exe --logpath "C:\MongoDBData\log\mongodb.log" --logappend --dbpath "c:\MongoDBData\db" --serviceName "MongoDB" --install(8)输入如下命令,启动MongoDB服务器。
bash
net start MongoDB(9)启动以后,可以看到如下所示的信息,表示成功启动了MongoDB服务。
(10)如果要关闭MongoDB服务,可以输入如下命令:
bash
net stop MongoDB当下次打开电脑时,无需再次输入配置和启动命令,可以直接进入MongoDB安装目录下的bin目录下,双击"mongo.exe"打开数据库的交互窗口(mongo shell)即可。
比较MongoDB和MySQL的术语
MongoDB是一种非关系型数据库,它没有表的概念,其数据库的基本组成单元是集合。
|--------------|------------------|-------------------------|
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | | 表连接/MongoDB不支持 |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
在MongoDB中最基本的概念就是数据库、集合和文档。
数据库(DataBase): 表示一个集合的物理容器。
一个MongoDB中可以建立多个数据库,默认的数据库为"db",它存储在data目录中。

文档(Document): 一组由键/值对组成的对象,对应着关系型数据库的行。
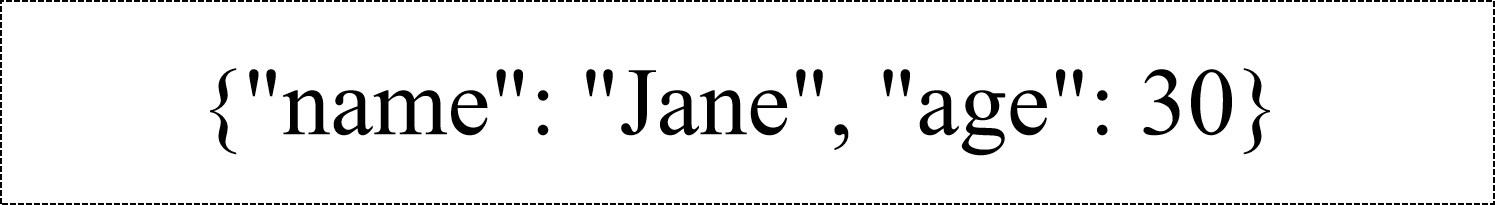
文档中的键/值对是有顺序的,文档中的值不仅可以是字符串类型,而且可以是其它数据类型。
集合(Collection): 集合就是一组文档,类似于关系数据库中的表。
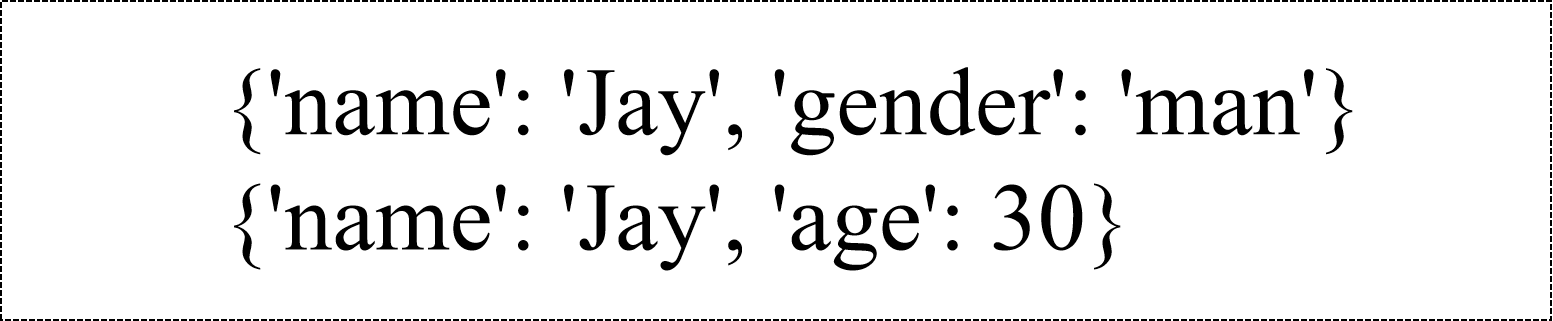
集合没有固定的结构,这意味着可以往集合中插入不同格式和类型的数据。
三、使用PyMongo库存储到数据库
什么是PyMongo
PyMongo是使用Python操作MongoDB数据库的开发工具。
常用的类
|--------------|-------------------------------|
| 类名 | 功能描述 |
| MongoClient类 | 用于与MongoDB服务器建立连接 |
| DataBase类 | 表示MongoDB中的数据库 |
| Collection类 | 表示MongoDB中的集合 |
| Cursor类 | 表示查询方法(find)返回的结果,用于对多行数据进行遍历 |
PyMongo的基本操作
1、安装第三方库PyMongo
在Windows系统下
bash
pip install pymongo2、导入pymongo库
python
from pymongo import *3、建立连接
创建一个MongoClient类的对象,建立与MongoDB服务器的连接。
构造方法:
python
class pymongo.mongo_client.MongoClient(host='localhost', port=27017,
document_class=dict, tz_aware=False, connect=True, **kwargs)参数: host -- 表示主机名或IP地址。 port -- 表示连接的端口号。
1️⃣可以显式地指定主机和使用端口:
python
client = MongoClient('localhost', 27017)2️⃣可以使用MongoDB的URL路径形式传入参数:
python
client = MongoClient('mongodb://localhost:27017')4、访问数据库
通过刚创建的MongoClient对象访问数据库。
python
db = client.pymongo_test
# 还可以使用字典的形式进行访问
db = client['pymongo_test']如果数据库不存在,自动创建一个数据库。
5、创建集合
使用上个步骤的数据库创建一个集合。
python
collection = db.startup_log如果集合不存在,自动创建一个集合。
6、操作集合
调用集合中提供的方法在集合中插入、删除、修改和查询文档。
1️⃣插入文档
insert_one()方法:插入一条文档对象。
insert_many()方法:插入列表形式的多条文档对象。
python
result = collection.insert_one({'name':'zhangsan', 'age':20})2️⃣查找文档
find_one()方法:查找一条文档对象。
find_many()方法:查找多条文档对象。
find()方法:查找所有文档对象。
python
result = collection.find({'age': 20})3️⃣更新文档
update_one()方法:更新一条文档对象。
update_many()方法:更新多条文档对象。
python
collection.update_one({'age': 22}, {'$set': {'name': 'zhaoliu'}})
collection.update_many({'age': 22}, {'$set': {'name': 'zhaoliu'}})4️⃣删除文档
delete_one()方法:删除一条文档对象。
delete_many()方法:删除所有记录。
python
collection.delete_many({})四、案例--存储网站的电影信息
先爬取豆瓣top250排行榜上的电影信息(电影名称、豆瓣评分、相关链接),再将这些信息存储到MongoDB数据库中。
1、分析待爬取的网页
点击https://movie.douban.com/top250打开排行榜网页,右击某个电影名称,选择"检查"命令,会打开对应的源代码,例如:
html
<div class="hd">
<a href="https://movie.douban.com/subject/1291546/">
<span class="title">霸王别姬</span>
<span class="other"> / 再见,我的妾 / Farewell My Concubine</span>
</a>
<span class="playable">[可播放]</span>
</div>我们需要的电影名称在第3行代码中,由于页面源代码包含多个span,为了区分其他span,需要向上查找父标签a,因此最终的查找路径为<a>/<spanclass='title'>/text()。
如果不想自己分析出路径,也可以右击span,选择copy-->copy xpath,得到如下路径:
//*@id="content"/div/div1/ol/li2/div/div2/div1/a/span1
按照同样的方式,得到评分的路径为div/spanclass='rating_num'/text(),相关链接的路径为a/href.