爬虫获取某鱼网页版商品数据
免责声明:本教程仅供学习交流,请勿用于非法用途。在编写爬虫时,请遵守网站的 robots.txt 规定,合理控制请求频率,避免对服务器造成压力。因使用本教程内容而产生的任何法律后果,由使用者自行承担。
完整代码:
https://github.com/ziyifast/ziyifast-code_instruction/tree/main/python-demo/spider-demo/xy-demo欢迎大家⭐️star~
常规爬虫流程:
- 访问页面,定位请求。通过页面文字值,定位对应接口
- 观察接口响应结果,通过代码解析返回值
- 翻页观察请求参数变化
- Debug逆向出请求参数sign,时间戳等
- 完善代码,构造请求,实现爬取多页数据
- 数据持久化
1. 流程教学
本部分将爬虫逆向的通用流程拆解为六个步骤,无论目标网站是什么,都可以遵循参考这一思路进行分析。
第一步:访问页面,定位请求
- 目标:找到承载目标数据的网络请求。
- 操作:
- 打开浏览器开发者工具(F12),切换到 Network(网络)选项卡。
- 在页面执行关键操作(如搜索、翻页、点击),观察 Network 中新增的请求。
- 利用页面上的可见文字(如商品标题、价格)在请求的 Response 中搜索(Ctrl+F),快速定位到包含该数据的请求。
- 注意筛选 XHR / Fetch 请求,通常数据接口为 JSON 格式。
第二步:观察接口响应结构
- 目标:理解返回数据的格式,明确所需字段的位置。
- 操作:
- 点击请求,查看 Preview 或 Response 标签,分析 JSON 结构。
- 确定商品列表所在的路径(如 data.items、data.resultList 等)。
- 记录每个商品包含的字段(标题、价格、图片、链接等)。
- 编写简单的解析代码(Python + json 模块)验证提取逻辑。
第三步:翻页观察请求参数变化
- 目标:找出控制分页的参数,为后续批量爬取做准备。
- 操作:
- 点击下一页,对比两次请求的 URL 或表单数据。
- 常见的翻页参数:page、pageNo、start、offset 等。
- 若只有页码变化,则翻页逻辑简单;若有动态加密参数(如 sign、token),则需要进一步逆向。
第四步:Debug 逆向请求参数(如 sign、时间戳)
- 目标:还原加密参数的生成过程,以便在代码中模拟。
- 操作:
- 在请求中找到疑似加密的参数,如 sign、_signature。
- 切换到 Sources 面板,全局搜索(Ctrl+Shift+F)参数名,定位到生成该值的 JS 代码。
- 在可疑位置打断点,重新触发请求,观察调用栈和变量作用域,追踪加密逻辑。
- 分析加密算法(MD5、SHA256、自定义拼接等),并尝试用 Python 实现或调用 JS 执行。
- 验证:手动计算的值与请求中的值一致。
第五步:完善代码,构造请求,实现多页爬取
- 目标:将逆向成果集成到爬虫脚本中,循环获取多页数据。
- 操作:
- 封装请求函数,动态生成参数(包括翻页参数、时间戳、sign 等)。
- 设置合理的请求头(User-Agent、Referer、Cookie 等)。
- 加入异常处理和随机延时,降低被封风险。
- 循环请求直到获取所有数据(根据总页数或直到返回空数据)。
第六步:数据持久化
- 目标:将爬取的数据保存到本地或数据库,便于后续分析。
- 常用方式:
- CSV:适合表格型数据,可用 Excel 打开。
- JSON:保留原始嵌套结构,方便程序读取。
- 数据库:如 MySQL、MongoDB,适合大规模数据存储。
2. 项目实战某鱼商品爬取
本部分将以闲鱼网页版(搜索"手机"这个商品为例)完整演示上述六个步骤的具体操作。
第一步:访问页面,定位请求
- 打开浏览器开发者工具(F12),切换到 Network(网络)选项卡。
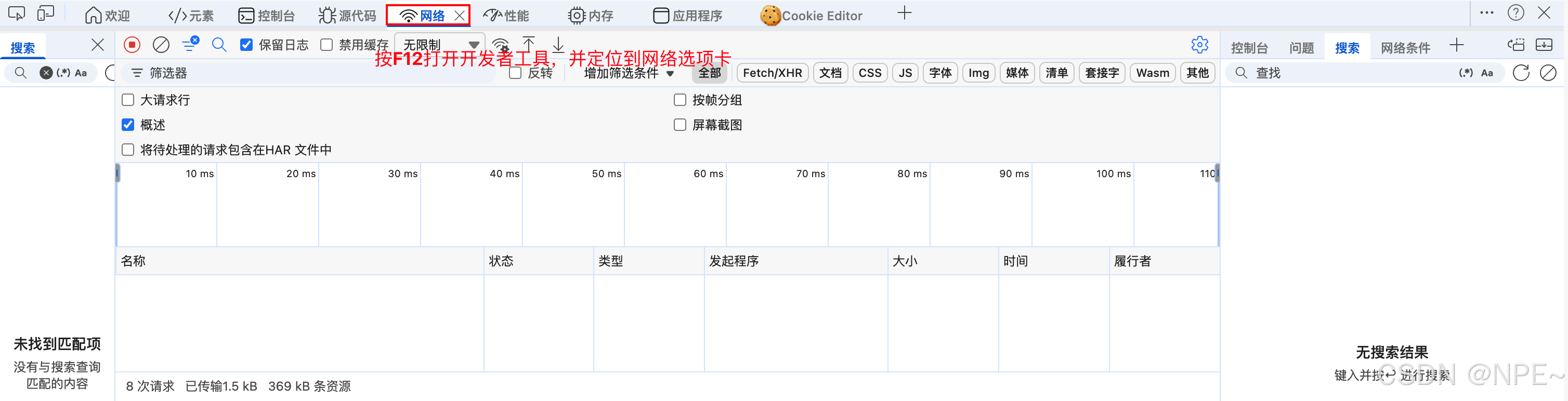
- 访问闲鱼网页版(如 https://2.taobao.com/),在搜索框输入关键词(如"手机"),点击搜索。
- 在 Network 面板中,观察加载的请求。通常数据接口是 XHR(XMLHttpRequest)或 Fetch 请求,可以筛选 XHR 或 Fetch 类型。
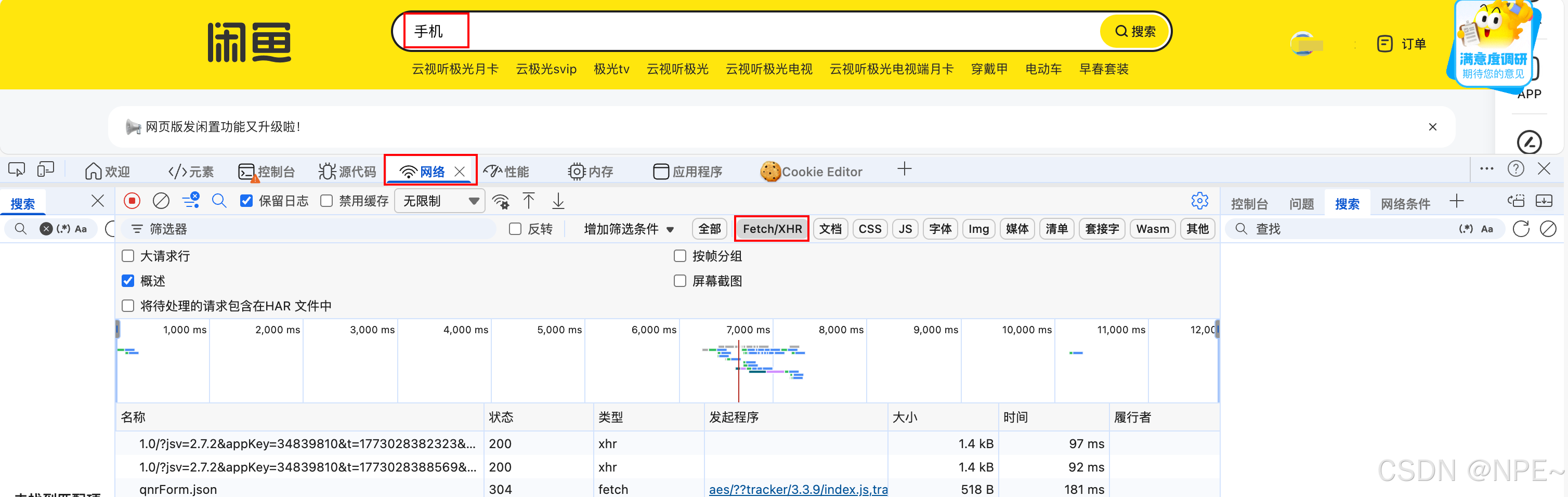
- 利用页面文字定位:随便选择一个商品描述(比如"女生自用的"),复制它。然后在 Network 面板按 Ctrl+F 搜索该标题,很快就能找到包含它的请求。
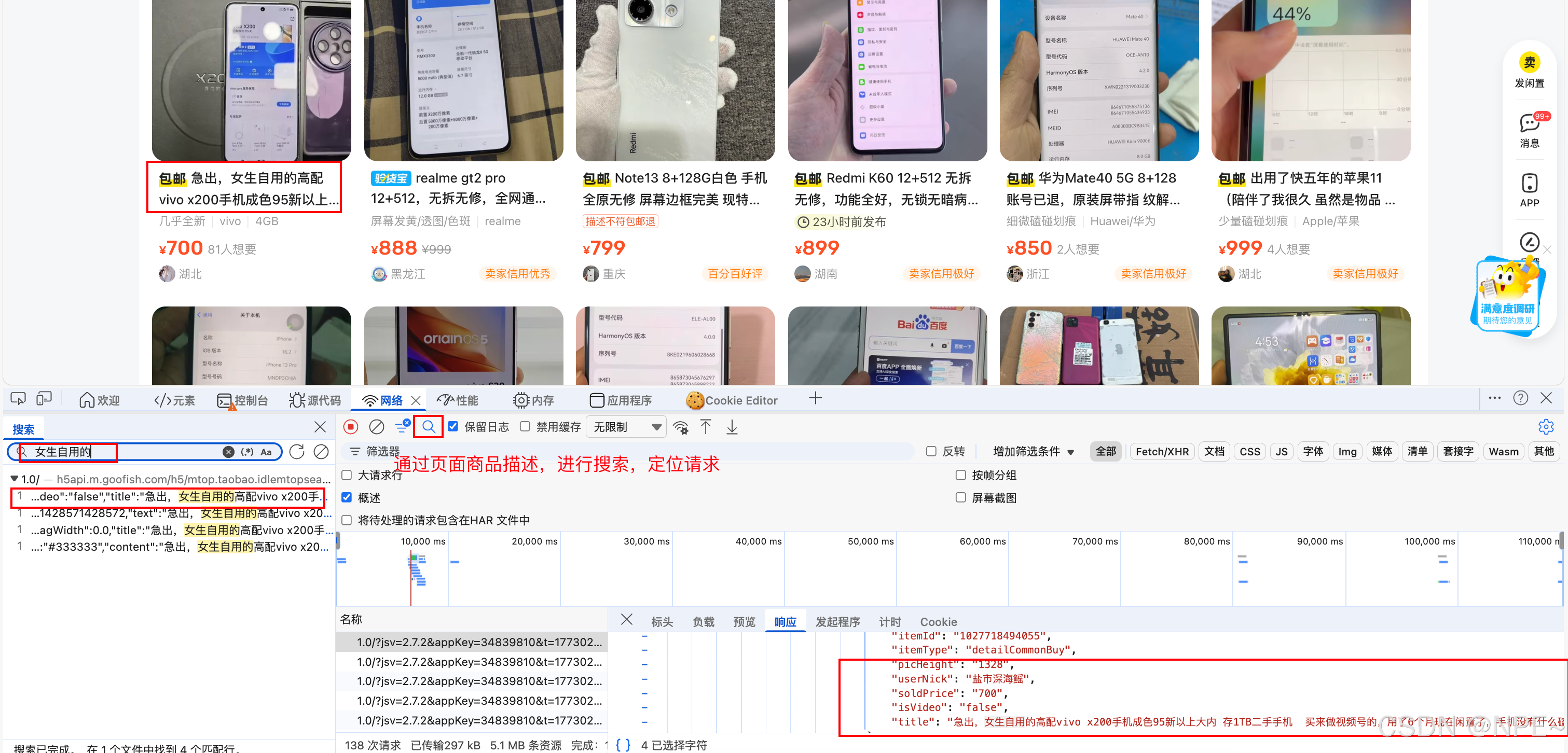
最终定位到该接口。
第二步:观察接口响应结构
目标:分析接口返回的数据格式,提取需要的字段。
- 在 Network 中点击该请求,查看 Preview 或 Response 标签,观察返回的 JSON 数据结构。
- 常见的结构:可能包含总页数、当前页、商品列表(items)等。每个商品通常包含标题、价格、图片链接、商品ID等字段。
- 编写解析代码:使用 Python 的 requests 库模拟请求,并使用 json 模块解析数据。
复制响应体结构(一般为json),然后可以用在线json格式化工具进行分析,找到自己想要的字段在哪个位置
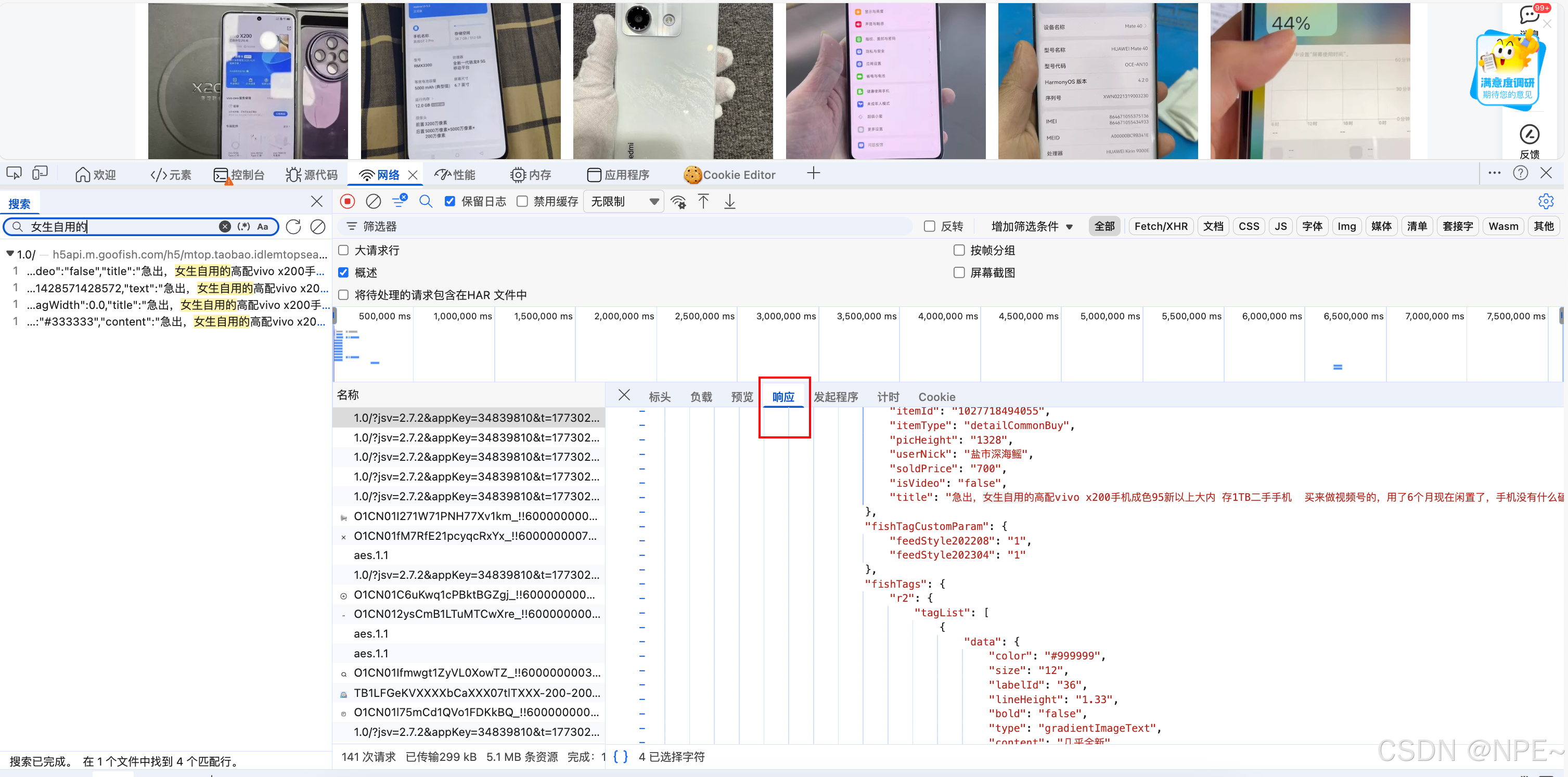
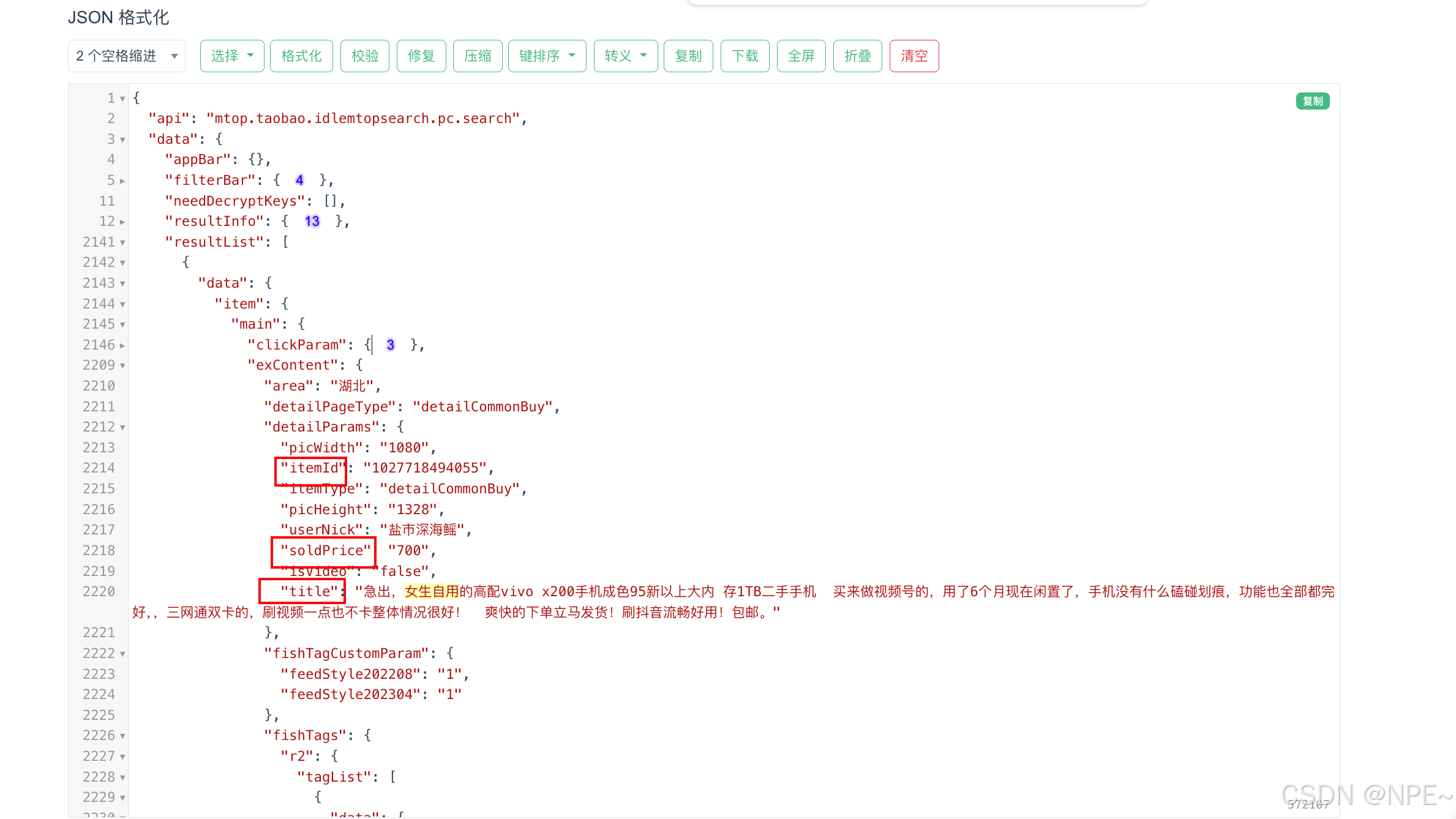
定位好之后,编写解析代码:
python
import json
import re
def parse_items_from_json(json_str: str):
"""
解析闲鱼商品 JSON 数据,提取标题、价格和链接。
"""
try:
data = json.loads(json_str)
except json.JSONDecodeError as e:
print(f"JSON 解析失败: {e}")
return []
# 定位商品列表
result_list = data.get("data", {}).get("resultList")
if not isinstance(result_list, list):
print("未找到商品列表数据")
return []
items = []
for result in result_list:
item = result.get("data", {}).get("item").get("main")
if not item:
continue
# 提取 exContent 部分
ex_content = item.get("exContent", {})
title = ex_content.get("title", "")
# 价格需要从 price 数组拼接
price_parts = ex_content.get("price", [])
price = "".join(part.get("text", "") for part in price_parts if part.get("text"))
# 商品链接(fleamarket://item?id=1028119642178&referPageArgs=)
# 提取出item?id=1028119642178
target_url = item.get("targetUrl", "")
url = "https://www.goofish.com/item?id=" + re.search(r"item\?id=(\d+)", target_url).group(1)
items.append({
"title": title,
"price": price,
"url": url
})
return items
# 将结果保存在xianyu.json文件中
with open('xianyu.json', 'r', encoding='utf-8') as f:
json_data = f.read()
parsed_items = parse_items_from_json(json_data)
print(f"共解析到 {len(parsed_items)} 条商品\n")
# 打印前5条作为示例
for i, item in enumerate(parsed_items[:5], 1):
print(f"商品 {i}:")
print(f"标题: {item['title']}")
print(f"价格: {item['price']}")
print(f"链接: {item['url']}")
print("-" * 50)效果:

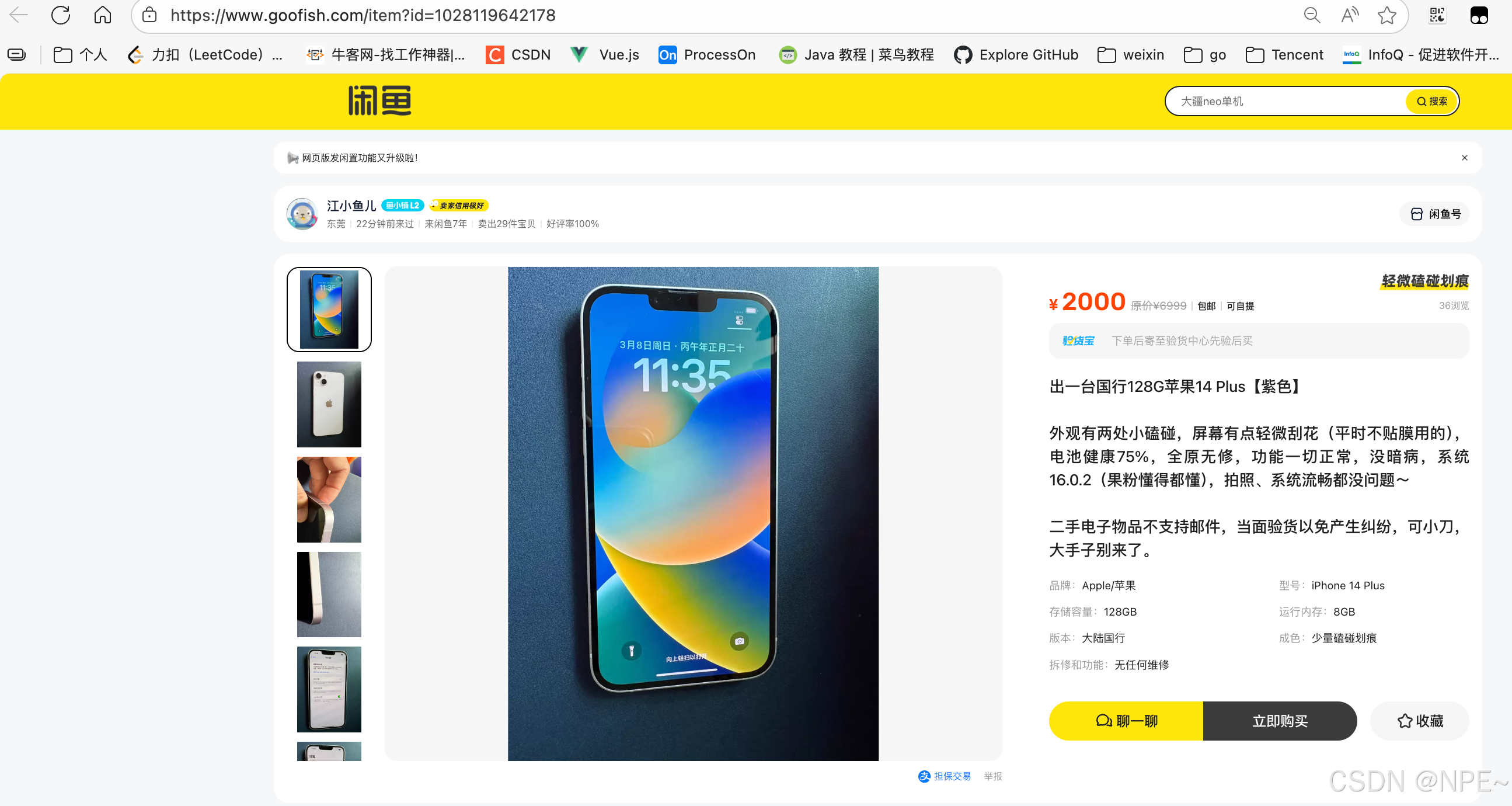
任意访问一个商品链接,可以看到商品描述、价格没问题:
第三步:翻页观察请求参数变化
- 点击负载,观察本次请求参数
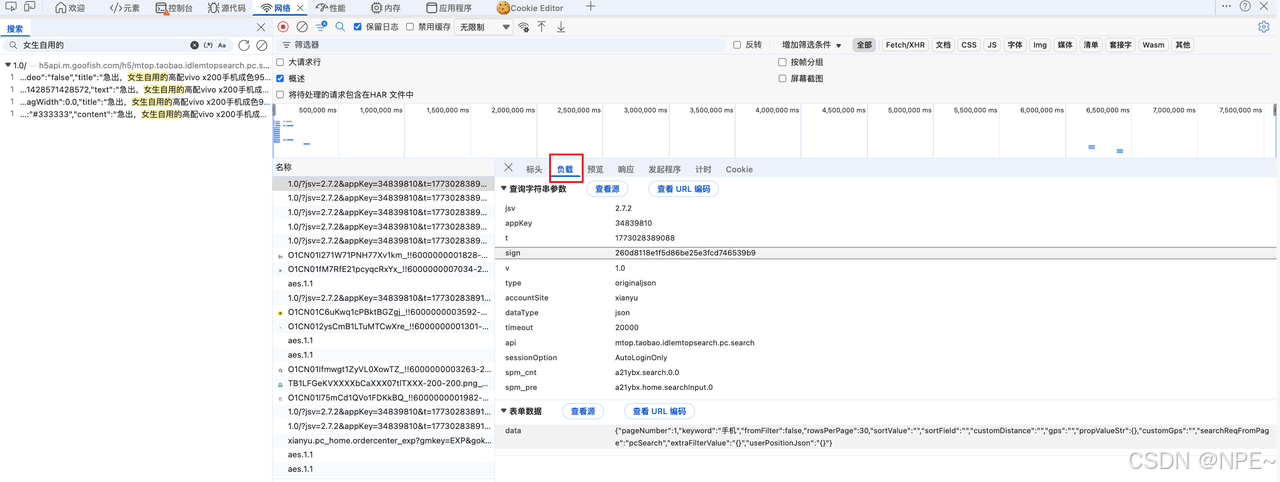
- 页面上点击下一页(翻页),并抓包,观察请求(定位具体请求方式跟之前一样)
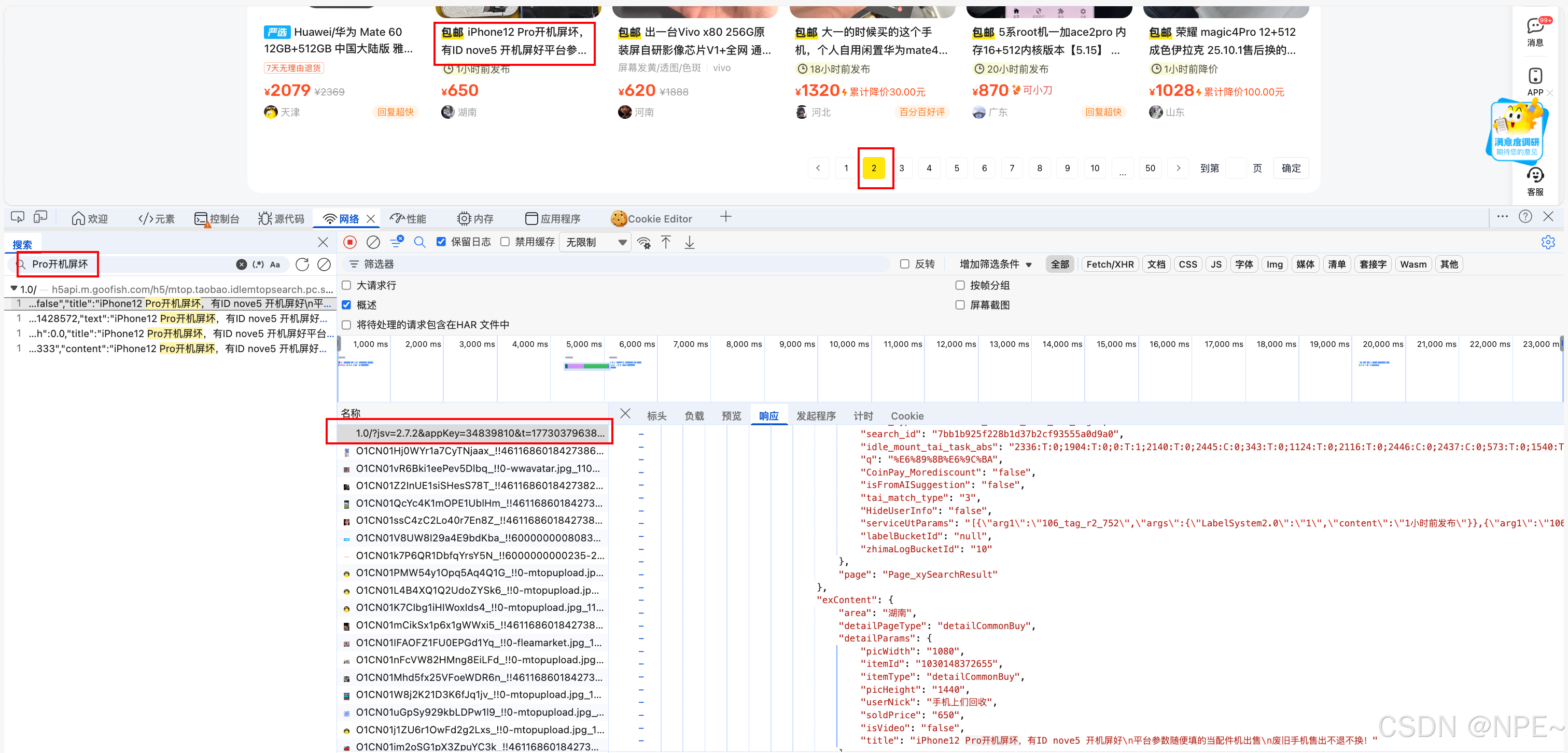
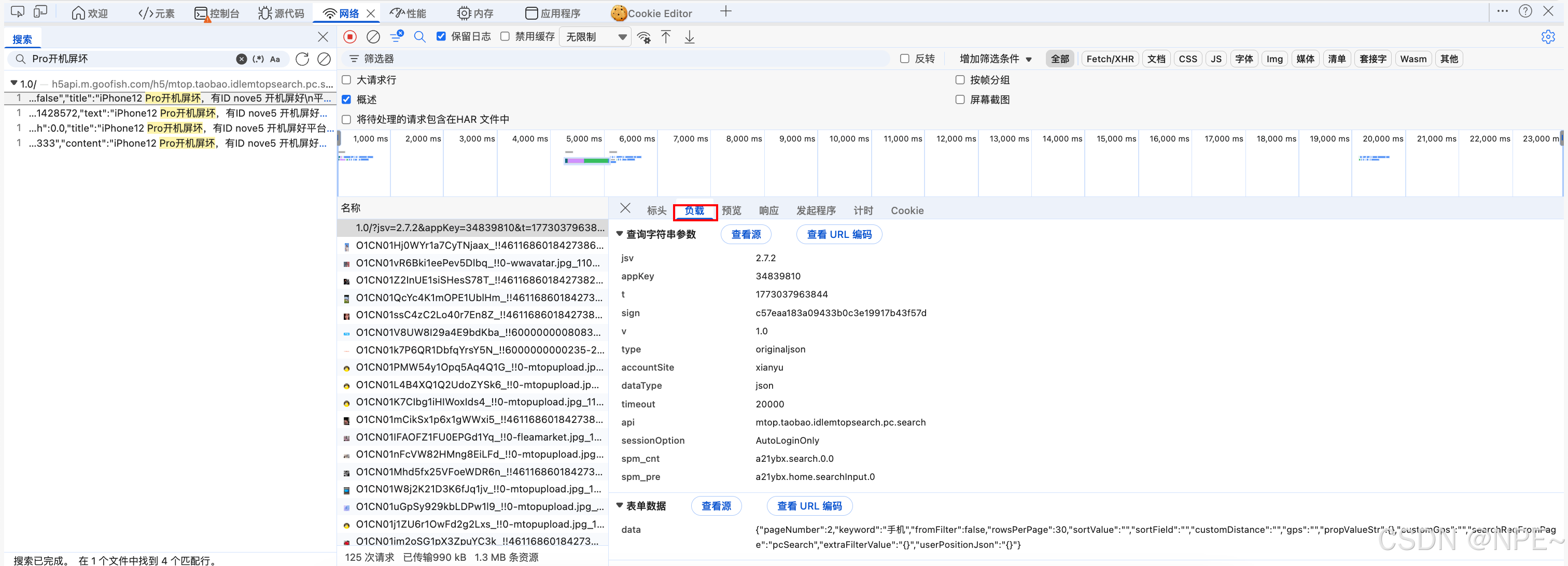
- 对比两次请求,可以发现两次请求上t和sign和表单数据中的pageNumber不同
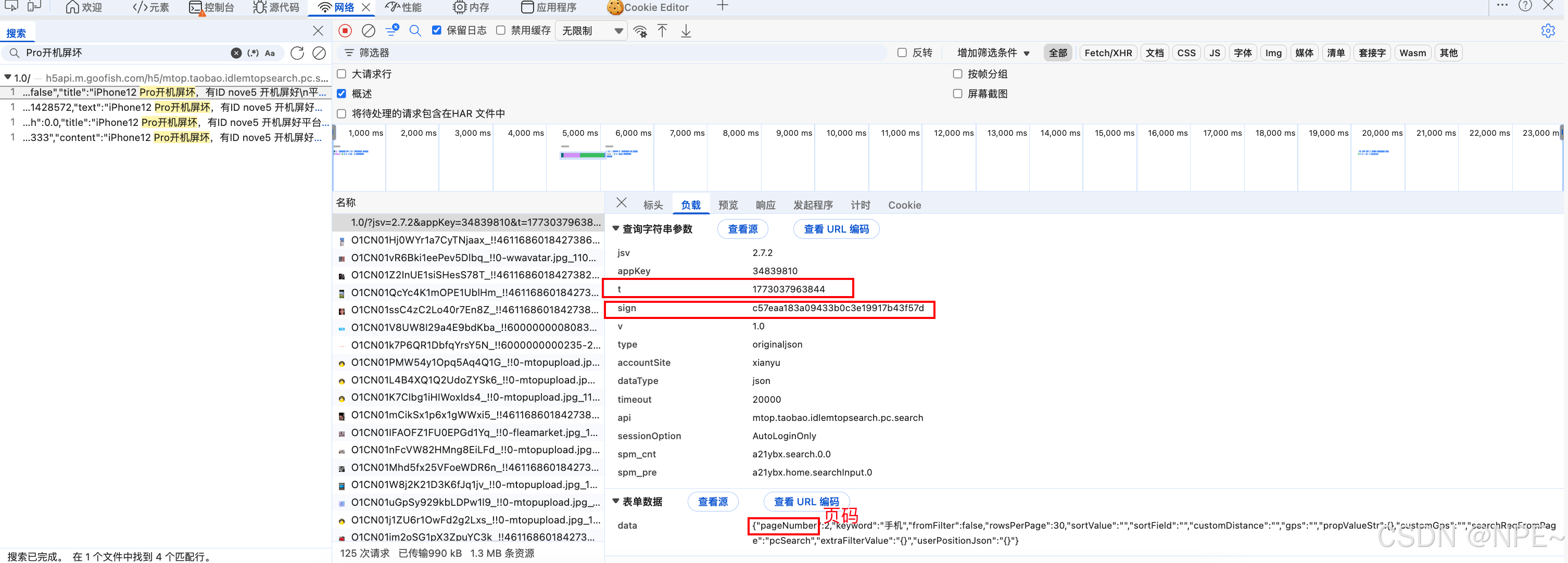
pageNumber可以直接知道是当前请求的页码,t根据数值和常理判断,应该是当前请求的时间戳(毫秒级时间戳),那么sign就是我们需要逆向的签名。
在线时间戳工具:https://tool.lu/timestamp/
第四步:Debug 逆向出请求参数
- 因为一般这类加密请求参数都是在前端生成的,所以我们可以直接在全局搜索面板输入sign: 尝试定位对应js
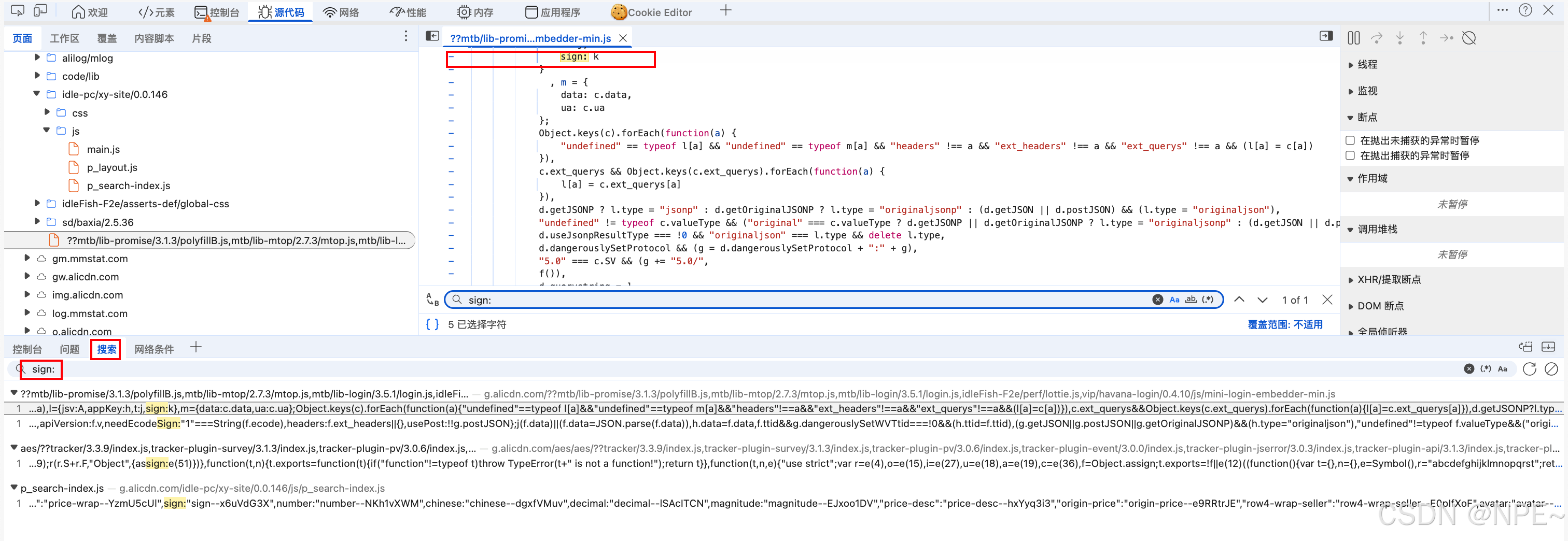
- 在此处单击鼠标左键,打上Debug分析其生成逻辑
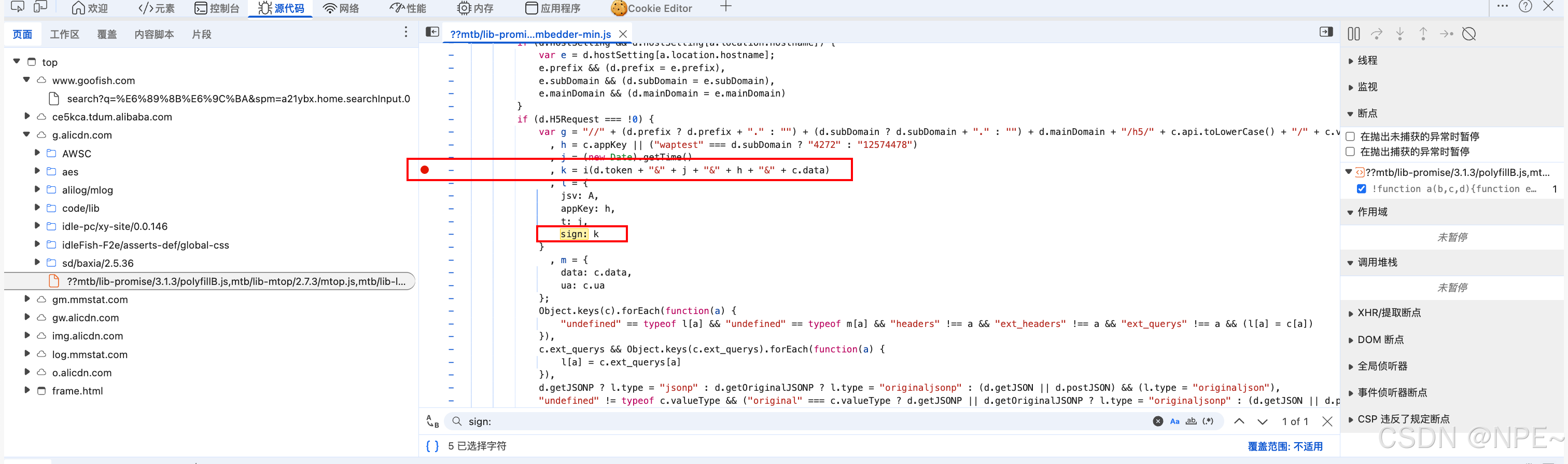
- 刷新页面重新请求,跟进断点,一步步分析。
- 跟进后可以发现sign是来自k变量
- k变量则是来自下面的方法
python
i(d.token + "&" + j + "&" + h + "&" + c.data)- 下面就主要看下i方法的入参,通过控制辅助定位
- token这里短时间内是固定的(主要用于校验用户身份),
- j这里分析后发现是t,也就是时间戳
- h这里分析后发现也是固定的
- c.data这里可以看到就是我们的请求负载
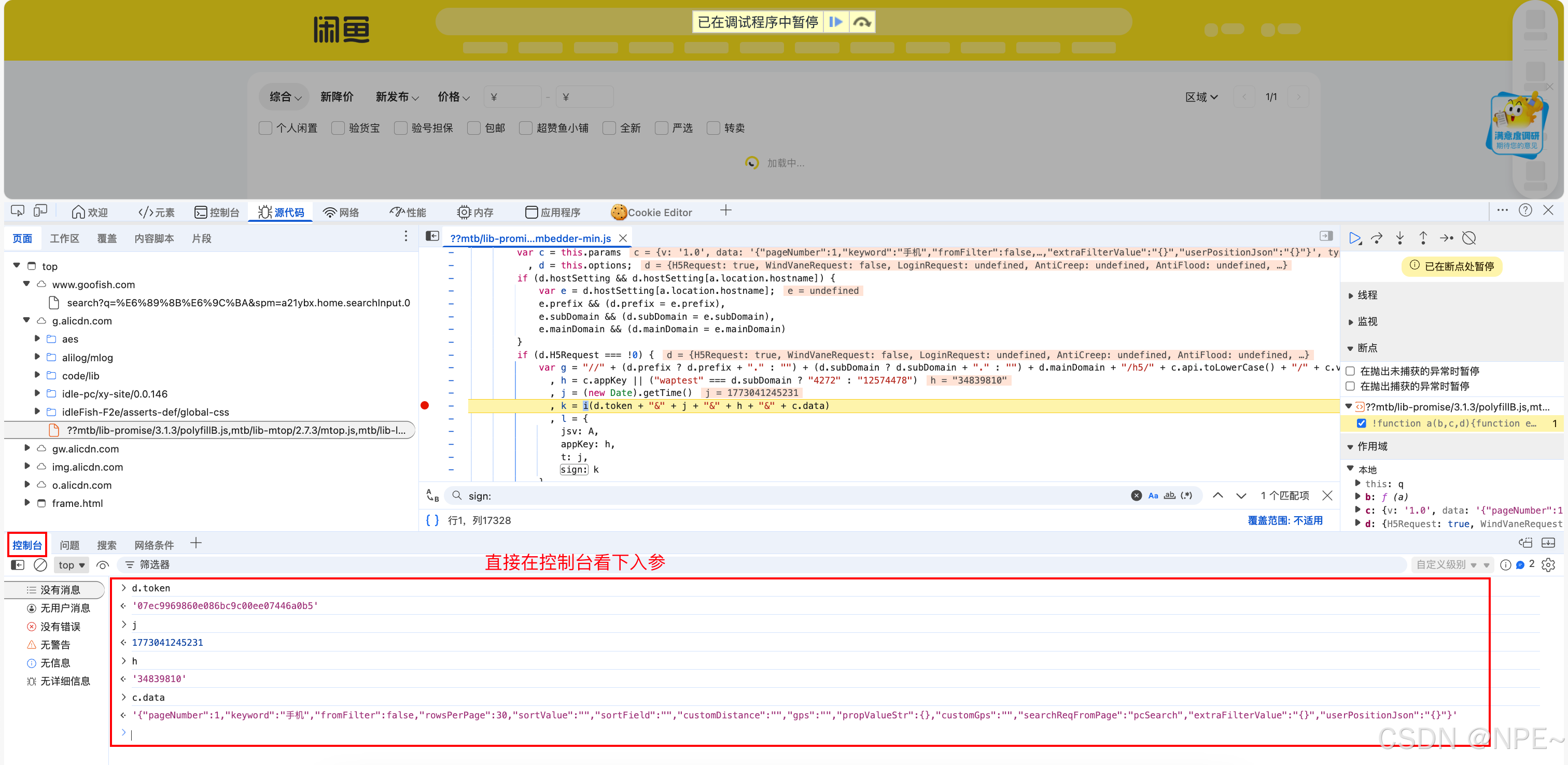
-
方法入参确认了之后,跟进确认一下方法内部的实现细节
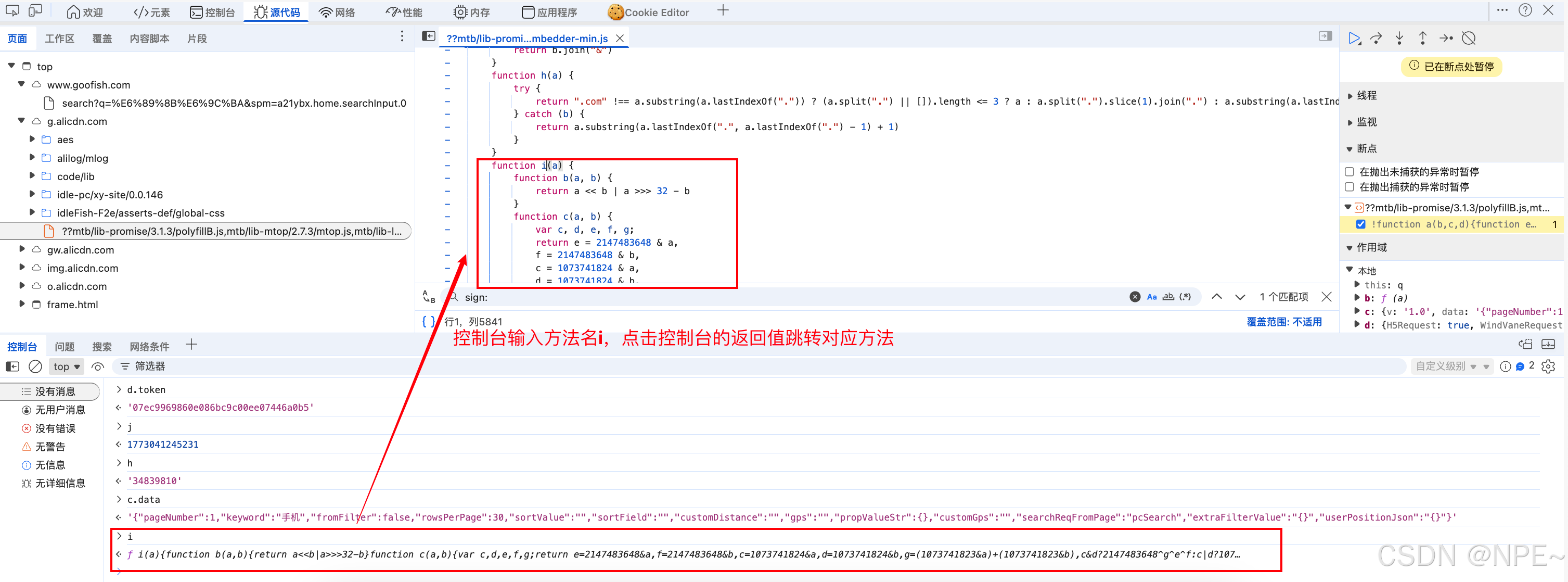
-
这里有两种方式:
- 一种是新建一个js文件,直接把实现流程复制到文件中,实现加密功能(针对非标准的加密,只有一步步扣js代码,在本地复现);
- 另外一个种是直接观察,可以看到这里加密的结果是32位,并且包含字母和数字的,盲猜是md5加密,同时这里看是否是标准的md5加密,直接找个在线网站验证一下,最终验证就是md5加密。那么我们可以直接用python的md5包实现加密
PS:MD5(Message-Digest Algorithm 5)是一种密码散列函数,能够将任意长度的数据转换为固定长度的128位(16字节)散列值(hash value)。这个散列值通常以32位的十六进制数字表示,类似于文件的"数字指纹",即使文件发生微小的改动,其MD5值也会发生巨大变化。
- md5加密不论入参多少,最后加密结果长度都是一致的,且包含字母和数字。
- 在线网站:https://www.sojson.com/md5/


- 放过断点,网络抓包观察sign参数解析逆向是否正确
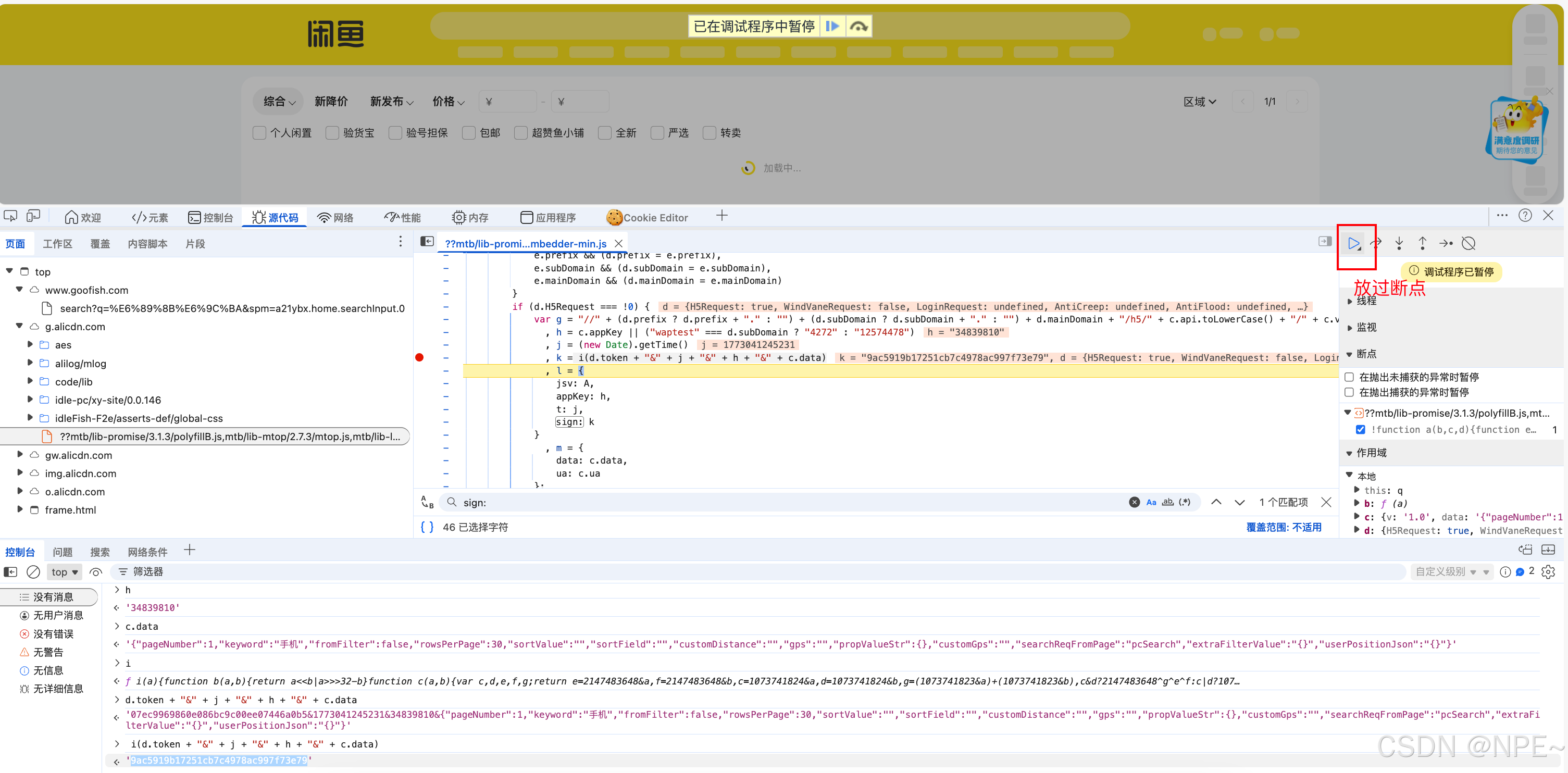
通过加密后结果定位请求,观察该参数是否就是sign:
python
9ac5919b17251cb7c4978ac997f73e79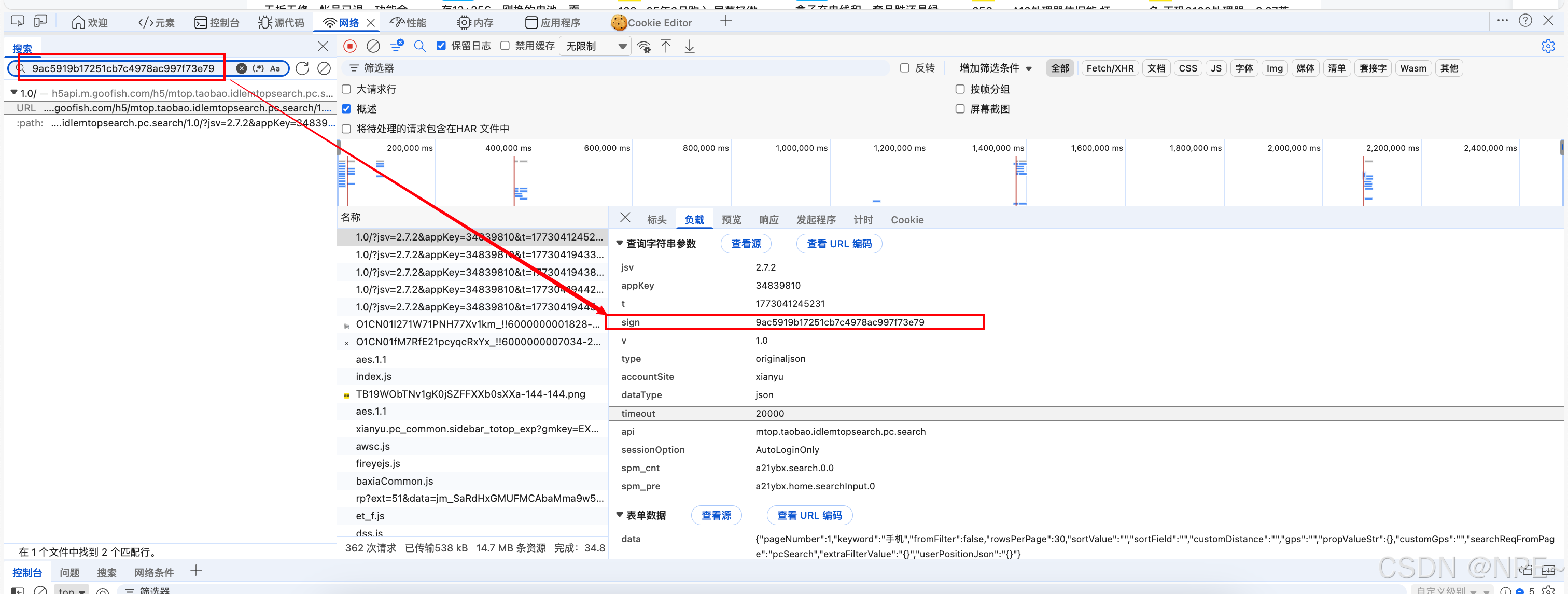
可以看到结果没问题,i方法加密后的结果就是sign的值。
第五步:完善代码,构造请求,实现爬取多页数据
代码: https://github.com/ziyifast/ziyifast-code_instruction/tree/main/python-demo/spider-demo/xy-demo
效果:
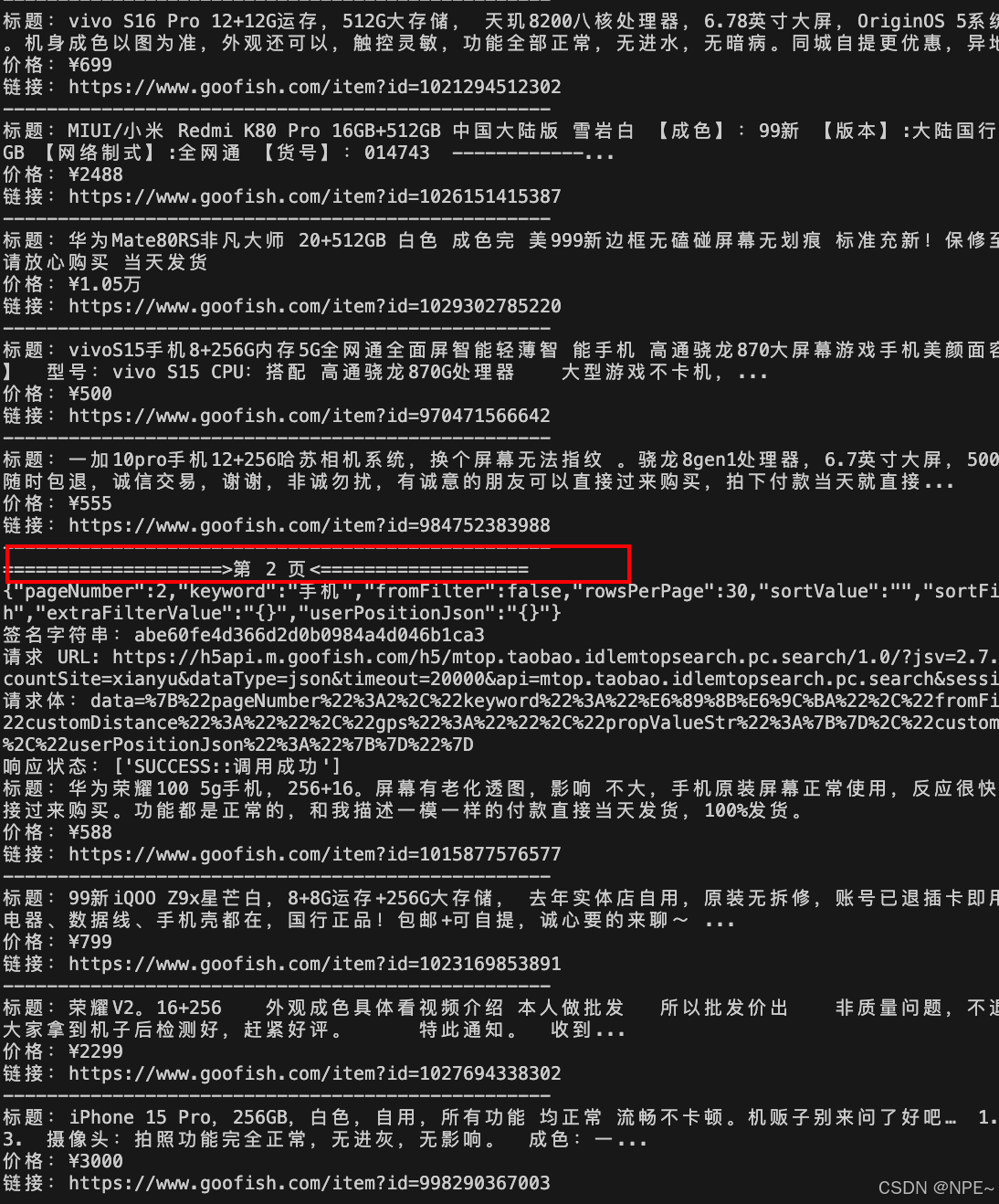
第六步:数据持久化
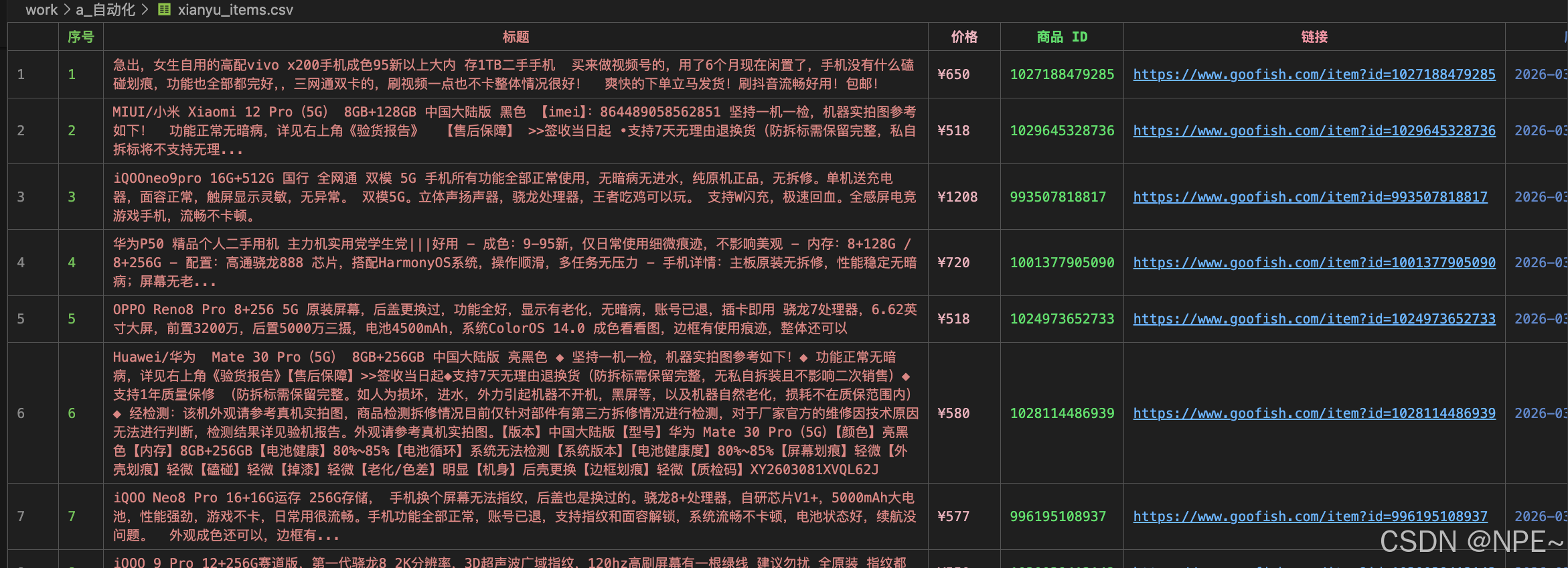
这里我们保存为csv文件。
代码: https://github.com/ziyifast/ziyifast-code_instruction/tree/main/python-demo/spider-demo/xy-demo
效果:
总结与进阶
在实际中,可能会遇到更复杂的反爬措施,例如:
- 请求参数加密算法不断更新(需要定期逆向)。
- 浏览器指纹检测(需要模拟 TLS 指纹、使用 selenium 或 puppeteer)。
- 验证码(可能需要打码平台或机器学习识别)。
建议进一步学习:
- JavaScript 逆向工程(AST、脱壳、动态调试)。
- 爬虫框架(Scrapy)的使用与分布式爬取。
- 代理池、Cookie 池的维护。