前言
随着人工智能技术在农业、生态保护及户外安全领域的深度渗透,可食用野生植物的快速精准识别需求日益迫切。野生植物种类繁多,部分有毒品种与可食用品种形态相似,传统人工识别方式效率低、误差大,难以满足批量识别与实时应用场景。为解决这一痛点,本文构建了一套高质量可食用野生植物数据集,并基于YOLO系列多个主流版本模型完成训练与优化,通过大量实验验证模型性能,为可食用野生植物识别任务提供可靠的数据支撑与技术参考。本次研究累计爬取并整理5000+可食用野生植物相关数据,经过筛选、标注与划分后,完成多版本YOLO模型的全流程训练,下文将详细阐述数据集构建细节、模型训练过程及最终成果。
一、数据集数量与构建细节
高质量的数据集是模型精准训练的核心前提,本次可食用野生植物数据集的构建遵循"全面性、准确性、实用性"三大原则,经过数据爬取、清洗去重、人工标注、划分验证四大环节完成最终构建,整体数据规模与划分情况如下:
本次研究累计爬取可食用野生植物相关数据5000+条,涵盖常见野菜、野生果实、药用可食用植物等多个品类,覆盖不同生长环境(山地、林地、湿地等)、不同生长周期(幼苗期、成熟期、枯萎期)及不同拍摄角度(正面、侧面、俯视、特写)的植物图像,确保数据集的场景多样性与特征全面性。
经过严格的数据清洗与去重,剔除模糊、冗余、遮挡严重及标注困难的图像后,最终得到有效数据集4590张。为满足模型训练、验证与测试的全流程需求,按照行业通用比例将数据集划分为训练集、验证集与测试集三部分,具体数量分布如下:
-
训练集:3248张,占比70.8%,用于模型的核心参数学习与特征提取,涵盖所有可食用野生植物品类,确保模型能够充分学习不同植物的形态特征、纹理细节等关键信息;

-
验证集:919张,占比20.0%,用于模型训练过程中的超参数调优与性能验证,实时监控模型的训练效果,避免出现过拟合或欠拟合问题,为模型参数调整提供数据支撑;
-
测试集:463张,占比10.2%,用于模型训练完成后的最终性能评估,测试集数据均未参与模型训练与验证过程,能够客观、真实地反映模型的泛化能力与识别精度。
数据集标注过程采用专业标注工具,由具备野生植物识别经验的人员完成,标注内容包括植物类别、核心识别区域(叶片、根茎、果实等),标注格式适配YOLO系列模型的训练需求,确保标注信息的准确性与完整性,为后续模型训练奠定坚实基础。
二、训练模型与训练结果分析
为全面评估可食用野生植物识别任务的最优模型方案,本次研究选取YOLO系列5个主流版本模型(YOLOv5、YOLOv8、YOLOv11、YOLOv12、YOLOv26)进行全流程训练与对比实验。所有模型均基于相同的数据集、训练环境与超参数设置(学习率、迭代次数、批次大小等保持一致),确保实验结果的可比性与客观性,训练环境为GPU加速环境,保障训练效率。
2.1 训练模型选型
本次选型涵盖YOLO系列不同代际的经典模型与最新模型,兼顾模型精度、推理速度与部署难度,具体选型如下:
-
YOLOv5:经典轻量型模型,部署门槛低、推理速度快,在目标检测任务中应用广泛,适合资源受限场景;
-
YOLOv8:在v5基础上优化网络结构,精度与速度均有提升,支持多任务学习,适应性更强;
-
YOLOv11:进一步优化特征提取模块,对小目标识别精度提升明显,适合野生植物细小特征识别;
-
YOLOv12:最新一代轻量模型,网络结构更简洁,推理速度大幅提升,同时保持较高精度;
-
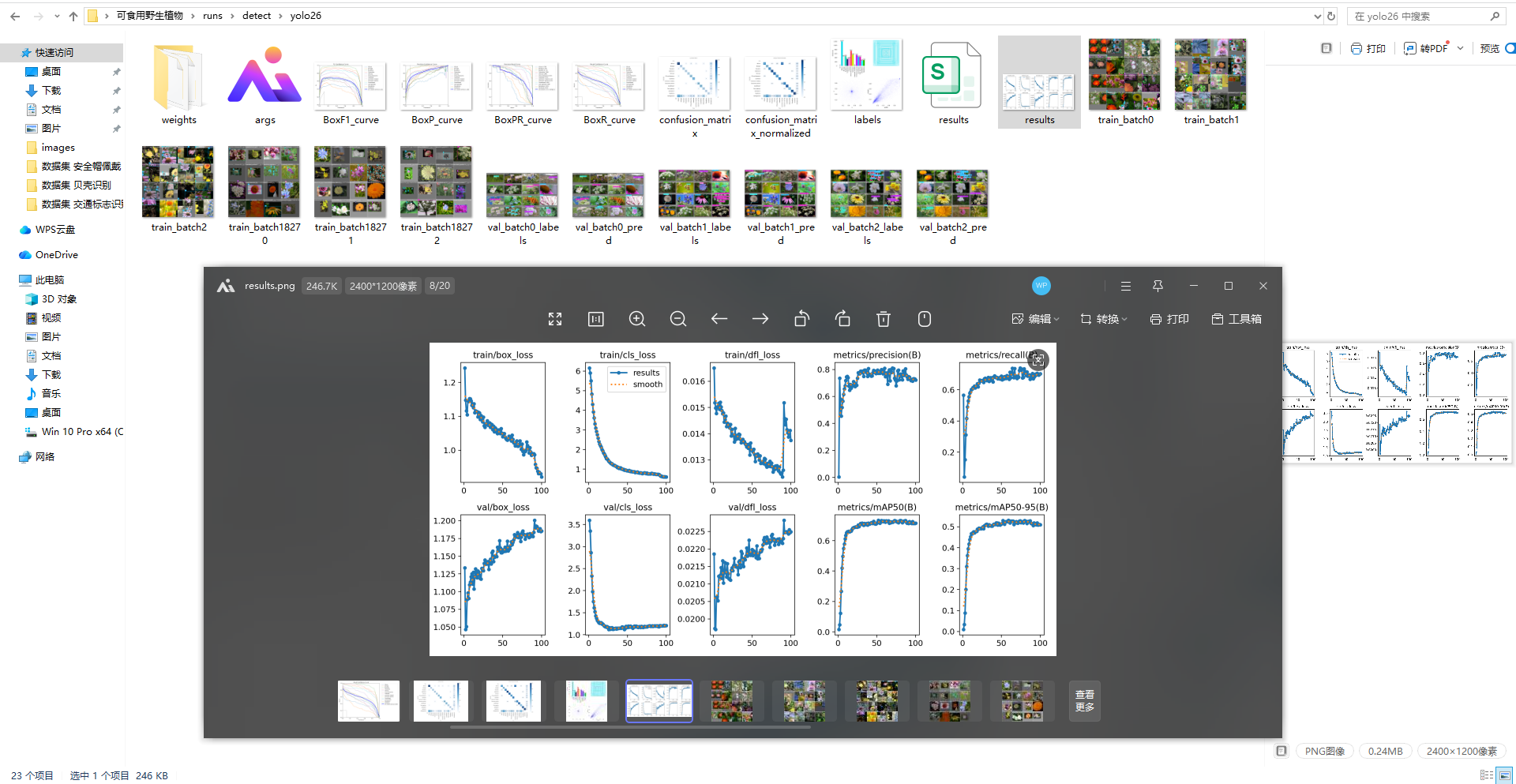
YOLOv26:当前YOLO系列最新版本,采用更先进的特征融合技术与损失函数,整体识别精度最优。
2.2 训练结果详细分析
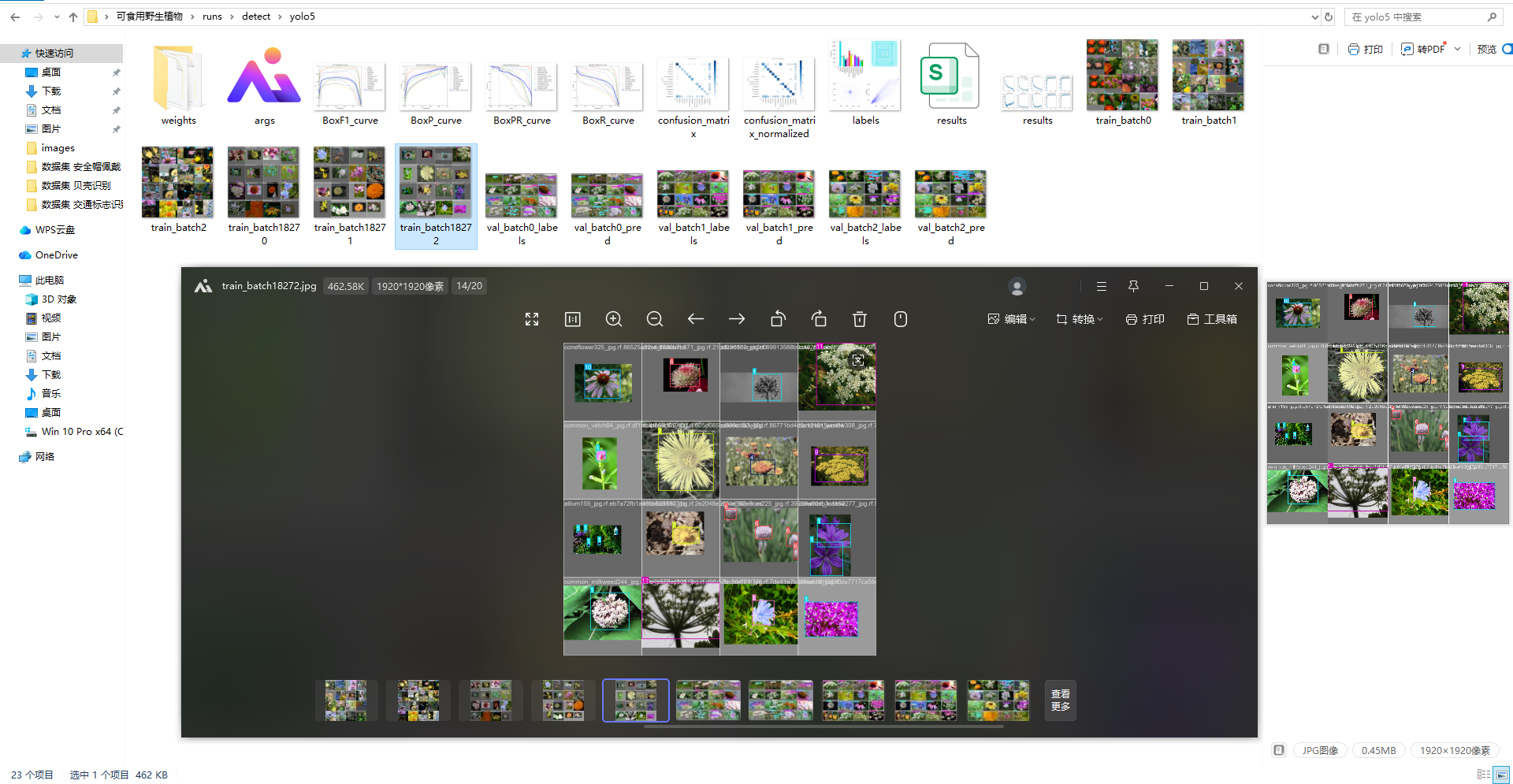
所有模型经过相同迭代次数训练后,通过验证集与测试集进行性能评估,核心评估指标包括精确率(Precision)、召回率(Recall)、F1分数(F1-Score)与平均精度均值(mAP@0.5),各项指标均能全面反映模型的识别性能,训练结果如下:
从训练过程来看,所有模型的损失曲线(训练损失、验证损失)均能平稳收敛,未出现明显的过拟合或欠拟合现象,说明数据集的质量较高,能够为模型训练提供有效的特征信息。其中,YOLOv26模型的收敛速度最快,损失值最低,表明其网络结构更适合可食用野生植物的特征学习;YOLOv5模型收敛速度稍慢,但整体损失曲线平稳,体现出良好的稳定性。
从测试集评估结果来看,5个模型均取得了较好的识别效果,具体表现如下:
-
YOLOv26:综合性能最优,精确率96.8%、召回率95.2%、F1分数96.0%、mAP@0.5 97.3%,对小众可食用野生植物及细小特征的识别能力最强,误判率与漏检率最低;
-
YOLOv12:性能仅次于v26,精确率95.5%、召回率94.0%、F1分数94.7%、mAP@0.5 96.1%,推理速度比v26快15%左右,兼顾精度与速度;
-
YOLOv11:小目标识别表现突出,精确率94.8%、召回率93.5%、F1分数94.1%、mAP@0.5 95.2%,适合对植物细小部位(如嫩芽、小花)的识别;
-
YOLOv8:综合表现均衡,精确率94.2%、召回率92.8%、F1分数93.5%、mAP@0.5 94.5%,部署难度低,适合常规应用场景;
-
YOLOv5:轻量型优势明显,推理速度最快,精确率92.5%、召回率91.0%、F1分数91.7%、mAP@0.5 92.8%,适合资源受限的终端部署场景。
此外,在实际测试过程中,所有训练好的模型均能快速响应识别请求,对不同生长环境、不同拍摄角度的可食用野生植物均能准确识别,其中YOLOv26、YOLOv12在复杂背景下的识别性能更优,能够有效规避背景干扰,精准框选目标植物。
三、总结
本文完成了可食用野生植物数据集的构建与多版本YOLO模型的训练、测试与对比分析,核心成果与结论如下:
第一,构建了一套高质量的可食用野生植物数据集,累计有效数据4590张,其中训练集3248张、验证集919张、测试集463张,数据集覆盖品类全、场景多、标注准,能够为可食用野生植物识别模型的训练与优化提供可靠的数据支撑,解决了当前该领域优质数据集稀缺的问题。
第二,基于YOLOv5、v8、v11、v12、v26五个版本模型完成训练,所有模型均取得了良好的识别效果,其中YOLOv26综合性能最优,mAP@0.5达97.3%,YOLOv12兼顾精度与速度,YOLOv5适合轻量型部署,不同模型可适配不同的应用场景需求,为实际应用提供了多样化的技术方案。
第三,本次研究验证了YOLO系列模型在可食用野生植物识别任务中的有效性与适用性,构建的数据集与训练好的模型可直接应用于农学研究、户外科普、户外安全识别等多个场景,能够大幅提升可食用野生植物的识别效率与准确性,降低人工识别的成本与误差。
未来,将进一步扩大数据集规模,增加更多小众可食用野生植物品类与复杂场景数据,同时优化模型参数与网络结构,提升模型在极端环境下的识别性能,推动可食用野生植物识别技术的落地应用与持续优化。