一、下载ES
ES官网:https://www.elastic.co/https://www.elastic.co/cn/https://www.elastic.co/
下载地址:https://www.elastic.co/cn/downloads/elasticsearch
我是选择docker安装:https://www.docker.elastic.co/r/elasticsearch
二、ES版本
1.如何选择版本
springboot集成了有es:Spring Boot Starter Data Elasticsearch
https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-data-elasticsearch
m1那个肯定不能选哈。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
<version>4.0.2</version>
</dependency>它其中的:
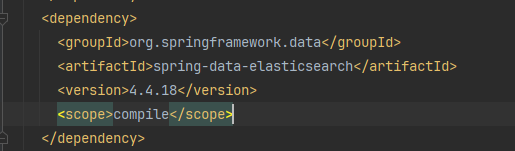
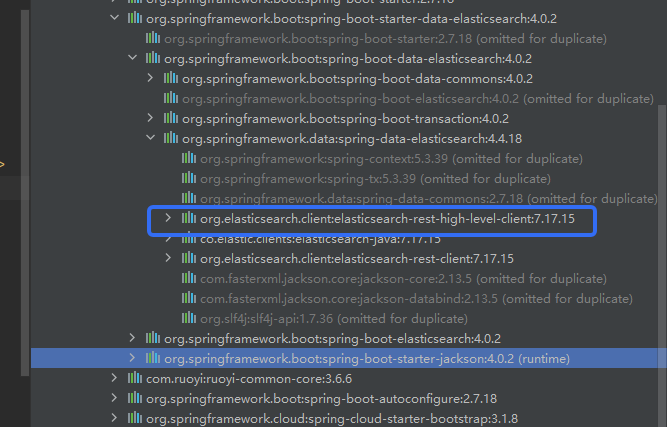
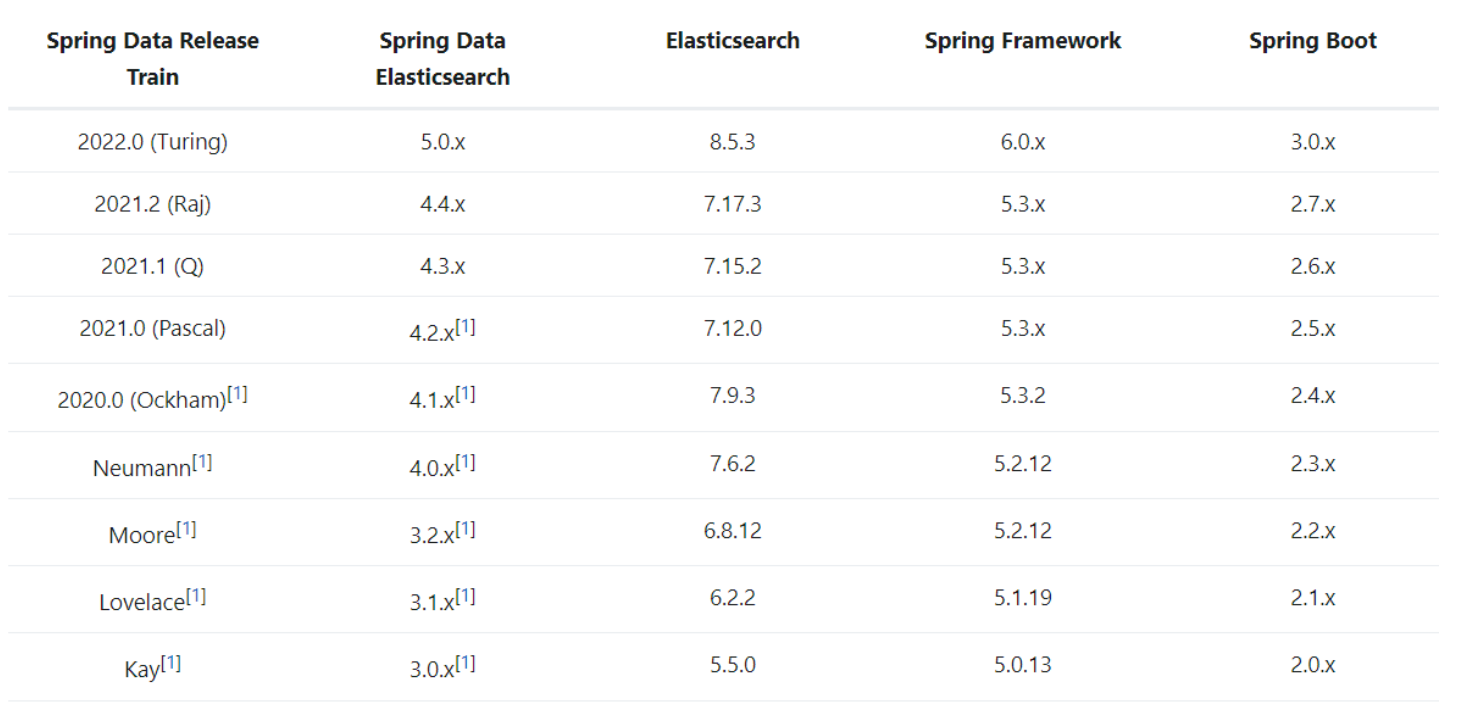
所以只能选择es 7.17.15.
2.版本对应关系
https://docs.spring.io/spring-data/elasticsearch/docs/4.4.0/reference/html/
三、docker安装ES
https://www.docker.elastic.co/r/elasticsearch?limit=50&offset=600&show_snapshots=false
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.17.15创建目录并且挂载:
mkdir -p /home/elasticsearch7/config
mkdir -p /home/elasticsearch7/data
mkdir -p /home/elasticsearch7/plugins设置es可以被远程任何的计算机访问,也就是设置bindip 0.0.0.0 同理redis和mysql都是这样的。
vim elasticsearch.yml
http.host: 0.0.0.0懒得做docker compose了,所以直接用
docker启动ES命令
docker run --name elasticsearch \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPS="-Xms64m -Xmx128m" \
-v /home/elasticsearch7/config/:/usr/share/elasticsearch/config \
-v /home/elasticsearch7/data:/usr/share/elasticsearch/data \
-v /home/elasticsearch7/plugins:/usr/share/elasticsearch/plugins \
--restart=always \
-d elasticsearch:7.17.15参数释义:
- docker run: 运行一个容器,每个容器相互隔离,他都是独立的运行环境,是一个完整的实例。
- --name elasticsearch:为容器取名,这个名字随意。
- -p 9200:9200 -p 9300:9300:把es容器自己的端口映射到虚拟主机,这样我们才能访问,这是端口映射,对外暴露。(9200是我们通过rest接口请求的端口,9300是内部通信端口,es集群之间会相互通信,他们有心跳机制)
- -e "discovery.type=single-node": 单节点形式运行
- -e ESJAVAOPS="-Xms64m -Xmx128m": 设置内存大小,如果不设置,es会占用虚拟机的全部内存,初始64m,最大128m,也够用了。
- -v:文件路径的挂载。(数据库文件,日志,配置文件)

自动重启
docker update elasticsearch --restart=always重启docker
systemctl restart docker查看日志
docker logs elasticsearch因为es启动是不能使用root的,我们以前使用源码安装的时候就是这样,必须要创建新的用户才行。所以这里也是一样的。我们需要为自己目录添加权限给es
chmod -R 777 /home/elasticsearch7/测试访问
http://192.168.1.xx1:9200/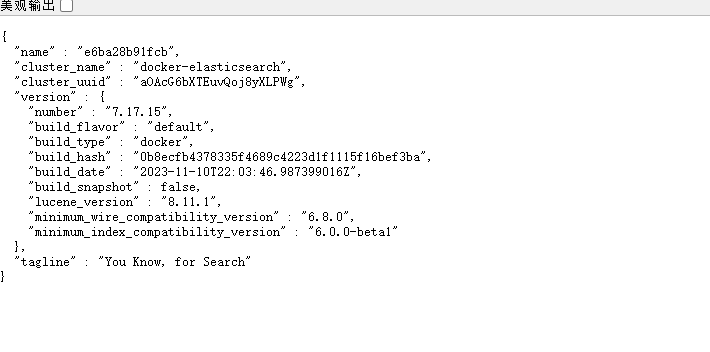
遇到好多问题:
(1)Exception in thread "main" java.nio.file.NoSuchFileException: /usr/share/elasticsearch/config/jvm.options
at java.base/sun.nio.fs.UnixException.translateToIOException(UnixException.java:92)
# 1. 完全清理
docker rm -f elasticsearch
sudo rm -rf /home/elasticsearch7
# 2. 重新创建目录
sudo mkdir -p /home/elasticsearch7/data
sudo chown -R 1000:1000 /home/elasticsearch7
# 3. 使用 Docker 卷存储配置(让Docker管理配置)
# 先运行一个容器让它生成默认配置
docker run -d --name es-temp \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms64m -Xmx128m" \
-e "xpack.security.enabled=false" \
elasticsearch:7.17.15 sleep 60
# 4. 复制配置出来
docker cp es-temp:/usr/share/elasticsearch/config /tmp/es-config
sudo mv /tmp/es-config /home/elasticsearch7/config
docker rm -f es-temp
# 5. 修改配置
sudo tee /home/elasticsearch7/config/elasticsearch.yml > /dev/null << 'EOF'
cluster.name: "docker-elasticsearch"
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["node-1"]
xpack.security.enabled: false
xpack.security.transport.ssl.enabled: false
discovery.type: single-node
EOF
# 6. 设置权限
sudo chown -R 1000:1000 /home/elasticsearch7/config
sudo chmod -R 755 /home/elasticsearch7/config
# 7. 运行最终容器
docker run --name elasticsearch \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms64m -Xmx128m" \
-v /home/elasticsearch7/config:/usr/share/elasticsearch/config \
-v /home/elasticsearch7/data:/usr/share/elasticsearch/data \
--restart=unless-stopped \
-d elasticsearch:7.17.15(2)uncaught exception in thread main java.lang.IllegalArgumentException: setting cluster.initial_master_nodes is not allowed when discovery.type is set to single-node
# 1. 停止容器
docker stop elasticsearch
docker rm elasticsearch
# 2. 修改配置文件,移除 cluster.initial_master_nodes
sudo tee /home/elasticsearch7/config/elasticsearch.yml > /dev/null << 'EOF'
cluster.name: "docker-elasticsearch"
network.host: 0.0.0.0
http.port: 9200
# 注意:单节点模式不能设置 cluster.initial_master_nodes
# cluster.initial_master_nodes: ["node-1"] # 注释掉或删除这行
xpack.security.enabled: false
xpack.security.transport.ssl.enabled: false
discovery.type: single-node
EOF
# 3. 重新启动
docker run --name elasticsearch \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx1024m" \
-v /home/elasticsearch7/config:/usr/share/elasticsearch/config \
-v /home/elasticsearch7/data:/usr/share/elasticsearch/data \
--restart=unless-stopped \
-d elasticsearch:7.17.15四、安装 ES-Head 插件
Elasticsearch Head 插件 是一个用于 Elasticsearch 的 Web 可视化管理和监控工具。它提供了一个直观的图形界面来查看和管理 Elasticsearch 集群,可以对集群进行傻瓜式操作。
es-head主要有三个方面的操作:
- 显示集群的拓扑,并且能够执行索引和节点级别操作
- 搜索接口能够查询集群中原始json或表格格式的检索数据
- 能够快速访问并显示集群的状态
- 有一个输入窗口,允许任意调用RESTful API。这个接口包含几个选项,可以组合在一起以产生有趣的结果;
- 请求方法(get、put、post、delete),查询json数据,节点和路径
- 支持JSON验证器
- 支持重复请求计时器
- 支持使用javascript表达式变换结果
- 收集结果的能力随着时间的推移(使用定时器),或比较的结果
- 能力图表转换后的结果在一个简单的条形图(包括时间序列)
1.git地址
https://github.com/mobz/elasticsearch-head
https://github.com/mobz/elasticsearch-head#running-with-built-in-server
2.安装
(1)谷歌插件安装方式(推荐)
我想安装es head谷歌插件,资源有,但是就是安装说有问题,不行。换成源码启动
(2)源码启动
git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head
npm install
npm run start
(3)docker安装
找到elasticsearch head镜像。
然后docker安装。
for Elasticsearch 5.x: docker run -p 9100:9100 mobz/elasticsearch-head:5
for Elasticsearch 2.x: docker run -p 9100:9100 mobz/elasticsearch-head:2
for Elasticsearch 1.x: docker run -p 9100:9100 mobz/elasticsearch-head:1
for fans of alpine there is mobz/elasticsearch-head:5-alpine我访问不到docker镜像库只能使用源码启动
3.解决跨域问题
Connecting to elasticsearch连接时,发现始终未连接,因为还需解决跨域问题。
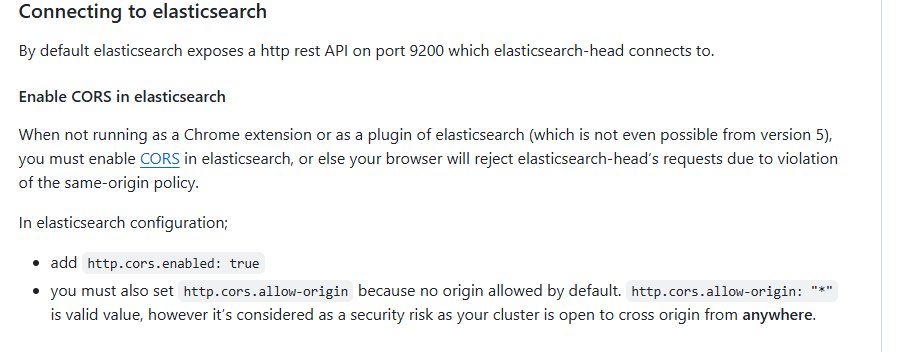
写在这里:
这个地址是前面安装es创建的:
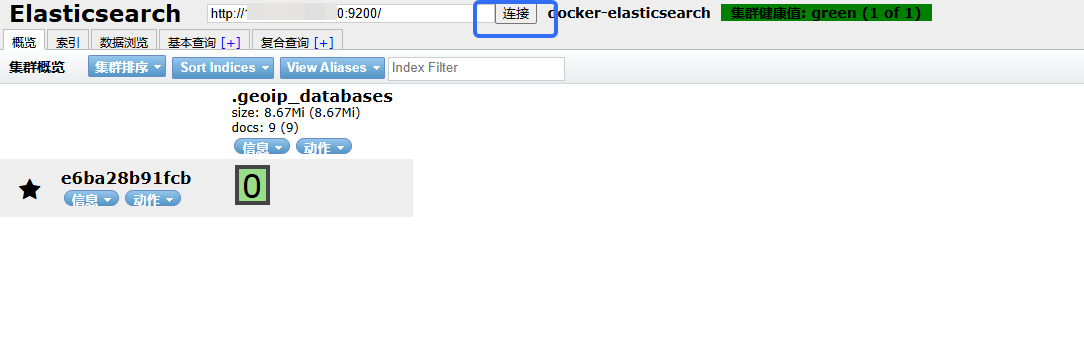
创建了一个索引,然后:
五.ES配套工具
1). 数据可视化工具(Kibana 的替代/补充)
| 工具 | 类别 | 特点 | 适用场景 |
|---|---|---|---|
| Kibana | Elastic官方 | 深度集成ES,功能全面 | Elastic Stack 标准可视化 |
| Grafana | 第三方 | 多数据源支持,图表丰富 | 多数据源监控、时序数据 |
| ElasticHD | 第三方开源 | 轻量级,中文界面 | 简单查看ES数据 |
| Dejavu | 第三方开源 | 专注于数据浏览和查询 | 开发调试、数据管理 |
2). 集群管理工具(Head 的替代)
| 工具 | 类别 | 特点 | 适用场景 |
|---|---|---|---|
| Elasticsearch Head | 浏览器插件 | 轻量、快速查看 | 开发环境快速检查 |
| Cerebro | 独立应用 | 功能强大,支持集群操作 | 生产环境集群管理 |
| Elasticvue | 浏览器插件 | 现代UI,支持认证 | 需要认证的集群 |
| Kopf (已弃用) | 插件 | 旧版集群管理工具 | 历史项目 |
3). 数据收集工具(Beats 的同类)
| 工具 | 类别 | 特点 | 适用场景 |
|---|---|---|---|
| Filebeat | Elastic官方 | 日志文件收集 | 日志收集 |
| Metricbeat | Elastic官方 | 系统指标收集 | 系统监控 |
| Fluentd/Fluent Bit | CNCF项目 | 多数据源,云原生 | Kubernetes 环境 |
| Logstash | Elastic官方 | 功能强大,支持处理 | 复杂数据处理 |
| Vector | 第三方 | 高性能,可观测性 | 高性能需求 |
| Telegraf | InfluxData | 指标收集,插件多 | InfluxDB 生态 |
六、elasticsearch - 分词与内置分词器
1.什么是分词
把文本转换为一个个的单词,分词称之为analysis。es默认只对英文语句做分词,中文不支持,每个中文字都会被拆分为独立的个体。
2.内置分词器
-
standard:默认分词,单词会被拆分,大小会转换为小写。
-
simple:按照非字母分词。大写转为小写。
-
whitespace:按照空格分词。忽略大小写。
-
stop:去除无意义单词,比如
the/a/an/is... -
keyword:不做分词。把整个文本作为一个单独的关键词。
整体看,更适合英文。
| 分词器 | 分词规则 | 示例 "The Quick Brown-Foxes" | 输出结果 | 优点 | 缺点 |
|---|---|---|---|---|---|
| standard(默认) | 1. 按单词边界分词 2. 移除标点符号 3. 转换为小写 4. 支持多语言 | ["the", "quick", "brown", "foxes"] |
1. 通用性强 2. 支持多语言 3. 标准化处理 | 1. 可能过于通用 2. 不支持中文分词 | 通用英文搜索 • 文档全文检索 • 日志分析 • 多语言内容 |
| simple | 1. 按非字母字符分词 2. 转换为小写 3. 丢弃非字母字符 | ["the", "quick", "brown", "foxes"] |
1. 简单高效 2. 内存占用低 | 1. 功能有限 2. 无法处理数字+字母混合 | 简单英文文本 • 纯字母内容 • 性能敏感场景 • 简单标签系统 |
| whitespace | 1. 仅按空格分词 2. 保留大小写 3. 保留标点符号 | ["The", "Quick", "Brown-Foxes"] |
1. 保留原始格式 2. 处理特殊字符 | 1. 大小写敏感 2. 标点影响搜索 | 保留格式文本 • 代码搜索 • URL/路径搜索 • 大小写敏感内容 |
| stop | 1. 同standard分词 2. 移除停用词(the, a, an等) 3. 转换为小写 | ["quick", "brown", "foxes"] |
1. 减少索引大小 2. 提升搜索精度 3. 移除噪声词 | 1. 停用词列表固定 2. 可能误删重要词 | 内容优化搜索 • 文章/博客搜索 • 文档检索系统 • 优化存储空间 |
| keyword | 1. 不进行分词 2. 整个文本作为一个词项 3. 保留原始大小写 | ["The Quick Brown-Foxes"] |
1. 精确匹配 2. 保留完整格式 3. 支持聚合 | 1. 无法部分匹配 2. 索引体积大 | 精确值匹配 • ID/编号搜索 • 分类标签 • 聚合分析字段 |
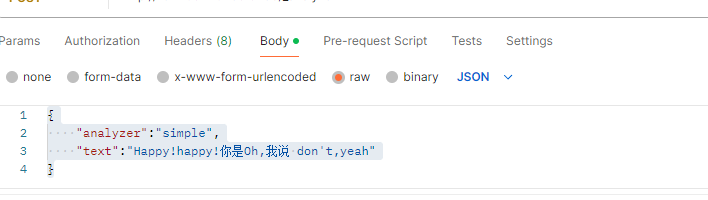
3.接口工具测试
postman
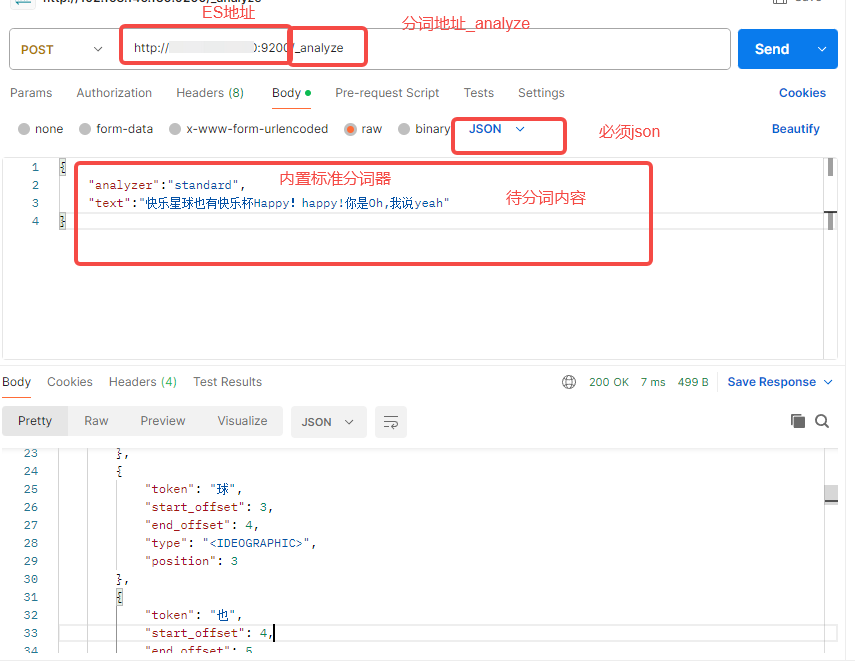
分词结果:
{
"tokens": [
{
"token": "快",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "乐",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "星",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "球",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
},
{
"token": "也",
"start_offset": 4,
"end_offset": 5,
"type": "<IDEOGRAPHIC>",
"position": 4
},
{
"token": "有",
"start_offset": 5,
"end_offset": 6,
"type": "<IDEOGRAPHIC>",
"position": 5
},
{
"token": "快",
"start_offset": 6,
"end_offset": 7,
"type": "<IDEOGRAPHIC>",
"position": 6
},
{
"token": "乐",
"start_offset": 7,
"end_offset": 8,
"type": "<IDEOGRAPHIC>",
"position": 7
},
{
"token": "杯",
"start_offset": 8,
"end_offset": 9,
"type": "<IDEOGRAPHIC>",
"position": 8
},
{
"token": "happy",
"start_offset": 9,
"end_offset": 14,
"type": "<ALPHANUM>",
"position": 9
},
{
"token": "happy",
"start_offset": 15,
"end_offset": 20,
"type": "<ALPHANUM>",
"position": 10
},
{
"token": "你",
"start_offset": 21,
"end_offset": 22,
"type": "<IDEOGRAPHIC>",
"position": 11
},
{
"token": "是",
"start_offset": 22,
"end_offset": 23,
"type": "<IDEOGRAPHIC>",
"position": 12
},
{
"token": "oh",
"start_offset": 23,
"end_offset": 25,
"type": "<ALPHANUM>",
"position": 13
},
{
"token": "我",
"start_offset": 26,
"end_offset": 27,
"type": "<IDEOGRAPHIC>",
"position": 14
},
{
"token": "说",
"start_offset": 27,
"end_offset": 28,
"type": "<IDEOGRAPHIC>",
"position": 15
},
{
"token": "yeah",
"start_offset": 28,
"end_offset": 32,
"type": "<ALPHANUM>",
"position": 16
}
]
}我们可以看到标准分词器,标点符号是抛弃了的,中文是单个字,英文,大写会转小写。
{
"tokens": [
{
"token": "happy",
"start_offset": 0,
"end_offset": 5,
"type": "word",
"position": 0
},
{
"token": "happy",
"start_offset": 6,
"end_offset": 11,
"type": "word",
"position": 1
},
{
"token": "你是oh",
"start_offset": 12,
"end_offset": 16,
"type": "word",
"position": 2
},
{
"token": "我说",
"start_offset": 17,
"end_offset": 19,
"type": "word",
"position": 3
},
{
"token": "don",
"start_offset": 20,
"end_offset": 23,
"type": "word",
"position": 4
},
{
"token": "t",
"start_offset": 24,
"end_offset": 25,
"type": "word",
"position": 5
},
{
"token": "yeah",
"start_offset": 26,
"end_offset": 30,
"type": "word",
"position": 6
}
]
}七、IK中文分词器
IK 分词器是 Elasticsearch 中最流行的中文分词器插件
1.官网及安装方式
Github:
https://github.com/medcl/elasticsearch-analysis-ik
下载:
https://github.com/infinilabs/analysis-ik/releases
https://release.infinilabs.com/analysis-ik/stable/
我打算下载个新的,看看。但是不行哈。
在选择Elasticsearch IK分词器版本时,必须确保其与Elasticsearch的主版本号完全一致,这是保证插件正常加载和稳定运行的首要前提。
IK分词器的版本号与Elasticsearch版本号严格绑定,例如:
- Elasticsearch 7.6.2 需搭配 ik-7.6.2.zip
- Elasticsearch 8.4.3 需搭配 ik-8.4.3.zip
- Elasticsearch 8.17.3 需搭配 ik-8.17.3.zip 16
若版本不匹配,Elasticsearch在启动时将因插件校验失败而无法正常运行。
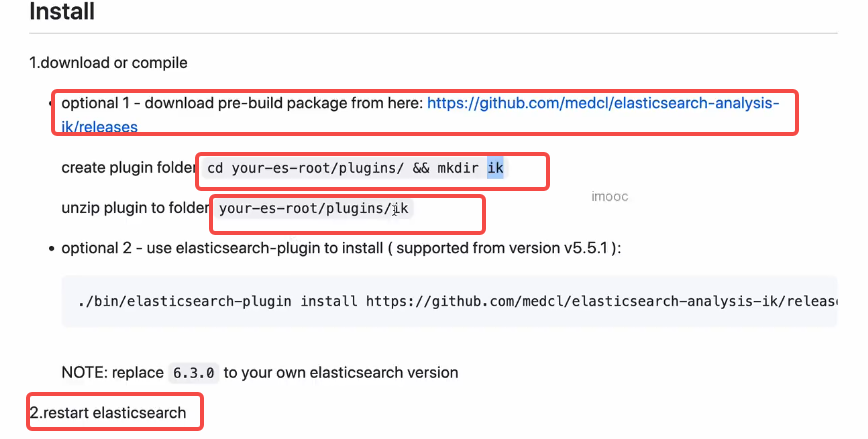
2.安装ik
在es路径下加一个plugins/ik,将下载的ik包解压后放进去。
路径不能错,启动命令中的挂载地址:
重新启动es
报了个错:
, "message": "error updating geoip database GeoLite2-City.mmdb", "cluster.uuid": "aOAcG6bXTEuvQoj8yXLPWg", "node.id": "a3IlBEsPQs-uMspZnLy4zg" , "stacktrace": "java.net.SocketTimeoutException: Connect timed out", "at sun.nio.ch.NioSocketImpl.timedFinishConnect(NioSocketImpl.java:546) \~\[?:?", "at sun.nio.ch.NioSocketImpl.connect(NioSocketImpl.java:592) ~?:?", "at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:327) ~?:?", "at java.net.Socket.connect(Socket.java:751) ~?:?", "at sun.security.ssl.SSLSocketImpl.connect(SSLSocketImpl.java:304) ~?:?", "at sun.net.NetworkClient.doConnect(NetworkClient.java:178) ~?:?", "at sun.net.www.http.HttpClient.openServer(HttpClient.java:531) ~?:?", "at sun.net.www.http.HttpClient.openServer(HttpClient.java:636) ~?:?", "at sun.net.www.protocol.https.HttpsClient.<init>(HttpsClient.java:264) ~?:?", "at sun.net.www.protocol.https.HttpsClient.New(HttpsClient.java:377) ~?:?", "at
我在配置文件中,增加
ingest.geoip.downloader.enabled: false3.两种分词模式
| 模式 | 算法特点 | 分词 粒度 | 示例 "我们是社会主义接班人" | 输出结果 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|---|---|
| ik_smart | 最小切分算法 | 粗粒度 | ["我们", "是", "社会主义", "接班人"] |
1. 词典匹配最优路径 2. 分词数量少 3. 语义完整性好 | 1. 搜索精度高 2. 索引体积小 3. 查询速度快 | 1. 可能漏掉长词 2. 召回率较低 | 搜索场景 • 用户查询分词 • 搜索建议 • 精准匹配 |
| ik_max_word | 最细粒度切分 | 细粒度 | ["我们", "是", "社会", "社会主义", "主义", "接班", "接班人"] |
1. 穷举所有可能分词 2. 覆盖所有词汇 3. 分词数量多 | 1. 召回率高 2. 覆盖全面 3. 不漏词 | 1. 索引体积大 2. 查询噪声多 3. 性能开销大 | 索引场景 • 文档内容索引 • 全文检索 • 高召回需求 |
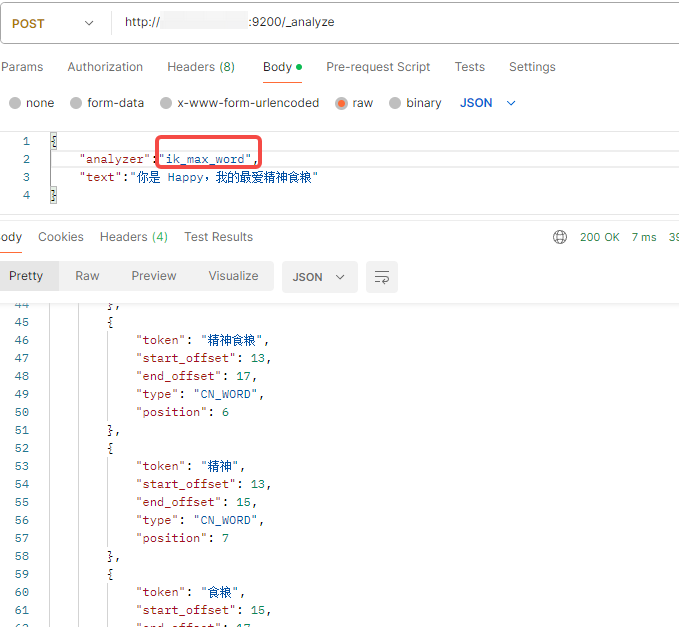
4.接口工具测试
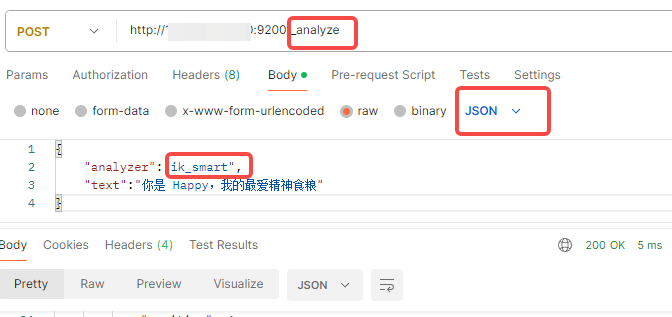
{
"tokens": [
{
"token": "你",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "happy",
"start_offset": 3,
"end_offset": 8,
"type": "ENGLISH",
"position": 2
},
{
"token": "我",
"start_offset": 9,
"end_offset": 10,
"type": "CN_CHAR",
"position": 3
},
{
"token": "的",
"start_offset": 10,
"end_offset": 11,
"type": "CN_CHAR",
"position": 4
},
{
"token": "最爱",
"start_offset": 11,
"end_offset": 13,
"type": "CN_WORD",
"position": 5
},
{
"token": "精神食粮",
"start_offset": 13,
"end_offset": 17,
"type": "CN_WORD",
"position": 6
}
]
}