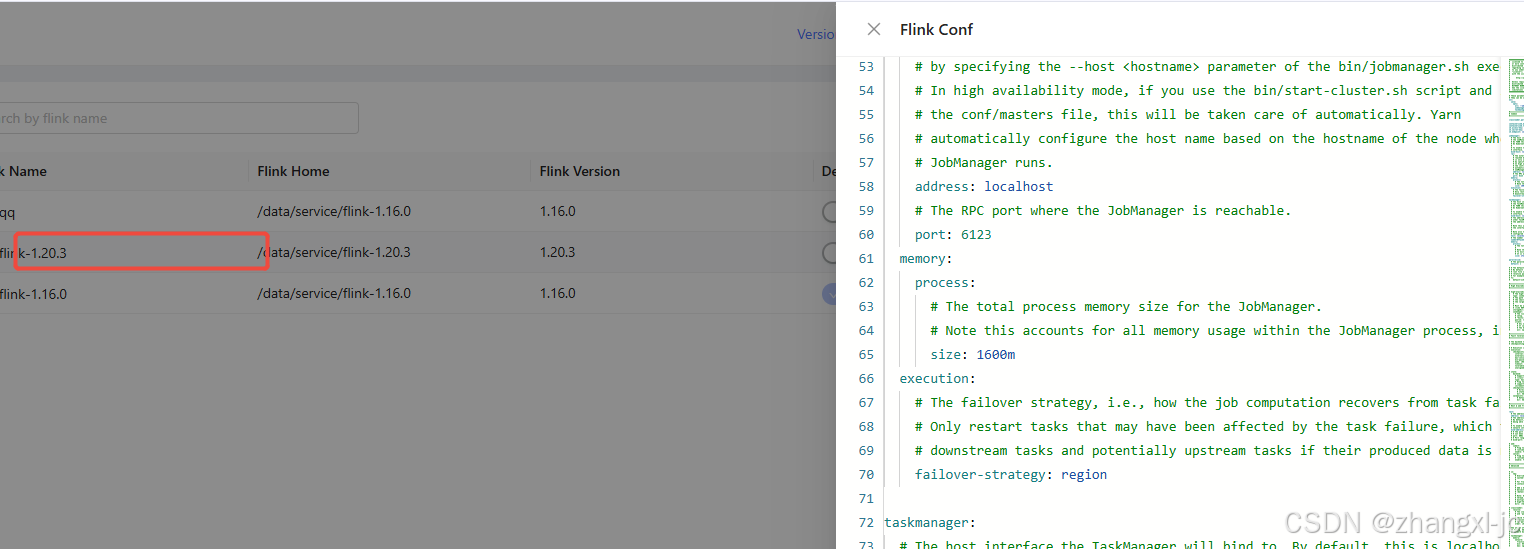
StreamPark 添加Flink Home 报如下错误:
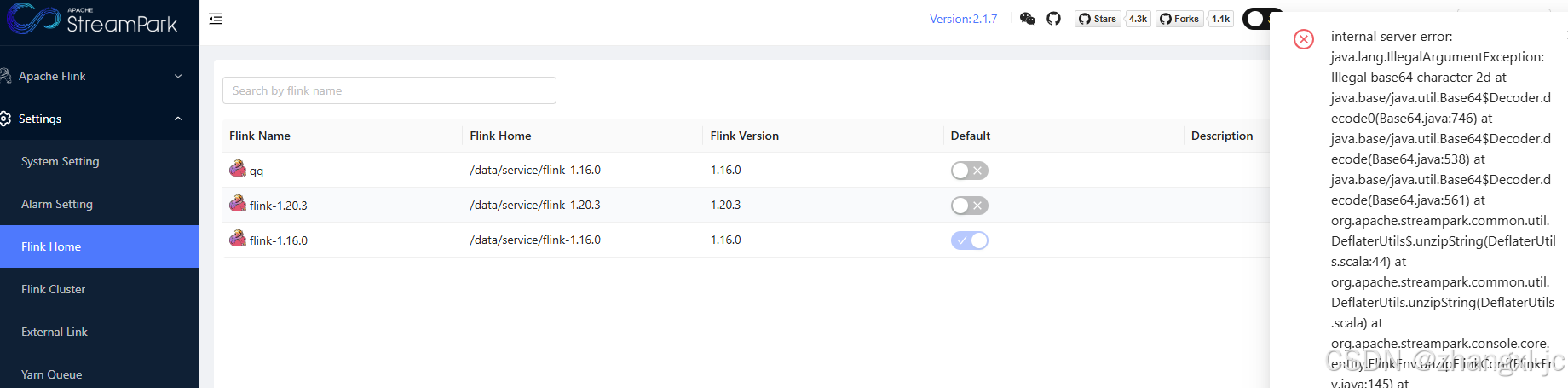
原因是这个版本本身的bug,没有将flink conf base64 编码,而是直接存到数据库。
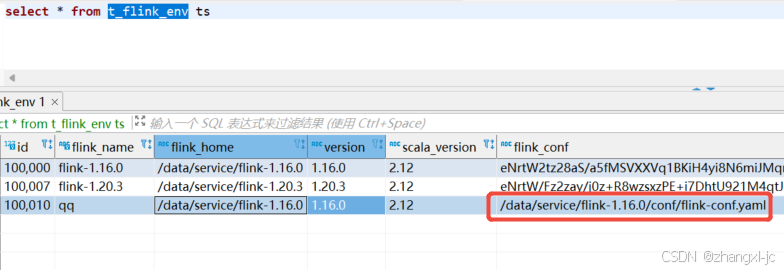
1.登录streampark 的数据库 查询 表 t_flink_env 如图,存储的是原始配置路径:
2.登录gitee 找到streampark 的源码类 DeflaterUtils
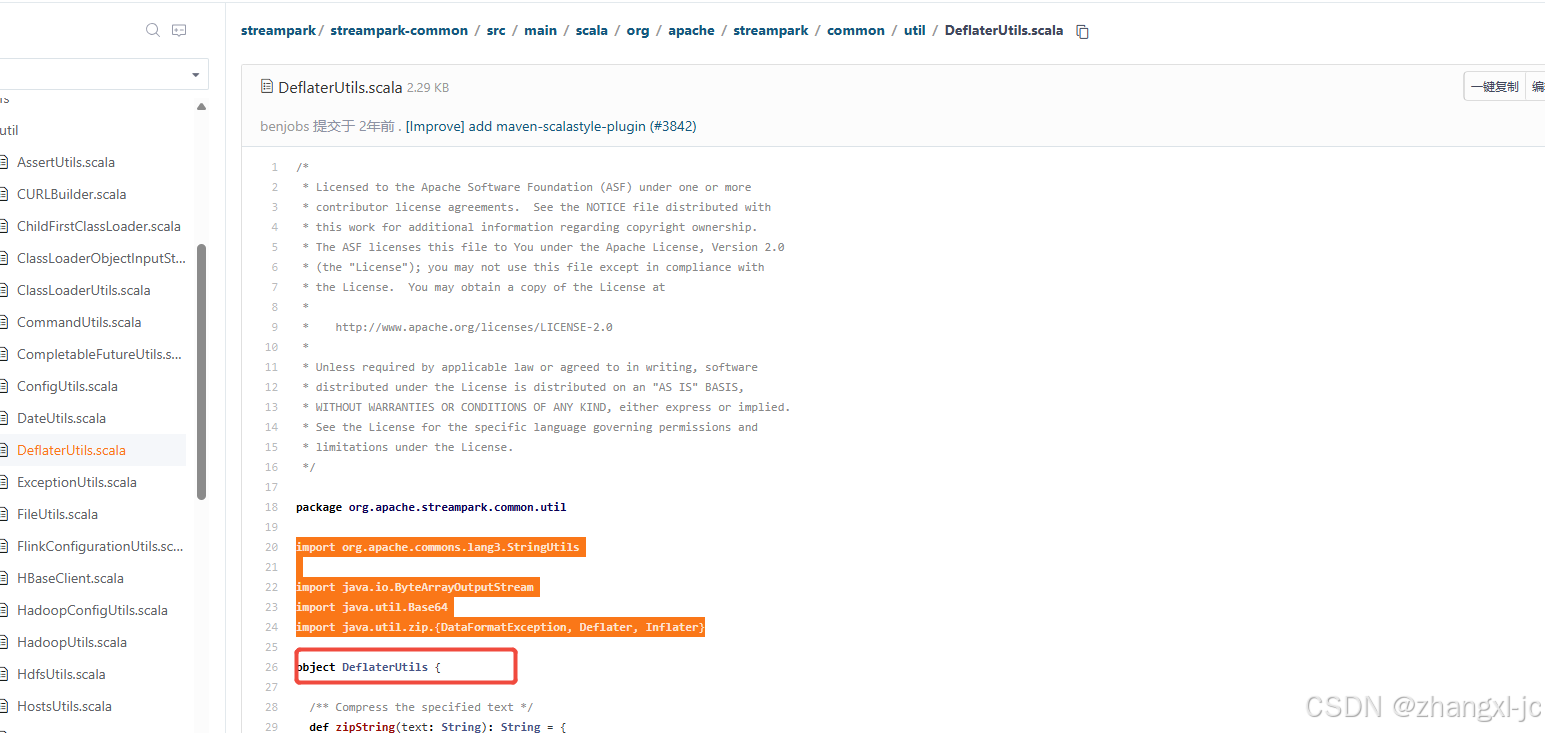
有两个编解码方法:
java
import org.apache.commons.lang3.StringUtils
import java.io.ByteArrayOutputStream
import java.util.Base64
import java.util.zip.{DataFormatException, Deflater, Inflater}
def zipString(text: String): String = {
if (StringUtils.isBlank(text)) return ""
// compression level (0 ~ 9): low to high
// create a new deflater with the specified compression level
val deflater = new Deflater(Deflater.BEST_COMPRESSION)
// set the compressed input data
deflater.setInput(text.getBytes)
deflater.finish()
val bytes = new Array[Byte](256)
val outputStream = new ByteArrayOutputStream(256)
while (!deflater.finished) {
val length = deflater.deflate(bytes)
outputStream.write(bytes, 0, length)
}
deflater.`end`()
Base64.getEncoder.encodeToString(outputStream.toByteArray)
}
def unzipString(zipString: String): String = {
val decode = Base64.getDecoder.decode(zipString)
val inflater = new Inflater
inflater.setInput(decode)
val bytes = new Array[Byte](256)
val outputStream = new ByteArrayOutputStream(256)
try {
while (!inflater.finished) { // decompress bytes array to the buffer
val length = inflater.inflate(bytes)
outputStream.write(bytes, 0, length)
}
} catch {
case e: DataFormatException =>
e.printStackTrace()
return null
} finally {
inflater.`end`()
}
outputStream.toString
}3.将streampark 低版本正常的配置拿过来解码一下,发现是将flink-conf.yaml原文直接编码的,而不是存储路径
- 将flink1.20.3 的fink conf 原文使用 zipString base64编码存储到数据库表的t_flink_env.flink_conf 替换原本的路径
5.刷新streamPark 页面,点击配置的flink1.20.3 可以看到ok了