本期我们就来学习一下C++更高 标准的特性。本期就先学习C++14标准的内容。
相关代码已经上传至作者的个人gitee:楼田莉子/CPP代码学习喜欢的话请关注一下谢谢
目录
std::shared_timed_mutex和std::shared_mutex
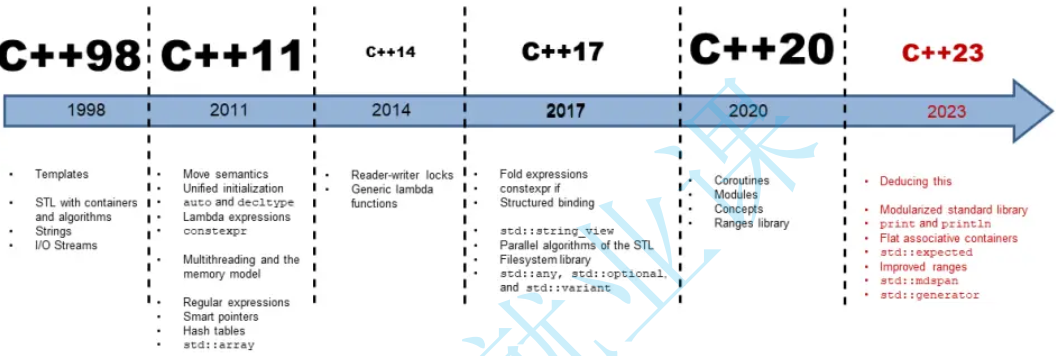
C++14的介绍
C++目前的标准是这样的:
C++官方英文文档:cppreference.com
变量模板
C++14中模板不可以用于类和函数,还可以用于变量
好处是可以用于模板函数的声明
cpp
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
using namespace std;
template<class T>
constexpr T pi = T(3.1415926535);
template<class T>
T circular_area(T r) // 函数模板
{
return pi<T> *r * r; // pi<T> 是变量模板实例化
}
int main()
{
// 使用不同精度的π
std::cout.precision(6);//设置 std::cout 输出浮点数时的精度为小数点后第6位
std::cout << "float π: " << pi<float> << std::endl;
std::cout.precision(10);
std::cout << "double π: " << pi<double> << std::endl;
//圆的半径
std::cout.precision(6);
float radius1 = 2.5;
std::cout << "半径为 " << radius1 << " 的圆⾯积: " << circular_area(radius1)
<< std::endl;
std::cout.precision(10);
double radius2 = 2.5;
std::cout << "半径为 " << radius2 << " 的圆⾯积: " << circular_area(radius2)
<< std::endl;
return 0;
}结果为:

泛型lambda表达式
C++14 允许 lambda 表达式使⽤ auto 作为参数类型,使其成为泛型。和前⾯模板的语法⾼度类似,auto&代表左值引⽤的形参,auto&&代表万能引⽤的的形参,auto&&...代表可变模板参数的
万能引⽤。
cpp
#include<iostream>
#include<string>
#include <utility>
#include<vector>
using namespace std;
int main()
{
auto Max=[](const auto& a, const auto& b) {//泛型lambda表达式以auto表示泛型
return a > b ? a : b;
};
cout << "最大整数为:" << Max(20, 30) << endl;
// 这里参数写成auto&&时类似引用折叠部分讲的万能引用
// 实参是左值就是左值引用,实参是右值就是右值引用
auto func = [](auto&& x, auto& y) {
x += 97;
y += 97;
};
/*func(1, 2);2为右值,编译不过*/
int x1 = 1, x2 = 2;
func(x1, x2);//编译通过
cout << "x1=" << x1 << "\nx2=" << x2 << endl;
string s1("hello world");
func(move(s1), x2);
vector<string >v;
auto get = [&v](auto&& ...ts) {
v.emplace_back(forward<decltype(ts)>(ts)...);
};
string s2("hello");
get(s2);
get(move(s2));
get(s2.begin(), s2.end());
for (auto& e : v)
{
cout << e << endl;
}
return 0;
}C++14 允许在 lambda 捕获中使⽤表达式初始化捕获的变量,这个变量可以是当前域定义的,也可以是没有定义的。
cpp
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
#include<string>
#include <utility>
#include<vector>
#include <algorithm>
#include<memory>
using namespace std;
int main()
{
std::vector<int> numbers = { 1, 2, 3, 4, 5 };
// 使用表达式初始化捕获的变量
auto p = std::make_unique<int>(10);
auto lambda1 = [value = 5, ptr = std::move(p), &numbers]() {
//value和ptr没有定义,需要补充初始值,否则会报错
std::cout << "捕获的值: " << value << std::endl;
std::cout << "捕获的智能指针值: " << *ptr << std::endl;
std::cout << "捕获的vector大小: " << numbers.size() << std::endl;
};
lambda1();
// 另一个例子 - 在捕获时计算值
int x = 10;
auto lambda2 = [y = x * 2]() {
std::cout << "y = x * 2 = " << y << std::endl;
};
lambda2();
return 0;
}C++20以后开始⽀持在捕捉列表和参数中间直接类似模板语法写模板参数
cpp
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
#include<string>
#include <utility>
#include<vector>
#include <algorithm>
#include<memory>
using namespace std;
int main()
{
// 以下带模板参数的写法是C++20才开始支持的
// 泛型 lambda,operator() 是一个拥有两个(模板)形参的模板
auto glambda = []<class T>(T a, auto&& b) {
return a < b;
};
// 泛型 lambda,operator() 是一个拥有一个形参包的模板
std::vector<std::string> v;
auto f2 = [&v]<typename... Args>(Args&&... ts) {
v.emplace_back(std::forward<Args>(ts)...);
};
std::string s1("hello world");
f2(s1);
f2("1111111");
f2(10, 'y');
for (auto& e : v) {
std::cout << e << " ";
}
std::cout << std::endl;
return 0;
return 0;
}函数返回类型推导
C++11中普通函数用auto做函数返回类型推导时,一般要求要配合尾置返回类型使用,相对比较局限。
cpp
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
// C++11中auto不能直接做函数返回类型,一般是跟尾置返回类型配合使用的
int x = 1;
auto f1() -> int { return x; } // 返回类型是 int
auto f2() -> int& { return x; } // 返回类型是 int&
auto f3(int x) -> decltype(x * 1.5) { return x * 1.5; } // 必须显式推导
int main()
{
cout << f1() << endl;
int& ret = f2();
cout << f3(3) << endl;
ret++;
cout << x << endl;
cout << ret << endl;
return 0;
}C++14直接支持auto推导,如果函数声明的声明说明符序列 包含关键词 auto,那么尾随返回类型可以省略,且编译器将从未舍弃的返回语句中所用的操作数的类型推导出它,如果有多条返回语句,那么它们必须推导出相同的类型。
cpp
// C++14 普通函数可以直接用auto做返回类型,自动推导返回类型
int x = 1;
auto f1() { return x; } // 返回类型是 int
auto& f2() { return x; } // 返回类型是 int&
auto f3(int x) { return x * 1.5; } // 返回类型是 double
// 报错,多返回语句需类型一致
/*
auto f4(int x) {
if (x > 0)
return 1.0; // double
else
return 2; // int → 错误:类型不一致
}
*/
int main()
{
using namespace std;
cout << f1() << endl;
int& ret = f2();
cout << f3(3) << endl;
ret++;
cout << x << endl;
cout << ret << endl;
return 0;
}如果返回类型没有使用 decltype(auto),那么推导遵循模板实参推导的规则进行。如果返回类型是 decltype(auto),那么返回类型是将返回语句中所用的操作数包裹到decltype中时所得到的类型
cpp
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <utility>
using namespace std;
int x = 1;
decltype(auto) f1() { return x; } // 返回类型是 int,同 decltype(x)
decltype(auto) f2() { return (x); } // 返回类型是 int&,同 decltype((x))
// C++14引入的decltype(auto)常用于完美转发返回类型:
// 需要精确保持返回值的值类别(左值/右值)
template<typename F, typename... Args>
decltype(auto) call(F&& f, Args&&... args)
{
return std::forward<F>(f)(std::forward<Args>(args)...);
}
int main()
{
cout << f1() << endl;
int& ret = f2();
ret++;
cout << x << endl;
cout << ret << endl;
return 0;
}二进制字面量
十进制字面量 是一个非零十进制数字(1、2、3、4、5、6、7、8、9)后随零或多个十进制数字(0、1、2、3、4、5、6、7、8、9)
八进制字面量 是数字零(0)后随零或多个八进制数字(0、1、2、3、4、5、6、7)
十六进制字面量 是字符序列 0x 或字符序列 0X 后随一或多个十六进制数字(0、1、2、3、4、5、6、7、8、9、a、A、b、B、c、C、d、D、e、E、f、F)
二进制字面量 是字符序列 0b 或字符序列 0B 后随一或多个二进制数字(0、1),二进制字面量是C++14开始支持的。主要可以应用于位图(bitset)的初始化等,进行高效的内存利用
cpp
int main()
{
cout << "=== 不同进制的整数表示 ===" << endl;
int d = 42; // 十进制
int o = 052; // 八进制
int x = 0x2a; // 十六进制(小写)
int X = 0X2A; // 十六进制(大写)
int b = 0b101010; // 二进制,C++14
cout << "十进制 42: " << d << endl;
cout << "八进制 052: " << o << endl;
cout << "十六进制 0x2a: " << x << endl;
cout << "十六进制 0X2A: " << X << endl;
cout << "二进制 0b101010: " << b << endl;
cout << endl;
// 实际应用示例 - 位标志
cout << "=== 位标志应用示例 ===" << endl;
const int FLAG_A = 0b0001; // 1
const int FLAG_B = 0b0010; // 2
const int FLAG_C = 0b0100; // 4
const int FLAG_D = 0b1000; // 8
int flags = FLAG_A | FLAG_C; // 0b0101
cout << "标志位: " << bitset<4>(flags) << endl;
if (flags & FLAG_A) {
cout << "FLAG_A 被设置" << endl;
}
if (flags & FLAG_B) {
cout << "FLAG_B 被设置" << endl;
}
else {
cout << "FLAG_B 未被设置" << endl;
}
cout << endl;
return 0;
}数字分隔符
C++14 允许在数字字⾯量中使⽤单引号作为分隔符,提⾼可读性
cpp
int main()
{
cout << "=== C++14 数字分隔符 ===" << endl;
// C++14 允许在数字字面量中使用单引号作为分隔符,提高可读性
int million = 100'0000;
long hexValue = 0xDEAD'BEEF;
double pi = 3.141'592'653'59;
unsigned long long bigBinary = 0b1010'1010'1010'1010;
cout << "一百万: " << million << endl;
cout << "十六进制值: 0x" << hex << hexValue << dec << endl;
cout << "π: " << pi << endl;
cout << "二进制值: " << bitset<16>(bigBinary) << endl;
cout << endl;
// 实际应用示例 - 定义常量
cout << "=== 数字分隔符在实际常量定义中的应用 ===" << endl;
const long long MAX_FILE_SIZE = 2'000'000'000; // 2GB
const double AVOGADRO_NUMBER = 6.022'140'76e23;
const long IP_ADDRESS = 0xC0'A8'00'01; // 192.168.0.1
cout << "最大文件大小: " << MAX_FILE_SIZE << " 字节" << endl;
cout << "阿伏伽德罗常数: " << AVOGADRO_NUMBER << endl;
cout << "IP地址: 0x" << hex << IP_ADDRESS << " (十进制: "\
<< dec << IP_ADDRESS << ")" << endl;
return 0;
}使用默认非静态成员初始化器的聚合类
聚合类的定义:
聚合类是指满足以下条件的类(包括结构体):
1. 没有用户提供的构造函数
2. 没有私有或受保护的非静态数据成员
3. 没有基类
4. 没有虚函数
关键点:
-
默认成员初始化器:当使用默认构造或值初始化时,成员会使用这些默认值
-
聚合初始化:仍然可以使用花括号初始化列表,未指定的成员会使用默认值
-
初始化顺序:初始化列表中的值按成员声明顺序应用于成员
聚合类的定义和初始化方式的变化
在C++11之前,聚合类不能有任何成员初始化器,但从C++14开始,这个限制被放宽了。
C++14允许聚合类包含默认的非静态成员初始化器(default member initializers),这使得聚合类的使用更加灵活。
在后续C++17、C++20对嵌套类定义在不断放宽,并且初始化方式也进一步优化,具体看文档和下面代码样例。
字面量后缀
字面量后缀是附加在字面量后面的标识符,用于明确指定该字面量的具体类型。这在避免歧义、确保精度、控制转换和提升代码可读性方面至关重要。
从 C++11 开始,允许整数、浮点数、字符和字符串字面量通过定义用户定义后缀来生成用户定义类型的对象。这是通过重载 operator"" 实现的。它允许程序员为字面量(数字、字符、字符串)定义自己的后缀,从而将这些"裸"字面量自动转换为具有特定类型和语义的对象。
注意内容:
cpp
ReturnType operator "" _YourSuffix(Parameters);
// ReturnType:你希望转换后的⽬标类型。
// _YourSuffix:关键:你⾃定义的后缀名。必须以下划线 _ 开头。
// 不以 _ 开头的(如 s, h,i)保留给标准库使⽤。
// Parameters:参数类型取决于你处理的是哪种字⾯量(整型、浮点、字符、字符串或原始形式)。以下以代码示例:
cpp
#include<iostream>
#include <typeinfo>
using namespace std;
int main()
{
auto s1 = "hello";
cout << typeid(s1).name() << endl;
return 0;
}结果为:

cpp
#include<iostream>
#include <typeinfo>
using namespace std;
std::string operator "" _s(const char* str, size_t len) {
return std::string(str, len);
}
int main()
{
auto s1 = "hello"_s;
cout <<"s1的类型为:" << typeid(s1).name() << endl;
string s2 = "hello";
cout<<"string对象s2的类型为" << typeid(s2).name() << endl;
return 0;
}结果为:

C++14/17/20 中库里面定义了一些实用的时间、字符串等字面量后缀。
cpp
#include<iostream>
#include <typeinfo>
#include<string>
using namespace std;
float operator ""_e(const char* str)
{
return std::stof(std::string(str));
}
constexpr long double operator "" _km(unsigned long long int x) {
return x * 1000.0; // 将公里转换为⽶
}
constexpr long double operator "" _pi(long double x) {
return x * 3.14159265358979323846L;
}
int main()
{
auto distance = 5_km; // 相当于 auto distance = 5000.0L;
auto angle = 2.0_pi; // 相当于 auto angle = 6.28318530717958647692L;
auto x = 12.3_e;
cout << "distance的类型为:" << typeid(distance).name() << endl;
cout << "angle的类型为:" << typeid(angle).name() << endl;
cout << "x的类型为:" << typeid(x).name() << endl;
}结果为:

C++14 起,标准库提供了大量开箱即用的字面量,它们定义在内联命名空间 std::literals 中。
cpp
#include<iostream>
#include <typeinfo>
#include<string>
#include <chrono>
#include <thread>
using namespace std;
using namespace std::string_literals;
using namespace std::chrono_literals;
int main()
{
// 字符串字面量
auto str = "Hello"s; // 类型是 std::string,不是 const char*
std::cout << str.size() << std::endl;
std::this_thread::sleep_for(std::chrono::milliseconds(500));
// 时间字面量
std::this_thread::sleep_for(500ms);
return 0;
}相关文档:用户定义文字(自C++11起)- cppreference.com
常见标准库字面量
| 后缀 | 例子 | 转换后的类型 | 头文件 | 标准 |
|---|---|---|---|---|
| s | "hello"s |
std::string |
<string> |
C++14 |
| sv | "hello"sv |
std::string_view |
<string_view> |
C++17 |
| h | 24h |
std::chrono::hours |
<chrono> |
C++14 |
| min | 30min |
std::chrono::minutes |
<chrono> |
C++14 |
| s | 10s |
std::chrono::seconds |
<chrono> |
C++14 |
| ms | 100ms |
std::chrono::milliseconds |
<chrono> |
C++14 |
| us | 100us |
std::chrono::microseconds |
<chrono> |
C++14 |
| ns | 100ns |
std::chrono::nanoseconds |
<chrono> |
C++14 |
| i | 2.0 + 3.0i |
std::complex<double> |
<complex> |
C++14 |
| if | 1.0if |
std::complex<float> |
<complex> |
C++14 |
| il | 1.0il |
std::complex<long double> |
<complex> |
C++14 |
| 0b | 0b1010 |
二进制整数(例如 int) |
语言核心 | C++14 |
标准库新功能
std::exchange
英文文档:std::exchange - cppreference.com
std::exchange 是 C++14 标准库在 <utility> 头文件中引入的一个实用函数模板,它提供了一种简洁高效的方式来替换一个对象的值并返回其旧值。
• 相比我们自己实现替换而言, std::exchange 使用使用上更加简洁,并且C++20以后库里面将这个函数实现为constexpr,效率更高了。
下面以代码展示:
cpp
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <iterator>
#include <utility>
#include <vector>
// std::exchange 函数说明:
// 以 new_value 替换 obj 的值,并返回 obj 的旧值。
// T 必须满足可移动构造 (MoveConstructible),而且必须能移动赋值 U 类型对象给 T 类型对象
// template< class T, class U = T >
// T exchange( T& obj, U&& new_value );
class stream
{
public:
using flags_type = int;
flags_type flags() const
{
return flags_;
}
// 以 newf 替换 flags_ 并返回旧值。
flags_type flags(flags_type newf) {
return std::exchange(flags_, newf);
}
private:
flags_type flags_ = 0;
};
void f()
{
std::cout << "f()";
}
int main()
{
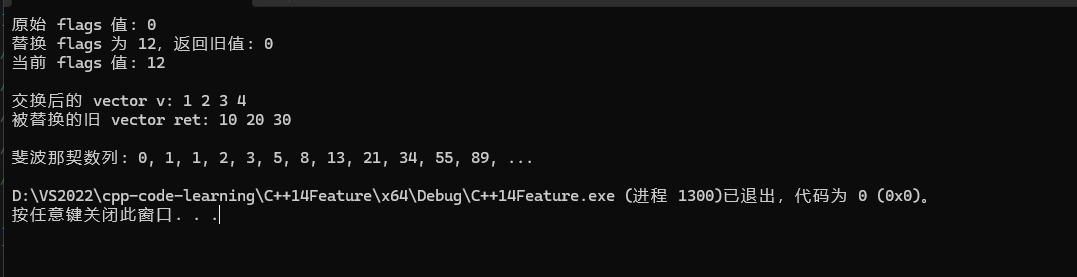
// 示例1:使用 std::exchange 替换类的成员变量并返回旧值
stream s;
std::cout << "原始 flags 值: " << s.flags() << '\n';
std::cout << "替换 flags 为 12,返回旧值: " << s.flags(12) << '\n';
std::cout << "当前 flags 值: " << s.flags() << "\n\n";
// 示例2:使用 std::exchange 替换整个 vector
std::vector<int> v = { 10, 20, 30 };
// 因为第二模板形参有默认值,故能以花括号初始化式列表为第二实参。
// 下方表达式等价于 std::exchange(v, std::vector<int>{1, 2, 3, 4});
std::vector<int> ret = std::exchange(v, { 1, 2, 3, 4 });
std::cout << "交换后的 vector v: ";
for (auto e : v) {
std::cout << e << " ";
}
std::cout << "\n";
std::cout << "被替换的旧 vector ret: ";
for (auto e : ret) {
std::cout << e << " ";
}
std::cout << "\n\n";
// 示例3:使用 std::exchange 生成斐波那契数列
std::cout << "斐波那契数列: ";
for (int a{ 0 }, b{ 1 }; a < 100; a = std::exchange(b, a + b)) {
std::cout << a << ", ";
}
std::cout << "...\n";
return 0;
}
std::make_unique
文档:Memory management library - cppreference.com
std::make_unique 是C++14引入的一个智能指针创建工具函数,用于安全地创建和管理std::unique_ptr 对象。它是现代C++中推荐的对象创建方式之一,类似于 C++11 的 std::make_shared
std::make_unique 相比直接构造 std::unique_ptr 对象而言更安全一些,当构造函数或初始化过程中抛出异常时, std::make_unique 能确保已分配的资源被正确释放。直接使用new可能导致在智能指针接管前发生异常,造成内存泄漏。所以现代C++中更推荐使用std::make_shared 和 std::make_unique 这类工具函数创建智能指针对象。
cpp
#include <iostream>
#include <iterator>
#include <utility>
#include <vector>
#include <cstddef>
#include <iomanip>
#include <memory>
//make_unique
// std::make_unique的使用演示,该代码来源于官方文档
struct Vec3
{
int x, y, z;
Vec3(int x = 0, int y = 0, int z = 0) noexcept : x(x), y(y), z(z) {}
friend std::ostream& operator<<(std::ostream& os, const Vec3& v)
{
return os << "{ x=" << v.x << ", y=" << v.y << ", z=" << v.z << " }";
}
};
// 向输出迭代器输出斐波那契数列。
template<typename OutputIt>
OutputIt fibonacci(OutputIt first, OutputIt last)
{
for (int a = 0, b = 1; first != last; ++first)
{
*first = b;
b += std::exchange(a, b);
}
return first;
}
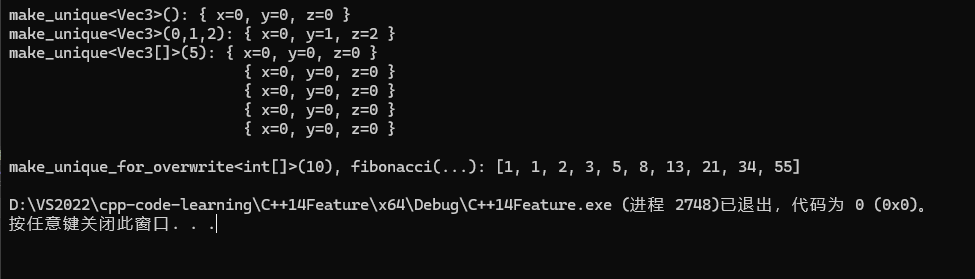
int main()
{
// 使用默认构造函数。
std::unique_ptr<Vec3> v1 = std::make_unique<Vec3>();
// 使用匹配这些参数的构造函数。
std::unique_ptr<Vec3> v2 = std::make_unique<Vec3>(0, 1, 2);
// 创建指向 5 个元素数组的 unique_ptr。
std::unique_ptr<Vec3[]> v3 = std::make_unique<Vec3[]>(5);
// 创建单个对象(会调用构造函数)
auto ptr1 = std::make_unique<int>(); // 初始化为0
auto ptr2 = std::make_unique<int>(42); // 初始化为42
// 创建数组(元素会被值初始化)
auto arr = std::make_unique<int[]>(5); // 5个int,都初始化为0
// make_unique_for_overwrite是C++20支持的,相比make_unique而言,它的特点是不初始化
// 创建指向未初始化的 10 个整数的数组的 unique_ptr,然后以斐波那契数列予以填充。
std::unique_ptr<int[]> i1 = std::make_unique_for_overwrite<int[]>(10);
fibonacci(i1.get(), i1.get() + 10);
std::cout << "make_unique<Vec3>(): " << *v1 << '\n'
<< "make_unique<Vec3>(0,1,2): " << *v2 << '\n'
<< "make_unique<Vec3[]>(5): ";
for (std::size_t i = 0; i < 5; ++i)
std::cout << std::setw(i ? 30 : 0) << v3[i] << '\n';
std::cout << '\n';
std::cout << "make_unique_for_overwrite<int[]>(10), fibonacci(...): ["
<< i1[0];
for (std::size_t i = 1; i < 10; ++i)
std::cout << ", " << i1[i];
std::cout << "]\n";
return 0;
}答案为:
std::integer_sequence
相关英文文档:std::integer_sequence - cppreference.com
std::integer_sequence 是 C++14 引入的一个模板类, std::integer_sequence 定义在 <utility> 头文件中,用于在编译时表示一个整数序列。它是模板元编程和编译时计算中的一个有用工具。
cpp
//integer_sequence
// T 是整数类型(如 int, size_t 等)
// Ints... 是一个非类型模板参数包,表示实际的整数序列
template<class T, T... Ints>
class integer_sequence;
template<typename T, T... ints>
void print_sequence(int id, std::integer_sequence<T, ints...> int_seq)
{
std::cout << id << ") 大小为 " << int_seq.size() << " 的序列: ";
((std::cout << ints << ' '), ...);
std::cout << '\n';
}
int main()
{
print_sequence(1, std::integer_sequence<unsigned, 9, 2, 5, 1, 9, 1, 6>{});
print_sequence(2, std::make_integer_sequence<int, 12>{});
print_sequence(3, std::make_index_sequence<10>{});
print_sequence(4, std::index_sequence_for<std::ios, float, signed>{});
return 0;
}下⾯我们⽤⼀个代码样例展示 std::integer_sequence 用于解包打印tuple。
cpp
// 实际应用 - 元组解包
template<typename... Args, std::size_t... Indices>
void print_tuple_impl(const std::tuple<Args...>& t,
std::index_sequence<Indices...>) {
// 使用折叠表达式(C++17)打印元组元素
((std::cout << std::get<Indices>(t) << " "), ...);
std::cout << std::endl;
}
template<typename... Args>
void print_tuple(const std::tuple<Args...>& t) {
print_tuple_impl(t, std::index_sequence_for<Args...>());
}
template<typename Array, std::size_t... I>
void print_array_impl(const Array& arr, std::index_sequence<I...>) {
((std::cout << arr[I] << ' '), ...);
}
template<typename T, std::size_t N>
void print_array(const std::array<T, N>& arr) {
print_array_impl(arr, std::make_index_sequence<N>{});
}
int main()
{
// 打印array
std::array<int, 4> arr{ 1, 2, 3, 4 };
std::cout << "数组内容: ";
print_array(arr); // 输出: 1 2 3 4
std::cout << std::endl;
// 打印元组
auto t = std::make_tuple(10, 3.14, "Hello", 'A');
std::cout << "元组内容: ";
print_tuple(t);
return 0;
}结果为:

std::quoted
英文文档:STD::引用 - cppreference.com
std::quoted 是 C++14 引入的一个 I/O 操纵器,用于简化带引号字符串的输入输出操作。它定义在 <iomanip> 头文件中
std::quoted 主要用于:
输出时:自动为字符串添加引号;
输入时:自动去除字符串周围的引号;
处理转义字符:自动处理引号内的转义序列
cpp
#include <iostream>
#include <sstream>
#include <iomanip>
#include <string>
#include <vector>
// ==================== 基础用法示例 ====================
void basic_examples() {
std::cout << "=== 基础用法示例 ===" << std::endl;
// 1. 输出时添加引号
{
std::string text = "Hello, World!";
std::cout << "原始字符串: " << text << std::endl;
std::cout << "带引号的字符串: " << std::quoted(text) << std::endl;
// 输出:
// 原始字符串: Hello, World!
// 带引号的字符串: "Hello, World!"
}
// 2. 输入时去除引号
{
std::istringstream input(R"("Hello, World!")"); // R"()" 原始字符串字面量
std::string extracted;
input >> std::quoted(extracted);
std::cout << "从带引号的字符串中提取: " << extracted << std::endl;
// 输出: 从带引号的字符串中提取: Hello, World!
}
std::cout << std::endl;
}
// ==================== 处理特殊字符示例 ====================
void special_characters_examples() {
std::cout << "=== 处理特殊字符示例 ===" << std::endl;
// 1. 字符串中包含引号
{
std::string text = R"(He said, "Hello!")";
std::cout << "原始字符串: " << text << std::endl;
std::cout << "带引号的字符串: " << std::quoted(text) << std::endl;
// 输出:
// 原始字符串: He said, "Hello!"
// 带引号的字符串: "He said, \"Hello!\""
// 注意:内部的引号被转义了
}
// 2. 包含转义字符
{
std::string text = R"(C:\Users\Name\Documents)";
std::cout << "原始路径: " << text << std::endl;
std::cout << "带引号的路径: " << std::quoted(text) << std::endl;
// 输出:
// 原始路径: C:\Users\Name\Documents
// 带引号的路径: "C:\\Users\\Name\\Documents"
// 注意:反斜杠被转义了
}
std::cout << std::endl;
}
// ==================== 自定义分隔符和转义符 ====================
void custom_delimiter_escape_examples() {
std::cout << "=== 自定义分隔符和转义符示例 ===" << std::endl;
// 1. 使用单引号作为分隔符
{
std::string text = "Hello, World!";
std::cout << "使用单引号: " << std::quoted(text, '\'') << std::endl;
// 输出: 使用单引号: 'Hello, World!'
}
// 2. 自定义转义字符
{
std::string text = R"(He said, "Hello!")";
std::cout << "使用自定义转义符(!): " << std::quoted(text, '"', '!') << std::endl;
// 输出: 使用自定义转义符(!): "He said, !"Hello!!""
}
// 3. 自定义分隔符输入
{
std::istringstream input("'Hello, World!'");
std::string extracted;
input >> std::quoted(extracted, '\'');
std::cout << "使用单引号提取: " << extracted << std::endl;
// 输出: 使用单引号提取: Hello, World!
}
std::cout << std::endl;
}
// ==================== 实际应用场景 ====================
void practical_scenarios() {
std::cout << "=== 实际应用场景 ===" << std::endl;
// 1. CSV格式处理
{
std::cout << "CSV格式处理:" << std::endl;
std::vector<std::string> fields = {"John", "Doe", "New York", "He said, \"Hello!\""};
// 将字段写入CSV格式
std::ostringstream csv_line;
for (size_t i = 0; i < fields.size(); ++i) {
if (i > 0) csv_line << ",";
csv_line << std::quoted(fields[i]);
}
std::cout << "CSV行: " << csv_line.str() << std::endl;
// 从CSV格式读取
std::istringstream csv_input(csv_line.str());
std::vector<std::string> parsed_fields;
std::string field;
while (csv_input >> std::quoted(field)) {
parsed_fields.push_back(field);
if (csv_input.peek() == ',') {
csv_input.ignore();
}
}
std::cout << "解析后的字段:" << std::endl;
for (const auto& f : parsed_fields) {
std::cout << " - " << f << std::endl;
}
}
std::cout << std::endl;
// 2. JSON格式字符串处理
{
std::cout << "JSON格式字符串处理:" << std::endl;
std::string name = "John";
int age = 30;
std::string city = "New York";
std::string quote = R"(He said, "Hello!")";
std::ostringstream json;
json << "{"
<< "\"name\": " << std::quoted(name) << ", "
<< "\"age\": " << age << ", "
<< "\"city\": " << std::quoted(city) << ", "
<< "\"quote\": " << std::quoted(quote)
<< "}";
std::cout << "JSON字符串: " << json.str() << std::endl;
}
std::cout << std::endl;
// 3. 配置文件解析
{
std::cout << "配置文件解析:" << std::endl;
std::string config_data = R"(
name = "John Doe"
path = "C:\Program Files\App"
message = "He said, \"Welcome!\""
)";
std::istringstream config_stream(config_data);
std::string line;
while (std::getline(config_stream, line)) {
std::istringstream line_stream(line);
std::string key, equals, value;
if (line_stream >> key >> equals && equals == "=") {
// 读取带引号的值
if (line_stream >> std::quoted(value)) {
std::cout << "配置项: " << key << " = " << value << std::endl;
}
}
}
}
std::cout << std::endl;
}
// ==================== 高级用法 ====================
void advanced_usage() {
std::cout << "=== 高级用法 ===" << std::endl;
// 1. 处理空字符串
{
std::string empty = "";
std::cout << "空字符串带引号: " << std::quoted(empty) << std::endl;
// 输出: 空字符串带引号: ""
std::istringstream input(R"("")");
std::string extracted;
input >> std::quoted(extracted);
std::cout << "提取的空字符串长度: " << extracted.length() << std::endl;
// 输出: 提取的空字符串长度: 0
}
std::cout << std::endl;
// 2. 处理包含换行符的字符串
{
std::string multiline = "Line 1\nLine 2\nLine 3";
std::cout << "多行字符串带引号: " << std::quoted(multiline) << std::endl;
// 注意:输出时换行符会被转义为\n
// 写入带引号的多行字符串
std::ostringstream output;
output << std::quoted(multiline);
// 读取回来
std::istringstream input(output.str());
std::string read_back;
input >> std::quoted(read_back);
std::cout << "读取回来的字符串:" << std::endl;
std::cout << read_back << std::endl;
}
std::cout << std::endl;
// 3. 与文件流配合使用
{
// 模拟写入文件
std::ostringstream file_content;
std::vector<std::string> data = {
R"(Simple string)",
R"(String with "quotes")",
R"(String with \backslashes)",
R"(Multi\nline\nstring)"
};
for (const auto& str : data) {
file_content << std::quoted(str) << '\n';
}
std::cout << "文件内容:" << std::endl;
std::cout << file_content.str() << std::endl;
// 模拟从文件读取
std::istringstream file_input(file_content.str());
std::string line;
int line_num = 1;
std::cout << "\n从文件读取:" << std::endl;
while (file_input >> std::quoted(line)) {
std::cout << "行 " << line_num++ << ": " << line << std::endl;
}
}
}
// ==================== 常见问题与解决方案 ====================
void common_problems_solutions() {
std::cout << "\n=== 常见问题与解决方案 ===" << std::endl;
// 1. 问题:不使用quoted时,空格会终止读取
{
std::cout << "问题1:空格终止读取" << std::endl;
std::istringstream input(R"("Hello World")");
std::string without_quoted, with_quoted;
// 错误的方式
input.seekg(0); // 重置流位置
input >> without_quoted;
std::cout << "不使用quoted: " << without_quoted << std::endl;
// 输出: 不使用quoted: "Hello
// 正确的方式
input.seekg(0);
input >> std::quoted(with_quoted);
std::cout << "使用quoted: " << with_quoted << std::endl;
// 输出: 使用quoted: Hello World
}
std::cout << std::endl;
// 2. 问题:混合使用quoted和非quoted输入
{
std::cout << "问题2:混合输入" << std::endl;
std::istringstream input(R"(123 "John Doe" 456)");
int num1, num2;
std::string name;
input >> num1 >> std::quoted(name) >> num2;
std::cout << "数字1: " << num1 << ", 姓名: " << name << ", 数字2: " << num2 << std::endl;
// 输出: 数字1: 123, 姓名: John Doe, 数字2: 456
}
}
int main() {
basic_examples();
special_characters_examples();
custom_delimiter_escape_examples();
practical_scenarios();
advanced_usage();
common_problems_solutions();
return 0;
}std::shared_timed_mutex和std::shared_mutex
英文文档:STD::shared_timed_mutex - cppreference.com
std::shared_mutex - cppreference.com
shared_timed_mutex 类是C++14提供的一种同步原语,能用于保护数据免受多个线程同时访问。与其他促进独占访问的互斥体类型相反,它拥有两个访问层次:
共享 - 多个线程能共享同一互斥体的所有权。
独占- 仅一个线程能占有互斥体。
shared_mutex 类是C++17提供的一个同步原语,可用于保护共享数据不被多个线程同时访问。与便于独占访问的其他互斥体类型不同,shared_mutex 拥有两个访问级别:
共享 - 多个线程能共享同一互斥体的所有权。
独占 - 仅一个线程能占有互斥体。
访问规则:
若一个线程已获取独占锁(通过 lock、try_lock),则无其他线程能获取该锁(包括共享的)。
若一个线程已获取共享锁(通过 lock_shared、try_lock_shared),则无其他线程能获取独占锁,但可以获取共享锁。
仅当任何线程均未获取独占锁时,共享锁能被多个线程获取;在一个线程内,同一时刻只能获取一个锁(共享或独占)。
主要区别:
shared_timed_mutex 提供超时锁定相关的接口:try_lock_for/try_lock_until 和 try_lock_shared_for/try_lock_shared_until。
C++14还提供了一个shared_lock的RAII管理共享锁的类型,一般建议,共享锁时使用shared_lock,独占锁时使用unique_lock。
使用建议:
-
日常中如果没有超时控制的需求且支持C++17,优先推荐shared_mutex,因为它通常更轻量,不需要实现复杂的超时逻辑。
cpp#include <iostream> #include <shared_mutex> #include <mutex> #include <thread> #include <vector> #include <chrono> #include <syncstream> using TimeMutex = std::shared_timed_mutex; #define _COUT // #define MY_COUT std::cout // C++20支持,用于多线程同步的输出,保证顺序不乱 #define MY_COUT std::osyncstream(std::cout) class ThreadSafeCounter { public: ThreadSafeCounter() = default; // 多个线程可以同时读取计数器 unsigned int get() const { // std::unique_lock<TimeMutex> lock(mutex_); std::shared_lock<TimeMutex> lock(mutex_); return value_; } // 只有一个线程可以修改计数器 void increment() { std::unique_lock<TimeMutex> lock(mutex_); ++value_; } // 尝试获取独占锁来修改计数器 bool try_increment() { std::unique_lock<TimeMutex> lock(mutex_, std::try_to_lock); if (lock.owns_lock()) { ++value_; return true; } return false; } // 一段时间内尝试获取独占锁来修改计数器 bool try_increment_for(int milliseconds) { std::unique_lock<TimeMutex> lock( mutex_, std::chrono::milliseconds(milliseconds)); if (lock.owns_lock()) { ++value_; return true; } return false; } private: // 这里添加mutable主要是在get函数是const成员函数,在get函数中是需要修改mutex_对象的 mutable TimeMutex mutex_; unsigned int value_ = 0; }; int main() { ThreadSafeCounter counter; const int N = 10; // 创建多个读取线程 auto reader = [&counter]() { for (int i = 0; i < N; ++i) { #ifdef _COUT std::this_thread::sleep_for(std::chrono::milliseconds(50)); MY_COUT << "Thread " << std::this_thread::get_id() << " read: " << counter.get() << std::endl; #else counter.get(); #endif } }; // 创建多个写入线程 auto writer = [&counter]() { for (int i = 0; i < N / 2; ++i) { #ifdef _COUT std::this_thread::sleep_for(std::chrono::milliseconds(100)); counter.increment(); MY_COUT << "Thread " << std::this_thread::get_id() << " incremented to: " << counter.get() << std::endl; #else counter.increment(); #endif } }; // 创建尝试写入的线程 auto try_writer = [&counter]() { for (int i = 0; i < N / 2; ++i) { #ifdef _COUT std::this_thread::sleep_for(std::chrono::milliseconds(75)); if (counter.try_increment()) { MY_COUT << "Thread " << std::this_thread::get_id() << " successfully incremented (try)" << std::endl; } else { MY_COUT << "Thread " << std::this_thread::get_id() << " failed to increment (try)" << std::endl; } #else counter.try_increment(); #endif } }; // 创建带超时的尝试写入线程 auto timeout_writer = [&counter]() { for (int i = 0; i < N / 2; ++i) { #ifdef _COUT std::this_thread::sleep_for(std::chrono::milliseconds(10)); if (counter.try_increment_for(30)) { MY_COUT << "Thread " << std::this_thread::get_id() << " successfully incremented (timeout)" << std::endl; } else { MY_COUT << "Thread " << std::this_thread::get_id() << " failed to increment (timeout)" << std::endl; } #else counter.try_increment_for(10); #endif } }; size_t begin = clock(); std::vector<std::thread> threads; threads.emplace_back(writer); // threads.emplace_back(try_writer); // threads.emplace_back(timeout_writer); // 创建多个读取线程 for (int i = 0; i < 3; ++i) { threads.emplace_back(reader); } for (auto& thread : threads) { thread.join(); } size_t end = clock(); std::cout << "Final counter value: " << counter.get() << " -> " << end - begin << std::endl; return 0; }
本期内容先到这里了,喜欢的话请点个赞谢谢。
封面图如下:
