go channel 深入解析
-
- [1. 为何不能只停留在`语法层`](#1. 为何不能只停留在
语法层) - [2. 揭开`channel`的两面](#2. 揭开
channel的两面) - [3. 重点是 4 种状态](#3. 重点是 4 种状态)
- [4. 四种状态,所衍生的四种行为](#4. 四种状态,所衍生的四种行为)
-
- [4.1 `nil channel`:](#4.1
nil channel:) - [4.2 无缓冲 channel:](#4.2 无缓冲 channel:)
- [4.3 有缓冲 channel:](#4.3 有缓冲 channel:)
- [4.4 关闭 channel:](#4.4 关闭 channel:)
- [4.1 `nil channel`:](#4.1
- [5. channel 让你意向不到的亮点](#5. channel 让你意向不到的亮点)
- [6. runtime 里 channel 的样子:](#6. runtime 里 channel 的样子:)
- [7. `send` / `recv` / `close` / `select` 底层怎么走?](#7.
send/recv/close/select底层怎么走?) -
- [7.1 `ch <- x` 的底层顺序](#7.1
ch <- x的底层顺序) - [7.2 `v := <-ch` 的底层顺序](#7.2
v := <-ch的底层顺序) - [7.3 `close(ch)` 做了什么](#7.3
close(ch)做了什么) - [7.4 `select` 为什么明显更复杂](#7.4
select为什么明显更复杂)
- [7.1 `ch <- x` 的底层顺序](#7.1
- [8. 工程实践](#8. 工程实践)
-
- [8.1 `close` 通常应该由发送方做](#8.1
close通常应该由发送方做) - [8.2 不要拿 `len(ch)` 做同步判断](#8.2 不要拿
len(ch)做同步判断) - [8.3 下游不收了,上游必须能停,不然就会 goroutine 泄漏](#8.3 下游不收了,上游必须能停,不然就会 goroutine 泄漏)
- [8.4 buffered channel 很适合做限流](#8.4 buffered channel 很适合做限流)
- [8.5 什么时候该用 channel,什么时候该用 mutex](#8.5 什么时候该用 channel,什么时候该用 mutex)
- [8.1 `close` 通常应该由发送方做](#8.1
- [9. 自检(来判断一下自己掌握的怎么样吧)](#9. 自检(来判断一下自己掌握的怎么样吧))
- [1. 为何不能只停留在`语法层`](#1. 为何不能只停留在
很多人写 Go 后端时都会用 channel。
任务分发要用它,worker pool 要用它,超时控制要配合 select,优雅退出常常是 done chan struct{},限流时又会拿 buffered channel 当信号量。
但真的遇到的时候,很多人一碰到下面这些问题就开始发虚:
nil channel为什么会永远阻塞?close之后到底还能不能继续读?v, ok := <-ch里的ok=false到底什么时候出现?- 无缓冲 channel 和有缓冲 channel,差别真的只是"一个有容量一个没容量"吗?
select为什么看起来简单,runtime 实现却明显更复杂?
如果面对这些问题时并不是胸有成竹,说明你对 channel 的理解,大概率还停留在"会用语法"这一步。
这篇文章我不打算只讲语法糖,而是顺着一条更实用的线讲清楚:
- 语言层,channel 到底承诺了什么语义。
- 同步层,它为什么不只是"传值工具"。
- runtime 层,
hchan、等待队列、唤醒逻辑到底怎么配合。 - 工程层,什么时候该用 channel,什么时候别硬上。
1. 为何不能只停留在语法层
只会写下面这种代码,其实不算真正理解 channel:
go
ch := make(chan int, 10)
ch <- 1
v := <-ch
_ = v真正的难点从来不是"怎么写",而是"它在什么状态下会阻塞、什么时候会 panic、为什么 close 可以做广播、为什么有些 goroutine 会莫名其妙泄漏"。
Go 后端里,channel 一般出现在这几类地方:
- 任务投递和 worker 协作。
- 请求超时与取消控制。
- 多 goroutine 之间的结果汇聚。
- 服务关闭时的广播通知。
- 有界并发控制。
这些场景背后,其实都不是"单纯传个值"那么简单,而是在依赖 channel 的同步语义和调度行为。
所以如果你只记住"channel 是管道",其实是远远不够的。
你还得知道它什么时候像队列,什么时候像同步握手,什么时候像广播器,什么时候又会把 goroutine 卡死在原地...
2. 揭开channel的两面
如果只用一句话概括 channel,我会这么讲:
对外,channel 是带类型的通信管道;对内,它是锁 + 环形缓冲区 + 等待队列 + 唤醒逻辑。
这句话非常重要,因为它同时解释了两层东西。
第一层是语言语义:
你可以发送、接收、关闭、range、select,这些都是 Go 语言承诺给你的可用行为。
第二层是底层实现:
runtime 为了把这些语义落地,需要去维护:
- 一把锁,保证 channel 操作本身并发安全。
- 一个环形缓冲区,用来承接 buffered channel 的元素。
- 发送等待队列
sendq。 - 接收等待队列
recvq。 - 关闭标记和唤醒逻辑。
这也是为什么你表面上看到的是 ch <- x 和 <-ch,但实际发生的是一整套状态判断和调度行为。
较真的家伙,可以具体了解一下:后续还会在细讲,这张图可以先略微看下

3. 重点是 4 种状态
理解 channel,最先要记住的不是源码,而是状态。
我建议可以先把这 4 种状态背下来:
| 状态 | 发送 | 接收 | close |
|---|---|---|---|
nil channel |
永远阻塞 | 永远阻塞 | panic |
| 无缓冲 channel | 必须等接收方 ready | 必须等发送方 ready | 可以关闭 |
| 有缓冲 channel | buffer 未满可直接发送 | buffer 非空可直接接收 | 可以关闭,剩余数据仍可读 |
| 已关闭且已空 | panic | 立刻返回零值,ok=false |
重复 close panic |
这张表之所以重要,平时我们项目遇到的,90%都源于此。
4. 四种状态,所衍生的四种行为
4.1 nil channel:
永远阻塞,却在 select 里很好用
未初始化的 channel 零值就是 nil。
这种行为非常的 "绝":
- 发送会永久阻塞。
- 接收会永久阻塞。
close(nil)会直接 panic。
go
var ch chan int
// ch <- 1 // 永久阻塞
// <-ch // 永久阻塞
// close(ch) // panic第一次了解到的时候是非常疑惑的,
因为这种特性挺直觉的,因为只是一个没初始化的值!为啥会好用呢?
其实,是因为可以通过select将其玩通。
因为把某个 case 对应的 channel 变量设成 nil,就等于临时禁用这个分支。
go
var in <-chan int
for {
select {
case v := <-in:
_ = v
default:
return
}
}如果运行过程中把 in = nil,那么这个 case v := <-in 就永远不会被选中。这个技巧在状态切换、阶段性关闭某条分支时非常顺手。
4.2 无缓冲 channel:
它通常被用作同步状态,撇开了对队列的幻想
很多人对无缓冲 channel 的第一理解是"没有 buffer"。
这没错,但不够准。
更准确的说法是:无缓冲 channel 的核心是发送和接收必须配对完成。
go
ch := make(chan int)
go func() {
ch <- 42
}()
v := <-ch
fmt.Println(v)这段代码里,发送方执行 ch <- 42 后,如果接收方还没 ready,就会阻塞;接收方执行 <-ch 后,如果发送方还没 ready,也会阻塞。
所以无缓冲 channel 本质上是一种同步握手。
它特别适合表达"我不是想排队,我就是要等对方真的接住"。
4.3 有缓冲 channel:
它是固定容量的环形队列
有缓冲 channel 会在 runtime 里维护一个固定容量的环形缓冲区。
go
ch := make(chan int, 8)它的行为可以简单记成 4 句话:
- buffer 未满,发送直接写入,不阻塞。
- buffer 非空,接收直接读取,不阻塞。
- buffer 满了,发送阻塞,进入
sendq。 - buffer 空了,接收阻塞,进入
recvq。
从值的角度看,它可以理解为 FIFO 队列。
但这里有个很容易被忽略的点:FIFO 不等于 goroutine 调度绝对公平。
也就是说,channel 内部的元素顺序可以按先入先出来理解,但多个 goroutine 谁先被调度到、谁先抢到执行机会,不是你靠 channel 就能绝对保证的。
4.4 关闭 channel:
不是销毁,而是告诉接收方"不会再有新值了"
close(ch) 最容易被误解成"把 channel 删除了"。
其实不是。
关闭的语义更像是一句广播声明:
发送方结束了,后面不会再有新值。
关闭之后要分两种情况看:
- 如果 buffer 里还有数据,接收方仍然可以继续读完。
- 当 buffer 被读空以后,再接收会立刻返回零值,且
ok=false。
go
ch := make(chan int, 2)
ch <- 1
ch <- 2
close(ch)
fmt.Println(<-ch) // 1
fmt.Println(<-ch) // 2
v, ok := <-ch
fmt.Println(v, ok) // 0 false而另外两件事一定会 panic:
- 向已关闭 channel 发送。
- 对同一个 channel 重复 close。
go官方推荐的优雅做法是,发送方主动close,而非接受方进行close
5. channel 让你意向不到的亮点
channel 不只是传值工具,它还是同步原语
这一部分是很多开发者容易忽略,但却很重要的点
channel 的意义不只是"传个数据过去",还包括:
建立 happens-before 关系。
也就是说,某次发送或者关闭之前发生的写操作,对后续被唤醒的接收方来说是可见的。
看一个最经典的例子:
go
var s string
done := make(chan struct{})
go func() {
s = "hello"
close(done)
}()
<-done
fmt.Println(s) // 一定能看到 hello这里真正关键的不是 done 里有没有值,而是:
- goroutine 先写
s = "hello"。 - 然后
close(done)。 - 主 goroutine 在
<-done之后继续往下走。
这个顺序能成立,不是靠"碰巧",而是因为 Go 内存模型明确给了你同步保证。
所以很多时候,channel 传递的不是数据,而是"某件事已经发生"的事实。
这也是为什么 done chan struct{} 这种写法在 Go 里这么常见:它利用的本质是同步语义,不是数据语义。
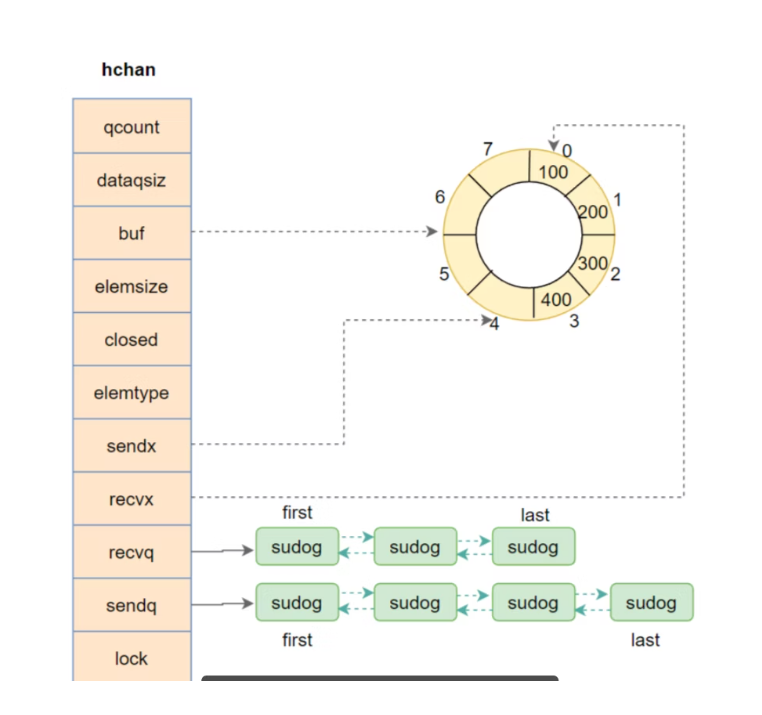
6. runtime 里 channel 的样子:
hchan、waitq、sudog
如果继续往底层看,channel 在 runtime 里的核心结构叫 hchan。
虽然没必要记完整源码,但下面这些字段最好了解:
| 字段 | 作用 |
|---|---|
qcount |
当前缓冲区里的元素个数 |
dataqsiz |
缓冲区容量 |
buf |
指向环形缓冲区 |
sendx |
下一次写入的位置 |
recvx |
下一次读取的位置 |
recvq |
等待接收的 goroutine 队列 |
sendq |
等待发送的 goroutine 队列 |
closed |
channel 是否已关闭 |
lock |
保护以上状态的互斥锁 |
可以把它理解成一个简化版结构:
go
type hchan struct {
qcount uint
dataqsiz uint
buf unsafe.Pointer
sendx uint
recvx uint
recvq waitq
sendq waitq
closed uint32
lock mutex
}这里还有个很关键的角色:sudog。
很多人第一次看到这个名字会觉得奇怪,但它解决的问题其实很现实:
goroutine 和 channel 不是一对一关系。
尤其是 select 里,一个 goroutine 可能同时等多个 channel;反过来,一个 channel 也可能同时被很多 goroutine 等待。
所以 runtime 不能简单在 goroutine 或 channel 上只挂一个指针,而是需要一个"等待记录单元"把两边串起来,这个记录单元就是 sudog。
你可以把它理解成:
某个 goroutine 正在某个 channel 上等待一次发送或接收。
7. send / recv / close / select 底层怎么走?
这一段不建议死记 runtime 代码,没啥意义。
所以会通过决策顺序来给大家描绘。
7.1 ch <- x 的底层顺序
我把发送流程,模拟成下面这棵决策树:
- 如果 channel 是
nil:
则是:永久阻塞。 - 如果 channel 已关闭:
则是:panic。 - 如果 有等待中的接收者:
则是:直接把值交给接收者,必要时绕过 buffer。 - 如果 buffer 还有空位:
则是:写入环形缓冲区。 - 否则:
当前 goroutine 封装成sudog,进入sendq,阻塞等待。
切记
即使是 buffered channel,只要此时已经有接收者在等,发送也可能直接把值交给接收者,而不是先进 buffer。
所以不要把 channel 想得太机械,好像任何值都必须先排进缓冲区。
7.2 v := <-ch 的底层顺序
接收的逻辑和发送基本对称,但对 closed 的处理更特殊:
- 如果 channel 是
nil:
则是:永久阻塞。 - 如果 channel 已关闭且已空:
则是:立刻返回零值,ok=false。 - 如果 有等待中的发送者:
则是:和发送者直接配对,必要时与 buffer 做一次交接。 - 如果 buffer 里有数据:
则是:直接从环形缓冲区读取。 - 否则:
当前 goroutine 进入recvq,阻塞等待发送者唤醒。
所以 ok=false 的真正含义不是"这次接收失败了",而是:
channel 已经关闭,并且已经没有剩余数据了。
go
v, ok := <-ch
if !ok {
// channel 已关闭且读空
}7.3 close(ch) 做了什么
close 的本质非常适合一句话记忆:
设置关闭标记,然后广播唤醒所有等待者。
它不是销毁 channel,而是做 3 件事:
- 检查
nil和重复关闭。 - 把
closed标记设为 1。 - 唤醒所有等待中的接收者和发送者。
等待中的接收者被唤醒后:
- 如果还有 buffer 数据,先继续读。
- 读空后再接收,返回零值和
ok=false。
等待中的发送者被唤醒后:
- 不会"补发成功"。
- 最终会走向 panic。
这也是为什么向已关闭 channel 发送是非常危险的。
7.4 select 为什么明显更复杂
语言层面上,select 规则不复杂:
- 所有 case 的 channel 表达式和发送值会先求值。
- 多个 case 同时 ready 时,伪随机选一个。
- 如果都不 ready 且有
default,走default。 - 否则当前 goroutine 阻塞。
但 runtime 难点在于:
一个 goroutine 同时等多个 channel,但最终只能有一个 case 赢。
所以实现时通常要做这些事:
- 随机化扫描顺序,避免固定偏向前面的 case。
- 按 channel 地址统一加锁顺序,避免死锁。
- 先尝试找立即可执行的 case。
- 如果都不 ready,就把当前 goroutine 以多个
sudog的形式挂到多个 channel 的等待队列。 - 某个 case 成功后,再把其它 case 的等待记录清理掉。
所以 select 语义不难,复杂度主要都在 runtime 的并发协调上。
8. 工程实践
讲到底层,不是为了背源码,而是为了更好的服务项目。
8.1 close 通常应该由发送方做
原因很简单:发送方最清楚"后面还有没有数据"。
如果由接收方随手关闭 channel,很容易导致另一个发送方还没停,结果下一次发送直接 panic。
单发送者场景下,发送方自己关闭,最简单也最安全。
多发送者场景下,最好由协调者统一关闭,比如:
- 一个专门的管理 goroutine。
sync.Once。- 更上层的退出控制逻辑。
8.2 不要拿 len(ch) 做同步判断
这是一个非常常见的坑。
len(ch) 只是某一瞬间的快照,不是同步保证。
go
if len(ch) > 0 {
v := <-ch
_ = v
}这段代码的问题在于:你检查完长度,到真正接收之间,别的 goroutine 完全可能已经把 channel 清空了。
这就是典型的 TOCTOU 问题。
更稳的写法一般是:
go
select {
case v := <-ch:
_ = v
default:
// 暂时没数据
}8.3 下游不收了,上游必须能停,不然就会 goroutine 泄漏
这是线上最容易踩的一个大坑。
如果消费者退出了,但生产者还在不停往 channel 发数据,生产者 goroutine 很可能永久阻塞在发送上。
这些 goroutine 不会自动被 GC 回收,因为它们还"活着",只是卡住了。
解决思路通常有两种:context 或 done channel。
go
func producer(ctx context.Context, ch chan<- int) {
for {
select {
case <-ctx.Done():
return
case ch <- getValue():
}
}
}或者:
go
done := make(chan struct{})
go func() {
for {
select {
case <-done:
return
case ch <- getValue():
}
}
}()
// 需要停止时
close(done)8.4 buffered channel 很适合做限流
这类写法在后端里非常常见,而且很好用。
go
limit := make(chan struct{}, 3) // 最多 3 个并发
for _, job := range jobs {
job := job
go func() {
limit <- struct{}{} // acquire
defer func() { <-limit }() // release
do(job)
}()
}本质上,这就是拿 buffered channel 充当一个计数信号量。
8.5 什么时候该用 channel,什么时候该用 mutex
这是我最想强调的一句判断:
channel 更擅长表达协作流程和所有权转移,mutex 更擅长保护共享状态。
如果你的问题本质上是:
- 任务分发。
- worker 协作。
- 广播退出。
- 流水线处理。
- 有界并发控制。
那 channel 往往很合适。
如果你的问题本质上只是:
- 保护一个共享
map。 - 修改一个共享
struct。 - 进入一个很短的临界区。
那 sync.Mutex 往往更直接,成本也更低。
不要为了"Go 很推崇 channel"就到处硬用。
9. 自检(来判断一下自己掌握的怎么样吧)
- channel 对外是带类型的通信管道,对内是
锁 + 环形缓冲区 + sendq/recvq + 唤醒逻辑。 nil channel发送和接收都会永久阻塞,close(nil)会 panic。- 无缓冲 channel 的本质是同步握手,不是队列。
- 有缓冲 channel 的本质是固定容量环形队列。
close不是销毁,而是广播"不会再有新值"。v, ok := <-ch里,ok=false只会在"channel 已关闭且已空"时出现。- channel 不只是传值工具,还是同步原语,会建立
happens-before。 hchan的关键字段要知道:qcount、dataqsiz、buf、sendx、recvx、recvq、sendq、closed、lock。sudog记录的是"某个 goroutine 正在某个 channel 上等待一次发送或接收"。select的复杂度来自"一个 goroutine 同时等多个 channel,但最终只能有一个 case 赢"。- 工程上,发送方通常负责
close,不要靠len(ch)做同步判断,下游不消费时上游必须可停。
最后还是回到最实用的那句话。
真正理解 channel,不是会写 make(chan T),而是你已经知道它什么时候像队列,什么时候像同步点,什么时候像广播器,什么时候会把 goroutine 永远卡住。
这一步迈过去,Go 并发编程才算真正入门。
1、菜鸟教程(channel)
2、go语言中文文档(channel)