在上一篇入门教程后,很多朋友问我如何应对更复杂的爬虫场景。今天我们就来深入聊聊,如何从基础的requests库出发,掌握处理表单提交、维持会话、突破反爬限制的进阶技巧,让你的爬虫真正"能用、好用、耐用"。
🚀 不止是GET:POST请求与数据提交
爬虫的核心是模拟人类行为,而人类上网不只是"看",更多时候是"交互"------登录、发帖、上传文件。这些操作都离不开POST请求。
- 提交表单数据:模拟用户登录
大多数网站的登录功能都是通过POST请求实现的。我们可以用requests轻松模拟这个过程:
python
import requests
d = {'OldPassword': '123python', 'NewPassword': '123456python', 'ConfirmPassword': '123456python'}
r = requests.post('https://account.ryjiaoyu.com/change-password', data = d)
print(r.text)
import requests
d = {'Password': 'Python123', 'Email': '15556520641'}
r = requests.post('https://account.ryjiaoyu.com/log-in', data = d)
print(r.text)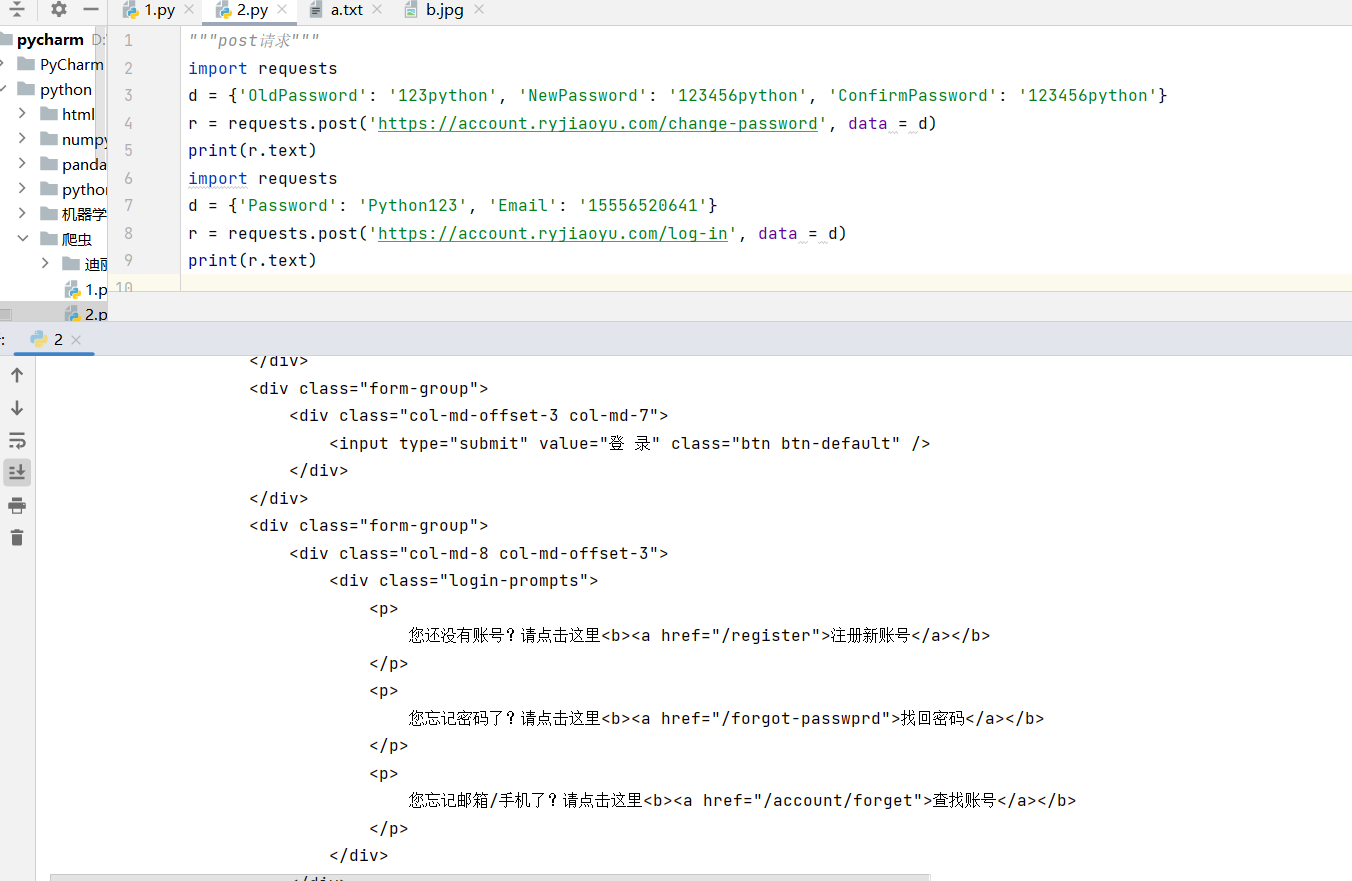
这个例子模拟了在人邮教育社区修改密码的过程,关键在于准确构造表单数据。
- 上传文件:突破静态内容限制有时候我们需要向服务器上传文件,比如头像、文档等。requests同样能轻松处理:
python
import requests
fp = {"file": open(r"C:\Users\Asus\Desktop\e3911e3b07be846cccfe2ed920807e69.png", 'rb')} # 上传的图片
r = requests.post('https://graph.baidu.com/s?card_key=material_sucai&entrance=GENERAL&extUiData%5BisLogoShow%5D=1&inspire=&promotion_name=pc_image_shituindex&session_id=17315232992771943543&sign=1264618b3c3e8e440f9a901769777928&tn=pc&tpl_from=pc', files=fp)
print(r.text)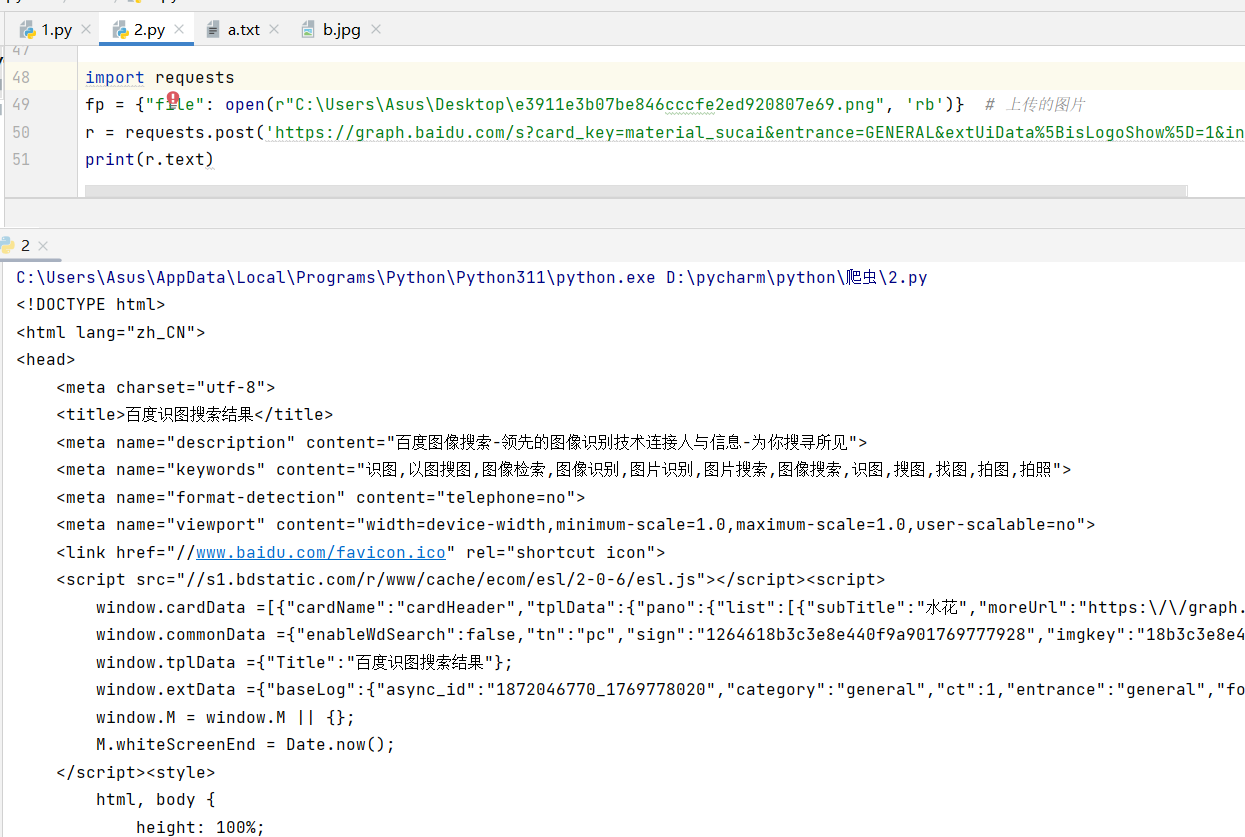
通过files参数,我们可以直接将文件对象传递给POST请求,实现文件上传。
🔐 会话管理:维持登录状态的秘密
很多网站会通过Cookies来识别用户身份。如果你每次请求都新建一个连接,就会丢失登录状态。requests的Session对象可以完美解决这个问题:
python
import requests
s = requests.Session()
data = {'Email': '15156883862', 'Password': '123python', 'RememberMe': 'true'}
r1 = s.post('https://account.ryjiaoyu.com/log-in?returnUrlhttps%3a%2f%2fwww.ryjiaoyu.com%2f', data=data)
r2 = s.get('https://www.ryjiaoyu.com/user')
print(r1.text,r2.text)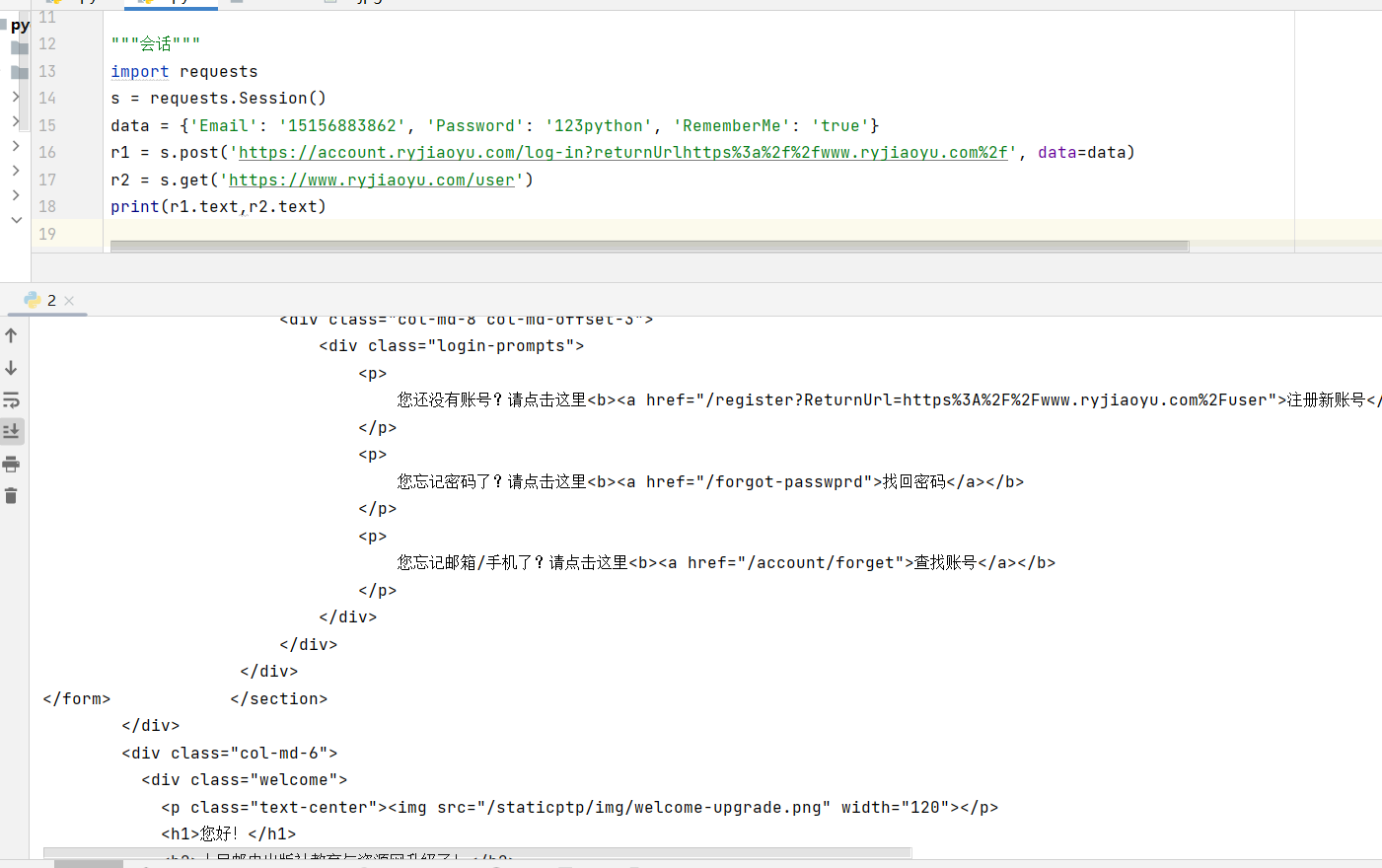
使用Session后,所有请求都会自动带上之前获取的Cookies,无需手动管理,就像你在浏览器中打开了一个标签页一样。
🛡️ 突破反爬:代理服务器的使用
当我们频繁访问一个网站时,很容易被封IP。这时代理服务器就成了我们的救星。它就像一个"中转站",让我们的请求看起来像是从不同的IP发出的。
- 配置简单代理
python
import requests
proxie = {'http':'http://115.29.199.16:8118'}
r = requests.get('https://www.ryjiaoyu.com/',proxies= proxie)
print(r.text)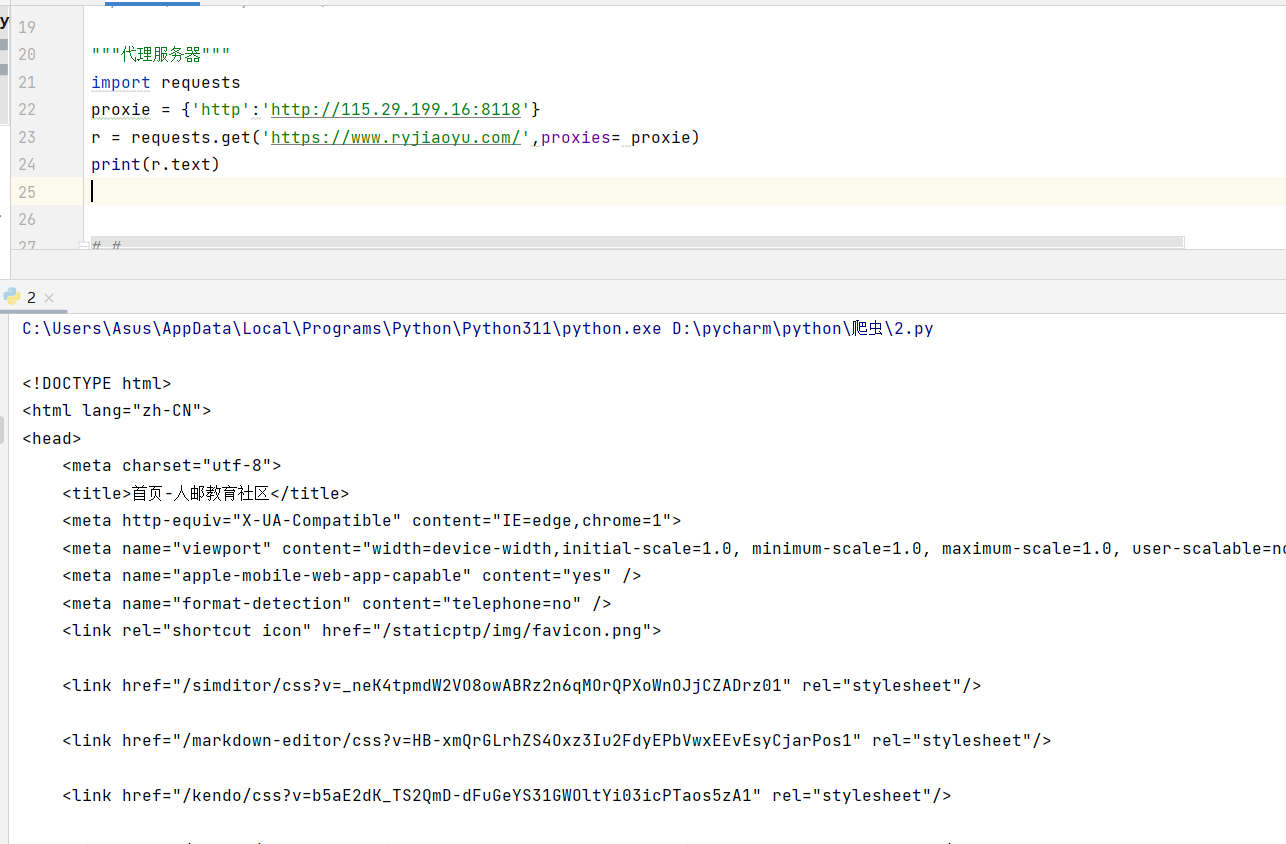
2. 代理的选择与注意事项
• 免费代理:如示例中的115.29.199.16,通常稳定性差、时效短,适合测试但不适合长期使用。
• 付费代理:稳定性高、速度快,适合生产环境。
• 代理池:对于大规模爬虫,建议构建代理池,自动切换代理以提高成功率。
📝实现人邮教育社区的自动登录
人邮教育社区的登录系统是一个非常典型的现代Web登录实现,它包含了以下几个关键技术点:
-
CSRF Token验证:网站使用_RequestVerificationToken来防止跨站请求伪造,这是目前主流网站的标配。
-
会话维持:通过Cookies来识别用户身份,需要我们使用Session对象来自动管理。
-
表单提交:登录信息通过POST请求提交,需要准确构造表单数据。
-
反爬机制:可能会有IP频率限制,需要使用代理来突破。
python
import requests
import re
def get_Token(s):
r0 = s.get('https://account.ryjiaoyu.com/log-in?ReturnUnlhttps%3A%2F%2Fwww.ryjiaoyu.com%2Fuser')
result = re.findall(r'_RequestVerificationToken(.+)value="(.+)" />', r0.text)
return r0,result[0][1]
s = requests.Session()#创建会话对象
r0,Token = get_Token(s)
data = {' RequestVenificationToken' : Token, 'Email': '15556520641', 'Password': 'Puthon123', 'RememberMe': 'true'}
r1 = s.post('https://account.ryjiaoyu.com/1og-in2returnurlhttps%a%2f%2fuuw.ryjiaouu.com%2f', data=data)
r2 = s.get('https://www.ryjiaoyu.com/user')
f0 =open('登录前前的网页.html','w',encoding='utf-8')
f1=open('登录前的网页.html','w',encoding='utf-8')
f2=open('登录后的网页.html','w',encoding='utf-8')
f0.write(r0.text)
f1.write(r1.text)
f2.write(r2.text)
f0.close()
f1.close()
f2.close()
📜 爬虫的"生存法则":伦理与效率的平衡
技术是中性的,但使用技术的人有善恶。作为一名负责任的爬虫开发者,我们需要遵守一些基本准则:
-
尊重网站规则:务必查看并遵守目标网站的robots.txt协议。
-
控制爬取频率:不要给目标服务器带来过大压力,建议在请求之间加入适当延迟。
-
数据用途合法:不要爬取和传播受版权保护的内容,避免侵犯他人隐私。
-
使用代理轮换:当需要大规模爬取时,务必使用代理池,避免被封IP。
记住,一个好的爬虫不仅要能"拿到数据",更要能"持续拿到数据"。
今天的分享就到这里。希望这些进阶技巧能帮你应对更复杂的爬虫场景。如果你有任何问题或想法,欢迎在评论区和我交流!