InternVL系列 technical report 解析
-
- [1. InternVL](#1. InternVL)
- [2. InternVL-1.5](#2. InternVL-1.5)
- [3. InternVL-2.5](#3. InternVL-2.5)
- [4. InternVL-3](#4. InternVL-3)
- [5. InternVL-3.5](#5. InternVL-3.5)
1. InternVL
论文链接: [2312.14238 InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks](https://arxiv.org/abs/2312.14238)
传统视觉模型(如CLIP)与当今千亿级参数的LLM之间存在两大差距:
- 参数规模不匹配:视觉模型通常仅10亿参数,而LLM已达千亿级,导致LLM能力未被充分利用。
- 特征表达不一致:视觉模型训练目标与LLM不兼容,需依赖轻量级"胶水层"(如线性投影)连接,效果受限。
因此internVL尝试构建一个参数均衡,特征对齐的vision-language model(将vision encoder的参数量提升至与LLM相当的程度)
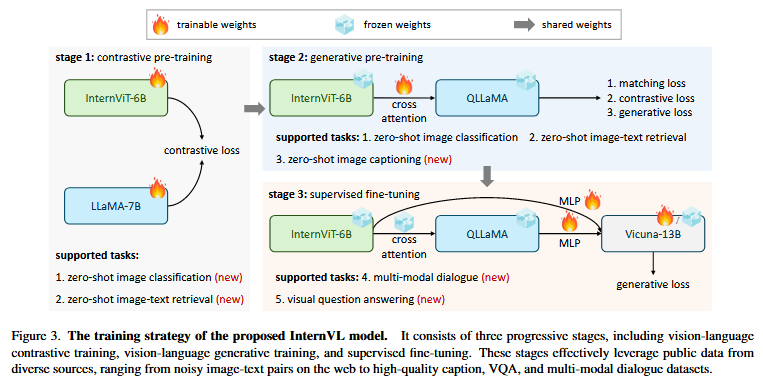
- 模型架构
- vision encoder:internViT-6B
- language encoder:Qllama
- 对齐策略
- 对比预训练:使用4.98B网络噪数据(如LAION、COYO)进行图像-文本对比训练,初步对齐特征。
- 生成预训练:使用1B高质量数据(如精标注标题),仅训练新增的可学习查询和交叉注意力层,强化跨模态理解。使用三类loss:
- image-text contrastive loss(ITC)
- image-text matching loss(ITM)
- image-text generationloss(ITG)
- SFT:通过MLP与其他现成的LLM解码器连接进行监督微调。收集高质量数据4M个样本。即使仅训练MLP层,也可以取得较为鲁棒的结果
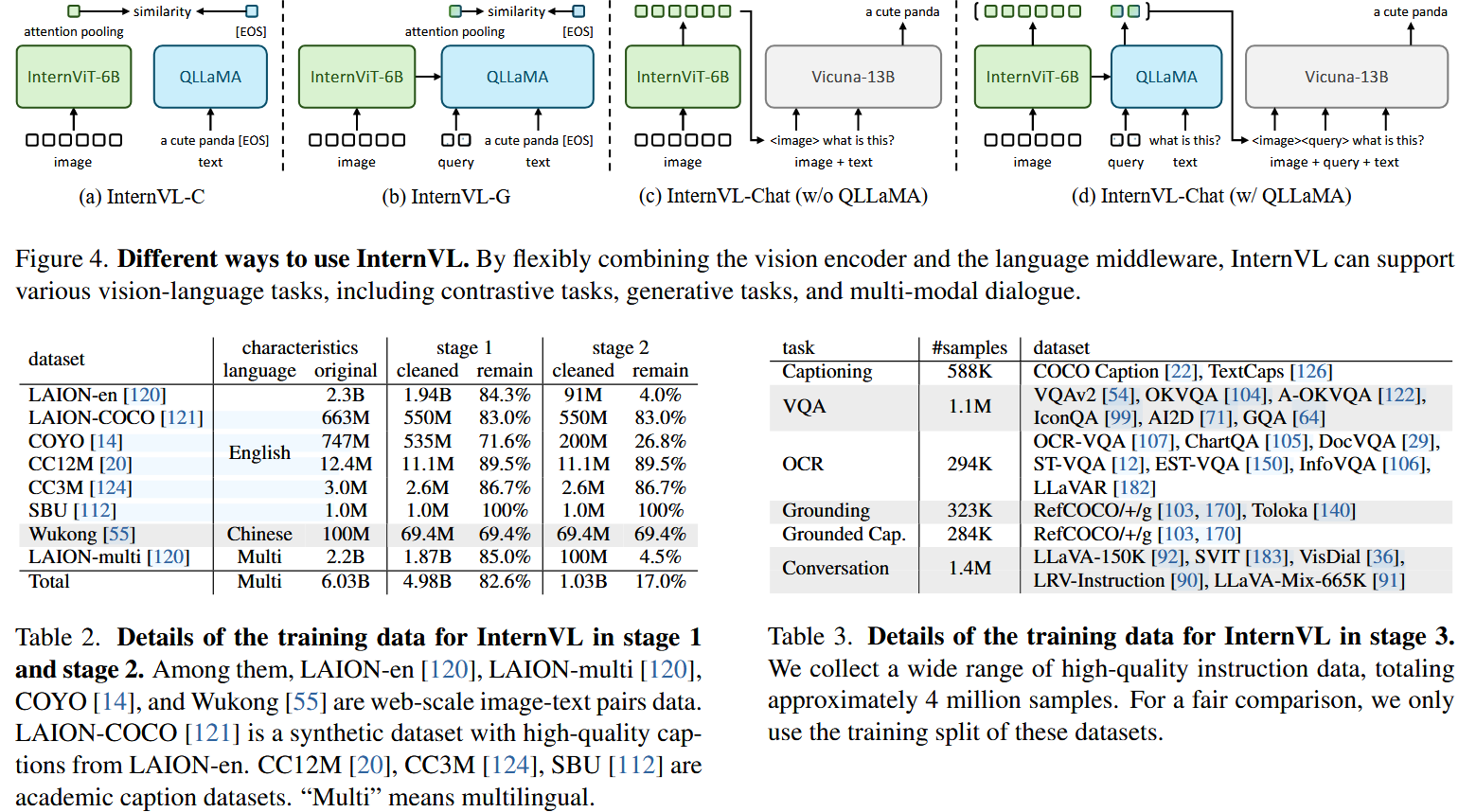
架构上,internVL与传统的单塔或双塔结构不同,根据任务的不同,internVL会采用不同的输入配置
2. InternVL-1.5
论文链接: [2404.16821 How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites](https://arxiv.org/abs/2404.16821)
针对当前开源模型与闭源商业模型的三大差距,提出internVL-1.5:
- 参数规模不匹配:商业模型参数达千亿级,开源模型通常仅70亿参数
- 图像分辨率限制:商业模型支持动态高分辨率(如4K),开源模型多用固定低分辨率(如448×448)
- 多语言能力不足:商业模型支持多语言,开源模型主要依赖英语数据
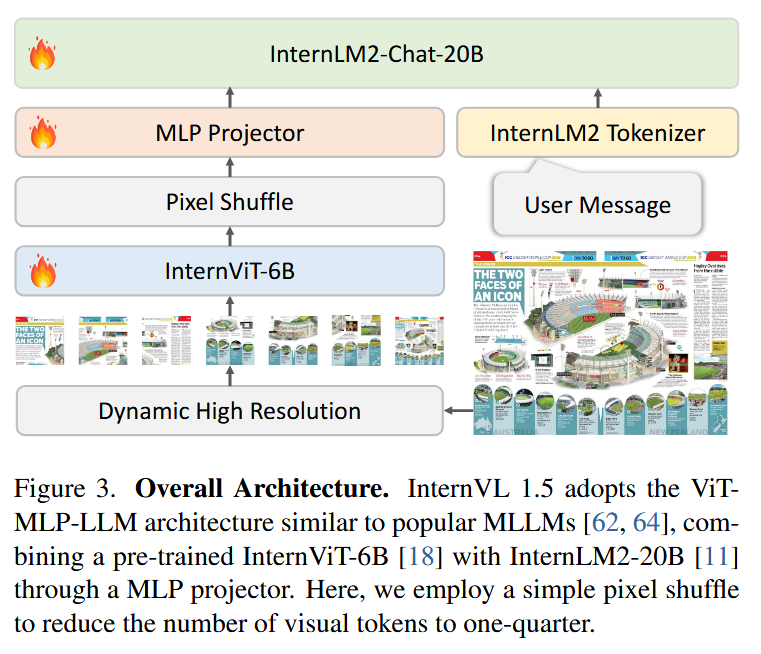
模型架构
回归更广泛使用的MLLM架构(利用MLP将视觉映射到LLM中)
- vision encoder:internViT-6B
- LLM:internLM2-Chat-20B(基于chat版本而非base版本)
训练细节
- 采用动态分辨率策略,将图像切分为12个448×448的方块,同时为了增强高分辨率的可扩展性,会采用pixel shuffle的策略将视觉标记采样到原来的四分之一, 保证高分辨率处理时的计算效率,单个448x448图块最终表示为256个视觉token
- 动态宽高比匹配:为了在处理过程中保持自然的宽高比,internVL-1.5动态匹配预定义集合中最佳的宽高比。训练中最多允许12个patch,预定义了35个不同组合。优先选择不超过输入图像面积两倍的宽高比,防止低分辨率图像的过度放大。
- 图像分割与全局缩略图:除了patch,模型还会输入全局缩略图(448×448),兼顾局部细节与全局信息,训练过程中,视觉标记的数量范围从 256 到 3,328。在测试时,tiles的数量最多可以增加到 40,从而产生 10,496 个视觉标记。
数据构成
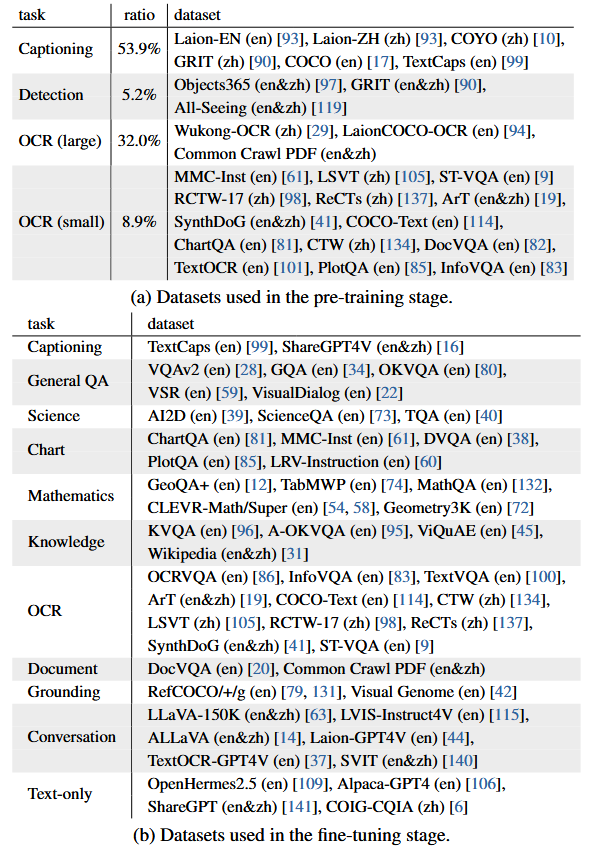
- 预训练数据:
- 微调数据:
- multilingual数据:利用当前SOT的开源闭源模型将英文数据翻译为其他语言
两阶段训练:
- 预训练阶段:仅训练internViT-6B与投影MLP层来优化视觉特征提取
- 微调阶段:模型的所有参数均更新,参考llava1.5,两阶段的context length均为4096
3. InternVL-2.5
论文链接: [2412.05271 Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling](https://arxiv.org/abs/2412.05271)
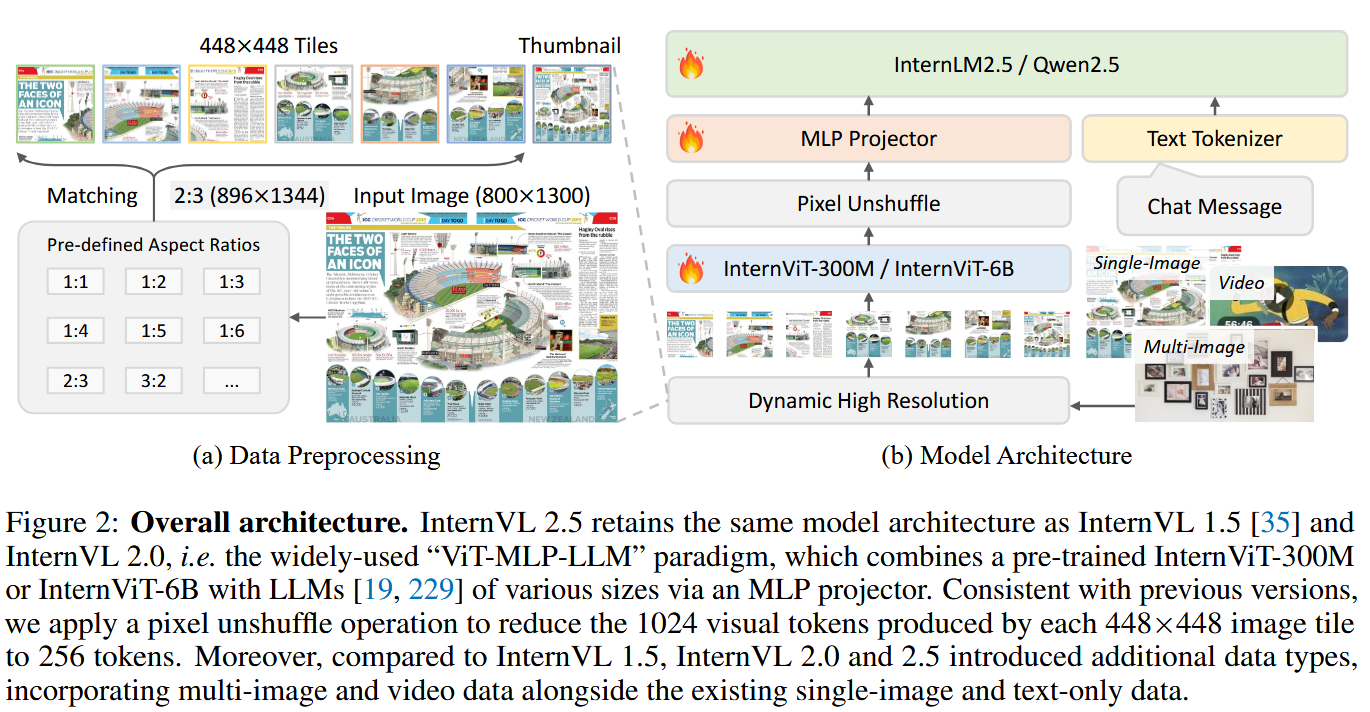
模型架构
延续了MLLM的主流架构:ViT-MLP-LLM
从internVL-2.0开始支持多图多视频的输入
vision encoder:internViT-6B or internViT-300M
LLM:internlm2.5, qwen2.5
对于图像和视频信息的处理

图3给出了三类图像与视频在LLM中的表征方式:
(a)单张图片:切成tiles并保留全景缩略图
(b)多种图片:每张图片前加id,单张图片的处理与(a)一致
(c)视频:按帧采样,不做切分,没有缩略图(不切分就没必要加缩略图来强调全局信息)
训练策略
- 动态高分辨率:根据图像宽高比自动选择最佳分片方案,最小化图像变形
训练方式
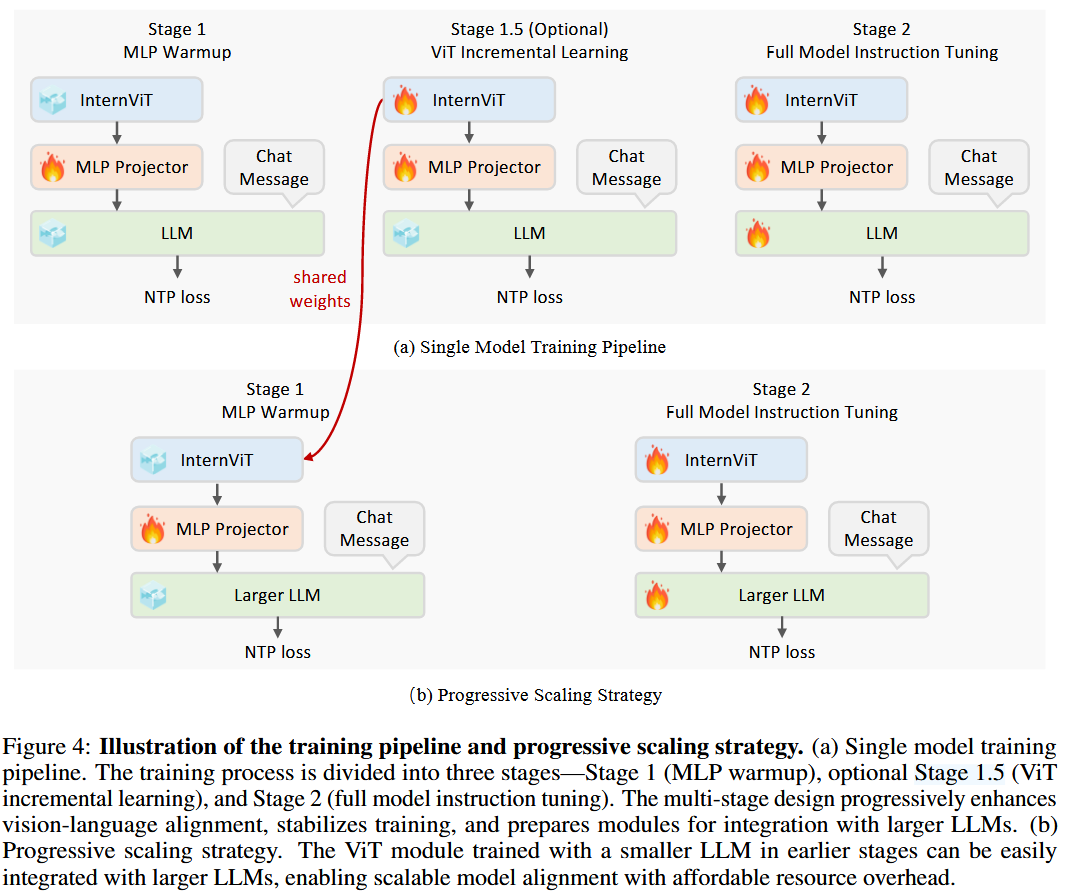
- stage 1:仅warm up MLP projector,在这一阶段就使用了动态高分辨率的训练策略。训练数据采用结构化的chatML格式,利用NTP损失进行优化。值得注意的是,这里采用了较高的lr来加速收敛,使得MLP可以快速适应LLM的输入空间并建立稳定的跨模态对齐。
- stage 1.5 :ViT增量学习(可选):视觉编码器和 MLP 投影器均可训练,训练使用与阶段 1 相同的预训练数据混合和 NTP 损失。此阶段使用较低的学习率以防止灾难性遗忘,确保编码器不会丢失之前学习到的能力。此外,视觉编码器只需训练一次,除非引入新的领域要求或数据。一旦训练完成,可以在不同的 LLM 中重复使用,而无需重新训练。
- stage 2:全模型指令微调:在此阶段我们实施严格的数据质量控制。此外,此阶段的训练超参数保持简单,对整个模型使用统一的学习率,而不是对不同组件使用不同的学习率。
渐进式scaling策略
- 复用小规模下训练得到的internViT,从而节省计算资源
训练增强
- 随机JPEG压缩:随机应用质量水平在75到100之间的JPEG压缩,以模拟互联网源图像中常见的劣化。这种增强提高了模型对噪声和压缩图像的鲁棒性,并通过确保在不同图像质量下更一致的性能来提升用户体验。
- 损失重加权:square averaging来平衡响应长度对贡献的影响
数据工作
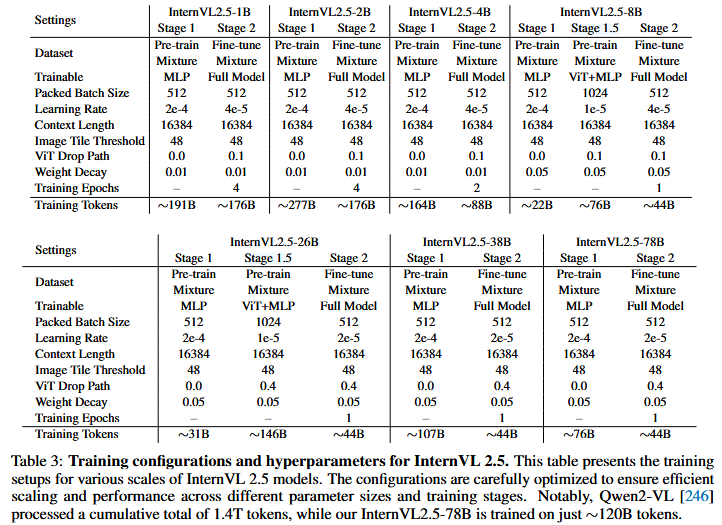
表3展示了internVL-2.5各版本训练的超参数与tokens总数
- 仅对图片数据集做数据增强(包括随机JPEG压缩等)
- 对所有数据集做采样,采样由repeat factor控制,<1则下采样(select),>1则上采样(repeat)范围为【0,4】
数据过滤
- LLM对于噪声数据相较于vision encoder更敏感
- 尽管传统观点认为在大规模数据集中可以忽略微小噪声,但研究结果表明情况并非如此:即使是微小比例的噪声样本也会降低大规模语言模型的性能和用户体验。
- 异常现象中重复生成(repetitive generation)危害最大
对于纯文本数据:
- 基于LLM进行质量评分:0-10分,低于指定阈值(比如7)剔除
- 重复检测:LLM结合特定提示来识别重复模式并进行人工审核,低于指定阈值(比如3)剔除
- 基于启发式规则过滤:应用特定规则,例如过滤掉长度异常的句子、过长的零序列、重复行过多的文本等,以识别数据中的异常。尽管这种方法有时可能产生假阳性,但它提高了异常样本的检测能力。所有标记的样本在最终移除之前都经过人工审查。
对于多模态数据:
- 重复检测:豁免高质量的学术数据集,并使用特定提示来识别其余数据中的重复模式。这些样本在处理过程中将遵循与文本数据相同的人工复审程序进行移除。
- 启发式规则过滤:应用类似的启发式规则,然后进行人工验证以确保数据集的完整性。这一严格的数据过滤管道显著减少了异常行为的发生,特别是在重复生成方面,在链式推理任务中有显著改善。
仅靠数据过滤无法完全消除此类问题。这可能是由于LLM预训练过程中引入的固有噪声,而我们的多模态后训练努力只能部分缓解这一问题,无法从根本上解决重复输出的问题。
数据混合
在InternVL 2.5的训练中,仅将微调数据中的一个子集的数据集包含在预训练数据中。
4. InternVL-3
论文链接: [2504.10479 InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models](https://arxiv.org/abs/2504.10479)

模型架构
- vision encoder:internViT-6B or internViT-300M
- LLMs:使用base版本而不是instruct版本的qwen2.5系列或internLM3-8B
- MLP projector:两层MLP
可变视觉位置编码(V2PE):为了解决长序列处理难题,internVL-3采用V2PE技术,基于特定模态的递归函数来计算位置索引。这导致文本和视觉令牌具有不同的位置索引分配,这可以降低视觉标记位置信息的增加速率,而文本标记则保持标准增量。
-
灵活增量:视觉token使用小于1的位置增量(δ),文本token保持标准增量1
-
多分辨率支持:从δ=1/256到δ=1的9种增量选择,适应不同长度需求
-
上下文扩展:有效支持长达32K token的超长序列处理
原生端到端的多模态预训练
- 将文本数据与多模态数据(图像-文本、视频-文本等)在预训练阶段混合训练
- 所有参数联合优化,避免传统多阶段训练中的对齐损失
- 训练速度比InternVL2.5提升50%-200%
两阶段后训练
- SFT:沿用了internVL-2.5所提出的随机JPEG压缩,平方损失重加权和多模态数据packing技术,并扩展了更多样化的训练数据
- MPO:混合偏好优化
L = w p L p + w q L q + w g L g \mathcal{L}=w_p\mathcal{L_p}+w_q\mathcal{L_q}+w_g\mathcal{L_g} L=wpLp+wqLq+wgLg
第一项是标准DPO损失
第二项是BCO损失用于控制正负样本质量
L q = L q + + L q − \mathcal{L_q}=\mathcal{L_q^+}+\mathcal{L_q^-} Lq=Lq++Lq−
其中:
L q + = − l o g σ ( β l o g π θ ( y w ∣ x ) π θ ( y w ∣ x ) − δ ) \mathcal{L_q^+}=-log\sigma\left(\beta log\frac{\pi_{\theta}(y_w|x)}{\pi_{\theta}(y_w|x)}-\delta\right) Lq+=−logσ(βlogπθ(yw∣x)πθ(yw∣x)−δ)
L q − = − l o g σ ( β l o g π θ ( y l ∣ x ) π θ ( y l ∣ x ) − δ ) \mathcal{L_q^-}=-log\sigma\left(\beta log\frac{\pi_{\theta}(y_l|x)}{\pi_{\theta}(y_l|x)}-\delta\right) Lq−=−logσ(βlogπθ(yl∣x)πθ(yl∣x)−δ)
第三项是SFT中使用的标准损失函数
数据
- SFT:从internVL-2.5的16.3M 到 internVL-3的21.7M
- MPO:300K samples
test-time scaling
在模型推理阶段(而非训练阶段)通过动态调整策略提升生成答案质量的技术。它的核心思想是:对同一问题生成多个候选答案,通过评估每个候选答案的推理过程,选择最优解输出。这种方法特别适用于需要多步推理的任务(如数学题求解、复杂逻辑分析)。
利用Visual Process Reward Model等模型对结果和推理过程进行打分
5. InternVL-3.5
论文链接: [2508.18265 InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency](https://arxiv.org/abs/2508.18265)
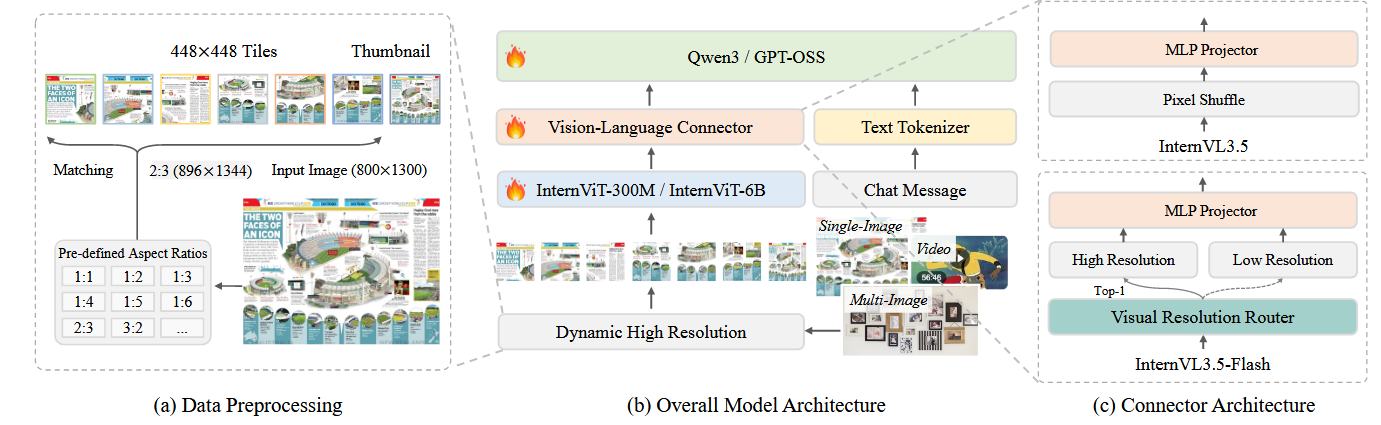
模型架构
- vision encoder:internViT-300M and internViT-8B
- language model: initialize using Qwen3 and GPT-OSS
- internVL-3.5-Flash继承了视觉分辨率路由器(ViR)。在internVL-3.5中image patch以1024个image token表征,并通过pixel shuffle模块呀u送为256个tokens,而对于Flash, 则将其压缩为64 tokens。而对于每个patch,路由器通过评估其语义丰富性来确定适当的压缩率,并相应地将其路由到相应的像素洗牌模块。
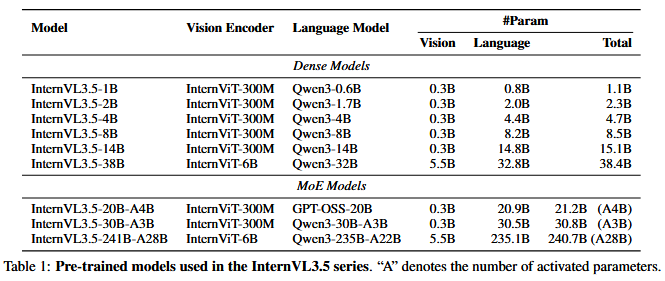
预训练
- 沿用之前的技术路线,采用端到端的原生多模态模型预训练方法,通过square averaging进行NTP损失的重加权,同时随机JPEG压缩方法也被沿用
- 数据:116M个样本,大约250B数据,文本:多模态=1:2.5,max sequence len=32K
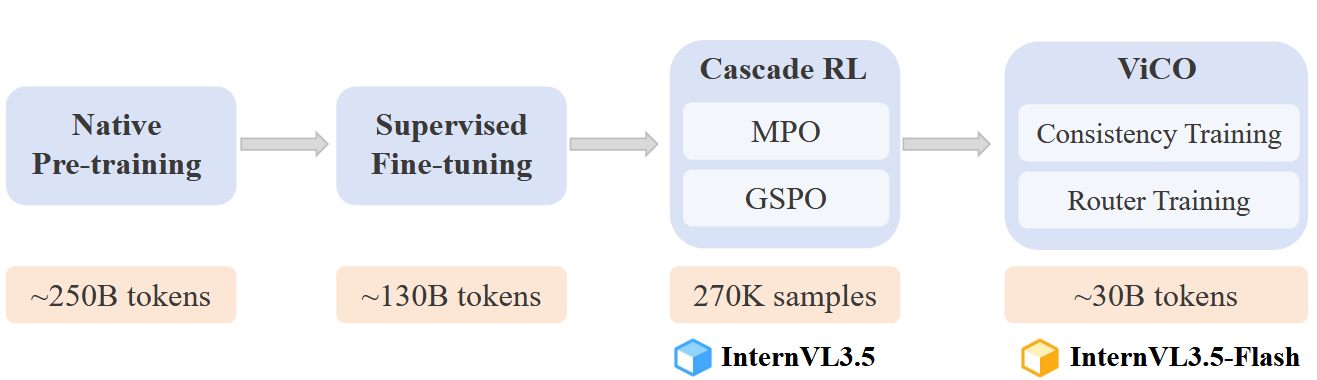
三阶段后训练
- SFT:监督微调
- cascade RL:级联强化学习,结合offline和online RL提升推理能力
- ViCO:视觉一致性训练,旨在将视觉分辨率路由器(ViR)集成到InternVL3.5中,以构建InternVL3.5-Flash,通过最小化不同视觉压缩率的输出偏差。
强化学习的核心优势在于其引入负样本的能力,这可以修剪模型输出空间中的低质量区域,从而提升整体响应质量。
首先使用离线强化学习算法作为高效的热身阶段对模型进行微调,以达到令人满意的结果,这可以保证后续阶段生成高质量的回合。随后,我们采用在线强化学习算法进一步根据模型自身生成的回合来优化输出分布。与单一的离线或在线强化学习阶段相比,我们的级联强化学习在GPU时间成本的一小部分下实现了显著的性能提升。
- offline RL:沿用MPO,利用DPO loss, BCO loss和SFT loss
- online RL:利用GSPO w/o reference model contrains
两阶段RL的优势:
- 更好的训练稳定性:在离线RL阶段,回滚收集和参数更新是解耦的,有效缓解了奖励操控等问题。在在线RL阶段,我们实证观察到更强的模型表现出更稳定和鲁棒的训练动态。因此,在MPO阶段获得的性能提升进一步增强了GSPO阶段的稳定性,并降低了对算法的敏感性。
- 提高了训练效率:在MPO阶段,回滚可以在不同模型之间共享,分摊在线RL中通常发生的采样成本。
- 更高的性能上限:经过MPO微调的模型在随后的在线RL阶段需要更少的训练步骤即可达到更高的性能,进一步降低了训练开销。
视觉一致性学习ViCO
- 一致性训练:在这个阶段,整个模型被训练以最小化在不同压缩率的视觉标记条件下反应分布之间的差异。在实践中,我们引入了一个额外的参考模型,该模型被冻结并初始化为InternVL3.5。给定一个样本,每个图像块表示为256个或64个标记,训练目标定义如下:
L V i C O = E ξ ∼ R 1 N ∑ i = 1 N KL ( π θ ref ( y i ∣ y \< i , I ) ∥ π θ policy ( y i ∣ y \< i , I ξ ) ) \mathcal{L}{\mathrm{ViCO}}=\mathbb{E}{\xi \sim \mathcal{R}}\left\\frac{1}{N} \\sum_{i=1}\^{N} \\operatorname{KL}\\left(\\pi_{\\theta_{\\text {ref }}}\\left(y_{i} \\mid y_{\
ξ为压缩率,采样取值为【1/4, 1/16】,reference model的ξ恒定为1/4
- 路由训练:该阶段旨在训练ViR为不同的输入选择合适的权衡解决方案。ViR被构建为一个二元分类器,并使用标准交叉熵损失进行训练。为了构造路线目标,我们首先计算模型输出在未压缩视觉标记(即每个补丁256个标记)和在压缩视觉标记(即每个补丁64个标记)条件下的KL散度。在此阶段,主要的MLLM(ViT、MLP和LLM)保持冻结,只有ViR被训练。具体而言,我们首先计算每个补丁的损失比率:
r i = L V i C O ( y i ∣ I 1 / 16 ) L V i C O ( y i ∣ I 1 / 4 ) r_i=\frac{\mathcal{L}{ViCO}(y_i|I{1/16})}{\mathcal{L}{ViCO}(y_i|I{1/4})} ri=LViCO(yi∣I1/4)LViCO(yi∣I1/16)
该比率量化了由于压缩视觉标记而导致的相对损失增加。基于比例,ViR的二进制真实标签定义为:
y i router = { 0 , r i < τ (compression has negligible impact) 1 , r i ≥ τ (compression has significant impact) y_{i}^{\text {router }}=\left\{\begin{array}{ll}0, & r_{i}<\tau \text { (compression has negligible impact) } \\1, & r_{i} \geq \tau \text { (compression has significant impact) }\end{array}\right. yirouter ={0,1,ri<τ (compression has negligible impact) ri≥τ (compression has significant impact)
在训练过程中,会存储滑动窗口的历史ri值,r是从历史ri值的第k个百分位数计算得出的动态阈值。在实际操作中,目标分布是平衡的。在一致性训练阶段,同一图像的所有补丁都以随机压缩率表示,以确保模型在不进行压缩时仍然保持其能力。
后训练数据:
- SFT:56M个样本,约130B tokens,文本:多模态=1:3.5
- RL:使用MMPR-V1.2作为训练数据,约200K样本对,并选取其中acc在0.2-0.8的query用于online RL(得到大约70K queries)
- ViCO:利用与SFT阶段相同的数据集进行一致性训练,以确保模型保持其原始性能。在路由器训练过程中,我们使用SFT数据的一个子集,主要由富含视觉信息的OCR和VQA示例组成,有时需要高分辨率的理解。这使得分辨率路由器能够学习如何根据视觉信息动态决定每个图像块是否可以被压缩。
test-time scaling
- 深度思考:通过激活思维模式,引导模型有意进行逐步推理(即将复杂问题分解为逻辑步骤并验证中间结论)。这种方法系统地改善了复杂问题解决方案的逻辑结构,特别是那些需要多步推理的问题,并增强了推理的深度。
- 并行思考:基于InternVL3,对于推理任务,采用最佳选择(BoN)策略,通过使用VisualPRM-v1.1 作为评估模型,选择多个推理候选中的最佳响应。这种方法提高了推理的广度。