原项目:【Boost搜索引擎】构建Boost站内搜索引擎实践-CSDN博客
项目源码: boost: boost搜索引擎项目的开发学习!
一、报告概要
测试报告的主要目的是验证搜索引擎的功能完整性和性能。通过对每个核心功能的综合测试,确保系统能够在真实环境中稳定运行,并满足用户的预期需求。
测试环境
软件:Google Chrome
开发工具:pycharm
测试工具:自动化测试工具Selenium
操作系统:Windows 11家庭中文版
浏览器版本:Google Chrome版本 144.0.7559.97(正式版本) (64 位)
二、项目功能
基于 Boost 文档的站内搜索引擎,用户可以根据浏览器访问该搜索引擎,当用户通过页面的
搜索框输入查询关键字后,就能快速的快速的查询出相关的Boost在线文档
三、测试用例
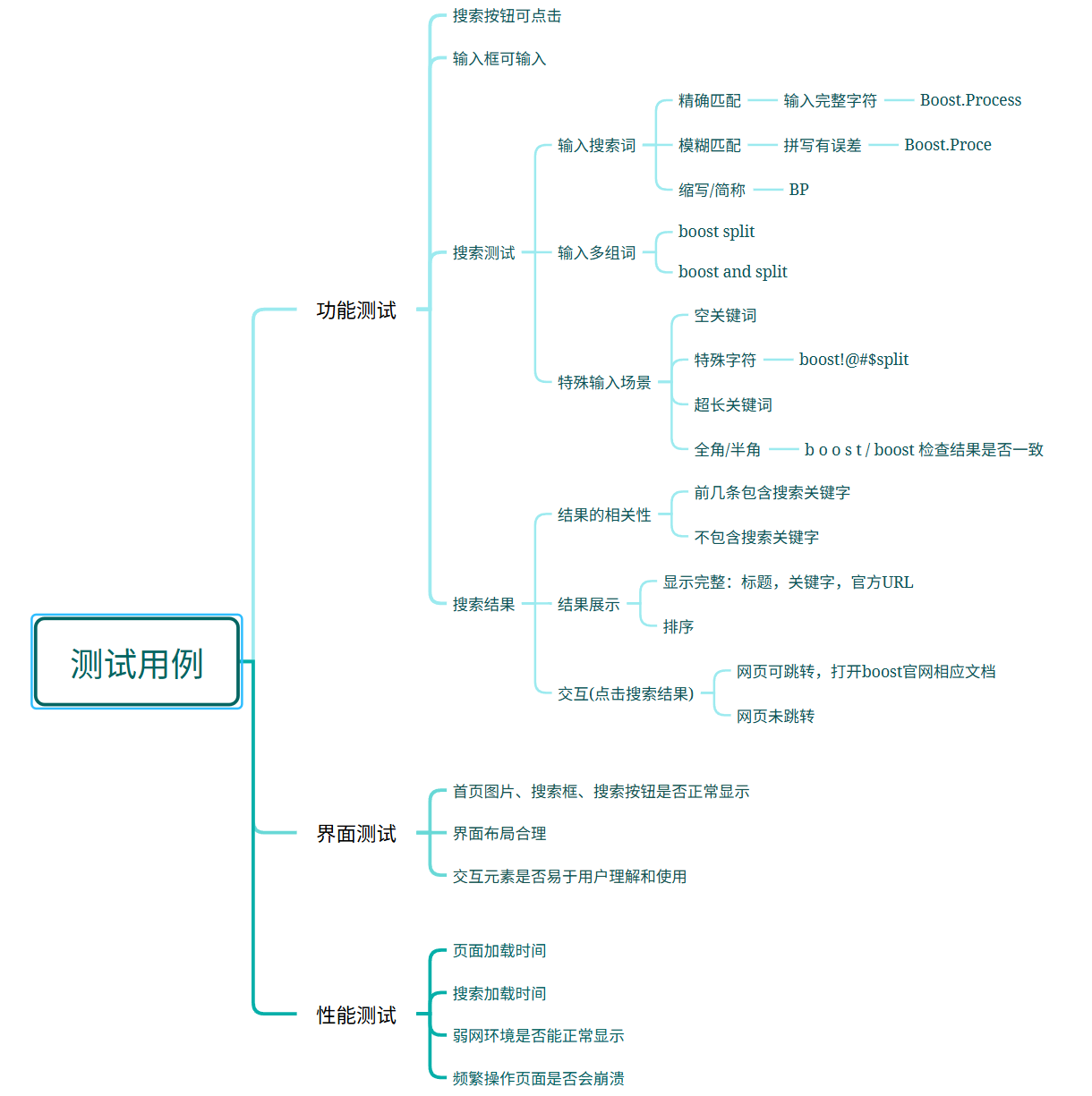
四、自动化测试
1. 创建一个公共类(安装驱动,保存截图)
①用户名、密码和预期的博客列表URL。
②打开博客登录页面并输入账号密码。
③点击提交按钮,验证是否成功跳转到博客列表页。
④ 检查页面上是否显示了正确的用户名。
注意:Chrome 要和 ChromeDriver的版本一致
python
#Utils.py
import datetime
import os
import sys
#创建一个浏览器对象
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
from selenium import webdriver
class Driver:
driver = ""
def __init__(self):
options = webdriver.ChromeOptions()
self.driver = webdriver.Chrome(service = Service(ChromeDriverManager().install(),options=options))
def getScreeShot(self):
#创建屏幕截图
#图片文件名称:2026-1-29-1834.png
#图片路径:../images/2026-1-29-1834.png
dirname = datetime.datetime.now().strftime("%Y-%m-%d")
if not os.path.exists("../images/" + dirname):
os.mkdir("../images/"+dirname)
filename = sys._getframe().f_back.f_code.co_name+datetime.datetime.now().strftime("%Y-%m-%d-%H%M%S")+".png"
self.driver.save_screenshot("../images/"+dirname+"/"+filename)
SearchDriver = Driver()首页、搜索、搜索结果等测试
python
#List.py
#首页测试
import time
from common.Utils import SearchDriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.alert import Alert
class ListTest:
url = ""
driver = ""
# 新增:定义实例变量,保存不同阶段的URL和窗口句柄
initial_url = "" # 初始页面URL
search_result_url = "" # 搜索结果页面URL
original_window_handle = "" # 原始窗口句柄(初始窗口)
def __init__(self):
self.url = "http://8.130.176.45:8081/"
self.driver = SearchDriver.driver
self.driver.get(self.url)
# 新增:获取初始页面URL和原始窗口句柄
self.initial_url = self.driver.current_url
self.original_window_handle = self.driver.current_window_handle # 获取当前窗口唯一标识
print(f"✅ 初始页面URL:{self.initial_url}")
print(f"✅ 原始窗口句柄:{self.original_window_handle}\n")
#测试首页
def ListTest(self):
time.sleep(3)
#测试首页图片是否存在
self.driver.find_element(By.CSS_SELECTOR,"body > div > div.header > img")
#测试标题是否存在
self.driver.find_element(By.CSS_SELECTOR,"body > div > div.header > h1")
#测试输入框是否存在
self.driver.find_element(By.CSS_SELECTOR,"body > div > div.search > input[type=text]")
#测试搜索按钮是否存在
self.driver.find_element(By.CSS_SELECTOR,"body > div > div.search > button")
time.sleep(3)
#截图
SearchDriver.getScreeShot()
#搜索测试
def SearchTest(self):
self.driver.find_element(By.CSS_SELECTOR, "body > div > div.search > input[type=text]").clear()
self.driver.find_element(By.CSS_SELECTOR,"body > div > div.search > input[type=text]").send_keys("split")
time.sleep(3)
self.driver.find_element(By.CSS_SELECTOR,"body > div > div.search > button").click()
time.sleep(3)
# 截图
SearchDriver.getScreeShot()
# 1. 记录搜索结果页面的URL和当前所有窗口(此时只有原始窗口)
self.search_result_url = self.driver.current_url
all_windows_before_click = self.driver.window_handles # 获取所有窗口句柄列表
print(f"🔍 点击搜索结果前(搜索结果页面)URL:{self.search_result_url}")
print(f"🔍 点击搜索结果前窗口数量:{len(all_windows_before_click)}")
#查看搜索的结构是否可以正常打开
self.driver.find_element(By.CSS_SELECTOR, "body > div > div.result > div:nth-child(1) > a").click()
time.sleep(3) # 等待新窗口完全打开(可根据网络调整时长)
# 2. 获取点击后所有窗口句柄,找到新打开的窗口
all_windows_after_click = self.driver.window_handles
print(f"📍 点击搜索结果后窗口数量:{len(all_windows_after_click)}")
# 判断是否新开了窗口
if len(all_windows_after_click) > len(all_windows_before_click):
# 遍历找到新增的窗口句柄(即新窗口)
for window_handle in all_windows_after_click:
if window_handle not in all_windows_before_click:
new_window_handle = window_handle
break
print(f"📍 新窗口句柄:{new_window_handle}")
# 3. 切换Selenium驱动焦点到新窗口
self.driver.switch_to.window(new_window_handle)
time.sleep(3) # 等待新窗口页面加载完成
# 4. 获取新窗口的URL,进行跳转判断
new_window_url = self.driver.current_url
print(f"📍 新窗口页面URL:{new_window_url}")
# 核心跳转判断逻辑
print("\n===== 跳转判断结果 =====")
if new_window_url != self.search_result_url:
print("✅ 检测到:新开窗口完成跳转!")
if self.initial_url not in new_window_url:
print("✅ 补充:新窗口跳转到了初始站点以外的外部页面!")
else:
print("ℹ️ 补充:新窗口仍在当前站点内跳转(未离开初始域名)。")
else:
print("❌ 检测到:新窗口未发生跳转,URL与搜索结果页面一致。")
# 5. 截图新窗口
SearchDriver.getScreeShot()
# 6. 切换回原始窗口
self.driver.switch_to.window(self.original_window_handle)
print(f"\n✅ 已切换回原始窗口,继续执行后续测试...")
else:
print("\n❌ 检测到:未新开任何窗口,也未发生跳转。")
# 截图
SearchDriver.getScreeShot()
time.sleep(3)
#输入为空
self.driver.find_element(By.CSS_SELECTOR, "body > div > div.search > input[type=text]").clear()
self.driver.find_element(By.CSS_SELECTOR, "body > div > div.search > button").click()
# 处理 Alert 弹窗
try:
alert = Alert(self.driver)
print("\nAlert 文本:", alert.text) # 可以打印弹窗内容
alert.accept() # 点击"确定"关闭弹窗
except:
pass # 如果没有弹窗,就跳过
self.driver.quit()
listtest = ListTest()
listtest.ListTest()
listtest.SearchTest()1.通过采用自动化测试工具如Selenium,项目实现了自动化测试脚本的编写,这有助于提高测试效率和系统运行的稳定性。
2.只创建一次驱动对象,避免每个用例重复创建驱动对象造成时间和资源的浪费。
3.使用参数化:保持用例的简洁,提高代码的可读性。
4.使用测试套件:降低了测试的工作量,通过套件一次执行所有要运行的测试用例。
5.使用了等待:测试脚本能够自动等待页面元素加载完成,这提高了自动化测试运行的效率和稳定性。
6.使用了屏幕截图:方便问题的追溯以及问题的解决。
7.使用了断言:验证测试结果是否符合预期,这是自动化测试中验证测试是否通过的关键部分。