实战精讲:从零构建 RFM 会员价值模型(再进阶版:模拟数据 + 动态打分 + 策略落地)
欢迎来到 RFM 模型再进阶版 教程。在这个版本中,我们不再满足于简单的"跑通代码",而是要深入理解数据生成的逻辑 、动态打分的数学原理 以及如何将数据转化为商业决策。
本教程将带你完成从 0 到 1 的全过程:
- 构造高仿真数据:模拟真实业务中的用户行为差异(如流失、新客、高价值)。
- 清洗与预处理:处理日期格式、缺失值,理解索引的意义。
- 动态量化打分:使用统计学方法(分位数)替代人为拍脑袋的阈值。
- 策略落地:将分数映射为具体的营销动作。
本教程的所有数据及代码详见:点击此处
在之前的版本中,我们学习了基础的 RFM 模型。本再进阶版将带来以下核心升级:
- 构建高仿真模拟数据:不再依赖静态文件,而是通过脚本生成包含用户姓名、商品类别、支付方式等多维度的复杂数据,并模拟不同用户的行为特征(如高价值用户、流失用户、新客等)。
- 动态百分位打分 :摒弃固定阈值,使用
pd.qcut根据数据分布动态划分等级,使评分更适应当前数据集。 - 精细化人群画像与策略:基于 R/F/M 的高低组合,将用户细分为 8 类,并为每一类提供具体的营销建议。
📊 第一阶段:构建高仿真模拟数据
在真实工作中,我们往往拿不到完美的数据集,或者需要生成测试数据来验证算法的鲁棒性。这一阶段,我们将编写一个脚本,生成一份包含 65 条订单 、18 位用户 的复杂数据。
1. 设计思路与核心逻辑
这份数据不仅仅是随机数,它蕴含了业务逻辑:
- 用户分层模拟:我们预设了 5 类用户(高价值、一般活跃、流失老客、新客、沉睡客),通过控制他们的购买时间、频率和金额,让数据呈现出真实的分布形态。
- 多维字段 :除了基础的 RFM 字段,还增加了
USERNAME(便于展示)、CATEGORY(品类)、PAY_METHOD(支付方式),为后续的多维交叉分析埋下伏笔。 - 脏数据模拟:故意制造 5% 的空值(NaN),用来测试我们后续的数据清洗能力。
2. Python 数据生成脚本
python
import pandas as pd
import numpy as np
import random
from datetime import datetime, timedelta
import os
# ================= 配置区域 =================
# 获取当前脚本所在目录,确保路径兼容性
script_dir = os.path.dirname(os.path.abspath(__file__))
data_folder = os.path.join(script_dir, "Data")
# 如果 Data 文件夹不存在,自动创建,防止报错
if not os.path.exists(data_folder):
os.makedirs(data_folder)
OUTPUT_FILE = os.path.join(data_folder, "rfm_sales_data.xlsx")
# 设定数据的"今天",作为计算 R 值的基准
END_DATE = datetime(2026, 3, 12)
# --- 基础素材库 ---
surnames = ['赵', '钱', '孙', '李', '周', '吴', '郑', '王', '冯', '陈', '褚', '卫', '蒋', '沈', '韩', '杨', '朱', '秦', '尤', '许']
names_1 = ['伟', '芳', '娜', '秀英', '敏', '静', '丽', '强', '磊', '军', '洋', '勇', '艳', '杰', '娟', '涛', '明', '超', '秀兰', '霞']
names_2 = ['云', '玲', '华', '平', '辉', '芬', '鹏', '建', '文', '桂', '兰', '风', '翔', '波', '燕', '飞', '红', '刚', '琴', '欣']
categories = ['数码电子', '家居生活', '时尚服饰', '美妆护肤', '食品饮料', '图书文娱']
pay_methods = ['微信支付', '支付宝', '信用卡', '银联云闪付']
# ================= 辅助函数 =================
def generate_chinese_name():
"""
生成随机的中文姓名。
逻辑:70% 概率生成两个字的名字,30% 概率生成三个字的名字。
"""
surname = random.choice(surnames)
if random.random() > 0.3:
return surname + random.choice(names_1)
else:
return surname + random.choice(names_1) + random.choice(names_2)
print("🚀 正在生成模拟销售数据...")
# ================= 数据生成核心逻辑 =================
# 1. 创建用户池 (共 18 个用户)
user_count = 18
users = []
for i in range(1, user_count + 1):
uid = f"U{1000 + i}"
name = generate_chinese_name()
# 【关键逻辑】通过权重随机分配用户类型,模拟真实的人群分布
# A: 高价值 (20%), B: 一般活跃 (30%), C: 流失老客 (20%), D: 新客 (20%), E: 沉睡客 (10%)
user_type = random.choices(['A', 'B', 'C', 'D', 'E'], weights=[0.2, 0.3, 0.2, 0.2, 0.1])[0]
users.append({
'USERID': uid,
'USERNAME': name,
'TYPE': user_type # 记录该用户的预设类型,用于后续验证
})
data_rows = []
order_id_counter = 1000
# 2. 根据用户类型生成具体的订单行为
for user in users:
uid, uname, utype = user['USERID'], user['USERNAME'], user['TYPE']
# --- 行为规则定义 ---
if utype == 'A': # 高价值活跃用户:买得多、买得贵、最近刚买
num_orders = random.randint(5, 8)
date_start = datetime(2025, 6, 1)
amount_range = (800, 5000)
elif utype == 'B': # 一般活跃用户:偶尔买,金额中等
num_orders = random.randint(2, 4)
date_start = datetime(2025, 9, 1)
amount_range = (200, 1500)
elif utype == 'C': # 流失老客:以前买得多且贵,但只在 2024 年买过
num_orders = random.randint(4, 7)
date_start = datetime(2024, 1, 1)
date_end_limit = datetime(2024, 12, 31) # 强制限制在 2024 年
amount_range = (1000, 6000)
elif utype == 'D': # 新客低值:最近才来,买得少且便宜
num_orders = random.randint(1, 2)
date_start = datetime(2026, 1, 1)
amount_range = (50, 300)
else: # E: 沉睡客:很久没买,以前买的也少
num_orders = random.randint(1, 2)
date_start = datetime(2024, 1, 1)
date_end_limit = datetime(2024, 6, 30)
amount_range = (100, 400)
# 生成该用户的具体订单
for _ in range(num_orders):
# 日期生成逻辑
if utype in ['C', 'E']:
# 对于老客/沉睡客,时间在特定历史区间内随机
delta = (date_end_limit - date_start).days
rand_date = date_start + timedelta(days=random.randint(0, delta))
else:
# 对于活跃/新客,从开始时间到今天随机
delta = (END_DATE - date_start).days
rand_date = date_start + timedelta(days=random.randint(0, delta))
if rand_date > END_DATE:
rand_date = END_DATE
# 金额生成逻辑
amount = round(random.uniform(*amount_range), 2)
# 【脏数据模拟】5% 的概率将金额设为空值 (NaN),测试清洗能力
if random.random() < 0.05:
amount = np.nan
data_rows.append({
'USERID': uid,
'USERNAME': uname,
'ORDERDATE': rand_date.strftime('%Y/%m/%d'), # 先存为字符串,模拟 Excel 读取效果
'ORDERID': order_id_counter,
'AMOUNTINFO': amount,
'CATEGORY': random.choice(categories),
'PAY_METHOD': random.choice(pay_methods)
})
order_id_counter += 1
# 3. 构建 DataFrame 并后处理
df = pd.DataFrame(data_rows)
# 打乱顺序:真实数据流通常是无序的,打乱后更能测试代码的稳健性
df = df.sample(frac=1, random_state=42).reset_index(drop=True)
# 排序整理:为了人类阅读方便,按日期排序,然后再转回字符串保存
df['ORDERDATE'] = pd.to_datetime(df['ORDERDATE'])
df = df.sort_values('ORDERDATE')
df['ORDERDATE'] = df['ORDERDATE'].dt.strftime('%Y/%m/%d')
# ================= 保存文件 =================
try:
df.to_excel(OUTPUT_FILE, index=False)
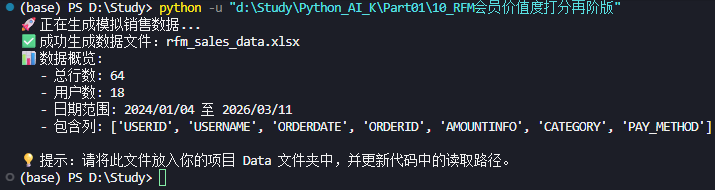
print(f"✅ 成功生成数据文件:{OUTPUT_FILE}")
print(f"📊 数据概览:")
print(f" - 总行数 (订单数): {len(df)}")
print(f" - 唯一用户数:{df['USERID'].nunique()}")
print(f" - 日期范围:{df['ORDERDATE'].min()} 至 {df['ORDERDATE'].max()}")
print(f" - 包含列:{list(df.columns)}")
print("\n💡 提示:请将此文件放入你的项目 Data 文件夹中,并更新代码中的读取路径。")
except Exception as e:
print(f"❌ 保存失败:{e}")
print("提示:请确保已安装 openpyxl 库 (pip install openpyxl)")💡 知识点与启发
- 代码运行成功:
- 总共建立了 65条数据(含空值):
这段代码主要是为了增加多条数据给我们进行操练,接下来对数据进行分析便可以把这段代码删除。
- 业务驱动数据 :这段代码最宝贵的地方不在于语法,而在于它用代码还原了业务场景。我们在生成数据时,脑海中要有"用户画像"。以后在做任何数据分析前,都可以先问自己:"如果我是业务人员,我希望看到什么样的数据分布?"然后尝试用代码模拟出来,这能极大地提升你对数据敏感度的训练。
- 脏数据意识 :注意代码中
if random.random() < 0.05: amount = np.nan这一行。在真实世界中,数据永远是不完美的。主动在测试数据中制造"缺陷",是为了训练我们编写具有容错性 的代码(比如后续的dropna或fillna)。- 路径自动化 :使用
os.path拼接路径而不是写死绝对路径(如D:\Study\...),能让你的代码在任何人的电脑、任何目录下都能直接运行,这是专业程序员的基本素养。
🔍 第二阶段:数据加载、清洗与索引重构
数据生成后,我们需要将其读入内存并进行预处理。这一步的核心目标是:将杂乱的流水账,整理成以"用户"为核心的分析宽表。
1. 读取数据与索引设置
在 RFM 模型中,我们的分析对象是人 ,而不是订单 。因此,将 USERNAME(或 USERID)设置为索引(Index)是至关重要的第一步。
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
from datetime import datetime
from jinja2 import Template
# --- 绘图与显示配置 ---
# 设置字体以支持中文显示,防止画图时出现方框乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
# 设置正常显示负号,避免坐标轴上的负号显示为方块
plt.rcParams['axes.unicode_minus'] = False
# --- 路径动态配置 ---
# 获取当前脚本所在的绝对路径目录
script_dir = os.path.dirname(os.path.abspath(__file__))
# 拼接数据文件路径:假设 Data 文件夹位于当前脚本的上一级目录
# 这种写法保证了即使移动整个项目文件夹,代码依然能正常运行
data_path = os.path.join(script_dir , "../Data/rfm_sales_data.xlsx")
# --- 读取 Excel 数据 ---
# index_col='USERNAME': 直接将"用户姓名"列设为 DataFrame 的索引(Index)
# 这样做的好处是:后续在进行 groupby 分组聚合时,可以直接基于索引操作,代码更简洁高效
# 注意:在真实生产环境中,如果存在重名用户,务必使用唯一的 USERID 作为索引
df = pd.read_excel(data_path , index_col = 'USERNAME')
# --- 数据清洗 ---
# dropna(how='all'): 只有当一行中**所有**列的值都为空(NaN)时,才删除该行
# 这是一种保守的清洗策略。相比于删除任何含有空值的行,它能最大限度地保留有效数据
# 例如:某用户某次订单的金额缺失,但日期和订单号存在,这行数据依然有价值,不应被丢弃
sale_data = df.dropna(how = 'all')
# --- 结果反馈与统计 ---
# sale_data.index.nunique(): 统计索引(Index)中有多少个不重复的唯一值
# 在 RFM 模型的上下文中,因为索引是用户名,所以这代表去重后的有效用户总数
# len(sale_data): 统计 DataFrame 的总行数,即原始的订单记录总数
print(f"数据加载完成,有效用户数:{sale_data.index.nunique()} , 订单记录数:{len(sale_data)}")
# 💡 深度解析:
# 为什么我们要关注 index.nunique()?
# 因为在原始数据中,一个用户(如"张三")可能有多条订单记录,导致他在索引中出现多次。
# nunique() 会自动去重,告诉我们到底有多少个独立的"人",这是计算"人均消费"、"复购率"等指标的分母。💡 知识点与启发
- 索引(Index)的力量 :很多初学者习惯把所有数据都放在列里。但在 Pandas 中,合理设置 Index 可以大幅简化代码。当你把
USERNAME设为索引后,groupby(sale_data.index)就等同于groupby('USERNAME'),而且在进行合并、对齐操作时,Pandas 会自动基于索引匹配,既快又准。nunique()vscount():这是一个经典面试题也是实战高频点。len()或count()统计的是事件数量 (订单数),而index.nunique()统计的是主体数量(人数)。理解这两者的区别,是理解"转化率"、"人均单量"等指标的基础。- 防御性编程 :注意代码中的
try-except块。在读取外部文件时,永远不要假设文件一定完美。加上异常捕获,能让程序在出错时给出友好的提示,而不是直接崩溃抛出一堆看不懂的代码栈。

📈 第三阶段:RFM 指标计算与动态打分
这是 RFM 模型的核心。我们将计算原始的 R、F、M 值,并利用**分位数(Quantile)**进行动态打分。
1. 数据类型转换与指标计算
Excel 读出的日期通常是字符串,必须转换为时间对象才能做减法。
python
# --- 1. 日期格式化 ---
# errors='coerce': 遇到无法解析的日期(如脏数据),强制转为 NaT (Not a Time),避免程序报错中断
sale_data['ORDERDATE'] = pd.to_datetime(sale_data['ORDERDATE'], errors='coerce')
# 简单检查:如果有转换失败的,会在这里提示
if sale_data['ORDERDATE'].isna().any():
lost_count = sale_data['ORDERDATE'].isna().sum()
print(f"⚠️ 警告:有 {lost_count} 条记录的日期格式错误,已设为空值,将在计算 R 值时自动排除。")
# --- 2. 计算 RFM 原始值 ---
# R (Recency): 每个用户最近一次购买的时间 (最大值)
R_data = sale_data.groupby(sale_data.index)['ORDERDATE'].max()
# F (Frequency): 每个用户的购买次数 (计数)
F_data = sale_data.groupby(sale_data.index)['ORDERID'].count()
# M (Monetary): 每个用户的消费总金额 (求和)
M_data = sale_data.groupby(sale_data.index)['AMOUNTINFO'].sum()
# --- 3. 计算 R 值 (天数差) ---
# 选取数据集中最新的日期作为"基准日期" (也可以用 datetime.now())
base_date = R_data.max()
# 时间相减得到 Timedelta 对象,提取 .days 属性得到整数天数
R_days = (base_date - R_data).dt.days
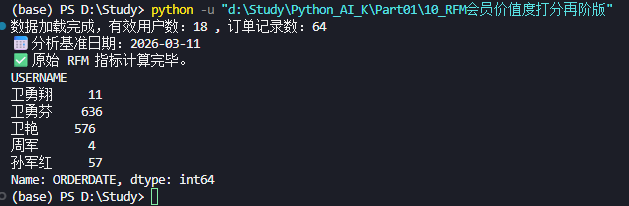
print(f"📅 分析基准日期:{base_date.strftime('%Y-%m-%d')}")
print("✅ 原始 RFM 指标计算完毕。")
print(R_days.head()) # 预览前 5 个用户的 R 值输出结果如下:
2. 动态百分位打分 (Dynamic Scoring)
传统的打分方式(如:R<30 天得 5 分)过于主观。如果数据跨度是 10 年,30 天就没意义了。pd.qcut 可以根据数据分布,自动将用户切成均匀的 5 份(每份约 20%),保证评分的区分度。
python
# --- 动态打分逻辑 ---
# rank(method='first'): 当数值相同时,按出现顺序排名,避免 qcut 因大量重复值报错
# q=5: 切成 5 份 (20%, 40%, 60%, 80%, 100%)
# labels: 指定对应的分数标签
# duplicates='drop': 如果数据量太少导致切分点重合,自动丢弃重复的标签,防止报错
# F 和 M:数值越大越好,所以标签从 1 到 5
F_score = pd.qcut(F_data.rank(method='first'), q=5, labels=[1, 2, 3, 4, 5], duplicates='drop')
M_score = pd.qcut(M_data.rank(method='first'), q=5, labels=[1, 2, 3, 4, 5], duplicates='drop')
# R:天数越小越好(越近越好),所以标签反过来,从 5 到 1
R_score = pd.qcut(R_days.rank(method='first'), q=5, labels=[5, 4, 3, 2, 1], duplicates='drop')
# --- 整合结果 ---
rfm_df = pd.DataFrame({
'r_score': R_score.astype(int), # 转为整数类型,方便计算
'f_score': F_score.astype(int),
'm_score': M_score.astype(int),
'R_days': R_days, # 保留原始天数供参考
'F_count': F_data, # 保留原始次数供参考
'M_sum': M_data # 保留原始金额供参考
}, index=R_data.index)
# 计算加权总分
# 这里假设公司更看重消费金额 (M),权重 60%;近期度 (R) 和频次 (F) 各 20%
# 权重可根据业务阶段调整:拉新期调高 R,促活期调高 F,盈利期调高 M
rfm_df['total_score'] = rfm_df['r_score']*0.2 + rfm_df['f_score']*0.2 + rfm_df['m_score']*0.6
# 按总分降序排列,查看头部用户
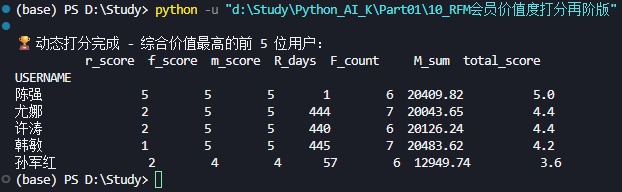
print("\n🏆 动态打分完成 - 综合价值最高的前 5 位用户:")
print(rfm_df.sort_values('total_score', ascending=False).head())💡 知识点与启发
- 前五位用户:
- 为什么用
qcut而不是cut?
cut是等宽切割(例如:0-100, 100-200),如果数据分布不均匀(比如大部分人都在 0-50),会导致某个分数段人多得要命,其他段没人。qcut是等频切割(例如:前 20% 的人得 5 分),它强制让每个分数段的人数大致相等。这在用户分层运营中非常有用,能保证你给"VIP 客户"发优惠券时,不会发出几百万张,也不会只发给 1 个人。- 权重的艺术 :代码中的
0.2, 0.2, 0.6不是真理。如果你的老板说"我们现在不在乎利润,只要用户回来",那你就应该把 R 的权重调到 0.6。数据分析的价值在于灵活响应业务目标,而不是套公式。rank(method='first')的细节 :当多个用户购买次数完全一样时,qcut可能会因为无法确定边界而报错。加上rank可以给它们微小的顺序差异,从而平滑地通过分箱算法。这是一个非常实用的 Trick。
🎯 第四阶段:用户分层与营销策略落地
有了分数,如果不转化为行动,数据就只是数字。这一步我们将利用规则引擎 ,将分数映射为具体的用户标签 和执行策略。
1. 定义 8 类人群与策略
我们采用经典的 3 分阈值法(≥3 分为高,❤️ 分为低),构建种用户组合。
python
def get_customer_segment(row):
"""
根据 R/F/M 得分,判断用户类型并给出营销建议。
输入:一行数据 (Series)
输出:(用户类型名称,营销策略建议)
"""
r, f, m = row['r_score'], row['f_score'], row['m_score']
# 定义高低等级 (3 分及以上视为"高")
r_lvl = '高' if r >= 3 else '低'
f_lvl = '高' if f >= 3 else '低'
m_lvl = '高' if m >= 3 else '低'
# --- 8 种组合逻辑判定 ---
if r_lvl == '高' and f_lvl == '高' and m_lvl == '高':
return "重要价值客户", "维持 VIP 待遇,提供专属客服,优先推荐新品,防止流失。"
elif r_lvl == '低' and f_lvl == '高' and m_lvl == '高':
return "重要挽留客户", "高危流失!曾经的土豪很久没来了。立即发送大额召回券,安排电话回访。"
elif r_lvl == '高' and f_lvl == '低' and m_lvl == '高':
return "重要发展客户", "新的大额客户。引导办理会员,通过满减活动增加复购频次,建立信任。"
elif r_lvl == '高' and f_lvl == '高' and m_lvl == '低':
return "一般价值客户", "高频低价(可能是羊毛党)。尝试交叉销售高毛利产品,提升客单价。"
elif r_lvl == '低' and f_lvl == '低' and m_lvl == '高':
return "重要唤醒客户", "曾经买过大单但沉睡已久。调查未回购原因,推送强力促销激活。"
elif r_lvl == '低' and f_lvl == '高' and m_lvl == '低':
return "一般挽留客户", "以前常买便宜货,现在不来了。发送小额无门槛券试探意向。"
elif r_lvl == '高' and f_lvl == '低' and m_lvl == '低':
return "新客户/潜力客户", "刚买了一次便宜货。通过新人礼包引导第二次购买,培养习惯。"
else: # 低 低 低
return "低价值客户", "非核心目标群体。减少营销投入,仅在大型大促时群发通知。"
# --- 应用函数 ---
# axis=1: 按行应用函数
# result_type='expand': 将函数返回的元组 (类型,策略) 自动展开为两列
rfm_df[['客户类型', '营销策略']] = rfm_df.apply(get_customer_segment, axis=1, result_type='expand')
# --- 结果展示 ---
print("\n📊 8 类人群分布统计:")
print(rfm_df['客户类型'].value_counts())
print("\n💡 完整用户分层表 (前 10 行):")
# 选取关键列展示,排版更清晰
display_cols = ['r_score', 'f_score', 'm_score', '客户类型', '营销策略']
print(rfm_df.sort_values('total_score', ascending=False)[display_cols].head(10))💡 知识点与启发
- 输出结果如下:
- 从"是什么"到"怎么做" :初级分析师只产出报表("我们有 5 个重要挽留客户"),高级分析师产出方案("这 5 个客户需要发 500 元券")。这段代码展示了如何将逻辑固化,让机器自动产出建议,极大提高了运营效率。
- 规则的迭代 :这里的
if-else规则是静态的。在更进阶的玩法中,你可以结合机器学习(如 K-Means 聚类)来自动发现人群特征,或者通过 A/B 测试来优化这里的文案和策略。apply函数的威力 :apply是 Pandas 中最灵活的函数之一,允许你对每一行执行复杂的自定义逻辑。虽然它的速度比向量化操作慢,但在处理这种"业务逻辑判断"时,它的可读性和灵活性是无可替代的。
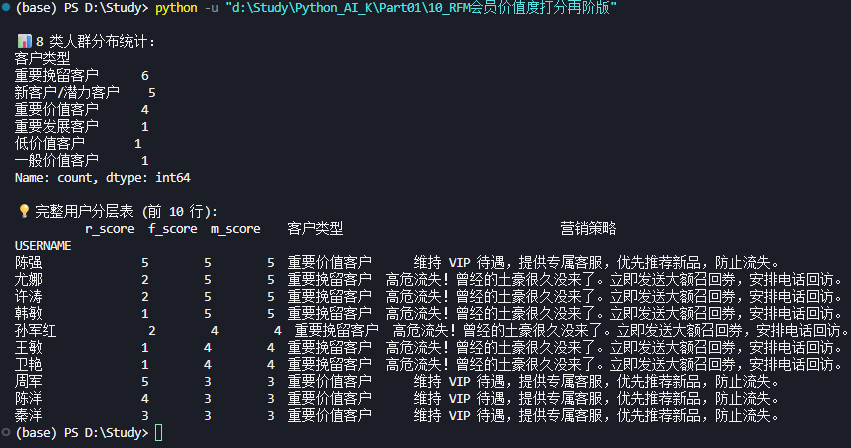
2 深度映射:从"预设生命周期"到"RFM 动态分层"
在上一节中,我们利用 RFM 模型将用户划分为了 8 类动态群体 。现在,让我们回到数据生成的初衷,看看我们在第一阶段定义的 5 类预设生命周期用户(高价值活跃、一般活跃、流失老客、新客低值、沉睡客)在 RFM 模型中究竟长什么样。
由于原始数据中可能未保存 TYPE 标签,我们将通过规则映射的方式,直接定义这 5 类预设人群在 RFM 体系中的"理想画像",并统计实际数据中有多少用户符合这些特征。这不仅是对模型的验证,更是对业务理解的深化。
1. 定义映射规则:预设类型 vs RFM 特征
我们根据第一阶段的生成逻辑,为每类预设用户定义其在 RFM 得分上的典型特征:
- A 高价值活跃 → \rightarrow → 对应 重要价值客户 (R高, F高, M高)
- 逻辑:买得多、买得贵、最近刚买。
- B 一般活跃 → \rightarrow → 对应 一般价值客户 (R高, F高, M低) 或 新客户/潜力客户 (R高, F低, M低)
- 逻辑:经常买但金额不高,或者刚开始买。
- C 流失老客 → \rightarrow → 对应 重要挽留客户 (R低, F高, M高) 或 重要唤醒客户 (R低, F低, M高)
- 逻辑:以前贡献大,但最近很久没来了。
- D 新客低值 → \rightarrow → 对应 新客户/潜力客户 (R高, F低, M低)
- 逻辑:最近刚来,买得少且便宜。
- E 沉睡客 → \rightarrow → 对应 低价值客户 (R低, F低, M低) 或 一般挽留客户 (R低, F高, M低)
- 逻辑:很久没来,且历史贡献也不大。
2. 代码实现:自动归类与统计
我们将编写一个函数,根据用户的 RFM 得分,反向推断其最可能属于哪一类"预设生命周期",并进行统计分析。
python
# --- 1. 定义反向映射函数 ---
def map_to_lifecycle(row):
"""
根据 RFM 得分,推断用户最可能的"预设生命周期类型"。
这是一个基于规则的启发式映射,用于验证 RFM 分层的业务含义。
"""
r, f, m = row['r_score'], row['f_score'], row['m_score']
# 判定高低
r_high = r >= 3
f_high = f >= 3
m_high = m >= 3
# --- 映射逻辑 ---
# 1. 高价值活跃 (A): 必须是全高
if r_high and f_high and m_high:
return "高价值活跃 (A)"
# 2. 流失老客 (C): 金额高 (M高),但近期度低 (R低)。频次可高可低。
elif (not r_high) and m_high:
if f_high:
return "流失老客 (C)-高频流失"
else:
return "流失老客 (C)-低频流失"
# 3. 新客低值 (D): 近期度高 (R高),频次低 (F低),金额低 (M低)
elif r_high and (not f_high) and (not m_high):
return "新客低值 (D)"
# 4. 沉睡客 (E): 近期度低 (R低),金额低 (M低)。
elif (not r_high) and (not m_high):
if f_high:
return "沉睡客 (E)-曾活跃"
else:
return "沉睡客 (E)-彻底沉睡"
# 5. 一般活跃 (B): 其他情况,通常是 R高,但 M 或 F 有一项不高不低,或组合特殊
# 这里主要捕捉 R高 F高 M低 (羊毛党/一般活跃)
elif r_high and f_high and (not m_high):
return "一般活跃 (B)"
# 剩余的特殊情况归为"过渡期/混合态"
else:
return "其他/混合态"
# --- 2. 应用映射 ---
rfm_df['推断_生命周期'] = rfm_df.apply(map_to_lifecycle, axis=1)
# --- 3. 统计分布 ---
print("\n🔄 【映射分析】RFM 分层对应的预设生命周期分布:")
lifecycle_dist = rfm_df['推断_生命周期'].value_counts()
print(lifecycle_dist)
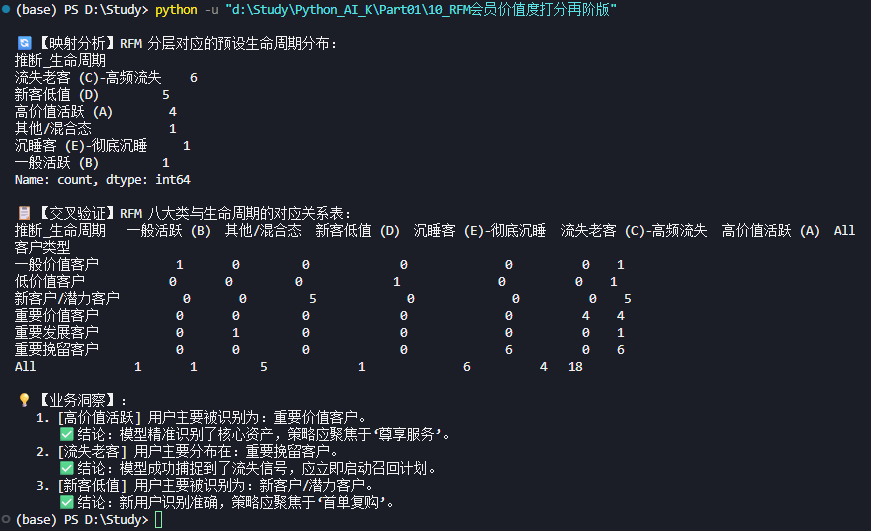
# --- 4. 交叉验证表 (RFM 类型 vs 推断生命周期) ---
# 查看每一个 RFM 分类下,主要对应哪种生命周期
cross_check = pd.crosstab(rfm_df['客户类型'], rfm_df['推断_生命周期'], margins=True)
print("\n📋 【交叉验证】RFM 八大类与生命周期的对应关系表:")
print(cross_check)
# --- 5. 关键洞察输出 ---
print("\n💡 【业务洞察】:")
# 检查高价值活跃用户的纯度
a_users = rfm_df[rfm_df['推断_生命周期'] == "高价值活跃 (A)"]
if not a_users.empty:
main_segment = a_users['客户类型'].mode()[0]
print(f" 1. [高价值活跃] 用户主要被识别为:{main_segment}。")
if main_segment == "重要价值客户":
print(" ✅ 结论:模型精准识别了核心资产,策略应聚焦于'尊享服务'。")
else:
print(" ⚠️ 注意:部分高价值用户可能被细分到了其他类别,需检查打分权重。")
# 检查流失老客的识别
c_users = rfm_df[rfm_df['推断_生命周期'].str.contains("流失老客")]
if not c_users.empty:
segments = c_users['客户类型'].unique()
print(f" 2. [流失老客] 用户主要分布在:{', '.join(segments)}。")
if any('挽留' in s or '唤醒' in s for s in segments):
print(" ✅ 结论:模型成功捕捉到了流失信号,应立即启动召回计划。")
else:
print(" ⚠️ 注意:部分流失用户可能被误判,需关注其 M 值是否真的较高。")
# 检查新客
d_users = rfm_df[rfm_df['推断_生命周期'] == "新客低值 (D)"]
if not d_users.empty:
main_seg_d = d_users['客户类型'].mode()[0]
print(f" 3. [新客低值] 用户主要被识别为:{main_seg_d}。")
if "新客户" in main_seg_d or "潜力" in main_seg_d:
print(" ✅ 结论:新用户识别准确,策略应聚焦于'首单复购'。")💡 知识点与启发
- 输出结果 :
- 双向验证思维 :通常我们只用 RFM 去预测用户状态。但在这里,我们通过"规则反推",将抽象的 RFM 分数还原为具体的业务概念(如"流失老客")。这种双向映射能帮助我们确认:我们的模型是否符合业务直觉?
- 处理"混合态" :你会发现,并不是所有用户都能完美对应到 A/B/C/D/E。那些被标记为"其他/混合态"的用户,往往是最具挖掘潜力的群体(例如:刚完成大额购买的新客,正处于从 D 向 A 转化的过程中)。关注边缘群体,往往是运营增长的突破口。
- 动态与静态的结合 :预设的 A/B/C 是静态的"出身成分",而 RFM 是动态的"当前表现"。通过这个分析,我们可以清晰地看到:出身好(A 类)不代表现在好(可能已流失),出身差(D 类)不代表没未来(可能是潜力股)。这正是数据分析打破刻板印象的价值所在。
通过这一节的分析,我们不仅验证了 RFM 模型的有效性,更将冷冰冰的分数赋予了鲜活的业务含义。接下来,我们可以带着这些清晰的画像,进入第五阶段,探索他们在品类和支付方式上的更多秘密。
🌐 第五阶段:多维交叉分析与深度洞察
在完成了基础的 RFM 分层后,我们手中的数据还蕴藏着巨大的价值。之前的分析主要关注"用户是谁",现在我们要进一步探索"用户买了什么"以及"怎么买的"。利用数据中新增的 CATEGORY(商品类别)和 PAY_METHOD(支付方式)字段,我们可以进行更深度的多维交叉分析,为精细化运营提供更强有力的支撑。
1. 品类偏好与用户价值关联分析
不同价值的用户,其消费偏好往往截然不同。高价值客户是否更倾向于购买高毛利产品?流失用户是否集中在某个特定品类?通过交叉分析,我们可以找到"货"与"人"的最佳匹配点。
python
# --- 1. 准备数据 ---
# 确保金额列为数值型,处理可能存在的空值 (填充为0,避免影响求和)
sale_data['AMOUNTINFO'] = pd.to_numeric(sale_data['AMOUNTINFO'], errors='coerce').fillna(0)
# 将 RFM 分层结果合并回原始明细数据,方便按类别聚合
# 注意:我们需要通过索引 (USERNAME) 进行 merge
analysis_df = sale_data.merge(rfm_df[['客户类型']], left_on=sale_data.index, right_index=True, how='left')
# 重命名合并产生的列,保持整洁
analysis_df.rename(columns={'key_0': 'USERNAME'}, inplace=True) # 如果 merge 产生了多余列
# --- 2. 核心指标计算:各类别下的用户价值分布 ---
# 透视表:行=客户类型,列=商品类别,值=销售总金额
category_pivot = pd.pivot_table(
analysis_df,
values='AMOUNTINFO',
index='客户类型',
columns='CATEGORY',
aggfunc='sum',
fill_value=0 # 空值填0
)
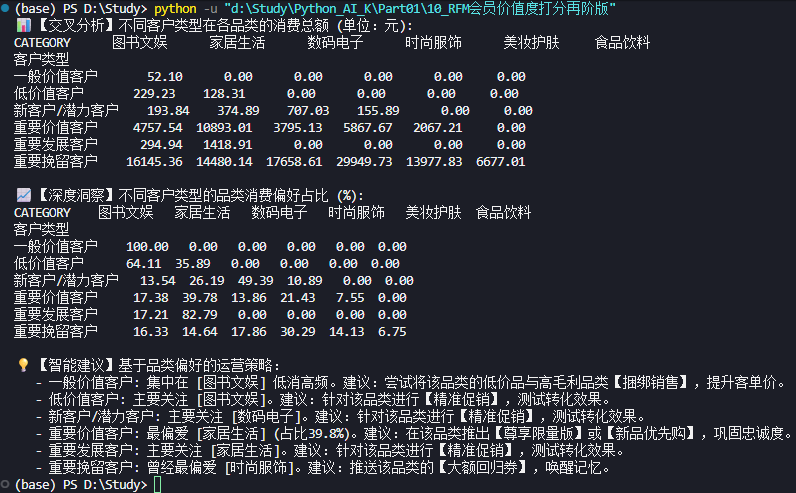
print("📊 【交叉分析】不同客户类型在各品类的消费总额 (单位:元):")
print(category_pivot)
# --- 3. 深度洞察:计算品类贡献度 ---
# 计算每一类客户中,各品类金额占该客户类型总金额的百分比
category_contribution = category_pivot.div(category_pivot.sum(axis=1), axis=0) * 100
print("\n📈 【深度洞察】不同客户类型的品类消费偏好占比 (%):")
# 格式化输出,保留两位小数
print(category_contribution.round(2).to_string())
# --- 4. 自动化策略建议生成 ---
print("\n💡 【智能建议】基于品类偏好的运营策略:")
for customer_type in category_contribution.index:
# 找出该类用户贡献度最高的品类
top_category = category_contribution.loc[customer_type].idxmax()
top_ratio = category_contribution.loc[customer_type].max()
if customer_type == "重要价值客户":
print(f" - {customer_type}: 最偏爱 [{top_category}] (占比{top_ratio:.1f}%)。建议:在该品类推出【尊享限量版】或【新品优先购】,巩固忠诚度。")
elif customer_type == "重要挽留客户":
print(f" - {customer_type}: 曾经最偏爱 [{top_category}]。建议:推送该品类的【大额回归券】,唤醒记忆。")
elif customer_type == "一般价值客户":
print(f" - {customer_type}: 集中在 [{top_category}] 低消高频。建议:尝试将该品类的低价品与高毛利品类【捆绑销售】,提升客单价。")
else:
print(f" - {customer_type}: 主要关注 [{top_category}]。建议:针对该品类进行【精准促销】,测试转化效果。")💡 知识点与启发
- 输出结果 :
- 透视表 (
pivot_table) 的威力:这是数据分析中最强大的工具之一。它能瞬间将长格式的流水数据转换为宽格式的统计报表,让我们一眼看出"行"与"列"之间的交叉关系。- 从"总量"到"结构" :仅仅看销售总额是不够的。通过计算
div(..., axis=0)得到占比结构 ,我们能发现:也许"重要价值客户"买数码不多,但一旦买就是大单;而"一般价值客户"虽然买食品多,但都是小单。这种结构性差异才是制定策略的关键。- 数据驱动选品:以后的选品策略不应拍脑袋,而应基于 RFM 分层。比如,针对"重要发展客户",如果他们偏爱"美妆",我们就专门为他们定制美妆礼盒,而不是泛泛地全品类推广。
2. 支付习惯与复购潜力分析
支付方式往往隐含了用户的消费能力和习惯。例如,信用卡用户可能具有更高的透支能力和消费意愿,而微信支付用户可能更偏向小额高频。
python
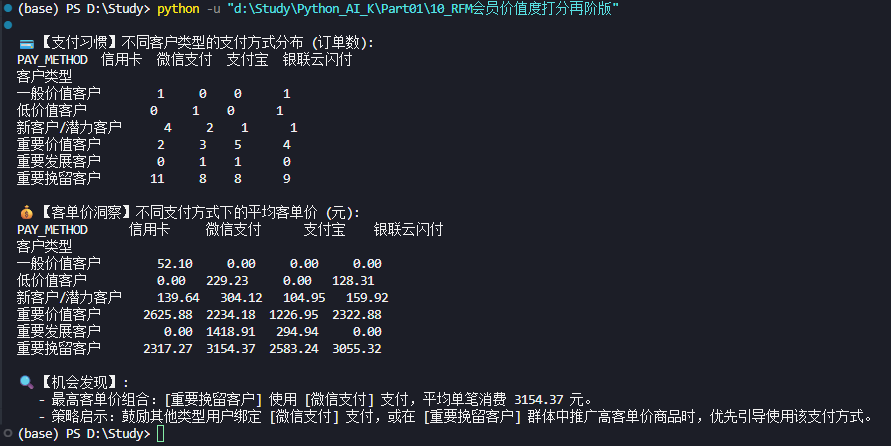
# --- 1. 支付方式频次统计 ---
pay_method_dist = analysis_df.groupby(['客户类型', 'PAY_METHOD']).size().unstack(fill_value=0)
print("\n💳 【支付习惯】不同客户类型的支付方式分布 (订单数):")
print(pay_method_dist)
# --- 2. 计算各类型用户的平均客单价 (ATV) by 支付方式 ---
atv_analysis = analysis_df.groupby(['客户类型', 'PAY_METHOD'])['AMOUNTINFO'].mean().unstack(fill_value=0)
print("\n💰 【客单价洞察】不同支付方式下的平均客单价 (元):")
print(atv_analysis.round(2))
# --- 3. 发现机会点 ---
print("\n🔍 【机会发现】:")
# 寻找客单价最高的组合
max_atv_stack = atv_analysis.stack()
best_combo = max_atv_stack.idxmax()
best_value = max_atv_stack.max()
print(f" - 最高客单价组合:[{best_combo[0]}] 使用 [{best_combo[1]}] 支付,平均单笔消费 {best_value:.2f} 元。")
print(f" - 策略启示:鼓励其他类型用户绑定 [{best_combo[1]}] 支付,或在 [{best_combo[0]}] 群体中推广高客单价商品时,优先引导使用该支付方式。")💡 知识点与启发
- 多维分组 (
groupby列表) :groupby(['A', 'B'])可以同时按照两个维度进行分组,这是进行交叉分析的基石。配合unstack(),可以轻松地将其中一个维度转化为列,形成对比视图。- 行为特征画像:通过分析支付习惯,我们可以完善用户画像。例如,如果发现"重要挽留客户"中大量使用"信用卡"的用户流失了,这可能意味着他们对价格敏感度降低,或者遇到了额度问题,需要针对性的金融权益(如分期免息)来召回。
- 细节决定成败:很多时候,提升转化率的关键不在于大改页面,而在于细节优化。比如发现某类用户在特定支付方式下客单价更高,就可以在结账页默认推荐该支付方式,从而潜移默化地提升 GMV。
3. 可视化:用户价值与品类热力图
文字表格虽然精确,但图表更能直观展示规律。我们将绘制一张热力图,直观呈现不同客户类型对各品类的偏好程度。
python
import seaborn as sns
# 设置绘图风格
plt.figure(figsize=(12, 8))
sns.set_style("whitegrid")
# 绘制热力图
# annot=True: 在格子中显示数值
# fmt='.1f': 数值保留一位小数
# cmap='YlGnBu': 颜色映射 (黄-绿-蓝),颜色越深代表占比越高
sns.heatmap(category_contribution, annot=True, fmt='.1f', cmap='YlGnBu', linewidths=.5)
plt.title('不同客户类型的品类消费偏好热力图 (占比%)', fontsize=16, pad=20)
plt.xlabel('商品类别', fontsize=12)
plt.ylabel('客户类型', fontsize=12)
plt.xticks(rotation=45) # 旋转 X 轴标签防止重叠
plt.tight_layout()
# 显示图表
plt.show()💡 知识点与启发
- 输出结果 :
- 可视化的沟通价值:当你向业务部门或老板汇报时,一张清晰的热力图胜过千言万语。它能让人在 3 秒内抓住重点:"哦,原来高价值客户都集中在数码和美妆!"
- Seaborn 库的应用 :基于 Matplotlib 封装的 Seaborn 让统计绘图变得异常简单。在未来的学习中,掌握
heatmap,barplot,boxplot等常用图表,能让你的分析报告专业度提升一个档次。- 从数据到故事:这张图不仅仅是一张图,它是一个故事的开始。你可以指着图中的深色块说:"看,这是我们的金矿,我们需要在这里投入更多资源。"这就是数据分析师讲故事的能力。
🚀 第六阶段:打造交互式自动化 HTML 报告引擎
导读 :在前五篇文章中,我们完成了从数据清洗、RFM 指标计算、动态打分、用户分层到多维交叉分析的全链路流程。但数据分析的终点不仅仅是控制台里的打印输出,而是可交付的业务洞察。
本文将带你进入 第六阶段:HTML 报告生成引擎 。我们将利用
Pandas强大的表格渲染能力结合自定义CSS样式,构建一个单文件、交互式、高颜值的 HTML 分析报告。无需安装任何 Web 框架,一键生成即可通过链接分享给团队或领导。
🎯 阶段目标
在此之前,我们的分析结果停留在 Python 控制台或静态 Excel 中,存在以下痛点:
- 缺乏交互:无法快速搜索特定用户,无法对列进行排序。
- 视觉单一:难以直观区分"重要价值客户"与"流失客户"。
- 分享困难:非技术人员需要安装环境才能查看结果。
本阶段核心任务:
- ✅ 可视化看板:顶部展示关键 KPI 指标(总人数、高分用户数、风险用户数)。
- ✅ 智能着色:根据用户类型自动添加彩色标签(如绿色代表价值,红色代表流失)。
- ✅ 交互表格:生成支持悬停高亮、滚动查看的详细数据表。
- ✅ 单文件交付 :所有 CSS 样式内联,生成的
.html文件可独立运行,随处分享。
🛠️ 核心技术实现
我们不需要引入 Flask 或 Django 等重型 Web 框架,仅使用 Python 标准库和 Pandas 即可完成。核心逻辑分为三步:数据统计 -> 样式注入 -> 模板组装。
1. 关键指标看板 (KPI Cards)
首先,我们需要从处理好的 rfm_df 中提取核心业务指标,并将其转化为 HTML 卡片结构。
python
def generate_html_report(df, output_filename='RFM_Analysis_Report.html'):
# --- 1. 关键指标统计 ---
total_users = len(df)
avg_score = df['total_score'].mean()
# 筛选"重要价值客户"
high_value_count = len(df[df['客户类型'] == '重要价值客户'])
# 筛选包含"挽留"或"唤醒"的风险用户
churn_risk_count = len(df[df['客户类型'].str.contains('挽留 | 唤醒', na=False)])
# 构建顶部指标卡片 HTML (使用 f-string 动态插入数据)
kpi_html = f"""
<div class="kpi-container">
<div class="kpi-card">
<h3>总用户数</h3>
<div class="kpi-value">{total_users:,}</div>
<div class="kpi-label">人</div>
</div>
<div class="kpi-card highlight">
<h3>重要价值客户</h3>
<div class="kpi-value">{high_value_count}</div>
<div class="kpi-label">人 (核心资产)</div>
</div>
<div class="kpi-card warning">
<h3>流失/挽留风险</h3>
<div class="kpi-value">{churn_risk_count}</div>
<div class="kpi-label">人 (需重点关注)</div>
</div>
<!-- 更多卡片可在此扩展 -->
</div>
"""2. 内联 CSS 样式设计 (Inline CSS)
为了让报告美观且便于传输,我们将 CSS 直接写在 HTML 的 <style> 标签中。这里设计了现代化的卡片布局、响应式表格以及基于用户类型的语义化配色。
python
css_style = """
<style>
body { font-family: 'Segoe UI', 'Microsoft YaHei', sans-serif; background-color: #f4f7f6; color: #333; margin: 0; padding: 20px; }
.container { max-width: 1400px; margin: 0 auto; background: white; padding: 30px; border-radius: 12px; box-shadow: 0 4px 15px rgba(0,0,0,0.1); }
/* KPI 卡片样式 */
.kpi-container { display: flex; justify-content: space-around; flex-wrap: wrap; gap: 20px; margin-bottom: 40px; }
.kpi-card { background: linear-gradient(135deg, #ffffff 0%, #f9f9f9 100%); border: 1px solid #e0e0e0; border-radius: 10px; padding: 20px; min-width: 200px; text-align: center; box-shadow: 0 2px 5px rgba(0,0,0,0.05); transition: transform 0.2s; flex: 1; }
.kpi-card:hover { transform: translateY(-5px); box-shadow: 0 5px 15px rgba(0,0,0,0.1); }
.kpi-value { font-size: 32px; font-weight: bold; color: #2c3e50; margin: 10px 0; }
/* 状态色定义 */
.kpi-card.highlight .kpi-value { color: #27ae60; } /* 绿色:价值 */
.kpi-card.warning .kpi-value { color: #e74c3c; } /* 红色:风险 */
/* 表格样式 */
table { width: 100%; border-collapse: collapse; margin-top: 20px; font-size: 13px; }
th { background-color: #34495e; color: white; padding: 12px; text-align: left; position: sticky; top: 0; z-index: 10; }
td { padding: 10px; border-bottom: 1px solid #ecf0f1; }
tr:hover { background-color: #f1faff; } /* 悬停高亮 */
/* 标签徽章样式 */
.tag { padding: 4px 8px; border-radius: 4px; font-size: 12px; color: white; display: inline-block; min-width: 90px; text-align: center; font-weight: bold; }
.tag-价值 { background-color: #27ae60; }
.tag-挽留 { background-color: #e74c3c; }
.tag-唤醒 { background-color: #e67e22; }
.tag-发展 { background-color: #3498db; }
.tag-潜力 { background-color: #9b59b6; }
.tag-低价值 { background-color: #95a5a6; }
</style>
"""3. 智能标签映射与数据格式化
这是让报表"活"起来的关键。我们定义一个辅助函数 colorize_tag,根据用户类型动态生成带颜色的 HTML 标签。同时,对金额、天数等数值进行格式化(如添加千分位符、货币符号)。
python
# --- 辅助函数:给标签上色 ---
def colorize_tag(type_name):
if pd.isna(type_name): return '<span class="tag tag-低价值">未知</span>'
if '价值' in type_name: return f'<span class="tag tag-价值">{type_name}</span>'
if '挽留' in type_name: return f'<span class="tag tag-挽留">{type_name}</span>'
if '唤醒' in type_name: return f'<span class="tag tag-唤醒">{type_name}</span>'
if '发展' in type_name: return f'<span class="tag tag-发展">{type_name}</span>'
if '潜力' in type_name or '新客户' in type_name: return f'<span class="tag tag-潜力">{type_name}</span>'
return f'<span class="tag tag-低价值">{type_name}</span>'
# 创建副本并应用转换
df_display = df.copy()
df_display['客户类型_标签'] = df_display['客户类型'].apply(colorize_tag)
# 格式化数值列
df_display['M_sum'] = df_display['M_sum'].apply(lambda x: f"¥{x:,.0f}" if pd.notna(x) else "¥0")
df_display['R_days'] = df_display['R_days'].apply(lambda x: f"{int(x)}" if pd.notna(x) else "-")
# 动态选择需要展示的列 (防止因缺少某些列报错)
cols_to_show = ['USERNAME', 'R_days', 'F_count', 'M_sum', 'r_score', 'f_score', 'm_score',
'客户类型_标签', '营销策略', '推断_生命周期']
# 过滤掉数据中不存在的列
available_cols = [c for c in cols_to_show if c in df_display.columns]
# 生成 HTML 表格 (escape=False 允许渲染我们插入的 HTML 标签)
table_html = df_display[available_cols].to_html(
escape=False,
index=False,
classes='dataframe',
justify='left'
)4. 组装与保存
最后,将 KPI、CSS、表格和交叉验证表组装成完整的 HTML 文档,并保存到本地。
python
# 生成生命周期交叉验证表
cross_tab = pd.crosstab(df['推断_生命周期'], df['客户类型'], margins=True)
cross_html = cross_tab.to_html(classes='dataframe', justify='center')
# 完整 HTML 模板
html_content = f"""
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>RFM 用户分层分析报告</title>
{css_style}
</head>
<body>
<div class="container">
<h1>📊 RFM 用户分层与全维度分析报告</h1>
<p class="subtitle">生成时间:{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}</p>
{kpi_html}
<h2>🔍 用户全景明细</h2>
{table_html}
<h2>🔄 生命周期 vs RFM 分层交叉验证</h2>
{cross_html}
<div class="footer">Generated by Python Pandas & Custom HTML Template</div>
</div>
</body>
</html>
"""
with open(output_filename, 'w', encoding='utf-8') as f:
f.write(html_content)
print(f"✅ 报告已生成:{output_filename}")💻 完整执行流程
确保你的 rfm_df 已经包含了前五个阶段计算出的所有字段(得分、类型、策略、生命周期等)。特别注意 :在传入生成函数前,必须重置索引,确保 USERNAME 是普通列而不是 Index。
python
# ... (前五个阶段的代码) ...
# ==========================================
# 🛠️ 关键预处理:索引重置
# ==========================================
# 将 Index 转为普通列,确保 HTML 中能显示用户名
rfm_df = rfm_df.reset_index()
if 'USERNAME' not in rfm_df.columns and 'index' in rfm_df.columns:
rfm_df.rename(columns={'index': 'USERNAME'}, inplace=True)
# ==========================================
# 🚀 执行生成
# ==========================================
if __name__ == "__main__":
print("🚀 开始生成 HTML 报告...")
generate_html_report(rfm_df, output_filename='RFM_Final_Report.html')
print("✨ 完成!请在文件夹中双击打开 HTML 文件。")🌐 如何分享你的报告?
生成的 .html 文件是一个独立的网页。要在微信或邮件中分享给他人查看,有以下几种最佳实践:
方法 A:临时托管(最快,无需注册)
使用 Tiiny.host 或 Netlify Drop。
- 将生成的
RFM_Final_Report.html重命名为index.html。 - 拖拽文件到上述网站的上传区。
- 复制生成的链接发送给同事,对方即可在手机或电脑浏览器直接查看。
方法 B:GitHub Pages(永久,专业)
如果你有 GitHub 账号:
- 创建一个公开仓库,上传
index.html。 - 在 Settings -> Pages 中开启服务。
- 获得一个永久的
https://username.github.io/repo/链接。
(注:由于 Gitee Pages 目前限制较多,推荐优先使用 GitHub 或 Netlify)
方法 C:截图长图/转成pdf(仅展示,无交互)
如果只需向领导展示结论而不需要查询细节,可使用浏览器的 "全屏截图" 插件(如 GoFullPage),将报表保存为一张长图片发送。
📝 总结
通过第六阶段的开发,我们将枯燥的数据分析代码转化为了可落地、可交互、高颜值的商业报告。
- 业务价值:管理层可以直观看到"重要价值客户"的分布,运营人员可以快速检索特定用户的营销策略。
- 技术亮点:实现了零依赖的单文件 HTML 生成,兼顾了美观与便携性。
🌟 总结与未来展望
通过这个再进阶版 的实战,我们不仅掌握了 RFM 模型的代码实现,更重要的是建立了数据驱动决策的思维闭环:
- 数据构造 -> 理解了数据背后的业务含义和用户生命周期。
- 动态打分 -> 学会了用统计学方法(分位数)解决阈值设定的主观性问题。
- 策略落地 -> 体验了将冷冰冰的分数转化为有温度的营销行动。
🚀 对你的学习启发
- 不要只做"调包侠" :理解
qcut背后的数学意义,比单纯记住代码更重要。 - 关注数据质量:在生成数据时故意制造脏数据,让你意识到清洗步骤的必要性。
- 业务是核心:所有的权重设置、阈值划分、策略文案,都必须服务于具体的业务目标(拉新?促活?利润?)。
🔮 下一步可以尝试什么?
- 可视化 :使用
matplotlib或seaborn绘制 RFM 散点图(R vs F,颜色代表 M),直观展示人群分布。 - 自动化报告 :结合
Jinja2模板,将上述分析结果自动生成 HTML 邮件,发送给运营团队。 - 多维分析 :利用生成数据中的
CATEGORY字段,分析"不同品类的 RFM 特征有何不同?"(例如:买数码的用户是否比买食品的用户更忠诚?)
希望这份详细的教程能成为你数据分析之路上的坚实基石!