深入理解 ElasticSearch 字段映射Mapping
想要理解下面的内容需要了解Elasticsearch 数据的完整存储结构.
Elasticsearch 数据的完整存储结构
1. 倒排索引(Inverted Index)
- 作用 :ES 最核心的存储结构,用于快速全文检索 (比如
match: {name: "张三"})。 - 原理 :将 "字段值→文档 ID" 映射(比如
张三 → [1,3,5]),替代传统数据库 "文档 ID→字段值" 的正向索引,能快速找到包含某个值的所有文档。 - 存储字段 :仅针对「静态字段」(如你定义的
name: text),dynamic: runtime的未定义字段不会生成倒排索引。 - 特点:不可变(写入后不能修改,更新文档本质是标记旧文档删除 + 写入新文档),按「分片→段(Segment)」组织,段是倒排索引的最小存储单元。
2. Doc Values(列式存储)
- 作用 :用于排序、聚合、过滤 (比如
sort: {age: "desc"}、aggs: {avg_age: {avg: {field: "age"}}})。 - 原理:以 "字段" 为维度存储(列式),而非 "文档"(行式),适合批量统计计算。
- 存储字段 :默认对所有「非 text 类型的静态字段」开启(如
integer/keyword/date),text 字段默认关闭(可通过fielddata: true临时开启),运行时字段无 Doc Values。 - 特点:持久化到磁盘,占用空间略大,但查询效率高。
3. _source(原始文档)
- 作用 :存储「原始 JSON 文档」(比如你写入的
{name: "张三", age: 25}),是 ES 的 "兜底存储"。 - 核心价值 :
- 查询时默认返回原始文档(不用手动拼接字段);
dynamic: runtime的字段依赖_source动态解析;- 数据恢复 / 重新索引的依据。
- 特点 :默认开启且持久化,可通过
_source.enabled: false关闭(节省磁盘,但会导致 runtime 字段无法解析、无法重新索引)。
4. 正排索引(Stored Fields)
- 作用 :补充
_source,用于「只返回指定字段」(比如查询时只要name字段,不要整个_source)。 - 原理 :显式指定需要单独存储的字段(如
properties: {name: {type: "text", store: true}}),默认关闭(因为_source已包含所有字段)。 - 特点 :持久化到磁盘,仅在需要 "精准返回少量字段" 时使用,优先级高于
_source。
5. 字段数据元数据(Mapping)
- 作用 :存储索引的映射规则(比如字段类型、
dynamic: runtime、分词器等)。 - 存储位置:每个索引的 mapping 会持久化到磁盘(集群状态中也会缓存),重启后依然生效。
- 特点:元数据不存储业务数据,但决定了 ES 如何解析 / 存储 / 查询业务数据。
ElasticSearch 映射配置是定义索引结构的关键环节,决定了数据如何被存储和检索。合理的映射设计能显著提升搜索性能和资源利用率。
mapping的创建
我们可以在创建索引的时候显示的创建索引的mapping,通过指定的方式确定字段的类型。
sql
PUT hdk_test_index@01
{
"aliases": {
"hdk_test_index": {
"is_write_index": true
}
},
"mappings": {
"properties": {
"name":{
"type": "keyword"
},
"age":{
"type": "integer"
},
"id":{
"type": "long"
}
}
}
}除了直接指定mapping的方式,我们也可以直接通过插入数据的方式插入数据:
PUT index01/_doc/1
{
"name":"厉",
"time":"34789207482",
"timestamp":47389207582
}
在上面的语句中,我直接插入了一条数据,没有创建这个索引的任何的mapping,但是我们可以直接查询这个索引的mapping,可以发现mapping已经被创建了。但是实际开发中不建议使用这种方式创建mapping。
GET index01/_mapping
{
"index01": {
"mappings": {
"properties": {
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"time": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"timestamp": {
"type": "long"
}
}
}
}
}
_source源数据
source关闭
在实际开发中,我们可以根据业务需求灵活控制 _source 元数据的启用状态,以实现性能与功能的最佳平衡。
如果业务场景仅依赖倒排索引进行检索或聚合,而不需要返回原始的 JSON 数据(例如纯统计报表或冷数据归档),那么在创建索引时直接关闭 _source 是一个极佳的优化手段。这不仅能大幅节约存储空间,还能有效提升数据写入性能。
示例代码:
sql
PUT index02
{
"mappings": {
"_source": {
"enabled": false
}
}
}_source: mode: synthetic模式
- 不存原始 JSON :不再存储
_source的二进制副本。 - 动态合成 :当需要返回数据时,实时从倒排索引 和Doc Values中读取字段值,现场拼接成 JSON 返回。
- 目的 :在极度节省磁盘空间 的同时,依然保留局部更新 (
_update) 和 返回原始数据 的能力。
3. 优缺点
表格
| 维度 | 优点 ✅ | 缺点 ❌ |
|---|---|---|
| 空间 | 极大节省 (接近关闭 _source 的效果,省30%-50%空间)。 |
无显著缺点。 |
| 功能 | 支持局部更新 (_update),这是相比 enabled:false 的最大优势。 |
丢失未索引字段:若字段未建索引且无 Doc Values,数据会丢失。 |
| 性能 | 写入更快 (少写大对象)。 | 读取稍慢:大文档需 CPU 实时拼接,增加查询延迟。 |
| 数据 | 满足大多数统计/日志场景。 | 格式不保真:字段顺序可能改变,浮点数精度可能微调,无法用于法律级审计。 |
代码示例
PUT index02
{
"mappings": {
"_source": {
"mode": "synthetic"
}
}
}
source源数据存储过滤
使用include/exclude限制数据,这个是支持通配符的。
sql
PUT index01
{
"mappings": {
"_source": {
"includes": [
"name"
],
"excludes": [
"tag"
]
},
"properties": {
"name": {
"type": "text"
},
"tag": {
"type": "keyword"
}
}
}
}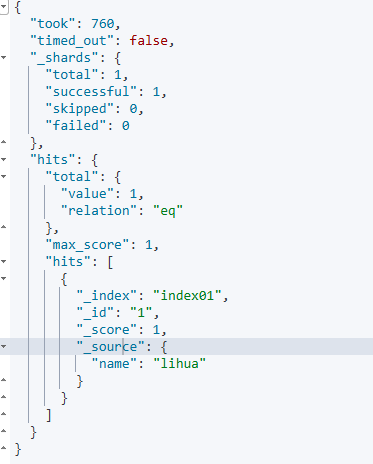 设置后,显示的是我们在上面设置的字段。
设置后,显示的是我们在上面设置的字段。
dynamic 属性
在 Elasticsearch 的 Mapping 中,dynamic 属性决定了 当遇到文档中包含未定义的新字段时,ES 该如何处理。
简单来说,它控制了 ES 的 "自动发现" 和 "自动添加字段" 的能力。
1. 四种可选值
dynamic 属性有三个主要取值,行为各不相同:
表格
dynamic 值 |
行为 |
|---|---|
true(默认) |
新字段自动创建静态映射,写入磁盘,查询性能高,但占用磁盘多 |
false |
忽略新字段,不创建映射、不存储,查询不到 |
strict |
严格模式,写入包含新字段的文档会报错 |
runtime |
新字段仅生成运行时字段,不持久化,查询时动态解析 |
代码案例:
sql
PUT index01
{
"mappings": {
"dynamic":"strict",
"properties": {
"name": {
"type": "text"
},
"tag": {
"type": "keyword"
}
}
}
}
PUT index01/_doc/1
{
"name":"lihua",
"tag":"shijian",
"age":1
}上述代码中插入了mapping中没有的字段,但是我们设置的dynamic是strict,这是就会出现异常:{
"error": {
"root_cause": [
{
"type": "strict_dynamic_mapping_exception",
"reason": "mapping set to strict, dynamic introduction of age within _doc is not allowed"
}
],
"type": "strict_dynamic_mapping_exception",
"reason": "mapping set to strict, dynamic introduction of age within _doc is not allowed"
},
"status": 400
}
ElasitSearch索引mapping元数据
我们再创建索引的mapping的时候可以指定一下mapping的元数据信息。
PUT test01
{
"mappings": {
"dynamic":"runtime",
"_meta":{
"create_name":"zhangsan" //这里表明了创建者是zhangsan
}
}
}
Mapping的更新规则
- 已有字段映射「只读不可改」,核心类型 / 属性无法直接修改;
- 仅支持新增字段、新增字段子属性、修改动态规则;
- 强制修改需通过重建索引实现。