note
- 原生多模态与早期融合训练:Kimi K2.5 打破"先训文本、后加视觉"的传统范式,采用早期融合策略(预训练早期即以10:90的低比例混合视觉-文本数据)。这种"联合优化"不仅避免了模态冲突,还实现了双向增强------视觉训练竟能提升纯文本推理能力(MMLU-Pro +1.7%),且仅用Zero-Vision SFT(纯文本代码代理)即可激活强大的视觉工具调用能力。
- Agent Swarm:并行智能体架构,提出PARL(并行代理强化学习)框架,通过可训练的"协调器"动态创建专门化的冻结子代理,将复杂任务并行分解执行。相比传统单代理顺序执行,此举在保持高精度的同时降低延迟达4.5倍(如BrowseComp任务从60.6%提升至78.4%,速度提升3-4.5倍),解决了长程任务的可扩展性瓶颈。
- 顶尖性能与统一架构:在15T token上预训练,基于1T参数的MoE基座,K2.5在智能体任务(DeepSearchQA等)、长视频理解(LVBench 75.9%,处理2000+帧)、文档OCR(92.3%)等多领域达到SOTA,性能对标或超越GPT-5.2、Claude Opus 4.5等闭源模型。
- 开源与工程创新,贡献多项工程优化:MoonViT-3D统一处理图像视频(4倍时序压缩)、Toggle算法减少25-30%推理token、DEP技术实现90%的纯文本训练效率。这些技术共同推进了通用智能体智能(General Agentic Intelligence)的实用化。
文章目录
-
- note
- 一、Kimi-K2.5模型
- 二、核心技术创新
-
- [2.1 文本与视觉的联合优化(Joint Optimization)](#2.1 文本与视觉的联合优化(Joint Optimization))
- [2.2 Zero-Vision SFT:纯文本激活视觉能力](#2.2 Zero-Vision SFT:纯文本激活视觉能力)
- [2.3 视觉 RL 的跨模态迁移](#2.3 视觉 RL 的跨模态迁移)
- [三、Agent Swarm:并行智能体架构](#三、Agent Swarm:并行智能体架构)
-
- [3.1 架构设计](#3.1 架构设计)
- [3.2 奖励函数设计](#3.2 奖励函数设计)
- [3.3 性能表现(图8)](#3.3 性能表现(图8))
- [3.4 上下文管理优势](#3.4 上下文管理优势)
- 四、训练基础设施与优化
-
- [4.1 MoonViT-3D 视觉编码器](#4.1 MoonViT-3D 视觉编码器)
- [4.2 Toggle:Token 效率优化](#4.2 Toggle:Token 效率优化)
- [4.3 解耦编码器进程(DEP)](#4.3 解耦编码器进程(DEP))
- 五、全面性能评估
-
- [5.1 与业界顶尖模型对比(表4)](#5.1 与业界顶尖模型对比(表4))
- [5.2 关键观察](#5.2 关键观察)
- 六、局限性与讨论
- 七、总结与影响
一、Kimi-K2.5模型
| 维度 | 内容 |
|---|---|
| 输入 | 多模态:文本 + 图像(可变分辨率)+ 视频(最长2000帧) |
| 输出 | 混合模式 : • Chat/Reasoning模式 :常规文本回答 • Agent模式 :Function Call(工具调用)+ 子代理创建/调度 • Coding模式:代码生成 |
Kimi K2.5 是 Moonshot AI 发布的开源多模态智能体模型,旨在推动通用智能体智能(General Agentic Intelligence)的发展。该模型采用原生多模态架构 ,通过文本与视觉的联合优化,以及创新的Agent Swarm(智能体集群)框架,在推理、编程、视觉理解和智能体任务上达到了业界领先水平。
核心数据概览:
- 基础架构:基于 Kimi K2(1.04T 参数 MoE,激活 32B)
- 预训练数据:15T 混合视觉-文本 token
- 关键突破:Agent Swarm 实现延迟降低 4.5× ,BrowseComp 任务性能从 60.6% 提升至 78.4%
【大模型技术报告进展】K2.5技术报告,https://github.com/MoonshotAI/Kimi-K2.5/blob/master/tech_report.pdf,开源多模态智能体模型,基于KimiK2万亿参数混合专家(MoE)构建,实现文本与视觉模态的协同增强及复杂任务的高效并行处理。
1)技术特点
- 1.原生多模态预训练,早期融合策略,视觉-文本比例恒定(低视觉占比),15万亿混合tokens训练;
- 2.零视觉SFT,纯文本SFT数据,通过IPython编程操作代理图像处理;
- 3.联合多模态RL,结果导向视觉RL,按能力划分训练领域,跨模态迁移优化;
- 4.AgentSwarm并行智能体,解决传统智能体串行执行导致的延迟高、复杂度受限问题。使用可训练协调器(Orchestrator)+冻结子智能体(Sub-agents),动态分解异质子任务并行执行,奖励机制上综合并行实例化奖励、子任务完成率奖励、任务结果奖励;
2)模型架构【MoonViT-3D视觉编码器(支持图像/视频统一处理,共享参数)、MLP投影层、KimiK2MoE语言模型,MoonViT-3D支持4倍帧压缩,可处理更长视频,图像与视频编码器完全权重共享】;
3)训练流程。【ViT单独训练,图像-文本对、视频-文本对(字幕、OCR等)1万亿token;联合预训练,文本、知识、视频、OS截图等混合数据15万亿token;长上下文中期训练,高质量长文本、长视频推理数据7000亿token;后训练(SFT+RL),多领域指令数据集、智能体任务数据】
二、核心技术创新
2.1 文本与视觉的联合优化(Joint Optimization)
传统方案的局限 :
常规多模态模型通常在文本模型训练后期(如 80% 进度后)以高比例(50%+)注入视觉数据,导致模态冲突和性能权衡。
K2.5 的策略:
- 早期融合(Early Fusion):从训练开始就以固定比例(Vision:Text = 10:90)混合数据
- 连续优化:在整个预训练过程中保持恒定比例,避免后期的域迁移冲击
实验验证(表1):
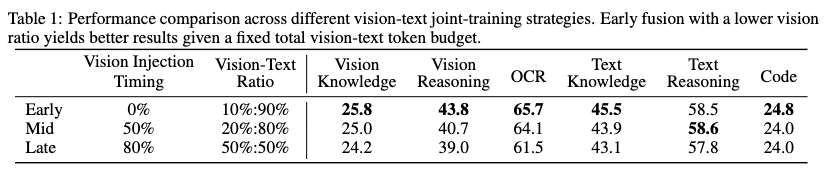
结论:早期融合+低视觉比例在固定总 token 预算下表现最优,且在文本和视觉任务上均有优势。
2.2 Zero-Vision SFT:纯文本激活视觉能力
问题:预训练 VLM 不会自然执行视觉工具调用,传统方法依赖人工标注的视觉轨迹数据,多样性受限且易过拟合。
解决方案:
- 纯文本 SFT:所有图像操作通过 IPython 代码代理(如像素级二值化、计数、裁剪)
- 零视觉数据:训练阶段完全不使用真实图像数据
- 泛化机制:依赖联合预训练建立的强视觉-文本对齐,使文本学习的能力自然迁移到真实视觉任务
效果 (图2):
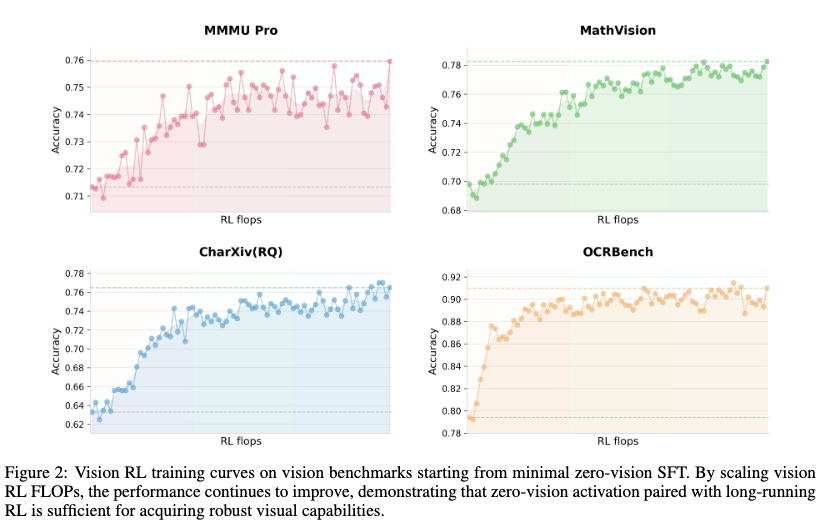
Zero-Vision SFT 启动后,通过长时程视觉 RL 训练,模型在 MMMU-Pro、MathVision、OCRBench 等基准上持续提升,证明纯文本激活足以获得鲁棒的视觉能力。
2.3 视觉 RL 的跨模态迁移
意外发现(表2):
视觉强化学习不仅提升视觉任务,还显著改善纯文本推理能力:

分析:视觉 RL 增强了模型在结构化信息提取领域的校准能力,减少了视觉推理类查询的不确定性。
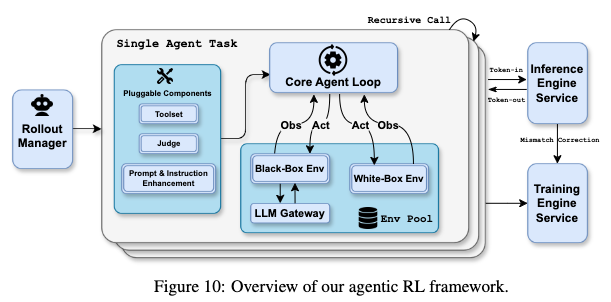
三、Agent Swarm:并行智能体架构
3.1 架构设计
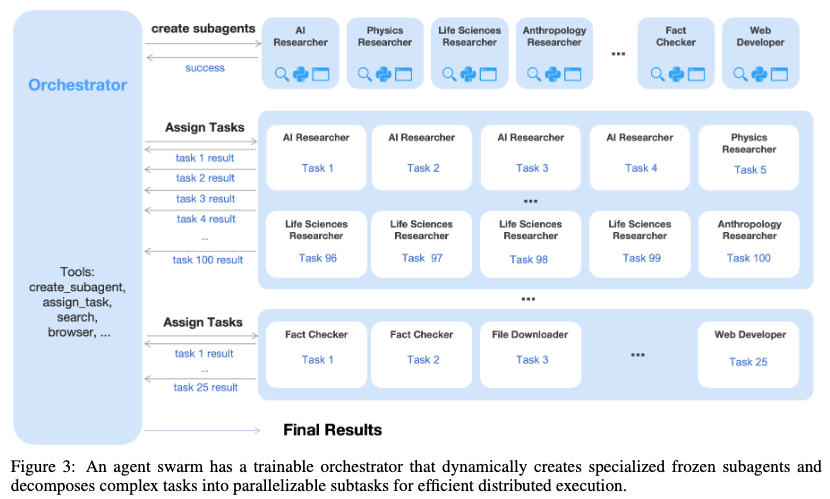
核心组件(图3):
- 可训练协调器(Orchestrator):动态分析任务,决策并行策略
- 冻结子代理(Frozen Sub-agents):从固定检查点实例化的领域专家(如 AI 研究员、物理研究员、事实核查员)
- 工具接口 :
create_subagent和assign_task支持动态创建和任务委派
训练范式 - PARL(Parallel-Agent Reinforcement Learning):
- 解耦训练:只更新协调器,子代理输出视为环境观测值
- 避免信用分配问题:子代理执行轨迹不纳入优化目标,解决多智能体训练的不稳定性
3.2 奖励函数设计
r PARL ( x , y ) = λ 1 ⋅ r parallel ⏟ 实例化奖励 + λ 2 ⋅ r finish ⏟ 完成率 + r perf ( x , y ) ⏟ 任务级结果 r_{\text{PARL}}(x,y) = \lambda_1 \cdot \underbrace{r_{\text{parallel}}}{\text{实例化奖励}} + \lambda_2 \cdot \underbrace{r{\text{finish}}}{\text{完成率}} + \underbrace{r{\text{perf}}(x,y)}_{\text{任务级结果}} rPARL(x,y)=λ1⋅实例化奖励 rparallel+λ2⋅完成率 rfinish+任务级结果 rperf(x,y)
- r parallel r_{\text{parallel}} rparallel:防止串行崩溃(Serial Collapse),激励子代理实例化
- r finish r_{\text{finish}} rfinish:防止虚假并行(Spurious Parallelism),确保子任务实际完成
- 关键步数(Critical Steps):类比计算图的关键路径,定义为各阶段最大执行时间之和,显式优化延迟而非仅吞吐量
3.3 性能表现(图8)
在 WideSearch 基准测试中,Agent Swarm 相比单代理基线:
- 速度提升 :目标 Item-F1 从 30% 提升到 70% 时,执行时间节省 3×--4.5×
- 准确率提升 :Item-F1 从 72.8%(单代理)提升至 79.0%
3.4 上下文管理优势
Agent Swarm 实现了主动上下文分片(Context Sharding):
- 子代理维护独立的工作记忆和局部推理上下文
- 只有任务相关输出返回给协调器,而非完整的交互轨迹
- 相比传统的 Discard-all 或 Summary 等被动压缩策略,保留了更多结构化信息
四、训练基础设施与优化
4.1 MoonViT-3D 视觉编码器
- 原生分辨率:采用 NaViT 打包策略,支持任意长宽比和分辨率
- 统一视频处理:连续4帧作为时空体处理,时序平均实现 4× 压缩,支持处理长达 2,000 帧的视频
- 权重共享:图像和视频完全共享参数和嵌入空间
4.2 Toggle:Token 效率优化
解决推理时的 token 膨胀问题:
- 交替训练:在预算受限阶段(强制简洁输出)和标准缩放阶段(充分推理)之间交替
- 动态预算:基于正确回答的 token 长度分布(ρ-百分位数)设定任务相关预算
- 效果 (图5):平均减少 25-30% 的输出 token,性能无显著下降
4.3 解耦编码器进程(DEP)
解决多模态训练中的负载不均衡问题:
- 视觉编码器与主 Transformer 解耦,支持独立的并行策略
- 实现多模态训练效率达到纯文本训练的 90%
五、全面性能评估
5.1 与业界顶尖模型对比(表4)
| 领域 | 基准测试 | Kimi K2.5 | Claude Opus 4.5 | GPT-5.2 | Gemini 3 Pro |
|---|---|---|---|---|---|
| 推理 | AIME 2025 | 96.1 | 92.8 | 100 | 95.0 |
| HLE-Full (工具) | 50.2 | 43.2 | 45.5 | 45.8 | |
| GPQA-Diamond | 87.6 | 87.0 | 92.4 | 91.9 | |
| 编程 | SWE-Bench Verified | 76.8 | 80.9 | 80.0 | 76.2 |
| LiveCodeBench v6 | 85.0 | 82.2 | - | 87.4* | |
| 智能体 | BrowseComp | 60.6 | 37.0 | 65.8 | 37.8 |
| BrowseComp (Agent Swarm) | 78.4 | - | - | - | |
| DeepSearchQA | 77.1 | 76.1* | 71.3* | 63.2* | |
| 图像 | MMMU-Pro | 78.5 | 74.0 | 79.5* | 81.0 |
| MathVision | 84.2 | 77.1* | 83.0 | 86.1* | |
| OCRBench | 92.3 | 86.5* | 80.7* | 90.3* | |
| 视频 | VideoMMMU | 86.6 | 84.4* | 85.9 | 87.6 |
| LongVideoBench | 79.8 | 67.2* | 76.5* | 77.7* | |
| LVBench | 75.9 | 57.3 | - | 73.5* | |
| 计算机使用 | OSWorld-Verified | 63.3 | 66.3 | 8.6* | 20.7* |
| WebArena | 58.9 | 63.4 | - | - |
注:带 * 号为内部评估结果;黑体表示最优或并列最优
5.2 关键观察
- 智能体任务领先:在 BrowseComp、DeepSearchQA 等深度研究任务上显著领先闭源模型,Agent Swarm 版本更是达到 SOTA
- 长视频理解优势:在 LongVideoBench 和 LVBench 上建立新的全球 SOTA,展示 MoonViT-3D 的时序压缩优势
- OCR 与文档理解:OCRBench(92.3%)和 OmniDocBench 1.5(88.8%)表现突出,超过所有对比模型
- 代码能力:LiveCodeBench 实时编码挑战中表现最强,SWE-Bench 系列与顶级模型竞争
六、局限性与讨论
- 计算机使用差距:在 OSWorld-Verified(63.3% vs 66.3%)和 WebArena(58.9% vs 63.4%)上仍略落后于 Claude Opus 4.5
- 基准测试覆盖:部分基准测试(如 SimpleQA Verified 36.9%)显著落后于 Gemini 3 Pro(72.1%),表明在特定知识检索任务上仍有提升空间
- 计算资源需求:Agent Swarm 虽然降低延迟,但需要并行执行多个子代理,对推理基础设施提出更高要求
七、总结与影响
Kimi K2.5 的核心贡献:
-
训练范式革新:证明早期融合+低比例视觉数据的联合预训练优于后期高比例注入,打破"视觉是文本附加能力"的传统认知
-
模态协同增强:首次系统验证视觉 RL 可反向提升文本推理能力,实现真正的双向跨模态迁移
-
智能体架构突破:Agent Swarm 通过 PARL 框架将任务复杂度从线性扩展转为并行处理,为复杂多步骤任务提供可扩展解决方案
-
工程实践价值:Zero-Vision SFT、Toggle 和 DEP 等技术显著降低多模态和智能体训练的成本门槛