文章目录
- [1. Update(改)](#1. Update(改))
-
- [1.1 将孙悟空同学的数学成绩变更为 80 分](#1.1 将孙悟空同学的数学成绩变更为 80 分)
- [1.2 将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分](#1.2 将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分)
- [1.3 将总成绩倒数前三的 3 位同学的数学成绩加上 30 分](#1.3 将总成绩倒数前三的 3 位同学的数学成绩加上 30 分)
- [1.4 将所有同学的语文成绩更新为原来的 2 倍](#1.4 将所有同学的语文成绩更新为原来的 2 倍)
- [2. Delete(删)](#2. Delete(删))
-
- [2.1 从表中删除孙悟空同学的记录](#2.1 从表中删除孙悟空同学的记录)
- [2.2 删除总分倒数第一名的同学的记录](#2.2 删除总分倒数第一名的同学的记录)
- [2.3 删除整张表中的数据](#2.3 删除整张表中的数据)
- [3. 截断表](#3. 截断表)
- [4. insert和select组合使用](#4. insert和select组合使用)
1. Update(改)
语法:
sql
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]对查询到的结果的对应列进行值更新,如果没有加条件,对应列的数据全部更新
案例:依然用我们上一篇文章中的exam_result表
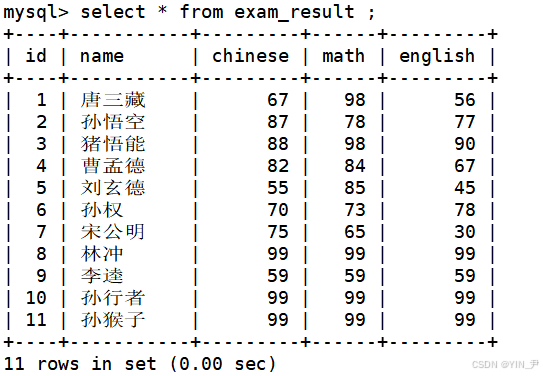
1.1 将孙悟空同学的数学成绩变更为 80 分
update exam_result set math=80 where name='孙悟空';
如果不加后面的条件where name='孙悟空';,则会把所有的数学成绩(即math列)改为80。
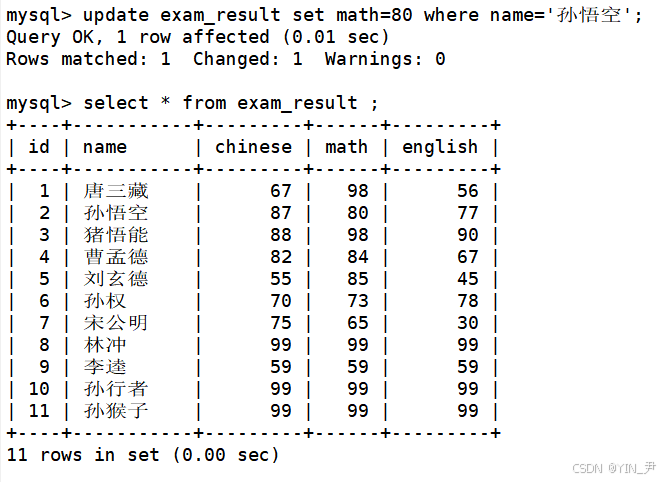
1.2 将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
先来看一下曹孟德原始的数学和语文成绩
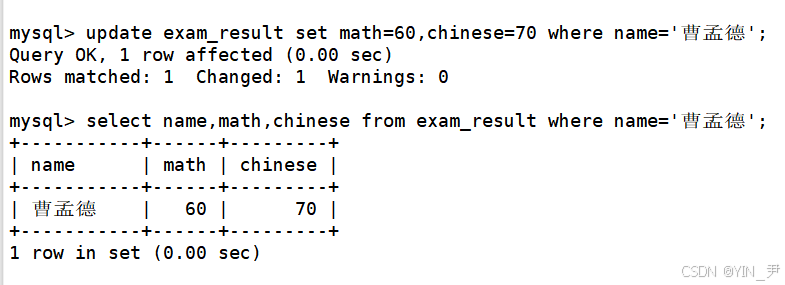
然后我们来将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
update exam_result set math=60,chinese=70 where name='曹孟德';
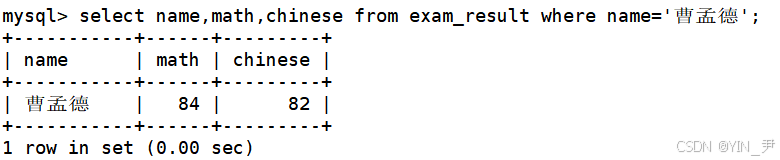
1.3 将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
同样,我们先来看一下总成绩倒数前三的 3 位同学的数学成绩,这是我们上一篇文章学的内容
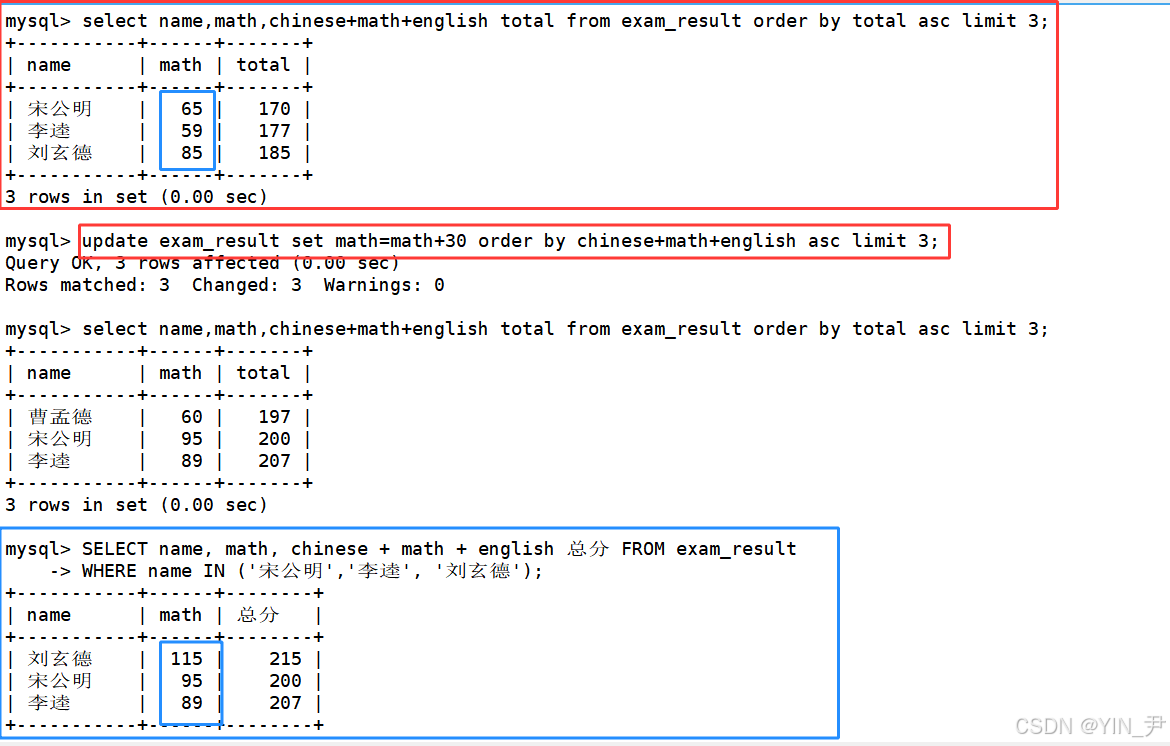
select name,math,chinese+math+english total from exam_result order by total asc limit 3;
然后我们来给他们的数学成绩+30分
update exam_result set math=math+30 order by chinese+math+english asc limit 3;
注意:MySQL中不支持 math += 30 这种写法。
就修改成功了。
然后我们再来查看一下那三个人的成绩。
但是,这里还可以按总分升序排序取前 3 个么?
不可以,因为刚才只给那三个人的数学成绩+30分,现在它们的总成绩就变了,所以再按这种方式查到的就不是前面那三个人了。
所以我们要来查加分之前的那三人,即宋公明、刘玄德、李逵。
能看到它们的数学成绩都比原来多了30分(当然总分也会多30)
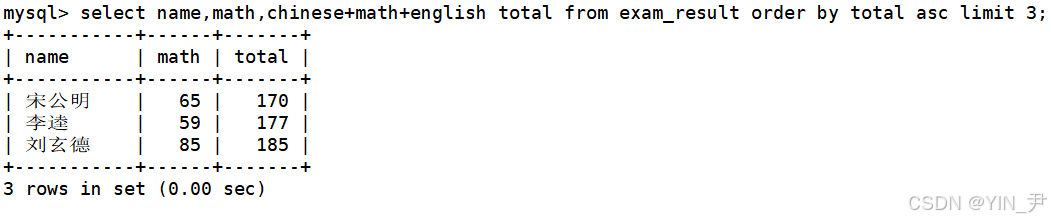
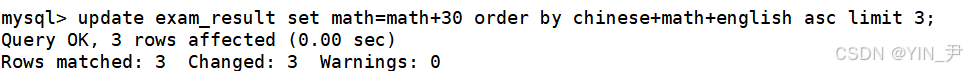

1.4 将所有同学的语文成绩更新为原来的 2 倍
注意:更新全表的语句慎用!
不加条件,则更新全表
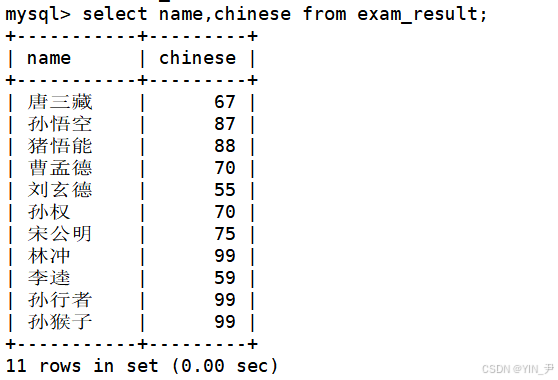
先看一下目前所有同学的语文成绩
update exam_result set chinese=chinese*2;

2. Delete(删)
语法:
sql
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]不加条件则把整张表的数据全删掉。
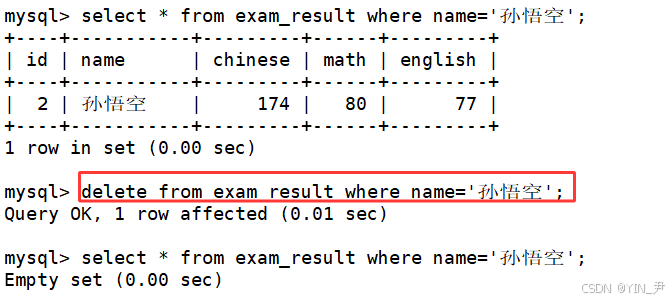
2.1 从表中删除孙悟空同学的记录
delete from exam_result where name='孙悟空';
2.2 删除总分倒数第一名的同学的记录
先找到这个同学(按总成绩升序,取第一个)
select name,chinese+math+english total from exam_result order by total asc limit 1;
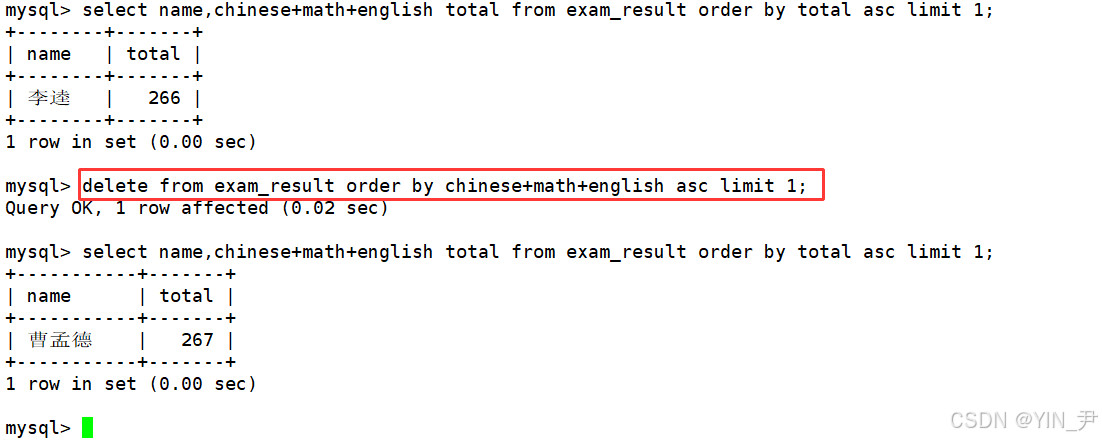
下面删掉这条记录
delete from exam_result order by chinese+math+english asc limit 1;
后面再查就没有李逵了,倒数第一自然也就变了。
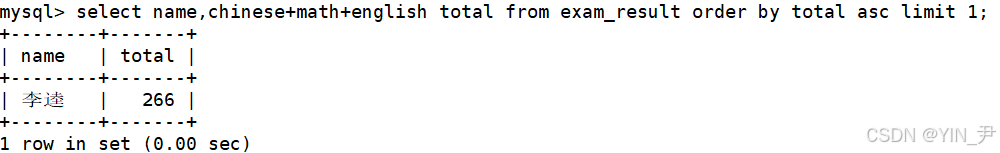
2.3 删除整张表中的数据
注意:删除整表中的数据操作要慎用!(删除表本身我们之前讲过,是用drop)
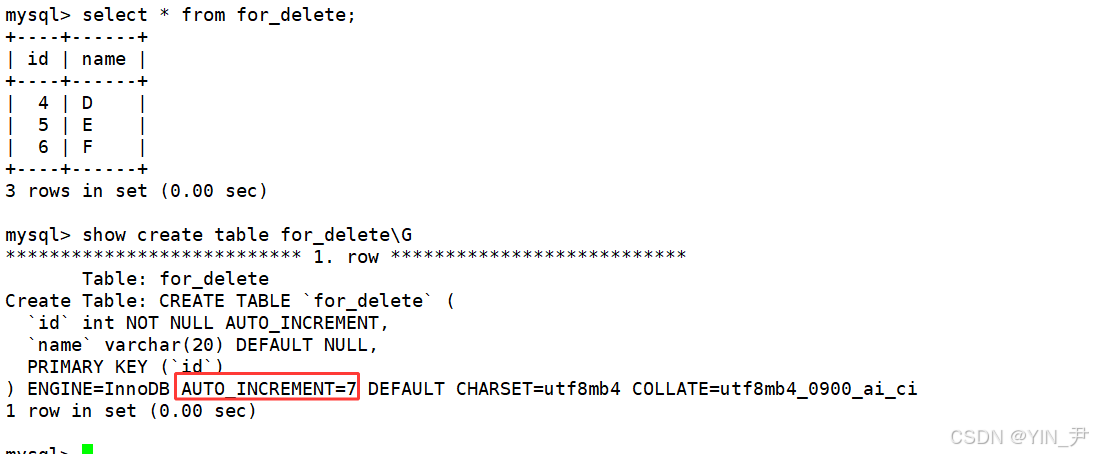
我们来新建一张表,用来讲解删除的操作
准备测试表:
sql
CREATE TABLE for_delete (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20));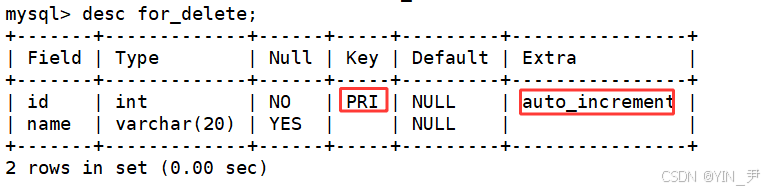
id列设置为主键,并添加了自增属性
然后插入一些数据
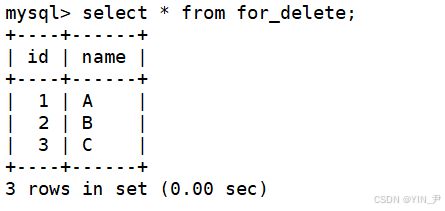
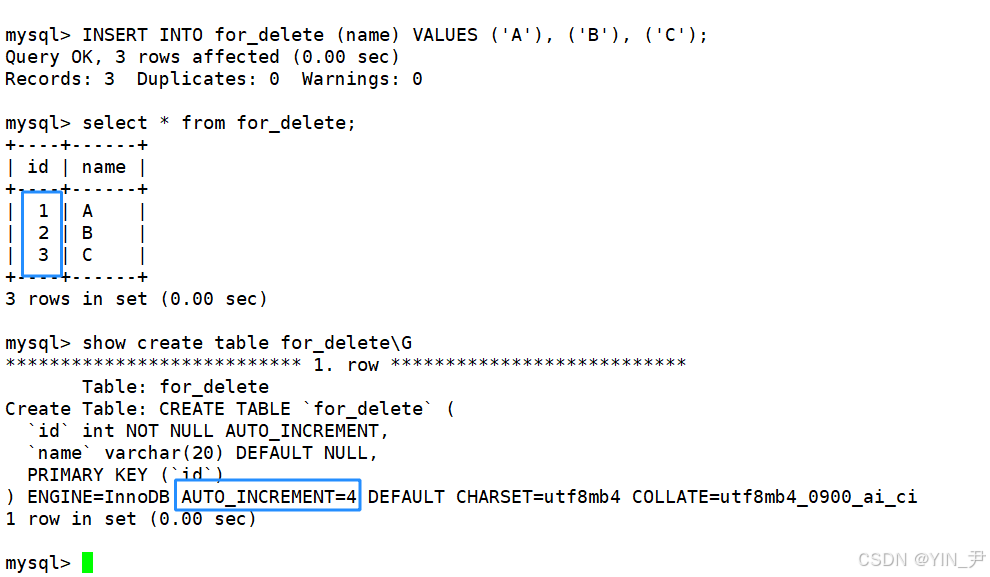
INSERT INTO for_delete (name) VALUES ('A'), ('B'), ('C');
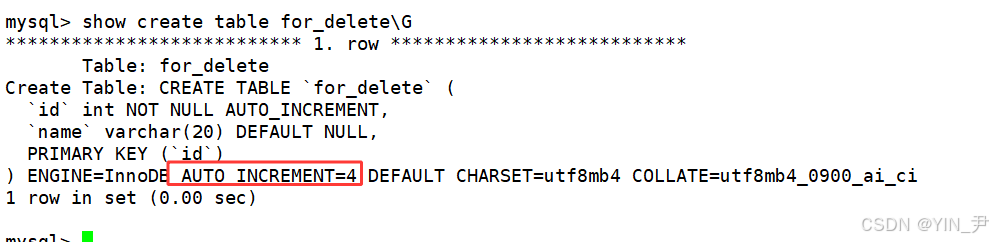
id列设置了auto_increment,所以可以忽略,并且我们讲过MySQL会维护一个自增计数器,下次插入如果我们进行了忽略,它默认就从这个值的基础上自增1。
show create table for_delete\G
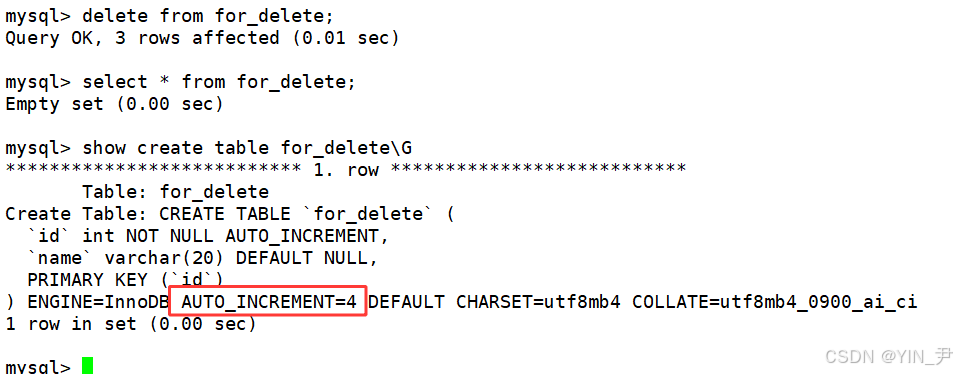
然后我们来删除表中所有数据
delete from 表名
然后这张表就空了
不过
我们看到这个自增计数器是没变的。(即清空表不会影响自增计数器的值)
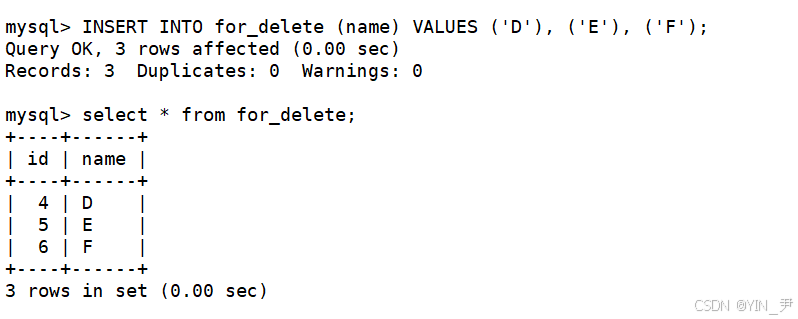
那么我们再插入数据,如果忽略id列,就默认从4开始递增

3. 截断表
语法:
sql
TRUNCATE [TABLE] table_nameTRUNCATE TABLE table_name 也是用于快速删除表中所有数据的 SQL 命令。它比使用 DELETE FROM table_name 更高效,但有一些重要的区别和限制。
所以同样也要慎用!那它与delete的区别是啥呢:
TRUNCATE [TABLE] table_name只能对整表操作,不能像 DELETE 一样针对部分数据操作;- 实际上 MySQL 不对数据操作(TRUNCATE是DDL,直接操作数据文件),所以比 DELETE 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事务,所以无法回滚(事务我们后面会讲)
- 会重置 AUTO_INCREMENT 计数器
还以上面for_delete表为例:
下面:
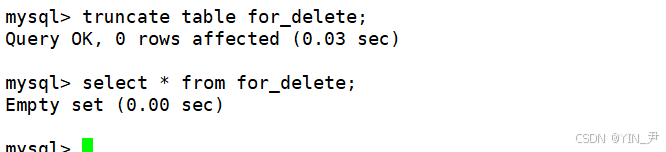
truncate table for_delete;
我们看到表中的数据也被清空了,同时注意到0 rows affected,即实际上没有一行行对数据进行操作。
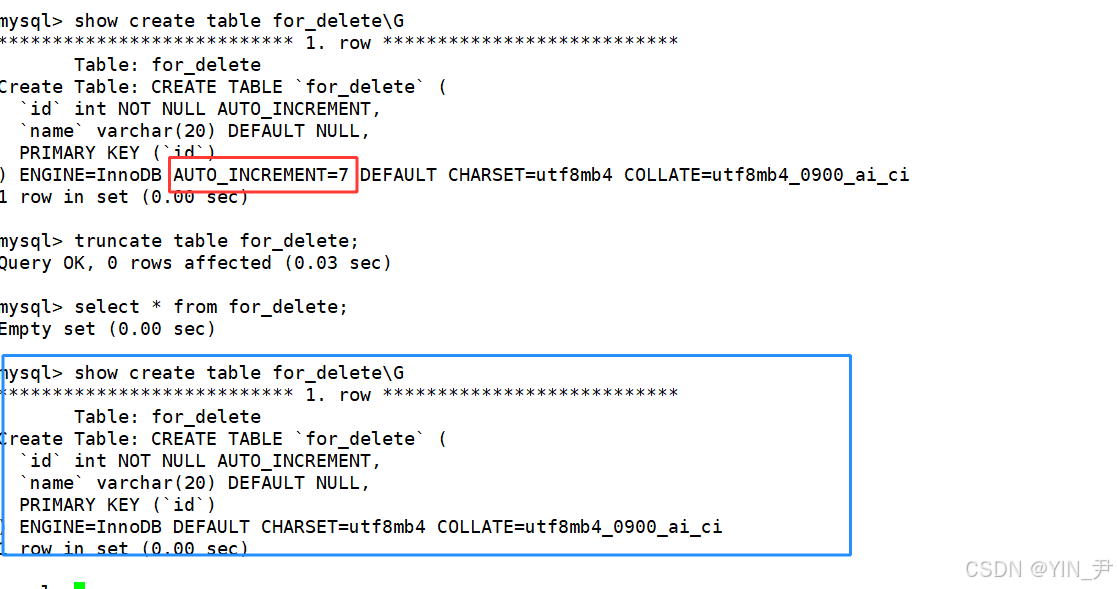
同时可以注意到:
截断表之后,auto_increment计数器没了(其实是被重置了)
我们再来插入数据,忽略id列
我们发现它又从1开始自增了。
4. insert和select组合使用
语法:
sql
INSERT INTO table_name [(column [, column ...])] SELECT ...案例:删除表中的的重复记录
先建个表:
CREATE TABLE duplicate_table (id int, name varchar(20));
然后插入一些数据
其中包含了一些重复数据

现在想要对表中的数据去重,怎么做?
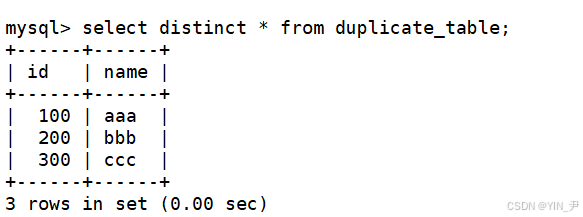
注意我们之前学的distinct是对查询结果去重,不影响表中数据
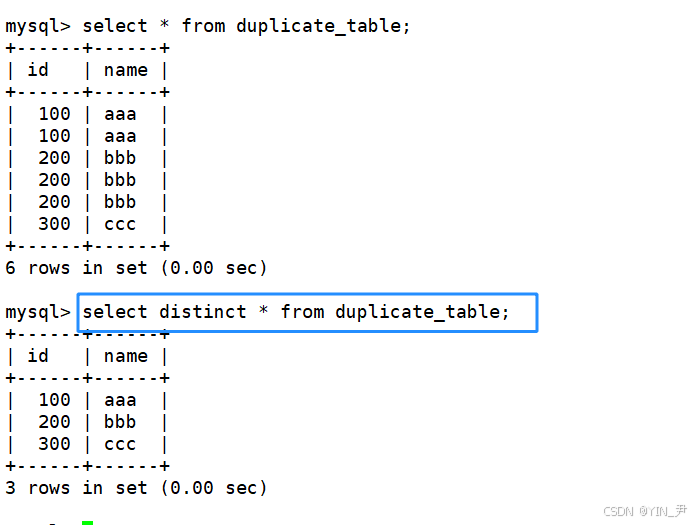
那这里要怎么做?
思路:
- 创建一张空表 no_duplicate_table,结构和 duplicate_table 一样
- 将 duplicate_table 的去重数据插入到 no_duplicate_table
- 将duplicate_table改一个名字,将no_duplicate_table的表名改为duplicate_table
下面按照步骤我们来做一下:
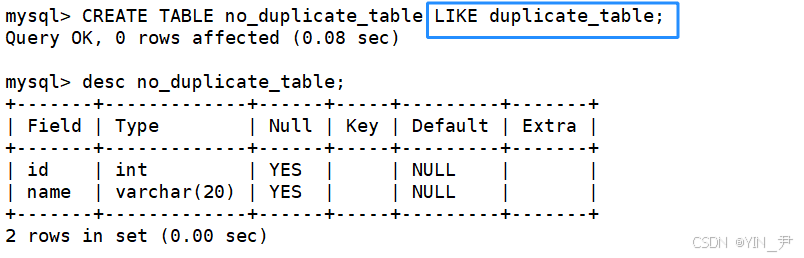
首先创建一张空表 no_duplicate_table,结构和 duplicate_table 一样。
CREATE TABLE no_duplicate_table LIKE duplicate_table;
在MySQL中,使用 CREATE TABLE ... LIKE 语句会创建一个新表,其结构与源表完全相同,包括列定义、索引等,但是不会复制数据
第二步,将 duplicate_table 的去重数据插入到 no_duplicate_table。
要获取duplicate_table 的去重数据很简单
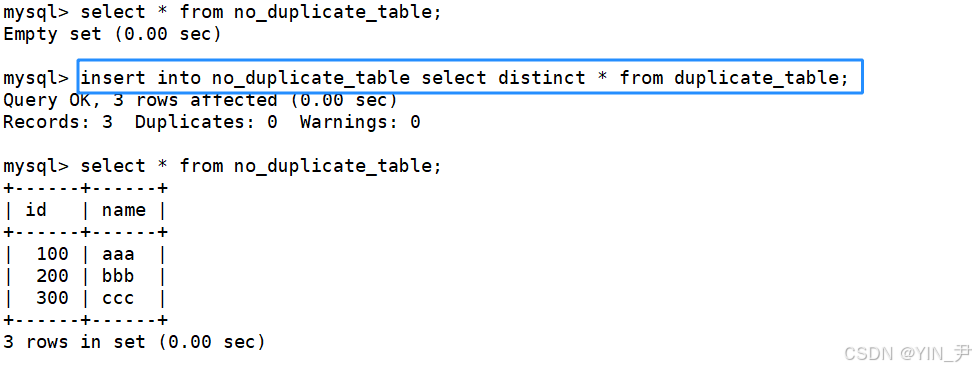
然后把这些数据插入到no_duplicate_table中,怎么做?
🆗,insert插入的时候可以直接把select的结果拿来插入
insert into no_duplicate_table select distinct * from duplicate_table;
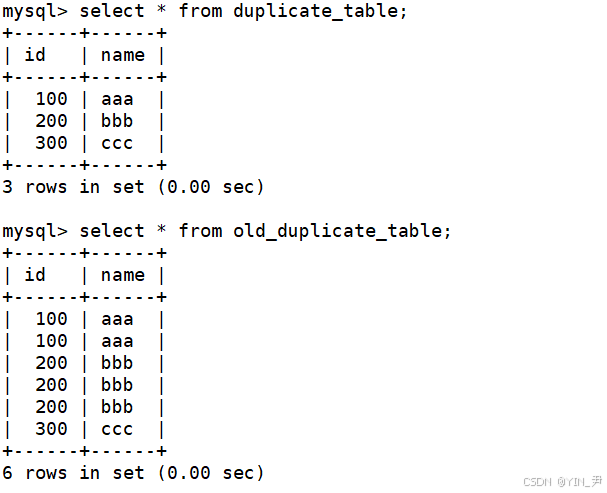
第三步:将duplicate_table改一个名字,将no_duplicate_table的表名改为duplicate_table
修改表名:RENAME TABLE 旧表名 TO 新表名;
那么现在duplicate_table表中放的就是去重之后的数据了