PostgreSQL快速入门
文章目录
- PostgreSQL快速入门
-
- 一:概述
-
- 1:PostgreSQL简介
- [2:PostgreSQL vs mysql](#2:PostgreSQL vs mysql)
- 3:linux部署PostgreSQL
-
- 3.1:ubuntu
- 3.2:centos
- [3.3:docker 单容器部署](#3.3:docker 单容器部署)
- 二:PostgreSQL基础语法
-
- 1:核心概念
- 2:基本操作
- 3:数据类型
- 4:表操作
- 5:数据操作语言-DML
-
- 5.1:数据插入
- 5.2:数据查询
- 5.3:数据更新
- 5.4:删除数据
- 5.5:连接查询
- 5.6:集合操作
- 5.7:常用函数
- 5.8:通用表表达式CTE
- 5.9:窗口函数
-
- 5.9.1:定义窗口函数
- [5.9.2:分区选项 PARTITION BY](#5.9.2:分区选项 PARTITION BY)
- [5.9.3:排序选项 ORDER BY](#5.9.3:排序选项 ORDER BY)
- [5.9.4:窗口选项 frame_clause](#5.9.4:窗口选项 frame_clause)
- 6:备份和恢复
- 7:事务和并发
- 8:索引和优化
- 9:视图
如果你有mysql的经验学起来会更快
b站大佬教程,https://space.bilibili.com/473901592/lists/391150?type=season
一:概述
1:PostgreSQL简介
PostgreSQL 是一款功能强大的开源对象-关系型数据库系统,具有以下特点:
- 开源免费:遵循 PostgreSQL 许可证(类似BSD/MIT)
- ACID 兼容:完全支持事务处理
- 标准兼容:高度符合 SQL 标准
- 可扩展:支持自定义函数、存储过程、触发器
- 数据类型丰富:内置 JSON/XML 支持、数组、范围类型等
- 并发控制:使用多版本并发控制(MVCC)
- 高可用性:支持复制、负载均衡
- 跨平台:支持 Windows、macOS、Linux 等主流操作系统
适用场景:
- Web 应用后端数据库
- 地理空间数据库(PostGIS 扩展)
- 数据分析与数据仓库
- 金融系统
- 内容管理系统
2:PostgreSQL vs mysql
| 特性 | PostgreSQL | MySQL |
|---|---|---|
| 许可证 | PostgreSQL License(类似MIT/BSD) | GPLv2(社区版)或商业许可 |
| 类型 | 对象关系型数据库(ORDBMS) | 关系型数据库(RDBMS) |
| SQL标准兼容性 | 高度兼容(支持窗口函数、CTE等高级特性) | 基本兼容,部分特性扩展 |
| ACID支持 | 完全支持(包括复杂事务) | 支持(InnoDB存储引擎) |
| 数据完整性 | 强约束(检查约束、外键等完善) | 基础支持(较新版本增强) |
| JSON支持 | 原生JSON/JSONB(支持索引、查询) | JSON类型(5.7+,支持有限查询) |
| 扩展性 | 高度可扩展(自定义函数、数据类型、索引等) | 有限扩展(存储引擎插件) |
| 复制 | 物理复制+逻辑复制(同步/异步) | 基于二进制日志的复制(半同步可选) |
| 分区 | 原生分区表(10.0+),声明式分区 | 分区表(水平分区) |
| 地理空间 | PostGIS(行业标准,功能强大) | 基础空间支持(有限功能) |
| 全文搜索 | 内置全文搜索(支持多语言) | 有限全文搜索(InnoDB支持) |
| 并发控制 | MVCC(多版本并发控制) | MVCC(InnoDB) |
| 性能特点 | 复杂查询、OLAP、高并发写入优化 | OLTP、简单查询、读密集型优化 |
| 存储引擎 | 单一存储引擎(设计统一) | 多存储引擎(InnoDB、MyISAM等) |
| 社区与生态 | 活跃社区,偏企业级应用 | 极活跃社区,广泛Web应用 |
| 主要应用场景 | 复杂业务逻辑、地理数据、数据分析、金融系统 | Web应用、高并发读、内容管理、SaaS |
| 默认配置 | 偏保守,强调数据安全 | 偏性能优化,快速启动 |
| 学习曲线 | 较陡峭(功能丰富) | 较平缓(简单易用) |
简要选择建议
选择 PostgreSQL 如果:
- 需要复杂查询、数据分析或地理空间功能
- 数据完整性要求极高
- 使用JSON数据并需要高效查询
- 需要自定义扩展(如数据类型、函数)
选择 MySQL 如果:
- 快速开发Web应用、读写分离架构
- 简单数据结构、高并发读取
- 需要广泛的管理工具和托管服务
- 已有大量MySQL生态经验
3:linux部署PostgreSQL
3.1:ubuntu
Ubuntu 22.04/20.04 部署 PostgreSQL 15 + PostGIS 3.3
bash
# ====================
# 1. 系统准备
# ====================
# 更新系统并安装基础工具
sudo apt update && sudo apt upgrade -y
sudo apt install -y curl wget gnupg lsb-release software-properties-common
# ====================
# 2. 添加 PostgreSQL 官方仓库
# ====================
# 创建仓库文件
sudo sh -c 'echo "deb [arch=amd64] http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list'
# 导入官方 GPG 密钥
curl -fsSL https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo gpg --dearmor -o /etc/apt/trusted.gpg.d/postgresql.gpg
# ====================
# 3. 添加 PostGIS 仓库(UbuntuGIS)
# ====================
sudo add-apt-repository -y ppa:ubuntugis/ppa
sudo apt update
# ====================
# 4. 安装 PostgreSQL 15 及相关组件
# ====================
sudo apt install -y \
postgresql-15 \
postgresql-client-15 \
postgresql-contrib-15 \
postgresql-15-postgis-3 \
postgresql-15-postgis-3-scripts \
postgis \
postgresql-server-dev-15
# ====================
# 5. 安装 PostGIS 依赖的 GDAL/GEOS/PROJ 库
# ====================
sudo apt install -y \
libgeos-c1v5 \
libgdal-dev \
libproj-dev \
libjson-c-dev \
libxml2-dev \
protobuf-c-compiler
# ====================
# 6. 启动并验证 PostgreSQL 服务
# ====================
sudo systemctl start postgresql
sudo systemctl enable postgresql
sudo systemctl status postgresql
# ====================
# 7. 配置 PostgreSQL
# ====================
# 修改密码加密方式为 scram-sha-256(更安全)
sudo -u postgres psql -c "ALTER SYSTEM SET password_encryption = 'scram-sha-256';"
# 重新加载配置
sudo systemctl reload postgresql
# ====================
# 8. 为 postgres 用户设置密码
# ====================
sudo -u postgres psql << EOF
ALTER USER postgres WITH PASSWORD '123456';
EOF
# ====================
# 9. 创建专用数据库并启用 PostGIS
# ====================
# 创建数据库用户
sudo -u postgres createuser --createdb --login --pwprompt gis_user
# 创建数据库
sudo -u postgres createdb -O gis_user gis_db
# 启用 PostGIS 扩展
sudo -u postgres psql -d gis_db << EOF
-- 启用 PostGIS 扩展
CREATE EXTENSION postgis;
CREATE EXTENSION postgis_topology;
CREATE EXTENSION postgis_raster;
CREATE EXTENSION fuzzystrmatch;
CREATE EXTENSION postgis_tiger_geocoder;
CREATE EXTENSION address_standardizer;
-- 查看安装的扩展
SELECT name, default_version, installed_version
FROM pg_available_extensions
WHERE name LIKE 'postgis%' OR name = 'address_standardizer';
-- 验证 PostGIS 版本
SELECT PostGIS_Version();
SELECT PostGIS_Full_Version();
EOF
# ====================
# 10. 配置远程访问(可选)
# ====================
# 备份原配置文件
sudo cp /etc/postgresql/15/main/postgresql.conf /etc/postgresql/15/main/postgresql.conf.backup
sudo cp /etc/postgresql/15/main/pg_hba.conf /etc/postgresql/15/main/pg_hba.conf.backup
# 修改 postgresql.conf
sudo sed -i "s/#listen_addresses = 'localhost'/listen_addresses = '*'/" /etc/postgresql/15/main/postgresql.conf
# 修改 pg_hba.conf
echo "host all all 0.0.0.0/0 scram-sha-256" | sudo tee -a /etc/postgresql/15/main/pg_hba.conf
# 开放防火墙端口
sudo ufw allow 5432/tcp
sudo ufw reload
# 重启 PostgreSQL
sudo systemctl restart postgresql3.2:centos
centos 部署 PostgreSQL 15 + PostGIS 3.3
shell
# ====================
# 1. 系统准备
# ====================
sudo yum update -y
sudo yum install -y epel-release
sudo yum install -y wget curl vim
# ====================
# 2. 添加 PostgreSQL 15 仓库
# ====================
# CentOS 8+/RHEL 8+/Rocky Linux 8+
sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
sudo dnf -qy module disable postgresql
# ====================
# 3. 添加 PostGIS 仓库
# ====================
# 启用 EPEL 和 PowerTools
sudo dnf config-manager --set-enabled powertools
sudo dnf install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm
# ====================
# 4. 安装 PostgreSQL 15 + PostGIS
# ====================
sudo dnf install -y \
postgresql15-server \
postgresql15-contrib \
postgresql15-devel \
postgis33_15 \
postgis33_15-client \
postgis33_15-devel \
postgis33_15-utils \
gdal \
geos \
proj
# ====================
# 5. 初始化数据库
# ====================
sudo /usr/pgsql-15/bin/postgresql-15-setup initdb
# ====================
# 6. 配置 PostgreSQL
# ====================
# 修改配置文件
sudo sed -i "s/#listen_addresses = 'localhost'/listen_addresses = '*'/" /var/lib/pgsql/15/data/postgresql.conf
# 修改认证配置
sudo tee -a /var/lib/pgsql/15/data/pg_hba.conf << EOF
# 允许远程连接
host all all 0.0.0.0/0 scram-sha-256
EOF
# ====================
# 7. 配置防火墙
# ====================
sudo firewall-cmd --permanent --add-port=5432/tcp
sudo firewall-cmd --reload
# ====================
# 8. 启动服务
# ====================
sudo systemctl enable postgresql-15
sudo systemctl start postgresql-15
# ====================
# 9. 设置 postgres 密码
# ====================
sudo -u postgres psql -c "ALTER USER postgres WITH PASSWORD '123456';"
# ====================
# 10. 创建 PostGIS 数据库
# ====================
sudo -u postgres createdb gis_db
sudo -u postgres psql -d gis_db << EOF
CREATE EXTENSION postgis;
CREATE EXTENSION postgis_topology;
CREATE EXTENSION postgis_raster;
SELECT PostGIS_Version();
EOF3.3:docker 单容器部署
bash
# ====================
# 1. 拉取 PostGIS 镜像
# ====================
docker pull postgis/postgis:15-3.3
# ====================
# 2. 创建数据卷(持久化存储)
# ====================
docker volume create postgis_data
docker volume create postgis_backup
# ====================
# 3. 运行 PostGIS 容器
# ====================
docker run -d \ # docker run -> 创建并启动容器,-d 后台启动
--name postgis \ # 指定容器的名称是postgis
--restart always \ # 指定重启策略为always
-p 5432:5432 \ # 设置端口映射:主机端口:容器内端口,容器内的5432映射到本机5432
-e POSTGRES_USER=gis_admin \ # 配置环境变量,username, password, db,
-e POSTGRES_PASSWORD=123456 \
-e POSTGRES_DB=gis_db \
# PostGIS 官方镜像的一个特性,用于批量自动创建 PostgreSQL 扩展
-e POSTGRES_MULTIPLE_EXTENSIONS=postgis,postgis_topology,postgis_raster,pgrouting \
-v postgis_data:/var/lib/postgresql/data \ # data卷持久化
-v postgis_backup:/backups \ # backups备份持久化
-v ./postgresql.conf:/etc/postgresql/postgresql.conf:ro \ # conf文件挂载到外部主机的文件
postgis/postgis:15-3.3 \ # 指定镜像名称
-c 'config_file=/etc/postgresql/postgresql.conf' # 指定运行参数,就是指定使用的配置文件
# ====================
# 4. 查看容器状态
# ====================
docker logs -f postgis
docker exec -it postgis psql -U gis_admin -d gis_db
# ====================
# 5. 创建自定义配置文件
# ====================
cat > postgresql.conf << 'EOF'
# 自定义配置
listen_addresses = '*' # 指定 PostgreSQL 监听的网络地址为*,所有,也就是允许远程连接
max_connections = 200 # 限制同时连接到数据库的最大客户端数
shared_buffers = 256MB # 数据库缓存数据的内存区域
effective_cache_size = 2GB # 查询优化器的假设值,告诉优化器操作系统和数据库有多少缓存可用
work_mem = 16MB # 每个查询操作(排序、哈希、合并)可使用的最大内存
maintenance_work_mem = 128MB # 维护操作(VACUUM、CREATE INDEX、ALTER TABLE)使用的内存
checkpoint_completion_target = 0.9 # 控制检查点写入的平滑程度0.0 ~ 1.0
wal_buffers = 16MB # 预写日志(WAL)的内存缓冲区大小
default_statistics_target = 100 # 控制 ANALYZE 收集的统计信息数量 1 ~ 10000
random_page_cost = 1.1 # 告诉优化器随机读取磁盘页面的相对成本, 机械硬盘:4.0(默认); SSD:1.1-1.5; 内存缓存:1.0-1.1
effective_io_concurrency = 200 # 预期操作系统可以处理的并发异步 I/O 请求数
min_wal_size = 1GB # WAL 文件的最小总大小
max_wal_size = 4GB # WAL 文件的最大总大小
EOF二:PostgreSQL基础语法
1:核心概念
| 核心概念 | 说明 |
|---|---|
| 数据库(Database) | 数据的容器 |
| 模式(Schema) | 数据库内的命名空间,用于组织数据库对象 |
| 表(Table) | 存储数据的基本结构,由行和列组成 |
| 视图(View) | 虚拟表,基于 SQL 查询的结果 |
| 索引(Index) | 提高数据检索速度的数据结构 |
| 序列(Sequence) | 生成唯一数值的对象 |
| 函数(Function) | 可重用的 SQL 代码块 |
| 触发器(Trigger) | 在特定事件发生时自动执行的函数 |
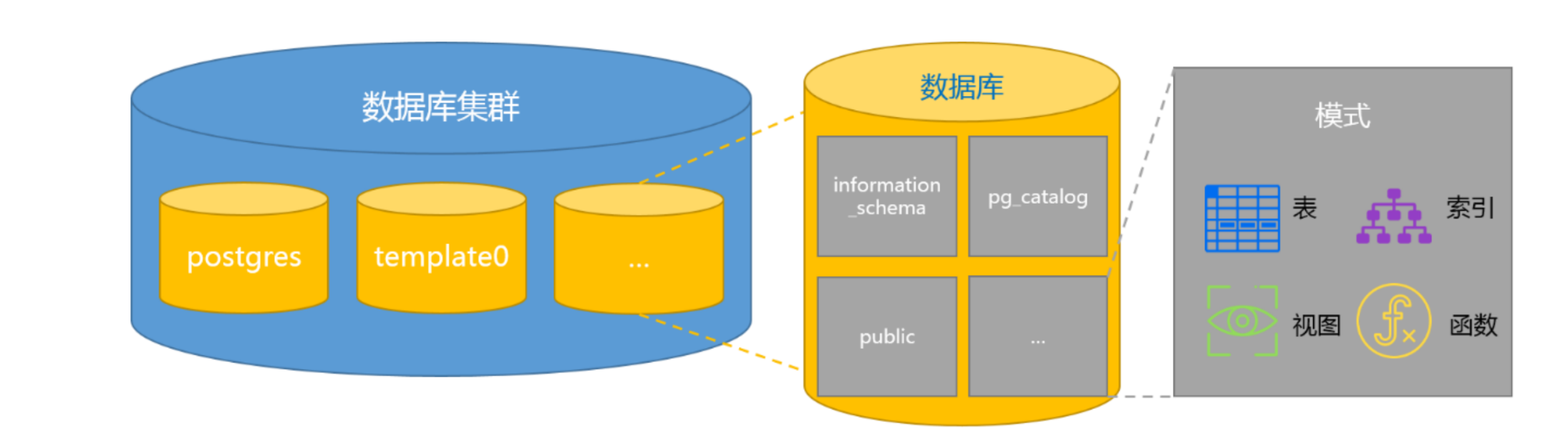
mysql和pg的schema的区别
mysql中database约等于schema, 创建database就是创建schema
但是postgreSQL中,可以在数据库中创建多个schema,如果将database比作一个大楼,那么schema就像是整理有序的办公室,schema是命名空间,是权限容器,是组织容器(按照业务模块组织,按照环境组织,按照团队组织...)。
| 方面 | MySQL | PostgreSQL |
|---|---|---|
| 基本概念 | Schema ≈ Database | Schema ≠ Database |
| 实际使用 | 创建数据库就是创建Schema | 数据库内创建多个Schema |
| 命令 | CREATE DATABASE shop; |
CREATE DATABASE company; CREATE SCHEMA sales; CREATE SCHEMA hr; |
| 切换 | USE shop; |
SET search_path TO sales; |
2:基本操作
2.1:用户和角色
2.1.1:创建角色
sql
-- name 指定了要创建的角色名称
CREATE ROLE name;
-- 如果想要显示当前数据库集群中已有的角色
SELECT rolname FROM pg_roles;
-- 或者使用 psql 中的\du 命令
postgres=# \d如果要删除对应的角色可以:
sql
DROP ROLE name;2.1.2:角色属性
角色可以拥有属性,属性确定了角色拥有的特权,并且在登录时与客户端认证系统进行交互
常见的角色属性包括:
- 登录特权,只有具有 LOGIN 属性的角色才能连接数据库。具有 LOGIN 角色的用户可以被看作一个"数据库用户"。使用以下语句创建具有登录特权的角色
sql
-- CREATE USER 默认包含了 LOGIN 选项,而 CREATE ROLE 没有
CREATE ROLE name LOGIN;
CREATE USER name;- 超级用户,数据的超级用户可以避开所有的权限检查,只验证登录权限,最好在日常的操作中避免使用超级用户。使用
以下命令创建一个新的超级用户,只有超级管理员用户才能创建其他的超级用户
sql
-- 创建一个用户,使其具备超级权限,除了登录验证,剩下可以避开所有的权限检查
CREATE ROLE name SUPERUSER;- 创建数据库,只有明确授权的角色才能够创建数据库(超级用户除外,因为他们可以避开权限检查)
sql
-- 创建一个用户,使其具备创建数据库的权限
CREATE ROLE name CREATEDB;- 创建角色,只有明确授权的角色才能够创建其他角色(超级用户除外,因为他们可以避开权限检查),具有 CREATEROLE 特权的角色还可以修改或删除其他角色,以及为这些角色授予或者撤销成员角色。但是,针对超级用户的创建、修改、删除,以及它的成员变更,需要超级用户特权;CREATEROLE 特权无法针对超级用户执行这些操作
sql
-- 创建一个用户,使其具备创建角色的权限
CREATE ROLE name CREATEROLE;- 启动复制,只有明确授权的角色才能够启动流复制(超级用户除外,因为他们可以避开权限检查)。用于流复制的角色还需要拥有 LOGIN 特权
sql
-- 创建一个用户,使其具备启动复制的权限,要求该用户同时又login权限
CREATE ROLE name REPLICATION LOGIN;- 只有当用户连接数据库使用的客户端认证方法要求提供密码时,密码属性才有意义。password 和 md5 认证方法需要使用密码。数据库的密码与操作系统的密码相互独立。
sql
-- 创建一个用户并指定密码
CREATE ROLE name PASSWORD 'string';
-- 还能指定过期时间
CREATE ROLE tony WITH LOGIN PASSWORD 'Pass2022' VALID UNTIL '2025-01-01';🚀 在实践中,最好创建一个拥有 CREATEDB 和 CREATEROLE 特权,但不具有超级用户特权的管理角色,然后使用该角色执行日常的数据库和角色的管理。这种方式可以避免过度使用超级用户可能带来的风险
一个角色被创建之后,可以通过 ALTER ROLE 语句修改它的属性。
sql
-- 以下命令可以撤销角色 admin 创建角色的特权
ALTER ROLE admin NOCREATEROLE;2.1.3:对象授权
PostgreSQL 使 GRANT 语句进行数据库对象的授权操作。
sql
-- 语法
-- privilege_list 权限列表可以是 SELECT、INSERT、UPDATE、DELETE、TRUNCATE等
-- ALL 表示表上的所有权限
GRANT [ privilege_list ] | ALL
ON [ TABLE ] table_name
TO role_name;
-- 举一个例子
-- 为tony用户在employees, departments, jobs三张表上授权,赋予基本的增删改查权限
GRANT SELECT, INSERT, UPDATE, DELETE ON employees, departments, jobs TO tony;还可以指定在哪个schema下
sql
-- ALL TABLES IN SCHEMA 表示某个模式中的所有表,可以方便批量授权操作
GRANT privilege_list | ALL
ON ALL TABLES IN SCHEMA schema_name
TO role_name;也可以在 GRANT 语句的最后指定一个 WITH GRANT OPTION,意味着被授权的角色可以将该权限授权其他角色。表示当前用户不但拥有这些表上的访问权限,还可以将这些权限授予其他角色
2.1.4:撤销授权
与授权操作相反的就是撤销权限,PostgreSQL 使 REVOKE 语句撤销数据库对象上的权限
其中的参数和 GRANT 语句一致
2.1.5:组角色
管理员通常需要管理大量的用户和对象权限。为了便于权限管理,减少复杂度,可以将用户进行分组,然后以组为单位进行权限的授予和撤销操作
具体来说,就是创建一个代表组的角色,然后将该组的成员资格授予其他用户,让其成为该组的成员
sql
-- 先创建一个组角色
-- 组角色通常不具有 LOGIN 特权,也就是不能作为一个用户登录
CREATE ROLE group_name;
-- 使用与对象授权操作相同的 GRANT 和 REVOKE 语句为组添加和删除成员
GRANT group_name TO user_role, ... ;
REVOKE group_name FROM user_role, ... ;
-- 举一个简单的例子
-- 先创建一个组 managers
CREATE ROLE managers;
-- 将用户 tony 添加为组 managers 的成员
GRANT managers TO tony;⚠️ PostgreSQL 不允许设置循环的成员关系,也就是两个角色互相为对方的成员
⚠️ 不能将特殊角色 PUBLIC 设置为任何组的成员
组角色中的成员可以通过以下方式使用该组拥有的特权:
-
首先,组中的成员可以通过 SET ROLE 命令将自己的角色临时性"变成"该组角色。此时,当前数据库会话拥有该组角色的权限,而不是登录用户的权限;并且会话创建的任何数据库对象归组角色所有,而不是登录用户所有。
-
其次,对于具有 INHERIT 属性的角色,将会自动继承它所属的组的全部特权,包括这些组通过继承获得的特权。
sql
-- 使用角色 user1 登录之后,数据库会话将会拥有 user1 自身的特权和 net_admins 所有的特权
-- 因为 net_admins在sys_admins组中,user1又在net_admins组中,并且user1又INHERIT属性,所以能够集成net_admins的属性
-- 但是 net_admins不能集成sys_admin的特权
CREATE ROLE user1 LOGIN INHERIT;
CREATE ROLE net_admins NOINHERIT;
CREATE ROLE sys_admins NOINHERIT;
GRANT net_admins TO user1;
GRANT sys_admins TO net_admins;
-- 如果执行了
SET ROLE net_admins;
-- 会话将会拥有 net_admins 所有的特权,但是不会拥有 user1 自身的特权,也不会继承sys_admins 所有的特权
-- 如果想要恢复
-- 如果想要恢复初始状态的会话特权,可以执行以下任意语句:
SET ROLE user1;
SET ROLE NONE;
RESET ROLE;只有数据库对象上的普通权限可以被继承,角色的 LOGIN、SUPERUSER、CREATEDB 以及 CREATEROLE 属性可以被认为是一些特殊的权限,不会被继承。如果想要使用这些权限,必须使用 SET ROLE 命令设置为具有这些属性的角色
sql
ALTER ROLE net_admins CREATEDB, CREATEROLE;
-- 再使用 user1 连接数据库,会话不会自动具有这些特权,而是需要执行以下命令:
SET ROLE net_admins;2.2:连接数据库
sql
-- 通过 psql 命令行连接
-- -h 后面指定pg主机名或者主机ip
-- -p 指定pg使用的端口
-- -U 登录的用户名
-- -d 要连接的数据
psql -h localhost -p 5432 -U username -d databasename
-- 查看当前连接信息
\conninfo
-- 切换数据库
\c databasename2.3:数据库管理
sql
-- 创建数据库
CREATE DATABASE mydb;
-- 查看所有数据库
SELECT datname FROM pg_database;
-- 修改数据库
ALTER DATABASE mydb RENAME TO newdb;
-- 删除数据库
DROP DATABASE mydb;2.4:模式管理
sql
-- 创建模式
CREATE SCHEMA myschema;
-- 查看所有模式
SELECT schema_name FROM information_schema.schemata;
-- 在模式中创建表
CREATE TABLE myschema.mytable (id INT);
-- 设置搜索路径
SET search_path TO myschema, public;3:数据类型
3.1:数值类型
| 类型 | 说明 |
|---|---|
SMALLINT |
2字节,-32768 到 32767 |
INTEGER |
4字节,-2147483648 到 2147483647 |
BIGINT |
8字节 |
NUMERIC(precision, scale) |
任意精度,如 NUMERIC(10,2) |
DECIMAL(precision, scale) |
同NUMERIC |
REAL |
4字节,6位十进制精度 |
DOUBLE PRECISION |
8字节,15位十进制精度 |
3.2:字符类型
| 类型 | 说明 |
|---|---|
CHAR(n) |
定长,空格填充 |
VARCHAR(n) |
变长,有长度限制 |
TEXT |
变长,无长度限制 |
3.3:日期时间类型
| 类型 | 说明 |
|---|---|
DATE |
日期 |
TIME |
时间 |
TIMESTAMP |
日期和时间 |
TIMESTAMPTZ |
带时区的时间戳 |
INTERVAL |
时间间隔 |
3.4:其他类型
| 类型 | 说明 |
|---|---|
BOOLEAN |
布尔类型,TRUE、FALSE、NULL |
ENUM |
枚举类型,例如:CREATE TYPE mood AS ENUM ('sad', 'ok', 'happy'); |
INT[] / TEXT[][] |
数组类型 |
JSON / JSONB |
存储 JSON 数据 / 二进制 JSON,支持索引 |
UUID |
通用唯一标识符 |
INET / CIDR / MACADDR |
IPv4 或 IPv6 地址 / IPv4 或 IPv6 网络地址 / MAC地址 |
4:表操作
4.1:创建表
sql
-- 基本创建,示例
CREATE TABLE public.employees (
id SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
age INT CHECK (age >= 18), -- age必须 >= 18才能通过校验
salary DECIMAL(10,2),
hire_date DATE DEFAULT CURRENT_DATE,
email VARCHAR(100) UNIQUE,
department_id INT REFERENCES departments(id)
);
-- 创建带约束的表
CREATE TABLE public.products (
product_id SERIAL PRIMARY KEY,
product_name VARCHAR(200) NOT NULL,
price DECIMAL(10,2) CHECK (price > 0),
category VARCHAR(50),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 默认是使用public这个schema
-- 为了避免混淆,强烈建议总是显式指定Schema:
-- 明确指定schema
CREATE TABLE public.employees (...);
CREATE TABLE hr.employees (...);
CREATE TABLE sales.customers (...);
-- 查询时也明确指定
SELECT * FROM hr.employees;
SELECT * FROM sales.customers
JOIN public.departments ON ...约束说明
sql
-- 主键约束
PRIMARY KEY (column1, column2, ...)
-- 外键约束
FOREIGN KEY (column) REFERENCES parent_table(parent_column)
ON DELETE CASCADE
ON UPDATE CASCADE
-- 唯一约束
UNIQUE (column1, column2, ...)
-- 检查约束
CHECK (condition)
-- 非空约束
NOT NULL
-- 默认值
DEFAULT value4.2:修改表
sql
-- 添加列 add column
ALTER TABLE table_name ADD COLUMN column_name [data_type];
-- 删除列 drop column
ALTER TABLE table_name DROP COLUMN column_name;
-- 修改列类型 alter column ... type
ALTER TABLE table_name ALTER COLUMN column_name TYPE new_data_type;
-- 添加约束 add constraint
ALTER TABLE table_name ADD CONSTRAINT constraint_name constraint_definition;
-- 重命名表 rename to
ALTER TABLE table_name RENAME TO new_table_name;
-- 重命名列 rename column ... to ...
ALTER TABLE table_name RENAME COLUMN old_name TO new_name;4.3:删除表
sql
-- 删除表
DROP TABLE table_name;
-- 删除表(如果存在)
DROP TABLE IF EXISTS table_name;
-- 清空表数据
TRUNCATE TABLE table_name;
-- 清空表数据并重置序列
TRUNCATE TABLE table_name RESTART IDENTITY;5:数据操作语言-DML
5.1:数据插入
sql
-- 插入单行
INSERT INTO table_name (column1, column2) VALUES (value1, value2);
-- 插入多行
INSERT INTO table_name (column1, column2)
VALUES
(value1, value2),
(value3, value4),
(value5, value6);
-- 插入查询结果
INSERT INTO table_name (column1, column2)
SELECT column1, column2 FROM another_table WHERE condition;
-- 插入并返回结果
INSERT INTO table_name (column1, column2)
VALUES (value1, value2)
RETURNING *;5.2:数据查询
sql
-- 基本查询
SELECT column1, column2 FROM table_name;
-- 查询所有列
SELECT * FROM table_name;
-- 使用别名
SELECT column1 AS alias1, column2 AS alias2 FROM table_name;
-- 去重
SELECT DISTINCT column1 FROM table_name;
-- 条件查询
SELECT * FROM table_name WHERE condition;
-- 排序
SELECT * FROM table_name ORDER BY column1 ASC, column2 DESC;
-- 限制结果
SELECT * FROM table_name LIMIT 10 OFFSET 20;
-- topN
-- fetch first ?? ROWS ONLY;
SELECT * FROM employees ORDER BY salary DESC FETCH FIRST 10 ROWS ONLY;
-- 聚合函数
-- AVG - 计算一组值的平均值。
-- COUNT - 统计一组值的数量。
-- MAX - 计算一组值的最大值。
-- MIN - 计算一组值的最小值。
-- SUM - 计算一组值的和值。
-- STRING_AGG - 连接一组字符串。
SELECT
COUNT(*) as total,
AVG(column1) as average,
SUM(column2) as sum,
MAX(column3) as maximum,
MIN(column4) as minimum
FROM table_name;
-- 分组
SELECT column1, COUNT(*)
FROM table_name
GROUP BY column1
HAVING COUNT(*) > 1;
-- 子查询
SELECT * FROM table_name
WHERE column1 IN (SELECT column1 FROM another_table);
-- case表达式
CASE expression
WHEN value1 THEN result1
WHEN value2 THEN result2
[...]
[ELSE default_result]
END;
SELECT SUM(CASE department_id WHEN 10 THEN 1 ELSE 0 END) AS dept_10_count,
SUM(CASE department_id WHEN 20 THEN 1 ELSE 0 END) AS dept_20_count,
SUM(CASE department_id WHEN 30 THEN 1 ELSE 0 END) AS dept_30_count
FROM employees;5.3:数据更新
sql
-- 更新所有行
UPDATE table_name SET column1 = value1;
-- 条件更新
UPDATE table_name SET column1 = value1, column2 = value2 WHERE condition;
-- 使用子查询更新
UPDATE table_name
SET column1 = (SELECT value FROM another_table WHERE condition)
WHERE condition;
-- 更新并返回结果
UPDATE table_name SET column1 = value1 WHERE condition RETURNING *;5.4:删除数据
sql
-- 删除所有行
DELETE FROM table_name;
-- 条件删除
DELETE FROM table_name WHERE condition;
-- 使用子查询删除
DELETE FROM table_name
WHERE column1 IN (SELECT column1 FROM another_table WHERE condition);
-- 删除并返回结果
DELETE FROM table_name WHERE condition RETURNING *;5.5:连接查询
INNER JOIN- 95%的情况LEFT JOIN- 4%的情况(找缺失数据)其他情况- 1%的情况
sql
-- 内连接
SELECT *
FROM table1
INNER JOIN table2 ON table1.column = table2.column;
-- 左连接
SELECT *
FROM table1
LEFT JOIN table2 ON table1.column = table2.column;
-- 右连接
SELECT *
FROM table1
RIGHT JOIN table2 ON table1.column = table2.column;
-- 全外连接
SELECT *
FROM table1
FULL OUTER JOIN table2 ON table1.column = table2.column;
-- 交叉连接
SELECT * FROM table1 CROSS JOIN table2;
-- 自连接
SELECT a.column, b.column
FROM table_name a
JOIN table_name b ON a.parent_id = b.id;| 连接方式 | 说明 |
|---|---|
| 内连接 | 只返回两个表都匹配的行 |
| 左外连接 | 返回左表所有行 + 右表匹配的行 |
| 右外连接 | 返回右表所有行 + 左表匹配的行 |
| 全外连接 | 返回两个表的所有行 |
| 交叉连接(了解,很少用) | 两个表的所有可能组合,就是笛卡尔积 |
| 自连接 | 表与自身连接 |
举一个简单的例子就清楚了:
员工表 (employees)
| id | name | department_id |
|---|---|---|
| 1 | 张三 | 101 |
| 2 | 李四 | 102 |
| 3 | 王五 | 101 |
| 4 | 赵六 | 103 |
| 5 | 钱七 | NULL |
部门表(departments)
| id | name |
|---|---|
| 101 | 技术部 |
| 102 | 销售部 |
| 104 | 市场部 |
| 105 | 人事部 |
🚀 如果是内连接
sql
SELECT e.name AS 员工, d.name AS 部门
FROM employees e
INNER JOIN departments d ON e.department_id = d.id;| 员工 | 部门 |
|---|---|
| 张三 | 技术部 |
| 李四 | 销售部 |
| 王五 | 技术部 |
- 只显示有部门的员工
- 只显示有员工的部门
- 赵六(部门103不存在)不显示
- 钱七(无部门)不显示
- 市场部、人事部(无员工)不显示
🚀 如果是左外连接
sql
SELECT e.name AS 员工, d.name AS 部门
FROM employees e
LEFT JOIN departments d ON e.department_id = d.id;| 员工 | 部门 | |
|---|---|---|
| 张三 | 技术部 | |
| 李四 | 销售部 | |
| 王五 | 技术部 | |
| 赵六 | NULL | ← 部门不存在 |
| 钱七 | NULL | ← 无部门 |
- 所有员工都显示,包括没有部门的
- 赵六的部门103在departments表中不存在 → 显示NULL
- 钱七的department_id是NULL → 显示NULL
🚀 如果是右外连接
sql
SELECT e.name AS 员工, d.name AS 部门
FROM employees e
RIGHT JOIN departments d ON e.department_id = d.id;| 员工 | 部门 | |
|---|---|---|
| 张三 | 技术部 | |
| 李四 | 销售部 | |
| 王五 | 技术部 | |
| NULL | 市场部 | ← 无员工 |
| NULL | 人事部 | ← 无员工 |
- 所有部门都显示,包括没有员工的
- 市场部、人事部没有员工 → 显示NULL
🚀 全外连接
sql
SELECT e.name AS 员工, d.name AS 部门
FROM employees e
FULL OUTER JOIN departments d ON e.department_id = d.id;| 员工 | 部门 | |
|---|---|---|
| 张三 | 技术部 | |
| 李四 | 销售部 | |
| 王五 | 技术部 | |
| 赵六 | NULL | ← 只有左表有 |
| 钱七 | NULL | ← 只有左表有 |
| NULL | 市场部 | ← 只有右表有 |
| NULL | 人事部 | ← 只有右表有 |
- 所有数据都显示,不管有没有匹配
- 相当于 LEFT JOIN + RIGHT JOIN
🚀 自连接
sql
-- 假设员工表有manager_id字段
SELECT e1.name AS 员工, e2.name AS 经理
FROM employees e1
LEFT JOIN employees e2 ON e1.manager_id = e2.id;5.6:集合操作
sql
-- 并集
SELECT column1 FROM table1
UNION
SELECT column1 FROM table2;
-- 并集(保留重复)
SELECT column1 FROM table1
UNION ALL
SELECT column1 FROM table2;
-- 交集
SELECT column1 FROM table1
INTERSECT
SELECT column1 FROM table2;
-- 差集
SELECT column1 FROM table1
EXCEPT
SELECT column1 FROM table2;5.7:常用函数
5.7.1:数学函数(了解)
- 算数运算符:
+,-,*,/,%,^,! - 绝对值:
abs(x) - 取整:
ceil(dp)/ceiling(dp)/floor(dp)/round(dp)/round(dp,s)/trunc(dp)/trunc(dp, s) - 乘方和开方:
power(a, b)/sqrt(dp)/cbrt(dp) - 指数和对数:
exp(dp)/ln(dp)/log(dp)/log10(dp)/log(b, x) - 商和余数:
div(y, x)/mod(y, x) - 符号函数:
sign(dp) - 随机数:
random() - 圆周率:
pi() - 三角函数:
sin(dp)/cos(dp)/tan(dp)/asin(dp)/acos(dp)/atan(dp)/atan2(y, x) - 双曲函数:
sinh(dp)/cosh(dp)/tanh(dp) - 度弧度转换:
degrees(dp)/radians(dp) - 最小值/最大值:
least(a, b, ...)/greatest(a, b, ...)
5.7.2:字符串函数(重点看下)
- 连接函数:
concat(str1, str2, ...)/concat_ws(sep, str1, str2, ...)/str1 || str2 - 长度函数:
length(str)/char_length(str)/octet_length(str) - 大小写转换:
lower(str)/upper(str)/initcap(str) - 子串函数:
substring(str from start for count)/substr(str, start, count)/left(str, n)/right(str, n) - 修剪函数:
trim([leading|trailing|both] [chars] from str)/ltrim(str, chars)/rtrim(str, chars)/btrim(str, chars) - 填充函数:
lpad(str, length, fill)/rpad(str, length, fill) - 替换函数:
replace(str, from_str, to_str)/translate(str, from_set, to_set) - 重复函数:
repeat(str, count) - 反转函数:
reverse(str) - 位置函数:
position(substring in str)/strpos(str, substring) - 提取函数:
split_part(str, delimiter, field) - 格式化函数:
format(formatstr, ...)
5.7.3:日期时间函数(了解)
- 当前时间:
current_date/current_time/current_timestamp/now() - 提取部分:
extract(field from timestamp)/date_part(field, timestamp) - 日期运算:
timestamp + interval/timestamp - interval/age(timestamp, timestamp)/age(timestamp) - 截断函数:
date_trunc(field, timestamp) - 格式化:
to_char(timestamp, format)/to_date(text, format)/to_timestamp(text, format) - 时间间隔:
interval 'value' unit/justify_days(interval)/justify_hours(interval)/justify_interval(interval)
5.7.4:条件函数
- 条件判断:
case when condition then result ... else default end - 空值处理:
coalesce(value1, value2, ...)/nullif(value1, value2) - 最大值最小值:
greatest(value1, value2, ...)/least(value1, value2, ...)
5.7.5:类型转换函数
- 类型转换:
cast(value as type)/value::type - 转换函数:
to_char(expression, format)/to_number(text, format)/to_date(text, format)/to_timestamp(text, format)
5.8:通用表表达式CTE
-
提高复杂查询的可读性。CTE 可以将复杂查询模块化,组织成容易理解的结构。
-
支持递归查询。CTE 通过引用自身实现递归,可以方便地处理层次结构数据和图数据。
就是可以提前定义一些代码片段,这些片段可以在后面的SQL中重复使用
sql
-- 基本语法
-- 定义一个通用表达式片段
WITH cte_name AS (
SELECT columns FROM table WHERE conditions
)
-- 这样就能在SQL语句中使用这个片段了
SELECT * FROM cte_name;
-- WITH 表示定义 CTE,因此 CTE 也称为 WITH 查询;
-- cte_name 指定了 CTE 的名称,后面是可选的字段名;
-- 括号内是 CTE 的内容,可以是 SELECT 语句,也可以是 INSERT、UPDATE、DELETE语句;
-- sql_statement 是主查询语句,可以引用前面定义的 CTE。该语句同样可以是 SELECT、INSERT、UPDATE 或者 DELETE。
WITH department_avg(department_id, avg_salary) AS (
SELECT department_id,
AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
)
SELECT d.department_name, da.avg_salary
FROM departments d JOIN department_avg da
ON (d.department_id = da.department_id)
ORDER BY d.department_name;递归 CTE 允许在它的定义中进行自引用,理论上来说可以实现任何复杂的计算功能,最常用的场景就是遍历层次结构的数据和图结构数据。
sql
-- RECURSIVE 表示递归;
-- cte_query_initial 是初始化查询,用于创建初始结果集;
-- cte_query_iterative 是递归部分,可以引用 cte_name;
-- 如果递归查询无法从上一次迭代中返回更多的数据,将会终止递归并返回结果
WITH RECURSIVE cte_name AS(
cte_query_initial -- 初始化部分
UNION [ALL]
cte_query_iterative -- 递归部分
) SELECT * FROM cte_name;
WITH RECURSIVE employee_path (employee_id, employee_name, path) AS
(
-- 初始化部分,递归出口
-- 当manager_id == null的时候,返回employee_id, 拼接好的用户名,拼接好的用户名作为path
SELECT employee_id, CONCAT(first_name, ',', last_name), CONCAT(first_name, ',', last_name) AS path
FROM employees
WHERE manager_id IS NULL
UNION ALL
-- 递归部分
-- 注意from a join a on id = id, 自连接
-- 然后注意path是上一个的path(from表)中的,拼接商当前的用户名(join表上的)
SELECT e.employee_id, CONCAT(e.first_name, ',', e.last_name), CONCAT(ep.path, '->', e.first_name, ',', e.last_name)
FROM employee_path ep
JOIN employees e ON ep.employee_id = e.manager_id
)
SELECT employee_name, path FROM employee_path ORDER BY employee_id;除了 SELECT 语句之外,INSERT、UPDATE 或者 DELETE 语句也可以与 CTE 一起使用
如果在 CTE 中使用 DML 语句,我们可以将数据修改操作影响的结果作为一个临时表,然后在其他语句中使用
sql
-- 复制表的一种骚操作,只复制表结构不复制数据
CREATE TABLE employees_history AS SELECT * FROM employees WHERE 1 = 0;
-- 创建一个cte, 将数据修改操作影响的结果作为一个临时表
WITH deletes AS (
DELETE FROM employees
WHERE employee_id = 206
RETURNING *
)
-- 使用cte
INSERT INTO employees_history SELECT * FROM DELETEs;5.9:窗口函数
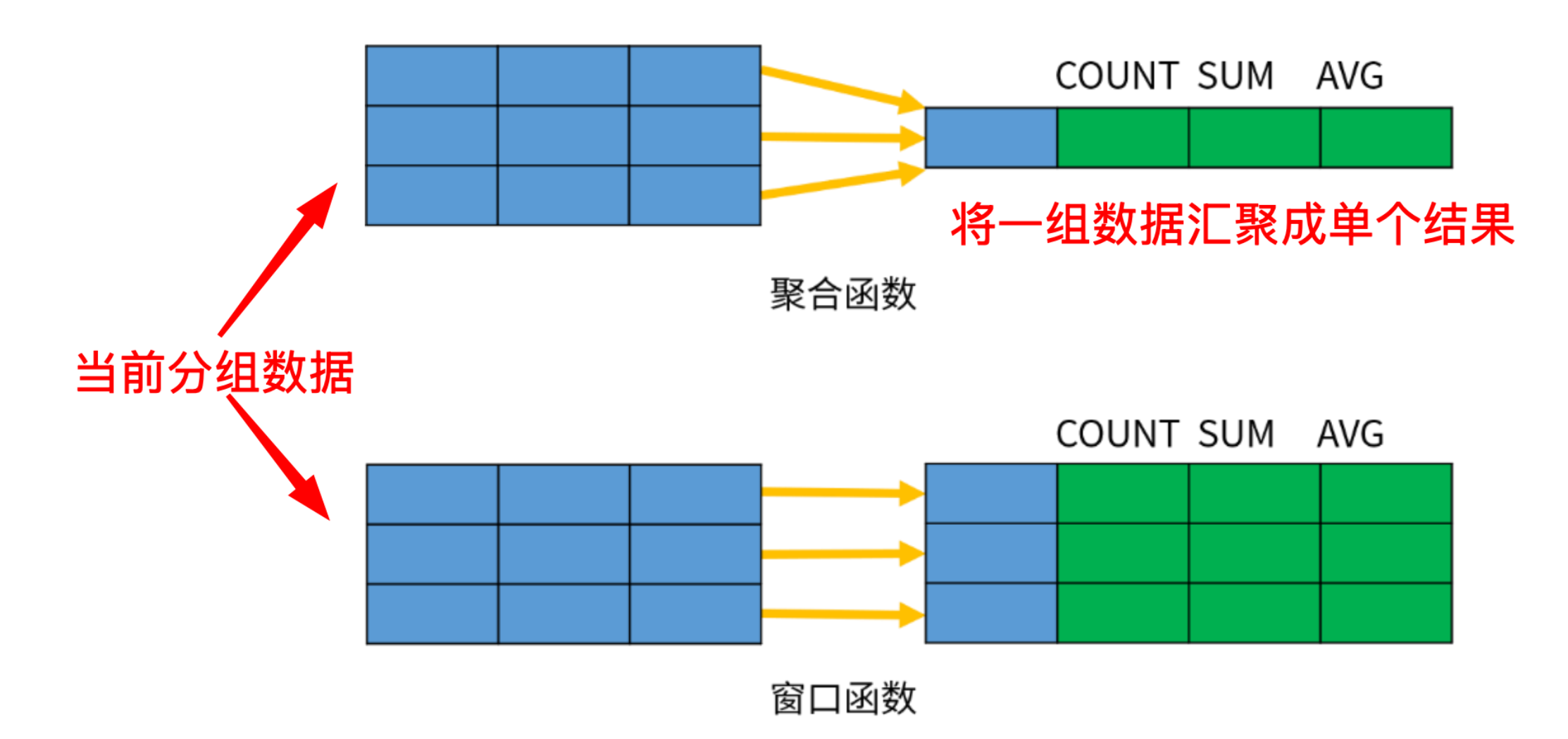
除了聚合函数之外,SQL 还定义了许多专门用于数据分析的窗口函数(Window Function)。不过,窗口函数不是将一组数据汇总为单个结果,而是针对每一行数据,基于和它相关的一组数据计算出一个结果。下图演示了聚合函数和窗口函数的区别:
sql
------- 举一个简单的例子就知道了 ----------
SELECT AVG(salary), COUNT(*), SUM(salary) FROM employees;
-------------avg---- |count|-- sum --|
---------------------|-----|---------|
6461.8317757009345794| 107 |691416.00|
SELECT
employee_id,
first_name,
last_name,
AVG(salary) OVER (),
COUNT(*) OVER (),
SUM(salary) OVER ()
FROM employees;
employee_id| first_name | last_name | avg | count | sum |
-----------|------------|-----------|---------------------|-------|---------|
100 | Steven | King |6461.8317757009345794| 107 |691416.00|
101 | Neena | Kochhar |6461.8317757009345794| 107 |691416.00|
102 | Lex | De Haan |6461.8317757009345794| 107 |691416.00|聚合函数通常也可以作为窗口函数,区别在于后者包含了 OVER 关键字;空括号表示将所有数据作为整体进行分析,所以得到的数值和聚合函数一样。显然,窗口函数为每一个员工都返回了一个结果
5.9.1:定义窗口函数
sql
window_function ( expression, ... ) OVER (
PARTITION BY ... -- 定义分区
ORDER BY ... -- 声明排序
frame_clause -- 窗口大小
)5.9.2:分区选项 PARTITION BY
作用类似于 GROUP BY 的分组。如果指定了分区选项,窗口函数将会分别针对每个分区单独进行分析
如果没有指定分区,所有的数据作为一个整体进行分析,就像上面的例子
sql
SELECT
first_name,
last_name,
department_id,
salary,
AVG(salary) OVER (PARTITION BY department_id) -- 指定按照部门分区
FROM employees
ORDER BY department_id;5.9.3:排序选项 ORDER BY
ORDER BY 选项用于指定分区内的排序方式,通常用于数据的排名分析
说到排名分析,先介绍下排名窗口函数
| 窗口函数 | 功能描述 |
|---|---|
| ROW_NUMBER | 为分区中的每行数据分配一个序列号,序列号从 1 开始分配。 |
| RANK | 计算每行数据在其分区中的名次;如果存在名次相同的数据,后续的排名将会产生跳跃。 |
| DENSE_RANK | 计算每行数据在其分区中的名次;即使存在名次相同的数据,后续的排名也是连续的值。 |
| PERCENT_RANK | 以百分比的形式显示每行数据在其分区中的名次;如果存在名次相同的数据,后续的排名将会产生跳跃。 |
| CUME_DIST | 计算每行数据在其分区内的累积分布,也就是该行数据及其之前的数据的比率;取值范围大于 0 并且小于等于 1。 |
| NTILE | 将分区内的数据分为 N 等份,为每行数据计算其所在的位置。 |
最常用的就是rank其他的都不常用
sql
SELECT
first_name,
last_name,
department_id,
hire_date,
-- 根据部门分区,然后根据hire_date排名
RANK() OVER (PARTITION BY department_id ORDER BY hire_date)
FROM employees
ORDER BY department_id;
first_name |last_name |department_id|hire_date |rank|
-----------|----------|-------------|----------|----|
Jennifer |Whalen | 10 |2003-09-17| 1 |
Michael |Hartstein | 20 |2004-02-17| 1 |
Pat |Fay | 20 |2005-08-17| 2 |
Den |Raphaely | 30 |2002-12-07| 1 |
Alexander |Khoo | 30 |2003-05-18| 2 |
Sigal |Tobias | 30 |2005-07-24| 3 |5.9.4:窗口选项 frame_clause
frame_clause 选项用于在当前分区内指定一个计算窗口。指定了窗口之后,分析函数不再基于分区进行计算,而是基于窗口内的数据进行计算
sql
-- 计算每个产品当当前月份的累计销量
SELECT
product AS "产品",
ym "年月",
amount "销量",
SUM(amount) OVER (
-- 按照产品分区
PARTITION BY product
-- 根据年月排序
ORDER BY ym
-- 指定窗口从当前分区的第一行开始到当前行结束
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
FROM sales_monthly
ORDER BY product, ym;具体来说,窗口大小的常用选项如下:
sql
{ ROWS | RANGE } frame_start
{ ROWS | RANGE } BETWEEN frame_start AND frame_end其中,ROWS 表示以行为单位计算窗口的偏移量,RANGE 表示以数值(例如 30 分钟)为单位计算窗口的偏移量。
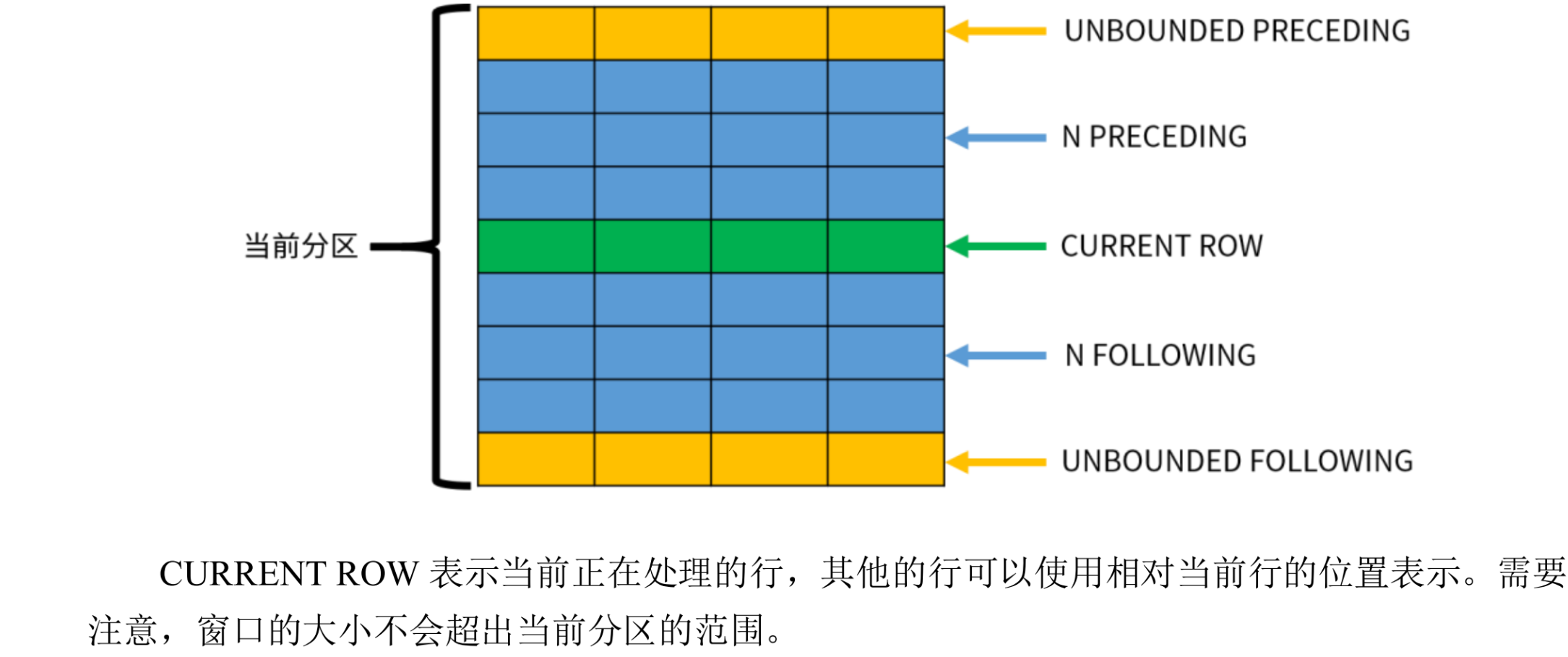
frame_start 用于定义窗口的起始位置,可以指定以下内容之一:
-
UNBOUNDED PRECEDING,窗口从分区的第一行开始,默认值; -
N PRECEDING,窗口从当前行之前的第 N 行或者数值开始; -
CURRENT ROW,窗口从当前行开始。
frame_end 用于定义窗口的结束位置,可以指定以下内容之一:
-
CURRENT ROW,窗口到当前行结束,默认值; -
N FOLLOWING,窗口到当前行之后的第 N 行或者数值结束; -
UNBOUNDED FOLLOWING,窗口到分区的最后一行结束。
6:备份和恢复
备份(backup)是通过某种方式(物理复制或者逻辑导出)将数据库的文件或结构和数据拷贝到其他位置进行存储。
还原(restore)是一种不完全的恢复,使用备份的文件将数据库恢复到执行备份时的状态。备份时间点之后的数据变更无法通过还原进行恢复。
恢复(recovery)通常是先使用物理备份文件进行还原,然后再应用备份时间点到故障点之间的日志文件(WAL),将数据库恢复到最新状态
6.1:备份分类
根据备份的方式和内容的不同,可以进行以下分类。
物理备份与逻辑备份
-
物理备份(Physical Backup)就是直接复制数据库相关的文件。通常来说,物理备份比逻辑备份更快,但是占用的空间也更大。PostgreSQL 支持在线和离线的物理备份。实际环境中应该以物理备份为主。
-
逻辑备份(Logical Backup)就是将数据库的结构和数据导出为 SQL 文件,还原时通过文件中的 SQL 语句和命令重建数据库并恢复数据。逻辑备份通常需要更多的备份和还原时间。逻辑备份可以作为物理备份的补充,或者用于测试目的的数据导入导出。
在线备份与离线备份
-
在线备份(Online Backup)是指 PostgreSQL 服务器处于启动状态时的备份,也称为热备份(Hot Backup)。由于逻辑备份需要连接到数据库进行操作,因此逻辑备份只能是在线备份。
-
离线备份(Offline Backup)是指 PostgreSQL 服务器处于关闭状态时的备份,也称为冷备份(Cold Backup)。离线状态只能执行数据库的物理备份,即复制数据库文件。
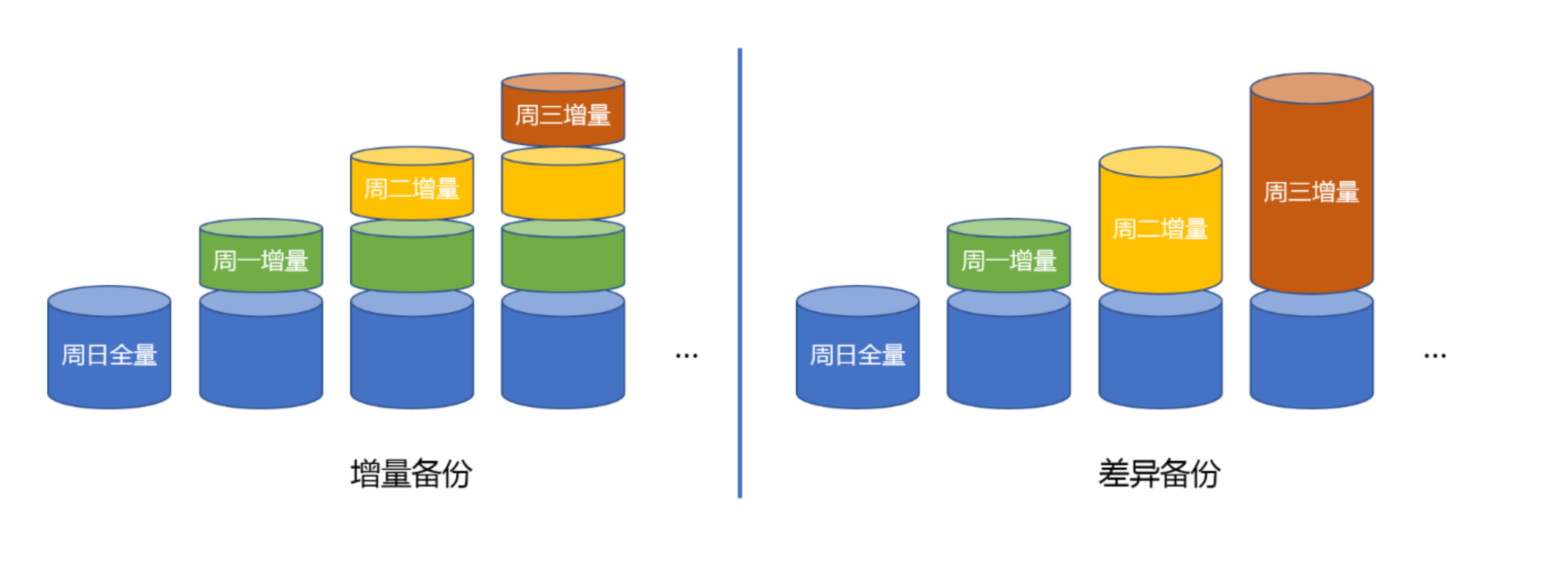
全量备份与增量备份
- 全量备份(Full Backup)就是备份所有的数据库文件,执行一次完整的 PostgreSQL 数据库集群备份。这种方式需要备份的内容较多,备份时较慢,但是恢复速度更快。
- 增量备份(Incremental Backup)就是备份上一次备份(任何类型)之后改变的文件。增量备份每次备份的数据量较小,但是恢复时需要基于全量备份,并依次恢复增量部分,时间较长。在 PostgreSQL 中通过一个基准备份(Base Backup),加上不断备份的事务日志文件(WAL)来达到增量备份的效果
- 差异备份(Differential Backup)是针对上一次完全备份后发生变化的所有文件进行备份。差异备份位于两者之间。
6.2:备份
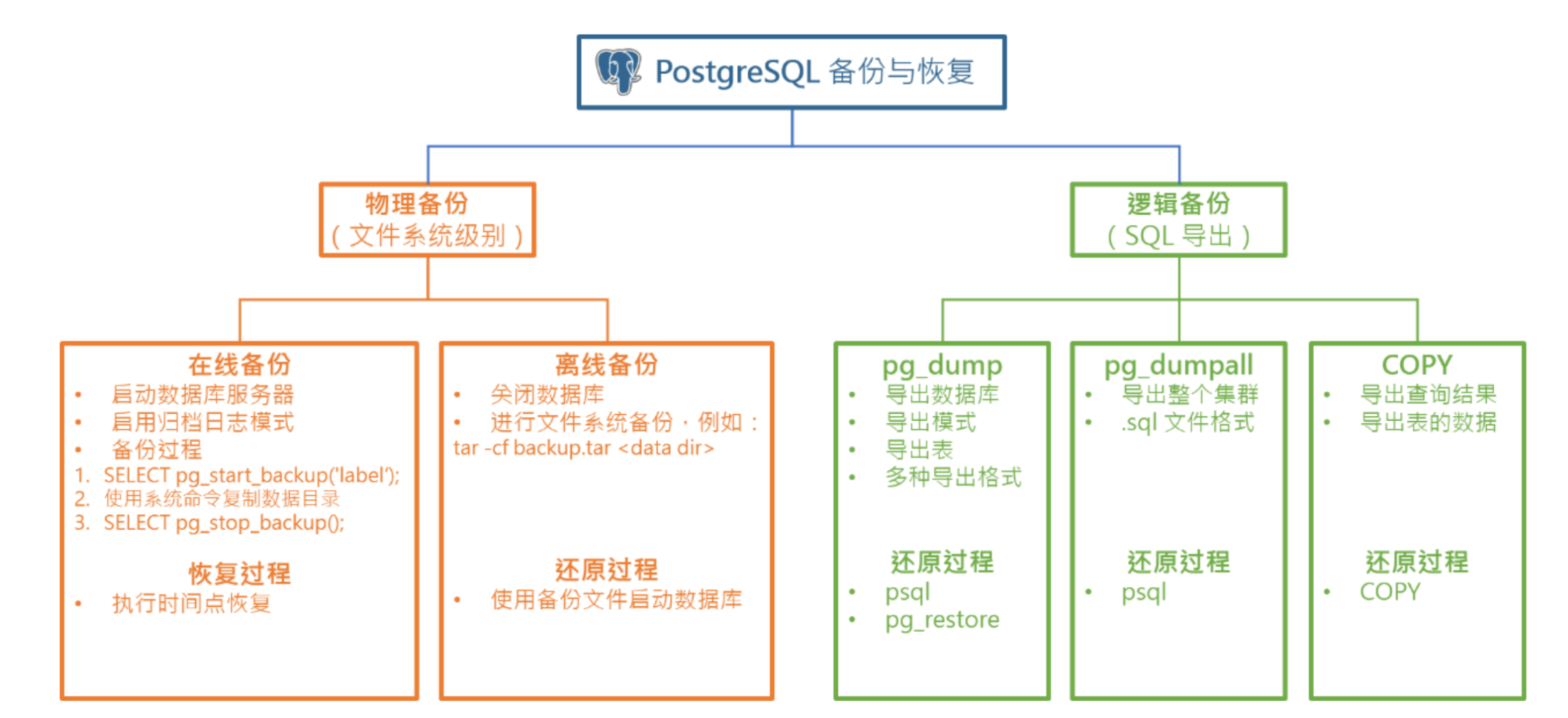
6.2.1:逻辑备份
执行逻辑备份时,PostgreSQL 服务器必须已经启动,备份工具(例如 pg_dump)通过建立数据库连接,从数据库中查询出相应的结构信息和数据,并生成备份文件
shell
# 备份单个数据库
pg_dump -U username -d dbname -f backup.sql
# 备份所有数据库(包括全局对象)
pg_dumpall -U username -f alldb.sql
# 压缩备份
pg_dump -U username dbname | gzip > backup.gz
# 并行备份(大数据库)
pg_dump -U username -j 4 -F d -f backup_dir dbname
# 逻辑恢复
psql -U username -d dbname -f backup.sql
# 恢复整个集群
psql -f alldb.sql6.2.2:物理备份
PostgreSQL 对于数据的修改,都会写入一个称为预写式日志(WAL)的文件中,该文件位于数据目录的 pg_wal(pg_xlog)子目录中。当系统出现故障需要恢复时,可以通过重做最后一次检查点(checkpoint)以来的 WAL 日志执行数据库的恢复
基于这个机制,我们可以先创建一个文件级别的完全备份,然后不断备份生成的 WAL 文件,达到增量备份的效果。这些备份操作都可以在线执行,因此对于无法接受停机的业务系统至关重要
预写式日志(Write-Ahead Logging)是实现可靠性和数据完整性的标准方法,同时还能减少磁盘 IO 的操作,提高数据库的性能(mysql也是这样)
归档日志模式
对于在线备份而言,数据库集群处于运行状态,而且必须使用归档日志模式(Archive Log)运行,这样才能不断备份(归档)生成的 WAL 日志文件。因此,我们首先来设置 WAL 归档
启用 PostgreSQL 的 WAL 归档需要在 postgresql.conf 文件中配置三个参数:
wal_level,决定写入 WAL 的信息量。要设置成为replicaarchive_mode,是否启动日志归档。默认值为 off。要设置为on。archive_command,执行日志归档操作的脚本命令。例如操作系统的 cp 命令。
python
# postgresql.conf配置
wal_level = replica
archive_mode = on
# %p 代表要归档的日志文件路径名称(相对于当前工作目录,即数据目录的文件名)
# %f 代表要归档的日志文件名(不包含路径)。
archive_command = 'cp %p /path/to/archive/%f'文件系统级备份
sql
# 需要先停止或进入备份模式
SELECT pg_start_backup('backup_label');
# 复制数据目录
SELECT pg_stop_backup();7:事务和并发
7.1:事务语法
sql
-- 事务示例
BEGIN; -- 开始事务
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
COMMIT; -- 提交事务7.2:事务ACID的实现原理
PostgreSQL通过WAL保证原子性和持久性,通过MVCC实现隔离性,三者共同保证一致性
预写日志 - WAL
WAL段文件结构:
段文件大小默认16MB,命名:0000000100000001000000DE
分段:
+----------------+----------------+----------------+
| 页头(8192字节) | WAL记录1 | WAL记录2 |
+----------------+----------------+----------------+
WAL记录结构:
+------------+------------+------------+------------+------------+
| 记录头 | 记录长度 | 事务ID | 资源管理器 | 数据负载 |
+------------+------------+------------+------------+------------+
(84位) (32位) (32位) (32位) (可变长)预写日志(Write-Ahead Logging)核心思想:
- 先日志,后数据:所有数据修改必须先记录到日志中,再写入数据文件
- 故障恢复基础:系统崩溃后,通过重放日志恢复数据一致性
- 原子性保证:确保事务要么完全应用,要么完全不应用
8:索引和优化
无索引查询:全表扫描(Sequential Scan) → 逐行读取 → 性能随数据量线性下降
有索引查询:索引查找 → 获取行指针 → 直接定位数据 → 性能对数级提升
可以通过如下的sql查看索引的信息和索引的使用统计
sql
-- 查看索引信息
SELECT
schemaname,
tablename,
indexname,
indexdef
FROM pg_indexes
WHERE tablename = 'your_table';
-- 查看索引使用统计
SELECT
schemaname,
relname AS tablename,
indexrelname AS indexname,
idx_scan, -- 索引扫描次数
idx_tup_read, -- 通过索引读取的行数
idx_tup_fetch -- 通过索引获取的行数
FROM pg_stat_user_indexes;通用创建索引语法
sql
-- index_name 是索引的名称,table_name 是表的名称;
-- method 表示索引的类型,例如 btree、hash、gist、spgist、gin 或者 brin。默认为 btree;
-- column_name 是字段名,ASC 表示升序排序(默认值),DESC 表示降序索引;
-- NULLS FIRST 和 NULLS LAST 表示索引中空值的排列顺序,升序索引时默认为 NULLS LAST,降序索引时默认为 NULLS FIRST。
CREATE INDEX index_name ON table_name
[USING method]
(column_name [ASC | DESC] [NULLS FIRST | NULLS LAST])删除索引
sql
DROP INDEX index_name [ CASCADE | RESTRICT ];8.1:索引的类型
PostgreSQL 提高了多种索引类型:B-树、哈希、GiST、SP-GiST、GIN 以及 BRIN 索引。每
种索引基于不同的存储结构和算法,用于优化不同类型的查询。默认情况下,PostgreSQL 创建
B-树索引,因为它适合大部分情况下的查询。
B-tree 索引(默认索引)
适用于:等值查询、范围查询、排序、唯一约束
sql
-- 适用范围
-- 支持的操作符:=, <, <=, >, >=, BETWEEN, IN, IS NULL, IS NOT NULL
-- 支持模式匹配:LIKE 'prefix%' (前导通配符)
-- 不支持:LIKE '%suffix' (后导通配符)
-- 创建B-tree索引
CREATE INDEX idx_users_email ON users USING btree (email);
-- 复合B-tree索引(注意顺序!)
CREATE INDEX idx_users_name ON users (last_name, first_name);
-- 能加速的查询:
-- 1. WHERE last_name = 'Smith' AND first_name = 'John'
-- 2. WHERE last_name = 'Smith'
-- 3. WHERE last_name LIKE 'Sm%'
-- 4. ORDER BY last_name, first_name
-- 无法加速的查询:
-- WHERE first_name = 'John' (没有以first_name开头的查询)
-- col1 上的索引不仅能够优化查询条件,也可以避免额外的排序操作;
SELECT col1, col2
FROM t
WHERE col1 BETWEEN 100 AND 200
ORDER BY col1;hash排序
适用于:精确等值查询,不关心排序
sql
-- 创建Hash索引
CREATE INDEX idx_users_id_hash ON users USING hash (id);
-- Hash索引特点:
-- 1. 只支持等值比较 (=)
-- 2. 不支持范围查询、排序
-- 3. 内存占用较大
-- 4. 事务安全(PostgreSQL 10+)gist(通用搜索树)索引
适用于:地理数据、全文搜索、区间查询、层次结构
sql
-- 地理空间数据
CREATE INDEX idx_geom_gist ON locations USING gist (geom);
-- 范围类型
CREATE INDEX idx_booking_dates
ON bookings
USING gist (reservation_dates);
-- 支持的操作符(示例):
-- && (重叠), @> (包含), <@ (被包含), ~= (相同)
-- <-> (距离), <#> (边界框距离)
-- 全文搜索(tsvector)
CREATE INDEX idx_document_content
ON documents
USING gist (to_tsvector('english', content));
-- 该语句用于查找距离某个目标地点最近的 10 个地方。
SELECT *
FROM places
ORDER BY location <-> point '(101,456)'
LIMIT 10;gin 广义倒排索引
适用于:数组、JSON/JSONB、全文搜索、多值列
sql
-- JSONB索引(最常用)
CREATE INDEX idx_users_profile ON users USING gin (profile);
-- 数组索引
CREATE INDEX idx_product_tags ON products USING gin (tags);
-- 全文搜索
CREATE INDEX idx_articles_content
ON articles
USING gin (to_tsvector('english', body));
-- 加速查询示例:
SELECT * FROM users
WHERE profile @> '{"city": "New York", "age": {"$gt": 25}}';
SELECT * FROM products
WHERE tags @> ARRAY['electronics', 'sale'];SP-GiST(空间分区GiST)索引
适用于:非平衡数据结构(IP地址、几何数据、文本)
与 GiST 类似,SP-GiST 也支持"最近邻"搜索
sql
-- IP地址范围
CREATE INDEX idx_ip_range ON network_logs USING spgist (ip_range);
-- 点数据
CREATE INDEX idx_points ON points USING spgist (location);
-- 支持的数据类型:point, box, circle, inet, text (前缀匹配)BRIN 块范围索引
适用于:按物理顺序存储的大型表(时间序列、日志数据)
sql
-- 时间序列数据
CREATE INDEX idx_logs_timestamp ON logs USING brin (created_at);
-- 可指定页面范围大小
CREATE INDEX idx_sensor_data ON sensor_readings USING brin (timestamp, value)
WITH (pages_per_range = 128);
-- BRIN优势:
-- 1. 索引大小极小(通常只有几MB)
-- 2. 创建速度快
-- 3. 维护成本低
-- BRIN劣势:
-- 1. 查询性能不如B-tree
-- 2. 数据必须按索引列物理排序存储
-- 3. 更新频繁的表效果差8.2:高级索引
部分索引:只索引部分行,减少索引大小
sql
-- 只索引活跃用户
CREATE INDEX idx_active_users ON users (email) WHERE active = true;
-- 只索引特定范围的数据
CREATE INDEX idx_recent_orders ON orders (order_date)
WHERE order_date > CURRENT_DATE - INTERVAL '30 days';
-- 只索引非空值
CREATE INDEX idx_not_null_phone ON customers (phone) WHERE phone IS NOT NULL;
-- 性能提升场景:
-- 查询活跃用户:SELECT * FROM users WHERE active = true AND email = '...';表达式索引:对函数计算结果进行索引
sql
-- 大小写不敏感搜索
CREATE INDEX idx_users_lower_email ON users (LOWER(email));
-- 日期部分索引
CREATE INDEX idx_orders_year ON orders (EXTRACT(YEAR FROM order_date));
-- JSON字段索引
CREATE INDEX idx_users_city ON users ((profile->>'city'));
-- 使用索引的查询:
SELECT * FROM users WHERE LOWER(email) = 'user@example.com';
SELECT * FROM orders WHERE EXTRACT(YEAR FROM order_date) = 2024;包含列索引:创建覆盖索引,避免回表
sql
-- PostgreSQL 11+
CREATE INDEX idx_orders_customer ON orders (customer_id)
INCLUDE (order_date, total_amount);
-- 查询可以直接从索引获取数据
-- 覆盖查询:SELECT customer_id, order_date, total_amount FROM orders WHERE customer_id = 100;
-- 优点:
-- 1. 索引叶子节点包含额外列
-- 2. 支持仅索引扫描(Index Only Scan)
-- 3. 不会影响索引排序(INCLUDE列不参与排序)多列索引策略
sql
-- 策略1:等值列在前,范围列在后
CREATE INDEX idx_users_status_date ON users (status, created_at);
-- WHERE status = 'active' AND created_at > '2024-01-01'
-- 策略2:区分度高的列在前
CREATE INDEX idx_users_country_city ON users (country, city);
-- 先按国家过滤(区分度高),再按城市
-- 策略3:考虑排序需求
CREATE INDEX idx_products_category_price ON products (category_id, price DESC);
-- ORDER BY category_id, price DESC
-- 多列索引的最左前缀原则
CREATE INDEX idx_abc ON table (a, b, c);
-- 可加速:WHERE a = ?, WHERE a = ? AND b = ?, WHERE a = ? AND b = ? AND c = ?
-- 无法加速:WHERE b = ?, WHERE c = ?, WHERE b = ? AND c = ?8.3:最佳实践和陷阱清单
索引设计的常见陷阱如下:
sql
-- 陷阱1:过多的索引(写性能下降)
-- 每个INSERT/UPDATE/DELETE需要更新所有相关索引
-- 陷阱2:不必要的索引
-- 区分度低的列(如:性别、状态字段)
-- 陷阱3:索引列顺序错误
-- 范围查询列放在复合索引最前面
-- 陷阱4:函数索引但查询未使用相同函数
CREATE INDEX idx_lower_email ON users (LOWER(email));
-- 错误:SELECT * FROM users WHERE email = 'TEST@EXAMPLE.COM';
-- 正确:SELECT * FROM users WHERE LOWER(email) = 'test@example.com';
-- 陷阱5:未维护的统计信息
-- 定期运行:ANALYZE table_name;最佳实践清单
text
索引策略选择:
B-tree:等值/范围查询、排序
Hash:精确等值查询(PostgreSQL 10+)
GiST:地理数据、全文搜索、范围类型
GIN:JSONB、数组、全文搜索
SP-GiST:IP地址、非平衡结构
BRIN:时间序列、物理排序的大表
索引设计原则
为WHERE、JOIN、ORDER BY、GROUP BY中的列创建索引
复合索引遵循最左前缀原则
区分度高的列放在复合索引前面
为外键列创建索引(避免锁问题)
定期监控和清理未使用的索引
性能优化建议
使用EXPLAIN ANALYZE分析查询计划
对于大表,使用CREATE INDEX CONCURRENTLY
考虑使用部分索引减少索引大小
对于只读查询,使用覆盖索引
定期REINDEX修复索引膨胀监控命令汇总
sql
-- 索引大小和使用情况
\di+ -- psql命令查看索引
-- 查询pg_stat视图
SELECT * FROM pg_stat_user_indexes;
SELECT * FROM pg_statio_user_indexes;
-- 索引膨胀检查
SELECT * FROM pgstatindex('index_name');
-- 使用pg_qualstats识别缺失索引
CREATE EXTENSION pg_qualstats;
SELECT * FROM pg_qualstats;9:视图
视图(View)本质上是一个存储在数据库中的查询语句。视图本身不包含数据,也被称为虚拟表。
9.1:创建视图
我们在创建视图时给它指定了一个名称,然后可以像表一样对其进行查询
sql
CREATE VIEW view_name AS query;视图通常创建的是多表查询的虚拟表,这样在后续使用多表查询的时候,直接使用视图就可以了,不用每次写一大串连接查询语句,例如:
sql
CREATE VIEW emp_details_view -- 创建一个视图名称是emp_details_view
AS SELECT -- 视图的数据构成
e.employee_id,
e.job_id,
e.manager_id,
e.department_id,
d.location_id,
e.first_name,
e.last_name,
e.salary,
e.commission_pct,
d.department_name,
j.job_title
FROM employees e
JOIN departments d ON (e.department_id = d.department_id)
JOIN jobs j ON (j.job_id = e.job_id); -- 三表联查
-- 们可以直接从视图中查询数据,不需要每次编写复杂的连接查询:
-- 该语句返回了 IT 部门的员工信息。
SELECT * FROM emp_details_view WHERE department_name = 'IT';9.2:修改视图
sql
CREATE OR REPLACE VIEW view_name AS query⚠️ PostgreSQL 目前只支持追加视图定义中的字段,不支持减少字段或者修改字段的名称或顺序。
PostgreSQL 还提供了 ALTER VIEW 语句修改视图的属性:
sql
ALTER VIEW emp_details_view RENAME TO emp_info_view9.3:删除视图
sql
-- CASCADE 表示级联删除依赖于该视图的对象;
-- RESTRICT 表示如果存在依赖对象则提示错误信息
DROP VIEW [ IF EXISTS ] name [ CASCADE | RESTRICT ]