1.线程基础
1.1线程概念
进程: 运行起来的程序->进程=内核数据结构+代码和数据->操作系统视角下:承担分配系统资源的基本实体。
**线程:**线程是进程内部的执行分支;Linux"线程"在进程内部运行,本质是在进程的地址空间内运行!
以前学习的进程是只有一个线程的进程;既进程内部只有一个执行分支。
进程:多个线程+地址空间+页表+代码和数据
进程内部会同时存在一个或多个线程。
1.2线程原理
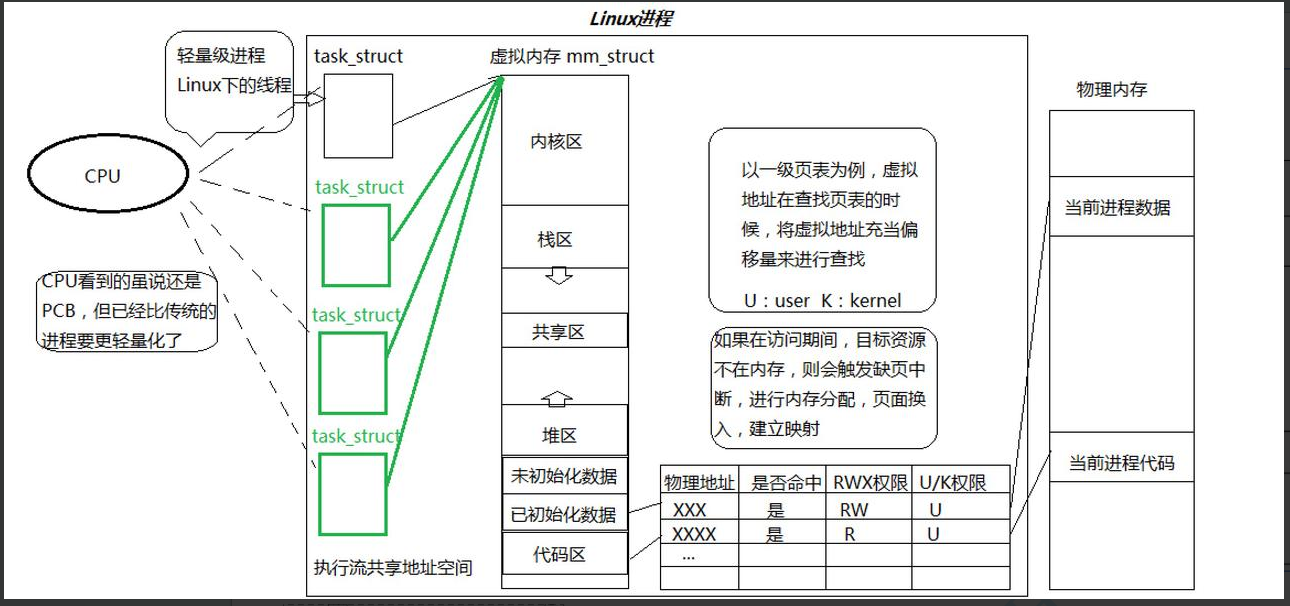
- 只创建PCB,并且该PCB只执行代码的一部分。
- 一份代码有多个main函数,创建多个PCB指向同一个虚拟地址空间,每一个PCB从各自的main函数开始执行。
- 这样的一个PCB执行流被称为一个线程。
- 线程属于操作系统调度的基本单位。
- 创建一个进程,就要预先申请一大批的资源,再将这些资源分配给各个线程。
- 所以进程是"承担分配系统资源的基本实体"。
1.2.1管理线程
线程内核数据结构:TCB(线程控制块)
- 在OS中,单独为线程设计TCB,将TCB套入PCB的工作流程,按照这种方法设计的操作系统就是windows
- linux复用进程相关数据结构,PCB,将代码分成很多份,平分给每一个线程,数据都从进程来,把进程想象成一个容器,在进程内部包含很多个执行流,这样就不用单独设计调度算法,运行队列等等。
- linux用"进程"内核结构模拟实现线程效果。
- cpu在选择线程执行时,就不需要关心TCB还是PCB,所以在cpu视角没有进程,只有线程,
- 线程有自己的优先级,pid,自己的虚拟地址空间,只不过这个虚拟地址空间是和其他线程公用的,和进程没什么区别。
- cpu执行线程的执行力度是小于进程的。
Linux执行流:执行流==轻量级进程;进程==一个或多个轻量级进程+其他资源
1.2.2创建线程

- 参数1:输出型参数,输出线程的tid。
- 参数2:线程的属性
- 参数3:返回值为void*,参数为void*的函数指针,回调函数,新线程会执行的代码。
- 参数4:给线程传递的参数。
- 这个函数并不属于系统调用,而是linux系统下的pthread库,所以在编译代码时,需要" -l "告诉系统要链接哪一个库。
cpp
thread:thread.cc
g++ -o thread thread.cc -lpthread
.PHONY: clean
clean:
rm -f thread
#include<iostream>
#include<unistd.h>
#include<pthread.h>
void* threadrun(void* arg)
{
while(true)
{
std::cout<<"new thread is running pid"<<getpid()<<std::endl;
sleep(1);
}
}
int main()
{
pthread_t tid;
pthread_create(&tid,nullptr,threadrun,nullptr);
while(true)
{
std::cout<<"main thread is running pid"<<getpid()<<std::endl;
sleep(1);
}
}
- 可以看到两个线程的pid相同,属于一个进程
- ps -aL查看系统中的轻量级进程

- 其中LWP为轻量级进程的编号,LWP和PID的值相等的是主线程。
- OS区分执行流是通过LWP进行区分的。
如何杀掉有两个执行流的线程呢?

只需要把进程杀掉即可
pthread库
在linux内核中确实没有明确意义上的线程,只存在轻量级进程,但是现在的用户都指认进程和线程两个概念,所以linux为了能够让更多的用户来使用linux系统,Linux在用户和内核之间创建了一个软件层-----thread库
thread库使用轻量级进程封装出线程库,叫用户级线程库。
thread库对上(用户)提供管理线程的接口,对下(内核)还是轻量级进程
thread库属于第三方库,在编译时要带上 -lpthread,但这个库在linux系统中自带的,有叫原生线程库。
1.3再谈虚拟地址空间和页表本质认识
1.3.1操作系统是如何对内存进行管理的
- 操作系统会将物理内存划分成一个个的数据块(4kb)
- 内存和磁盘数据交换,在文件系统角度基本单位是4kb
- 我们把物理内存中一个个的4kb数据块叫做页框或页帧
操作系统对页框的管理
页框在内核中也有自己的内核数据结构:struct page{}
- 因为内存中的数据块比较多,所以内核数据结构就多,如果结构体太大就会浪费太多的内存空间。
- 所以结构体内部更多的是标志位(位图)
cpp
struct page {
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
atomic_t _count; /* Usage count, see below. */
atomic_t _mapcount; /* Count of ptes mapped in mms,
* to show when page is mapped
* & limit reverse map searches.
*/
union {
struct {
unsigned long private; /* Mapping-private opaque data:
* usually used for buffer_heads
* if PagePrivate set; used for
* swp_entry_t if PageSwapCache;
* indicates order in the buddy
* system if PG_buddy is set.
*/
struct address_space *mapping; /* If low bit clear, points to
* inode address_space, or NULL.
* If page mapped as anonymous
* memory, low bit is set, and
* it points to anon_vma object:
* see PAGE_MAPPING_ANON below.
*/
};
#if NR_CPUS >= CONFIG_SPLIT_PTLOCK_CPUS
spinlock_t ptl;
#endif
};
pgoff_t index; /* Our offset within mapping. */
struct list_head lru; /* Pageout list, eg. active_list
* protected by zone->lru_lock !
*/
/*
* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
* Note that this field could be 16 bits on x86 ... ;)
*
* Architectures with slow multiplication can define
* WANT_PAGE_VIRTUAL in asm/page.h
*/
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
};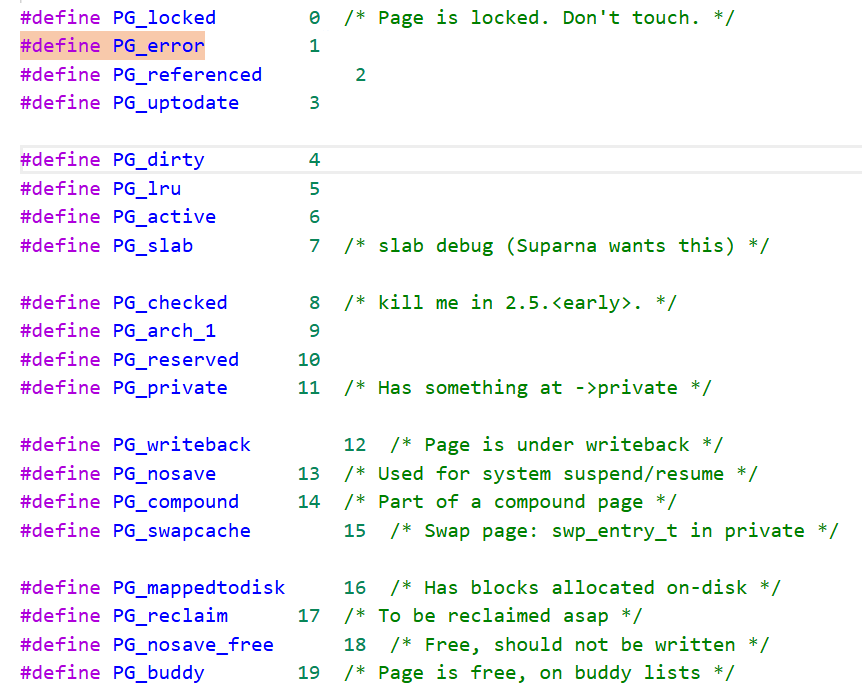
flags:用来存放页的状态。这些状态包括页是不是脏的,是不是被锁定在内存中等。flag的
每一位单独表示一种状态,所以它至少可以同时表示出32种不同的状态。这些标志定义在
<linux/page-flags.h>中。其中一些比特位非常重要,如PG_locked用于指定页是否锁定,
PG_uptodate用于表示页的数据已经从块设备读取并且没有出现错误
- 在内核中会有一个数组struct page mem1048576来组织内存的数据结构体。
- 所以OS对内存的管理就转换成了对数组的增删查改。
- 物理地址和数组下标的映射:物理地址=下标*4096+|偏移量|
- 我们拿到任意一个物理地址都可以直接找到它所处page的属性。
1.3.2页表
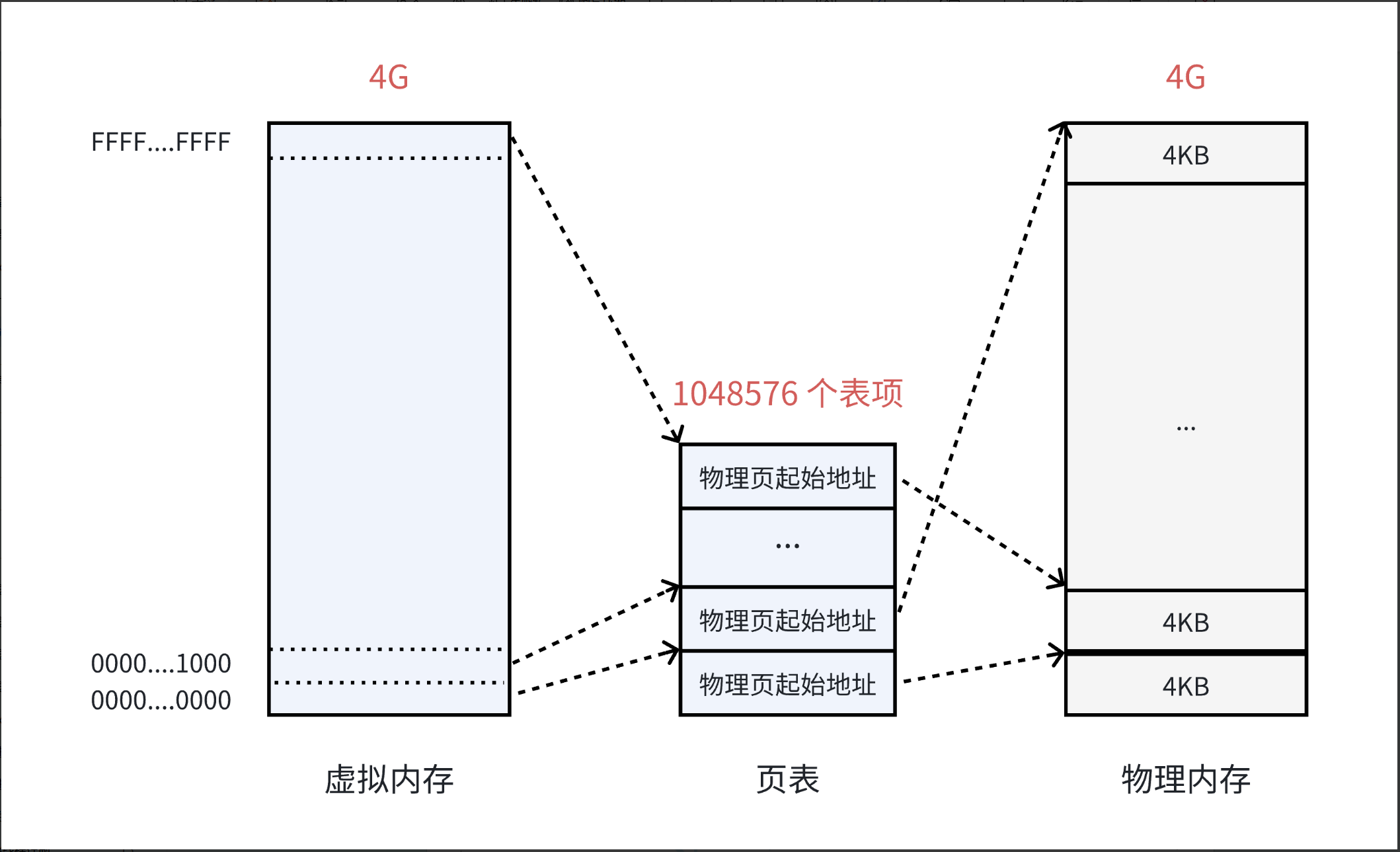
- 页表一对物理和虚拟地址的映射被称为一个条目。
- 物理地址有2^32个,那么就有2^32个条目,页表本身就需要物理内存,这么多条目算下来就有40GB,肯定不行。
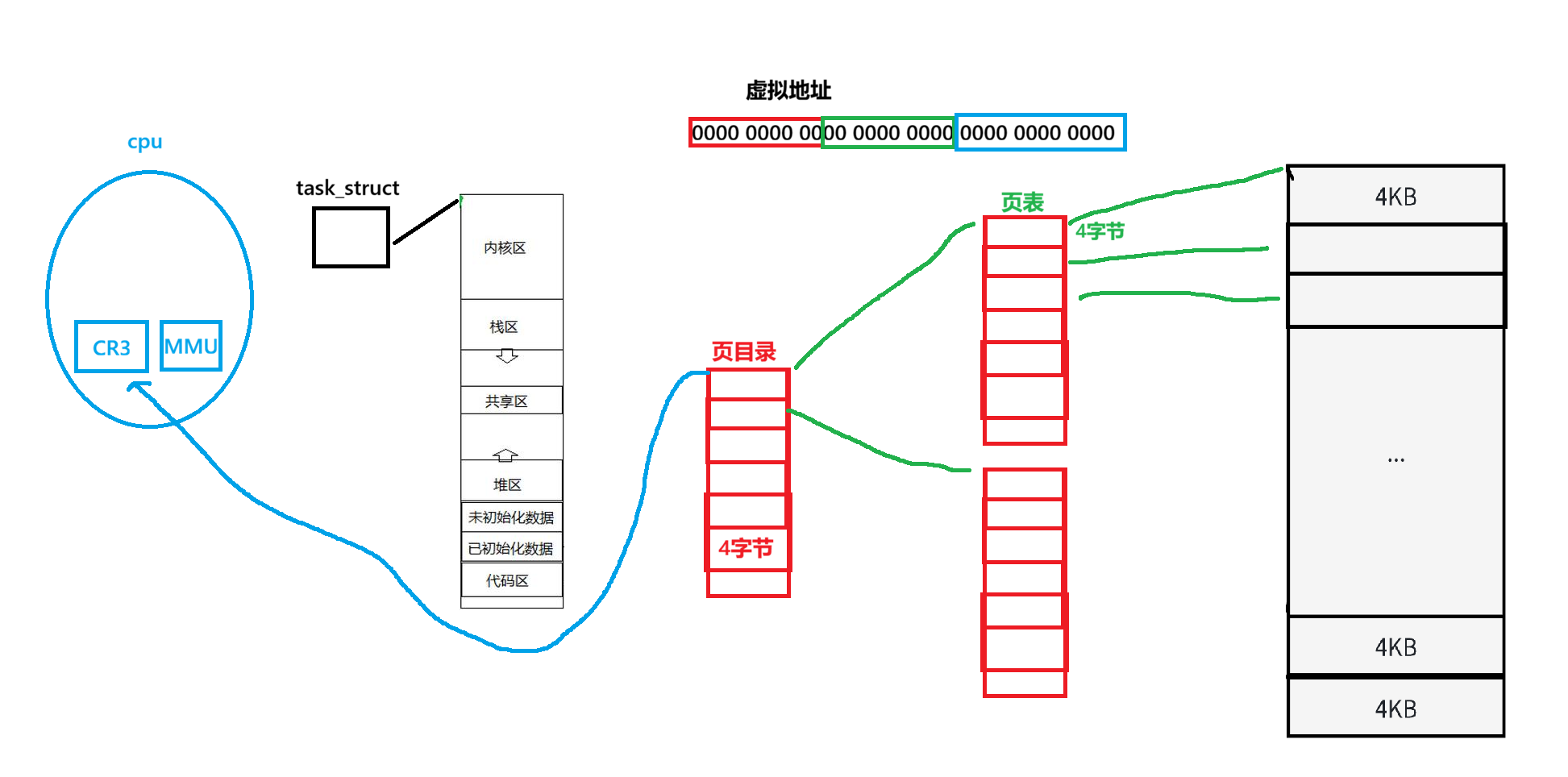
- 虚拟地址有32个bit位的整数,在内核中被分成了3部分,前10位,中10位,后12位。
- 页表并不是只有一个表
- 第一级称为页目录,其中每一个项为4字节,一共有2^10个项,总共大小为4KB。
- 第二级才被称为页表,页表也都是4KB的,页目录中的每一项,保存的是下一级页表的起始地址
- 页表和页目录也都要保存在物理内存中,并且都刚好是4KB,所以页表和页目录都有自己的页框,也就有自己的页数组下标,有下标,页表和页目录的起始地址就都是已知的。
- cpu中的CR3寄存器保存的就是当前cpu执行的进程的页目录。
- cpu就可以通过寄存器找到页目录,通过页目录找到进程的一张张页表
- 当cpu收到一个虚拟地址,需要将其转化为物理地址,MMU会拿着虚拟地址的前10位来作为页目录的数组下标,直接映射对应的页表,所以虚拟地址的前十位用来索引页目录。
- 虚拟地址的中间10位用来索引页表(前十位找到的页表)
- 一个进程拉满的情况下有1024*1024(1048576)个页表项,恰好对应页框的个数,所以页表的页表项保存的就是页框的物理地址。
- 页表:用虚拟地址的前20位,找到任意一个页框的物理地址。
- 此时找页框已经解决了,接下来要找页框中的一个字节。
- 一个页框4kb(2^12)个字节,正好虚拟地址还剩下12字节
- 具体物理地址:找到页框后,通过虚拟地址的后12个字节找到特定页框下的特定字节(偏移量)。
细节:
- 一共1025张表,一张表4kb,总共4MB+4kb,因为页表只会映射到物理内存的页框,至于框内偏移量是存储在虚拟地址的后12位中的
- 单个进程不可能拥有全部物理内存,当前进程页表总数远远小于4MB
- 懒加载,页表少(需要多少代码数据,就加载多少,不会同时加载全部代码数据),写时拷贝,缺页中断,写时拷贝会把变量所处的页框全部拷贝一份。
- 任何一个页框的地址,用20个bit位就可以表示页框的起始地址(找具体物理地址时*4096,后12位全0),页表中一项是4字节,32bit位,20个bit位用来存页框的地址,还剩下12个bit位,就可以用来存标志位了(是否命中,RWX权限,U/K权限)。
- 虚拟到物理的转化工作,由MMU硬件自动帮我们完成映射转化,因为查表频率高,使用硬件比较快。
- CR3:页目录基址寄存器,保存页目录起始物理地址,CR3就是进程的上下文,进程在运行时,把页目录的物理地址保存在CR3中
- CR2:保存引起崩溃的虚拟地址,比如野指针。

结论:页表的本质:是进程看到内存资源的窗口,拥有的虚拟地址越多,拥有的物理内存也就越多。
1.4线程的优点
创建一个新线程的代价要比创建一个新进程小得多
与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多
- 最主要的区别是线程的切换虚拟内存空间依然是相同的,但是进程切换是不同的。这两种上下文切换的处理都是通过操作系统内核来完成的。内核的这种切换过程伴随的最显著的性能损耗是将寄存器中的内容切换出。
- 另外一个隐藏的损耗是上下文的切换会扰乱处理器的缓存机制。简单的说,一旦去切换上下文,处理器中所有已经缓存的内存地址一瞬间都作废了。还有一个显著的区别是当你改变虚拟内存空间的时候,处理的页表缓冲TLB(快表)会被全部刷新,这将导致内存的访问在段时间内相当的低效。但是在线程的切换中,不会出现这个问题,当然还有硬件cache。
线程占用的资源要比进程少
能充分利用多处理器的可并行数量
在等待慢速I/O操作结束的同时,程序可执行其他的计算任务
计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作。
1.5线程缺点
性能损失
- 一个很少被外部事件阻塞的计算密集型线程往往无法与其它线程共享同一个处理器。如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的同步和调度开销,而可用的资源不变。
健壮性降低
- 编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因共享了不该共享的变量而造成不良影响的可能性是很大的,换句话说线程之间是缺乏保护的。
缺乏访问控制
- 进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响。
编程难度提高
- 编写与调试一个多线程程序比单线程程序困难得多
1.6线程异常
单个线程如果出现除零,野指针问题导致线程崩溃,进程也会随着崩溃
线程是进程的执⾏分⽀,线程出异常,就类似进程出异常,进⽽触发信号机制,终⽌进程,进程
终⽌,该进程内的所有线程也就随即退出
1.7用途
合理的使⽤多线程,能提⾼CPU密集型程序的执⾏效率
合理的使⽤多线程,能提⾼IO密集型程序的⽤⼾体验(如⽣活中我们⼀边写代码⼀边下载开发⼯
具,就是多线程运⾏的⼀种表现)
2.linux进程和线程----哪些资源共享,哪些资源独占
- 进程间具有独⽴性
- 线程共享地址空间,也就共享进程资源
2.1进程和线程
进程是资源分配的基本单位
线程是调度的基本单位
线程共享进程数据,但也拥有自己的一部分"私有"数据:
- 线程ID
- 一组寄存器,线程的上下文数据
- 栈
- errno
- 信号屏蔽字
- 调度优先级
2.2进程的多个线程共享
同一地址空间,因此TextSegment、DataSegment都是共享的,如果定义一个函数,在各线程中都可以调用,如果定义一个全局变量,在各线程中都可以访问到,除此之外,各线程还共享以下进程资源和环境:
- ⽂件描述符表
- 每种信号的处理⽅式(SIG_ IGN、SIG_ DFL或者⾃定义的信号处理函数)
- 当前⼯作⽬录
- ⽤⼾id和组id
3.线程控制
3.1创建轻量级进程
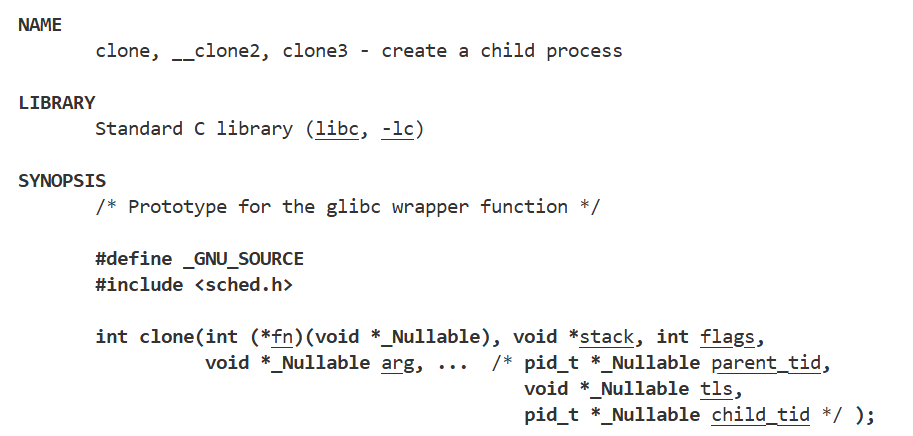
- 创建轻量级进程的系统调用
- 参数1:回调指针,表示当前执行流要执行哪段代码。
- 参数flag:表示要不要复制地址空间,页表等资源。
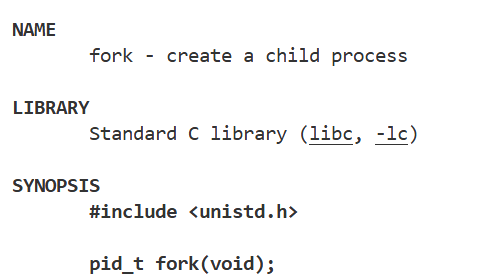
- fork底层调用的就是clone,flag标志位需要复制虚拟地址空间等资源。

- vfork与fork的区别是不复制虚拟地址空间等资源,是真正创建轻量级进程的接口。
3.2创建线程


- 参数arg:回调函数的参数
- 返回值:只能主线程接收,成功返回0,失败返回错误码,并且tid未定义。
cpp
#include<iostream>
#include<cstdio>
#include<pthread.h>
#include<unistd.h>
#include<string>
void* routine(void* arg)
{
std::string name=(char*)arg;
while(true)
{
std::cout<<"new thread:"<<name<<std::endl;
sleep(1);
}
}
int main()
{
pthread_t tid;
int n=pthread_create(&tid,nullptr,routine,(void*)"thread-1");
std::cout<<"new thread id:"<<tid<<std::endl;
while(true)
{
std::cout<<"main thread"<<std::endl;
sleep(1);
}
return 0;
}
- pthread库是系统调用封装出来的库,就像fread封装read一样,fread也没有显示fd文件描述符,所以不会显示LWP
- 以16进制打印:

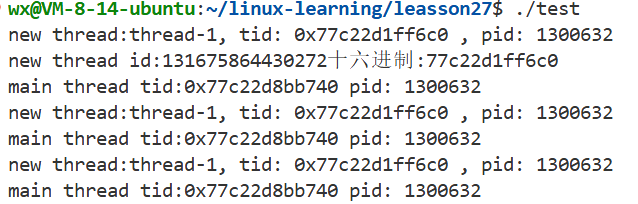
- 可以看到tid是一个很大的数字:地址
pthread_self

- 获取调用线程的id
cpp
#include<iostream>
#include<cstdio>
#include<pthread.h>
#include<unistd.h>
#include<string>
void* routine(void* arg)
{
std::string name=(char*)arg;
while(true)
{
//std::cout<<"new thread:"<<name<<std::endl;
printf("new thread:%s, tid: %p , pid: %d\n",name.c_str(),(void*)pthread_self(),getpid());
sleep(1);
}
}
int main()
{
pthread_t tid;
int n=pthread_create(&tid,nullptr,routine,(void*)"thread-1");
std::cout<<"new thread id:"<<tid<<"十六进制:"<<std::hex<<tid<<std::dec<<std::endl;
while(true)
{
std::cout<<"main thread tid:"<<(void*)pthread_self()<<" pid: "<<getpid()<<std::endl;
sleep(1);
}
return 0;
}
cpp
#include<iostream>
#include<cstdio>
#include<pthread.h>
#include<unistd.h>
#include<string>
#include<vector>
using namespace std;
void* routine(void* arg)
{
std::string name=(char*)arg;
while(true)
{
//std::cout<<"new thread:"<<name<<std::endl;
printf("new thread:%s, tid: %p , pid: %d\n",name.c_str(),(void*)pthread_self(),getpid());
sleep(1);
}
}
int main()
{
const int num=10;
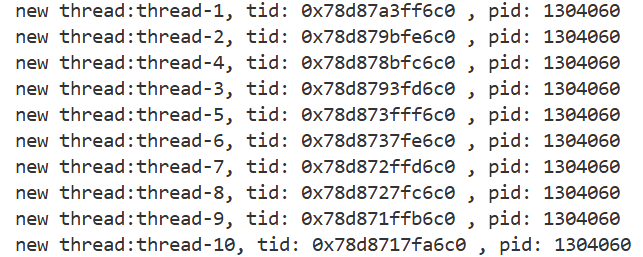
for(int i=0;i<num;i++)
{
pthread_t tid;
string threadname="thread-"+std::to_string(i+1);
int n=pthread_create(&tid,nullptr,routine,(void*)threadname.c_str());
(void)n;
sleep(1);
}
while(true)
{
printf("main thread tid: %p , pid: %d\n",(void*)pthread_self(),getpid());
sleep(1);
}
}
- routine函数就是可重入函数,重入函数中调用的函数也会成为重入函数。
cpp
#include<iostream>
#include<cstdio>
#include<pthread.h>
#include<unistd.h>
#include<string>
#include<vector>
using namespace std;
int g_val = 100;
void printname(const std::string& name)
{
printf("new thread:%s, tid: %p , pid: %d, g_val: %d, &g_val: %p\n",
name.c_str(), (void*)pthread_self(), getpid(), g_val, &g_val);
}
void* routine(void* arg)
{
std::string name=(char*)arg;
printf("------------------------------------------\n");
while(true)
{
//std::cout<<"new thread:"<<name<<std::endl;
printname(name);
sleep(1);
g_val++;
}
}
int main()
{
const int num=1;
for(int i=0;i<num;i++)
{
pthread_t tid;
string threadname="thread-"+std::to_string(i+1);
int n=pthread_create(&tid,nullptr,routine,(void*)threadname.c_str());
(void)n;
sleep(1);
}
while(true)
{
printf("main thread tid: %p , pid: %d, g_val: %d, &g_val: %p\n",
(void*)pthread_self(), getpid(), g_val, &g_val);
sleep(1);
}
}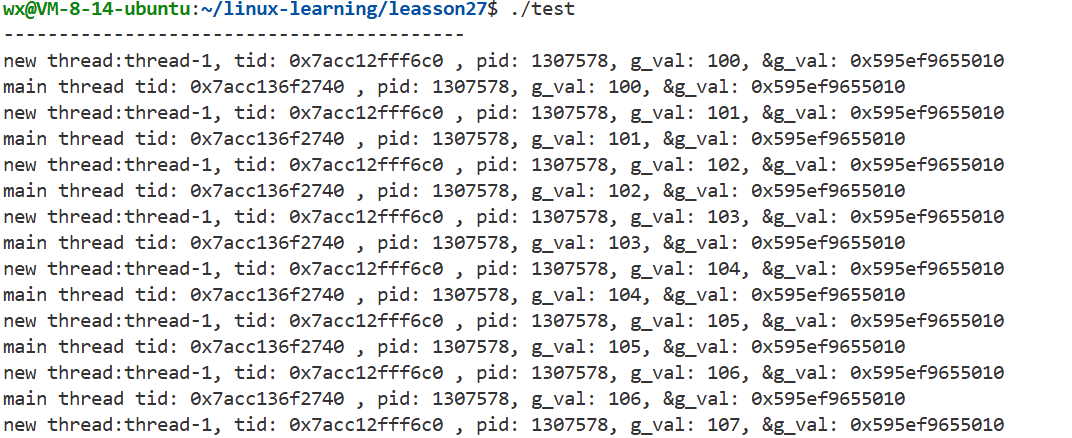
- 可以看到线程之间资源是共享的,整个虚拟地址空间中的数据都可以互相看到。
- 一个线程的局部变量也可以被其他线程看到,想要修改需要拿到局部变量的地址(栈区)。
多线程之间的异常问题
cpp
#include<iostream>
#include<cstdio>
#include<pthread.h>
#include<unistd.h>
#include<string>
#include<vector>
using namespace std;
int g_val = 100;
void printname(const std::string& name)
{
printf("new thread:%s, tid: %p , pid: %d, g_val: %d, &g_val: %p\n",
name.c_str(), (void*)pthread_self(), getpid(), g_val, &g_val);
}
void* routine(void* arg)
{
std::string name=(char*)arg;
printf("------------------------------------------\n");
while(true)
{
//std::cout<<"new thread:"<<name<<std::endl;
printname(name);
sleep(1);
g_val++;
if(name == "thread-8")
{
cout<<"异常"<<endl;
int a=10;
a/=0;
}
}
}
int main()
{
const int num=10;
for(int i=0;i<num;i++)
{
pthread_t tid;
string threadname="thread-"+std::to_string(i+1);
int n=pthread_create(&tid,nullptr,routine,(void*)threadname.c_str());
(void)n;
sleep(1);
}
while(true)
{
printf("main thread tid: %p , pid: %d, g_val: %d, &g_val: %p\n",
(void*)pthread_self(), getpid(), g_val, &g_val);
sleep(1);
}
}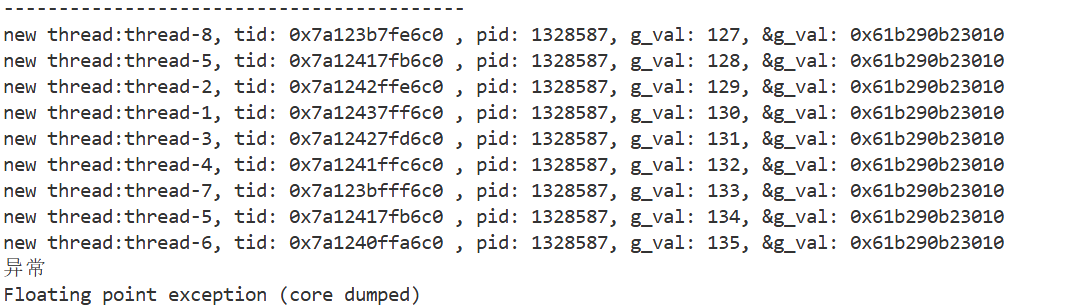
- 多线程中任意一个线程崩溃,会导致整个进程挂掉。
cpp
#include<iostream>
#include<cstdio>
#include<pthread.h>
#include<unistd.h>
#include<string>
#include<vector>
using namespace std;
int g_val = 100;
void printname(const std::string& name)
{
printf("new thread:%s, tid: %p , pid: %d, g_val: %d, &g_val: %p\n",
name.c_str(), (void*)pthread_self(), getpid(), g_val, &g_val);
}
void* routine(void* arg)
{
std::string name=(char*)arg;
printname(name);
//printf("------------------------------------------\n");
while(true)
{
//std::cout<<"new thread:"<<name<<std::endl;
//printname(name);
sleep(1);
g_val++;
// if(name == "thread-8")
// {
// cout<<"异常"<<endl;
// int a=10;
// a/=0;
// }
}
}
int main()
{
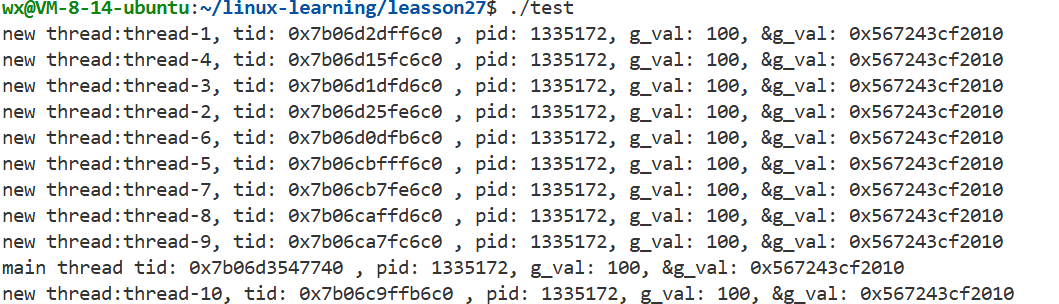
const int num=10;
for(int i=0;i<num;i++)
{
pthread_t tid;
string threadname="thread-"+std::to_string(i+1);
int n=pthread_create(&tid,nullptr,routine,(void*)threadname.c_str());
(void)n;
//sleep(1);
}
while(true)
{
printf("main thread tid: %p , pid: %d, g_val: %d, &g_val: %p\n",
(void*)pthread_self(), getpid(), g_val, &g_val);
sleep(1);
}
}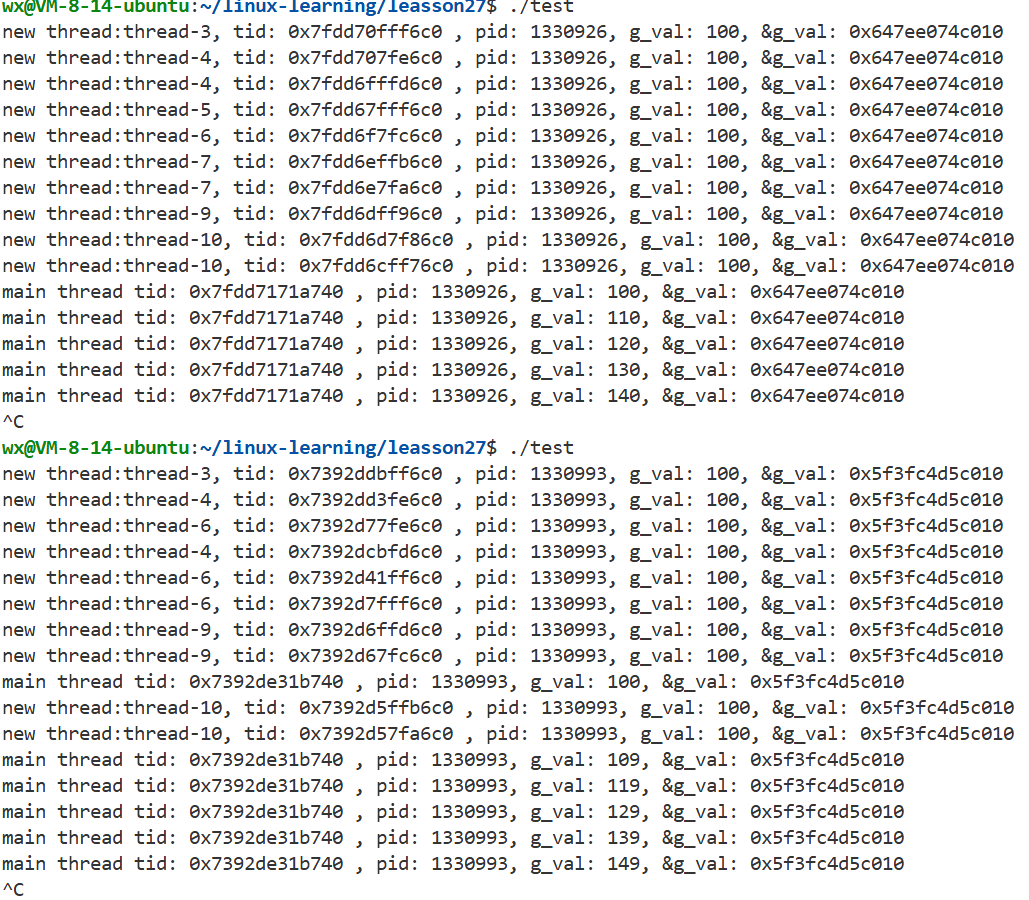
- 这种异常发生是因为主线程在给新线程创建名字时,在内存中开辟了一块空间,来存储这个字符串,然后函数参数传递的是这个string的起始地址,可能这个字符串还没来得及到回调函数中进行拷贝或打印呢,主线程就开始了下一次的循环,重新在同一块地址空间处,覆盖式的创建了下一个新线程的字符串,此时上一个线程才开始打印或拷贝,此时不就出错了。
- 这个资源其实也就是多线程的共享资源,多线程并发的访问这一个资源,每次访问都修改资源,导致数据不一致问题。
解决问题的写法:

传参问题
- pthread_create:该函数的参数,传地址时都是void*类型,说明传什么类型的地址都可,整形地址,字符地址,字符传地址,甚至类地址和结构体地址都可以。
- 所以我们可以只派一个任务给线程。
cpp
#pragma once
#include<string>
using namespace std;
class task
{
public:
task(int x,int y)
:_x(x)
,_y(y)
{}
void Excute()
{
_ret=_x+_y;
}
string result()
{
return to_string(_x)+" + "+to_string(_y)+" = "+to_string(_ret);
}
~task()
{}
private:
int _x;
int _y;
int _ret;
};
cpp
#include<iostream>
#include<cstdio>
#include<pthread.h>
#include<unistd.h>
#include<string>
#include<vector>
#include"task.hpp"
#include<cstdlib>
#include<time.h>
using namespace std;
int g_val = 100;
void printname(const std::string& name)
{
printf("new thread:%s, tid: %p , pid: %d, g_val: %d, &g_val: %p\n",
name.c_str(), (void*)pthread_self(), getpid(), g_val, &g_val);
}
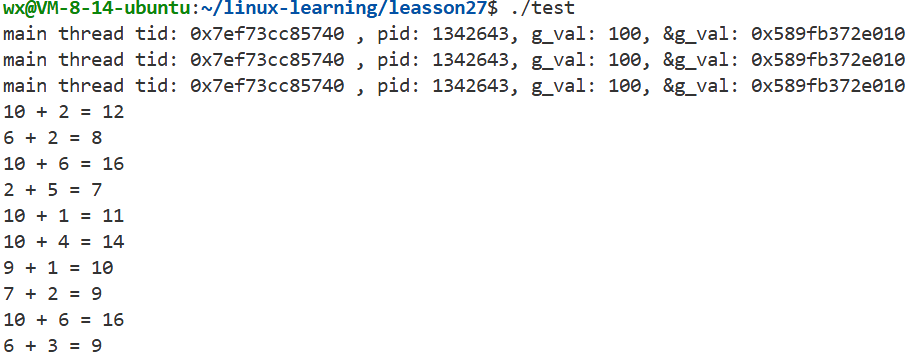
void* routine(void* arg)
{
sleep(3);
task* t = (task*)arg;
t->Excute();
cout<<t->result()<<endl;
return nullptr;
//printf("------------------------------------------\n");
while(true)
{
//std::cout<<"new thread:"<<name<<std::endl;
//printname(name);
sleep(1);
g_val++;
// if(name == "thread-8")
// {
// cout<<"异常"<<endl;
// int a=10;
// a/=0;
// }
}
}
int main()
{
srand(time(nullptr) ^ getpid());
const int num=10;
for(int i=0;i<num;i++)
{
pthread_t tid;
//string threadname="thread-"+std::to_string(i+1);//出现数据不一致问题吗?会
//正确写法
// char* threadname=new char[64];
// sprintf(threadname,"thread-%d",i+1);
int x=rand()%10+1;
usleep(234);
int y=rand()%7+1;
task* t=new task(x,y);
int n=pthread_create(&tid,nullptr,routine,t);
(void)n;
//sleep(1);
}
while(true)
{
printf("main thread tid: %p , pid: %d, g_val: %d, &g_val: %p\n",
(void*)pthread_self(), getpid(), g_val, &g_val);
sleep(1);
}
}
3.3线程终止
- 从线程函数return。这种方法对主线程不适用,从main函数return相当于调用exit。
- 线程可以调用pthread_exit终止自己,回调函数跑完也会自动退出。
- 一个线程可以调用pthread_cancel终止同一进程中的另一个线程

- 在线程流中使用exit终止会使所有线程全部退出。
cpp
#include<iostream>
#include<cstdio>
#include<pthread.h>
#include<unistd.h>
#include<string>
#include<vector>
#include"task.hpp"
#include<cstdlib>
#include<time.h>
using namespace std;
int g_val = 100;
void printname(const std::string& name)
{
printf("new thread:%s, tid: %p , pid: %d, g_val: %d, &g_val: %p\n",
name.c_str(), (void*)pthread_self(), getpid(), g_val, &g_val);
}
void* routine(void* arg)
{
sleep(3);
task* t = (task*)arg;
t->Excute();
cout<<t->result()<<endl;
while(true)
{
sleep(1);
//pthread_exit(nullptr);
//exit(10);
}
//return nullptr;
//printf("------------------------------------------\n");
while(true)
{
//std::cout<<"new thread:"<<name<<std::endl;
//printname(name);
sleep(1);
g_val++;
cout<<"g_val:"<<g_val<<endl;
// if(name == "thread-8")
// {
// cout<<"异常"<<endl;
// int a=10;
// a/=0;
// }
}
}
int main()
{
srand(time(nullptr) ^ getpid());
const int num=10;
vector<pthread_t> tids;
for(int i=0;i<num;i++)
{
pthread_t tid;
//string threadname="thread-"+std::to_string(i+1);//出现数据不一致问题吗?会
//正确写法
// char* threadname=new char[64];
// sprintf(threadname,"thread-%d",i+1);
int x=rand()%10+1;
usleep(234);
int y=rand()%7+1;
task* t=new task(x,y);
int n=pthread_create(&tid,nullptr,routine,t);
(void)n;
tids.push_back(tid);
}
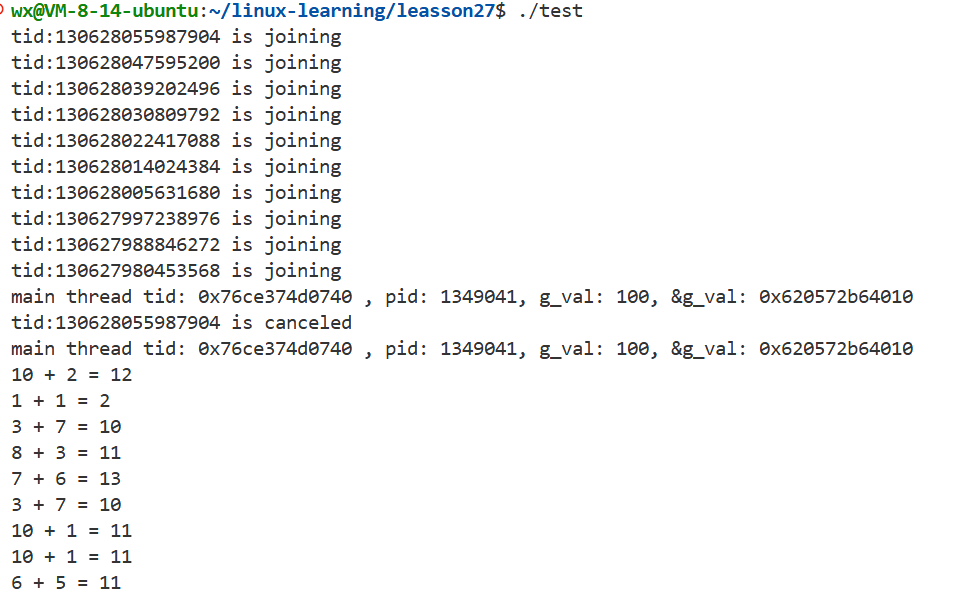
for(auto &tid:tids)
{
cout<<"tid:"<<tid<<" is joining"<<endl;
}
while(true)
{
printf("main thread tid: %p , pid: %d, g_val: %d, &g_val: %p\n",
(void*)pthread_self(), getpid(), g_val, &g_val);
int who=rand()%tids.size();
sleep(1);
if(tids[who]==-1)
{
continue;
}
else
{
pthread_cancel(tids[who]);
cout<<"tid:"<<tids[who]<<" is canceled"<<endl;
tids[who]=-1;
}
sleep(1);
}
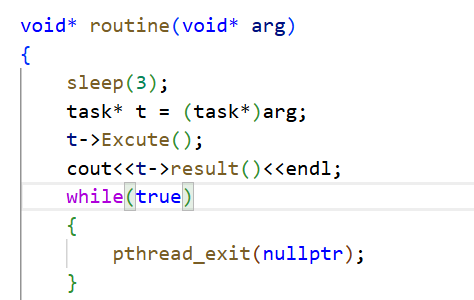
}
- 使用pthread_cancel取消线程。
- 注意:新线程不能使用pthread_cancel取消主线程
3.4线程等待
新线程必须被主进程等待
- 类似进程等待的僵尸进程问题。
- 主线程要获取新线程的执行结构

- 等待一个终止的线程,新线程不终止,主线程会阻塞等待。
- 参数1:目标线程的id
- 参数2:函数调用完成返回值的指针。
- 返回值:成功返回0,失败返回错误码
cpp
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include<cstdio>
#include<cstdlib>
#include<ctime>
#include<vector>
#include<string>
void* routine(void* arg)
{
std::string name=static_cast<char*>(arg);
while(true)
{
std::cout<<"new thread:"<<name<<std::endl;
sleep(1);
break;
}
return (void*)10;
}
int main()
{
pthread_t tid;
pthread_create(&tid,nullptr,routine,(void*)"thread-1");
//线程等待
sleep(3);
void* retval;
int n=pthread_join(tid,&retval);
if(n==0)
{
std::cout<<"join success,retval="<<(long)retval<<std::endl;
}
return 0;
}
新线程返回类对象:
cpp
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include<cstdio>
#include<cstdlib>
#include<ctime>
#include<vector>
#include<string>
class res
{
public:
int code;
std::string name;
std::string info;
};
void* routine(void* arg)
{
std::string name=static_cast<char*>(arg);
while(true)
{
std::cout<<"new thread:"<<name<<std::endl;
sleep(1);
break;
}
res* r=new res();
r->code=10;
r->name="thread-1";
r->info="this is thread-1";
return (void*)r;
}
int main()
{
pthread_t tid;
pthread_create(&tid,nullptr,routine,(void*)"thread-1");
//线程等待
sleep(3);
void* retval;
int n=pthread_join(tid,&retval);
if(n==0)
{
res* r=static_cast<res*>(retval);
std::cout<<"code:"<<r->code<<std::endl;
std::cout<<"name:"<<r->name<<std::endl;
std::cout<<"info:"<<r->info<<std::endl;
delete r;
}
return 0;
}
传递一个任务:
cpp
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include<cstdio>
#include<cstdlib>
#include<ctime>
#include<vector>
#include<string>
#include"task.hpp"
void* routine(void* arg)
{
task* t=static_cast<task*>(arg);
t->Excute();
return (void*)t;
}
int main()
{
task t(10,20);
pthread_t tid;
pthread_create(&tid,nullptr,routine,(void*)&t);
//线程等待
sleep(3);
task*tp;
int n=pthread_join(tid,(void**)&tp);
if(n==0)
{
std::cout<<tp->result()<<std::endl;
}
return 0;
}
等待已经取消的线程:
cpp
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include<cstdio>
#include<cstdlib>
#include<ctime>
#include<vector>
#include<string>
#include"task.hpp"
void* routine(void* arg)
{
while(true)
{
sleep(1);
}
}
int main()
{
task t(10,20);
pthread_t tid;
pthread_create(&tid,nullptr,routine,(void*)&t);
sleep(7);
pthread_cancel(tid);
void* retval;
int n=pthread_join(tid,&retval);
if(n==0)
{
std::cout<<"join success!"<<(long long)retval<<std::endl;
}
return 0;
}
3.5分离线程
3.5.1线程程序替换
线程之间内存资源是共享的,同时程序替换,替换的是内存中的数据和代码,一个线程进行程序替换,那么整个进程都会被替换。
线程程序替换可以通过在线程中调用fork,线程调用fork就相当于进程fork,新线程也是执行流,之前学习的进程也是执行流,没什么区别,但是fork后的新进程只有一个PCB。
所以想要在新线程中进行程序替换,推荐再fork后的,子进程执行流中进行exec。
3.5.2线程自动释放
- 默认情况下,新创建的线程是joinable的,线程退出后,需要对其进行pthread_join操作,否则无法释放资源,从而造成系统泄漏。
- 如果不关心线程的返回值,join是一种负担,这个时候,我们可以告诉系统,当线程退出时,自动释放线程资源。
- 把目标被等待的线程设置为:分离状态。

- 将线程设置为detach状态
- 新线程既可以被主线程分离,也可以自己给自己设置分离。
cpp
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include<cstdio>
#include<cstdlib>
#include<ctime>
#include<vector>
#include<string>
#include"task.hpp"
void* routine(void* arg)
{
int cnt=5;
while(cnt)
{
std::cout<<"thread running:"<<cnt--<<std::endl;
sleep(1);
}
return nullptr;
int main()
{
pthread_t tid;
pthread_create(&tid,nullptr,routine,nullptr);
sleep(1);
std::cout<<"main thread detach "<<std::endl;
pthread_detach(tid);
void* retval;
int n=pthread_join(tid,&retval);
if(n==0)
{
std::cout<<"join success!"<<(long long)retval<<std::endl;
}
else
{
std::cout<<"join fail! n:"<<n<<std::endl;
}
return 0;
}
cpp
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include<cstdio>
#include<cstdlib>
#include<ctime>
#include<vector>
#include<string>
#include"task.hpp"
void* routine(void* arg)
{
pthread_detach(pthread_self());
int cnt=5;
while(cnt)
{
std::cout<<"thread running:"<<cnt--<<std::endl;
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t tid;
pthread_create(&tid,nullptr,routine,nullptr);
sleep(1);
void* retval;
int n=pthread_join(tid,&retval);
if(n==0)
{
std::cout<<"join success!"<<(long long)retval<<std::endl;
}
else
{
std::cout<<"join fail! n:"<<n<<std::endl;
}
return 0;
}
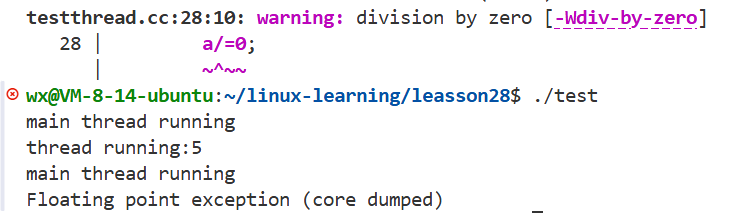
- 一旦新线程要被设置为分离,主线程不能提前退,即使新进程是被分离了,但内存资源还是共享,如果主线程提前退,新线程连任务都没有做完。
- 如果新线程已经分离,新线程在分离后出异常,所有线程还是会一起退出。
cpp
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include<cstdio>
#include<cstdlib>
#include<ctime>
#include<vector>
#include<string>
#include"task.hpp"
void* routine(void* arg)
{
pthread_detach(pthread_self());
int cnt=5;
while(cnt)
{
std::cout<<"thread running:"<<cnt--<<std::endl;
sleep(1);
int a =10;
a/=0;
}
return nullptr;
}
int main()
{
// task t(10,20);
pthread_t tid;
pthread_create(&tid,nullptr,routine,nullptr);
// sleep(1);
while(true)
{
std::cout<<"main thread running"<<std::endl;
sleep(1);
}
return 0;
}
3.6线程控制与库
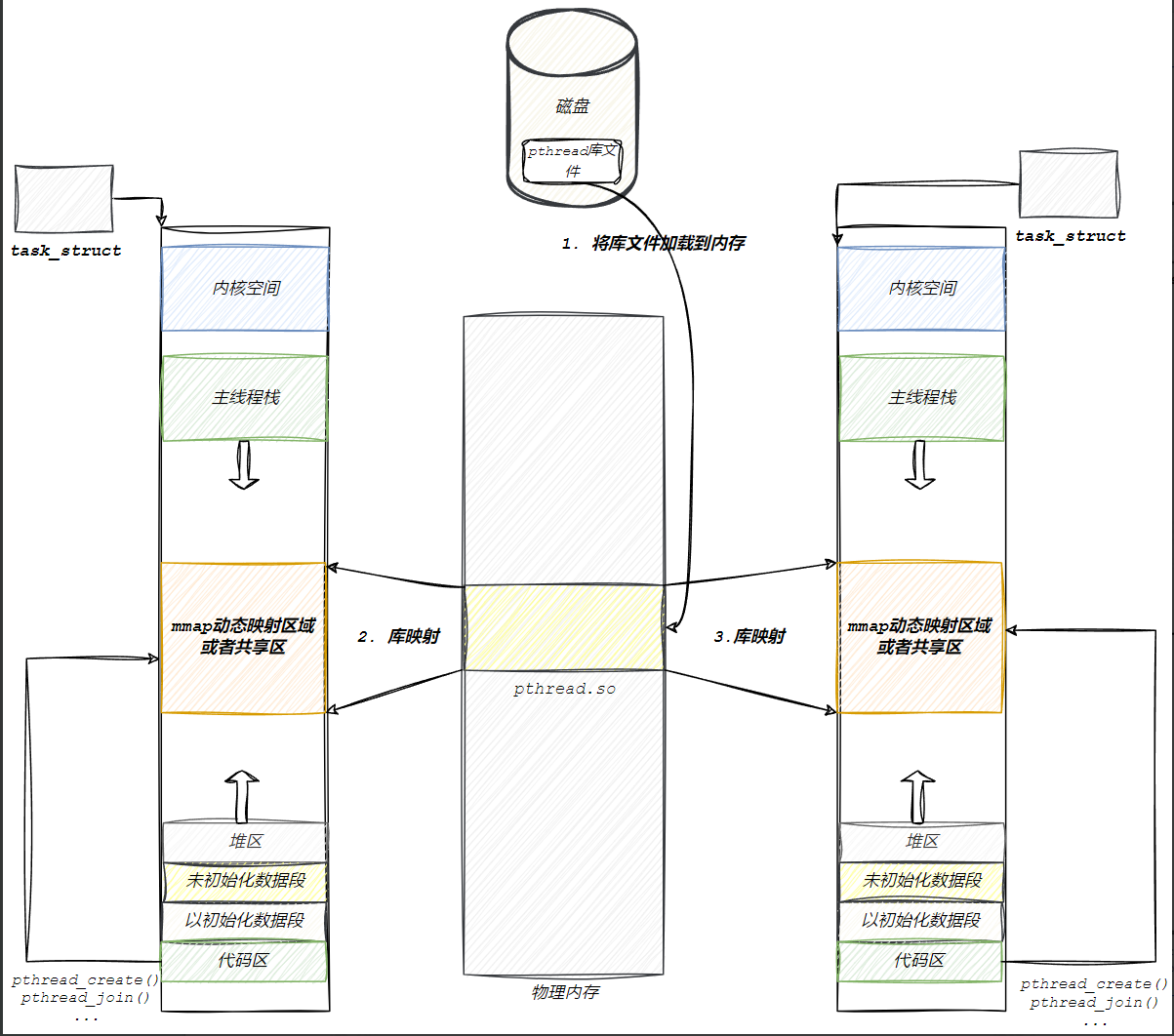
- pthread库要被映射到当前进程的虚拟地址空间,以支持线程控制。
- 我们代码中的tid其实是一个地址。
- 在linux内核中没有线程这一概念,但是线程库是对系统调用的封装,线程是被封装出来的,属于线程库,线程相关的属性都被保存在线程库中,那么线程库就要对线程进行管理。
- 既然线程库实现了对线程的封装,那么线程库中就要有描述线程的结构体。
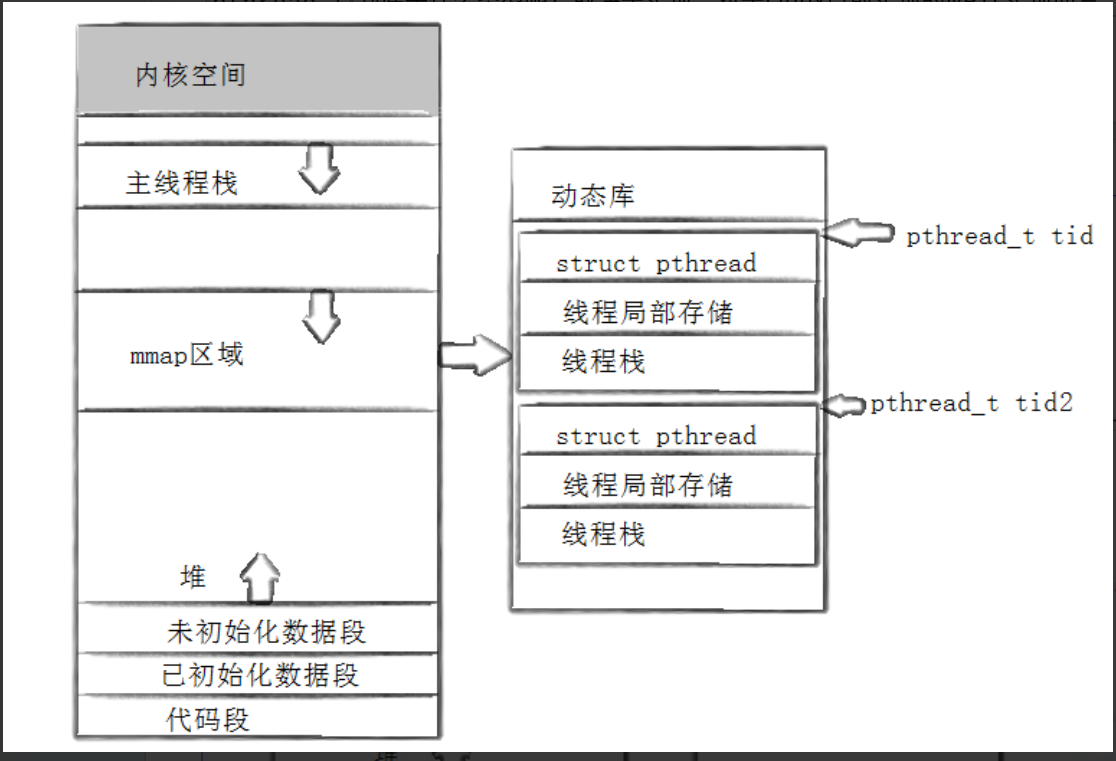
-
每创建一个线程,动态库代码中都会多一个TCB,每一个TCB结构体的起始地址就是tid。
-
主线程的栈由虚拟地址空间提供,新线程的栈由线程库提供。
-
当新线程退出时,我们使用ps -al查看线程时,其实线程已经被释放,为什么还要pthread_join?
-
当线程退出时,其实在内核中的PCB(轻量级进程的资源)已经被释放了,但是在线程库中的TCB资源并没有被释放。
3.6.1线程局部存储
每一个线程都有自己的线程局部存储
cpp
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include<cstdio>
#include<cstdlib>
#include<ctime>
#include<vector>
#include<string>
#include"task.hpp"
pid_t id =0;
void* routine(void* arg)
{
std::string name=static_cast<char*>(arg);
while(true)
{
std::cout<<"new thread id:"<<id<<std::endl;
id++;
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t tid;
pthread_create(&tid,nullptr,routine,(void*)"thread-1");
while(true)
{
std::cout<<"main thread id:"<<id<<std::endl;
sleep(1);
}
pthread_join(tid,nullptr);
return 0;
}- 该代码中的id属于数据,其中的数据是共享的。
- 一个线程修改另一个也可以看到。

__thread
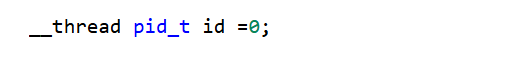

- 被__thread修饰的变量叫做:线程局部存储
- 在编译时,会在每一个线程的局部存储空间中开辟一个"变量名相同"同等大小的空间,每一个线程有属于自己的变量,每一个线程在修改此变量时,只会修改自己的,不共享。
- 不同线程,变量的地址不相同。
- 线程局部存储:只能用来保存基本的内置类型
3.7C++中的多线程
cpp
#include<iostream>
#include<thread>
#include<unistd.h>
void routine(int n)
{
while(n--)
{
std::cout<<"new thread n:"<<n<<std::endl;
sleep(1);
}
}
int main()
{
std::thread t(routine,10);
while(true)
{
std::cout<<"main thread "<<std::endl;
sleep(1);
}
t.join();
return 0;
}
4.线程库源码
4.1pthread_create
cpp
int __pthread_create_2_1(newthread, attr, start_routine, arg)
pthread_t* newthread;
const pthread_attr_t* attr;
void* (*start_routine)(void*);
void* arg;
{
STACK_VARIABLES;
// 重点1: 线程属性,虽然我们不设置,但是不妨碍我们了解
const struct pthread_attr* iattr = (struct pthread_attr*)attr;
if (iattr == NULL)
/* Is this the best idea? On NUMA machines this could mean
accessing far-away memory. */
iattr = &default_attr;
// 重点2:传说中的原⽣线程库中的⽤来描述线程的tcb
struct pthread* pd = NULL;
// 重点3: ALLOCATE_STACK会在先申请struct pthread对象,当然其实是申请⼀⼤块空间,
// struct pthread在空间的开头,⼀会追
int err = ALLOCATE_STACK(iattr, &pd);
if (__builtin_expect(err != 0, 0))
/* Something went wrong. Maybe a parameter of the attributes is
invalid or we could not allocate memory. */
versioned_symbol return err;
/* Initialize the TCB. All initializations with zero should be
performed in 'get_cached_stack'. This way we avoid doing this if
the stack freshly allocated with 'mmap'. */
#ifdef TLS_TCB_AT_TP
/* Reference to the TCB itself. */
pd->header.self = pd;
/* Self-reference for TLS. */
pd->header.tcb = pd;
#endif
/* Store the address of the start routine and the parameter. Since
we do not start the function directly the stillborn thread will
get the information from its thread descriptor. */
// 重点4:向线程tcb中设置未来要执⾏的⽅法的地址和参数
pd->start_routine = start_routine;
pd->arg = arg;
/* Copy the thread attribute flags. */
struct pthread* self = THREAD_SELF;
pd->flags = ((iattr->flags & ~(ATTR_FLAG_SCHED_SET | ATTR_FLAG_POLICY_SET))
| (self->flags & (ATTR_FLAG_SCHED_SET | ATTR_FLAG_POLICY_SET)));
/* Initialize the field for the ID of the thread which is waiting
for us. This is a self-reference in case the thread is created
detached. */
pd->joinid = iattr->flags & ATTR_FLAG_DETACHSTATE ? pd : NULL;
/* The debug events are inherited from the parent. */
pd->eventbuf = self->eventbuf;
/* Copy the parent's scheduling parameters. The flags will say what
is valid and what is not. */
pd->schedpolicy = self->schedpolicy;
pd->schedparam = self->schedparam;
/* Copy the stack guard canary. */
#ifdef THREAD_COPY_STACK_GUARD
THREAD_COPY_STACK_GUARD(pd);
#endif
/* Copy the pointer guard value. */
#ifdef THREAD_COPY_POINTER_GUARD
THREAD_COPY_POINTER_GUARD(pd);
#endif
// ⼀堆参数设定,我们不关⼼
/* Determine scheduling parameters for the thread. */
if (attr != NULL && __builtin_expect((iattr->flags &
ATTR_FLAG_NOTINHERITSCHED) != 0, 0) && (iattr->flags & (ATTR_FLAG_SCHED_SET |
ATTR_FLAG_POLICY_SET)) != 0)
{
INTERNAL_SYSCALL_DECL(scerr);
/* Use the scheduling parameters the user provided. */
if (iattr->flags & ATTR_FLAG_POLICY_SET)
pd->schedpolicy = iattr->schedpolicy;
else if ((pd->flags & ATTR_FLAG_POLICY_SET) == 0)
{
pd->schedpolicy = INTERNAL_SYSCALL(sched_getscheduler, scerr, 1, 0);
pd->flags |= ATTR_FLAG_POLICY_SET;
}
if (iattr->flags & ATTR_FLAG_SCHED_SET)
memcpy(&pd->schedparam, &iattr->schedparam,
sizeof(struct sched_param));
else if ((pd->flags & ATTR_FLAG_SCHED_SET) == 0)
{
INTERNAL_SYSCALL(sched_getparam, scerr, 2, 0, &pd->schedparam);
pd->flags |= ATTR_FLAG_SCHED_SET;
}
/* Check for valid priorities. */
int minprio = INTERNAL_SYSCALL(sched_get_priority_min, scerr, 1,
iattr->schedpolicy);
int maxprio = INTERNAL_SYSCALL(sched_get_priority_max, scerr, 1,
iattr->schedpolicy);
if (pd->schedparam.sched_priority < minprio || pd -
>schedparam.sched_priority > maxprio)
{
err = EINVAL;
goto errout;
}
}
/* Pass the descriptor to the caller. */
// 重点5:把pd(就是线程控制块地址)作为ID,传递出去,所以上层拿到的就是⼀个虚拟地址
*newthread = (pthread_t)pd;
/* Remember whether the thread is detached or not. In case of an
error we have to free the stacks of non-detached stillborn
threads. */
// 重点6: 检测线程属性是否分离,这个很好理解
bool is_detached = IS_DETACHED(pd);
/* Start the thread. */
err = create_thread(pd, iattr, STACK_VARIABLES_ARGS); // 重点函数
if (err != 0)
{
/* Something went wrong. Free the resources. */
if (!is_detached)
{
errout:
__deallocate_stack(pd);
}
return err;
}
return 0;
}
// 版本确认信息,意思就是如果⽤的库是GLIBC_2_1,pthread_create函数就是
__pthread_create_2_1
versioned_symbol(libpthread, __pthread_create_2_1, pthread_create, GLIBC_2_1);4.2线程属性
cpp
struct pthread_attr
{
/* Scheduler parameters and priority. */
struct sched_param schedparam;
int schedpolicy;
/* Various flags like detachstate, scope, etc. */
int flags;
/* Size of guard area. */
size_t guardsize;
/* Stack handling. */
void* stackaddr;
size_t stacksize;
/* Affinity map. */
cpu_set_t* cpuset;
size_t cpusetsize;
};4.3线程TCB
cpp
/* Thread descriptor data structure. */
struct pthread
{
union
{
#if !TLS_DTV_AT_TP
/* This overlaps the TCB as used for TLS without threads (see tls.h). */
tcbhead_t header;
#else
struct
{
int multiple_threads;
} header;
#endif
/* This extra padding has no special purpose, and this structure layout
is private and subject to change without affecting the official ABI.
We just have it here in case it might be convenient for some
implementation-specific instrumentation hack or suchlike. */
void* __padding[16];
};
/* This descriptor's link on the `stack_used' or `__stack_user' list. */
list_t list;
/* Thread ID - which is also a 'is this thread descriptor (and
therefore stack) used' flag. */
pid_t tid;
/* Process ID - thread group ID in kernel speak. */
pid_t pid;
/* List of robust mutexes the thread is holding. */
#ifdef __PTHREAD_MUTEX_HAVE_PREV
__pthread_list_t robust_list;
# define ENQUEUE_MUTEX(mutex) \
do { \
__pthread_list_t *next = THREAD_GETMEM (THREAD_SELF, robust_list.__next);
\
next->__prev = &mutex->__data.__list; \
mutex->__data.__list.__next = next; \
mutex->__data.__list.__prev = &THREAD_SELF->robust_list; \
THREAD_SETMEM(THREAD_SELF, robust_list.__next, &mutex->__data.__list);
\
} while (0)
# define DEQUEUE_MUTEX(mutex) \
do { \
mutex->__data.__list.__next->__prev = mutex->__data.__list.__prev;
\
mutex->__data.__list.__prev->__next = mutex->__data.__list.__next;
\
mutex->__data.__list.__prev = NULL; \
mutex->__data.__list.__next = NULL; \
} while (0)
#else
__pthread_slist_t robust_list;
# define ENQUEUE_MUTEX(mutex) \
do { \
mutex->__data.__list.__next \
= THREAD_GETMEM (THREAD_SELF, robust_list.__next); \
THREAD_SETMEM (THREAD_SELF, robust_list.__next, &mutex->__data.__list);
\
} while (0)
# define DEQUEUE_MUTEX(mutex) \
do { \
__pthread_slist_t *runp = THREAD_GETMEM (THREAD_SELF,
robust_list.__next); \
if (runp == &mutex->__data.__list) \
THREAD_SETMEM(THREAD_SELF, robust_list.__next, runp->__next); \
else \
{ \
while (runp->__next != &mutex->__data.__list) \
runp = runp->__next; \
\
runp->__next = runp->__next->__next; \
mutex->__data.__list.__next = NULL; \
} \
} while (0)
#endif
/* List of cleanup buffers. */
struct _pthread_cleanup_buffer* cleanup;
/* Unwind information. */
struct pthread_unwind_buf* cleanup_jmp_buf;
#define HAVE_CLEANUP_JMP_BUF
/* Flags determining processing of cancellation. */
int cancelhandling;
/* Bit set if cancellation is disabled. */
#define CANCELSTATE_BIT 0
#define CANCELSTATE_BITMASK 0x01
/* Bit set if asynchronous cancellation mode is selected. */
#define CANCELTYPE_BIT 1
#define CANCELTYPE_BITMASK 0x02
/* Bit set if canceling has been initiated. */
#define CANCELING_BIT 2
#define CANCELING_BITMASK 0x04
/* Bit set if canceled. */
#define CANCELED_BIT 3
#define CANCELED_BITMASK 0x08
/* Bit set if thread is exiting. */
#define EXITING_BIT 4
#define EXITING_BITMASK 0x10
/* Bit set if thread terminated and TCB is freed. */
#define TERMINATED_BIT 5
#define TERMINATED_BITMASK 0x20
/* Bit set if thread is supposed to change XID. */
#define SETXID_BIT 6
#define SETXID_BITMASK 0x40
/* Mask for the rest. Helps the compiler to optimize. */
#define CANCEL_RESTMASK 0xffffff80
#define CANCEL_ENABLED_AND_CANCELED(value) \
(((value) & (CANCELSTATE_BITMASK | CANCELED_BITMASK | EXITING_BITMASK
\
| CANCEL_RESTMASK | TERMINATED_BITMASK)) == CANCELED_BITMASK)
#define CANCEL_ENABLED_AND_CANCELED_AND_ASYNCHRONOUS(value) \
(((value) & (CANCELSTATE_BITMASK | CANCELTYPE_BITMASK | CANCELED_BITMASK
\
| EXITING_BITMASK | CANCEL_RESTMASK | TERMINATED_BITMASK)) \
== (CANCELTYPE_BITMASK | CANCELED_BITMASK))
/* We allocate one block of references here. This should be enough
to avoid allocating any memory dynamically for most applications. */
struct pthread_key_data
{
/* Sequence number. We use uintptr_t to not require padding on
32- and 64-bit machines. On 64-bit machines it helps to avoid
wrapping, too. */
uintptr_t seq;
/* Data pointer. */
void* data;
} specific_1stblock[PTHREAD_KEY_2NDLEVEL_SIZE];
/* Two-level array for the thread-specific data. */
struct pthread_key_data* specific[PTHREAD_KEY_1STLEVEL_SIZE];
/* Flag which is set when specific data is set. */
bool specific_used;
/* True if events must be reported. */
bool report_events;
/* True if the user provided the stack. */
bool user_stack;
/* True if thread must stop at startup time. */
bool stopped_start;
/* Lock to synchronize access to the descriptor. */
lll_lock_t lock;
/* Lock for synchronizing setxid calls. */
lll_lock_t setxid_futex;
#if HP_TIMING_AVAIL
/* Offset of the CPU clock at start thread start time. */
hp_timing_t cpuclock_offset;
#endif
/* If the thread waits to join another one the ID of the latter is
stored here.
In case a thread is detached this field contains a pointer of the
TCB if the thread itself. This is something which cannot happen
in normal operation. */
struct pthread* joinid;
/* Check whether a thread is detached. */
#define IS_DETACHED(pd) ((pd)->joinid == (pd))
/* Flags. Including those copied from the thread attribute. */
int flags;
/* The result of the thread function. */
// 线程运⾏完毕,返回值就是void*, 最后的返回值就放在tcb中的该变量⾥⾯
// 所以我们⽤pthread_join获取线程退出信息的时候,就是读取该结构体
// 另外,要能理解线程执⾏流可以退出,但是tcb可以暂时保留,这句话
void* result;
/* Scheduling parameters for the new thread. */
struct sched_param schedparam;
int schedpolicy;
/* Start position of the code to be executed and the argument passed
to the function. */
// ⽤⼾指定的⽅法和参数
void* (*start_routine) (void*);
void* arg;
/* Debug state. */
td_eventbuf_t eventbuf;
/* Next descriptor with a pending event. */
struct pthread* nextevent;
#ifdef HAVE_FORCED_UNWIND
/* Machine-specific unwind info. */
struct _Unwind_Exception exc;
#endif
/* If nonzero pointer to area allocated for the stack and its
size. */
// 线程⾃⼰的栈和⼤⼩
void* stackblock;
size_t stackblock_size;
/* Size of the included guard area. */
size_t guardsize;
/* This is what the user specified and what we will report. */
size_t reported_guardsize;
/* Resolver state. */
struct __res_state res;
/* This member must be last. */
char end_padding[];
#define PTHREAD_STRUCT_END_PADDING \
(sizeof (struct pthread) - offsetof (struct pthread, end_padding))
} __attribute((aligned(TCB_ALIGNMENT)));4.4do_clone
cpp
static int
do_clone(struct pthread* pd, const struct pthread_attr* attr,
int clone_flags, int (*fct)(void*), STACK_VARIABLES_PARMS,
int stopped)
{
#ifdef PREPARE_CREATE
PREPARE_CREATE;
#endif
if (stopped)
/* We Make sure the thread does not run far by forcing it to get a
lock. We lock it here too so that the new thread cannot continue
until we tell it to. */
lll_lock(pd->lock);
/* One more thread. We cannot have the thread do this itself, since it
might exist but not have been scheduled yet by the time we've returned
and need to check the value to behave correctly. We must do it before
creating the thread, in case it does get scheduled first and then
might mistakenly think it was the only thread. In the failure case,
we momentarily store a false value; this doesn't matter because there
is no kosher thing a signal handler interrupting us right here can do
that cares whether the thread count is correct. */
atomic_increment(&__nptl_nthreads);
// 执⾏特性体系结构下的clone函数
if (ARCH_CLONE(fct, STACK_VARIABLES_ARGS, clone_flags,
pd, &pd->tid, TLS_VALUE, &pd->tid) == -1)
{
atomic_decrement(&__nptl_nthreads); /* Oops, we lied for a second. */
/* Failed. If the thread is detached, remove the TCB here since
* the caller cannot do this. The caller remembered the thread
as detached and cannot reverify that it is not since it must
not access the thread descriptor again. */
if (IS_DETACHED(pd))
__deallocate_stack(pd);
return errno;
}
/* Now we have the possibility to set scheduling parameters etc. */
// 下⾯是调⽤相关系统调⽤,设置轻量级进程的调度参数和⼀些异常处理,不关⼼
if (__builtin_expect(stopped != 0, 0))
{
INTERNAL_SYSCALL_DECL(err);
int res = 0;
/* Set the affinity mask if necessary. */
if (attr->cpuset != NULL)
{
res = INTERNAL_SYSCALL(sched_setaffinity, err, 3, pd->tid,
sizeof(cpu_set_t), attr->cpuset);
if (__builtin_expect(INTERNAL_SYSCALL_ERROR_P(res, err), 0))
{
/* The operation failed. We have to kill the thread. First
send it the cancellation signal. */
INTERNAL_SYSCALL_DECL(err2);
err_out:
#if __ASSUME_TGKILL
(void)INTERNAL_SYSCALL(tgkill, err2, 3,
THREAD_GETMEM(THREAD_SELF, pid),
pd->tid, SIGCANCEL);
#else
(void)INTERNAL_SYSCALL(tkill, err2, 2, pd->tid, SIGCANCEL);
#endif
return (INTERNAL_SYSCALL_ERROR_P(res, err)
? INTERNAL_SYSCALL_ERRNO(res, err)
: 0);
}
}
/* Set the scheduling parameters. */
if ((attr->flags & ATTR_FLAG_NOTINHERITSCHED) != 0)
{
res = INTERNAL_SYSCALL(sched_setscheduler, err, 3, pd->tid,
pd->schedpolicy, &pd->schedparam);
if (__builtin_expect(INTERNAL_SYSCALL_ERROR_P(res, err), 0))
goto err_out;
}
}
/* We now have for sure more than one thread. The main thread might
not yet have the flag set. No need to set the global variable
again if this is what we use. */
THREAD_SETMEM(THREAD_SELF, header.multiple_threads, 1);
return 0;
}5.线程封装
cpp
#pragma once
#include <iostream>
#include <string>
#include <functional>
#include <pthread.h>
namespace ThreadModule
{
static int gnumber = 1;
using callback_t = std::function<void()>;
enum class TSTATUS
{
THREAD_NEW,
THREAD_RUNNING,
THREAD_STOP
};
std::string Status2String(TSTATUS s)
{
switch (s)
{
case TSTATUS::THREAD_NEW:
return "THREAD_NEW";
case TSTATUS::THREAD_RUNNING:
return "THREAD_RUNNING";
case TSTATUS::THREAD_STOP:
return "THREAD_STOP";
default:
return "UNKNOWN";
}
}
std::string IsJoined(bool joinable)
{
return joinable ? "true" : "false";
}
class Thread
{
private:
void ToRunning()
{
_status = TSTATUS::THREAD_RUNNING;
}
void ToStop()
{
_status = TSTATUS::THREAD_STOP;
}
static void *ThreadRoutine(void *args)
{
Thread *self = static_cast<Thread *>(args);
pthread_setname_np(self->_tid, self->_name.c_str());
self->_cb();
self->ToStop();
return nullptr;
}
public:
Thread(callback_t cb)
: _tid(-1), _status(TSTATUS::THREAD_NEW), _joinable(true), _cb(cb), _result(nullptr)
{
_name = "New-Thread-" + std::to_string(gnumber++);
}
bool Start()
{
int n = pthread_create(&_tid, nullptr, ThreadRoutine, this);
if (n != 0)
return false;
ToRunning();
return true;
}
void Join()
{
if (_joinable)
{
int n = pthread_join(_tid, &_result);
if (n != 0)
{
std::cerr << "join error: " << n << std::endl;
return;
}
(void)_result;
_status = TSTATUS::THREAD_STOP;
}
else
{
std::cerr << "error, thread join status: " << IsJoined(_joinable) << std::endl;
}
}
// 暂停
// void Stop() // restart()
// {
// // 让线程暂停
// }
void Die()
{
if (_status == TSTATUS::THREAD_RUNNING)
{
pthread_cancel(_tid);
_status = TSTATUS::THREAD_STOP;
}
}
void Detach()
{
if (_status == TSTATUS::THREAD_RUNNING && _joinable)
{
pthread_detach(_tid);
_joinable = false;
}
else
{
std::cerr << "detach " << _name << " failed" << std::endl;
}
}
void PrintInfo()
{
std::cout << "thread name : " << _name << std::endl;
std::cout << "thread _tid : " << _tid << std::endl;
std::cout << "thread _status : " << Status2String(_status) << std::endl;
std::cout << "thread _joinable : " << IsJoined(_joinable) << std::endl;
}
~Thread()
{
}
private:
std::string _name;
pthread_t _tid;
TSTATUS _status;
bool _joinable;
// 线程要有自己的任务处理,即回调函数
callback_t _cb;
// 线程退出信息
void *_result;
};
}- pthread_setname_np和pthread_getname_np是两个用于设置和获取线程名称的非标准函数(np表示"non-portable",即非可移植的)。它们通常在Linux和其他一些类Unix系统中可用,用于调试和多线程程序的管理
- 线程名称长度限制:在Linux上,线程名称的最大长度为16个字符(包括结尾的\0)。如果名称超过这个长度,会被截断。
- 权限:通常,只有线程自身可以设置自己的名称。尝试设置其他线程的名称可能会导致错误。
cpp
#include "Thread.hpp"
#include <unistd.h>
#include <ctime>
#include <cstdlib>
#include <vector>
#include <signal.h>
#include <wait.h>
class Task
{
public:
Task(int x, int y):_x(x), _y(y)
{}
void Execute()
{
// signal(SIGCHLD, SIG_IGN);
pid_t id = fork();
if(id == 0)
{
execl("/usr/bin/ls", "ls", "-a", "-l", nullptr);
exit(0);
}
sleep(1);
wait(nullptr);
}
void Print()
{
std::cout << _x << " + " << _y << " = " << _result << std::endl;
}
private:
int _x;
int _y;
int _result;
};
int main()
{
Task tk(10, 20); // 任务类
ThreadModule::Thread t([&tk]()->void{
tk.Execute();
});
t.Start();
t.Join();
tk.Print();
return 0;
}6.线程同步与互斥
6.1线程互斥
- 共享资源
- 临界资源:多线程执行流被保护的共享的资源就叫做临界资源
- 临界区:每个线程内部,访问临界资源的代码就叫做临界区
- 互斥:任何时刻,互斥保证有且只有一个执行流进入临界区,访问临界资源,通常对临界资起保护作用
- 原子性(后面讨论如何实现):不会被任何调度机制打断的操作,该操作只有两态,要么完成,要么未完成
6.1.1互斥量mutex
- 大部分情况,线程使用的数据都是局部变量,变量的地址空间在线程栈空间内,这种情况,变量归属单个线程,其他线程无法获得这种变量。
- 但有时候,很多变量都需要在线程间共享,这样的变量称为共享变量,可以通过数据的共享,完成线程之间的交互。
- 多个线程并发的操作共享变量,可能会导致数据不一致问题。
cpp
// 操作共享变量会有问题的售票系统代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
int ticket = 100;
void* route(void* arg)
{
char* id = (char*)arg;
while (1) {
if (ticket > 0) {
usleep(1000);
printf("%s sells ticket:%d\n", id, ticket);
ticket--;
}
else {
break;
}
}
return 0;
}
int main()
{
pthread_t t1, t2, t3, t4;
pthread_create(&t1, NULL, route, (void*)"thread 1");
pthread_create(&t2, NULL, route, (void*)"thread 2");
pthread_create(&t3, NULL, route, (void*)"thread 3");
pthread_create(&t4, NULL, route, (void*)"thread 4");
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_join(t3, NULL);
pthread_join(t4, NULL);
}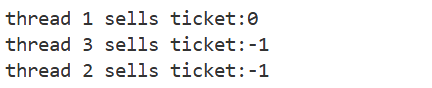
- usleep的目的就是为了出现内存不一致问题。
- 代码中的ticket--操作在汇编语言中其实是有3步的。
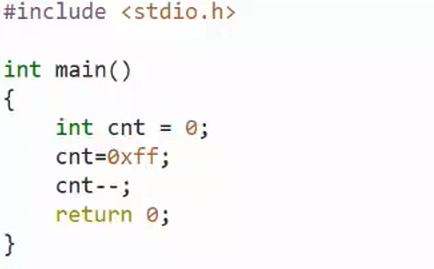
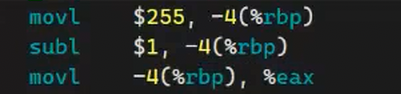
1.把内存中的变量加载到寄存器
2.在寄存器中把变量做减操作
3.再把变量从寄存器中加载回内存。
编译器导致数据不一致问题的步骤:
- 第一个线程把内存中的数据加载到寄存器,还没开始做减法操作,时间片就到了,该进程被切走,寄存器中的上下文被保存在进程中,内容:eax:100 ,执行的代码位置:eax--;
- 第二个线程被执行时,拿到的数据还是100,可能这个线程的时间片非常足,一致把该变量减到了50,此时线程2被切走,进程中的内容:eax:50 执行代码的位置:eax-- ;
- 这次cpu调度的是第一个线程,此时该线程中ezx的内容是100,然后cpu要做的操作是把eax--,减到99,再把99加载回内存,可是该变量在之前的线程中已经被减到50,这次线程运行又把变量变回了99.
全局变量的++和--操作对于多线程会导致数据不一致问题,这种问题可能会导致,线程崩溃和逻辑错误,进而引起线程安全问题。
- if判断语句也会出现该问题
- 当变量减到0时,第一个线程通过if语句判断,>=0,允许进行减操作,但是可能会出现,还没来得及减操作,该线程就被切到下一个线程,此时第一个线程,寄存器内容:0 ,操作:eax--
- 由于第一个线程没来得及做减操作,或减操作结束,但没加载回内存,此时内存中的变量内容还是0,但该变量并没有被加载到寄存器,第二个线程又被切走了。
- 回到第一个线程,操作结束后把-1加载回内存,第二个线程开始运行,由于上次运行,变量数据被判定为0,但此时数据已经变为-1,线程2还要对变量做减操作,此时就导致了逻辑错误。
6.1.2解决问题
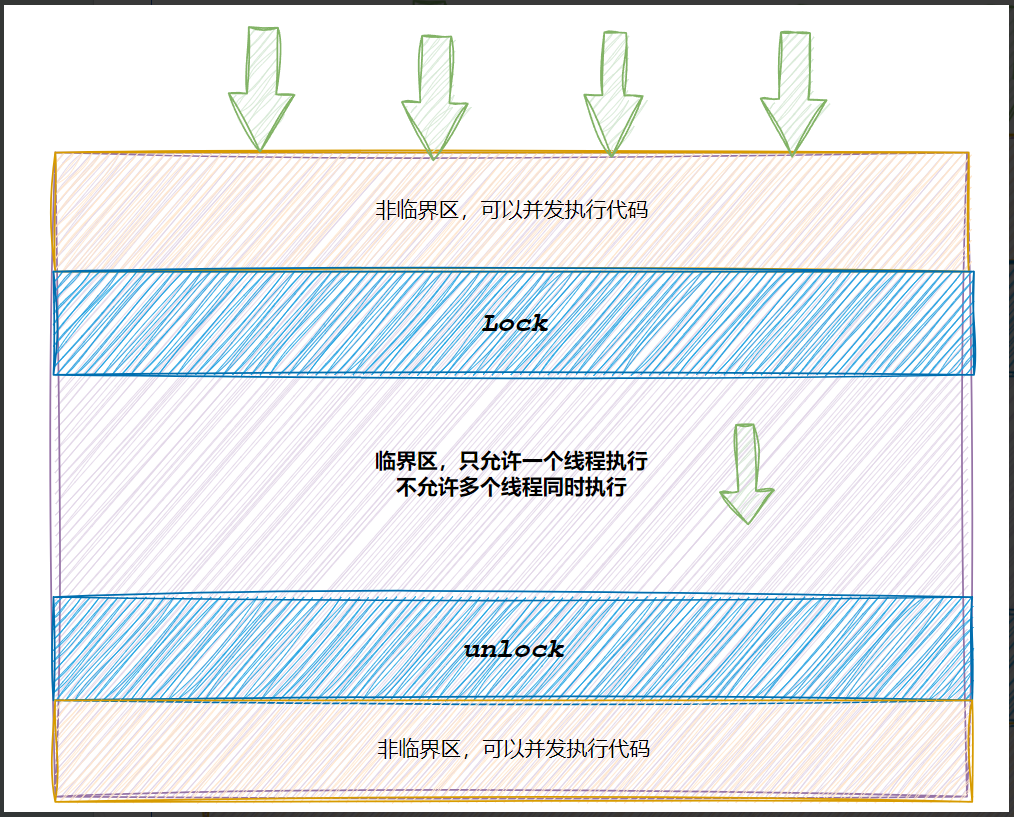

- 我们把会导致问题的共享资源称为临界资源,要把临界资源保护起来。
- 访问临界资源的代码叫做临界区
- 保护临界资源,本质是保护临界区(互斥保护)
- 互斥保护:被保护起来的临界区代码,在同一时间段内只能有一个线程访问,只有当该线程完全执行结束临界区的代码,下一个线程才被允许访问临界区代码,就是串型执行临界区代码。
- 我们需要用锁来对临界区代码进行保护。
线程锁
现象演示:
cpp
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
//定义互斥锁
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
int ticket = 100;
void* route(void* arg)
{
char* id = (char*)arg;
while (1)
{
//临界区加锁
pthread_mutex_lock(&mutex);
if (ticket > 0)
{
usleep(1000);
printf("%s sells ticket:%d\n", id, ticket);
ticket--;
//临界区解锁
pthread_mutex_unlock(&mutex);
}
else
{
pthread_mutex_unlock(&mutex);
break;
}
//不能放在这里解锁,因为线程通过break跳出循环后,临界区没有解锁
//pthread_mutex_unlock(&mutex);
}
return 0;
}
int main()
{
pthread_t t1, t2, t3, t4;
pthread_create(&t1, NULL, route, (void*)"thread 1");
pthread_create(&t2, NULL, route, (void*)"thread 2");
pthread_create(&t3, NULL, route, (void*)"thread 3");
pthread_create(&t4, NULL, route, (void*)"thread 4");
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_join(t3, NULL);
pthread_join(t4, NULL);
}
问题:
1.加锁原则问题:
加锁会导致效率降低,所以加锁的力度越小越好。
2.mutex是共享资源,谁来保护?
lock&unlock被设计成为了原子的。
原子性:该操作不会被任何调度机制打断,该操作只有两种形态,要么完成,要么未完成,比如不会被线程调度打断。
3.申请锁失败的线程,在做什么?
申请失败的线程就必须在锁上阻塞等待,加锁可以保证原子性。
4.只对个别线程加锁,一些线程不加锁,这种操作是无意义的。
局部锁:
cpp
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
#include<string>
//定义互斥锁
// pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
class thread_data
{
public:
thread_data(pthread_mutex_t* mtx, std::string n)
{
pmutex = mtx;
name = n;
}
public:
pthread_mutex_t* pmutex;
std::string name;
};
int ticket = 100;
void* route(void* arg)
{
thread_data* td = (thread_data*)arg;
// char* id = (char*)arg;
while (1)
{
// pthread_mutex_t& mutex = *(td->pmutex);
//临界区加锁
pthread_mutex_lock(td->pmutex);
if (ticket > 0)
{
usleep(1000);
printf("%s sells ticket:%d\n", td->name.c_str(), ticket);
ticket--;
//临界区解锁
pthread_mutex_unlock(td->pmutex);
}
else
{
pthread_mutex_unlock(td->pmutex);
break;
}
//不能放在这里解锁,因为线程通过break跳出循环后,临界区没有解锁
//pthread_mutex_unlock(&mutex);
}
return 0;
}
int main()
{
pthread_mutex_t mutex;
pthread_mutex_init(&mutex, nullptr);
pthread_t t1, t2, t3, t4;
thread_data td1(&mutex, "thread 1");
thread_data td2(&mutex, "thread 2");
thread_data td3(&mutex, "thread 3");
thread_data td4(&mutex, "thread 4");
pthread_create(&t1, NULL, route, (void*)&td1);
pthread_create(&t2, NULL, route, (void*)&td2);
pthread_create(&t3, NULL, route, (void*)&td3);
pthread_create(&t4, NULL, route, (void*)&td4);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_join(t3, NULL);
pthread_join(t4, NULL);
}锁的原理:
软件实现:
- 经过上面的例子,大家已经意识到单纯的i++或者++i都不是原子的,有可能会有数据一致性问题
- 为了实现互斥锁操作,大多数体系结构都提供了swap或exchange指令,该指令的作用是把寄存器和内存单元的数据相交换,由于只有一条指令,保证了原子性,即使是多处理器平台,访问内存的总线周期也有先后,一个处理器上的交换指令执行时另一个处理器的交换指令只能等待总线周期。在我们把lock和unlock的伪代码改一下
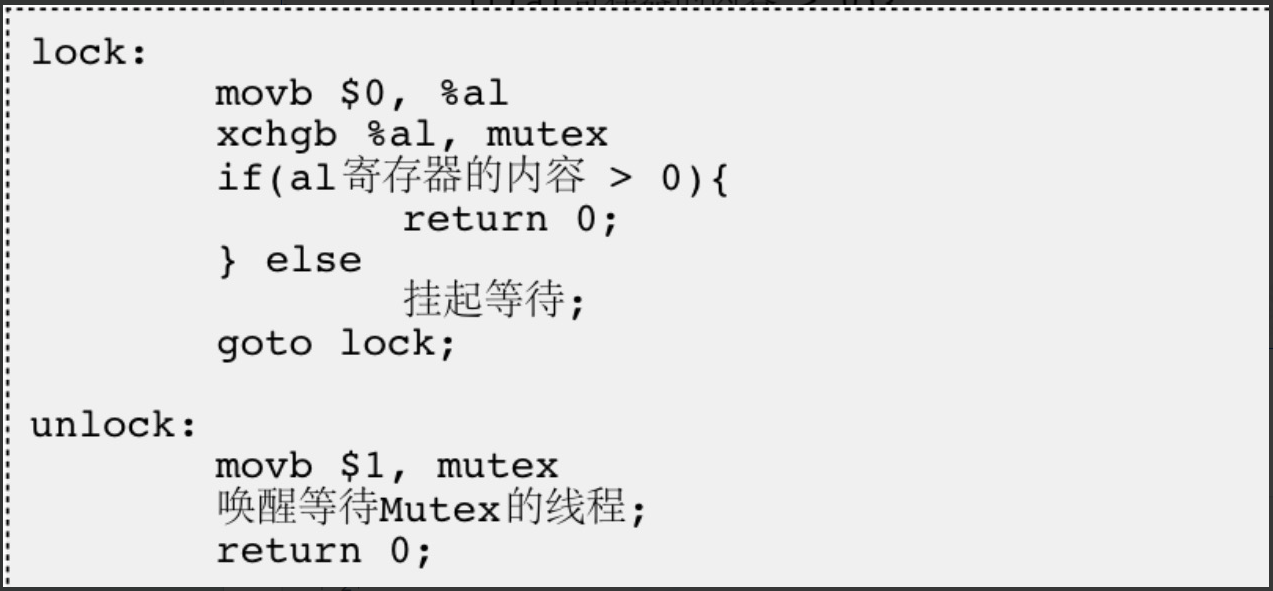
具体实现步骤:
- 锁变量mutex中存储的变量是1,通过伪代码我们可以看到,cpu执行一个线程A,把cpu寄存器al的数据初始化为0,然后把内存中mutex的数据"1"与寄存器al交换,交换后mutex的内容就变为了0,寄存器中的内容就变为了1.
- 如果此时发生线程切换,al中的数据"1"被线程A拿走,成为自己的上下文,此时线程B被cpu调度也执行同样的代码,初始化al寄存器为"0",但此时mutex中的数据也为0,所以交换后,线程B的al中的数据依旧为0.
- 这种情况下,不管之后来多少线程执行该段代码,最终的结果都是自己的al寄存器中的值为0。
- 如果线程B交换结束后,还没被切走,继续执行,只会陷入"初始化al,交换al与mutex,如果为0,继续初始化al......"的死循环。
- 直到cpu再次开始调度线程A,线程A的al寄存器中为1,从上次被切走的位置继续执行,判断al中的内容是否大于0。
- 大于0,退出函数,有资格执行临界区的代码,此时其他线程还被困在死循环中。
- **转折点:**直到线程A执行结束临界区的代码,线程A执行解锁代码,将mutex中的内容置为1,解锁成功,自己退出解锁函数。
- 此时线程B被cpu再调度,进程B终于从死循环中解脱,发现自己交换数据后,自己的al寄存器中的数据变为1,mutex再次变为0,线程B上锁成功,被允许执行临界区的代码。
这就实现了只有当前线程执行结束临界区的代码,下一个进程才允许被放进来执行代码。
换个角度理解:
mutex就像一个钥匙,被放在工厂外,工人们(线程)需要抢夺钥匙来进入工厂,完成自己的任务,拿到钥匙的人可以进入工厂,没拿到钥匙的人就一直在放置钥匙的位置一直等,直到钥匙被上一个完成任务的工人送回来,下一个工人才可以拿到钥匙,做自己的工作。
**硬件实现:**在给代码上锁时,在临界区代码开始时,关闭硬件的时钟中断,代码执行结束后,再打开时钟中断。
使用C++完成加锁和解锁
cpp
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
#include<string>
#include<mutex>
//定义互斥锁
// pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
class thread_data
{
public:
thread_data(pthread_mutex_t* mtx, std::string n)
{
pmutex = mtx;
name = n;
}
public:
pthread_mutex_t* pmutex;
std::string name;
};
std::mutex mtx;
int ticket = 100;
void* route(void* arg)
{
thread_data* td = (thread_data*)arg;
// char* id = (char*)arg;
while (1)
{
// pthread_mutex_t& mutex = *(td->pmutex);
//临界区加锁
// pthread_mutex_lock(td->pmutex);
mtx.lock();
if (ticket > 0)
{
usleep(1000);
printf("%s sells ticket:%d\n", td->name.c_str(), ticket);
ticket--;
//临界区解锁
// pthread_mutex_unlock(td->pmutex);
mtx.unlock();
}
else
{
// pthread_mutex_unlock(td->pmutex);
mtx.unlock();
break;
}
//不能放在这里解锁,因为线程通过break跳出循环后,临界区没有解锁
//pthread_mutex_unlock(&mutex);
}
return 0;
}
int main()
{
pthread_mutex_t mutex;
pthread_mutex_init(&mutex, nullptr);
pthread_t t1, t2, t3, t4;
thread_data td1(&mutex, "thread 1");
thread_data td2(&mutex, "thread 2");
thread_data td3(&mutex, "thread 3");
thread_data td4(&mutex, "thread 4");
pthread_create(&t1, NULL, route, (void*)&td1);
pthread_create(&t2, NULL, route, (void*)&td2);
pthread_create(&t3, NULL, route, (void*)&td3);
pthread_create(&t4, NULL, route, (void*)&td4);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_join(t3, NULL);
pthread_join(t4, NULL);
}7.锁的封装
cpp
#pragma once
#include <iostream>
#include <pthread.h>
class Mutex
{
public:
Mutex()
{
pthread_mutex_init(&_lock, nullptr);
}
void Lock()
{
pthread_mutex_lock(&_lock);
}
void Unlock()
{
pthread_mutex_unlock(&_lock);
}
~Mutex()
{
pthread_mutex_destroy(&_lock);
}
private:
pthread_mutex_t _lock;
};
class LockGuard // RAII风格代码
{
public:
LockGuard(Mutex &lock):_lockref(lock)
{
_lockref.Lock();
}
~LockGuard()
{
_lockref.Unlock();
}
private:
Mutex &_lockref;
};
cpp
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
#include "Mutex.hpp"
int ticket = 1000;
Mutex lock;
void *route(void *arg)
{
char *id = (char *)arg;
while (1)
{
printf("AAAAAA\n");
// 临界区!
{
LockGuard lockguard(lock);
if (ticket > 0)
{
usleep(1000);
printf("%s sells ticket:%d\n", id, ticket);
ticket--;
}
else
{
break;
}
}
printf("AAAAAA\n");
}
return nullptr;
}
int main(void)
{
pthread_t t1, t2, t3, t4;
pthread_create(&t1, NULL, route, (void *)"thread 1");
pthread_create(&t2, NULL, route, (void *)"thread 2");
pthread_create(&t3, NULL, route, (void *)"thread 3");
pthread_create(&t4, NULL, route, (void *)"thread 4");
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_join(t3, NULL);
pthread_join(t4, NULL);
}8.线程同步
在临界资源安全的前提下,让访问临界资源具有一定的顺序性。
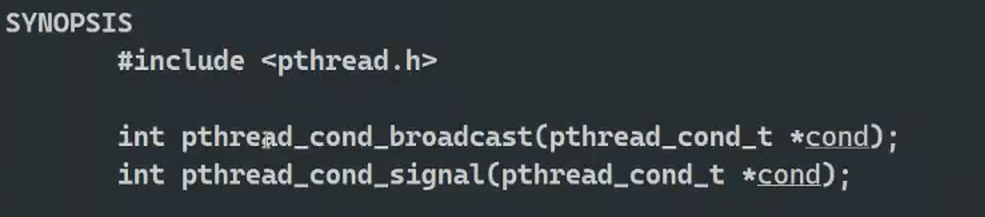
8.1条件变量
8.1.1线程同步的方法
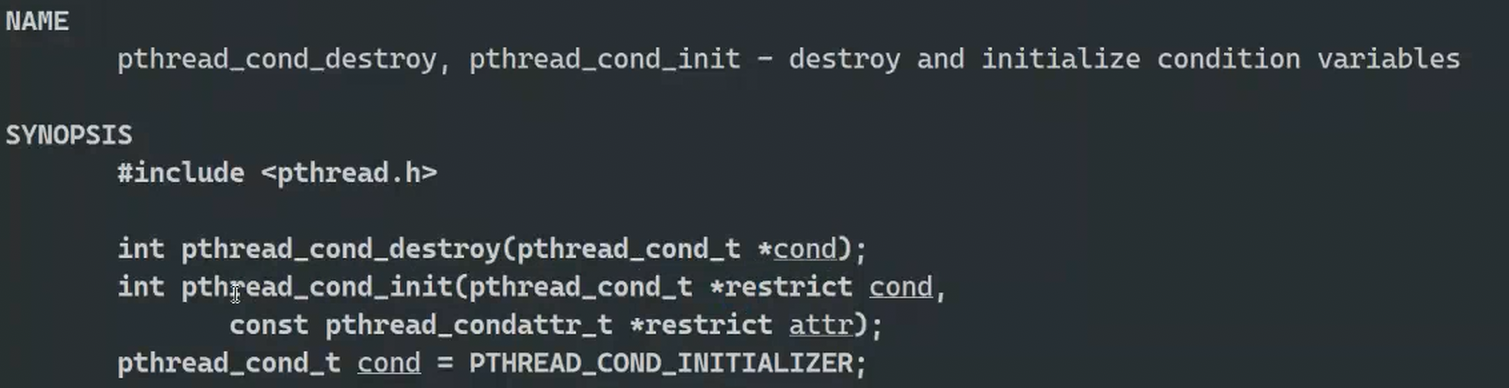
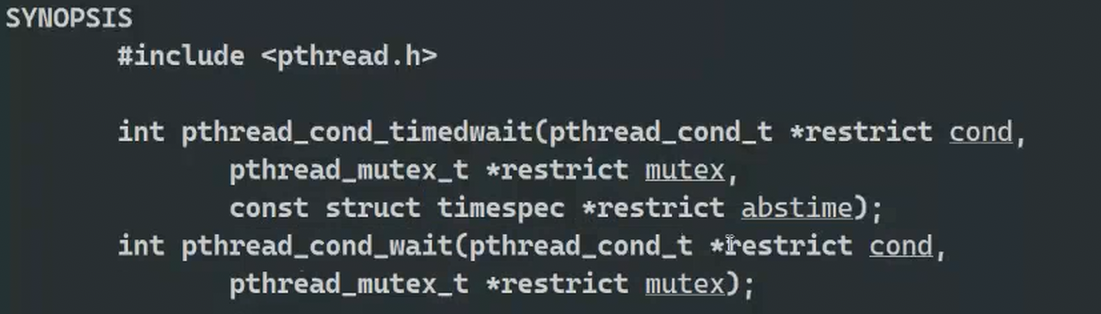
8.1.2生产者消费者模型
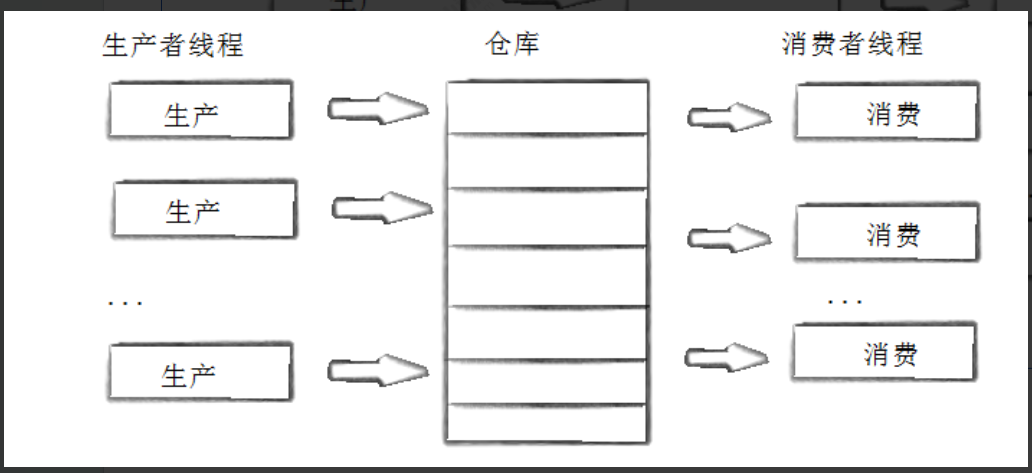
- 生产者消费者模式是一种多线程协同方案,由生产者提供资源,由消费者消耗资源。
- 生产者和消费者线程可以有一个或多个
- 图中的仓库就是共享/临界资源
- 生成者线程与线程生成者之间是互斥关系
- 消费者线程与消费者线程之间也是互斥关系
- 生成者线程与消费者线程之间是同步&& ||互斥关系

生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个阻塞队列就是用来给生产者和消费者解耦的
生产者消费者模型是多线程协同的一种模式,提高协作效率,本质是一种通信工作。
生产者线程创作问题,创造工作,消费者线程解决问题,处理工作。
**优点:**解耦,支持并发,支持忙闲不均。
8.1.3理解条件变量
由生产者线程提供数据资源,由消费者线程获取数据资源,临界区就是交换传输资源的场所。
如果没有条件变量:
- 生产者线程申请锁资源,进入临界区,查看是否存在未被处理的资源,如果没有,放入数据资源,释放锁资源。
- 生产者线程刚放入资源,为了提高效率,将下一份资源放入,还没等消费者线程申请锁拿资源,生产者线程为了检查临界区中的资源是否被拿走,又一次的申请锁资源。
- 因为生产者线程一直在申请锁一直都是生产者线程在执行放入资源的流程,消费者线程无法申请到锁资源,无法拿到资源,进而导致线程阻塞,降低效率
条件变量的作用:
- 在生成者线程放入资源后,生成者会处于条件变量的状态(类似处于一种容器),不会再去申请锁资源,查看临界区中的资源是否被处理。
- 此时没有线程与消费者线程争抢锁资源,消费者线程进入临界区拿到资源后,更改条件变量的状态,通知容器中的生成者线程,临界区没有资源了,让生产者继续放入资源。

生成者线程处于等待状态

通知生产者线程继续放入数据
扩展:
多个生成者线程:当临界区资源满后,后面的生成者线程检查一次,发现临界区中的资源还未被拿走,就会进入等待队列中。

消费者线程处理结束资源后,signal函数唤醒一个生产者线程,broadcast唤醒全部的生产者线程
多消费者线程:消费者线程等待队列,生产者或消费者一方放入或获取资源,就会唤醒对方的等待队列中的线程,让对方运行。
8.1.4编码--接口使用
测试接口
cpp
#include<iostream>
#include<pthread.h>
#include<string>
#include<unistd.h>
using namespace std;
pthread_mutex_t gmutex = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t gcond = PTHREAD_COND_INITIALIZER;
void* Print(void* arg)
{
string name = (char*)arg;
while(true)
{
pthread_mutex_lock(&gmutex);
std::cout<<name<<" is waiting for cond var"<<std::endl;
pthread_mutex_unlock(&gmutex);
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t tids[4];
for(int i=0;i<4;i++)
{
char* name = new char[64];
snprintf(name,64,"thread-%d",i+1);
pthread_create(tids+i,nullptr,Print,(void*)name);
}
for(int i=0;i<4;i++)
{
pthread_join(tids[i],nullptr);
}
}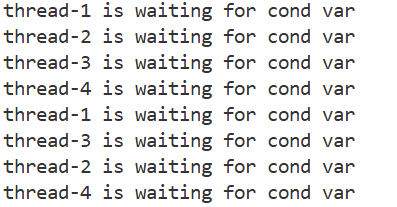
- 可以看到打印是无序的
有序打印,引入条件变量,一个一个唤醒
cpp
#include<iostream>
#include<pthread.h>
#include<string>
#include<unistd.h>
using namespace std;
pthread_mutex_t gmutex = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t gcond = PTHREAD_COND_INITIALIZER;
void* Print(void* arg)
{
string name = (char*)arg;
while(true)
{
pthread_mutex_lock(&gmutex);
std::cout<<name<<" is waiting for cond var"<<std::endl;
pthread_cond_wait(&gcond,&gmutex);
pthread_mutex_unlock(&gmutex);
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t tids[4];
for(int i=0;i<4;i++)
{
char* name = new char[64];
snprintf(name,64,"thread-%d",i+1);
pthread_create(tids+i,nullptr,Print,(void*)name);
sleep(1);
}
while(true)
{
pthread_cond_signal(&gcond);
sleep(1);
}
for(int i=0;i<4;i++)
{
pthread_join(tids[i],nullptr);
}
}一次性唤醒全部线程
cp模型代码--基于阻塞队列
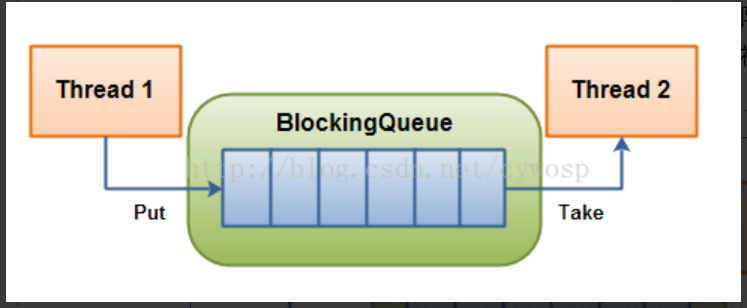
在多线程编程中阻塞队列(BlockingQueue)是一种常用于实现生产者和消费者模型的数据结构。其与普通的队列区别在于,当队列为空时,从队列获取元素的操作将会被阻塞,直到队列中被放入了元素;当队列满时,往队列里存放元素的操作也会被阻塞,直到有元素被从队列中取出(以上的操作都是基于不同的线程来说的,线程在对阻塞队列进程操作时会被阻塞
为什么线程在条件变量中等的时候需要把锁传递进去:等待的时候,是在临界区内部等待的,需要把锁传进去,让pthread_cond_wait自动释放mutex锁,当线程被唤醒的时候,pthread_cond_wait会自动竞争锁,把锁给被唤醒的线程。
cpp
#ifndef __BLOCK_QUEUE_H
#define __BLOCK_QUEUE_H
#include <iostream>
#include <queue>
#include <pthread.h>
const int defaultcap = 5;
template <typename T>
class BlockQueue
{
public:
BlockQueue(int cap = defaultcap): _cap(cap)
{
pthread_mutex_init(&_mutex, nullptr);
pthread_cond_init(&_consumer_cond, nullptr);
pthread_cond_init(&_productor_cond, nullptr);
// _blockqueue_low_water = _cap*1/3;
// _blockqueue_high_water = _cap*2/3;
sleep_productor_num = 0;
sleep_consumer_num = 0;
}
void Enqueue(T &in) // 生产者
{
pthread_mutex_lock(&_mutex);
while(_bq.size() == _cap)
{
sleep_productor_num++;
pthread_cond_wait(&_productor_cond, &_mutex);
sleep_productor_num--;
}
_bq.push(in);
// if(_bq.size() > _blockqueue_high_water)
// pthread_cond_signal(&_consumer_cond);
if(sleep_consumer_num > 0)
pthread_cond_signal(&_consumer_cond);
pthread_mutex_unlock(&_mutex);
}
void Pop(T *out) // 消费者
{
pthread_mutex_lock(&_mutex);
while(_bq.empty())
{
sleep_consumer_num++;
pthread_cond_wait(&_consumer_cond, &_mutex); // 1. 过量的唤醒信息 2. 函数调用失败 3. 伪唤醒
sleep_consumer_num--;
}
*out = _bq.front();
_bq.pop();
// if(_bq.size() < _blockqueue_low_water)
// pthread_cond_signal(&_productor_cond);
if(sleep_productor_num > 0)
pthread_cond_signal(&_productor_cond);
pthread_mutex_unlock(&_mutex);
}
~BlockQueue()
{
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_consumer_cond);
pthread_cond_destroy(&_productor_cond);
}
private:
std::queue<T> _bq;
int _cap;
pthread_mutex_t _mutex;
pthread_cond_t _consumer_cond;
pthread_cond_t _productor_cond;
// 1. 水位线
// int _blockqueue_low_water; // bq低水位线
// int _blockqueue_high_water; // bq高水位线
// 2. sleep thread num
int sleep_productor_num;
int sleep_consumer_num;
};
#endif
cpp
#include "blockqueue.hpp"
#include <unistd.h>
int num = 1;
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
int GetNumber()
{
pthread_mutex_lock(&lock);
int number = num++;
pthread_mutex_unlock(&lock);
return number;
}
void *ConsumerRoutine(void *args)
{
int nunmber = GetNumber();
std::string name = "Consumer-" + std::to_string(nunmber);
pthread_setname_np(pthread_self(), name.c_str());
BlockQueue<int> *bq = static_cast<BlockQueue<int> *>(args);
while (true)
{
sleep(5);
int data;
bq->Pop(&data);
std::cout << name << " 消费: " << data << std::endl;
}
}
void *ProductorRouine(void *args)
{
int nunmber = GetNumber();
std::string name = "Productor-" + std::to_string(nunmber);
pthread_setname_np(pthread_self(), name.c_str());
BlockQueue<int> *bq = static_cast<BlockQueue<int> *>(args);
int data = 10;
while (true)
{
bq->Enqueue(data);
std::cout << name << " 生产: " << data++ << std::endl;
}
}
int main()
{
BlockQueue<int> *bq = new BlockQueue<int>();
pthread_t c, p;
pthread_create(&c, nullptr, ConsumerRoutine, bq);
pthread_create(&p, nullptr, ProductorRouine, bq);
pthread_join(c, nullptr);
pthread_join(p, nullptr);
// pthread_t c[3], p[2];
// pthread_create(c, nullptr, ConsumerRoutine, bq);
// pthread_create(c + 1, nullptr, ConsumerRoutine, bq);
// pthread_create(c + 2, nullptr, ConsumerRoutine, bq);
// pthread_create(p, nullptr, ProductorRouine, bq);
// pthread_create(p + 1, nullptr, ProductorRouine, bq);
// pthread_join(c[0], nullptr);
// pthread_join(c[1], nullptr);
// pthread_join(c[2], nullptr);
// pthread_join(p[0], nullptr);
// pthread_join(p[1], nullptr);
return 0;
}C++封装锁和条件变量
cpp
#pragma once
#include <iostream>
#include <pthread.h>
class Mutex
{
public:
Mutex()
{
pthread_mutex_init(&_lock, nullptr);
}
void Lock()
{
pthread_mutex_lock(&_lock);
}
pthread_mutex_t *Ptr()
{
return &_lock;
}
void Unlock()
{
pthread_mutex_unlock(&_lock);
}
~Mutex()
{
pthread_mutex_destroy(&_lock);
}
private:
pthread_mutex_t _lock;
};
class LockGuard // RAII风格代码
{
public:
LockGuard(Mutex &lock):_lockref(lock)
{
_lockref.Lock();
}
~LockGuard()
{
_lockref.Unlock();
}
private:
Mutex &_lockref;
};
cpp
#ifndef __COND_HPP
#define __COND_HPP
#include <pthread.h>
#include "Mutex.hpp"
class Cond
{
public:
Cond()
{
pthread_cond_init(&_cond, nullptr);
}
void Wait(Mutex &mutex)
{
int n = pthread_cond_wait(&_cond, mutex.Ptr());
(void)n;
}
void Signal()
{
int n = pthread_cond_signal(&_cond);
(void)n;
}
void Broadcast()
{
int n = pthread_cond_broadcast(&_cond);
(void)n;
}
~Cond()
{
pthread_cond_destroy(&_cond);
}
private:
pthread_cond_t _cond;
};
#endif生产消费者模型高效:生产者获取任务,消费者处理任务都是需要时间的,每生产一个任务,来一个消费者处理任务,所有消费者共同处理任务的过程就是并发,提升处理速度,刚好在消费者处理任务的这段时间中,所有生产者把自己的任务都交给了消费者去处理,生产者都在共同的获取任务,也是一种并发,提高效率。
8.2POSIX信号量
8.2.1概念
信号量本质是一个计数器,是对资源的预定机制。
描述临界资源中,资源数目的计数器。
8.2.2信号量接口

- 初始化信号量
- 参数2:选择进程间信号量还是线程间信号量,传参为0,表示线程间信号量。
- 参数3:给信号量定义初始值。

- 消除不再使用的信号量。

- 获得一个信号量,让信号量计数器减减。
- sem_wait:申请失败会使线程阻塞。
- 申请成功返回0,失败返回-1

- 释放一个信号量,对信号量做++
8.2.3新的cp问题---环形缓冲区
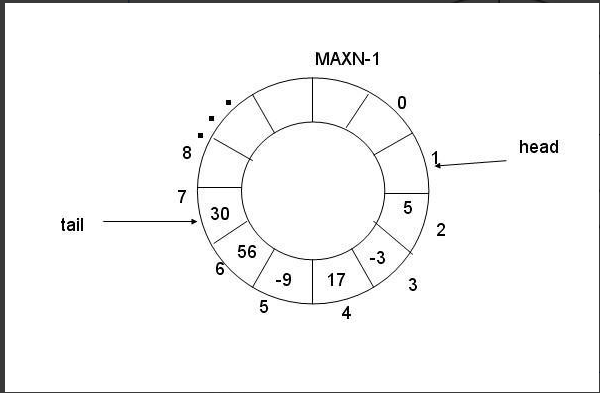
环形队列:使用数组和取模运算实现。
- 当环形队列为空时:head==tall
- 当环形队列为满时:head==tall
- 其他情况:head!=tall
- 区分是否为空和满:计数器,浪费一个位置
使用多线程,基于环形队列进行数据交换,多线程并发访问环形队列,环形对列为空时,优先运行生产者线程,环形队列为满时,优先运行消费者线程,其他情况并发生产消费。
线程引入环形队列
这一模型需要两个信号量
- 生产者角度:环形队列中为空的节点是资源,是信号量
- 消费者角度:环形队列中不为空的节点是资源,是信号量。
- 生产者:申请信号量(生产者信号量--) -> 生产数据 -> 消费者信号量++
- 消费者:申请信号量(消费者信号量--)-> 处理数据 -> 生产者信号量++
8.2.4编码
信号量封装:
cpp
#ifndef __SEM_HPP
#define __SEM_HPP
#include <iostream>
#include <semaphore.h>
class Sem
{
public:
Sem(int init_val)
{
if (init_val >= 0)
{
int n = sem_init(&_sem, 0, init_val);
(void)n;
}
}
void P()
{
int n = sem_wait(&_sem);
(void)n;
}
void V()
{
int n = sem_post(&_sem);
(void)n;
}
~Sem()
{
int n = sem_destroy(&_sem);
(void)n;
}
private:
sem_t _sem;
};
#endif
cpp
#pragma once
#include <iostream>
#include <pthread.h>
class Mutex
{
public:
Mutex()
{
pthread_mutex_init(&_lock, nullptr);
}
void Lock()
{
pthread_mutex_lock(&_lock);
}
pthread_mutex_t *Ptr()
{
return &_lock;
}
void Unlock()
{
pthread_mutex_unlock(&_lock);
}
~Mutex()
{
pthread_mutex_destroy(&_lock);
}
private:
pthread_mutex_t _lock;
};
class LockGuard // RAII风格代码
{
public:
LockGuard(Mutex &lock):_lockref(lock)
{
_lockref.Lock();
}
~LockGuard()
{
_lockref.Unlock();
}
private:
Mutex &_lockref;
};
cpp
#pragma once
#include <iostream>
#include <string>
#include <vector>
#include <pthread.h>
#include "Sem.hpp"
#include "Mutex.hpp"
// header only .hpp
const int defaultcap = 5;
template <typename T>
class RingQueue
{
public:
RingQueue(int cap = defaultcap)
: _cap(cap),
_rq(cap),
_consumer_step(0),
_productor_step(0),
_blank_sem(cap),
_data_sem(0)
{
}
void Enqueue(T &in) // 生产者调用 --- mutex
{
// 1. 预定资源
_blank_sem.P(); // 买票
{
LockGuard lockguard(_pmutex); // 排队
// 2. 找位置生产
_rq[_productor_step++] = in;
_productor_step %= _cap;
}
// 3. 释放数据资源
_data_sem.V();
}
void Pop(T *out) // 消费者调用 --- mutex
{
_data_sem.P();
{
LockGuard lockguard(_cmutex);
*out = _rq[_consumer_step++];
_consumer_step %= _cap;
}
_blank_sem.V();
}
~RingQueue()
{
}
private:
int _cap; // 环形队列的容量
std::vector<T> _rq; // 环形队列
int _consumer_step; // 消费位置
int _productor_step; // 生产位置
Sem _blank_sem; // 格子资源计数器,生产者关心
Sem _data_sem; // 数据信号量,消费者关心
Mutex _cmutex;
Mutex _pmutex;
};
cpp
#ifndef __TASK_HPP
#define __TASK_HPP
#include <iostream>
#include <string>
#include <functional>
// using task_t = std::function<void()>;
// void Print()
// {
// std::cout << "我是一个任务...." << std::endl;
// }
class Task
{
public:
Task()
{
}
Task(int x, int y)
: _x(x), _y(y)
{
}
void Execute()
{
_result = _x + _y;
}
void operator()()
{
Execute();
}
std::string getResult()
{
return std::to_string(_x) + "+" + std::to_string(_y) + "=" + std::to_string(_result);
}
std::string Question()
{
return std::to_string(_x) + "+" + std::to_string(_y) + "=?";
}
~Task() {}
private:
int _x;
int _y;
int _result;
};
// class CalTask : public Task{};
// class StorageTask : public Task{};
// class NetTask : public Task{};
#endif
cpp
#include "RingQueue.hpp"
#include "Task.hpp"
#include <unistd.h>
#include <ctime>
#include <cstdlib>
// Mutex cnt_lock;
// Mutex screen_lock;
// int data = 1; // 问题
// int GetData()
// {
// cnt_lock.Lock();
// int result = data++;
// cnt_lock.Unlock();
// return result;
// }
// void Print(const std::string &name, const std::string &info)
// {
// screen_lock.Lock();
// std::cout << name << " : " << info << std::endl;
// screen_lock.Unlock();
// }
// class ThreadData
// {
// public:
// ThreadData(RingQueue<int> * r, const std::string &n):rq(r), name(n)
// {}
// ~ThreadData()
// {}
// public:
// std::string name;
// RingQueue<int> *rq;
// };
void *ProductorRoutine(void *args)
{
RingQueue<Task> *rq = static_cast<RingQueue<Task> *>(args);
while (true)
{
// 1. 获取数据 -- 花时间的!
int x = rand() % 10 + 1;
usleep(123);
int y = rand() % 10 + 1;
Task t(x, y);
// 2. 生产数据
rq->Enqueue(t);
std::cout << "生成任务: " << t.Question() << std::endl;
// int data = GetData();
// sleep(3);
// td->rq->Enqueue(data);
// Print(td->name, " 生产数据:" + std::to_string(data));
}
}
void *ConsumerRoutine(void *args)
{
RingQueue<Task> *rq = static_cast<RingQueue<Task> *>(args);
int data = 0;
while (true)
{
sleep(1);
// 1. 消费
Task t;
rq->Pop(&t);
// 2. 处理任务
t();
std::cout << "消费并完成任务: " << t.getResult() << std::endl;
// td->rq->Pop(&data);
// Print(td->name, " 消费数据:" + std::to_string(data));
}
}
int main()
{
srand(time(nullptr) ^ getpid());
RingQueue<Task> *rq = new RingQueue<Task>();
// 单单
pthread_t c, p;
pthread_create(&p, nullptr, ProductorRoutine, rq);
pthread_create(&c, nullptr, ConsumerRoutine, rq);
pthread_join(c, nullptr);
pthread_join(p, nullptr);
// pthread_t c[2], p[3];
// ThreadData *td0 = new ThreadData(rq, "product-1");
// pthread_create(p, nullptr, ProductorRoutine, td0);
// ThreadData *td1 = new ThreadData(rq, "product-2");
// pthread_create(p+1, nullptr, ProductorRoutine, td1);
// ThreadData *td2 = new ThreadData(rq, "product-3");
// pthread_create(p+2, nullptr, ProductorRoutine, td2);
// ThreadData *td3 = new ThreadData(rq, "consumer-1");
// pthread_create(c, nullptr, ConsumerRoutine, td3);
// ThreadData *td4 = new ThreadData(rq, "consumer-2");
// pthread_create(c+1, nullptr, ConsumerRoutine, td4);
// pthread_join(c[0], nullptr);
// pthread_join(c[1], nullptr);
// pthread_join(p[0], nullptr);
// pthread_join(p[1], nullptr);
// pthread_join(p[2], nullptr);
return 0;
}9.线程池
9.1日志
9.1.1介绍日志
一、日志的核心定义
简单来说,日志就是程序运行时自动记录下来的 "行为日记"。就像你写日记记录一天的生活(几点起床、吃了什么、遇到了什么事),程序的日志会记录:
- 程序运行到了哪个环节
- 某个操作执行成功 / 失败
- 发生错误时的具体原因、时间、涉及的数据
- 用户的关键操作(比如登录、下单、支付)
日志不是给程序本身用的,而是给开发、测试、运维人员看的,是排查问题、监控系统、分析行为的核心依据。
二、日志的常见内容
一条标准的日志通常包含这些关键信息(不同框架格式略有差异):
bash
[可读性很好的时间] [⽇志等级] [进程pid] [打印对应⽇志的⽂件名][⾏号] - 消息内容,⽀持可变参数]
[2024-08-04 12:27:03] [DEBUG] [202938] [main.cc] [16] - hello world拆解来看:
- 时间戳:2026-01-26 10:25:30(记录事件发生的精确时间)
- 日志级别:ERROR(标识事件的严重程度,下文会详细说)
- 模块 / 位置:订单模块(定位问题发生的程序模块)
- 上下文信息:用户 ID:10086(辅助定位问题的关键数据)
- 事件描述:创建订单失败:库存不足(商品 ID:789)(具体发生了什么)
三、日志的核心作用
-
**排查问题(最核心)**程序报错时,光看 "程序崩溃" 的提示没用,查看日志能精准定位:是代码逻辑错了?数据库连接失败?还是用户输入了非法数据?比如用户反馈 "下单失败",你查日志看到 "库存不足",就能直接定位问题,而不用盲猜。
-
监控系统状态通过分析日志,能知道程序是否正常运行:比如每小时有多少用户登录、接口响应时间是否过长、是否有频繁的错误请求。
-
安全审计记录敏感操作(比如管理员修改权限、用户登录异常),方便追溯责任、排查安全问题(比如有人多次尝试登录他人账号)。
四、日志的常见级别(按严重程度从低到高)
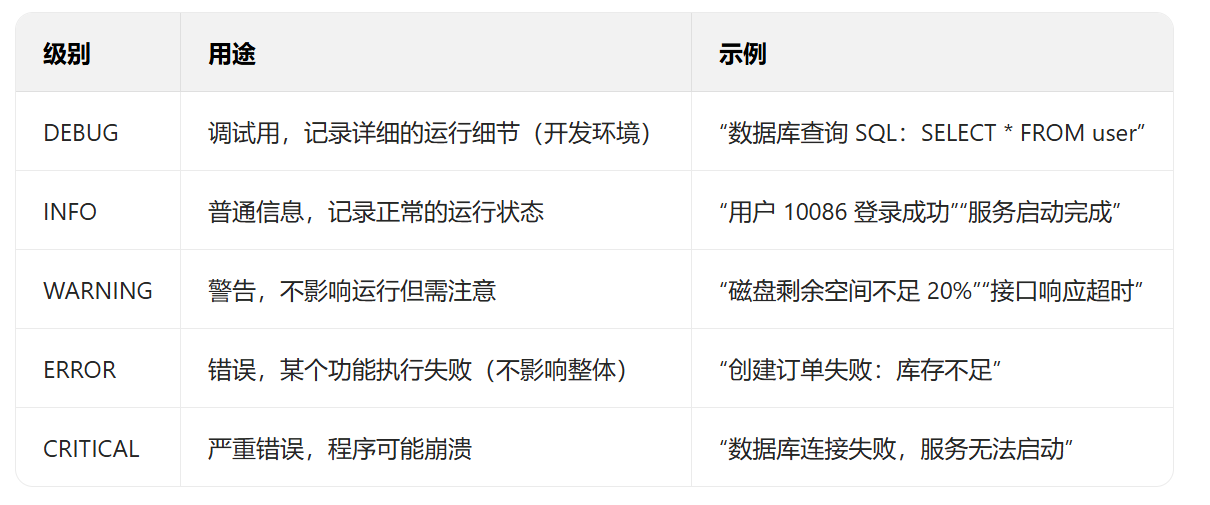
不同级别帮你快速筛选重要信息,避免日志太多无从下手:
总结
- 核心本质:日志是程序的 "行为日记",记录运行过程中的关键事件,供人分析和排查问题。
- 核心价值:定位问题、监控系统、安全审计,是开发 / 运维不可或缺的工具。
- 关键特性:包含时间、级别、上下文等信息,按严重程度分为 DEBUG/INFO/WARNING/ERROR/CRITICAL 等级别。
简单来说,没有日志的程序,就像没有黑匣子的飞机 ------ 出了问题根本不知道发生了什么;而完善的日志体系,能让你快速定位问题、保障系统稳定运行。
9.1.2日志实现
将时间戳改成年月日



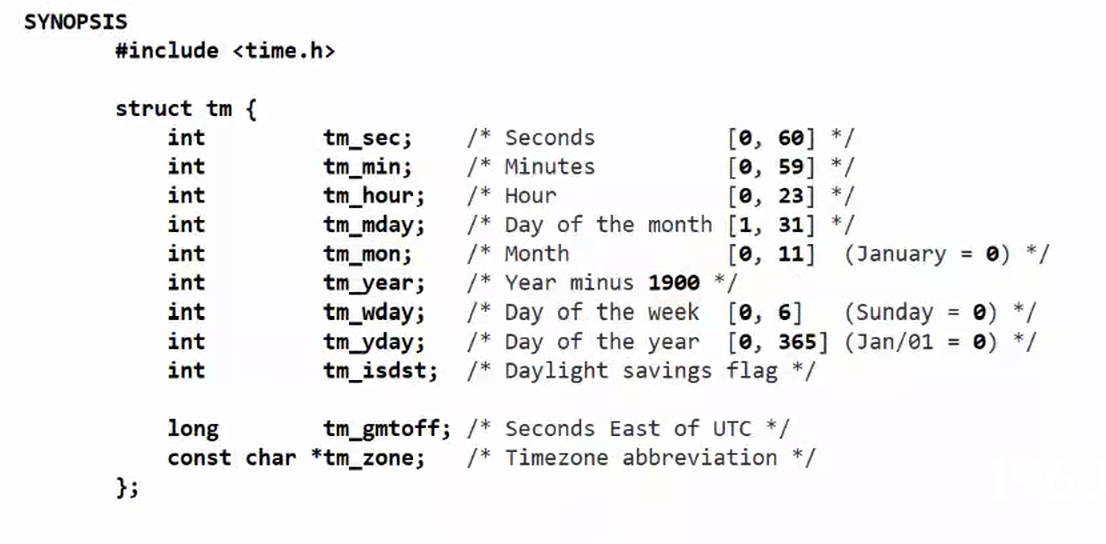
- 获取时间戳
- 参数1:输出型参数,时间戳是结构体的第一个变量,第二个变量是微秒。
- 参数2:时区,直接null

- localtime_r:可重入函数---线程安全的
- 输出型参数。
- 将时间戳转化成我们日常用的时间。
cpp
#ifndef __LOGGER_HPP
#define __LOGGER_HPP
#include <iostream>
#include <cstdio>
#include <string>
#include <memory>
#include <sstream>
#include <ctime>
#include <sys/time.h>
#include <unistd.h>
#include <filesystem> // C++17
#include <fstream>
#include "Mutex.hpp"
namespace NS_LOG_MODULE
{
enum class LogLevel
{
INFO,
WARNING,
ERROR,
FATAL,
DEBUG
};
std::string LogLevel2Message(LogLevel level)
{
switch (level)
{
case LogLevel::INFO:
return "INFO";
case LogLevel::WARNING:
return "WARNING";
case LogLevel::ERROR:
return "ERROR";
case LogLevel::FATAL:
return "FATAL";
case LogLevel::DEBUG:
return "DEBUG";
default:
return "UNKNOWN";
}
}
// 1. 时间戳 2. 日期+时间
std::string GetCurrentTime()
{
struct timeval current_time;
int n = gettimeofday(¤t_time, nullptr);
(void)n;
// current_time.tv_sec; current_time.tv_usec;
struct tm struct_time;
localtime_r(&(current_time.tv_sec), &struct_time); // r: 可重入函数
char timestr[128];
snprintf(timestr, sizeof(timestr), "%04d-%02d-%02d %02d:%02d:%02d.%ld",
struct_time.tm_year + 1900,
struct_time.tm_mon + 1,
struct_time.tm_mday,
struct_time.tm_hour,
struct_time.tm_min,
struct_time.tm_sec,
current_time.tv_usec);
return timestr;
}
// 输出角度 -- 刷新策略
// 1. 显示器打印
// 2. 文件写入
// 策略模式,策略接口
class LogStrategy
{
public:
virtual ~LogStrategy() = default;
virtual void SyncLog(const std::string &message) = 0;
};
// 控制台日志刷新策略, 日志将来要向显示器打印
class ConsoleStrategy : public LogStrategy
{
public:
void SyncLog(const std::string &message) override
{
LockGuard lockguard(_mutex);
std::cerr << message << std::endl; // ??
}
~ConsoleStrategy()
{
}
private:
Mutex _mutex;
};
const std::string defaultpath = "./log";
const std::string defaultfilename = "log.txt";
// 文件策略
class FileLogStrategy : public LogStrategy
{
public:
FileLogStrategy(const std::string &path = defaultpath, const std::string &name = defaultfilename)
: _logpath(path),
_logfilename(name)
{
LockGuard lockguard(_mutex);
if (std::filesystem::exists(_logpath))
return;
try
{
std::filesystem::create_directories(_logpath);
}
catch (const std::filesystem::filesystem_error &e)
{
std::cerr << e.what() << '\n';
}
}
void SyncLog(const std::string &message) override
{
{
LockGuard lockguard(_mutex);
if (!_logpath.empty() && _logpath.back() != '/')
{
_logpath += "/";
}
std::string targetlog = _logpath + _logfilename; // "./log/log.txt"
std::ofstream out(targetlog, std::ios::app); // 追加方式写入
if (!out.is_open())
{
std::cerr << "open " << targetlog << "failed" << std::endl;
return;
}
out << message << "\n";
out.close();
}
}
~FileLogStrategy()
{
}
private:
std::string _logpath;
std::string _logfilename;
Mutex _mutex;
};
// 日志类:
// 1. 日志的生成
// 2. 根据不同的策略,进行刷新
class Logger
{
// 日志的生成:
// 构建日志字符串
public:
Logger()
{
UseConsoleStrategy();
}
void UseConsoleStrategy()
{
_strategy = std::make_unique<ConsoleStrategy>();
}
void UseFileStrategy()
{
_strategy = std::make_unique<FileLogStrategy>();
}
// 内部类, 标识一条完整的日志信息
// 一条完整的日志信息 = 做半部分固定部分 + 右半部分不固定部分
// LogMessage RAII风格的方式,进行刷新
class LogMessage
{
public:
LogMessage(LogLevel level, std::string &filename, int line, Logger &logger)
: _level(level),
_curr_time(GetCurrentTime()),
_pid(getpid()),
_filename(filename),
_line(line),
_logger(logger)
{
// 先构建出来左半部分
std::stringstream ss;
ss << "[" << _curr_time << "] "
<< "[" << LogLevel2Message(_level) << "] "
<< "[" << _pid << "] "
<< "[" << _filename << "] "
<< "[" << _line << "] "
<< " - ";
_loginfo = ss.str();
}
template <typename T>
LogMessage &operator<<(const T &info)
{
std::stringstream ss;
ss << info;
_loginfo += ss.str();
return *this; // 返回当前LogMessage对象,方便下次继续进行<<
}
~LogMessage()
{
if (_logger._strategy)
{
_logger._strategy->SyncLog(_loginfo);
}
}
private:
LogLevel _level;
std::string _curr_time;
pid_t _pid;
std::string _filename;
int _line;
std::string _loginfo; // 一条完整的日志信息
Logger &_logger;
};
LogMessage operator()(LogLevel level, std::string filename, int line)
{
return LogMessage(level, filename, line, *this);
}
~Logger()
{
}
private:
std::unique_ptr<LogStrategy> _strategy; // 刷新策略
};
// 日志对象,全局使用
Logger logger;
#define ENABLE_CONSOLE_LOG_STRATEGY() logger.UseConsoleStrategy();
#define ENABLE_FILE_LOG_STRATEGY() logger.UseFileStrategy();
#define LOG(level) logger(level, __FILE__, __LINE__)
}
#endif9.2线程池实现
cpp
#pragma once
#include <iostream>
#include <vector>
#include <queue>
#include "Logger.hpp"
#include "Thread.hpp"
#include "Mutex.hpp"
#include "Cond.hpp"
namespace NS_THREAD_POOL_MODULE
{
using namespace NS_LOG_MODULE;
using namespace NS_THREAD_MODULE;
const int defaultnum = 5;
// void Test()
// {
// char name[128];
// pthread_getname_np(pthread_self(), name, sizeof(name));
// while (true)
// {
// LOG(LogLevel::DEBUG) << "我是一个线程,我要进行运行:" << name;
// sleep(1);
// }
// }
template <typename T>
class ThreadPool
{
private:
void HandlerTask()
{
char name[128];
pthread_getname_np(pthread_self(), name, sizeof(name));
while (true)
{
T task;
{
// 保护临界区
LockGuard lockguard(_mutex);
// 检测任务。不休眠:1. 队列不为空 2. 线程池退出 -> 队列为空 && 线程池不退出
while (_tasks.empty() && _isrunning)
{
// 没有任务, 休眠
_slaver_sleep_count++;
_cond.Wait(_mutex);
_slaver_sleep_count--;
}
// 线程池退出了-> while 就要break -> 不能
// 1. 线程池退出 && _tasks empty
if (!_isrunning && _tasks.empty())
{
_mutex.Unlock();
break;
}
// 有任务, 取任务,本质:把任务由公共变成私有
// T -> task*
task = _tasks.front();
_tasks.pop();
}
// 处理任务, 约定
LOG(LogLevel::INFO) << name << "处理任务:";
task();
LOG(LogLevel::DEBUG) << task.Result();
}
// 线程退出
LOG(LogLevel::INFO) << name << " quit...";
}
ThreadPool(int slaver_num = defaultnum) : _isrunning(false), _slaver_sleep_count(0), _slaver_num(slaver_num)
{
// ThreadPool对象已经存在
for (int idx = 0; idx < _slaver_num; idx++)
{
// auto f = std::bind(&ThreadPool::HandlerTask, this);
// // auto f = [this](){
// // this->HandlerTask();
// // };
// _slavers.emplace_back(f);
_slavers.emplace_back([this]()
{ this->HandlerTask(); });
}
}
// 赋值 拷贝构造禁止
ThreadPool<T> &operator=(const ThreadPool<T> &) = delete;
ThreadPool(const ThreadPool<T> &) = delete;
public:
static ThreadPool<T> *Instance()
{
if(nullptr == _instance) // 双if判断
{
// 多线程
LockGuard lockguard(_lock);
if (nullptr == _instance)
{
// 第一次调用
_instance = new ThreadPool<T>();
_instance->Start();
LOG(LogLevel::INFO) << "第一次使用线程池,创建线程池对象";
}
}
return _instance;
}
void Start()
{
if (_isrunning)
{
LOG(LogLevel::WARNING) << "Thread Pool Is Already Running";
return;
}
_isrunning = true;
for (auto &slave : _slavers)
{
slave.Start();
}
}
void Stop()
{
// version1 -- 后续调整
// if (!_isrunning)
// {
// LOG(LogLevel::WARNING) << "Thread Pool Is Not Running";
// return;
// }
// for (auto &slave : _slavers)
// {
// slave.Die(); // 太简单粗暴了
// }
// _isrunning = false;
// version 2
// 1. _isrunning = false
// 2. 处理完成tasks所有的任务
// 线程状态: 休眠,正在处理任务 -> 让所有线程全部唤醒
// HandlerTask自动break
_mutex.Lock();
_isrunning = false;
if (_slaver_sleep_count > 0)
_cond.Broadcast();
_mutex.Unlock();
}
void Wait()
{
for (auto &slave : _slavers)
{
slave.Join();
}
}
void Enqueue(T in)
{
_mutex.Lock();
_tasks.push(in);
if (_slaver_sleep_count > 0)
_cond.Signal();
_mutex.Unlock();
}
~ThreadPool()
{
}
private:
bool _isrunning;
int _slaver_num;
std::vector<Thread> _slavers;
std::queue<T> _tasks; // 任务队列,临界资源
Mutex _mutex;
Cond _cond;
int _slaver_sleep_count;
// 添加单例模式
static ThreadPool<T> *_instance;
static Mutex _lock; // 保证单例的安全
};
template <typename T>
ThreadPool<T> *ThreadPool<T>::_instance = nullptr;
template <typename T>
Mutex ThreadPool<T>::_lock;
}
cpp
#include "Logger.hpp"
#include "ThreadPool.hpp"
#include <iostream>
#include <memory>
#include <functional>
#include <ctime>
#include <cstdlib>
using namespace NS_LOG_MODULE;
using namespace NS_THREAD_POOL_MODULE;
// using task_t = std::function<void()>;
class Task
{
public:
Task() {}
Task(int x, int y) : _x(x), _y(y)
{
}
void operator()()
{
_result = _x + _y;
}
std::string Result()
{
return std::to_string(_x) + "+" + std::to_string(_y) + "=" + std::to_string(_result);
}
~Task() {}
private:
int _x;
int _y;
int _result;
};
int main()
{
// 创建对象的时机
// 单例模式,就是只允许在加载或者运行期间,整体最多创建一个该类对象
// 1. 加载到内存的时候,创建对象, int gval = 100;
// 2. 进程在运行期间,创建对象, int *val = (int *)malloc(sizeof(int)); -- 最佳实践
// pthread_create()
// pthread_create()
// pthread_create()
ENABLE_CONSOLE_LOG_STRATEGY();
srand((long)time(nullptr) ^ getpid());
sleep(5);
int cnt = 10;
while (cnt--)
{
int x = rand() % 10 + 1;
usleep(137);
int y = rand() % 20;
Task t(x, y);
//
ThreadPool<Task>::Instance()->Enqueue(t);
sleep(1);
// tp->Enqueue([](){
// LOG(LogLevel::DEBUG) << "我是一个任务, 正在被处理...";
// }
// );
// sleep(1);
}
ThreadPool<Task>::Instance()->Stop();
ThreadPool<Task>::Instance()->Wait();
// sleep(5);
// ThreadPool tp;
// tp->Start();
// while(true)
// {
// // 获取任务
// // tp->Enqueue(t);
// }
// tp->Stop();
return 0;
}10常见锁概念
10.1死锁
- 死锁是指在一组进程中的各个进程均占有不会释放的资源,但因互相申请被其他进程所占用不会释放的资源而处于的一种永久等待状态。
- 为了方便表述,假设现在线程A,线程B必须同时持有锁1和锁2,才能进行后续资源的访问
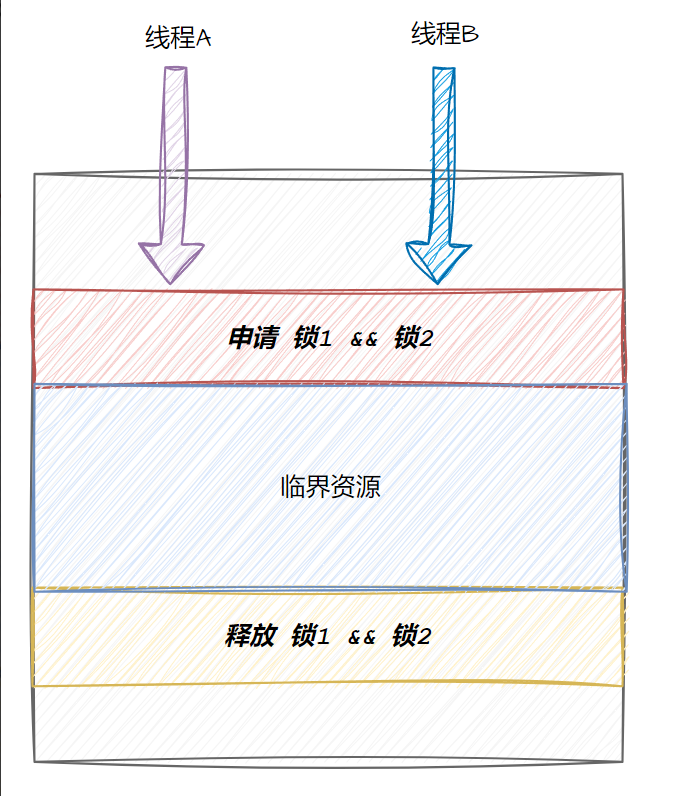
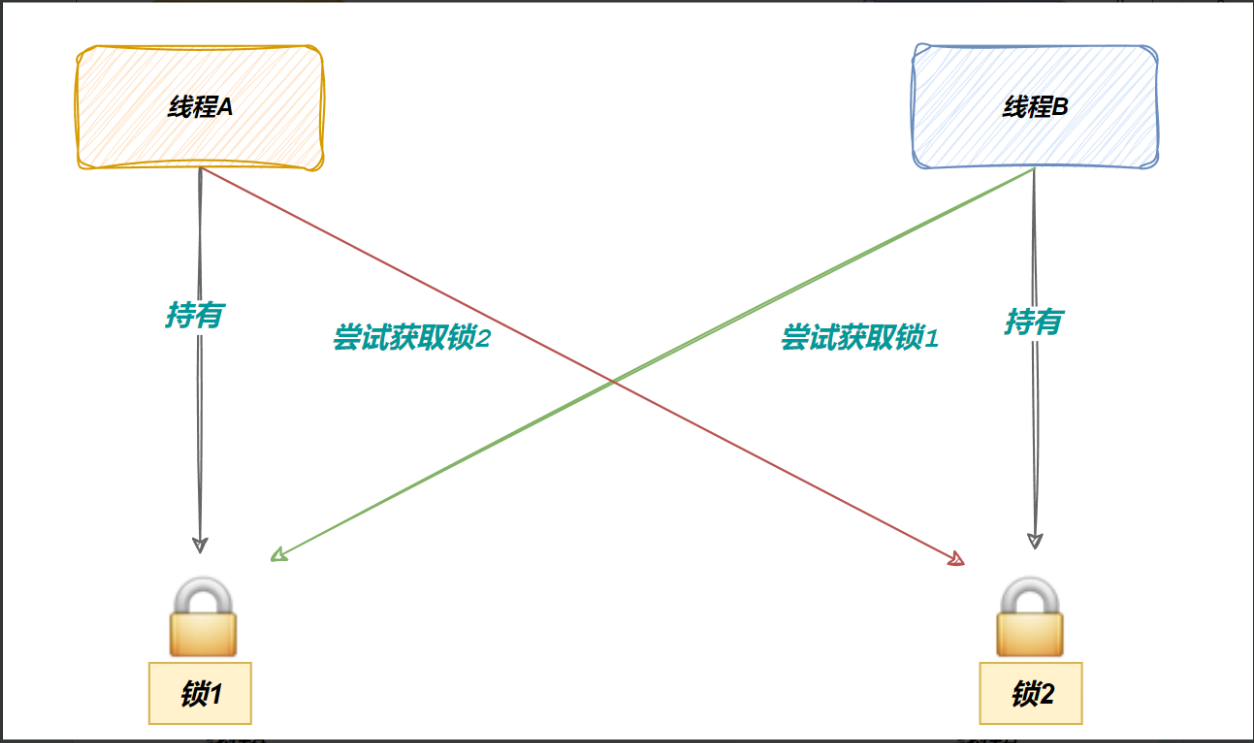

10.2产生死锁的四个条件
1.互斥条件: ⼀个资源每次只能被⼀个执⾏流使⽤
2.请求与保持: ⼀个执⾏流因请求资源⽽阻塞时,对已获得的资源保持不放
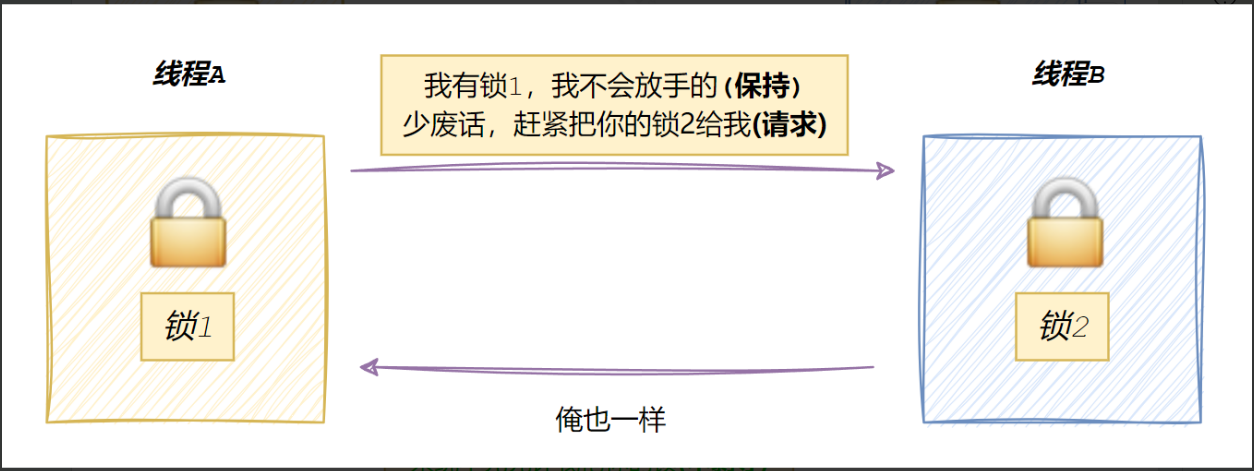
3.不剥夺条件: ⼀个执⾏流已获得的资源,在末使⽤完之前,不能强⾏剥夺
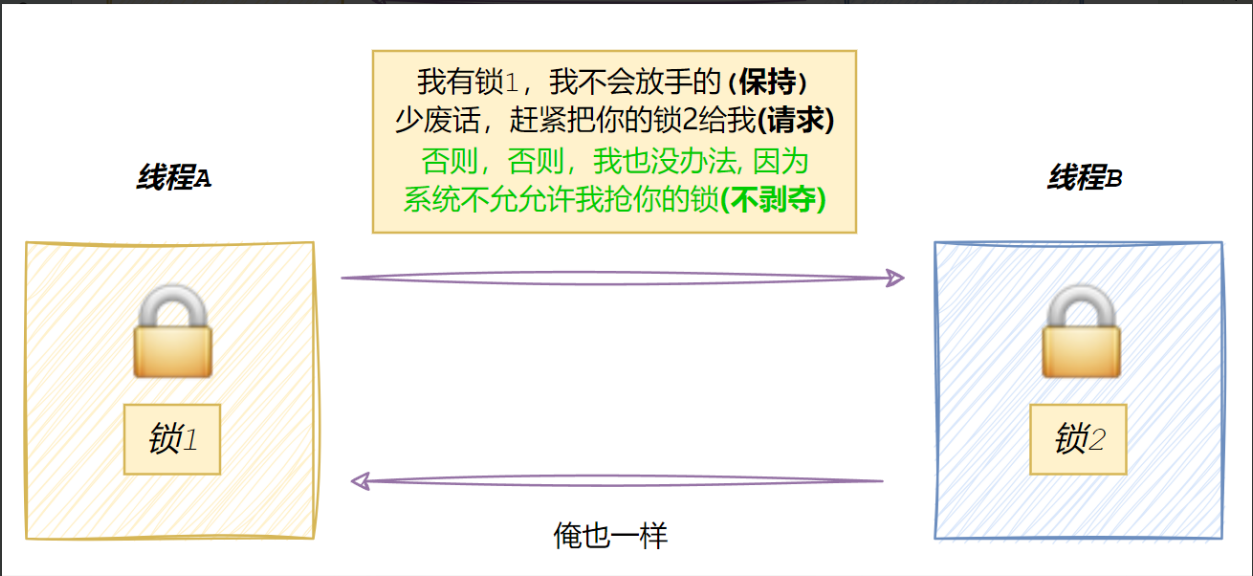
4.循环等待条件: 若⼲执⾏流之间形成⼀种头尾相接的循环等待资源的关系
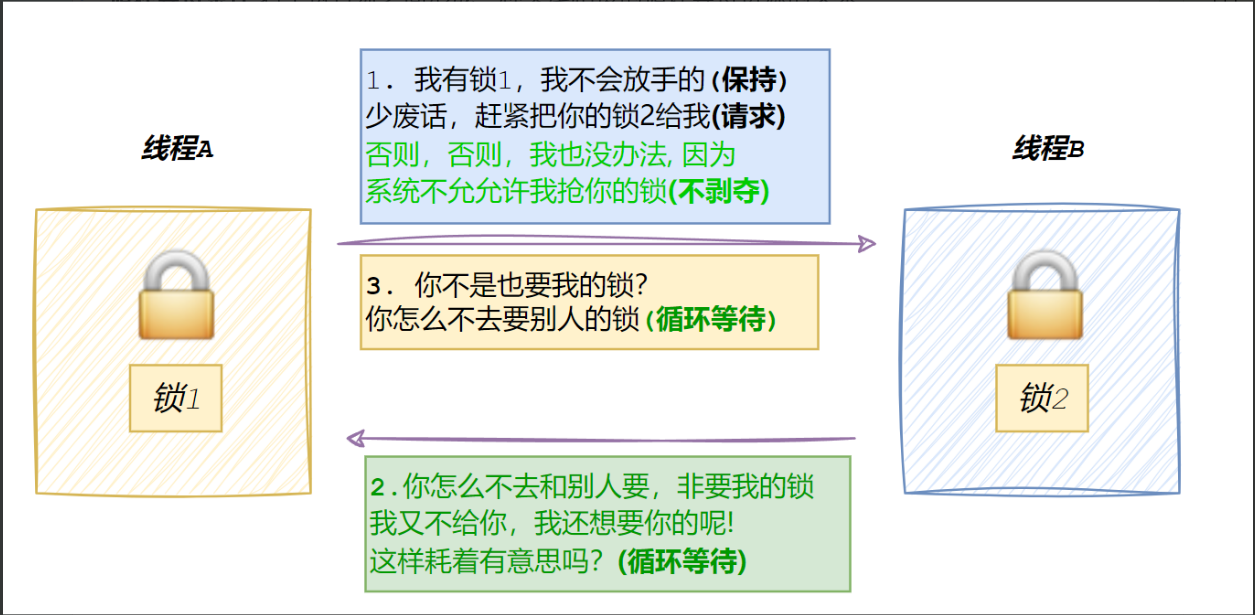
解决办法:可以在两个锁之前添加第三个锁。
智能指针本身是线程安全的