目录
[三、磁盘的线性化:LBA 地址](#三、磁盘的线性化:LBA 地址)
[四、LBA 地址转物理地址的计算示例](#四、LBA 地址转物理地址的计算示例)
[一、磁盘线性化与分区管理(C/D/F 盘的由来)](#一、磁盘线性化与分区管理(C/D/F 盘的由来))
[二、Boot Block 的作用与备份](#二、Boot Block 的作用与备份)
[三、分区内的 Block group 划分](#三、分区内的 Block group 划分)
[四、Block group 内的核心组件解析](#四、Block group 内的核心组件解析)
五、删除文件的原理
新建/写入/删除/查找/修改文件时,系统要做什么[一、核心前提:inode 的分区独立性与文件关联规则](#一、核心前提:inode 的分区独立性与文件关联规则)
[二、新建 + 写入文件(echo "hello Linux" >> test.txt)](#二、新建 + 写入文件(echo "hello Linux" >> test.txt))
[五、修改文件(属性 / 内容)](#五、修改文件(属性 / 内容))
[五、目录 inode 的递归查找逻辑与 dentry 缓存](#五、目录 inode 的递归查找逻辑与 dentry 缓存)
如何把磁盘看作线性结构

一、磁盘与磁头的读写数据原理
磁盘是磁性存储介质 ,核心是通过磁头与盘片的电磁感应 完成数据读写,且读写过程为无接触式(避免磨损盘片),具体过程如下:
- 盘片与磁介质 :磁盘由多个圆形盘片堆叠组成,盘片表面覆盖磁性涂层,每个磁介质单元可呈现两种极性(对应二进制
0和1); - 磁头的作用 :每个盘面配备一个独立磁头,磁头悬浮于盘面上方极近距离。
- 写入:磁头通电产生可变磁场,改变盘片对应位置磁介质的极性,将电信号转换为磁信号,完成数据写入;
- 读取:盘片高速旋转时,磁介质的极性变化会在磁头线圈中感应出微弱电流,磁头将磁信号转换为电信号,传输给控制器解析为数据;
- 核心前提:盘片需以固定转速(如 7200 转 / 分钟)旋转,磁臂带动磁头沿径向移动,定位到目标位置后才能进行读写操作。
二、磁盘的物理结构:面、磁道、扇区
磁盘的物理存储是三维结构,核心组成单元包括面、磁道、扇区,三者共同定位一个物理存储位置:
- 面(盘面):每个盘片有上下两个可读写的表面,称为盘面;每个盘面由一个独立磁头负责读写。盘面通常从 0 开始编号(如 0 号面、1 号面);
- 磁道 :每个盘面被划分为多个同心圆轨迹,这些轨迹就是磁道;磁道从外向内编号(如 0 号磁道、1 号磁道)。示例中每个盘面有 50 个磁道;
- 扇区 :每个磁道被均匀划分为多个弧形段 ,这些弧形段就是扇区。扇区是磁盘访问的最小基本单元 ,无法对半个扇区进行读写。早期标准扇区大小为512 字节 ,现代磁盘多采用4KB高级格式扇区。示例中每个磁道有 400 个扇区。
盘面扇区总数验证:每个盘面的扇区数 = 磁道数 × 每个磁道扇区数,示例中 50 × 400=20000,与给定条件一致。
三、磁盘的线性化:LBA 地址
操作系统难以直接管理三维的物理地址(面、磁道、扇区),因此引入LBA(Logical Block Address,逻辑块地址) ,将整个磁盘的所有扇区线性化为一个一维数组,数组的下标就是 LBA 地址。
- 线性化规则 :按盘面→磁道→扇区的顺序,依次对所有扇区进行连续编号;
- 核心优势 :操作系统只需使用 LBA 地址发起读写请求,磁盘控制器(如硬盘固件)会自动完成LBA 地址到物理地址(面、磁道、扇区)的转换,简化了操作系统的磁盘管理逻辑;
- 示例对应:整个磁盘可看作无数个扇区构成的数组,每个扇区对应一个唯一的 LBA 地址(如 28888)。
四、LBA 地址转物理地址的计算示例
已知条件
- LBA 地址:28888
- 每个盘面扇区数:20000(50 磁道 × 400 扇区 / 磁道)
- 每个磁道扇区数:400
转换公式(编号从 0 开始)
- 盘面号 = LBA ÷ 每个盘面扇区数
- 盘面内剩余扇区数 = LBA % 每个盘面扇区数
- 磁道号 = 盘面内剩余扇区数 ÷ 每个磁道扇区数
- 扇区号 = 盘面内剩余扇区数 % 每个磁道扇区数
代入计算
- 盘面号 = 28888 ÷ 20000 = 1(商为 1,余数 8888)
- 盘面内剩余扇区数 = 28888 % 20000 = 8888
- 磁道号 = 8888 ÷ 400 = 22(商为 22,余数 88)
- 扇区号 = 8888 % 400 = 88
结果 LBA=28888 对应的物理地址为:1 号盘面、22 号磁道、88 号扇区。
核心总结
- 磁盘读写:通过磁头与盘片的电磁感应实现,依赖盘片旋转和磁头径向移动定位;
- 物理结构:面、磁道、扇区构成三维存储,扇区是最小读写单元(512 字节 / 4KB);
- 线性化方案:LBA 将三维物理地址转为一维数组下标,由磁盘控制器完成地址转换;
- 地址转换:通过除法和取模运算,可将 LBA 地址精准映射到对应的盘面、磁道、扇区。
磁盘文件系统
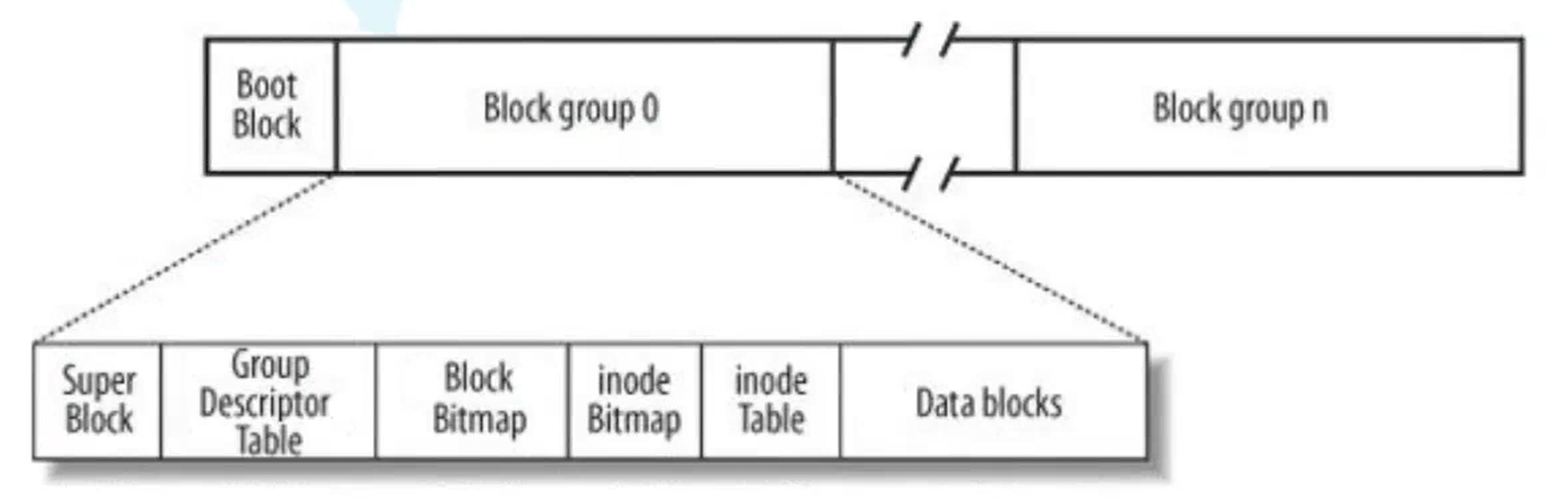
一、磁盘线性化与分区管理(C/D/F 盘的由来)
磁盘从三维结构(面、磁道、扇区)转换为 LBA 线性数组后,操作系统会对这个LBA 数组进行分区划分------ 这就是 C 盘、D 盘、F 盘的本质。
内核通过struct partion结构体管理这些分区,每个结构体记录一个分区在 LBA 数组中的起始 LBA(start)和 结束 LBA(end) ,例如struct partion part[3]可管理 3 个分区(对应 C/D/F 盘)。每个part元素对应一个分区的 LBA 范围,实现不同分区的独立管理。
二、Boot Block 的作用与备份
LBA 线性数组的第一个位置 (通常对应第 0 盘面、第 0 磁道、第 1 扇区)会预留为Boot Block,用于存储操作系统的启动信息(如引导加载程序、分区表等)。
为避免该区域损坏导致系统无法启动,通常会在其他盘面的起始 LBA 位置备份一份 Boot Block,后续可通过修复工具读取备份恢复启动信息。
三、分区内的 Block group 划分
每个分区(如 C 盘)会被进一步划分为多个Block group(块组),每个块组是分区内的独立管理单元,包含统一的管理结构(对应图中的 Super Block、inode Table 等),以此分散管理压力、避免单个管理结构过大。
四、Block group 内的核心组件解析
每个 Block group 包含以下关键部分,共同实现文件的管理:
| 组件 | 核心作用 |
|---|---|
| Super Block(超级块) | 存储整个分区(文件系统)的全局信息:文件系统类型、块大小(通常 4KB)、inode 总数、块总数等操作系统管理所需的元数据。 |
| Group Descriptor Table(组描述符表) | 记录当前 Block group 的资源分布:inode Table、Data blocks 的起始位置、已用 / 空闲的块和 inode 数量等,用于快速定位资源。 |
| Block Bitmap(块位图) | 用比特位映射 Data blocks 中的块 :比特位下标对应块编号,1表示块已使用,0表示块空闲。分配 / 释放块时,只需修改对应比特位。 |
| inode Bitmap(inode 位图) | 用比特位映射 inode Table 中的 inode :比特位下标对应 inode 编号,1表示 inode 有效(对应文件),0表示 inode 空闲。创建 / 删除文件时,修改对应比特位。 |
| inode Table(inode 表) | 由多个struct inode结构体(每个占 128 字节)组成,每个结构体对应一个文件的属性信息 ,包含:1. 文件类型、权限、引用计数、拥有者、所属组、ACM 时间(访问 / 修改 / 状态变更时间);2. inode number(inode 唯一编号,可通过ls -li查看);3. int blocks[15]数组:记录文件数据在 Data blocks 中的位置,分为三类索引: - 直接索引(0~11 下标) :元素直接存数据块编号,可直接定位数据; - 两级索引(12~13 下标) :元素存 "索引块编号",索引块内再存数据块编号,需两次定位; - 三级索引(14 下标) :元素存 "两级索引块编号",需三次定位才能找到数据块。通过 inode Table 找到对应struct inode,即可获取文件属性 + 定位文件数据。 |
| Data blocks(数据块) | 存储文件的实际内容,以块为单位(通常 4KB),是文件系统访问文件的最小单位。文件内容拆分后存于此处,块编号记录在对应 inode 的blocks数组中。 |
五、删除文件的原理
删除文件时,无需清空 Data blocks 的实际数据,只需做两步操作:
- 在inode Bitmap 中,将文件对应 inode 的比特位设为
0(标记该 inode 为空闲); - 在Block Bitmap 中,将文件
blocks数组对应的所有块的比特位设为0(标记这些块为空闲)。
后续分配资源时,这些被标记为空闲的 inode 和块会被新数据覆盖,原文件数据自然被替代,实现 "删除" 效果。
新建/写入/删除/查找/修改文件时,系统要做什么
一、核心前提:inode 的分区独立性与文件关联规则
Linux 系统中,一个文件对应一个 inode ,每个 inode 有唯一的inode编号,但该编号的唯一性仅局限于当前分区(如 C 盘的 inode 1 和 D 盘的 inode 1 无冲突)------ 因为 inode 的分配、管理均以分区为单位,不同分区的 inode Bitmap、inode Table 相互独立,无法跨分区共享 inode 资源。
二、新建 + 写入文件(echo "hello Linux" >> test.txt)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ pwd
/home/ranjiaju/test/testdir
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ ll
total 0
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ echo "hello Linux" >> test.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ ll
total 4
-rw-rw-r-- 1 ranjiaju ranjiaju 12 Jan 27 22:34 test.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ cat test.txt
hello Linux执行echo命令创建并写入test.txt时,系统会按以下步骤完成操作:
- 定位分区与 Block group :根据文件路径
/home/ranjiaju/test/testdir/test.txt,系统解析出该路径所属的分区,再从分区中选择一个 inode 使用率较低的 Block group(通过 Group Descriptor Table 查看 inode 使用情况,确保有空闲 inode)。 - 分配并激活 inode :
- 从 Block group 的
inode Bitmap中找到首个值为0的比特位(对应空闲 inode 编号,示例中为 1188687),将该比特位设为1(标记 inode 已使用); - 从 Block group 的
inode Table中找到该 inode 编号对应的struct inode结构体,填充文件基础属性(如权限 0664、拥有者 ranjiaju、创建时间等)。
- 从 Block group 的
- 分配数据块并写入内容 :
- 计算待写入数据大小("hello Linux" 共 12 字节),确定需分配的 Data blocks 数量(示例中块大小 4KB,仅需 1 个数据块);
- 从 Block group 的
Block Bitmap中找到首个值为0的比特位(对应空闲数据块编号),将该比特位设为1(标记数据块已使用); - 将数据块编号填入 inode 结构体的
blocks数组(直接索引位,如 blocks 0); - 把 "hello Linux" 写入该数据块,完成内容写入。
三、删除文件
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ ls -li
total 4
1188687 -rw-rw-r-- 1 ranjiaju ranjiaju 12 Jan 27 22:34 test.txt删除文件时,系统不会清空 Data blocks 中的实际数据,仅修改位图标记,步骤如下:
- 定位分区与 Block group:根据文件路径确定所属分区和 Block group。
- 释放数据块 :从 inode 结构体的
blocks数组中获取数据块编号,在 Block Bitmap 中将对应比特位由1置为0(标记数据块空闲,可被覆盖)。 - 释放 inode :在 inode Bitmap 中将该文件 inode 编号对应的比特位由
1置为0(标记 inode 空闲)。 - 核心特性:删除操作仅修改位图,原数据仍存于 Data blocks 中,直到新数据覆盖该块 ------ 因此 "删除" 对系统而言等价于 "标记为可覆盖"。
四、查找文件(cat/ll/stat)
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ cat test.txt
hello Linux
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ ll
total 4
-rw-rw-r-- 1 ranjiaju ranjiaju 12 Jan 27 22:34 test.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ stat test.txt
File: 'test.txt'
Size: 12 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 1188687 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1001/ranjiaju) Gid: ( 1001/ranjiaju)
Access: 2026-01-27 22:34:30.794385385 +0800
Modify: 2026-01-27 22:34:23.550094623 +0800
Change: 2026-01-27 22:34:23.550094623 +0800
Birth: -查找文件(查看属性或内容)的核心是通过 inode 关联属性和数据,步骤如下:
- 定位分区与 Block group:根据文件路径找到所属分区和 Block group。
- 验证 inode 有效性 :从 inode Bitmap 中检查该文件 inode 编号对应的比特位是否为
1(确认 inode 有效)。 - 读取文件信息 :
- 查属性(
ll/stat):直接从 inode Table 的对应struct inode中读取权限、大小、inode 编号、ACM 时间等属性并展示; - 查内容(
cat):从 inode 结构体的blocks数组中获取数据块编号,读取 Data blocks 中的内容并拼接显示。
- 查属性(
五、修改文件(属性 / 内容)
修改文件的核心是定位到目标 inode,再针对性更新属性或数据,步骤如下:
- 定位并验证 inode:同查找文件步骤,找到所属分区、Block group,验证 inode 编号有效。
- 修改文件属性 :直接修改 inode Table 中对应
struct inode的属性字段(如修改权限chmod 777 test.txt则更新 inode 的权限位,修改拥有者chown则更新 UID/GID),并更新 inode 的 Change 时间(stat 中的 Change 字段)。 - 修改文件内容 :
- 内容追加(如
echo "new" >> test.txt):计算新增数据大小,分配新的空闲数据块(Block Bitmap 置 1),将新数据块编号填入blocks数组,写入新增内容; - 内容覆盖(如
echo "new" > test.txt):若新内容大小≤原数据块容量,直接覆盖原数据块内容;若超出,则分配新数据块,更新blocks数组,释放原数据块(Block Bitmap 置 0)。
- 内容追加(如
核心总结
- inode 是文件核心 :一个文件对应一个 inode,inode 存储属性,Data blocks 存储内容,两者通过
blocks数组关联; - 位图控资源:inode Bitmap 管理 inode 空闲状态,Block Bitmap 管理数据块空闲状态,新建 / 删除仅修改位图;
- 分区独立性:inode 编号仅在分区内唯一,不同分区可重复;
- 操作核心逻辑:所有文件操作的本质是 "定位 inode→通过 inode 关联属性 / 数据→修改 inode / 位图 / 数据块"。
通过系统角度理解目录
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ pwd
/home/ranjiaju/test/testdir
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ ll
total 0
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ mkdir dir
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ ls -li
total 4
1310770 drwxrwxr-x 2 ranjiaju ranjiaju 4096 Jan 27 23:11 dir一、核心前提:目录是特殊的文件
Linux 遵循 "一切皆文件" 的设计理念,目录本质是一种特殊类型的文件,因此具备普通文件的核心特征:
- 有独立的
inode(示例中dir的 inode 编号为 1310770),用于存储目录自身的属性(如权限drwxrwxr-x、拥有者ranjiaju、大小 4096 字节等); - 有专属的 Data blocks(数据块),但数据块中不存储文件内容 ,而是存储
<文件名: inode编号>的键值(KV)映射关系(即该目录下所有子文件 / 子目录的名称与对应 inode 的关联)。
二、ll命令的执行逻辑
执行ll查看目录内容时,系统按以下步骤完成:
- 定位目录本身的 inode :根据当前目录的路径,找到其所属分区和 Block group,通过 inode Bitmap 验证目录 inode 有效后,从 inode Table 中获取目录的
blocks数组(数据块编号); - 读取目录数据块 :根据
blocks数组读取目录的 Data blocks,解析其中存储的<文件名: inode编号>映射关系(如示例中dir目录的 data block 中暂存自身子项的映射); - 加载子文件属性:对每个映射关系中的 inode 编号,找到对应文件的 inode Table,读取文件属性(权限、大小、时间等);
- 整合并展示:将所有子文件的属性加载到内存,格式化后打印给用户。
三、同一目录下不能有同名文件的原因
目录数据块中的<文件名: inode编号>是KV 键值结构:
key:文件名(如test.txt、dir),要求唯一性;value:文件名对应的 inode 编号。
若同一目录下存在同名文件,会导致key重复,系统无法确定该文件名应映射到哪个 inode,因此 Linux 强制保证同一目录下文件名的唯一性。
四、目录权限(w/r/x)的核心作用
目录的读、写、执行权限直接影响对其下文件的操作,本质是限制对目录数据块的访问 / 修改:
| 目录权限 | 缺失后果 | 底层原因 |
|---|---|---|
| w(写)权限 | 无法创建文件 / 目录 | 新建文件时,需将<新文件名: 新inode编号>写入目录数据块;无 w 权限则无法修改目录数据块,即便文件本身能创建,也无法完成映射关联 |
| r(读)权限 | 无法读取目录下文件(如ll/ls失败) |
无 r 权限则无法读取目录数据块中的<文件名: inode编号>映射关系,无法定位子文件的 inode,进而无法获取文件属性 / 内容 |
| x(执行)权限 | 无法cd进入目录 |
cd命令的核心是验证目录的 x 权限,这是 Linux 的安全机制 ------ 无 x 权限则禁止访问目录的任何子项(即便有 r/w 权限也无效) |
五、目录 inode 的递归查找逻辑与 dentry 缓存
1. 目录 inode 的递归查找
当前目录的 inode 需从父目录的数据块 中获取(因为当前目录是父目录的子项,父目录数据块存储<当前目录名: 当前目录inode>);而父目录的 inode 又需从祖父目录的数据块中获取,以此形成递归查找链 ,直到最终的根目录(/):
- 根目录是 Linux 文件系统的起点,其名称固定为
/,inode 编号(通常为 2)是系统预设的、永不改变的; - 从根目录的数据块开始,可逐级解析子目录的
<目录名: inode>映射,最终递归找到目标目录的 inode。
2. dentry 缓存(目录项缓存)的作用
若每次访问文件都递归到根目录查找 inode,会产生大量 I/O 操作,导致效率极低。因此 Linux 引入dentry 缓存(目录项缓存):
- 缓存内容:常用目录 / 文件的
<文件名、父目录、inode>等核心信息; - 核心作用:访问文件时优先从 dentry 缓存中查找目标目录 / 文件的 inode,无需递归到根目录,大幅提升文件访问效率;
- 缓存特性:缓存会自动更新(如文件 / 目录修改时),且会淘汰不常用的缓存项,平衡内存占用与访问效率。
核心总结
- 目录是特殊文件 :有 inode(存属性)、数据块(存
<文件名: inode>映射); - 目录权限控制访问:w 控制创建、r 控制读取、x 控制进入,本质是限制对目录数据块的操作;
- inode 查找的递归与缓存:目录 inode 需从父目录递归查找至根目录,dentry 缓存优化该过程;
- 同名文件限制:目录数据块的 KV 结构要求文件名(key)唯一,保证映射不冲突。
硬链接
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ pwd
/home/ranjiaju/test/testdir
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ ll
total 0
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ touch test.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ ls -li
total 0
1188688 -rw-rw-r-- 1 ranjiaju ranjiaju 0 Jan 28 00:08 test.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ ln test.txt hard-link
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ ls -li
total 0
1188688 -rw-rw-r-- 2 ranjiaju ranjiaju 0 Jan 28 00:08 hard-link
1188688 -rw-rw-r-- 2 ranjiaju ranjiaju 0 Jan 28 00:08 test.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ unlink hard-link一、硬链接的核心本质
硬链接不是独立的文件 ,它没有专属的 inode------ 其本质是在指定目录的数据块中新增一条<文件名: 原文件inode编号>的映射关系。
以示例为例:
- 创建
test.txt后,testdir目录的数据块中存储<test.txt: 1188688>的映射; - 执行
ln test.txt hard-link创建硬链接时,系统仅在testdir目录的数据块中新增一条<hard-link: 1188688>的映射,并未创建新 inode,也未分配新数据块; - 这种机制类似于 C++ 中的 "取别名":
hard-link和test.txt是同一个文件的两个不同名称,共享同一个 inode(1188688)、数据块及所有属性。
二、权限列数字:硬链接的引用计数
ll输出中,权限(如-rw-rw-r--)后的数字(示例中初始为 1,创建硬链接后为 2)是inode 的引用计数(link count):
- 每个 inode 内部维护一个计数器,用于统计 "有多少个文件名(硬链接)指向该 inode";
- 初始状态:
test.txt是唯一指向 inode 1188688 的文件名,引用计数为 1; - 创建硬链接后:新增
hard-link指向该 inode,引用计数递增为 2; - 核心特性:仅当引用计数减至 0 时,系统才会真正释放该 inode(inode Bitmap 置 0)和对应数据块(Block Bitmap 置 0)------ 即便删除
test.txt,只要引用计数≥1(如hard-link仍存在),文件数据仍可通过hard-link访问,不会被删除。
三、unlink命令的作用
unlink hard-link的核心行为是:
- 删除
testdir目录数据块中<hard-link: 1188688>的映射关系; - 将 inode 1188688 的引用计数从 2 递减为 1;
- 仅当引用计数递减至 0 时,系统才会标记该 inode 和对应数据块为空闲(可被覆盖);若引用计数仍≥1(如示例中
test.txt仍存在),则仅删除硬链接名称,文件本身不受影响。
简单来说,unlink是 "删除硬链接映射、减少引用计数" 的操作,而非直接删除文件数据 ------ 文件的真正删除,仅发生在引用计数为 0 的时刻。
核心总结
- 硬链接无独立 inode,本质是目录数据块中新增的文件名 - 原文件 inode 映射,等同于文件的 "别名";
- 权限后的数字是 inode 引用计数,统计指向该 inode 的硬链接数量;
unlink仅删除硬链接映射并减少引用计数,只有引用计数为 0 时,文件才会被真正删除。
软链接
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ pwd
/home/ranjiaju/test/testdir
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ ll
total 0
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ touch file.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ ln -s file.txt soft-link
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ ll
total 0
-rw-rw-r-- 1 ranjiaju ranjiaju 0 Jan 28 00:05 file.txt
lrwxrwxrwx 1 ranjiaju ranjiaju 8 Jan 28 00:05 soft-link -> file.txt
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ testdir]$ ls -li
total 0
1188688 -rw-rw-r-- 1 ranjiaju ranjiaju 0 Jan 28 00:05 file.txt
1188689 lrwxrwxrwx 1 ranjiaju ranjiaju 8 Jan 28 00:05 soft-link -> file.txt一、软链接的核心本质
软链接(符号链接,Symbolic Link)是完全独立的文件,与硬链接有本质区别:
- 有专属的 inode(示例中
soft-link的 inode 编号为 1188689,与原文件file.txt的 1188688 完全不同); - 有独立的 Data blocks(数据块),但数据块中不存储文件内容,仅存储原文件的路径字符串(示例中为 "file.txt");
- 从
ll输出可直观识别:权限位以l开头(lrwxrwxrwx),并通过->标注指向的原文件路径,这与 Windows 系统的 "快捷方式" 逻辑完全一致。
二、软链接与硬链接的核心差异(对比强化)
| 特性 | 软链接 | 硬链接 |
|---|---|---|
| inode 归属 | 有独立的 inode | 复用原文件的 inode |
| 数据块内容 | 存储原文件的路径 | 无新增数据块(仅目录映射) |
| 文件独立性 | 完全独立的文件 | 非独立文件(原文件的别名) |
| 原文件删除后 | 软链接失效(路径指向不存在) | 仍可访问(引用计数≥1 时) |
| 权限显示 | 固定lrwxrwxrwx(仅标识链接类型) |
与原文件权限完全一致 |
三、原文件删除对软链接的影响
当删除file.txt后:
- 软链接
soft-link本身仍存在(其 inode 和数据块未被释放); - 但软链接数据块中存储的路径 "file.txt" 对应的文件已不存在,此时访问
soft-link会提示 "No such file or directory",即软链接失效; - 核心原因:软链接的访问逻辑是 "先解析路径,再找文件"------ 系统访问软链接时,会先读取其数据块中的原文件路径,再根据该路径查找文件,原文件删除后路径失效,软链接自然无法访问。
核心总结
- 软链接是独立文件,有专属 inode 和数据块,数据块仅存储原文件路径,等价于 Windows 的快捷方式;
- 软链接的 inode 与原文件无关联,
ll中以l标识、->标注指向路径; - 原文件删除后,软链接因路径失效而无法使用,这是与硬链接的核心区别。