首先你要明白kerberos是用来干什么的?举一个通俗易懂的例子,你将一台服务器看作是一座办公大楼,部署在这台服务器上的所有服务就相当于是一间间的办公室,当你用办公楼大门的密码进入办公楼内的时候,对于那些没有独立用户验证的房间来讲,对你来说就是不设防的,这里说的独立用户验证,就比如说你要连一个数据库你要用jdbc去携带专属的数据库用户密码,而反之,对于其他的比如hdfs来讲,你既然能够进入大楼,那么他就认为你是一个可信用户,对你不设防,只认你手里的用户凭证或者说是工卡是谁?一个最直观的表现,只要登录hadoop的一个节点,就可以提交MR任务或者是访问hdfs都会按照你当前使用的linux用户来去做对应的验证。此时就有两个企业级安全关键问题,第一是无法细化控制你能否访问哪个服务,第二是不会去验证你持有凭证的有效性,如果你持有的这个凭证,是你捡的,你用它来冒名顶替了别人,那服务就会发生危险,kerberos就是用来解决这两个问题,它的核心是一个叫KDC的服务,也就是票据发放中心,所有的用户访问办公大楼,都需要持有未过期的票据凭证,且凭证代替了原始密码,原始密码只有你获取初始票据的时候去 KDC 要求输入,票据本身拥有时效性,而且kerberos为每一个服务都充当了一个门卫的角色,每一次访问服务,都会验证你当前的票据是否合法。同时,不只会验证访问者的票据,还通过keyteb文件的方式,在服务启动时,要求服务向他注册验明正身,这样就防止别人恶意加入一台服务节点,比如任意一个未知datanode,直接加入生产集群这种安全隐患
部署前,要说明一点,Kerberos的搭建在单个服务来讲默认是单域,而且在工作中Kerberos这个东西,就和LDAP服务一样是公司的安全部负责,不归搞引擎的管,使用时跨部门协作即可,使用经验来讲工作中拿到手能要配的主体也是单域内的,所以如果你确实需要多域部署甚至是KDC服务HA,这篇文章帮不到你,本篇的侧重点是hadoop如何用Kerberos
1、安装部署前基础准备:所有涉及到的节点网络互通,最好是DNS通讯,且DNS中配置的域名不能有大写!!这点非常重要,否则搭建时会出现一些奇奇怪怪的问题。系统使用Centos 7 64位 ,yum源用阿里的,系统时间要一致
2、本次测试集群部署算hadoop集群节点在内,总共四台服务器,三台hadoop集群节点,外加一台运行Kerberos票据服务的节点。分布如下
bash
192.168.239.130 node1
192.168.239.131 node2
192.168.239.132 node3
192.168.239.133 node4 Kerberos服务运行节点,也就是KDC3、在node4上安装Kerberos服务、Kerberos资源包、Kerberos工具包,其他三个hadoop节点安装Kerberos资源包、Kerberos工具包即可
bash
#node4执行
yum install -y krb5-server krb5-libs krb5-workstation
#其他三个hadoop节点执行
yum install -y krb5-workstation krb5-libs4、修改所有节点上,Kerberos客户端配置文件/etc/krb5.conf,该文件中定义了整个服务使用时的全局变量属性。由于文件中有默认内容,建议是重命名备份默认文件后,自己新建一个写入如下内容
conf
[logging]
default = FILE:/var/log/krb5libs.log
kdc = FILE:/var/log/krb5kdc.log
admin_server = FILE:/var/log/kadmind.log
[libdefaults]
default_realm = HADOOP.COM
dns_lookup_realm = false
dns_lookup_kdc = false
ticket_lifetime = 24h
renew_lifetime = 7d
forwardable = true
udp_preference_limit = 1
default_tkt_enctypes = aes256-cts-hmac-sha1-96 aes128-cts-hmac-sha1-96 des3-hmac-sha1
default_tgs_enctypes = aes256-cts-hmac-sha1-96 aes128-cts-hmac-sha1-96 des3-hmac-sha1
permitted_enctypes = aes256-cts-hmac-sha1-96 aes128-cts-hmac-sha1-96 des3-hmac-sha1
[realms]
HADOOP.COM = {
kdc = node4:88
admin_server = node4:749
}
[domain_realm]
.hadoop.com = HADOOP.COM
hadoop.com = HADOOP.COM
[appdefaults]
pam = {
debug = false
ticket_lifetime = 36000
renew_lifetime = 36000
forwardable = true
krb4_convert = false
}logging是整个服务的日志路径,分别是默认日志文件位置(default)、KDC服务日志(kdc)、KDC管理服务日志(admin_server)
libdefaults定义操作客户端的默认行为配置
default_realm指当前客户端默认连接哪个域,它的值建议严格使用大写,不然后面使用会出毛病。但注意它本身不是IP协议的域名,而是标识Kerberos服务中的一个组织一样的对象
dns_lookup_realm 、dns_lookup_kdc :这两个是配置是指,是否识别你写的Kerberos域为一个DNS,如非特殊需求,始终为false
ticket_lifetime 是票据的有效时间
renew_lifetime 票据最大可续约多长时间
forwardable 票据是否可以被转发,由于服务之间涉及SSH等代理协议,所以需要设置为true,让SSH可以正常使用
proxiable 是否允许被代理,无特殊需求始终为默认的false,不需要额外配置
no_addresses 票据中是否有ip地址,同上
clockskew 客户端和KDC服务各自运行的服务器系统时间,允许的时间偏差,默认是300,也就是5分钟,在生产环境下要小一点,防止申请票据的请求可能是重放攻击,也就是被恶意拦截了请求做了一些灰色操作后,请求才到达KDC,KDC验证请求的时间戳和当前时间大于这个时间偏差就不给过了
ignore_acceptor_hostname 忽略主机名称的验证,非必要,默认false
udp_preference_limit 使用TCP协议,不用UDP,UDP服务不安全
default_tkt_enctypes 、default_tgs_enctypes 、permitted_enctypes 这是选择支持的票据加密,一般就这三个即可,aes256-cts-hmac-sha1-96 - AES-256加密最安全、aes128-cts-hmac-sha1-96 - AES-128加密次一级、des3-hmac-sha1 是为了兼容一些旧服务或者平台
realms定义当前客户端可达那些Kerberos域,它们的KDC、admin服务端口在哪里,以及域下的一些其他配置,注意,多个域之间可以用同一个KDC,换句话说KDC自身是没有专属于那个域这一限制的
kdc 同一个域自身可以配置多个,多个时,保持键值对形式多个kdc=ip即可,不用一个kdc后面逗号多个,但是!要特别说明,在这里配置多个kdc只是起到负载均衡作用,有客户端去选择一个KDC服务做后续操作,而KDC之间并不是高可用,它们是相互独立的,客户端直接访问不同KDC会收到服务元数据不同的影响,所以一般只写一个,如果实在需要高可用,去看其他文献,本文不涉及
admin_server管理服务器的地址,它和kdc配置同一个节点端口不一样即可
auth_to_local 是当前这个Kerberos的域用户识别为本地哪个linux用户,配置值不要动,当前配置取开头第一个组件名称,例如bob@HADOOP.COM 取得是 bob
bash
RULE:[<n>:<pattern>](<regexp>)[s/<pattern>/<replacement>[/<g>]][<L|U>]
RULE: 固定前缀
[<n>:<pattern>] 主体在被解析时,会把 @ 后的内容注入为 $0 也就是域名,其他的按照 / 切分后从左到右开始 $1 第一个 ... 注入,n 表示从 $1 开始取几个注入的值,随后使用 pattern 写好的格式输出
(<regexp>) 对前面输出的字符串做正则,如果符合这个正则继续执行后面的替换,这里可以反向使用 $1 这些注入表达式,但基本不这样用
[s/<pattern>/<replacement>[/<g>]] 替换规则,比如 s/.*/user/ 替换整个输出为user字符串 ,g 标识全局替换,就是所有被正则匹配到字串都换
[<L|U>] L小写 U大写 输出
RULE:[2:$1@$0](.*@HADOOP.COM)s/@HADOOP.COM//L --》 Test/node1@HADOOP.COM 映射为 test顺带说一下Kerberos常用命令,kinit 用来向KDC获取初始票据,也就是你没有任何票据时使用,类似于你登陆linux服务器提供用户密码操作,运行它也需要提供主体的原始密码或者keytab文件,后期hadoop服务自己获取节点票据,其实就是kinit -kt /etc/security/keytabs/nn.service.keytab nn/hadoop1@HADOOP.COM这种keytab文件代替手动输入原始密码的方式。klist 用来列出你当前获取的票据有那些。kvno 是你有了自己的初始票据后,获取其他服务票据时用的
domain_realm这部分是DNS域名和Kerberos的关联关系, .hadoop.com意思是hadoop.com的所有子域,hadoop.com是精确的某个顶级域,它们都属于HADOOP.COM这个Kerberos域,当后期访问 server1.hadoop.com 时,客户端会自动采用 HADOOP.COM 域的相关规则配置,这是 dns_lookup_realm = true 的替代方案
appdefaults是为特定服务配置一些特定的行为,比如下面这种,要是没有特殊需求可以不写
bash
[appdefaults]
telnet = {
forwardable = true # telnet应用可转发票据
}
pam = { # PAM认证模块设置
debug = false
ticket_lifetime = 36000
renew_lifetime = 36000
forwardable = true
krb4_convert = false
ccache_type = 3
}
ssh = { # SSH设置
forwardable = true
gssapikeyexchange = true
}5、在node4上,修改KDC服务的配置文件/var/kerberos/krb5kdc/kdc.conf
bash
[kdcdefaults]
kdc_ports = 88
kdc_tcp_ports = 88
[realms]
HADOOP.COM = {
master_key_type = aes256-cts
acl_file = /var/kerberos/krb5kdc/kadm5.acl
dict_file = /usr/share/dict/words
admin_keytab = /var/kerberos/krb5kdc/kadm5.keytab
supported_enctypes = aes256-cts:normal aes128-cts:normal des3-hmac-sha1:normal arcfour-hmac:normal camellia256-cts:normal camellia128-cts:normal des-hmac-sha1:normal des-cbc-md5:normal des-cbc-crc:normal
max_life = 24h
max_renewable_life = 7d
}kdcdefaults是基本配置,里面就是TCP和UDP的服务端口
realms和上面的配置文件一样,是不同域的专属配置
master_key_type 主密钥加密类型
acl_file 文件在哪里存放,yum安装后会自带一个
dict_file 密码字典,用来检查弱密码的,yum安装后会自带一个
admin_keytab kadmin管理员的keytab文件在哪里,kadmin这个主体是个内置主体,yum安装方式会自带一个
supported_enctypes 支持的加密
max_life 、max_renewable_life 票据的两个时间
6、node4节点上,还要按需配置KDC的acl文件,它用来规定那个Kerberos的主体能改配置和数据库,这里指定所有二级主体下的admin用户
bash
*/admin@HADOOP.COM *注意,这里要特意补充一点,Kerberos的主体格式为组件1/组件2/组件3..@Kerberos域,组件是一个逻辑概念,它是配置时一种约定俗成的格式,用来这不同场景上其他不同的区分作用,且Kerberos5内部用斜杠作为一些识别的依据,比如alice@HADOOP.COM 和 alice/admin@HADOOP.COM 是两个不同的主体,有着不同的权限和密码
7、生成Kerberos的数据库
bash
[root@node4 ~]# kdb5_util create -s -r HADOOP.COM
Loading random data
Initializing database '/var/kerberos/krb5kdc/principal' for realm 'HADOOP.COM',
master key name 'K/M@HADOOP.COM'
You will be prompted for the database Master Password.
It is important that you NOT FORGET this password.
Enter KDC database master key: #这里输入密码
Re-enter KDC database master key to verify: #确定密码注意命令中,-s 是生产环境下一般都会用的,它使得服务生成/var/kerberos/krb5kdc/下的.k5stash文件,重启服务自动读取,不用人工输入密码等,-r是指定域,一定要是配置文件中写的,通常就是你用那个写那个
8、启动服务
bash
systemctl start krb5kdc
systemctl start kadmin
systemctl enable krb5kdc
systemctl enable kadmin9、现在Kerberos服务就搭起来了,要为它创建管理主体。由于上面第六步规定好了管理用户的主体格式,所以要注意格式
bash
kadmin.local -q "addprinc admin/admin"
[root@node4 ~]# kadmin.local -q "addprinc admin/admin"
Authenticating as principal root/admin@HADOOP.COM with password.
WARNING: no policy specified for admin/admin@HADOOP.COM; defaulting to no policy
Enter password for principal "admin/admin@HADOOP.COM": #这里输入密码
Re-enter password for principal "admin/admin@HADOOP.COM": #这里再次输入密码
Principal "admin/admin@HADOOP.COM" created.命令中 -p 是主体 、-r 是域 、 -q是要执行的命令 ,随后用这个主体去登录一下
bash
[root@node4 ~]# kadmin -r HADOOP.COM -p admin/admin@HADOOP.COM
Authenticating as principal admin/admin with password.
Password for admin/admin@HADOOP.COM: #这里输入密码
kadmin: #出现这个就说明成功了,它类似于mysql的 mysql> 或者 Redis的 127.0.0.1:6379>在 kadmin: 提示符下,你可以:
创建、删除、修改Kerberos主体(用户/服务)
管理密码和密钥
设置权限和策略
导出keytab文件
查询数据库信息
bash
kadmin: ? # 显示所有可用命令
kadmin: help # 显示帮助信息
# 或查看特定命令帮助
kadmin: help add_principal
kadmin: help listprincs常用命令:
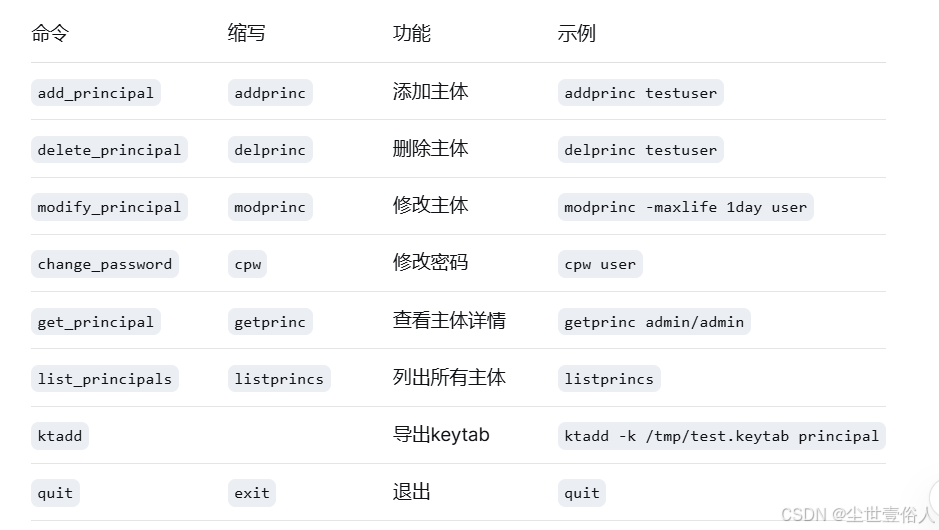
常用的使用案例
bash
# 进入kadmin @HADOOP.COM是默认缺省的可写可不写,这也是最上面改配置时不建议写Kerberos域下dns域的原因,会影响使用,容易混淆
kadmin -p admin/admin
kadmin: # 进入交互模式
# 1. 列出所有主体
kadmin: listprincs
K/M@HADOOP.COM
krbtgt/HADOOP.COM@HADOOP.COM
admin/admin@HADOOP.COM
# 2. 添加新用户
kadmin: addprinc alice
Enter password for principal "alice@HADOOP.COM":
Re-enter password for principal "alice@HADOOP.COM":
Principal "alice@HADOOP.COM" created.
# 3. 查看用户详情
kadmin: getprinc alice
Principal: alice@HADOOP.COM
Expiration date: [never]
Last password change: Thu Feb 15 10:00:00 CST 2024
Password expiration date: [none]
Maximum ticket life: 1 day 00:00:00
Maximum renewable life: 7 days 00:00:00
Last modified: Thu Feb 15 10:00:00 CST 2024 (admin/admin@HADOOP.COM)
Last successful authentication: [never]
Last failed authentication: [never]
Failed password attempts: 0
Number of keys: 8
Key: vno 1, aes256-cts-hmac-sha1-96
Key: vno 1, aes128-cts-hmac-sha1-96
Key: vno 1, des3-cbc-sha1
Key: vno 1, arcfour-hmac
Key: vno 1, des-hmac-sha1
Key: vno 1, des-cbc-md5
Key: vno 1, des-cbc-crc
Key: vno 1, des-cbc-crc:v4
MKey: vno 1
Attributes:
Policy: [none]
# 4. 退出
kadmin: quit同时要注意两个管理命令的区别,这也是前面涉及管理主体,如果有多个域时,可以在服务搭建过程中,直接用kadmin.local创建不同域的kadmin主体,而不是在启动后创建admin/admin那样

bash
# 1. 远程管理(推荐日常工作)
kadmin -p admin/admin
# 需要:网络连通、票据有效、ACL权限
# 2. 本地紧急操作(KDC服务器上)
kadmin.local
# 需要:root权限,直接在KDC服务器执行
# 绕过所有ACL检查!首先在 node4 上新建zk、http、hadoop集群管理用户的主体。创建时要明白一点,kerberos有个很恶心的地方,应用在不同场景下,主体格式会有固定的格式要求,并且Kerberos的一些内部执行逻辑用这些格式去辅助完成,比如下面要配置的zookeeper,你必须要为每一个节点都要有一个单独的主体,在申请票据时通过一个叫SASL的协议验证双方的节点地址是否正常,例如zookeeper/$host@HADOOP.COM中的$host就是这个节点的标识,必须用节点主机名,一般公司内搭建服务器的DNS和主机名是一致的,所以这一块容易混淆。而换一种情况就不一定了,比如常规用户在命令行使用的票据,可以不带,hadoop用的主体也可以没有
还要明白的是,主体它就只是一个票据,就比如你去洗脚,你的手牌只是你在消费时标记你的代称,你下一次可能是另一个手牌,这个手牌同样有其他人要来消费也会用,所以要明白票据主体和linux用户直接并不是身份证一样的存在,它只是一个门票
bash
#主备namenode节点一份即可,共两个
kadmin.local -q "addprinc -randkey nn/node1"
kadmin.local -q "ktadd -k /opt/keytab/hadoop.keytab nn/node1"
#所有JournalNode节点要有,共三个
kadmin.local -q "addprinc -randkey jn/node1"
kadmin.local -q "ktadd -k /opt/keytab/hadoop.keytab jn/node1"
#所有datanode节点要有,共六个
kadmin.local -q "addprinc -randkey dn/node1"
kadmin.local -q "ktadd -k /opt/keytab/hadoop.keytab dn/node1"
kadmin.local -q "addprinc -randkey nm/node1"
kadmin.local -q "ktadd -k /opt/keytab/hadoop.keytab nm/node1"
#主备yarn节点一份即可,共两个
kadmin.local -q "addprinc -randkey rm/node1"
kadmin.local -q "ktadd -k /opt/keytab/hadoop.keytab rm/node1"
#历史服务器所在节点一份即可,共一个
kadmin.local -q "addprinc -randkey jhs/node1"
kadmin.local -q "ktadd -k /opt/keytab/hadoop.keytab jhs/node1"
#每台节点都要有
kadmin.local -q "addprinc -randkey HTTP/node1"
kadmin.local -q "ktadd -k /opt/keytab/hadoop.keytab HTTP/node1"
#每台zookeeper的凭据,共三个
kadmin.local -q "addprinc -randkey zookeeper/node1@HADOOP.COM"
kadmin.local -q "ktadd -k /opt/keytab/hadoop.keytab zookeeper/node1"
#先创建,最后一起导出也可以,我是为了使用方便放在一个文件中,一般是分开放的
kadmin.local -q "ktadd -k /opt/keytab/hadoop.keytab nn/node1 nn/node2 jn/node1 jn/node2 jn/node3 dn/node1 dn/node2 dn/node3 nm/node1 nm/node2 nm/node3 rm/node2 rm/node3 jhs/node3 HTTP/node1 HTTP/node2 HTTP/node3 zookeeper/node1 zookeeper/node2 zookeeper/node3"
# 确定一下文件中该有的都有,!!!一定要检查,因为我在工作中确实发现有点时候没导出来
klist -k /opt/keytab/hadoop.keytab随后将得到的证书文件,发送到对应服务要部署的节点上,最好是同一个路径,后期也方便使用
bash
[root@node4 keytab]# scp hadoop.keytab node1:/opt/keytab/
hadoop.keytab 100% 1482 1.2MB/s 00:00
[root@node4 keytab]# scp hadoop.keytab node2:/opt/keytab/
hadoop.keytab 100% 1482 1.2MB/s 00:00
[root@node4 keytab]# scp hadoop.keytab node3:/opt/keytab/
hadoop.keytab 100% 1482 1.2MB/s 00:00 公司部署的时候,hadoop集群一定会有多个用户分别不同维护各个组件,比如hdfs用hdfs用户,yarn用yarn用户这种,它们的用户组一般是同一个比如叫hadoop,所以因此这里同样在所有节点上创建这些用户
bash
groupadd hadoop
useradd -g hadoop hdfs
useradd -g hadoop yarn
useradd -g hadoop mapred
useradd -g hadoop http
#分别修改它们的密码
passwd hdfs
#修改keytab存放目录的用户组
chown -R root:hadoop /opt/keytab/
#修改hadoop.keytab证书的权限为440
chmod 440 /opt/keytab/hadoop.keytab
#zk的没有特殊要求可以不变用户和用户组,通常是root后面这些hadoop用户常见操作如下服务,这个也是hadoop官网建议的
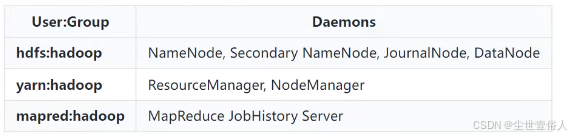
随后你要把所有节点上hadoop安装路径下的资源分别交给这些用户,这块内容按照官网的来就行 https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SecureMode.html,local部分,至于官网的其他内容不要全看,官网的文档是单例测试环境做的kerberos流程,商用的要求HA

需要留意的是,开头两个就是hdfs-site中写的datanode、namenode数据存储路径,HADOOP_LOG_DIR、YARN_LOG_DIR 不用特意修改,它本身就是一个在hadoop_home下的logs中,只需要把log路径交给hdfs用户,组必须是hadoop组,权限775即可,yarn.nodemanager.local-dirs是nodemanger跑任务时的工作路径,如果你没在yarn-site中修改,默认是 hadoop.tmp.dir/nm-local-dir ,yarn.nodemanager.log-dirs是nodemanager的本地任务日志存放地址,默认是 logs/userlogs 。此外还要改一个官网上没有的,journal服务的本地edits数据路径,所有人hdfs,组hadoop,权限755,下面两个container的要改一些东西,下面会说
bash
#按照你自己实际配置来
chown -R hdfs:hadoop /opt/hadoop323
chmod -R 755 /opt/hadoop323
chown -R hdfs:hadoop /opt/hadoop323/hdpData/dfs
chmod -R 700 /opt/hadoop323/hdpData/dfs
chown -R hdfs:hadoop /opt/hadoop323/logs
chmod -R 775 /opt/hadoop323/logs
chown -R yarn:hadoop /opt/hadoop323/hdpData/tmp/nm-local-dir
chmod -R 755 /opt/hadoop323/hdpData/tmp/nm-local-dir
chown -R yarn:hadoop /opt/hadoop323/logs/userlogs
chmod -R 755 /opt/hadoop323/logs/userlogs
chown -R hdfs:hadoop /opt/hadoop323/hdpData/journaldata
chmod -R 755 /opt/hadoop323/hdpData/journaldataapache版本的hadoop在配置kerberos认证上需要单独确保系统安装两个依赖库,JSVC和libcrypto.os
JSVC去官网下载:https://commons.apache.org/proper/commons-daemon/download_daemon.cgi 下载的时候,src包和bin包都要下载!!!!
bash
#先解压src包,用gcc依赖编辑,得到 jsvc 命令
tar -xzvf commons-daemon-1.2.4-src.tar.gz
cd commons-daemon-1.2.4-src/src/native/unix/
./configure --with-java=/opt/jdk1.8.0_411
# 编译
make
# 编译之后目录下会生成一个jsvc的指令
# 验证
./jsvc --help
#把这个命令放到hadoop的libexec下面
cp jsvc /opt/hadoop323/libexec/
#随后删除自带的daem jar包
${HADOOP_HOME}/share/hadoop/hdfs/lib 路径下所有自带的 commons-daemon-*.jar 都删掉,正常只有一个
#最后解压bin包,把里面的同名jar放到lib路径下
。。。。加压拷贝这里命令就不展示了
#权限给hdfs
chown -R hdfs:hadoop ${HADOOP_HOME}/share/hadoop/hdfs/lib
chown -R hdfs:hadoop ${HADOOP_HOME}/libexec
chmod -R 755 ${HADOOP_HOME}/share/hadoop/hdfs/lib
chmod -R 755 ${HADOOP_HOME}/libexec
#随后在hadoop-env文件中追加一个配置
export JSVC_HOME=/opt/hadoop323/libexec
#之后把这些东西同步其他节点同步其他节点libcrypto.os,需要先下载openssl的源码https://github.com/openssl/openssl/releases,这里用3.5.5,有的地方会用1.1.1
bash
#安装前先检查一下系统有没有,通常情况下是有的,只是版本比较低,不影响使用
ll /usr/lib64 |grep libcrypto
#确保有编译依赖
yum -y install gcc+ gcc-c++ zlib-devel perl-IPC-Cmd perl-Time-Piece
tar -zxf openssl-openssl-3.5.5.tar.gz
./config --prefix=/usr/local/ssl --openssldir=/usr/local/ssl shared zlib
make
make install
上面的操作完成后在你编译路径下存在一个 libcrypto.os.版本号 文件,把它 cp 到集群所有节点的 /usr/lib64 路径下在zookeeper服务的节点上,开始配置认证,可以先改一台,其他的同步后改配置文件中节点名称即可。需要在zookeeper的zoo.cfg文件中追加如下内容
bash
kerberos.removeHostFromPrincipal=true
kerberos.removeRealmFromPrincipal=true
authProvider.1=org.apache.zookeeper.server.auth.SASLAuthenticationProvider
jaasLoginRenew=3600000在zookeeper的配置路径下新增jaas.conf文件,这个文件中的$host部分要换成对应的节点自身标识,且不能有注释,配置的时候注意,建议公司搭建时写个xshell脚本用EOF的方式动态拼接然后推送
bash
Server {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/opt/keytab/hadoop.keytab" #keytab证书的位置
storeKey=true
useTicketCache=false
principal="zookeeper/$host@HADOOP.COM"; #这个必须是zookeeper的主体
};
Client {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/opt/keytab/hadoop.keytab"
storeKey=true
useTicketCache=false
principal="zookeeper/$host@HADOOP.COM"; #这个就可以随意一点了,一般配置一个合适的主体
};zk的配置文件夹下还要创建 java.env 文件
bash
export JVMFLAGS="-Djava.security.auth.login.config=$ZOOKEEPER_HOME/conf/jaas.conf"随后把配置文件同步到其他zookeeper节点上,并注意变更zookeeper主体中携带的节点标识,配置文件路径权限一定要是755
这里要说一个非常重要的事情!!如果你偷懒上面给zk服务用的主体没有带节点标识,服务确实能启动起来,但是日志文件中会报如下错误,并且影响后期使用
bash
2026-01-27 22:39:25,166 [myid:] - ERROR [NIOServerCxnFactory.SelectorThread-0:o.a.z.u.SecurityUtils@240] - server principal name/hostname determination error
java.lang.StringIndexOutOfBoundsException: String index out of range: -1
at java.lang.String.substring(String.java:1967)
at org.apache.zookeeper.util.SecurityUtils.createSaslServer(SecurityUtils.java:176)
at org.apache.zookeeper.server.ZooKeeperSaslServer.createSaslServer(ZooKeeperSaslServer.java:44)
at org.apache.zookeeper.server.ZooKeeperSaslServer.<init>(ZooKeeperSaslServer.java:38)
at org.apache.zookeeper.server.NIOServerCnxn.<init>(NIOServerCnxn.java:100)
at org.apache.zookeeper.server.NIOServerCnxnFactory.createConnection(NIOServerCnxnFactory.java:823)
at org.apache.zookeeper.server.NIOServerCnxnFactory$SelectorThread.processAcceptedConnections(NIOServerCnxnFactory.java:455)
at org.apache.zookeeper.server.NIOServerCnxnFactory$SelectorThread.run(NIOServerCnxnFactory.java:369)
2026-01-27 22:39:25,168 [myid:] - INFO [CommitProcessor:1:o.a.z.s.q.LearnerSessionTracker@116] - Committing global session 0x10000509f030001
2026-01-27 22:39:25,200 [myid:] - INFO [ListenerHandler-node1/192.168.239.130:3888:o.a.z.s.q.QuorumCnxManager$Listener$ListenerHandler@1076] - Received connection request from /192.168.239.132:51182
2026-01-27 22:39:25,202 [myid:] - INFO [WorkerReceiver[myid=1]:o.a.z.s.q.FastLeaderElection$Messenger$WorkerReceiver@391] - Notification: my state:FOLLOWING; n.sid:3, n.state:LOOKING, n.leader:3, n.round:0x1, n.peerEpoch:0x4b, n.zxid:0x4b00000045, message format version:0x2, n.config version:0x0
2026-01-27 22:39:27,637 [myid:] - ERROR [NIOServerCxnFactory.SelectorThread-0:o.a.z.u.SecurityUtils@240] - server principal name/hostname determination error
java.lang.StringIndexOutOfBoundsException: String index out of range: -1
at java.lang.String.substring(String.java:1967)
at org.apache.zookeeper.util.SecurityUtils.createSaslServer(SecurityUtils.java:176)
at org.apache.zookeeper.server.ZooKeeperSaslServer.createSaslServer(ZooKeeperSaslServer.java:44)
at org.apache.zookeeper.server.ZooKeeperSaslServer.<init>(ZooKeeperSaslServer.java:38)
at org.apache.zookeeper.server.NIOServerCnxn.<init>(NIOServerCnxn.java:100)
at org.apache.zookeeper.server.NIOServerCnxnFactory.createConnection(NIOServerCnxnFactory.java:823)
at org.apache.zookeeper.server.NIOServerCnxnFactory$SelectorThread.processAcceptedConnections(NIOServerCnxnFactory.java:455)zk服务启动后用客户端连接查看是否正常,要注意的是,配置了krb的zk,连接时会控制台输出一堆INFO日志,最后会卡在WatchedEvent state:SaslAuthenticated type:None path:null这样类似的日志上,敲一个回车就好了
bash
./bin/zkCli.sh -server node1:2181现在就可正式配置hadoop使用kerberos了,首先在原先集群的core-site.xml文件中新增如下配置
xml
<!-- 启用Hadoop集群Kerberos安全认证 -->
<property>
<name>hadoop.security.authentication</name>
<value>kerberos</value>
</property>
<!-- 启用Hadoop集群授权管理 -->
<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
<!-- 外部系统用户携带的主体映射成hadoop用户的处理方式 ,还有一个可选的hadoop,但是最好不要用后面使用会有问题-->
<property>
<name>hadoop.security.auth_to_local.mechanism</name>
<value>MIT</value>
</property>
<!-- Kerberos主体到系统用户的具体映射规则 -->
<!-- 这个配置非常重要,它指定了所有票据在hadoop服务中转换成那个linux本地用户的规则细节,通常公司内搭建一般就是 nn/nn.com@HADOOP.COM 这种组件实体映射成相关的本地用户,其他的还要为普通用户写映射,出于让大家好理解,我这里给大家的是正常配置,但本地测试搭建都用的是上面的root主体,所以也就没这么多 -->
<property>
<name>hadoop.security.auth_to_local</name>
<value>
<!-- ========== 第一部分:服务主体映射 ========== -->
<!-- HTTP服务主体 -->
RULE:[2:$1](HTTP.*)s/.*/http/
<!-- NameNode服务主体 -->
RULE:[2:$1](nn.*)s/.*/hdfs/
<!-- DataNode服务主体 -->
RULE:[2:$1](dn.*)s/.*/hdfs/
<!-- ResourceManager服务主体 -->
RULE:[2:$1](rm.*)s/.*/yarn/
<!-- NodeManager服务主体 -->
RULE:[2:$1](nm.*)s/.*/yarn/
<!-- JobHistory服务主体 -->
RULE:[2:$1](jhs.*)s/.*/mapred/
<!-- ========== 第二部分:默认规则 ========== -->
DEFAULT
</value>
</property>在 hdfs-site.xml 文件中追加如下配置
xml
<!-- 访问数据块需要经过kerberos认证-->
<property>
<name>dfs.block.access.token.enable</name>
<value>true</value>
</property>
<!-- NameNode服务的Kerberos主体,_HOST会自动解析为服务所在的主机名 -->
<property>
<name>dfs.namenode.kerberos.principal</name>
<value>nn/_HOST@HADOOP.COM</value>
</property>
<!-- NameNode服务的Kerberos密钥文件路径 ,注意我用的是统一的文件,大家如果用的是分开的,自己指定对应的就行-->
<property>
<name>dfs.namenode.keytab.file</name>
<value>/opt/keytab/hadoop.keytab</value>
</property>
<!-- DataNode服务的Kerberos主体 -->
<property>
<name>dfs.datanode.kerberos.principal</name>
<value>dn/_HOST@HADOOP.COM</value>
</property>
<!-- DataNode服务的Kerberos密钥文件路径 -->
<property>
<name>dfs.datanode.keytab.file</name>
<value>/opt/keytab/hadoop.keytab</value>
</property>
<!-- journalnode服务的Kerberos 主体 -->
<property>
<name>dfs.journalnode.kerberos.principal</name>
<value>jn/_HOST@HADOOP.COM</value>
</property>
<!-- journalnode服务的Kerberos密钥文件路径 -->
<property>
<name>dfs.journalnode.keytab.file</name>
<value>/opt/keytab/hadoop.keytab</value>
</property>
<!-- 配置NameNode Web UI 使用HTTPS协议 , 有kerberos必须用HTTPS-->
<property>
<name>dfs.http.policy</name>
<value>HTTPS_ONLY</value>
</property>
<!-- 配置DataNode数据传输保护策略为仅认证模式 -->
<property>
<name>dfs.data.transfer.protection</name>
<value>authentication</value>
</property>
<!-- WebHDFS 服务的Kerberos主体 -->
<property>
<name>dfs.web.authentication.kerberos.principal</name>
<value>HTTP/_HOST@EXAMPLE.COM</value>
</property>
<!-- WebHDFS的Kerberos密钥文件路径 -->
<property>
<name>dfs.web.authentication.kerberos.keytab</name>
<value>/opt/keytab/hadoop.keytab</value>
</property>
<!-- journalnode web服务用的主体,和的journalnode不是一个意思 ,它不需要指定秘钥文件路径吗????-->
<property>
<name>dfs.journalnode.kerberos.internal.spnego.principal</name>
<value>HTTP/_HOST@HADOOP.COM</value>
</property>
<!-- 这个非常重要一定要改成hdfs的,不然后面会服务启动报错不是特权用户-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hdfs/.ssh/id_rsa</value>
</property>yarn-site.xml 文件中追加如下内容
xml
<!-- Resource Manager 服务的Kerberos主体 -->
<property>
<name>yarn.resourcemanager.principal</name>
<value>rm/_HOST@HADOOP.COM</value>
</property>
<!-- Resource Manager 服务的Kerberos密钥文件 -->
<property>
<name>yarn.resourcemanager.keytab</name>
<value>/opt/keytab/hadoop.keytab</value>
</property>
<!-- Node Manager 服务的Kerberos主体 -->
<property>
<name>yarn.nodemanager.principal</name>
<value>nm/_HOST@HADOOP.COM</value>
</property>
<!-- Node Manager 服务的Kerberos密钥文件 -->
<property>
<name>yarn.nodemanager.keytab</name>
<value>/opt/keytab/hadoop.keytab</value>
</property>
<!-- kerberos 必须指定yarn启动和管理执行容器的类为LinuxContainerExecutor -->
<property>
<name>yarn.nodemanager.container-executor.class</name>
<value>org.apache.hadoop.yarn.server.nodemanager.LinuxContainerExecutor</value>
</property>
<!-- 指定运行容器执行器(container-executor)二进制文件的所属组,这个文件所属用户不用特意改,但所属组必须改成hadoop管理用户的共同组,比如叫hadoop -->
<property>
<name>yarn.nodemanager.linux-container-executor.group</name>
<value>hadoop</value>
</property>
<!-- LinuxContainerExecutor脚本路径 -->
<property>
<name>yarn.nodemanager.linux-container-executor.path</name>
<value>/opt/hadoop323/bin/container-executor</value>
</property>由于上面hdfs的访问方式配置成了HTTPS,因此你要去用前面安装好的插件生成自签证书,现在回到你上面编译openssl的节点上,执行下面的操作,openssl命令CentOS 7 系统自带
bash
# 生成一个自签的X.509根证书和密钥,运行后要求输入一个生成密钥的密码,按需设置,这里设置123456
# -keyout 密钥路径 -out 根证书路径 -days 有效天数 -subj 这个是根证书签名中的附加信息,就是这个证书CA机构在那里,那个城市这些自定义信息
openssl req -new -x509 -keyout /root/hdfs_ca_key -out /root/hdfs_ca_cert -days 36500 -subj '/C=CN/ST=beijing/L=haidian/O=devA/OU=devB/CN=devC'
#随后把根证书和秘钥同步给其他所有节点
scp /root/hdfs_ca_key /root/hdfs_ca_cert node2:/root/随后每个节点用拿到的证书,生成受信库,并生成自己的密钥库
bash
# 每个节点先生成密钥库
# keytool 命令是JavaJDK提供的工具 -keystore 是密钥库路径 -alias 是秘钥的别名 -keyalg 是采用的算法 -genkey是生成新的密钥对
# -dname这部分是密钥的签名,和上面生成根证书一样是附加信息,CN一定要是当前执行命令节点的hostname,其他的可以自定义
# -storepass 是生成的密钥库密码 -keypass 是密钥库中密钥对的密码
keytool -keystore /root/keystore -alias node1 -genkey -keyalg RSA -dname "CN=node1, OU=dev,O=dev,L=dev,ST=dev,C=CN" -storepass 123456 -keypass 123456
# 用拿到的根证书生成受信库,其实本身也是一个密钥库,只不过里面是信任的CA证书,而且就是一个单独要使用的库
# -alias 别名按需自定义即可 -import 是导入用的参数 -file 是指定导入的证书 -storepass 密钥库密码 -trustcacerts 标记为ca证书,这个可以不带 -noprompt 是非交互默认受信
keytool -keystore /root/truststore -alias ca -import -file /root/hdfs_ca_cert -storepass 123456 -trustcacerts -noprompt
# 用自己生成的秘钥库中的密钥生成一个签名请求文件, 别名一定要是密钥文件中的别名 运行输入的也是密钥库的密码
keytool -certreq -keystore /root/keystore -alias node1 -file /root/cert -storepass 123456 -keypass 123456
# 用ca给传来的根证书和ca的密钥,给当前节点签名,运行后输入ca根证书的密码
# 如果你用脚本生成,可以带 -passin pass:123456 这个配置
openssl x509 -req -CA /root/hdfs_ca_cert -CAkey /root/hdfs_ca_key -in /root/cert -out /root/cert_signed -days 36500 -CAcreateserial
# 将ca根证书导入 和 签名过的自签签名,导入到节点自己生成的密钥库中
keytool -keystore /root/keystore -alias ca -import -file /root/hdfs_ca_cert -storepass 123456 -noprompt
keytool -keystore /root/keystore -alias node1 -import -file /root/cert_signed -storepass 123456 -noprompt
#最后把受信库和秘钥库,放在一个hadoop用户都可以访问的统一路径中
cp /root/keystore /root/truststore /home
chown -R root:hadoop /home/keystore
chown -R root:hadoop /home/truststore
chmod 770 /home/keystore /home/truststore由于确实有点绕,我这里要特别说明一下,总体思路就是用一台机器做CA,生产根证书和CA密钥库,随后每个节点用拿到后,根证书直接生成一个单独的密钥库,该库后面用来给hadoop校验节点之间交互大家信任的是那个CA,是不是同一个,如果是同一个,则按照 A 信任 CA + B 信任 CA = A 信任 B的原则通过SSL校验。至于自己生成的密钥库中,有三个东西,分别是自身的密钥、CA的根证书、经过CA签名认证后的自签证书(本质上是一个owner为CA,使用者为当前节点的密钥对),用来在SSL校验时,证明你是你。此外,还要特别说明,网上有的文献会告诉你直接用 keytool 生成的秘钥和秘钥自己的签名来做受信库和密钥库,这种操作自身上没问题,但是!!!hadoop不认,甚至大多数架构都不认,因为证书类型 keytool 无法控制,当然还有一些其他的细节影响,所以 keytool 只适合管理,不适合生产证书,我经验中也就presto这个引擎jdbc连接的时候认 keytool 生成的证书签名,而在工作中,一般是公司花钱从正式CA机构买的证书,到你手上直接就是可用的受信库和秘钥库
用这两个文件配置hadoop的两个ssl配置文件
bash
mv $HADOOP_HOME/etc/hadoop/ssl-server.xml.example $HADOOP_HOME/etc/hadoop/ssl-server.xml
mv $HADOOP_HOME/etc/hadoop/ssl-client.xml.example $HADOOP_HOME/etc/hadoop/ssl-client.xml
# client 文件就不展示了,里面内容高度类似的
vi $HADOOP_HOME/etc/hadoop/ssl-server.xml
<!-- SSL信任库路径 ,这个就所有节点一样了,用来表名自身是谁-->
<property>
<name>ssl.server.truststore.location</name>
<value>/home/truststore</value>
</property>
<!-- SSL信任密钥库密码 -->
<property>
<name>ssl.server.truststore.password</name>
<value>123456</value>
</property>
<!-- SSL信任密钥库类型,一把都是jks就行 -->
<property>
<name>ssl.server.truststore.type</name>
<value>jks</value>
</property>
<!-- SSL信任密钥库重新加载的时间间隔,默认10秒 -->
<property>
<name>ssl.server.truststore.reload.interval</name>
<value>10000</value>
</property>
<!-- SSL密钥库路径 -->
<!-- 配置时注意,它是给namenode和历史服务器各用各的,其他节点这个配置没用 -->
<property>
<name>ssl.server.keystore.location</name>
<value>/home/keystore</value>
</property>
<!-- SSL密钥库密码 -->
<property>
<name>ssl.server.keystore.password</name>
<value>123456</value>
</property>
<!-- SSL密钥库中秘钥的密码 -->
<property>
<name>ssl.server.keystore.keypassword</name>
<value>123456</value>
</property>
<!-- SSL密钥库文件类型 -->
<property>
<name>ssl.server.keystore.type</name>
<value>jks</value>
</property>
<!-- 可选配置。希望从SSL通信中排除的弱安全密码套件-->
<property>
<name>ssl.server.exclude.cipher.list</name>
<value>TLS_ECDHE_RSA_WITH_RC4_128_SHA,SSL_DHE_RSA_EXPORT_WITH_DES40_CBC_SHA,
SSL_RSA_WITH_DES_CBC_SHA,SSL_DHE_RSA_WITH_DES_CBC_SHA,
SSL_RSA_EXPORT_WITH_RC4_40_MD5,SSL_RSA_EXPORT_WITH_DES40_CBC_SHA,
SSL_RSA_WITH_RC4_128_MD5</value>
</property>到此,kerberos下hadoop需要使用LinuxContainerExecutor类型的容器,而非默认的,因此所有节点要去调整hadoop的bin/container-executor命令,它的所有权限必须为root用户,用户组必须为hadoop管理用户的共同组,这里为hadoop,注意!!!!由于这个文件要求的权限特殊,所以只能每个节点本地做,不同同步
bash
chown root:hadoop /opt/hadoop323/bin/container-executor
# 6050 是个特殊权限,固定的,不要改
chmod 6050 /opt/hadoop323/bin/container-executor编辑etc/hadoop/container-executor.cfg文件,它的作用是规定hadoop具体如何操作executor容器,修改为如下内容
bash
yarn.nodemanager.linux-container-executor.group=hadoop #谁能操作容器,这个一定要指定为hadoop管理用户的用户组
banned.users=hdfs,yarn,mapred #绑定到用户级别
min.user.id=1000 #用户id范围限制,这个默认1000就行,这个id之前的不允许操作
#allowed.system.users= #保持默认空着,或者注释掉,这个是单独运行某些用户运行允许操作
feature.tc.enabled=false #这个默认false就行随后修改container-executor.cfg配置文件,这个文件的要求是从根路径开始到它自身,所属用户为root,所属组为hadoop管理用户组,它自身的权限设置为440
bash
chown root:hadoop /opt/hadoop323/etc/hadoop/container-executor.cfg
chown root:hadoop /opt/hadoop323/etc/hadoop
chown root:hadoop /opt/hadoop323/etc
chown root:hadoop /opt/hadoop323
chmod 440 /opt/hadoop323/etc/hadoop/container-executor.cfgmapred-site.xml 文件新增如下内容
xml
<!-- 历史服务器的Kerberos主体 -->
<property>
<name>mapreduce.jobhistory.principal</name>
<value>jhs/_HOST@HADOOP.COM</value>
</property>
<!-- 历史服务器的Kerberos密钥文件 -->
<property>
<name>mapreduce.jobhistory.keytab</name>
<value>/opt/keytab/hadoop.keytab</value>
</property>
<!-- 历史服务器服务通道用那种策略,这里按需选择,一般用的是 HTTP_ONLY 比较多 -->
<property>
<name>mapreduce.jobhistory.http.policy</name>
<value>HTTP_ONLY</value>
</property>
<!-- shuffle安全按需配置,一般为了效率选择false -->
<property>
<name>mapreduce.shuffle.ssl.enabled</name>
<value>false</value>
</property>hadoop-env.sh 文件中修改如下内容。注意有的地方只单独修改 start-dfs.sh 、 stop-dfs.sh 、start-yarn.sh 、 stop-yarn.sh ,而且以shell变量的方式追加存在,而非 export 环境变量这也是可以的,但是比较麻烦
bash
#首先是组件用户,在非kerberos的3.x下,你会有一个 export HDFS_NAMENODE_USER=hdfs 配置,但在kerberos下,需要用下面这个
export HDFS_DATANODE_SECURE_USER=hdfs
# 把原来的注释掉
#export HDFS_DATANODE_USER=hdfs
#其他的一些 yarn组件用户等等也是配置上面准备好的用户
export HDFS_NAMENODE_USER=hdfs
export HDFS_JOURNALNODE_USER=hdfs
export HDFS_ZKFC_USER=hdfs
#这两个有点方法放在yarn的启停脚本中
export YARN_RESOURCEMANAGER_USER=yarn
export YARN_NODEMANAGER_USER=yarn
#kerberos下的hadoop尽量不要用root启动,会出现问题现在检查上面这些变动,是否已经同步到所有节点,没同步的同步,确保所有使用到的用户是免密的,随后开始启动hadoop集群
启动时,确保ZK服务启动成功,随后切换到 hdfs 用户,hadoop3.x可以在root下执行,因为有环境变量,2.x的不行
bash
在node4上先给hdfs用户准备一个kerberos主体
kadmin.local -q "addprinc -pw 123456 hdfs"
在node1上,切换hdfs,获取票据,启动hdfs
kinit hdfs@HADOOP.COM
${HADOOP_HOME}/sbin/start-dfs.sh
启动注意,hdfs认证比较慢,尤其是链接jn服务的时候,所以你可能会在日志文件中看到连接超时,但是会自动重试,等等一般问题不大
而且namenode的访问端口,默认是 https://host:9871 ,这个可以在hdfs-site文件中改,给原来的配置项加个 s 就行
!!!!!和无认证的hadoop集群不一样的是,配置好认证后第一次运行start-dfs.sh,是不会启动datanode的,不止不会启动,还会报错
如果你是在非root用户下启动,报错是 You must be a privileged user in order to run a secure service.
如果是在root用户下启动,命令行的报错通常是 一个认证主体类的错误,然后再logs下的hadoop-hdfs-root-datanode-node1.log文件中,你会看到巨量的 org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server 重试日志
因此,配置好认证后第一次hadoop集群运行start-dfs后,要切换到root用户下,运行 sbin/start-secure-dns.sh 命令,随后在datanode节点上 jps 你会看到一个叫做 Secur 进程,它就是安全模式下的 datanode
随后必须重启一遍 hdfs ,后续的使用才会正常,不过后续启动hdfs的datanode同样也必须用root执行start-secure-dns.sh命令,这本质上是收到上面修改container容器类型的影响,视为root为唯一的可启动守护进程特权用户,所以如果你用的是3.x的hadoop,配好上面的文件后,用root身份正常执行命令即可,hadoop自己会除了身份
随后启动yarn,但有认证的hadoop,启动yarn,对hdfs路径权限有严格要求,因此你需要先改hdfs权限。也就是`https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SecureMode.html`,hdfs部分
#根路径不能,也不用 -R
hadoop fs -chown hdfs:hadoop /
hadoop fs -chmod 777 /
hadoop fs -chown -R hdfs:hadoop /tmp
hadoop fs -chmod -R 777 /tmp
hadoop fs -chown -R hdfs:hadoop /user
hadoop fs -chmod -R 755 /user
#下面这三个路径用你自己的配置
hadoop fs -chown -R yarn:hadoop /mrlogs
hadoop fs -chmod -R 777 /mrlogs
hadoop fs -chown -R mapred:hadoop /hisdata
hadoop fs -chmod -R 777 /hisdata
hadoop fs -chown -R mapred:hadoop /history
hadoop fs -chmod -R 750 /history
#如果你是已有集群添加认证,还要注意一个路径,这个是配置了标签后生成的,虽然标签在hadoop中是个不完整的假功能,但它的权限会影响启动
hadoop fs -chown -R yarn:hadoop /node-labels
hadoop fs -chmod -R 755 /node-labels
#随后yarn启动命令不变
${HADOOP_HOME}/sbin/start-yarn.sh
yarn也可以用https,在yarn-site 和 mapred-site 配置中修改 yarn.http.policy 和 mapreduce.jobhistory.http.policy 为 HTTPS_ONLY
#启动his服务
${HADOOP_HOME}/sbin/mr-jobhistory-daemon.sh start historyserver
#随后给所有节点新增一个linux普通用户,携带这个普通用户的主体,跑一个测试任务试一下
hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.3.jar wordcount /hs /output
#一定要要用hdfs这些用户,因为上面的配置文件中限制了它们的使用,会报下面的错误
main : run as user is hdfs
main : requested yarn user is hdfs
Requested user hdfs is banned这里重点要说的是,认证下的hadoop集群,在后续日常使用命令行客户端时,你需要先认证,说白了,你要在同一个kerberos域下存在一个比如说叫hdfs@HADOOP.COM的主体,注意上面有说到主体票据和用户不是一对一关系,所以并不是说hdfs@HADOOP.COM主体必须是hdfs用户才能用,当用户通过kinit认证完成后,会存在一个default principal的默认票据
在商用环境下,kerberos认证通常给多租户、高安全、高负载集群使用,本地文件对于其他用户来讲,让用户属于hadoop组即可操作集群。当然,如果是客户端分离的使用场景下,用户测的客户端权限都是用户自己就行,因为它不涉及集群自己内部运行等等。还要明白的是,kerberos只是解决了你能不能用这个服务,而不是服务内你能干什么,就像最开头说的那样,你使用linux账户密码,能进入服务器大楼,通过票据能进入hdfs的房间,但是在房间里你干什么那就是另一回事了,这部分你可以使用ranger,具体可以看我另一篇改造ranger配合其他引擎做表字段级鉴权的文章,并且如果你也有改造需求,有了kerberos,就能使用hadoop的tokens携带一些东西,这些token会随着你操作集群而存在,比如默认提交一个mr任务,你就会看到日志里有

有个悖论要注意一下,比如现在有个张三用户,kerberos里存在着一个李四的主体,张三操作集群,获取的是李四的票据,那么这个时候当操作到达hdfs上时,hadoop认为这次操作的用户是李四,并以李四为核心鉴权,而不是张三,所以商用化,公司内,用户和主体通常是1对1,且名字相同的,而且涉及到的用户主体格式都是用户名@域名,这个解析格式的策略是由上面配置文件中控制的,本文档中选择的是MIT,也就是最小简写,另外还有一个可选的hadoop,这个配置在使用时会出现一些怪怪的问题,总之尽量不要用
注意!!!如果你浏览器访问 hdfs 的ui界面,你会发现报错
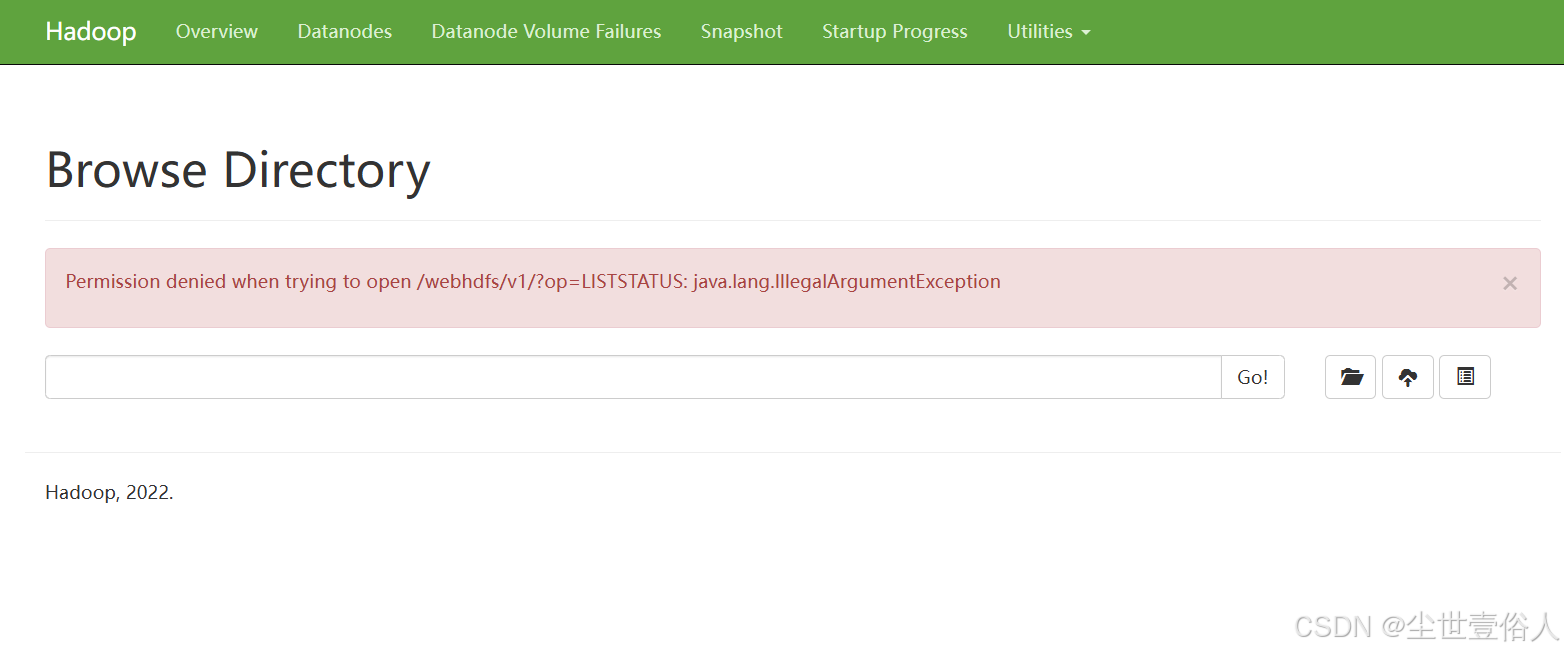
这个是因为,你的Windows电脑需要安装kerberos插件,下载地址-》http://web.mit.edu/kerberos/dist/index.html
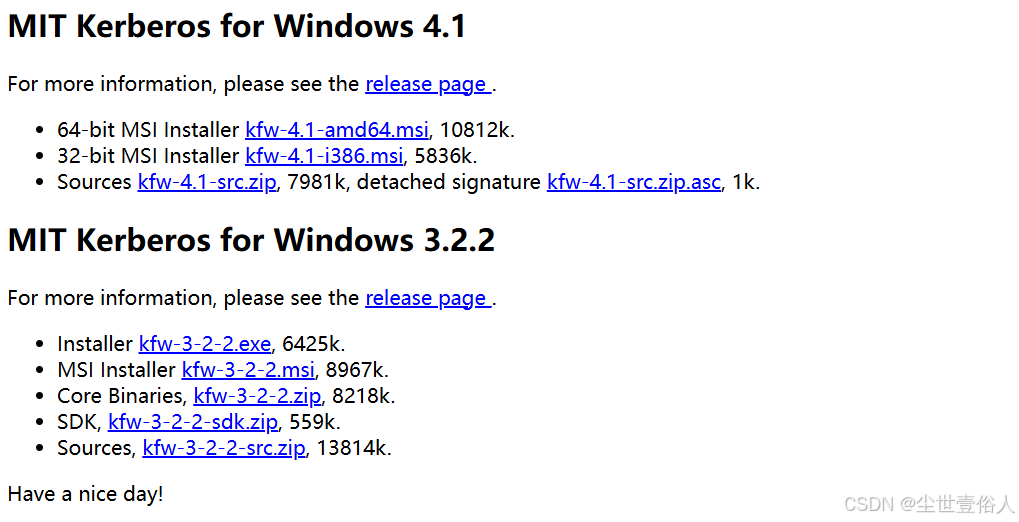
我常用的是 64-bit MSI Installer kfw-4.1-amd64.msi, 10812k. 这个,安装后,把服务器上的 /etc/krb5.conf 文件下载下来,里面的除了日志部分,其他的内容复制到C:\ProgramData\MIT\Kerberos5\krb5.ini文件中,安装这个程序要求重启电脑。后续打开输入你用的主体即可
然后!!!!你的浏览器也有要求,大多数国产浏览器不能用,最好是谷歌、火狐、firefox这三种,谷歌配置比较麻烦,火狐配置最简单,浏览器搜索about:config,在配置页中搜索并修改network.negotiate-auth.trusted-uris,追加namenode和kdc节点以及端口号多个用逗号分割。network.auth.use-sspi设置为false,即可。此外,如果你hadoop用的是3.3.x及其以上,浏览器是不能通过kerberos访问的,这是个hadoop自身的bug
后续使用代码调用Java API时,对于非认证集群,非常简单,调用get,或者指定url和用户即可,但是对认证集群,你需要调用apache的用户身份类从Kerberos认证中提取
bash
package com.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.security.UserGroupInformation;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.security.PrivilegedExceptionAction;
public class Test {
public static void main(String[] args) throws IOException, URISyntaxException, InterruptedException {
Configuration cfg =new Configuration();
//非认证集群可以不带配置文件,手动指定url
//cfg.set("fs.defaultFS","hdfs://192.168.85.128:9000");
//FileSystem fs=FileSystem.get(new URI("hdfs://192.168.85.128:9000"),cfg,"root");
//认证集群,你需要将集群的core、hdfs配置文件放到source下
//随后用 用户UGI身份信息类获取Kerberos用户下的票据
// 使用代理方式获取文件系统
System.setProperty("java.security.krb5.conf", "C:\\Users\\wang\\Desktop\\krb5.conf");
UserGroupInformation zhangsan = UserGroupInformation.loginUserFromKeytabAndReturnUGI("zhangsan", "C:\\Users\\wang\\Desktop\\zhangsan.keytab");
FileSystem fs = (FileSystem) zhangsan.doAs(new PrivilegedExceptionAction<Object>() {
public Object run() throws Exception {
FileSystem fs = FileSystem.get(cfg);
return fs;
}
});
fs.mkdirs(new Path("/test_mkdir"));
fs.close();
}
}spark同样也要认证
bash
import org.apache.hadoop.security.UserGroupInformation
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//spark运行程序认证也是类似的操作,不过不需要代理
System.setProperty("java.security.krb5.conf", "C:\\Users\\wang\\Desktop\\krb5.conf")
//用身份信息类重置当前用户票据即可
UserGroupInformation.loginUserFromKeytab("zhangsan", "C:\\Users\\wang\\Desktop\\zhangsan.keytab")
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(conf)
sc.textFile("hdfs://hdp/input").foreach(println(_))
sc.stop()
}
}flink和spark认证上一样,都是放在程序最上方,注意!只有在本地执行的时候才这样,你把这个包放到集群上提交的时候,kinit认证票据即可,不需要代码里写什么
当你的Hadoop配置了认证,Hive就必须同样配置,因为你在linux命令行下获取的票据,是你操作hadoop客户端可以识别的,但默认情况下hive不会去识别,任然是之前默认的那一套,此时hive带着你的任务去对接hadoop时,就会由于hadoop不认为hive是一个可信的服务端而报错,此时的hive就和hadoop中的一个服务一样,也需要认证。好在是hive配置认证没hadoop那么麻烦
首先同样的操作,所有节点创建linux用户
bash
useradd -g hadoop hive
chown -R hive:hadoop /opt/hive313Kerberos上创建主体,只需为hive服务运行的节点创建即可,至于上面所有集群节点都要创建hive用户,这点操作完有认证hadoop集群应该都知道任意节点没有任务涉及的linux用户都会报错本地用户不存在
bash
# 用Kerberos另一种原密码导出keytab文件方式,这里只是起到演示作用,你任然可以用随机密码,hive的主体和hadoop不一样的是它必须有节点标识
kadmin.local -q "addprinc -pw 123456 hive/node2"
kadmin.local -q "ktadd -norandkey -k /opt/keytab/hive.keytab hive/node2"
#发到运行服务的节点
scp ....目标节点收到后同样,改权限
bash
chown hive:hadoop hive.keytab
chmod 770 hive.keytab 修改hive配置文件hive-site.xml,追加
bash
<!-- hive2连接 启用kerberos认证用户身份,如果你用过我开源的自定义插件,开到和这个冲突不要疑惑,你选择那个方式都可以,本身就只是识别操作hive的用户是谁的 -->
<property>
<name>hive.server2.authentication</name>
<value>kerberos</value>
</property>
<property>
<name>hive.server2.authentication.kerberos.principal</name>
<value>hive/node2@HADOOP.COM</value>
</property>
<property>
<name>hive.server2.authentication.kerberos.keytab</name>
<value>/opt/keytab/hive.keytab</value>
</property>
<!-- hivemeta 启用kerberos认证 -->
<property>
<name>hive.metastore.sasl.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.kerberos.principal</name>
<value>hive/node2@HADOOP.COM</value>
</property>
<property>
<name>hive.metastore.kerberos.keytab.file</name>
<value>/opt/keytab/hive.keytab</value>
</property>hadoop的core-site中需要允许hive做用户代理,配置这个的时候要注意,非认证集群非必要hadoop.proxyuser.root.users,但是认证集群下hive必须配置
bash
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>随后就可以正常使用了,使用前和hadoop客户端一样,先获取票据
bash
[root@node2 conf]# klist
Ticket cache: FILE:/tmp/krb5cc_0
Default principal: zhangsan@HADOOP.COM
Valid starting Expires Service principal
02/01/2026 22:12:05 02/02/2026 22:12:05 krbtgt/HADOOP.COM@HADOOP.COM
[root@node2 conf]# /opt/hive313/bin/hive
which: no hbase in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/opt/jdk1.8.0_411/bin:/opt/zookeeper384/bin:/opt/hadoop323/bin:/opt/hadoop323/sbin:/opt/scala-2.12.15/bin:/opt/hive313/bin:/opt/prestoserver272/bin:/opt/spark322/bin:/opt/kafka2.13_372/bin:/root/bin)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive313/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop323/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Hive Session ID = 8b50f9f3-7a18-44bd-adaf-21daec53bf58
Logging initialized using configuration in file:/opt/hive313/conf/hive-log4j2.properties Async: true
Hive Session ID = b2293bdd-2b5c-4cdf-9d29-d61906d21c27
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive (default)> select sum(a) from test_tbl; #查询一下
Query ID = root_20260201221228_950b5432-4543-42e8-b9f2-bd5def5d1783
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
2026-02-01 22:12:30,889 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
2026-02-01 22:12:31,897 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries
2026-02-01 22:12:31,899 INFO lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev 52decc77982b58949890770d22720a91adce0c3f]
Starting Job = job_1769929290151_0007, Tracking URL = http://node3:8088/proxy/application_1769929290151_0007/
Kill Command = /opt/hadoop323/bin/mapred job -kill job_1769929290151_0007
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2026-02-01 22:12:39,610 Stage-1 map = 0%, reduce = 0%
2026-02-01 22:12:46,782 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.53 sec
2026-02-01 22:12:53,920 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.29 sec
MapReduce Total cumulative CPU time: 3 seconds 290 msec
Ended Job = job_1769929290151_0007
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.29 sec HDFS Read: 12039 HDFS Write: 101 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 290 msec
OK
_c0
1
Time taken: 26.495 seconds, Fetched: 1 row(s)
hive (default)>
hive (default)> insert into test_tbl values(3);
Query ID = zhangsan_20260201234820_d240a73f-f590-481d-84e9-8a3312c1311b
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
2026-02-01 23:48:23,318 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
2026-02-01 23:48:24,370 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries
2026-02-01 23:48:24,372 INFO lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev 52decc77982b58949890770d22720a91adce0c3f]
Starting Job = job_1769929290151_0009, Tracking URL = http://node3:8088/proxy/application_1769929290151_0009/
Kill Command = /opt/hadoop323/bin/mapred job -kill job_1769929290151_0009
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2026-02-01 23:48:30,023 Stage-1 map = 0%, reduce = 0%
2026-02-01 23:48:37,180 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.89 sec
2026-02-01 23:48:42,280 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.29 sec
MapReduce Total cumulative CPU time: 3 seconds 290 msec
Ended Job = job_1769929290151_0009
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://hdp/hiveData/test_tbl/.hive-staging_hive_2026-02-01_23-48-20_685_2390562501530959721-1/-ext-10000
Loading data to table default.test_tbl
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.StatsTask # 这个报错不用理会,它是个性能观测守护进程的中断错误
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.29 sec HDFS Read: 12533 HDFS Write: 203 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 290 msec
hive (default)> select * from test_tbl;
OK
test_tbl.a
1
2
3
Time taken: 0.153 seconds, Fetched: 3 row(s)
如果你用beeline连接,说白了就是jdbc,则你要在连接路径中带上你的主体
bash
[root@node2 ~]# su hive
[hive@node2 root]$ klist
Ticket cache: FILE:/tmp/krb5cc_1008
Default principal: hive/node2@HADOOP.COM
Valid starting Expires Service principal
02/01/2026 22:48:29 02/02/2026 22:48:29 krbtgt/HADOOP.COM@HADOOP.COM
[hive@node2 root]$ /opt/hive313/bin/beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive313/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop323/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 3.1.3 by Apache Hive
#连接信息的主体必须用hive/node2@HADOOP.COM
beeline> !connect jdbc:hive2://node2:10000/default;principal=hive/node2@HADOOP.COM
Connecting to jdbc:hive2://node2:10000/default;principal=hive/node2@HADOOP.COM
Connected to: Apache Hive (version 3.1.3)
Driver: Hive JDBC (version 3.1.3)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://node2:10000/default> show tables;
INFO : Compiling command(queryId=root_20260201225652_9c2f422c-e99c-46ba-825e-9ece524fea1c): show tables
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:tab_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=root_20260201225652_9c2f422c-e99c-46ba-825e-9ece524fea1c); Time taken: 0.485 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20260201225652_9c2f422c-e99c-46ba-825e-9ece524fea1c): show tables
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=root_20260201225652_9c2f422c-e99c-46ba-825e-9ece524fea1c); Time taken: 0.029 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+-----------+
| tab_name |
+-----------+
| test_tbl |
+-----------+
1 row selected (0.799 seconds)
0: jdbc:hive2://node2:10000/default> select * from test_tbl;
INFO : Compiling command(queryId=root_20260201225701_470ae04f-91a6-4095-a689-520a615b9ebb): select * from test_tbl
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:test_tbl.a, type:int, comment:null)], properties:null)
INFO : Completed compiling command(queryId=root_20260201225701_470ae04f-91a6-4095-a689-520a615b9ebb); Time taken: 1.181 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20260201225701_470ae04f-91a6-4095-a689-520a615b9ebb): select * from test_tbl
INFO : Completed executing command(queryId=root_20260201225701_470ae04f-91a6-4095-a689-520a615b9ebb); Time taken: 0.0 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+-------------+
| test_tbl.a |
+-------------+
| 1 |
| 2 |
+-------------+
2 rows selected (1.383 seconds)
0: jdbc:hive2://node2:10000/default> 但是这个时候,又有一个悖论出现了,凡是使用kerberos认证集群的公司,普遍不提供hive的JDBC方式连接,不是他们不想,是不能!!下面我以四种使用逻辑正常需求的场景来体现为什么不能用
第一种其他用户使用 hive/node2 ,在任务执行时,会报错代理无权限,这个问题的根本原因我不太确定,我猜测是发生了双层代理,也就是用户连接hive时,用主体认证,获得了hive服务的权限,服务在处理完身份后,再跑任务内部到了hadoop上主体被映射成了hive,此时自己代理自己不可行
bash
[zhangsan@node2 keytab]$ klist
Ticket cache: FILE:/tmp/krb5cc_1007
Default principal: hive/node2@HADOOP.COM
Valid starting Expires Service principal
02/01/2026 23:05:23 02/02/2026 23:05:23 krbtgt/HADOOP.COM@HADOOP.COM
[zhangsan@node2 keytab]$ /opt/hive313/bin/beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive313/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop323/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 3.1.3 by Apache Hive
beeline> !connect jdbc:hive2://node2:10000/default;principal=hive/node2@HADOOP.COM
Connecting to jdbc:hive2://node2:10000/default;principal=hive/node2@HADOOP.COM
Connected to: Apache Hive (version 3.1.3)
Driver: Hive JDBC (version 3.1.3)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://node2:10000/default> select sum(a) from test_tbl;
INFO : Compiling command(queryId=root_20260201230620_b090a4e8-5fb7-48da-86d1-9dccaa6e80ce): select sum(a) from test_tbl
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:_c0, type:bigint, comment:null)], properties:null)
INFO : Completed compiling command(queryId=root_20260201230620_b090a4e8-5fb7-48da-86d1-9dccaa6e80ce); Time taken: 0.62 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20260201230620_b090a4e8-5fb7-48da-86d1-9dccaa6e80ce): select sum(a) from test_tbl
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
INFO : Query ID = root_20260201230620_b090a4e8-5fb7-48da-86d1-9dccaa6e80ce
INFO : Total jobs = 1
INFO : Launching Job 1 out of 1
INFO : Starting task [Stage-1:MAPRED] in serial mode
INFO : Number of reduce tasks determined at compile time: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
ERROR : Job Submission failed with exception 'org.apache.hadoop.security.authorize.AuthorizationException(User: hive/node2@HADOOP.COM is not allowed to impersonate hive)'
org.apache.hadoop.security.authorize.AuthorizationException: User: hive/node2@HADOOP.COM is not allowed to impersonate hive
ERROR : FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. User: hive/node2@HADOOP.COM is not allowed to impersonate hive
INFO : Completed executing command(queryId=root_20260201230620_b090a4e8-5fb7-48da-86d1-9dccaa6e80ce); Time taken: 0.923 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
Error: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. User: hive/node2@HADOOP.COM is not allowed to impersonate hive (state=08S01,code=1)第二种其他用户使用自己的主体,会导致主体不符合预期的三部分格式
bash
[zhangsan@node2 keytab]$ kinit -kt ./zhangsan.keytab zhangsan
[zhangsan@node2 keytab]$ klist
Ticket cache: FILE:/tmp/krb5cc_1007
Default principal: zhangsan@HADOOP.COM
Valid starting Expires Service principal
02/01/2026 23:08:12 02/02/2026 23:08:12 krbtgt/HADOOP.COM@HADOOP.COM
[zhangsan@node2 keytab]$ /opt/hive313/bin/beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive313/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop323/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 3.1.3 by Apache Hive
beeline> !connect jdbc:hive2://node2:10000/default;principal=zhangsan@HADOOP.COM
Connecting to jdbc:hive2://node2:10000/default;principal=zhangsan@HADOOP.COM
26/02/01 23:08:53 [main]: WARN jdbc.HiveConnection: Failed to connect to node2:10000
Error: Could not open client transport with JDBC Uri: jdbc:hive2://node2:10000/default;principal=zhangsan@HADOOP.COM: Kerberos principal should have 3 parts: zhangsan@HADOOP.COM (state=08S01,code=0)第三种舍弃服务成本,给其他用户一个符合规范的主体,就会发生主体对于hive服务来讲不正确的错误
bash
beeline> !connect jdbc:hive2://node2:10000/default;principal=zhangsan/node2@HADOOP.COM
Connecting to jdbc:hive2://node2:10000/default;principal=zhangsan/node2@HADOOP.COM
26/02/01 23:24:25 [main]: WARN jdbc.HiveConnection: Failed to connect to node2:10000
Unknown HS2 problem when communicating with Thrift server.
Error: Could not open client transport with JDBC Uri: jdbc:hive2://node2:10000/default;principal=zhangsan/node2@HADOOP.COM: Peer indicated failure: GSS initiate failed (state=08S01,code=0)第四种让 hive 用户用 hive的主体,携带一个其他用户的username
bash
[hive@node2 keytab]$ /opt/hive313/bin/beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive313/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop323/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 3.1.3 by Apache Hive
beeline> !connect jdbc:hive2://node2:10000/default;principal=hive/node2@HADOOP.COM&username=zhangsan
Connecting to jdbc:hive2://node2:10000/default;principal=hive/node2@HADOOP.COM&username=zhangsan
26/02/01 23:36:27 [main]: WARN jdbc.HiveConnection: Failed to connect to node2:10000
Unknown HS2 problem when communicating with Thrift server.
Error: Could not open client transport with JDBC Uri: jdbc:hive2://node2:10000/default;principal=hive/node2@HADOOP.COM&username=zhangsan: Peer indicated failure: Unsupported mechanism type PLAIN (state=08S01,code=0)上面这四种使用场景,确定了一个问题hive配置完kerberos认证后,就只能通过客户端去操作,才能正常识别用户自己的身份,但是这个时候,肯定有人在想,难道只能 hive 用户携带 hive服务主体,去跑任务吗?只能说这个想法想简单了,hive用户自己都没有办法使用jdbc
bash
[hive@node2 keytab]$ klist
Ticket cache: FILE:/tmp/krb5cc_1008
Default principal: hive/node2@HADOOP.COM
Valid starting Expires Service principal
02/01/2026 22:48:29 02/02/2026 22:48:29 krbtgt/HADOOP.COM@HADOOP.COM
[hive@node2 keytab]$ /opt/hive313/bin/beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive313/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop323/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 3.1.3 by Apache Hive
beeline> !connect jdbc:hive2://node2:10000/default;principal=hive/node2@HADOOP.COM
Connecting to jdbc:hive2://node2:10000/default;principal=hive/node2@HADOOP.COM
Connected to: Apache Hive (version 3.1.3)
Driver: Hive JDBC (version 3.1.3)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://node2:10000/default> select sum(a) from test_tbl;
INFO : Compiling command(queryId=root_20260201234114_97ffa99b-d297-4e93-9e6b-ae8b263caed2): select sum(a) from test_tbl
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:_c0, type:bigint, comment:null)], properties:null)
INFO : Completed compiling command(queryId=root_20260201234114_97ffa99b-d297-4e93-9e6b-ae8b263caed2); Time taken: 0.168 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20260201234114_97ffa99b-d297-4e93-9e6b-ae8b263caed2): select sum(a) from test_tbl
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
INFO : Query ID = root_20260201234114_97ffa99b-d297-4e93-9e6b-ae8b263caed2
INFO : Total jobs = 1
INFO : Launching Job 1 out of 1
INFO : Starting task [Stage-1:MAPRED] in serial mode
INFO : Number of reduce tasks determined at compile time: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
ERROR : Job Submission failed with exception 'org.apache.hadoop.security.authorize.AuthorizationException(User: hive/node2@HADOOP.COM is not allowed to impersonate hive)'
org.apache.hadoop.security.authorize.AuthorizationException: User: hive/node2@HADOOP.COM is not allowed to impersonate hive
ERROR : FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. User: hive/node2@HADOOP.COM is not allowed to impersonate hive
INFO : Completed executing command(queryId=root_20260201234114_97ffa99b-d297-4e93-9e6b-ae8b263caed2); Time taken: 0.134 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
Error: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. User: hive/node2@HADOOP.COM is not allowed to impersonate hive (state=08S01,code=1)因此,在工作中不要觉得公司内部引擎部门不提供hive-jdbc是不配合,是他们真的提供不出来,hive自身内的就没兼容好kerberos,要改造成本太大了,不过话说回来,也不是完全没有办法提供基地bc,通常是通过presro提供远程连接数据查询能力,因为presro走的和hive客户端一样直连元数据服务