Ubuntu22.04安装Hadoop3.3.0
-
- 参考
- 一、环境的选择
- 二、创建Hadoop账户
- 三、更新apt
- 四、安装SSH、配置SSH免密码登录
-
- 一、前提说明
- 二、完整操作步骤
-
- [1. 检查并安装 SSH(确保基础环境)](#1. 检查并安装 SSH(确保基础环境))
- [2. 生成 ED25519 密钥对(核心步骤)](#2. 生成 ED25519 密钥对(核心步骤))
- [3. 设置密钥文件权限(关键!SSH 对权限敏感)](#3. 设置密钥文件权限(关键!SSH 对权限敏感))
- [4. 分发公钥到目标节点(实现免密登录)](#4. 分发公钥到目标节点(实现免密登录))
-
- [步骤 4.1:先授权本机免密登录(必做)](#步骤 4.1:先授权本机免密登录(必做))
- [步骤 4.2:分发公钥到远程节点(以 node2 为例)-不需要做](#步骤 4.2:分发公钥到远程节点(以 node2 为例)-不需要做)
- [步骤 4.3:对所有节点重复分发-不需要做](#步骤 4.3:对所有节点重复分发-不需要做)
- [5. 验证免密登录(关键测试)](#5. 验证免密登录(关键测试))
- [6. (可选)从节点免密登录主节点](#6. (可选)从节点免密登录主节点)
- 五、安装Java环境
- 六、Hadoop3.3.0的安装
- 七、Hadoop单机配置(非分布式)
- 八、Hadoop伪分布式安装
-
- 1.修改hadoop-env.sh
- [3.修改配置文件 hdfs-site.xml](#3.修改配置文件 hdfs-site.xml)
- 4.Hadoop的启动
- vim使用教程
- hadoop-mapreduce-examples实例
-
- 一、先确认示例包路径(通用前置步骤)
- 二、核心示例及完整运行教程
-
- [1. 基础文本处理类](#1. 基础文本处理类)
- [2. 排序/统计类](#2. 排序/统计类)
- [3. 数值计算类](#3. 数值计算类)
-
- [(1)pi(计算圆周率 π:蒙特卡洛算法)](#(1)pi(计算圆周率 π:蒙特卡洛算法))
- (2)randomtextwriter(生成随机文本数据)
- [4. 数据关联/聚合类](#4. 数据关联/聚合类)
-
- [(1)join(两表关联:模拟数据库 Join 操作)](#(1)join(两表关联:模拟数据库 Join 操作))
- (2)aggregate(通用聚合:自定义统计指标)
- [5. 其他实用示例](#5. 其他实用示例)
- 三、通用注意事项
- 总结
参考

一、环境的选择
本教程使用Ubtuntu-22.04做为系统环境,在安装好Ubtuntu系统后,方可继续进行以下操作。
二、创建Hadoop账户
如果你安装 Ubuntu 的时候不是用的 "hadoop" 用户,那么需要增加一个名为 hadoop 的用户。
首先按 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 :
cpp
sudo useradd -m hadoop -s /bin/bash这条命令创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为 shell。
给 hadoop用户设置密码,按提示输入两次密码,密码可以为hadoop:
cpp
sudo passwd hadoop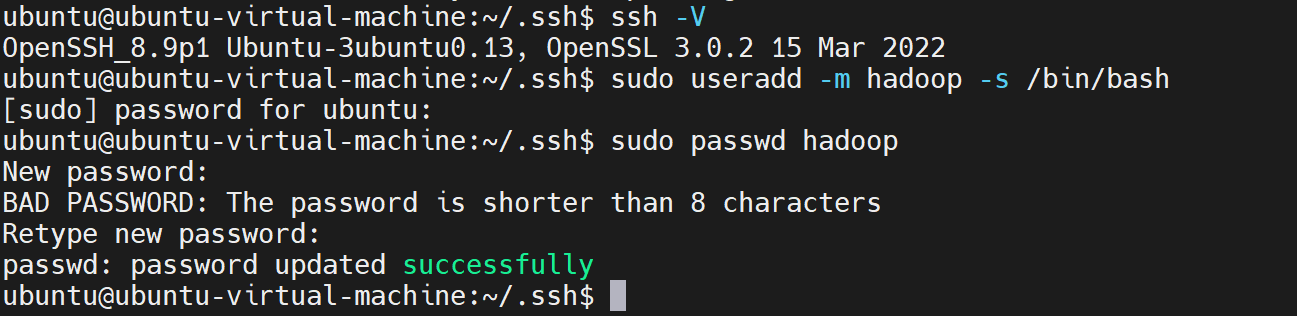
为 hadoop 用户增加sudo权限:
cpp
sudo adduser hadoop sudo
最后注销当前用户(点击屏幕右上角的齿轮,选择注销),返回登陆界面。在登陆界面中选择刚创建的 hadoop 用户进行登陆。
三、更新apt
用 hadoop 用户登录后,更新一下 apt,执行如下命令:
cpp
sudo apt-get update安装vim:
cpp
sudo apt-get install vim安装软件时若需要确认,在提示处输入 y 即可。
四、安装SSH、配置SSH免密码登录
集群、单节点模式都需要用到 SSH 登陆,Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
cpp
sudo apt-get install openssh-server安装后,可以使用如下命令登陆本机:
cpp
ssh localhost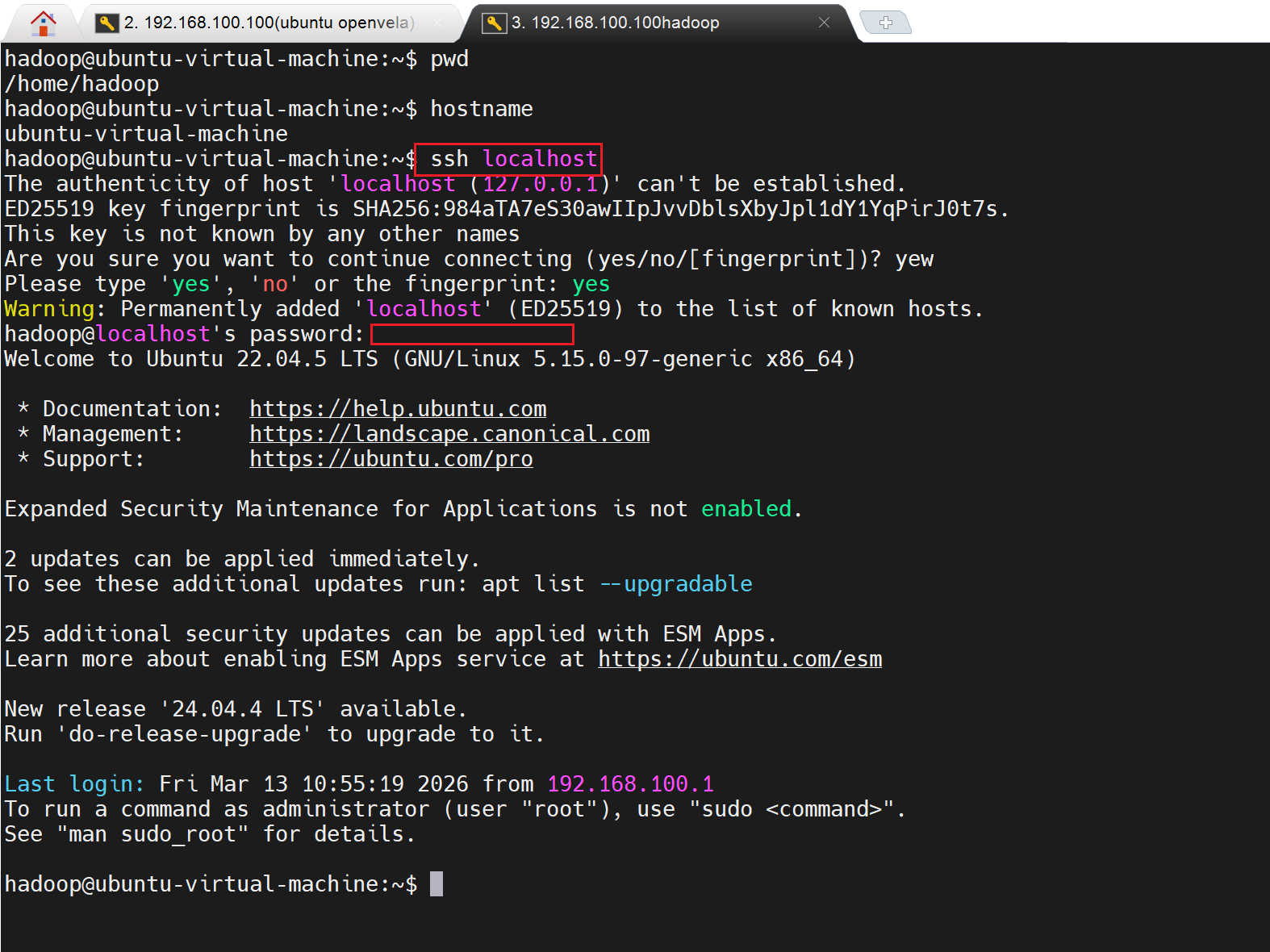
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了。
但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
cpp
exit # 退出刚才的 ssh localhost下面是一份 从生成 ED25519 密钥对到实现跨节点免密 SSH 登录 的完整、可执行步骤,以 Ubuntu 系统为例(Hadoop 部署常用),全程适配 Hadoop 集群的使用场景。
一、前提说明
- 操作用户:建议使用 Hadoop 运行用户(如
hadoop),或你当前的ubuntu用户; - 操作节点:在集群主节点(NameNode) 执行(后续分发公钥到从节点);
- 核心目标:实现主节点免密登录所有从节点,且从节点可免密登录主节点(可选,Hadoop 部分命令需要)。
二、完整操作步骤
1. 检查并安装 SSH(确保基础环境)
bash
# 检查 SSH 是否安装
ssh -V
# 若未安装,执行以下命令安装
sudo apt update && sudo apt install -y openssh-server openssh-client
# 启动 SSH 服务(确保开机自启)
sudo systemctl enable --now ssh2. 生成 ED25519 密钥对(核心步骤)
bash
# 进入 .ssh 目录(无则自动创建)
mkdir -p ~/.ssh && cd ~/.ssh
# 生成 ED25519 密钥对(-t 指定类型,-f 指定文件名,-N 空密码)
ssh-keygen -t ed25519 -f ~/.ssh/id_ed25519 -N ""
# 执行后输出示例(无需任何手动输入,直接回车即可):
# Generating public/private ed25519 key pair.
# Your identification has been saved in /home/ubuntu/.ssh/id_ed25519
# Your public key has been saved in /home/ubuntu/.ssh/id_ed25519.pub- 参数说明:
-t ed25519:指定密钥类型为 ED25519(比 RSA 更安全、更快);-f ~/.ssh/id_ed25519:指定私钥文件名(默认就是这个,可省略);-N "":设置空密码(免密登录的核心,避免每次用密钥还要输密码)。
3. 设置密钥文件权限(关键!SSH 对权限敏感)
SSH 严格要求密钥权限,权限错误会直接导致免密登录失败:
bash
# 私钥(id_ed25519)必须是 600(仅当前用户可读可写)
chmod 600 ~/.ssh/id_ed25519
# 公钥(id_ed25519.pub)设为 644(只读)
chmod 644 ~/.ssh/id_ed25519.pub
# .ssh 目录设为 700(仅当前用户可访问)
chmod 700 ~/.ssh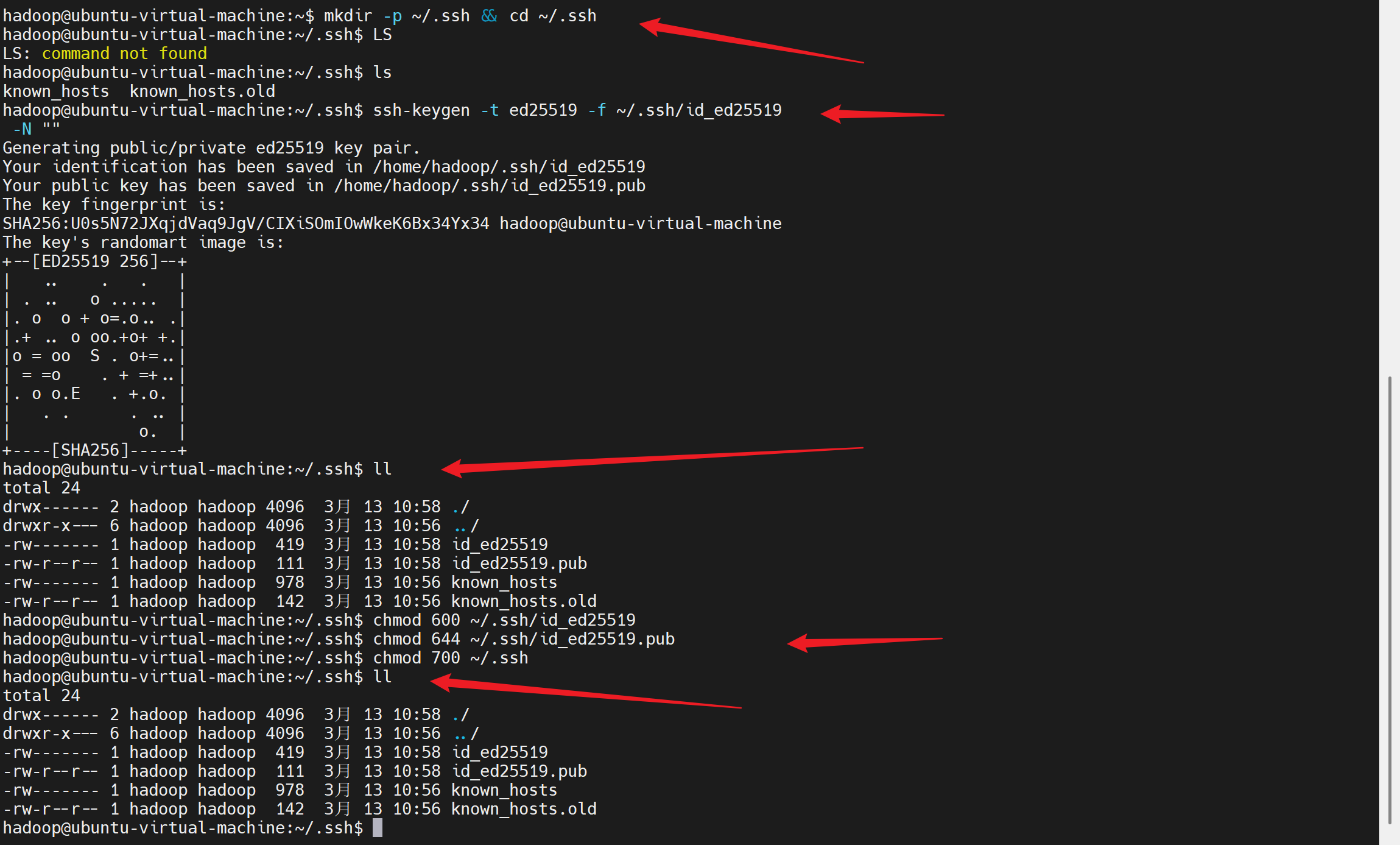
4. 分发公钥到目标节点(实现免密登录)
假设你要免密登录的目标节点信息:
- 目标节点 1:
node2(IP:192.168.100.102),用户:hadoop; - 目标节点 2:
node3(IP:192.168.100.103),用户:hadoop; - 本机(主节点):也需要免密登录自己(Hadoop 脚本会用到)。
步骤 4.1:先授权本机免密登录(必做)
bash
# 将公钥添加到本机的 authorized_keys(免密登录自己)
cat ~/.ssh/id_ed25519.pub >> ~/.ssh/authorized_keys
# 设置 authorized_keys 权限(必须 600)
chmod 600 ~/.ssh/authorized_keys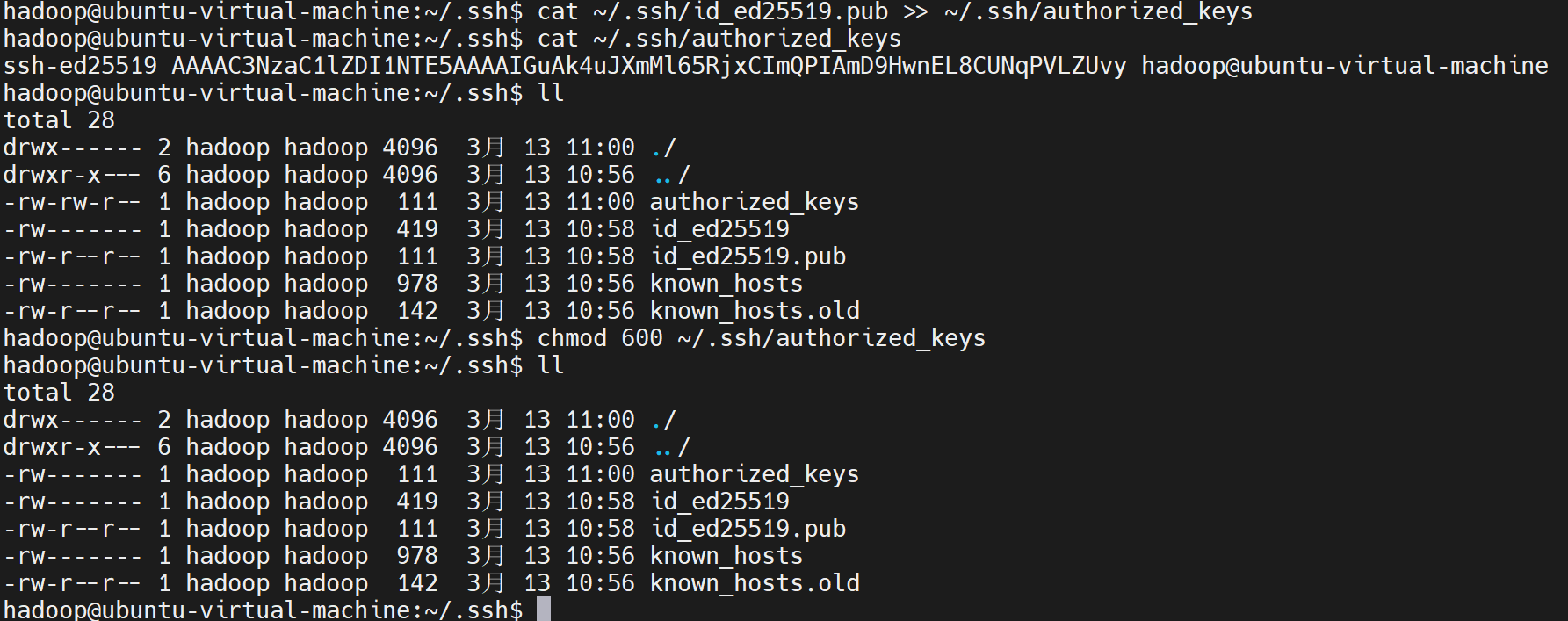
步骤 4.2:分发公钥到远程节点(以 node2 为例)-不需要做
bash
# 方法 1:用 ssh-copy-id 自动分发(推荐,简化操作)
ssh-copy-id -i ~/.ssh/id_ed25519.pub hadoop@192.168.1.102
# 首次执行会提示验证主机指纹,输入 yes 并回车,然后输入目标节点的 ubuntu 用户密码
# 执行成功后输出:Number of key(s) added: 1
# 方法 2:手动分发(若 ssh-copy-id 不可用)
# 1. 把公钥内容复制到远程节点的 authorized_keys
# scp ~/.ssh/id_ed25519.pub hadoop@192.168.1.102:/tmp/
# 2. 登录远程节点执行:
# ssh hadoop@192.168.1.102
# mkdir -p ~/.ssh && chmod 700 ~/.ssh
# cat /tmp/id_ed25519.pub >> ~/.ssh/authorized_keys
# chmod 600 ~/.ssh/authorized_keys
# rm /tmp/id_ed25519.pub步骤 4.3:对所有节点重复分发-不需要做
bash
# 分发到 node3
ssh-copy-id -i ~/.ssh/id_ed25519.pub hadoop@192.168.1.103
# 若有更多节点,依次执行...5. 验证免密登录(关键测试)
bash
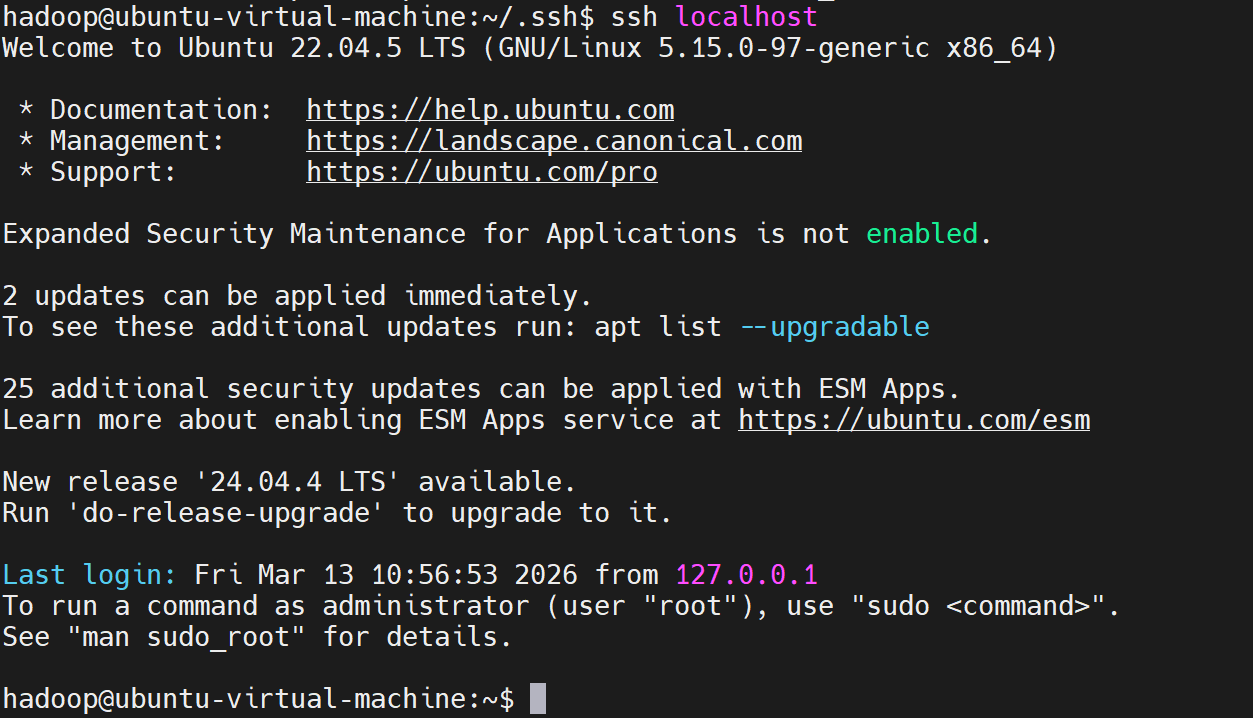
# 测试登录本机(无密码提示则成功)
ssh hadoop@localhost
# 测试登录 node2(无密码提示则成功)-不需要执行,因为还没有
ssh hadoop@192.168.100.102
# 登录成功后,输入 exit 退出远程节点
exit- 若仍提示输入密码:
- 检查目标节点的
~/.ssh/authorized_keys是否有你的公钥; - 检查所有密钥文件权限(尤其是
authorized_keys必须 600); - 重启目标节点的 SSH 服务:
sudo systemctl restart ssh。
- 检查目标节点的
6. (可选)从节点免密登录主节点
如果需要从节点反向免密登录主节点,需在每个从节点 重复步骤 2-4(生成密钥并分发公钥到主节点),或直接把从节点的公钥手动添加到主节点的 authorized_keys。
五、安装Java环境
Hadoop3.3.0需要使用JDK版本在1.8以上,这里采用jdk-8u241-linux-x64_.tar.gz
在Linux命令行界面中,执行如下Shell命令(注意:当前登录用户名是hadoop):
cpp
sudo mkdir -p /opt/software #创建 /opt/software目录用来存放JDK文件
sudo mkdir -p /opt/app # 创建应用存放的空间
cpp
# 关键:把目录的 owner 改为 hadoop 用户,group 改为 hadoop 组
sudo chown -R hadoop:hadoop /opt/software /opt/app
# 验证权限(owner 和 group 变为 hadoop)
ls -ld /opt/software /opt/app
cpp
cd /opt/software
sudo tar -zxvf ./jdk-8u241-linux-x64_.tar.gz -C /opt/app #把JDK文件解压到/opt/app目录下JDK文件解压缩以后,可以执行如下命令到//opt/app目录查看一下:
cpp
cd /opt/app
ls
可以看到,在/usr/lib/jvm目录下有个jdk1.8.0_241目录。
下面继续执行如下命令,设置环境变量:
cpp
cd ~
vim ~/.bashrc上面命令使用vim编辑器(注:vim的使用请参看教程目录)打开了hadoop这个用户的环境变量配置文件,请在这个文件的开头位置,添加如下几行内容:
cpp
export JAVA_HOME=/opt/app/jdk1.8.0_241
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH保存.bashrc文件并退出vim编辑器。然后,继续执行如下命令让.bashrc文件的配置立即生效:
cpp
source ~/.bashrc这时,可以使用如下命令查看是否安装成功:
cpp
java -version
如果能够在屏如果能够在屏幕上返回如下信息,则说明安装成功:
至此,成功安装了Java环境,下面就可以安装Hadoop了。
六、Hadoop3.3.0的安装
我们选择将 Hadoop 安装至 /opt/app/ 中:
cpp
cd ~ #进入hadoop用户的主目录
cd /opt/software #jdk压缩包默认下载在该位置
sudo tar -zxf /opt/software/hadoop-3.3.0.tar.gz -C /opt/app # 解压到/opt/app中
cpp
cd /opt/app/
sudo mv ./hadoop-3.3.0/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限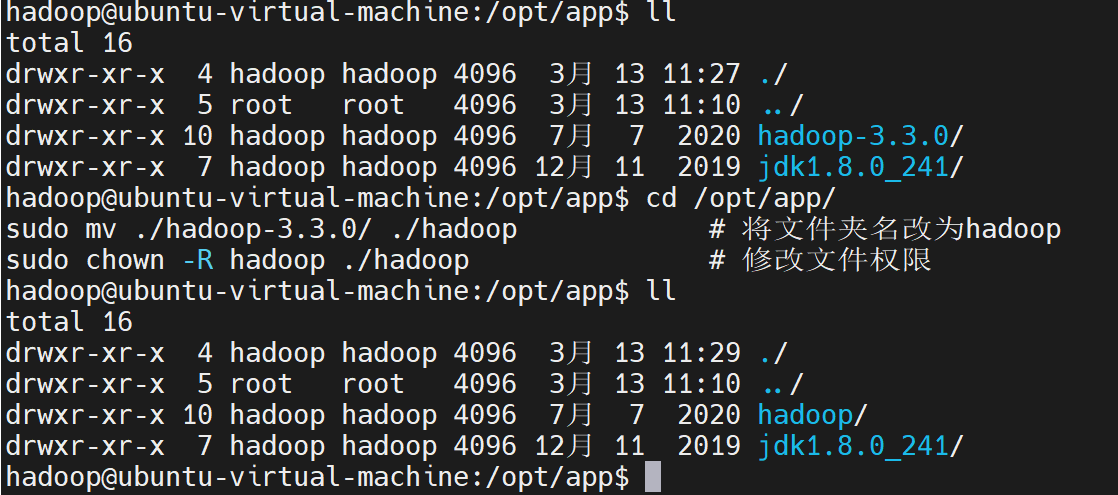
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
cpp
cd /opt/app/hadoop
./bin/hadoop version
七、Hadoop单机配置(非分布式)
Hadoop 默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
现在我们可以执行例子来感受下 Hadoop 的运行。Hadoop 附带了丰富的例子(运行 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar 可以看到所有例子),包括 wordcount、terasort、join、grep 等。
在此我们选择运行 grep 例子,我们将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfsa-z.+ 的单词并统计出现的次数,最后输出结果到 output 文件夹中。
bash
cd /opt/app/hadoop
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/* # 查看运行结果执行成功后如下所示,输出了作业的相关信息,输出的结果是符合正则的单词 dfsadmin 出现了1次
注意:Hadoop 默认不会覆盖结果文件,因此再次运行上面实例会提示出错,需要先将 ./output 删除。
cpp
rm -r ./output八、Hadoop伪分布式安装
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于
cpp
/opt/app/hadoop/etc/hadoop/中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
1.修改hadoop-env.sh
你遇到的 ERROR: JAVA_HOME is not set and could not be found 是 Hadoop 启动最常见的错误之一,核心原因是 Hadoop 的 hadoop-env.sh 配置文件中未正确指定 JAVA_HOME 路径。下面我会一步步告诉你需要添加的配置,以及完整的验证和修复步骤。
一、第一步:先找到你的 JAVA_HOME 路径
首先要确认 JDK 安装的实际路径(这是配置的关键,路径错误会导致配置无效):
bash
# 方法1:如果已配置全局 JAVA_HOME,直接查看
echo $JAVA_HOME
# 方法2:如果未配置,通过 java 命令找路径(推荐)
which java # 输出示例:/opt/app/jdk1.8.0_381/bin/java
# 截取到 jdk 根目录(去掉 /bin/java)
# 比如上面的输出,JAVA_HOME 就是 /opt/app/jdk1.8.0_381
# 方法3:通过 update-alternatives 查找(系统级 JDK)
update-alternatives --config java
# 输出示例中会显示 JDK 安装路径,比如 /usr/lib/jvm/java-8-openjdk-amd64⚠️ 注意:一定要确认路径真实存在 ,执行 ls /opt/app/jdk1.8.0_381(替换为你的路径),确保目录存在。
二、第二步:修改 hadoop-env.sh 配置
hadoop-env.sh 是 Hadoop 核心环境配置文件,需要在其中显式指定 JAVA_HOME:
- 打开配置文件
bash
# 进入 Hadoop 配置目录(你的 Hadoop 安装路径是 /opt/app/hadoop)
cd /opt/app/hadoop/etc/hadoop
# 编辑 hadoop-env.sh
vim hadoop-env.sh- 添加/修改 JAVA_HOME 配置
在文件中找到# export JAVA_HOME=这一行(通常在文件开头),去掉注释(删除#),并替换为你的实际 JAVA_HOME 路径。
示例配置(根据你的 JDK 路径修改):
bash
# 核心配置:指定 JDK 安装根目录(替换为你的实际路径!)
export JAVA_HOME=/opt/app/jdk1.8.0_241
# 可选:防止 Hadoop 自动检测 JAVA_HOME 出错
export JRE_HOME=${JAVA_HOME}/jre
export PATH=$PATH:${JAVA_HOME}/bin:${JRE_HOME}/bin- 保存退出
在 vim 中按Esc→ 输入:wq→ 回车保存。
三、第三步:验证配置是否生效
修改后先验证配置,避免启动仍报错:
bash
# 1. 加载配置并检查 JAVA_HOME
source /opt/app/hadoop/etc/hadoop/hadoop-env.sh
echo $JAVA_HOME # 输出你的 JDK 路径,说明配置生效
### 2.修改配置文件 core-site.xml
使用下面的命令(注:vim的使用请参看教程目录)
```cpp
cd /opt/app/hadoop/etc/hadoop/
vim core-site.xml修改配置文件 core-site.xml ,将当中的
xml
<configuration>
</configuration>修改为下面配置:
xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/app/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>3.修改配置文件 hdfs-site.xml
使用下面的命令:
cpp
vim hdfs-site.xml修改配置文件 hdfs-site.xml
xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/app/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/app/hadoop/tmp/dfs/data</value>
</property>
</configuration>4.Hadoop的启动
配置完成后,执行 NameNode 的格式化:
cpp
cd /opt/app/hadoop
./bin/hdfs namenode -format成功的话,会返回很多行非常长的提示信息。
接着开启 NameNode 和 DataNode 守护进程。
cpp
cd /opt/app/hadoop
./sbin/start-dfs.sh #启动Hadoop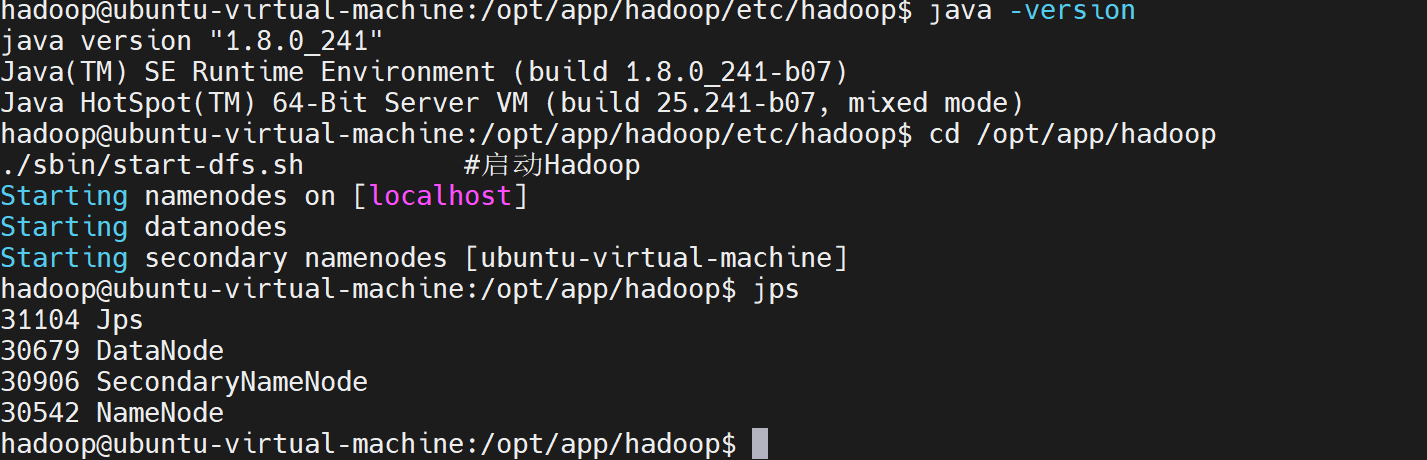
若出现SSH提示信息,输入yes即可。
启动时可能会出现WARN 提示,可以忽略WARN 提示,并不会影响正常使用。
成功启动后,可以访问 Web 界面 http://localhost:9870 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
关闭Hadoop,则运行:
cpp
./sbin/stop-dfs.sh注意:当下次启动 hadoop 时,无需再进行 NameNode 的初始化,只需要运行
cpp
./sbin/start-dfs.sh就可以!
vim使用教程
说明:以下vim使用方法只是在该教程用到的,如想了解更多,请参考菜鸟教程
i 切换到输入模式,以输入字符。
: 切换到底线命令模式,以在最底一行输入命令。
ESC,退出输入模式,切换到命令模式。
q 退出程序。
w 保存文件。
备注:在vim编辑文档时,输入 i 以输入字符;写入文档后,按 Esc 键,输入 :wq 以退出和保存文件。
hadoop-mapreduce-examples实例
Hadoop 的 hadoop-mapreduce-examples 包包含了大量经典的 MapReduce 示例,覆盖了数据统计、排序、计算、文本处理等典型场景,非常适合新手理解 MapReduce 核心思想。以下是基于 Hadoop 3.x(如 3.3.0)版本的常用示例分类及完整运行命令,并附带每个示例的功能说明和运行步骤,方便你实操验证。
一、先确认示例包路径(通用前置步骤)
首先确保你能找到示例 jar 包(路径适配 3.3.0 版本,若版本不同,只需替换 jar 包的版本号):
bash
# 进入 Hadoop 安装目录(假设安装在 /opt/app/hadoop-3.3.0)
cd /opt/app/hadoop-3.3.0
# 查看所有可用示例(核心命令)
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar执行后会输出所有示例列表,下面挑选高频实用示例 详细说明。
二、核心示例及完整运行教程
1. 基础文本处理类
(1)wordcount(最经典:单词计数)
-
功能:统计文本文件中每个单词的出现次数,MapReduce 入门必测。
-
运行步骤 :
bash# 1. 创建输入目录并准备测试文本 ./bin/hdfs dfs -mkdir -p /input # 新建本地测试文件(内容自定义,如 hello world hello hadoop) echo -e "hello world\nhello hadoop\nhello mapreduce" > test.txt # 上传文件到 HDFS 输入目录 ./bin/hdfs dfs -put test.txt /input/ # 2. 运行 wordcount 示例 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /input /output # 3. 查看结果(/output 是 HDFS 输出目录,不能提前存在) ./bin/hdfs dfs -cat /output/part-r-00000 -
输出示例 :
hadoop 1 hello 3 mapreduce 1 world 1
(2)grep(文本匹配:筛选含指定正则的行)
-
功能:从文本中筛选出匹配指定正则表达式的行,并统计每行出现次数。
-
运行步骤 :
bash# 1. 复用上面的 /input/test.txt,匹配含 "hello" 的行 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar grep /input /output_grep 'hello' # 2. 查看结果 ./bin/hdfs dfs -cat /output_grep/part-r-00000 -
输出示例 :
hello 3(表示含 "hello" 的行共出现 3 次)。
2. 排序/统计类
(1)terasort(大数据排序:Tera级数据排序)
-
功能:针对海量数据的高效排序(Hadoop 官方基准测试工具),适合测试集群排序性能。
-
运行步骤 (先生成测试数据,再排序):
bash# 1. 生成 1GB 测试数据(输入目录 /terasort-input) ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar teragen 10000000 /terasort-input # 2. 执行排序(输出目录 /terasort-output) ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar terasort /terasort-input /terasort-output # 3. 验证排序结果(可选) ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar teravalidate /terasort-output /terasort-validate -
参数说明 :
10000000表示生成约 1GB 数据(可调整数值,如 1000000 为 100MB)。
(2)sort(基础排序:对输入数据按行排序)
-
功能:简单的文本行排序,比 terasort 轻量,适合小数据测试。
-
运行命令 :
bash# 复用 /input/test.txt,排序输出到 /output_sort ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar sort /input /output_sort
3. 数值计算类
(1)pi(计算圆周率 π:蒙特卡洛算法)
-
功能:通过随机数模拟计算圆周率,支持多节点并行计算,测试集群计算能力。
-
运行命令 :
bash# 参数说明:2(map 任务数) 5(每个 map 任务的采样次数,数值越大越精准) ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar pi 2 5 -
输出示例 (最终会输出 π 的近似值):
Job Finished in 10.2 seconds Estimated value of Pi is 3.20000000000000000000
(2)randomtextwriter(生成随机文本数据)
-
功能:生成指定大小的随机文本文件,用于测试读写性能。
-
运行命令 :
bash# 生成 10 个文件,每个文件 100MB,输出到 /random-text ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar randomtextwriter -D mapreduce.randomtextwriter.totalbytes=1073741824 /random-text
4. 数据关联/聚合类
(1)join(两表关联:模拟数据库 Join 操作)
-
功能:对两个数据集按关键字段进行等值连接(类似 SQL 的 JOIN)。
-
运行步骤 :
bash# 1. 准备两个关联文件 # 文件 1:用户表(id, name) echo -e "1,zhangsan\n2,lisi\n3,wangwu" > user.txt # 文件 2:订单表(id, order_id) echo -e "1,order001\n2,order002\n3,order003" > order.txt # 上传到 HDFS ./bin/hdfs dfs -mkdir -p /join-input ./bin/hdfs dfs -put user.txt order.txt /join-input/ # 2. 运行 join 示例(按第一列关联) ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar join -joinType inner /join-input /output_join
(2)aggregate(通用聚合:自定义统计指标)
-
功能:无需编写代码,通过参数指定聚合函数(如求和、计数、最大值)统计数据。
-
运行命令 (统计数字列的总和):
bash# 准备含数字的文件(如 10 20 30 40) echo -e "10\n20\n30\n40" > num.txt ./bin/hdfs dfs -put num.txt /input/ # 按 SUM 聚合第一列数字 ./bin/hadoop jar ./share/hadoop/mapreduce-examples-3.3.0.jar aggregate -D aggregate.mapreduce.aggregation.type=SUM /input /output_aggregate
5. 其他实用示例
| 示例名称 | 功能说明 | 核心运行命令(简化版) |
|---|---|---|
count |
统计输入文件的行数、单词数、字符数 | hadoop jar ... count /input /output_count |
distcp |
分布式拷贝(跨 HDFS 集群/节点拷贝数据) | hadoop jar ... distcp hdfs://node1/input hdfs://node2/output |
sleep |
模拟长时间运行的任务(测试集群资源占用) | hadoop jar ... sleep 100(休眠 100 秒) |
wordmean |
计算文本中单词长度的平均值 | hadoop jar ... wordmean /input /output_mean |
wordmedian |
计算文本中单词长度的中位数 | hadoop jar ... wordmedian /input /output_median |
三、通用注意事项
- 输出目录必须不存在 :HDFS 不允许输出目录提前存在,运行前需删除旧目录(
./bin/hdfs dfs -rm -r /output); - 权限问题 :确保
hadoop用户对 HDFS 目录有读写权限(避免Permission denied); - 本地模式 vs 集群模式:以上命令在本地模式(非分布式)下也可运行,Hadoop 会自动适配;
- 资源调整 :运行大数据量示例(如 terasort)时,可通过
-D mapreduce.job.maps=4调整 Map 任务数。
总结
- Hadoop 示例包覆盖文本处理、排序、计算、关联 等核心场景,
wordcount/pi/terasort是新手必练的经典示例; - 所有示例运行的核心格式:
hadoop jar 示例jar包 示例名称 输入路径 输出路径 [参数]; - 关键注意点:HDFS 输出目录需提前删除,确保
hadoop用户有目录操作权限。
通过这些示例的实操,你可以快速理解 MapReduce "分而治之"的核心思想,也能验证 Hadoop 环境是否配置正常。