一、prometheus的常见数据类型
1.1、Counter 计数器
这是一种累加的指标(metric),典型的应用(如:请求的总数、CPU每秒处理的任务数、网络接受包数、出现的错误次数等等)。可以把Counter理解为计数器,数据量从0开始累积计算,在理想状态下数值只能是永远的增加,不会降低。常见的监控指标(如: http_requests_total、node_cpu_seconds_total、node_network_receive_packets_total)都是 Counter 类型的监控指标。
例如:操作系统自启动以来指定网卡接收到的所有流量包的数量
bash
#操作系统自启动以来指定网卡接收到的所有流量包的数量
#每接受到一个包,操作系统就会加1,因此这个值是持续递增的。但是操作系统可能会重启,导致这个值出现重置
#(如:第一次是从0到25535)然后设备重启了,则新采集的数据是比25535小的,这种情况如何处理?
#通常面对这种情况,prometheus看到的值是没有递增的,那么就能够感知到应该是被重置了;因此,prometheus会把新采集的值加上25535再做计算
node_network_receive_packets_total{device="ens33"}
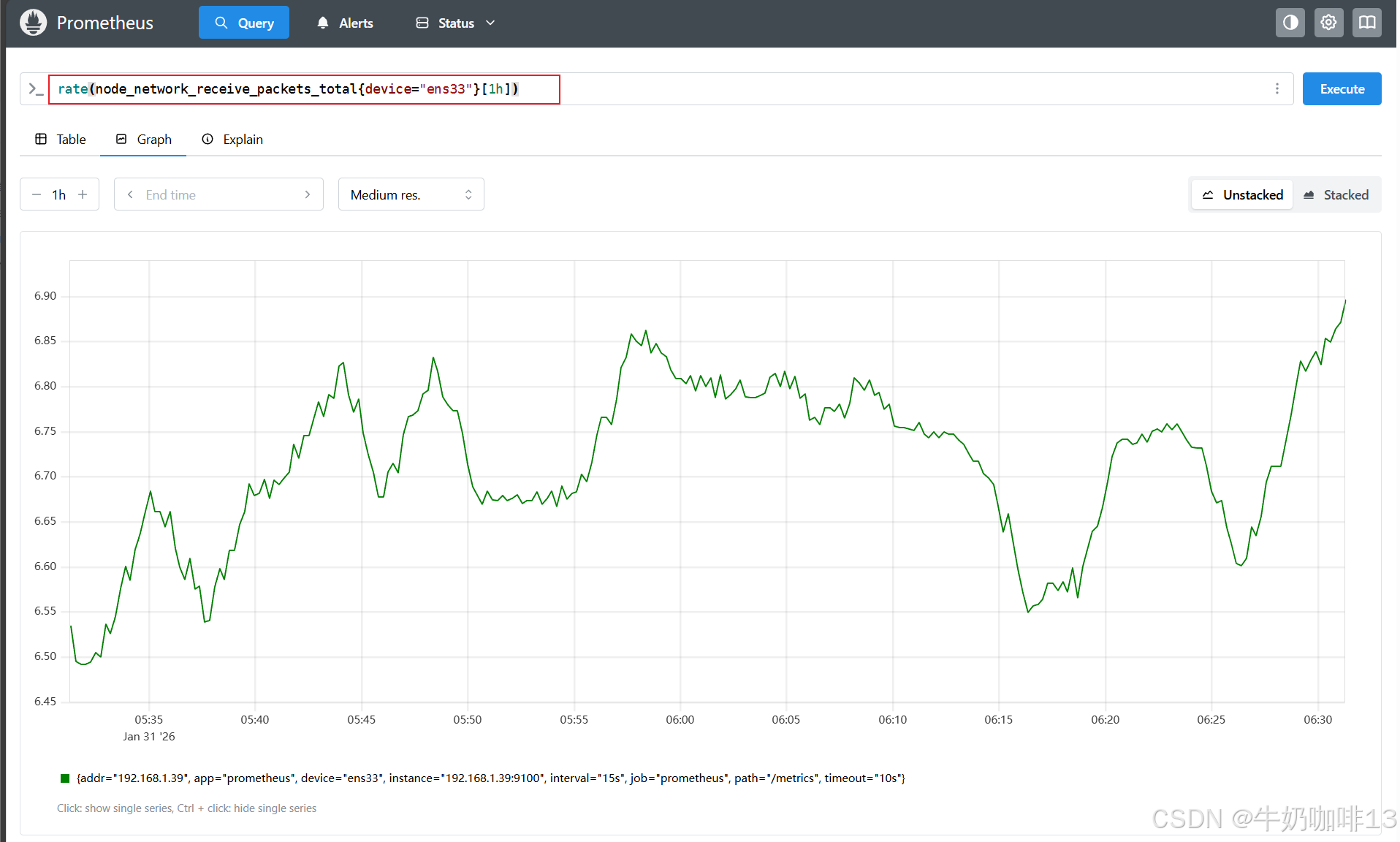
#对于 counter 类型的监控指标,通过 PromQL 内置函数 rate() 可以获取样本在一段时间范围内的变化率情况(在时间范围内是增加还是减少)。
#示例:在1个小时内指定网卡接收到的所有流量包的数量变化比例情况
rate(node_network_receive_packets_total{device="ens33"}[1h])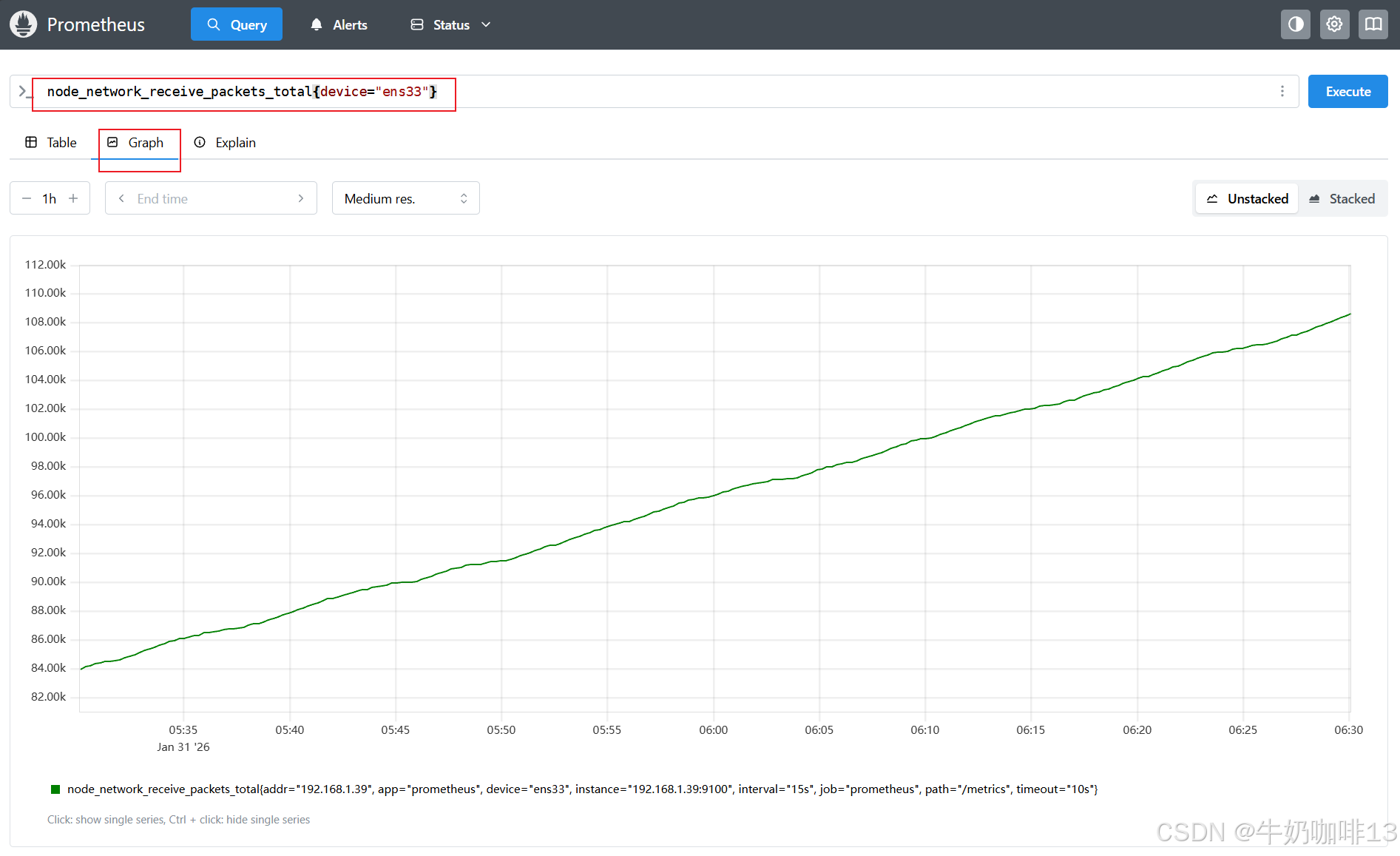

1.2、Gauge 仪表盘
Gauge(可增、可减的仪表盘)类型的指标样本数据可增可减, 典型的应用(如:温度,运行的任务的个数)。可以任意增、减。对这种类型的数据,我们通常关注的是当前值(如:现在系统内存的使用大小、现在队列积压的消息数)。 常见指标(如: node_memory_MemFree_bytes(当前主机空闲的内存大小)、node_memory_MemAvailable_bytes(可用内存大小))都是 Gauge 类型的监控指标。由于 Gauge 指标仍然带有时间戳存储,所有我们可以看到随时间变化的值,通常可以直接把它们绘制出来,这样就可以看到值本身而不是变化率了,通过 Gauge 指标,用户可以直接查看系统的当前状态。
示例:查看系统的可用内存大小、查看系统可用内存在2小时内的差异情况
bash
#查看系统内存的可用大小
#1-可用内存是随着时间的推移不断的瞬时且没有规则变化的,这种变化没有规律,当前是多少,采集回来的就是多少,可以是增加,也可以是降低,这种就是Gauges使用类型的代表。
node_memory_MemAvailable_bytes
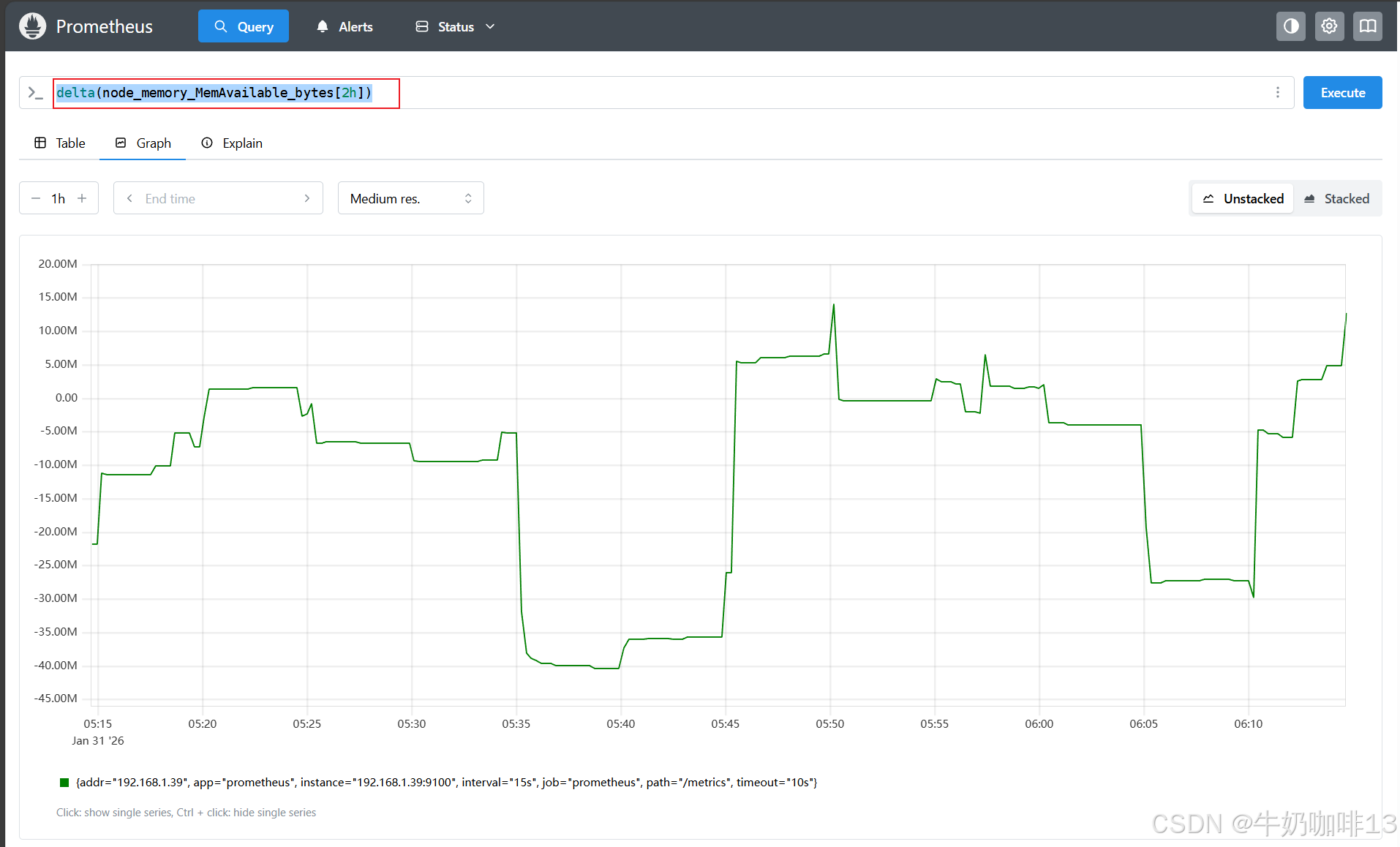
#2-对于 Gauge 类型的监控指标,通过 PromQL 内置函数 delta() 可以获取样本在一段时间范围内的变化情况。#2.1-示例:计算系统可用内存在两个小时内的差异:
delta(node_memory_MemAvailable_bytes[2h])
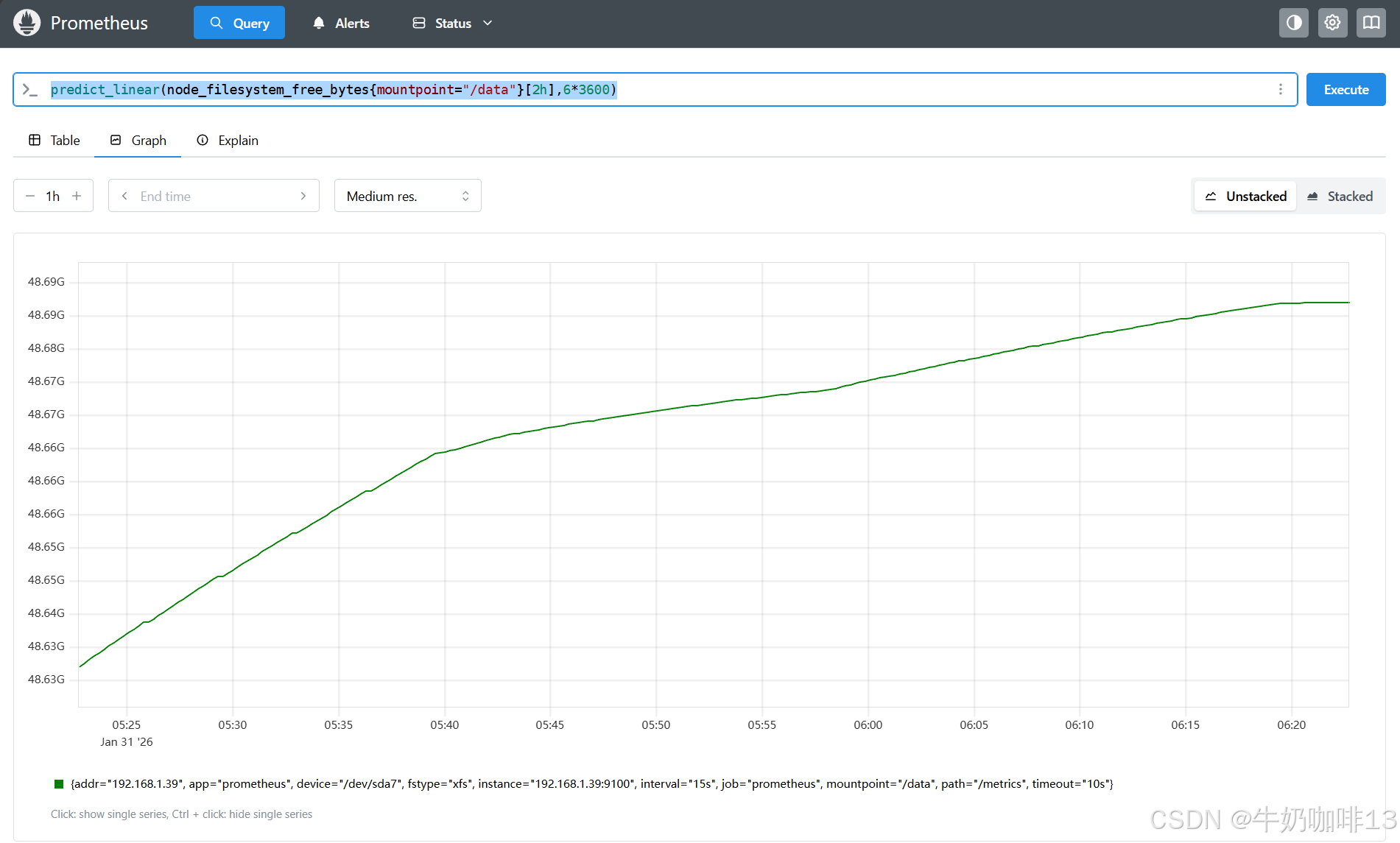
#3-对于 Gauge 类型的监控指标,通过 PromQL 内置函数 predict_linear() 可以获取样本在一段时间范围内的变化情况来预测未来指定时间范围的消耗情况。
#3.1-以现有的2小时系统可用内存的消耗情况,来预测未来6小时的系统可用内存消耗情况
predict_linear(node_filesystem_free_bytes{mountpoint="/data"}[2h],6*3600)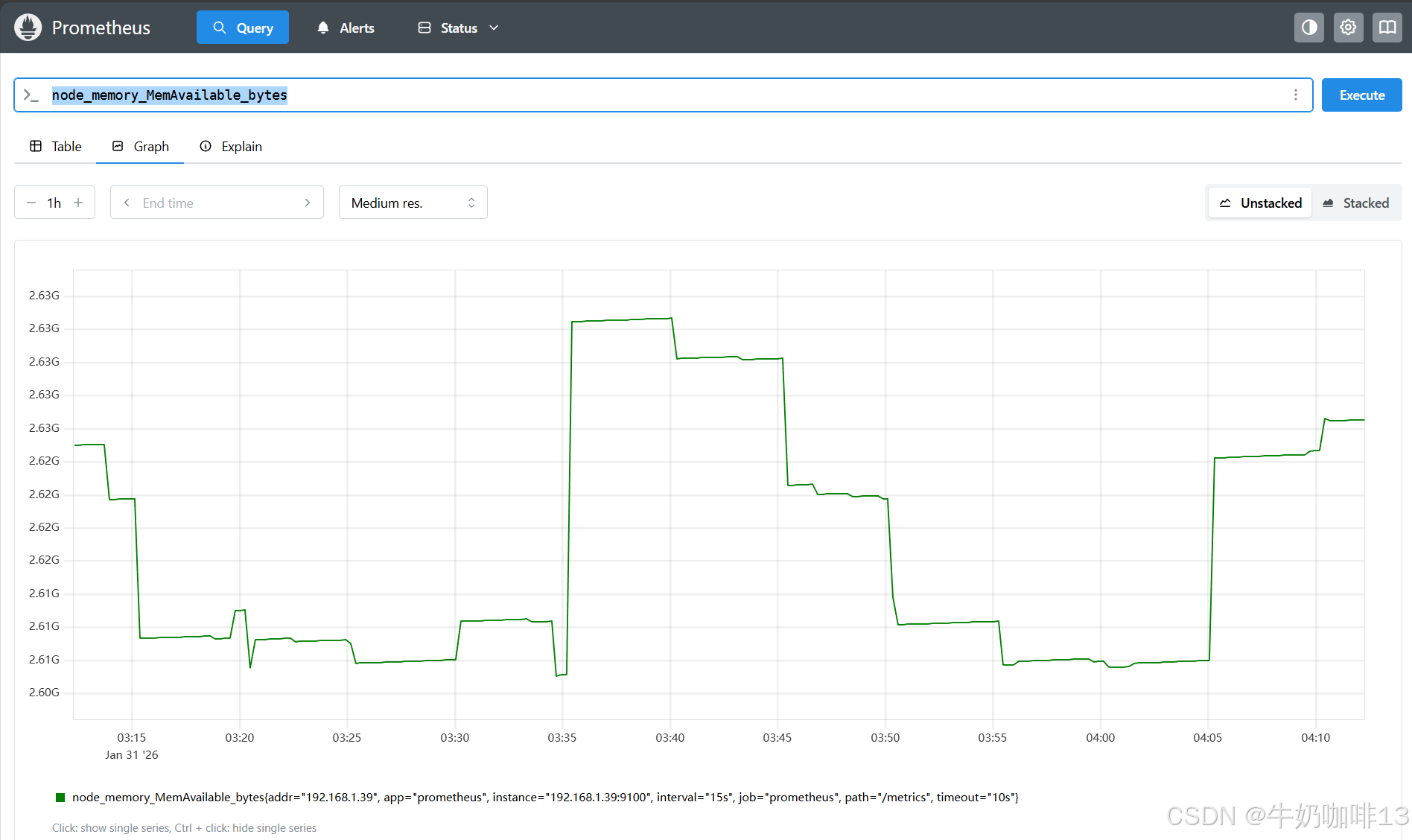
1.3、summary 摘要
在大多数情况下人们都倾向于使用某些量化指标的平均值(如: CPU 的平均使用率、页面的平均响应时间),这种方式也有很明显的问题,以系统 API 调用的平均响应时间为例:若大多数 API 请求都维持在 100ms 的响应时间范围内,而个别请求的响应时间需要 5s,那么就会导致某些 WEB 页面的响应时间落到中位数 上,而这种现象被称为长尾问题 。因此,长尾是因为它用平均值将峰值削平了,无法反映时间窗口内样本数据的快速变化。
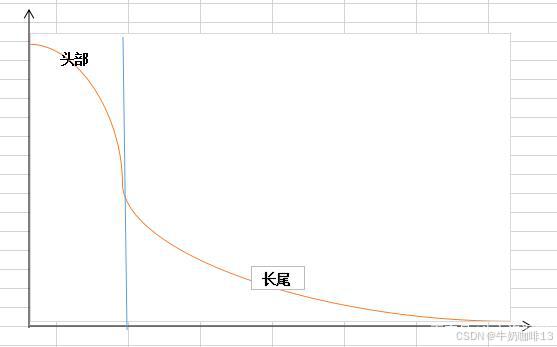
为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在 0-10ms 之间的请求数有多少,而 10-20ms 之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。Histogram 和 Summary 都是为了能够解决这样的问题存在的,通过 Histogram 和Summary 类型的监控指标,我们可以快速了解监控样本的分布情况。
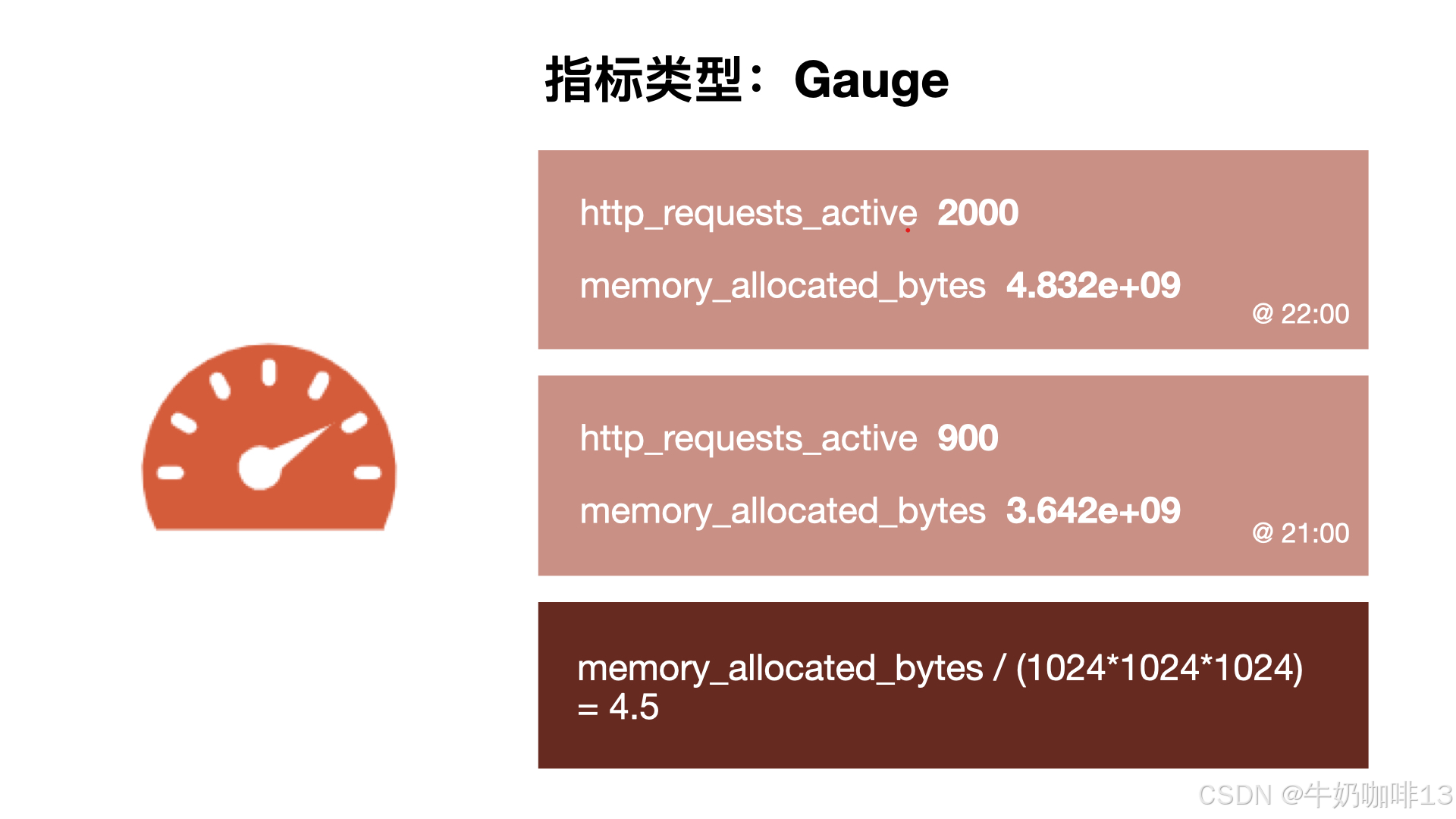
摘要用于记录某些东西的平均大小,可能是计算所需的时间或处理的文件大小, 摘要显示两个相关的信息:count(事件发生的次数)和 sum(所有事件的总大小)。如下图所示:

上图中,计算摘要指标21点整时返回次数为 3 和总和 15,也就意味着 3 次计算总共需要 15s 来处理,平均每次计算需要花费 5s。下一个样本的计算摘要指标21点零一份时返回的次数为 10,总和为 113,那么平均值为 11.3,因为两组指标都记录有时间戳,所以我们可以使用摘要来构建一个图表,显示平均值的变化率,比如上图中的rate语句表示的是 5 分钟时间段内的平均速率。
Summary 直接存储的就是百分位数或分位数,如下所示:可以直观的观察到样本的中位数,90分位和99分位。

从上面的样本中可以得知当前 Prometheus Server 进行查询操作的总次数为 387 次,耗时 0.21823991400000015s。其中中位数(quantile=0.5)的耗时为 0.000124711,9 分位数(quantile=0.9)的耗时为0.000124711s。
最后,需要知道的是,Summary 这种类型是在客户端计算分位值的,然后把计算之后的结果推给服务端存储,展示的时候直接查询即可,不需要做很重的计算,性能大幅提升。
1.4、Histogram直方图
摘要非常有用,但是平均值会隐藏一些细节,如summary 摘要中 10 与 113 的总和包含非常广的范围,如果我们想查看时间花在什么地方了,那么我们就需要直方图了。直方图以 bucket 桶的形式记录数据,也就是返回每个存储桶的计数,可以观察到指标在各个不同的区间范围的分布情况。可以观察到请求耗时在各个桶的分布 。如下图所示:
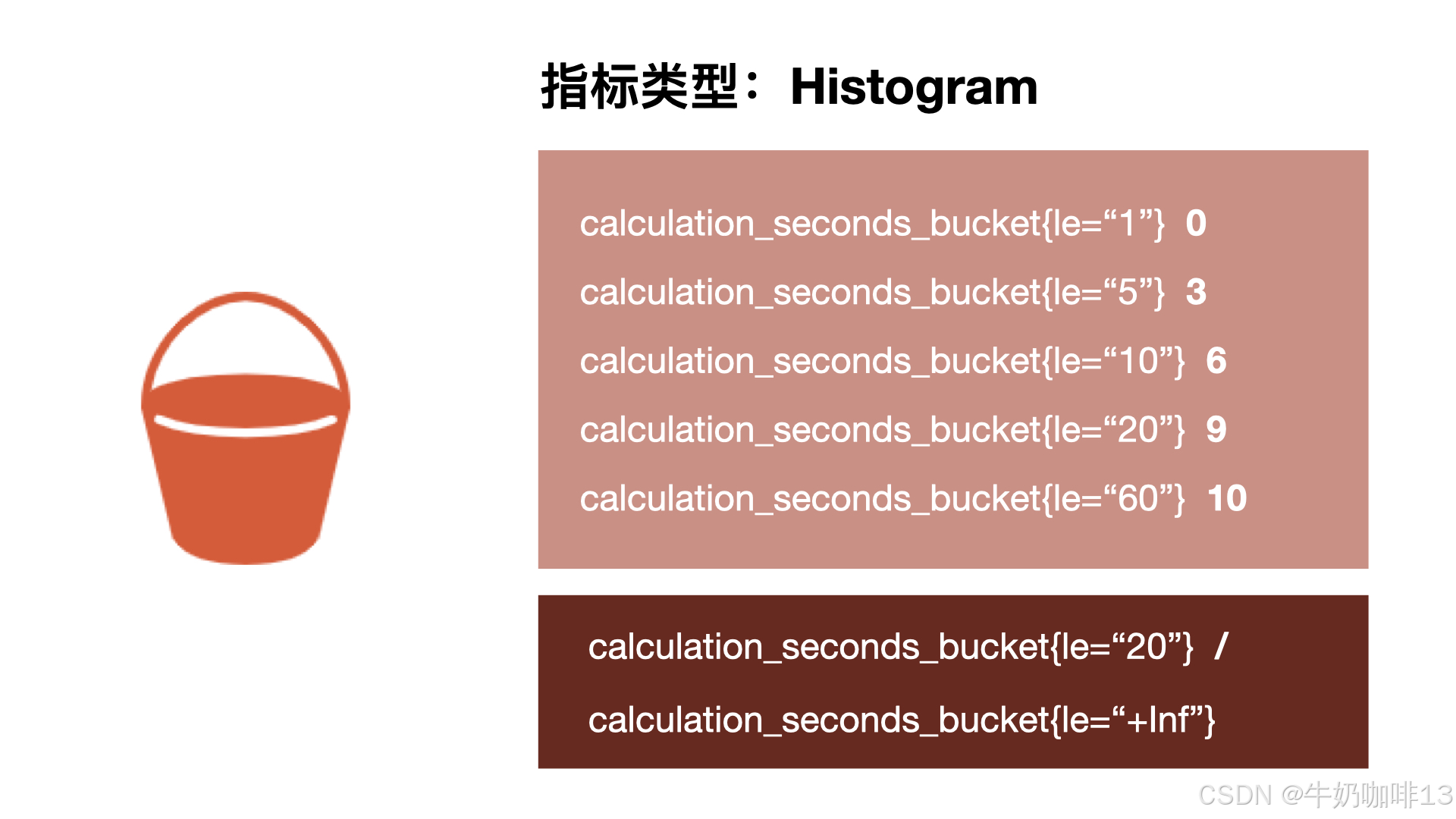
上图中,展示了在1秒、5秒、10秒、20秒、60秒内存储桶的计数,其中 3 个在 5 秒或更短的时间内完成,6 个在 10 秒内或更短的时间内完成(严格来说,应该是3个在5-10秒内完成)。由于Prometheus 中的直方图是累积的,因此,所有 10个计数都属于 60 秒或更少的时间段,而在这 10 次中,有 9 个的处理时间为 20 秒或更少,这显示了数据的分布。同时,可以看到我们的大部分计数都在 10 秒以下,只有一个超过 20 秒。
与 Summary摘要 类型的指标对比,不同在于 Histogram直方图 指标直接反应了在不同区间内样本的个数,区间通过标签 le 进行定义。
在 Prometheus Server 自身返回的样本数据中,我们也能找到类型为 Histogram 的监控指标prometheus_tsdb_compaction_chunk_range_seconds_bucket,如下图:
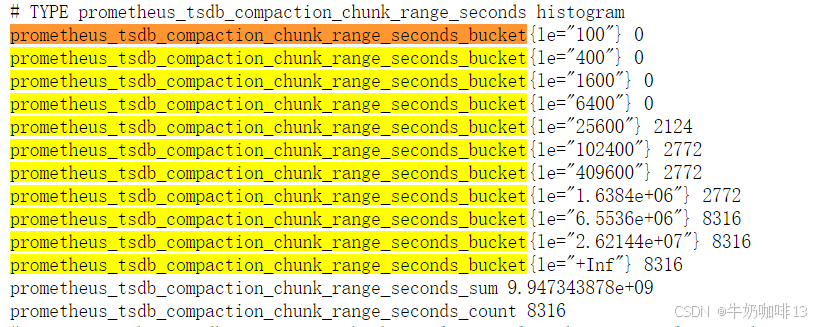
在Histogram 类型中,如果想得到分位值,可以通过【histogram_quantile】函数求出,,比如 中位数50、90、99分位数等数据。
注意,直方图是通过内置函数 histogram_quantile 在 Prometheus 服务端计算求出分位值的。
总结:不同的数据类型,可使用的函数也不相同,也就是说,某些函数只适用于特定类型的指标!例如,histogram_quantile函数只适用于直方图指标,rate只适用于计数器指标,而deriv只适用于仪表。
二、PromQL的使用场景及其表达式类型
2.1、PromQL的使用场景
|--------|-----------------|-----------------------------------------------------------------------------------|
| 序号 | PromQL的使用场景 | 说明 |
| 1 | 临时查询 | 可在prometheus的web界面Query界面查询一些标签内容了解与验证执行效果。 注意:prometheus中,指标名称相同,但标签不同就是不同的时间序列。 |
| 2 | 仪表盘 | 主要用于数据可视化展示(prometheus+grafana);可通过编写不同的PromQL语句实现不同维度内容的监控展现。 |
| 3 | 报警 | 通过Altermanager对报警信息阈值的设置,来实现达到什么条件才报警;而报警条件就是通过promQL表达式来实现的。 |
[PromQL的使用场景]
2.2、PromQL表达式语言数据类型
|--------|-------------------------------|------------------------------------------------------------------------------------------------|
| 序号 | PromQL表达式 语言数据类型 | 说明 |
| 1 | 瞬时向量 (Instant vector) | 一组时间序列,每个时间序列包含单个样本,它们共享相同的时间戳。 也就是说,表达式的返回值中只会包含该时间序列中的最新的一个样本值。而相应的这样的表达式称之为瞬时向量表达式。 |
| 2 | 区间向量 (Range vector) | 一组时间序列,每个时间序列包含一段时间范围内的样本数据。 这些是通过将时间选择器附加到方括号中的瞬时向量(例如5m5 分钟)而生成的。 |
| 3 | 标量 (Scalar) | 一个浮点型的数据值 |
| 4 | 字符串 (String) | 一个简单的字符串值 |
[PromQL表达式语言数据类型]
2.2.1、瞬时查询与瞬时向量
瞬时查询用于类似表格的视图,瞬时查询查看的是,在同一个时间点,所有或者指定标签 ,在这个时间点的瞬时值。
可以通过向花括号({})里附加一组标签来进一步过滤时间序列。
在 Prometheus 的 WebUI 界面中表格视图中的查询就是瞬时查询,API 接口 /api/v1/query?query=xxxx&time=xxxx 中的 query 参数就是 PromQL 表达式,time 参数就是评估的时间戳。瞬时查询可以返回任何有效的 PromQL 表达式类型(字符串、标量、即时和范围向量)。
PromQL 还支持用户根据时间序列的标签匹配模式来对时间序列进行过滤,目前主要支持两种匹配模式:完全匹配和正则匹配。总共有以下四种标签匹配运算符。
|--------|-------------|------------------------------|
| 序号 | 标签匹配运算符 | 说明 |
| 1 | = | 选择与提供的字符串完全相同的标签。 |
| 2 | != | 选择与提供的字符串不相同的标签。 |
| 3 | =~ | 选择正则表达式与提供的字符串(或子字符串)相匹配的标签。 |
| 4 | !~ | 选择正则表达式与提供的字符串(或子字符串)不匹配的标签。 |
[PromQL的四种标签匹配运算符]
bash
#瞬时查询与瞬时向量
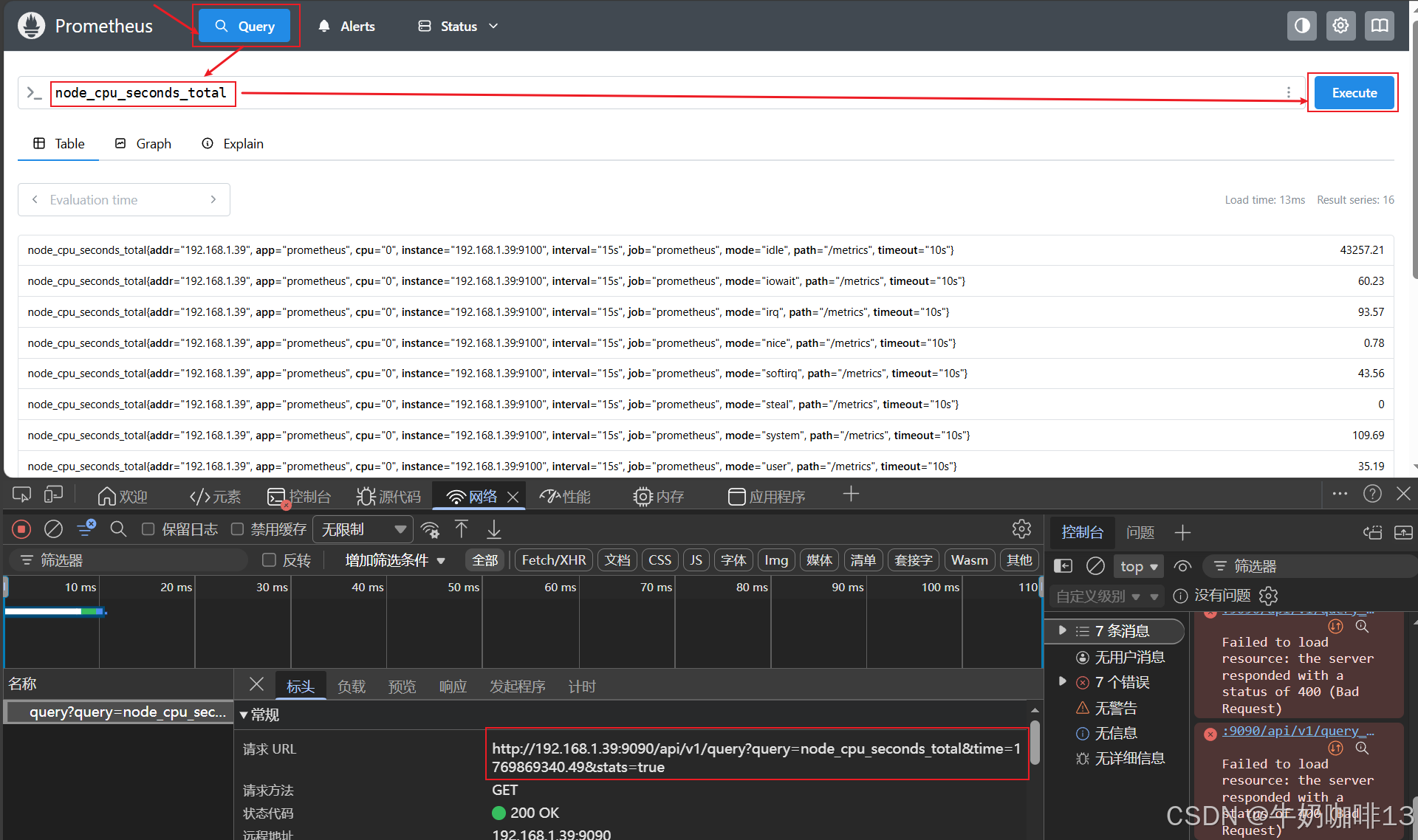
#示例1:查看cpu消耗的秒数的所有时间序列内容
node_cpu_seconds_total
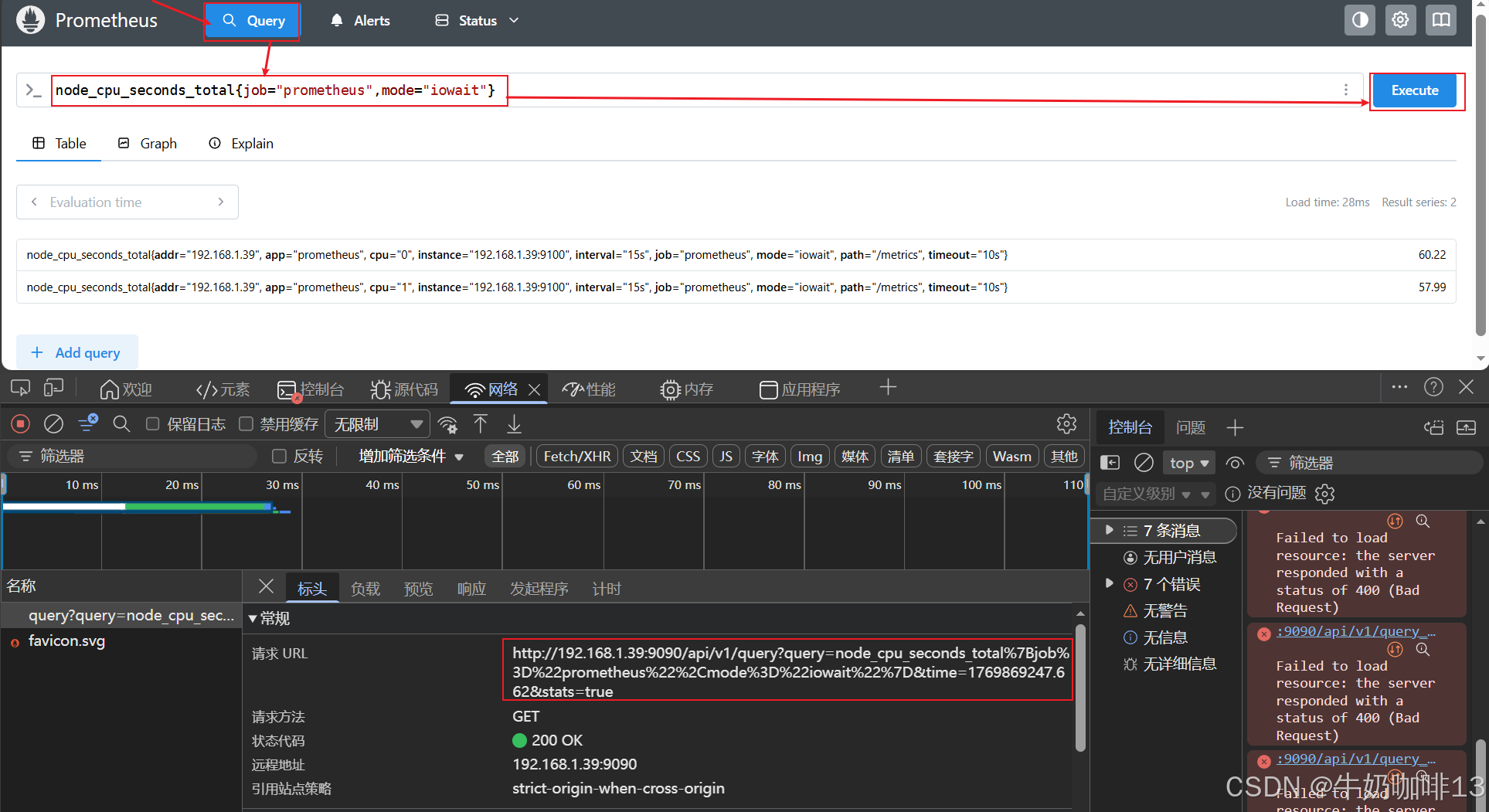
#示例2:查看指标名称是【node_cpu_seconds_total】,job标签值为【prometheus】,mode标签值为【iowait】的时间序列
node_cpu_seconds_total{job="prometheus",mode="iowait"}
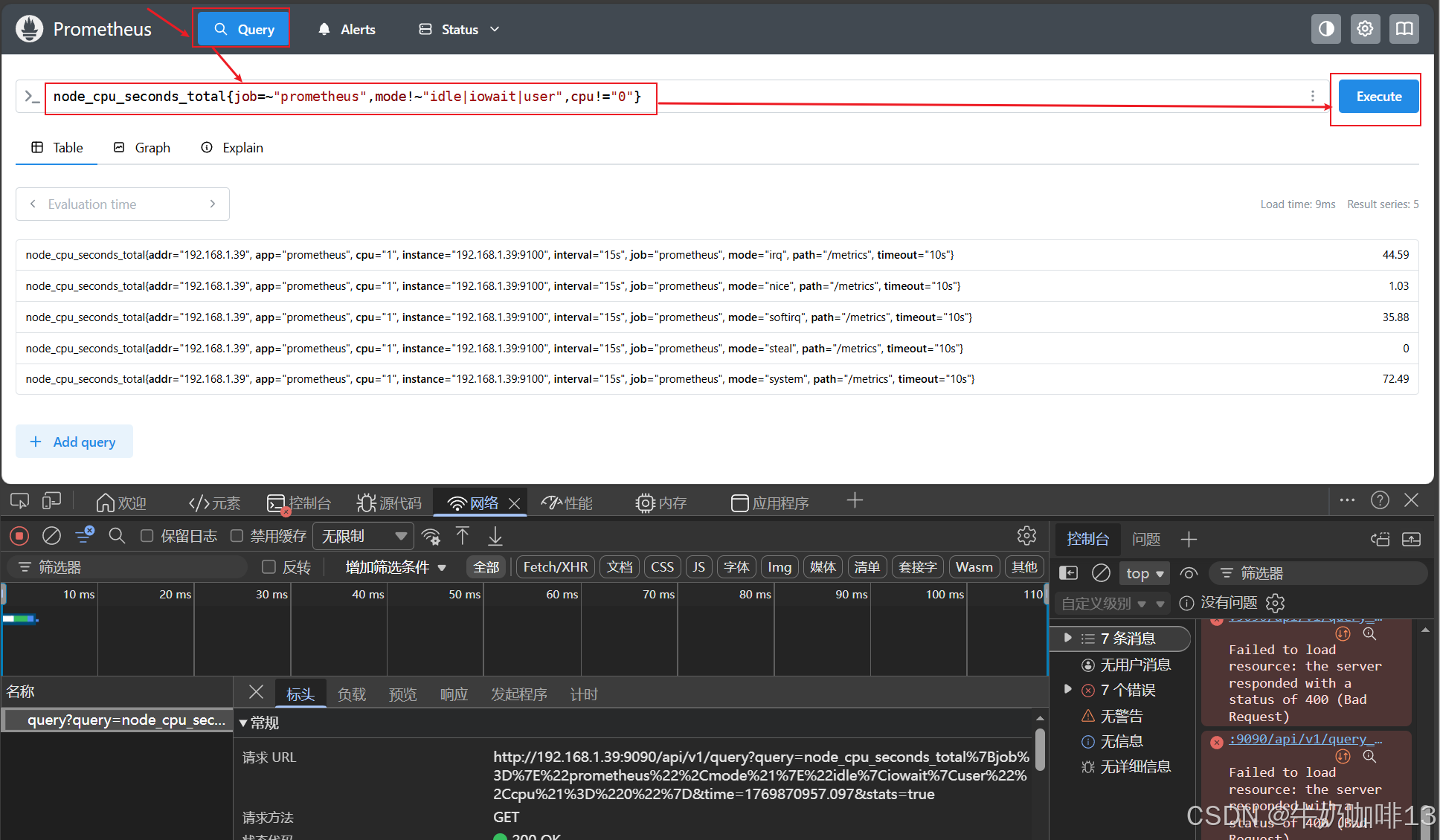
#示例3:选择指标名称为【node_cpu_seconds_total】,mode不是【idle、iowait、user】CPU为非【CPU0】的时间序列
node_cpu_seconds_total{job=~"prometheus",mode!~"idle|iowait|user",cpu!="0"}没有指定标签的标签过滤器 会选择该指标名称的所有时间序列。上面的例子中,给出的PromQL 都叫做瞬时查询(Instant Query),返回的内容叫做瞬时向量( Instant Vector)。
2.2.1.1、PromQL 表达式规范
所有的 PromQL 表达式必须至少包含一个指标名称,或者一个不会匹配到空字符串的标签过滤器。
bash
#非法表达式(因为会匹配到空字符串):
#.*表示任意一个字符,但标签可能匹配到空字符串。
{job=~".*"} 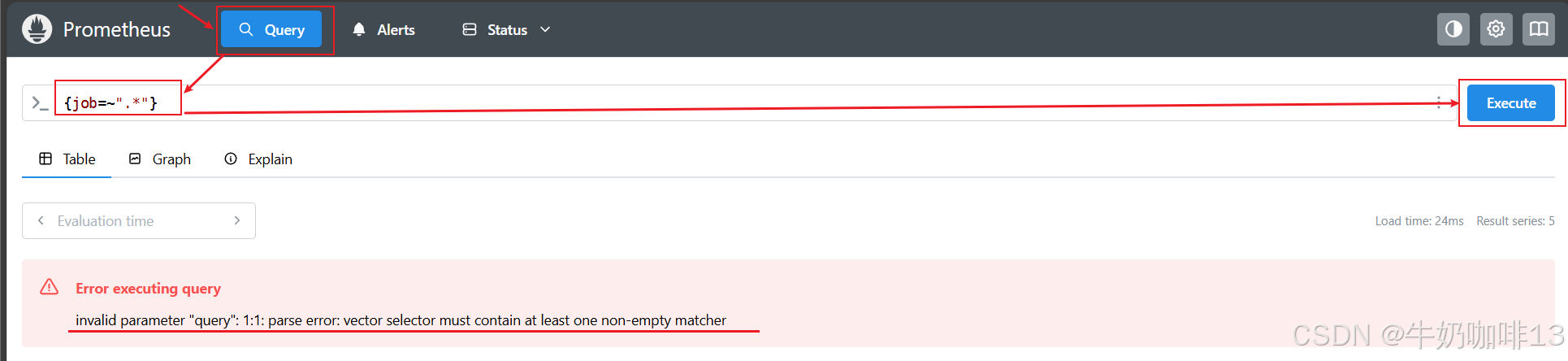
bash
#PromQL合法表达式
#.+表示至少一个字符
{job=~".+"}
#.*表示任意一个字符,虽然标签可能匹配到空字符串;但是由于后面还有instance能够匹配到因此是合法的
{job=~".*",instance=~"192.168.1.39:9100"}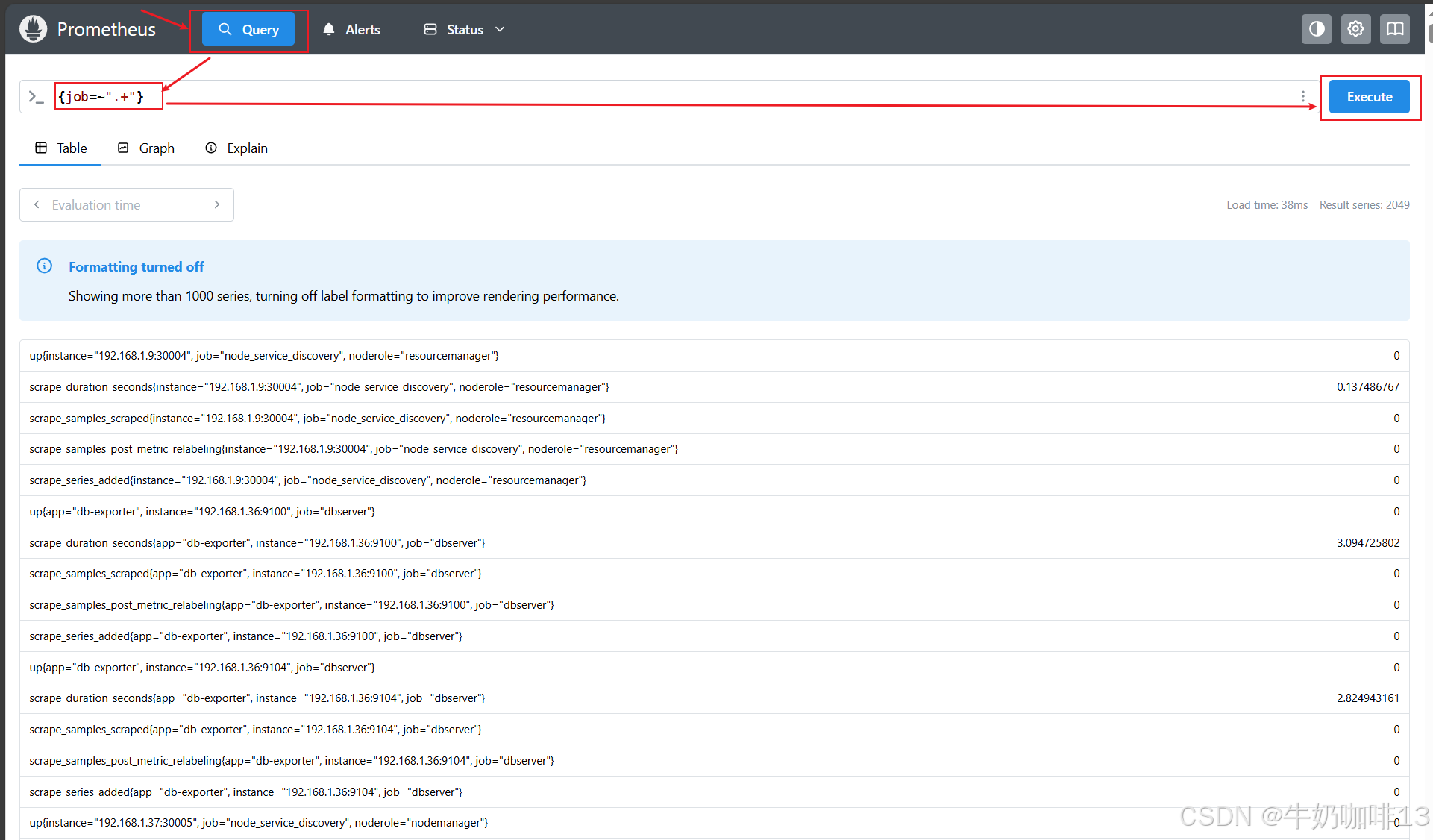
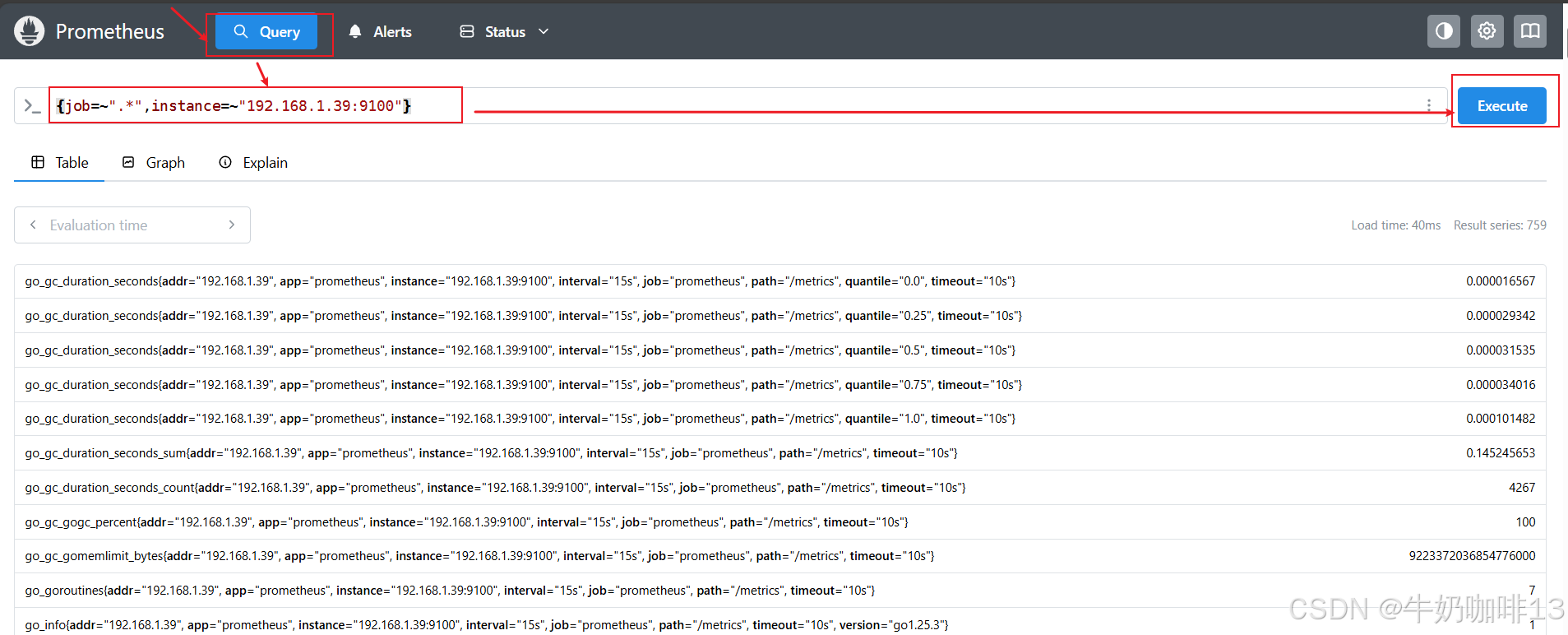
除了使用 <metric name>{label=value} 的形式以外,还可以使用内置的【 __name__ 】标签来指定监控指标名称。例如:表达式 node_cpu_seconds_total 等效于 {__name__="node_cpu_seconds_total"}。也可以使用除 = 之外的过滤器(=,=~,~)。以下表达式选择指标名称以 go_ 开头的所有指标:
bash
#选择指标名称以【go_】开头的所有指标
{__name__=~"go_.*"}
#选择指标名称以【node_memory】开头的所有指标
{__name__=~"node_memory.*"}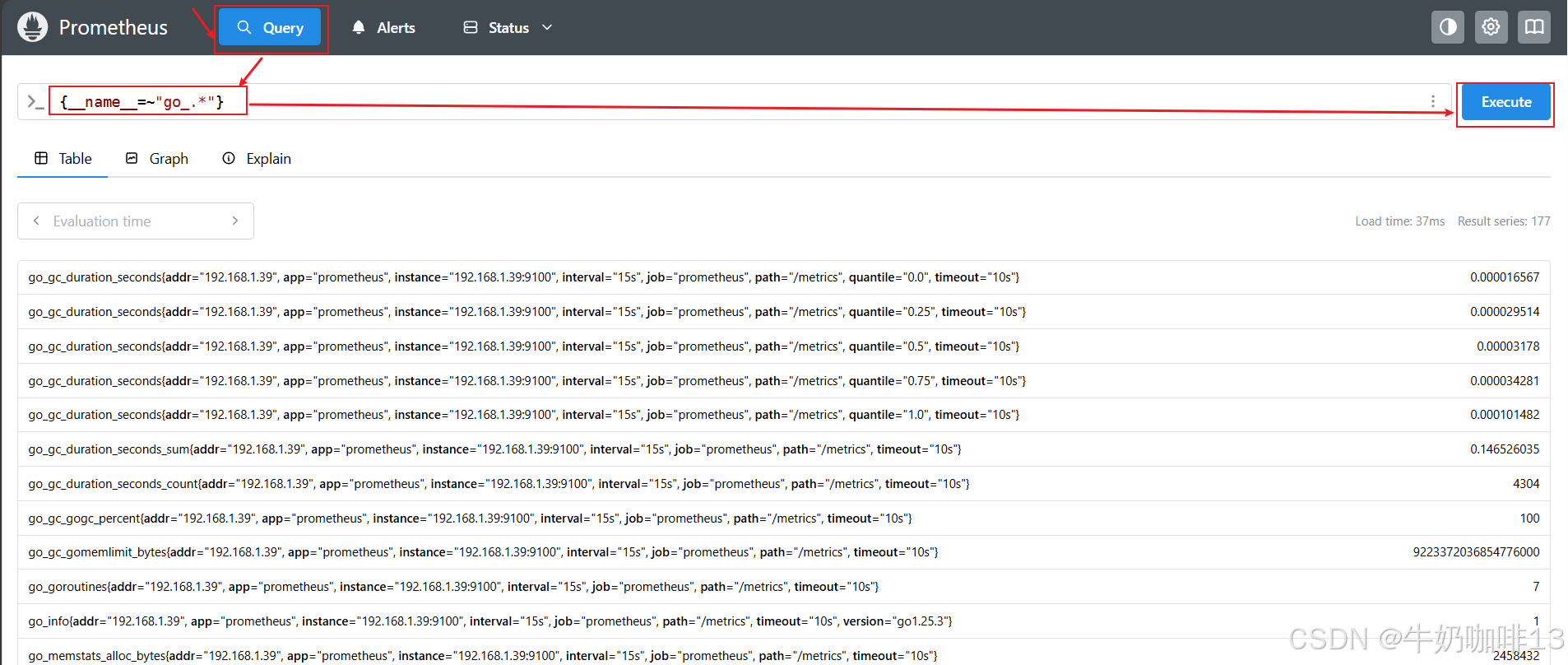
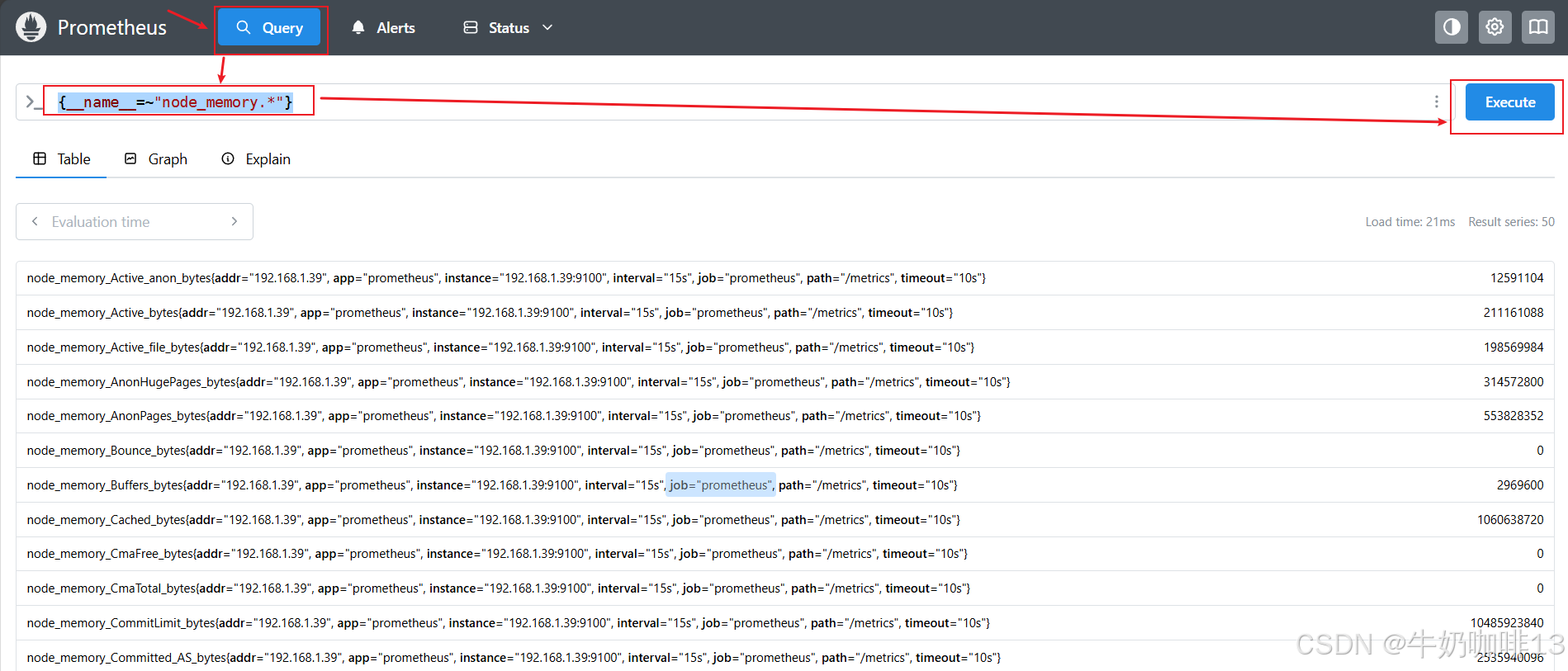
2.2.1.2、瞬时查询与最新值
瞬时查询返回的是当前的最新值,比如 10点整发起的查询,返回的就是 10 点整这一时刻对应的数据。
但是监控数据是周期性上报的,并非每时每刻都有数据上报,10 点整的时候可能恰恰没有数据进来,此时 Prometheus 就会往前看,看看 9 点 59、9 点 58、9 点 57 等时间点有没有上报数据。最多往前看多久呢?这个数据由 Prometheus 的启动参数【--query.lookback-delta】控制,参数默认是 5 分钟。此值可修改小一点。
因此,最新 意味着查询最近 5 分钟内的样本数据。如果发现5分钟内,没有任何样本数据,则返回空。
2.2.2、区间查询与区间向量
区间查询主要用于图形,区间向量与瞬时向量的工作方式类似,唯一的差异在于在区间向量表达式中我们需要定义时间选择的范围 ,时间范围通过时间范围选择器中括号 [] 进行定义,以指定应为区间向量样本值中提取多长的时间范围。
时间范围通过数字来表示,单位可以使用以下其中之一的时间单位:
|--------|------------|--------|
| 序号 | 时间范围单位 | 说明 |
| 1 | s | 秒 |
| 2 | m | 分钟 |
| 3 | h | 小时 |
| 4 | d | 天 |
| 5 | w | 周 |
| 6 | y | 年 |
[区间查询的时间范围单位]
bash
#查看在过去1分钟内指标为【node_cpu_seconds_total】job标签是【prometheus】mode标签是【idle】cpu标签是0的所有时间序列(由于我们目前使用默认的15秒采集一次,因此一分钟内有四条记录)
node_cpu_seconds_total{job="prometheus",mode="idle",cpu="0"}[1m]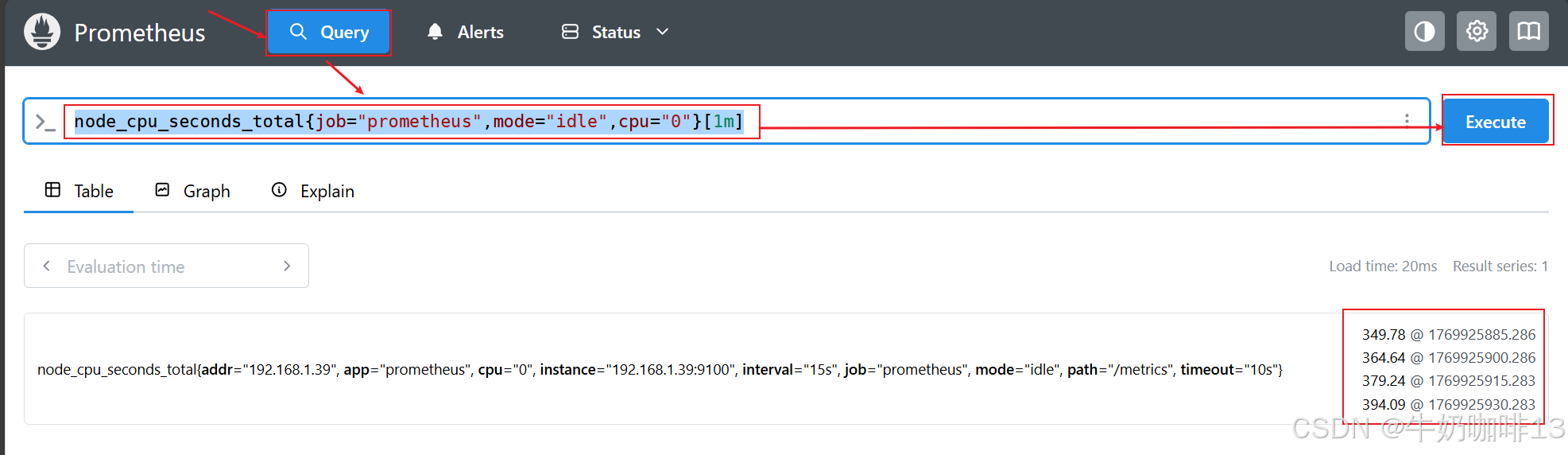
在 Prometheus 的 WebUI 界面中图形视图中的查询就是区间查询 :区间查询包括【PromQL表达式】【开始时间】【结束时间】【评估步长】四个内容。API 接口 /api/v1/query_range?query=xxx&start=xxxxxx&end=xxxx&step=14 中的 query 参数就是 PromQL 表达式,start 为开始时间,end 为结束时间,step 为评估的步长。
bash
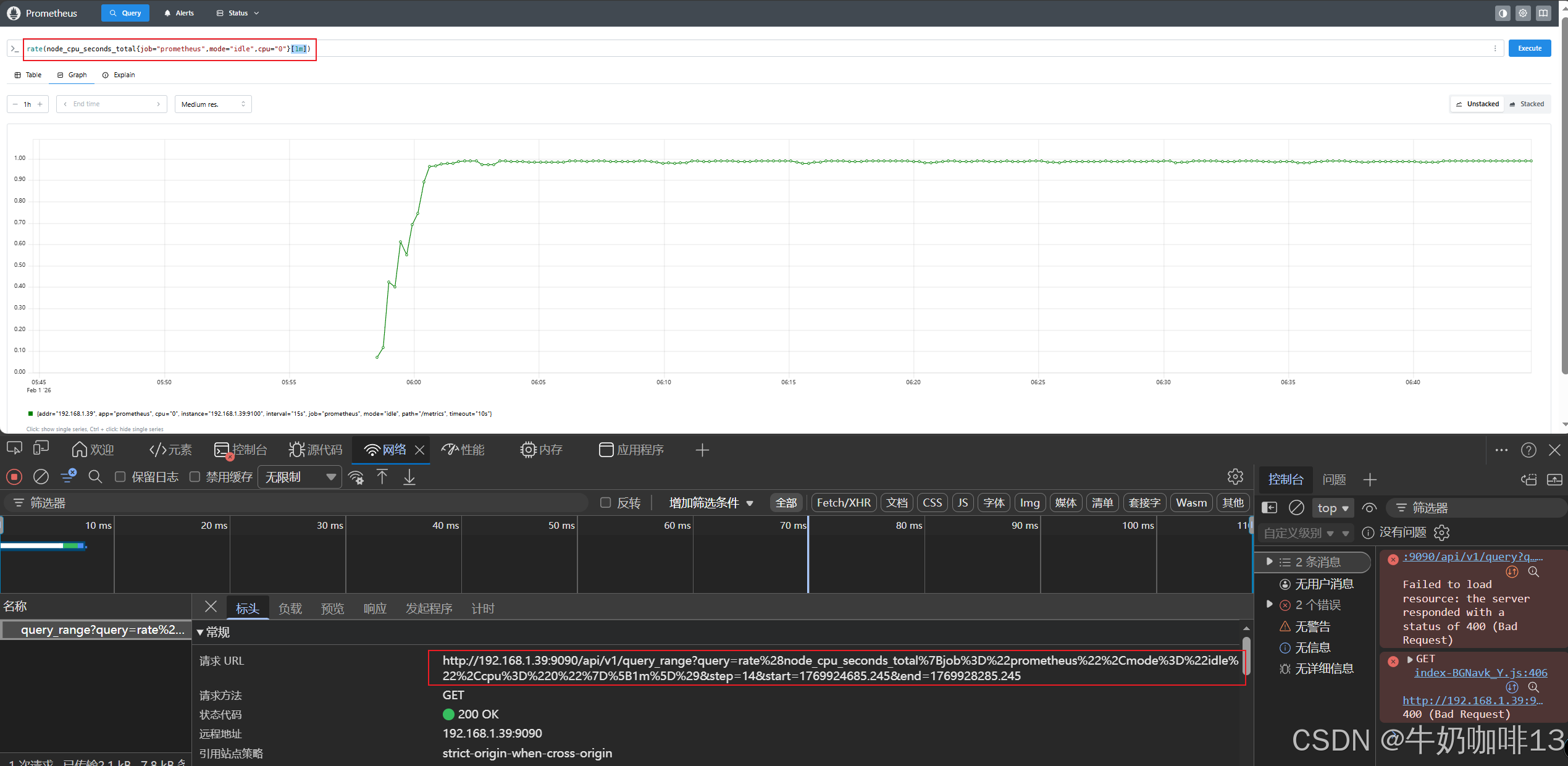
#区间查询示例(查询1分钟之内的时间数据)
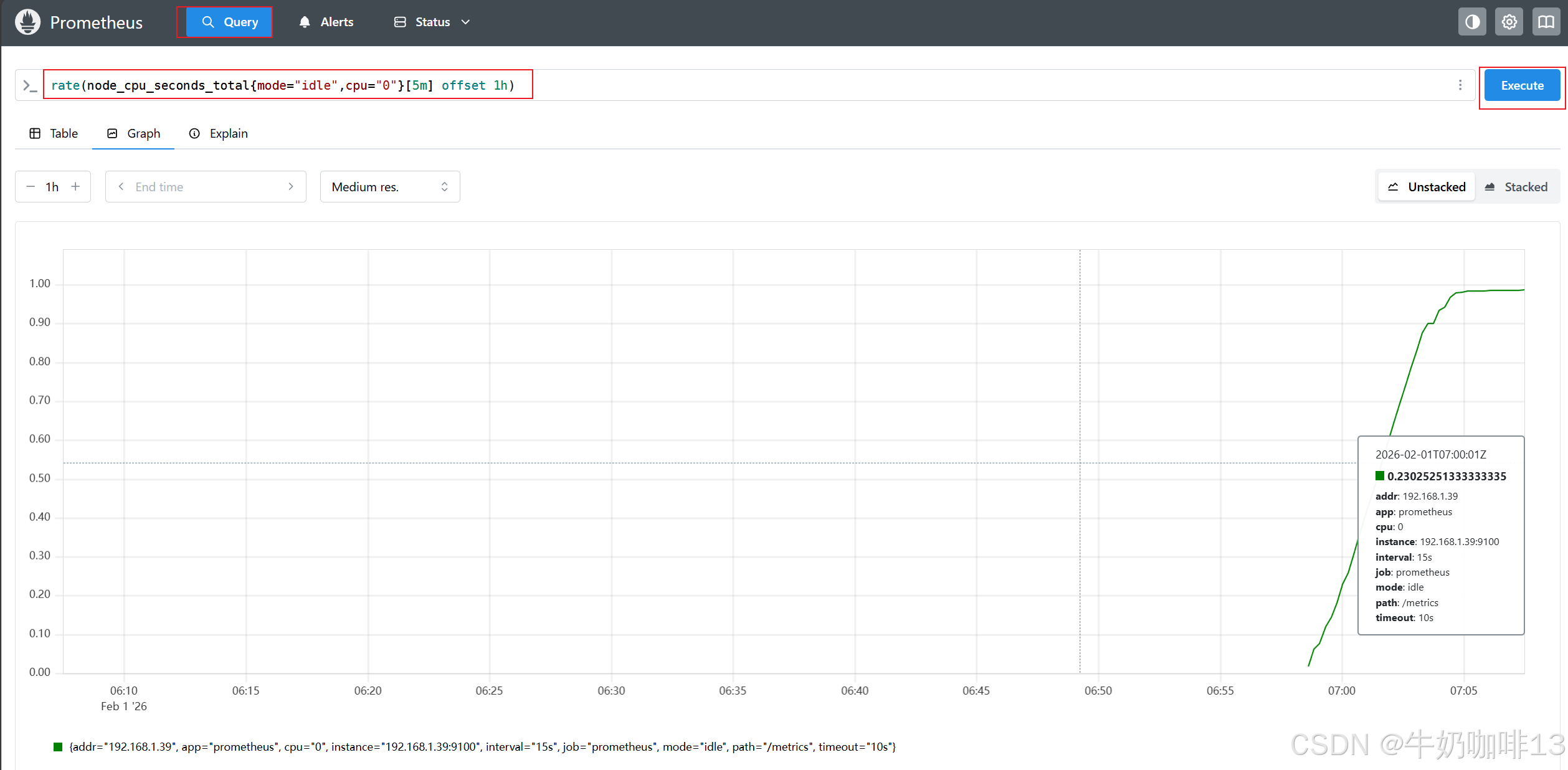
rate(node_cpu_seconds_total{job="prometheus",mode="idle",cpu="0"}[1m])注意: 由于区间向量选择器返回的是区间向量型数据,它不能用于表达式浏览器中图形绘制功能,但是结合【rate】函数使用,返回的就不是区间向量型数据,可以显示Graph中,因此,区间向量选择器往往和速率类的函数rate一起使用。如下图所示:
2.2.3、时间位移操作
在瞬时向量表达式或者区间向量表达式中,都是以当前时间为基准。如果想查询,5 分钟前的瞬时样本数据,或昨天一天的区间内的样本数据呢? 这个时候我们就可以使用位移操作,位移操作的关键字为【offset】。注意: offset 关键字需要紧跟在选择器({})后面。
bash
#示例1:查询【node_cpu_seconds_total】指标5分钟之前的时间序列数据
node_cpu_seconds_total offset 5m
#示例2:查询【node_cpu_seconds_total】指标1小时之前,5分钟以内的数据
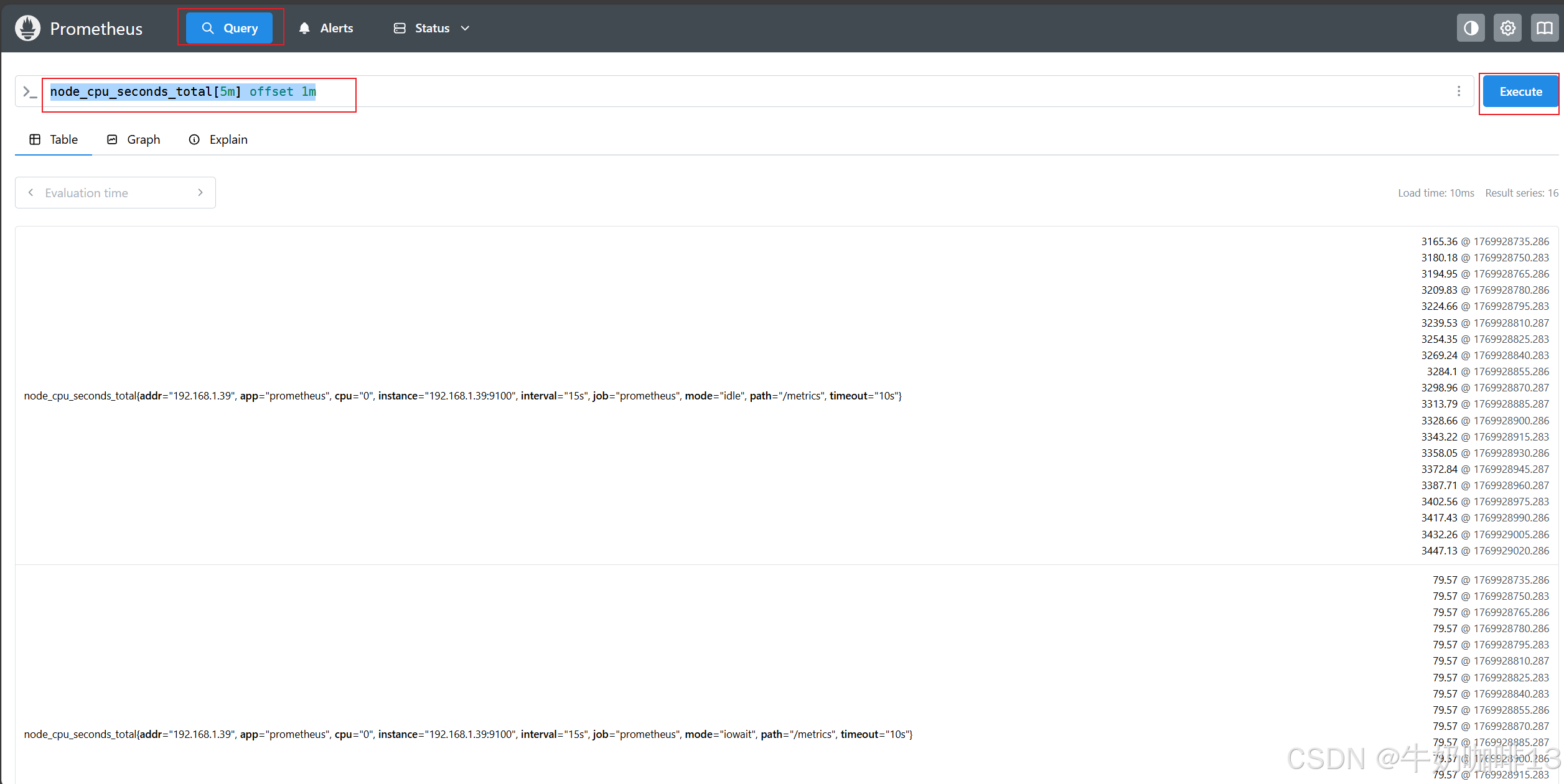
node_cpu_seconds_total[5m] offset 1m
#示例3:查询【node_cpu_seconds_total】指标1小时之前,5分钟以内的增长比例情况
rate(node_cpu_seconds_total{mode="idle",cpu="0"}[5m] offset 1h)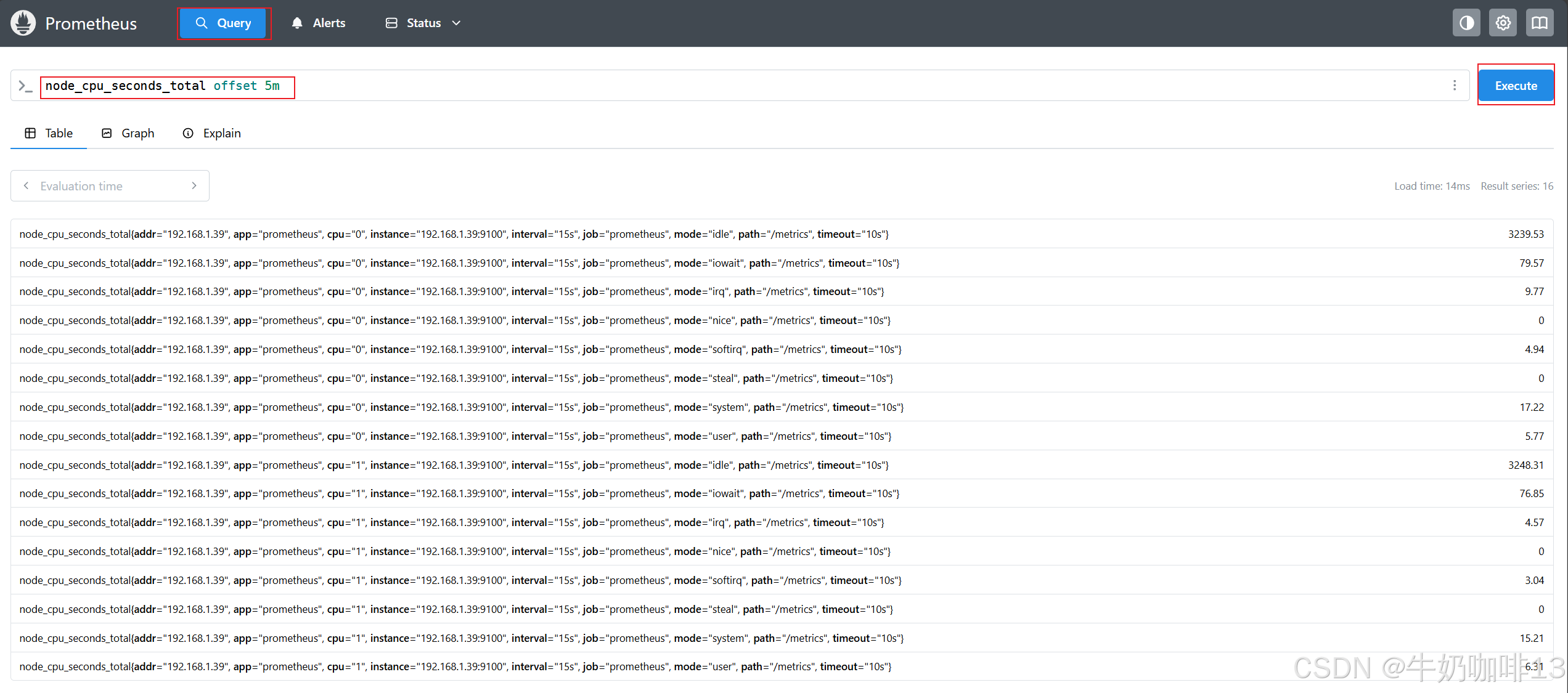
三、prometheus的相关基础
Prometheus+Grafana构建云原生分布式监控系统(一)_监控的方法论与监控指标解析![]() https://blog.csdn.net/xiaochenXIHUA/article/details/157059743?spm=1001.2014.3001.5501Prometheus+Grafana构建云原生分布式监控系统(二)_prometheus的原理、构成与使用场景解析及其安装配置
https://blog.csdn.net/xiaochenXIHUA/article/details/157059743?spm=1001.2014.3001.5501Prometheus+Grafana构建云原生分布式监控系统(二)_prometheus的原理、构成与使用场景解析及其安装配置![]() https://blog.csdn.net/xiaochenXIHUA/article/details/157094525?spm=1001.2014.3001.5501Prometheus+Grafana构建云原生分布式监控系统(三)_监控主机、数据库的完整实践教程
https://blog.csdn.net/xiaochenXIHUA/article/details/157094525?spm=1001.2014.3001.5501Prometheus+Grafana构建云原生分布式监控系统(三)_监控主机、数据库的完整实践教程![]() https://blog.csdn.net/xiaochenXIHUA/article/details/157127991?spm=3001.10796
https://blog.csdn.net/xiaochenXIHUA/article/details/157127991?spm=3001.10796