本系列主要旨在帮助初学者学习和巩固Linux系统。也是笔者自己学习Linux的心得体会。

个人主页: 爱装代码的小瓶子
文章系列: Linux
2. C++
文章目录
- [1. 前言:一次open()调用背后的史诗](#1. 前言:一次open()调用背后的史诗)
- [2. 全景概览:open() 调用的七个阶段](#2. 全景概览:open() 调用的七个阶段)
-
- [2.1 七个阶段概览](#2.1 七个阶段概览)
- [2.2 核心数据结构关系](#2.2 核心数据结构关系)
- [3. 深入内核:从 sys_open 到 do_sys_open](#3. 深入内核:从 sys_open 到 do_sys_open)
-
- [3.1 系统调用的入口](#3.1 系统调用的入口)
- [3.2 do_sys_open:协调者](#3.2 do_sys_open:协调者)
- [4. 核心揭秘:do_filp_open 与路径解析](#4. 核心揭秘:do_filp_open 与路径解析)
-
- [4.1 打开操作的入口](#4.1 打开操作的入口)
- [4.2 路径解析的核心:path_openat](#4.2 路径解析的核心:path_openat)
- [5. 核心数据结构源码解析](#5. 核心数据结构源码解析)
-
- [5.1 task_struct:进程控制块](#5.1 task_struct:进程控制块)
- [5.2 files_struct 与 fdtable:打开文件表](#5.2 files_struct 与 fdtable:打开文件表)
- [5.3 struct file:打开的文件对象](#5.3 struct file:打开的文件对象)
- [5.4 inode 与 dentry:文件的"灵魂"与"导航"](#5.4 inode 与 dentry:文件的"灵魂"与"导航")
- [6. 总结:open() 的本质](#6. 总结:open() 的本质)
-
- [6.1 open() 做了什么?](#6.1 open() 做了什么?)
- [6.2 为什么要这么多数据结构?](#6.2 为什么要这么多数据结构?)
- [6.3 核心设计思想](#6.3 核心设计思想)
-
- [1. 分层与抽象](#1. 分层与抽象)
- [2. 缓存加速](#2. 缓存加速)
- [3. 引用计数与生命周期管理](#3. 引用计数与生命周期管理)
- [7. 结语:打开文件,打开一扇门](#7. 结语:打开文件,打开一扇门)
1. 前言:一次open()调用背后的史诗
在之前的文章中,我们已经深入探讨了文件在磁盘上的静态存储结构(ext2文件系统),也了解了VFS如何通过"一切皆文件"的哲学统一了各种设备。今天,我们将把目光聚焦在一个看似简单却暗藏玄机的问题上:当进程调用 open() 时,内核究竟发生了什么?
想象一下:你写下一行代码
int fd = open("test.txt", O_RDONLY);,短短几个字符,却触发了一场跨越用户空间与内核空间、贯穿磁盘与内存的"信息接力"。
学习完这篇文章,你将彻底理解:
- open() 系统调用的完整调用链:从用户态到内核态的切换
- 路径解析的艺术:如何从 "/home/user/test.txt" 找到对应的 inode
- 核心数据结构的关系 :
task_struct、files_struct、fdtable、struct file、inode、dentry是如何协作的 - 文件描述符的分配机制:为什么 fd 总是从最小的空闲数字开始
- 缓存的力量:dentry cache 和 inode cache 如何加速文件访问
这是一场关于"连接"的旅程------连接用户与内核、连接路径与inode、连接进程与文件。让我们开始吧。
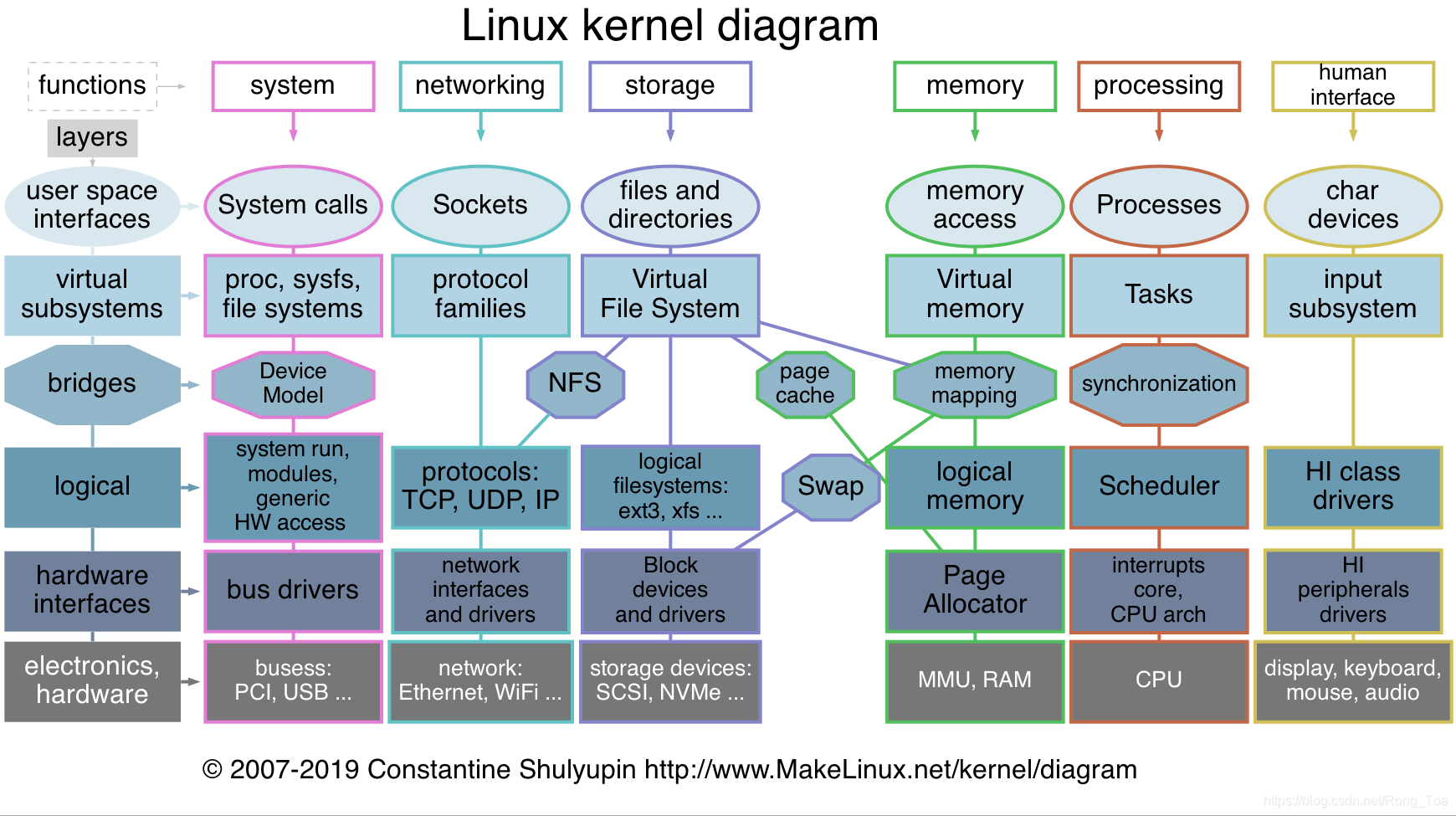
2. 全景概览:open() 调用的七个阶段
一次 open() 调用,内核经历了七个关键阶段。在深入源码之前,让我们先建立整体认知。
2.1 七个阶段概览
| 阶段 | 名称 | 核心函数/操作 | 作用 |
|---|---|---|---|
| 1 | 系统调用入口 | SYSCALL_DEFINE3(open) |
从用户态陷入内核态 |
| 2 | 参数解析 | build_open_flags() |
解析 flags 和 mode |
| 3 | 分配 fd | get_unused_fd_flags() |
在 fdtable 中找到空闲 fd |
| 4 | 路径解析 | do_filp_open() → path_openat() |
解析路径,查找/创建 inode |
| 5 | 创建 file | alloc_empty_file() |
创建 struct file 结构体 |
| 6 | 关联 fd 与 file | fd_install() |
将 file 指针填入 fd_arrayfd |
| 7 | 返回用户态 | 系统调用返回 | 将 fd 返回给用户程序 |
2.2 核心数据结构关系
在深入源码之前,我们需要理解五个核心数据结构之间的关系:
task_struct (进程)
└── files (files_struct)
└── fdt (fdtable)
└── fd_array[]
└── struct file
├── f_inode → inode
└── f_dentry → dentry这个关系链是理解 open() 实现的核心。接下来,我们将从源码层面深入分析每个阶段。
3. 深入内核:从 sys_open 到 do_sys_open
3.1 系统调用的入口
当用户程序调用 open() 时,glibc 会将其封装为系统调用。内核的入口点是 sys_open,由 SYSCALL_DEFINE3 宏定义:
c
// fs/open.c
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)
{
// 如果强制使用大文件支持,设置 O_LARGEFILE 标志
if (force_o_largefile())
flags |= O_LARGEFILE;
// 调用核心的 do_sys_open
// AT_FDCWD 表示从当前工作目录开始解析相对路径
return do_sys_open(AT_FDCWD, filename, flags, mode);
}这个函数非常简单,只是做了一些标志位的检查,然后调用 do_sys_open。真正的逻辑都在 do_sys_open 中。
3.2 do_sys_open:协调者
do_sys_open 是整个打开流程的"总导演",它协调了 fd 分配、路径解析、file 结构创建等所有步骤:
c
// fs/open.c
long do_sys_open(int dfd, const char __user *filename, int flags, umode_t mode)
{
struct open_flags op; // 存储解析后的打开标志
struct filename *tmp; // 内核空间的路径名
int fd, error;
// ===== 步骤1:解析用户传入的 flags =====
// build_open_flags 将用户空间的 flags(如 O_RDONLY, O_CREAT)
// 转换为内核使用的 open_flags 结构
error = build_open_flags(flags, mode, &op);
if (error)
return error;
// ===== 步骤2:将用户空间的路径名拷贝到内核空间 =====
// getname 会做以下事情:
// - 检查路径名是否合法(长度、字符等)
// - 将路径名从用户空间拷贝到内核空间
// - 处理一些特殊情况(如空路径、绝对路径等)
tmp = getname(filename);
if (IS_ERR(tmp))
return PTR_ERR(tmp);
// ===== 步骤3:获取一个未使用的文件描述符 fd =====
// get_unused_fd_flags 会在当前进程的 fdtable 中
// 找到最小的空闲 fd 编号
fd = get_unused_fd_flags(flags);
if (fd >= 0) {
// ===== 步骤4:执行真正的文件打开操作(核心!)=====
// do_filp_open 会完成以下工作:
// - 路径解析(path_openat)
// - 查找/创建 inode
// - 创建 struct file
struct file *f = do_filp_open(dfd, tmp, &op);
if (IS_ERR(f)) {
// 打开失败,释放之前分配的 fd
put_unused_fd(fd);
fd = PTR_ERR(f);
} else {
// ===== 步骤5:将 struct file 与 fd 关联 =====
// fd_install 会将 file 指针填入 fd_array[fd]
// 这样以后通过 fd 就能找到这个 file 结构体
fd_install(fd, f);
}
}
// ===== 步骤6:清理,释放临时分配的内存 =====
putname(tmp);
// 返回 fd 给用户空间
// 如果 fd < 0,表示出错,fd 的绝对值就是错误码
return fd;
}这个函数的逻辑非常清晰,可以分为六个步骤,我在代码注释中已经详细标注了。接下来,我们将深入最核心的 do_filp_open,看看文件是如何被真正"打开"的。
4. 核心揭秘:do_filp_open 与路径解析
4.1 打开操作的入口
do_filp_open 是文件打开的核心实现,它负责协调路径解析和文件创建。让我深入分析这个关键函数的源码:
c
// fs/namei.c
struct file *do_filp_open(int dfd, struct filename *pathname,
const struct open_flags *op)
{
struct nameidata nd; // 路径解析的核心数据结构
struct file *filp;
int error;
// 初始化 nameidata 结构体
// nameidata 是"namei data"的缩写,namei 是"name to inode"的缩写
// 这个结构体贯穿整个路径解析过程,存储中间状态和结果
nd.mnt = NULL; // 当前挂载点
nd.dentry = NULL; // 当前 dentry
nd.flags = op->lookup_flags; // 查找标志
// ===== 核心:执行路径解析和文件打开 =====
// path_openat 是实际干活的地方
// 它会解析路径、查找/创建 inode、创建 struct file
error = path_openat(dfd, pathname, &nd, op);
if (IS_ERR_VALUE(error)) {
// 路径解析失败,返回错误指针
return ERR_PTR(error);
}
// 成功!从 nameidata 中获取创建的 struct file
filp = nd.filp;
// ===== 后续处理 =====
// 如果设置了 O_TRUNC 标志,需要截断文件
if (op->open_flag & O_TRUNC) {
error = handle_truncate(filp);
if (error) {
// 截断失败,释放 file 结构体
fput(filp);
return ERR_PTR(error);
}
}
return filp;
}这个函数虽然代码量不大,但每一个调用都隐藏着复杂的逻辑。接下来,我将深入分析 path_openat,这是路径解析的核心实现。
4.2 路径解析的核心:path_openat
path_openat 是路径解析的核心函数,它负责将路径字符串(如 /home/user/test.txt)转换为内核中的 inode 对象。让我详细分析这个函数:
c
// fs/namei.c
static int path_openat(int dfd, struct filename *name,
struct nameidata *nd, const struct open_flags *op)
{
struct file *base = NULL;
struct dentry *dentry;
struct path path;
int error;
// ===== 步骤1:初始化查找标志 =====
// 设置查找标志,如 LOOKUP_FOLLOW(跟随符号链接)等
nd->flags |= op->lookup_flags;
// ===== 步骤2:获取起始路径 =====
// 根据 dfd(目录文件描述符)确定路径解析的起点
// - 如果 dfd == AT_FDCWD,从当前工作目录开始
// - 如果路径以 / 开头,从根目录开始
// - 否则,从 dfd 指定的目录开始
error = path_init(dfd, nd->flags, name, nd);
if (error)
return error;
// ===== 步骤3:逐级解析路径 =====
// 这是一个循环,每次处理路径的一个分量(component)
// 例如:/home/user/test.txt 会被分解为:""、"home"、"user"、"test.txt"
while (!(nd->flags & LOOKUP_ROOT)) {
// 3.1 获取下一个路径分量
// path_walk 会解析路径字符串,返回下一个分量
const char *s = path_walk(name->name, nd);
if (IS_ERR(s)) {
error = PTR_ERR(s);
break;
}
// 如果已经到达路径末尾,跳出循环
if (!*s)
break;
// 3.2 查找当前分量的 dentry
// 首先在 dentry cache 中查找
error = lookup_fast(nd, &path, &inode);
if (unlikely(error)) {
// cache 未命中,进行慢速查找(可能需要读取磁盘)
error = lookup_slow(nd, &path);
}
if (error)
break;
// 3.3 处理符号链接
// 如果当前分量是符号链接,需要跟随链接
if (nd->flags & LOOKUP_FOLLOW) {
error = follow_link(&path, nd);
if (error)
break;
}
// 3.4 继续解析下一个分量
nd->path = path;
}
// ===== 步骤4:创建或打开文件 =====
if (!error) {
// 4.1 获取最终的 dentry
// 如果文件不存在且设置了 O_CREAT,会创建新的 dentry
dentry = lookup_create(nd, op->open_flag);
// 4.2 分配 struct file
// alloc_empty_file 会分配一个 file 结构体,并进行基本初始化
nd->filp = alloc_empty_file(op->open_flag, current_cred());
if (IS_ERR(nd->filp)) {
error = PTR_ERR(nd->filp);
goto out_dput;
}
// 4.3 调用具体文件系统的 open 方法
// 这是 VFS 多态的核心体现
// 对于 ext4 文件系统,会调用 ext4_file_open
// 对于 procfs,会调用 proc_file_open
error = do_open(nd->filp, dentry, op);
if (error) {
// 打开失败,释放 file 结构体
fput(nd->filp);
nd->filp = NULL;
}
}
out_dput:
dput(dentry);
path_cleanup(nd);
return error;
}这个函数是路径解析的核心,它展示了 Linux 内核如何将一个路径字符串转换为一组内核数据结构(dentry、inode、file)。
5. 核心数据结构源码解析
理解 open() 的实现,必须深入理解五个核心数据结构。让我逐一分析它们的源码:
5.1 task_struct:进程控制块
task_struct 是 Linux 内核中描述一个进程的核心结构体。其中与文件相关的字段是 files:
c
// include/linux/sched.h
struct task_struct {
// ... 大量其他字段 ...
// 进程 ID
pid_t pid;
pid_t tgid;
// 进程名称
char comm[TASK_COMM_LEN];
// 内存描述符(虚拟地址空间)
struct mm_struct *mm;
// ★★★ 打开文件表 ★★★
// files_struct 包含了该进程打开的所有文件
struct files_struct *files;
// 文件系统信息(根目录、当前工作目录)
struct fs_struct *fs;
// ... 大量其他字段 ...
};task_struct->files 指向一个 files_struct 结构体,后者包含了该进程打开的所有文件的信息。
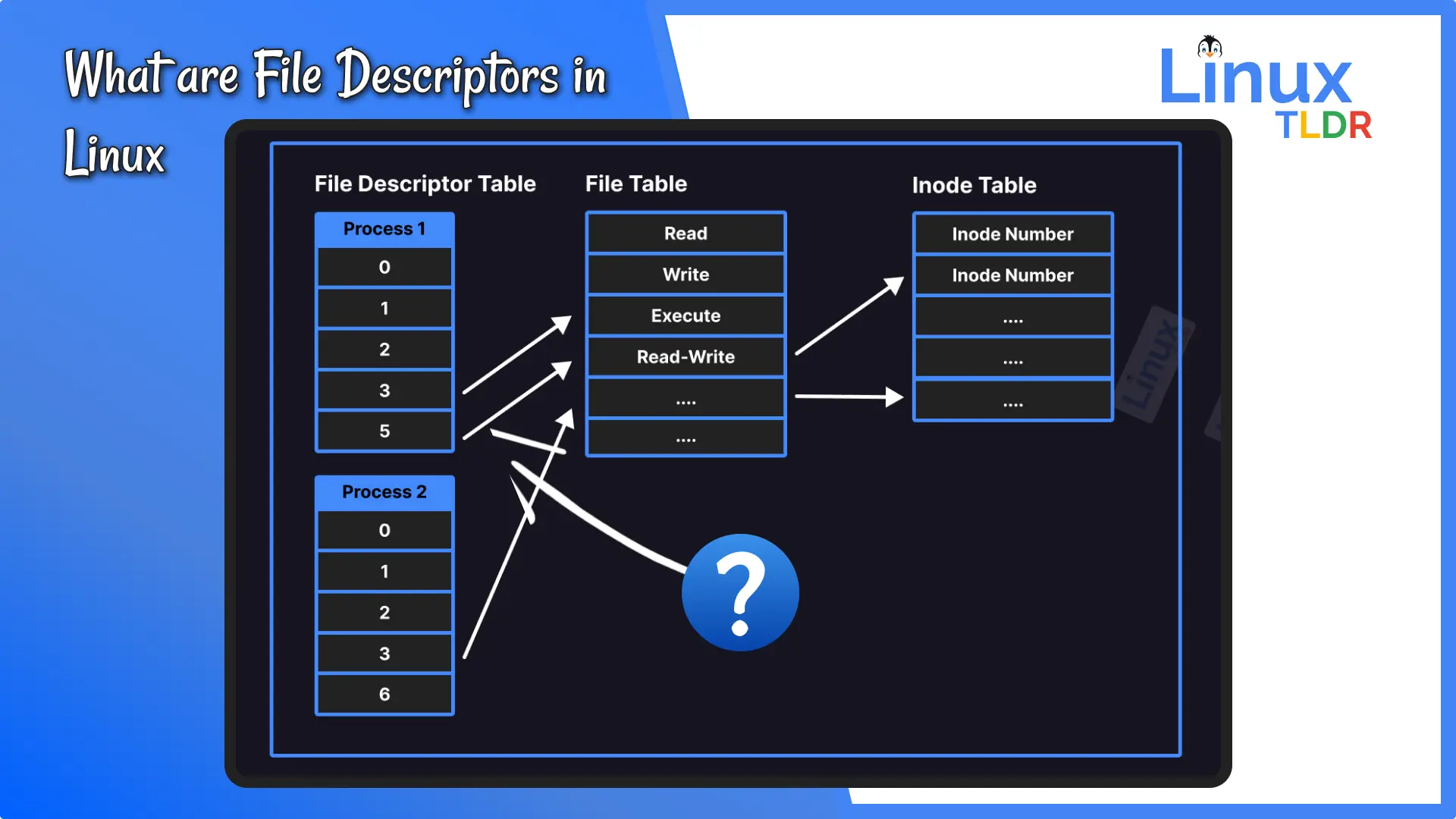
5.2 files_struct 与 fdtable:打开文件表
files_struct 是进程的打开文件表,它管理着该进程的所有文件描述符:
c
// include/linux/fdtable.h
struct fdtable {
unsigned int max_fds; // 当前 fd_array 的最大容量
struct file __rcu **fd_array; // ★★★ fd 数组,核心!★★★
// fd_array[fd] 指向对应的 struct file
unsigned long *close_on_exec; // exec 时关闭的 fd 位图
unsigned long *open_fds; // 已打开的 fd 位图
};
// include/linux/file.h
struct files_struct {
atomic_t count; // 引用计数(共享此表的进程数)
struct fdtable __rcu *fdt; // ★ 指向 fdtable(动态扩展)★
struct fdtable fdtab; // 内嵌的小容量 fdtable(优化)
spinlock_t file_lock; // 保护并发访问的自旋锁
int next_fd; // 下一个可能空闲的 fd(优化搜索)
};关键理解:
files_struct是每个进程独有的(除非通过clone(CLONE_FILES)共享)fdtable存储了 fd 到struct file的映射fd_array是一个指针数组,fd_array[fd]指向对应的struct file
5.3 struct file:打开的文件对象
struct file 代表一次打开操作。同一个文件被多次打开,会产生多个 struct file:
c
// include/linux/fs.h
struct file {
// ===== 文件位置和状态 =====
loff_t f_pos; // ★ 当前文件读写位置(字节偏移)★
fmode_t f_mode; // 打开模式(读/写/读写)
unsigned int f_flags; // 打开标志(O_APPEND, O_NONBLOCK等)
// ===== 核心关联指针 =====
struct inode *f_inode; // ★ 指向 inode(文件元数据)★
struct dentry *f_dentry; // ★ 指向 dentry(路径缓存)★
struct vfsmount *f_vfsmnt; // 指向挂载点
// ===== 操作函数表(VFS多态核心)=====
const struct file_operations *f_op; // ★★★ 文件操作函数表 ★★★
// read, write, mmap, poll...
// ===== 引用计数和状态 =====
atomic_t f_count; // 引用计数(fget/fput)
struct address_space *f_mapping; // 页面缓存映射
// ... 其他字段(锁、私有数据等)
};关键理解:
struct file是"一次打开"的抽象,同一个文件多次打开会产生多个struct file- 但所有
struct file都指向同一个inode(共享文件元数据) f_pos是每个打开独立的,这就是为什么多个进程可以同时读写同一个文件的不同位置
5.4 inode 与 dentry:文件的"灵魂"与"导航"
inode:文件的元数据
c
// include/linux/fs.h
struct inode {
// ===== 唯一标识 =====
umode_t i_mode; // 文件类型和权限
kuid_t i_uid; // 文件所有者UID
kgid_t i_gid; // 文件所属组GID
unsigned long i_ino; // ★★★ inode 编号(在分区中唯一)★★★
// ===== 文件大小和时间 =====
loff_t i_size; // 文件大小(字节)
struct timespec64 i_atime; // 最后访问时间
struct timespec64 i_mtime; // 最后修改时间
struct timespec64 i_ctime; // 最后状态改变时间
// ===== 数据块定位 =====
struct address_space *i_mapping; // 页面缓存映射
// ===== 引用计数和状态 =====
atomic_t i_count; // 引用计数
unsigned int i_nlink; // 硬链接数
unsigned long i_state; // 状态标志
// ===== 操作函数表 =====
const struct inode_operations *i_op; // inode 操作
};dentry:路径解析的缓存
c
// include/linux/dcache.h
struct dentry {
// ===== 关键关联 =====
struct inode *d_inode; // ★ 指向对应的 inode
struct dentry *d_parent; // ★ 指向父目录的 dentry
// ===== 标识信息 =====
struct qstr d_name; // ★ 文件名(qstr = quick string)
unsigned int d_flags; // dentry 标志
// ===== 缓存组织 =====
struct hlist_bl_node d_hash; // 哈希表节点(用于 dentry cache 查找)
struct list_head d_lru; // LRU 链表节点(用于缓存回收)
// ===== 引用计数 =====
atomic_t d_count; // 引用计数
int d_lockref; // 锁和引用计数
};关键理解:
dentry是内核的"导航仪",它将"文件名"映射到"inode"dentry cache(dcache)缓存了这些映射,避免每次都从磁盘读取目录dentry形成了一个树状结构(通过d_parent),反映了文件系统的目录结构
6. 总结:open() 的本质
经过这篇长文的探索,让我们总结 open() 的本质:
6.1 open() 做了什么?
open() 的本质是:建立一条从"文件描述符"到"磁盘文件"的通路。
这条通路涉及多个数据结构的协作:
用户空间:fd (int)
↓ 系统调用
内核空间:fd_array[fd] → struct file
→ f_inode → inode (文件元数据)
→ f_dentry → dentry (路径缓存)
→ f_op → file_operations (操作函数表)6.2 为什么要这么多数据结构?
| 数据结构 | 解决的问题 | 设计思想 |
|---|---|---|
task_struct |
如何表示一个进程 | 进程是资源分配的基本单位 |
files_struct |
进程如何管理打开的文件 | 封装进程的文件访问能力 |
fdtable |
如何快速将 fd 映射到 file | 数组索引,O(1) 查找 |
struct file |
如何表示"一次打开" | 每次打开是独立的,有自己的状态和位置 |
inode |
如何表示文件的"本质" | 元数据和数据块位置 |
dentry |
如何加速路径解析 | 缓存文件名到 inode 的映射 |
6.3 核心设计思想
1. 分层与抽象
- VFS 层提供统一接口,不关心底层是哪个文件系统
- 具体文件系统(ext4/xfs/btrfs)实现 VFS 接口
- 设备驱动处理硬件细节
2. 缓存加速
dentry cache:避免重复路径解析inode cache:避免重复读取元数据page cache:避免重复读取文件内容
3. 引用计数与生命周期管理
- 每个共享资源都有引用计数
- 当引用归零时,资源被安全释放
- 实现资源共享与安全回收的平衡
7. 结语:打开文件,打开一扇门
"The art of progress is to preserve order amid change and to preserve change amid order."
------ Alfred North Whitehead
当我们写下 int fd = open("test.txt", O_RDONLY);,表面上是简单的函数调用,实际上却是打开了一扇通往操作系统内核深处的大门。
这扇门的背后:
- 有 VFS 的优雅抽象,让万千设备都化作"文件"
- 有 缓存 的精妙设计,让慢速磁盘也能飞速响应
- 有 引用计数 的谨慎管理,在共享与独占间寻找平衡
- 有 分层架构 的智慧,让复杂系统也能井然有序
理解 open() 的实现,不仅是学习一个系统调用的工作原理,更是领悟一种设计哲学:在复杂度面前,如何用分层、抽象、缓存等手段,构建出既高效又可靠的系统。
希望这篇文章能帮助你真正理解 Linux 文件系统的精髓。下次当你写下 open() 时,愿你能想起这一趟内核之旅,想起那些数据结构体的精密协作,想起 VFS 层的优雅调度------想起这扇通往操作系统深处的门。
Keep exploring, keep learning.
本文深入剖析了 Linux 内核中 open() 系统调用的完整实现,从用户空间到内核空间,从系统调用入口到 VFS 层,从路径解析到文件描述符分配,力图呈现一幅完整的"进程如何打开磁盘文件"的全景图。希望对你理解 Linux 文件系统有所帮助。
感谢各位对本篇文章的支持。谢谢各位点个三连吧!

