目录
[一、列表初始化:C++11 的 "统一初始化语法"](#一、列表初始化:C++11 的 “统一初始化语法”)
[二、initializer_list 对象:STL 容器列表初始化的核心](#二、initializer_list 对象:STL 容器列表初始化的核心)
[三、关键区别:普通类 vs STL 容器的列表初始化](#三、关键区别:普通类 vs STL 容器的列表初始化)
[二、auto 关键字:「初始化驱动」的类型推导](#二、auto 关键字:「初始化驱动」的类型推导)
[三、decltype 关键字:「表达式分析」的类型推导](#三、decltype 关键字:「表达式分析」的类型推导)
[四、auto vs decltype 核心区别对比](#四、auto vs decltype 核心区别对比)
[二、左值(lvalue):有 "身份" 的持久值](#二、左值(lvalue):有 “身份” 的持久值)
[三、右值(rvalue):"一次性" 的临时值](#三、右值(rvalue):“一次性” 的临时值)
[四、左值引用(lvalue reference,T&):给左值取 "别名"](#四、左值引用(lvalue reference,T&):给左值取 “别名”)
[五、右值引用(rvalue reference,T&&):给右值取 "别名"](#五、右值引用(rvalue reference,T&&):给右值取 “别名”)
[1. 核心需求梳理](#1. 核心需求梳理)
[2. 纯右值(prvalue)与将亡值(xvalue):右值的两个细分类型](#2. 纯右值(prvalue)与将亡值(xvalue):右值的两个细分类型)
[3. 移动构造函数:接管将亡值的资源(替代深拷贝的拷贝构造)](#3. 移动构造函数:接管将亡值的资源(替代深拷贝的拷贝构造))
[4. 移动赋值运算符:已有对象接管将亡值的资源(替代深拷贝的赋值重载)](#4. 移动赋值运算符:已有对象接管将亡值的资源(替代深拷贝的赋值重载))
[5. 结合main函数的执行流程:移动语义的效率优势](#5. 结合main函数的执行流程:移动语义的效率优势)
[6. 总结](#6. 总结)
可变参数模板[一、Lambda 表达式的核心定义](#一、Lambda 表达式的核心定义)
[二、Lambda 表达式的基础语法](#二、Lambda 表达式的基础语法)
[三、Lambda 表达式的捕捉列表(核心)](#三、Lambda 表达式的捕捉列表(核心))
[四、Lambda 表达式 vs 仿函数(实际应用优势)](#四、Lambda 表达式 vs 仿函数(实际应用优势))
五、总结(关键点回顾)
function包装器和bind包装器[一、function 包装器:统一可调用对象的 "类型容器"](#一、function 包装器:统一可调用对象的 “类型容器”)
[二、bind 包装器:调整可调用对象的 "参数规则"](#二、bind 包装器:调整可调用对象的 “参数规则”)
列表初始化与initializer_list对象
// 定义普通结构体:用于演示结构体的列表初始化
struct point
{
int _x; // x坐标
int _y; // y坐标
};
// 定义普通类:用于演示类的列表初始化(依赖多参数构造函数)
class Data
{
public:
// 带默认参数的构造函数:支持列表初始化的核心(编译器可通过列表参数匹配构造函数)
Data(int year = 1, int month = 1, int day = 1)
: _year(year)
, _month(month)
, _day(day)
{ }
private:
int _year; // 年
int _month; // 月
int _day; // 日
};
// 自定义vector容器:模拟STL容器,支持initializer_list列表初始化
template<class T>
class myvector
{
public:
// 【核心】支持列表初始化的构造函数:参数为initializer_list<T>类型
// initializer_list是C++11新增的模板类,用于接收列表初始化的参数集合
myvector(initializer_list<T> lt)
{
// 预留空间:避免频繁扩容
reserve(lt.size());
// 遍历initializer_list中的元素,逐个插入容器
for (auto& e : lt)
{
push_back(e);
}
}
// 尾插元素(模拟实现,仅保留接口)
void push_back(const T& vlua)
{
// ... 实际实现需处理内存扩容、元素拷贝等逻辑
}
// 预留空间(模拟实现,仅保留接口)
void reserve(size_t size)
{
// ... 实际实现需重新分配内存、拷贝元素等逻辑
}
// 其他成员函数(如迭代器、size、empty等)...
private:
// 成员变量(模拟):
// T* _start; // 数据起始地址
// T* _finish; // 已用数据末尾地址
// T* _end_of_storage; // 内存容量末尾地址
};
int main()
{
// ===================== 1. 基础类型的列表初始化 =====================
// C++11核心语法:一切皆可列表初始化,可省略等号(=)
// 原理:编译器直接将列表中的值赋值给变量,本质是直接初始化
int j = { 1 }; // 带等号的列表初始化
int k{ 2 }; // 省略等号的列表初始化(C++11推荐写法)
// ===================== 2. 数组的列表初始化 =====================
// 传统数组初始化可省略等号,列表元素个数需≤数组大小(超出编译报错)
int arr1[] = { 1,2,3,4,5 }; // 带等号
int arr2[]{ 1,2,3,4,5 }; // 省略等号
// ===================== 3. 结构体的列表初始化 =====================
// 结构体无自定义构造函数时,编译器支持直接用列表初始化成员变量
// 列表元素顺序需与结构体成员声明顺序一致
point p1 = { 1,2 }; // 带等号
point p2{ 1,2 }; // 省略等号
// ===================== 4. 字符串的隐式构造(对比参考) =====================
// 单参数构造函数支持隐式类型转换:
// "abcdefg" → 调用string(const char*)构造临时string对象 → 拷贝构造s1
// 编译器优化:直接用"abcdefg"构造s1(省略临时对象)
string s1 = "abcdefg";
// ===================== 5. 类的列表初始化 =====================
// 原理:多参数构造函数支持列表初始化,编译器将列表元素匹配构造函数参数
// 过程:{2026,1,28} → 调用Data(int,int,int)构造临时Data对象 → 拷贝构造d1
// 编译器优化:直接用列表元素构造d1(省略临时对象)
Data d1 = { 2026,1,28 }; // 带等号
// ===================== 6. new对象的列表初始化 =====================
// C++11前:new数组需用已构造的对象初始化
Data* pd1 = new Data[3]{ d1,d1,d1 };
// C++11后:new数组可直接用列表初始化每个元素(匹配构造函数)
Data* pd2 = new Data[3]{ { 2026,1,26 },{ 2026,1,27 },{ 2026,1,28 } };
// ===================== 7. STL容器的列表初始化(核心:initializer_list) =====================
// 原理:C++11为STL容器新增了initializer_list<T>参数的构造函数
// 编译器将{1,2,3,4,5}强行解析为initializer_list<int>对象,传给容器构造函数
vector<int> v1 = { 1,2,3,4,5 };
list<int> l1 = { 1,2,3,4,5,6,7 };
// ===================== 8. initializer_list对象的本质 =====================
// auto推导:编译器将{1,2,3,4,5}识别为initializer_list<int>类型对象
// initializer_list<T>是C++11新增的轻量级模板类,仅包含两个指针:
// - start:指向列表数据的起始地址
// - finish:指向列表数据末尾的下一个地址(左闭右开区间)
auto il = { 1,2,3,4,5 };
// 打印il的类型:输出为std::initializer_list<int>(不同编译器命名可能略有差异)
cout << typeid(il).name() << endl;
// ===================== 9. 复杂容器(map)的列表初始化 =====================
// 原理:
// 1. {"sort", "排序"} → 隐式转换为pair<string, string>(匹配pair的构造函数)
// 2. 编译器将整个列表解析为initializer_list<pair<string, string>>对象
// 3. map的initializer_list构造函数遍历该对象,插入每个pair
map<string, string> dict = { {"sort", "排序"},{"left", "左边"} };
return 0;
}一、列表初始化:C++11 的 "统一初始化语法"
你想要理解的列表初始化 是 C++11 引入的核心语法改进,核心目标是统一所有类型的初始化方式 ,解决 C++98 中初始化语法混乱(比如数组用{}、类用构造函数、基础类型用=)的问题。
1. 列表初始化的核心定义
列表初始化指用花括号{} 包裹初始化值的语法,可选择带等号(=)或不带等号,语法形式:
// 两种写法等价(C++11推荐省略等号)
类型 变量 = {值1, 值2, ...};
类型 变量 {值1, 值2, ...};其核心特性:
- 语法统一 :基础类型、数组、结构体、类、STL 容器都能通过
{}初始化; - 强类型检查 :禁止 "窄化转换"(比如
int a{3.14}会编译报错,而int a=3.14仅警告),更安全; - 适配灵活:编译器会根据被初始化的对象类型,自动匹配对应的初始化逻辑。
2. 代码中不同场景的列表初始化原理
结合代码逐一拆解:
(1)基础类型 / 数组:直接初始化
int k{ 2 }; // 基础类型:直接赋值,禁止窄化转换
int arr2[]{ 1,2,3 }; // 数组:按列表元素初始化,长度自动推导为3- 原理:编译器直接将列表中的值赋值给变量 / 数组元素,列表元素个数不能超过数组大小(否则编译报错)。
(2)结构体:聚合初始化运行
struct point { int _x; int _y; };
point p2{ 1,2 }; // 结构体列表初始化- 前提:结构体是聚合类型(无自定义构造函数、无私有 / 保护成员、无继承等);
- 原理:按结构体成员的声明顺序 ,将列表元素依次赋值给成员(
_x=1,_y=2)。
(3)普通类:匹配多参数构造函数
class Data {
public:
Data(int year = 1, int month = 1, int day = 1) : _year(year), _month(month), _day(day) {}
};
Data d1 = { 2026,1,28 }; // 类的列表初始化- 原理:编译器将列表中的元素(
2026,1,28)按顺序匹配构造函数的参数,本质是调用Data(2026,1,28)构造对象; - 编译器优化:原本会先构造临时
Data对象,再拷贝构造d1,但实际会直接用列表元素构造d1(省略临时对象)。
(4)new 对象:数组元素逐个初始化
Data* pd2 = new Data[3]{ { 2026,1,26 },{ 2026,1,27 },{ 2026,1,28 } };- C++11 新增特性:
new数组时,内层{}匹配类的构造函数,逐个初始化数组元素; - 对比 C++98:只能用已构造的对象初始化数组(如
new Data[3]{d1,d1,d1}),灵活性差。
二、initializer_list 对象:STL 容器列表初始化的核心
initializer_list是 C++11 新增的轻量级模板类 (定义在<initializer_list>头文件),是实现 STL 容器(如vector/list/map)列表初始化的底层核心,和普通类的列表初始化(如Data)无关。
1. initializer_list 的本质:"只读视图" 而非容器
initializer_list<T>不是真正的容器(不管理内存),而是对 "列表初始化参数集合" 的只读视图,内部仅包含两个指针(x86 下共 8 字节):运行
// initializer_list的简化内部结构(编译器实现)
template<class T>
class initializer_list {
private:
const T* _start; // 指向列表数据的起始地址
const T* _finish; // 指向列表数据末尾的下一个地址(左闭右开)
public:
// 迭代器相关函数,支持范围for遍历
const T* begin() const { return _start; }
const T* end() const { return _finish; }
size_t size() const { return _finish - _start; }
};关键特性:
- 列表数据存储在编译器管理的只读内存 (栈 / 静态区),
initializer_list仅指向数据,不拥有、不修改数据; - 元素不可修改(
const T),一旦创建就固定; - 模板参数
T是列表元素的类型,比如{1,2,3}会被推导为initializer_list<int>。
2. initializer_list 的核心作用:为容器提供统一的列表初始化接口
代码中自定义myvector的构造函数,完美复刻了 STL 容器的列表初始化逻辑:
template<class T>
class myvector {
public:
// 接收initializer_list的构造函数(核心)
myvector(initializer_list<T> lt) {
reserve(lt.size()); // 预留空间
for (auto& e : lt) { // 遍历initializer_list(支持范围for)
push_back(e); // 尾插元素
}
}
// ...其他成员函数
};- 原理:当写
myvector<int> v{1,2,3}时,编译器会将{1,2,3}强行解析为initializer_list<int>对象,传给构造函数; - STL 容器(
vector/list/map)的列表初始化,底层都是这个逻辑。
3. 代码中 initializer_list 的典型用法
// 1. auto推导类型:il的类型是initializer_list<int>
auto il = { 1,2,3,4,5 };
cout << typeid(il).name() << endl; // 输出:std::initializer_list<int>
// 2. map的列表初始化(嵌套initializer_list)
map<string, string> dict = { {"sort", "排序"},{"left", "左边"} };{"sort", "排序"}:先隐式调用pair<string,string>的构造函数,生成pair对象;- 整个列表
{``{"sort", "排序"},{"left", "左边"}}:被解析为initializer_list<pair<string,string>>; map的构造函数遍历该对象,将每个pair插入容器。
三、关键区别:普通类 vs STL 容器的列表初始化
| 场景 | 依赖的核心机制 | 是否用到 initializer_list |
|---|---|---|
| 基础类型 / 数组 / 结构体 | 直接赋值 / 聚合初始化 | ❌ 否 |
| 普通类(如 Data) | 匹配多参数构造函数 | ❌ 否 |
| STL 容器(如 vector) | 接收 initializer_list 的构造函数 | ✅ 是 |
四、总结
- 列表初始化 是 C++11 的统一初始化语法,用
{}包裹值(可省等号),有强类型检查,适配所有类型; - initializer_list是接收列表参数的轻量级模板类,仅存两个指针(不管理内存),是 STL 容器列表初始化的核心;
- 普通类的列表初始化匹配构造函数,STL 容器的列表初始化依赖
initializer_list构造函数,二者原理不同但语法统一。
这个设计既解决了 C++98 初始化语法混乱的问题,又为容器提供了简洁的初始化方式,是 C++11 提升开发效率的重要特性。
auto和decltype
int main()
{
// ===================== auto 关键字使用场景 =====================
// auto 核心特性:编译期根据【初始化值】自动推导变量类型,必须初始化(无初始化则编译报错)
// 场景1:推导基础数据类型(简化基础类型的书写,无需手动写int/double)
auto i = 1; // 右侧是int型常量1 → auto推导i的类型为int
auto d = 2.2; // 右侧是double型常量2.2 → auto推导d的类型为double
// 场景2:推导复杂类型(如STL容器迭代器,避免冗长的类型书写)
// map<string, string>的迭代器原生类型为map<string,string>::iterator,手写繁琐
map<string, string> dict = { {"sort", "排序"},{"left","左边"} };
auto it = dict.begin(); // auto自动推导it的类型为map<string,string>::iterator
// ===================== decltype 关键字使用场景 =====================
// decltype 核心特性:编译期分析【表达式的类型】(不执行表达式),无需初始化变量
int j = 1; // 定义int型变量j
double k = 2.2; // 修正原代码int为double,更易体现decltype的推导效果
// 场景1:推导表达式的类型,并用该类型定义新变量
// j是int、k是double → 表达式j+k的类型为double → decltype推导ret的类型为double
decltype(j + k) ret = 3.3; // ret的类型是double,赋值3.3后值为3.3(无截断)
cout << ret << endl; // 输出:3.3(若k为int,j+k为int,ret会被截断为3)
// 场景2:推导类型并作为模板参数(auto无法直接实现此功能)
// decltype(j+k)推导为double → 实例化vector<double>类型的容器v1
vector<decltype(j + k)> v1; // v1是存储double类型的vector,auto无法直接作为模板参数
return 0;
}一、先明确你的核心需求
你想通过这段代码理解 C++11 引入的auto和decltype两个关键字的核心特性、推导规则、使用场景,以及它们的关键区别 ------ 尤其是两者在 "类型推导依据" 和 "适用场景" 上的差异。
二、auto 关键字:「初始化驱动」的类型推导
auto是 C++11 的核心语法糖,核心目标是让编译器在编译期根据变量的「初始化值」自动推导变量类型,彻底简化 "冗长类型手写" 的问题。
1. auto 的核心规则
- ✅ 必须初始化 :
auto的推导完全依赖 "初始化值的类型",无初始化时编译器无法确定类型,直接编译报错(比如auto x;会报错); - ✅ 编译期推导:推导过程在编译阶段完成,无任何运行时开销;
- ❌ 不能直接作为模板参数 :比如
vector<auto> v;编译报错,auto仅用于变量类型推导,无法直接传给模板。
2. 代码中 auto 的使用场景拆解
// 场景1:推导基础数据类型(简化基础类型书写)
auto i = 1; // 初始化值1是int → auto推导i的类型为int
auto d = 2.2; // 初始化值2.2是double → auto推导d的类型为double
// 场景2:推导复杂类型(核心优势,避免冗长手写)
map<string, string> dict = { {"sort", "排序"},{"left","左边"} };
auto it = dict.begin();
// dict.begin()返回map<string,string>::iterator类型
// auto自动推导it的类型为该迭代器,无需手写冗长的原生类型- 基础类型场景:
auto的优势不明显,但能保持代码风格统一; - 复杂类型场景(迭代器、函数返回值等):
auto是 "刚需"------ 比如map迭代器的原生类型map<string,string>::iterator手写易出错,auto可一键推导,大幅提升代码简洁性。
三、decltype 关键字:「表达式分析」的类型推导
decltype(全称declare type)也是 C++11 引入的,核心目标是编译器在编译期分析「表达式的类型」(不执行表达式) ,推导依据是 "表达式的类型" 而非 "变量的初始化值",弥补了auto的短板。
1. decltype 的核心规则
- ✅ 不执行表达式:仅分析表达式的类型,哪怕表达式包含自增 / 函数调用等操作,也不会实际执行;
- ✅ 无需初始化:推导的是 "类型",可仅用该类型定义变量(无需给变量赋值);
- ✅ 可作为模板参数 :这是
decltype最核心的优势,auto无法实现。
2. 代码中 decltype 的使用场景拆解
int j = 1;
double k = 2.2;
// 场景1:推导表达式类型,并用该类型定义新变量
decltype(j + k) ret = 3.3;
// 分析:j(int) + k(double) → 表达式类型为double(隐式类型提升)
// decltype推导ret的类型为double,赋值3.3后无截断,输出3.3
cout << ret << endl;
// 场景2:推导类型并作为模板参数(auto无法直接实现)
vector<decltype(j + k)> v1;
// decltype(j+k)推导为double → 实例化vector<double>,v1是存储double的容器
// 若用auto:vector<auto> v1; 编译报错(auto不能直接作为模板参数)- 场景 1 关键:哪怕
j/k未初始化(比如int j; double k; decltype(j+k) ret;),代码依然合法 ------decltype只分析类型,不依赖变量是否赋值; - 场景 2 关键:
auto只能推导 "变量的类型",但无法直接作为模板参数,而decltype可推导表达式类型并传给模板,这是两者的核心功能差异。
四、auto vs decltype 核心区别对比
| 特性 | auto | decltype |
|---|---|---|
| 推导依据 | 变量的「初始化值」类型 | 表达式的「类型」(不执行表达式) |
| 初始化要求 | 必须初始化(无值无法推导) | 无需初始化(仅分析类型) |
| 模板参数支持 | 不能直接作为模板参数 | 可作为模板参数推导类型 |
| 适用场景 | 简化变量声明(尤其是复杂类型) | 分析表达式类型、模板参数推导 |
| 典型示例 | auto it = vec.begin(); |
vector<decltype(a+b)> v; |
五、总结
- auto:「初始化驱动」的类型推导,核心是 "简化变量声明",必须初始化,适合替代冗长的类型名(如迭代器),但不能作为模板参数;
- decltype :「表达式分析」的类型推导,核心是 "分析类型不执行代码",无需初始化,可作为模板参数,弥补
auto的功能短板; - 两者都是编译期推导 ,无运行时开销,是 C++11 提升代码简洁性和灵活性的核心工具 ------ 日常写代码时,简单变量用
auto,需要分析表达式类型 / 模板参数推导用decltype。
左值和右值以及左值引用和右值引用的定义
// 普通加法函数:返回值为右值(临时值)
int Add(const int x, const int y)
{
return x + y;
}
int main()
{
// ===================== 核心概念前提 =====================
// 1. 左值:能取地址、可被修改(const左值除外)、有名字的变量/对象;
// 2. 左值引用(T&):给左值取别名,绑定后可通过引用修改原左值(const左值引用除外);
// 3. 右值:不能取地址、无名字、临时存在的数值(字面常量/表达式结果/函数返回值);
// 4. 右值引用(T&&):给右值取别名,用于绑定临时值,实现移动语义等特性。
// ===================== 1. 左值举例 =====================
int* p = new int(0); // p是左值(有名字、可取地址&p);new int(0)返回的是右值(临时地址)
int b = 1; // b是左值(有名字、可取地址&b、可修改)
const int c = 1; // c是const左值(有名字、可取地址&c,但不可修改,本质仍是左值)
// ===================== 2. 左值引用(取别名)举例 =====================
int*& rp = p; // rp是左值引用,绑定左值p(指针类型的左值引用)
int& rb = b; // rb是左值引用,绑定左值b(通过rb可修改b,如rb=2 → b=2)
const int& rc = c; // const左值引用,绑定const左值c(不可通过rc修改c,权限平移)
// 左值总结:有名字、能取地址的变量/对象都是左值(const修饰仅限制修改,不改变左值属性)
// ===================== 3. 右值举例 =====================
10; // 字面常量10:右值(无名字、不可取地址&10,编译报错)
b + c; // 表达式结果:右值(临时值,无名字、不可取地址)
Add(b, c); // 函数返回值:右值(临时值,函数调用后返回的加法结果无名字)
// ===================== 4. 右值引用(取别名)举例 =====================
int&& rr1 = 10; // rr1是右值引用,绑定右值10(给临时字面量取别名)
int&& rr2 = b + c; // rr2是右值引用,绑定表达式b+c的右值结果
auto&& rr3 = Add(b, c);// rr3是右值引用,绑定函数返回的右值(auto推导为int&&)
// 右值总结:无名字、不可取地址的临时值/字面量/表达式结果都是右值
// ===================== 问题1:左值引用能否给右值取别名? =====================
// int& ri = 10; // 编译报错!普通左值引用(非const)不能绑定右值
/* 报错原因:权限放大
10是右值(字面常量),自带const属性(不可修改);
普通左值引用(int&)允许修改绑定的对象,相当于用"可修改的引用"绑定"不可修改的右值",权限放大,编译器禁止。
*/
const int& ri = 10; // 编译通过!const左值引用可以绑定右值
/* 原因:权限平移
const左值引用(const int&)限制了修改权限,与右值的const属性匹配,属于"权限平移",编译器允许。
(const左值引用是"万能引用",可绑定左值/右值/const左值)
*/
// ===================== 问题2:右值引用能否给左值取别名? =====================
int s = 0; // s是左值(有名字、可取地址)
// int&& rrs = s; // 编译报错!右值引用不能直接绑定左值
/* 报错原因:右值引用的设计初衷是绑定右值(临时值),左值有持久生命周期,不符合右值引用的语义。
*/
int&& rrs = move(s); // 编译通过!std::move将左值s"强制转换"为右值属性
/* 解释:
std::move是一个类型转换函数,不改变s的实际值/生命周期,仅将其属性标记为右值;
此时右值引用rrs可绑定"被move后的左值",但注意:move后s的资源可能被转移,建议不再使用s。
*/
return 0;
}一、核心需求梳理
你希望通过这段代码,清晰理解 C++ 中左值、右值 的本质定义与特征,以及左值引用(T&)、右值引用(T&&) 的定义、绑定规则,还有两者的核心区别 ------ 这也是理解 C++11 移动语义、完美转发的基础。
二、左值(lvalue):有 "身份" 的持久值
1. 定义
左值是程序中有名字、能取地址、生命周期持久 的变量 / 对象 / 表达式,是可被识别、可修改(const左值除外)的 "实体"。
2. 核心特征(代码对应示例)
| 特征 | 代码示例 | 验证方式 |
|---|---|---|
| 有名字 | int b = 1; 中的b |
b是标识符,可直接使用 |
| 能取地址 | &b、&c、&p |
编译通过,返回内存地址 |
| 生命周期持久 | b在main中定义 |
直到main结束才销毁 |
const左值 |
const int c = 1; |
能取地址(&c合法),但不可修改(c=2报错),本质仍是左值 |
3. 关键补充
new int(0)返回的是右值 (临时地址),但接收它的p是左值(p有名字、能取地址);- 左值的核心是 "有身份"------ 哪怕是
const修饰的左值,只是限制了 "修改权限",并未改变 "左值属性"。
三、右值(rvalue):"一次性" 的临时值
1. 定义
右值是程序中无名字、不能取地址、生命周期短暂的数值 / 表达式结果 / 函数返回值,是 "用完即销毁" 的临时值,也是 C++11 引入右值引用的核心处理对象。
2. 核心特征(代码对应示例)
| 特征 | 代码示例 | 验证方式 |
|---|---|---|
| 无名字 | 10、b+c、Add(b,c) |
无标识符,无法直接引用 |
| 不能取地址 | &10、&(b+c) |
编译报错(右值无内存地址可取) |
| 生命周期短暂 | b+c的计算结果 |
表达式执行完毕后立即销毁 |
自带const |
10=2、(b+c)=3 |
编译报错(右值不可修改) |
3. 关键补充
- 函数返回值(如
Add返回的x+y)是典型右值:函数执行完后,返回的临时值无名字,仅在当前表达式有效; - 右值的核心是 "无身份、临时"------ 所有字面常量、表达式结果、临时对象都是右值。
四、左值引用(lvalue reference,T&):给左值取 "别名"
1. 定义
左值引用是给左值 绑定的 "别名",语法为类型& 引用名 = 左值;,本质是和原左值共享同一块内存空间,是 C++98 就有的基础引用类型。
2. 核心绑定规则(代码对应示例)
| 引用类型 | 可绑定对象 | 代码示例 | 结果 |
|---|---|---|---|
| 普通左值引用(T&) | 非const左值 |
int& rb = b; |
编译通过 |
| 普通左值引用(T&) | 右值 | int& ri = 10; |
编译报错 |
const左值引用 |
非const左值 |
const int& rb2 = b; |
编译通过 |
const左值引用 |
const左值 |
const int& rc = c; |
编译通过 |
const左值引用 |
右值 | const int& ri = 10; |
编译通过 |
3. 规则解释
- 普通左值引用绑定右值报错:因为右值自带
const(不可修改),而普通左值引用允许修改绑定对象,属于 "权限放大",编译器禁止; const左值引用是 "万能引用":绑定后不可修改对象,与右值的const属性匹配(权限平移),因此可绑定所有类型(左值 /const 左值 / 右值)。
五、右值引用(rvalue reference,T&&):给右值取 "别名"
1. 定义
右值引用是 C++11 新增的引用类型,专门给右值 绑定的 "别名",语法为类型&& 引用名 = 右值;,核心目的是延长右值的生命周期、实现 "移动语义"(接管临时资源)。
2. 核心绑定规则(代码对应示例)
| 引用类型 | 可绑定对象 | 代码示例 | 结果 |
|---|---|---|---|
| 右值引用 | 右值 | int&& rr1 = 10; |
编译通过 |
| 右值引用 | 左值 | int&& rrs = s; |
编译报错 |
| 右值引用 | std::move转换后的左值 |
int&& rrs = move(s); |
编译通过 |
3. 规则解释
- 右值引用不能直接绑定左值:设计初衷是处理 "临时值",左值有持久生命周期,无需右值引用接管;
std::move的作用:不是 "移动数据",而是将左值强制转换为右值属性(仅改变类型属性,不修改值、不销毁对象);- 注意:
move后的左值虽可被右值引用绑定,但建议不再使用原左值(避免后续代码访问已被 "接管" 的资源)。
六、总结:核心概念对比
| 概念 | 核心特征 | 语法形式 | 核心用途 |
|---|---|---|---|
| 左值 | 有名字、能取地址、生命周期长 | - | 存储持久数据 |
| 右值 | 无名字、不能取地址、临时 | - | 临时计算结果、函数返回值 |
| 左值引用(T&) | 绑定左值,const版可绑定所有 |
int& ref = b; |
共享数据、函数参数传递 |
| 右值引用(T&&) | 绑定右值,move左值后也可绑定 |
int&& ref = 10; |
移动语义、完美转发、接管临时资源 |
核心记忆点:
- 左值看 "身份"(有名字、能取地址),右值看 "临时"(无名字、用完就没);
- 左值引用服务于 "共享",右值引用服务于 "接管临时资源";
const T&是万能引用,T&&仅绑定右值(或move后的左值)。
移动构造和移动赋值
一、模拟实现string简易版
这是模拟实现string的简易版,只是为讲解移动构造 和移动赋值做铺垫
#include <iostream>
#include <cstring>
#include <cassert>
#include <utility> // std::swap
using namespace std;
// 命名空间封装模拟的string类
namespace obj
{
// 模拟实现简易版string类(用于教学理解移动构造/移动赋值)
class string
{
public:
// -------------- 迭代器相关 --------------
// 迭代器类型定义(简易版:用char*表示)
typedef char* iterator;
// 返回字符串起始位置的迭代器
iterator begin()
{
return _str;
}
// 返回字符串末尾('\0'前)位置的迭代器
iterator end()
{
return _str + _size;
}
// -------------- 默认构造函数 --------------
// 参数:C字符串,默认值为空字符串
string(const char* str = "")
: _size(strlen(str)) // 初始化字符串长度(不含'\0')
, _capacity(_size) // 初始化容量(与长度一致)
{
cout << "string(const char* str = \"\") -- 默认构造函数" << endl;
_str = new char[_capacity + 1]; // 分配内存(+1存'\0')
strcpy(_str, str); // 拷贝C字符串内容
}
// -------------- 拷贝构造函数 --------------
// 作用:用已存在的string对象初始化新对象(深拷贝)
string(const string& s)
{
cout << "string(const string& s) -- 拷贝构造函数 -- 深拷贝" << endl;
_str = new char[s._capacity + 1]; // 重新分配内存
// 逐字符拷贝(含'\0')
for (size_t i = 0; i <= s._size; i++)
{
_str[i] = s._str[i];
}
_size = s._size; // 拷贝长度
_capacity = s._capacity; // 拷贝容量
}
// -------------- 赋值重载函数 --------------
// 作用:已存在的对象赋值给另一个已存在的对象(深拷贝)
string& operator=(const string& s)
{
cout << "string& operator=(const string& s) -- 赋值重载函数 -- 深拷贝" << endl;
// 防止自赋值
if (this != &s)
{
char* tmp = new char[s._capacity + 1]; // 新分配内存
// 逐字符拷贝(含'\0')
for (size_t i = 0; i <= s._size; i++)
{
tmp[i] = s._str[i];
}
delete[] _str; // 释放原内存
_str = tmp; // 指向新内存
_size = s._size; // 更新长度
_capacity = s._capacity; // 更新容量
}
return *this; // 返回自身支持连续赋值
}
// -------------- 重载[]运算符 --------------
// 作用:通过下标访问字符串字符(支持修改),越界断言
char& operator[](size_t pos)
{
assert(pos < _size); // 下标越界检查
return _str[pos]; // 返回对应位置字符的引用
}
// -------------- 扩容函数reserve --------------
// 作用:修改字符串容量(仅扩容,不缩容)
void reserve(size_t newcapacity)
{
if (newcapacity > _capacity) // 仅当新容量更大时扩容
{
char* tmp = new char[newcapacity + 1]; // 新内存
strcpy(tmp, _str); // 拷贝内容
delete[] _str; // 释放原内存
_str = tmp; // 指向新内存
_capacity = newcapacity; // 更新容量
}
}
// -------------- 尾插字符push_back --------------
// 作用:在字符串末尾插入一个字符,满了则扩容
void push_back(const char ch)
{
// 容量满时扩容:空字符串默认扩到4,否则扩2倍
if (_size == _capacity)
reserve(_capacity == 0 ? 4 : _capacity * 2);
_str[_size++] = ch; // 尾插字符,长度+1
_str[_size] = '\0'; // 保证字符串以'\0'结尾
}
// -------------- 重载+=运算符(字符) --------------
// 作用:字符串末尾追加字符,返回自身支持连续+=
string& operator+=(const char ch)
{
push_back(ch); // 复用push_back逻辑
return *this; // 返回自身
}
// -------------- 交换函数swap --------------
// 作用:交换两个string对象的所有成员
void swap(string& s)
{
std::swap(_str, s._str); // 交换字符数组指针
std::swap(_size, s._size); // 交换长度
std::swap(_capacity, s._capacity); // 交换容量
}
// -------------- 析构函数 --------------
// 作用:释放字符串占用的内存,置空成员
~string()
{
delete[] _str; // 释放动态分配的字符数组
_str = nullptr; // 指针置空防止野指针
_size = 0; // 长度置0
_capacity = 0; // 容量置0
}
private:
char* _str = nullptr; // 存储字符串的动态字符数组指针
size_t _size = 0; // 字符串有效长度(不含'\0')
size_t _capacity = 0; // 字符串容量(可存储的最大字符数,不含'\0')
};
}二、左值引用无法解决的问题
namespace obj
{
class string
{
// ...
};
// -------------- 测试函数 --------------
obj::string test()
{
obj::string ret; // 局部对象,存储在test函数的栈帧中
ret += 'a'; // 尾插字符,构造出 "abc"
ret += 'b';
ret += 'c';
// 【关键】ret是局部对象,生命周期仅在test函数内
// 不能用左值引用返回(obj::string& test()):
// 因为函数返回后栈帧销毁,ret的内存被回收,返回的引用会指向无效内存(野引用)
return ret; // 返回时:先拷贝ret生成一个临时对象(右值),再销毁ret
}
}
int main()
{
// 左值引用没有解决的核心问题:返回局部对象时的深拷贝开销
obj::string s1; // 默认构造s1
// 执行s1 = obj::test()的过程:
// 第一步:调用test(),返回时触发【第一次深拷贝】:test内的ret拷贝构造出临时对象
// 第二步:临时对象赋值给s1,触发【第二次深拷贝】:赋值重载函数深拷贝临时对象到s1
// 第三步:临时对象用完后销毁
// 问题:两次深拷贝都要重新分配内存、逐字符拷贝,性能损耗大;且ret和临时对象都是"用完就销毁"的临时值,深拷贝完全没必要
s1 = obj::test();
return 0;
}-
为什么 test 不能用左值引用返回?
ret是 test 函数的局部栈对象 ,函数返回后栈帧销毁,ret的内存被回收。如果用obj::string& test()返回,得到的引用会指向 "已销毁的内存"(野引用),访问该引用会触发程序崩溃 / 乱码。 -
左值引用没解决的核心问题:两次无意义的深拷贝 执行
s1 = obj::test()时:- 第一次深拷贝:test 返回
ret时,因为不能返回引用,只能拷贝ret生成一个临时对象(右值); - 第二次深拷贝:临时对象赋值给
s1时,赋值重载函数又做了一次深拷贝; - 关键痛点:
ret和临时对象都是 "用完就销毁" 的临时值,深拷贝会重复分配 / 拷贝内存,造成巨大性能浪费 ------ 这也是后续要引入移动构造 / 移动赋值的核心原因(用 "浅拷贝转移资源" 替代 "深拷贝复制资源")。
- 第一次深拷贝:test 返回
三、移动构造和移动赋值
namespace obj
{
class string
{
public:
// 其他函数......
// -------------- 移动构造函数(核心)--------------
// 参数:右值引用(string&& s),仅接收右值(将亡值)
// 作用:接管右值对象的资源(浅拷贝),替代深拷贝,避免内存浪费
string(string&& s)
{
cout << "string(string&& s) -- 移动构造 -- 仅交换指针" << endl;
// 核心逻辑:调用swap交换当前对象和s的所有资源
// 当前对象是刚创建的空对象,交换后就"拿走"了s的资源
// s变成空对象,析构时释放空资源,不会重复释放
swap(s);
}
// -------------- 移动赋值函数(核心)--------------
// 参数:右值引用,仅接收右值(将亡值)
// 作用:已有对象接管右值对象的资源,替代深拷贝的赋值重载
string& operator=(string&& s)
{
cout << "string& operator=(string&& s) -- 移动赋值 -- 仅交换指针" << endl;
// 核心逻辑:交换当前对象和s的资源
// 当前对象原来的资源会被交换到s中,s析构时自动释放
swap(s);
return *this; // 返回自身支持连续赋值
}
// 其他函数......
};
// -------------- 测试函数 --------------
obj::string test()
{
obj::string ret; // 局部左值对象
ret += 'a';
ret += 'b';
ret += 'c';
// std::move(ret):将左值ret强制转为右值(将亡值)
// 标记ret是"即将销毁的对象",让返回时调用移动构造而非拷贝构造
return move(ret);
}
}
int main()
{
// 纯右值:内置类型的临时值(如10、a+b)
// 将亡值:自定义类型的临时值(如函数返回的局部对象、move后的左值)
obj::string s1; // 默认构造空对象s1
// 执行s1 = obj::test()的过程(有移动构造/赋值后):
// 1. test函数return move(ret):ret被转为右值,调用【移动构造】创建临时对象
// → 仅交换指针,把ret的资源("abc")转移给临时对象,无深拷贝
// 2. 临时对象赋值给s1:调用【移动赋值】,把临时对象的资源转移给s1
// → 仅交换指针,无深拷贝
// 3. 临时对象析构(空对象,释放无意义),全程无内存重复分配/拷贝
s1 = obj::test();
// 对比无移动构造的情况:
// - 无移动构造:test返回时深拷贝ret→临时对象,赋值时深拷贝临时对象→s1,两次深拷贝(浪费内存/性能)
// - 有移动构造:全程仅两次资源交换(浅拷贝),无内存分配,效率极大提升
return 0;
}1. 核心需求梳理
通过这段自定义string的代码,理解 C++11 中右值的两个细分类型(纯右值、将亡值) 的定义与特征,以及移动构造函数、移动赋值运算符 的核心作用、实现逻辑和效率优势(对比深拷贝的拷贝构造 / 赋值)。
2. 纯右值(prvalue)与将亡值(xvalue):右值的两个细分类型
C++11 将右值(rvalue)细分为纯右值 和将亡值 ,二者都具备 "无名字、不能取地址、临时存在" 的右值核心特征,但适用场景和处理方式截然不同 ------将亡值是移动语义(移动构造 / 赋值)的核心处理对象。
1. 纯右值(Pure Rvalue,prvalue):无资源的基础临时值
- 定义 :仅存于栈 / 寄存器的内置类型临时值,无自定义资源(如堆内存、文件句柄等),无需 "资源转移",仅需简单拷贝。
- 核心特征:无自定义析构逻辑,拷贝成本极低,无需移动语义优化。
- 代码示例 (对应注释 / 常识):
- 字面常量:
10、'a'、true、nullptr; - 表达式结果:
a + b、Add(1,2)(内置类型加法的临时结果); - 注意:字符串字面量
"hello"是const char*类型的纯右值(无自定义资源)。
- 字面常量:
2. 将亡值(eXpiring Value,xvalue):有资源的 "待销毁" 对象
- 定义 :自定义类型的临时对象,是 "即将被销毁、可以安全接管其资源的对象"------ 这类对象持有堆内存、文件句柄等昂贵资源,直接深拷贝会浪费内存 / 性能,因此 C++11 设计移动语义专门处理它。
- 核心特征 :有自定义资源(如
string的堆内存、vector的动态数组),销毁前可 "转移资源" 而非 "拷贝资源",是移动构造 / 赋值的唯一触发对象。 - 代码示例 (结合代码):
- 函数返回的局部自定义对象:
test函数中return move(ret)生成的临时string对象; std::move后的左值:move(ret)将左值ret强制转为将亡值(仅标记 "即将销毁",不修改值 / 生命周期);- 临时创建的自定义对象:如
obj::string("abc")生成的临时对象。
- 函数返回的局部自定义对象:
| 类型 | 本质 | 资源特征 | 处理方式 |
|---|---|---|---|
| 纯右值 | 内置类型临时值 | 无自定义资源 | 简单拷贝(无优化必要) |
| 将亡值 | 自定义类型临时值 | 有自定义资源 | 移动语义(资源转移) |
3. 移动构造函数:接管将亡值的资源(替代深拷贝的拷贝构造)
1. 定义
移动构造函数是 C++11 新增的构造函数,语法为:
类名(类名&& 形参); // 参数是右值引用,仅接收右值(将亡值)核心作用:接管将亡值的资源(浅拷贝),替代 "深拷贝 + 内存分配" 的拷贝构造,避免资源浪费。
2. 为什么需要移动构造?(对比拷贝构造)
- 拷贝构造(深拷贝):为新对象分配独立内存,逐字节拷贝源对象的资源(如
string的_str),耗时且浪费内存; - 移动构造(资源转移):源对象是 "即将销毁的将亡值",直接 "拿走" 其资源(仅交换指针 / 长度 / 容量),无需分配新内存,效率提升几个量级。
3. 代码中移动构造的实现逻辑(自定义string)
string(string&& s)
{
cout << "string(string&& s) -- 移动构造 -- 仅交换指针" << endl;
swap(s); // 核心:交换当前对象和s的所有资源
}- 执行时机 :用将亡值初始化新对象时触发(如
test函数返回move(ret)时,用将亡值ret创建临时对象); - 核心逻辑 :
- 当前对象是刚创建的空对象(
_str=nullptr、_size=0); - 调用
swap交换当前对象和参数s(将亡值)的_str、_size、_capacity; - 交换后:当前对象接管
s的资源(如"abc"),s变成空对象(_str=nullptr); s(将亡值)析构时,释放的是空指针,无任何副作用(避免重复释放)。
- 当前对象是刚创建的空对象(
4. 触发条件
必须通过右值引用参数 接收将亡值(如string&& s),普通左值(如未加move的ret)会触发拷贝构造,而非移动构造。
4. 移动赋值运算符:已有对象接管将亡值的资源(替代深拷贝的赋值重载)
1. 定义
移动赋值运算符是 C++11 新增的赋值重载,语法为:
类名& operator=(类名&& 形参); // 参数是右值引用,仅接收右值(将亡值)核心作用:给已有对象接管将亡值的资源,替代 "深拷贝 + 旧资源释放" 的普通赋值重载。
2. 为什么需要移动赋值?(对比普通赋值重载)
- 普通赋值重载(深拷贝):先为源对象分配新内存→拷贝资源→释放当前对象旧资源,两次内存操作 + 一次拷贝,效率极低;
- 移动赋值(资源转移):仅交换当前对象和将亡值的资源,旧资源被交换到将亡值中,析构时自动释放,无额外内存分配。
3. 代码中移动赋值的实现逻辑
string& operator=(string&& s)
{
cout << "string& operator=(string&& s) -- 移动赋值 -- 仅交换指针" << endl;
swap(s); // 核心:交换当前对象和s的所有资源
return *this; // 支持连续赋值
}- 执行时机 :已有对象(如
main中的s1)赋值给将亡值(如test返回的临时对象)时触发; - 核心逻辑 :
- 当前对象
s1有旧资源(空字符串,_str=nullptr); - 调用
swap交换s1和临时对象的_str、_size、_capacity; - 交换后:
s1接管临时对象的"abc"资源,临时对象接管s1的空资源; - 临时对象析构时释放空指针,无任何开销。
- 当前对象
5. 结合main函数的执行流程:移动语义的效率优势
以main中s1 = obj::test()为例,对比 "有 / 无移动构造 / 赋值" 的执行效率:
有移动构造 / 赋值(代码当前逻辑):
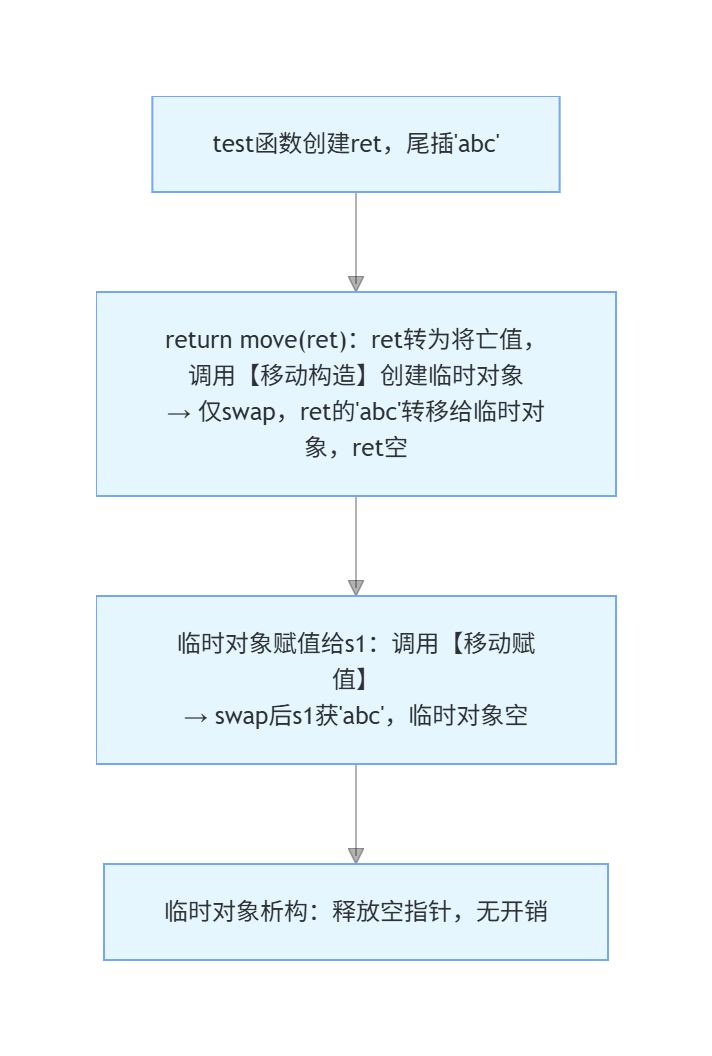
- 全程:2 次
swap(浅拷贝),0 次深拷贝,0 次额外内存分配,效率接近 "零开销"。
无移动构造 / 赋值(对比):
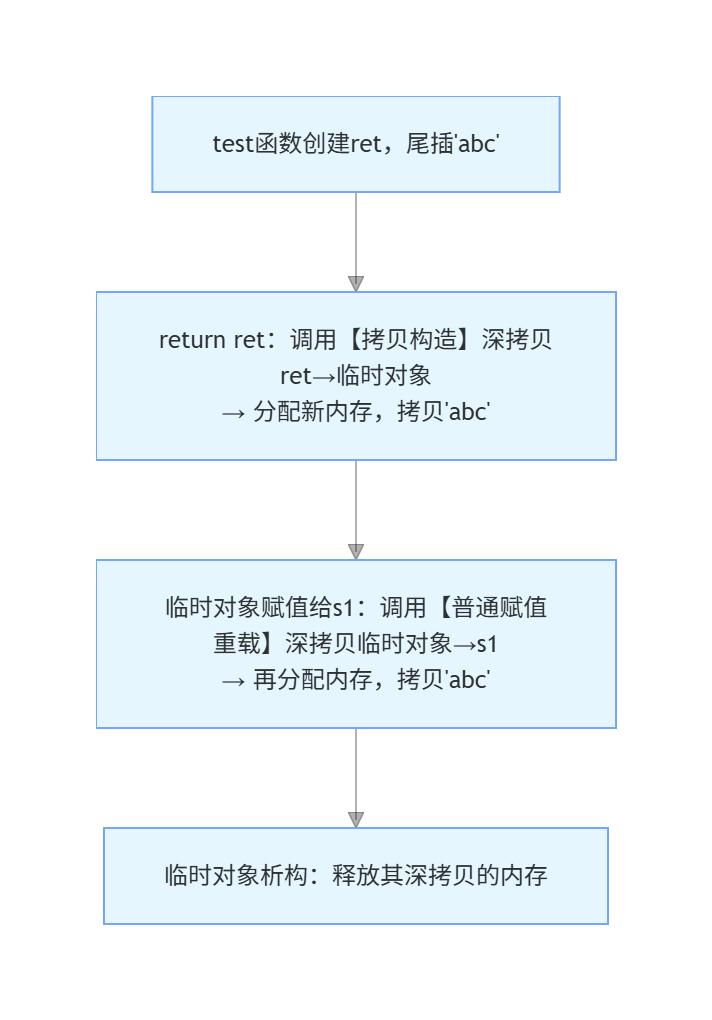
- 全程:2 次深拷贝,2 次内存分配 / 释放,严重浪费内存和 CPU。
6. 总结
1. 纯右值 vs 将亡值
- 纯右值:内置类型临时值,无自定义资源,无需移动语义;
- 将亡值:自定义类型临时值,有昂贵资源,是移动语义的核心处理对象(
move后的左值 / 函数返回的局部对象)。
2. 移动构造 vs 移动赋值
| 特性 | 移动构造函数 | 移动赋值运算符 |
|---|---|---|
| 触发时机 | 用将亡值初始化新对象 | 已有对象赋值给将亡值 |
| 核心逻辑 | swap 空对象与将亡值的资源 | swap 已有对象与将亡值的资源 |
| 核心优势 | 替代深拷贝的拷贝构造 | 替代深拷贝的普通赋值重载 |
| 实现关键 | 右值引用参数(T&&)+ swap |
右值引用参数(T&&)+ swap |
3. 核心记忆点
- 移动语义的本质是 "资源转移 " 而非 "资源拷贝",通过
swap实现浅拷贝,避免深拷贝的内存开销; - 移动构造 / 赋值仅对 "有自定义资源的将亡值" 有意义,纯右值无需优化;
std::move的作用是 "标记左值为将亡值",不修改值 / 生命周期,仅改变类型属性。
可变参数模板
// -------------- 可变参数模板的递归终止函数 --------------
// 作用:当参数包完全展开、无剩余参数时,触发此函数结束递归
// 无参数版本,是递归的"出口"
void _SlowList()
{
cout << endl; // 所有参数打印完毕后换行
}
// -------------- 可变参数模板的递归展开函数 --------------
// 模板参数说明:
// T :参数包中【第一个参数】的类型(提取单个参数)
// Args... :剩余的参数集合(称为"参数包",可包含任意个数/类型的参数)
template<class T, class... Args>
void _SlowList(const T& val, Args... args)
{
cout << val << " "; // 打印当前提取出的第一个参数
_SlowList(args...); // 递归调用:将剩余参数包传入,继续展开(参数包逐步缩短)
}
// -------------- 对外提供的接口函数(可变参数模板) --------------
// Args... :接收任意个数、任意类型的参数(核心:参数包)
template<class... Args>
void SlowList(Args... args)
{
// sizeof...(args):编译期运算符,获取参数包中参数的总个数(无运行时开销)
cout << sizeof...(args) << endl;
// 调用递归展开函数,开始逐个解析并打印参数
_SlowList(args...);
}
int main()
{
// 测试1:传入1个参数
// 执行流程:
// 1. SlowList(1) → 打印参数个数1 → 调用_SlowList(1)
// 2. _SlowList(1) → 打印1 → 调用_SlowList()(无参数版本)
// 3. _SlowList() → 换行
SlowList(1);
// 测试2:传入3个参数(int类型)
// 执行流程:
// 1. SlowList(1,2,3) → 打印3 → 调用_SlowList(1,2,3)
// 2. _SlowList(1,2,3) → 打印1 → 调用_SlowList(2,3)
// 3. _SlowList(2,3) → 打印2 → 调用_SlowList(3)
// 4. _SlowList(3) → 打印3 → 调用_SlowList()
// 5. _SlowList() → 换行
SlowList(1, 2, 3);
// 测试3:传入4个不同类型参数(int/double/char/字符串)
// 可变参数模板支持任意类型的参数,编译器自动推导每个参数的类型
SlowList(1, 2.2, 'x', "abc");
return 0;
}一、核心需求梳理
理解 C++11 引入的可变参数模板的核心概念、语法规则、参数包的递归展开方式,以及递归终止函数的作用,搞清楚它为什么能接收任意个数、任意类型的参数并逐个处理。
二、可变参数模板的核心定义
可变参数模板(Variadic Templates)是 C++11 新增的模板特性,突破了传统模板 "只能接收固定个数参数" 的限制,允许模板接收任意个数、任意类型 的参数(比如int/double/char/ 字符串混合传入),核心用于实现 "泛化的参数处理逻辑"(如 STL 的emplace_back、printf风格的打印函数、函数转发等)。
三、核心语法拆解(从代码中抽离关键规则)
1. 参数包(Parameter Pack):存储任意参数的 "容器"
参数包是可变参数模板的核心,分为 "类型参数包" 和 "值参数包",语法靠...标识:
// 模板参数包(类型集合):class... Args 表示"一组类型的集合"
// 函数参数包(值集合):Args... args 表示"一组值的集合"
template<class... Args>
void SlowList(Args... args)class... Args:模板参数包,编译器会自动推导所有传入实参的类型并 "打包" 成这个集合;Args... args:函数参数包,对应模板参数包推导的具体值(比如传入1,2.2,'x',args就是1,2.2,'x');- 关键:
...是可变参数的核心符号,必须紧跟在参数包名称前 / 后(位置固定),无...则不是参数包。
2. 单个参数提取:从参数包中 "拆出第一个参数"
递归展开函数_SlowList的定义是拆包的核心:
// T:提取参数包中【第一个参数】的类型
// val:对应第一个参数的值
// Args... args:剩余参数组成的新参数包(长度比原包少1)
template<class T, class... Args>
void _SlowList(const T& val, Args... args)示例:传入1,2.2,'x',"abc"时:
- 第一次调用:
T=int、val=1,剩余参数包args=2.2,'x',"abc"; - 第二次调用:
T=double、val=2.2,剩余参数包args='x',"abc"; - 第三次调用:
T=char、val='x',剩余参数包args="abc"; - 第四次调用:
T=const char*、val="abc",剩余参数包args=(空)。
3. sizeof...运算符:编译期获取参数包个数
语法:sizeof...(args)(注意是sizeof...,不是普通sizeof):
- 作用:编译期计算参数包中参数的总个数(无运行时开销,结果是常量);
- 示例:
SlowList(1,2.2,'x',"abc")中,sizeof...(args)=4,编译期直接确定为 4,无需运行时计算。
四、参数包的递归展开逻辑(核心难点)
可变参数模板无法直接 "遍历" 参数包,必须通过递归展开 + 终止函数的方式,把参数包 "拆成单个参数" 处理,直到参数包为空。
1. 递归展开函数:拆包 + 递归传递剩余参数
template<class T, class... Args>
void _SlowList(const T& val, Args... args)
{
cout << val << " "; // 处理当前拆出的第一个参数
_SlowList(args...); // 递归:将剩余参数包传入,继续拆包
}- 每次调用都会 "拆出第一个参数" 处理,剩余参数包长度减 1;
- 递归的本质是 "参数包逐步缩短",直到参数包为空。
2. 递归终止函数:参数包为空时的 "出口"
void _SlowList()
{
cout << endl; // 所有参数处理完后换行
}- 必须定义无参数的重载版本:当参数包完全展开(无剩余参数)时,编译器会匹配这个无参数函数,终止递归;
- 注意:终止函数的函数名必须和递归展开函数一致(重载),否则递归无法终止,编译会报错。
五、结合代码测试案例的执行流程(最易理解的方式)
以最复杂的SlowList(1, 2.2, 'x', "abc")为例,完整执行流程如下:
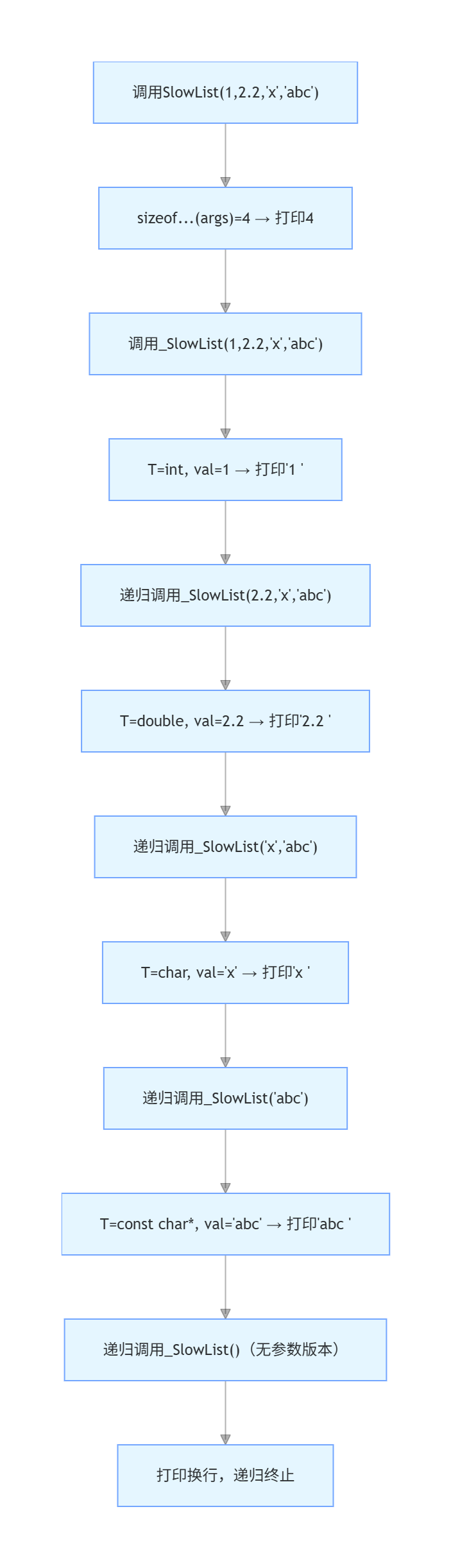
4
1 2.2 x abc 六、可变参数模板的核心优势
- 泛化能力极强:无需为不同参数个数 / 类型写多个重载函数(比如打印 1 个参数、3 个参数、混合类型参数,只用一套逻辑);
- 编译期推导:所有参数类型、个数的推导都在编译期完成,无运行时开销;
- 底层支撑 :STL 容器的
emplace_back、智能指针的make_shared等核心功能,都依赖可变参数模板实现。
七、总结(关键点回顾)
- 可变参数模板的核心是参数包(Args...),用于存储任意个数 / 类型的参数;
- 参数包必须通过递归展开 + 终止函数处理:每次拆出第一个参数,剩余参数递归传递,空参数包触发终止函数;
sizeof...(args)是编译期运算符,用于获取参数包个数,无运行时开销;- 递归展开的本质:将 "任意个数的参数包" 拆解为 "单个参数 + 剩余参数包",直到参数包为空。
可变参数模板是 C++ 泛型编程的核心工具,也是理解 STL 底层实现的关键,这段打印参数的代码是它最基础、最易理解的应用示例。
lamdba表达式
#include <iostream>
#include <vector>
#include <algorithm>
#include <string>
using namespace std;
// 商品结构体:用于演示Lambda表达式的实际应用场景
struct Goods
{
string _name; // 商品名称
double _price; // 商品价格
int _evaluate; // 商品评价
// 构造函数:初始化商品信息
Goods(const char* name, double price, int evaluate)
: _name(name)
, _price(price)
, _evaluate(evaluate)
{ }
};
// 仿函数:按价格升序比较(需自定义结构体,代码量大)
struct ComparePriceLess
{
bool operator()(const Goods& g1, const Goods& g2)
{
return g1._price < g2._price;
}
};
// 仿函数:按价格降序比较(每新增一种比较规则,需新增一个仿函数)
struct ComparePriceGreater
{
bool operator()(const Goods& g1, const Goods& g2)
{
return g1._price > g2._price;
}
};
int main()
{
// ===================== Lambda表达式基础语法 =====================
// Lambda语法格式:[捕捉列表](参数列表)->返回值类型 {函数体}
// 核心:匿名函数,无需定义函数/仿函数,直接编写逻辑,轻量灵活
// 完整语法的Lambda:带返回值类型(->int)
// f1是Lambda表达式的"句柄"(可调用对象),相当于函数指针
auto f1 = [](int x)->int {cout << x << endl; return 0; };
f1(1); // 调用Lambda,输出1
// 简化语法的Lambda:返回值可省略(编译器自动推导)
// 若函数体只有return,或无返回值,可省略->返回值类型
auto f2 = [](int x) {cout << x << endl; return 0; };
f2(1); // 调用Lambda,输出1
// ===================== Lambda vs 仿函数(实际场景) =====================
// 初始化商品列表(C++11列表初始化)
vector<Goods> v1 = { {"苹果", 2.1, 5}, {"香蕉", 3, 4}, {"橙子", 2.2, 3}, {"菠萝", 2.7, 4} };
// 方式1:用仿函数排序(传统方式,需提前定义结构体,代码冗余)
sort(v1.begin(), v1.end(), ComparePriceLess()); // 价格升序
sort(v1.begin(), v1.end(), ComparePriceGreater()); // 价格降序
// 方式2:用Lambda表达式排序(推荐,无需提前定义,直接写逻辑)
sort(v1.begin(), v1.end(), [](const Goods& g1, const Goods& g2)->bool {
return g1._price > g2._price; // 价格降序
});
sort(v1.begin(), v1.end(), [](const Goods& g1, const Goods& g2)->bool {
return g1._price < g2._price; // 价格升序
});
// 新增排序规则:按评价升序(无需新增仿函数,直接改Lambda逻辑)
sort(v1.begin(), v1.end(), [](const Goods& g1, const Goods& g2)->bool {
return g1._evaluate < g2._evaluate;
});
// 核心对比:仿函数需定义结构体(代码重),Lambda是匿名函数(代码轻、直接明了)
// ===================== Lambda表达式的捕捉列表(核心) =====================
// 捕捉列表:[]内的内容,用于捕获外部变量,让Lambda内部可以访问
int x = 0, y = 1;
// 场景1:无捕捉列表,仅通过参数传递外部变量(和普通函数一样)
auto f3 = [](int& r1, int& r2)->void {
int tmp = r1; r1 = r2; r2 = tmp; // 交换两个变量的值
};
f3(x, y); // 传入x、y的引用,交换后x=1,y=0
cout << x << " " << y << endl; // 输出:1 0
// 场景2:值捕捉([x,y]):拷贝外部变量到Lambda内部,默认不可修改
// mutable:取消值捕捉变量的const属性,允许在Lambda内部修改(仅修改拷贝,不影响外部)
auto f4 = [x, y]() mutable {
int tmp = x; x = y; y = tmp; // 交换的是内部拷贝的x、y,外部x、y不变
};
f4(); // 调用后,外部x仍为1,y仍为0
cout << x << " " << y << endl; // 输出:1 0
// 场景3:引用捕捉([&x,&y]):捕获外部变量的引用,可直接修改外部变量
// mutable可加可不加(引用本身可修改,mutable无实际作用)
auto f5 = [&x, &y]() mutable {
int tmp = x; x = y; y = tmp; // 交换的是外部x、y的引用,影响外部
};
f5(); // 调用后,外部x=0,y=1
cout << x << " " << y << endl; // 输出:0 1
// 场景4:全值捕捉([=]):捕获所有外部变量的拷贝,内部不可修改(除非加mutable)
auto f6 = [=]() {
cout << x << " " << y << endl; // 仅读取x、y的值,输出:0 1
// x=10; // 报错!值捕捉默认const,加mutable后可修改(但仅修改拷贝)
};
f6();
// 场景5:全引用捕捉([&]):捕获所有外部变量的引用,可修改外部变量
auto f7 = [&]() {
int tmp = x; x = y; y = tmp; // 交换外部x、y,x=1,y=0
};
f7();
cout << x << " " << y << endl; // 输出:1 0
return 0;
}一、Lambda 表达式的核心定义
Lambda 表达式是 C++11 引入的匿名函数 特性,无需提前定义函数 / 仿函数结构体,可在需要的位置直接编写可调用的逻辑块,本质是编译器自动生成的 "匿名仿函数对象"(可调用对象),核心优势是轻量、灵活、代码内聚性强,尤其适合临时的、简单的逻辑场景(如排序、遍历的比较规则)。
二、Lambda 表达式的基础语法
Lambda 的完整语法格式为:
[捕捉列表](参数列表)->返回值类型 {函数体};各部分的核心作用如下:
| 语法部分 | 核心作用 | 简化规则 |
|---|---|---|
[捕捉列表] |
捕获外部作用域的变量,让 Lambda 内部可访问(核心,后文详细拆解) | 无外部变量需捕获时,可写[] |
(参数列表) |
接收调用 Lambda 时传入的参数,语法与普通函数参数一致 | 无参数时可省略()(如[](){cout<<"test";}) |
->返回值类型 |
指定 Lambda 的返回值类型(编译器可自动推导) | 函数体仅含return语句,或无返回值时,可省略该部分(编译器自动推导) |
{函数体} |
Lambda 的核心逻辑,编写具体的执行代码 | 无逻辑时可写空{},但实际场景需包含有效代码 |
代码中的语法示例拆解
// 完整语法:显式指定返回值类型(->int)
auto f1 = [](int x)->int {cout << x << endl; return 0; };
f1(1); // 调用Lambda,传入参数1,输出1,返回0
// 简化语法:省略返回值类型(编译器自动推导为int)
auto f2 = [](int x) {cout << x << endl; return 0; };
f2(1); // 效果与f1完全一致auto f1:Lambda 表达式本身是 "可调用对象",需用auto推导其类型(编译器生成的匿名类型,无法手动命名);- 调用方式:与普通函数一致(
f1(1)),参数传递规则也与普通函数相同。
三、Lambda 表达式的捕捉列表(核心)
捕捉列表([]内的内容)是 Lambda 的核心特性,用于捕获外部作用域的变量,让 Lambda 内部可访问 / 修改这些变量,分为以下 5 种核心场景:
场景 1:无捕捉列表([])
仅通过参数列表传递外部变量,与普通函数逻辑完全一致,无外部变量捕获:
int x = 0, y = 1;
// 无捕捉列表,通过引用参数接收外部变量x、y
auto f3 = [](int& r1, int& r2)->void {
int tmp = r1; r1 = r2; r2 = tmp; // 交换两个变量的引用,修改外部值
};
f3(x, y); // 调用后x=1,y=0场景 2:值捕捉([变量名1, 变量名2])
-
核心:拷贝外部变量到 Lambda 内部,形成独立的拷贝(与外部变量无关联);
-
默认限制:值捕捉的变量在 Lambda 内部是
const属性,不可修改; -
mutable关键字:取消const限制,允许修改内部拷贝(仅影响拷贝,不改变外部变量)。auto f4 = x, y mutable {
int tmp = x; x = y; y = tmp; // 修改的是内部拷贝的x、y,外部x=1、y=0不变
};
f4();
cout << x << " " << y << endl; // 输出:1 0
场景 3:引用捕捉([&变量名1, &变量名2])
-
核心:捕获外部变量的引用,Lambda 内部操作的是外部变量本身;
-
特性:可直接修改外部变量,
mutable无实际作用(引用本身支持修改)。auto f5 = &x, &y mutable {
int tmp = x; x = y; y = tmp; // 操作外部变量的引用,x=0、y=1
};
f5();
cout << x << " " << y << endl; // 输出:0 1
场景 4:全值捕捉([=])
-
核心:捕获当前作用域所有外部变量的拷贝,无需逐个列出变量名;
-
限制:默认
const,修改需加mutable(仅修改内部拷贝)。auto f6 = = {
cout << x << " " << y << endl; // 仅读取拷贝值,输出:0 1
// x=10; // 报错!值捕捉默认const,加mutable后可修改(不影响外部)
};
f6();
场景 5:全引用捕捉([&])
-
核心:捕获当前作用域所有外部变量的引用,无需逐个列出变量名;
-
特性:可直接修改所有外部变量,是最便捷的 "批量引用捕捉" 方式。
auto f7 = & {
int tmp = x; x = y; y = tmp; // 交换外部x、y,x=1、y=0
};
f7();
cout << x << " " << y << endl; // 输出:1 0
捕捉列表核心规则总结
| 捕捉方式 | 语法 | 变量关联方式 | 能否修改外部变量 | 关键注意点 |
|---|---|---|---|---|
| 值捕捉 | [x,y] |
拷贝 | 否(mutable仅改拷贝) |
拷贝开销,适合小体积变量 |
| 引用捕捉 | [&x,&y] |
引用 | 是 | 无拷贝开销,需注意变量生命周期 |
| 全值捕捉 | [=] |
批量拷贝 | 否(mutable仅改拷贝) |
简化多变量值捕捉 |
| 全引用捕捉 | [&] |
批量引用 | 是 | 简化多变量引用捕捉 |
四、Lambda 表达式 vs 仿函数(实际应用优势)
以商品排序场景为例,对比传统仿函数和 Lambda 的实现逻辑:
1. 传统仿函数方式(代码冗余)
需提前定义多个结构体,每新增一种排序规则,就要新增一个仿函数:
// 按价格升序的仿函数
struct ComparePriceLess
{
bool operator()(const Goods& g1, const Goods& g2)
{
return g1._price < g2._price;
}
};
// 按价格降序的仿函数(新增规则需新增结构体)
struct ComparePriceGreater
{
bool operator()(const Goods& g1, const Goods& g2)
{
return g1._price > g2._price;
}
};
// 调用排序(需传入仿函数对象)
sort(v1.begin(), v1.end(), ComparePriceLess());2. Lambda 表达式方式(轻量灵活)
无需提前定义结构体,直接在排序位置编写比较逻辑,新增规则仅需修改 Lambda 内部:
// 价格降序排序(直接编写逻辑)
sort(v1.begin(), v1.end(), [](const Goods& g1, const Goods& g2)->bool {
return g1._price > g2._price;
});
// 新增:按评价升序排序(仅修改Lambda逻辑,无需新增代码)
sort(v1.begin(), v1.end(), [](const Goods& g1, const Goods& g2)->bool {
return g1._evaluate < g2._evaluate;
});核心优势对比
| 维度 | 仿函数 | Lambda 表达式 |
|---|---|---|
| 代码量 | 大(需定义结构体) | 小(内联编写逻辑) |
| 灵活性 | 低(新增规则需新增结构体) | 高(直接修改逻辑) |
| 内聚性 | 差(逻辑与调用位置分离) | 好(逻辑就近编写) |
| 适用场景 | 复杂、可复用的逻辑 | 临时、简单的逻辑 |
五、总结(关键点回顾)
- Lambda 表达式是 C++11 的匿名函数,本质是编译器生成的匿名仿函数对象,可通过
auto接收其句柄; - 核心语法:
[捕捉列表](参数列表)->返回值类型 {函数体},返回值可省略(编译器自动推导); - 捕捉列表是核心:值捕捉拷贝外部变量(默认 const),引用捕捉关联外部变量(可修改),
mutable仅影响值捕捉的 const 属性; - 对比仿函数,Lambda 更轻量灵活,适合临时、简单的逻辑场景(如排序、遍历),是 C++ 简化代码的核心工具。
function包装器和bind包装器
#include <iostream>
#include <functional> // 必须包含:function/bind/placeholders都在该头文件
#include <map>
#include <string>
using namespace std;
using namespace placeholders; // 引入bind的占位符(_1/_2)
// -------------- 普通函数:用于被function包装 --------------
// 功能:交换两个int变量的值(按引用传递)
void Swap_Func(int& r1, int& r2)
{
int tmp = r1;
r1 = r2;
r2 = tmp;
}
// -------------- 仿函数:用于被function包装 --------------
// 功能:和普通函数Swap_Func逻辑一致,重载()运算符
struct Swap_Functor
{
void operator()(int& r1, int& r2)
{
int tmp = r1;
r1 = r2;
r2 = tmp;
}
};
// -------------- 测试类:用于演示function包装成员函数 --------------
class Plus
{
public:
// 静态成员函数:无this指针,可直接包装
static int plusi(int x, int y)
{
return x + y;
}
// 非静态成员函数:隐含this指针,包装时需特殊处理
double plusd(double a, double b)
{
return a + b;
}
};
// -------------- 测试函数:用于演示bind包装器 --------------
// 功能:减法运算(a - b)
int Sub(int a, int b)
{
return a - b;
}
int main()
{
int x = 0, y = 1;
// -------------- Lambda表达式:用于被function包装 --------------
// 功能:和Swap_Func/Swap_Functor逻辑一致(匿名函数)
auto Swap_Lamdba = [](int& r1, int& r2) {
int tmp = r1; r1 = r2; r2 = tmp;
};
// ===================== function包装器(核心:统一可调用对象类型) =====================
// function是模板类,语法:function<返回值类型(参数类型列表)>
// 作用:将"普通函数、仿函数、Lambda、成员函数"等不同类型的可调用对象,统一为同一类型
// 场景1:包装普通函数
function<void(int&, int&)> f1 = Swap_Func;
f1(x, y); // 调用包装后的函数,交换x=1, y=0
cout << x << " " << y << endl; // 输出:1 0
// 场景2:包装仿函数(需创建仿函数对象)
function<void(int&, int&)> f2 = Swap_Functor();
f2(x, y); // 调用仿函数的(),交换x=0, y=1
cout << x << " " << y << endl; // 输出:0 1
// 场景3:包装Lambda表达式
function<void(int&, int&)> f3 = Swap_Lamdba;
f3(x, y); // 调用Lambda,交换x=1, y=0
cout << x << " " << y << endl; // 输出:1 0
// 场景4:map搭配function(核心价值:统一类型后可存入容器)
// 普通函数/仿函数/Lambda原本类型不同,但function可将其转为同一类型,存入map
map<string, function<void(int&, int&)>> cmpop = {
{"函数指针", Swap_Func}, // 键:名称,值:包装后的普通函数
{"仿函数", Swap_Functor()}, // 键:名称,值:包装后的仿函数
{"lamdba", Swap_Lamdba} // 键:名称,值:包装后的Lambda
};
// 通过map键调用不同的可调用对象,逻辑统一
cmpop["函数指针"](x, y); // 交换x=0, y=1
cout << x << " " << y << endl; // 输出:0 1
cmpop["仿函数"](x, y); // 交换x=1, y=0
cout << x << " " << y << endl; // 输出:1 0
cmpop["lamdba"](x, y); // 交换x=0, y=1
cout << x << " " << y << endl; // 输出:0 1
// 场景5:function包装成员函数
// 5.1 包装静态成员函数:无this指针,直接取地址赋值
function<int(int, int)> f4 = &Plus::plusi;
cout << f4(1, 2) << endl; // 调用静态成员函数,输出:3
// 5.2 包装非静态成员函数(方式1:传递对象指针)
// 非静态成员函数隐含第一个参数是this指针,因此function的参数列表需加"类指针"
function<double(Plus*, double, double) > f5 = &Plus::plusd;
Plus ps; // 创建类对象
cout << f5(&ps, 1.1, 2.2) << endl; // 传入对象指针,调用成员函数,输出:3.3
// 5.3 包装非静态成员函数(方式2:传递对象值)
// function参数列表加"类对象",调用时传入对象(会拷贝)
function<double(Plus, double, double) > f6 = &Plus::plusd;
cout << f6(Plus(), 1.1, 2.2) << endl; // 传入临时对象,输出:3.3
// ===================== bind包装器(核心:调整可调用对象的参数) =====================
// bind是函数模板,作用:绑定可调用对象的参数(调整顺序/固定参数/调整个数)
// 语法:bind(可调用对象, 参数1, 参数2, ...)
// 占位符:_1/_2/_3... 代表调用bind后的函数时,传入的第1/2/3个参数
// 场景1:基础调用(无bind,直接包装Sub函数)
function<int(int, int)> f7 = Sub;
cout << f7(10, 5) << endl; // 10-5=5,输出:5
// 场景2:bind调整参数顺序
// Sub原本是a-b,bind(Sub, _2, _1) → 调用时传入的第2个参数 - 第1个参数
function<int(int, int)> f8 = bind(Sub, _2, _1);
cout << f8(10, 5) << endl; // 5-10=-5,输出:-5
// 场景3:bind固定参数(调整参数个数)
// Sub原本需要2个参数,bind(Sub, 10, _1) → 固定第一个参数为10,仅需传入第2个参数
function<int(int)> f9 = bind(Sub, 10, _1);
cout << f9(5) << endl; // 10-5=5,输出:5
return 0;
}一、function 包装器:统一可调用对象的 "类型容器"
function是 C++11 引入的模板类(定义在<functional>头文件),核心作用是类型擦除 ------ 将 "普通函数、仿函数、Lambda 表达式、类成员函数" 等不同类型的可调用对象,统一为同一类型的function对象,解决可调用对象类型不统一、无法存入容器(如map)的问题。
1. function 的核心语法
// 模板参数:返回值类型(参数类型列表)
function<返回值类型(参数类型1, 参数类型2, ...)> 变量名 = 可调用对象;- 模板参数需严格匹配可调用对象的 "返回值类型 + 参数类型列表";
- 可调用对象的类型无需手动指定,
function会自动完成 "类型擦除",仅保留调用接口。
2. function 的核心应用场景(结合代码拆解)
场景 1:包装普通函数
普通函数的类型是 "函数指针",function可直接包装,调用方式与原函数一致:
// 普通函数:void Swap_Func(int&, int&)
function<void(int&, int&)> f1 = Swap_Func;
f1(x, y); // 等价于直接调用Swap_Func(x, y),交换x、y的值场景 2:包装仿函数
仿函数是 "重载 ()` 运算符的结构体对象",包装时需创建仿函数实例:
// 仿函数:Swap_Functor()的()运算符是void(int&, int&)
function<void(int&, int&)> f2 = Swap_Functor();
f2(x, y); // 等价于调用Swap_Functor()(x, y)场景 3:包装 Lambda 表达式
Lambda 表达式是编译器生成的匿名仿函数,function可直接包装其句柄(auto推导的对象):
// Lambda:auto Swap_Lamdba = [](int&, int&){...}
function<void(int&, int&)> f3 = Swap_Lamdba;
f3(x, y); // 等价于直接调用Swap_Lamdba(x, y)场景 4:存入容器(function 的核心价值)
普通函数、仿函数、Lambda 的原生类型不同,无法直接存入同一容器;但function统一类型后,可作为map的 value,实现 "按名称调用不同可调用对象":
map<string, function<void(int&, int&)>> cmpop = {
{"函数指针", Swap_Func}, // 包装普通函数
{"仿函数", Swap_Functor()}, // 包装仿函数对象
{"lamdba", Swap_Lamdba} // 包装Lambda
};
// 统一调用接口:通过键名调用不同可调用对象
cmpop["函数指针"](x, y);
cmpop["仿函数"](x, y);
cmpop["lamdba"](x, y);场景 5:包装类成员函数
类成员函数的包装需注意 "this 指针" 的处理(非静态成员函数隐含this指针):
-
静态成员函数 :无
this指针,可直接取地址包装:// 静态成员函数:int Plus::plusi(int, int) function<int(int, int)> f4 = &Plus::plusi; f4(1, 2); // 等价于Plus::plusi(1, 2),输出3 -
非静态成员函数 :隐含第一个参数是
this指针,function的参数列表需新增 "类指针 / 类对象":// 方式1:参数列表加类指针(Plus*),调用时传入对象地址 function<double(Plus*, double, double)> f5 = &Plus::plusd; Plus ps; f5(&ps, 1.1, 2.2); // 等价于ps.plusd(1.1, 2.2),输出3.3 // 方式2:参数列表加类对象(Plus),调用时传入对象(会拷贝) function<double(Plus, double, double)> f6 = &Plus::plusd; f6(Plus(), 1.1, 2.2); // 等价于Plus().plusd(1.1, 2.2),输出3.3
3. function 的核心优势
- 统一可调用对象类型,解决 "不同可调用对象无法存入同一容器" 的问题;
- 隐藏可调用对象的具体类型,仅暴露调用接口,降低代码耦合度;
- 支持包装类成员函数(含静态 / 非静态),扩展可调用对象的覆盖范围。
二、bind 包装器:调整可调用对象的 "参数规则"
bind是 C++11 引入的函数模板(定义在<functional>头文件),核心作用是参数绑定与调整 ------ 对已有可调用对象的参数进行 "顺序调整、固定参数、减少参数个数",返回一个新的可调用对象(可被function包装)。
1. bind 的核心语法与占位符
// 语法:bind(可调用对象, 参数1, 参数2, ...)
// 占位符:_1/_2/_3...(需using namespace placeholders;),代表调用新对象时传入的第1/2/3个参数
auto 新可调用对象 = bind(原可调用对象, 绑定参数/占位符);- 绑定参数:直接传入的常量(如
10),会被固定为原函数的对应参数; - 占位符:
_N代表 "调用新对象时传入的第 N 个参数",用于保留参数位置或调整顺序。
2. bind 的核心应用场景(结合代码拆解)
以int Sub(int a, int b)(功能:a - b)为例,拆解 bind 的参数调整逻辑:
场景 1:基础调用(无参数调整)
bind 仅包装原函数,占位符_1/_2对应原函数的a/b,调用逻辑与原函数一致:
function<int(int, int)> f7 = bind(Sub, _1, _2);
cout << f7(10, 5) << endl; // 10-5=5,输出5(等价于Sub(10,5))场景 2:调整参数顺序
通过占位符_2/_1交换原函数的参数顺序,将a - b改为b - a:9
function<int(int, int)> f8 = bind(Sub, _2, _1);
cout << f8(10, 5) << endl; // 5-10=-5,输出-5(等价于Sub(5,10))场景 3:固定参数(减少参数个数)
将原函数的某个参数固定为常量,新对象仅需传入剩余参数,减少调用时的参数个数:
// 固定第一个参数为10,占位符_1对应原函数的第二个参数b
function<int(int)> f9 = bind(Sub, 10, _1);
cout << f9(5) << endl; // 10-5=5,输出5(等价于Sub(10,5))3. bind 的核心优势
- 灵活调整参数规则:无需修改原函数,即可实现参数顺序交换、参数固定;
- 适配不同调用接口:将多参数函数转为少参数函数,适配特定调用场景(如仅需单参数的接口);
- 与
function无缝结合:bind 返回的新可调用对象可直接被function包装,进一步统一类型。
三、总结(关键点回顾)
- function 包装器 :核心是 "类型统一",将普通函数、仿函数、Lambda、成员函数等不同类型的可调用对象,转为同一类型的
function对象,支持存入容器、统一调用; - bind 包装器:核心是 "参数调整",通过占位符和固定参数,修改可调用对象的参数顺序 / 个数,返回新的可调用对象;
- 组合使用:
bind调整参数规则后,可通过function包装新对象,既统一类型,又适配不同调用场景,是 C++11 简化可调用对象管理的核心工具。