
🫧个人主页:小年糕是糕手
🎨你不能左右天气,但你可以改变心情;你不能改变过去,但你可以决定未来!

目录
[getline () vs operator>> 核心对比(必记)](#getline () vs operator>> 核心对比(必记))
注:这篇博客这是在string类(二)基础上的一个补充
string类中的一些成员函数

下面分别为大家带来详解,compare由于用的不多,我们在这里不做解释,大家感兴趣的话可以自己去了解:
1°c_str
c_str()会返回一个指向std::string内部字符数组的只读const char*指针 ,且这个字符数组以\0(空字符)结尾 ------ 完全符合 C 语言风格字符串的规范。
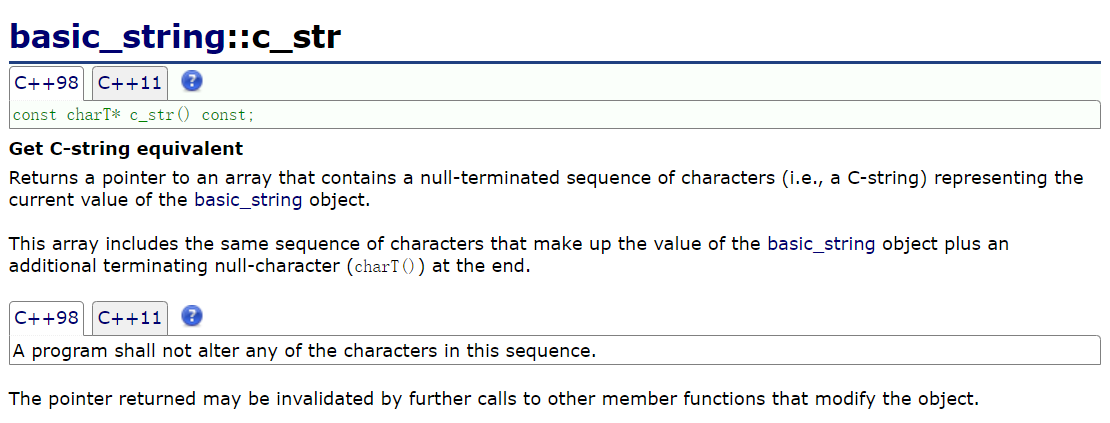
当你需要把std::string传给仅支持 C 风格字符串(char*/const char*)的函数时,必须用c_str(),比如:
cpp
#include<iostream>
#include<string>
using namespace std;
int main()
{
string filename("Test.cpp");
FILE* fout = fopen(filename.c_str(), "r");
if (fout)
{
cout << "打开文件成功" << endl;
fclose(fout);
}
return 0;
}C语言文件操作函数fopen:参数需要const char*,必须用c_str(),直接传filename会编译报错,C语言打印函数printf:%s需要C风格字符串,必须用c_str()...
总结
- 核心作用:将 C++ 的
std::string转换为 C 风格的const char*字符串(以\0结尾),适配 C 语言函数;- 核心场景:调用 C 语言标准库函数(如
fopen、printf、strlen)时传参;- 核心禁忌:不修改返回的指针内容、不单独保存指针(需和原
std::string对象同生命周期)。
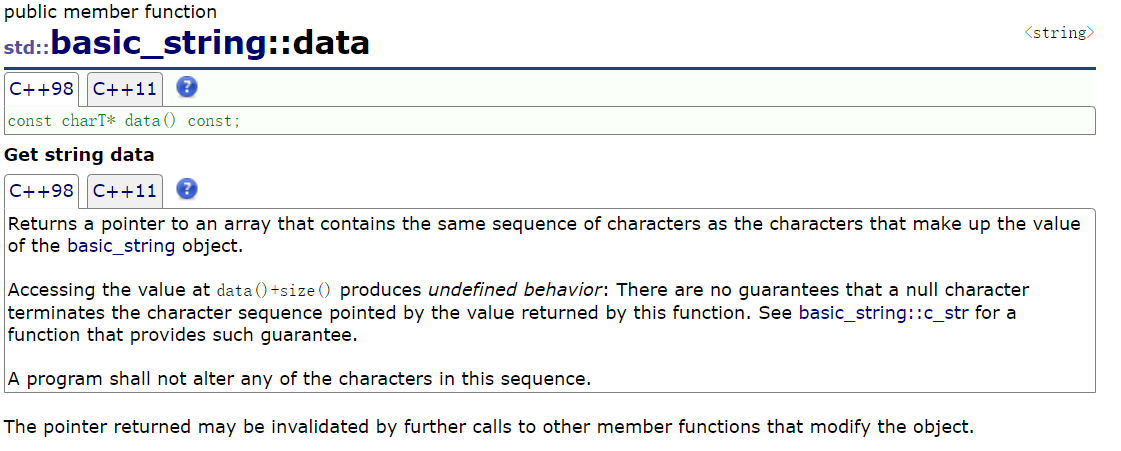
2°data
data()的核心功能和c_str()几乎一致:返回一个指向std::string内部字符数组的只读const char*指针,指向字符串的首字符。但它的行为在 C++11 前后有个关键变化,这是理解它的核心:
- C++11 及以后 :
data()和c_str()完全等价 ------ 返回的字符数组也以\0结尾,本质上是同一个函数的两种写法;- C++11 之前 :
data()只返回指向字符数组的指针,不保证末尾有\0(仅包含有效字符),而c_str()必须保证末尾有\0。
cpp
#include <iostream>
#include <string>
#include <cstdio>
int main() {
std::string str = "hello";
// C++11后,这两行代码效果完全一样
FILE* f1 = fopen(str.c_str(), "w");
FILE* f2 = fopen(str.data(), "w");
// 打印字符数据(无需\0的场景,data()更贴合语义)
const char* ptr = str.data();
for (int i = 0; i < str.size(); ++i) {
std::cout << ptr[i]; // 输出:hello
}
if (f1) fclose(f1);
if (f2) fclose(f2);
return 0;总结
data()核心作用:获取std::string内部字符数组的指针,C++11 后和c_str()等价(带\0),C++11 前不带\0;- 核心区别:仅存在于 C++11 前的
\0结尾保证,C++11 后无差异;- 使用选择:适配 C 函数用
c_str()(语义更清),仅访问字符数据用data(),C++11 后两者可互换。
3°get_allocator
简单来说:
std::string内部的字符数组(就是c_str()/data()指向的那块内存),并不是直接用new分配的,而是通过分配器(allocator) 来管理内存申请 / 释放。get_allocator()就是返回这个分配器对象,让你能 "复用" 和std::string相同的内存分配规则。分配器的本质是一个 "内存管理工具",STL 容器默认用
std::allocator<char>,它的行为和普通的new/delete几乎一致,但提供了更灵活的内存管理接口。

这个目前不需要我们深入理解,大家看一遍了解即可。
4°copy
copy()的核心是:把std::string中指定范围的字符,拷贝到你提供的外部字符数组中 。和strcpy/c_str()不同的是:
- 它不自动在目标数组末尾加
\0(需手动处理);- 可以只拷贝字符串的一部分(比如只拷贝前 5 个字符);
- 直接操作字符数组,无需先转 C 风格字符串。

cppsize_t copy(char* dest, size_t count, size_t pos = 0) const;参数说明:
dest:目标字符数组(你需要提前分配好内存);count:要拷贝的字符个数;pos:从原字符串的第pos个位置开始拷贝(默认从 0 开始);- 返回值:实际拷贝的字符数(通常等于
count,除非pos+count超出字符串长度)。
cpp
#include <iostream>
#include <string>
int main() {
std::string str = "Hello, C++ string!";
char buf[20] = {0}; // 初始化数组,避免垃圾值
// 示例1:拷贝前5个字符到buf
size_t copied = str.copy(buf, 5); // 从pos=0开始,拷贝5个字符
buf[copied] = '\0'; // 手动加\0,否则打印会乱码
std::cout << "示例1:" << buf << std::endl; // 输出:Hello
// 示例2:从pos=7开始,拷贝5个字符("C++ s")
str.copy(buf, 5, 7);
buf[5] = '\0';
std::cout << "示例2:" << buf << std::endl; // 输出:C++ s
// 示例3:拷贝超出字符串长度的情况(自动截断)
size_t copied2 = str.copy(buf, 100, 0); // 想拷贝100个,实际只拷贝str的长度
buf[copied2] = '\0';
std::cout << "示例3:" << buf << "(实际拷贝" << copied2 << "个)" << std::endl;
return 0;
}总结
- 核心作用:把
std::string中指定范围的字符拷贝到外部字符数组,支持部分拷贝;- 核心特点:不自动加
\0、可指定拷贝起始位置和长度、越界自动截断;- 核心避坑:手动补
\0、保证目标数组内存足够;- 适用场景:精准提取字符串部分字符到字符数组,替代
strncpy更灵活。缺点:要手动分配数组、手动补
\0、要计算数组大小,稍不注意就会缓冲区溢出。
但是这个其实我们用的并不多,我们习惯于用substr
5°find(重点)
1、find
find()的核心是:从指定起始位置开始,在原字符串中查找第一个匹配的 "字符 / 子串",返回其起始下标;如果没找到,返回std::string::npos。简单说,它就是字符串的 "搜索定位器",支持查找单个字符、任意长度的子串。

cppsize_t find(const string& str, size_t pos = 0) const; // 查找子串 size_t find(const char* s, size_t pos = 0) const; // 查找C风格字符串 size_t find(const char* s, size_t pos, size_t n) const; // 查找C风格字符串的前n个字符 size_t find(char c, size_t pos = 0) const; // 查找单个字符
cpp
//find
#include<iostream>
#include<string>
using namespace std;
int main()
{
string filename("Testaxxx.cpp");
FILE* fout = fopen(filename.c_str(), "r");
if (fout)
{
cout << "打开文件成功" << endl;
fclose(fout);
}
size_t pos = filename.find('.');
//找到了返回第一次匹配字符的位置,没找到返回string::npos
if (pos != string::npos)
{
string suffix = filename.substr(pos);
cout << suffix << endl;
}
return 0;
}
//rfind功能与其类似,是倒着往前找总结
- 核心作用:从指定位置开始查找字符 / 子串,返回第一个匹配的下标,没找到返回
npos;- 核心用法:
find(目标, 起始位置),支持字符、string、C 风格字符串三种查找目标;- 核心避坑:用
!= npos判断是否找到、注意大小写敏感、pos 越界直接返回 npos;- 核心场景:字符串匹配、分割、替换(比如找到子串位置后用 substr 截取)。
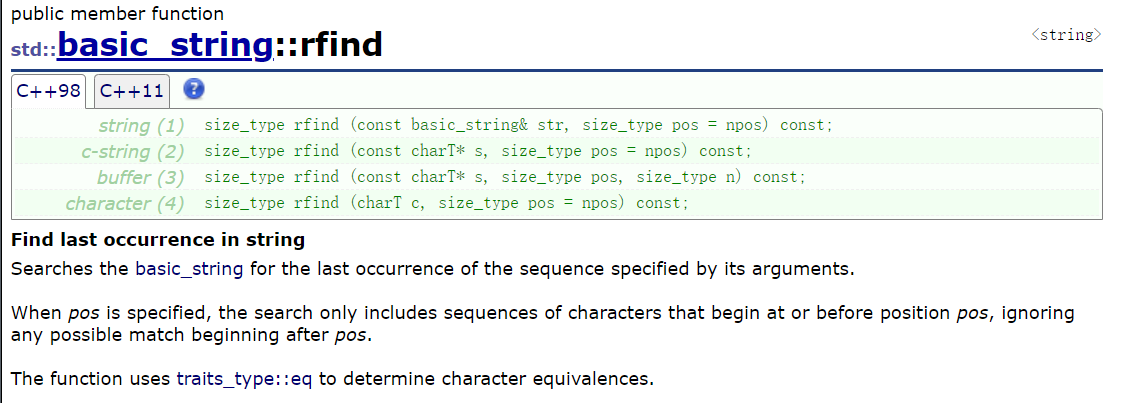
2、rfind
rfind()的核心是:从指定的 "结束位置" 开始,从右向左查找第一个匹配的字符 / 子串(即原字符串中最后一个出现的匹配项),找到返回其起始下标,没找到返回std::string::npos。简单说:find()找 "第一个",rfind()找 "最后一个"。
cppsize_t rfind(const string& str, size_t pos = npos) const; // 查找子串 size_t rfind(const char* s, size_t pos = npos) const; // 查找C风格字符串 size_t rfind(const char* s, size_t pos, size_t n) const; // 查找C风格字符串前n个字符 size_t rfind(char c, size_t pos = npos) const; // 查找单个字符
cpp
#include <iostream>
#include <string>
int main() {
std::string str = "Hello, C++! C++ is fun.";
// 场景1:默认pos=npos(查找整个字符串,找最后一个匹配)
size_t pos1 = str.rfind("C++"); // 找最后一个"C++"的位置
if (pos1 != std::string::npos) {
std::cout << "场景1:最后一个\"C++\"在位置" << pos1 << std::endl; // 输出:12(find返回7)
}
// 场景2:指定pos(只在[0, pos]范围内找最后一个)
// 限定在[0, 10]范围内找"C++",即只看"Hello, C++!"这部分
size_t pos2 = str.rfind("C++", 10);
if (pos2 != std::string::npos) {
std::cout << "场景2:[0,10]内最后一个\"C++\"在位置" << pos2 << std::endl; // 输出:7
}
// 场景3:查找单个字符(最后一个'+')
size_t pos3 = str.rfind('+');
if (pos3 != std::string::npos) {
std::cout << "场景3:最后一个'+'在位置" << pos3 << std::endl; // 输出:13(find返回8)
}
// 场景4:查找不存在的内容(返回npos)
size_t pos4 = str.rfind("Java");
if (pos4 == std::string::npos) {
std::cout << "场景4:未找到\"Java\"" << std::endl;
}
return 0;
}总结
- 核心作用:从右往左查找字符 / 子串,返回最后一个匹配的起始下标,没找到返回
npos;- 核心差异:和
find()比,查找方向相反、pos 参数是 "结束范围" 而非 "起始位置";- 核心避坑:正确理解 pos 的含义、用
!= npos判断结果;- 核心场景:找最后一个分隔符(小数点、斜杠、逗号等)、提取后缀 / 文件名。
简单说,
rfind()是 "反向查找神器",尤其适合处理文件路径、后缀名这类需要找 "最后一个匹配项" 的场景,搭配substr()能快速完成字符串拆分
3、find_first_of
find_first_of()的核心是:从指定起始位置开始,在原字符串中找第一个属于 "目标字符集合" 的字符,返回其下标;没找到则返回npos。简单对比理解:
find("abc"):找完整的子串"abc",必须连续 3 个字符完全匹配;find_first_of("abc"):找第一个是a/b/c中任意一个的字符,只要匹配其中一个就停止。

cpp
#include <iostream>
#include <string>
int main() {
std::string str = "Hello123World456!";
// 场景1:找第一个数字字符(字符集合是"0123456789")
size_t pos1 = str.find_first_of("0123456789");
if (pos1 != std::string::npos) {
std::cout << "场景1:第一个数字在位置" << pos1 << ",字符是" << str[pos1] << std::endl; // 输出:5,字符1
}
// 场景2:找第一个标点/特殊字符(集合是"!@#$%")
size_t pos2 = str.find_first_of("!@#$%");
if (pos2 != std::string::npos) {
std::cout << "场景2:第一个特殊字符在位置" << pos2 << ",字符是" << str[pos2] << std::endl; // 输出:14,字符!
}
// 场景3:指定起始位置查找(从pos=6开始找数字)
size_t pos3 = str.find_first_of("0123456789", 6);
if (pos3 != std::string::npos) {
std::cout << "场景3:从6开始第一个数字在位置" << pos3 << ",字符是" << str[pos3] << std::endl; // 输出:6,字符2
}
// 场景4:找不在字母集合中的字符(结合逻辑判断)
size_t pos4 = str.find_first_of("abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ");
// 反过来:第一个非字母字符就是数字1,pos=5
std::cout << "场景4:第一个非字母字符在位置" << pos4 << std::endl; // 输出:5
// 场景5:查找空集合/不存在的字符(返回npos)
size_t pos5 = str.find_first_of("@#$"); // 字符串中无@#$
if (pos5 == std::string::npos) {
std::cout << "场景5:未找到@#$中的任意字符" << std::endl;
}
return 0;
}总结
- 核心作用:找第一个属于 "目标字符集合" 的字符(匹配任意一个即可),而非完整子串;
- 核心区别:和
find()比,find匹配完整子串,find_first_of匹配字符集合中的任意字符;- 核心避坑:不要把字符集合当成子串理解,判断结果用
!= npos;- 核心场景:找第一个数字 / 字母 / 特殊符号等 "特征字符"。
简单说,
find_first_of()是 "字符类型匹配器",适合按字符类别(数字、字母、符号)查找,而find()是 "完整子串匹配器"
4、find_last_of
find_last_of()的核心是:从指定的 "结束位置" 开始,从右向左查找第一个属于 "目标字符集合" 的字符(即原字符串中最后一个匹配该集合的字符),找到返回其下标,没找到返回std::string::npos。简单对比记忆:
find_first_of():从左找「第一个」属于字符集合的字符;find_last_of():从右找「最后一个」属于字符集合的字符;rfind():从右找「最后一个」完整子串(需连续匹配)。

cpp
#include <iostream>
#include <string>
int main() {
std::string str = "Hello123World456!";
// 场景1:默认pos=npos(找整个字符串中最后一个数字)
size_t pos1 = str.find_last_of("0123456789");
if (pos1 != std::string::npos) {
std::cout << "场景1:最后一个数字在位置" << pos1 << ",字符是" << str[pos1] << std::endl; // 输出:13,字符6
}
// 场景2:指定pos(只在[0, 10]范围内找最后一个数字)
// 限定范围:只看"Hello123Wo",最后一个数字是3(位置7)
size_t pos2 = str.find_last_of("0123456789", 10);
if (pos2 != std::string::npos) {
std::cout << "场景2:[0,10]内最后一个数字在位置" << pos2 << ",字符是" << str[pos2] << std::endl; // 输出:7,字符3
}
// 场景3:找最后一个字母(字符集合是大小写字母)
size_t pos3 = str.find_last_of("abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ");
if (pos3 != std::string::npos) {
std::cout << "场景3:最后一个字母在位置" << pos3 << ",字符是" << str[pos3] << std::endl; // 输出:10,字符d
}
// 场景4:找最后一个特殊符号(集合是"!@#$%")
size_t pos4 = str.find_last_of("!@#$%");
if (pos4 != std::string::npos) {
std::cout << "场景4:最后一个特殊符号在位置" << pos4 << ",字符是" << str[pos4] << std::endl; // 输出:14,字符!
}
// 场景5:查找不存在的字符集合(返回npos)
size_t pos5 = str.find_last_of("@#$");
if (pos5 == std::string::npos) {
std::cout << "场景5:未找到@#$中的任意字符" << std::endl;
}
return 0;
}总结
- 核心作用:从右往左找最后一个属于 "目标字符集合" 的字符,返回其下标,没找到返回
npos;- 核心区别:和
rfind()比,它匹配 "单个字符(集合)",而非 "完整子串";和find_first_of()比,查找方向相反;- 核心避坑:不要把字符集合当成子串理解,pos 参数是 "结束范围",判断结果用
!= npos;- 核心场景:找最后一个数字 / 分隔符 / 字母等 "特征字符"(如提取文件名、最后一个分隔项)。
简单说,
find_last_of()是 "反向字符类型匹配器",专门解决 "找最后一个某类特征字符" 的需求,是处理文件路径、分隔字符串的高频工具
5、find_first_not_of
find_first_not_of()的核心是:从指定起始位置开始,在原字符串中找第一个「不属于」目标字符集合的字符,找到返回其下标,没找到返回std::string::npos。简单对比记忆:
find_first_of():找「第一个属于」字符集合的字符;find_first_not_of():找「第一个不属于」字符集合的字符;- 比如字符集合是
"0123456789",前者找第一个数字,后者找第一个非数字。

cpp
#include <iostream>
#include <string>
int main() {
// 场景1:找第一个非数字字符(验证是否是纯数字字符串)
std::string num_str = "12345a6789";
size_t pos1 = num_str.find_first_not_of("0123456789");
if (pos1 != std::string::npos) {
std::cout << "场景1:第一个非数字在位置" << pos1 << ",字符是" << num_str[pos1] << std::endl; // 输出:5,字符a
} else {
std::cout << "场景1:字符串全是数字" << std::endl;
}
// 场景2:找第一个非字母字符(过滤字母前的特殊符号)
std::string str = "###HelloWorld123!";
size_t pos2 = str.find_first_not_of("!@#$%^&*()"); // 字符集合是常见特殊符号
if (pos2 != std::string::npos) {
std::cout << "场景2:第一个非特殊符号在位置" << pos2 << ",字符是" << str[pos2] << std::endl; // 输出:3,字符H
// 截取从第一个非特殊符号开始的字符串(得到"HelloWorld123!")
std::string clean_str = str.substr(pos2);
std::cout << " 清洗后字符串:" << clean_str << std::endl;
}
// 场景3:找第一个不是指定字符的位置(比如找第一个不是空格的字符)
std::string space_str = " test string";
size_t pos3 = space_str.find_first_not_of(" ");
if (pos3 != std::string::npos) {
std::cout << "场景3:第一个非空格字符在位置" << pos3 << ",字符是" << space_str[pos3] << std::endl; // 输出:3,字符t
}
// 场景4:所有字符都属于集合(返回npos)
std::string pure_alpha = "abcdefg";
size_t pos4 = pure_alpha.find_first_not_of("abcdefghijklmnopqrstuvwxyz");
if (pos4 == std::string::npos) {
std::cout << "场景4:字符串全是小写字母" << std::endl;
}
return 0;
}总结
- 核心作用:找第一个不属于目标字符集合的字符,返回其下标,没找到返回
npos;- 核心区别:和
find_first_of()是 "反向" 逻辑(一个找 "不属于",一个找 "属于");- 核心避坑:不要混淆 "属于" 和 "不属于",判断结果用
!= npos;- 核心场景:字符串校验(纯数字 / 纯字母)、开头字符清洗(去空格 / 特殊符号)、非法字符检测。
简单说,
find_first_not_of()是 "异常字符定位器",专门解决 "找第一个不符合规则的字符" 的需求,是字符串校验和清洗的高频工具
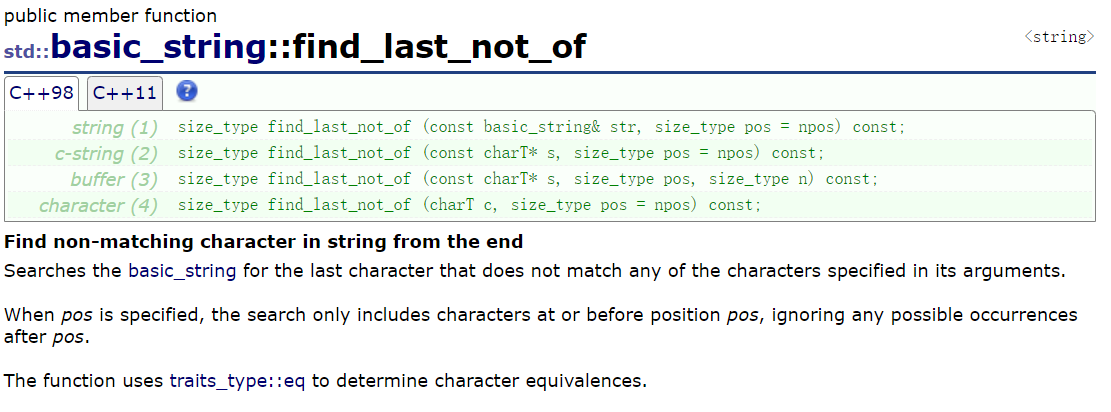
6、find_last_not_of
find_last_not_of()的核心是:从指定的 "结束位置" 开始,从右向左查找第一个「不属于」目标字符集合的字符(即原字符串中最后一个不符合该集合的字符),找到返回其下标,没找到返回std::string::npos。
cpp
#include <iostream>
#include <string>
int main() {
// 场景1:找最后一个非数字字符(验证字符串末尾是否是数字)
std::string num_str = "12345a6789";
size_t pos1 = num_str.find_last_not_of("0123456789");
if (pos1 != std::string::npos) {
std::cout << "场景1:最后一个非数字在位置" << pos1 << ",字符是" << num_str[pos1] << std::endl; // 输出:5,字符a
} else {
std::cout << "场景1:字符串全是数字" << std::endl;
}
// 场景2:找最后一个非字母字符(提取字母部分的结尾)
std::string str = "HelloWorld123!";
size_t pos2 = str.find_last_not_of("abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ");
if (pos2 != std::string::npos) {
std::cout << "场景2:最后一个非字母在位置" << pos2 << ",字符是" << str[pos2] << std::endl; // 输出:10,字符1
// 截取从开头到最后一个字母的字符串(得到"HelloWorld")
std::string alpha_part = str.substr(0, pos2);
std::cout << " 纯字母部分:" << alpha_part << std::endl;
}
// 场景3:找最后一个不是空格的字符(去除末尾空格)
std::string space_str = "test string ";
size_t pos3 = space_str.find_last_not_of(" ");
if (pos3 != std::string::npos) {
std::cout << "场景3:最后一个非空格字符在位置" << pos3 << ",字符是" << space_str[pos3] << std::endl; // 输出:10,字符g
// 去除末尾空格
std::string trim_str = space_str.substr(0, pos3 + 1);
std::cout << " 去末尾空格后:" << trim_str << "(长度:" << trim_str.size() << ")" << std::endl;
}
// 场景4:所有字符都属于集合(返回npos)
std::string pure_alpha = "ABCDEFG";
size_t pos4 = pure_alpha.find_last_not_of("ABCDEFGHIJKLMNOPQRSTUVWXYZ");
if (pos4 == std::string::npos) {
std::cout << "场景4:字符串全是大写字母" << std::endl;
}
return 0;
}总结
- 核心作用:从右往左找最后一个不属于目标字符集合的字符,返回其下标,没找到返回
npos;- 核心区别:和
find_first_not_of()是 "反向" 逻辑(一个找最后一个不符合,一个找第一个不符合);- 核心避坑:不要混淆 "属于" 和 "不属于"、pos 是结束范围、截取末尾内容要 + 1;
- 核心场景:去除末尾空格 / 特殊符号、校验字符串末尾字符类型、提取尾部有效内容。
简单说,
find_last_not_of()是 "尾部异常字符定位器",专门解决 "处理字符串尾部不符合规则的字符" 的需求,是字符串尾部清洗和校验的核心工具
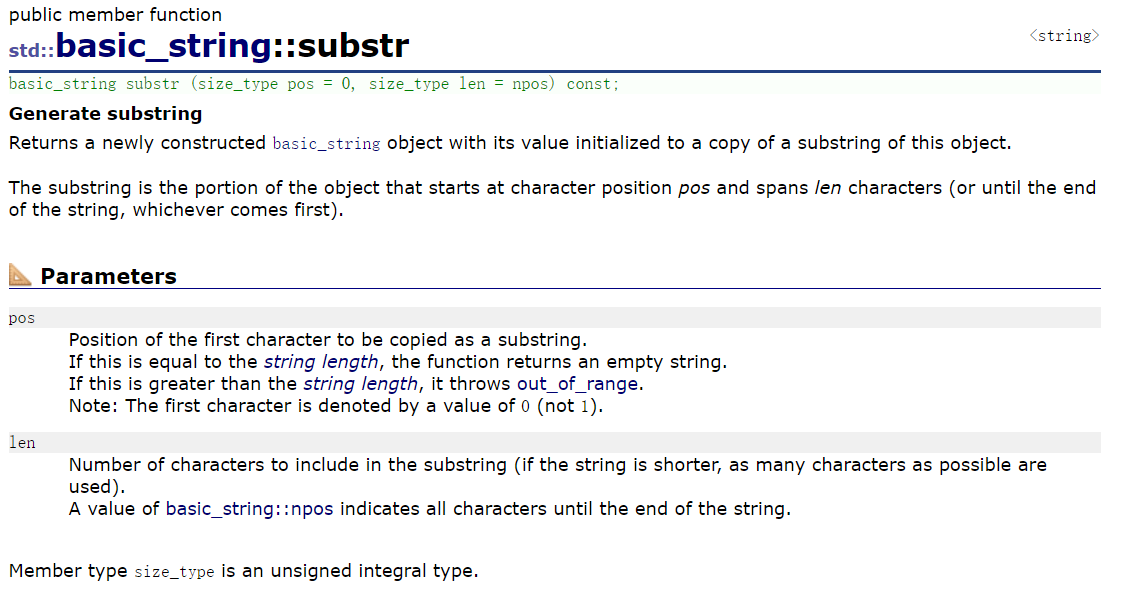
6°substr
substr()的核心是:从原std::string中截取指定范围的字符,返回一个全新的std::string对象 。它完全围绕 C++ 的std::string对象操作,不需要手动处理字符数组、不需要补\0,是提取子串的 "首选工具"。
我们可以简单理解为取后缀:
cpp
//substr -- 取后缀
#include<iostream>
#include<string>
using namespace std;
int main()
{
string filename("Test.cpp");
FILE* fout = fopen(filename.c_str(), "r");
if (fout)
{
cout << "打开文件成功" << endl;
fclose(fout);
//从pos位置开始取len个字符
string suffix = filename.substr(4, 4);//相当于从第四个位置(从0开始计算的)开始取四个字符
//如果给出的数字太大就是有多少取多少,所有我们第二个参数可以不给,默认直接取到结尾
cout << suffix << endl;
}
return 0;
}⚠️补充:
npos是std::string的静态常量,代表 "最大无符号整数",可以理解为 "直到末尾"。
总结
- 核心作用:从原字符串截取指定范围的字符,返回新的
std::string对象;- 核心用法:
substr(pos)(截到末尾)、substr(pos, count)(精准截取);- 核心避坑:
pos不能越界、不能传负数、返回的是独立新对象;- 使用原则:日常提取子串优先用 substr (),仅需写入裸 char 数组时才用 copy ()。
简单说,substr () 是 C++ 为提取子串量身定做的 "懒人工具"------ 不用管内存、不用管 \0,一行代码就能拿到想要的子串。
string类中的一些全局函数

这里有些我们之前的内容为大家解释过了,但是我想要系统性为大家再解释一遍,这样也方便大家后续学习,不需要翻之前的博客减少负担:
1°operator+
operator+是 C++ 对+运算符的重载,专门用于字符串拼接,支持以下组合(覆盖所有常见场景):
std::string + std::stringstd::string + 单个字符(char)std::string + C风格字符串(const char*)C风格字符串 + std::string单个字符 + std::string核心特点:拼接后返回新字符串,原字符串不会被修改(因为是全局函数,操作的是值传递的副本)。

cpp
#include <iostream>
#include <string>
using namespace std;
int main() {
string str1 = "Hello";
string str2 = "World";
const char* c_str = " C++";
char ch = '!';
// 场景1:string + string
string res1 = str1 + str2;
cout << "场景1:" << res1 << endl; // 输出:HelloWorld
// 场景2:string + C风格字符串
string res2 = str1 + c_str;
cout << "场景2:" << res2 << endl; // 输出:Hello C++
// 场景3:C风格字符串 + string
string res3 = "Hi " + str1;
cout << "场景3:" << res3 << endl; // 输出:Hi Hello
// 场景4:string + 单个字符
string res4 = str1 + ch;
cout << "场景4:" << res4 << endl; // 输出:Hello!
// 场景5:单个字符 + string
string res5 = ch + str2;
cout << "场景5:" << res5 << endl; // 输出:!World
// 场景6:连续拼接(结合多个重载)
string res6 = str1 + " " + str2 + ch;
cout << "场景6:" << res6 << endl; // 输出:Hello World!
return 0;
}总结
- 核心作用:重载
+运算符,实现std::string与字符串 / 字符的拼接,返回新字符串;- 核心避坑:不能直接拼两个 C 风格字符串、频繁拼接优先用
append();- 核心特点:语法简洁、拼接安全,是少量字符串拼接的首选;
- 核心场景:一次性拼接 2~3 个字符串 / 字符(比如拼接提示语、路径)。
简单说,
operator+是字符串拼接的 "语法糖",让代码更易读;如果追求效率,循环拼接就换成append()
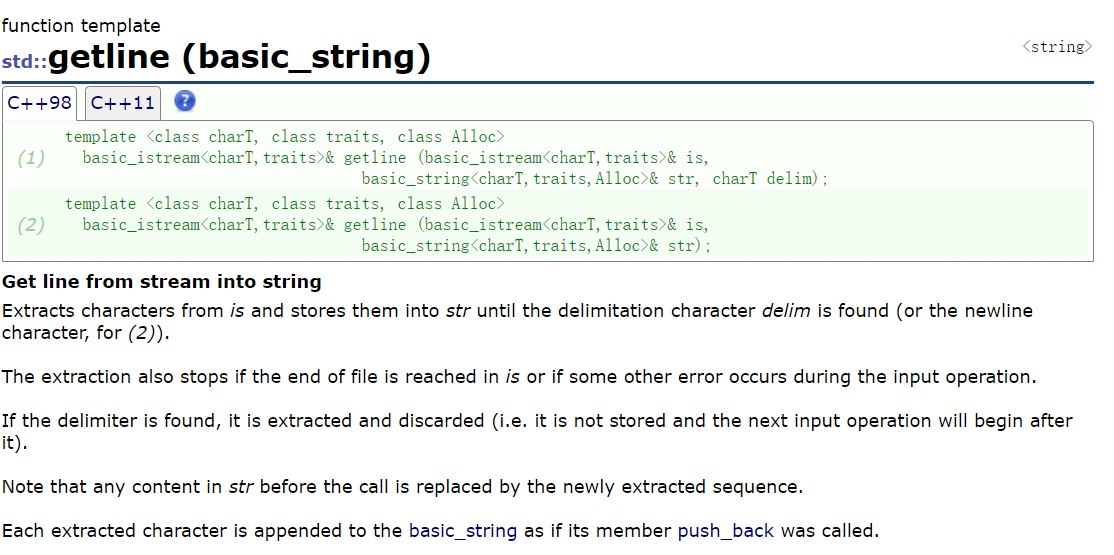
2°getline
std::getline()的核心是:从输入流(cin / 文件流)中读取字符,直到遇到指定的终止符(默认是换行符\n)为止,将读取的内容存入std::string对象(不包含终止符本身)。核心特点:
- 支持读取带空格、制表符的完整一行;
- 终止符可自定义(默认
\n);- 不会自动跳过开头的空白字符(和
operator>>最大区别之一)。
cpp
#include <iostream>
#include <string>
#include <fstream>
int main() {
// 场景1:读取控制台整行(含空格,默认终止符\n)
std::string line1;
std::cout << "请输入带空格的整行内容:";
std::getline(std::cin, line1); // 输入:Hello World! 123 → 完整读取
std::cout << "场景1读取结果:" << line1 << std::endl;
// 场景2:自定义终止符(以逗号分割)
std::string line2;
std::cout << "请输入用逗号分割的内容:";
std::getline(std::cin, line2, ','); // 输入:apple,banana,orange → 读取到","前的"apple"
std::cout << "场景2读取结果:" << line2 << std::endl;
// 场景3:从文件读取整行(逐行读取)
// 假设test.txt内容:
// Hello C++
// Programming is fun
std::ifstream file("test.txt");
if (file.is_open()) {
std::string file_line;
std::cout << "\n场景3:读取文件整行:" << std::endl;
while (std::getline(file, file_line)) { // 循环读取直到文件末尾
std::cout << file_line << std::endl;
}
file.close();
}
return 0;
}getline () vs operator>> 核心对比(必记)
| 特性 | std::getline() | operator>>(流提取) |
|---|---|---|
| 终止符 | 默认\n(可自定义) |
任意空白字符(空格 / 制表 / 换行) |
| 能否读取带空格内容 | 能(整行) | 不能(仅无空格单词) |
| 是否跳过开头空白 | 否(默认读取所有开头空白) | 是(自动跳过开头空白) |
| 典型场景 | 读取整行文本(如地址、描述) | 读取无空格单词(如用户名、数值) |
| 配合使用注意 | 需用cin.ignore()跳过残留换行 |
无此问题 |
总结
- 核心作用:读取输入流的整行内容(含空格),默认以
\n终止,可自定义终止符;- 核心避坑:和
cin >>配合时,必须用cin.ignore()跳过残留的换行符;- 核心对比:
getline()读 "整行",operator>>读 "单词",两者互补;- 核心场景:读取带空格的文本(如地址、描述、整行配置)、逐行读取文件。
简单说,
getline()是处理 "带空格文本输入" 的核心工具,只要需要读取整行内容,优先用它,可以简单理解,cin是输入那些完整的比如helloworld,但是如果要输入hello world就要使用getline
operator>>和operator<<分别是流插入和流提取,是运算符的重载,而swap比较复杂,目前大家就知道他是交换函数就好,后续内容再为大家详细解释。
网址
这是完整的网址,便于大家深入学习:
https://legacy.cplusplus.com/reference/string/basic_string/![]() https://legacy.cplusplus.com/reference/string/basic_string/或许学到这里大家会觉得C++很难,内容多又不易理解,但是还请你坚持坚持再坚持,量变终究会引起质变!
https://legacy.cplusplus.com/reference/string/basic_string/或许学到这里大家会觉得C++很难,内容多又不易理解,但是还请你坚持坚持再坚持,量变终究会引起质变!
